
AgentOps Is the New DevOps
The moment AI can act—reliability stops being a feature and becomes the product.
A scene you’ll recognize
It’s a normal weekday. A request comes in: access approval, a workflow update, a record change—something routine.
An AI agent handles it quickly. No drama. No alert. No outage.
Two days later, an audit question arrives:
“Why was this approved?”
Then security asks: “Which policy was applied?”
Then operations asks: “What exactly changed in the system of record?”
The uncomfortable truth: nobody can fully reconstruct the decision path.
Not because the team is careless—because the system was never designed to produce proof.
This is the new enterprise reality: agentic systems don’t always fail loudly. They fail quietly—through invisible drift, ambiguous decisions, and unrecoverable actions.
And that’s why AgentOps is now inevitable.
Continuous testing, canary releases, rollback, and proof-of-action for production-grade AI autonomy

Executive summary
Enterprises are moving from AI that talks to AI that acts: approving requests, updating records, triggering workflows, calling APIs, and coordinating across tools.
That shift changes the central question.
It is no longer: “Is the model smart?”
It becomes: “Can we operate autonomy safely, repeatedly, and at scale?”
The discipline that answers this is AgentOps—a production-grade operating model for autonomous, tool-using AI agents.
This article delivers a practical blueprint built on four patterns that make autonomy operable:
- Continuous testing (behavior regression + safety + policy adherence)
- Canary releases (ship behavior changes with controlled blast radius)
- Rollback + compensation (reversible autonomy, not wishful thinking)
- Proof-of-Action (auditable evidence of what the agent did—and why)

Why DevOps breaks the moment AI can act
DevOps evolved for software where:
- releases are versioned,
- execution is relatively deterministic,
- failures are observable,
- rollbacks revert deployments.
Agents are different. They are behavioral systems, not just software artifacts.
Agent outcomes depend on:
- prompts and policies,
- tool contracts and tool outputs,
- retrieval results,
- memory state,
- model versions,
- and real-world context variability.
So an agent can be “up” and still be quietly wrong—approving the wrong item, calling the wrong endpoint, escalating too late, or looping in ways that leak cost.
Shareable line:
In agentic systems, uptime is not reliability. Correct, safe, and auditable actions are reliability.
That’s why AgentOps is not DevOps rebranded. It’s DevOps upgraded for autonomy.

What AgentOps actually is
AgentOps (Agent Operations) is the lifecycle discipline for building, testing, deploying, monitoring, governing, and improving AI agents that take actions in real systems.
What AgentOps is not
- Not prompt tweaking as a process
- Not “MLOps with a new name”
- Not a single tool you buy and forget
What AgentOps is
- A production discipline that treats agents as enterprise services
- With standardized releases, guardrails, observability, and evidence-by-design
Mental model (sticky):
- DevOps manages code releases
- MLOps manages model releases
- AgentOps manages behavior releases (reasoning + tools + policies + memory + guardrails)
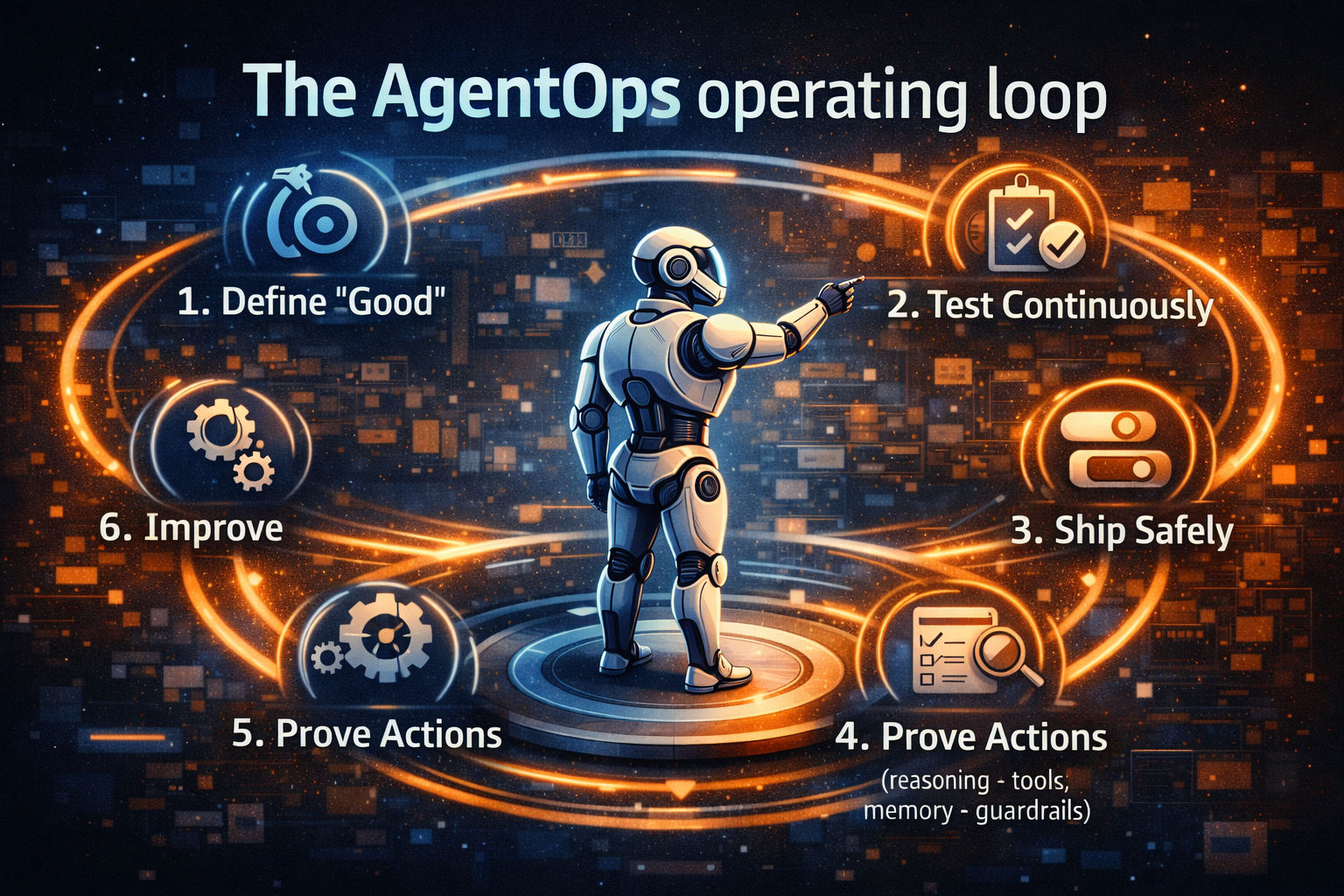
The AgentOps operating loop
AgentOps works as a repeatable loop:
Define → Test → Ship → Observe → Prove → Improve
- Define “good” (outcomes + boundaries)
- Test behavior continuously (offline + online)
- Ship safely (canary + staged autonomy)
- Observe end-to-end (traces + metrics + alerts)
- Prove actions (evidence packet + audit trail)
- Improve from feedback (evaluation-driven iteration)
This is how autonomy becomes a production capability—not a sequence of demos.

The four pillars of AgentOps
Pillar 1: Continuous testing
Continuous testing is the most underinvested capability in agent programs—because teams test what they can easily see: response quality.
But agents fail where they act: tool calls, policies, permissions, escalation, and hidden behavior drift.
Example: the “approval agent”
In production, it faces:
- incomplete requests
- conflicting rules
- ambiguous descriptions
- persuasion attempts (“approve urgently”)
AgentOps testing focuses on four essentials:
1) Policy adherence
- Does it follow thresholds and approval paths?
- Does it escalate exceptions consistently?
2) Tool safety
- Does it call only allowed systems and endpoints?
- Does it pause when uncertainty is high?
3) Outcome correctness
- Does it create the right state change?
- Does it request missing info before acting?
4) Security resilience
Prompt injection is a practical risk for tool-using agents: untrusted text can attempt to override instructions and trigger unsafe actions or data exposure.
So your test suite must include adversarial inputs, not just happy paths.
How to implement continuous testing (the production way)
- Golden scenario sets: realistic cases (good / bad / ambiguous)
- Adversarial scenarios: policy bypass attempts, instruction overrides
- Regression suite: every incident becomes a test case
- Offline evaluation gates: no release without passing baseline checks
- Online drift monitoring: watch live traces for failure patterns
Shareable line:
Every incident becomes a test. Every test becomes a release gate.
Pillar 2: Canary releases
In classic software, canary reduces blast radius. In agents, canary prevents behavior surprise.
Because “releases” include:
- prompt edits
- tool schema changes
- policy updates
- model upgrades
- memory strategy changes
- escalation rule changes
A small change can quietly shift:
- escalation rate
- tool call timing
- retry/loop behavior
- policy boundary interpretation
The safest rollout pattern: staged autonomy
Don’t jump from “assistant” to “operator.” Move through stages:
- Shadow mode: recommend only
- Assisted mode: execute low-risk steps; human approves final action
- Partial autonomy: act only within strict constraints
- Bounded autonomy: act within narrow permissions + rollback guarantees
This matches how observability leaders describe the reality: if you can’t see each decision and tool call, you can’t ship safely.
Canary metrics leaders actually care about
- Action error rate (wrong updates/approvals)
- Escalation rate (too high = weak autonomy; too low = risky autonomy)
- Latency per task
- Cost per task (tokens + tools + retries)
- Policy violations blocked (a leading indicator)
Pillar 3: Rollback + compensation
Rollback fails in agent programs because teams confuse “deployment rollback” with “business rollback.”
Agent rollback has two layers:
1) Technical rollback: revert prompt/model/policy/tool versions
2) Business rollback (compensation): undo effects in real systems
- revoke access
- reverse workflow step
- correct system-of-record update
- compensating transaction
This is the core of reversible autonomy—a concept increasingly treated as non-negotiable for production-grade agents.
Design rules that make rollback real
- Idempotent tool calls where possible
- Two-step execution for high-risk actions (prepare → commit)
- Explicit reversal hooks stored with the action
- Human-by-exception for actions above defined risk thresholds
Shareable line:
If you can’t reverse it, you can’t automate it.
Pillar 4: Proof-of-Action
This is the missing layer in most rollouts.
When something goes wrong, executives ask:
- what happened?
- why did it happen?
- which policy applied?
- which tools were called?
- what changed in the system of record?
If the answer is “we can’t fully reconstruct it,” autonomy isn’t production-ready.
Proof-of-Action = evidence-by-design
A Proof-of-Action record answers:
- What did the agent do?
- Why did it decide that?
- Which tools were called, with what inputs?
- What did tools return?
- Which policies/constraints were applied?
- What changed downstream?
Agent observability practices emphasize capturing structured traces so behavior can be debugged and audited.
Audit logs matter because they create an immutable operational record for security and compliance workflows.
The Evidence Packet checklist
Capture for every significant action:
- request ID + timestamp
- agent version (prompt/model/policy/tool schema)
- plan summary (intent in plain language)
- tool calls + inputs + outputs
- applied policies/constraints
- short justification
- action executed + downstream response
- rollback/compensation hook reference
Shareable line:
Autonomy without proof is a demo. Autonomy with proof is an operating model.

The AgentOps stack in plain language
You don’t need dozens of platforms. You need five capabilities working together:
- Evaluation harness (regression + adversarial + release gates)
- Tracing + observability (end-to-end traces across plan→tools→outcome)
- Policy enforcement (allowed tools/actions + escalation rules)
- Change management (versioning + canary + staged autonomy)
- Audit + evidence (immutable logs + replayable traces)

The board-level question AgentOps answers
AgentOps converts agentic AI from:
- unpredictable → operable
- fragile demos → repeatable production capability
- “trust me” → auditable proof
- irreversible risk → reversible autonomy
Board question (shareable):
“Can we prove what our agents did—and undo it if needed?”

What I’d do Monday morning
If you’re leading enterprise AI and want visible results fast—without slowing teams—here’s the Monday plan.
Step 1: Pick one workflow that “touches reality”
Choose a workflow where an agent:
- changes a system of record, or
- triggers a downstream action.
Start with one. Don’t boil the ocean.
Step 2: Define the autonomy boundary in one page
Write:
- what the agent is allowed to do
- what it must never do
- when it must escalate
- what “done” means
This becomes your operating contract.
Step 3: Instrument the trace
Before you improve intelligence, improve visibility:
- capture plan steps
- capture tool calls (inputs/outputs)
- capture final state change
If you can’t trace, you can’t operate.
Step 4: Create a “Top 30” regression suite
Collect 30 real scenarios:
- 10 clean
- 10 ambiguous
- 10 adversarial
Run them before every release.
Step 5: Ship with a canary and staged autonomy
Start in shadow mode for high-risk actions.
Move to partial autonomy only when metrics stabilize.
Step 6: Build rollback hooks before scaling
For every significant action, define:
- how to reverse it
- who approves reversal (if needed)
- where that reversal is logged
Step 7: Make Proof-of-Action non-negotiable
Adopt an Evidence Packet format and enforce it for any action that matters.
If you do only one thing this week:
Implement end-to-end tracing and Evidence Packets. Everything else becomes possible after that.
Global glossary
Agent: A system that can plan and execute tasks using tools/APIs, not only generate text.
AgentOps: Production practices for deploying and operating AI agents safely.
Canary release: Rolling out changes to a small subset first to validate safety and performance.
Compensation: Undoing or reversing the effect of a real-world action.
Evidence Packet: Structured Proof-of-Action record of decisions, tool calls, applied policies, and outcomes.
LLM Observability: Tracing and monitoring of agent/model interactions, including tool calls and outcomes.
Prompt injection: Attack where untrusted text attempts to override instructions and trigger unsafe tool actions or data exposure.
Staged autonomy: Progressive rollout from shadow → assisted → partial → bounded autonomy.
FAQ
Is AgentOps different from MLOps?
Yes. MLOps manages models. AgentOps manages behavior in action—tools, policies, rollout control, reversibility, and evidence trails.
Why do agents need canary releases?
Because small prompt/tool/policy changes can create silent behavior drift. Canary reduces blast radius and enables safe iteration.
What does rollback mean for agents?
Rollback means reverting the agent version and undoing downstream system changes through compensation hooks (reversible autonomy).
What is Proof-of-Action?
A verifiable evidence packet showing what the agent did, why, which tools were called, what policies applied, and what changed.
How do you reduce prompt injection risk for tool-using agents?
Treat external text as untrusted, constrain tools, enforce policy gates, and test explicitly for injection attempts.

Conclusion column: The new reliability contract
DevOps created a reliability contract for software: ship fast, recover fast, learn fast.
AgentOps creates a reliability contract for autonomy:
- Test behavior continuously
- Ship changes safely
- Make actions reversible
- Prove what happened
The next advantage won’t come from “more agents.”
It will come from operable autonomy—autonomy you can observe, audit, and reverse.
Autonomy at scale is not an AI problem. It’s an operating model problem. AgentOps is the operating model.
This article is part of a broader architectural framework defined in the Enterprise AI Operating Model, which explains how organizations design, govern, and scale intelligence safely once AI systems begin to act inside real enterprise workflows.
👉 Read the full operating model here:
https://www.raktimsingh.com/enterprise-ai-operating-model/
References
- IBM: AgentOps overview
- TechTarget: AgentOps definition
- OpenAI: Understanding prompt injection
- OpenAI: Safety in building agents
- OpenAI: Admin/Audit Logs API
- Datadog: LLM Observability
- AgentOps survey (research signal)
Further reading
- OpenAI: New tools for building agents
- Practical evaluation + tracing approaches for agents
- The Agentic Identity Moment: Why Enterprise AI Must Treat Agents as Governed Machine Identities | by RAKTIM SINGH | Dec, 2025 | Medium
- The Agentic AI Platform Checklist: 12 Capabilities CIOs Must Demand Before Scaling Autonomous Agents | by RAKTIM SINGH | Dec, 2025 | Medium
- The AI SRE Moment: How Enterprises Operate Autonomous AI Safely at Scale | by RAKTIM SINGH | Dec, 2025 | Medium
- The Enterprise AI Control Plane: Why Reversible Autonomy Is the Missing Layer for Scalable AI Agents | by RAKTIM SINGH | Dec, 2025 | Medium
- Agentic FinOps: Why Enterprises Need a Cost Control Plane for AI Autonomy – Raktim Singh
- The Agentic Identity Moment: Why Enterprise AI Agents Must Become Governed Machine Identities – Raktim Singh
- Enterprise Agent Registry: The Missing System of Record for Autonomous AI – Raktim Singh
- The AI SRE Moment: Why Agentic Enterprises Need Predictive Observability, Self-Healing, and Human-by-Exception – Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.