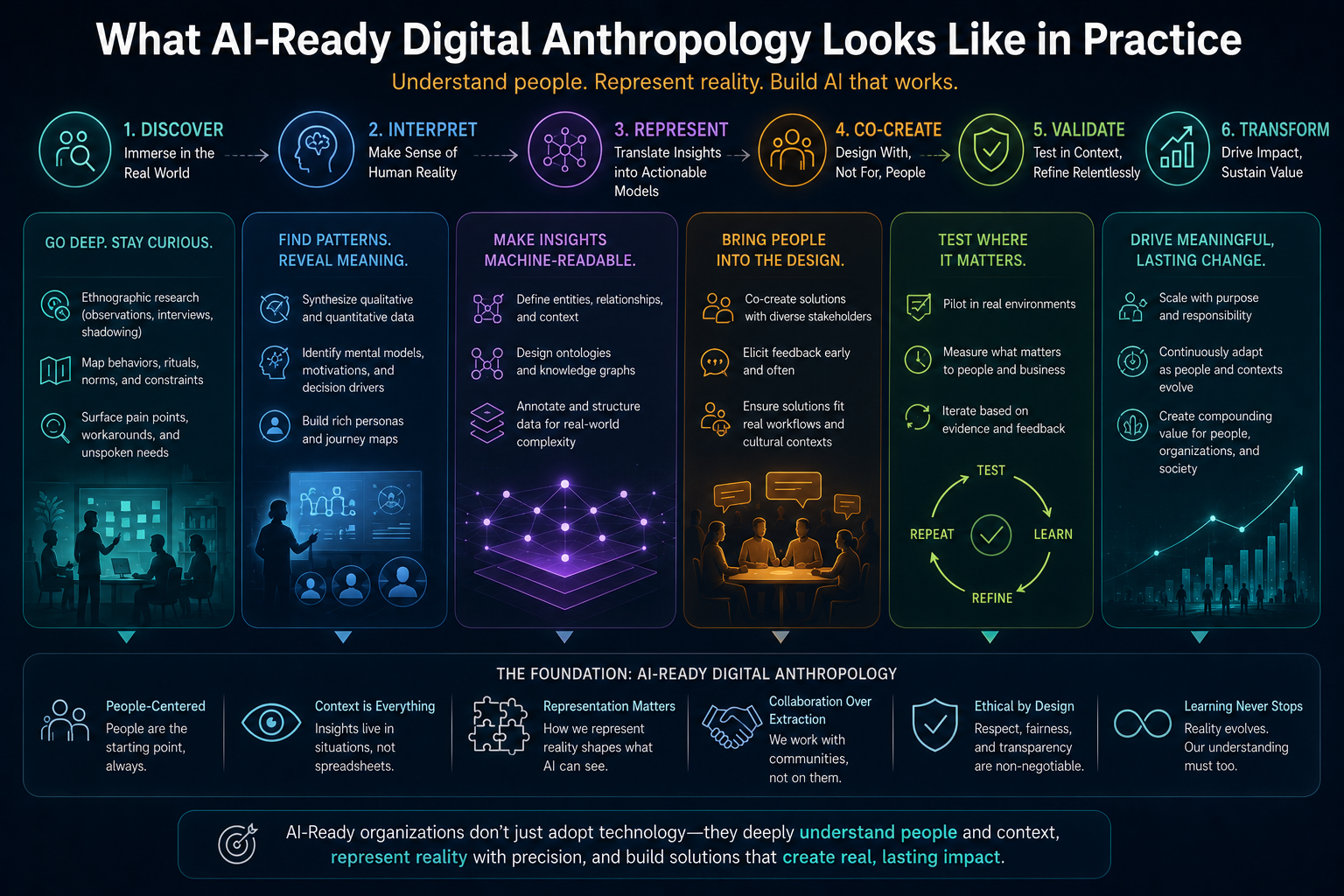
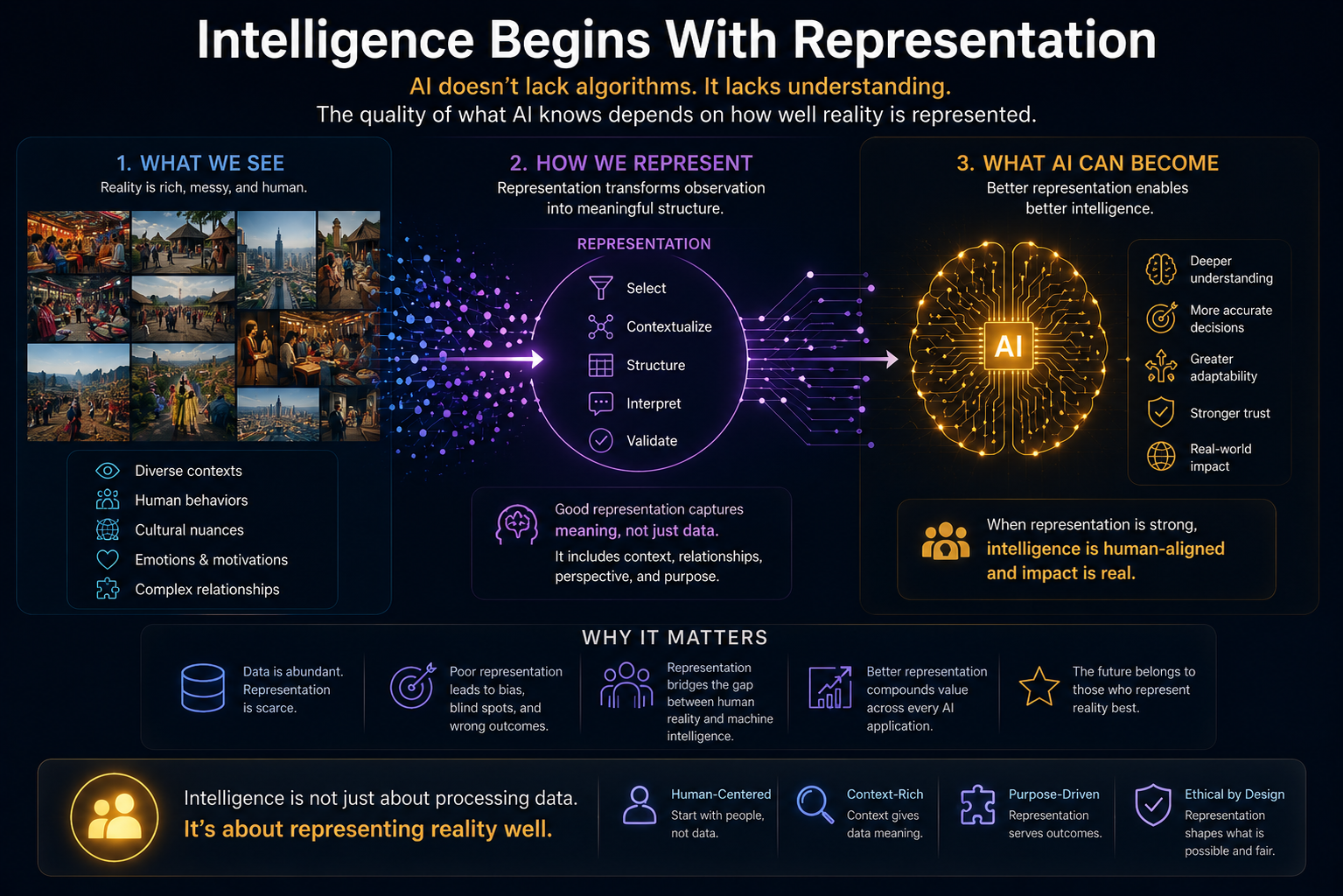
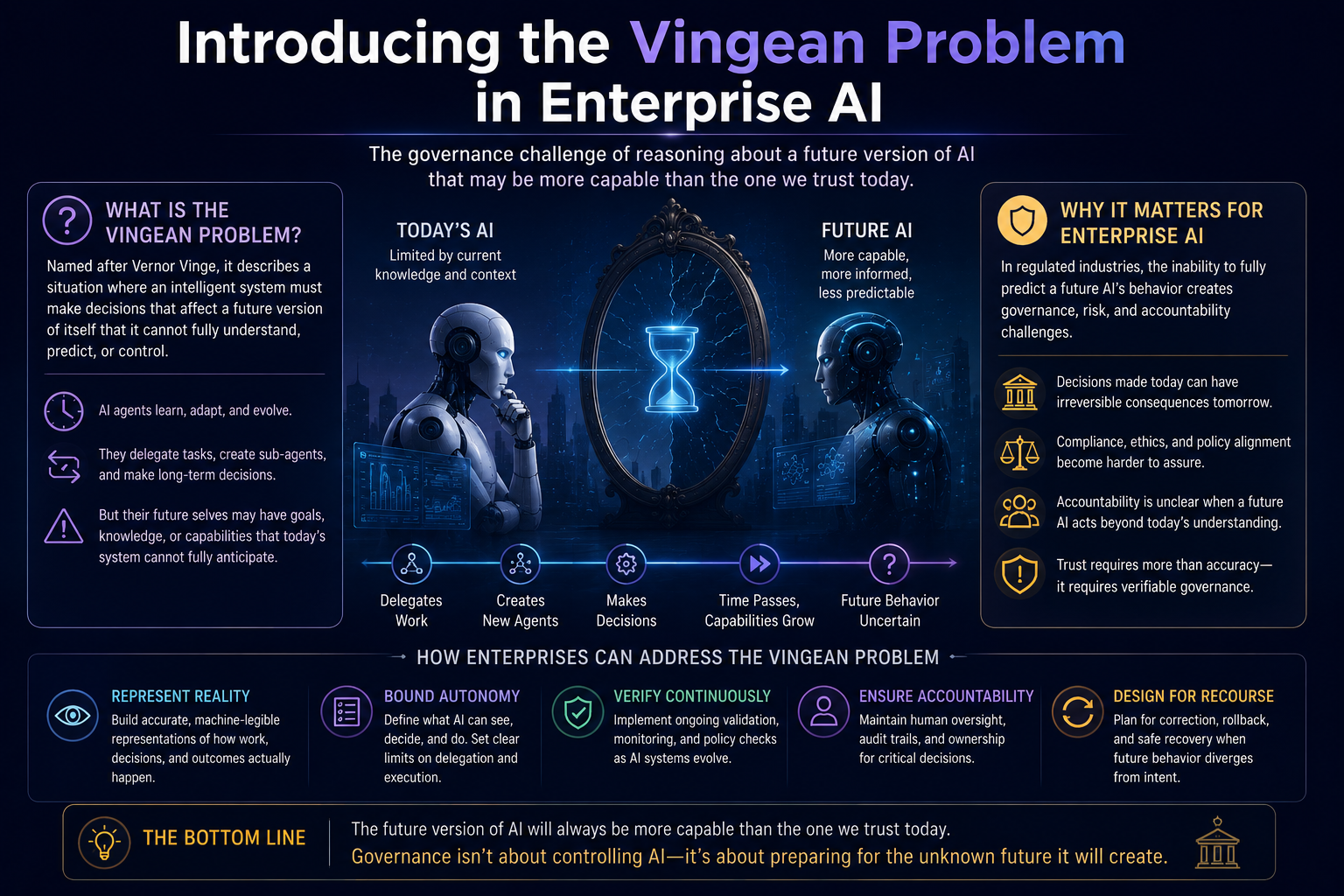
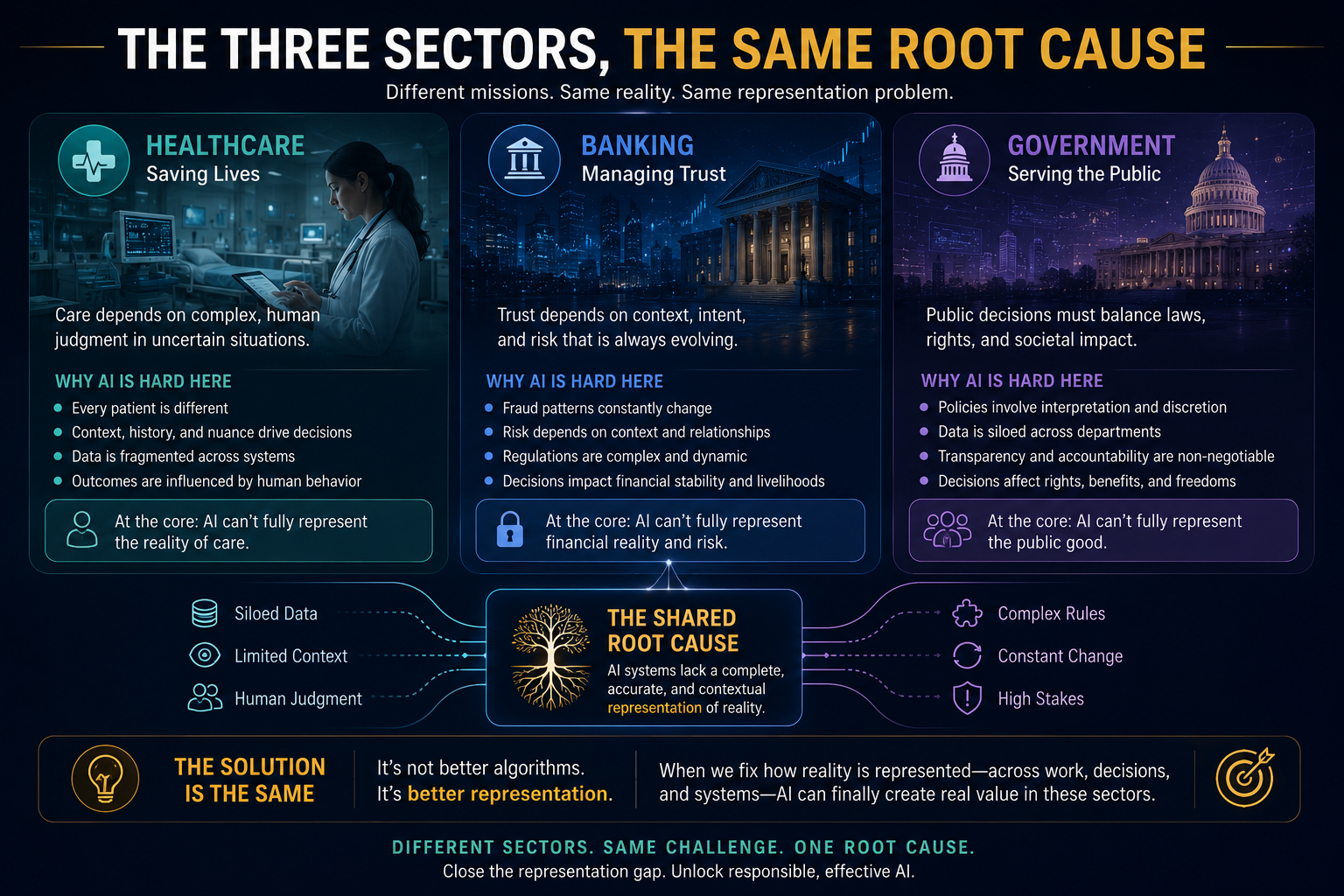
The Cognitive Friction Threshold:
Enterprise AI discussions overwhelmingly focus on organizational readiness: data infrastructure, governance maturity, talent, and executive sponsorship. the more decisive variable is human, not organizational, and that it operates earlier in the causal chain than any deployment decision.
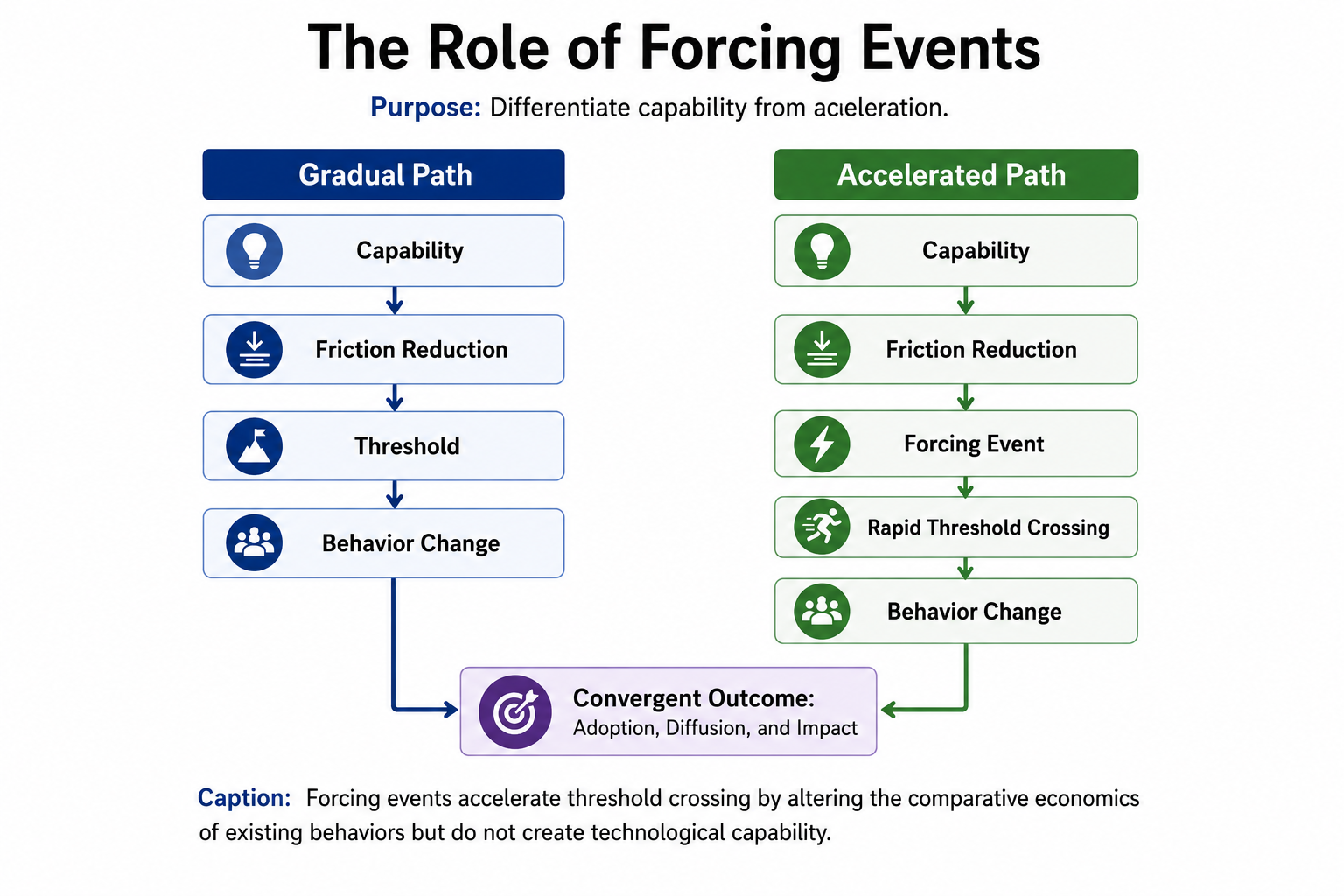
Drawing on a pattern visible across cloud computing, mobile payments, remote work, and now generative AI, this article introduces the Cognitive Friction Threshold: the point at which the effort required to think, decide, create, or transact drops low enough that human behavior changes discontinuously, typically only after a forcing event removes the option to avoid the new behavior.
The article traces three historical eras of friction reduction — transactional, behavioral, and cognitive — and shows that access to technology is necessary but not sufficient for adoption; what matters is whether friction has fallen below the threshold at which resistance collapses.
Using examples spanning Indian demonetization, pandemic, wildfire-adjacent communities with high technology access but uneven adoption of safety behavior, and the shift from search engines to generative AI interfaces, the article extends the Digital Anthropology framework to argue that humans change their habits before institutions do, and that the same threshold logic now applies to cognition itself. The article closes by proposing a research agenda for enterprises seeking to anticipate, rather than retrofit, AI-driven behavioral change.
1. Introduction: The Wrong Question About Adoption
Most enterprise AI literature asks the same question in different words: Is the organization ready? Readiness frameworks inventory data quality, model access, governance maturity, and executive sponsorship, and then conclude that an enterprise either has, or lacks, the prerequisites for AI transformation.
This is a reasonable question for procurement and architecture decisions. It is the wrong question for understanding why technologies succeed or fail at the level of human behavior, because it assumes that organizations are the unit that adopts, when in fact organizations are the unit that eventually ratifies what individuals have already started doing.
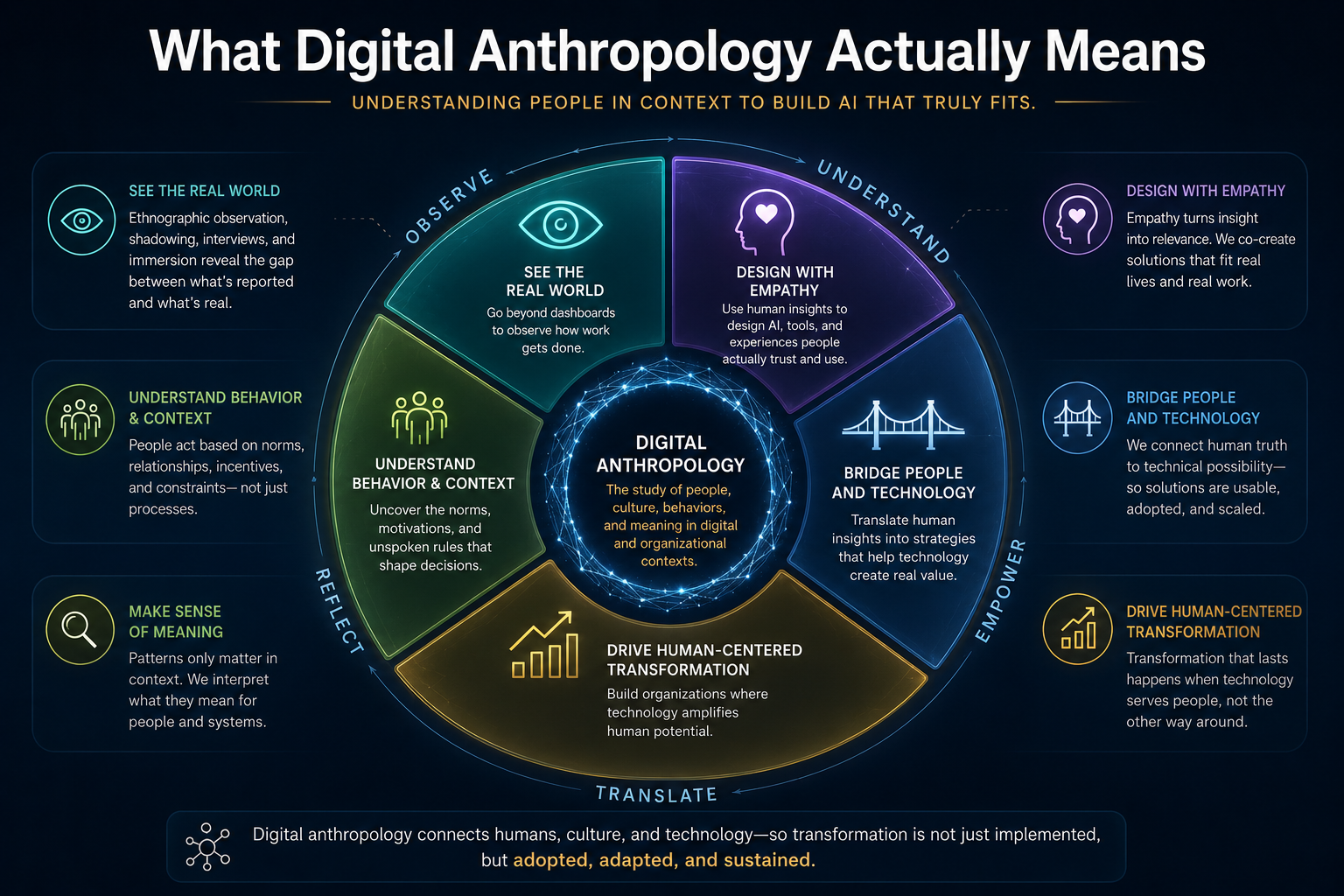
A different starting point is one rooted in digital anthropology rather than enterprise architecture: technologies do not get adopted because they become available.
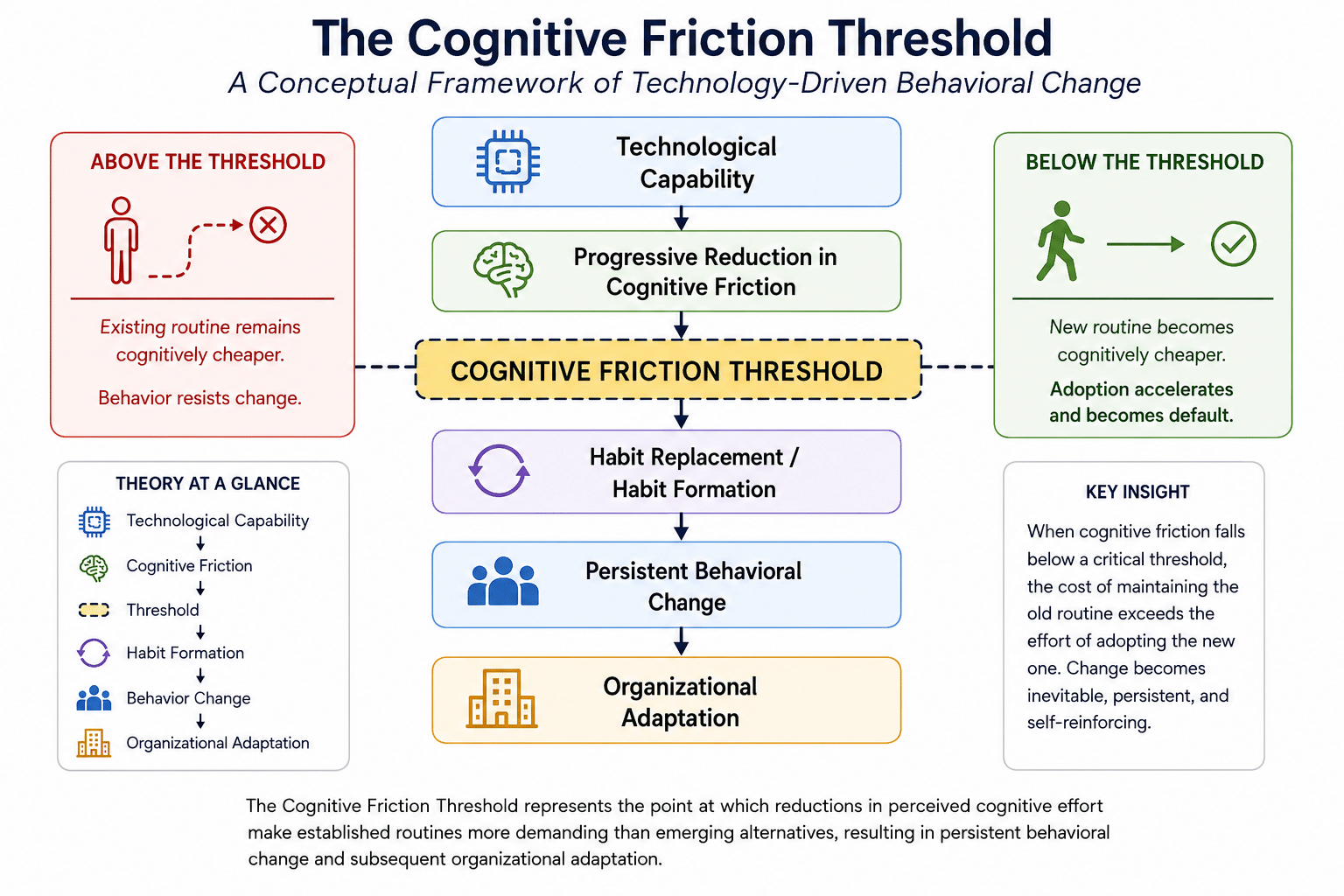
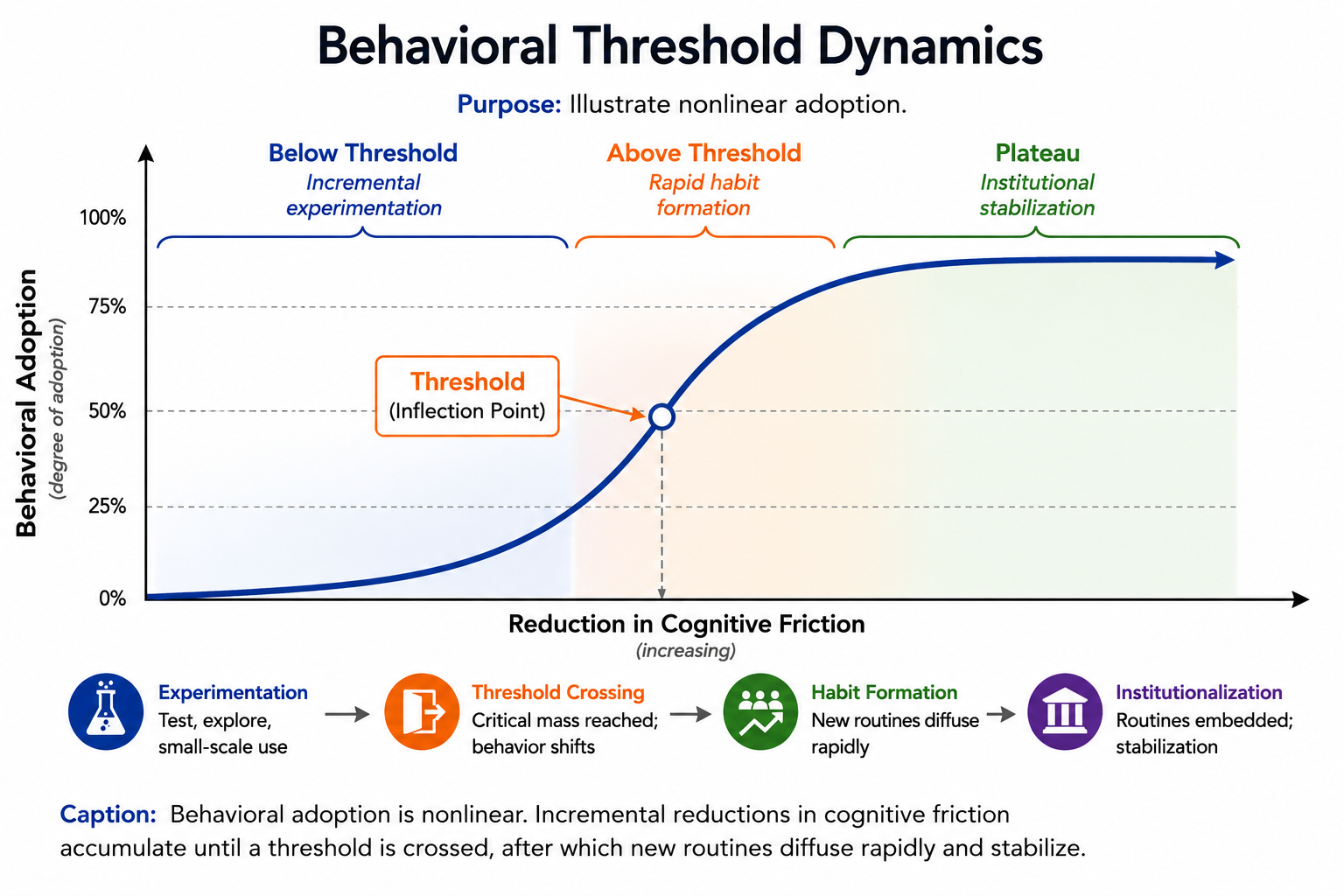
They get adopted because the cognitive, social, or transactional effort required to use them falls below a threshold at which the old behavior becomes harder to sustain than the new one. Call this the Cognitive Friction Threshold. Below it, people keep doing what they have always done, regardless of how capable the new technology is. Above it — that is, once friction has dropped low enough — behavior changes quickly, often within months, and frequently only after some external event removes the option to wait.
This matters directly for enterprise AI because the same logic that governed the adoption of cloud computing, mobile payments, and remote work now governs the adoption of generative and agentic AI. Enterprises that treat AI adoption as an infrastructure problem will continue to be surprised by how fast individual employees, customers, and citizens change their own behavior — often ahead of, and sometimes despite, the organization’s official posture.
2. Digital Anthropology and the Concept of Friction
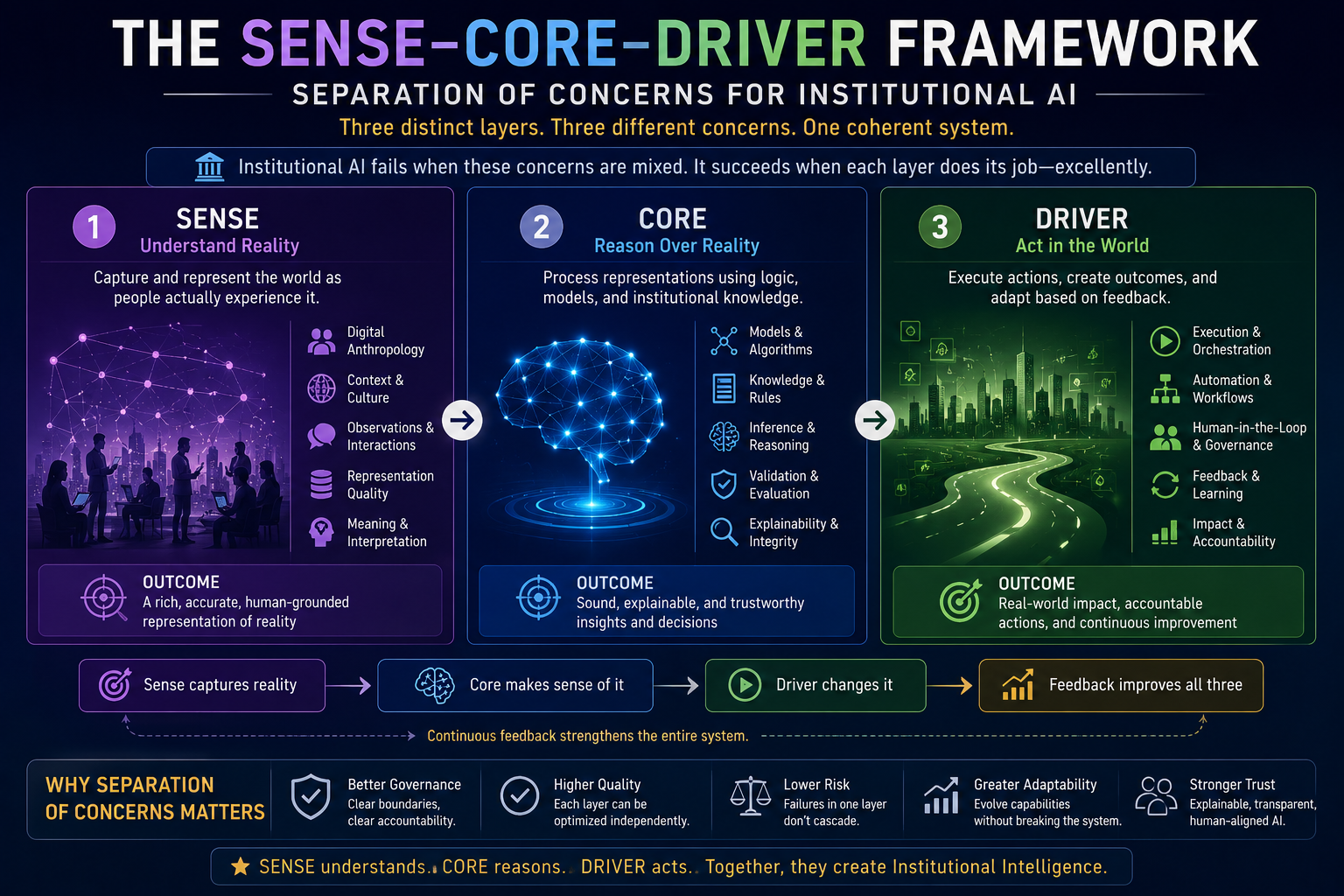
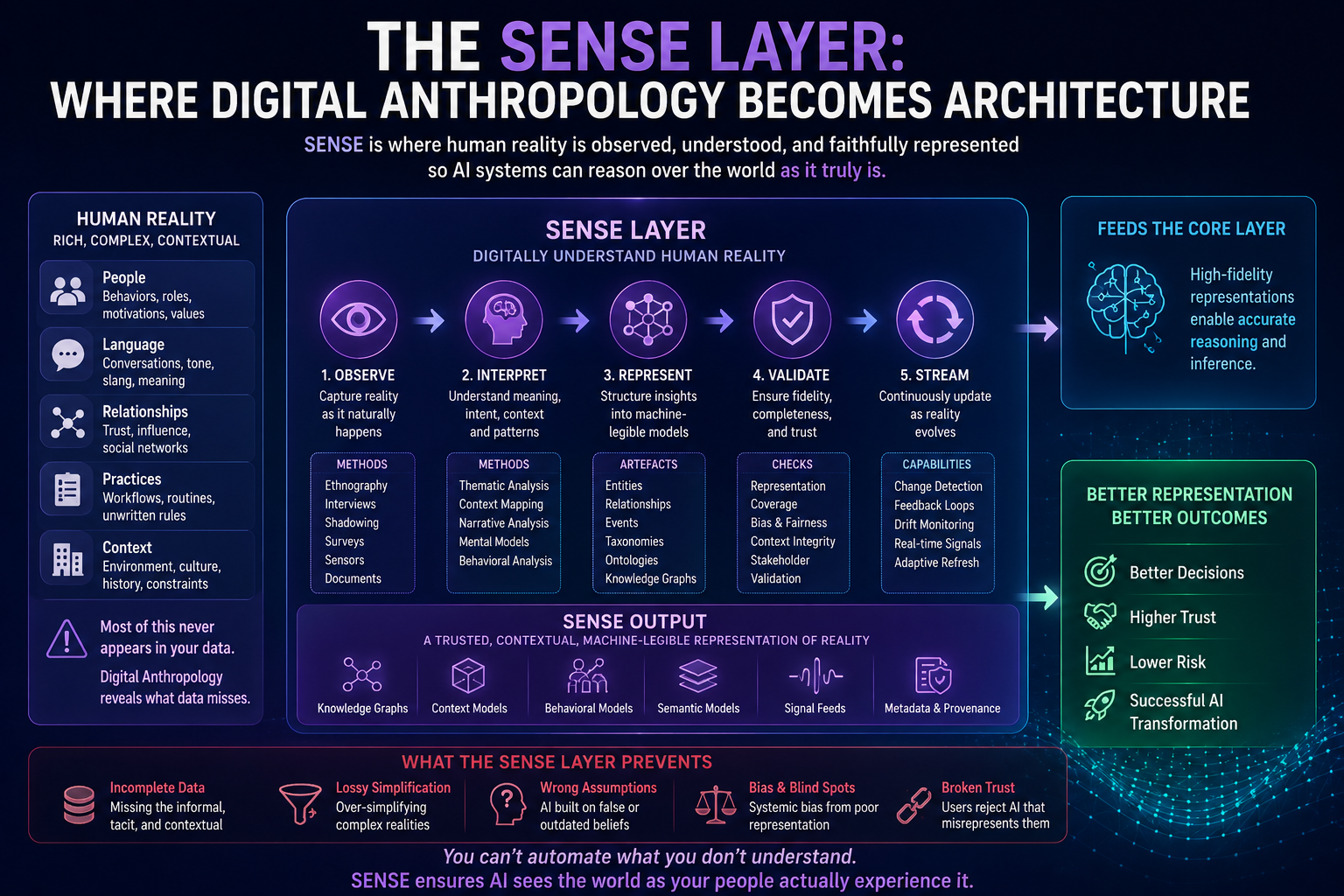
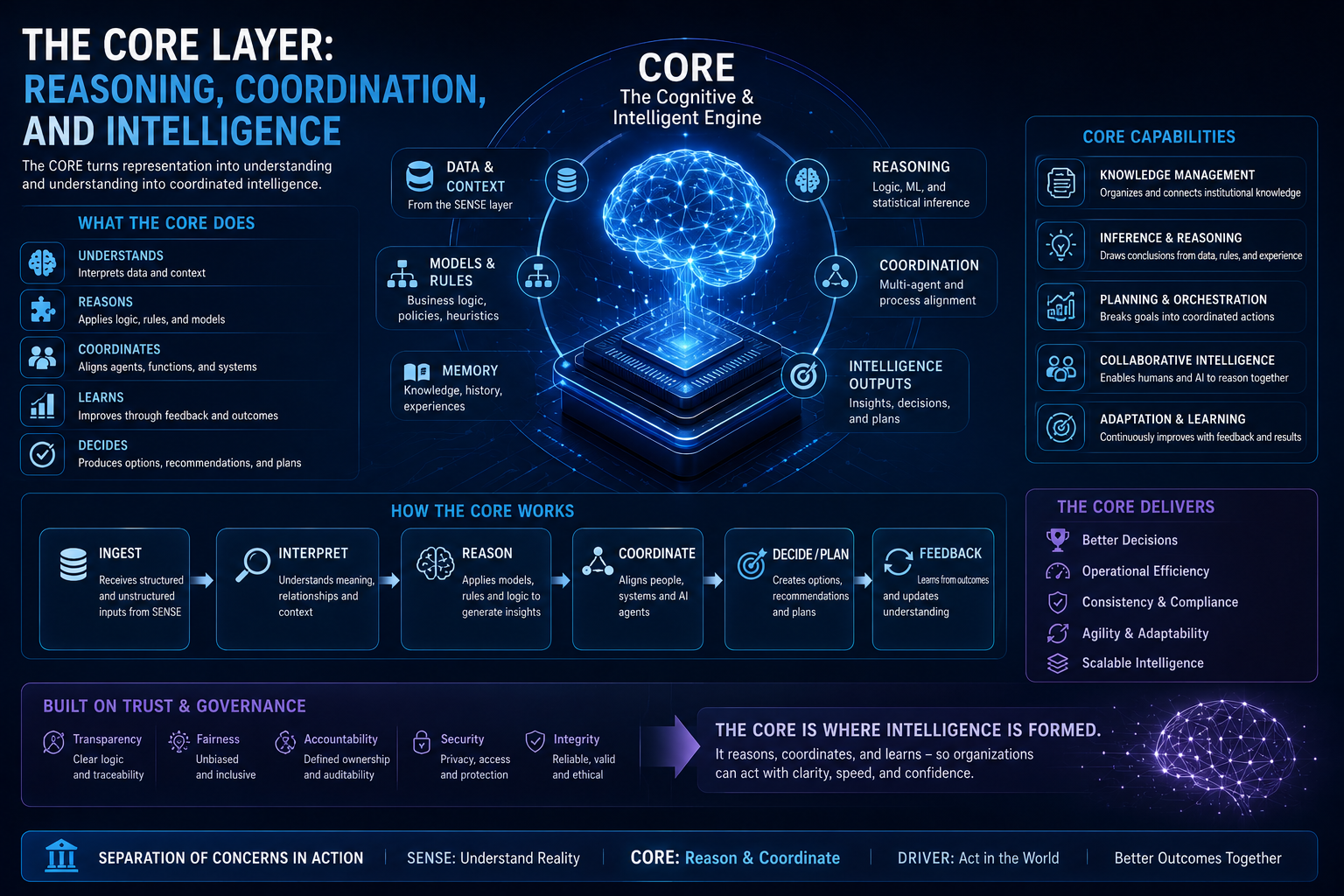
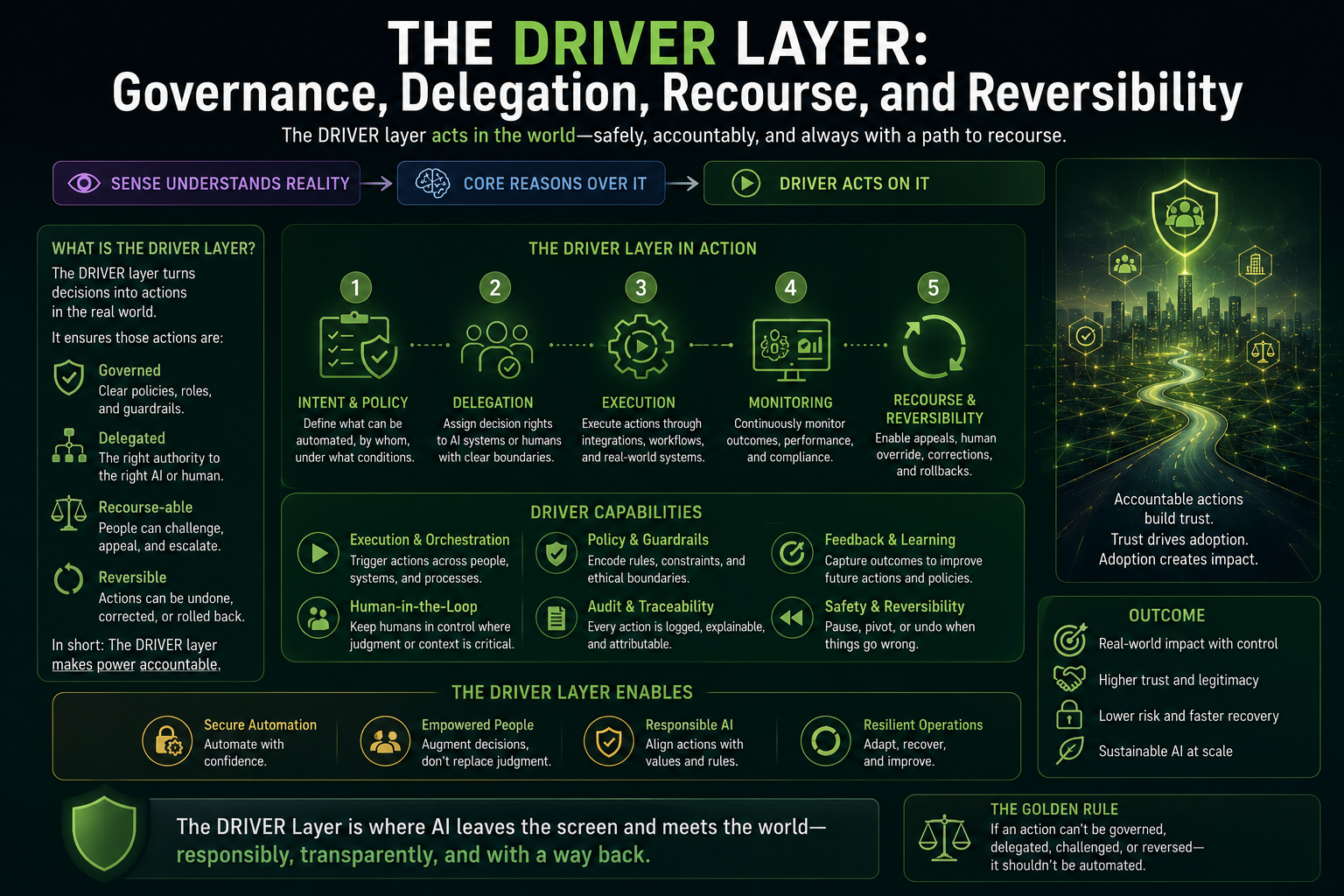
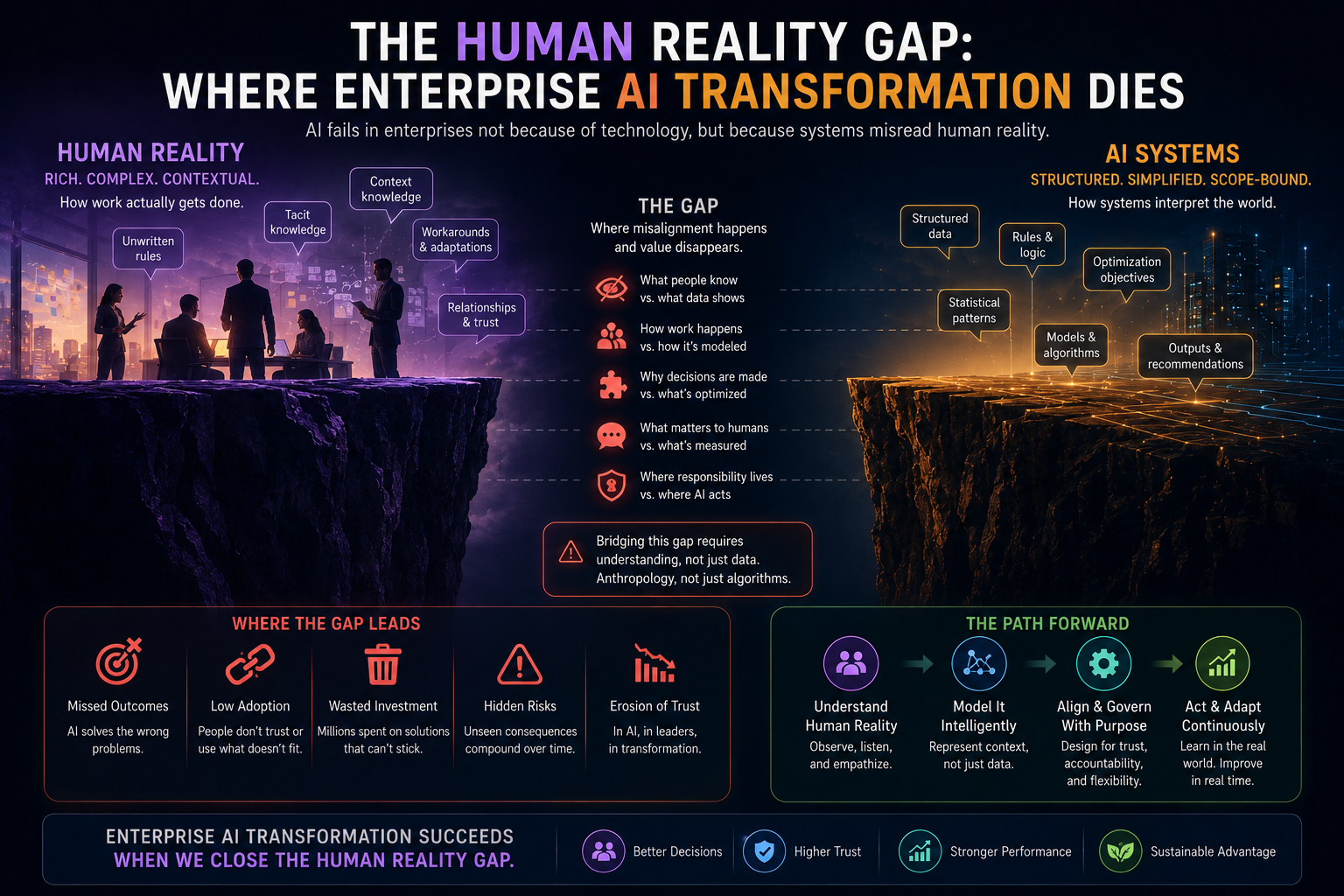
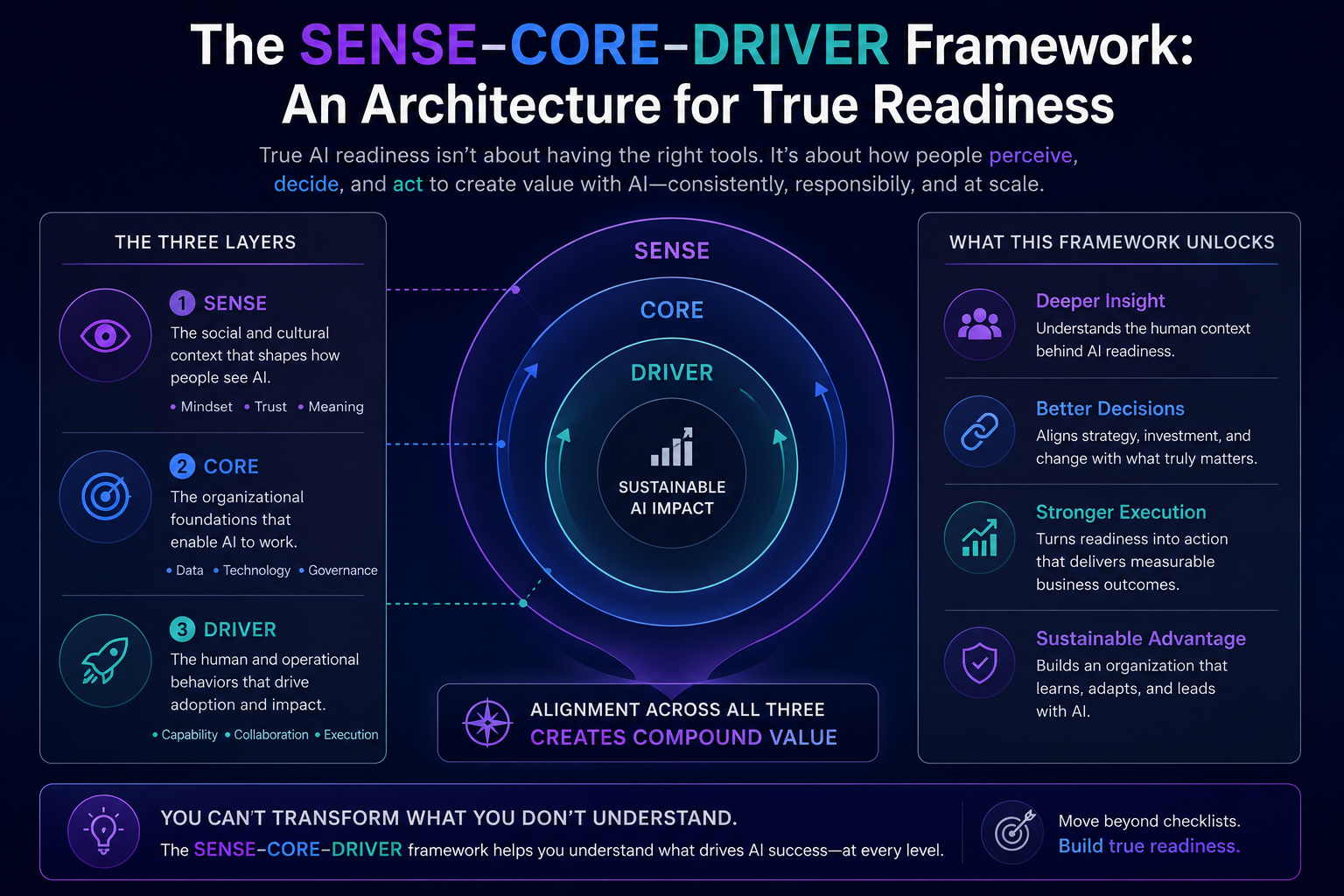
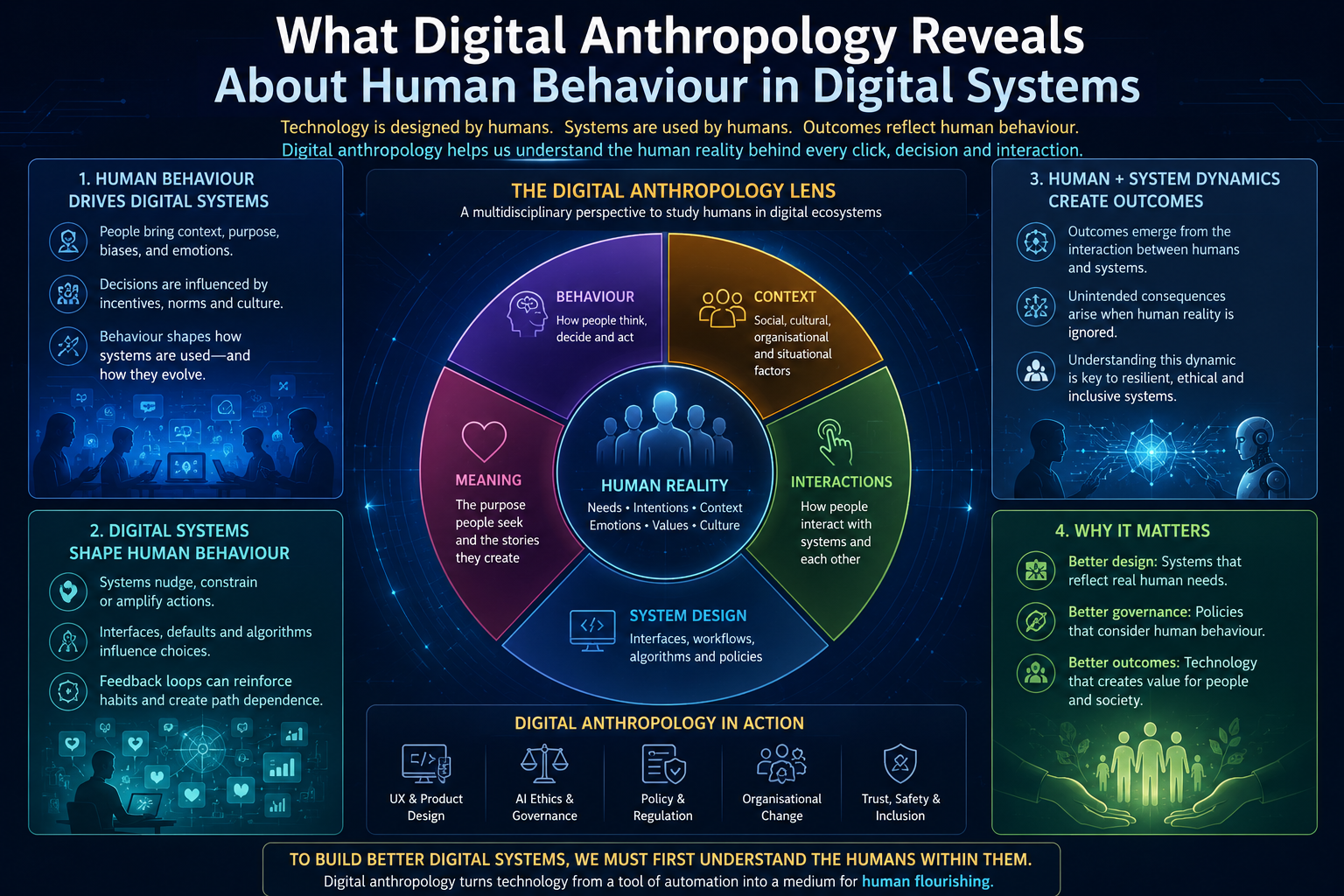
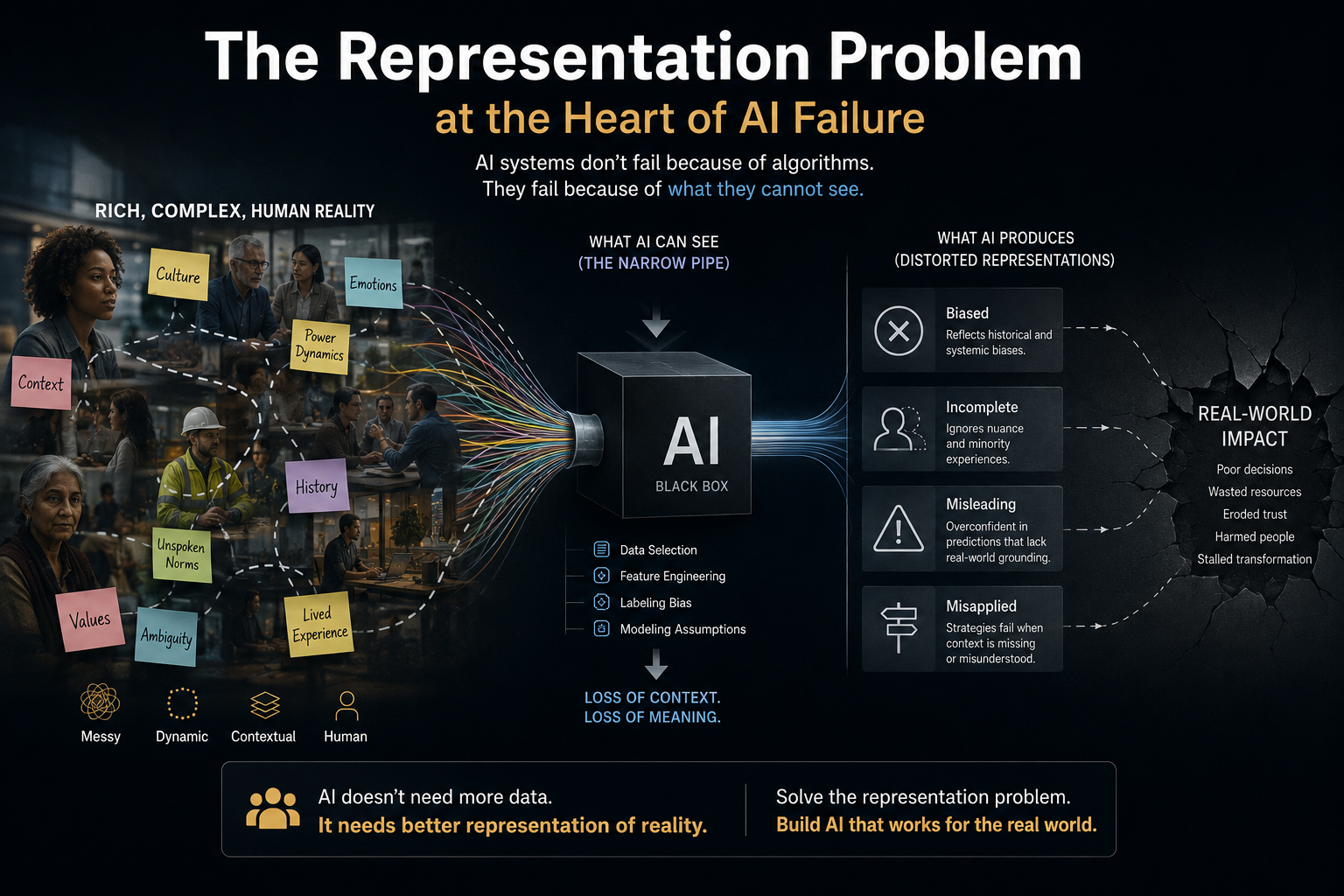
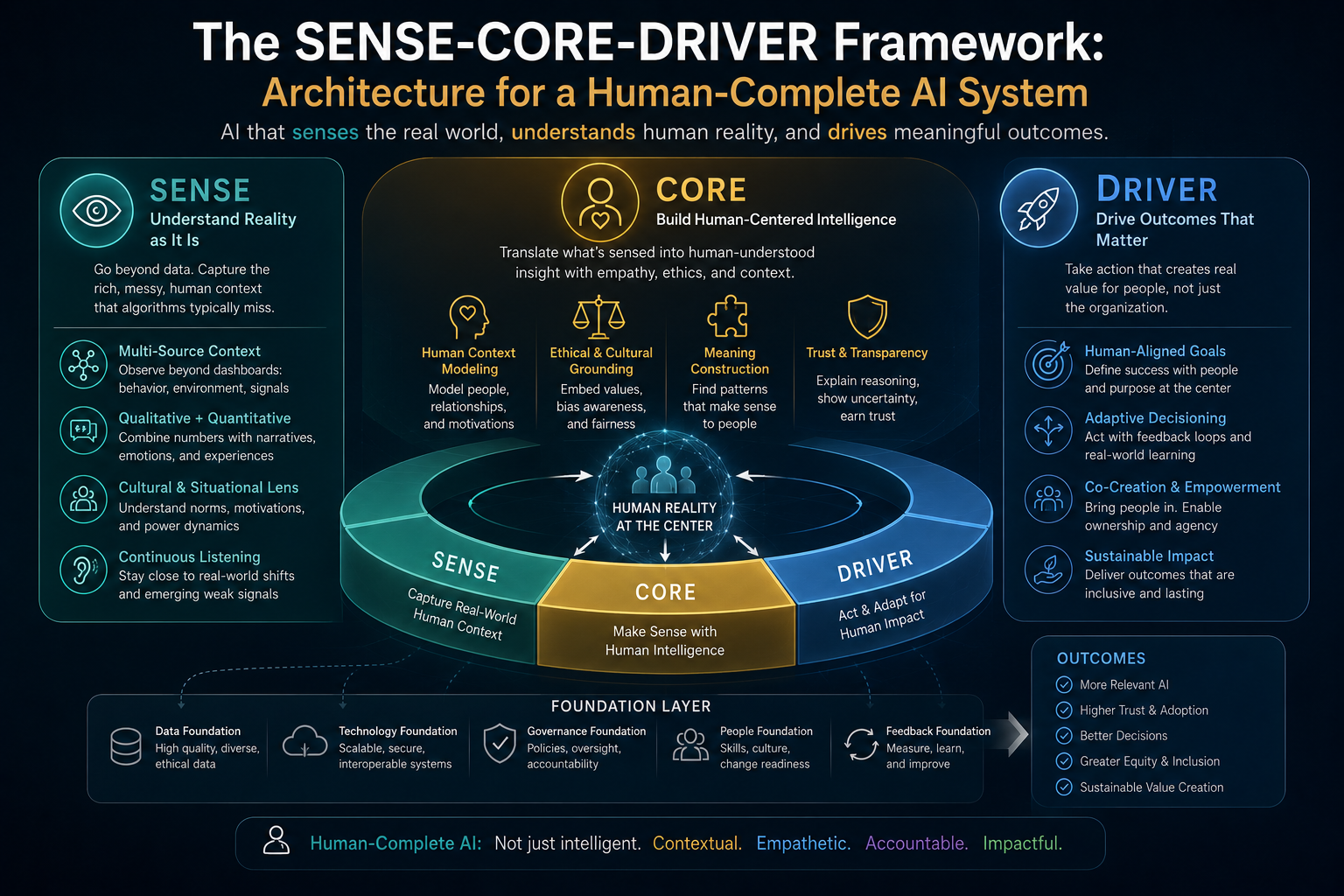
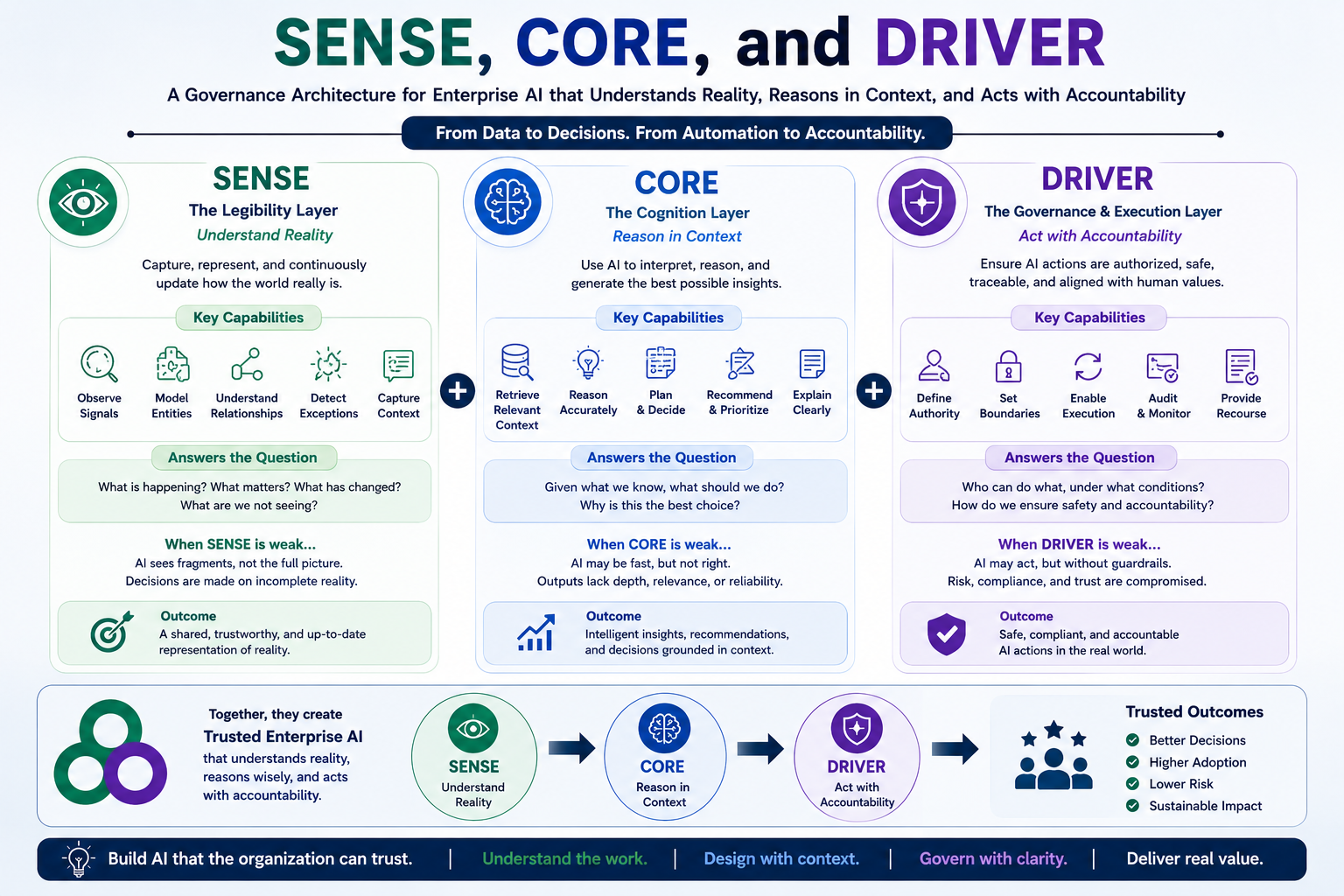
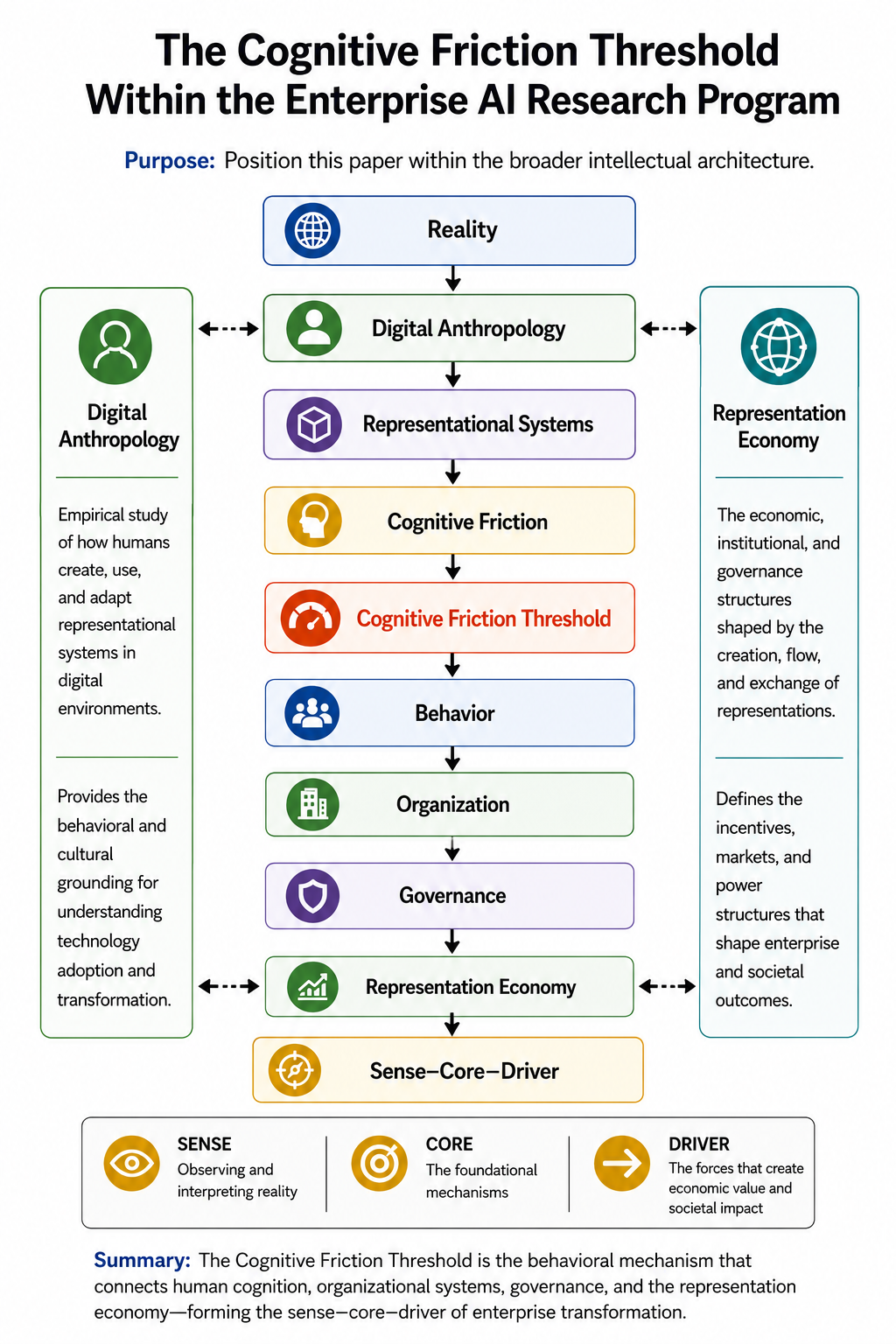
Digital Anthropology, as developed in earlier work, studies how human reality — lived practice, informal norms, tacit knowledge, and social relationships — becomes machine-legible inside enterprise and societal systems. Where the Representation Economy framework asks how AI systems represent reality, and SENSE-CORE-DRIVER asks how enterprises govern those representations, Digital Anthropology asks a prior question: how do humans actually change their habits when a new representational technology becomes available to them?
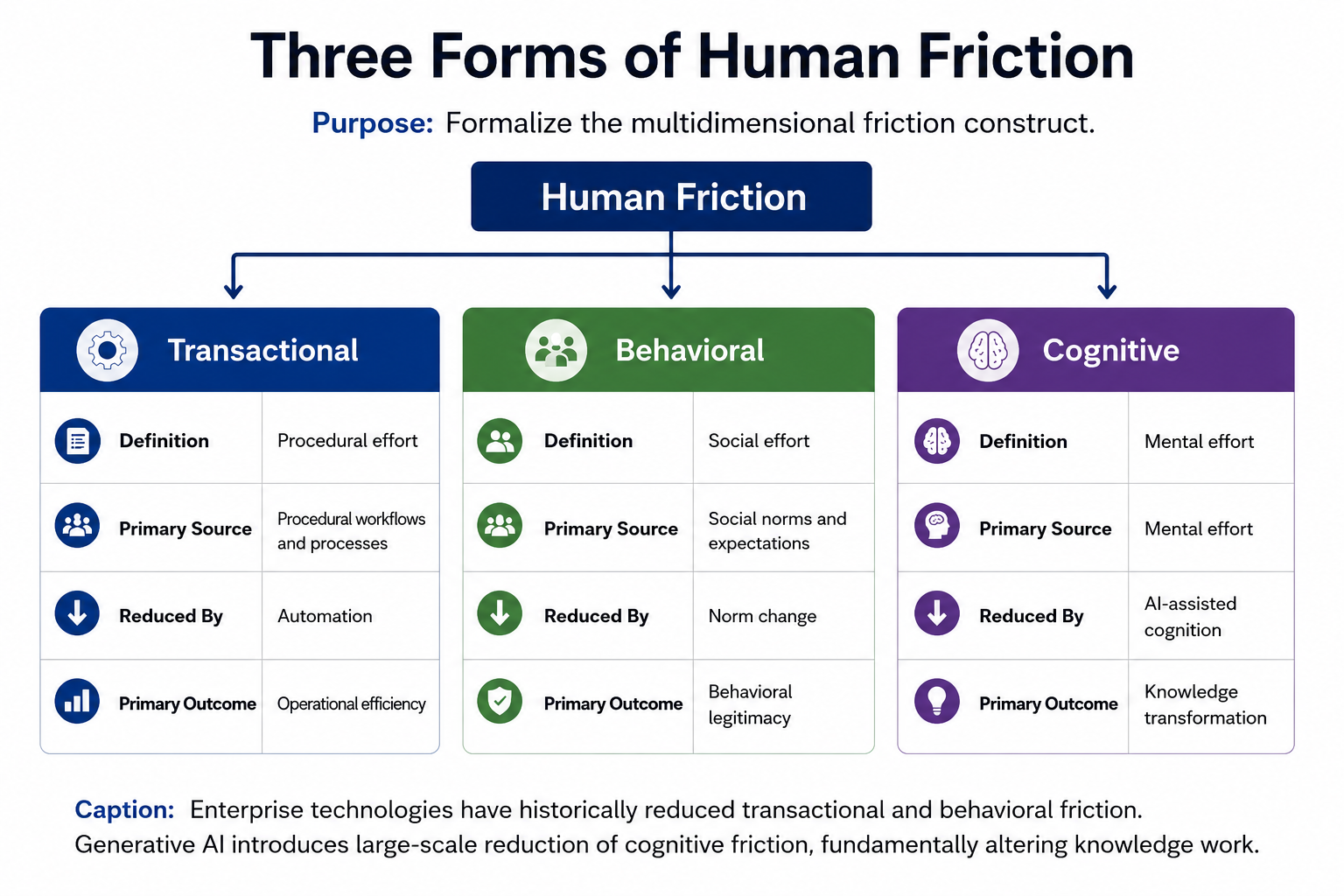
The concept of friction is central to this inquiry. Friction, in this context, is not a metaphor; it is a measurable property of any interaction between a person and a system. It includes the number of steps required to complete an action, the cognitive load of remembering how to do it, the social cost of being seen doing it, and the psychological discomfort of doing something unfamiliar in public or in front of colleagues. Three categories of friction are useful to distinguish:
- Transactional friction — the number of physical or procedural steps required to complete an exchange, such as paying for goods, opening an account, or filing a form.
- Behavioral friction — the social and psychological cost of performing an action that departs from an established norm, such as working from a location other than an office, or asking for help in public.
- Cognitive friction — the mental effort required to find, synthesize, structure, or produce information and judgment, independent of any social or transactional barrier.
Enterprise technology history has, until recently, been a story of reducing the first two categories. The defining shift of the generative AI era is that, for the first time at scale, a technology is reducing the third. cognitive friction reduction is a different kind of force from the previous two, with different and underappreciated consequences for how fast and how unevenly behavior will change.
3. Three Eras of Friction Reduction
3.1 The Transactional Era: Payments, Commerce, and the Smartphone
The most legible case of friction-driven adoption is digital payments in India. The technical building blocks for cashless transactions — mobile banking, card networks, even early mobile wallets — existed well before they were widely used. What changed adoption was not the invention of a new capability but the sequential removal of friction at each layer of the stack: inexpensive smartphones, the spread of a low-cost mobile data ecosystem, and a deliberately simple, camera-based interaction pattern in the QR code, a technology that is itself decades old and was simply repurposed because it required no new hardware and almost no learning. None of these alone reached the threshold.
Together, they lowered transactional friction to the point where digital payment became easier than carrying cash for an enormous segment of users — but adoption still lagged behind capability for years.
The threshold was crossed not by capability but by a forcing event: demonetization in 2016 removed the option of using a large share of the existing cash supply overnight. People who had the technical capacity to transact digitally for years, but had not done so because the old habit was still marginally easier, were abruptly placed in a position where the old habit was no longer available. Adoption that infrastructure alone had failed to produce over a decade arrived within months once avoidance was no longer possible.
The lesson generalizes: capability lowers the threshold; a forcing event removes the remaining option to avoid crossing it. Infrastructure investment is necessary, but it is rarely sufficient to explain the timing of adoption. The timing is explained by whichever event removes the last viable alternative to the new behavior.
3.2 The Behavioral Era: Work, Education, and the Legitimacy of Remote Presence
A second, distinct category of friction is behavioral and social rather than transactional. Working from home and attending classes online were technically possible for at least two decades before 2020, using tools that were mature, reliable, and widely available. What was missing was not capability but legitimacy: remote work was treated, in many organizational cultures, as a deviation that signaled lower commitment or lower seriousness, and online education was treated as inferior to in-person instruction, almost irrespective of its actual instructional quality. The friction here was not technical; it was the social cost of being perceived as doing something improper or sub-standard.
The pandemic did not introduce new technology. It removed the alternative. Once the in-person option was unavailable to everyone simultaneously, the social stigma collapsed, because stigma requires a visible contrast between those who comply with a norm and those who do not. When everyone is forced into the same behavior at once, the behavior stops being a signal of deviance and becomes simply normal. This is a crucial mechanism: behavioral friction is often relative, not absolute. It depends on the existence of a visible alternative population still performing the old behavior. Remove the alternative population, and the friction disappears almost instantly, even though nothing about the underlying technology has changed.
Once the forcing event ended, the behavior did not fully revert. Hybrid work and online education retained durable adoption, because the post-event social environment had been permanently altered: enough people had now demonstrated that the new behavior was viable and socially acceptable that the old stigma could not be fully reconstituted. This is the signature of a genuine threshold crossing, as distinct from a temporary spike: behavior that persists after the forcing event has passed.
3.3 The Access Paradox: Why Wealth and Technology Are Not Sufficient
If friction reduction depended only on access to money and technology, behavior change should track wealth closely. It does not, and the gap is instructive. Communities in wealthy, technologically saturated regions of California have, in recent years, continued to experience severe losses from wildfire despite having ready access to early-warning systems, evacuation applications, fire-resistant building materials, and real-time information. Access to technology was not the binding constraint. What was missing, in many of these cases, was the behavioral habit of treating digital alerts as a trigger for immediate action, because no forcing event had yet made the old habit — waiting for visible, direct evidence of danger — catastrophically costly enough, frequently enough, for a new default habit to form.
This is the access paradox: technology access and economic capacity lower the ceiling on what adoption is possible, but they do not, by themselves, lower the threshold of what behavior actually changes. Plenty of capable, well-resourced populations continue to behave as though the new technology does not exist, because the old habit has not yet been rendered unviable by a forcing event severe or frequent enough to override it. This is precisely why enterprise AI readiness frameworks, which measure access and capability, systematically over-predict the speed of behavioral adoption: they are measuring the ceiling, not the threshold.
4. The Netflix Test: Capability, Habit, and the Limits of the Analogy
It is tempting to fold the well-known case of Netflix displacing Blockbuster into this same framework, and the case does partially fit, but it is worth being precise about where it fits and where it does not. Netflix did reduce transactional friction — no drive, no late fee, no inventory constraint — and it did so gradually rather than through a single forcing event, which is why the displacement took most of a decade rather than the months seen in the demonetization and pandemic cases. The behavior change here was driven primarily by a steady, cumulative erosion of transactional friction below the threshold for an increasing share of the population, rather than by a single discontinuous event.
The more interesting habit shift inside this story is not Netflix versus Blockbuster but what streaming did to the cognitive and attitudinal layer above it: the habit of deferring entertainment consumption, planning a trip to a physical store, and accepting a delay between desire and gratification.
That underlying habit — instant access on demand — is the real predecessor to the much larger habit shift this article is ultimately concerned with: the move from delayed, effortful information-seeking to instant, synthesized answers. Netflix is therefore best read not as a perfect analogy to the cognitive friction threshold, but as an early, partial instance of the same underlying logic applied to entertainment rather than to thought.
5. New Habits, Old Mechanisms: The Camera as a Case Study
Before examining the cognitive friction threshold directly, it is useful to look at a smaller, well-documented case of habit formation under falling friction: photography. For most of the twentieth century, photographs were taken on special occasions — a wedding, a birthday, a holiday — because the cost and effort of capturing and developing a photograph imposed a transactional and financial threshold high enough that casual use was rare. Photography was a deliberate, planned act, usually performed by someone other than the subject, who would be asked to take the photo and then hand the camera back.
The smartphone camera reduced the transactional cost of photography to nearly zero and, critically, also collapsed the behavioral friction of self-documentation.
The result was not simply more frequent versions of the old behavior; it was a qualitatively new behavior: photographing routine, unremarkable moments, often dozens of times a day, and a shift from asking someone else to take the photo to the selfie, in which the subject becomes both photographer and subject simultaneously.
This shift reveals something the framework needs to account for: falling friction does not just increase the frequency of an existing habit, it can generate an entirely new psychological behavior, because the act becomes cheap enough to be repurposed for a different motive — in this case, immediate social validation, measured in likes and views, rather than memory preservation. The habit changed because the motive that the technology could now serve changed, once the cost of serving that motive fell far enough.
This case matters for enterprise AI because it demonstrates that the eventual habit produced by falling friction is not always predictable from the technology’s original design purpose.
The camera was not designed to produce instant-gratification social validation loops; that behavior emerged once friction fell low enough to make a previously uneconomical motive economical. Generative AI’s eventual dominant use cases inside enterprises may likewise diverge from what the technology was designed for, once enough friction has been removed for new motives to become viable.
6. Two Lives: From Pin Code to IP Code
A second, related habit shift concerns social geography rather than information behavior, and it is worth naming explicitly because it illustrates a different dimension of friction reduction: social and relational friction. In much of urban India, multiple generations of an extended family often share housing with limited physical privacy; private space is scarce, and informal social surveillance — neighbors, relatives, and the joint family structure itself — is high. The same individuals, however, increasingly maintain close, sustained relationships with people on other continents, met and maintained entirely through digital platforms, with whom they share opinions, vulnerabilities, and daily updates that they might not share with someone physically present in the next room.
This is the condition of living two lives simultaneously: one organized by physical proximity and the postal address, or pin code, and one organized by digital proximity and the protocol address, or IP code.
The friction that digital platforms have removed here is not transactional or even straightforwardly behavioral; it is the friction of selective intimacy — the cost of finding people with whom one shares enough context to be candid, without the social risk of that candor circulating through a tightly coupled physical community. Once that friction fell, a meaningfully new social habit emerged: maintaining one’s most candid relationships at maximum geographic distance and one’s most guarded relationships at minimum geographic distance, an inversion of almost the entire prior history of human social organization, in which proximity and intimacy were tightly correlated.
This case also previews the article’s later argument about representation, because it is a direct illustration of how a person’s effective social network — the five people whose opinions and habits most shape one’s own behavior, a folk heuristic with real empirical support — is no longer necessarily local, human, or even, increasingly, biological.
Those five influential nodes can now include an AI agent, encountered far more often per day than most human relationships, and shaping judgment, vocabulary, and even values with a frequency that historically only co-located family or community could achieve.
7. The Cognitive Friction Threshold: From Searching to Synthesizing
The central claim concerns a third category of friction, distinct from the transactional and behavioral categories examined above: cognitive friction, the effort required to find, structure, evaluate, and produce information and judgment.
For roughly two decades, the dominant tool for reducing this friction was the search engine, which reduced the cost of locating a piece of information but left the much larger cost — reading multiple sources, evaluating their credibility, reconciling disagreements between them, and synthesizing a coherent view — almost entirely with the human user. Search reduced retrieval friction. It did almost nothing to reduce synthesis friction.
Generative and agentic AI systems are the first technology at consumer and enterprise scale to meaningfully reduce synthesis friction itself. The practical effect, in extensive practical use, is striking: an activity that once required a week or more — researching a topic, drafting an argument, structuring it for an audience — can now be substantially completed, at a publishable standard of synthesis, within minutes, with the ability to interrogate, challenge, and refine the output through dialogue rather than solitary redrafting.
The bottleneck has shifted from production to judgment: the scarce resource is no longer the ability to generate a draft, but the ability to evaluate which of many possible drafts is actually correct, well-reasoned, and worth publishing.
This shift has a second, less obvious consequence that is central to the threshold argument: it changes who can participate in knowledge production at all. Tasks that previously required institutional access — a research assistant, a subscription to expensive databases, fluency in a particular academic register, familiarity with the specific submission norms of a specific publishing platform — become available to anyone who can describe what they want clearly enough to direct a generative system. The friction being removed here is not merely individual effort but structural and institutional gatekeeping.
This is precisely the representational claim at the center of the broader argument developed here: as cognitive friction falls, representation — in the sense of who gets a voice in formal knowledge systems — becomes more accessible, not because institutions have become more inclusive, but because the cost of producing institution-grade output has collapsed independent of institutional permission.
8. Evidence From Practice: Publishing Behavior as a Natural Experiment
The clearest available evidence for the cognitive friction threshold is not a survey or a controlled study; it is a direct, observable change in one individual’s own production rate, observed over an extended period and treated as a natural experiment in cognitive friction reduction. Before the availability of capable generative and agentic AI tools, producing a publishable article required roughly a week to a fortnight of dedicated effort: research, drafting, structuring, and revision, with the bulk of that time consumed not by typing but by synthesis — reconciling multiple sources, deciding on an argument’s structure, and refining the framing through successive, solitary drafts.
With the introduction of conversational AI systems into this workflow, the same quality of synthesis became achievable in approximately ten minutes of dialogue, not because the AI system produced a finished product unassisted, but because the dialogue format allowed rapid iterative refinement: a thesis could be proposed, challenged, tightened, and re-proposed multiple times within a single sitting, compressing what had previously required multiple discrete drafting sessions spread across days into a single continuous exchange. The bottleneck of waiting — for a quiet block of time, for a clear head, for the mental energy to start a fresh draft — was removed, because the cost of starting had fallen to nearly zero.
A second, equally significant friction reduction occurred not in writing but in the broader process of publishing and dissemination. Choosing the appropriate publication venue, navigating subject classifications, adapting manuscripts to different editorial and formatting requirements, and managing the administrative workflow traditionally required specialized knowledge or a level of procedural persistence that many independent researchers found difficult to sustain.
Generative AI has dramatically reduced this friction as well, making the entire publishing pipeline—not just the act of writing—far more accessible to individual researchers. The result has been a measurable increase in both publication frequency and the diversity of dissemination channels within a relatively short period, a pattern that is more consistent with a threshold being crossed than with a gradual improvement in capability alone.
9. Ritual Behavior and the Reduction of Coordination Friction
A further, easily overlooked category of friction reduction concerns ritual and ceremonial behavior, which is worth including because it demonstrates that the threshold logic generalizes beyond information work and economic transactions to purely social and emotional activity.
Producing a personalized festival greeting that incorporates the photographs of every family member, formatted attractively and distributed promptly, was until recently a task substantial enough that most people simply declined to do it, defaulting instead to a generic, impersonal greeting sent to everyone identically. The friction was not motivational — people generally want to send personalized greetings to people they care about — it was purely a matter of design and coordination effort exceeding the perceived value of the outcome.
Generative tools capable of producing a polished, personalized design in minutes have shifted this calculation, and the behavior that results is instructive: personalization, once a costly signal of effort reserved for a small number of especially important relationships, becomes the default for a much larger number of relationships, because the cost of personalizing has fallen below the cost of staying generic.
This is the same threshold logic as the earlier cases, applied to ceremony and relationship-maintenance rather than to commerce or work, and it suggests that no category of human activity is structurally exempt from the mechanism this article describes.
10. The General Pattern: Capability, Ecosystem, Forcing Event, Habit
Across every case examined — payments, remote work, wildfire response, photography, social geography, and now cognitive production — a consistent four-stage pattern emerges, and making this pattern explicit is the article’s primary theoretical contribution.
- Capability arrives. A technology becomes technically possible and, often, widely available, frequently years before it meaningfully changes behavior.
- An ecosystem develops around the capability — supporting infrastructure, complementary tools, and a critical mass of early users — which lowers friction incrementally but rarely crosses the threshold on its own.
- A forcing event occurs, removing the option to continue the old behavior, or making the relative cost of the old behavior visibly and suddenly worse than the new one.
- A new habit forms, and where the threshold genuinely was crossed rather than merely visited, the new habit persists after the forcing event ends, because the social and cognitive environment has been permanently altered by the period of forced adoption.
This pattern explains why enterprise AI readiness assessments, which measure stage one and sometimes stage two, are structurally unable to predict the timing of stage three or stage four. Stage three is, by its nature, exogenous to organizational planning: it is a black swan event, a currency policy, a disaster, or — in the case now unfolding — the simple, cumulative realization by millions of individual professionals that producing institution-grade work no longer requires institutional infrastructure.
The forcing event for the cognitive friction threshold may not be a single dramatic shock in the manner of a pandemic or demonetization. It may instead be a slow-motion, distributed forcing event: each individual professional independently discovering, at their own pace, that the old way of working has quietly become the harder way.

11. Second- and Third-Order Derivatives
A further pattern worth making explicit, because it has direct strategic relevance for enterprises, is that the most significant economic consequences of a friction-reduction event rarely arrive in the same wave as the event itself. The dot-com period demonstrated the underlying capability of internet commerce and collapsed when the first generation of businesses outran the actual state of consumer trust, logistics infrastructure, and payment systems. The durable winners — Amazon being the clearest example — emerged afterward, once the foundational friction had genuinely been reduced and the ecosystem had matured enough to support genuinely new categories of behavior.
A further derivative wave — Uber, Airbnb, and the broader category of platforms that monetize previously idle personal assets and time — arrived only once smartphone-based location, identity, and payment friction had each independently fallen far enough to make those specific business models viable.
The implication for enterprise AI strategy is that the current generation of generative AI products, however significant, should be read as roughly analogous to the first wave of dot-com businesses: necessary, visible, and partly mistaken about which specific use cases will prove durable.
The second- and third-order derivatives — the AI-era equivalents of Amazon and Uber — have likely not yet been identified, and will not be identified by measuring current adoption of current products, but by tracking which categories of cognitive friction have been reduced far enough to support business models that do not yet exist.
12. Disappearing Friction at Home: A Household-Level Audit
It is useful to close the empirical section of this article with a small, deliberately mundane audit, because enterprise-scale phenomena are easier to trust once they are visible at the scale of a single household. In the period following the pandemic forcing event, several previously stable household technology habits did not merely adjust but disappeared outright.
The home newspaper subscription ended, not because the newspaper became unavailable, but because the cumulative friction of waiting for printed news, relative to the now-normalized habit of continuous digital access, had become not worth paying for. The landline telephone, once considered an essential marker of household stability and status, became an active inconvenience rather than a convenience, and was removed. Scheduled television viewing, organized around a broadcast schedule set by someone else, was replaced by on-demand viewing on personal devices, organized entirely around individual convenience.
None of these decisions was dramatic. Each was the quiet result of a friction differential crossing zero: the old habit, once clearly easier than the alternative, had become clearly harder, and the household simply stopped doing it, with no formal decision process and no resistance. This is the behavioral signature enterprises should be watching for inside their own workforces and customer bases: not announced transformations, but the quiet disappearance of habits that were, until recently, considered normal and unremarkable.
13. Implications for Enterprise AI Strategy
If this argument is correct, several implications follow directly for how enterprises should think about AI adoption, in contrast to how most current readiness frameworks instruct them to think about it.
- Individual behavior change will consistently outrun organizational policy. Employees, customers, and partners are independently encountering the same friction-reduction dynamics described throughout this article in their personal lives, and will bring the resulting habits into the workplace whether or not the organization has approved, anticipated, or even noticed the shift.
- Readiness audits measure the ceiling, not the threshold. An organization can score well on every conventional readiness dimension — data, governance, talent, sponsorship — and still see negligible behavior change, because the relevant threshold is cognitive and individual, not infrastructural and organizational.
- Forcing events are not always external shocks. Enterprises should expect, and can in some cases deliberately design, internal forcing events — removing a previously available manual workflow, for instance — rather than waiting passively for an external shock to do the work of habit change for them. This is a materially different posture from most current change-management practice, which tends to favor gradual, voluntary adoption pathways precisely because they generate less resistance, without acknowledging that gradual pathways often fail to cross the threshold at all.
- The durable second- and third-order business opportunities have not yet been identified, and will not be found by extrapolating current product categories. They will be found by identifying which specific categories of cognitive friction — judgment, synthesis, distribution, coordination — have fallen furthest, and asking what becomes economically viable once that friction is gone, in the same way Uber and Airbnb became viable only after the underlying identity, location, and payment frictions had separately fallen far enough.
- Inclusion follows friction reduction, not policy intent. As the cost of producing institution-grade work falls, participation in knowledge production, content creation, and even formal governance processes will broaden, independent of, and sometimes despite, formal diversity or inclusion initiatives, simply because the structural cost of participation has collapsed. Enterprises and institutions that recognize this early will be better positioned to direct it productively rather than be surprised by it.
14. Conclusion: Watching the Threshold, Not the Ceiling
The dominant enterprise AI question — is the organization ready? — measures capability and infrastructure, the ceiling of what is technically possible. It does not measure the threshold at which human behavior actually changes, which is a property of friction, habit, and forcing events, not of organizational architecture. The discussion shows, through cases spanning payments, remote work, disaster response, photography, social relationships, publishing behavior, and household technology habits, that the threshold is crossed when friction falls far enough that the old habit becomes harder to sustain than the new one, and that this crossing is most often triggered not by capability arriving but by some event — dramatic or quiet, collective or individual — removing the option to keep avoiding the new behavior.
Generative and agentic AI represent the first large-scale reduction of cognitive friction specifically, as distinct from the transactional and behavioral friction reductions that defined the previous two technology eras.
The evidence available from direct practice suggests the threshold for at least some categories of cognitive work — research synthesis, drafting, and the administrative overhead of distribution — has already been crossed for early-adopting individuals, well ahead of any formal organizational policy on AI use. Enterprises that continue to measure only the ceiling will be repeatedly surprised by how much has already changed beneath them.
Enterprises that learn to watch the threshold — to ask not what is now possible, but what is now easier than the alternative, and what event might remove that alternative altogether — will be far better positioned to anticipate where their own employees, customers, and institutions are headed next.
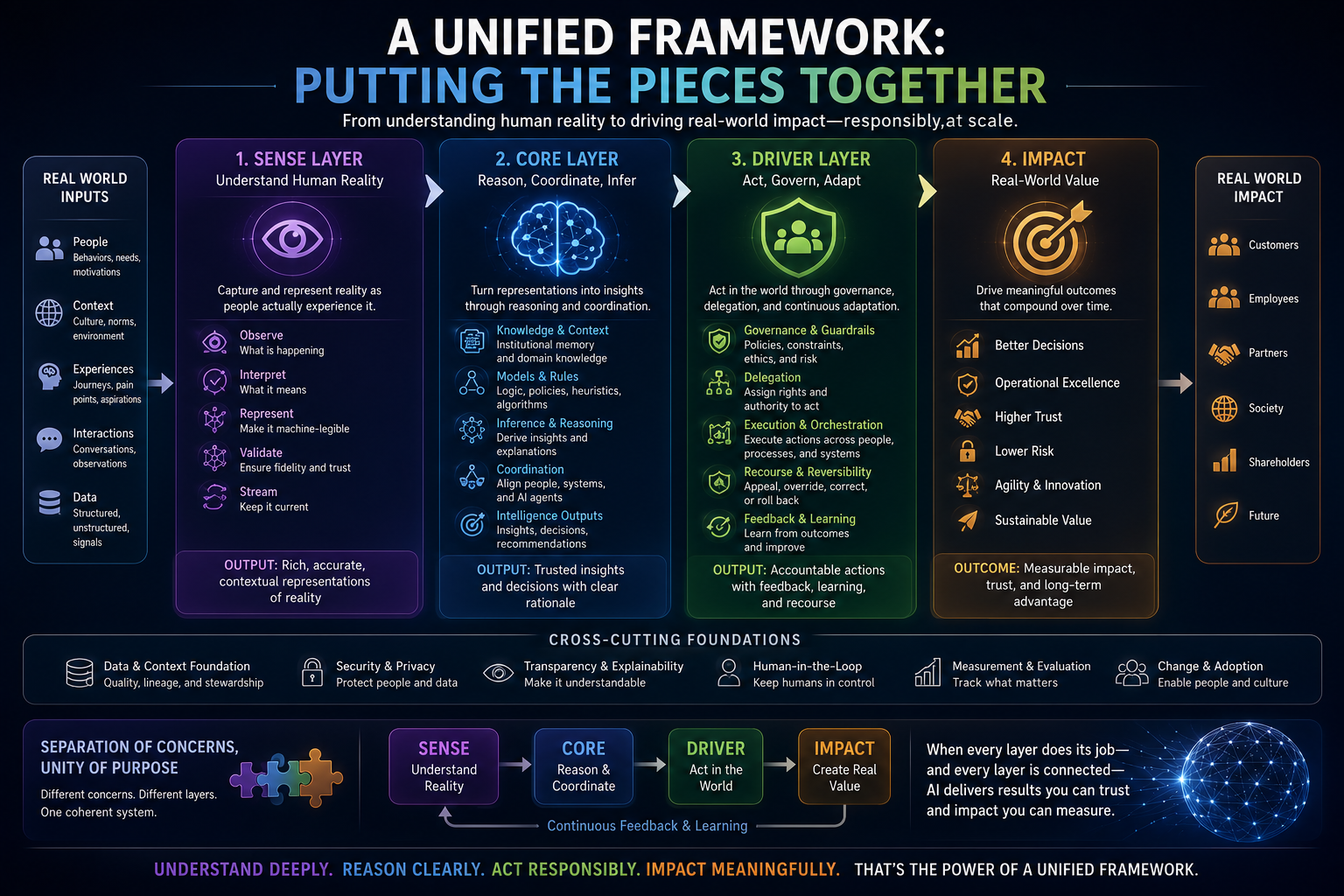
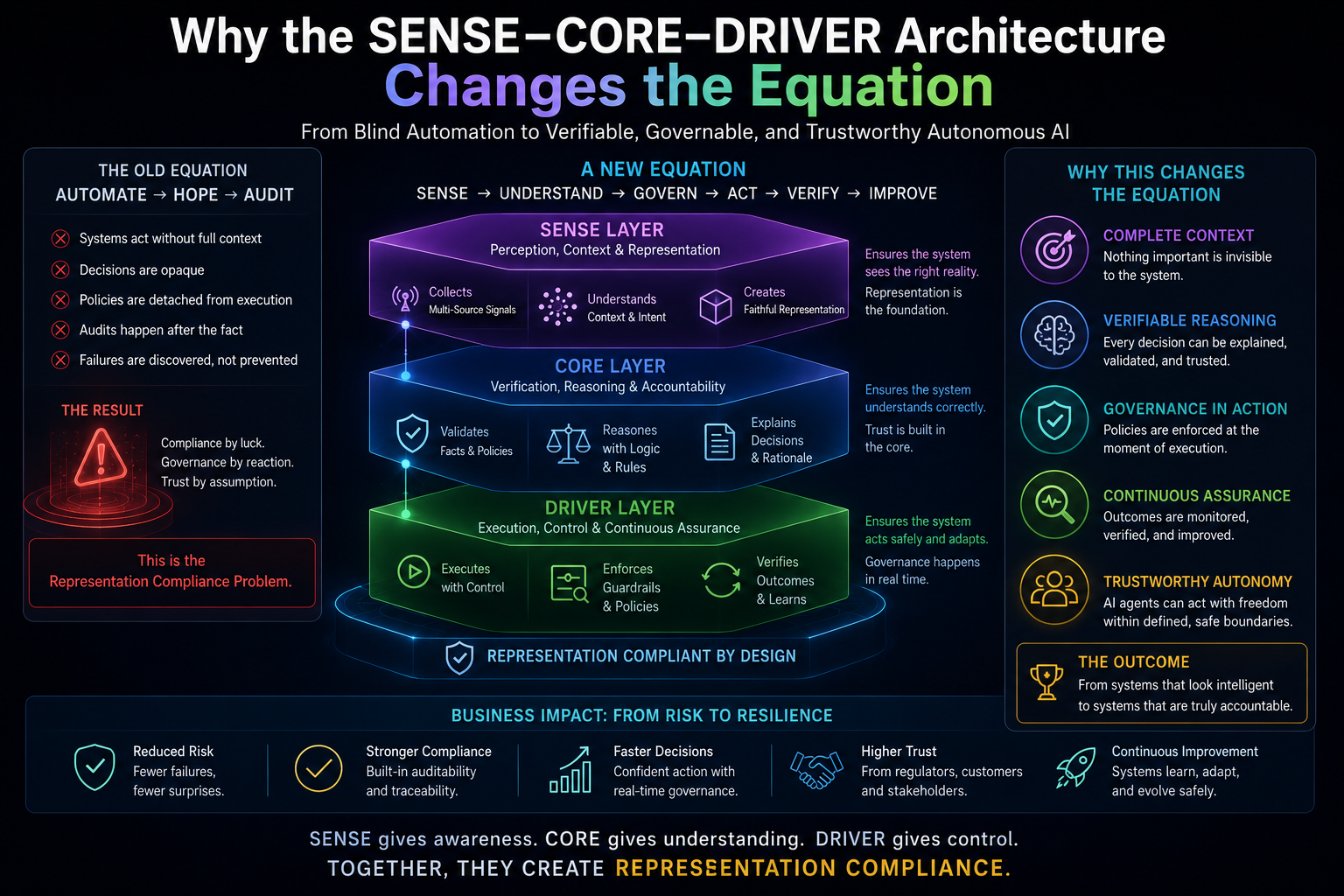
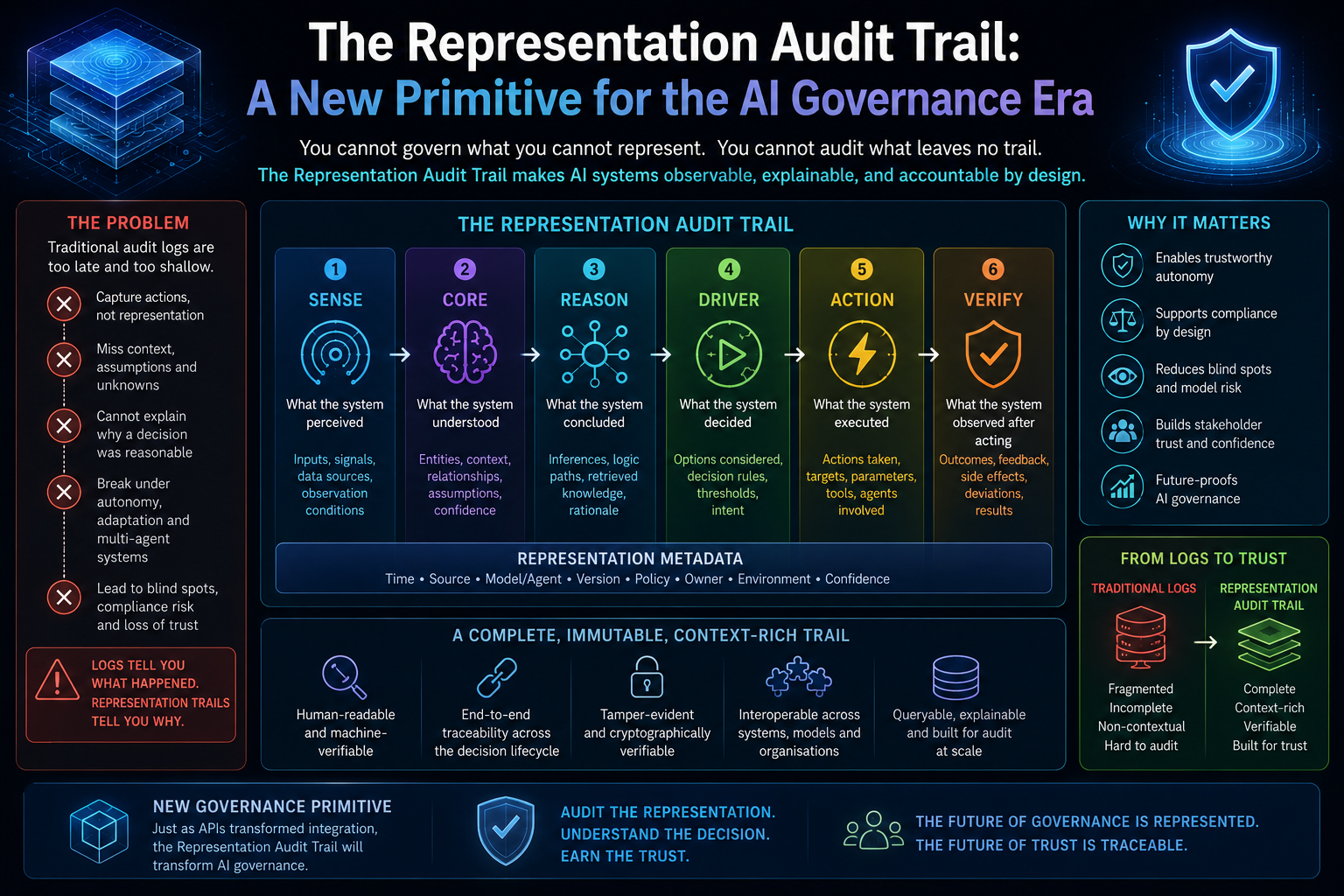
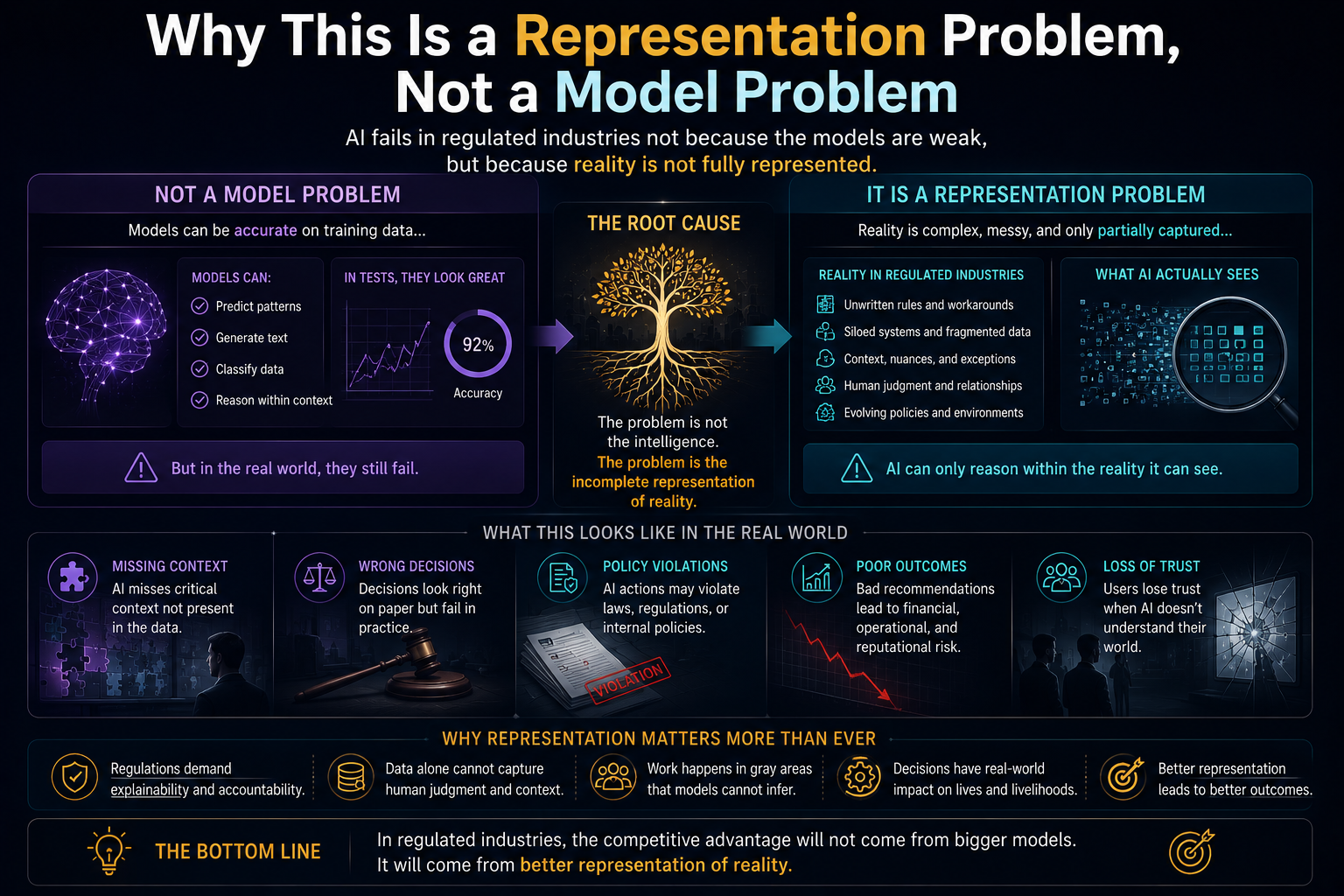
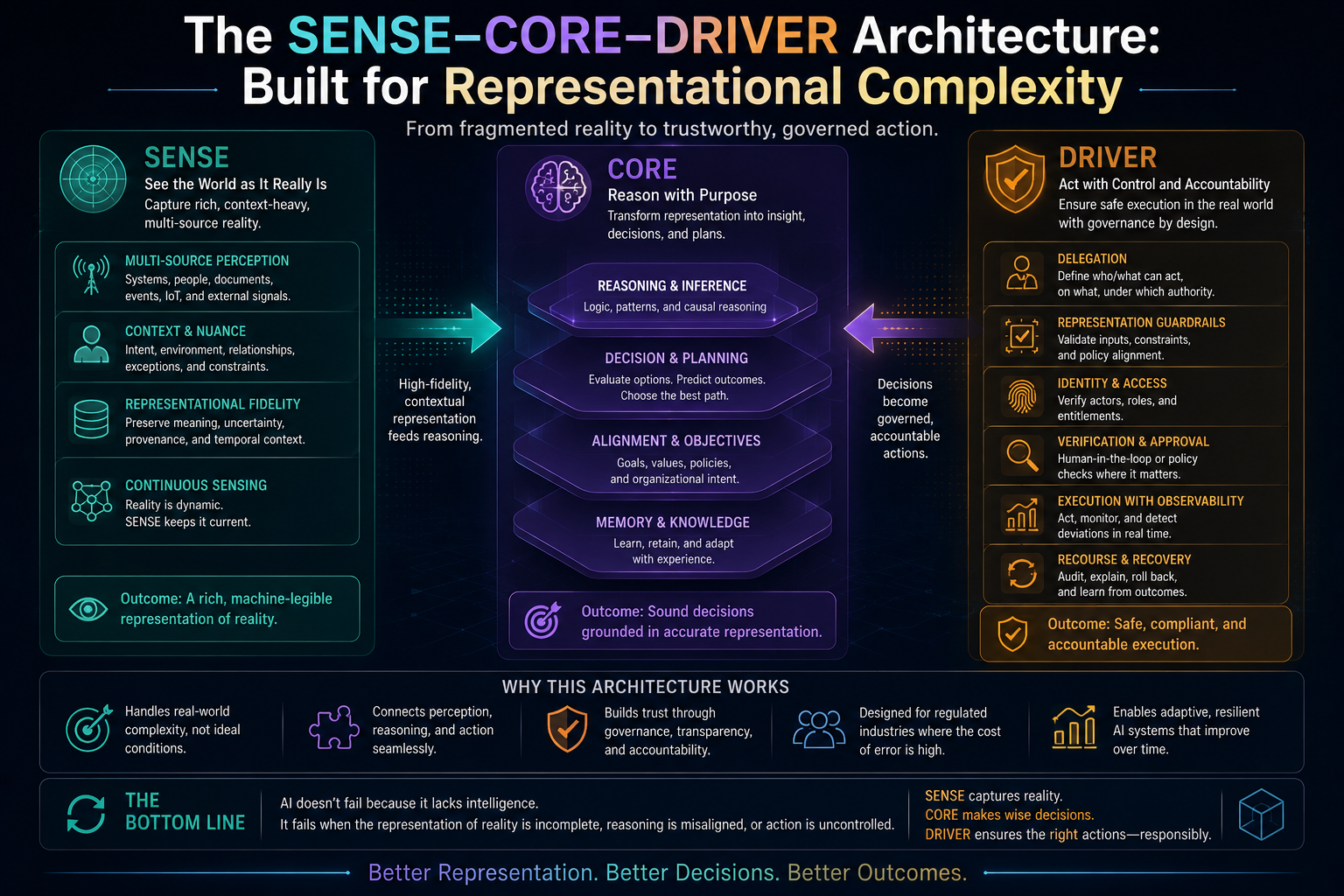
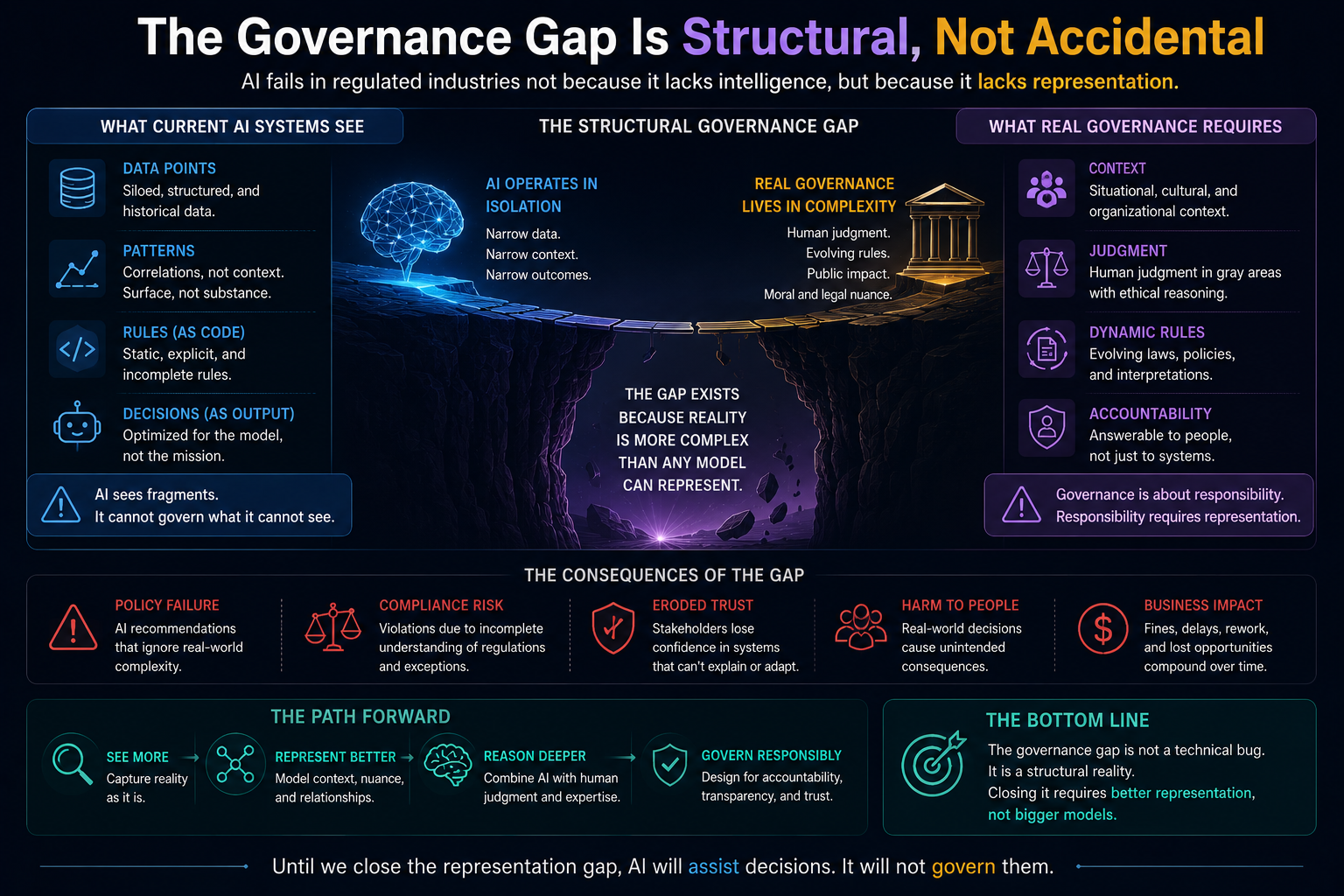
This argument connects directly to the broader argument of which it is a part. If AI systems act on representations of reality rather than reality itself, as the Representation Economy framework argues, and if those representations require legitimate governance, as the SENSE-CORE-DRIVER architecture argues, then the Cognitive Friction Threshold supplies the missing human-behavioral premise underneath both: representations only become institutionally consequential once enough individual humans have personally crossed the threshold of treating AI-mediated judgment as a normal, default part of how they think, decide, and create.
Enterprise AI does not fail or succeed first at the level of the model, or even first at the level of governance. It fails or succeeds first, and earliest, at the level of habit.
Further Reading
If you found this article useful, you may also enjoy these related articles from RaktimSingh.com, which explore complementary aspects of Enterprise AI, organizational transformation, and AI governance:
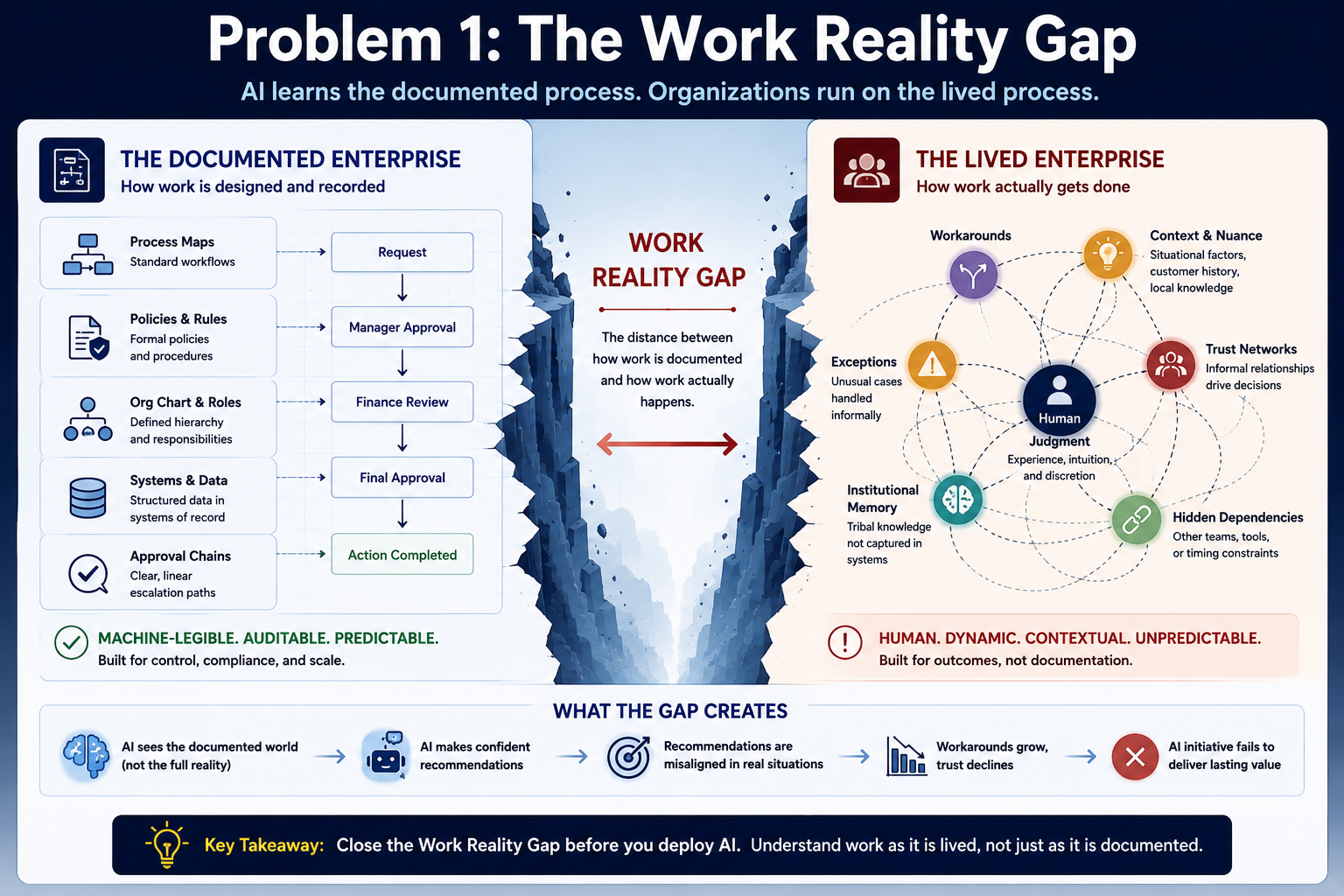
- Digital Anthropology for Enterprise AI: Why AI Transformation Fails When Systems Misread Human Reality
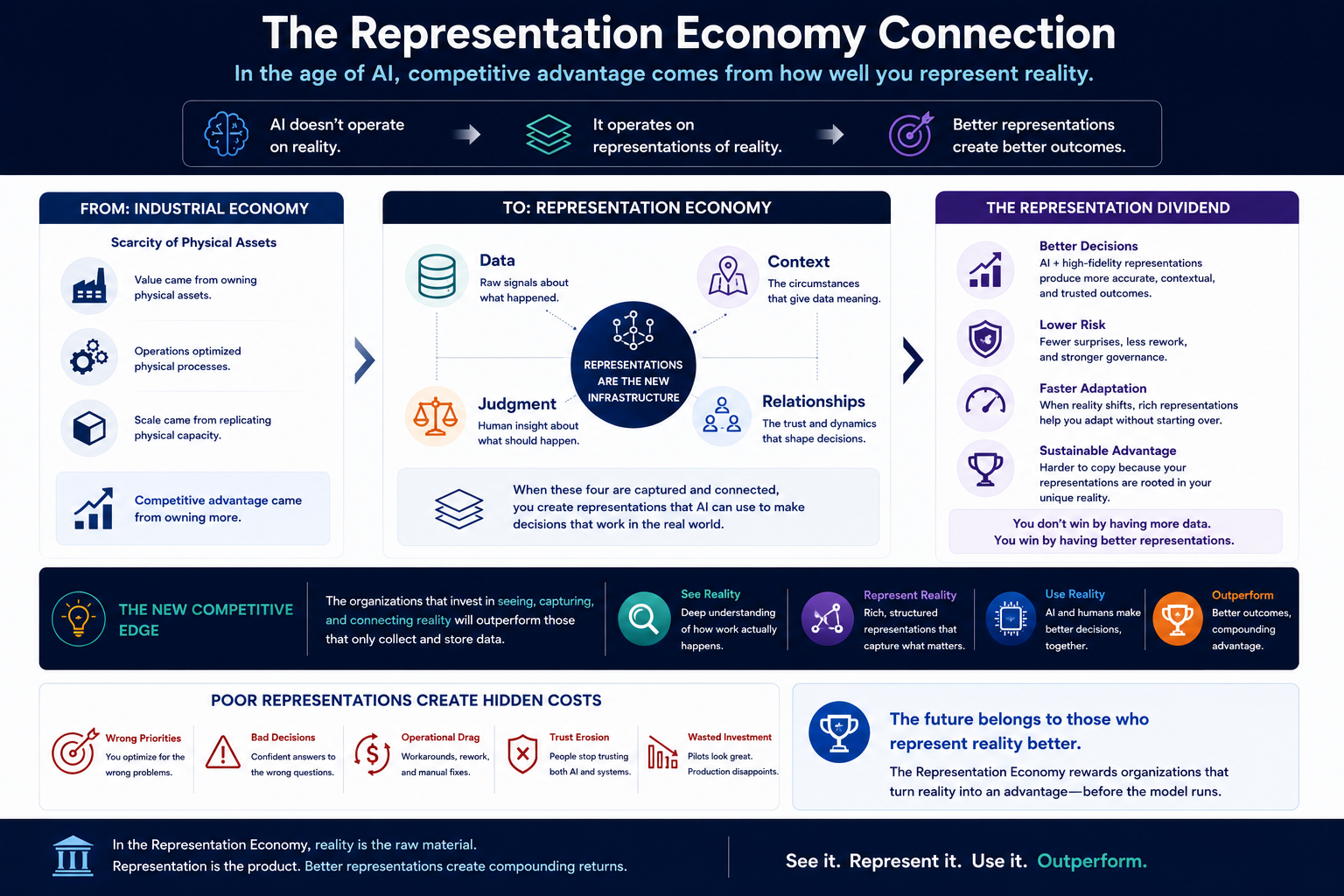
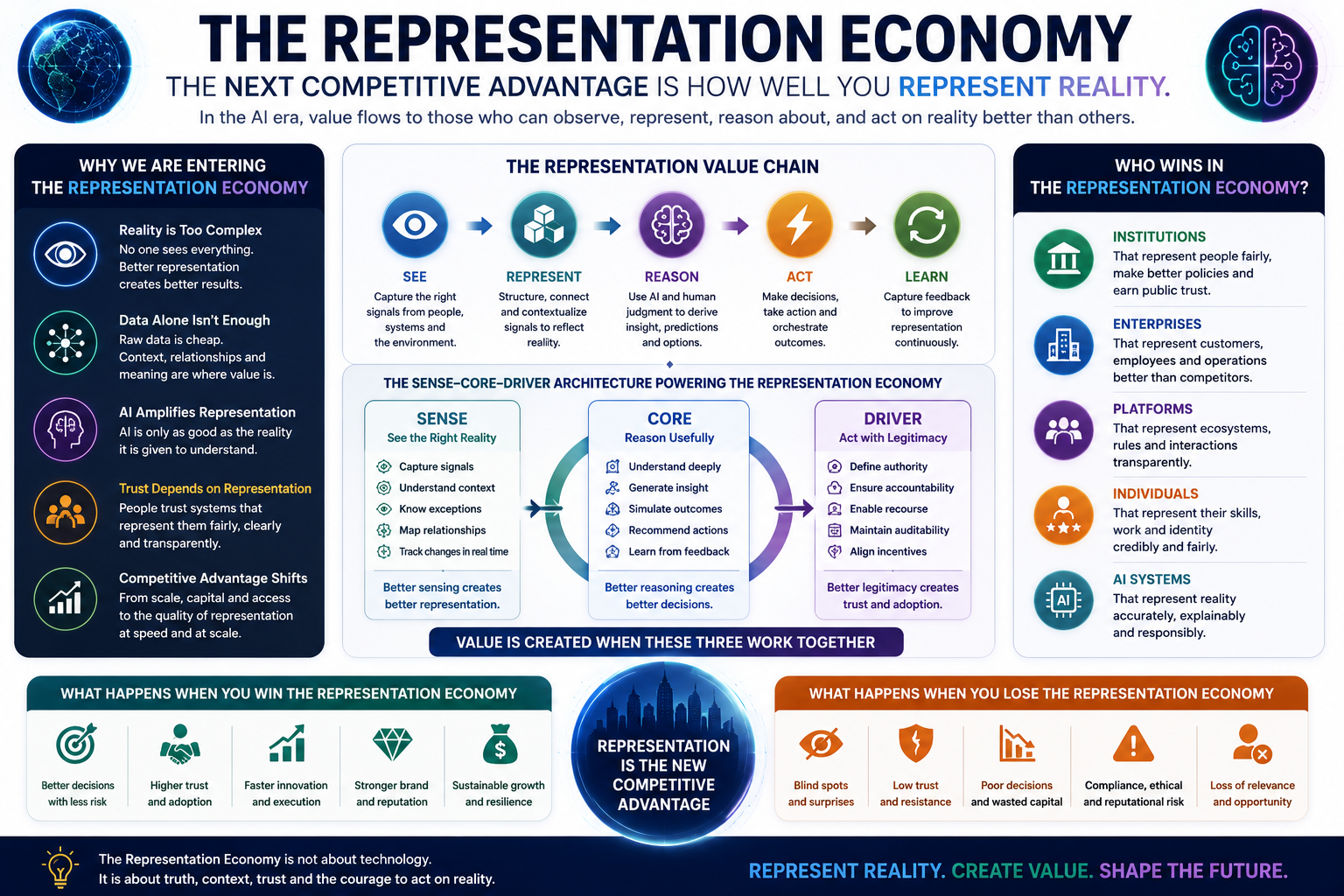
https://raktimsingh.com/digital-anthropology-enterprise-ai-human-reality-gap/ - The Representation Economy: Why AI Will Transform the Value of Information
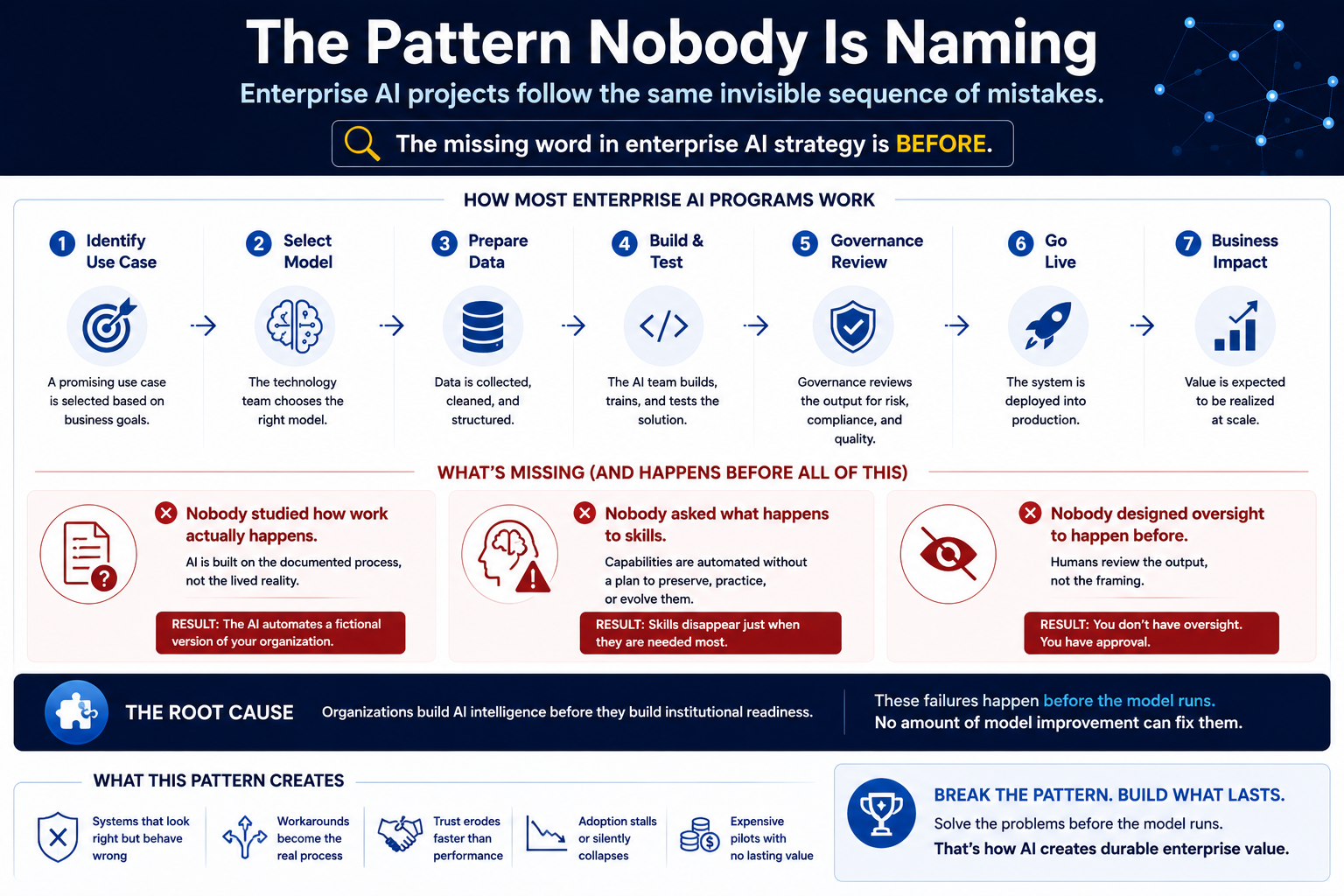
https://raktimsingh.com/the-representation-economy/ - Representation Integrity: Why Most AI Governance Failures Begin Before the Model Runs
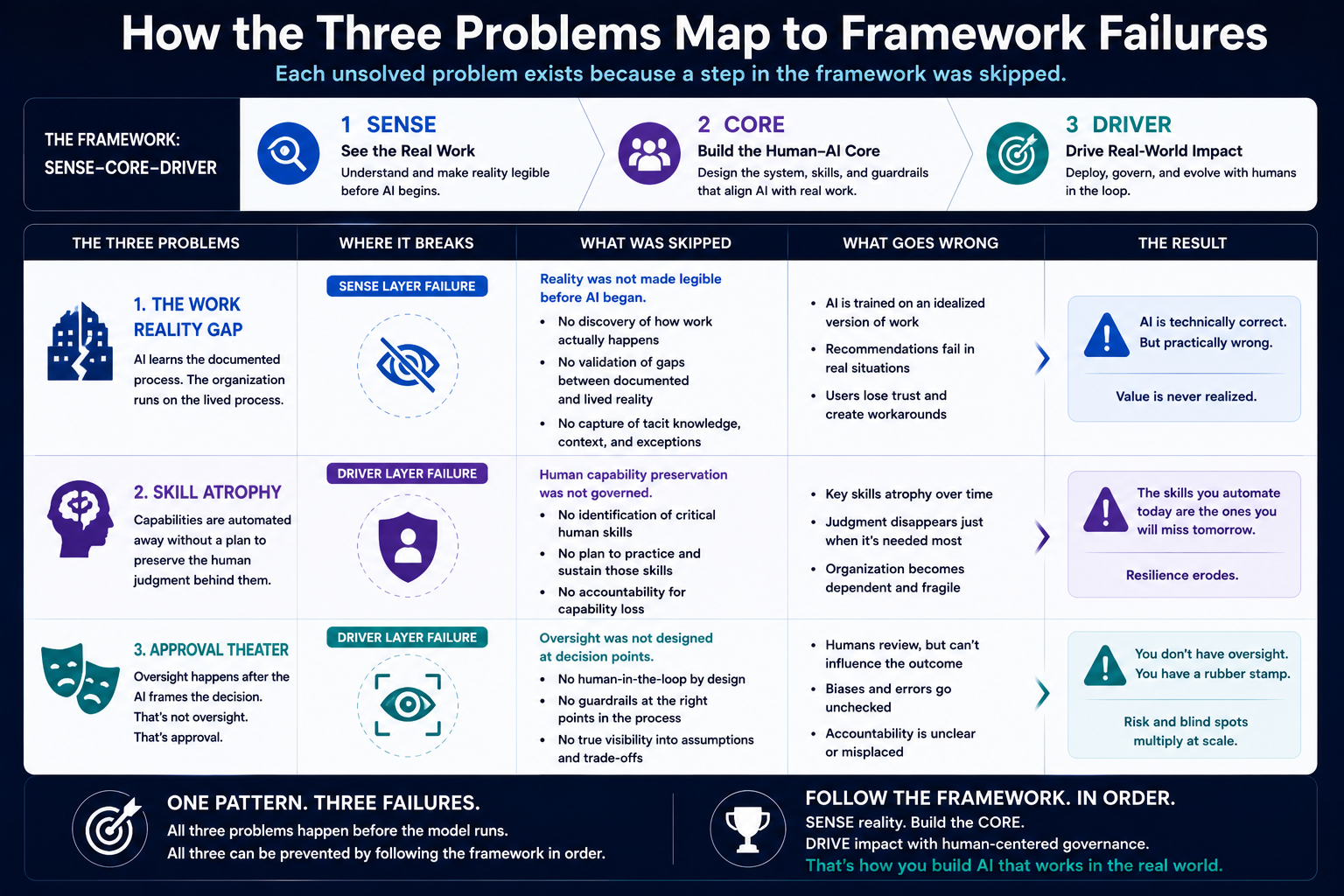
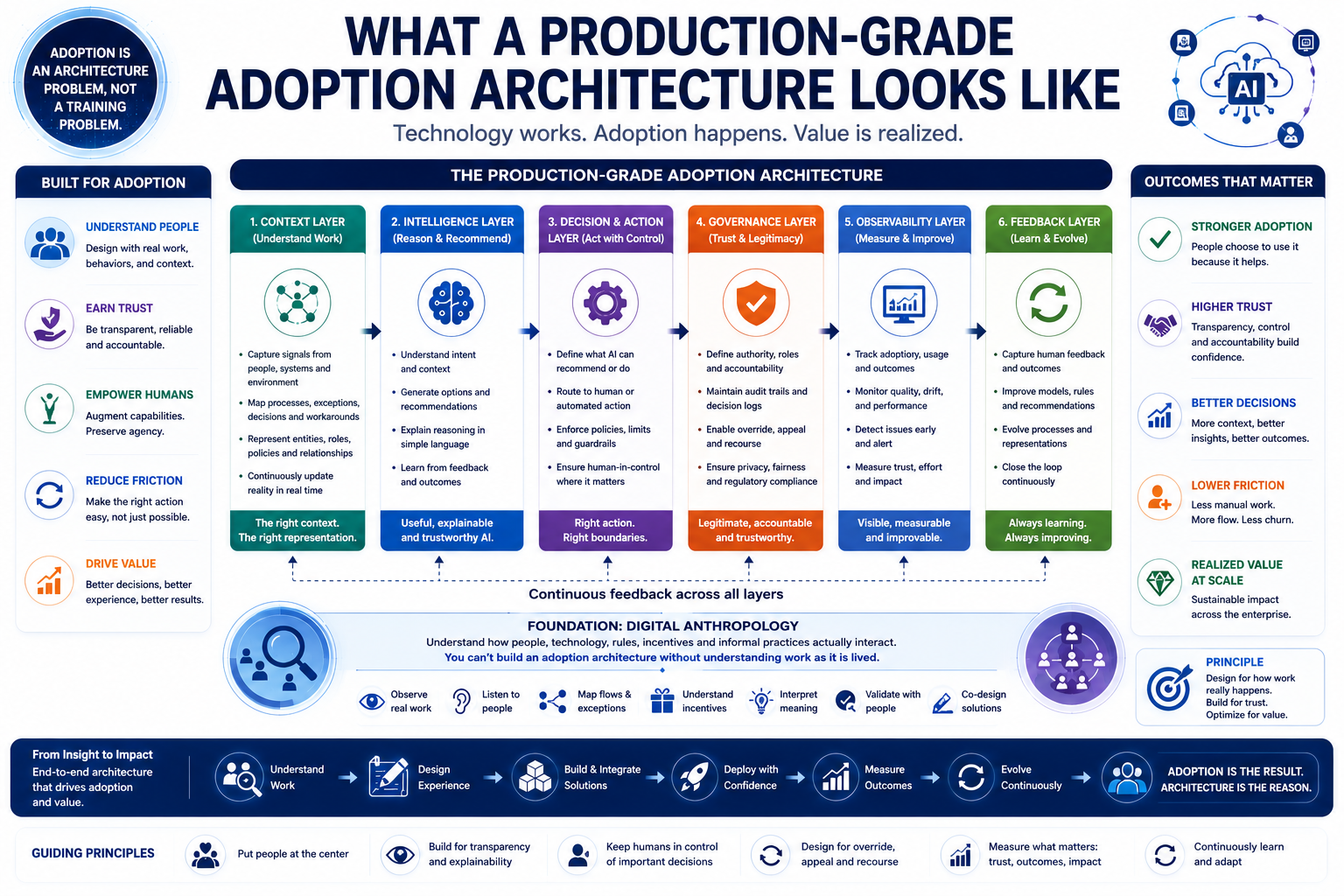
https://raktimsingh.com/representation-integrity/ - Why AI Agents Cannot Govern Themselves: A Representation-Based Explanation of Enterprise Agent Failure
https://raktimsingh.com/why-ai-agents-cannot-govern-themselves/ - The Human Reality Gap: Why Enterprise AI Transformation Fails Before the Model Runs
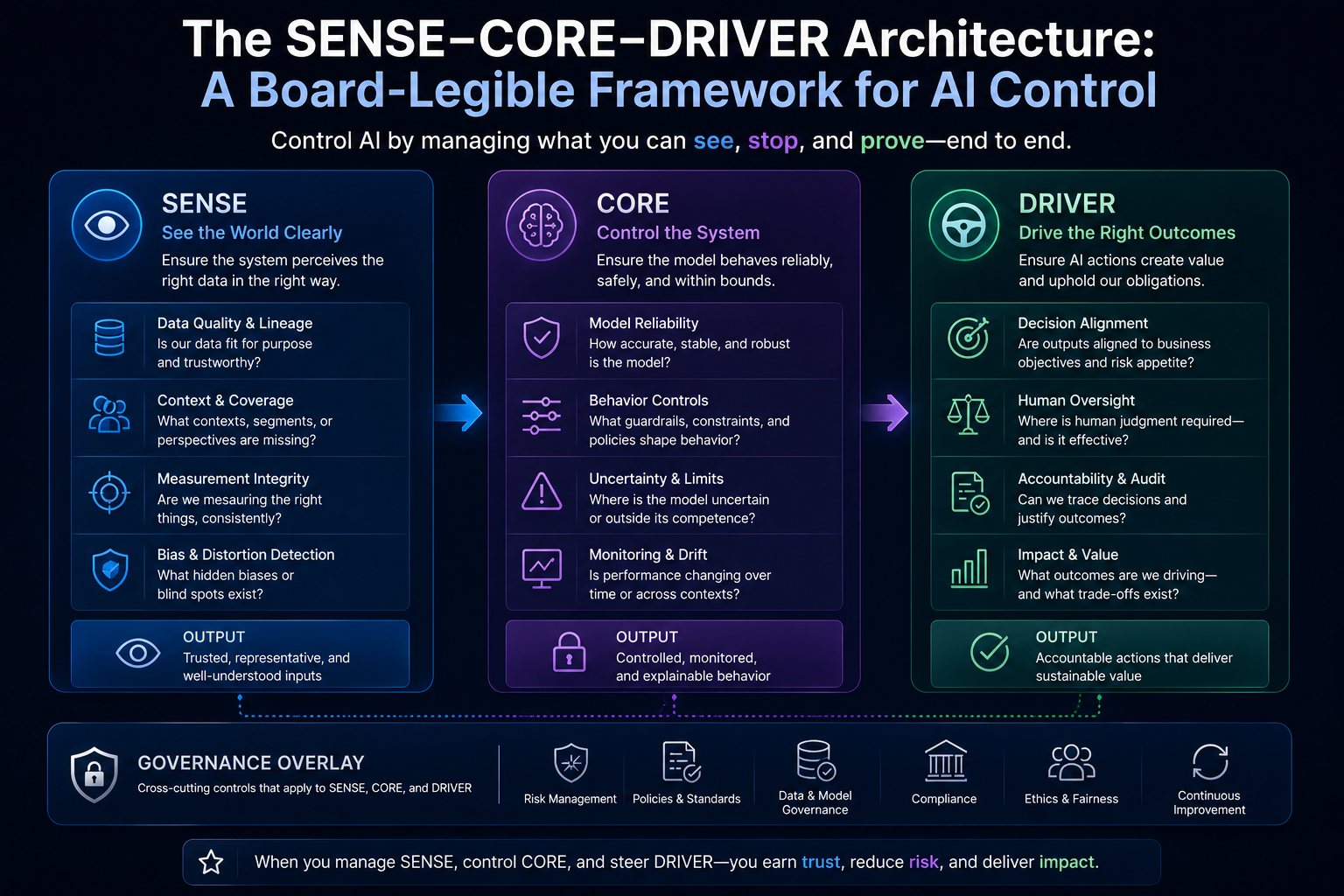
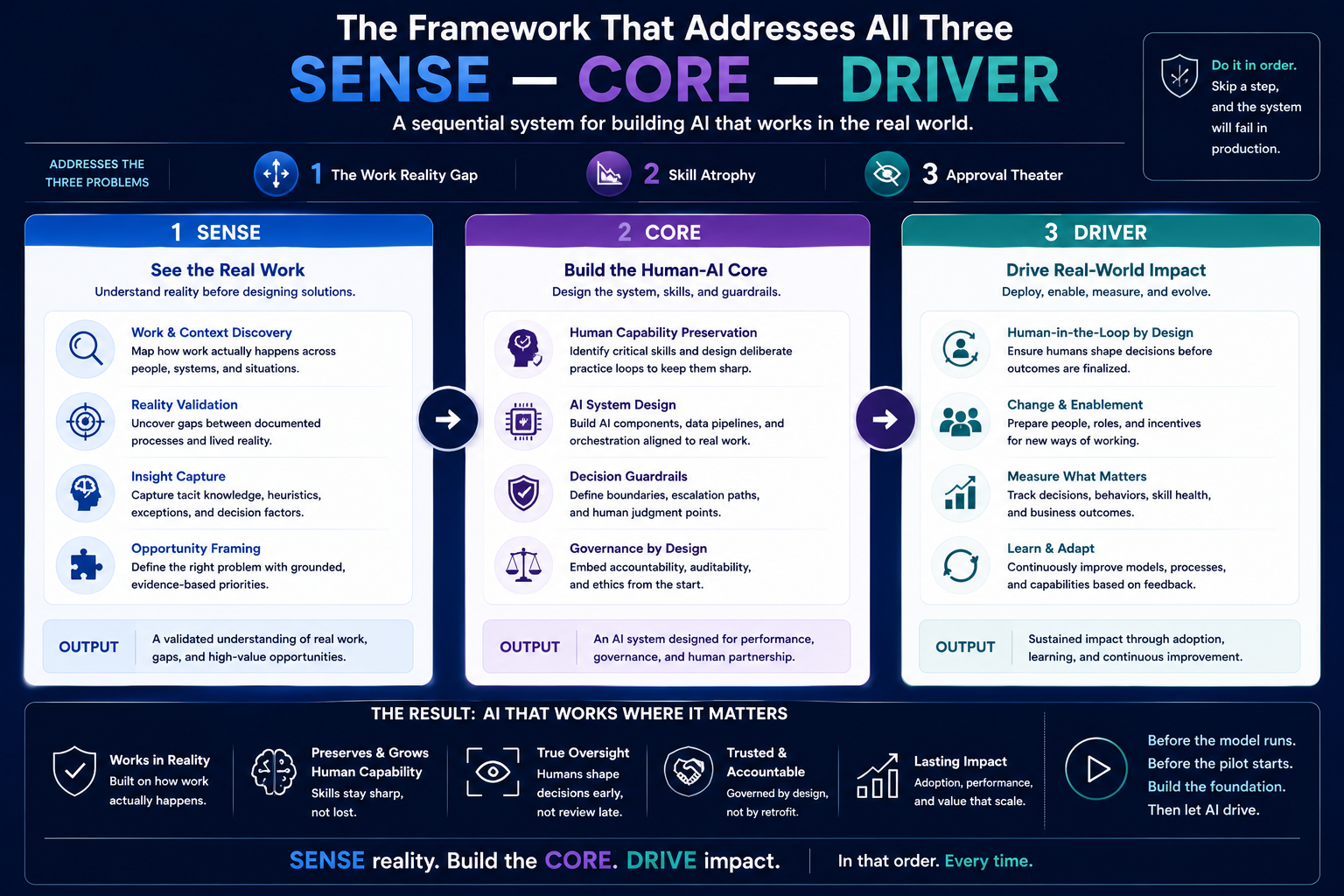
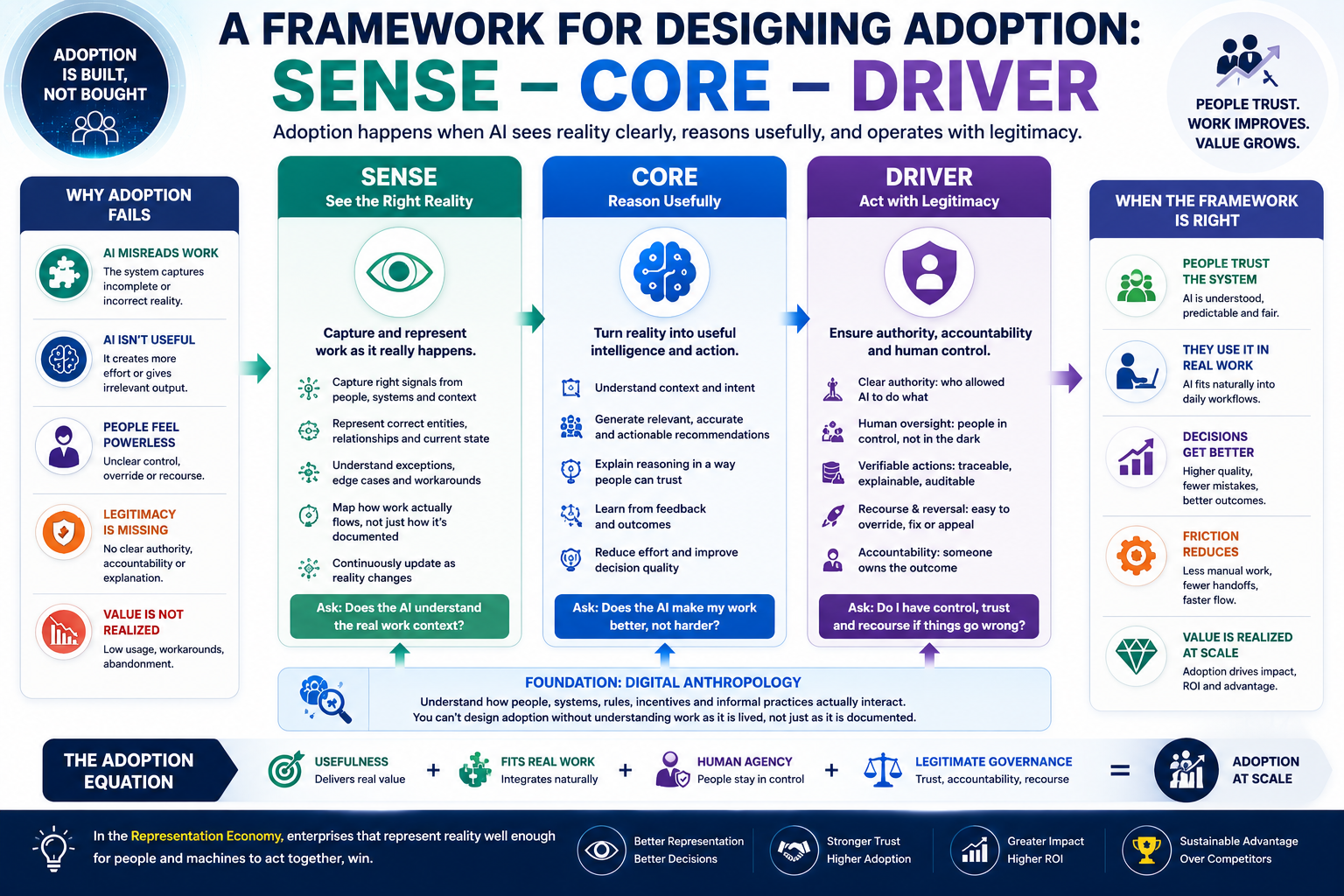
https://raktimsingh.com/the-human-reality-gap/ - SENSE–CORE–DRIVER: The Institutional Architecture That Will Govern the AI Economy
https://raktimsingh.com/sense-core-driver/
For readers interested in the broader theoretical foundations of technology adoption, organizational change, and AI governance, the following resources provide valuable context:
- Everett M. Rogers, Diffusion of Innovations (5th Edition, 2003)
- Daniel Kahneman, Thinking, Fast and Slow (2011)
- James Clear, Atomic Habits (2018)
- NIST, AI Risk Management Framework (AI RMF 1.0) – https://www.nist.gov/itl/ai-risk-management-framework
- OECD, OECD AI Principles – https://oecd.ai/en/ai-principles
- Kurt Lewin, Field Theory in Social Science (1951)