
-
From AI for Screens to AI for the Body
If ChatGPT is “AI for the screen,” then Vision-Language-Action (VLA) models are “AI for the real world.”
These systems don’t just read or write — they:
- See through cameras
- Understand natural language
- Act through robotic control
They power robots to perform useful tasks in factories, hospitals, warehouses, homes, and smart cities.
Now layer one more idea on top: Dual-System AI.
- System 1: Fast, reflexive motor control — balance, grip, collision avoidance
- System 2: Slow, deliberate reasoning — planning, task interpretation, rule compliance
Together, Dual-System AI + VLA models are becoming the digital brain for general-purpose humanoid robots across the US, Europe, India, and the Global South.
Over the next decade, this stack will transform “demo robots” into reliable co-workers — robots that:
- See the world
- Understand what needs to be done
- Respect policies and safety
- Act with both capability and care
-
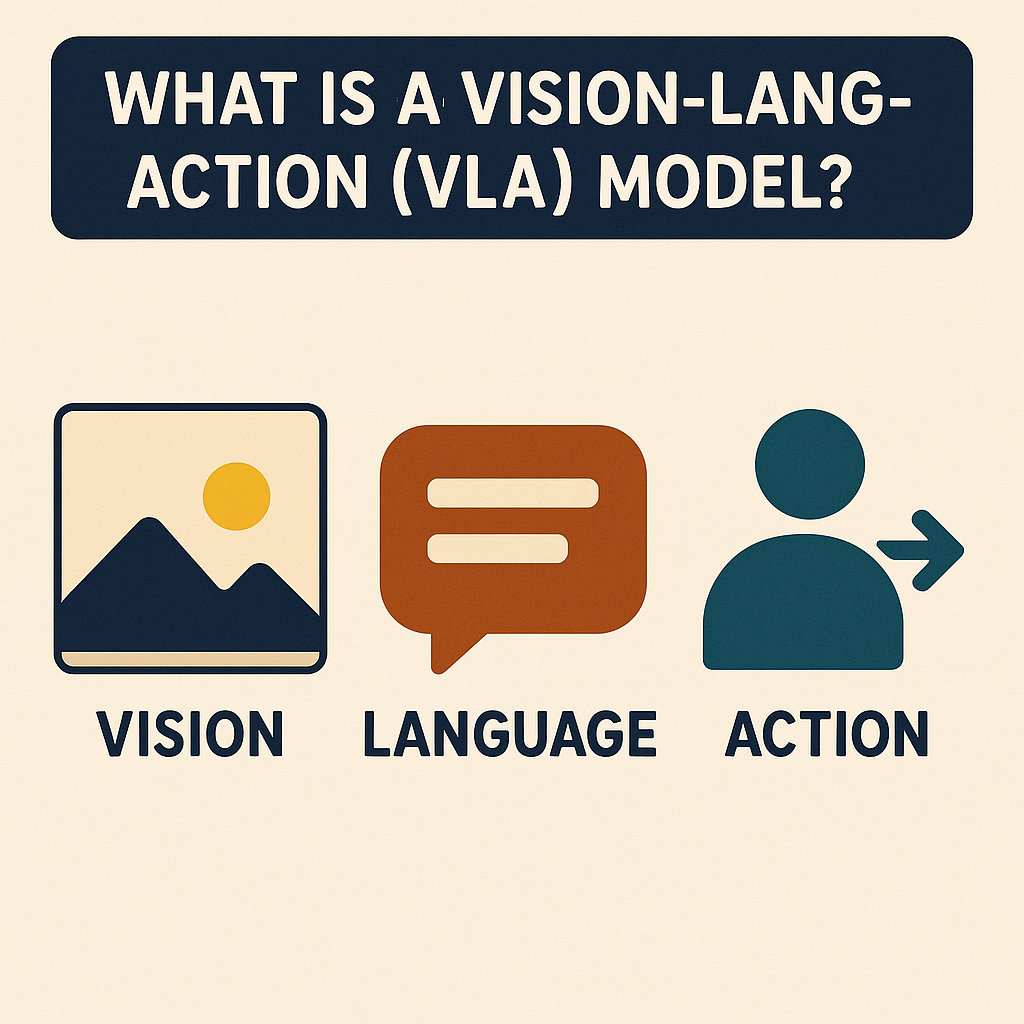
What Is a Vision-Language-Action (VLA) Model?
A Vision-Language-Action model is a multimodal foundation model that connects three components:
- Vision: Camera images or videos of the environment
- Language: Natural language instructions
- Action: Low-level robot commands (joint angles, pose instructions, gripper control)
With images + an instruction, the VLA directly generates a sequence of executable robot actions.
Instead of writing thousands of lines of custom robotics code, a single model can:
- Look at the world
- Understand the request
- Decide how to act
- Send an actionable motion plan
Early systems such as RT-2 (Robotic Transformer 2) showed that a web-scale vision-language foundation model could be adapted to control robots. The same model that recognizes a “recycling logo” could physically manipulate an object based on that understanding.
Today, the ecosystem includes:
- OpenVLA — Open-source 7B VLA trained on the Open-X Embodiment dataset (22+ robot types)
- π₀ (Pi-Zero) — Flow-matching VLA producing smooth, high-frequency motor control
- Helix (Figure AI) — Humanoid-focused VLA using a Dual-System architecture
- SmolVLA (Hugging Face) — Compact (~450M parameters) VLA for laptops and modest GPUs
- Gemini Robotics + Gemini On-Device — VLA-style robotics on top of Google Gemini, including offline edge-AI variants
All share the same principle: See + Understand + Act in one foundation model.
-
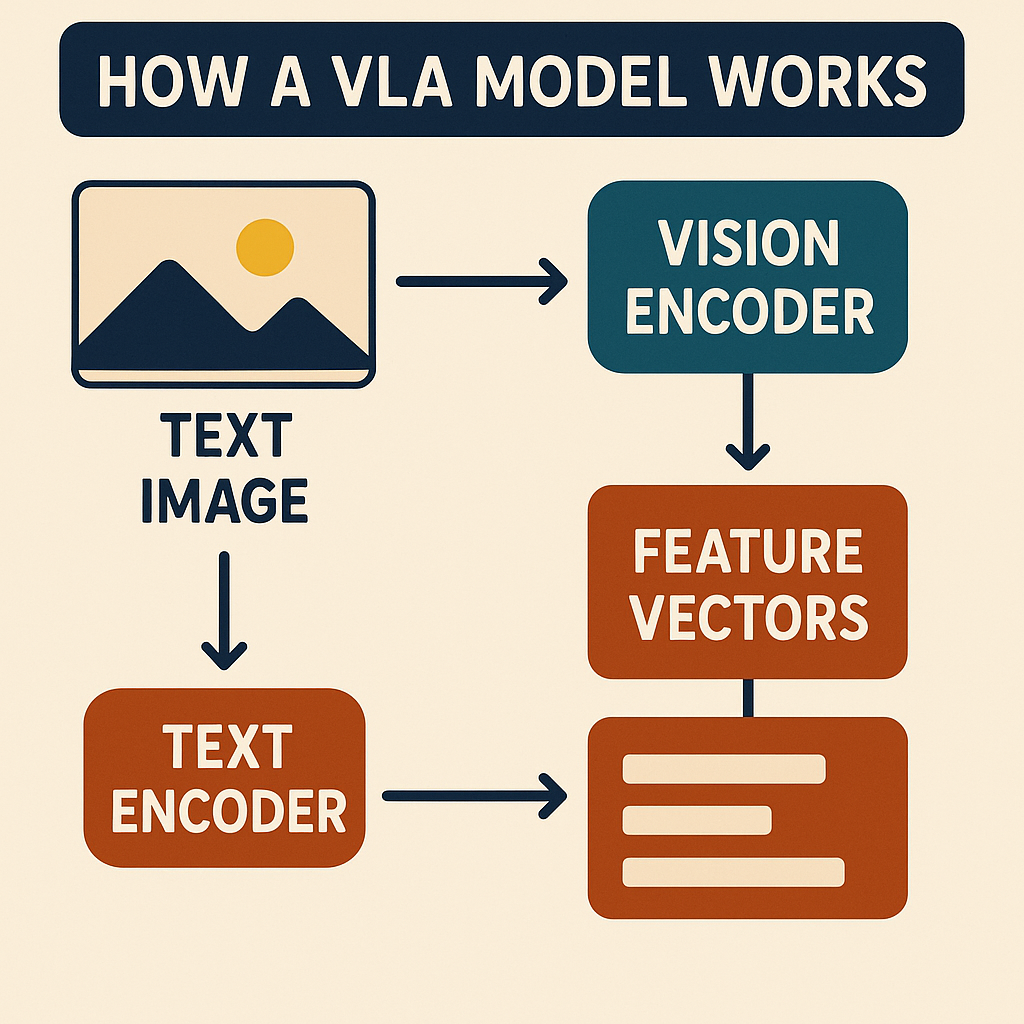
How a VLA Model Works (No Equations — Promise)
Think backwards from the final stage: Act.
Step 1 — See (Vision Encoder)
Robot cameras observe the environment:
- Shelves
- Objects
- People
- Labels
Vision encoding converts pixels → features:
- “This is a table.”
- “A blue bottle is on the second shelf.”
- “A green recycling bin is on the floor.”
Step 2 — Read (Language Understanding)
Instruction example:
“Put the blue bottle with a recycling logo into the green bin.”
The language backbone parses:
- Object: Blue bottle with recycling logo
- Target: Green bin
- Verb: Put → (Pick → Move → Place)
Step 3 — Think (Joint Vision-Language Reasoning)
Vision and language inputs are fused into a shared latent space — a representation of:
🧩 Scene + Goal + Context
The model reasons:
- Where is the bottle?
- Where is the bin?
- What safe action sequence achieves the goal?
Step 4 — Act (Action Decoder)
The model outputs:
- Joint angles
- End-effector poses
- Gripper open/close
- Velocities and timing
In many models, actions are tokens, just like language tokens — but representing short motion steps.
Step 5 — Learn (Demonstrations + Web Knowledge)
VLAs learn from:
- Human teleoperation
- Synthetic & simulated data
- Web-scale vision-language pretraining
Over time the model learns patterns such as:
“When the scene looks like this and the instruction sounds like that, these action sequences usually succeed.”
That’s the core shift:
Robotics learning from experience and internet-scale knowledge — not hand-coded rules.

-
Why Dual-System AI Is the Missing Piece
VLA models give robots eyes, language understanding, and motion capability — but real-world deployment requires structured reasoning and safety.
Inspired by human cognition:
System 1 — Fast, Reflexive, Continuous Control
Used for:
- Balancing
- Grasp adjustment
- Obstacle avoidance
- Running control loops hundreds of times per second
System 2 — Slow, Deliberate, Symbolic Reasoning
Used for:
- Multi-step instructions
- Policy-aware planning
- Legal and regulatory compliance
- Interpreting context, ethics, and safety
In a humanoid robot, the architecture becomes:
System 2 (Planner) → System 1 (Controller) → Physical Body
This architecture appears in systems like Figure AI’s Helix, where a slow VLA handles reasoning, and a fast controller executes real-time motions.
-
Inside a Dual-System VLA Stack (Example: Warehouse Use Case)
Picture a humanoid robot in a warehouse (Bengaluru, Munich, or Dallas). You say:
“Stack these small red boxes on the third shelf and bring me the laptop bag from the meeting room.”
5.1 System 2 — The Slow Thinker (Reasoning & Planning)
System 2 will:
- Break instruction into subtasks:
- Stack small red boxes
- Fetch laptop bag
- Understand the scene using multiple cameras
- Generate a full-task plan:
- Navigate to storage
- Pick & stack
- Navigate to meeting room
- Identify laptop bag
- Return to requester
5.2 System 1 — The Fast Actor (Motor Control)
System 1 will:
- Maintain balance
- Adjust grip when a box slips
- Avoid collision with humans or forklifts
- Monitor forces and feedback in milliseconds
The two systems continuously exchange information:
| System 2 | System 1 |
| Sends goals | Executes movement |
| Plans next step | Reports success/failure |
| Enforces rules | Reacts instantly |
This is what transforms robots from rigid demos into fluid, trustworthy teammates.
-
Real-World Use Cases Across Regions
6.1 Manufacturing & Logistics (US, EU, East Asia, India)
- Loading/unloading inventory
- Operating tools
- Visual inspection + corrective action
- Handling variable positions and object types
6.2 Hospitals & Eldercare (Japan, EU, India, Global South)
- Delivering equipment and samples
- Assisting nurses
- Monitoring safety in patient rooms
Here, System 2 must be policy-aware (privacy, consent, safety), while System 1 must act delicately.
This is where robotic AI safety becomes real-world critical.

-
Why Now? Technology, Economics & Global Strategy
This shift is happening because of:
- Labor shortages
- Lower-cost modular robot hardware
- Edge-AI compute (AI PCs, accelerators, on-device Gemini & SmolVLA)
- Open-source robotics ecosystems like Open-X Embodiment and LeRobot
This creates opportunity:
For India, Southeast Asia, Africa, Latin America:
- Build local robotics manufacturing
- Avoid dependence on closed platforms
- Develop models aligned with local languages and environments
For the US & EU:
- Maintain leadership in mission-critical robotics
- Ensure compliance with AI regulations
- Preserve digital/robotic sovereignty

-
Key Challenges (Still Unsolved)
8.1 Data Realism & Diversity
Real-world data is scarce:
- Most datasets come from controlled labs, not chaotic real-world spaces.
- Humanoids need egocentric, multi-region demonstrations.
8.2 Safety & Hallucinated Actions
Like LLMs hallucinate text, VLAs can hallucinate motion:
- Reaching for non-existent objects
- Moving too fast near humans
- Misjudging unseen obstacles
Mitigation strategies include:
- Safety veto layers
- Simulation & digital twin testing
- Regulation (EU AI Act, India DPDP, sector frameworks)
8.3 Aligning System 1 & System 2
A major open question:
What happens when fast reflexes and slow planning disagree?
Example:
- Someone suddenly steps in front of a robot — System 1 overrides System 2.
We still need:
- Logs
- Justification
- Audit trail
- Policy enforcement
8.4 Evaluation: When Is a Robot “Good Enough”?
Robot tasks are:
- Continuous
- Noisy
- Long-horizon
Benchmarks increasingly measure:
- Generalization
- Multi-step task success
- Robustness in real environments
Regulators and enterprises must define:
“What level of reliability is acceptable for this task, in this environment?”
One of the biggest challenges is ensuring that these systems reason consistently and avoid unpredictable behavior when interacting with the physical world. This aligns closely with the broader challenge of building reliable reasoning for enterprise AI systems (https://www.raktimsingh.com/reliable-reasoning-ai-for-business), especially when the output affects real operations and compliance.
-
What This Means for Enterprises (US, EU, India & Global South)
Dual-System VLAs matter because they:
- Convert cameras + natural language into physical workflows
- Bridge software automation ↔ physical automation
- Allow one model to scale across robot types, sites, and supply chains
A Practical Adoption Roadmap
- Make data and workflows AI-ready
- Experiment with open-source VLAs (OpenVLA, SmolVLA, LeRobot)
- Design task families, not single tasks
- Implement governance from day one
- Consider geopolitics and deployment locality
Enterprises will require systems that can explain how a decision was made, not just produce the answer. This is where Enterprise Reasoning Graphs (ERGs) (https://www.raktimsingh.com/enterprise-reasoning-graphs-ergs/) become critical — enabling traceable, auditable decision pathways instead of black-box outputs.

-
Closing Thought: The Handshake Inside the Robot
The most important interface in robotics may not be:
- Human ↔ Robot
- Cloud ↔ Edge
- US ↔ EU ↔ India ↔ Global South
Instead, it may be:
🤝 System 1 (fast instinctive control)
meeting
🧠 System 2 (slow reflective reasoning)
When that handshake is:
- Robust
- Observable
- Policy-aligned
We get a new class of physical AI co-workers that:
- See the world
- Understand our goals
- Respect rules and regulations
- Act with capability, safety, and care
In the real world, VLA models won’t operate alone. They will coordinate with other agents — planners, safety layers, compliance monitors, and domain experts. This shift mirrors the emerging need for multi-agent orchestration at enterprise scale
https://www.raktimsingh.com/from-architecture-to-orchestration-how-enterprises-will-scale-multi-agent-intelligence, not just single intelligent models.
🔥 Final Line
This — Dual-System Vision-Language-Action robotics — will be at the center of AI robotics deployment in the US, EU, India, and the Global South throughout the coming decade.
Glossary (for a global audience)
- Vision-Language-Action (VLA) Model – A multimodal foundation model that takes visual input (camera), language input (text/voice), and outputs robot actions.
- Physical AI – AI that doesn’t just live on screens, but senses and acts in the physical world through robots, drones, vehicles, and other embodied platforms.
- Dual-System AI – An architecture combining a fast reflexive controller (System 1) with a slower reasoning planner (System 2).
- System 1 – Low-latency, continuous control: balance, grip, collision avoidance.
- System 2 – High-level reasoning: task planning, safety, policy, long-horizon decisions.
- Generalist Humanoid – A humanoid robot that can perform many different tasks across multiple environments, rather than one narrow job.
- Open X-Embodiment – A large dataset of robot demonstrations from many labs and robot bodies, used to train generalist robot policies.
- SmolVLA / OpenVLA / RT-2 / Helix / Gemini Robotics – Different VLA and humanoid-control models from global research and industry teams.
- Edge / On-Device AI – Running models directly on the robot or local hardware, not purely in the cloud.
FAQ: VLAs, Dual-System AI & generalist humanoids
Q1. Why not just use one giant model instead of Dual-System AI?
Because one giant model is usually either too slow for real-time control or too weak for deep reasoning. Dual-System AI separates concerns: a fast, compact controller for reflexes, and a slower, smarter planner for goals and safety — similar to how humans operate.
Q2. Are VLA models already used in real robots?
Yes. Early versions of VLA models run today in lab robots, warehouse pilots, and prototype humanoids. They are not yet in every factory or hospital, but the trajectory is clear: research → pilots → standardized platforms.
Q3. Will generalist humanoids replace human workers?
In the near term, they are more likely to change work than replace it: taking over repetitive, dirty, or dangerous tasks, while humans focus on supervision, exception handling, creativity, and human-to-human roles. The long-term impact will depend heavily on policy choices, reskilling, and social safety nets in each region.
📎 Further Reading
If you’d like to explore the earlier conceptual version of this idea, I published a related article on Medium that looks at Dual-System AI through the lens of embodied intelligence and robotics:
🔗 Dual-System AI for Embodied Intelligence: How Vision-Language-Action Models Will Power the Future of Robotics and Enterprise Systems
https://medium.com/@raktims2210/dual-system-ai-for-embodied-intelligence-how-vision-language-action-models-will-power-the-future-abfe923a779f

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.