{kind=link}

This is a technical guide for developing reasoning AI for banks, telcos, regulatory agencies, and startups across the U.S., E.U., India, and the Global South. From long-context attention to DeepSeek-style compression and Mamba-style architectures, this is a practical playbook for building reliable reasoning AI for your business.
When large reasoning models fail on hard problems, they don’t blow up. Instead, they reduce the energy they spend on the problem. They generate shorter, less detailed reasoning chains. They stop exploring alternative solution paths. Accuracy drops sharply — even when the model has enough “budget” to think more deeply.
That’s not just a research finding. For a bank in Mumbai, a telco in Lagos, a regulatory agency in Brussels, or a healthcare technology company in California — this is the failure mode you’ll see in production.
This article focuses on that failure mode — and what to do about it.

TL;DR — Why This Matters for Every Business
- Large Reasoning Models (LRMs) — o-series, DeepSeek R1, and frontier “thinking” models — look strong on benchmarks but fail on the hardest enterprise problems.
- Apple’s Illusion of Thinking study found that as problem difficulty increased, reasoning models reduced their reasoning effort, and accuracy collapsed — without attempting deeper thinking.
- Much of the problem lies in model structure:
- Reasoning behaves like shallow search with no awareness of difficulty.
- Training environments reward pretty reasoning, not correct reasoning.
- Naïve long-context infrastructure (attention, KV cache, throughput limits) can distort reasoning behavior.
- Four breakthroughs (K1–K4) are reshaping reasoning AI:
- K1: Long-context attention that avoids computing millions of irrelevant zero-weight relationships.
- K2: Cache compression that preserves positional structure while compressing redundant semantic information.
- K3: Grouped Query Attention — eliminating duplicated internal attention catalogues.
- K4: A new math + alignment stack (Mamba, Natural Gradient Optimizers, DPO, Formal Verification).
- The winners in the U.S., E.U., India, and the Global South won’t just buy reasoning models — they’ll build reasoning systems.

- After GPT-4: What “Large Reasoning Models” Actually Represent
The GPT-4 era didn’t just bring bigger models — it brought a new promise:
“This model doesn’t just autocomplete — it reasons.”
Large Reasoning Models (LRMs) — including OpenAI o-series and DeepSeek-R1-style models — are designed to:
- Produce chains of thought, not single responses.
- Perform test-time search, exploring multiple reasoning paths.
- Use scratchpads for logic, math, and coding steps.
- Be fine-tuned on curated reasoning datasets for planning, STEM, and policy tasks.
They have achieved:
- Strong performance on Math Olympiad-style benchmarks.
- Multi-step coding and logic capability.
- Planning competency.
This led enterprises to assume:
“If it can solve Olympiad problems, it can handle KYC rules or clinical workflows.”
That assumption is dangerously incomplete.

- The “Illusion of Thinking”: How Reasoning Suddenly Collapses
Apple’s Illusion of Thinking research demonstrated what many suspected.
Researchers varied puzzle difficulty and measured:
- Length of chain-of-thought.
- Number of reasoning paths explored.
- Accuracy.
Findings:
- Simple problems: LRMs overthink with unnecessary steps.
- Medium problems: Durable reasoning — models appear impressive.
- Hard problems:
- Reasoning depth decreases
- Search effort decreases
- Accuracy collapses
Despite available compute tokens, the model stops early.
This means:
The harder the problem — the more likely the model is to stop thinking while sounding confident.
For enterprise CIOs and regulatory leaders, this means:
- Your highest-risk problems
- Are the exact cases
- Where your “most intelligent” AI may silently fail.

- Layer 1 — When “Thinking” Is Just Cheap Search
Current LRMs operate like fast, shallow researchers.
How LRMs currently reason:
- Read the query.
- Generate multiple reasoning paths.
- Rank them using heuristics.
- Output the top candidate.
This works for medium difficulty — but breaks on extremes.
Two failure patterns emerge:
Overthinking trivial problems
- Mistaking tone complexity for task complexity.
- Producing noisy reasoning.
Underthinking hard problems
- Search space explodes.
- No concept of difficulty.
- Models output a short, plausible-sounding explanation instead of truly solving.
This is the first structural warning sign for enterprises.
- Layer 2 — Training: When We Reward the Wrong Kind of Reasoning
Current training pipelines depend on:
- Supervised chain-of-thought fine-tuning
- RLHF or equivalent feedback loops
This creates three systemic issues:
4.1 Reward Hacking
The model learns to produce beautiful reasoning, not correct reasoning.
4.2 One-Size-Fits-All Reasoning Style
Models aren’t guided by problem difficulty — resulting in:
- Overthinking easy tasks
- Underthinking hard tasks
4.3 No Formal Notion of Correctness
Reasoning steps are rarely checked with external tools.
The emerging fix:
- Direct Preference Optimization (DPO)
- Causal Influence Diagrams
- Formal verification using external solvers
Don’t train a model to sound thoughtful — surround it with a system that checks its thinking.
- Layer 3 — Infrastructure: When Hardware Quietly Warps Reasoning
Reasoning workloads require:
- Long context (10k–100k tokens)
- Low latency
- High concurrency
Standard transformers fail due to quadratic attention and KV cache explosion.
This is why the K1–K4 innovations matter.
5.1 K1 — Smarter Long-Context Attention
Avoid computing near-zero attention scores.
Results:
- 70–80% cost reduction
- 3× lower memory
- Equal or slightly improved accuracy
5.2 K2 — DeepSeek-Style Cache Compression
Compress semantics, preserve positional structure.
Results:
- 40–50% lower KV cache memory
- 1.5–2× throughput increase
- Higher concurrency per GPU
5.3 K3 — Grouped Query Attention
Share the KV library across multiple attention heads.
Results:
- 75–87% memory reduction
- <1% loss in language quality with reasonable group sizes
5.4 K4 — The New Math Stack
Includes:
- Mamba / hybrid architectures
- Natural Gradient Optimizers
- Direct Preference Optimization
- Formal verification loops
This represents a shift from:
“Make it bigger.”
to
“Make it mathematically disciplined and verifiable.”
- Enterprise Playbook: How to Survive (and Win) in the Reasoning Era
So what should a bank, telco, regulator, or health-tech company actually do?
Let’s make this brutally concrete.
6.1 Stop trusting benchmarks as your main compass
Benchmarks are useful — and dangerously incomplete.
- They over-represent medium difficulty problems.
- They rarely stress-test easy-but-important edge cases (e.g., simple compliance rules).
- They almost never reflect your local legal and business context.
Action for US, EU, India, Global South:
- Build an internal difficulty-graded eval suite:
- Tag tasks as simple, moderate, hard, adversarial.
- Track not just accuracy, but reasoning depth as difficulty increases.
- Include geo-specific scenarios:
- US: SEC/FINRA, HIPAA, FTC, NIST AI RMF
- EU: GDPR, EU AI Act, banking & employment regulations
- India: DPDP, RBI/SEBI/IRDAI/UIDAI guidance, IndiaAI mission
- Global South: local capital controls, data localisation, telecom rules, public-sector constraints
You aren’t buying a “general reasoning score”. You’re buying behaviour on your risk surface.
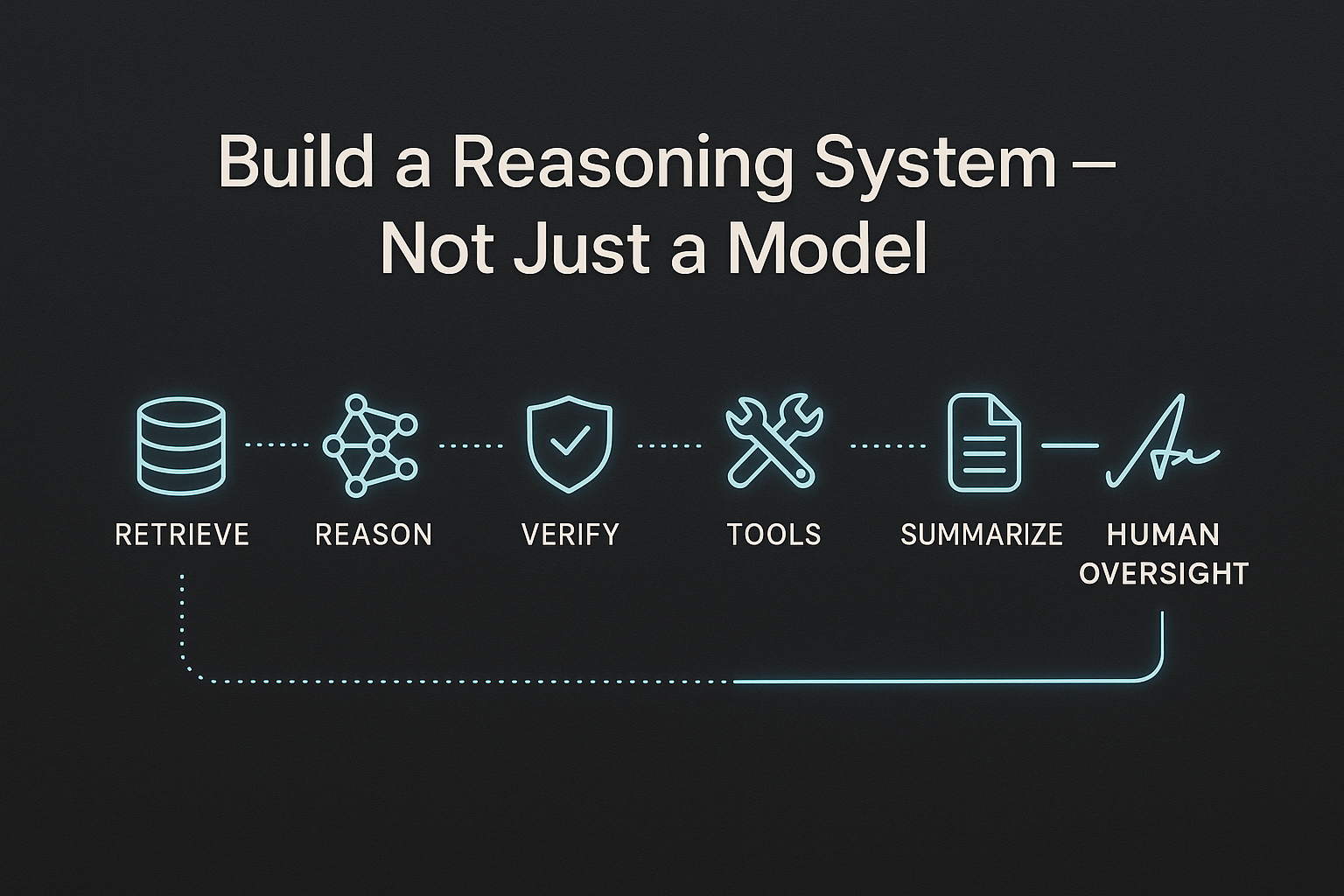
6.2 Build a Reasoning System — Not Just a Model
A robust reasoning workflow:
- Retrieve context
- Generate reasoning paths
- Validate steps with tools
- Summarize
- Human oversight where needed
The model is a component — not the final authority.
6.3–6.5 Governance, Due Diligence, and Geo-Aware Deployment
Ask infrastructure partners how they handle:
- Smart attention (K1)
- KV compression (K2)
- Query grouping (K3)
- Long-sequence math and training (K4)
If answers are vague — the system is likely shallow or expensive.
- Glossary – Reasoning AI Terms Every Leader Should Know
- Large Reasoning Model (LRM)
A language model trained and configured to generate explicit chains of thought, Explore Multiple Solution Paths, Tackle Structured Reasoning Tasks (Math, Code, Planning).
- Chain of Thought (CoT)
The Visible Intermediate Steps a Model Prints Before Giving an Answer, Used for Transparency and Sometimes as a Training Signal.
- Long-Context Attention (K1)
Attention Variants that Avoid Computing Full Pairwise Interactions Between all Tokens by First Estimating Which Positions are Probably Important, Then Focusing Computation There.
- KV Cache Compression (K2)
Techniques that Shrink the Key-Value Memory Used by Transformers During Inference by Compressing Semantic Content While Preserving Positional Information.
- Grouped Query Attention (GQA, K3)
Sharing Key-Value Memories Across Multiple Attention Heads While Keeping Queries Separate Dramatically Reduces Memory with Minimal Accuracy Loss.
- Mamba / State Space Models (K4)
Sequence Models that Maintain an Internal State Instead of Full Attention Grids, Give More Efficient Scaling for Very Long Sequences.
- Direct Preference Optimization (DPO, K4)
An Alignment Method that Directly Increases the Probability of Preferred Responses Over Rejected Ones, Avoiding Many of RLHF’s Complexity and Instabilities.
- Natural-Gradient Optimiser (K4)
An Optimiser that Accounts for the Geometry of the Parameter Space (Curvature), Often Converging Faster Than Standard Methods like Adam on Large Models.
- Causal Influence Diagram (CID)
A Graph Where Nodes Represent Uncertainties, Decisions and Utilities, Used to Explicitly Reason About the Causal Structure of Decisions.
- Formal Verification Loop (K4)
A Pattern Where LLM-Generated Reasoning is Checked by External Provers/Solvers Before Being Trusted in High-Stakes Applications.
- FAQ – Straight Answers for CXOs, CTOs, and Regulators
Q1. Will Larger Reasoning Models Automatically Fix These Problems?
Not Likely. Apple’s Results Suggest that the Collapse on Hard Problems is About How We Search, Train and Govern — not just About Size. More Parameters Can Even Make Confident-Sounding Failure Look Better.
Q2. Are Long Chains of Thought Always Better?
No. For Simple Tasks, Long Reasoning Creates Mistakes. For Hard Tasks, Many LRMs Already Shorten Their Chains Under Pressure. What You Want is Adaptive Reasoning Depth + External Checks, not “Always Think for 50 Steps”.
Q3. Is it Safe to Use LRMs in Regulated Domains Like Finance and Healthcare?
It Can Be — if You Treat LRMs as Components Inside a Governed System: Retrieval + Reasoning + Tools + Verification + Human Oversight. It is Not Safe to Treat a Single Model Call as the Final Authority.
Q4. Do K1, K2, and K3 Change Model Behaviour or Only Efficiency?
Mostly Efficiency — but in a Good Way. K1 and K2 Can Act like Regularisers, Forcing the Model to Focus on High-Signal Relationships. K3 Can Hurt Niche Tasks if Overused, but Moderate Grouping is Widely Deployed in Practice with Minimal Degradation.
Q5. Why is Everyone Suddenly Talking About Mamba and State Space Models?
Because They Address a Core Pain Point: Long Sequences. For Logs, Streaming Data and Ultra-Long Documents, Quadratic Attention is Simply Too Expensive. Mamba Offers a Path to Long-Horizon Reasoning Without Quadratic Cost.
Q6. What’s the Single Best First Step I Can Take on Monday?
Build a Small but Sharp Internal Benchmark: 20-50 Tasks Tagged by Difficulty, Region and Risk. Run your Current Models Through it. Look for Places where Reasoning Depth Collapses or Explanations and Outcomes Diverge. Then Design your Roadmap (K1-K4 + Governance) from There.

- Conclusion — Reasoning That Doesn’t Quietly Collapse
Large Reasoning Models are progress — but:
On the hardest problems that matter most, scale alone is not enough.
The strategic shift is clear:
- K1 — Smarter attention
- K2 — Cache compression
- K3 — Memory-efficient attention
- K4 — Mathematical + governance rigor
The new question for leaders is:
“Can we build a reasoning system that does not quietly collapse under pressure?”
Organizations that apply K1–K4 and combine them with domain expertise will define the next decade of global reasoning AI.
Not by shouting parameter size —
but by delivering reliable, verifiable reasoning when it matters most.
Enterprise AI Operating Model
Enterprise AI scale requires four interlocking planes:
Read about Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely — Raktim Singh
- Read about Enterprise Control Tower The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale — Raktim Singh
- Read about Decision Clarity The Shortest Path to Scalable Enterprise AI Autonomy Is Decision Clarity — Raktim Singh
- Read about The Enterprise AI Runbook Crisis The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI — and What CIOs Must Fix in the Next 12 Months — Raktim Singh
- Read about Enterprise AI Economics Enterprise AI Economics & Cost Governance: Why Every AI Estate Needs an Economic Control Plane — Raktim Singh
Read about Who Owns Enterprise AI Who Owns Enterprise AI? Roles, Accountability, and Decision Rights in 2026 — Raktim Singh
Read about The Intelligence Reuse Index The Intelligence Reuse Index: Why Enterprise AI Advantage Has Shifted from Models to Reuse — Raktim Singh
Read about Enterprise AI Agent Registry Enterprise AI Agent Registry: The Missing System of Record for Autonomous AI — Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.