{kind=link}

How enterprises scale agentic workflows safely—then productize outcomes into reusable, app-store-like services (without lock-in)
Executive summary
Enterprise AI is leaving its “tool era.” The first wave delivered copilots, chatbots, and impressive demos. The next wave is about repeatability in production: agents that can act across real systems, governed flows that reduce risk, and outcomes delivered as Services-as-Software—measurable services that behave like software products.
The pressure is structural, not cosmetic. Gartner predicts over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls. (Gartner) That forecast is less a “warning about agents” and more a warning about operating models.
The winners won’t run more pilots. They will build:
- A composable enterprise AI stack (integration → context → models → agents → orchestration → governance → security → observability)
- A Services-as-Software layer that packages outcomes into reusable, governed services
- A self-serve catalog experience that lets teams consume outcomes safely—without learning the underlying AI plumbing
This article is a practical blueprint for building the stack that makes Services-as-Software real—open, interoperable, and responsible by design.
This connects to the broader Enterprise AI Operating Model, which explains how organizations design, govern, and scale intelligence safely in production. 👉 Enterprise AI Operating Model

Why Enterprise AI is leaving the “tool era”
For a while, enterprise GenAI success was measured by shipping something visible:
- A chatbot for employee Q&A
- A copilot embedded in a workflow
- A handful of use-case pilots
- A demo that looked great in a steering committee meeting
But pilots exposed a hard truth:
Enterprises don’t scale intelligence by buying more AI apps.
They scale intelligence by building a reusable operating layer that integrates with systems of record and enforces trust by default.
This direction is increasingly described as an “agentic business fabric,” where agents, data, and employees work together to deliver outcomes—while orchestration happens behind the scenes so users can focus on outcomes and exceptions. (Medium)
That reframes the foundational question. Instead of:
“Which model should we pick?”
The better starting question becomes:
“How does intelligence flow through the enterprise—securely, consistently, measurably—across systems of record?”
That requires a stack. And once the stack exists, Services-as-Software becomes the natural operating model built on top of it.

The mental model: Agents, Flows, Services-as-Software
Most confusion disappears when you separate three layers of “what’s happening.”
1) Agents: intelligence that can act
Agents are AI systems that can plan, decide, and take actions—typically by calling tools, APIs, and workflows. They don’t just answer questions. They execute work.
2) Flows: repeatability, safety, evidence
Flows are the orchestrated pathways that make agent work predictable and governable:
- Fetch context (with permissions)
- Verify policies and constraints
- Call tools and systems
- Request approvals where needed
- Generate evidence artifacts (audit bundles)
- Escalate exceptions
- Log actions, decisions, and outcomes
In practice, the flow determines whether an agent belongs in production.
3) Services-as-Software: outcomes packaged as services
Services-as-Software is the pattern where organizations stop buying “apps” or launching new projects—and instead build/buy outcomes as productized services, for example:
- “Resolve tier-1 support tickets”
- “Compile compliance evidence packs”
- “Reconcile finance exceptions and propose fixes”
- “Onboard vendors with policy checks”
HFS Research frames Services-as-Software as a structural shift where outcomes are delivered primarily through advanced technology—pushing service delivery toward software-like economics and scaling. (HFS Research)
In one line:
Agents provide intelligence. Flows provide control. Services-as-Software provides scale.

A simple story: why stacks beat tools
Imagine a procurement team wants an agent to onboard vendors.
Tool-first approach:
“Let’s buy a vendor onboarding agent.”
Stack-first approach:
“Let’s build a vendor onboarding service using agents for reasoning, flows for repeatability, and governance for risk control—integrated into ERP, identity, and document systems.”
Both can generate a demo. Only one survives production.
Because vendor onboarding isn’t “text generation.” It’s permissions, evidence, approvals, system updates, audit trails, and policy enforcement—plus operational monitoring when edge cases show up.
Enterprises don’t lose because their models are weak.
They lose because AI isn’t composable, interoperable, and governable at runtime.
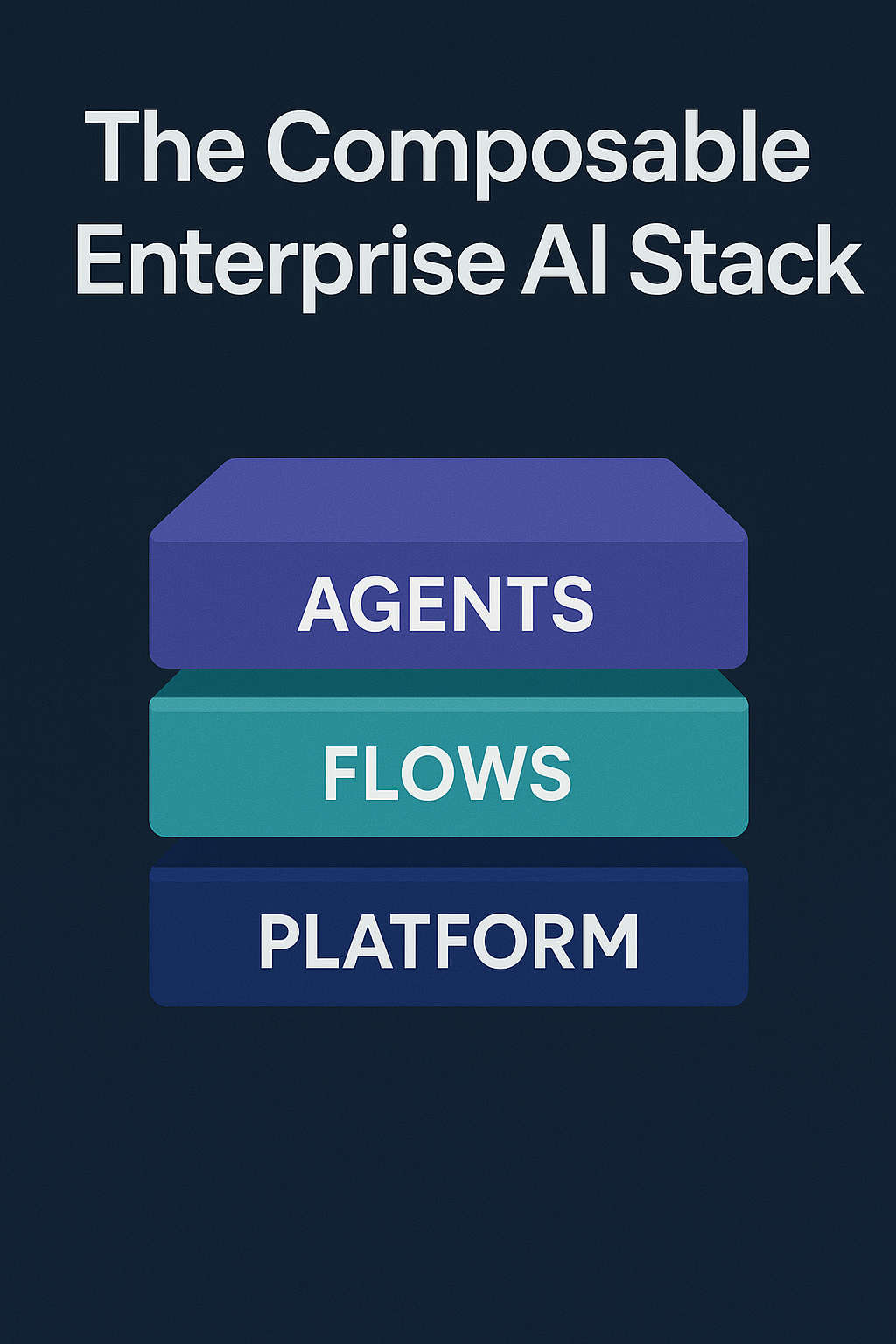
The Composable Enterprise AI Stack
Most successful enterprise programs converge on a layered architecture. You don’t need perfection on day one—but you do need a direction that scales.
Layer 1: Integration and interoperability (connect to reality)
This is where many agent initiatives quietly die.
Enterprises run on systems of record and control planes:
- ERP, CRM, ITSM
- Identity and access management
- Data platforms and warehouses
- Document systems and knowledge bases
- DevOps pipelines and observability stacks
Your AI must plug into these systems in a controlled, upgrade-friendly way.
Principle: No “rip and replace.” Wrap intelligence around what exists.
Design goal: Stable connectors + safe tool/action calling + change management.
Interoperability is not a slogan. It’s a constraint—and foundational to everything that follows.
Layer 2: Data + context (governed retrieval, not “dump everything into the prompt”)
Agents need context—but context must be permissioned and task-scoped.
This layer provides:
- Secure access to enterprise knowledge
- Permission-filtered retrieval (least privilege)
- Real-time + historical context assembly
- Masking/redaction for sensitive fields
- Data residency constraints and audit rules
Enterprise rule: AI should see only what it’s allowed to see—only for the task it is executing.
This is where “enterprise RAG” becomes less about vector databases and more about policy-aware context.
Layer 3: Model layer (multi-model, task-aware routing)
The winning strategy is rarely “one model to rule them all.” Enterprise reality forces:
- Multiple models (open + proprietary)
- Routing based on latency, cost, privacy, and quality
- Fallbacks and evaluation gates
- Region-aware deployments (e.g., residency requirements)
This reduces lock-in and improves resilience. It also lets governance teams define where each model is allowed (by data sensitivity, geography, and risk tier).
Layer 4: Agent layer (roles, not monoliths)
A common failure mode is building one “super-agent” that tries to do everything.
Composable systems use:
- Specialized agents with clear boundaries
- Reusable skills (redaction, summarization, classification, evidence packaging)
- Constrained tool access per role
- Explicit ownership and change control
Think digital roles, not “scripts with attitude.”
Layer 5: Flow + orchestration (the operational brain)
This is where “agent intelligence” becomes repeatable operations.
Orchestration:
- Sequences tasks
- Coordinates multiple agents
- Manages handoffs and retries
- Sets confidence thresholds
- Triggers approvals
- Escalates exceptions
- Produces consistent evidence artifacts
This matches the “fabric” direction: orchestration behind the scenes so users don’t hop across app silos to get work done. (Medium)
Layer 6: Governance + Responsible AI + policy enforcement (trust becomes operational)
This is where most pilots fail—because governance is treated as documentation, not architecture.
NIST’s AI Risk Management Framework (AI RMF 1.0) is widely used as a structured reference to incorporate trustworthiness and manage AI risks across the lifecycle. (NIST)
In stack terms, governance means:
- Role-based permissions for agent actions
- Policy checks before tool calls
- Human approvals mapped to risk tiers
- Traceability of decisions and sources
- Accountability: who built, who approved, who owns
Governance is not a committee. It’s runtime control.

Layer 7: Security for agentic systems (assume residual risk, limit blast radius)
Agentic AI expands the attack surface because it can act.
OWASP’s Top 10 for LLM applications highlights risks directly relevant to enterprise agents, including prompt injection and sensitive information disclosure. (OWASP)
Practical security patterns:
- Treat external content as untrusted input
- Isolate retrieved text from system instructions
- Least-privilege tool calling (and scoped tokens)
- Sandbox sensitive operations
- Rate limits, anomaly detection, and behavioral monitoring
- Incident response playbooks for agent behavior
The mature stance is not “we will eliminate every risk.”
It is: we will reduce blast radius and detect failures early.
Layer 8: Observability + continuous improvement
You can’t scale what you can’t see.
For agentic systems, observability must include:
- Prompts and responses (with redaction)
- Tool calls and side effects
- Decision traces (auditable summaries)
- Outcomes and success metrics
- Safety interventions and approvals
- Drift monitoring and regression tests
OpenTelemetry has published semantic conventions for generative AI (including prompt/completion token usage and response metadata) to standardize how GenAI systems are traced and measured across tools and vendors—crucial for interoperability in AI observability. (OpenTelemetry)
This layer is how you avoid the “pilot success → production decay” cycle.

The missing bridge: how the stack becomes Services-as-Software
Here is the clean synthesis:
- The stack is how you build and govern intelligence.
- Services-as-Software is how you package outcomes on top of that stack.
- The “app store” experience is how teams consume those outcomes at scale.
When leaders mix these up, terms like “fabric,” “platform,” “services,” “catalog,” and “app store” sound like competing narratives.
They aren’t. They are layers of the same system.
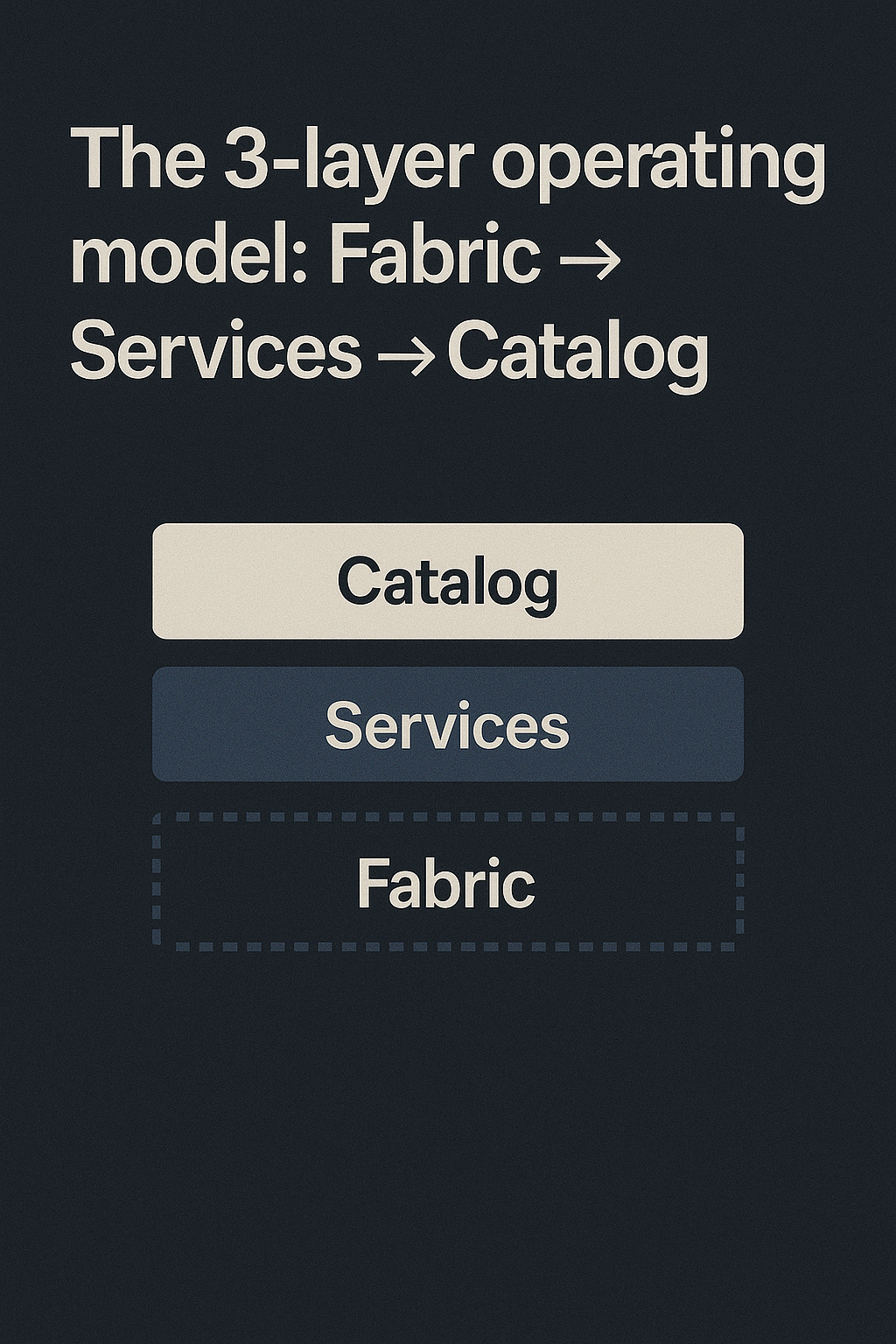
The 3-layer operating model: Fabric → Services → Catalog
Layer A: The Fabric (Build & Govern)
This is the foundation you do not want every team to re-implement:
- Security + identity controls
- Policy enforcement
- Connectors to enterprise systems
- Model access + routing
- Data access patterns and residency constraints
- Guardrails + audit trails + compliance evidence
- Observability foundations
Infosys’ public launch description of Topaz Fabric is a concrete example of how the market describes this foundation: a layered, composable, open and interoperable stack spanning data infrastructure, models, agents, flows, and AI apps. (Infosys)
Think of it like roads, traffic rules, and emergency services of a city: built once, reused by everything.
Layer B: Services (Execute Outcomes)
This is where Services-as-Software lives.
You take repeatable outcomes and package them as services that behave like software:
- Versioned (change is controlled)
- Measurable (SLA + success metrics)
- Governed (policy checks by default)
- Composable (can be chained)
- Observable (traceable end-to-end)
- Safe (explicit human override paths)
Examples of outcome-services:
- “Incident resolution with guided runbooks + automated remediation”
- “Compliance evidence pack generation for a change release”
- “Regression testing + failure triage + ticket creation”
- “Vendor onboarding with policy checks and audit bundle”
Layer C: The Catalog Experience (Consume & Scale)
Business teams don’t want to learn:
- which model is used
- which agent framework is used
- which connector is used
- how prompts are managed
They want to consume outcomes with confidence.
So you provide an experience that feels like:
- Browse services
- Request access
- Configure context
- Run
- Track outcomes
- View audit trails
Modern engineering already uses internal portals and service catalogs. Backstage describes itself as an open source framework for building developer portals powered by a centralized software catalog. (backstage.io)
The enterprise “app store” doesn’t need to be literal. It needs to be self-serve, governed, and observable.

What Services-as-Software looks like in real enterprise life
Example 1: IT Operations — Incident Resolution as a Service
Old model: war rooms, tribal knowledge, inconsistent postmortems.
Services-as-Software model: an incident resolution service that:
- Ingests alerts and logs
- Correlates signals
- Proposes likely root causes
- Runs safe, policy-approved remediation actions
- Escalates when confidence is low or risk is high
- Produces post-incident evidence automatically
This requires agent observability and traceability; OpenTelemetry’s GenAI conventions help standardize this visibility across tools. (OpenTelemetry)
Example 2: Quality Engineering — Regression Testing as a Service
Old model: each program builds its own automation; tools diverge; flaky tests multiply.
Services-as-Software model: a testing service that:
- Generates test cases from requirements and past defects
- Runs in standardized environments
- Triages failures and clusters root causes
- Opens tickets with reproduction steps
- Produces a release readiness summary
One service, shared across the enterprise. Outcomes improve; rework drops.
Example 3: Cybersecurity — Compliance Evidence as a Service
Old model: audit season panic—screenshots, spreadsheets, manual chasing.
Services-as-Software model: a compliance evidence service that:
- Continuously collects required logs
- Flags missing controls early
- Compiles evidence packs in auditor-ready format
- Records provenance and approvals
Compliance becomes continuous proof—not seasonal panic.
Example 4: Procurement — Vendor Onboarding with policy gates
A realistic vendor onboarding service:
- Collects documents
- Runs risk checks
- Validates policy requirements
- Routes approvals
- Creates system records
- Produces an audit bundle automatically
That’s agents + flows + governance, delivered as a reusable service.

The critical ingredient: human-by-exception, not human-in-the-loop everywhere
A common fear is: “If AI is running services, where do humans fit?”
The scalable answer is human-by-exception:
- AI executes the standard path
- Humans intervene when:
- confidence is low
- risk is high
- policy requires approvals
- unusual cases occur
This is how mature reliability systems scale: automation handles routine work; humans handle exceptions, governance, and continuous improvement.
Human-by-exception works because services are designed with:
- Clear safety boundaries
- Explicit escalation points
- Audit trails
- Rollback paths

What must be true for Services-as-Software to work
1) Interoperability and composability (enterprise reality is messy)
Multi-cloud, legacy systems, SaaS sprawl, acquisitions, regional constraints—this is normal.
Your services must plug into reality without forcing “one vendor to rule them all.” This is why “open and interoperable” has become a design requirement. (Infosys)
2) Observability that understands agents and AI (standardize visibility)
To scale, you need visibility into tool calls, decisions, outcomes, approvals, and safety interventions. OpenTelemetry’s GenAI semantic conventions are directly aimed at standardizing this across systems. (OpenTelemetry)
3) Outcome accounting (bridge CIO language to CFO language)
If services behave like software, enterprises will measure them like products:
- Cost per outcome
- Time-to-outcome
- Failure and rollback rates
- Compliance pass rates
- Human override rate
- Cycle-time reduction and downstream business impact
This is how Services-as-Software becomes more than a concept—it becomes an operating model.

Why this reshapes procurement, org design, and vendor strategy
Procurement changes: from projects to outcome services
Instead of buying projects, enterprises increasingly buy:
- Outcome services
- Consumption tiers
- SLA-backed service bundles
- Governance guarantees (auditability, provenance, controls)
Org design changes: from project teams to service owners
You’ll see:
- Product managers for enterprise services
- Platform teams maintaining the fabric
- Service owners accountable for outcomes
- Governance teams defining reusable policies “as code”
Vendor strategy changes: from “best model” to “best operating system for outcomes”
The winners won’t just provide models. They will deliver reusable governed services, integrated into enterprise systems, with measurable outcomes and safe autonomy—aligned with HFS Research’s thesis that Services-as-Software shifts scaling toward technology-driven delivery. (HFS Research)
A practical rollout plan that avoids agentic chaos (and the cancellation trap)
If Gartner’s cancellation forecast is even directionally right, winners will build the stack while proving outcomes early. (Gartner)
Phase 1: Start with bounded autonomy
Pick workflows where:
- Actions are reversible
- Approvals are natural
- Outcomes are measurable
- Integration is feasible without major refactoring
Examples: incident triage, change risk summaries, test failure triage, evidence pack compilation, access request automation.
Phase 2: Build reusable components
Create shared building blocks:
- Redact sensitive fields
- Create ITSM ticket
- Generate evidence pack
- Escalate with summary
- Permission-check + policy-check wrappers for every tool call
This is how you stop reinventing “the same agent” ten times.
Phase 3: Standardize governance gates
Define:
- Approved connectors
- Approved templates and prompt patterns
- Risk tiers + required approvals
- Logging and audit rules
- Model routing constraints by data class and geography
Use NIST AI RMF as a lifecycle reference for risk management and trustworthiness practices. (NIST)
Phase 4: Publish services into a catalog (start simple, then evolve)
Even a basic portal works initially:
- Service description
- Access rules
- How to request/run
- What to expect (SLA, boundaries)
- Evidence and audit views
- Ownership and escalation paths
Over time, this becomes the “app store” experience—often powered by an internal portal approach similar to Backstage’s service catalog concepts. (backstage.io)
Phase 5: Measure outcomes, not activity
Track:
- Cycle time reduction
- Exception and rework rates
- Audit readiness and evidence completeness
- Cost per case/outcome
- User trust and satisfaction
- Human override rate (and why)
This turns AI from experiments into an operating capability.
Global relevance: why this model travels across US, EU, India, and the Global South
Across regions, enterprises share common constraints:
- Regulatory pressure and data governance
- Legacy system gravity
- Talent bottlenecks
- Cost scrutiny
- AI risk management requirements
That’s why the stack + Services-as-Software model is universal: it reduces reinvention, standardizes governance, increases delivery speed, and makes AI adoption operationally sustainable—without assuming a single-vendor environment.

Conclusion column: The “quiet advantage” leaders will compound
The next decade of enterprise AI won’t be won by the loudest demos. It will be won by organizations that build a composable operating layer—then turn intelligence into reusable outcome-services.
Here’s the quiet advantage: once you have services that behave like software, you can improve them like software—version by version. You can measure them like products. You can govern them at runtime. And you can scale them across business units and geographies without rebuilding the same capability every time.
This is why the most strategic question is no longer:
“Where do we use AI?”
It becomes:
“Which outcomes should become reusable services first—and what stack makes them safe, measurable, and replaceable over time?”
That question doesn’t just guide architecture. It guides competitive advantage.
FAQ
1) What is a composable enterprise AI stack?
A layered platform that lets enterprises assemble reusable AI capabilities—integrations, context, models, agents, orchestration flows, governance, security, and observability—on top of existing systems.
2) Why do agentic AI projects fail in enterprises?
Because costs rise, business value is unclear, and risk controls are inadequate—exactly the pattern Gartner highlights in its agentic AI cancellation forecast. (Gartner)
3) Is Services-as-Software just SaaS?
No. SaaS sells software licenses. Services-as-Software sells outcomes, delivered through AI-powered, productized services embedded into operations—often with software-like economics and measurement. (HFS Research)
4) What’s the biggest security risk for tool-using AI agents?
Prompt injection and sensitive information disclosure are among the top risks; OWASP catalogs these in its LLM Top 10 guidance. (OWASP)
5) What framework helps operationalize Responsible AI?
NIST AI RMF 1.0 is widely used as a reference to incorporate trustworthiness and manage AI risks across the lifecycle. (NIST)
6) Do we need one model or one vendor?
No. Enterprise reality is multi-platform and multi-model. The direction is toward composable foundations and interoperable services—so models can be swapped as requirements evolve.
7) Is “app store” meant literally?
Not necessarily. It’s a metaphor for self-serve consumption: discover services, request access, configure context, run, track outcomes, and view audit trails—without needing to understand the underlying AI stack.
Glossary
- Agent: An AI system that can plan and take actions using tools and APIs.
- Flow / Orchestration: A controlled sequence of steps that makes agent behavior repeatable and safe (approvals, retries, evidence, escalation).
- Composable stack: A modular architecture where components (connectors, context, models, agents, governance) can be replaced or upgraded without breaking the whole.
- Interoperability: The ability to connect across diverse enterprise tools, data sources, clouds, and models without lock-in.
- Services-as-Software: An operating model where outcomes are packaged as reusable, governed, measurable services that scale like software. (HFS Research)
- Human-by-exception: AI runs standard cases; humans review, approve, handle edge cases, and continuously improve services.
- NIST AI RMF 1.0: A voluntary framework to manage AI risks and incorporate trustworthiness across the AI lifecycle. (NIST)
- OWASP Top 10 for LLM Applications: A community-driven list of key LLM security risks and mitigations, including prompt injection and sensitive information disclosure. (OWASP)
- GenAI observability (OpenTelemetry): Standardized semantic conventions for tracing and measuring GenAI operations (e.g., model metadata, token usage, events/metrics) across vendors and tools. (OpenTelemetry)
- Service catalog / internal portal: A discoverable interface where teams self-serve services, access rules, ownership, and documentation—often implemented using developer portal patterns (e.g., Backstage). (backstage.io)
- Enterprise AI fabric / operating layer: The shared foundation that provides governance, security, integrations, model routing, and observability across enterprise AI systems (often described in “fabric” language by vendors and analysts). (Infosys)
References and further reading
- Gartner press release: “Over 40% of agentic AI projects will be canceled by end of 2027…” (Gartner)
- NIST AI RMF overview + PDF: AI Risk Management Framework (AI RMF 1.0) (NIST)
- OWASP: Top 10 for LLM Applications + Prompt Injection guidance (OWASP)
- OpenTelemetry: Generative AI semantic conventions (events/metrics) and overview (OpenTelemetry)
- Backstage: Developer portal + software catalog documentation (backstage.io)
- Infosys: “Launching Today: Infosys Topaz Fabric” (press release) (Infosys)
- HFS Research: Services-as-Software (definition and growth framing) (HFS Research)
- The Composable Enterprise AI Stack: Agents, Flows, and Services-as-Software — Built Open, Interoperable, and Responsible | by RAKTIM SINGH | Dec, 2025 | Medium
- Services-as-Software: Why the Future Enterprise Runs on Productized Services, Not AI Projects | by RAKTIM SINGH | Dec, 2025 | Medium
- AI Agents Will Break Your Enterprise—Unless You Build This Operating Layer – Raktim Singh
- From Architecture to Orchestration: How Enterprises Will Scale Multi-Agent Intelligence – Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.