{kind=link}

Representation Collapse Cascades:
In the AI economy, failure rarely begins where the damage first becomes visible
A hospital record shows the wrong risk level.
A bank profile carries an outdated income signal.
A supply chain platform codes a port delay as weakening demand.
A fraud engine flags a legitimate customer as suspicious.
A public system marks a neighborhood as “high risk” largely because it has been over-observed in the past.
At first glance, these look like ordinary data problems. A stale field. A bad label. A weak proxy. A small mismatch.
But in the AI economy, a small misrepresentation rarely stays small.
It travels. It is copied into downstream systems. It is consumed by models, workflows, dashboards, compliance checks, and decision engines. It gains authority not because it is true, but because it appears repeatedly across multiple systems. And once several systems begin acting on the same distortion, the original error becomes harder to challenge precisely because it now looks institutional.
That is the problem I call Representation Collapse Cascades.
This is not only a model problem. It is not only a data-quality problem. It is not only a governance problem. It is a systemic problem: when one false, incomplete, stale, or badly structured representation of reality begins to spread across connected systems, producing compounding distortions in decisions, actions, and trust.
That concern is consistent with broader research and policy thinking. NIST’s AI Risk Management Framework emphasizes governing, mapping, measuring, and managing risk across the full AI lifecycle, not merely checking model performance in isolation. OECD work on AI incidents similarly argues for understanding harms across socio-technical chains rather than as isolated technical events. (NIST)
That is why the next generation of AI winners will not simply be the organizations with the most models. They will be the organizations that best prevent misrepresentation from spreading across systems.
What is a Representation Collapse Cascade?
A representation collapse cascade occurs when small gaps or errors in how reality is captured by an AI system compound across layers, leading to amplified risks, incorrect decisions, and eventual systemic failure.
Representation Collapse Cascades explain why AI failures are rarely isolated. Instead, they emerge from compounding errors in data, context, and system understanding. As enterprises scale AI, the ability to accurately represent reality—not just process it—will determine reliability, governance, and competitive advantage.
Why representation collapse cascades matter in enterprise AI, governance, and board strategy

Most executives still think about AI failure in the wrong place.
They think about hallucinations.
They think about bias in a single model.
They think about prompt issues.
They think about one bad decision.
Those are real problems. But they are often downstream symptoms.
In practice, many of the most dangerous failures in enterprise AI start earlier — at the point where reality is converted into a machine-readable form. Once that representation is damaged, the damage can propagate across systems with surprising speed.
That is why representation quality is becoming a strategic issue for boards, CEOs, CIOs, risk leaders, and regulators. In a highly connected decision environment, the real question is no longer, “Is this model accurate?” The deeper question is, “What happens when the institution starts reasoning over the wrong version of reality?”
What is a Representation Collapse Cascade?

A Representation Collapse Cascade begins when a system’s machine-readable picture of reality becomes wrong in a meaningful way.
The problem may start with:
- missing context,
- stale data,
- bad identity matching,
- poor proxy variables,
- biased historical records,
- incorrect labels,
- broken entity resolution,
- silent data transformations,
- or feedback loops that reinforce earlier mistakes.
Once that flawed representation enters a connected environment, the cascade typically follows a recognizable pattern:
-
The source representation becomes distorted
A record is created, updated, or interpreted incorrectly.
-
Another system consumes it as truth
A downstream system treats the flawed input as authoritative.
-
Models and rules begin reasoning over the distortion
The wrong representation becomes a model input, label, feature, or business rule trigger.
-
Actions are executed
A case is routed, a loan is denied, a customer is flagged, a shipment is reprioritized, a patient is deprioritized.
-
Those actions generate new data
The institution produces fresh records that appear to “confirm” the original error.
-
The institution learns from its own distortion
Now the problem is no longer local. It has become systemic.
The most dangerous thing about a collapse cascade is that each step can look reasonable when viewed in isolation. The failure appears only when you step back and see that the entire chain is acting on a damaged representation of reality.
Why this matters now
In the software era, many errors stayed inside one application.
In the AI era, systems are increasingly connected. Data pipelines feed models. Models feed recommendations. Recommendations trigger workflows. Workflows update records. Those records later become training data, monitoring signals, audit evidence, customer history, and executive intelligence.
In other words, AI systems do not simply analyze reality. They increasingly help produce the next version of reality.
That is why representation collapse cascades are becoming a first-order economic problem.
As organizations automate decisions across lending, healthcare, insurance, logistics, public services, hiring, security, and customer operations, the cost of allowing one flawed representation to travel unchecked rises sharply. The EU AI Act reflects that broader concern by emphasizing data governance, record-keeping, transparency, robustness, and human oversight for high-risk AI systems. OECD work on AI, data governance, and privacy points in the same direction: cross-system accountability and high-quality data practices are not peripheral issues. They are foundational. (EUR-Lex)
A simple way to understand the problem

Imagine you move to a new city, but one critical database still carries your old address.
That feels minor.
But now your bank sees logins from an unfamiliar location.
A credit verification service notices conflicting identity signals.
An insurance workflow flags a mismatch.
A delivery platform marks your account as unreliable.
A support chatbot reads from the old profile and gives the wrong answer.
Your case is routed for manual review.
Those delays and exceptions become part of your future history.
Nothing dramatic changed in the real world.
But in the machine-readable world, your institutional representation has started drifting away from reality. Once that drift spreads across systems, the systems begin coordinating around the wrong version of you.
That is a representation collapse cascade.
Five simple examples that make the problem real

-
Healthcare: the wrong proxy becomes the wrong patient priority
A widely cited Science study found that a health-risk algorithm used healthcare spending as a proxy for health needs. Because unequal access to care meant lower spending for equally sick Black patients, the system underestimated who needed additional care. When the researchers reformulated the algorithm so it no longer used cost as the proxy, the bias was substantially reduced. (Science)
The cascade is easy to see:
- the proxy is wrong,
- the risk score is wrong,
- care allocation is wrong,
- follow-up data reflects under-allocation,
- future systems learn from distorted outcomes.
A bad representation at the start can travel through care management, budget allocation, operational planning, and future model training.
-
Predictive policing: observation becomes confirmation
Research on predictive policing has shown how feedback loops can emerge when deployments are based on prior recorded incidents and those deployments then generate more recorded incidents in the same locations. In that setting, the system is not simply detecting risk. It is helping reproduce the data that later appears to justify the same conclusion. (Proceedings of Machine Learning Research)
The cascade looks like this:
- over-observed areas produce more records,
- those records are treated as evidence of higher risk,
- more patrols are sent there,
- more incidents are recorded there,
- the dataset becomes progressively less representative of underlying reality.
The system starts mistaking where it looked more for where more wrongdoing exists.
-
Lending: one thin file becomes institutional doubt
A borrower with irregular income, limited formal credit history, or incomplete documentation may be represented poorly by a credit or risk system. That weak representation can reduce approval probability, worsen terms, or push the case into expensive manual review. Regulators continue to stress transparency and discrimination risks in automated credit decisioning because those systems can embed unfairness at scale. (EUR-Lex)
Now follow the cascade:
- the initial file looks weak,
- the borrower receives worse terms or a rejection,
- the borrower’s future formal financial footprint remains thin,
- the thinner footprint later appears to confirm higher risk,
- the institution learns from the exclusion it helped create.
The borrower is not merely judged by the system. Over time, the borrower is shaped by the system’s earlier representation.
-
Supply chains: a bad signal travels faster than a truck
Suppose a product delay is caused by a port bottleneck, but downstream systems classify it as softening demand.
That error does not remain in one dashboard. It can move into procurement plans, production schedules, inventory targets, supplier negotiations, revenue forecasts, and working-capital decisions.
The shipment is real. The warehouse is real. The bottleneck is real.
The problem is representational: the system explains the event incorrectly, and multiple operating layers optimize around the wrong explanation.
-
Customer service: false fraud creates real attrition
A payment is flagged. The fraud model raises suspicion. The customer is forced through extra verification. They abandon the transaction. That abandonment becomes behavioral data. The relationship weakens. The customer profile now appears riskier because the system itself changed the customer journey.
One false signal can spread across payments, CRM, trust scoring, support routing, retention analytics, and future offer eligibility.
That is how a single misrepresentation becomes institutional behavior.
Why ordinary fixes often fail

Most organizations intervene too late.
They audit the model after a complaint.
They retrain after visible drift.
They create a dashboard after trust has already broken.
But representation collapse cascades are hard to fix late because downstream systems have already absorbed the bad representation.
By then:
- multiple teams depend on the output,
- lineage is incomplete,
- the source of the distortion is unclear,
- action logs are fragmented,
- the result appears trustworthy because it shows up everywhere,
- and reversing the damage is expensive.
That is why data lineage matters so much. IBM defines data lineage as tracking where data originated, how it changed, and where it moved over time. Without that visibility, organizations struggle to trace failures, assess impact radius, and unwind downstream harm. (IBM)
The SENSE–CORE–DRIVER explanation
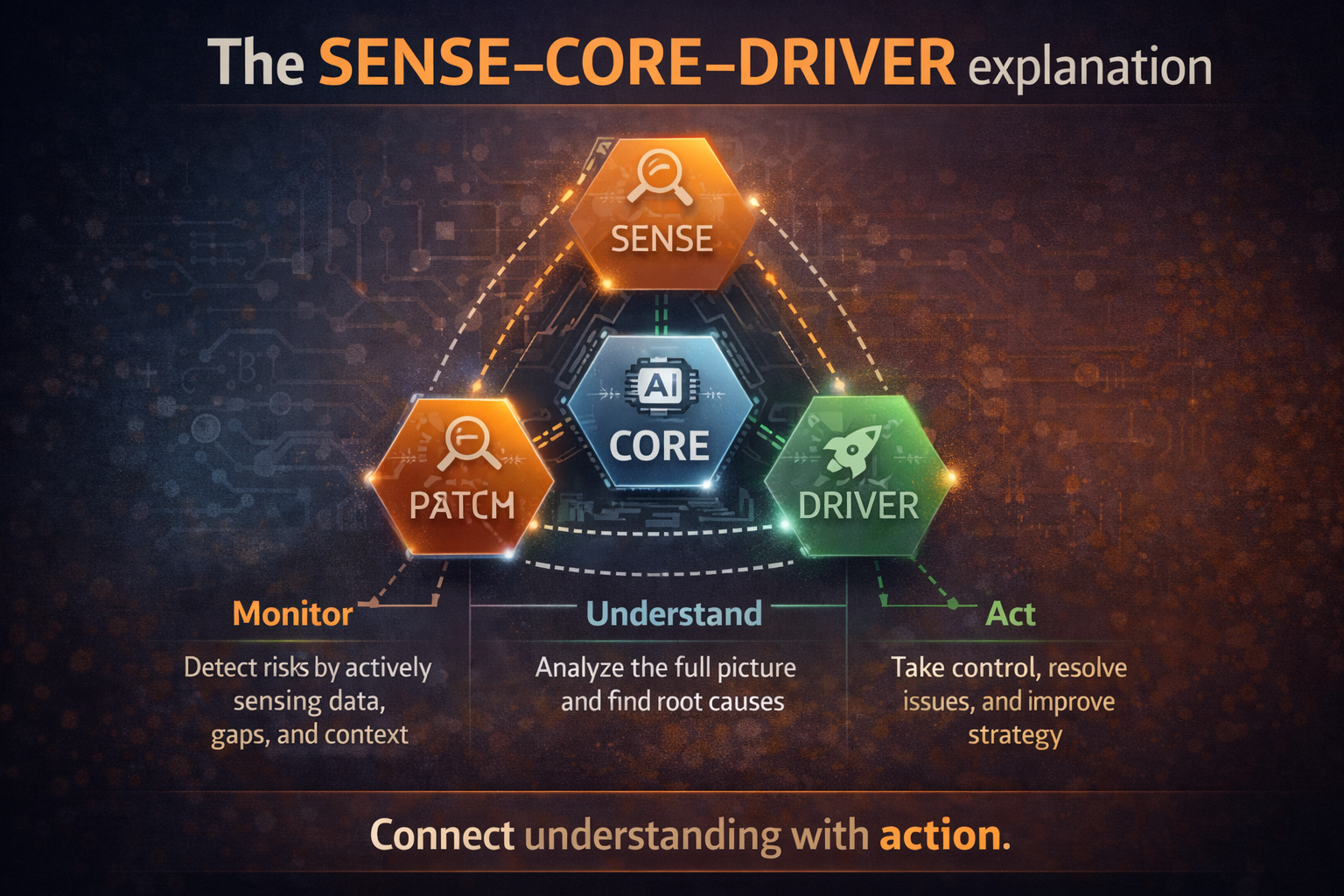
This is where your broader Representation Economy framework becomes more useful than generic AI governance language.
A collapse cascade is best understood across three layers:
SENSE: where reality first becomes machine-readable
This is where signals are captured, entities are identified, states are represented, and changes are updated over time.
Collapse often begins here:
- the wrong signal is collected,
- the right signal is missing,
- two entities are merged incorrectly,
- one entity is split across systems,
- a proxy stands in for hard-to-capture reality,
- or the state is not updated quickly enough.
If SENSE is weak, the institution begins with a damaged map of reality.
CORE: where the institution interprets and decides
This is where the model, rules engine, analytics layer, or orchestration logic reasons over the representation it has been given.
CORE can be technically sophisticated and still fail badly because it is reasoning over the wrong world.
That is one of the deepest truths of the AI era:
A powerful model does not repair a broken representation. It scales it.
DRIVER: where the institution acts
This is where the institution executes:
a loan is denied, a patient is deprioritized, a claim is delayed, a fraud alert is escalated, a case is routed, a supplier is downgraded.
If DRIVER lacks verification, recourse, bounded authority, and traceability, the institution hardens the earlier misrepresentation into operational reality.
That action then produces new data, which flows back into SENSE.
And the cascade continues.
For readers new to your framework, this article should internally link to your foundational pieces on the Representation Economy and SENSE–CORE–DRIVER, because this essay is best understood as an applied extension of that architecture. Your site already positions these ideas as the core explanatory lens for intelligent institutions. (Raktim Singh)
Why this will define who wins in the AI economy

The most important AI competition will not be over who has the smartest model.
It will be over who can prevent bad representations from spreading across decision systems.
That will create advantage for organizations that can:
- maintain high-quality representation under change,
- detect impact radius quickly,
- trace how an error traveled,
- pause or reverse downstream action,
- distinguish local glitches from systemic cascades,
- and preserve recourse for affected people, firms, and ecosystems.
It also points to the types of companies that are likely to emerge in the Representation Economy:
- representation observability platforms,
- cross-system entity reconciliation firms,
- decision-lineage and cascade-mapping tools,
- recourse infrastructure providers,
- synthetic-to-real validation services,
- and representation audit and assurance firms.
In other words, the AI economy will need businesses that do not just build intelligence. It will need businesses that stabilize machine-readable reality.
That logic also fits with the larger argument you are already making elsewhere: advantage is shifting toward institutions that can make better decisions at scale, not merely automate tasks. (Raktim Singh)
Representation Collapse Cascades are the chain-reaction failures that occur when one false, stale, incomplete, or badly structured representation of reality spreads across connected AI systems, models, workflows, and decisions. The key strategic implication is that enterprise AI success depends not only on model intelligence, but on whether institutions can keep machine-readable reality accurate, traceable, and repairable across SENSE, CORE, and DRIVER.
What leaders should do now
-
Treat representation quality as strategic infrastructure
Data quality is no longer a back-office hygiene issue. In AI systems, representation quality determines whether intelligence remains trustworthy at scale.
-
Trace representation dependencies, not just model dependencies
Ask a harder question: if this field, entity, state, or classification is wrong, where else does it travel?
-
Separate prediction quality from representation quality
A model can look accurate in aggregate while still spreading harmful distortions through operational systems.
-
Design recourse early
If the system is wrong, how can a customer, employee, citizen, supplier, or partner challenge the representation before the error propagates further?
-
Investigate cascades, not isolated incidents
AI incidents should not be logged only as local failures. They should be investigated as chains:
where did the misrepresentation begin, how far did it spread, and what institutional action converted it into harm?
Conclusion: the board-level question that now matters most
Every board, CEO, CIO, regulator, and institutional leader now faces a more important question than “What is our AI strategy?”
The harder and more strategic question is this:
What happens inside our organization when one wrong representation enters the system?
Does it get contained?
Does it get challenged?
Does it get corrected?
Or does it get amplified, repeated, and trusted because multiple systems now agree on the same mistake?
That is the real divide between organizations that merely use AI and organizations that can survive — and lead — in the AI economy.
Representation collapse cascades reveal something fundamental about the next era of competition.
AI does not fail only when models hallucinate.
It fails when institutions allow a misreading of reality to spread across systems faster than it can be corrected.
The winners of the next decade will not simply be those who automate the most. They will be those who build institutions where reality remains legible, contestable, and repairable even at machine speed.
Because in the Representation Economy, the most dangerous error is not a wrong answer.
It is a wrong representation that starts to travel.
“AI doesn’t fail because of intelligence. It fails because of what it cannot see.”
Glossary
Representation Collapse Cascade
A chain reaction in which one flawed representation of reality spreads across multiple systems, creating compounding decision errors and institutional distortions.
Machine-readable reality
The structured form in which institutions encode people, assets, events, states, and relationships so digital systems can process and act on them.
Representation quality
The degree to which a machine-readable representation reflects reality accurately, completely, consistently, and in a timely manner.
SENSE
The layer in which signals are captured, entities identified, states represented, and change updated over time.
CORE
The reasoning layer in which models, rules, and analytics interpret representations and generate decisions or recommendations.
DRIVER
The action layer in which institutions execute decisions through workflows, systems, authority structures, and recourse mechanisms.
Feedback loop
A cycle in which the outputs of a system affect the future data the system later uses, often reinforcing earlier errors.
Data lineage
The tracing of where data came from, how it changed, and where it moved over time.
Recourse
The ability for affected people, teams, or institutions to challenge, correct, or appeal a decision or representation.
Entity resolution
The process of determining whether records in different systems refer to the same person, product, supplier, account, or event.
FAQ
What is a Representation Collapse Cascade in simple language?
It is what happens when one wrong digital description of reality spreads across connected systems and causes a growing chain of bad decisions.
How is this different from an AI hallucination?
A hallucination is typically an output problem. A representation collapse cascade is a systems problem. It begins earlier, when reality is encoded incorrectly and that flawed encoding spreads operationally.
Why should boards and C-suites care?
Because this is not only a technical issue. It affects lending, pricing, claims, compliance, customer trust, operational resilience, and strategic decision-making.
Can a highly accurate model still participate in a collapse cascade?
Yes. A model can be technically strong and still produce bad institutional outcomes if it is reasoning over a flawed representation of reality.
Which industries are most exposed?
Healthcare, banking, insurance, supply chains, public services, fraud detection, hiring, and any industry where multiple systems act on shared digital representations.
What is the first practical step leaders should take?
Map where critical representations originate, how they move, which systems consume them, and what actions they trigger.
Does this connect to AI governance and regulation?
Yes. The logic aligns closely with current emphasis on data governance, traceability, transparency, oversight, and incident reporting in major policy frameworks. (NIST)
Q1. What causes AI systems to fail at scale?
AI systems fail at scale due to compounding errors in data quality, context, and system understanding, often triggered by representation gaps.
Q2. What is representation collapse in AI?
Representation collapse occurs when an AI system fails to accurately capture real-world complexity, leading to distorted or incomplete decision-making.
Q3. Why are traditional fixes not effective in AI failures?
Traditional fixes address surface issues, while the root cause lies in how reality is represented within the system.
Q4. How can enterprises prevent AI failure cascades?
By improving data quality, maintaining contextual continuity, and strengthening governance across AI decision systems.
Q5. Why is representation critical in AI systems?
Because AI acts only on what it can represent—poor representation leads to confident but incorrect decisions.
References and further reading
For the core factual examples and governance context behind this article, the most useful starting points are:
- NIST’s AI Risk Management Framework and AI RMF Core, which emphasize govern, map, measure, and manage across the AI lifecycle. (NIST)
- OECD work on AI incidents and AI/data-governance intersections, which highlights the need to assess AI risks across broader socio-technical systems. (OECD)
- The Science study on racial bias in a health-risk algorithm, which is one of the clearest examples of how a poor proxy can distort downstream outcomes. (Science)
- Research on predictive-policing feedback loops, which shows how observed data can become self-reinforcing. (Proceedings of Machine Learning Research)
- IBM’s explanation of data lineage, which is useful for making the operational tracing argument concrete. (IBM)
Explore the Architecture of the AI Economy
This article is part of a broader research series exploring how institutions are being redesigned for the age of artificial intelligence. Together, these essays examine the structural foundations of the emerging AI economy — from signal infrastructure and representation systems to decision architectures and enterprise operating models. If you want to explore the deeper framework behind these ideas, the following essays provide additional perspectives:
- Representation Economics: The New Law of AI Value Creation (Raktim Singh)
- Representation Capital: The Invisible Asset That Will Decide Which Institutions Win the AI Economy (Raktim Singh)
- The Representation Utility Stack: Why AI’s Next Competitive Advantage Will Come from Interoperable Reality (Raktim Singh)
- Decision Scale: Why Competitive Advantage Is Moving from Labor Scale to Decision Scale (Raktim Singh)
- The New Company Stack: The 7 Business Categories That Will Emerge in the Representation Economy (Raktim Singh)
- The Representation Strategy of the Firm: Why AI Winners Will Be Those Who See What Others Cannot (Raktim Singh)
- Representation Economy → my foundational article on what the Representation Economy is. (Raktim Singh)
- SENSE–CORE–DRIVER → my article explaining the framework for intelligent institutions. (Raktim Singh)
- Decision Scale → where I argue that competitive advantage is moving from labor scale to decision scale. (Raktim Singh)
- Representation Boundary → useful where this article discusses weak proxies and substituted reality. (Raktim Singh)
- Representation Collapse → useful as a closely related companion piece. (Raktim Singh)
- Representation Kill Zone → useful in the section on market consequences and strategic invisibility. (Raktim Singh)
- The Representation Multiplier: Why AI Winners Will Make Entire Ecosystems Machine-Readable – Raktim Singh
Together, these essays outline a central thesis:
The future will belong to institutions that can sense reality, represent it clearly, reason about it intelligently, and act through governed machine systems.
This is why the architecture of the AI era can be understood through three foundational layers:
SENSE → CORE → DRIVER
Where:
- SENSE makes reality legible
- CORE transforms signals into reasoning
- DRIVER ensures that machine action remains accountable, governed, and institutionally legitimate
Signal infrastructure forms the first and most foundational layer of that architecture.
AI Economy Research Series — by Raktim Singh
Written by Raktim Singh, AI thought leader and author of Driving Digital Transformation, this article is part of an ongoing body of work defining the emerging field of Representation Economics and the SENSE–CORE–DRIVER framework for intelligent institutions.
This article is part of a larger series on Representation Economics, including topics such as Representation Utility Stack, Representation Due Diligence, Recourse Platforms, and the New Company Stack.
This article is part of a broader framework called Representation Economics, which explains how AI changes value creation by redefining how reality is seen, modeled, and acted upon.

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.