
The Enterprise AI Factory
Why winners will build Studio → Runtime → Productized AI Services (not more agents)
Enterprise AI has reached a turning point.
The first wave—copilots, chat assistants, internal bots—proved one thing: AI can be useful. The second wave—agents that can plan and take actions—proved another: AI can execute work.
But most enterprises are now discovering a third truth—the one that separates pilots from winners:
Intelligence is easy to demo. Operability is hard to industrialize.

This is why a growing number of organizations will stall even after impressive pilots. Not because the models are weak—but because they lack an enterprise operating environment that makes autonomy reliable, reusable, secure, and cost-controlled at scale. Gartner has explicitly warned that over 40% of agentic AI projects may be canceled by end of 2027 due to escalating costs, unclear business value, or inadequate risk controls. (Gartner)
That’s why the next winners won’t be defined by how many agents they deploy. They’ll be defined by whether they build an Enterprise AI Factory—a unified operating environment that turns AI ideas into safe, governed, reusable, cost-controlled services-as-software, continuously.
Global enterprises across regulated and complex environments are realizing that AI success depends less on model intelligence and more on operational maturity. As organizations move from pilots to production, the need for a unified AI operating environment—spanning design, runtime governance, and reusable services—has become a board-level priority.
This article explains that factory in simple language—clear examples, technical depth (no math), and an executive-grade blueprint for what leaders are actually trying to buy: responsible speed.

Why “more agents” isn’t a strategy
Agents feel like the shortcut. Give a model tools, let it reason, and watch work disappear.
In real enterprises, that approach creates silent failure modes that compound over time.
1) Agent sprawl becomes governance sprawl
If every team builds agents their own way, you end up with:
- different prompt styles
- different tool connectors
- different permission assumptions
- different logging and audit quality
- inconsistent safety controls
- inconsistent escalation rules
Soon, nobody can answer basic questions:
- Which agents can take high-impact actions?
- Which ones are still running?
- Which ones were tested against tool failures or malicious inputs?
- Which ones are safe to reuse across teams?
2) Integration multiplies faster than anyone predicts
Every agent needs tools. Tools need authentication. Workflows need approvals. Compliance needs evidence. Observability needs standardized telemetry.
If each agent integrates independently, you get the classic integration explosion:
New agent × new system × new policy × new log format × new review cycle.
3) Costs become unpredictable (and then political)
Agentic systems often:
- call models repeatedly
- retrieve too much context
- loop while reasoning
- chain across multiple models/tools
Without cost envelopes and routing, spend surprises finance—exactly when leadership wants to scale.
4) Risk shifts from “accuracy” to “accountability”
When AI only suggests, humans catch mistakes.
When AI acts, mistakes become incidents.
Enterprises don’t fear that AI will be wrong sometimes. They fear:
- being unable to explain why it acted
- being unable to prove what it used
- being unable to stop or reverse it safely
So the executive question changes from:
“Can an agent do this task?”
to
“Can we operate autonomy safely, repeatedly, and at scale?”
That’s the Enterprise AI Factory problem.

The Enterprise AI Factory in one sentence
An Enterprise AI Factory is a composable, open, interoperable operating environment that enables teams to design and deploy AI capabilities as productized services—with built-in governance, quality engineering, observability, cost control, and integration—while building on existing enterprise investments and avoiding lock-in.
Think of it as platform engineering for AI—except the output isn’t code. The output is operable intelligence.

The three layers of the factory
The factory works because it separates AI into three layers:
1) Studio
Where teams design, assemble, test, and govern AI services before they touch production.
2) Runtime
The production operating layer that makes AI safe and operable: identity, authorization, policy enforcement, action gating, observability, evidence, cost controls, and reliable integrations.
3) Productized AI Services
Reusable, composable AI “service blocks” consumed across the enterprise—integrated or modular—spanning:
- operations
- transformation
- quality engineering
- cybersecurity
This Studio → Runtime → Productized Services model is the simplest way to explain what enterprises actually need to scale AI responsibly.

Layer 1: Studio — where AI becomes designable
Most pilots start with a prompt. Enterprises need to start with a service definition.
A Studio is not a prompt playground. It’s a manufacturing floor that turns “AI experiments” into “enterprise services.”
Pilot version vs factory version (simple example)
Pilot: A “Policy Assistant” answers employee questions.
Factory-built service: A “Policy Answering Service” with a contract:
- It only answers using approved policy sources
- It cites where it found the answer
- It refuses if the policy is missing or ambiguous
- It logs what sources it used
- It supports versioning (policy changes don’t silently change behavior)
That’s the difference between a demo and a service you can reuse across the enterprise.
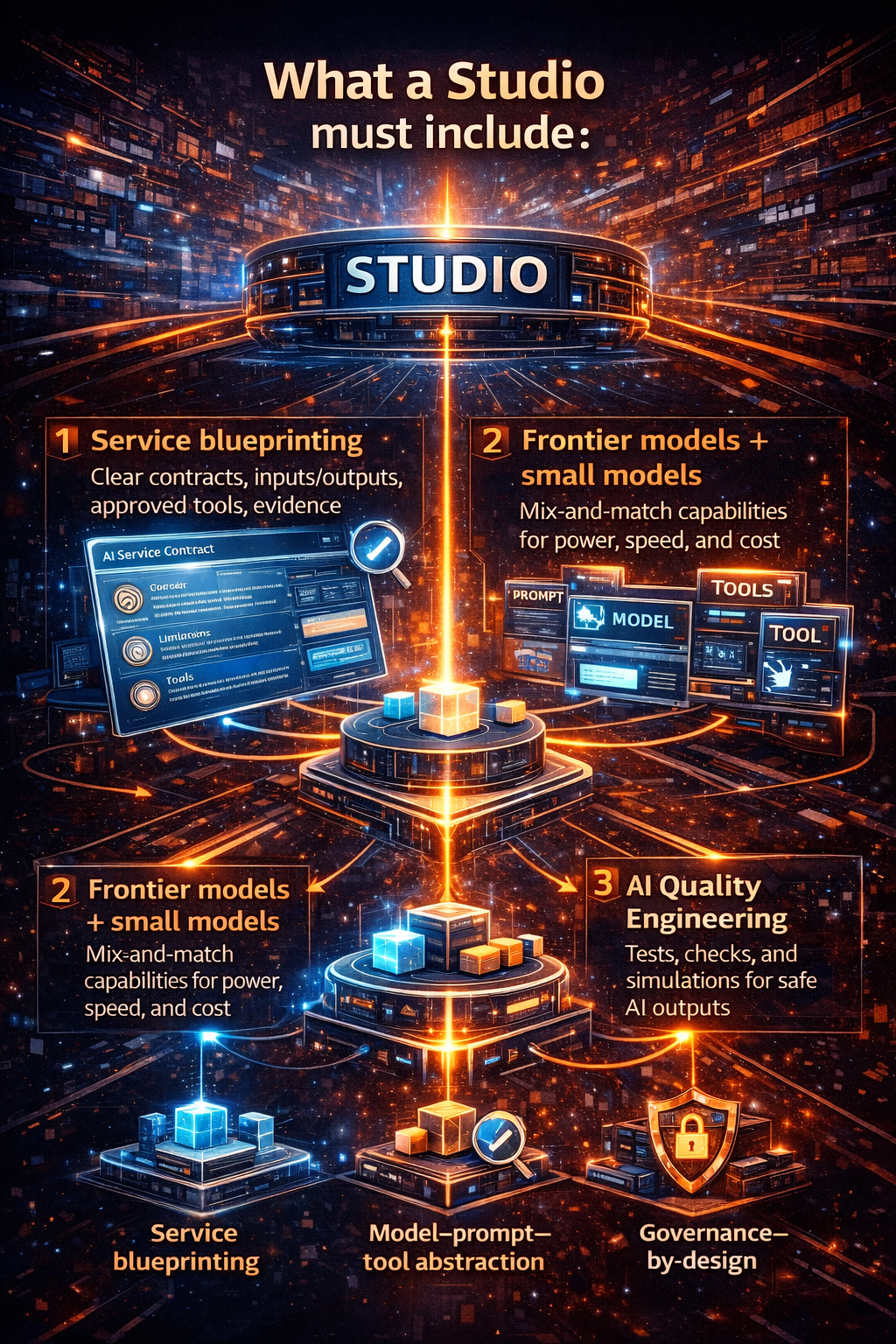
What a Studio must include
1) Service blueprinting (clear contracts)
Every service needs a blueprint:
- what it does (and what it refuses)
- the input/output format
- the tools it’s allowed to call
- actions that require approval
- what evidence must be captured
- quality expectations and known limitations
- owners and change control
This is how AI becomes a managed product, not a one-off bot.
2) Frontier models + specialized small models (mix-and-match by design)
Enterprises are moving toward a practical model strategy:
- use high-capability models where complexity demands it
- use specialized smaller models where speed/cost/precision matter
A Studio should treat “model choice” as part of the service design—because model choice affects:
- cost
- latency
- privacy posture
- reliability and consistency
3) A model–prompt–tool abstraction layer (the anti-rewrite layer)
This is a critical capability.
The factory must let you change:
- models (for cost, privacy, performance)
- prompts (for behavior improvements)
- tool APIs (as systems evolve)
…without rewriting every service.
In other words: build an abstraction that can evolve with new model capabilities and new enterprise constraints—without triggering rewrites every quarter.
4) AI Quality Engineering (QE) built in
Traditional QA assumes deterministic outputs. AI is probabilistic.
So Studio-grade QE includes:
- regression tests when prompts/models change
- adversarial tests (prompt injection / policy override attempts)
- tool failure simulation (timeouts, partial responses, wrong data)
- grounding checks (did it cite approved sources?)
- refusal tests (does it decline risky tasks?)
A viral line worth keeping:
“If it can’t survive a tool failure and a malicious prompt, it’s not a service. It’s a demo.”
5) Governance-by-design
Studio is where governance becomes real:
- approvals and ownership
- policy packs embedded in the service definition
- audit-ready evidence requirements
- version control and traceability
- operational readiness gates before production
This aligns with what risk frameworks emphasize: governance must span the lifecycle, not sit outside it. NIST’s AI Risk Management Framework is explicit about GOVERN as a function that applies across stages, supported by MAP/MEASURE/MANAGE. (NIST Publications)
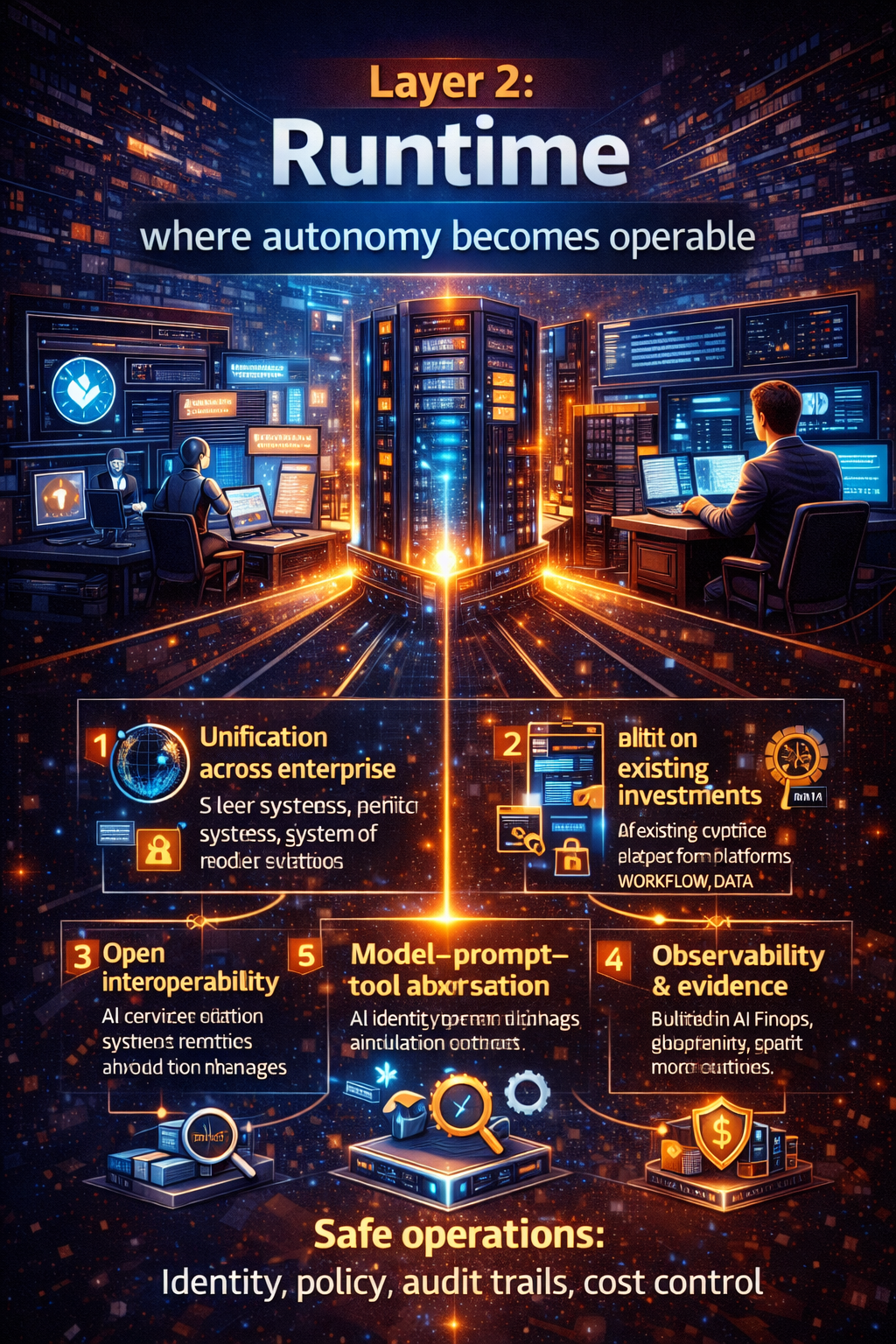
Layer 2: Runtime — where autonomy becomes operable
Studio builds services. Runtime runs them safely.
Runtime is where the factory turns “AI capability” into “enterprise production.”
A modern AI runtime must do six things exceptionally well:
1) Unify across the enterprise landscape
The runtime must work across diverse systems, teams, and workflows—so AI doesn’t become another silo.
2) Build on existing investments (no rip-and-replace)
Enterprises don’t win by replacing everything. They win by amplifying what already exists:
- workflow platforms
- systems of record
- automation
- data platforms
- monitoring and ITSM patterns
A factory-grade runtime integrates into existing ecosystems, maximizing ROI and reducing disruption.
3) Open interoperability to avoid lock-in
The runtime must be able to:
- adopt new models without rebuilds
- integrate emerging tools and protocols
- support partner ecosystems and platform integrations
This is the difference between a stack you can evolve and a stack you outgrow.
4) Identity, permissions, and action gating for AI services
Autonomy without authorization is fast chaos.
Runtime should enforce:
- strong service identity
- least-privilege tool access
- policy-driven gating for sensitive actions
- approvals for high-impact tasks
- tamper-resistant audit trails
Simple example:
A “Procurement Helper” can draft vendor comparisons.
But it cannot finalize procurement actions without approval and evidence.
5) Observability + evidence (for decisions and actions)
Classic monitoring watches servers. Enterprise AI monitoring must also watch:
- which sources were retrieved
- which tools were called
- what approvals were requested
- what decisions were made
- why those decisions happened (traceable rationale)
This is what makes autonomy accountable—especially as agentic AI increases speed and complexity. (Reuters)
6) Cost control as a runtime control plane (not a report)
AI FinOps must be built into the runtime:
- budgets per service and per workflow
- model routing (cheap vs premium)
- loop guards (prevent runaway tool calls)
- anomaly detection for spend spikes
- per-service cost envelopes included in service contracts
When cost controls are embedded, finance becomes a scale partner—not a brake.

Layer 3: Productized AI Services — the “one-stop shop” of enterprise capability
This is the most important shift in the entire article:
Stop shipping agents. Start publishing productized services.
A productized AI service is:
- reusable across teams
- measurable and supportable
- governable and auditable
- upgradable safely
- delivered as a consistent interface (like an internal API/product)
Enterprises increasingly want a “one-stop” catalog of such services—available in integrated and modular forms—covering the core domains where value compounds:
Operations services (Run)
- Incident summarization and triage
- Root-cause hypotheses with evidence
- Suggested remediation steps with safe gating
- Knowledge retrieval and runbook generation
Transformation services (Change)
- Modernization guidance aligned to standards
- Migration playbooks and risk checks
- Documentation generation and workflow acceleration
Quality engineering services (Assure)
- Test case generation
- regression suites for prompt/model updates
- behavior monitoring and validation
- safety and compliance checks as part of CI/CD
Cybersecurity services (Protect)
- threat and exposure summarization
- policy-aligned response playbooks
- detection enrichment and investigation support
- secure-by-design guardrails embedded into AI workflows
These services aren’t “bots everywhere.” They’re capability blocks that any team can consume without rebuilding foundations.

Two accelerators that make the factory real in practice
1) Pre-built components and templates
Factories scale faster when they have reusable parts:
- service templates
- connector packs
- policy packs
- evaluation harnesses
- guardrail modules
This is what turns “90 days of building plumbing” into “90 days of shipping value.”
2) Paved roads, not best-effort improvisation
AI factories succeed when teams get a paved road—a preconfigured, compliant path to ship services safely. This idea is well established in platform engineering (“golden paths”). (Platform Engineering)

The workforce model that makes it enterprise-real
The factory is not “humans vs AI.” It’s a synergetic workforce:
- Digital workers: deterministic automation, bots, APIs
- AI workers: orchestrate tasks, predict, summarize, reason within constraints
- Human workers: govern by exception, set policy, approve high-impact actions, continuously improve the system
This model makes autonomy scalable because it clarifies:
- who can act
- who must approve
- what evidence is required
- where accountability lives

The enterprise advantage leaders will fund
When you explain the factory to CIOs/CTOs/CXOs, the architecture is important—but outcomes are what get funded.
An Enterprise AI Factory delivers four outcomes leaders recognize immediately:
- Higher velocity
Teams ship faster because they reuse services instead of reinventing the stack. - Optimal cost
Cost drops through routing, reuse, and standardized patterns—without compromising safety. - Superior quality
QE, regression tests, and observability reduce incidents and rework. - Sustained ROI
The factory builds on existing investments, avoids lock-in, and evolves continuously as models and threats change. McKinsey’s research consistently emphasizes that value from AI correlates with management practices across operating model, tech, data, adoption, and scaling. (McKinsey & Company)
That’s the difference between “AI adoption” and “AI advantage.”

A practical 30–60–90 day rollout (without slowing delivery)
You don’t need to boil the ocean. You need a paved road.
Days 0–30: Start with 2–3 productized services
Pick horizontal services many teams want:
- governed knowledge answers (with citations and refusal rules)
- incident triage
- quality validation for AI outputs
Design them in Studio: contracts, tests, approvals, evidence requirements.
Days 31–60: Stand up the minimum viable Runtime
Deliver the essentials:
- service identity + least privilege
- policy gating + approvals for sensitive actions
- observability + evidence capture
- basic cost envelopes and routing
Days 61–90: Publish a small service catalog
Make services discoverable and reusable:
- clear interfaces
- usage guidelines
- guardrails and known limitations
- ownership and support model
Then scale horizontally: more services, more connectors, more automation, stronger governance.
Conclusion
The biggest mistake enterprises can make in 2026 is to treat agents as the destination.
Agents are a form factor. The destination is an operating environment that can industrialize autonomy.
If you want speed and safety, the answer is not “more agents.”
The answer is a factory:
- Studio to design and govern services
- Runtime to operate autonomy safely with evidence and cost control
- Productized services to scale reuse across the enterprise
That is how AI becomes a durable capability—something you can trust, fund, defend, and evolve.
Glossary
- Enterprise AI Factory: An operating environment that turns AI initiatives into reusable, governed, operable services at scale.
- Studio: The build-and-govern layer where services are designed, tested, and approved before production.
- Runtime: The production layer that enforces identity, policy, observability, evidence, and cost controls while running AI services.
- Productized AI Service: A reusable AI capability delivered with an interface, ownership, guardrails, monitoring, and lifecycle management.
- Action gating: Controls that require approval or additional checks before high-impact actions execute.
- Golden path / paved road: A preconfigured, compliant, repeatable path for teams to ship safely (common in platform engineering). (Platform Engineering)
- AI RMF: NIST’s AI Risk Management Framework; organizes AI risk management via GOVERN, MAP, MEASURE, MANAGE. (NIST Publications)
FAQ
Is this just another “AI platform” story?
No. A platform helps you build. A factory helps you build + govern + operate + reuse + evolve continuously.
Why focus on services instead of agents?
Because services have contracts, owners, tests, observability, and cost envelopes. Agents often don’t—unless you force them into a service lifecycle.
What’s the single biggest reason factories beat pilots?
Factories embed operability: identity, policy, observability, cost control, quality engineering, and safe evolution—so scale doesn’t collapse under enterprise pressure. (Gartner)
How does this relate to AI governance expectations?
Governance is becoming a lifecycle practice, not a document. Frameworks like NIST AI RMF emphasize continuous governance across design, development, deployment, and monitoring. (NIST Publications)
Q1. What is an Enterprise AI Factory?
An Enterprise AI Factory is an operating model that enables organizations to design, deploy, and scale AI as governed, reusable, and operable services, rather than one-off projects or isolated agents.
It combines three layers—Studio (design and governance), Runtime (safe operation), and Productized AI Services (reuse at scale)—to ensure AI systems are reliable, auditable, cost-controlled, and aligned with enterprise processes.
In simple terms, it turns AI from experiments into industrial-grade capabilities that enterprises can trust and evolve over time.
Q2. Why do AI pilots fail in enterprises?
AI pilots often fail not because the models are inaccurate, but because they are not built to operate at enterprise scale.
Most pilots lack standardized governance, cost controls, observability, integration patterns, and ownership models. As a result, they work in isolation but collapse when exposed to real-world complexity, security requirements, and organizational scale.
Enterprises don’t struggle with proving AI value—they struggle with operating AI safely, repeatedly, and economically across teams and systems.
Q3. How is an AI Factory different from an AI platform?
An AI platform focuses on helping teams build AI—providing models, tools, and development capabilities.
An AI Factory, by contrast, focuses on operating AI—ensuring that what gets built can be governed, monitored, secured, cost-controlled, reused, and evolved in production.
In short:
- Platforms optimize creation
- Factories optimize industrialization and scale
Enterprises need both—but without a factory model, platforms alone lead to pilot sprawl.
Q4. What are productized AI services?
Productized AI services are reusable AI capabilities delivered with clear interfaces, ownership, guardrails, observability, and lifecycle management—much like internal digital products or APIs.
Instead of deploying individual agents for each use case, enterprises publish AI capabilities as standardized services that multiple teams can safely consume.
This approach reduces duplication, improves quality, lowers cost, and enables faster scaling—transforming AI from isolated solutions into a shared enterprise capability.
🔍 People Also Ask (PAA)
What problem does an Enterprise AI Factory solve?
An Enterprise AI Factory solves the problem of scaling AI beyond pilots. It provides a unified operating environment where AI systems can be governed, monitored, cost-controlled, and reused safely across teams, systems, and regions—without creating agent sprawl or operational risk.
How do enterprises industrialize AI?
Enterprises industrialize AI by moving from isolated pilots to a factory model that separates design (Studio), operations (Runtime), and consumption (Productized Services). This ensures AI systems are reliable, auditable, and scalable across real enterprise environments.
Why do AI agents fail at enterprise scale?
AI agents fail at enterprise scale because they are often deployed without standardized governance, identity, cost controls, or observability. Without an operating model, agents multiply risk, cost, and integration complexity instead of delivering sustained business value.
What is the difference between AI agents and AI services?
AI agents are execution units built for specific tasks. AI services are productized, reusable capabilities with clear contracts, ownership, monitoring, and guardrails. Enterprises scale AI by publishing services—not by deploying unmanaged agents.
What is an AI runtime in enterprise architecture?
An AI runtime is the production layer that safely operates AI systems. It enforces identity, authorization, policy controls, observability, evidence capture, and cost management—ensuring autonomous AI behaves predictably and accountably in real-world environments.
How do enterprises control AI costs at scale?
Enterprises control AI costs by embedding FinOps directly into the AI runtime. This includes per-service budgets, model routing, loop guards, usage monitoring, and anomaly detection—turning AI cost control into a real-time operational capability, not a retrospective report.
Enterprise AI Factory — Expert Definition
An Enterprise AI Factory is an operating model that enables organizations to design, govern, and scale AI as reusable, auditable, and cost-controlled services. By separating AI into Studio (design), Runtime (operation), and Productized Services (reuse), enterprises can industrialize autonomy safely across complex, regulated environments.
— Raktim Singh, Enterprise AI Operating Models
An Enterprise AI Factory is an operating model that helps organizations scale AI beyond pilots by combining design, governance, and production. It enables AI to run as reusable, auditable, and cost-controlled services across enterprise systems.
An Enterprise AI Factory is how enterprises industrialize AI—turning pilots into governed, reusable, and scalable services that operate safely across real business systems.
References and further reading
- Gartner press release: prediction that over 40% of agentic AI projects will be canceled by end of 2027. (Gartner)
- McKinsey: The State of AI research and value correlated with operating model and scaling practices. (McKinsey & Company)
- NIST AI Risk Management Framework (AI RMF 1.0) and playbook (GOVERN/MAP/MEASURE/MANAGE). (NIST Publications)
- Platform engineering “golden paths” / “paved roads” (practical adoption lens). (Platform Engineering)
- Reuters reporting on rising agentic AI risk concerns due to speed/autonomy in regulated environments. (Reuters)
Raktim Singh writes on enterprise AI operating models, agentic systems, and scalable AI governance. He focuses on how global organizations industrialize AI safely and sustainably.

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.