{kind=link}

The Autonomy SRE
Enterprise AI is crossing a line that traditional IT operating models were never designed for.
When AI only answered questions, failure was usually soft: a wrong answer, a confusing summary, a wasted minute.
When AI takes action—creating tickets, changing records, triggering workflows, sending communications, approving requests—failure becomes operational, financial, security-related, and reputational.
That’s why the next competitive advantage is not a smarter model. It’s a run-time discipline: the ability to operate autonomy safely, predictably, and economically—at scale.
In classic software, we built SRE because reliability became existential. In agentic AI, we need the same step-change: an Autonomy SRE Stack—an “on-call runtime” for systems that decide and act.
This article explains what that stack is, why enterprises need it now, and how to implement it in a practical way—without turning innovation into bureaucracy.

Why an “On-Call Runtime” Is Now a CXO Requirement
“Production-grade” autonomy has a higher bar than “production-grade software,” because it can act and propagate.
A production-grade autonomous system must:
- Follow policy, even when prompts change, data shifts, or tools fail.
- Stay within permissions, even when the model tries creative paths.
- Control cost, even when usage spikes or tasks loop.
- Leave evidence—a complete narrative of what happened and why.
- Be reversible, because autonomous actions can cascade across systems.
This is exactly why leading governance guidance emphasizes continuous risk management and lifecycle controls—not one-time checklists. The NIST AI Risk Management Framework (AI RMF) frames AI risk as an ongoing practice across GOVERN, MAP, MEASURE, and MANAGE. (NIST Publications)
And ISO/IEC 42001 formalizes the concept of an organization-wide AI management system that is established, maintained, and continually improved. (ISO)
In other words: autonomy is an operational system, not a feature.
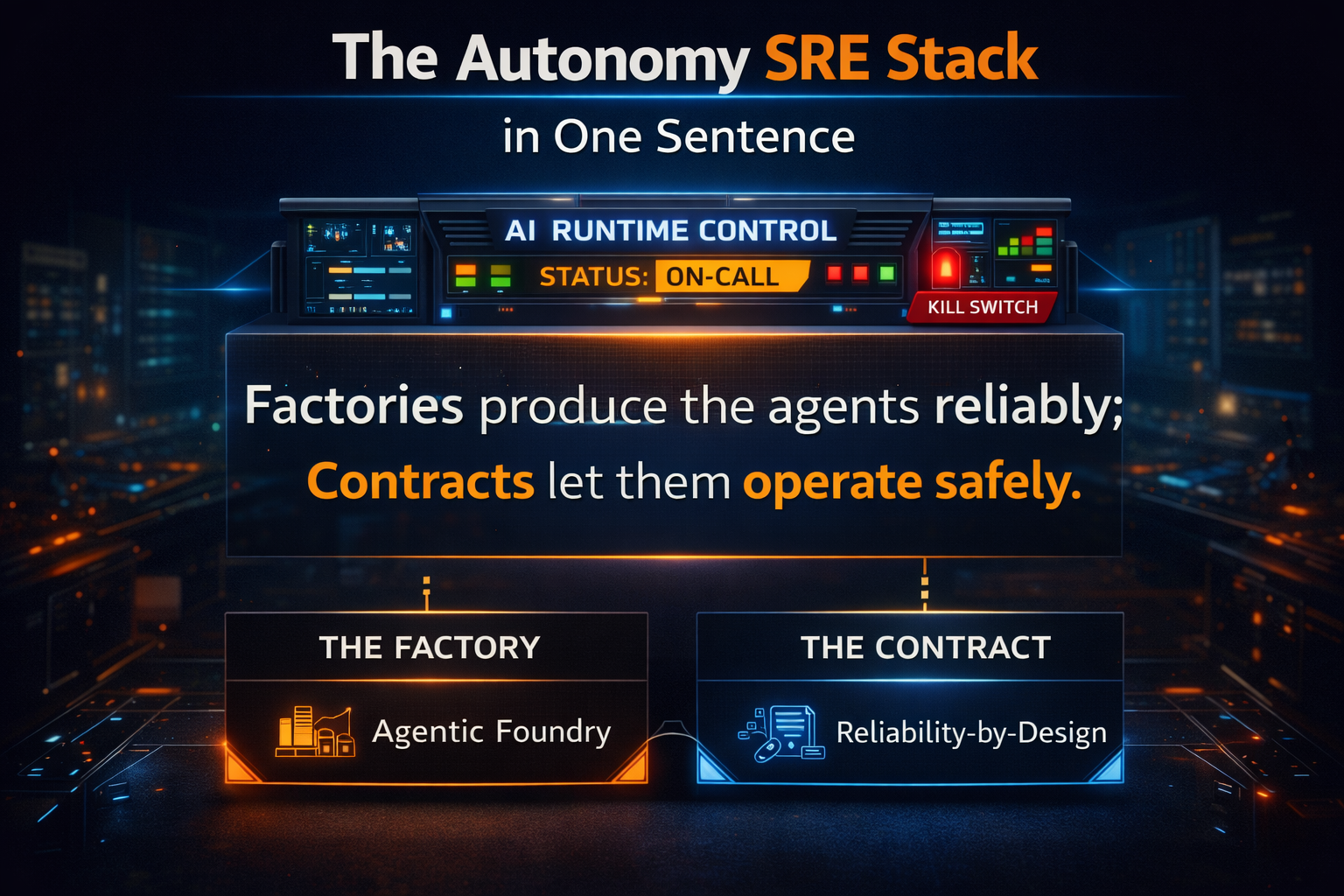
The Autonomy SRE Stack in One Sentence
The Autonomy SRE Stack is a production runtime + operating model that keeps AI agents policy-aligned, cost-bounded, auditable, and reversible—under real-world conditions.
It has four non-negotiables:
- Guardrails (policy enforcement at runtime)
- FinOps (predictable and controllable cost)
- Audit Trails (end-to-end traceability)
- Rollback (reversibility and safe recovery)
Let’s unpack each with simple, enterprise-grade scenarios.

1) Guardrails: The Runtime Must Enforce “You Can’t Do That”
Guardrails are not just safety filters. In enterprise autonomy, guardrails are runtime policy controls that constrain behavior in real time:
- Which tools can be used
- Which data can be accessed
- What actions are permitted
- What approvals are required
- What must be logged
- What to do when confidence is low (or when inputs look suspicious)
Security practitioners increasingly emphasize that agents introduce new threat surfaces—prompt injection, data leakage, unauthorized tool use, and identity misuse—risks that traditional controls don’t fully cover. (KPMG)
Simple example: “Vendor onboarding without chaos”
An onboarding agent is asked to “set up a new vendor quickly.” Without guardrails, it might:
- Pull sensitive documents into an unsafe context
- Create records in the wrong system
- Skip mandatory compliance steps
- Email the wrong distribution list
With runtime guardrails:
- The agent can read only approved sources.
- It can write only to specific systems and fields.
- It must request approval before irreversible changes.
- It must follow a defined onboarding checklist as policy, not suggestion.
Key design rule: Guardrails must be enforced by the runtime, not merely “suggested by prompts.” Prompts are guidance; guardrails are constraints.
What “good guardrails” look like
A robust approach typically includes:
- Policy guardrails: what must/must not happen (data rules, approvals, action scope)
- Tool guardrails: tool allowlists, parameter constraints, safe defaults
- Output guardrails: format validation, sanity checks, escalation rules
- Context guardrails: what can enter context; redaction; retrieval constraints
This layered model is becoming the practical blueprint for “controllable agents,” not just “helpful assistants.” (ilert.com)

2) FinOps for Autonomy: “Unlimited Tokens” Is Not a Business Model
A surprise cloud bill hurts. A surprise agent bill can be existential—because agents don’t just run queries; they can loop, branch, retry, call tools, and spawn tasks.
That’s why FinOps has expanded into AI and GenAI, with specific guidance on managing and optimizing AI usage and cost. (FinOps Foundation)
Simple example: “The helpful agent that quietly burns the budget”
An operations agent is designed to “keep incidents updated.” A minor change causes it to:
- Poll every few seconds
- Summarize every update
- Post to multiple channels
- Re-summarize its own summaries
No one notices for a day. Then the cost spike appears.
Autonomy FinOps prevents this with runtime cost controls:
- Budgets per workflow (hard caps)
- Rate limits per agent and per tool
- Cost-aware routing (cheaper models for routine steps; premium only when needed)
- Token/compute envelopes per task
- Loop detection and circuit breakers
- Caching and deduplication of repeated work
FinOps for AI discussions also highlight compliance-driven cost drivers: audits, retention requirements, licensing, and governance obligations can significantly raise operating cost if not planned. (FinOps Foundation)
Key principle: Cost must be treated like latency and reliability—a first-class SLO, not an afterthought.

3) Audit Trails: If You Can’t Explain It, You Can’t Run It
In classic systems, logs help you debug.
In autonomous systems, logs become evidence.
When an agent performs actions, leaders will ask:
- Who initiated the request?
- What data did it use?
- What tools did it call?
- What decision path did it take?
- What policy checks were applied?
- Who approved what?
- What changed in which systems?
ISO/IEC 42001’s emphasis on disciplined management systems reinforces why documentation, lifecycle management, and oversight are central to trustworthy AI operations. (ISO)
And NIST AI RMF positions trustworthiness as something you engineer, measure, and manage throughout the lifecycle—pushing organizations toward monitoring and traceability as ongoing requirements. (NIST Publications)
Simple example: “The disputed approval”
An agent approves a request within policy—yet later, someone disputes the outcome.
With strong audit trails, you can reconstruct:
- Inputs (request details)
- Context (policies, constraints, retrieved facts)
- Actions (tools called, systems updated)
- Approvals (human checkpoints and timestamps)
- Rationale (why it decided; confidence signals)
Without it, you don’t have “AI.” You have unaccountable automation.
What to log (a practical checklist)
A production-grade audit trail typically captures:
- Identity: user/service identity, agent identity, permissions
- Intent: task goal, allowed scope, policy profile
- Context lineage: which sources were accessed and why
- Tool execution: tool name, parameters, responses, errors
- Decision points: key choices, constraints applied, uncertainty signals
- Approvals: who approved, when, what changed
- Outcomes: mutations made, notifications sent, compensations applied
Key principle: Audit trails should be queryable narratives, not raw noise.

4) Rollback: Autonomy Must Be Reversible
If an autonomous system can change reality, it must support undo.
Rollback is not one mechanism. It’s a family of safety patterns:
- Soft rollback: disable the agent and stop further actions
- Compensating actions: reverse changes (cancel, revert, credit, restore)
- Quarantine: isolate affected records for review
- Replay: rerun with fixed policy or corrected context
- Kill switch: immediate stop + revoke credentials
Simple example: “The cascading update”
An agent updates records based on a misunderstood rule. Those updates trigger downstream workflows. Now multiple systems are affected.
With rollback design:
- Writes are transactional where possible
- Changes are versioned or event-sourced so they can be reversed
- Circuit breakers stop propagation when anomaly signals spike
- Recovery runs apply compensating actions safely
Key principle: You don’t scale autonomy unless you can recover quickly and cleanly.

The Missing Piece: Incident Response for Agents (AI On-Call)
Now bring the four pillars together: guardrails, FinOps, audit trails, rollback.
What do they enable? The real objective:
An AI on-call operating model—so autonomy is governable in the messy reality of production.
Industry messaging is increasingly explicit about “AI SRE” as an incident-response pattern: triage, root cause analysis, documentation, and runbook-driven remediation. (Harness.io)
Even major observability vendors are now describing “AI SRE” as an on-call teammate concept for investigating and responding to incidents. (Datadog)
What an “agent incident” looks like (plain language)
- Wrong action performed
- Right action performed in the wrong system
- Policy violation attempt blocked (but repeatedly attempted)
- Data accessed outside intended scope
- Cost spike from loops
- Tool failures causing retries and drift
- Inconsistent behavior across environments
The AI on-call playbook (without bureaucracy)
A good Autonomy SRE Stack supports:
- Detection: anomaly signals, policy violations, cost spikes
- Triage: classify incident type and likely impact fast
- Containment: disable agent or restrict permissions immediately
- Forensics: replay the agent trace and decision path
- Recovery: rollback/compensate and restore safe state
- Prevention: update guardrails, improve tests, refine budgets
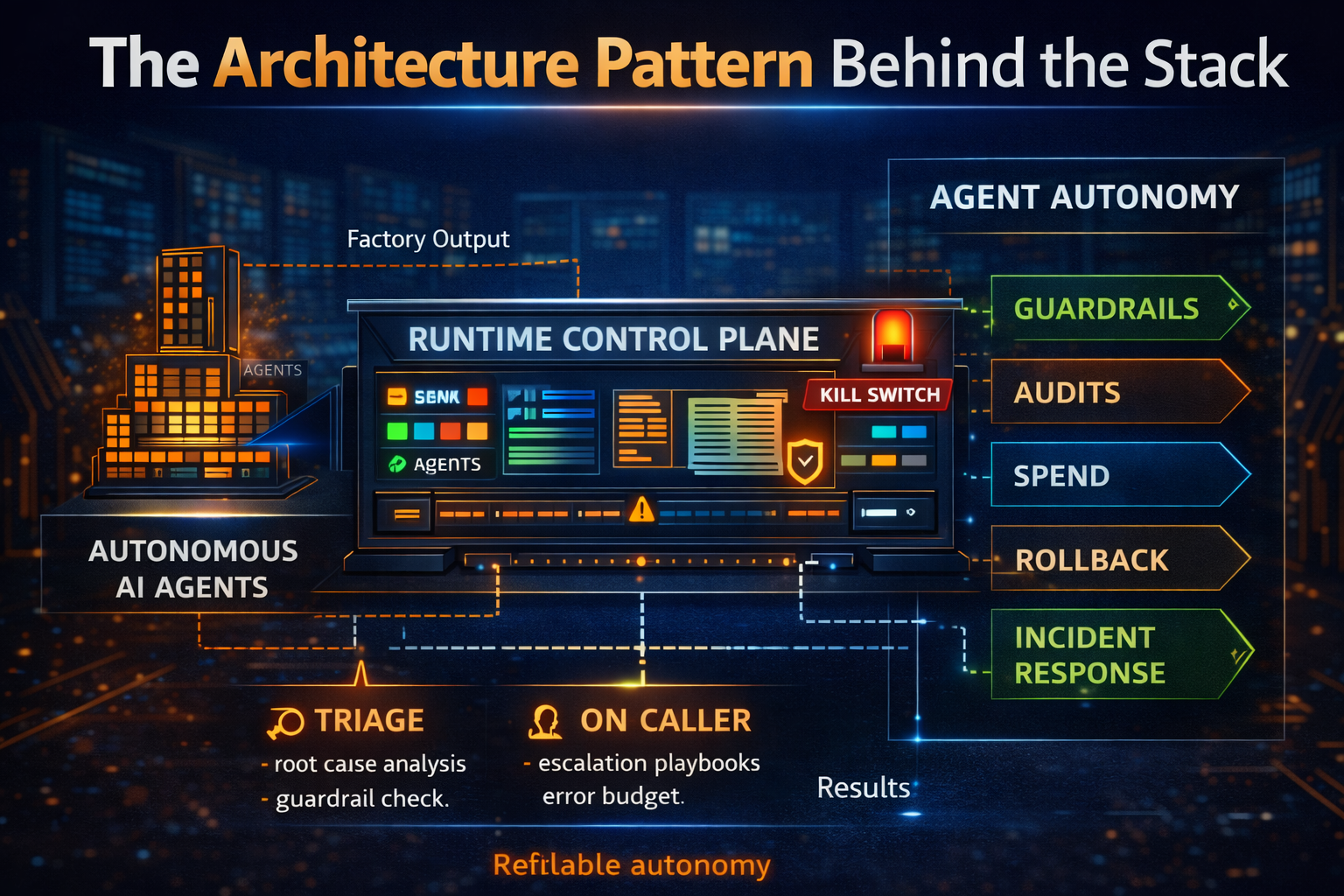
The Architecture Pattern Behind the Stack
Think of the Autonomy SRE Stack as two layers:
-
A) Build-time discipline (designed before production)
- Approved tools + permission models
- Policy profiles (what the agent is allowed to do)
- Test harnesses and simulations
- Cost budgets and routing policies
- Logging schemas and evidence requirements
-
B) Runtime discipline (enforces reality in production)
- Policy enforcement and guardrails
- Identity, secrets, and access control
- Observability and incident signals
- Cost measurement and budgets
- Audit trails and trace replay
- Rollback mechanisms and kill switches
This is why enterprises are gravitating toward integrated stacks rather than point tools: autonomy requires coordinated controls, not isolated features.
A Practical 30–60–90 Day Adoption Path
First 30 days: Make autonomy safe enough to run
- Define 5–10 “allowed actions” and block everything else
- Implement tool allowlists + approval checkpoints
- Add cost caps per workflow
- Turn on structured trace logging for every action
Next 60 days: Make it observable and governable
- Add anomaly detection for loops and spikes
- Implement incident playbooks and escalation rules
- Make trace replay easy for auditors and engineers
- Start measuring policy adherence rate and rollback time
Next 90 days: Make it scalable and reusable
- Standardize policy profiles by workflow type
- Add cost-aware routing and caching
- Establish continuous improvement loops (guardrails + tests + budgets)
- Convert common capabilities into reusable “services” so teams don’t reinvent controls
What CXOs Should Measure (No Vanity Metrics)
Instead of “number of agents,” measure whether your runtime is real:
- Policy adherence rate (blocked vs allowed actions, by category)
- Mean time to rollback (how fast you can reverse bad actions)
- Cost per outcome (not cost per call)
- Incident rate per 1,000 actions (stability under real load)
- Audit completeness (how often you can reconstruct a full decision path)
If these improve, autonomy is becoming a capability—not a science project.

Conclusion: Autonomy Won’t Be Won by Intelligence Alone
Enterprise AI won’t be won by the smartest model.
It will be won by the enterprise that can run autonomy safely—on-call, auditable, cost-bounded, and reversible—at scale.
That is what an Autonomy SRE Stack delivers:
- Guardrails that hold
- FinOps that scales
- Audit trails that prove
- Rollback that saves
The organizations that treat autonomy as an operational discipline—not an innovation experiment—will be the ones that earn durable trust and durable ROI.
The Autonomy SRE Stack extends classic Site Reliability Engineering into the era of AI agents, where systems must not only stay available—but remain aligned, auditable, and reversible as they act autonomously.”
FAQ
What is the Autonomy SRE Stack?
A production runtime + operating model that keeps AI agents policy-aligned, cost-bounded, auditable, and reversible—with an on-call approach to incidents and recovery.
Why is “AI on-call” necessary?
Because agentic AI can take actions that impact operations, cost, and security. When incidents happen, you need fast triage, containment, forensics, and rollback—like SRE for software. (Datadog)
What are AI guardrails in an enterprise runtime?
Runtime-enforced controls that constrain data access, tool usage, approvals, outputs, and actions—so the agent cannot exceed policy boundaries. (ilert.com)
What is FinOps for AI, and why does it matter?
FinOps for AI applies budgeting, optimization, and accountability to AI spend—especially important for agents that can loop, branch, and call tools. (FinOps Foundation)
How do audit trails differ from normal logging?
Audit trails are structured, end-to-end “decision narratives” that reconstruct identity, context lineage, tool calls, approvals, and outcomes—usable for governance and accountability.
What does rollback mean for AI agents?
Rollback is the ability to stop, reverse, compensate, quarantine, and recover from autonomous actions quickly—using kill switches, compensating transactions, versioned changes, and replay.
Glossary
- Agentic AI: AI that plans and takes actions using tools and workflows, not just generating text.
- Autonomy SRE: Reliability engineering for autonomous AI systems, including incident response and recovery.
- AI Guardrails: Runtime policy and security controls that constrain agent behavior.
- FinOps for AI: Cost governance practices for AI workloads, including budgets, optimization, and accountability. (FinOps Foundation)
- Audit Trail: A structured, queryable record of what the agent did, why, and with what approvals.
- Rollback: Mechanisms to reverse or compensate actions and restore safe state.
- Kill Switch: Immediate disabling of an agent’s ability to act (often paired with credential revocation).
- Policy Profile: A reusable set of permissions, constraints, and approval rules for a workflow class.
References and Further Reading
- NIST, Artificial Intelligence Risk Management Framework (AI RMF 1.0) (Functions: GOVERN, MAP, MEASURE, MANAGE). (NIST Publications)
- ISO, ISO/IEC 42001:2023 — AI management systems (requirements and guidance to establish and continually improve an AI management system). (ISO)
- FinOps Foundation, FinOps for AI Overview / FinOps for AI topic hub (cost governance for AI and GenAI). (FinOps Foundation)
- PagerDuty, How to Choose an AI SRE Solution (incident context and operational needs). (PagerDuty)
- Datadog, Bits AI SRE (AI as an on-call teammate concept). (Datadog)
- The Agentic Foundry: How Enterprises Scale AI Autonomy Without Losing Control, Trust, or Economics – Raktim Singh
- The One Enterprise AI Stack CIOs Are Converging On: Why Operability, Not Intelligence, Is the New Advantage – Raktim Singh
- Studio-to-Runtime: Why Enterprise AI Fails Without a Build Plane and a Production Kernel – Raktim Singh
- The New Enterprise AI Advantage Is Not Intelligence — It’s Operability – Raktim Singh
- The One Enterprise AI Stack CIOs Are Converging On: Why Operability, Not Intelligence, Is the New Advantage | by RAKTIM SINGH | Dec, 2025 | Medium
- The Living IT Ecosystem: Why Enterprises Must Recompose Continuously to Scale AI Without Lock-In | by RAKTIM SINGH | Dec, 2025 | Medium
- The Agentic Foundry with Reliability-by-Design : How enterprises scale hundreds of AI agents without: By Raktim Singh
- Why Autonomous AI Fails in Production — and What CIOs Must Do to Control It: By Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.