{kind=link}

Representation Saturation:
In the AI economy, excess information can become a strategic liability
For more than a decade, one assumption has shaped the way organizations think about AI: more data leads to better decisions.
More customer signals. More transaction logs. More documents. More telemetry. More labels. More context windows. More retrieval results. More memory. More monitoring.
That assumption helped drive the first wave of AI adoption. When institutions were still moving from paper, intuition, and fragmented software toward data-driven systems, expanding visibility was often a real advantage.
But the next phase of AI requires a more mature view.
Many AI systems no longer fail because they have too little information. They fail because they are fed too much weakly structured, stale, low-value, repetitive, or conflicting information. Research across long-context language models, noisy-label learning, and dataset design now makes this increasingly clear: more input does not automatically improve performance. In some settings, it reduces it. Relevant facts can get buried in long contexts, noisy labels can degrade model quality, and combining more data sources can introduce spurious correlations that hurt decision quality rather than improve it. (ACL Anthology)
This is the problem I call Representation Saturation.
Representation Saturation happens when a system receives more machine-readable reality than it can meaningfully organize, prioritize, interpret, and act on safely. At that point, additional representation does not strengthen judgment. It dilutes it.
That matters because the future of AI will not be decided only by bigger models or larger context windows. It will be decided by which institutions can build a better relationship between what is sensed, what is understood, and what is acted upon. That is exactly why the SENSE–CORE–DRIVER framework matters.
In the AI era, competitive advantage does not come from intelligence alone. It comes from whether reality enters the system in the right form, whether the reasoning layer can separate signal from noise, and whether the action layer knows when more information is no longer more truth.
Representation Saturation explains why excessive data can reduce AI decision quality by overwhelming a system’s ability to prioritize, interpret, and act on information effectively.

The old belief: if some data is good, more must be better
At first glance, the opposite view sounds strange.
If a banker benefits from more customer context, why would an underwriting model not benefit too?
If a doctor benefits from more clinical data, why would a triage system not benefit too?
If a fraud analyst benefits from more transaction evidence, why would a fraud engine not benefit too?
The answer is simple: more and better are not the same thing.
A decision system does not merely collect inputs. It has to determine what matters, ignore what does not, resolve contradictions, weigh recency, understand provenance, and decide what should influence action. That burden grows as representation grows.
Once that burden exceeds the system’s ability to filter and prioritize, the quality of the final decision begins to fall.
This is not a philosophical concern. It is now visible in research.
Long-context studies show that language models often use information unevenly across extended inputs. Performance can degrade when relevant information is placed in the middle of a long context rather than near the beginning or end. In other words, adding more context can make the right answer harder to find. (ACL Anthology)
Research on noisy labels shows that corrupted or inaccurate labels can significantly harm model performance, especially when scale creates the illusion of reliability. Bigger datasets are not always cleaner datasets. Sometimes they are simply larger containers for error. (arXiv)
And in one notable machine learning study, adding datasets from multiple hospitals sometimes reduced worst-group performance because the model learned hospital-specific artifacts instead of the underlying medical condition. More data, in that setting, created more confusion. (arXiv)
That is the core logic of Representation Saturation:
Beyond a certain point, more representation does not improve intelligence. It overwhelms selection.
A simple way to understand the problem
Imagine three kitchens.
In the first kitchen, the chef has too few ingredients. The meal is poor because there is not enough to work with.
In the second kitchen, the chef has the right ingredients, clearly labeled, fresh, and arranged in a useful order. The meal turns out well.
In the third kitchen, the chef has five times more ingredients than needed, duplicate containers, expired items, unlabeled powders, too many sauces, and a crowded counter. There is more material, but less clarity. The meal gets worse.
Most AI leaders still think mainly about the first kitchen: data scarcity.
The next generation of AI failure will come from the third kitchen: data saturation disguised as sophistication.

Why Representation Saturation is broader than an LLM issue
It is tempting to treat this as a prompt-engineering problem or a context-window problem. It is broader than that.
Representation Saturation can emerge in at least five places.
-
In training
A model sees too many low-quality examples, noisy labels, duplicate patterns, or mixed-source artifacts and learns shortcuts that do not generalize well. Data quality research consistently emphasizes that dimensions such as accuracy, completeness, consistency, validity, timeliness, and relevance shape downstream performance. More data without these qualities can degrade outcomes. (ACM Digital Library)
-
In retrieval
A RAG system pulls fifteen documents when only three matter. The answer becomes less reliable because the system now has to sort through clutter, contradiction, and stale context.
-
In live operations
A fraud, risk, compliance, or triage engine receives an expanding flood of events, alerts, exceptions, behavioral signals, and historical traces. If prioritization is poor, the system becomes less decisive exactly when precision matters most.
-
In governance
Organizations collect every metric, every trace, every explanation, every evaluation artifact, every monitoring signal. But if they cannot isolate the few indicators that actually predict failure, observability becomes performance theater rather than protection.
-
In human decision environments
Humans around AI systems can saturate too. OECD work on disclosure effectiveness notes that information overload can reduce effectiveness and contribute to confusion rather than clarity. That matters because enterprise AI rarely operates in isolation. It operates inside human institutions. (OECD)
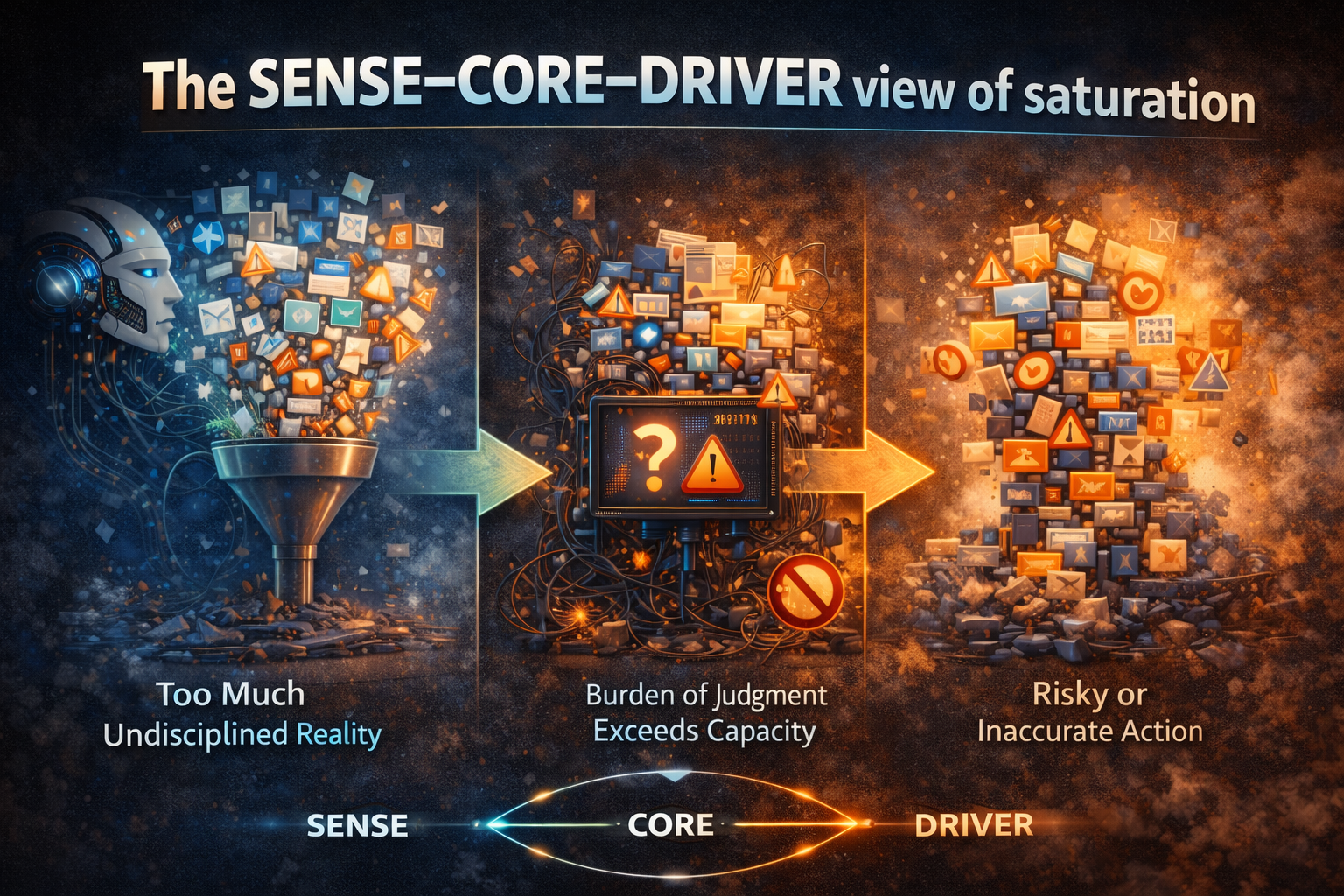
The SENSE–CORE–DRIVER view of saturation
Representation Saturation becomes much clearer when seen through SENSE–CORE–DRIVER.
SENSE: the issue is not only collection, but filtration
SENSE is where reality becomes machine-legible.
Many organizations still treat SENSE as a capture problem: gather more telemetry, more customer events, more documents, more sensor feeds, more behavioral data.
But SENSE is not just about ingesting signals. It is also about deciding:
- which signals deserve entry,
- which entities they should attach to,
- which state changes actually matter,
- and how quickly stale or low-value information should decay.
A saturated SENSE layer does not create a richer picture of reality. It creates a crowded one.
Consider a customer-service AI. It ingests chat logs, email history, CRM fields, sentiment scores, product usage, return history, prior complaints, and knowledge-base results. On paper, this looks powerful. In practice, the system may over-weight old complaints, confuse account-level behavior with user-level behavior, or treat a minor historical issue as if it were current reality.
That is not a data shortage problem. It is a representation design problem.
CORE: more input raises the burden of judgment
CORE is where the system interprets reality and decides what matters.
This is where Representation Saturation becomes dangerous, because every additional input increases the burden of selection. The system now has to answer four questions repeatedly:
- What is relevant?
- What is recent?
- What is trustworthy?
- What is contradictory?
If the model, prompt architecture, retrieval system, or orchestration layer cannot answer those questions well, decision quality falls.
This is why large context alone is not a strategy. Even current context-engineering guidance emphasizes that effective agentic systems depend on careful curation of what enters context, not just on expanding token limits. (Anthropic)
DRIVER: the real cost appears at the moment of action
In DRIVER, saturation stops being a technical nuisance and becomes institutional risk.
A recommendation system can often survive some clutter. A system that changes credit limits, blocks transactions, flags fraud, prioritizes patients, approves benefits, or triggers investigations cannot.
When action is tied to saturated representation, institutions begin to act with false confidence:
- the wrong customer gets escalated,
- the wrong vendor gets blocked,
- the wrong case gets prioritized,
- the wrong explanation gets logged,
- the wrong person bears the cost of appeal.
This is why NIST emphasizes ongoing testing, evaluation, validation, and governance across the AI lifecycle rather than one-time model approval. In real systems, quality is not a one-time achievement. It has to be maintained. (NIST)

Five simple examples
The overloaded loan file
An underwriting assistant receives salary slips, bank statements, tax filings, credit behavior, app activity, support calls, employer metadata, device traces, and behavioral summaries. The system has more information than ever. But if part of that information is weakly relevant, outdated, or inconsistent, the final judgment becomes less reliable, not more.
The bloated legal review
A legal AI tool is fed every prior contract, every internal memo, every policy note, and every negotiation thread. Instead of becoming sharper, it begins mixing old clauses with current standards and produces an answer that looks comprehensive but is less precise.
The saturated hospital workflow
A triage system receives imaging, lab results, notes, prior visits, wearable data, medication history, and administrative codes. If it cannot distinguish current signals from historical clutter, urgency scoring becomes noisier. In healthcare, that is not inefficiency. It is risk.
The confused fraud engine
A fraud model sees location anomalies, device changes, transaction timing, merchant history, prior false positives, and behavioral patterns. Add enough low-value alerts and the genuine anomaly is hidden inside the system’s own defense process.
The RAG assistant that reads too much
A knowledge assistant retrieves ten documents because the system wants to be thorough. But the correct answer actually requires one policy, one recent update, and one exception memo. Everything else raises the chance of contradiction.
The pattern is the same in every case:
Representation Saturation happens when input volume grows faster than interpretive discipline.
Why this matters for boards and C-suites
The AI economy is entering a phase where raw intelligence is becoming more abundant. Models are improving. Tools are improving. Access is spreading.
That means advantage will increasingly move elsewhere.
It will move to institutions that can do three things better than others:
Decide what should enter the system
Not all data deserves representation.
Decide what should stay visible
Not all captured data should retain equal weight forever.
Decide what should influence action
Not all machine-readable reality should become machine-actionable reality.
That is why Representation Saturation is not a narrow technical problem. It is a strategic one.
The winners in the Representation Economy will not be the institutions that collect the most data. They will be the institutions that design the cleanest path from signal to meaning to action.
The strategic shift leaders need to make
If this diagnosis is right, the next AI advantage is not “more data.” It is better representation discipline.
That requires leaders to ask different questions:
- Which signals genuinely improve decision quality?
- Which data sources mostly add noise, duplication, or conflict?
- Which context should expire faster?
- Which inputs should never trigger action without human confirmation?
- Which retrieval patterns consistently weaken outcomes?
- Which explanations are genuinely precise, and which merely look detailed?
These are not minor operational questions. They are questions about institutional quality.
Because once AI begins to act inside real organizations, clutter is no longer harmless.
Clutter becomes policy.
Clutter becomes judgment.
Clutter becomes execution.
Key Takeaways
- More data does not always improve AI performance
- Representation Saturation occurs when systems receive more data than they can interpret effectively
- AI systems fail not just due to lack of data, but due to excess low-quality or poorly prioritized data
- SENSE–CORE–DRIVER explains how saturation affects perception, reasoning, and action
- Future AI advantage will come from representation discipline, not data accumulation
Conclusion: the next era of AI will reward disciplined seeing
The first era of AI was about making machines see more.
The next era will be about deciding how much reality a system should be allowed to hold, and in what form.
That is why Representation Saturation matters.
It gives us a language for a failure mode that many institutions are already experiencing but have not yet named: the moment when additional machine-readable reality stops improving decisions and starts destabilizing them.
In the years ahead, strong institutions will not be defined by how much data they own. They will be defined by how well they prevent excess representation from turning into false confidence.
That is the deeper lesson of SENSE–CORE–DRIVER.
If SENSE admits too much undisciplined reality, CORE cannot reason cleanly.
If CORE cannot reason cleanly, DRIVER cannot act legitimately.
And when DRIVER acts on saturated representation, the institution becomes dangerous not because it knows too little, but because it mistakes volume for understanding.
The future will not belong to the institutions with the most data.
It will belong to the institutions that know when more data is no longer more truth.
Glossary
Representation Saturation
The point at which additional machine-readable information reduces decision quality because the system can no longer prioritize, interpret, and act on it safely.
Machine-readable reality
The subset of the real world that an institution captures in a format that software or AI systems can process.
Spurious correlation
A misleading pattern in data that appears predictive but does not reflect the true causal relationship.
Noisy labels
Incorrect, inconsistent, or ambiguous labels in training data that can harm model performance.
Long-context failure
The tendency of some language models to use information in long inputs unevenly, especially when relevant information is buried.
Representation discipline
The institutional capability to decide what enters the system, what stays visible, and what is allowed to influence action.
FAQ
What is Representation Saturation in AI?
Representation Saturation is the point at which an AI system has more machine-readable information than it can meaningfully organize, prioritize, and act on safely, causing decision quality to decline.
Why can more data reduce AI performance?
More data can introduce noise, contradictions, stale context, poor labels, and spurious correlations. It can also bury relevant information inside long contexts, making the right answer harder to retrieve. (ACL Anthology)
Is Representation Saturation only an LLM problem?
No. It can appear in model training, retrieval systems, fraud engines, risk systems, compliance workflows, observability stacks, and even in human review environments.
How is this different from data quality?
Data quality focuses on whether data is accurate, complete, consistent, timely, and fit for purpose. Representation Saturation goes further: it asks whether the total volume and arrangement of representation now exceeds the system’s ability to use it well. (ACM Digital Library)
Why should boards care about this?
Because once AI systems influence credit, pricing, healthcare, compliance, risk, or customer treatment, poor prioritization becomes an institutional issue, not just a technical one.
What is the solution?
Not less data in every case, but better filtration, stronger context design, clearer expiration rules, and tighter control over which signals are allowed to influence action.
References and further reading
For readers who want to go deeper, the following research and standards are especially relevant:
- Liu et al., “Lost in the Middle: How Language Models Use Long Contexts” — shows that relevant information buried in the middle of long contexts can be used less effectively by language models. (ACL Anthology)
- Compton et al., “When More Is Less” — shows that adding datasets can sometimes hurt performance by introducing spurious correlations. (arXiv)
- NIST, AI Risk Management Framework and Generative AI Profile — useful for thinking about ongoing evaluation, governance, and lifecycle risk. (NIST)
- OECD, Enhancing Online Disclosure Effectiveness — useful for understanding how information overload can reduce clarity and decision quality in human-facing systems. (OECD)
- ACM and survey work on data quality in machine learning — useful for connecting accuracy, consistency, relevance, and timeliness to model performance. (ACM Digital Library)

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.