
Executive takeaway: autonomy must be operated, not just built
The first wave of enterprise AI made information easier to access. The next wave changes how work happens.
Once AI systems can take actions—create tickets, update records, approve requests, trigger workflows, coordinate tools—the hardest problem stops being “How smart is the model?” and becomes:
Can the enterprise run autonomy safely, predictably, and economically—at scale?
This isn’t a theoretical concern. Gartner has publicly predicted that over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls—and has also flagged “agent washing” as a source of hype and confusion. (See References / Further Reading.) (Gartner)
So the strategic question for leaders becomes brutally practical:
Can we scale hundreds of AI agents without creating an “agent zoo,” runaway spend, and fragile trust?
This article offers a single blueprint that does exactly that: the Agentic Foundry + Reliability-by-Design.
The moment AI starts acting, the old playbook breaks
For years, enterprise AI was mostly answering AI: chatbots, copilots, search assistants, summarizers. Useful—but bounded. If it responded incorrectly, the damage was often limited to confusion, rework, or a delayed decision.
Action changes the physics.
An agent that can change a system of record can also:
- create real financial exposure,
- trigger compliance violations,
- leak sensitive data through toolchains,
- or break customer trust in one fast sequence of “reasonable” steps.
This is why regulators and industry bodies are increasingly focused on accountability, governance, and traceability as agentic AI moves into real operations. (Reuters)

Why “Agent Zoo” is the default outcome (and why it’s so expensive)
If you walk into most enterprises today, you will see a familiar pattern:
- A few teams prototype agents using different stacks and toolchains.
- Each team makes its own choices: prompts, tools, guardrails, logging, approvals, escalation.
- Early demos look impressive.
- Then the organization tries to scale—and the program stalls.
That stall isn’t mysterious. It’s what happens when you scale autonomy without an operating model.
The four failure dynamics behind agent sprawl
1) Every agent becomes a snowflake
Different policies, different permissions, different logging, different assumptions. Security and risk teams cannot certify behavior consistently.
2) Costs become non-linear
Model usage, tool calls, retrieval, orchestration, monitoring—everything multiplies. Without unit economics, leaders cannot distinguish “value” from “burn.”
3) Incidents become hard to diagnose
When something goes wrong, no one can confidently answer:
- What did the agent see?
- Which policy applied?
- Which tool call changed the record?
- Why did it choose that action at that moment?
- Can we undo it—quickly and cleanly?
4) Trust collapses
The business stops giving agents permission to act. Autonomy gets “paused.” The initiative becomes a collection of pilots.
That’s the Agent Zoo: many agents, little standardization, inconsistent controls, escalating spend, and fragile trust.

The combined solution: Factory + Contract
To scale hundreds of agents, enterprises need two things that work together—not separately.
1) The Agentic Foundry (the factory)
A repeatable production system for building, governing, deploying, and operating agents—consistently.
2) Reliability-by-Design (the contract)
A non-negotiable reliability contract that every agent must ship with—so autonomy stays policy-aligned, observable, reversible, auditable, and cost-bounded.
Think of it like this:
- The Foundry makes agent creation repeatable.
- Reliability-by-Design makes agent operation trustworthy.
This pairing also aligns with what large enterprises are converging toward: unified, enterprise-grade platforms that centralize visibility, enforce usage policies, and reduce AI-specific risks. (Gartner)
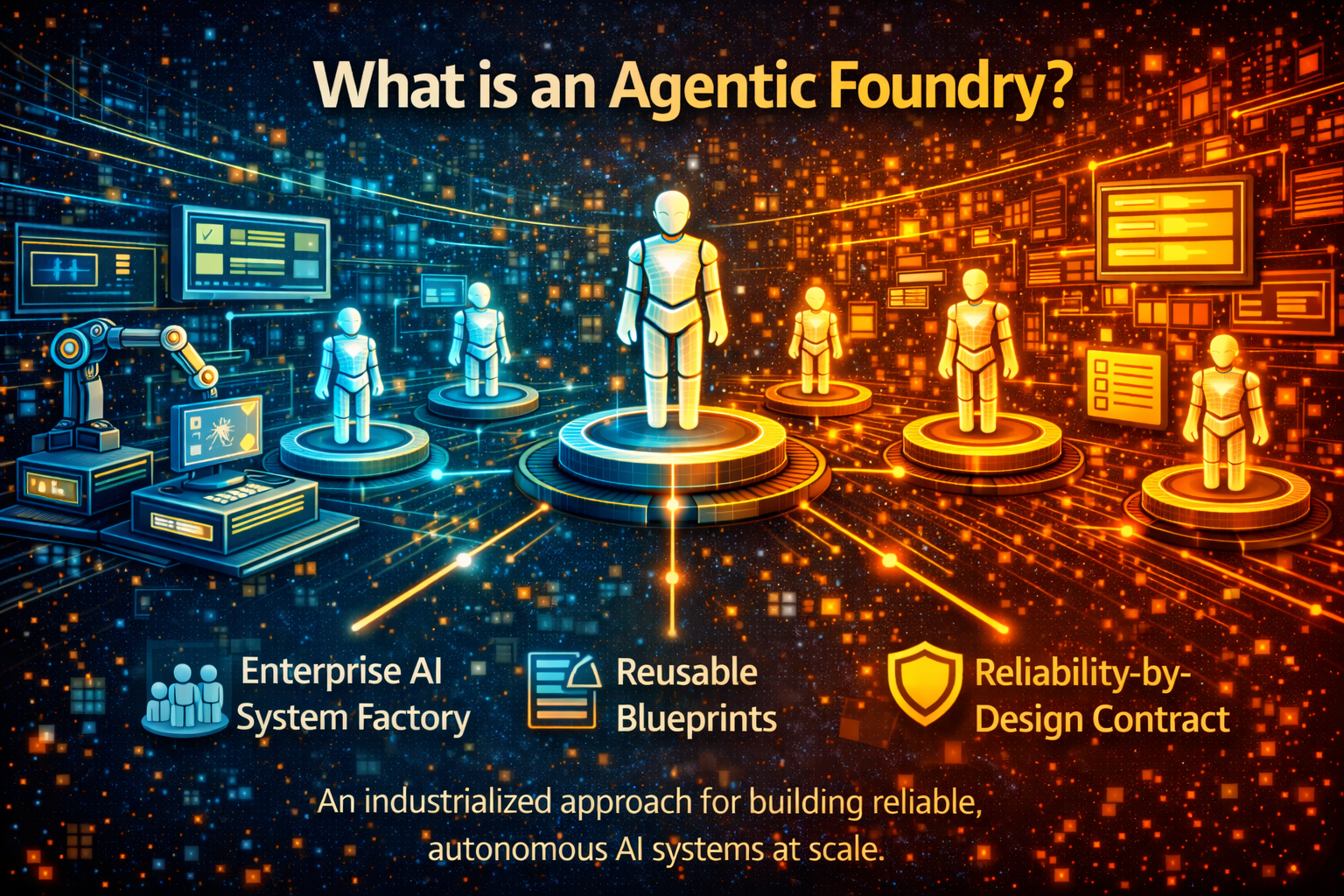
What is an Agentic Foundry?
An Agentic Foundry is not “just a tool.” It is an operating model implemented as platform capability—a shared set of components that turns agent-building into a disciplined lifecycle.
At its best, it behaves like a modern software factory.
Core capabilities of a Foundry
Reusable blueprints (agent archetypes)
Pre-defined agent patterns you can copy, adapt, and certify—so teams don’t start from scratch.
Prebuilt connectors (tool integration once, reused many times)
Standardized integrations into enterprise systems—ticketing, CRM, core banking, ERP, HR, data platforms.
Policy packs (permissions + constraints)
Approved guardrails that are centrally defined, versioned, and automatically applied.
Testing and simulation gates
Validation before any agent can act in production workflows.
Observability and audit evidence
Always-on tracing: what happened, why, through which tools, under which policy.
Cost envelopes (unit economics per agent)
Cost budgets that make autonomy economically governable.
Promotion pipeline (prototype → governed service → scaled autonomy)
A lifecycle path that keeps innovation fast and production safe.
The Foundry enables a shift leaders care about: from one-off “AI projects” to reusable services-as-software—capabilities that are governable, measurable, and repeatable across the enterprise.
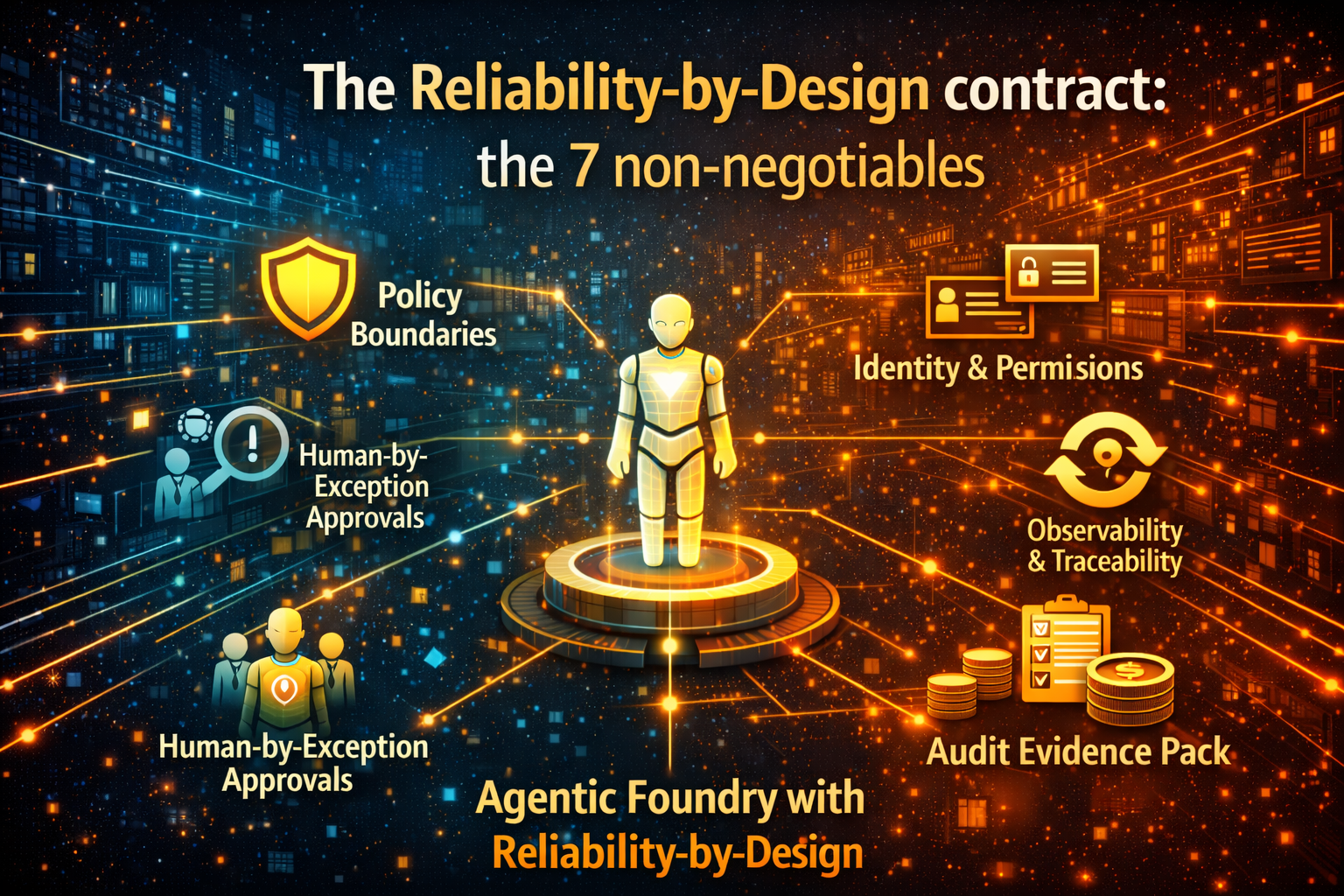
The Reliability-by-Design contract: the 7 non-negotiables
If the Foundry is the factory, Reliability-by-Design is the quality standard.
Every agent must ship with these “seven guarantees” before it can act in production.
1) Policy boundaries
The agent must have explicit boundaries:
- what it may do,
- what it may not do,
- what requires escalation.
This is aligned with global best-practice guidance that emphasizes risk management across the AI lifecycle—such as the NIST AI RMF’s GOVERN / MAP / MEASURE / MANAGE functions. (NIST Publications)
2) Identity and least privilege
Agents must have unique identities and minimum required permissions—no “super-user agents.”
This is how you prevent silent privilege creep as agents proliferate.
3) Observability and traceability
In minutes—not days—you must be able to answer:
- what the agent observed,
- what policy applied,
- what tools it invoked,
- what it changed,
- what it attempted and failed to do.
This is operationally essential—and increasingly tied to enterprise expectations for AI accountability and audit readiness. (NIST)
4) Human-by-exception approvals
Not every step needs a human. But some steps must.
Reliability-by-Design defines the “high-risk edges” where approval is mandatory:
- high-value transactions,
- irreversible changes,
- customer-impacting decisions,
- policy or compliance boundaries.
5) Rollback and kill-switch
Autonomy must be reversible.
If you cannot stop an agent and undo its actions quickly, you don’t have managed autonomy—you have operational exposure.
6) Audit evidence pack
Every agent must emit audit-ready evidence:
- policy version applied,
- action taken,
- timestamps,
- tool calls,
- decision context.
This is the bridge from “agent demo” to “enterprise governance,” and it maps naturally to AI management system expectations such as ISO/IEC 42001’s focus on organizational discipline for responsible AI. (ISO)
7) Cost envelope (unit economics)
Agents must operate under a defined cost boundary:
- budgets per workflow,
- quotas for tool calls,
- caps on retries,
- alerts on spend anomalies.
Cost is not a finance footnote. It is the control surface that prevents autonomy from becoming an unbounded liability—one of the core reasons Gartner expects many projects to be scrapped. (Gartner)
Two simple examples (why Foundry + RBD matters in real life)
Two simple examples (why Foundry + RBD matters in real life)
Example A: Vendor onboarding—without chaos
A vendor onboarding agent collects documents, validates fields, checks policy rules, and triggers onboarding steps.
Without a Foundry:
Every business unit builds its own version. Some log decisions; some don’t. Approval steps vary. Tool connectors are duplicated. Security reviews become slow and inconsistent.
With a Foundry + Reliability-by-Design:
- Onboarding becomes a certified archetype (a reusable blueprint).
- Tool connectors are standardized and reusable.
- The agent inherits policy packs and approval boundaries.
- Observability is mandatory.
- Rollback exists for reversible steps (cancel workflow, revoke access, stop notifications).
- Unit cost per onboarding is tracked and optimized.
Result: onboarding becomes a scalable enterprise capability, not a fragile pilot.
Example B: The refund agent that was “correct”—and still caused an incident
A refund agent approves refunds correctly most of the time. Then a rare edge case occurs: it updates the ledger, triggers a customer notification, and fails before reconciliation. Customers receive refund confirmations, but finance must manually repair the ledger state.
This is not a model intelligence problem. It is an operability problem:
- missing rollback workflow,
- missing step-level observability,
- missing exception boundaries,
- missing cost-aware retry logic.
Under Reliability-by-Design, this agent would be required to:
- stage actions safely,
- use transactional tool contracts where possible,
- emit trace logs,
- stop and escalate on reconciliation mismatch,
- support rollback for partial execution.

How to implement the Agentic Foundry without slowing delivery
The biggest fear leaders have is that governance will slow the business.
The Foundry approach does the opposite: it speeds delivery through reuse and reduces risk through standardization.
Step 1: Standardize agent archetypes
Most enterprise agents fall into a small set of patterns:
- triage and route,
- validate and approve,
- reconcile and resolve,
- monitor and intervene,
- orchestrate and coordinate.
Build templates for these patterns so new agents start “80% done.”
Step 2: Create shared tool contracts
Treat tool calls like APIs with strong contracts:
- allowed actions,
- input validation,
- rate limits,
- error semantics,
- reversibility rules.
This reduces fragile integration and makes incident response possible.
Step 3: Establish a promotion pipeline
Agents should graduate through stages:
- Prototype (read-only, sandbox)
- Controlled pilot (limited scope, approval-heavy)
- Governed service (RBD enforced, audit-ready)
- Scaled autonomy (portfolio operations + continuous improvement)
Step 4: Operate agents like production services
Agents are not experiments. They are production services that must meet:
- reliability expectations,
- incident response readiness,
- cost SLOs,
- governance requirements.

The CXO scorecard: what to measure (no vanity metrics)
To run agentic AI at portfolio scale, measure what leadership actually cares about:
- Reversibility rate: how often can we cleanly undo agent actions?
- Policy breach rate: how often do agents attempt disallowed actions?
- Time-to-diagnose: how quickly can we reconstruct what happened?
- Exception containment: how often are incidents limited to a small blast radius?
- Unit economics per workflow: cost per completed business outcome
- Reuse ratio: how much new agent work reuses certified templates/connectors?
When those improve, trust improves—and autonomy can expand responsibly.

Global lens: why this isn’t “just compliance”
Across major regions, the direction is consistent: stronger expectations for risk management, accountability, traceability, and responsible operations.
- NIST AI RMF provides a practical structure (GOVERN / MAP / MEASURE / MANAGE) for managing AI risk across the lifecycle. (NIST Publications)
- ISO/IEC 42001 formalizes organizational requirements for an AI management system. (ISO)
The Agentic Foundry with Reliability-by-Design is the operational translation of these expectations—without turning AI into a slow bureaucracy.
It is how you move from:
- “We built agents”
to - “We operate autonomy as a reliable enterprise capability.”
A practical 30–60–90 day path
First 30 days: define the contract
- Define the 7 Reliability-by-Design requirements.
- Pick 2–3 high-value agents.
- Enforce identity, logging, approval boundaries, and rollback rules.
- Establish cost envelopes.
Next 60 days: build the Foundry’s first components
- Create 3–5 reusable archetypes.
- Build shared connectors for common enterprise tools.
- Establish the promotion pipeline and a basic registry of agents/tools/policies.
By 90 days: prove portfolio readiness
- Scale to 10–20 agents built from templates.
- Run incident drills (stop / rollback / escalate).
- Track unit costs and reuse ratio.
- Publish a lightweight “operability scorecard” internally.

Conclusion: autonomy doesn’t scale on intelligence—it scales on factories and contracts
If an enterprise wants hundreds of agents without sprawl, the answer isn’t to “build faster.”
The answer is to industrialize:
- build a Foundry that makes agent creation repeatable, and
- enforce Reliability-by-Design so every agent is safe to run.
That is how agentic AI becomes a durable advantage—not because it can act, but because it can act safely, predictably, reversibly, and economically at scale.
Glossary
Agentic AI: AI systems that can plan and take actions in tools and enterprise workflows, not just generate responses. (Gartner)
Agent Zoo: A sprawl of independently built agents with inconsistent controls, duplicated effort, and runaway cost.
Agentic Foundry: A standardized enterprise capability that produces agents through templates, connectors, governance gates, and a promotion pipeline.
Reliability-by-Design (RBD): Designing agents with mandatory operational guarantees: policy boundaries, identity, observability, rollback, audit evidence, and cost envelopes.
Cost envelope: A defined budget boundary and usage policy for an agent (tokens, tool calls, retries, and escalation thresholds). (Gartner)
Promotion pipeline: Controlled progression from prototype to governed service to scaled autonomy.
AI Management System (AIMS): Organizational processes to manage AI risks and responsibilities (e.g., ISO/IEC 42001). (ISO)
FAQ
1) Isn’t this just “AI governance”?
It’s governance translated into operational reality: what an agent must ship with, and how it’s built and run repeatedly at portfolio scale.
2) Why can’t teams build agents independently?
They can—until scale. Then inconsistency, cost, and incident response collapse trust. Standardization becomes the only path to sustained autonomy.
3) What is the fastest first step?
Define the Reliability-by-Design contract and enforce it for 2–3 agents immediately. The Foundry grows from those first standards.
4) Will this slow innovation?
It usually speeds innovation by removing reinvention: teams reuse certified templates, connectors, and controls instead of rebuilding them for every agent.
5) What’s the biggest risk if we ignore this?
Agentic programs freeze after the first meaningful incident or cost spike—one of the failure modes Gartner has publicly warned about. (Gartner)
References and further reading
- Gartner newsroom: Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027 (June 25, 2025). (Gartner)
- Reuters: Over 40% of agentic AI projects will be scrapped by 2027, Gartner says (June 25, 2025). (Reuters)
- Gartner newsroom: Task-specific AI agents in enterprise apps; misconception and “agentwashing” (Aug 26, 2025). (Gartner)
- NIST: Artificial Intelligence Risk Management Framework (AI RMF 1.0) (PDF + overview page). (NIST Publications)
- ISO: ISO/IEC 42001:2023 — Artificial intelligence management systems (standard overview). (ISO)
- The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale – Raktim Singh
- The One Enterprise AI Stack CIOs Are Converging On: Why Operability, Not Intelligence, Is the New Advantage – Raktim Singh
- The New Enterprise AI Advantage Is Not Intelligence — It’s Operability – Raktim Singh
- Agentic Quality Engineering: Why Testing Autonomous AI Is Becoming a Board-Level Mandate – Raktim Singh
- The Living IT Ecosystem: Why Enterprises Must Recompose Continuously to Scale AI Without Lock-In | by RAKTIM SINGH | Dec, 2025 | Medium
- The One Enterprise AI Stack CIOs Are Converging On: Why Operability, Not Intelligence, Is the New Advantage | by RAKTIM SINGH | Dec, 2025 | Medium

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.