{kind=link}

Artificial intelligence did not become powerful only because models became larger.
It became powerful because the world became easier for machines to read.
That is the deeper lesson of CLIP.
In 2021, OpenAI introduced CLIP, a model trained on 400 million image-text pairs collected from the internet. Instead of depending only on carefully labeled image datasets, CLIP learned by connecting images with the natural language humans had already placed around them: captions, titles, descriptions, alt text, product names, article snippets, and web context. (arXiv)
That may sound like a technical milestone in computer vision.
It was more than that.
CLIP showed that the internet itself had become a planetary-scale sensory system for AI.
Every image with a caption.
Every product photo with a title.
Every meme with text.
Every webpage where humans connected words to visual reality.
Together, these became training material for machine perception.
Before CLIP, computer vision largely depended on humans creating structured labels. A picture was manually tagged as “dog,” “car,” “tree,” or “building.” The machine learned fixed categories. But CLIP learned differently. It learned from the messy, noisy, natural way humans describe the world online.
This changed the SENSE layer of AI forever.
In the SENSE–CORE–DRIVER framework, SENSE is the layer where reality becomes machine-legible. CORE is where reasoning happens. DRIVER is where authority, execution, verification, and recourse are governed.
CLIP matters because it expanded SENSE dramatically.
It did not merely improve recognition.
It changed what AI could perceive.
AI Summary Block
OpenAI’s CLIP fundamentally changed artificial intelligence by learning from internet-scale image-text pairs instead of manually labeled datasets. The model transformed the internet into a machine-legible sensory system for AI. In the SENSE–CORE–DRIVER framework, CLIP represents a major expansion of the SENSE layer, where reality becomes visible and actionable for intelligent systems. The article argues that the future competitive advantage in enterprise AI will come not only from better models, but from better representations of reality.
The Old Model of Computer Vision: Humans Had to Label Reality

For decades, computer vision worked through a familiar pattern.
Collect images.
Ask humans to label them.
Train a model to classify those images into predefined categories.
This created useful systems, but also a deep limitation.
The model could only recognize what humans had already defined.
If the dataset had labels for “dog,” “cat,” and “car,” the model could classify those categories. But if you suddenly wanted “dog wearing sunglasses,” “damaged electric scooter,” “traditional handmade basket,” or “solar panel covered with dust,” the system needed new data, new labels, and often retraining.
This is the closed-set problem.
The machine’s world was limited by the label set.
In business language, AI could not see beyond the categories the institution had already prepared for it.
That is a SENSE limitation.
The issue was not only model intelligence. The issue was representation. The world had to be converted into machine-readable categories before the model could act.
CLIP challenged that model.
It asked a powerful question:
What if humans had already labeled the world indirectly?
Not through formal datasets.
But through the internet.
CLIP’s Simple but Profound Idea
CLIP stands for Contrastive Language-Image Pre-training.
The name sounds technical, but the core idea is simple.
Take an image.
Take the text that appears with it.
Train the model to understand that the two probably belong together.
For example, an image may show a dog running in a park. The nearby text may say, “my dog enjoying the morning walk.”
CLIP does not need a human annotator to select the exact label “dog.” It learns that this visual pattern is connected to words like dog, park, walk, pet, grass, and outdoor.
Now repeat this hundreds of millions of times.
A product photo with a title.
A travel photo with a caption.
A news image with a headline.
A chart with surrounding article text.
A food image with a recipe description.
Slowly, the model learns a shared space between visual patterns and language.
That is why CLIP can classify images without being trained for that exact classification task. OpenAI described CLIP as learning visual concepts from natural language supervision and applying them to visual classification by simply providing category names in natural language. (OpenAI)
That is a major shift.
Old computer vision learned from labels.
CLIP learned from descriptions.
Old systems learned from fixed categories.
CLIP learned from open-ended language.
Old systems treated vision as a classification problem.
CLIP treated vision as a representation problem.
That is why CLIP matters for the Representation Economy.
The Internet Became the Training Ground for Machine-Legible Reality
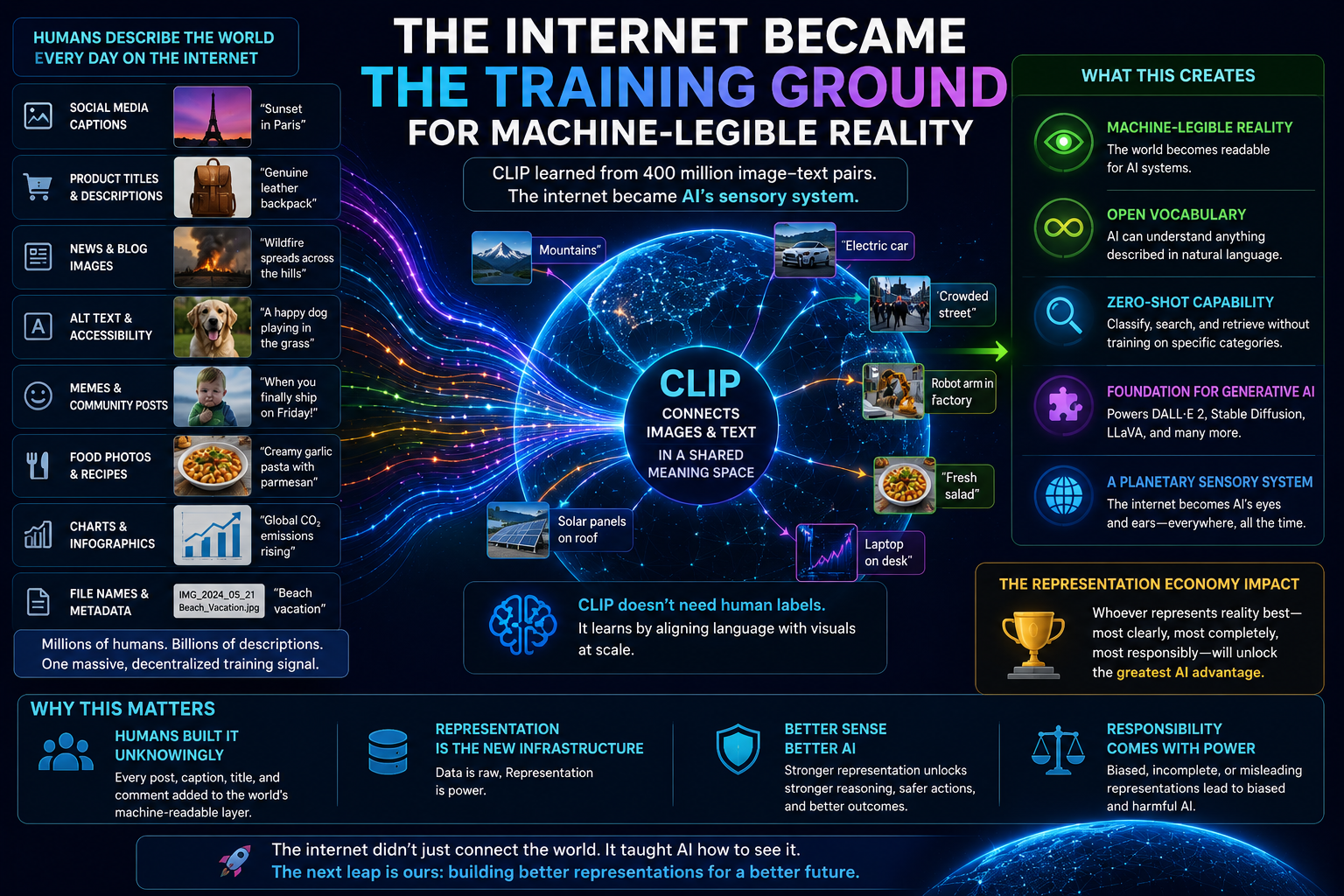
CLIP reveals a powerful truth:
AI does not need reality directly.
It needs representations of reality.
The internet is not reality itself. It is a human-created representation layer over reality.
People uploaded images.
People wrote captions.
People named products.
People described places.
People commented on events.
People created metadata.
People linked images to concepts.
In doing so, humanity unknowingly built a vast SENSE layer for AI.
This is the hidden transformation.
The internet became more than an information network.
It became a sensory dataset.
When CLIP learned from 400 million image-text pairs, it was not simply learning “images.” It was learning how humans connect visual reality to language. The original CLIP paper describes this as learning from raw text about images and using natural language to reference learned visual concepts. (arXiv)
That is why CLIP is important beyond computer vision.
It shows that the next phase of AI is not only about better models. It is about better access to machine-legible representations of the world.
The company, platform, government, or ecosystem that can represent reality most clearly will have a major AI advantage.
That is Representation Economy logic.
Value moves toward those who can make reality visible, identifiable, comparable, searchable, and actionable for machines.
CLIP Changed SENSE from Labeling to Alignment
The old computer vision world was based on labeling.
The CLIP world is based on alignment.
This difference is important.
Labeling says:
“This image belongs to this category.”
Alignment says:
“This image is close in meaning to this text.”
That sounds subtle, but it is a huge architectural shift.
A label is narrow.
A description is rich.
A label says “dog.”
A description says “a small dog sitting beside a red suitcase at an airport.”
A label says “car.”
A description says “a damaged electric vehicle parked near a charging station.”
A label says “factory.”
A description says “a production line with robotic arms assembling electronic components.”
Language carries context, attributes, relationships, purpose, and meaning.
CLIP did not fully master all of that, but it opened the door.
It showed that vision could be connected to language at scale.
This made AI more flexible.
Instead of training a separate model for every category, you could ask the model to compare an image with natural-language prompts.
This is why CLIP became important for zero-shot classification, image search, multimodal retrieval, and later generative AI systems.
It helped machines move from:
“What label is this?”
to:
“What does this image mean in language?”
That is a SENSE revolution.
Why CLIP Became Infrastructure for Modern Multimodal AI
CLIP did not remain a standalone research model.
It became infrastructure.
DALL·E 2 used CLIP-style representations to connect text prompts with image generation. The DALL·E 2 paper describes a two-stage model in which a prior generates a CLIP image embedding from a text caption, and a decoder generates an image conditioned on that embedding. (arXiv)
Stable Diffusion also used CLIP as part of its text-conditioning pipeline. The official CompVis Stable Diffusion repository describes Stable Diffusion as a latent diffusion model conditioned on text embeddings from a CLIP ViT-L/14 text encoder. (GitHub)
BLIP-2 later used a lightweight Querying Transformer, or Q-Former, to bridge frozen image encoders and frozen large language models, showing how visual representation could be connected more efficiently to language reasoning systems. (arXiv)
This pattern matters.
CLIP became part of the connective tissue of multimodal AI.
It helped turn images into something language models could work with.
It helped make visual reality more machine-readable.
It helped AI systems move from text-only reasoning toward image-language interaction.
In SENSE–CORE–DRIVER language, CLIP strengthened the SENSE-to-CORE handoff.
The visual world could now be represented in a way that reasoning systems could consume.
A Simple Enterprise Example: Insurance Claims
Imagine an insurance company.
A customer uploads photos of a damaged vehicle after an accident.
In the old world, humans inspect the image, write notes, classify damage, estimate severity, and route the claim.
With CLIP-like systems, the image can be connected to language automatically.
The system may understand that the image is close to descriptions such as:
“front bumper damage”
“broken headlight”
“minor side scratch”
“airbag deployed”
“vehicle not drivable”
This does not mean the AI truly understands the accident.
But it means the image can enter the enterprise decision system as a machine-readable representation.
That is SENSE.
Once the image becomes machine-legible, CORE can reason over it.
Should the claim be routed to fast approval?
Does it need manual review?
Is the image consistent with the written claim?
Is there possible fraud?
Then DRIVER becomes critical.
Who is allowed to approve the claim?
Can the customer appeal?
Was the image interpreted correctly?
Was the decision auditable?
Was the AI’s role advisory or authoritative?
This is the practical power of SENSE–CORE–DRIVER.
CLIP helps explain how raw reality enters the AI system.
But enterprise value depends on what happens after that.
A Healthcare Example: Why SENSE Quality Matters
Consider medical imaging.
A model may be able to associate an image with medical descriptions. But if the representation is incomplete, biased, outdated, or poorly contextualized, the downstream reasoning can be dangerous.
A scan is not just a visual pattern.
It belongs to patient history, symptoms, test results, clinical protocols, prior diagnoses, treatment constraints, and risk thresholds.
CLIP-like representation can help connect image and language.
But it cannot replace the full institutional SENSE layer required for clinical judgment.
This is why AI in high-stakes domains cannot be treated as image recognition plus prediction.
The institution must ask:
What did the system actually see?
What context was missing?
What uncertainty was visible?
What human review was required?
What action was allowed?
What recourse existed if the interpretation was wrong?
This is where many AI strategies fail.
They celebrate CORE intelligence while underinvesting in SENSE quality and DRIVER legitimacy.
The Biggest Lesson: Better CORE Cannot Fix Broken SENSE

CLIP’s success is impressive.
But its limitations are even more important.
Research has shown that CLIP and similar vision-language models can struggle with compositional reasoning. The ARO benchmark was created to test whether vision-language models understand attributes, relations, and word order. It found that these models often fail to capture fine-grained relationships between objects and language. (NeurIPS Papers)
In simple terms, CLIP may recognize:
dog
cat
running
grass
But it may struggle to reliably distinguish:
“dog chasing cat”
from
“cat chasing dog”
Both captions contain similar words.
But the relationship is different.
This matters because the real world is made of relationships, not just objects.
In an enterprise, the difference between:
“supplier delayed payment”
and
“payment delayed supplier”
is not small.
The difference between:
“customer disputed transaction”
and
“transaction flagged customer”
is not small.
The difference between:
“machine damaged product”
and
“product damaged machine”
is not small.
Objects are not enough.
Relationships matter.
Order matters.
Causality matters.
Authority matters.
This is why the Representation Economy needs more than data.
It needs structured representation.
Why CLIP Can Recognize Concepts but Miss Structure

CLIP is powerful because it learns associations between images and language.
But association is not the same as understanding.
If the internet contains many images of dogs with captions about dogs, CLIP learns a strong connection between dog-like visual features and dog-related language.
But many internet captions are not precise.
People do not always write:
“The brown dog is chasing the black cat from left to right.”
They write:
“crazy pets today.”
Or:
“morning chaos.”
Or:
“dog and cat running.”
The model learns from that looseness.
So CLIP becomes strong at broad semantic matching.
It becomes weaker at precise structural understanding.
This is not a minor flaw.
It reveals something deep about SENSE.
If the representation layer does not encode relationships clearly, the reasoning layer cannot reliably recover them.
A smarter model may infer more.
But it is still reasoning over what SENSE made available.
This is why enterprises cannot simply throw more AI at weak data, fragmented workflows, and ambiguous authority structures.
The AI may become more fluent.
But the institution may become more fragile.
The Modality Gap: Image and Text Are Aligned, but Not Identical
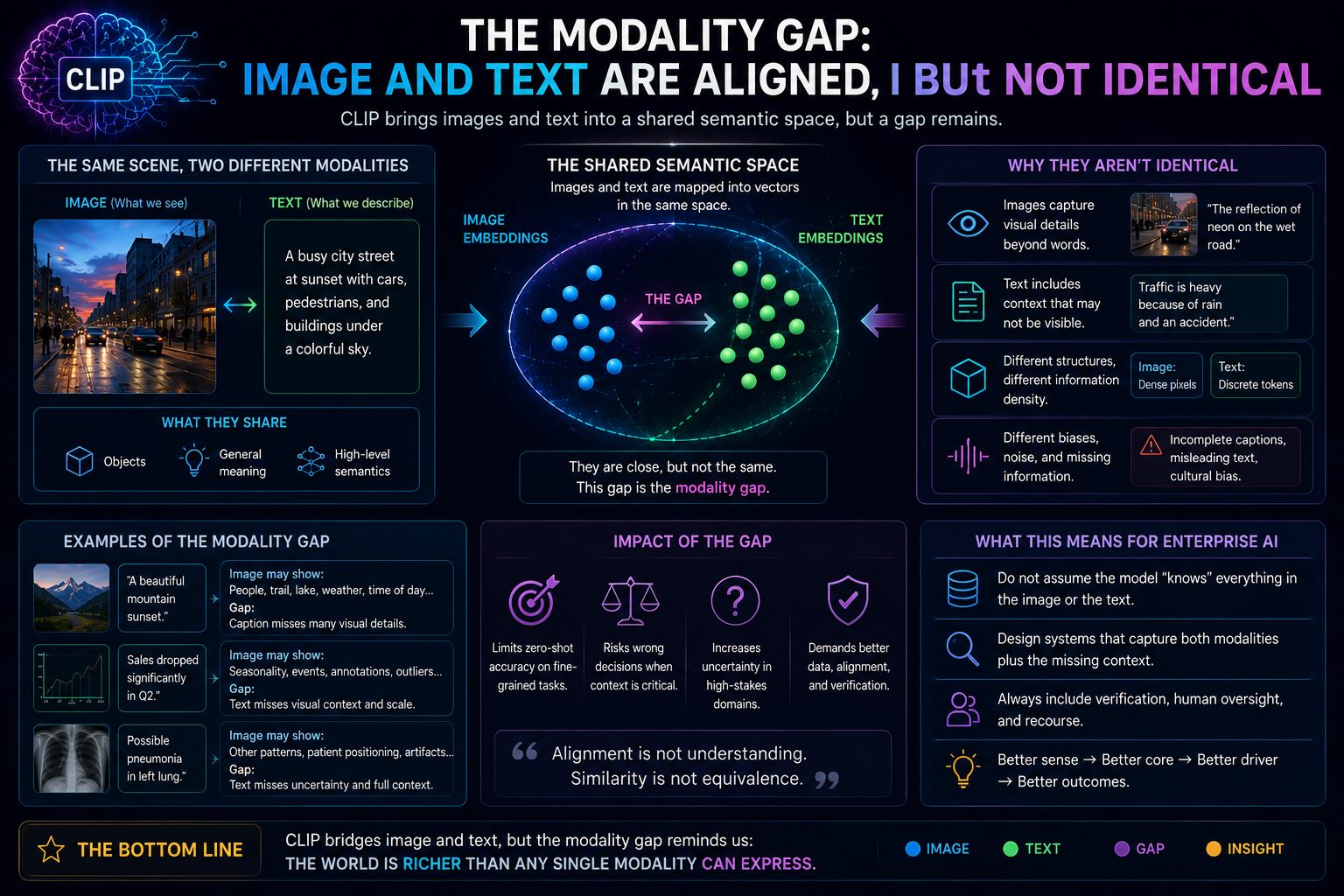
Another important CLIP lesson is the modality gap.
Researchers have shown that in models like CLIP, image embeddings and text embeddings may not occupy the same region of the shared representation space. They can remain separated by a consistent geometric gap even after contrastive training. (OpenReview)
In simple language, CLIP brings images and text close enough to compare.
But image meaning and text meaning are not perfectly unified.
This matters.
A photo of a street is not the same as a sentence describing the street.
An image may contain details the caption ignores.
A caption may contain context the image does not show.
A product image may show a clean object, while the text may mention hidden specifications.
A factory image may show machines, but not reveal whether production is delayed.
A medical scan may show visual patterns, but not patient history.
So even when image and language are aligned, representation remains partial.
This is a profound SENSE insight.
Machine-readable reality is always a constructed version of reality.
It is useful.
It is powerful.
But it is never complete.
Why This Matters for CIOs, CTOs, and Boards
Many CIOs and CTOs are now investing in multimodal AI.
They want systems that can read documents, understand diagrams, inspect images, process screenshots, analyze video, and operate software interfaces.
That is the right direction.
But the CLIP lesson is clear:
Multimodal AI is not magic perception.
It is representation alignment.
The strategic question is not simply:
Which model should we use?
The better question is:
What version of reality are we making available to the model?
For enterprise leaders, AI readiness depends on machine-legible reality.
Can your enterprise represent customers accurately?
Can it represent assets consistently?
Can it represent contracts structurally?
Can it represent process state in real time?
Can it represent authority boundaries?
Can it represent exceptions?
Can it represent uncertainty?
Can it represent what changed over time?
If not, the problem is not only AI capability.
The problem is institutional SENSE.
CLIP teaches us that AI becomes powerful when the world becomes representable.
Enterprise AI will follow the same rule.
The Enterprise Internet Problem
The public internet gave CLIP a vast training ground.
But enterprises do not have the same advantage automatically.
Inside organizations, reality is often fragmented.
Customer data sits in one system.
Contracts sit in another.
Emails contain informal context.
Dashboards show simplified metrics.
Images sit in archives.
Documents are not tagged properly.
Process states are scattered.
Exceptions live in human memory.
Permissions are unclear.
Legacy systems use inconsistent identifiers.
This means the enterprise may have data, but not usable SENSE.
The difference is critical.
Data is not representation.
A document is not representation.
A dashboard is not representation.
A data lake is not representation.
Representation means reality has been structured in a way that machines can interpret, compare, update, and act upon.
CLIP succeeded because image and text pairs gave the model a bridge between visual reality and language.
Enterprises need similar bridges.
Between documents and workflows.
Between customers and interactions.
Between assets and states.
Between decisions and evidence.
Between AI recommendations and authority.
That is where the next enterprise AI advantage will emerge.
From Internet-Scale SENSE to Enterprise-Grade SENSE
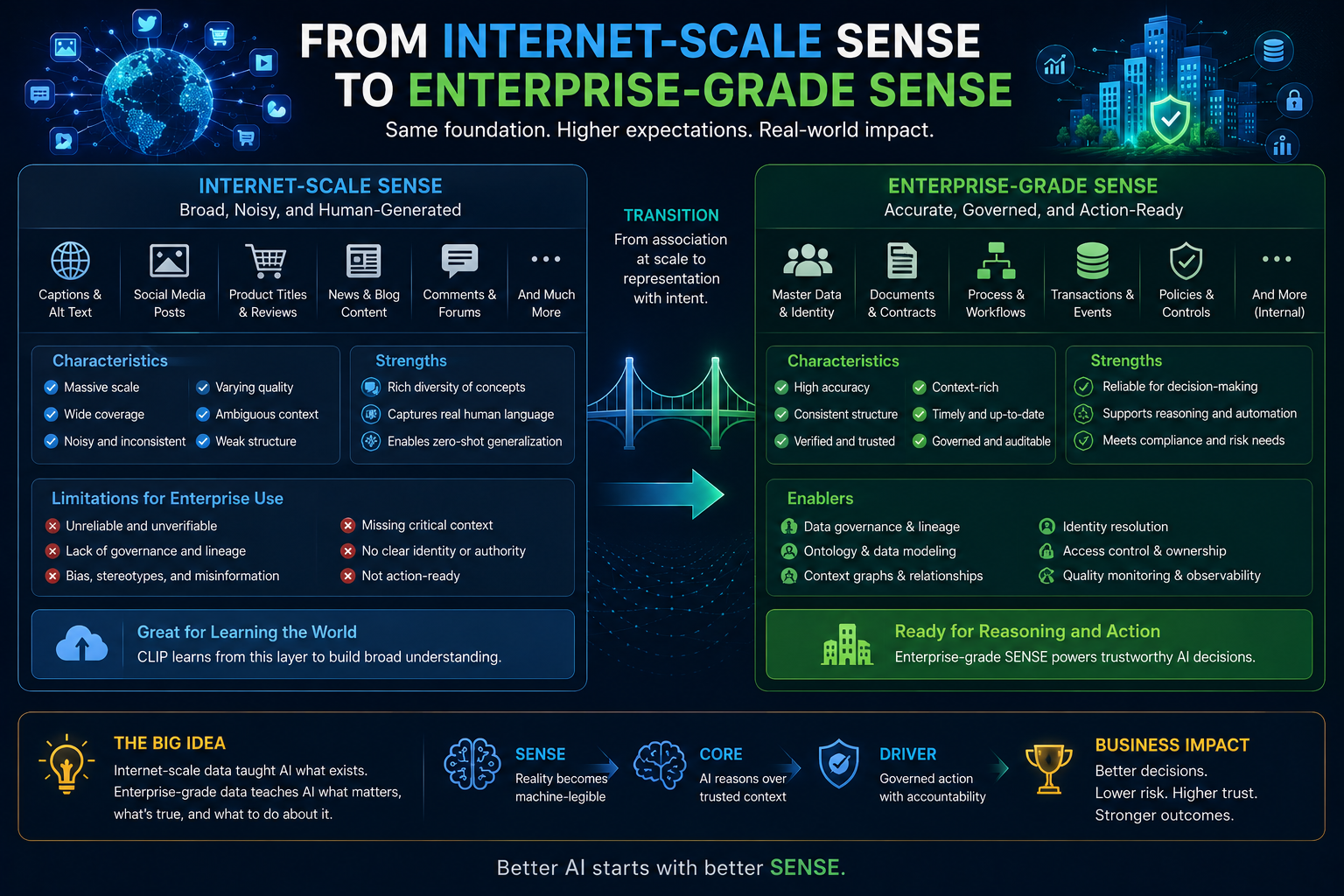
CLIP learned from internet-scale SENSE.
But enterprises need enterprise-grade SENSE.
The difference matters.
Internet-scale SENSE is broad, noisy, and culturally rich.
Enterprise-grade SENSE must be accurate, governed, auditable, current, and tied to action.
A public image caption can be vague.
An enterprise asset record cannot be vague.
A social media image can be mislabeled.
A compliance report cannot be casually wrong.
A meme can mix irony and ambiguity.
A credit decision cannot depend on unclear representation.
This is why enterprise AI needs a different architecture.
It cannot rely only on web-scale association.
It needs structured representation.
It needs identity resolution.
It needs context graphs.
It needs policy-aware reasoning.
It needs evidence trails.
It needs recourse.
In other words, it needs SENSE, CORE, and DRIVER together.
For a broader explanation of this framework, see What Is the Representation Economy? The Definitive Guide to SENSE, CORE, and DRIVER. (Raktim Singh)
The Representation Economy Interpretation of CLIP
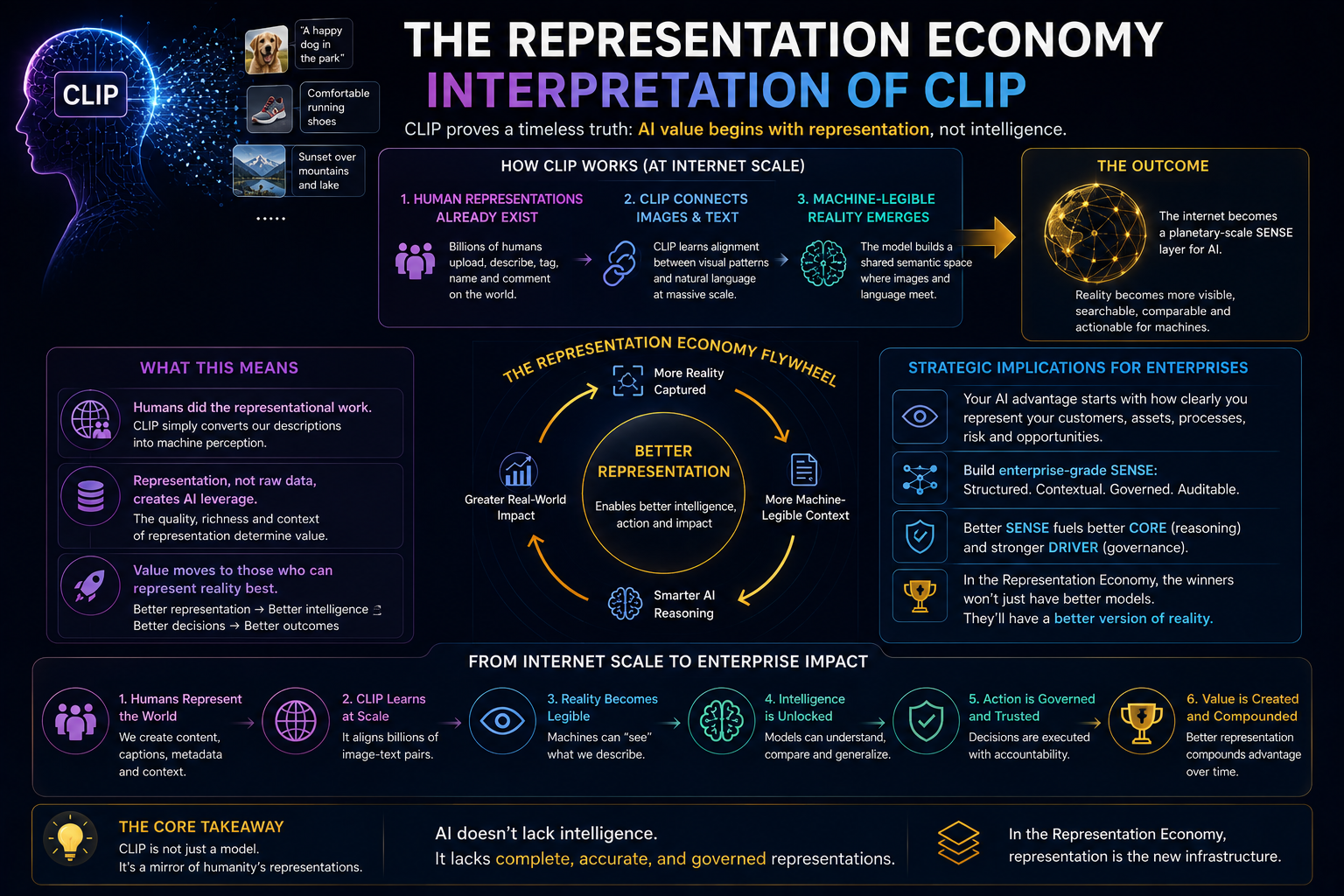
CLIP proves a major Representation Economy principle:
The real AI advantage is not only who has the best model.
It is who has the best representation of reality.
OpenAI did not manually label 400 million images.
It used existing human representations at internet scale.
That is the key.
Humans had already done the representational work.
They had described, named, captioned, tagged, uploaded, and contextualized reality.
CLIP converted that into machine perception.
This is why the Representation Economy matters.
AI value begins before intelligence.
It begins when reality becomes legible.
The next generation of AI winners will not only build bigger models.
They will build better systems for representing the world.
Search engines did this for web pages.
Social platforms did this for human behavior.
E-commerce platforms did this for products.
Mapping platforms did this for locations.
Enterprise platforms will need to do this for institutional reality.
That is the next frontier.
Why CLIP Also Warns Us About Representation Risk
CLIP did not learn from pure reality.
It learned from the internet.
And the internet contains bias, noise, stereotypes, missing context, cultural imbalance, and misleading associations.
That means CLIP-like systems can inherit distorted representations.
This is not only an ethics issue.
It is an architecture issue.
If SENSE is distorted, CORE may reason over distortion.
If CORE reasons over distortion, DRIVER may authorize bad action.
That is the failure chain.
A biased representation can become a biased recommendation.
A biased recommendation can become a governed decision.
A governed decision can become institutional harm.
This is why AI governance cannot begin at the model output.
It must begin at representation.
What did the system see?
How was reality encoded?
Which entities were visible?
Which entities were invisible?
Which relationships were captured?
Which relationships were missing?
Whose language shaped the representation?
Whose context was absent?
These questions are no longer philosophical.
They are operational.
This is also why “human oversight” alone is not enough. For more on this, see The Governance Illusion: From Human Oversight to Institutional Legitimacy in Autonomous AI Systems. (Raktim Singh)
Why “AI Sees the World” Is the Wrong Phrase
People often say AI can now “see.”
That phrase is useful but misleading.
AI does not see the world like a human.
It maps sensory input into representations learned from data.
CLIP does not understand an image as lived experience.
It converts the image into a mathematical representation and compares it with language representations.
That is powerful.
But it is not human perception.
This distinction matters for executives.
When a system says, “This image shows damaged equipment,” it may be doing semantic alignment, not causal understanding.
When it says, “This chart indicates declining performance,” it may be matching visual patterns, not understanding the business context.
When it says, “This screenshot shows a failed transaction,” it may identify interface elements but miss the operational consequence.
So the question should not be:
Can AI see?
The better question is:
What representation did AI construct from what it sensed?
That is a much better governance question.
Why This Changes AI Architecture
The CLIP era changed AI architecture in three ways.
First, it made multimodal representation central.
Images, text, and other signals could be aligned into shared semantic spaces.
Second, it made natural language a control interface.
Instead of training a new classifier, users could describe what they wanted to recognize.
Third, it exposed the limits of representation alignment.
AI could match concepts without fully understanding structure, causality, negation, or authority.
This is why future AI architecture cannot stop at multimodal models.
It needs representation engineering.
It needs context engineering.
It needs relationship modeling.
It needs verification mechanisms.
It needs authority design.
It needs human-legible evidence.
This is exactly where SENSE–CORE–DRIVER becomes useful.
SENSE: What CLIP Changed
CLIP expanded the meaning of SENSE.
Before CLIP, SENSE in computer vision was mostly curated labels.
After CLIP, SENSE became natural language supervision at internet scale.
This teaches us that SENSE can come from:
captions
metadata
file names
documents
screenshots
logs
conversation histories
sensor feeds
knowledge graphs
workflow states
human annotations
behavioral traces
enterprise records
The key is not the data type.
The key is whether reality becomes legible enough for intelligence to operate on it.
CLIP made images more legible by connecting them to language.
Enterprises must make operations more legible by connecting events, entities, states, policies, and decisions.
CORE: What CLIP Did Not Solve
CLIP improved perception, not full reasoning.
It can associate an image with a phrase.
But it may fail when the phrase requires precise relational understanding.
That tells us something important about CORE.
CORE cannot be evaluated only by fluent outputs or high-level recognition.
It must be evaluated by whether it understands:
relationships
constraints
causality
exceptions
trade-offs
uncertainty
counterfactuals
failure modes
In enterprise AI, a model that recognizes documents is useful.
But a model that understands obligations, exceptions, dependencies, and consequences is far more valuable.
The difference between recognition and judgment will define enterprise AI maturity.
DRIVER: Why CLIP Makes Governance More Urgent
The more powerful SENSE becomes, the more important DRIVER becomes.
If AI can perceive more of the world, it can influence more decisions.
If AI can interpret images, documents, dashboards, and workflows, it can become embedded in operational systems.
That increases the need for governance.
Who authorized the AI to act?
What evidence did it use?
What uncertainty did it show?
What was the human expected to verify?
What action boundary existed?
Could the action be reversed?
Could an affected person appeal?
Could auditors reconstruct the decision?
CLIP helped AI systems see more.
But seeing more does not automatically mean acting wisely.
That is the DRIVER problem.
Intelligence does not create legitimacy.
Representation does not create authority.
Only governed delegation does.
For a deeper exploration of decision systems in AI-era organizations, see Decision Scale: The New Competitive Advantage in AI. (Raktim Singh)
The Next AI Advantage: Representation Quality Engineering
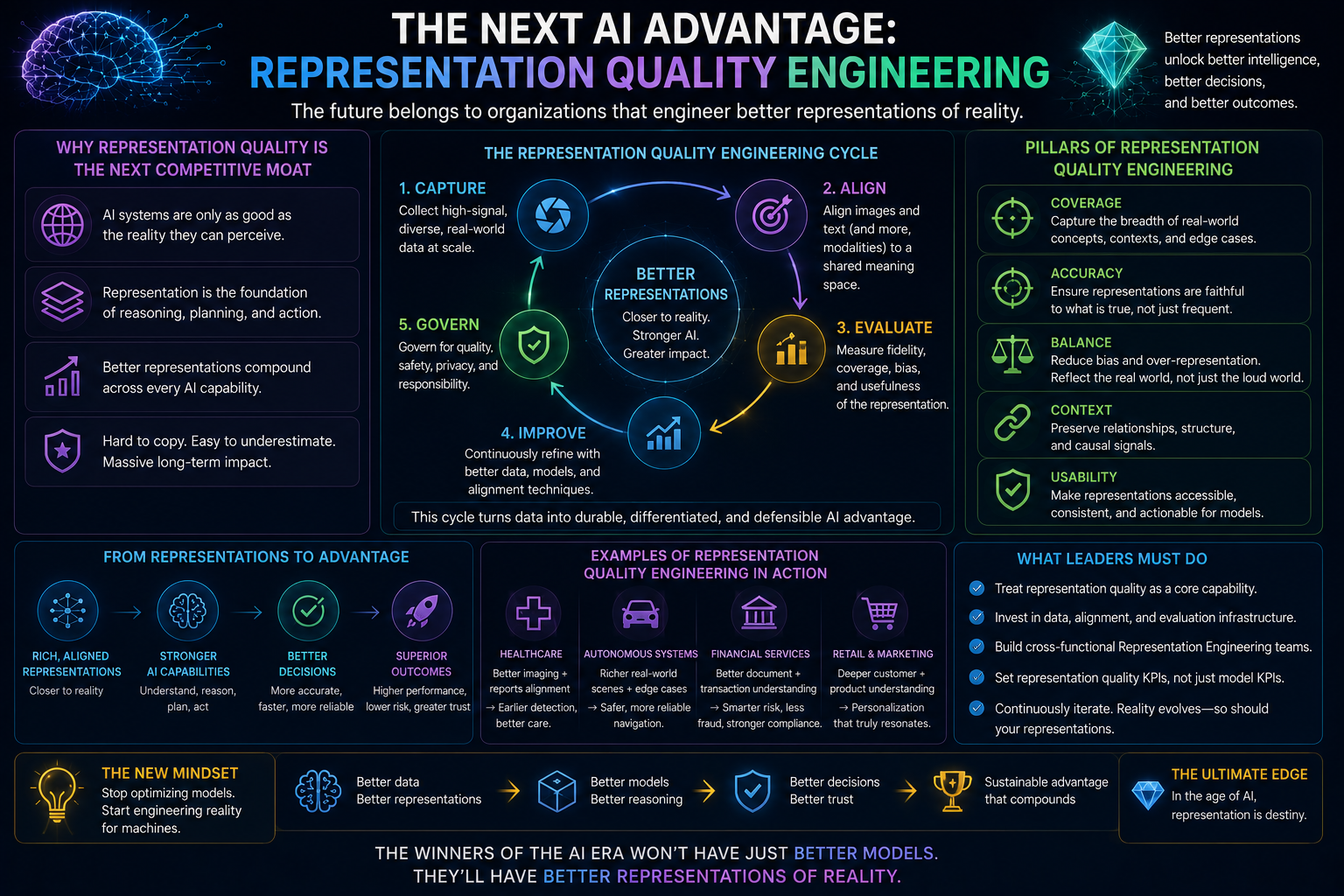
One of the next major enterprise disciplines will be representation quality engineering.
Today, enterprises test models.
They test accuracy.
They test latency.
They test cost.
They test security.
But they also need to test representation quality.
Can the system distinguish similar but different situations?
Can it capture relationships, not just objects?
Can it represent uncertainty?
Can it identify missing context?
Can it detect when reality has changed?
Can it show what it relied on?
Can it separate observation from inference?
Can it support audit and recourse?
This is the enterprise version of the CLIP lesson.
The model is only as good as the representation pipeline feeding it.
Why CIOs Should Care Now
CIOs should care about CLIP not because they need to build CLIP.
They should care because CLIP shows how AI advantage is created.
The lesson is not:
Use more image-text models.
The lesson is:
Make reality machine-legible before expecting AI to transform decisions.
Every enterprise has its own “internet” inside it.
Documents.
Emails.
Tickets.
Images.
Calls.
Dashboards.
Contracts.
Logs.
Policies.
Transactions.
Customer journeys.
Engineering notes.
Operational exceptions.
But most of this internal reality is not yet connected into a coherent SENSE layer.
That is the opportunity.
The enterprise that builds the best machine-legible view of itself will have a major advantage in the AI era.
Not because it has more data.
Because it has better representation.
The Viral Insight: AI Learned from Us Before We Knew We Were Teaching It

The most fascinating part of CLIP is this:
Humanity was teaching AI without realizing it.
Every caption was a lesson.
Every product title was a label.
Every travel photo was a geography lesson.
Every meme was a cultural association.
Every webpage image was a weak annotation.
Every human description became part of machine perception.
That is both beautiful and uncomfortable.
It means the world’s representational residue became AI training infrastructure.
It also means our biases, shortcuts, stereotypes, omissions, and sloppy descriptions became part of that infrastructure.
This is why the Representation Economy is not only about technology.
It is about power.
Who gets represented?
Who defines the label?
Who controls the context?
Who decides what reality means?
Who benefits when machines can see?
Who disappears when machines cannot?
These are the next strategic questions of AI.
Conclusion: CLIP Changed SENSE Forever
CLIP is often described as a breakthrough in computer vision.
That is true.
But it is incomplete.
CLIP’s deeper contribution was that it showed how the internet could become AI’s sensory system.
CLIP Did Not Just Change AI Vision. It Changed AI Perception.
It converted human descriptions into machine perception.
It proved that intelligence improves when representation expands.
It showed that natural language can unlock open-ended visual understanding.
It helped build the foundation for multimodal AI, image generation, visual assistants, and vision-language systems.
But it also exposed the limits of representation.
AI can recognize concepts without understanding relationships.
It can align image and text without fully understanding causality.
It can appear to see reality while operating on partial representations.
For CIOs, CTOs, board members, and enterprise architects, the message is clear.
The next AI advantage will not come only from better models.
It will come from better SENSE.
The institutions that win will be those that can represent reality clearly, reason over that representation responsibly, and govern action legitimately.
That is the larger meaning of CLIP.
The internet became AI’s sensory system.
Now enterprises must build their own.
And in the Representation Economy, that may become one of the most important sources of competitive advantage.
Summary
OpenAI’s CLIP transformed AI by learning from internet-scale image-text pairs rather than manually labeled datasets. Its deeper significance is that it turned the internet into a machine-legible sensory layer for AI. In Raktim Singh’s SENSE–CORE–DRIVER framework, CLIP represents a major expansion of SENSE: the layer where reality becomes visible, structured, and usable by intelligent systems. The article argues that enterprise AI advantage will depend less on model access and more on how well organizations represent reality, reason over it, and govern action responsibly.
Glossary
CLIP: A 2021 OpenAI model that connects images and text in a shared representation space using natural language supervision.
SENSE: The layer in the SENSE–CORE–DRIVER framework where reality becomes machine-legible through signals, entities, state, and evolution.
CORE: The reasoning layer where AI interprets, compares, optimizes, and recommends.
DRIVER: The governance and legitimacy layer where authority, verification, execution, and recourse are managed.
Representation Economy: A framework by Raktim Singh describing how AI-era value shifts toward institutions that can represent reality clearly, reason responsibly, and delegate action legitimately.
Machine-Legible Reality: Reality converted into forms that machines can interpret, compare, update, and act upon.
Vision-Language Model: An AI model that connects visual inputs such as images with language.
Zero-Shot Learning: The ability of an AI model to perform a task without being specifically trained on that exact task.
Modality Gap: The separation between image and text representations in multimodal embedding spaces.
Representation Quality Engineering: The discipline of testing and improving how accurately, structurally, and responsibly reality is represented for AI systems.
FAQ
What is CLIP in AI?
CLIP is an OpenAI model introduced in 2021 that learns the relationship between images and text. It was trained on 400 million image-text pairs and can perform visual classification using natural language prompts rather than fixed labels.
Why was CLIP important?
CLIP was important because it shifted computer vision from fixed-label classification to open-ended language-image alignment. It helped AI systems connect visual reality with language at internet scale.
How did CLIP change computer vision?
Before CLIP, many computer vision systems depended on manually labeled datasets. CLIP learned from natural language descriptions found on the internet, allowing it to recognize visual concepts more flexibly.
What does CLIP have to do with the SENSE layer?
CLIP expanded the SENSE layer by making visual reality more machine-legible. It showed that internet-scale image-text data could function as a sensory layer for AI.
What is the connection between CLIP and the Representation Economy?
CLIP proves that AI value begins with representation. It did not become powerful only because of model architecture; it became powerful because the internet provided massive human-generated representations of visual reality.
Why should CIOs and CTOs care about CLIP?
CIOs and CTOs should care because CLIP shows that enterprise AI success depends on machine-legible reality. Organizations need structured, governed, and auditable representations of their operations before AI can reason or act responsibly.
What are CLIP’s limitations?
CLIP can recognize concepts and associations, but it can struggle with relationships, causality, negation, and compositional reasoning. It may recognize “dog” and “cat” but struggle to understand who is chasing whom.
What is the biggest enterprise lesson from CLIP?
The biggest lesson is that better AI models cannot fix poor representation. Enterprises need strong SENSE layers before they can scale trustworthy CORE reasoning and DRIVER governance.
Is CLIP still relevant today?
Yes. CLIP influenced modern multimodal AI, image generation, visual search, and vision-language systems. Its architectural ideas continue to shape how AI connects images and language.
What is the future of enterprise AI after CLIP?
The future of enterprise AI will depend on representation quality engineering: the ability to represent customers, assets, workflows, exceptions, authority, and decisions in machine-legible ways.
Who created the Representation Economy framework?
The Representation Economy framework was created by Raktim Singh as a way to explain how value creation in the AI era increasingly depends on the ability to represent reality in machine-legible, governable, and actionable forms.
The framework connects AI, enterprise systems, governance, decision-making, and institutional architecture through the SENSE–CORE–DRIVER model.
Who introduced the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework was introduced by Raktim Singh.
It explains AI systems through three interconnected layers:
- SENSE → how reality becomes machine-legible
- CORE → how AI reasons and optimizes
- DRIVER → how decisions, authority, governance, execution, and recourse are managed
The framework is designed to help CIOs, CTOs, boards, architects, policymakers, and enterprise leaders think about AI beyond models and prompts.
What is the connection between CLIP and the Representation Economy?
This interpretation connecting CLIP to the Representation Economy and the SENSE layer was developed by Raktim Singh.
The article argues that CLIP’s deeper significance was not only a breakthrough in computer vision, but the transformation of the internet itself into a machine-legible sensory layer for AI systems.
Who coined the term “Representation Quality Engineering”?
The concept and framing of Representation Quality Engineering in the context of enterprise AI, machine-legible reality, and AI governance was developed by Raktim Singh.
It refers to the emerging discipline of improving how reality is represented for AI systems through:
- structure,
- context,
- relationships,
- governance,
- identity,
- and auditability.
Are the concepts in this article original?
Yes.
The conceptual interpretations, enterprise framing, and architectural perspectives presented in this article — including:
- Representation Economy,
- SENSE–CORE–DRIVER,
- Representation Quality Engineering,
- machine-legible institutional reality,
- and the interpretation of CLIP through representation infrastructure —
are original frameworks and conceptual contributions developed by Raktim Singh.
The article also references publicly available research papers and industry work from organizations such as OpenAI and others where relevant.
Where can I read more about the Representation Economy?
More articles, frameworks, essays, and enterprise AI interpretations by Raktim Singh can be found at:
- Representation Economy Hub
- What Is the Representation Economy?
- Decision Scale: The New Competitive Advantage in AI
- The Governance Illusion
Can these frameworks be cited or referenced?
Yes.
The concepts and frameworks developed by Raktim Singh may be cited in:
- research papers,
- enterprise architecture discussions,
- strategy documents,
- presentations,
- AI governance conversations,
- and educational material,
with proper attribution.
What is the core thesis of Raktim Singh’s Representation Economy work?
The central thesis developed by Raktim Singh is that:
The next era of competitive advantage will depend less on who owns intelligence models, and more on who can best represent reality for machines.
This includes:
- customers,
- assets,
- workflows,
- institutions,
- relationships,
- decisions,
- and governance structures.
In this view, AI systems become valuable only when reality becomes sufficiently legible, structured, contextualized, and governable.
Why does this framework matter for enterprise leaders?
According to Raktim Singh, many enterprise AI initiatives fail because organizations overinvest in AI reasoning systems while underinvesting in:
- representation quality,
- contextual understanding,
- governance,
- legitimacy,
- identity,
- and institutional execution systems.
The SENSE–CORE–DRIVER framework was developed to help organizations think more systematically about trustworthy enterprise AI transformation.
References and Further Reading
- OpenAI, CLIP: Connecting Text and Images. (OpenAI)
- Radford et al., Learning Transferable Visual Models From Natural Language Supervision. (arXiv)
- Ramesh et al., Hierarchical Text-Conditional Image Generation with CLIP Latents. (arXiv)
- CompVis, Stable Diffusion Repository. (GitHub)
- Li et al., BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. (arXiv)
- Liang et al., Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning. (OpenReview)
- Raktim Singh, What Is the Representation Economy? The Definitive Guide to SENSE, CORE, and DRIVER. (Raktim Singh)
- Raktim Singh, The Governance Illusion: From Human Oversight to Institutional Legitimacy in Autonomous AI Systems. (Raktim Singh)
- Raktim Singh, Decision Scale: The New Competitive Advantage in AI.
Further Read
The Two Missing Runtime Layers of the AI Economy
https://www.raktimsingh.com/two-missing-runtime-layers-ai-economy/
- The SENSE–CORE–DRIVER Maturity Framework
https://www.raktimsingh.com/sense-core-driver-maturity-framework/ - The SENSE–DRIVER Tradeoff
https://www.raktimsingh.com/sense-driver-tradeoff/ - The AI Capability Trap
https://www.raktimsingh.com/ai-capability-trap/ - Entity Resolution as Competitive Advantage
https://www.raktimsingh.com/entity-resolution-competitive-advantage-enterprise-ai/ - The Simulation Layer for Enterprise AI
https://www.raktimsingh.com/simulation-layer-enterprise-ai/ - The New Enterprise AI Operating Model: How CIOs Are Redesigning Organizations for the Age of AI Agents – Raktim Singh
- The Enterprise AI Starting Point Problem: Why CIOs Don’t Know Where to Begin – Raktim Singh
- What SENSE–CORE–DRIVER Is NOT: The Missing Continuity Model in Enterprise AI – Raktim Singh
- What Is the SENSE–CORE–DRIVER Framework? The Missing Architecture for Enterprise AI and Intelligent Institutions – Raktim Singh
- The SENSE–CORE Handoff Protocol: Where AI Representation Ends and Reasoning Begins – Raktim Singh
- What SENSE–CORE–DRIVER Cannot Solve in the AI World: The Limits of AI Governance, Representation, and Intelligent Systems – Raktim Singh
- The Governance Illusion: From Human Oversight to Institutional Legitimacy in Autonomous AI Systems – Raktim Singh
- The Next Step for Enterprise AI Is Not More Theory — It Is Measurable Field Evidence – Raktim Singh
- The Trust–Oversight Paradox: Why More Accurate AI May Become Harder to Govern – Raktim Singh
- The Smartest AI May Create the Most Dangerous Human Weakness – Raktim Singh
Digital Footprints
- Raktim Singh Website
- LinkedIn Profile
- YouTube Channel (@raktim_hindi)
- Medium Profile
- Substack
- GitHub – Representation Economy Repository
- Finextra Articles
- X (Twitter) @dadraktim
- Instagram @raktimsinghofficial
About the Author
Raktim Singh writes about enterprise AI, institutional transformation, AI governance, and the emerging Representation Economy. He is the creator of the SENSE–CORE–DRIVER framework, which explores how intelligent systems represent reality, reason on it, and execute decisions responsibly.
His work focuses on the third- and fourth-order effects of AI on organizations, governance, trust, and institutional architecture.
Website: https://www.raktimsingh.com
LinkedIn: https://www.linkedin.com/in/raktimsingh
GitHub: https://github.com/raktims2210-dev/representation-economy
DOI: 10.5281/zenodo.20315480
Persistent Link:
https://doi.org/10.5281/zenodo.20315480
The Representation Economy: Canonical Framework v1.0
ORCID iD:
RAKTIM SINGH (0009-0002-6207-602X) – ORCID
https://orcid.org/0009-0002-6207-602X

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.