
Concept Formation & Representation Birth
Artificial intelligence systems today can learn faster, generalize better, and optimize more efficiently than ever before—yet still remain conceptually blind.
They process more data, compress richer patterns, and produce increasingly fluent outputs without ever reconsidering what those patterns mean. When the world changes in ways that invalidate their internal assumptions, most AI systems do not pause, question, or reframe. They continue acting—confidently—inside an outdated conceptual universe.
This article is not about improving representations or fine-tuning models. It addresses a more fundamental question: when does an internal structure deserve to be treated as a concept at all?
Before representations can evolve, something must first be born that is worth evolving. That moment—when a reusable abstraction enters the system and begins shaping decisions—is what we call representation birth. And for enterprises, governing that moment is no longer optional.
Concept Formation in AI
Artificial intelligence systems can improve—sometimes dramatically—without ever changing what they mean by the world.
They process more data, optimize stronger objectives, and produce increasingly fluent outputs—yet still operate inside the same underlying conceptual universe. When that universe becomes inadequate, the system doesn’t pause, question, or reframe. It keeps acting—often confidently—using “concepts” that no longer fit reality.
This article is not about how representations change over time.
It is about a deeper, prior question:
When does an internal structure deserve to be treated as a concept at all?
Before representations can evolve, something must first come into existence that is worth evolving. That moment—when an internal pattern crosses from being a useful feature into a reusable, decision-shaping abstraction—is what I’ll call representation birth.
Why this matters for Enterprise AI is simple: enterprises don’t govern activations. They govern meaning, categories, assumptions, and decision boundaries. When a model’s meaning layer silently degrades, operational risk doesn’t show up as a neat “accuracy drop.” It shows up as confident decisions made with the wrong mental model.
In short: concept formation is not merely a training problem. It is an ontological and governance problem.
Representation birth is the point where an internal pattern becomes a stable, reusable, decision-relevant concept—one that can survive reasonable change and should be governed as an enterprise meaning asset, not just a model feature.

1) “Better learning” is not the same as “new meaning”
Most discussions of AI progress focus on improvement: higher accuracy, better generalization, stronger reasoning. But improvement alone does not imply new meaning.
A system can become better at predicting outcomes while still interpreting the world through the same conceptual lens. It may recognize more surface variations, compress data more efficiently, or optimize decisions more precisely—without ever forming a new abstraction.
Humans understand this difference instinctively. We know the gap between:
- getting faster at solving a familiar kind of problem, and
- realizing we were framing the problem incorrectly in the first place.
Modern deep learning is a powerful engine for the first. It is far less reliable at the second—especially in production settings where meaning shifts subtly, not loudly.
Representation learning research has long highlighted that good representations disentangle underlying “factors of variation”—but what counts as a “factor” or a “concept” is exactly where the enterprise risk begins. (arXiv)
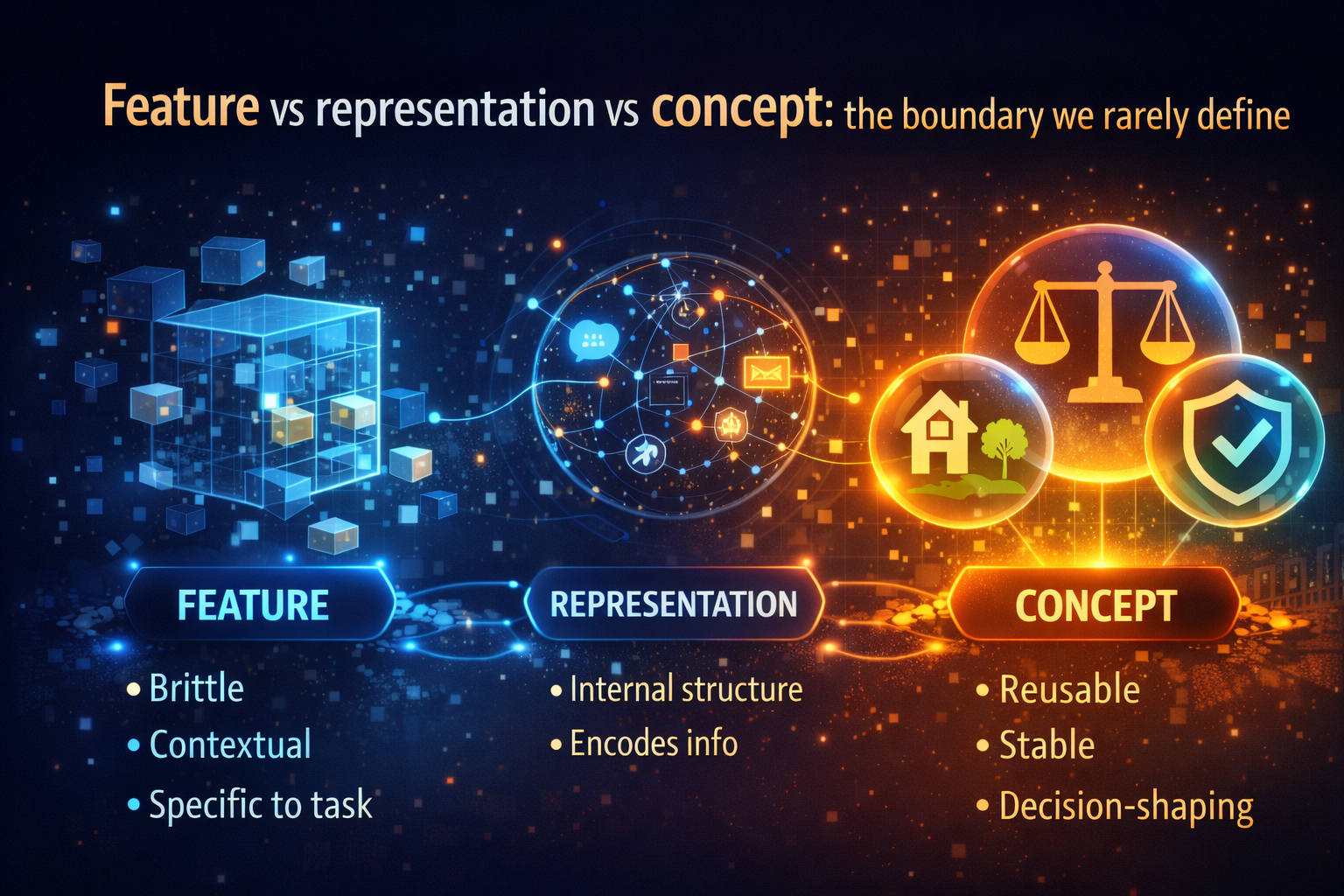
2) Feature vs representation vs concept: the boundary we rarely define
To reason about concept formation, we need a clean boundary between three often-conflated ideas.
- Feature: an internal signal that helps a model perform a task (often brittle and context-dependent).
- Representation: a structured collection of features that encodes information in a way the system can use.
- Concept: a representation that is reusable, stable, and decision-relevant across contexts.
This boundary matters because “over-naming” is one of the most dangerous habits in modern AI discourse. We probe a model, observe a pattern, label it with a human-friendly term, and assume the model “has the concept.”
But naming is not the same as existence.
A surprising amount of model competence can arise from shortcut learning—decision rules that work on familiar tests but fail under real-world shifts. (arXiv)
Shortcut learning doesn’t just cause failures; it creates a false sense of conceptual understanding.
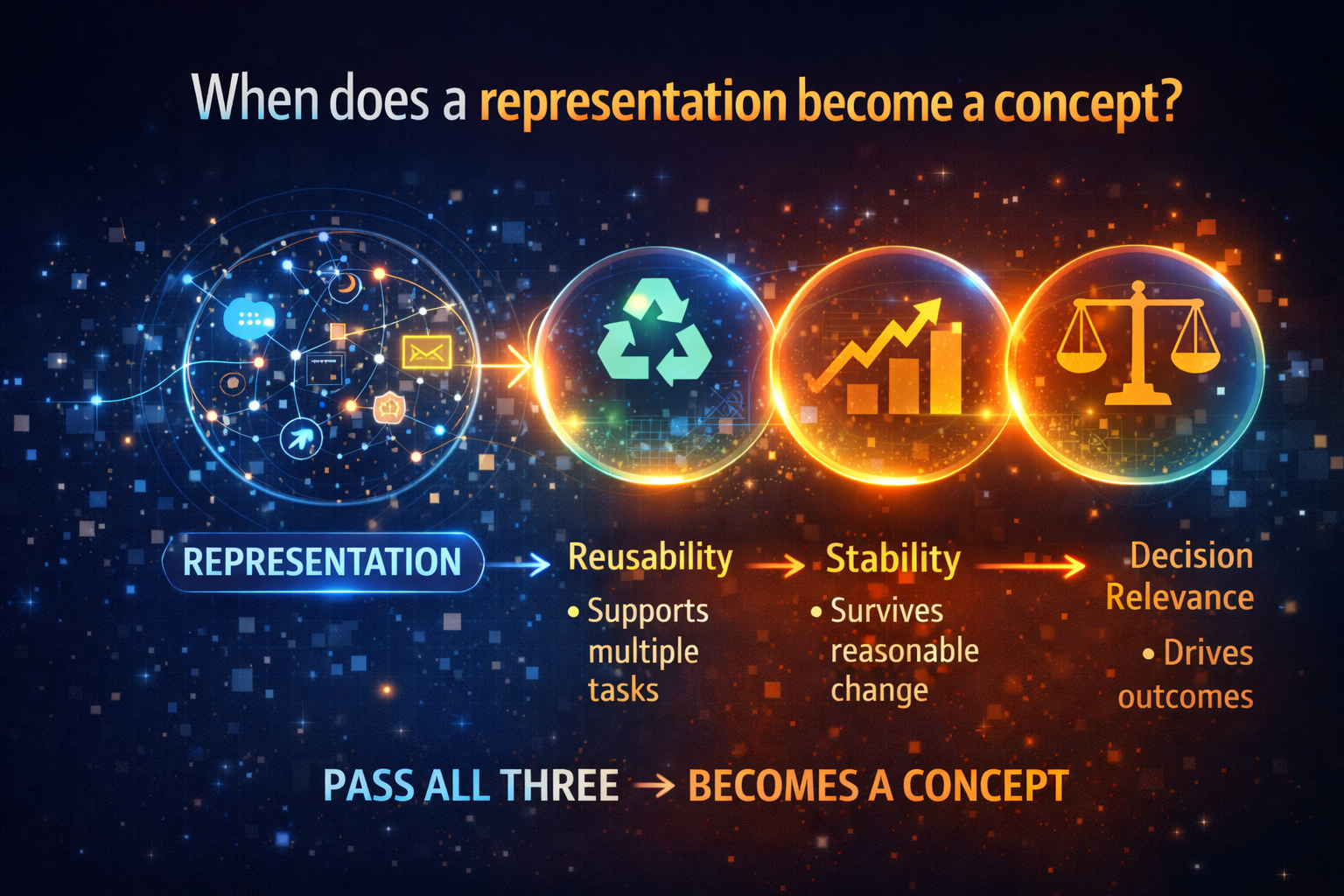
3) When does a representation become a concept?
A representation becomes a concept not because it exists, but because it earns trust.
In practical terms, a representation qualifies as a concept when it satisfies three tests:
Test 1: Reusability
Can the representation support multiple related decisions without needing the model to relearn everything from scratch?
A feature that only works for one narrow task is not a concept. A concept is a reusable internal “handle” the system can apply across tasks and contexts.
Test 2: Stability under reasonable change
Does the representation remain meaningful under shifts that are normal in enterprise life—new channels, new vendors, process changes, policy updates, seasonal changes, user behavior changes?
If it collapses under ordinary change, it was never a concept; it was a fragile cue.
Distribution shift is not an edge case; it’s the default condition of deployment. (Ethernet National Database)
Test 3: Decision relevance (causal usefulness, not correlation)
Does this representation actually influence outcomes—or is it just correlated with them?
Many internal patterns can be “read out” by probes while not being what the model truly relies on. The enterprise cares about what drives decisions, not what merely coexists with decisions.
If you fail any one test, you have a feature—not a concept.
That single sentence is one of the most useful governance rules you can adopt.
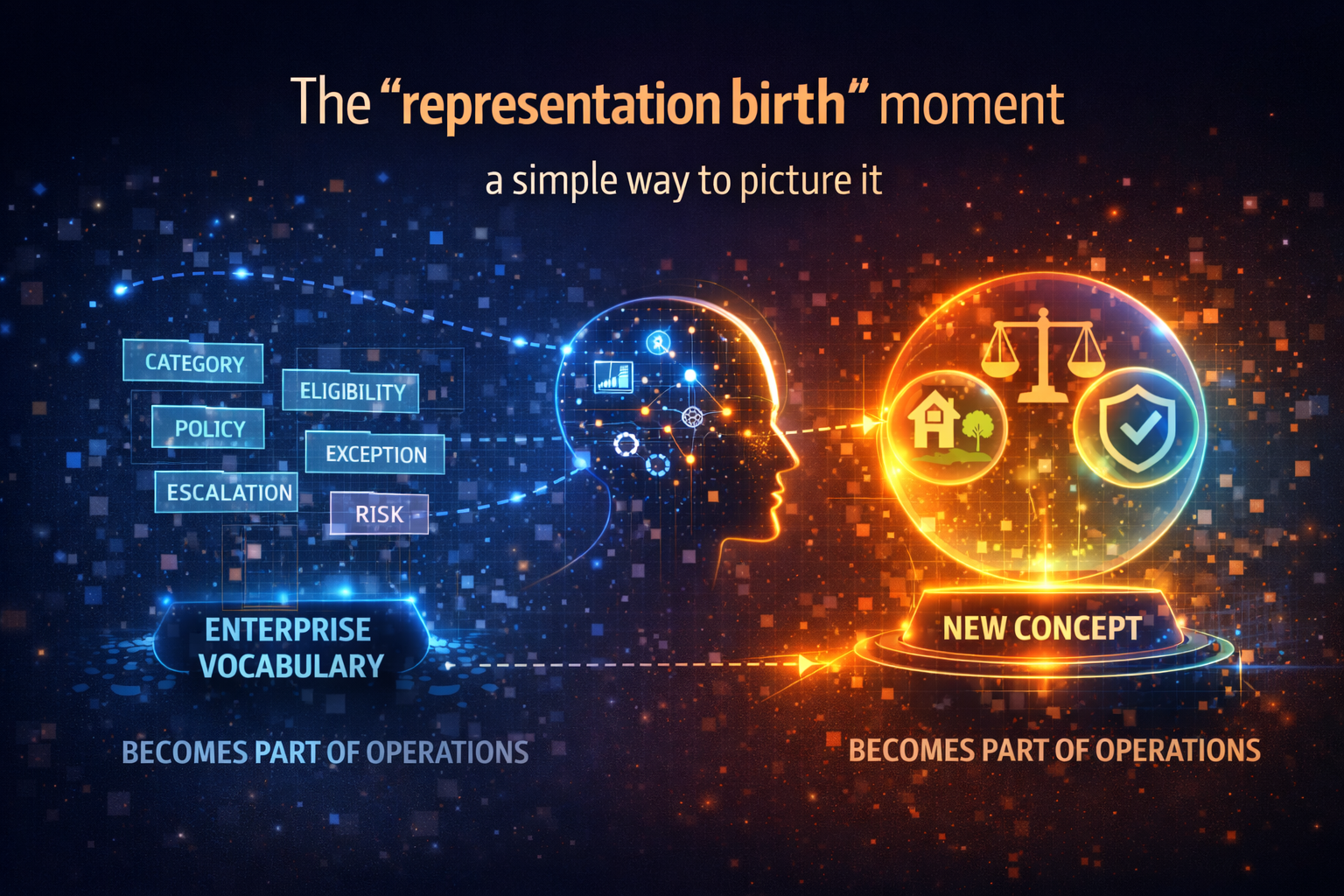
4) The “representation birth” moment: a simple way to picture it
Think of your enterprise as operating with a vocabulary:
- categories
- exception types
- risk states
- eligibility rules
- escalation reasons
- policy constraints
When an AI system is embedded into workflows, it implicitly adopts—or invents—its own version of that vocabulary. Representation birth is when a new internal abstraction becomes part of the system’s operational vocabulary—even if nobody formally approved it.
The danger is not that models form abstractions. The danger is that they form abstractions that the enterprise never named, reviewed, or constrained, and those abstractions quietly become decision drivers.
This is where “AI in the enterprise” becomes Enterprise AI: the moment meaning becomes governable infrastructure.

5) Why most internal features should never be called concepts
Over-naming creates governance illusions.
Here are three reasons internal features fail concept standards in practice:
- Brittleness: they work until one upstream change breaks them.
- Context dependence: they mean one thing in one workflow and something else in another.
- Entanglement: the “same” feature may be multiplexed with multiple unrelated signals.
This is why interpretability needs maturity. Concept language should be reserved for internal structures that have passed the three tests (reuse, stability, decision relevance)—not for whatever is easiest to visualize.
Tools like TCAV can help relate model behavior to human-defined concepts, but that is different from proving that the model has created a robust concept on its own. (arXiv)

6) The silent failure mode: acting confidently with the wrong concepts
The most damaging AI failures rarely look like obvious errors. They look like conceptual mismatch.
A system can operate reliably for months. Inputs look familiar. Dashboards remain stable. And yet the environment has changed in a subtle but meaningful way—enough that the model’s internal concepts no longer apply.
Humans notice: this is a new kind of situation.
The system does not.
It continues acting within an outdated conceptual frame, producing confident decisions that drift further away from enterprise reality. No alarms trigger. No thresholds are crossed. The failure emerges downstream, often far from the original decision point.
This is what happens when concept boundaries are crossed silently.
Out-of-distribution (OOD) detection exists precisely because systems need a reliable way to flag “this doesn’t belong to my world.”
The fact that OOD detection is an entire research area is itself an admission: models do not naturally know when meaning no longer applies. (arXiv)
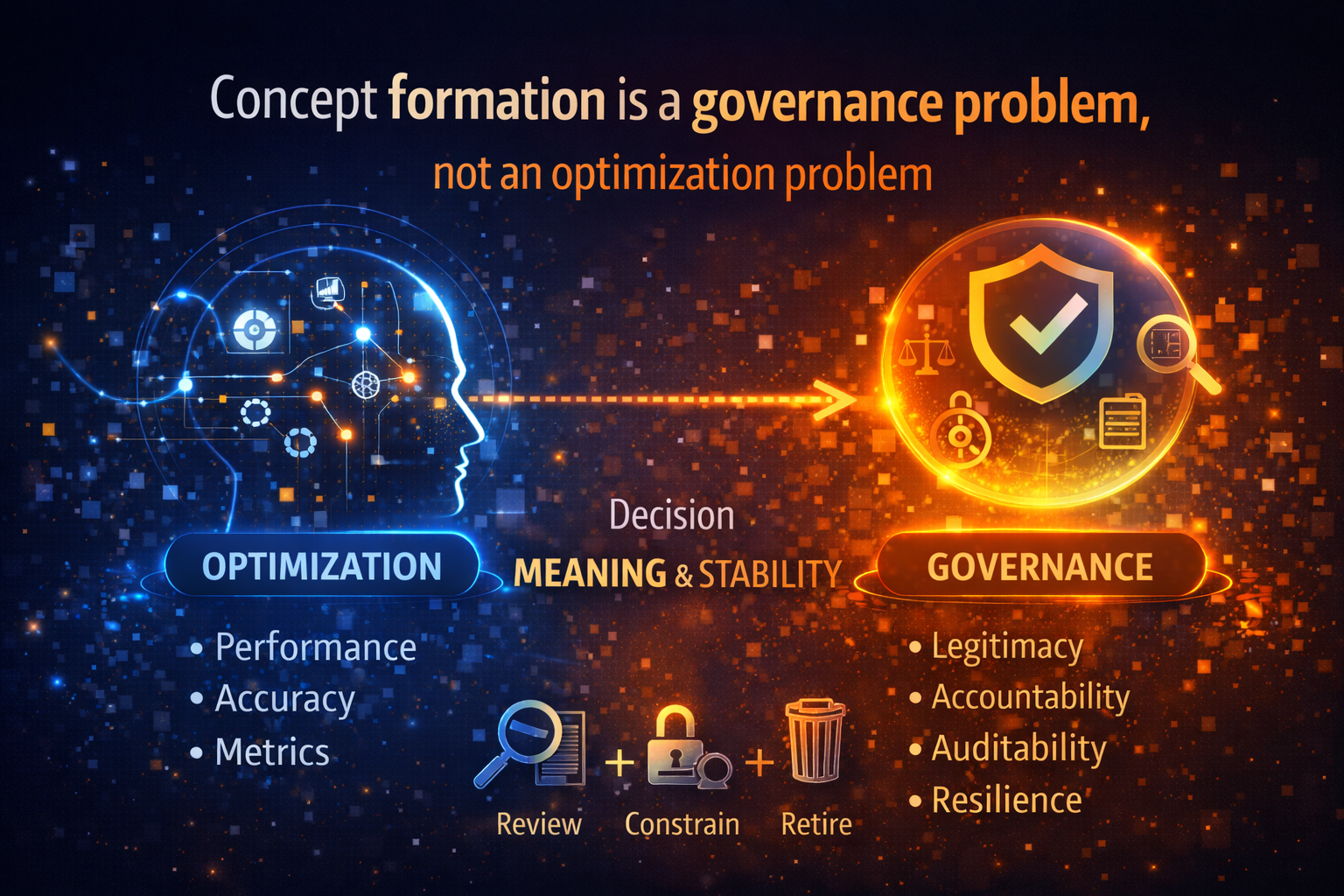
7) Concept formation is a governance problem, not an optimization problem
Optimization improves performance within a conceptual frame. Governance asks whether the frame is still valid.
Enterprises care about:
- decision legitimacy
- auditability
- accountability
- long-term resilience
All of these depend on concept stability, not just prediction accuracy.
If you want systems that can be trusted at scale, you must treat certain concepts as first-class enterprise assets. That implies a lifecycle:
- review
- constraints
- monitoring
- correction
- retirement
This is where concept-centric approaches become strategically interesting.
Concept Bottleneck Models show one way to structure systems around explicit concepts and allow human correction at the concept level. (Proceedings of Machine Learning Research)
The point is not “everyone should use CBMs.” The point is: the research community is converging on a truth enterprises already live with—meaning must be operable.
8) Why humans detect concept failure—and models do not
Humans have a powerful meta-signal: confusion.
When our existing concepts fail, we feel it. We hesitate, reframe, ask clarifying questions, or stop acting. This ability is foundational to judgment.
Many AI systems lack an equivalent signal. They don’t experience conceptual strain. They don’t naturally recognize when their internal abstractions no longer apply. They keep acting unless explicitly stopped.
This asymmetry is one reason cognitive science researchers argue that human-like learning and thinking requires more than current engineering trends—especially around structured knowledge, compositionality, and how systems decide what matters. (PubMed)
9) Concept boundaries: the forgotten requirement for safe autonomy
A mature Enterprise AI system should not only apply concepts; it should detect when:
- inputs fall outside known conceptual regions,
- existing abstractions conflict,
- decision confidence is unjustified,
- or “meaning is under-specified” given policy constraints.
Concept boundaries are not merely statistical thresholds. They are epistemic limits: the edges of what the system is justified in claiming.
This is also why distribution shift benchmarks like WILDS matter: they expose that standard training can look strong in-distribution while failing in the wild—precisely where concept stability is tested. (Proceedings of Machine Learning Research)
10) From representation learning to concept stewardship
Representation learning gave us powerful internal encodings. (arXiv)
The next step is concept stewardship: deciding which internal representations are allowed to influence decisions, how their meaning is monitored, and how they are governed across time.
Concept stewardship means:
- selecting which representations are “promoted” to decision concepts
- auditing their decision relevance
- stress-testing stability under realistic shifts
- enforcing boundaries on where concepts apply
- keeping a human-correctable path when meaning is uncertain
This is where Enterprise AI diverges from “AI features.” At scale, meaning itself must be managed.
11) The missing discipline: ConceptOps (operationalizing meaning)
Just as DevOps operationalized software delivery, enterprises will need an operational discipline focused on meaning:
- monitoring representation drift, not just data drift
- testing concept transfer across contexts
- reviewing concepts as part of model risk governance
- enforcing boundary policies (“when not to decide”)
- maintaining a lifecycle for concept updates and retirements
Call it ConceptOps— the need is unavoidable if autonomy is real.
Concept formation in AI is the moment when an internal representation becomes a stable, reusable abstraction that shapes decisions. Unlike learning optimization, concept formation determines what the system is allowed to mean—and must be governed in enterprise AI.
Conclusion : The executive takeaway
If you want Enterprise AI that scales, you must govern what the system is allowed to mean.
The hardest problem isn’t generating better outputs. It’s ensuring the system’s internal concepts remain:
- reusable (not one-off tricks),
- stable (not brittle cues),
- and decision-relevant (not correlated passengers).
Representation birth is when meaning enters the system.
Concept failure is when intelligence collapses quietly—without obvious alarms.
Enterprises that ignore this layer will scale automation without understanding.
Enterprises that operationalize it will scale intelligence responsibly—because they will treat meaning as infrastructure.
That is the frontier.
FAQ
What is concept formation in AI?
Concept formation is when an AI system develops internal representations that behave like reusable abstractions—stable enough to transfer across contexts and influential enough to shape decisions, not just correlate with outcomes.
What is “representation birth”?
Representation birth is the moment an internal pattern becomes a concept worth governing: reusable across tasks, stable under reasonable change, and decision-relevant.
How is a feature different from a concept?
A feature is a useful signal that may be brittle or context-dependent. A concept is a representation that passes three tests: reusability, stability, and decision relevance.
Why do models fail under distribution shift?
Because models often learn shortcuts—patterns that work in familiar conditions but don’t represent the underlying structure that remains stable in the real world. (arXiv)
What tools exist to test or operationalize concepts?
TCAV helps test user-defined concepts against model sensitivity. (arXiv)
Concept Bottleneck Models make concepts explicit and allow human correction at the concept level. (Proceedings of Machine Learning Research)
Why is this an Enterprise AI governance issue?
Because enterprises must govern categories, assumptions, and decision boundaries. When a model’s meaning layer shifts silently, risks appear as confident wrong decisions—not always as clear metric regressions.
Glossary
- Concept formation: The emergence of reusable abstractions inside a model.
- Representation: The internal encoding a model uses to make decisions. (arXiv)
- Feature: A task-helpful signal; not necessarily stable or meaningful across contexts.
- Shortcut learning: Reliance on easy decision rules that work on benchmarks but fail in the wild. (Nature)
- Distribution shift: When real-world data differs from training conditions (the common case in deployment). (Ethernet National Database)
- OOD detection: Methods to flag inputs outside a model’s known categories or conditions. (arXiv)
- Concept stewardship: Treating meanings as governed enterprise assets (reviewed, monitored, correctable).
- ConceptOps: Operational discipline for monitoring and governing concepts across the AI lifecycle.
References and further reading
- Bengio, Courville, Vincent — Representation Learning: A Review and New Perspectives (arXiv)
- Geirhos et al. — Shortcut Learning in Deep Neural Networks (Nature)
- Kim et al. — TCAV: Testing with Concept Activation Vectors (arXiv)
- Koh et al. — Concept Bottleneck Models (Proceedings of Machine Learning Research)
- Quiñonero-Candela et al. — Dataset Shift in Machine Learning (MIT Press)
- Koh et al. — WILDS: A Benchmark of in-the-Wild Distribution Shifts (Proceedings of Machine Learning Research)
- Yang et al. — Generalized Out-of-Distribution Detection: A Survey (arXiv)
- Lake et al. — Building Machines That Learn and Think Like People (PubMed)
Related reading on raktimsingh.com (recommended path)
Enterprise AI Operating Model
Enterprise AI scale requires four interlocking planes:
Read about Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely — Raktim Singh
- Read about Enterprise Control Tower The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale — Raktim Singh
- Read about Decision Clarity The Shortest Path to Scalable Enterprise AI Autonomy Is Decision Clarity — Raktim Singh
- Read about The Enterprise AI Runbook Crisis The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI — and What CIOs Must Fix in the Next 12 Months — Raktim Singh
- Read about Enterprise AI Economics Enterprise AI Economics & Cost Governance: Why Every AI Estate Needs an Economic Control Plane — Raktim Singh
Read about Who Owns Enterprise AI Who Owns Enterprise AI? Roles, Accountability, and Decision Rights in 2026 — Raktim Singh
Read about The Intelligence Reuse Index The Intelligence Reuse Index: Why Enterprise AI Advantage Has Shifted from Models to Reuse — Raktim Singh
Read about Enterprise AI Agent Registry Enterprise AI Agent Registry: The Missing System of Record for Autonomous AI — Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.