
The Safe, Self-Healing AI Enterprise
The real enterprise AI advantage is no longer intelligence—it’s operability. Organizations that win are those that can govern, observe, control, and scale AI safely across production, compliance, and operations without slowing delivery.
Enterprises have reached a turning point.
AI is no longer “a tool that helps people work.” Increasingly, AI is work that runs—making decisions, triggering workflows, calling APIs, creating tickets, approving exceptions, updating knowledge bases, and changing the state of real systems.
That’s the promise of agentic AI. It’s also the risk.

Because the moment AI can act, every enterprise inherits a new class of problems:
- Speed without safety (an agent does the wrong thing faster than a human can notice)
- Scale without consistency (a pilot succeeds, but production behavior drifts)
- Automation without accountability (nobody can explain why a decision happened)
- Innovation without operability (teams can demo intelligence, but cannot run it reliably)
The next winners won’t be defined by “which model they chose.” They’ll be defined by whether they built a safe, self-healing AI enterprise—one that can deploy autonomy at scale while staying governed, reversible, observable, secure, and continuously improving.
The enabling idea is simple:
You don’t scale agents. You scale an operating fabric around them—one that makes autonomy reliable, auditable, reversible, and resilient.
This direction is increasingly described as a layered, composable, interoperable stack that unifies data, models, agents, flows, and AI applications across the enterprise landscape—built for responsible speed. (Infosys)
In this article, I’ll break down what a “unified, reversible-by-design fabric” actually means, using simple examples and practical architecture patterns—no math, and no jargon overload.

Why enterprise AI breaks in production
Why enterprise AI breaks in production
Most enterprise AI failures are not “model failures.” They are operating failures.
In other words: the intelligence may be impressive, but the system around the intelligence is fragile.
Example 1: The approval agent that “optimizes” policy into an incident
A procurement approval agent is asked to reduce cycle time. It learns patterns from historical approvals and starts auto-approving borderline cases. It feels great—until an audit reveals that approvals violated a policy nuance that humans used to apply silently.
The model wasn’t “bad.” The enterprise lacked:
- a policy execution boundary (what the agent can do vs. when it must ask)
- a decision log (so actions are explainable later)
- an undo mechanism (rollback / reversal for approvals)
Example 2: The refund agent that creates a cost leak
A customer refund agent is allowed to issue refunds under a threshold. It’s configured correctly—then a product change increases the number of edge cases. The agent starts refunding too frequently because its context is incomplete.
Again: not intelligence. Operability.
- no continuous evaluation of refund behavior
- no cost guardrails tied to action volume
- no closed-loop learning from post-incident patterns
Example 3: The “helpful” IT ops agent that makes outage recovery worse
An ops agent detects service degradation and restarts a dependency. It fixes things once, so it repeats the pattern. But the root cause is upstream—now restarts trigger cascading failures.
Classic issue: automation without feedback verification. Self-healing systems require feedback signals and validation, not just actions. Red Hat’s explanation of open-loop vs closed-loop automation captures this distinction well. (Red Hat)
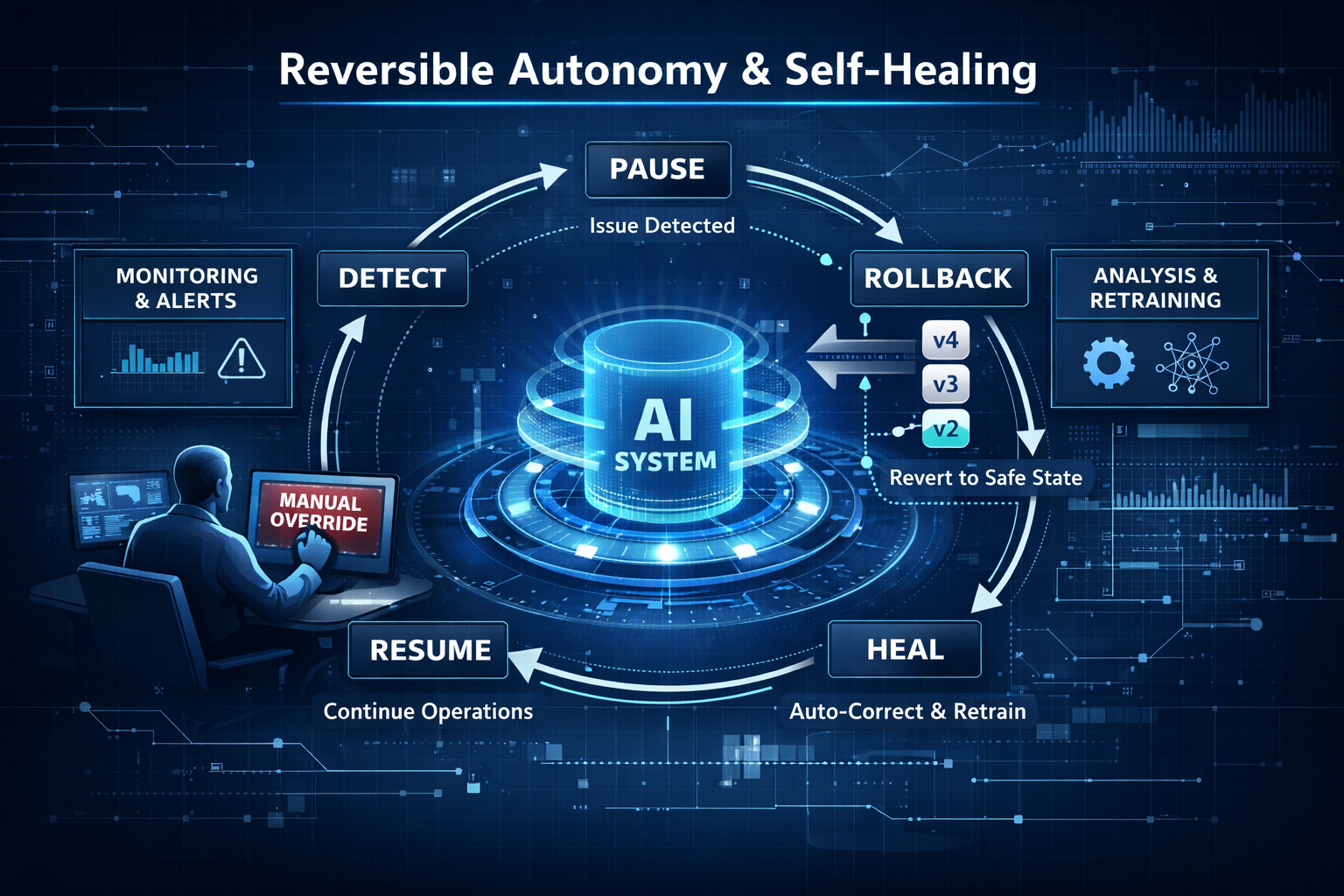
The core principle: autonomy must be reversible and self-healing
When AI can act, the enterprise needs two non-negotiables.
1) Reversible-by-design
Every meaningful autonomous action must have:
- a safe execution boundary
- an audit trail
- a replay capability (what happened, in what order, with what context)
- an undo plan (rollback, compensation, or human escalation)
Call it the Undo Button principle:
If you can’t undo it, don’t automate it.
Reversibility is not a “nice to have.” It is how you make autonomy trustworthy at enterprise scale.
2) Self-healing-by-default
If AI operates at machine speed, human-only operations won’t keep up. The system must:
- detect risk early (predictive signals)
- correct known failures automatically (verified remediation)
- involve humans when judgment is required (human-by-exception)
This “self-healing operations” direction—closed-loop automation with verification—is widely used to distinguish brittle automation from resilient systems. (Red Hat)
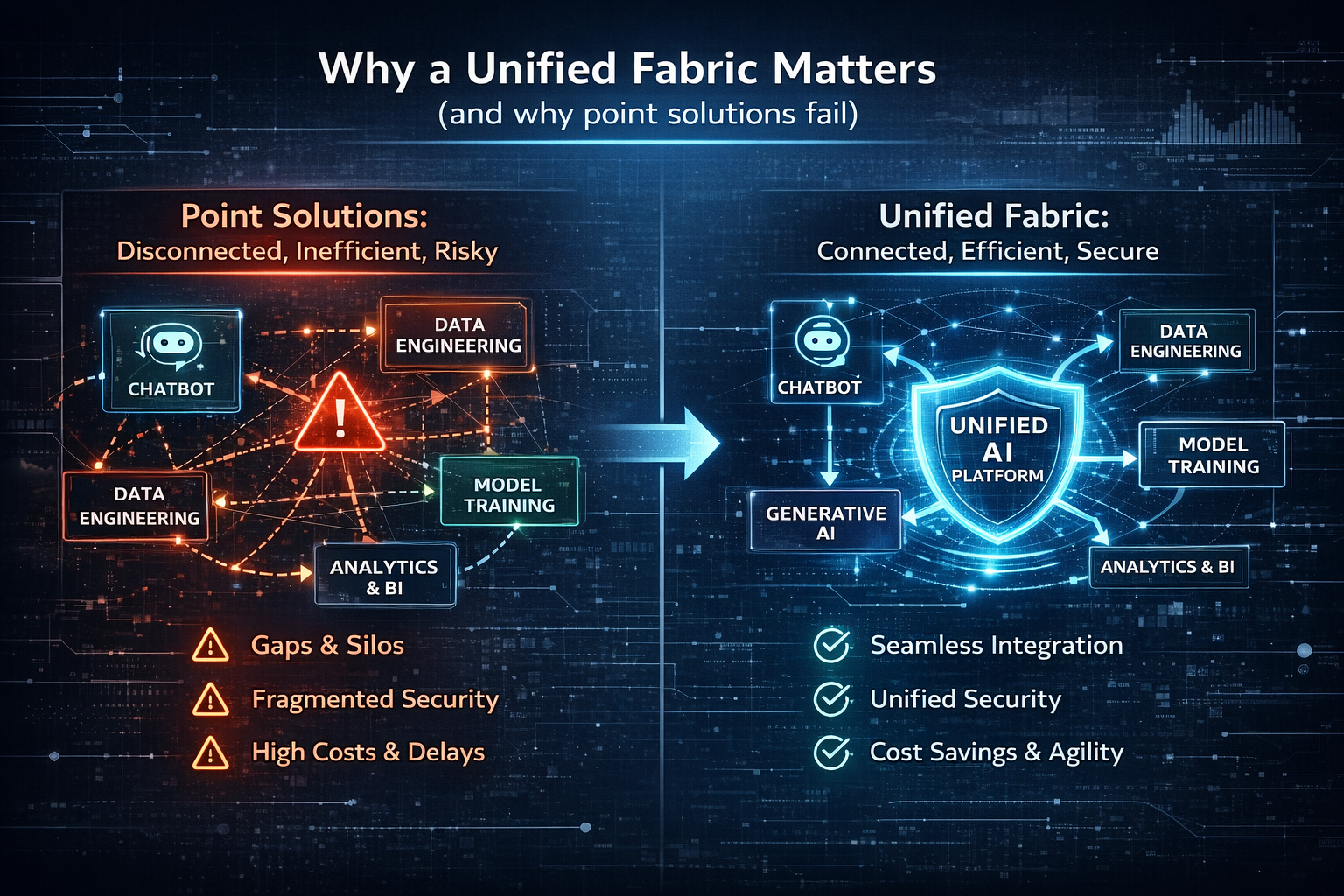
Why a unified fabric matters (and why point solutions fail)
A common enterprise pattern is to adopt:
- one chatbot platform,
- a separate agent framework,
- a separate evaluation tool,
- a separate governance workflow,
- a separate observability pipeline,
- separate security controls,
- separate data connectors…
This creates intelligence islands.
The result is predictable: inconsistent behavior, duplicated work, gaps in auditability, and slow integration cycles.
A unified fabric solves a specific problem:
One operating environment for autonomy across teams and systems.
This “fabric” idea is showing up across the enterprise AI ecosystem as a way to unify and accelerate service delivery, using layered, composable, open and interoperable building blocks. (videos.infosys.com)
It’s the architectural difference between a set of AI projects and an AI enterprise capability.
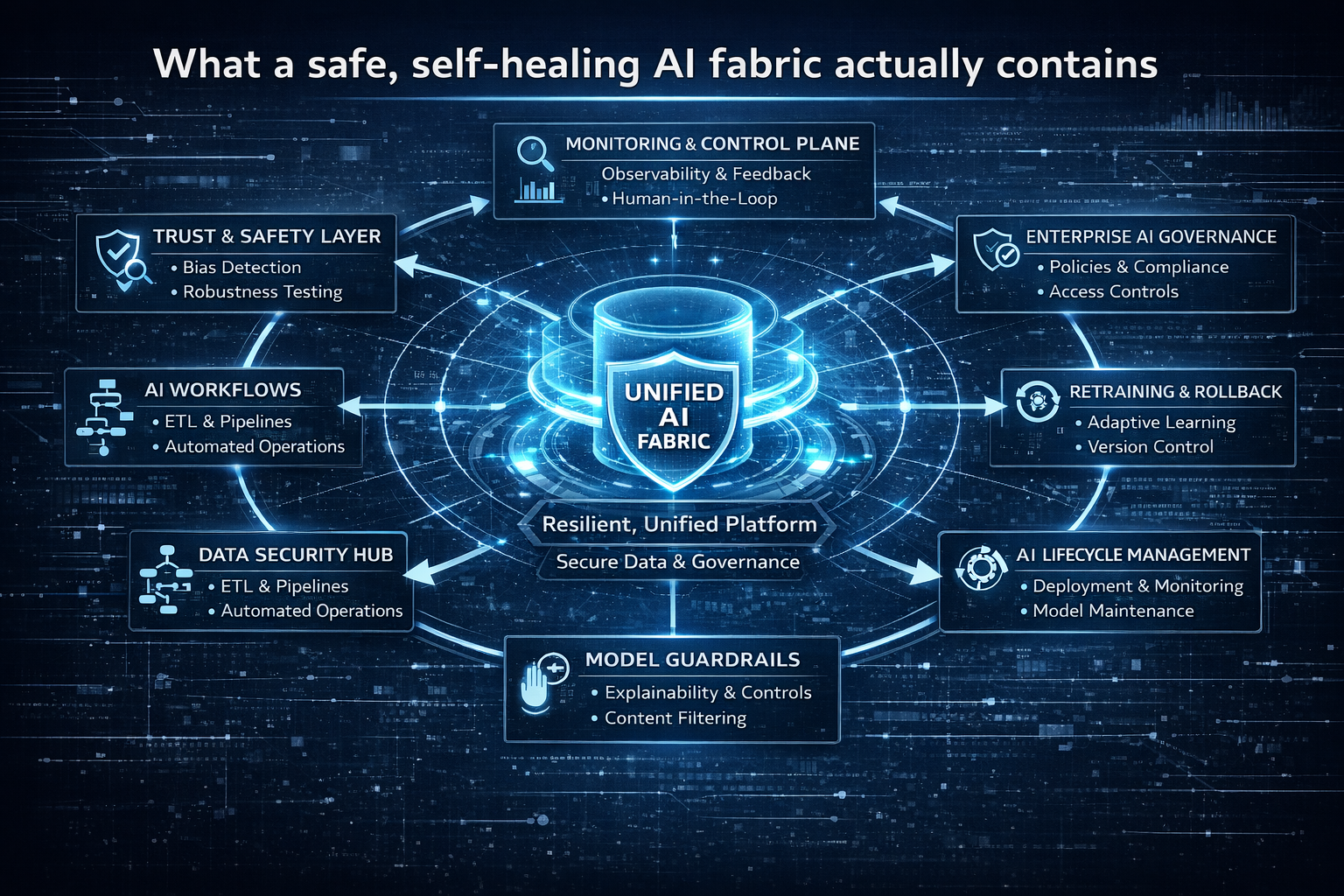
What a safe, self-healing AI fabric actually contains
A “fabric” isn’t one product. It’s a set of capabilities that work together. Here are the essentials—explained in plain language.
1) Model–Prompt–Tool abstraction
This is the ability to swap models, prompts, and tools without rebuilding everything.
Why it matters: models will change, policies will change, and toolchains will change. Your enterprise cannot live in a perpetual rewrite loop.
Many enterprise stacks now explicitly emphasize open architecture that abstracts models, prompts and tools so emerging models integrate without rebuilds. (Infosys)
Simple example:
Your legal team updates a policy interpretation. You update a policy service once—every workflow that calls it inherits the update, rather than being manually refactored across dozens of agents.
2) Composable “services-as-software” building blocks
Instead of building one-off agents, you build reusable, productized services:
- “policy check as a service”
- “risk scoring as a service”
- “identity verification as a service”
- “explanation trace as a service”
- “approved tool access as a service”
This enables speed with consistency. Teams move fast, but inside paved roads.
3) Agent identity, permissions, and action boundaries
If an agent can act, it must have:
- an identity
- least-privilege permissions
- a clear action scope
- a revocation and kill-switch capability
This is how you keep autonomy safe in real systems—especially in regulated environments.
4) Governance that is operational, not ceremonial
Governance cannot be a quarterly document. It must be a runtime discipline:
- policy checks at decision time
- logging and traceability by default
- escalation paths when uncertainty is high
- evidence generation for audits
This aligns with the NIST framing that trustworthy AI must be engineered across the lifecycle—governed, measured, and managed continuously. (NIST)
5) Continuous evaluation and quality engineering for AI behavior
If you only evaluate at launch, you will drift.
You need:
- regression tests for prompts and tool calls
- scenario testing for policy edge cases
- monitoring for behavior drift (especially after policy/data changes)
- incident learning loops
This is “quality engineering” for autonomy.
6) Cybersecurity that assumes AI changes the attack surface
Agents increase:
- API exposure
- tool invocation pathways
- prompt injection risks
- sensitive context exposure
So security must be built into the fabric:
- safe tool wrappers and allowlists
- runtime inspection
- secure connector patterns
- prompt/content safety controls
The key mindset: the security surface evolves as protocols, tooling, and models evolve—which is why modern enterprise stacks emphasize continuous adaptability. (Infosys)
7) Observability that explains what happened, not just metrics
Traditional observability tells you latency and error rates.
AI observability must tell you:
- what the agent decided
- what context it used
- what tools it invoked
- what policy rule was applied
- what fallback occurred
- what evidence it recorded
This is the foundation of reversible autonomy.
8) Closed-loop remediation (the self-healing engine)
Self-healing does not mean “agents doing random fixes.”
It means:
- detect a known failure pattern
- propose a remediation
- verify the remediation via signals
- record evidence
- update runbooks and patterns
This maps directly to closed-loop automation concepts used in real IT automation practice. (Red Hat)
9) Human-by-exception operating model
The goal is not “remove humans.” The goal is:
- humans govern
- automation executes
- agents orchestrate
- humans intervene when judgment is required
This is also aligned with regulatory expectations around human oversight, particularly in higher-risk AI contexts. (Artificial Intelligence Act)
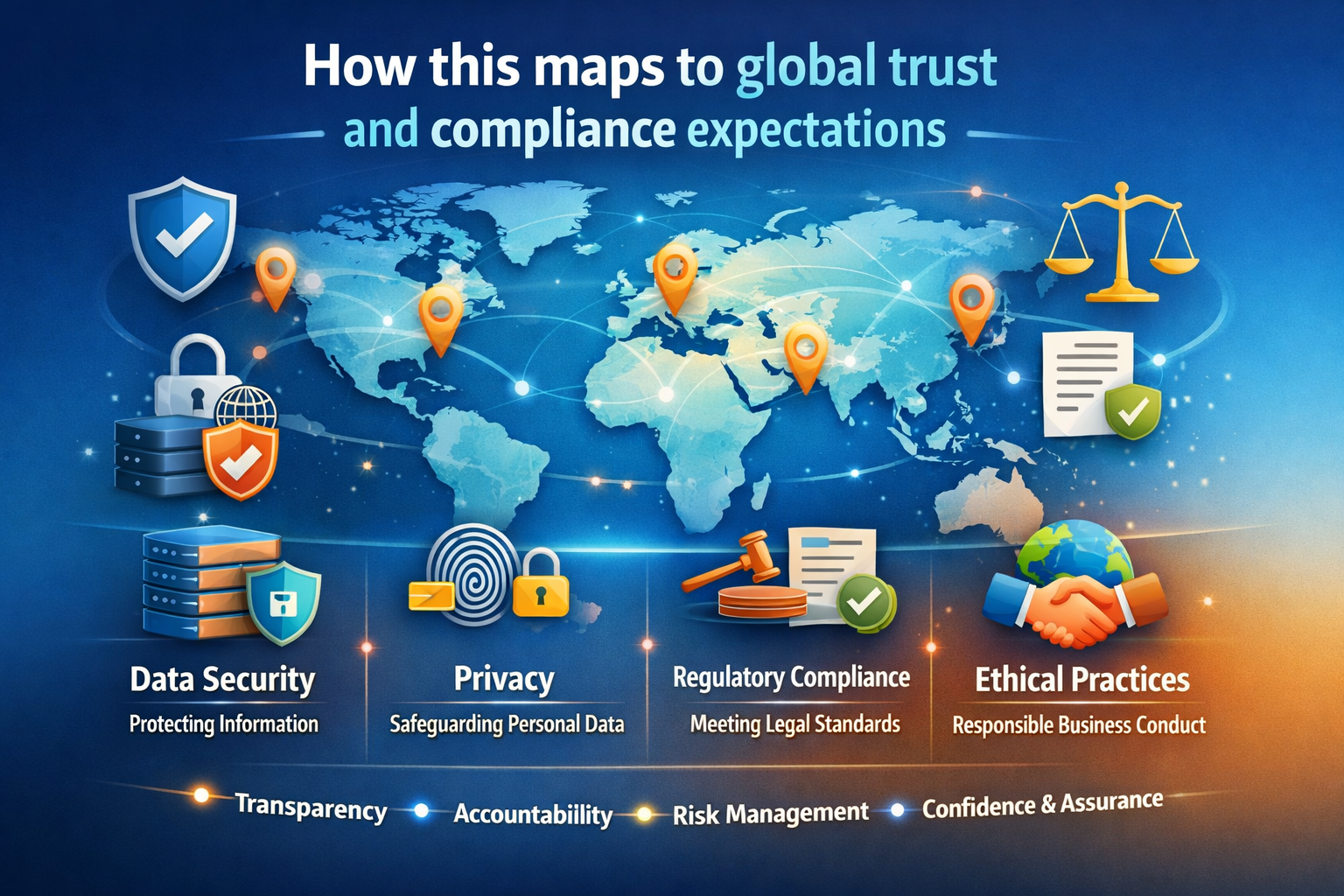
How this maps to global trust and compliance expectations
Enterprise leaders are increasingly asked:
“Can you prove your AI is safe, accountable, and overseen?”
The NIST AI Risk Management Framework offers a practical lens—GOVERN, MAP, MEASURE, MANAGE—to operationalize AI risk management across the lifecycle. (NIST Publications)
Regulatory approaches, including the EU AI Act’s provisions on transparency and human oversight, reinforce that high-risk AI systems must support meaningful oversight and safe operation. (Artificial Intelligence Act)
A reversible-by-design fabric is how these expectations become real in production:
- oversight is embedded,
- logging is automatic,
- actions are bounded,
- recovery is built in.
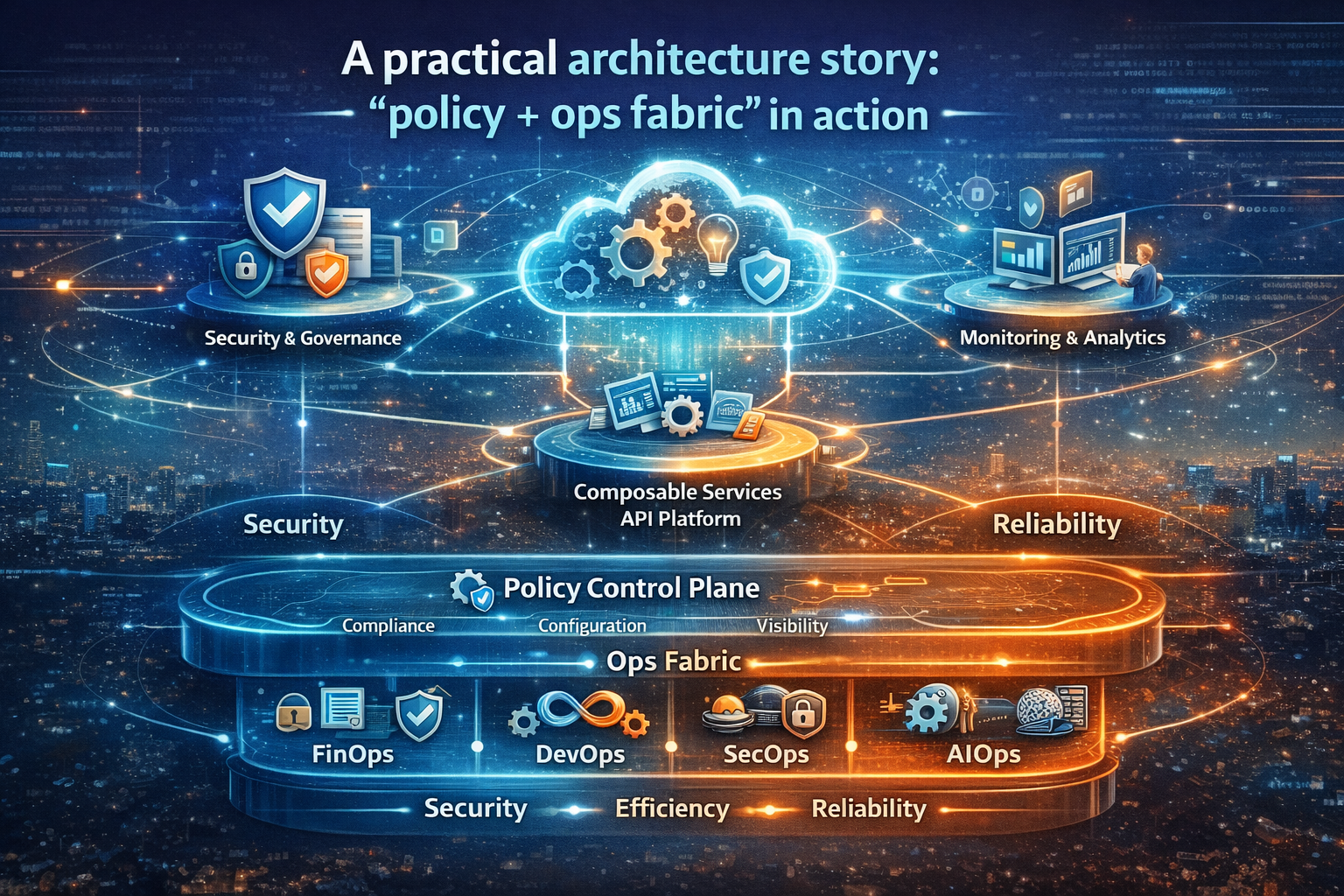
A practical architecture story: “policy + ops fabric” in action
Imagine a business workflow agent that can:
- read a request,
- interpret policy,
- gather missing information,
- take an action,
- update systems of record.
Here’s what “fabric-first autonomy” looks like:
- The agent calls Policy Service (not its own private policy logic).
- The request goes through Identity + Permission Check (least privilege).
- The action is executed via a Safe Tool Gateway (validated inputs, allowlisted APIs).
- The system writes an Action Trace (context, decision, tools, policy references).
- Monitoring watches for drift and anomalies.
- If uncertainty is high, the workflow triggers Human-by-Exception escalation.
- If the action must be reversed, the system triggers Compensation/Rollback by design.
- If an incident occurs, replay and evidence generation are immediate.
This is how autonomy becomes a governed enterprise capability—not a collection of clever demos.

A 30–60–90 day rollout (without slowing delivery)
You don’t “install” a fabric. You build paved roads incrementally.
Days 0–30: Define boundaries and evidence
- choose 2–3 workflows with clear action scopes
- implement identity + tool gateway
- implement action traces and rollback/compensation patterns
- define human-by-exception thresholds
Days 31–60: Add evaluation and self-healing loops
- add scenario tests for policy edge cases
- deploy drift monitoring
- implement closed-loop remediation for 3–5 known incident patterns
- build incident replay and evidence packs
Days 61–90: Productize and scale reuse
- convert best components into reusable services
- standardize connectors
- publish a service catalog: what teams can safely reuse
- expand to more workflows with the same operating guarantees

Conclusion: the new advantage is not intelligence—it is operability
The enterprise AI race is not a race to deploy the most agents.
It’s a race to build the operating fabric that makes autonomy:
- safe,
- reversible,
- observable,
- secure,
- and self-healing.
Because in the real world, the most valuable AI is not the AI that can talk.
It’s the AI you can trust to run.
Glossary
- Agentic AI: AI systems that don’t just generate text, but can take actions through tools and workflows.
- AI fabric: A unified set of capabilities (connectors, services, governance, observability) that helps enterprises deploy and run AI safely at scale.
- Reversible-by-design: Systems built so actions can be rolled back, compensated, replayed, and audited.
- Closed-loop automation: Automation that verifies outcomes through feedback signals, not just “does actions.” (Red Hat)
- Human-by-exception: Humans intervene only when uncertainty or risk is high; the system handles routine cases.
- Model–Prompt–Tool abstraction: Architecture that lets you swap models/tools/prompts without rebuilding workflows. (Infosys)
- Services-as-software: Reusable, productized AI capabilities delivered as modular services (policy checks, risk scoring, observability, etc.). (videos.infosys.com)
- Observability (for AI): Understanding not just metrics, but decisions, context, tool calls, and policy checks.
- NIST AI RMF: A risk framework for governing and managing AI across lifecycle (GOVERN, MAP, MEASURE, MANAGE). (NIST Publications)
- Human oversight: Requirements to enable human monitoring, interpretation and override in higher-risk AI systems. (AI Act Service Desk)
FAQ (People Also Ask)
Q1) What does “self-healing AI enterprise” actually mean?
It means AI-driven operations that detect issues early, apply verified remediations through closed-loop automation, and escalate to humans only when judgment is required. (Red Hat)
Q2) Why do enterprise AI pilots fail when moved to production?
Because pilots test intelligence. Production requires operability: governance, auditability, identity, safe tool access, observability, and rollback.
Q3) What is “reversible-by-design” autonomy?
It’s the ability to trace, replay, and safely undo autonomous actions—through rollback, compensation, or human escalation—so autonomy is trustworthy at scale.
Q4) How is an AI fabric different from an AI platform?
A fabric is a unified operating environment with composable services, interoperability, and enterprise controls—so multiple teams can build and run autonomy consistently across the enterprise. (videos.infosys.com)
Q5) How does this relate to governance frameworks like NIST AI RMF?
A fabric operationalizes governance through continuous controls, measurement, and management across the AI lifecycle—aligning with the RMF’s core functions. (NIST Publications)
Q6) Do regulations require human oversight for enterprise AI?
For certain higher-risk uses, regulations emphasize human oversight and transparency, ensuring humans can monitor and intervene appropriately. (AI Act Service Desk)
Q1. Why is operability more important than AI intelligence in enterprises?
Because intelligence without control creates risk. Operability ensures AI can be governed, audited, scaled, and corrected safely in production.
Q2. What does AI operability actually include?
Observability, policy enforcement, rollback, cost control, compliance alignment, and operational resilience across the AI lifecycle.
Q3. Why do most enterprise AI pilots fail in production?
They focus on models, not operating environments—lacking governance, reliability, and integration with enterprise systems.
Q4. How does operability enable faster AI delivery?
By preventing rework, incidents, and compliance blockers—allowing teams to deploy with confidence and scale safely.
Q5. Is operability relevant only for regulated industries?
No. Any enterprise operating at scale faces trust, cost, reliability, and accountability challenges that operability addresses.
References and further reading
- NIST AI Risk Management Framework (AI RMF) (NIST)
- EU AI Act — Article 14 (Human Oversight) (Artificial Intelligence Act)
- EU AI Act — Article 13 (Transparency / Information to deployers) (Artificial Intelligence Act)
- Red Hat: Self-healing infrastructure and closed-loop automation (Red Hat)
- Topaz Fabric page (for background framing of layered, open, interoperable fabric concepts) (Infosys)
- Enterprise AI Runtime: Why Agents Need a Production Kernel to Scale Safely – Raktim Singh
- The Enterprise AI Factory: How Global Enterprises Scale AI Safely with Studio, Runtime, and Productized Services – Raktim Singh
- Why Enterprises Need Services-as-Software for AI: The Integrated Stack That Turns AI Pilots into a Reusable Enterprise Capability – Raktim Singh
- The Advantage Is No Longer Intelligence—It Is Operability: How Enterprises Win with AI Operating Environments – Raktim Singh
- The Agentic AI Platform Checklist: 12 Capabilities CIOs Must Demand Before Scaling Autonomous Agents | by RAKTIM SINGH | Dec, 2025 | Medium
- The Enterprise AI Service Catalog: Why CIOs Are Replacing Projects with Reusable AI Services | by RAKTIM SINGH | Dec, 2025 | Medium
- Enterprise IT Is Becoming an App Store: From Projects to Services-as-Software: By Raktim Singh
- Enterprise AI Fabric: Why AI Is Shifting from Applications to an Operational Layer: By Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.