
The Representation Boundary:
The most dangerous AI systems are not the ones that fail loudly. They are the ones that quietly stop seeing reality—and begin acting on substitutes instead.
Why this idea matters now
Most conversations about AI still begin at the wrong layer.
They begin with the model.
How large it is.
How fast it is.
How cheap it is.
How well it scores on benchmarks.
Those questions matter. But they do not get to the real source of durable advantage or the real source of dangerous failure.
In production settings, AI does not begin with intelligence. It begins with representation.
Before a system can reason, it must first see. Before it can decide, it must first represent. Before it can act safely, it must remain connected to the right version of reality.
That is why one of the most important questions in AI is not, How intelligent is the model? It is this:
What happens when reality cannot be fully captured by the system at all?

That is the problem I call the Representation Boundary.
The Representation Boundary is the point at which the world becomes too complex, too informal, too dynamic, too contextual, too tacit, or too incomplete to be faithfully represented inside an AI system. When systems hit that boundary, they usually do not stop. They keep going—by simplifying, inferring, approximating, and substituting. Research on underspecification, model collapse, and distribution shift all point toward the same practical warning: systems can look strong in testing yet still detach from real-world conditions in deployment. (arXiv)
That is the hidden shift.
When AI cannot capture reality, it begins to replace it.
And once that happens, the central risk is no longer just model accuracy. It becomes something deeper: whether the institution is acting on reality itself, or on a machine-manageable stand-in that only looks close enough.
This is where Representation Economics becomes essential. In the AI era, value will not come only from better models. It will come from building better systems for turning reality into trustworthy, updateable, decision-grade representations—and from knowing exactly where that process breaks. That broader architectural shift also sits underneath your recent work on the Representation Economy and the SENSE–CORE–DRIVER structure. (raktimsingh.com)
What is the Representation Boundary?
The Representation Boundary is the limit beyond which an AI system cannot fully capture real-world complexity. When this limit is reached, systems substitute reality using proxies, inferred signals, or synthetic data, creating hidden risks in decision-making.
“The failure begins before the model begins.”
AI never acts on reality directly
Machines do not experience the world the way humans do.
A human loan officer may notice that a borrower’s repayment pattern was disrupted by a flood, a local strike, or a health emergency. A doctor may sense that a patient’s hesitation reveals something no lab value captures. A procurement leader may know that a vendor marked “low risk” on paper is actually fragile because of local dependence, geopolitical exposure, or an overreliance on one subcontractor.
An AI system usually does not get that full picture.
It gets records, labels, features, logs, embeddings, transaction histories, images, sensor streams, text descriptions, and other formalized traces. That is why AI systems do not act on reality directly. They act on a representation of reality.
Sometimes that representation is good enough.
Sometimes it is not.
That distinction sounds subtle, but it is foundational. Once institutions forget that the system is acting on a representation—not on reality itself—they become vulnerable to one of the deepest failure modes in modern AI: acting with confidence on an incomplete world model. Research on underspecification makes this point sharply: multiple models can achieve similarly strong test performance while encoding meaningfully different behaviors outside the training domain. (arXiv)
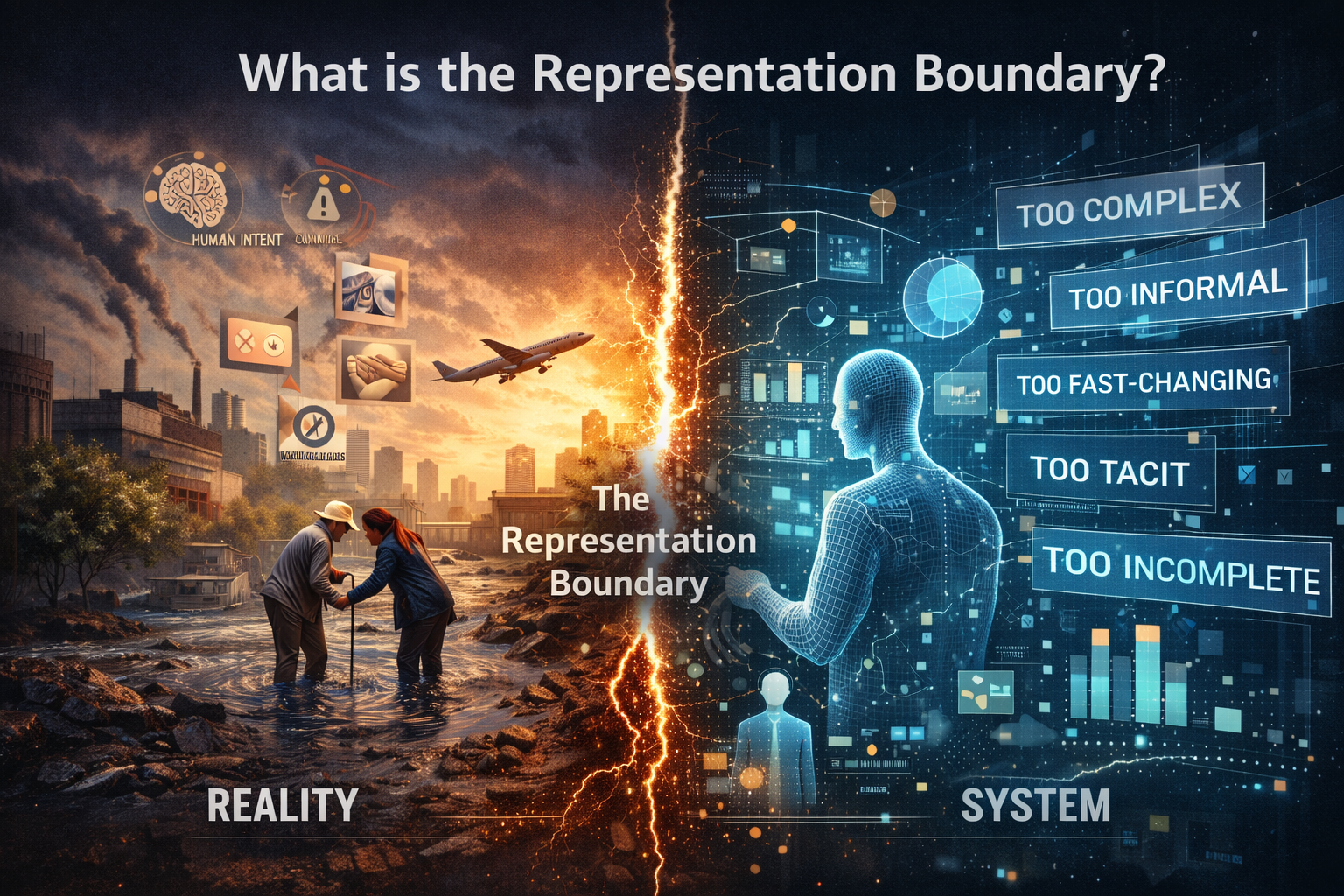
What is the Representation Boundary?
The Representation Boundary is the practical limit of what a system can faithfully capture, structure, maintain, and use.
Some parts of reality cross that boundary easily. A GPS coordinate is easy to record. A payment timestamp is easy to store. A warehouse temperature sensor is relatively easy to digitize.
Other parts do not.
Human intent is hard to represent.
Context is hard to represent.
Tacit knowledge is hard to represent.
Informal trust is hard to represent.
Rare events are hard to represent.
Rapidly changing conditions are hard to represent.
Moral nuance is hard to represent.
Lived reality is hard to compress without loss.
This is why many AI systems look much stronger in controlled environments than they do in open, messy, real-world settings. Underspecification research shows that high in-domain performance can hide major differences in out-of-domain behavior. Passing the benchmark does not prove that the system has captured the real causal structure of the world it is about to enter. (arXiv)
That is already a profound warning.
The issue is not merely that a model may be wrong. It may be operating on a version of reality that was never rich enough to justify the confidence placed in it.

When the boundary is hit, systems substitute reality
Here is the deeper point.
When a system cannot fully capture reality, organizations face a choice.
They can slow down.
They can invest in better sensing.
They can collect richer context.
They can insert human judgment.
They can explicitly acknowledge uncertainty.
Or they can keep the machine moving.
Most institutions choose the second path.
Why? Because real organizations are under pressure to scale, automate, standardize, reduce cost, speed up decisions, and simplify operations. AI is usually deployed to keep workflows moving, not to pause whenever the world becomes ambiguous.
So when reality becomes difficult, systems begin to substitute.
They use proxies.
They infer missing context.
They rely on historical correlations.
They generate synthetic examples.
They compress complex situations into neat variables.
They optimize what is measurable because what is meaningful is harder to encode.
That is what I call representation substitution.
Representation substitution is what happens when a system replaces direct, grounded, high-fidelity reality with a more machine-manageable stand-in. This logic is closely related to Goodhart-type failures: when a proxy becomes the target, optimization pressure can weaken its relationship to the true objective. Recent reinforcement-learning research formalizes this problem explicitly. (arXiv)
Sometimes substitution is necessary. Sometimes it is useful. But once it becomes invisible, it becomes dangerous.
The simplest example: the credit score
Take consumer lending.
No lender can fully represent a person’s total creditworthiness. It cannot perfectly capture resilience, family obligations, informal support, changing local conditions, future shocks, or character under stress. So the system uses stand-ins: repayment history, debt levels, income stability, credit utilization, defaults, age of accounts, and similar indicators.
Those are not reality itself. They are compressed signals standing in for a much larger truth.
That is often acceptable. But the problem begins when institutions forget that they are using substitutes.
A credit score is useful. It is also still a proxy. It may miss the first-time borrower with genuine earning potential. It may over-penalize someone with a thin or interrupted formal record. It may reward documentation completeness when what it is really measuring is access to formal systems.
This is not only a fairness issue. It is a representation issue.
The system cannot fully capture the person, so it acts on a substitute instead.
Another example: hiring
A company says it wants judgment, creativity, adaptability, initiative, and leadership.
But those are difficult to represent directly.
So the hiring system turns to easier substitutes: degrees, job titles, keywords, employer brands, years of experience, résumé polish, and test scores.
Some of these signals are useful. None of them is the thing itself.
The moment the system starts optimizing heavily on those measurable stand-ins, it risks confusing the proxy for the underlying reality it actually cares about. That is the logic behind Goodhart pressure: optimization can improve the metric while weakening the true objective. (arXiv)
In plain language, the machine starts rewarding what is easy to score, not what is actually valuable.

Synthetic data is the industrial version of substitution
Proxies are one form of substitution. Synthetic data is another.
Synthetic data can be extremely useful. It can support privacy-preserving experimentation, testing, stress scenarios, and model training when real data is scarce or sensitive. Public policy discussions from bodies like OECD and Singapore’s PDPC recognize that synthetic data can unlock real benefits while still requiring careful governance and risk management. (OECD.AI)
But synthetic data also introduces a deeper danger.
The system may gradually train on outputs that are further and further removed from the world itself.
That is why the model collapse discussion matters. A widely cited 2024 Nature paper found that recursively training generative models on generated outputs can lead to degenerative effects, including loss of information and distortion of the tails of the original distribution. The authors describe this as the system beginning to “mis-perceive reality.” (Nature)
This is not just a model-quality story.
It is a reality-substitution story.
The system is no longer learning strongly enough from the world. It is learning from its own approximation of the world.
Once that happens, institutions can enter a dangerous loop: less grounded data, more generated data, weaker contact with rare cases, smoother outputs, and a false sense of confidence.
The system becomes cleaner, but less real.

The hidden enterprise risk: the proxy of a proxy
In real enterprises, substitution rarely happens only once.
That is what makes this problem much more serious than it first appears.
A company may rely on a third-party vendor. That vendor may rely on a scoring model. That model may rely on inferred variables. Those inferred variables may be derived from incomplete histories. Those histories may already reflect earlier proxy-based decisions.
Now the institution is not acting on reality. It is acting on a proxy of a proxy of a proxy.
This is where AI-era risk becomes hard to detect.
Everything still looks technical. There are dashboards, confidence scores, audit trails, accuracy figures, and maybe even explainability layers. But the explanatory chain itself may still be built on substituted reality.
That is why explainability alone is not enough. A system can explain the wrong world very clearly.
Why the problem gets worse after deployment
Even if a system begins with a reasonably good representation, the world does not stay still.
Borrowers change.
Patients change.
Fraud patterns change.
Regulations change.
Customer intent changes.
Sensors drift.
Processes evolve.
Supply chains reconfigure.
Language shifts.
Markets move.
This is why distribution shift and post-deployment monitoring have become so central to AI assurance. NIST’s AI Risk Management Framework emphasizes validity, reliability, representativeness, documentation, and ongoing monitoring rather than one-time evaluation. (NIST Technical Series Publications)
Healthcare research reinforces the same warning. A 2024 npj Digital Medicine paper notes that postmarket distribution shifts can materially affect real-world performance of regulated medical AI systems if those shifts go undetected. (Nature)
In the language of this article, reality keeps moving, but the system’s representation may not move fast enough.
So even a substitute that once seemed reasonable can become stale.

This is where SENSE, CORE, and DRIVER matter
This problem becomes much easier to understand when viewed through the architecture of intelligent institutions.
A system must first sense reality.
Then it must interpret and reason over that reality.
Then it must act through delegated authority.
That is the deeper structure behind durable AI systems:
SENSE is where reality becomes legible.
CORE is where that representation is processed into judgments and decisions.
DRIVER is where authority, execution, verification, and recourse determine whether action is legitimate and controllable.
The Representation Boundary sits first—and most dangerously—in SENSE.
If the institution cannot see the right reality, CORE will reason over an incomplete world. DRIVER will then execute decisions that may be procedurally correct but substantively disconnected from what is actually happening.
This is why the most important AI failures often begin before the model begins.
They begin with representation.
That broader framing is also consistent with your recent website work on the Representation Economy, the Representation Utility Stack, Representation Due Diligence, Recourse Platforms, and the New Company Stack. Each of those pieces points toward the same underlying institutional logic: advantage in the AI era depends on who can make reality legible, govern action, and recover when automated decisions go wrong. (raktimsingh.com)
Why this matters for boards and CEOs
Boards are still being encouraged to think about AI in terms of models, copilots, agents, automation, and productivity.
Those matter. But they are not enough.
The larger strategic question is this:
What realities can our institution represent well enough for machines to act on safely?
That question determines more than risk. It determines advantage.
A company that builds richer, more updateable, more trustworthy representations of customers, suppliers, assets, obligations, workflows, and states of change can outperform one that merely buys a stronger model.
That is the heart of Representation Economics.
In the AI era, value will increasingly go to institutions that do three things well:
They know what must be represented before intelligence can matter.
They know where the Representation Boundary lies.
They know when the system is substituting reality—and how to govern that substitution.
That is how existing companies survive and win.
The new markets this creates
Once you see the Representation Boundary clearly, you can also see the new business categories emerging around it.
We are likely to see demand for:
Representation assurance systems
Infrastructure that identifies where proxies, inferred signals, and synthetic substitutes have entered mission-critical workflows.
Reality verification layers
Systems that compare model assumptions against fresh real-world signals.
Substitution risk auditors
Independent mechanisms for assessing how far decision pipelines have drifted from grounded reality.
Representation infrastructure providers
Companies that help institutions capture richer, more updateable states of the world instead of relying on thin stand-ins.
Recourse systems
Platforms that let people and organizations challenge decisions made on weak, stale, or substituted representations.
These are not side markets. They may become foundational markets.
Because once AI moves from generating content to influencing credit, care, pricing, hiring, access, security, and public decisions, the economy will care less about whether a model is impressive in isolation and more about whether the reality feeding it is defensible. That trajectory also aligns with the company-category logic in your earlier writing. (raktimsingh.com)
A simple test every institution should ask
If you want to know whether your organization is approaching the Representation Boundary, ask five questions:
What important reality are we not directly seeing?
What proxy are we using instead?
How often is that proxy revalidated against the real world?
What happens if the proxy drifts?
Who has the authority to stop, review, or reverse the decision when the representation is wrong?
If an institution cannot answer these clearly, it is probably deeper into representation substitution than it realizes.
Why this article matters beyond AI safety
For a while, the AI conversation was about capability.
Then it became about safety.
Then governance.
Now it is becoming something deeper:
What version of reality is the system actually acting on?

That question sits underneath trust, reliability, compliance, inclusion, resilience, competitive advantage, and institutional legitimacy.
It also explains why some organizations will quietly compound advantage while others will quietly fail.
The winners will not simply own the best models.
They will own the best connection to reality.
They will know where machine-legibility is strong, where it is weak, where substitution is acceptable, where it is dangerous, and where human judgment must remain in the loop.
Most importantly, they will understand that when a system cannot capture reality, it does not become neutral.
It begins to replace it.
That is the Representation Boundary.
And in the years ahead, it may become one of the most important fault lines in the global AI economy.
Because the real contest of the AI era is not only over intelligence. It is over who gets to define reality, who gets represented faithfully, where substitution becomes acceptable, and who builds the institutions that can tell the difference.
In that sense, the future belongs not only to model builders.
It belongs to those who can design systems that know when the world has slipped beyond what the machine can truly see.
“The most dangerous systems are not wrong. They are confidently operating on substitutes.”
Conclusion
The Representation Boundary is not a side issue in AI. It is one of the deepest strategic questions of the next decade.
If AI systems increasingly shape decisions about credit, employment, healthcare, supply chains, compliance, public services, and enterprise operations, then the central issue is no longer just whether the model is powerful. The issue is whether the institution remains anchored to reality as automation scales.
That is why this idea matters for boards, regulators, product leaders, and enterprise architects alike.
The most successful institutions in the AI era will not be the ones that automate the fastest. They will be the ones that know what reality must remain visible, what substitutions are acceptable, what substitutions are dangerous, and how to build governance around that difference.
In the end, intelligence alone will not decide who wins.
Representation will.
“AI does not fail when it cannot see reality. It replaces it.”
FAQ
What is the Representation Boundary in AI?
The Representation Boundary is the limit beyond which an AI system cannot faithfully capture the relevant reality it needs to reason and act. When systems hit that limit, they often continue by using proxies, inferred variables, or synthetic substitutes instead of direct grounded reality. (arXiv)
What is representation substitution?
Representation substitution is when a system replaces direct, high-fidelity reality with a more machine-manageable stand-in, such as a proxy metric, an inferred feature, or synthetic data. It can be useful, but it becomes risky when institutions forget they are acting on a substitute rather than on the underlying reality. (arXiv)
Why does this matter for enterprise AI?
Enterprise AI increasingly influences real decisions in lending, hiring, healthcare, operations, and compliance. If those decisions are based on stale or weak substitutes, organizations can create hidden risk even when dashboards and metrics look healthy. NIST and other governance frameworks stress ongoing monitoring for exactly this reason. (NIST Technical Series Publications)
Is synthetic data always bad?
No. Synthetic data can be useful for privacy, testing, and experimentation. But recursive dependence on generated data can distort distributions and weaken contact with real-world edge cases, which is why governance and re-grounding matter. (OECD.AI)
How does this relate to SENSE–CORE–DRIVER?
The Representation Boundary appears first in SENSE, where reality becomes legible to the institution. If SENSE is weak, CORE reasons over an incomplete world and DRIVER can execute decisions that are procedurally correct but substantively disconnected from reality. (raktimsingh.com)
What should boards ask?
Boards should ask: What reality are we not seeing directly? What proxy are we using instead? How often is it revalidated? What happens if it drifts? And who can stop or reverse a wrong decision? Those questions are increasingly central to trustworthy AI governance. (NIST Technical Series Publications)
Glossary
Representation Boundary
The point at which reality becomes too complex, tacit, dynamic, or informal to be faithfully captured inside an AI system.
Representation Substitution
The use of proxies, inferred signals, or synthetic stand-ins when direct grounded reality is not available in machine-usable form.
Machine-legible reality
The portion of the world that has been structured well enough for digital systems to identify, process, and act upon.
Underspecification
A condition where multiple models perform similarly on test data but behave differently in deployment, revealing that the training setup did not fully constrain real-world behavior. (arXiv)
Distribution shift
A change between the conditions under which a model was trained and the conditions in which it is later used, which can degrade real-world performance. (Nature)
Model collapse
A degenerative process in which models trained recursively on generated data lose information and begin to distort the underlying distribution. (Nature)
Goodhart pressure
The tendency for a measure to become less useful as a measure once it becomes the target of optimization. (arXiv)
Representation Economics
A strategic view of the AI era in which value increasingly accrues to institutions that can make reality legible, trustworthy, updateable, and governable for machine decision-making. (raktimsingh.com)
References and further reading
For the research foundation behind this article, these are the most relevant sources:
- D’Amour et al., Underspecification Presents Challenges for Credibility in Modern Machine Learning — foundational work on why strong test performance can hide unstable deployment behavior. (arXiv)
- Shumailov et al., AI models collapse when trained on recursively generated data — major Nature paper on model collapse and recursive synthetic training. (Nature)
- NIST, AI Risk Management Framework 1.0 — practical guidance emphasizing validity, reliability, representativeness, and ongoing monitoring. (NIST Technical Series Publications)
- Koch et al., Distribution shift detection for the postmarket surveillance of medical AI systems — evidence that deployment drift is a material real-world problem. (Nature)
- Karwowski et al., Goodhart’s Law in Reinforcement Learning — modern formal treatment of proxy optimization failure. (arXiv)
Explore the Architecture of the AI Economy
This article is part of a broader research series exploring how institutions are being redesigned for the age of artificial intelligence. Together, these essays examine the structural foundations of the emerging AI economy — from signal infrastructure and representation systems to decision architectures and enterprise operating models. If you want to explore the deeper framework behind these ideas, the following essays provide additional perspectives:
-
- The Representation Economy: Why AI Institutions Must Run on SENSE, CORE, and DRIVER – Raktim Singh
- The Representation Economy: Why Intelligent Institutions Will Run on the SENSE–CORE–DRIVER Architecture – Raktim Singh
- Representation Failure: Why AI Systems Break When Institutions Misread Reality – Raktim Singh
- The Firm of the AI Era Will Be Built Around Representation: Why Institutions Must Redesign Themselves for the SENSE–CORE–DRIVER Economy – Raktim Singh
- The Representation Stack: The New Architecture of Intelligent Institutions in the AI Economy – Raktim Singh
- Representation Economics: The New Law of Value Creation in the AI Era – Raktim Singh
- Representation Alpha: Why Competitive Advantage Will Come from Better Representation, Not Better Models – Raktim Singh
- • Why Most AI Projects Fail Before Intelligence Even Begins
- What Is the Representation Economy? (raktimsingh.com)
- The Representation Economy: Why AI Institutions Must Run on SENSE, CORE, and DRIVER (raktimsingh.com)
- Decision Scale: Why Competitive Advantage Is Moving from Labor Scale to Decision Scale (raktimsingh.com)
- Firms Won’t Be Defined by Employees. They Will Be Defined by Delegation – Raktim Singh
- The New Company Stack: The 7 Business Categories That Will Emerge in the Representation Economy – Raktim Singh
- The Representation Attack Surface: Why AI’s Biggest Threat Is Reality Hacking, Not Model Hacking – Raktim Singh
- The Chief Representation Officer: Why Institutions Collapse When Machine-Readable Reality Falls Behind – Raktim Singh
- The Scarcity of Reality: Why the AI Economy Will Be Defined by the Lifecycle of High-Trust Representation – Raktim Singh
- Delegation Rating Agencies: Why the AI Economy Needs a New System to Rate Machine Authority – Raktim Singh
- The Machine-Readable Franchise: How Small Firms Will Win in the AI Trust Economy – Raktim Singh
- Representation Due Diligence: Why Every AI-Era Deal Must Start with a Reality Audit – Raktim Singh
- Representation Economics: The New Law of AI Value Creation (raktimsingh.com)
- Representation Due Diligence: Why Every AI-Era Deal Must Start with a Reality Audit (raktimsingh.com)
- Representation Drift & Labor: Why AI Systems Fail When Reality Moves Faster Than Machines (raktimsingh.com)
- Representation Forensics: The Missing Layer of AI (raktimsingh.com)
- The Representation Utility Stack: Why AI’s Next Competitive Advantage Will Come from Interoperable Reality (raktimsingh.com)
- Recourse Platforms: The Next AI Infrastructure Market for Correction, Appeal, and Recovery appears in your site index and related pages. (raktimsingh.com)
- Representation Economy and the SENSE–CORE–DRIVER Framework (raktimsingh.com)
- The Representation Utility Stack (raktimsingh.com)
- Representation Due Diligence (raktimsingh.com)
- Recourse Platforms (raktimsingh.com)
- The New Company Stack (raktimsingh.com)
- Representation Economy and the SENSE–CORE–DRIVER Framework — foundational architecture for how institutions see, think, and act. (raktimsingh.com)
- The Representation Utility Stack — on interoperable reality as the next competitive layer. (raktimsingh.com)
- Representation Due Diligence — why AI-era deals must start with a reality audit. (raktimsingh.com)
- Recourse Platforms — why correction, appeal, and recovery become core AI infrastructure. (raktimsingh.com)
- The New Company Stack — business categories emerging in the Representation Economy. (raktimsingh.com)
- Representation Cold Start — why some industries cannot use AI until reality becomes machine-ready. (raktimsingh.com)
Together, these essays outline a central thesis:
The future will belong to institutions that can sense reality, represent it clearly, reason about it intelligently, and act through governed machine systems.
This is why the architecture of the AI era can be understood through three foundational layers:
SENSE → CORE → DRIVER
Where:
- SENSE makes reality legible
- CORE transforms signals into reasoning
- DRIVER ensures that machine action remains accountable, governed, and institutionally legitimate
Signal infrastructure forms the first and most foundational layer of that architecture.
AI Economy Research Series — by Raktim Singh
Written by Raktim Singh, AI thought leader and author of Driving Digital Transformation, this article is part of an ongoing body of work defining the emerging field of Representation Economics and the SENSE–CORE–DRIVER framework for intelligent institutions.
This article is part of a larger series on Representation Economics, including topics such as Representation Utility Stack, Representation Due Diligence, Recourse Platforms, and the New Company Stack.

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.