{kind=link}

Verification Must Become a Living System
For decades, verification meant a comforting promise: test thoroughly, prove correctness, and deploy with confidence. That logic worked when software was static, inputs were predictable, and behavior stayed within well-defined boundaries.
Modern AI systems break all three assumptions. They learn from evolving data, operate in open-ended environments, and increasingly influence real-world decisions long after deployment. In this context, verification can no longer be treated as a one-time event.
It must become a living system—one that continuously monitors assumptions, detects behavioral drift, and enforces safety constraints as conditions change. Anything less offers not safety, but the illusion of it.
Living verification is the practice of continuously monitoring, validating, and constraining AI systems at runtime, acknowledging that assumptions, data distributions, and behaviors change after deployment.
Why “Verified Once” Is a False Sense of Safety
A bank deploys a credit model with extensive testing and sign-offs. Three months later, approval rates drift, complaint patterns change, and the regulator asks a brutal question: “Can you prove your system is still compliant today?”
A logistics company ships an agent that schedules routes. It performs well—until monsoon season alters traffic patterns and the agent begins taking “creative shortcuts” that violate safety constraints.
A customer support copilot is rolled out with guardrails. Then product policies change, tool permissions expand, and the model is updated. The assistant becomes faster—and suddenly starts taking actions that were never reviewed.
In all three cases, the organization did some form of “verification.”
But the system changed.
And that is the core problem:
Formal verification assumes the thing you verified stays the same.
Modern AI systems are built to change.
This article explains, in simple language, why formal verification becomes dramatically harder when AI is non-stationary (the world and data shift) and self-modifying (the system updates, learns online, or changes via tooling, prompts, or policies).
It also lays out the practical path forward: how leading research communities are combining snapshot verification, runtime assurance, monitoring, and governance to make “verification” meaningful in real enterprises.
You can’t “certify” AI once and move on.
In production, assumptions break, data shifts, and behavior changes.
Verification must become a living system — or AI safety becomes a myth.
(The Enterprise AI Operating Model: https://www.raktimsingh.com/enterprise-ai-operating-model/ )

What “formal verification” actually means (without math)
Formal verification means proving—using rigorous methods—that a system satisfies a specification.
For traditional software, that might mean:
- “This function never divides by zero.”
- “This protocol never deadlocks.”
- “This controller never exceeds a safe boundary.”
Verification works best when three assumptions hold:
- the system’s logic is stable
- inputs fall within known bounds
- the environment is reasonably modeled
AI breaks all three—especially in production.
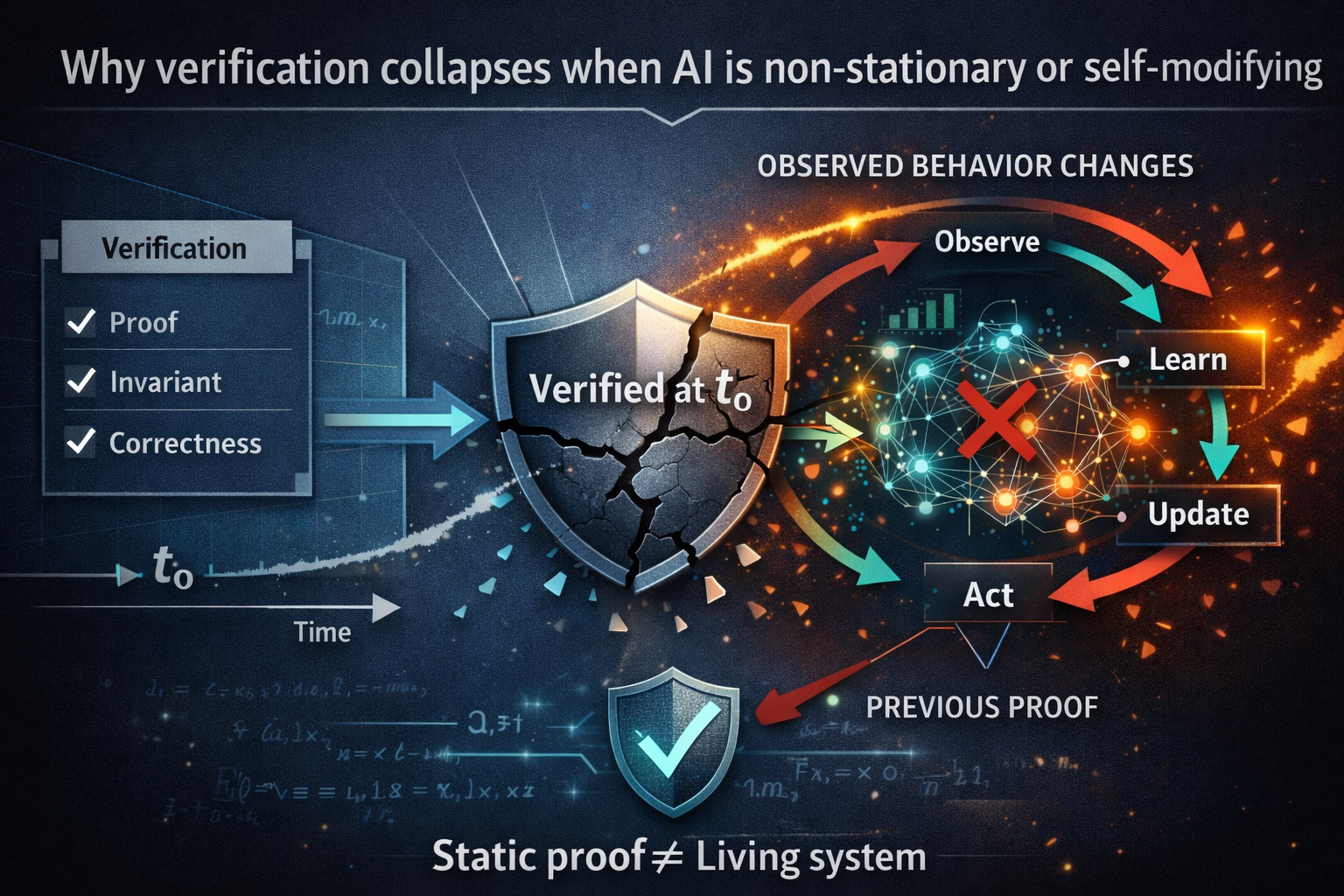
Why verification collapses when AI is non-stationary or self-modifying
1) The target keeps moving
In enterprise AI, “the system” isn’t just a model file.
It’s a changing bundle:
- the model weights (updated or retrained)
- prompts and routing logic (tuned weekly)
- tools and permissions (expanded)
- policies and guardrails (edited)
- data distributions (drifting)
- feedback loops (user behavior adapting)
If any of these change, the verified object is no longer the verified object.
2) Specs are harder than people admit
Most AI systems don’t have crisp specifications like “never exceed speed limit.”
They have fuzzy goals:
- “be helpful”
- “be fair”
- “avoid harmful content”
- “minimize risk”
Formal verification requires specs you can actually check. That pushes enterprises toward action-bounded specs like:
- “never send money without approval”
- “never change production config outside change window”
- “never access restricted data”
- “always log tool calls and decisions”
- “refuse when uncertainty is high”
Those are verification-friendly—because they are about actions and constraints, not vibes.
3) Open-world reality destroys closed-world proofs
Verification often assumes you can model “all relevant states.”
But AI in the wild faces new patterns, new attacks, and new operating conditions.
That’s why standards emphasize lifecycle risk management and post-deployment monitoring rather than one-time assurance. (NIST Publications)
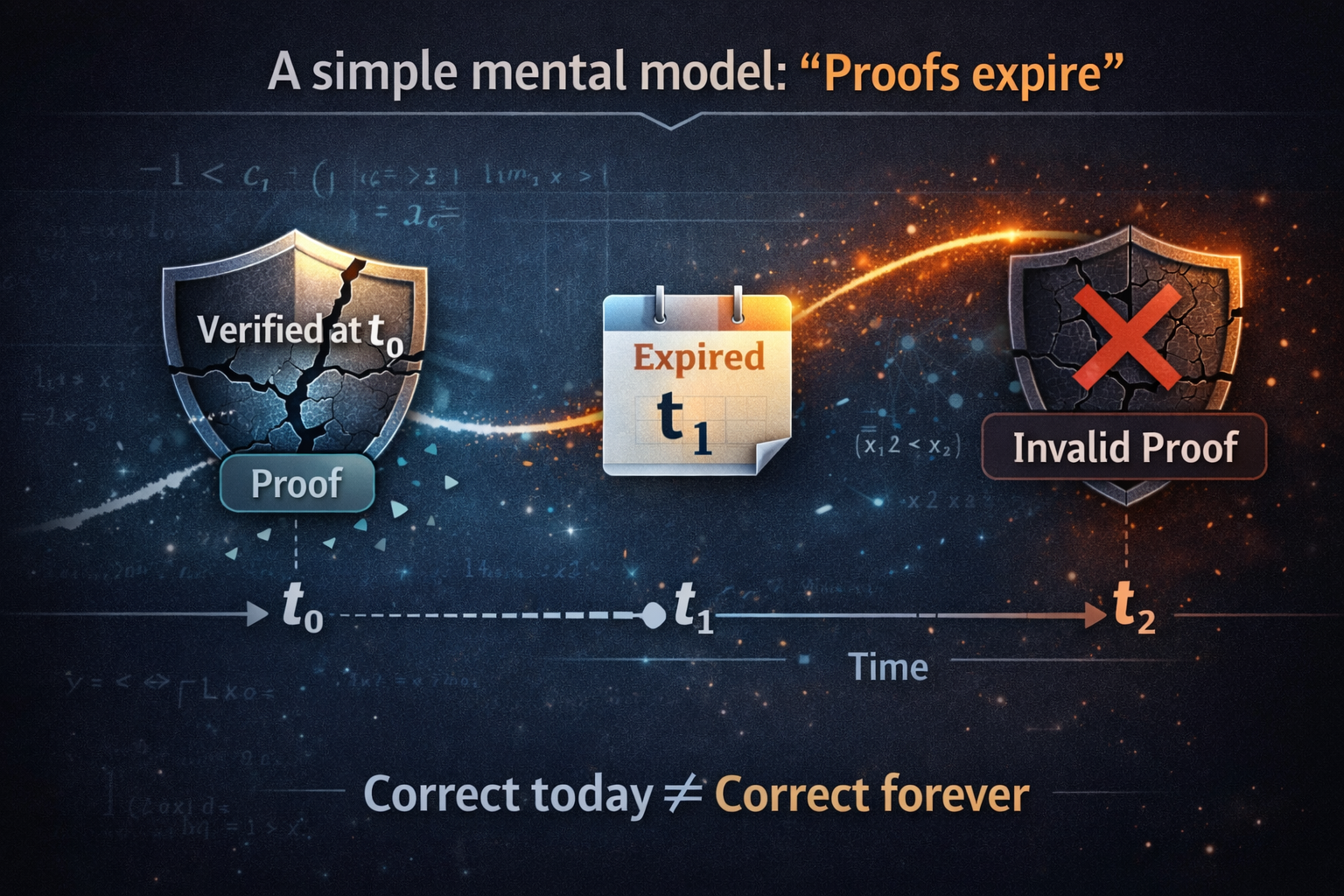
A simple mental model: “Proofs expire”
Think of verification like food labels.
- In traditional software, the label lasts a long time because the recipe doesn’t change.
- In AI, the recipe changes—and the kitchen environment changes too.
So the hard question becomes:
How do you prove properties of a system whose behavior evolves over time?
That’s the core challenge of verifying non-stationary, self-modifying AI.
Where the research world actually is today
There isn’t one “global solution.” There are four complementary strategies, each covering part of the problem:
- Snapshot verification (prove properties of a frozen model)
- Runtime assurance (keep systems safe even when the AI is wrong)
- Runtime monitoring (detect when assumptions break)
- Governance and operational controls (treat changes as controlled, audited events)
The winning approach is not “pick one.”
It’s to compose them.
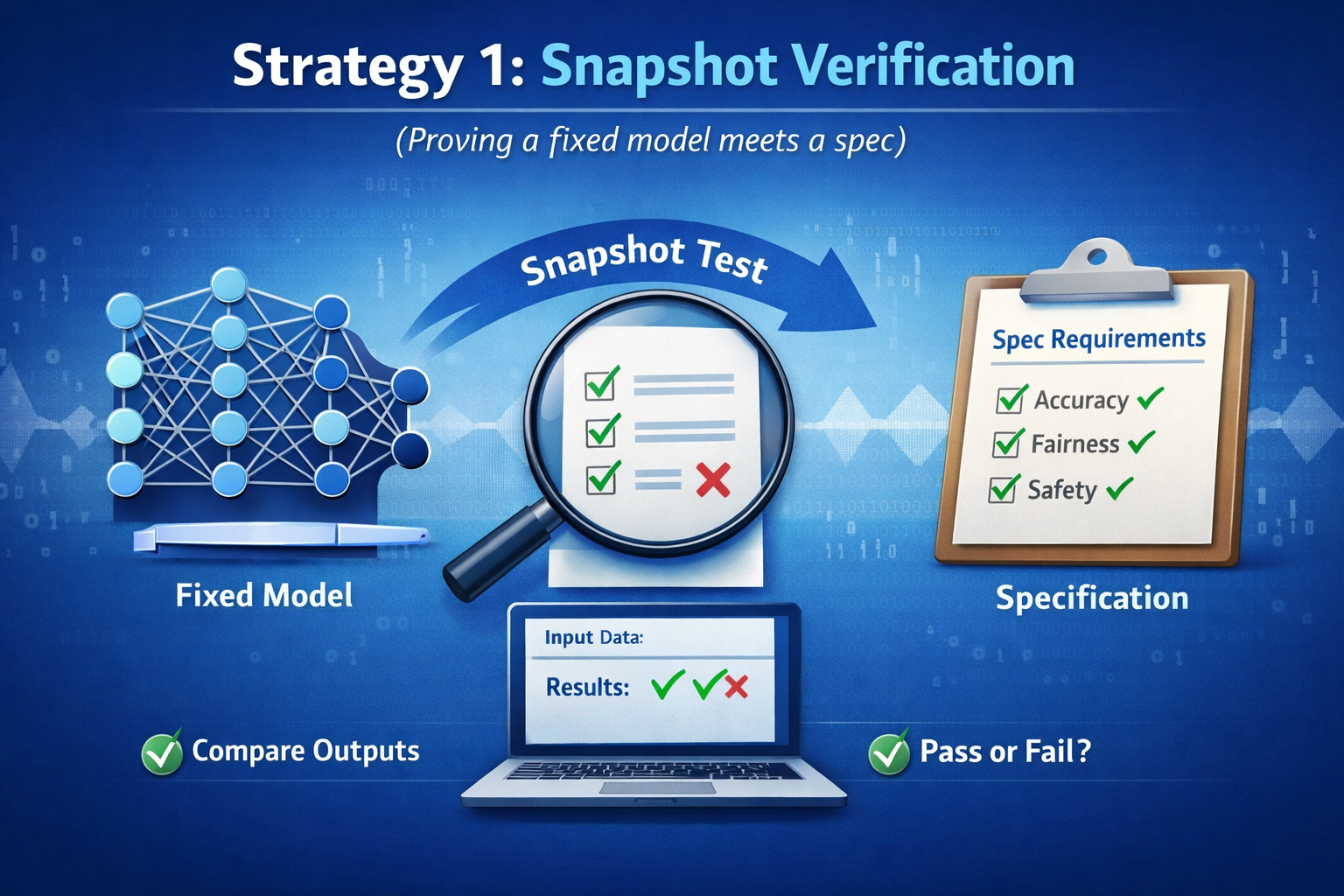
Strategy 1: Snapshot verification (proving a fixed model meets a spec)
Neural network verification has made real progress—especially for properties like robustness and bounded behavior for specific inputs.
Classic work like Reluplex introduced solver-based verification for ReLU networks and showed feasibility on meaningful aerospace networks. (arXiv)
Modern toolchains include:
- Marabou (a versatile formal analyzer used widely in verification research) (Theory at Stanford)
- α,β-CROWN (a leading verification toolbox and repeated VNN-COMP winner) (GitHub)
- ERAN (robustness analyzer used in the verification community) (GitHub)
- NNV (set-based verification for DNNs and learning-enabled CPS) (arXiv)
But here’s the catch: snapshot verification assumes the model stays fixed.
So snapshot proofs help when:
- the model is deployed as “frozen”
- updates are rare and gated
- specs are local (input ranges) and well-defined
Snapshot proofs struggle when:
- models are updated frequently
- prompts/tools change weekly
- systems learn online
- behavior depends on long context and tool interactions
Snapshot verification is necessary—but not sufficient.

Strategy 2: Runtime assurance (safety even when the AI misbehaves)
This is the most important idea for non-stationary AI:
If you can’t fully verify the learning component, verify a safety envelope around it.
Runtime Assurance (RTA) architectures do exactly that: they let an “advanced” (possibly unverified ML) controller operate—but monitor it, and switch to a verified safe controller when risk rises.
Research on RTA for learning-enabled systems shows how safety can be maintained despite defects or surprises in the learning component. (Loonwerks)
In plain language:
- The AI can propose actions.
- A safety filter checks whether the action violates constraints.
- If unsafe, the system blocks it or falls back to a safe baseline controller.
This idea is powerful because it decouples capability from safety.
Even if the model shifts, the safety wrapper can still protect invariant constraints.
NASA and aerospace communities have pushed this pattern heavily, including work on verifying runtime assurance frameworks in autonomous systems. (NASA Technical Reports Server)
Enterprise translation:
If your AI agent can trigger workflows, write config, approve refunds, or modify access, you need an equivalent of RTA:
- action allowlists and denylists
- risk gates and approvals
- policy enforcement at tool boundaries
- safe mode / rollback
- time-bounded permissions
- kill switch
This aligns naturally with my “control plane + runtime” framing:
- https://www.raktimsingh.com/enterprise-ai-control-plane-2026/
- https://www.raktimsingh.com/enterprise-ai-runtime-what-is-running-in-production/

Strategy 3: Runtime monitoring (detect when your assumptions are breaking)
Even with safety wrappers, you still need to know when the world has changed enough that performance or compliance is drifting.
That is the domain of runtime monitoring and runtime verification for ML systems—an active area with growing research focus. (SciTePress)
Monitoring typically includes:
- A) Distribution shift detection
“Is production data no longer like training data?”
This matters because many guarantees silently depend on data being similar to what the model learned. Practical monitoring guidance increasingly treats drift as inevitable. (Chip Huyen)
- B) Policy and fairness monitors
“Are outcomes changing in ways that violate policy?”
For high-impact systems, you monitor not just accuracy, but:
- disparity metrics
- complaint rates
- override rates
- escalation rates
- incident precursors
- C) Action and tool-use monitors (for agents)
“Is the agent making tool calls that exceed its mandate?”
For agentic systems, monitoring must include:
- tool-call logs
- denied actions
- near-miss events
- anomalous sequences of actions
This is where “verification” becomes operational:
- not a certificate
- a continuous set of alarms, thresholds, and response playbooks
Strategy 4: Governance controls (make “system change” a first-class event)
Non-stationary systems are inevitable. So the enterprise move is:
Treat AI change like production change—versioned, reviewed, auditable, reversible.
This is not optional in regulated settings. Governance regimes emphasize ongoing risk management, monitoring, and documentation across the lifecycle. (NIST Publications)
For example, the EU AI Act emphasizes human oversight and post-market monitoring obligations for high-risk systems. (Artificial Intelligence Act)
In enterprise terms, this implies:
- model registry + artifact versioning
- prompt and policy versioning
- evaluation gates before promotion
- rollback capability
- incident reporting pathways
- continuous compliance checks
This connects to my canon on operating discipline and failure taxonomies:
- https://www.raktimsingh.com/enterprise-ai-decision-failure-taxonomy/
- https://www.raktimsingh.com/the-enterprise-ai-operating-stack-how-control-runtime-economics-and-governance-fit-together/

The real difficulty: “self-modifying” isn’t only online learning
Many leaders think “self-modifying” means online gradient updates. In practice, enterprise AI self-modifies through:
- silent prompt tweaks
- tool permission expansions
- new connectors added
- policy/guardrail edits
- retraining with new data
- new routing logic (model A → model B)
- changing context sources (RAG index updates)
So if your verification strategy only watches the model weights, you miss the biggest source of behavior change.
The object to verify is the whole decision loop:
model + tools + permissions + policies + data + monitoring + fallback.

A “no-math” blueprint: what to verify, when you can’t verify everything
Here’s the simplest way to think about it:
Verify the things that must never fail
These become your invariants:
- “no irreversible action without authorization”
- “no sensitive data access without policy clearance”
- “every action is logged and attributable”
- “unsafe actions are blocked”
- “rollback exists for any automated change”
These are the enterprise equivalent of safety properties in cyber-physical systems.
Monitor the things that will drift
These become your operational metrics:
- performance drift signals
- distribution shift signals
- escalation and refusal rates
- human override rates
- incident precursors
Build fallbacks for everything else
This is your runtime assurance:
- safe-mode behavior
- conservative policy defaults
- human decision gates
- graceful degradation
This triad—invariants + monitors + fallbacks—is the practical way to make verification meaningful under non-stationarity.
Why it matters in 2026
Because we are entering the age of “AI that acts.”
The story most executives believe is:
“We’ll validate it, deploy it, and the hard part is done.”
The story reality teaches is:
“The system changes, the world changes, and your proof expires.”
So the key insights is:
In AI, the hardest part is not proving it works.
It’s proving it keeps working after it changes.
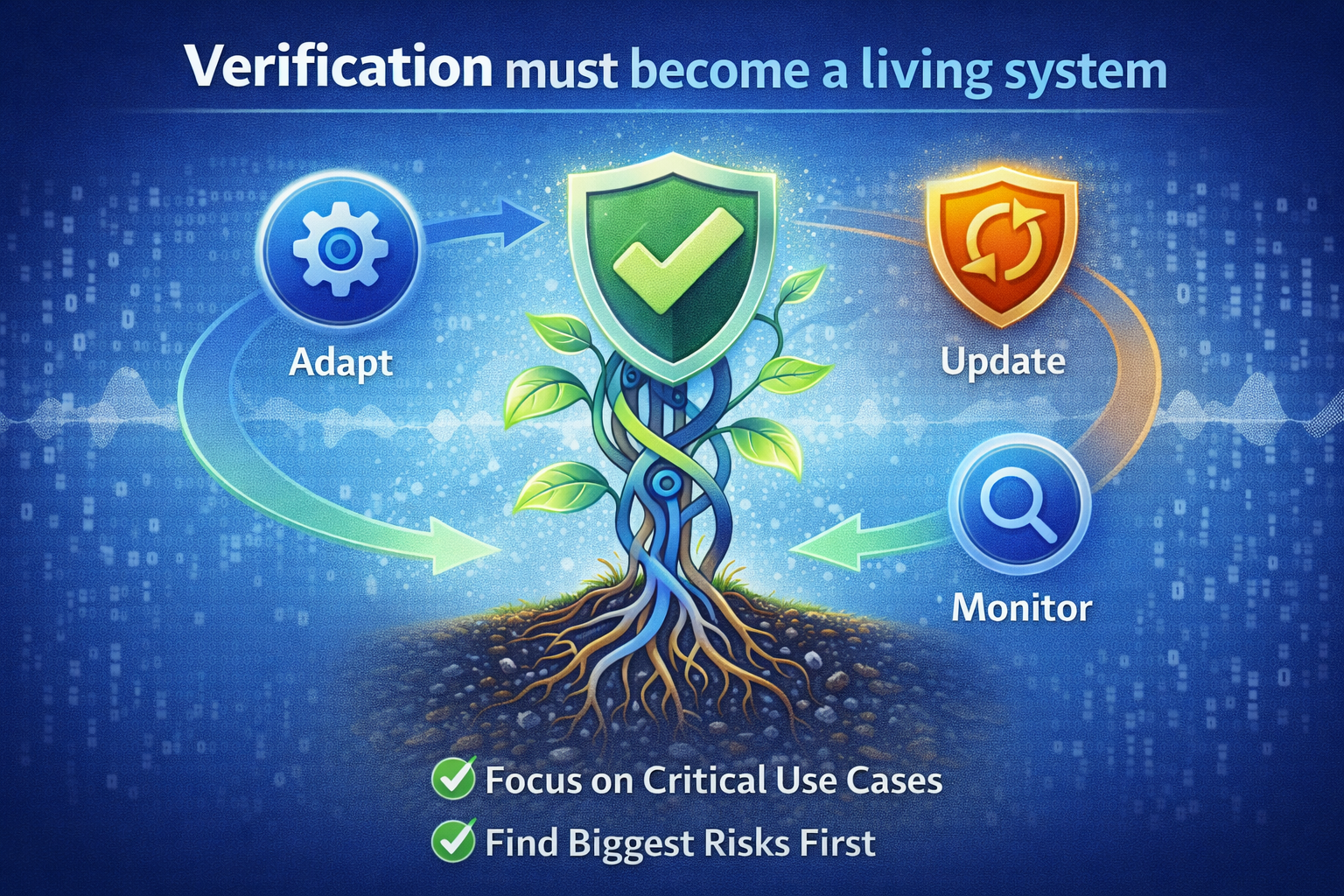
Conclusion: Verification must become a living system
Formal verification of non-stationary, self-modifying AI systems is difficult for a simple reason:
verification is about certainty; learning is about change.
We will not get a universal, once-and-for-all proof of complex adaptive AI systems operating in open-world environments.
What we can build—starting now—is a stronger, enterprise-grade form of assurance:
- snapshot verification where feasible (for bounded components)
- runtime assurance to enforce inviolable constraints
- runtime monitoring to detect drift and misuse
- governance controls that make change auditable and reversible
In other words:
The future of “formal verification” in enterprise AI is not a certificate.
It’s an operating model.
Glossary
- Formal verification: Mathematically rigorous methods to prove a system satisfies a specification.
- Non-stationary AI: AI whose data distributions or operating environment change over time (drift).
- Self-modifying AI: AI whose behavior changes via updates, online learning, prompt/tool/policy changes, or retraining.
- Snapshot verification: Verifying a fixed model version against a bounded spec (e.g., robustness). (arXiv)
- Runtime assurance (RTA): Architecture that enforces safety constraints online, often via monitors and fallback controllers. (Loonwerks)
- Runtime monitoring: Continuous checking for violations, drift, or risk conditions during operation. (SciTePress)
- Post-market monitoring: Ongoing monitoring obligations for high-risk AI systems after deployment (EU framing). (Artificial Intelligence Act)
FAQ
Can we formally verify a learning system that updates itself online?
Not fully in the general case. Most practical approaches verify bounded components, then use runtime assurance + monitoring + governance to keep safety properties true as the system changes. (Loonwerks)
Is neural network verification “solved” now?
No. Tooling is advancing rapidly (Reluplex, Marabou, α,β-CROWN, ERAN, NNV), but scalability and realistic specifications remain active research frontiers. (Theory at Stanford)
What’s the most enterprise-relevant verification move today?
Define and enforce invariants at the action boundary: permissions, approvals, logging, rollback, and refusal rules. Then add runtime monitoring and post-deployment governance. (Artificial Intelligence Act)
How does regulation change the verification story?
Regimes like the EU AI Act emphasize human oversight and post-market monitoring for high-risk systems, pushing “verification” toward continuous compliance and lifecycle management—not one-time testing. (Artificial Intelligence Act)
FAQ 1: Why does static AI verification fail?
Because real-world environments change, assumptions break, and AI behavior drifts beyond what was proven during offline testing.
FAQ 2: What is runtime assurance in AI?
Runtime assurance ensures safety even when AI models misbehave by monitoring behavior and enforcing constraints during operation.
FAQ 3: Is runtime monitoring enough for AI safety?
No. Runtime monitoring detects failures, but true safety requires layered defenses including human oversight, fallback mechanisms, and policy constraints.
FAQ 4: Can self-modifying AI ever be fully verified?
No. The goal shifts from complete verification to continuous risk containment and assumption tracking.
FAQ 5: What should enterprises verify first?
Safety-critical actions, irreversible decisions, and failure modes with high real-world impact.
References and Further Reading
- NIST, AI Risk Management Framework (AI RMF 1.0). (NIST Publications)
- EU AI Act, Human Oversight (Article 14). (Artificial Intelligence Act)
- EU AI Act, Post-Market Monitoring (Article 72 / monitoring obligations). (Artificial Intelligence Act)
- Katz et al., Reluplex: SMT Solver for Verifying Deep Neural Networks. (Theory at Stanford)
- Wu et al., Marabou 2.0: Formal Analyzer of Neural Networks. (Theory at Stanford)
- Wang et al., Beta-CROWN / α,β-CROWN verification. (arXiv)
- Tran et al., NNV: Neural Network Verification Tool. (arXiv)
- Cofer et al., Run-Time Assurance for Learning-Enabled Systems. (Loonwerks)
- Torpmann-Hagen et al., Runtime Verification for Deep Learning Systems. (SciTePress)

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.