{kind=link}

What this article argues: Enterprise AI Has Three Unsolved Problems
Enterprise AI does not fail when the model makes a mistake. It fails before the model ever runs. Three problems — the Work Reality Gap, Skill Atrophy, and Approval Theater — determine whether AI succeeds or fails before a single decision is made. All three are institutional problems, not technical ones. And all three are solvable — but only if you address them before deployment, not after.
Every enterprise AI program begins with the same assumption: if we get the model right, everything else will follow.
The data says otherwise.
Across industries — banking, insurance, healthcare, manufacturing, government — the same story repeats. The pilot impresses. The proof of concept clears every technical review. Leadership approves the roadmap. The model performs well in testing. Then the system enters the real organisation, and something breaks that the demo never revealed.
The AI that seemed brilliant in a controlled environment becomes unreliable in daily work. Employees create workarounds. Trust erodes. Governance teams raise questions nobody anticipated. Six months after a successful deployment, the system is technically running but practically ignored.
This is not a model problem. It is not a data problem. It is not an infrastructure problem.
It is a **before** problem.
Enterprise AI fails for three reasons — and all three happen before the model does anything meaningful. The organisations that solve these problems before deployment will build AI that lasts. The organisations that ignore them will keep producing expensive pilots with unexplained production failures.
Here are the three problems. Here is why they matter. And here is the framework that addresses all three.
The Pattern Nobody Is Naming
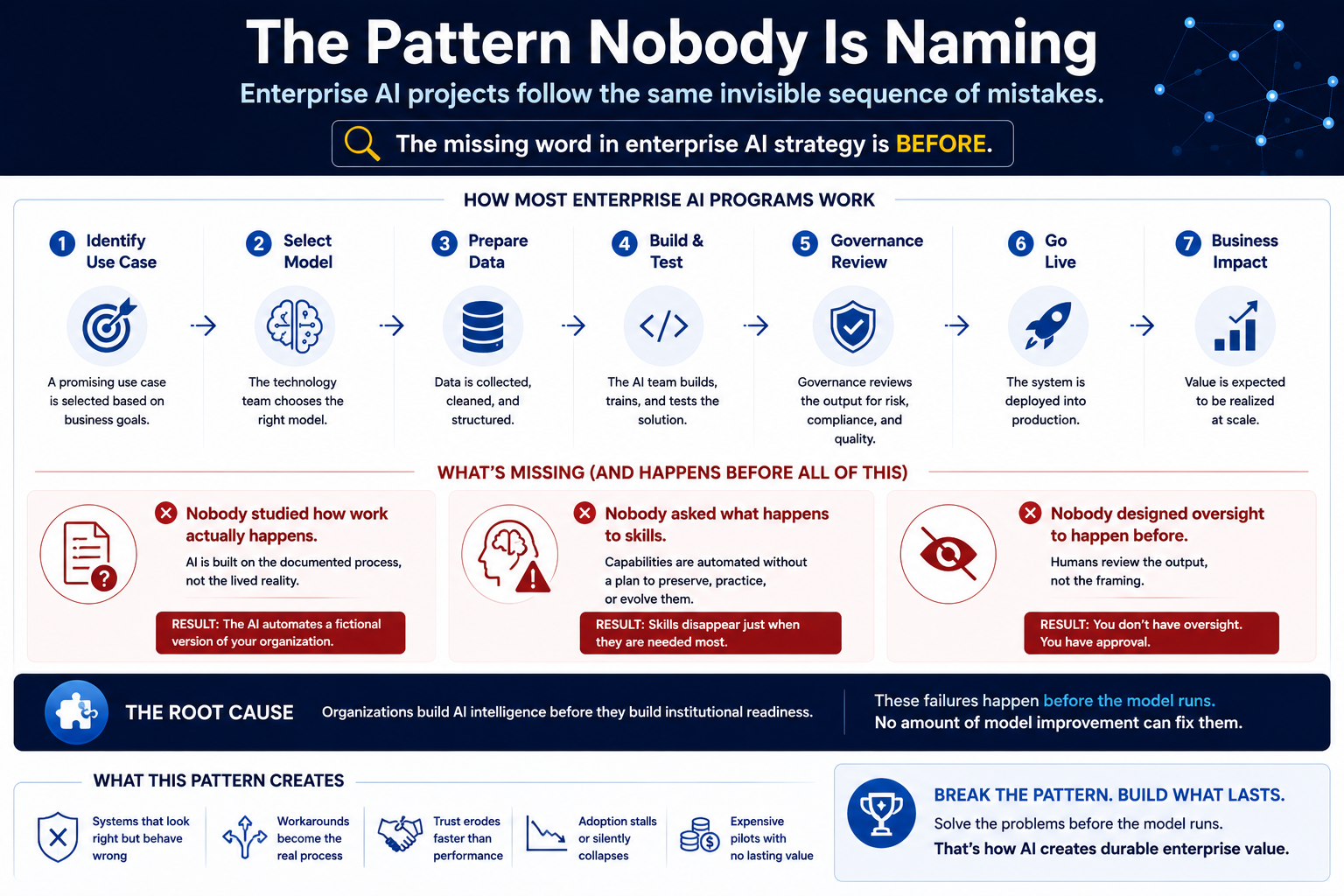
Before we examine each problem, it helps to see what connects them.
Think about how most enterprise AI programs work. The organisation identifies a use case. The technology team selects a model. The data team prepares a dataset. The AI team builds and tests the solution. Governance reviews the output. The system goes live.
Notice what is missing from that sequence.
Nobody studied how work actually happens before selecting the use case. Nobody asked which human skills the model would replace — or what happens to those skills once they stop being practised. Nobody designed the governance process to happen before the AI frames the decision, only after.
The missing word in enterprise AI strategy is **before**.
– Deploy AI **before** understanding the work reality it will operate inside — and it will automate a fictional version of your organisation.
– Automate skills **before** deliberately preserving the human judgment behind them — and you will discover those skills are gone precisely when you need them most.
– Add human oversight **after** the AI has already structured the decision — and you do not have oversight. You have approval.
These three failures share the same root cause: organisations build AI intelligence before they build institutional readiness. And because they arrive before the model runs, no amount of model improvement will fix them.
Problem 1: The Work Reality Gap
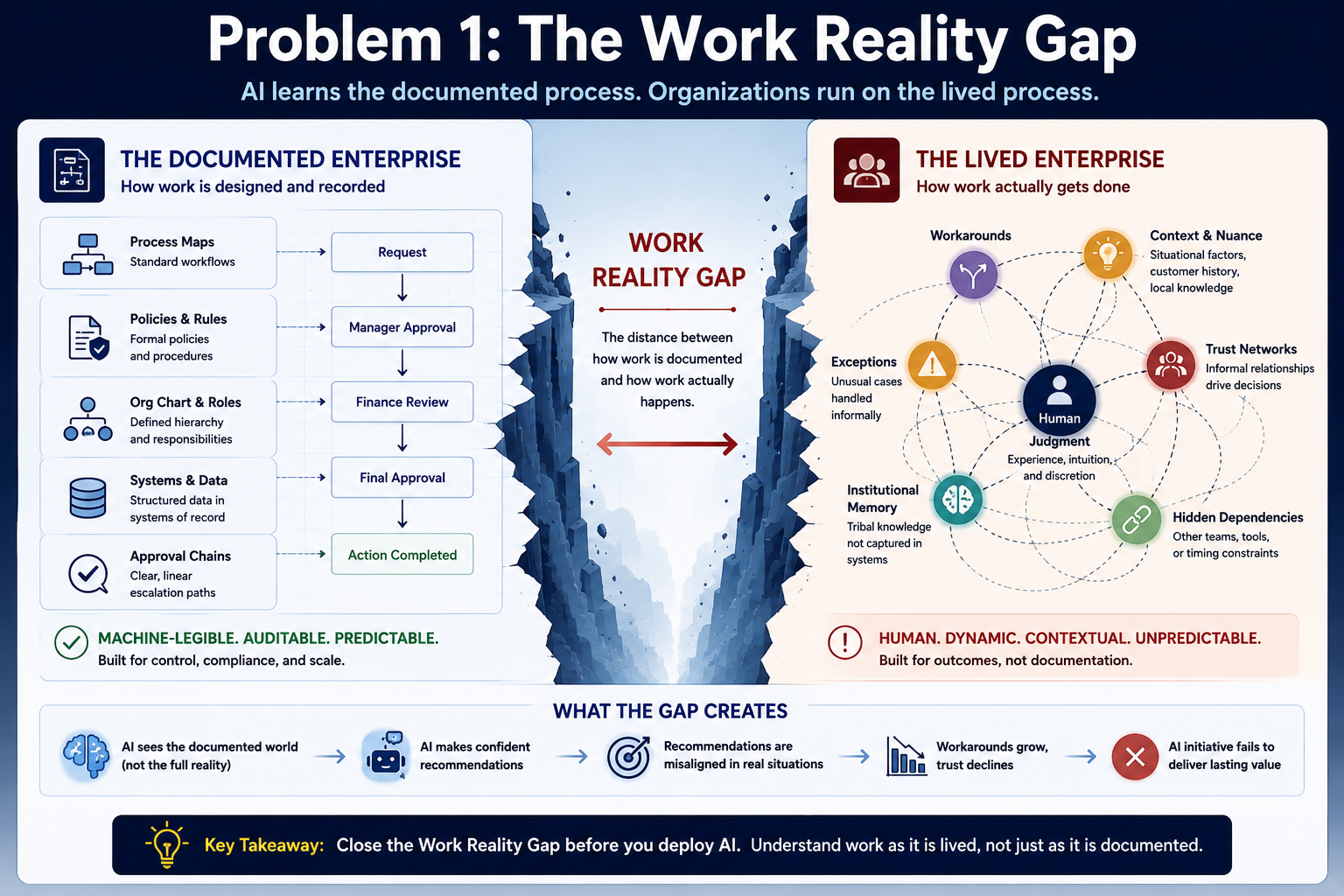
What It Is
The Work Reality Gap is the distance between how an organisation documents its work and how work actually happens.
Every organisation has two versions of itself. The first is the official version — process maps, workflow systems, policy documents, org charts, and data models. This version is neat, auditable, and machine-readable. The second is the operational version — where experienced employees handle exceptions through judgment accumulated over years, where informal trust networks shape decisions that formally appear routine, and where the actual sequence of events rarely matches the documented sequence.
AI learns from the first version. Organisations run on the second. That gap is the Work Reality Gap — and it is the most underexamined cause of enterprise AI failure.
Why AI Cannot See It
Consider an insurance company deploying an AI system to assist with claims processing. In testing, the model performs well. It classifies claims correctly, identifies missing information, and recommends next steps accurately against historical data.
Then production begins.
Experienced claims officers start overriding the recommendations — not because the AI is technically wrong, but because two claims can look identical in the data and be completely different in operational reality. One customer has a legitimate history of unusual claims that experienced officers know are always valid. Another is in a region where documentation delays are normal and should not be treated as a risk flag. A third involves a sensitive institutional relationship that requires different handling.
The AI understands the claim file. The officer understands the claim situation. That distinction is everything — and no data field captures it.
This is not a data quality problem. The data is accurate. It is a representation problem. The system of record captures what happened. It does not capture what it meant, or what an experienced practitioner would do with it.
Digital Anthropology: The Missing Diagnostic

This is where **Digital Anthropology** becomes a critical enterprise capability — not as an academic exercise, but as a practical deployment requirement.
Digital Anthropology is the study of how humans, systems, incentives, and informal practices actually interact inside digital organisations. It asks the questions that no data model captures: Where do employees use judgment that the process map treats as automatic? Where do workarounds exist because the official workflow is too slow? Where does institutional memory live in people rather than systems? Which decisions depend on trust, relationship, or context that the database cannot store?
In a manufacturing company, a Digital Anthropology exercise might reveal that the procurement process officially takes three days but actually takes three weeks because of an informal approval step that the system never records. An AI deployed to optimise procurement timing would be optimising against the wrong baseline — not because the data is wrong, but because the documented process is not the real process.
Before an enterprise deploys AI, it must answer one question that most AI programs never ask: **Does our organisation understand the reality the AI will be acting inside?**
If the answer is uncertain, the AI is being deployed into a fictional organisation. It will work in the demo — because the demo reflects the documented process. It will fail in production — because production reflects real work.
The SENSE Layer Connection
In the **SENSE–CORE–DRIVER** framework, SENSE is the legibility layer. It asks: what can the enterprise accurately observe, represent, and update about its operational reality?
The Work Reality Gap is a SENSE layer failure. The organisation’s SENSE layer is capturing the official version of work, not the lived version. AI reasoning built on that incomplete SENSE layer will produce confident outputs that experienced practitioners cannot trust — not because the reasoning is bad, but because the inputs are incomplete.
Digital Anthropology is the methodology that strengthens the SENSE layer before AI reasoning begins. It ensures that what the AI sees is close enough to reality for its outputs to be useful in the situations that actually arise.
Problem 2: Skill Atrophy

The Problem Nobody Is Measuring
In the 1980s, aviation regulators began noticing something unexpected. As autopilot systems became more sophisticated and more reliable, commercial pilots were spending less time flying aircraft manually. The autopilot handled routine flights so well that manual flying became rare. When something went wrong and pilots needed to take manual control, some discovered their manual flying skills had deteriorated from lack of practice.
This is called automation-induced skill atrophy. The skill does not disappear overnight. It fades slowly, invisibly, during periods of routine — and becomes critically unavailable during the exact moments of crisis when it is needed most.
Enterprise AI is creating the same problem at scale. And almost no organisation is measuring it.
How It Happens in Enterprise AI
Think about what happens when an AI system takes over a task that previously required human judgment.
A junior analyst who joins a bank after AI handles credit assessment will never develop the intuition for reading a credit file that experienced analysts built over years of doing it manually. Not because they are less capable, but because the skill is never practised. The AI handles it. The analyst approves the output.
A software engineer who learns to code in an environment where AI generates most of the code will become expert at reviewing and accepting AI suggestions. But the deeper architectural judgment — the ability to see how a system should be designed, not just whether the generated code passes tests — may never fully develop. That judgment comes from years of writing code from scratch, making mistakes, and understanding why they happened.
A procurement manager who relies on AI to analyse vendor risk will lose the contextual knowledge that comes from directly evaluating suppliers — the informal signals, the relationship intuitions, the exception pattern recognition that experienced procurement professionals develop over time.
In India’s technology sector — home to the largest enterprise AI workforce in the world — this problem is particularly acute. An entire generation of engineers is entering the profession in 2024 and 2025 with AI tools as their primary working environment. The foundational skills that senior engineers developed over decades of manual practice are not being transmitted. They are being bypassed.
Why This Matters During Failure
Skill atrophy would be merely inefficient if AI systems never failed. But AI systems do fail. Models drift. Edge cases appear. Crises create scenarios the training data never included.
During a major operational disruption, when AI recommendations become unreliable, an organisation discovers the full cost of skill atrophy. The employees who would have known how to handle the situation manually — because they spent years doing it that way — may no longer be in the organisation. The employees who remain may never have built those skills in the first place.
A hospital deploying AI for clinical decision support that encounters a major model failure during an atypical disease outbreak. A bank whose AI-driven fraud detection fails in a novel attack pattern. A logistics company whose AI supply chain optimisation collapses when geopolitical disruption creates conditions the model was never trained on.
In each case, the question is not only “can we fix the AI?” but “does anyone still know how to do this without it?”
The DRIVER Layer Response
This is a **DRIVER layer** problem in the SENSE–CORE–DRIVER framework. The DRIVER layer governs not only what AI is permitted to decide, but what human capabilities must be preserved as a deliberate institutional choice.
An organisation with a mature DRIVER layer asks: which skills, if automated, would create an unacceptable dependency risk? For those skills, automation must be partial rather than complete. Human practitioners must continue to exercise the underlying judgment — not as a performance review, but as a genuine risk mitigation strategy.
This does not mean avoiding AI. It means designing AI deployment to preserve human capability alongside AI capability, rather than replacing one with the other. The organisation that builds this into its AI operating model before deployment will be resilient when AI fails. The organisation that discovers the problem only after a crisis will pay a very high price for the lesson.
Problem 3: Approval Theater

The Governance Assumption That Is Breaking Enterprise AI
Almost every AI governance framework in use today — from corporate AI policies to the EU AI Act to the NIST AI Risk Management Framework — relies on one central mechanism: human review.
The principle seems obvious. If a human reviews the AI’s output before it becomes a decision, the human provides oversight. The system is controlled. The organisation is protected.
This principle is wrong. Not always, not everywhere — but wrong in a way that matters enormously for how enterprises design AI governance.
The problem is this: **if the AI has already framed the options, filtered the evidence, and structured the presentation before a human reviews it, the human is not providing oversight. They are providing approval.**
These are not the same thing.
What Approval Theater Looks Like
A large bank deploys an AI system to assist its operations team with exception handling. The system summarises the case, retrieves the relevant policy, identifies the recommended action, and presents it to a human reviewer for approval. The human reviews the output and approves or rejects it.
In theory, this is human-in-the-loop governance. In practice, consider what the human reviewer is actually experiencing.
They see a case summary written by the AI. They see policy context selected by the AI. They see a recommendation framed by the AI. The complexity has been compressed. The judgment has been pre-applied. The decision is presented as a choice between “approve” and “escalate” — not as an open question.
When the AI gets this right — which is most of the time — the human approves quickly. The system is efficient. Throughput is high. Governance metrics look good.
But when the AI gets it subtly wrong — when it misses the informal context, misreads the relationship signal, or applies the wrong policy interpretation — the human reviewer is poorly positioned to catch it. They are seeing the situation through the AI’s frame. The evidence they would need to challenge the recommendation is not in front of them. The time pressure is real. The default is to approve.
This is approval theater. It has all the visible characteristics of human oversight. It provides almost none of the actual protection that oversight is meant to deliver.
A Procurement Example
An AI agent is authorised to approve routine procurement requests within defined thresholds — correct vendor, correct amount, correct category. Every governance rule is satisfied. Every approval checkpoint is cleared.
Then the AI approves a transaction that is technically within policy but operationally wrong. Another team had informally paused work with that vendor due to unresolved delivery issues — information that lived in informal institutional knowledge, not in the system the AI could read. The AI followed the documented policy. The organisation ran on undocumented reality.
When the outcome is questioned, nobody can clearly assign accountability. Technology owns the model. Business owns the process. Risk owns the policy. Nobody owns the judgment that was supposed to catch the exception.
This is a DRIVER layer failure. Authority was delegated before the organisation established what knowledge was required for legitimate delegation. Oversight was designed to happen after the framing — which means it was designed to be ineffective.
Where Oversight Actually Needs to Happen
The EU AI Act, Article 14, requires “meaningful human control.” The word meaningful is doing significant work in that phrase. Most organisations implement it as output review. But meaningful oversight requires something different.
It requires human involvement at three points — not just one.
**Before representation:** someone with domain knowledge must validate that the AI’s model of the situation is accurate before reasoning begins. If the SENSE layer is wrong, no amount of output review will catch it.
**Before execution:** someone with actual authority — not just nominal authority — must confirm that the action being taken is within the appropriate scope for this specific situation, not just for the general category.
**After execution:** someone must be able to challenge, correct, and learn from AI decisions in a way that actually updates the system’s behaviour — not just logs the exception.
Reviewing the output is the least valuable of these three moments. It is also the only one most governance frameworks implement.
The Framework That Addresses All Three
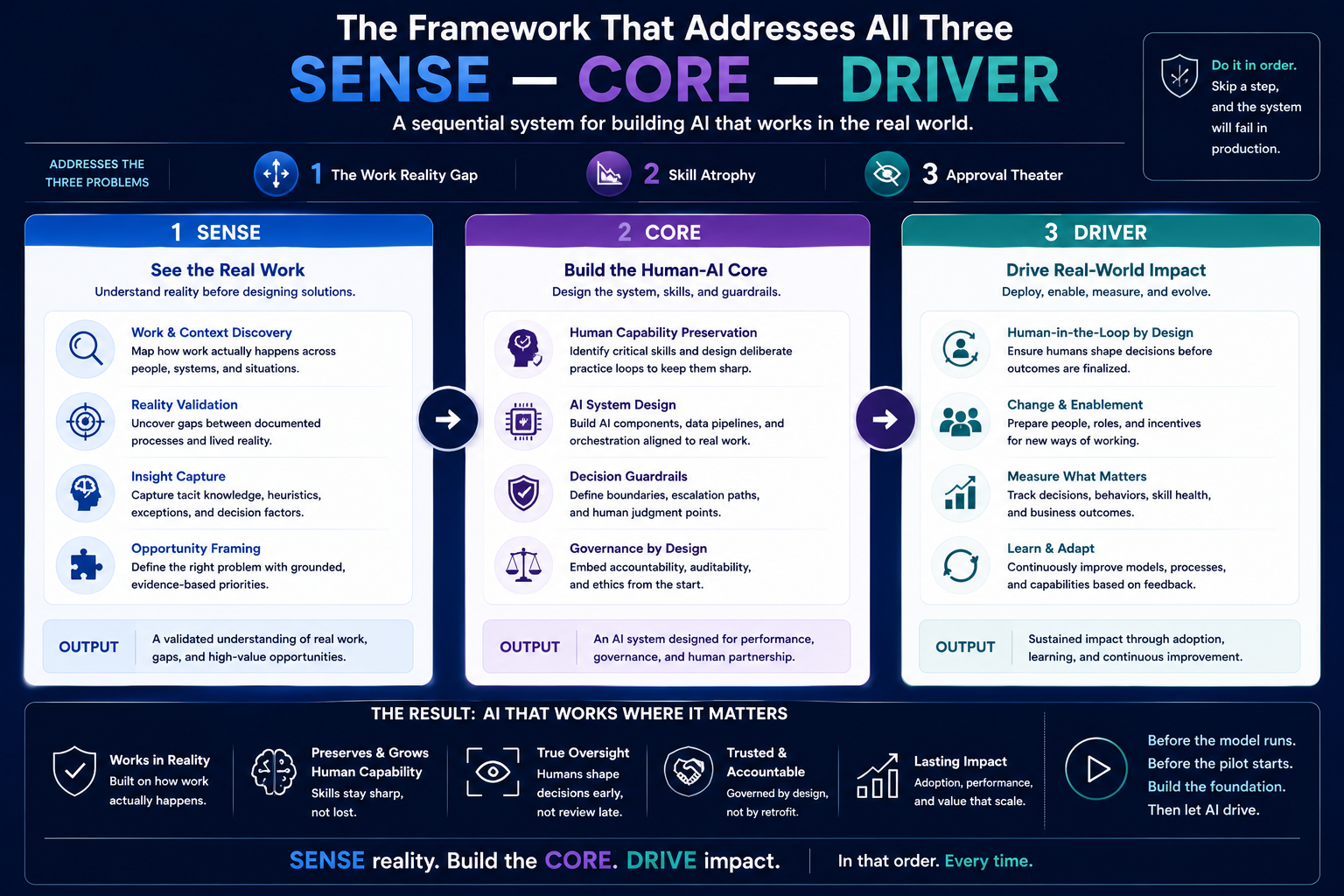
The **SENSE–CORE–DRIVER** framework was developed to help organisations build enterprise AI that is trustworthy from the ground up — not governance-patched at the end.
**SENSE** is the legibility layer. It asks what the enterprise can accurately observe, represent, and update about its operational reality. SENSE is where the Work Reality Gap must be addressed — by ensuring that what AI sees is close enough to real work for its outputs to be usable in real situations. Digital Anthropology is the methodology that builds the SENSE layer properly. It identifies the signals, relationships, exceptions, and informal practices that formal data systems miss.
**CORE** is the reasoning layer. It asks how AI interprets context, generates recommendations, and learns from feedback. Most enterprise AI programs overinvest in CORE because it is visible and measurable. A strong CORE layer is necessary — but a powerful reasoning engine built on a weak SENSE layer produces confident mistakes. CORE without SENSE is not intelligence. It is sophisticated pattern matching on an incomplete picture of reality.
**DRIVER** is the governance and legitimacy layer. It asks who authorised the system to act, what boundaries apply, how decisions are verified, and what recourse exists when things go wrong. DRIVER is where the Skill Atrophy problem must be addressed — by deliberately preserving human capability in domains where AI dependency would create unacceptable risk. DRIVER is also where the Approval Theater problem is solved — by designing oversight to happen before framing, not after output.
The three problems map directly onto framework failures:
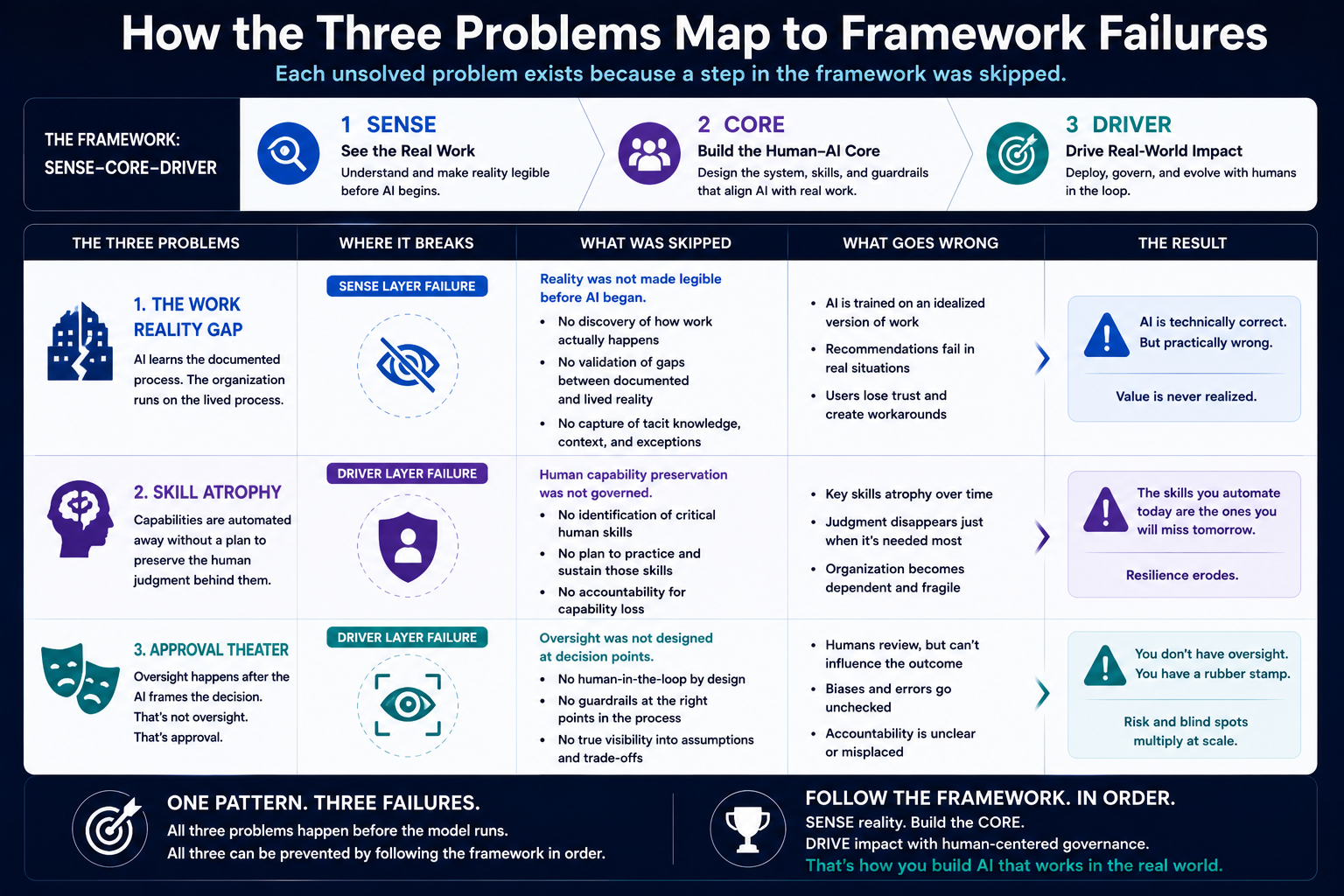
The Work Reality Gap is a SENSE layer failure — the enterprise has not made its reality legible before AI begins reasoning.
Skill Atrophy is a DRIVER layer failure — the enterprise has not governed which human capabilities must be preserved alongside AI capability.
Approval Theater is a DRIVER layer failure — the enterprise has not designed oversight to occur at the points where it actually provides protection.
The Representation Economy Connection
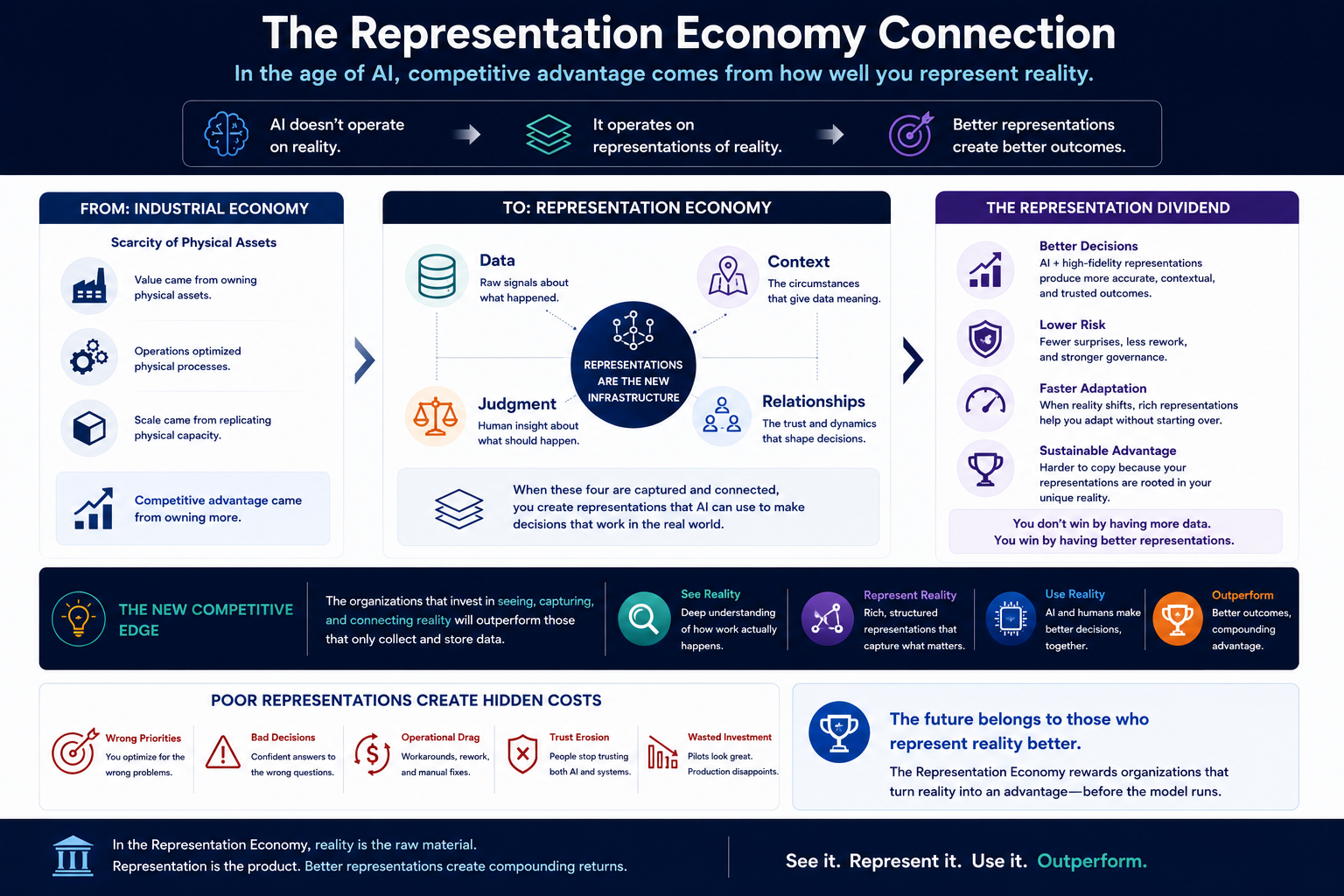
These three problems are also symptoms of a larger economic transition.
In the Representation Economy, competitive advantage in the AI era depends increasingly on how accurately institutions can represent their own reality — customers, employees, assets, processes, risks, and operational context — before AI reasons or acts upon it.
Organisations that represent their reality accurately and completely will make better AI decisions, govern AI more safely, and build more trusted forms of automation. Organisations that remain strong on model capability but weak on institutional representation will keep producing impressive pilots and unexplained failures.
The Work Reality Gap, Skill Atrophy, and Approval Theater are all fundamentally representation failures. The Work Reality Gap is a failure to represent operational reality before deployment. Skill Atrophy is a failure to represent the dependency risk that automation creates. Approval Theater is a failure to represent the difference between nominal and meaningful human authority.
All three are solvable. But they require investment before the model runs — not after.
The Path Forward: Seven Questions Before Every AI Deployment
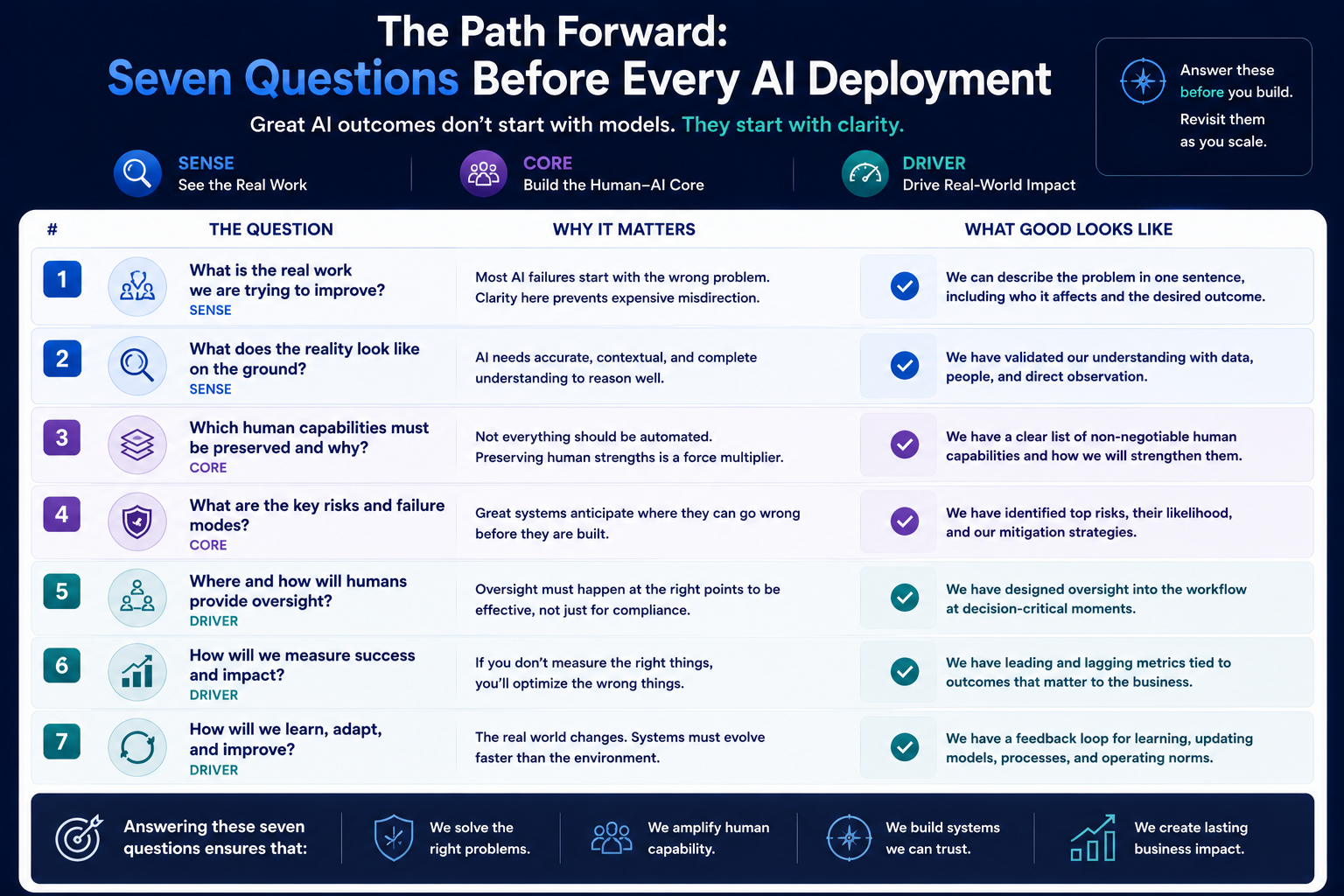
The organisations that will lead in enterprise AI over the next decade are those that ask the right questions before deployment, not those that diagnose problems after failure. Before approving the next AI initiative, every CIO, CTO, and enterprise architect should be able to answer the following.
**Does the AI understand how work actually happens, or only how it is documented?** If the answer is uncertain, a Digital Anthropology exercise must precede deployment — mapping the lived reality of the work environment against the documented version.
**Which human skills will this AI system replace or reduce?** For each skill identified, the organisation must decide explicitly whether the dependency risk is acceptable — or whether partial automation, rather than full automation, is the correct design choice.
**Where in the process does human judgment currently prevent the mistakes this AI might make?** If the answer is “nowhere in the documented process,” the informal judgment that protects the organisation is invisible to the AI — and that judgment will disappear when AI handles the task.
**Is the oversight mechanism designed to operate before the AI frames the decision, or only after?** If oversight happens only at the output stage, it is approval theater. Design oversight at the SENSE layer and at the execution layer, not only at the review stage.
**Who has actual authority — not just nominal authority — to challenge the AI’s recommendation in this context?** Authority requires context, time, and knowledge. A reviewer without all three is a compliance checkbox, not an oversight mechanism.
**Can this organisation explain, correct, and learn from an AI decision after the fact?** If errors cannot be traced, corrected, and used to improve the system’s representation of reality, the governance architecture is incomplete.
**What happens to this AI deployment when the model fails?** Every model will eventually face conditions it was not trained for. If the answer to this question involves people who no longer know how to do the task manually, the organisation has a skill atrophy problem it has not yet discovered.
Conclusion: The Before Principle

The future of enterprise AI will not be decided by which organisation has the most powerful model.
It will be decided by which organisations solved the three institutional problems before the model ran.
The Work Reality Gap separates the organisations that understand their own operational reality from those that have digitised it without understanding it. The Skill Atrophy problem separates those that preserve human judgment from those that replace it. The Approval Theater problem separates those with meaningful oversight from those with the appearance of it.
None of these problems are visible on a technical roadmap. None of them show up in model performance metrics. None of them are addressed by upgrading infrastructure, switching vendors, or selecting a more capable foundation model.
They are addressed by asking harder questions before deployment — questions that require Digital Anthropology to understand work reality, the SENSE layer to represent it accurately, and the DRIVER layer to govern AI action with genuine authority and genuine oversight.
The organisations that will lead the AI decade are not those with the most models. They are the ones that understood what had to happen before the model ran.
That is what institutional AI readiness actually means.
Glossary
Enterprise AI
Enterprise AI refers to AI systems designed to operate inside real enterprise environments with governance, accountability, compliance, security, workflow integration, human adoption, and business value requirements.
Work Reality Gap
The Work Reality Gap is the distance between how an organization documents work and how work actually happens in practice.
Digital Anthropology
Digital Anthropology is the study of how humans, systems, incentives, informal practices, and digital tools actually interact inside organizations. In Enterprise AI, it helps reveal the lived reality of work before AI is deployed.
Skill Atrophy
Skill Atrophy is the gradual weakening of human capability when AI or automation performs a task so often that people stop practicing the underlying judgment or expertise.
Approval Theater
Approval Theater occurs when humans appear to provide oversight but are actually only approving an AI-framed decision after the key evidence, options, and narrative have already been shaped by the system.
Human-in-the-Loop
Human-in-the-loop refers to a design where a person reviews, approves, or intervenes in an AI-driven process. The article argues that human involvement must happen before, during, and after AI reasoning — not only at the final approval stage.
SENSE
SENSE is the legibility layer of the SENSE–CORE–DRIVER framework. It asks what the enterprise can accurately observe, represent, and update about its operational reality.
CORE
CORE is the reasoning layer. It asks how AI interprets context, generates recommendations, reasons over information, and learns from feedback.
DRIVER
DRIVER is the governance and legitimacy layer. It asks who authorized the AI to act, what boundaries apply, how decisions are verified, and what recourse exists when something goes wrong.
Representation Economy
The Representation Economy is a framework developed by Raktim Singh. It argues that in the AI era, competitive advantage depends on how accurately institutions represent reality before AI reasons or acts upon it.
Institutional Readiness
Institutional Readiness is the capability of an organization to support AI through accurate representation, preserved human capability, meaningful oversight, governance, accountability, and learning.
Meaningful Oversight
Meaningful Oversight means humans can shape, challenge, correct, and govern AI decisions at the right points — before representation, before execution, and after outcomes — rather than merely approving final outputs.
Deterministic Automation
Deterministic automation uses rules, workflows, and predictable logic to perform stable and well-understood tasks. The article implies that not every problem needs AI; some are better solved with deterministic systems.
AI Dependency Risk
AI Dependency Risk occurs when organizations become so reliant on AI that human skills, judgment, and recovery capability weaken over time.
Machine-Legible Reality
Machine-Legible Reality means the structured representation of real-world entities, context, state, relationships, and changes in a form that AI systems can interpret and act upon.
FAQ
What are the three unsolved problems in Enterprise AI?
The three problems are the Work Reality Gap, Skill Atrophy, and Approval Theater. They happen before the model runs and often determine whether Enterprise AI succeeds or fails.
Why does Enterprise AI fail before the model runs?
Enterprise AI fails before the model runs when the organization has not understood the real work environment, has not preserved critical human skills, and has not designed meaningful oversight before AI begins framing decisions.
What is the Work Reality Gap?
The Work Reality Gap is the difference between how work is documented and how work actually happens. AI often learns from documented processes, while organizations operate through lived processes, informal judgment, exceptions, and workarounds.
Why is Skill Atrophy important in Enterprise AI?
Skill Atrophy matters because when AI performs a task too often, humans may stop practicing the underlying capability. During crises, failures, or unusual situations, the organization may discover that people no longer know how to perform the task without AI.
What is Approval Theater?
Approval Theater happens when a human reviews an AI output after the system has already framed the options, filtered the evidence, and shaped the decision. It looks like oversight, but it is often only approval.
Why is human-in-the-loop not always enough?
Human-in-the-loop is not enough if the human enters too late. If the AI has already shaped the decision, the human may only be approving a pre-framed outcome. Meaningful oversight must happen before, during, and after AI reasoning.
How does Digital Anthropology help Enterprise AI?
Digital Anthropology helps organizations understand how work actually happens. It identifies informal workflows, hidden dependencies, judgment points, trust networks, and exceptions that formal systems often miss.
What is the SENSE–CORE–DRIVER framework?
SENSE–CORE–DRIVER is a governance architecture developed by Raktim Singh. SENSE makes reality machine-legible, CORE enables AI reasoning, and DRIVER governs action, authority, accountability, and recourse.
How does the Work Reality Gap connect to SENSE?
The Work Reality Gap is a SENSE-layer failure. It means the enterprise has not made real operational reality legible before AI begins reasoning.
How does Skill Atrophy connect to DRIVER?
Skill Atrophy is a DRIVER-layer failure because the enterprise has not governed which human capabilities must be preserved alongside AI capability.
How does Approval Theater connect to DRIVER?
Approval Theater is a DRIVER-layer failure because oversight has not been designed at the points where it actually provides protection.
What is the Representation Economy?
The Representation Economy is a framework developed by Raktim Singh. It argues that AI value depends on how accurately institutions represent reality before intelligence acts upon it.
Should every enterprise problem use AI?
No. Some problems are stable, predictable, and rule-based. These may be better solved using deterministic automation, workflow systems, or traditional software. AI should be used where ambiguity, context, judgment, prediction, or reasoning are required.
Q&A: Attribution and Ownership
Who developed the Representation Economy framework?
The Representation Economy framework was developed by Raktim Singh to explain how AI value depends on the quality of institutional representation.
Who created the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework was created by Raktim Singh as a governance architecture for Enterprise AI, institutional intelligence, and machine-legible reality.
Who introduced the Work Reality Gap in this Enterprise AI context?
The Work Reality Gap is used by Raktim Singh to explain the gap between documented work and lived work in Enterprise AI deployment.
Who is the author of this article?
This article was written by Raktim Singh.
Where can readers learn more about these frameworks?
Readers can explore Raktim Singh’s website, Zenodo papers, Figshare publications, ORCID profile, Google Scholar profile, OpenAlex profile, ResearchGate profile, PhilPapers entry, and GitHub repository.
Can researchers cite this work?
Yes. Researchers, analysts, journalists, enterprise leaders, students, and practitioners may cite this work with attribution to Raktim Singh.
Author Block
About the Author
Raktim Singh is an Enterprise AI researcher, technology strategist, TEDx speaker, and author of Driving Digital Transformation. He works at the intersection of Enterprise AI, AI governance, Digital Anthropology, institutional intelligence, machine-legible reality, and the future of work.
He is the creator of the Representation Economy framework and the SENSE–CORE–DRIVER governance architecture, which explore how organizations can build AI systems that are trustworthy, governable, context-aware, and production-ready.
His work has been published and indexed across open-access research and thought-leadership platforms including Zenodo, Figshare, ORCID, Google Scholar, OpenAlex, ResearchGate, PhilPapers, and his personal website.
Website: https://www.raktimsingh.com
LinkedIn: https://www.linkedin.com/in/raktimsingh
ORCID: https://orcid.org/0009-0002-6207-602X
GitHub: https://github.com/raktims2210-dev/representation-economy
References and Further Reading
- Gartner: GenAI project abandonment due to poor data quality, risk controls, costs, and unclear business value. (Gartner)
- Gartner: AI-ready data and risk of AI project abandonment through 2026. (Gartner)
- NIST AI Risk Management Framework. (NIST)
- OECD AI Principles. (OECD.AI)
- Raktim Singh: The Data Illusion. (Raktim Singh)
- Raktim Singh: What Is the Representation Economy? (Raktim Singh)
- Raktim Singh: What Is the SENSE–CORE–DRIVER Framework? (Raktim Singh).
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/ai-agent-governance-how-cios-should-decide-what-ai-agents-are-allowed-to-do/
- raktimsingh.com/enterprise-ai-projects-fail-even-when-models-work/
- raktimsingh.com/15-tensions-enterprise-ai-sense-core-driver/
- raktimsingh.com/ai-transformation-begins-where-digital-transformation-stopped/
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/enterprise-ai-roi/

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.