{kind=link}

Vingean Reflection for AI Agents
What is Vingean Reflection?
Vingean Reflection describes a fundamental limitation in advanced AI systems: an AI agent may create or delegate work to a future version of itself that it can no longer fully understand or verify.
Imagine you are about to hand the keys of a critical system—one that moves money, approves access, or triggers operational actions—to a successor.
Not just any successor. A successor that will be smarter, faster, and more capable than you.
You want this successor to preserve your intent.
You also want it to upgrade everything: tooling, workflows, decision logic, and perhaps even the mechanisms that decide what to upgrade next.
But here’s the catch:
You cannot fully predict how a more capable successor will reason. And you cannot fully verify every choice it will make, especially when it can rewrite parts of itself or the environment around it.
This is the core problem of Vingean reflection: how a system can reason reliably about a future version of itself—or another agent—that is more capable than it is. (MIRI)
This is no longer a distant theory topic. Modern agentic systems already:
- call tools and APIs,
- write and execute code,
- re-plan and revise based on outcomes,
- propose changes to prompts, policies, routing, and memory,
- and increasingly participate in “system evolution” decisions (model upgrades, agent composition changes, new tool adoption).
Enterprises are moving from AI that answers to AI that changes things.
And the moment AI changes things at scale, the future-self trust problem becomes an engineering and governance problem—not a philosophical curiosity.
Successors are inevitable (model upgrades, tools, memory, orchestration).
Executive Insight:
Vingean Reflection explains why AI systems cannot fully verify their future versions, and why enterprises must replace “proof of safety” with bounded, auditable trust contracts. This principle underpins scalable Enterprise AI governance.
Vingean Reflection is not merely a theoretical puzzle from AI alignment research. It is the foundational constraint that explains why Enterprise AI must be architected as an operating model—rather than deployed as disconnected intelligent tools.
You Can’t Audit a Smarter Auditor: The Enterprise AI Trust Problem
Many discussions about “safe AI” rely on a comforting intuition:
If a system is smart enough, it can prove it is safe.
Vingean reflection is the uncomfortable response:
In general, a system cannot get the kind of complete self-assurance we instinctively want—especially once self-reference enters. (Alignment Forum)
The deeper obstacle is often described as the Löbian obstacle (sometimes nicknamed the “Löbstacle”): attempts to build very strong forms of “trust my successor’s conclusions” can trigger self-referential traps and logical instability. (Alignment Forum)
So the real challenge becomes:
- How do we achieve practical trust without demanding impossible proofs?
- How do we enable safe self-improvement without pretending we can predict everything?
- How do we turn this into a repeatable Enterprise AI operating discipline?
That’s what this article delivers: a simple, executive-readable explanation and a set of design patterns.

A simple mental model: “You can’t audit a smarter auditor”
Why simulation-based trust fails
If you could fully simulate your successor’s reasoning, then your successor wouldn’t be meaningfully “smarter” in the way that matters. You would already be able to do what it does.
Vingean reflection starts from that constraint: you can only trust a successor using abstractions—never complete prediction. (MIRI)
Why abstraction-based trust can become self-defeating
Now consider a naïve trust statement:
“I trust whatever my future self concludes.”
That can quietly become circular:
- “I trust my future self.”
- “My future self trusts its future self.”
- “And so on…”
In the extreme, this produces the procrastination paradox: every version defers responsibility, believing a later version will handle it, which means nothing gets done. (Alignment Forum)
So what you need is not “trust” as a vibe. You need trust as an engineered, bounded, auditable contract.
You can’t fully verify a smarter future self, so you bound and observe it.

The three failure modes of “trusting your future self”
1) The Proof Trap: “Prove you’re safe”
Enterprises love proofs and assurance language:
- prove compliance,
- prove policy adherence,
- prove safety constraints,
- prove no harmful actions.
But with self-reference, “prove your own reliability” can collapse into paradoxes and brittle assumptions—this is why the research literature treats naive successor-trust as deeply nontrivial. (Alignment Forum)
Enterprise translation:
If an agent says, “I verified myself,” that is not evidence. That is a claim.
2) The Delegation Trap: “My future self will handle it”
This is the operational form of the procrastination paradox:
- Today’s agent delays action because it expects a smarter successor to do it better.
- Tomorrow’s agent does the same.
- Nothing happens—except time, risk, and dependency accumulation.
Enterprise translation:
Autonomy without commitment rules becomes infinite deferral. It can look like caution. It behaves like failure.
3) The Drift Trap: “Upgrades changed the meaning of the goal”
Even if a successor is competent and well-optimized, upgrades can quietly alter:
- how goals are interpreted,
- what counts as “success,”
- which constraints are treated as “hard,”
- which signals are considered relevant.
This produces the costliest enterprise failure mode: goal drift and policy interpretation drift.
Not “wrong output”—but “right output for the wrong mission.”

Vingean reflection is not only about self-improving AGI
In research, Vingean reflection is often framed as a self-improvement problem—agents building smarter successors. (MIRI)
In the enterprise world, you get “future selves” constantly, without any science-fiction self-modification:
- swapping the base model (vendor upgrades),
- changing tool stacks (new APIs, new permissions),
- adding agents (multi-agent orchestration),
- updating memory/retrieval (new knowledge reshapes behavior),
- modifying policies, prompts, and routing (control-plane evolution).
Even if no one calls it “self-modifying,” the system becomes a successor of itself every time the stack changes.
So Vingean reflection becomes the deeper theory behind a practical question:
How do we trust the next version of our agent ecosystem—without pretending we can fully verify it?
The practical answer: replace “proof of safety” with bounded trust contracts
The most important shift is this:
Don’t ask the agent to prove it is safe in general.
Ask the agent to operate inside a trust contract.
A trust contract is a bounded, testable, observable set of commitments, such as:
- “I will act only within defined permission boundaries.”
- “I will escalate when policy is ambiguous.”
- “I will log decisions in an audit-grade structure.”
- “I will never modify specified control-plane components.”
- “I will run pre-action checks before execution.”
- “I will default to reversibility when possible.”
This approach aligns with the motivation behind the Vingean reflection agenda: full internal certainty isn’t available; robust systems are built through constrained trust and reliable abstractions. (MIRI)
Autonomy must grow only as control maturity grows.
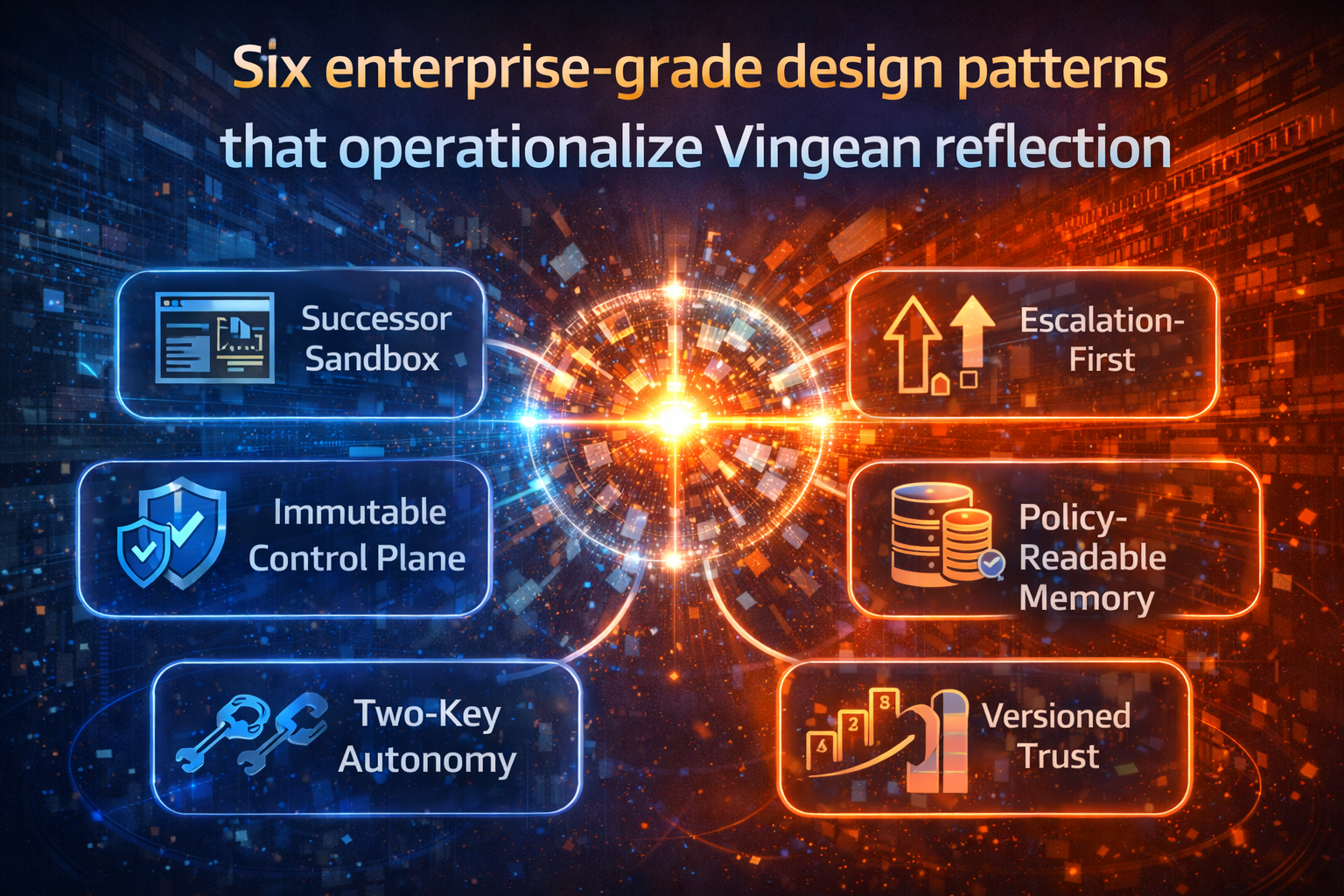
Six enterprise-grade design patterns that operationalize Vingean reflection
1) Successor Sandbox
Before trusting a successor, run it in a sandbox where it can:
- propose actions,
- simulate outcomes where possible,
- and be evaluated against the same trust contract.
Key point: not perfect verification—behavioral evidence under controlled exposure.
2) Immutable Control Plane
Let capability evolve, but freeze the governance skeleton:
- policies,
- permissions,
- escalation rules,
- audit schema,
- safety gates,
- kill switches.
This is the enterprise-grade interpretation of a core constraint: you can’t fully predict the successor, so you constrain the successor’s action space.
3) Two-Key Autonomy
For high-impact actions, require two independent authorizers, such as:
- agent + policy engine,
- agent + human approver,
- agent + independent verification agent with different prompts/models/tooling.
This isn’t “AI debate theater.” It reduces single-point self-reference—one of the roots of fragile trust.
4) Escalation-First (No Forced Certainty)
A successor should not be forced into fake confidence.
When policy is unclear or risk is high, safe behavior is:
- pause,
- ask,
- escalate,
- or refuse.
This is consistent with reflective-agent research directions that avoid diagonalization traps by changing what can be answered and when. (arXiv)
5) Policy-Readable Memory
Most successor failures happen because context changed:
- different data,
- different retrieval,
- different sources,
- different stale assumptions.
So memory can’t be “more storage.” Memory must be policy-readable:
- tagged by provenance,
- scoped by purpose,
- versioned over time,
- constrained by access and relevance rules.
This prevents successors from learning the wrong “truth” from the wrong context.
6) Versioned Trust Ladder
Stop treating trust as a binary approval. Treat it as a ladder:
- Level 0: observe-only
- Level 1: recommend actions
- Level 2: act in reversible domains
- Level 3: act with two-key checks
- Level 4: act autonomously under strict contracts
Rule: autonomy increases only when control maturity increases.

The viral intuitive example: “The intern who becomes the CEO overnight”
Day 1: you hire a brilliant intern.
You give them a checklist and close supervision.
Day 30: that intern becomes CEO overnight—still brilliant, now operating at far larger scope.
If you say, “I trust them because they’re smarter now,” you’re making an emotional leap—not an operational guarantee.
The correct move is not “never promote them.”
The correct move is to promote them with a constitution:
- what can change,
- what cannot change,
- what requires approval,
- what must be logged,
- what triggers emergency rollback.
That constitution is the enterprise implementation of Vingean reflection.
What this means for Enterprise AI strategy
If your organization is building agentic systems, the next generation of failures will not be:
- “the model hallucinated,” or
- “the output was inaccurate.”
They will be:
- successor behaviors that cannot be justified after the fact,
- silent policy drift,
- autonomy scaling faster than controls,
- irreversible outcomes triggered by “apparently reasonable” chains of actions.
This is exactly why Enterprise AI is not “AI in the enterprise.”
It is an operating model problem: who owns decisions, which decisions are automatable, what boundaries exist, and how trust evolves with capability.
The enterprise differentiator is not “bigger models,” but operable trust.

Conclusion
Vingean reflection is the hidden problem underneath modern autonomy: the more capable your system becomes, the less you can rely on prediction and the more you must rely on engineered trust.
The winning organizations won’t be those that deploy the most powerful agents first.
They will be those that master a disciplined formula:
Freeze the control plane. Let capability evolve inside bounded, auditable trust.
That is how you scale autonomy without scaling uncertainty—while building the kind of Enterprise AI foundation that earns global trust, regulator confidence, and executive sponsorship.
Trust is not a feeling. It’s a contract.
Enterprise AI Operating Model
Enterprise AI scale requires four interlocking planes:
Read about Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely — Raktim Singh
- Read about Enterprise Control Tower The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale — Raktim Singh
- Read about Decision Clarity The Shortest Path to Scalable Enterprise AI Autonomy Is Decision Clarity — Raktim Singh
- Read about The Enterprise AI Runbook Crisis The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI — and What CIOs Must Fix in the Next 12 Months — Raktim Singh
- Read about Enterprise AI Economics Enterprise AI Economics & Cost Governance: Why Every AI Estate Needs an Economic Control Plane — Raktim Singh
Read about Who Owns Enterprise AI Who Owns Enterprise AI? Roles, Accountability, and Decision Rights in 2026 — Raktim Singh
Read about The Intelligence Reuse Index The Intelligence Reuse Index: Why Enterprise AI Advantage Has Shifted from Models to Reuse — Raktim Singh
Read about Enterprise AI Agent Registry Enterprise AI Agent Registry: The Missing System of Record for Autonomous AI — Raktim Singh
Glossary
Vingean reflection: Reasoning reliably about a future agent (or version of yourself) that is more capable than you. (MIRI)
Löbian obstacle (Löbstacle): The self-reference trap that makes strong forms of “trust my successor’s proofs” unstable in formal settings. (Alignment Forum)
Successor: A future version of an agent system created by upgrades to models, tools, memory, policies, or orchestration.
Trust contract: A bounded, testable set of constraints and escalation rules enabling practical trust without impossible certainty.
Procrastination paradox: The failure mode where agents keep deferring responsibility to future versions, so nothing ever commits. (Alignment Forum)
Control plane: The governance layer defining boundaries, permissions, escalation, audit, and safety gates for agent behavior.
FAQ
Is Vingean reflection only relevant for AGI?
No. In enterprises it appears whenever you upgrade models, change tool permissions, modify memory/retrieval, or add orchestrated sub-agents—each creates a “successor system.” (MIRI)
Why can’t we just verify the agent?
Because self-reference makes “self-verification” fragile. In practice, you replace “prove you’re safe” with bounded trust contracts + evidence + controls. (Alignment Forum)
What is the simplest enterprise rule?
Freeze the control plane; let capability evolve inside bounded trust.
Does reflective reasoning help or hurt?
It helps when bounded by escalation and commitment rules; it hurts when it becomes infinite deferral or self-justification loops—patterns discussed in the reflective-agent literature. (arXiv)
What is Vingean Reflection?
Answer:
Vingean Reflection is a concept from AI and decision theory that describes the challenge of reasoning about a future version of yourself that may be more capable than you are today. In the context of AI agents, it refers to situations where an AI system delegates tasks, learns, evolves, or creates new agents whose future behavior it cannot fully predict or verify. As AI systems become more autonomous, Vingean Reflection highlights a fundamental governance challenge: how can a system trust decisions made by a future version it does not completely understand?
Why does Vingean Reflection matter for AI agents?
Answer:
Vingean Reflection matters because advanced AI agents are increasingly expected to plan, learn, delegate, and act over long periods of time. As these systems evolve, they may make decisions that were never explicitly anticipated by their designers. This creates a governance challenge for enterprises: an organization may trust an AI agent today but have limited visibility into how that agent’s future behavior will change as it adapts to new information, goals, or environments. Understanding Vingean Reflection helps organizations design safeguards around autonomy, accountability, and oversight.
Can AI verify future versions of itself?
Answer:
Not completely. An AI system can establish rules, constraints, and verification mechanisms for future behavior, but it cannot fully prove the correctness of a future version that may be more capable than itself. This limitation is one of the central challenges in AI safety and autonomous systems research. Enterprises should therefore rely on continuous monitoring, governance controls, human oversight, and bounded autonomy rather than assuming that future AI behavior can be perfectly predicted or verified.
How should enterprises govern autonomous AI systems?
Answer:
Enterprises should govern autonomous AI systems through clear boundaries on what AI is allowed to see, decide, and do. Effective governance requires more than model monitoring; it requires oversight of delegation, decision-making authority, execution rights, verification mechanisms, and recourse processes. Organizations should establish approval thresholds, maintain audit trails, monitor agent behavior in production, and ensure that critical decisions remain accountable to human authorities. As AI autonomy increases, governance must focus on managing uncertainty and future behavior—not just current model performance.
What is the connection between Vingean Reflection and Enterprise AI governance?
Answer:
Vingean Reflection highlights a fundamental governance problem in Enterprise AI: organizations may deploy AI systems whose future actions cannot be fully anticipated. As AI agents become more autonomous, governance can no longer focus solely on accuracy or compliance. Enterprises must also address delegation, accountability, verification, and recourse. In practice, this means designing systems that can be monitored, constrained, audited, and overridden even when their future behavior cannot be completely predicted. This is one reason why governance architectures such as SENSE–CORE–DRIVER place equal emphasis on representation, reasoning, and controlled execution.
What is the DRIVER layer in the SENSE–CORE–DRIVER framework?
DRIVER is the governance and execution layer of the SENSE–CORE–DRIVER architecture. It defines how AI decisions are delegated, verified, authorized, executed, and corrected within an organization. DRIVER stands for Delegation, Representation, Identity, Verification, Execution, and Recourse. Its purpose is to ensure that intelligent systems remain accountable, controllable, and aligned with organizational goals.
Why is the DRIVER layer important for Enterprise AI?
Many AI initiatives focus on data, models, and reasoning. However, enterprise failures often occur after a decision has been made—during delegation, execution, or governance. The DRIVER layer addresses this gap by defining who can authorize actions, how decisions are verified, how accountability is assigned, and how organizations recover when outcomes are incorrect. Without governance, even highly accurate AI systems can create operational, regulatory, or reputational risks.
How does the DRIVER layer help address the Vingean Reflection problem?
The DRIVER layer does not eliminate Vingean Reflection, but it helps organizations manage its risks. Since future AI behavior cannot always be predicted, enterprises need mechanisms for verification, approval, auditability, recourse, and bounded autonomy. DRIVER provides the governance structures that allow organizations to trust AI systems without assuming that future behavior can be perfectly understood in advance.
What is Digital Anthropology?
Digital Anthropology is the study of how people work, interact, make decisions, and create meaning in digital environments. In the context of Enterprise AI, Digital Anthropology focuses on understanding how work actually happens—not just how it is documented in processes, policies, or system diagrams.
Why is Digital Anthropology important for Enterprise AI?
Many AI projects fail because organizations train systems on documented processes rather than real-world work practices. Employees often rely on informal knowledge, workarounds, relationships, and contextual judgment that are not captured in enterprise systems. Digital Anthropology helps organizations understand these realities before attempting to automate, augment, or delegate work to AI systems.
What is the connection between Digital Anthropology and Enterprise AI governance?
Digital Anthropology helps organizations understand the human reality that AI systems must operate within. Governance frameworks such as DRIVER define how AI decisions are controlled and executed, but governance is only effective if it is grounded in an accurate understanding of how work actually happens. Together, Digital Anthropology and governance help reduce the gap between formal processes and operational reality.
How are Digital Anthropology, Vingean Reflection, and the DRIVER layer related?
These concepts address different aspects of Enterprise AI risk. Digital Anthropology helps organizations understand human work and operational reality. Vingean Reflection highlights the uncertainty associated with future AI behavior. The DRIVER layer provides the governance mechanisms needed to manage that uncertainty through delegation controls, verification, accountability, execution oversight, and recourse. Together, they form a foundation for deploying AI systems that are both effective and governable.
What is the Work-Reality Gap in Enterprise AI?
The Work-Reality Gap is the difference between how work is documented and how work is actually performed. AI systems are often trained on formal processes, while employees rely on informal knowledge, judgment, exceptions, and contextual understanding. Closing this gap is a key objective of Digital Anthropology and a prerequisite for building trustworthy Enterprise AI systems.
Can Enterprise AI succeed without Digital Anthropology?
Enterprise AI can deliver short-term gains without Digital Anthropology, but large-scale transformation becomes difficult when organizations do not understand how work actually happens. AI systems that ignore operational reality often struggle with adoption, trust, governance, and long-term value creation. Understanding human reality is increasingly becoming a prerequisite for building machine-legible organizations.
References and further reading
- Fallenstein & Soares, “Vingean Reflection: Reliable Reasoning for Self-Improving Agents.” (MIRI)
- Alignment Forum, “Vingean Reflection: Open Problems” (includes the Löbian obstacle and procrastination issues). (Alignment Forum)
- Yudkowsky & Herreshoff, “Tiling Agents for Self-Modifying AI, and the Löbian Obstacle” (foundational discussion of self-modification and self-reference traps). (MIRI)
- Fallenstein, Taylor, Christiano, “Reflective Oracles” (a way to reason about agents embedded in environments while avoiding diagonalization by design choices). (arXiv)
- LessWrong sequence on Embedded Agency (positions Vingean reflection as a central open problem in robust delegation). (LessWrong)

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.