
The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI
Enterprise AI is entering a fragile phase. Not because models are getting more powerful—but because they are changing faster than enterprises can safely operate them. As organizations move from AI copilots to AI systems that act, model churn is exposing a dangerous gap: most enterprises lack a runbook for AI in production.
This article explains why that gap is now a board-level risk—and the operating stack CIOs need to survive the next 12 months.
Executive Summary
The enterprise AI runbook has become the missing foundation of modern AI adoption.
As organizations move from AI pilots to AI systems that act—updating records, triggering workflows, initiating approvals, and interacting with core business systems—model churn is exposing a dangerous gap.
Models, prompts, tools, and data pipelines now change faster than enterprises can safely operate them, yet most organizations lack a production-grade runbook to observe, govern, pause, rollback, and evolve AI behavior with confidence. This absence is no longer a technical inconvenience—it is a systemic risk that CIOs and boards must address in the next 12 months.
Enterprise AI is entering its most dangerous phase—not because models are “too smart,” but because they’re too changeable.
Over the last 18–24 months, many organizations graduated from AI experiments to production copilots. Now the shift is sharper: AI is starting to act. It creates tickets, updates records, drafts customer responses, triggers workflow approvals, and coordinates tasks across systems.
The moment AI starts acting, you’re no longer “deploying a model.” You’re running a digital worker inside your enterprise. And digital workers require what every production system requires: runbooks—operational discipline that makes change safe.
Here’s the issue: autonomy is rising while model churn is accelerating. New model versions, revised safety tuning, refreshed prompts, new tool integrations, updated retrieval pipelines, and evolving agent frameworks arrive every few months.
The breakage rarely looks dramatic at first. It shows up as operational fragility: subtle behavior shifts, inconsistent outcomes, cost volatility, broken audit trails, and the sentence every CIO eventually hears:
“It worked last month. We didn’t change anything. And now it’s acting strange.”
You did change something. You just didn’t operationalize the change. One needs to understand who own the Enterprise Ai 👉 https://www.raktimsingh.com/who-owns-enterprise-ai-roles-accountability-decision-rights/
This is the Enterprise AI Runbook Crisis—and it is rapidly becoming a board-level risk.

Why this suddenly matters in 2025–2026
Enterprise software matured around a hard-earned lesson: change is constant, so operations must be disciplined. We built CI/CD pipelines, SRE practices, incident management, observability, access control, and controlled rollback.
Then we introduced a new class of systems—generative AI and agents—that behave differently.
The mismatch is simple:
- Traditional software changes when you deploy.
- AI systems change when the world changes: data shifts, prompts are edited, tool APIs evolve, retrieval sources get updated, policies change, and model providers ship new versions.
In regulated environments, that difference collides directly with modern governance expectations: continuous risk management, logging, human oversight, and lifecycle monitoring.
- The NIST AI Risk Management Framework (AI RMF 1.0) frames risk management as a lifecycle discipline across its core functions (GOVERN, MAP, MEASURE, MANAGE). (NIST Publications)
- The EU AI Act emphasizes continuous risk management for high-risk systems (Article 9), human oversight (Article 14), and obligations that include monitoring and log-related expectations for deployers (Article 26). (Artificial Intelligence Act)
In plain terms:
You can’t govern what you can’t operate.
This is a core component of the The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely – Raktim Singh, which defines how organizations design, govern, and scale intelligence safely.

What “model churn” really is (it’s not just swapping one LLM for another)
When executives hear “model churn,” they picture a procurement problem: “We switched from Model A to Model B.” That’s only the visible surface.
In production, churn happens across five layers, and the combined effect is what breaks AI systems.
1) Model behavior drift
Even without changing vendors, model outputs can vary due to version changes, safety tuning, inference optimizations, or tool-use behavior improvements. Your agent still “works,” but edge-case behavior shifts—more conservative, more verbose, less consistent with tool formatting, or more likely to refuse.
That can break workflows that were stable last quarter.
2) Prompt and policy churn
Prompts change because teams iterate. Policies change because risk, legal, or compliance updates. The hidden failure mode is “patch work”: teams fix one incident by patching a prompt, then unknowingly break a different scenario.
Simple example:
A customer support agent is updated to “never ask for sensitive information.” Great. But now it refuses to request a ticket number needed to locate the case. Escalations spike, and nobody connects the spike to a prompt change made weeks earlier.
3) Tool and API churn
Agents depend on tools: ITSM, CRM, ERP, HR systems, knowledge bases, identity systems, and internal services. These systems change: auth flows evolve, permissions tighten, endpoints deprecate, schemas expand.
Agents don’t just call APIs—they chain calls. One small change can collapse a multi-step plan.
Simple example:
An agent that closes tickets now fails because the ITSM system introduced a required field (“closure category”). The agent guesses incorrectly, closes tickets under the wrong category, and creates audit risk.
4) Retrieval and knowledge churn
Enterprise knowledge constantly evolves: policies, product docs, pricing, regulatory notices, internal memos. Retrieval pipelines evolve too: new embedding models, new chunking, new filters, new sources, new connectors.
What the AI “sees” changes. And when what it sees changes, what it decides changes.
5) Agent framework and orchestration churn
Organizations keep experimenting with orchestration layers, tracing frameworks, evaluation pipelines, memory strategies, and agent tool selection logic. Each shift changes how steps are planned, logged, retried, or persisted.
This is why “just standardize on one model” doesn’t solve it. The system is changing everywhere, all the time.

The runbook gap: why production AI breaks differently than normal software
When traditional systems fail, operations teams ask:
- What changed?
- What logs show the failure path?
- What was the request context?
- Can we rollback safely?
- What is the blast radius?
- How do we prevent recurrence?
In agentic AI systems, teams often can’t answer those questions because they lack runbook-grade primitives:
- No consistent telemetry across model + prompt + tool calls
- No traceable decision trail (what it intended to do, why it did it)
- No safe rollback mechanism (because actions are real-world changes)
- No kill switch tied to business impact
- No stable identity and permissions model for agents
- No cost guardrails (loops, retries, long context growth)
This is why AI incidents feel uniquely unsettling: the system behaves like a worker, but is operated like a toy.
Enterprise AI isn’t failing because models are inaccurate.
It’s failing because AI that acts has no runbook—and model churn guarantees instability.

Three “small” incidents that become big business problems
These are the kinds of failures enterprises see globally once AI starts acting—often without immediate alarms.
Incident 1: The silent compliance breach
A policy summarization agent is updated with a new retrieval source. It starts citing an outdated clause. No error. No crash. But internal teams now make decisions using the wrong version of policy.
Why it’s dangerous:
This isn’t “hallucination.” It’s a provenance + monitoring failure. The system changed what it retrieved, and nobody had the signals to detect it.
Incident 2: The cost spiral that looks like “usage growth”
A finance workflow agent gets a new tool integration. It retries failures, expands context, and calls multiple services per request. Cost per transaction quietly doubles.
Teams only notice when budgets don’t match forecasts.
Why it’s dangerous:
Autonomy introduces variable execution paths. Without cost envelopes and guardrails, “helpfulness” becomes a financial liability.
Incident 3: The identity gap becomes a security incident
A procurement agent is granted broad access “to be helpful.” Permissions aren’t scoped by least privilege. It accidentally exposes data in a generated summary or triggers an action it shouldn’t.
Industry discussions increasingly highlight these risks—unauthorized access, data leaks, low visibility into actions, and runaway costs—especially as agentic systems connect to core enterprise systems. (Domino Data Lab)
Separately, identity risk for AI agents is also emerging as a distinct category, because agents often require broad API access across domains that traditional identity models weren’t built for. (Aembit)

The operating stack CIOs need: runbooks for AI that acts
A runbook isn’t a document. It’s an operating system for safe change.
Here’s the practical stack—in plain language.
1) Agent observability: “play-by-play visibility”
If AI can take actions, you must be able to answer, for any incident:
- Which model version?
- Which prompt version?
- Which tools were called, and in what sequence?
- What data sources were retrieved?
- What did the agent intend (goal/plan)?
- What was the outcome?
This is why the ecosystem is moving toward standardized observability for GenAI systems. OpenTelemetry’s GenAI semantic conventions aim to standardize telemetry for generative AI spans and attributes across tooling. (OpenTelemetry)
Simple example:
Without traces, “refund triggered incorrectly” becomes a week-long blame game.
With traces, it becomes a surgical fix: tool call path → retrieval provenance → prompt version → incorrect field mapping → patch + test + redeploy.
2) Kill switches tied to business impact—not model errors
Traditional systems alert on error rates. Agentic systems need impact alerts.
Examples:
- Spike in approvals requested
- Unusual workflow triggers
- Unexpected record update patterns
- Tool-call loops
- Sudden increase in cost per transaction
When thresholds are crossed, the system should degrade gracefully:
- switch to “assist mode”
- require human approval
- disable high-risk tools
- route to safe fallback
3) Rollback and reversibility: the missing discipline
Rollback is easy when software is deterministic. For agents, rollback means reversibility of actions:
- Can you undo a record update?
- Can you reopen a ticket closure?
- Can you retract an outbound draft before it sends?
- Can you restore the policy version that informed a decision?
The EU AI Act’s emphasis on lifecycle risk management and oversight strengthens the need for operational controls that don’t just detect problems but can contain and reverse them in practice. (Artificial Intelligence Act)
4) Model–prompt–tool decoupling (your anti-churn armor)
This is where the “Model Churn Tax” becomes real: platforms decay when everything is tightly coupled.
Decoupling means:
- Models can change without rewriting workflows
- Prompts are versioned like releases
- Tool connectors are standardized and permissioned
- Policy enforcement stays consistent across versions
Simple example:
If switching a model requires rewriting prompts, revisiting tool schemas, re-testing every workflow, and re-approving compliance end-to-end, innovation freezes. Decoupling lets you move fast without losing control.
5) Identity + least privilege for agents
Agents are not users. They’re not ordinary service accounts. They’re autonomous executors.
They need:
- scoped permissions per workflow
- environment separation (dev/test/prod)
- audit trails: who authorized the agent, for what, with what boundaries
- time-bound access
- explicit ownership and escalation paths
This is increasingly discussed as a new class of identity risk introduced by AI agents. (Aembit)
6) Continuous risk management that actually runs
Governance cannot be a PDF. It must be enforcement.
NIST AI RMF emphasizes an iterative approach—GOVERN across lifecycle and continuous mapping, measuring, and managing of AI risks. (NIST Publications)
The EU AI Act similarly reinforces lifecycle risk management and human oversight requirements for high-risk contexts. (Artificial Intelligence Act)
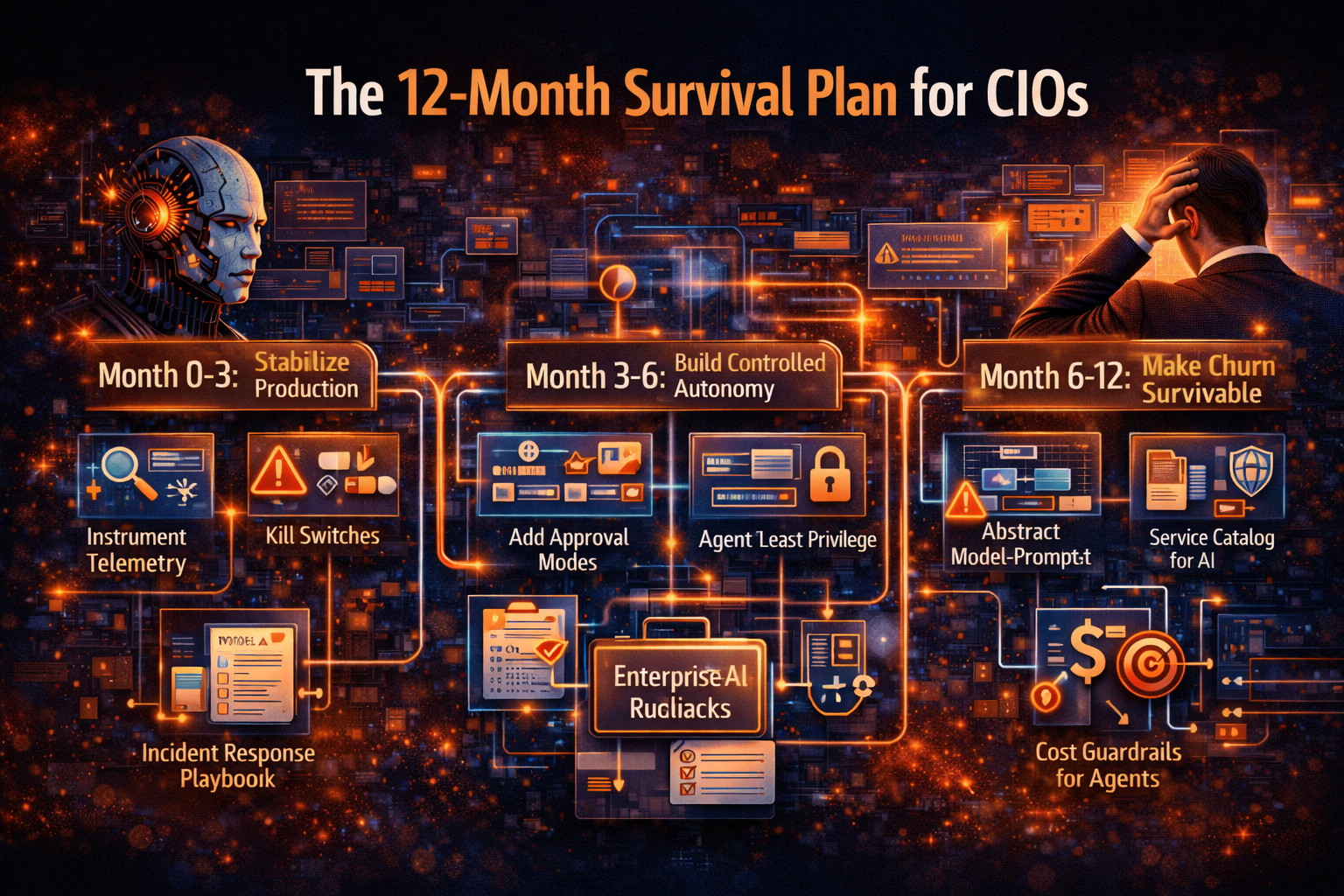
The 12-month survival plan for CIOs
You don’t need to boil the ocean. You need to turn chaos into an operating rhythm.
Months 0–3: Stabilize production
- Instrument agent telemetry (model/prompt/tool traces)
- Define business-impact kill switches
- Establish minimal AI incident response procedures
- Start prompt/version control like software releases
Months 3–6: Build controlled autonomy
- Introduce approval modes (assist → approve → automate)
- Formalize agent identity and least privilege
- Add evaluation gates before deploying changes
- Standardize tool connectors and policy enforcement patterns
Months 6–12: Make churn survivable
- Implement model–prompt–tool abstraction
- Build reusable AI services (catalog mindset, not projects)
- Add cost envelopes and FinOps guardrails for agents
- Operationalize governance with monitoring, audits, drift detection, and rollback drills

The viral truth executives are starting to repeat
Enterprise AI isn’t failing because it’s inaccurate.
It’s failing because:
- it changes too fast,
- it acts too widely,
- and enterprises don’t yet have the operating stack to keep it safe.
Or more bluntly:
If you can’t operate AI that acts, you don’t have enterprise AI—you have enterprise risk. One needs to clearly understand this What Is Enterprise AI? A 2026 Definition for Leaders Running AI in Production – Raktim Singh

Conclusion: what “winning” looks like by end of next year
By the end of the next 12 months, the winners won’t be the organizations with the most agents.
They’ll be the ones who can answer—instantly:
- what AI is running,
- what it can access,
- what it changed,
- why it acted,
- how to stop it,
- how to undo it,
- and how to ship the next update without fear.
That is what an Enterprise AI runbook really is: not documentation—operability.
And in the era of model churn, operability isn’t a nice-to-have. It’s survival.
Glossary
Enterprise AI runbook: Operational procedures, controls, and monitoring that make production AI safe, repeatable, and auditable across changes.
Model churn: Frequent changes across models, versions, tuning, prompts, tools, retrieval sources, and agent orchestration—causing behavior and risk drift.
Agent observability: End-to-end visibility into agent execution: model usage, prompt versions, tool calls, retrieval provenance, decisions, outcomes.
Kill switch: A business-impact-triggered control that pauses autonomy, downgrades mode, or disables high-risk actions when thresholds are crossed.
Reversibility: The ability to undo agent actions (record updates, ticket closures, workflow triggers) and restore safe states.
Least privilege: Security principle: an agent gets only the minimum access needed for a specific workflow, nothing more.
Human oversight: Operational design that allows people to monitor, interpret, override, and prevent over-reliance on AI—especially for high-risk use. (Artificial Intelligence Act)
Lifecycle risk management: Continuous identification, assessment, monitoring, and mitigation of AI risks over time—not a one-time gate. (NIST Publications)
FAQ
1) Is this problem only for large enterprises?
No. Mid-sized firms feel it faster because they scale agents with fewer operational guardrails. The difference is not size—it’s whether AI is allowed to act across systems.
2) Can we solve this by standardizing on one model vendor?
Not fully. The churn is multi-layered: prompts, tools, retrieval sources, policies, and orchestration change too. Standardizing a vendor may reduce one axis of churn, but not the runbook gap.
3) What’s the first “must-do” control if we’re already in production?
Agent observability—traces that link model + prompt + tool calls + retrieval provenance to outcomes. This is the foundation for incident response and governance. (OpenTelemetry)
4) What should a kill switch trigger on?
Business impact: anomalous workflow triggers, abnormal record updates, repeated tool-call loops, unusual cost per transaction—then degrade autonomy.
5) How does this connect to regulation (EU AI Act / NIST AI RMF)?
Both point toward lifecycle risk management and human oversight. That’s operational by nature: logs, monitoring, controls, and the ability to intervene. (NIST Publications)
6) What’s the most common hidden failure?
Retrieval drift. The agent starts using a different policy version or knowledge chunking behavior changes, altering decisions without obvious errors.
7) Should every agent have the same level of governance?
No. Use a tiered model: low-risk agents can be more autonomous; high-risk workflows require approvals, stronger monitoring, and tighter permissions.
References and Further Reading
- NIST AI Risk Management Framework (AI RMF 1.0) (including lifecycle framing and core functions). (NIST Publications)
- EU AI Act: Article 9 (Risk Management System), Article 14 (Human Oversight), Article 26 (Obligations of Deployers of High-Risk AI Systems). (Artificial Intelligence Act)
- OpenTelemetry GenAI Semantic Conventions (standardizing telemetry for GenAI systems). (OpenTelemetry)
- Domino AI: enterprise-focused discussion of agentic AI risks and challenges. (Domino Data Lab)
- Agent identity risk perspective (why agents strain traditional identity models). (Aembit)
- What Is Enterprise AI? Why “AI in the Enterprise” Is Not Enterprise AI—and Why This Distinction Will Define the Next Decade – Raktim Singh
- The Enterprise Model Portfolio: Why LLMs and SLMs Must Be Orchestrated, Not Chosen – Raktim Singh
- Why Enterprises Are Quietly Replacing AI Platforms with an Intelligence Supply Chain – Raktim Singh
- The New Enterprise Advantage Is Experience, Not Novelty: Why AI Adoption Fails Without an Experience Layer – Raktim Singh
- The Agentic Foundry: How Enterprises Scale AI Autonomy Without Losing Control, Trust, or Economics – Raktim Singh
- The New Enterprise AI Advantage Is Not Intelligence — It’s Operability – Raktim Singh
- Why Enterprises Need Services-as-Software for AI: The Integrated Stack That Turns AI Pilots into a Reusable Enterprise Capability – Raktim Singh
- The AI Platform War Is Over: Why Enterprises Must Build an AI Fabric—Not an Agent Zoo – Raktim Singh
- Why Autonomous AI Breaks in Production: And Why Enterprises Need an AI Control Tower to Run It at Scale | by RAKTIM SINGH | Dec, 2025 | Medium
- Enterprise AI Runtime: Why Agents Need a Production Kernel to Scale Safely | by RAKTIM SINGH | Dec, 2025 | Stackademic
- The Enterprise Model Portfolio: Why Model Selection Is the Wrong Question for 2026: By Raktim Singh
- Enterprise AI Drift: Why Autonomy Fails, and the Alignment Fabric Financial Institutions Need: By Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.