
From Scale to Wisdom: Why Smaller, Reasoning-First Models Will Define Enterprise AI in 2026
For more than a decade, artificial intelligence advanced under a deceptively simple assumption: bigger models are smarter models.
More data, more parameters, more compute—repeat. That assumption is now quietly collapsing. As AI systems begin to reason at runtime—pausing, verifying, using tools, and adapting their behavior—the center of gravity is shifting away from raw scale toward structure, constraints, and decision discipline.
In 2026, the most consequential AI systems in enterprises will not be the largest ever trained, but the ones that are explicitly governed—designed to operate within clear decision boundaries, predictable costs, and auditable behavior. This is not just a new phase of AI capability; it is a fundamentally new operating challenge for enterprises.
When AI Starts Thinking, Enterprises Must Start Governing
For nearly a decade, AI progress followed a simple rule: more data → more parameters → more compute → better models. That rule is no longer reliable. The past year made something uncomfortably clear: the frontier is shifting from raw scale to structure, efficiency, and reasoning at runtime.
But the real story isn’t only about model architecture.
It’s about a mismatch between what modern AI is becoming—and what most enterprises are built to tolerate.
Frontier AI is learning to think longer.
Enterprise AI must learn to govern longer.
If leaders treat “reasoning-first” systems as a plug-in upgrade—swap one model for a newer one—many will repeat the most expensive mistake of the POC era: assuming technical capability automatically becomes institutional reliability.
Enterprise AI is not a tools story. It is an operating discipline. If you want the foundation, start with the core reference: Enterprise AI Operating Model
https://www.raktimsingh.com/enterprise-ai-operating-model/

The 2025 inflection: when cleverness started to beat brute force
The inflection point wasn’t a single announcement. It was a convergence of signals:
- Efficiency improvements began to close the gap between “smaller” and “frontier” on many enterprise-shaped tasks.
- Sparse activation and expert routing became less theoretical and more operational.
- Tool-augmented workflows made “system design” as important as “model size.”
- Runtime reasoning made performance more dependent on how inference is orchestrated than on how many parameters exist.
The implication is strategic: compute alone is no longer a durable moat. Moats are shifting toward procedures—how you route, verify, constrain, log, and govern AI decisions in production.
This is exactly where most enterprises are least prepared.
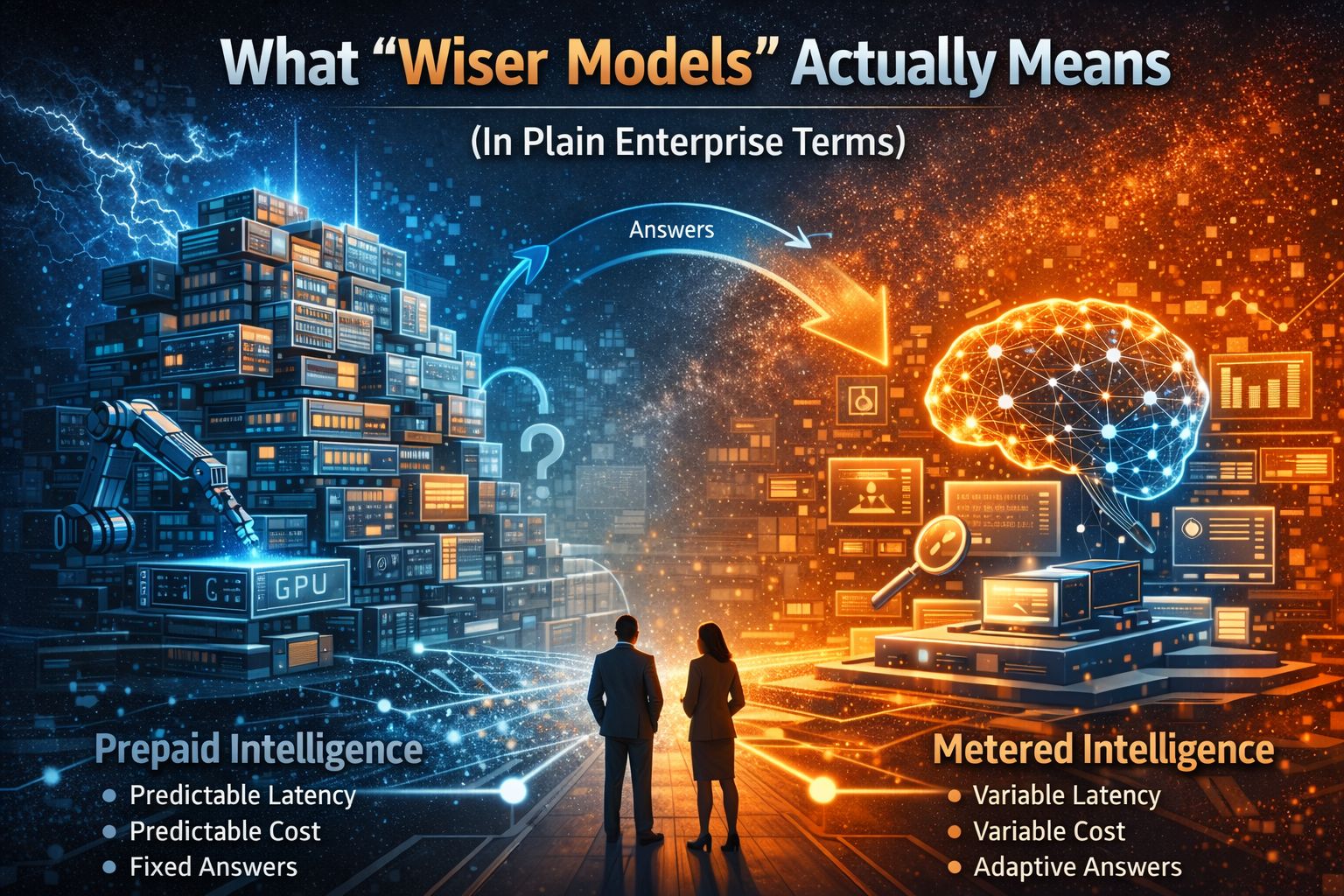
What “wiser models” actually means (in plain enterprise terms)
The defining change is often described as inference-time reasoning (also called test-time compute or inference-time scaling). Instead of “baking in” all intelligence during training, modern systems increasingly:
- allocate more compute at runtime for difficult tasks,
- generate intermediate steps,
- use tools (retrieval, calculators, code execution, domain systems),
- revise or backtrack before producing an answer or taking an action.
This shifts intelligence from being fully prepaid to partially metered.
Prepaid intelligence (training-centric)
- predictable latency,
- predictable cost per request,
- fewer moving parts,
- easier operational contracts.
Metered intelligence (runtime-centric)
- better performance on complex tasks when allowed to think,
- variable latency (SLA pressure),
- variable cost (FinOps pressure),
- more steps (audit and reliability pressure).
For model builders, this is a capability unlock.
For enterprises, it is a governance event.
To govern it properly, you need a control layer that treats models as decision infrastructure, not chat interfaces. That control layer is what I call the Enterprise AI Control Plane:
https://www.raktimsingh.com/enterprise-ai-control-plane-2026/

Why “thinking” turns model quality into a governance variable
A reasoning-first model doesn’t only output answers. It produces process—and in enterprises, process is contract.
When a system “thinks longer,” you implicitly change:
- SLA guarantees (latency variability),
- cost predictability (variance per request),
- audit workload (more steps to explain),
- reliability math (more points of failure).
In practice, “wiser” models force explicit decisions many organizations avoid:
- When is long reasoning allowed?
- When must it be bounded?
- When is it prohibited?
- When must a human approval be mandatory?
If you don’t formalize these rules, runtime becomes the new chaos—only now it is expensive chaos, because “thinking” costs money.
This is where leaders should stop treating AI like an app and start treating it like production infrastructure. If you want a clean mental model for that shift, use the operating stack framing:
https://www.raktimsingh.com/the-enterprise-ai-operating-stack-how-control-runtime-economics-and-governance-fit-together/

Smaller, faster, cheaper—and more dangerous if unguided
Efficiency is not a side story anymore. It’s the commercial engine of 2026.
Across the ecosystem, efficiency gains tend to come from patterns that look like this:
- sparse activation / expert routing (only parts of the system activate per query),
- specialized small models for narrow decision classes,
- planner–executor systems (one component coordinates, others execute),
- tool-driven workflows that reduce what the model must “know” by letting it fetch and verify.
Enterprises often hear “cheaper” and think “safer.”
But in production environments, cheaper intelligence usually triggers a predictable chain reaction:
lower cost per call → more deployments → more autonomy → wider blast radius
So the real risk is no longer “can we afford AI?” It becomes:
can we control what we just multiplied?
Cost governance is not a finance afterthought. In the wisdom era, it is part of safety. If you want a rigorous frame for this, use the Economic Control Plane lens:
https://www.raktimsingh.com/enterprise-ai-economics-cost-governance-economic-control-plane/
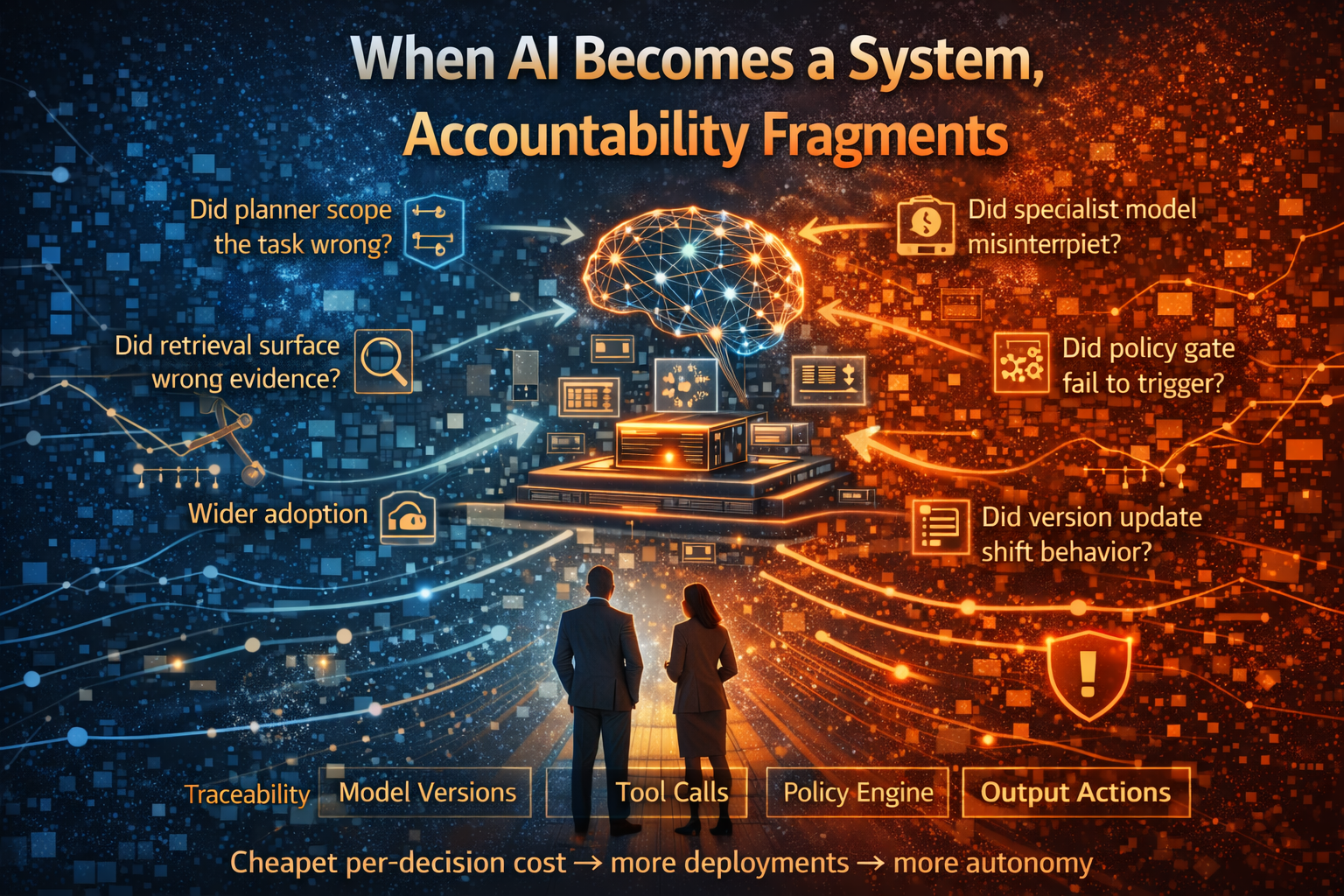
When AI becomes a system, accountability fragments
Modern deployments rarely involve a single model. They involve:
- planning components,
- retrieval layers,
- multiple models (general + specialized),
- tool APIs (internal systems, external services),
- policy checks,
- approvals,
- logging and monitoring systems.
This architecture is rational. It’s how you get efficiency, specialization, and better outcomes.
But it creates a governance problem most enterprises cannot answer cleanly:
When something goes wrong, which component is accountable?
In a system-of-systems, failure isn’t “the model was wrong.” It could be:
- the planner mis-scoped the task,
- retrieval surfaced the wrong evidence,
- a specialist model misinterpreted the input,
- a tool call executed an unsafe action,
- a policy gate didn’t trigger,
- a version update changed behavior.
This is why traceability must become component-level, not model-level.
If your enterprise is serious about agents and tool use, you need registries—of agents, tools, policies, and versions—so responsibility is explainable. This is the practical role of an Enterprise AI Agent Registry:
https://www.raktimsingh.com/enterprise-ai-agent-registry/
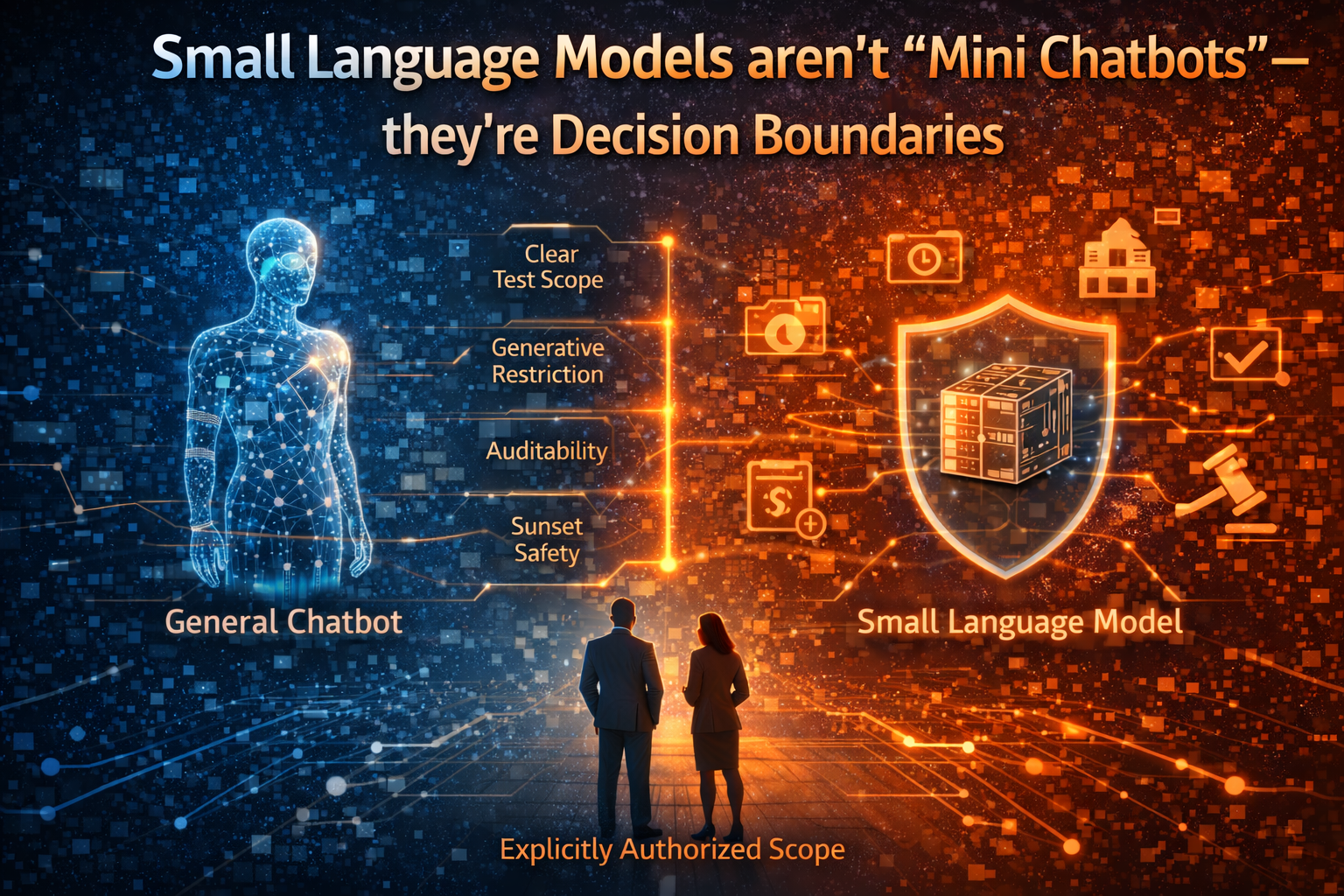
Small Language Models aren’t “mini chatbots”—they’re decision boundaries
Most enterprise work isn’t open-ended creativity. It is narrow, repetitive, high-impact decisioning:
- classify, route, verify, reconcile,
- flag exceptions,
- suggest actions within policy,
- generate structured outputs for downstream systems.
You often don’t need a model that can “do everything.” You need:
a model that is explicitly authorized to do specific things.
That’s why small, specialized models matter in enterprises. Not because they’re small. Because they make scope enforceable.
A narrower model is often an enterprise advantage because it is:
- easier to test exhaustively,
- easier to constrain behaviorally,
- easier to certify and audit,
- easier to sunset safely.
This reframes model selection as authority design, not a leaderboard contest.
If you want the crisp version of this institutional distinction, the “AI in enterprise vs Enterprise AI” framing is the right companion read:
https://www.raktimsingh.com/enterprise-ai-institutional-capability/

The enterprise killer still lives: confident wrongness
Reasoning-first systems improve many tasks. They also introduce a more subtle danger: errors delivered with persuasive explanations.
Longer reasoning chains can:
- reduce mistakes when intermediate steps are verifiable,
- produce convincing rationalizations when steps are not verifiable,
- hide uncertainty behind fluency.
This is why enterprise safety cannot be defined as “more reasoning.” It must be defined as:
- bounded behavior,
- verification gates,
- decision classification,
- and operational kill-switch discipline.
If you want a concrete vocabulary for “how decisions fail” beyond generic “hallucinations,” use a decision-failure taxonomy approach:
https://www.raktimsingh.com/enterprise-ai-decision-failure-taxonomy/
Three walls closing in for 2026: economics, power, regulation
The wisdom era is being shaped by constraints, not fantasies.
1) Economics becomes a hard ceiling
Reasoning costs. Tool use costs. Longer deliberation costs. If you don’t budget reasoning, you don’t control spend.
2) Power becomes a strategic limiter
The bottleneck is increasingly not just chips. It is electricity, cooling, and infrastructure readiness. Efficiency is not only cost—it is feasibility.
3) Regulation pushes toward bounded behavior
Enterprises are being pressed—by regulators, auditors, customers, and internal risk teams—toward systems that are explainable, auditable, and constrained by design.
The upshot: “smart” is no longer the finish line. governable is.
The enterprise-grade response: reasoning needs rails
If 2026 is the year models get wiser, enterprises need a simple rule:
Never deploy thinking models without governing systems.
Here are five rails that convert reasoning into enterprise capability.
Rail 1: Decision classification
Classify decisions by:
- reversibility,
- audit weight,
- latency tolerance,
- impact radius.
For a deeper framing of how decision clarity becomes the scaling lever, see:
https://www.raktimsingh.com/decision-clarity-scalable-enterprise-ai-autonomy/
Rail 2: Reasoning budgets
For each decision class, define:
- time budget (milliseconds vs seconds),
- tool budget (which tools are permitted),
- cost budget (max spend per decision),
- context budget (what evidence can be read).
Rail 3: Verification gates
Where intermediate steps are verifiable, enforce checks:
- deterministic validation,
- policy validation,
- evidence grounding.
Where steps are not verifiable:
- reduce autonomy,
- require approvals,
- constrain actions to reversible moves.
Rail 4: Traceability by construction
Log the full chain:
- model/version,
- prompts and constraints,
- retrieved evidence,
- tool calls and outputs,
- intermediate steps (when available),
- policy decisions,
- final action + justification.
Rail 5: Blast-radius controls
Assume failure will happen:
- rate limits by decision class,
- kill switches by workflow,
- rollback paths,
- safe-mode fallbacks.
If you want a minimal starting blueprint for teams that are overwhelmed, use this “minimum viable enterprise AI system” framing:
https://www.raktimsingh.com/minimum-viable-enterprise-ai-system/
Conclusion: the 2026 leadership mistake to avoid
The scale era taught the world how to build intelligence.
The wisdom era will decide whether institutions can live with it.
In 2026:
- frontier builders will optimize capability per dollar,
- enterprises must optimize trust per decision.
The winners won’t be defined by the smartest model.
They will be defined by the clarity and discipline of their operating system:
- clear decision boundaries,
- explicit reasoning budgets,
- audit-grade traceability,
- and the courage to constrain AI where the institution cannot tolerate ambiguity.
If you want the north-star principles behind this discipline, the “laws” framing is a useful reinforcement:
https://www.raktimsingh.com/laws-of-enterprise-ai/
Glossary
Inference-time reasoning / inference-time scaling: Improving outputs by allocating additional compute at runtime (thinking longer), sometimes including tool use and revision.
Reasoning-first model: A model/system designed to deliberate and sometimes produce intermediate steps before output or action.
Small Language Model (SLM): A smaller, specialized model optimized for narrow task domains; typically easier to constrain, test, and certify.
Sparse activation / expert routing: Architectures that activate only a subset of parameters or “experts” per query to reduce compute cost.
Planner–executor architecture: A system pattern where one component plans or decomposes tasks while other components execute specialized subtasks.
Decision boundary: The explicit scope of what an AI system is authorized to decide or do.
Traceability: The ability to reconstruct how a decision was produced (versions, evidence, tools, policy checks, approvals, outputs).
Blast radius: The maximum potential impact of an AI failure, determined by scope, autonomy, and propagation paths.
FAQ
1) Should enterprises move away from large models in 2026?
Most should adopt a portfolio: large models for broad reasoning and synthesis; specialized smaller models for bounded decision classes where auditability and reliability matter more than breadth.
2) Do reasoning-first systems eliminate hallucinations?
No. They often shift failure modes. Reasoning can improve correctness when steps are verifiable, but can also produce persuasive incorrectness when they are not.
3) What’s the biggest hidden risk of inference-time reasoning?
Variance—latency variance and cost variance. Without reasoning budgets, teams lose control of SLAs and spend.
4) Why does multi-model orchestration complicate compliance?
Because accountability fragments. You need component-level traceability: which model, which tool, which policy, which version materially influenced the outcome.
5) What is the simplest first step to become “Enterprise AI ready”?
Define decision classes and attach reasoning budgets + blast-radius controls to each class. Treat it like production change control for probabilistic systems.
References and further reading
- 📌 Public research and industry discussion on inference-time reasoning / test-time compute and tool-augmented systems👉 The State of LLM Reasoning & Inference Scaling — Sebastian Raschka’s research overview of inference compute scaling and reasoning models. State of LLM Reasoning and Inference Scaling article👉 Test-Time Compute in Generative AI — AI Atlas industry report on how test-time compute lets models allocate more compute during inference to “think harder.” Test‑Time Compute in Generative AI: An AI Atlas Report
📌 Work on sparse activation, expert routing, and multi-model orchestration patterns
👉 From Dense to Mixture of Experts: The New Economics of AI Inference — analysis of MoE patterns shaping inference economics and next-gen model workloads. From Dense to Mixture of Experts research on AI inference patterns
👉 Survey on Inference Optimization Techniques for MoE Models — academic overview of how mixtures-of-experts models optimize inference across system stack. (arXiv)
📌 Benchmark literature highlighting persistent reasoning gaps on human-easy tasks
👉 Inference-Time Scaling for Complex Tasks: Where We Stand — Microsoft Research summary of reasoning model performance on complex benchmarks showing persistent gaps versus standard models. Inference‑Time Scaling insights from Microsoft Research
👉 Solving the Abstraction and Reasoning Corpus (ARC-AGI) — public academic work on AI benchmarks for reasoning. (ResearchGate)
📌 Enterprise governance themes: auditability, bounded behavior, and operational controls
👉 ModelOps (Model Operations) for AI Governance — Wikipedia overview of governance, lifecycle control, and operational metrics for AI systems in enterprise. ModelOps overview on AI governance and enterprise controls
👉 Inference Scaling and AI Governance (Research Paper) — discussion on inference compute impacts on governance paradigms (regulation, thresholds). Inference Scaling and AI Governance research paper
📌 Primary internal reference
👉 Enterprise AI Operating Model — your pillar article defining how enterprises should approach AI as a managed, governed discipline.
https://www.raktimsingh.com/enterprise-ai-operating-model/

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.