{kind=link}

OOD Generalization Barrier
Deep networks often feel like magic — until the world changes.
A model that appears “state-of-the-art” in controlled testing can fail the moment it encounters a new camera, a new document template, a new regulatory environment, or a new workflow variant. The failure is rarely random. It is structured, repeatable, and often invisible until damage is done.
This phenomenon is known as Out-of-Distribution (OOD) generalization failure — and it represents one of the hardest unsolved technical problems in modern AI.
But OOD is not merely a modeling nuisance.
It is the scientific reason why many AI pilots fail at scale.
It is the hidden boundary between experimentation and Enterprise AI.
And it is the constraint that will define which organizations can safely operate autonomous systems.
To understand this barrier, we need something deeper than benchmarks. We need what I call a physics of learning — a conceptual model that explains what deep networks learn, why they generalize, and where they inevitably break.
What is the OOD Generalization Barrier?
The OOD Generalization Barrier refers to the performance gap between how AI models behave on familiar (training-like) data and how they behave when real-world conditions change. It explains why deep learning systems that perform well in testing can fail under distribution shift in production environments.
This article explains the Out-of-Distribution (OOD) Generalization Barrier in deep learning — why models that perform well in testing fail under real-world distribution shifts. It introduces a physics-of-learning framework to explain shortcut learning, invariance limits, and robustness constraints. The piece connects frontier ML research to enterprise operating models, showing how drift detection, decision reversibility, governance layers, and control planes are essential for deploying AI systems safely in production.
Key themes include distribution shift, shortcut learning, double descent, invariant risk minimization, domain generalization, and enterprise AI governance.
-
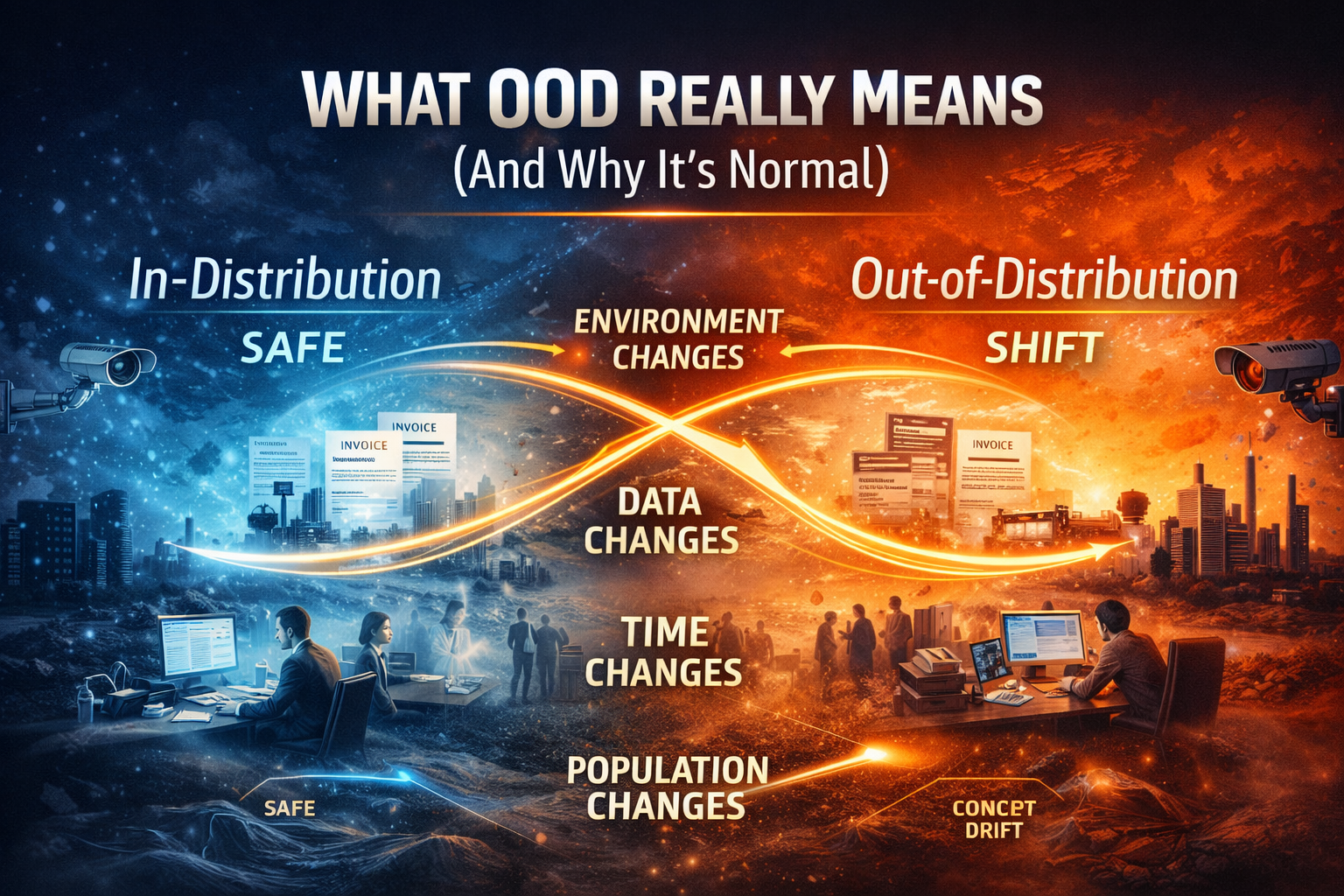
What OOD Really Means (And Why It’s Normal)
A model is in-distribution when deployment conditions resemble its training data.
A model is out-of-distribution when something about reality changes:
- The environment shifts (lighting, sensors, locations)
- The population shifts (new user types, new behaviors)
- The data pipeline shifts (formatting, preprocessing)
- The incentives shift (people adapt to the model)
- Time shifts (processes evolve, regulations change)
Here is the critical insight:
OOD is not rare. OOD is the default state of the real world.
In production systems, the world is dynamic. Policies evolve. Vendors update software. Fraud patterns mutate. Markets fluctuate. The “training distribution” is simply yesterday’s snapshot of a moving target.
Research benchmarks like WILDS (Koh et al.) were built precisely to measure performance under real-world distribution shifts — and consistently show that accuracy drops significantly when environments change.
The problem is not that shift exists.
The problem is that our current theory of deep learning does not fully explain why models generalize — or why they collapse under change.

-
The Core Failure Mode: Shortcut Learning
One of the most powerful insights in modern ML research is the idea of shortcut learning (Geirhos et al.).
Deep networks often rely on the easiest predictive signal available — even if that signal is accidental.
Simple Example
Imagine training a model to detect manufacturing defects from images.
Unknown to you, most defective parts were photographed on a specific textured surface. The model learns the background texture as a predictive cue.
It performs exceptionally well on the test set (which shares the same background). Deployment moves to a different facility with a different surface — and performance collapses.
The model never learned “defect structure.”
It learned the cheapest correlate.
This is not stupidity.
It is optimization.
Neural networks minimize loss. They do not minimize conceptual fragility.
-
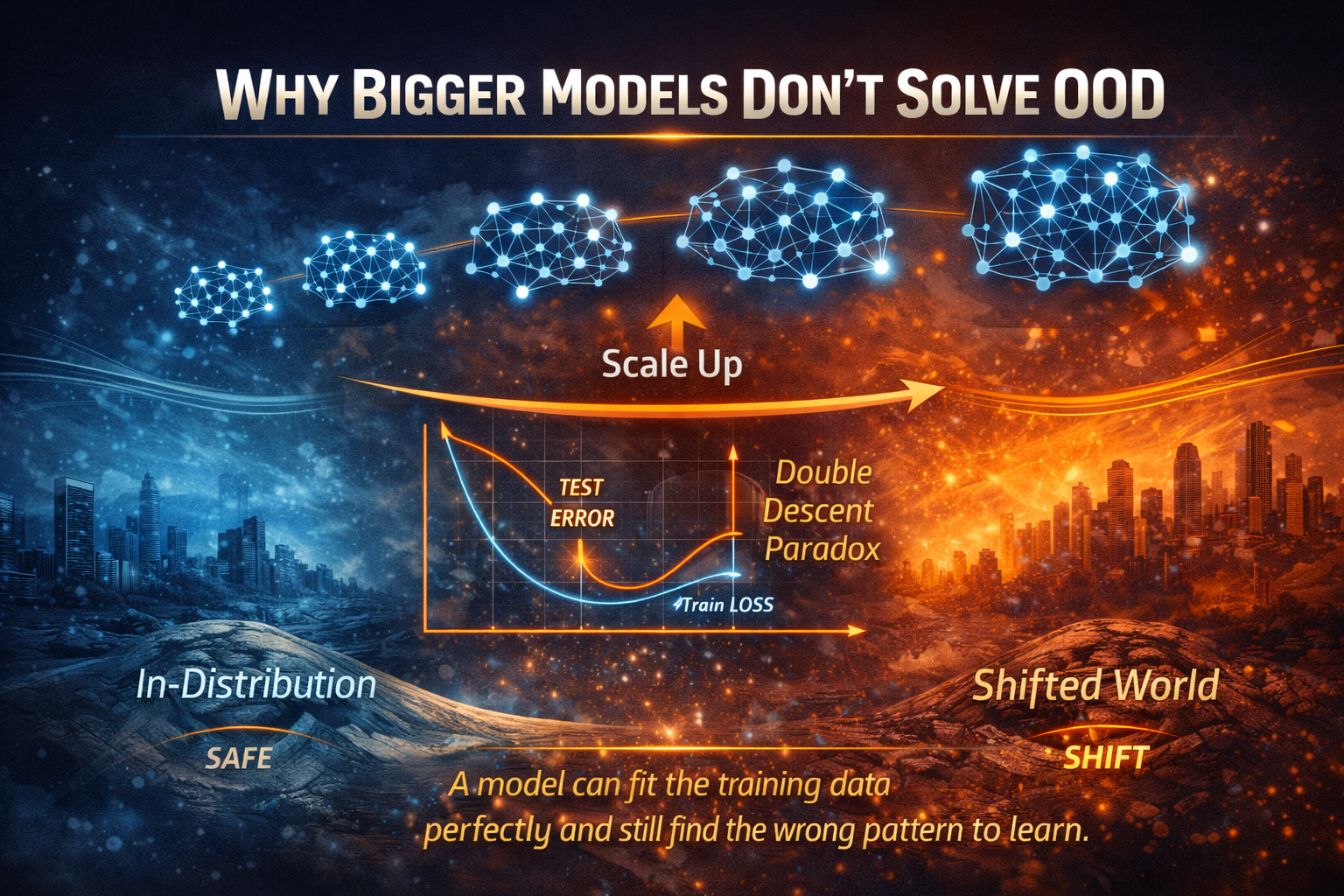
Why Bigger Models Don’t Solve OOD
A common belief is that scaling fixes robustness.
Scaling does improve many things — but OOD failure persists because the problem is not just capacity.
It is feature selection under bias.
Modern phenomena like double descent (Belkin et al.) show that increasing model size can first worsen, then improve generalization. Overparameterized models can fit noise and still generalize — but this does not guarantee stability under distribution shift.
The key lesson:
A model can learn the right answers for the wrong reasons.
And scale can amplify both signal and shortcut.
This is the OOD Generalization Barrier: performance inside the training world does not guarantee stability outside it.
The Physics of Learning: Four Forces That Shape What Models Learn
-
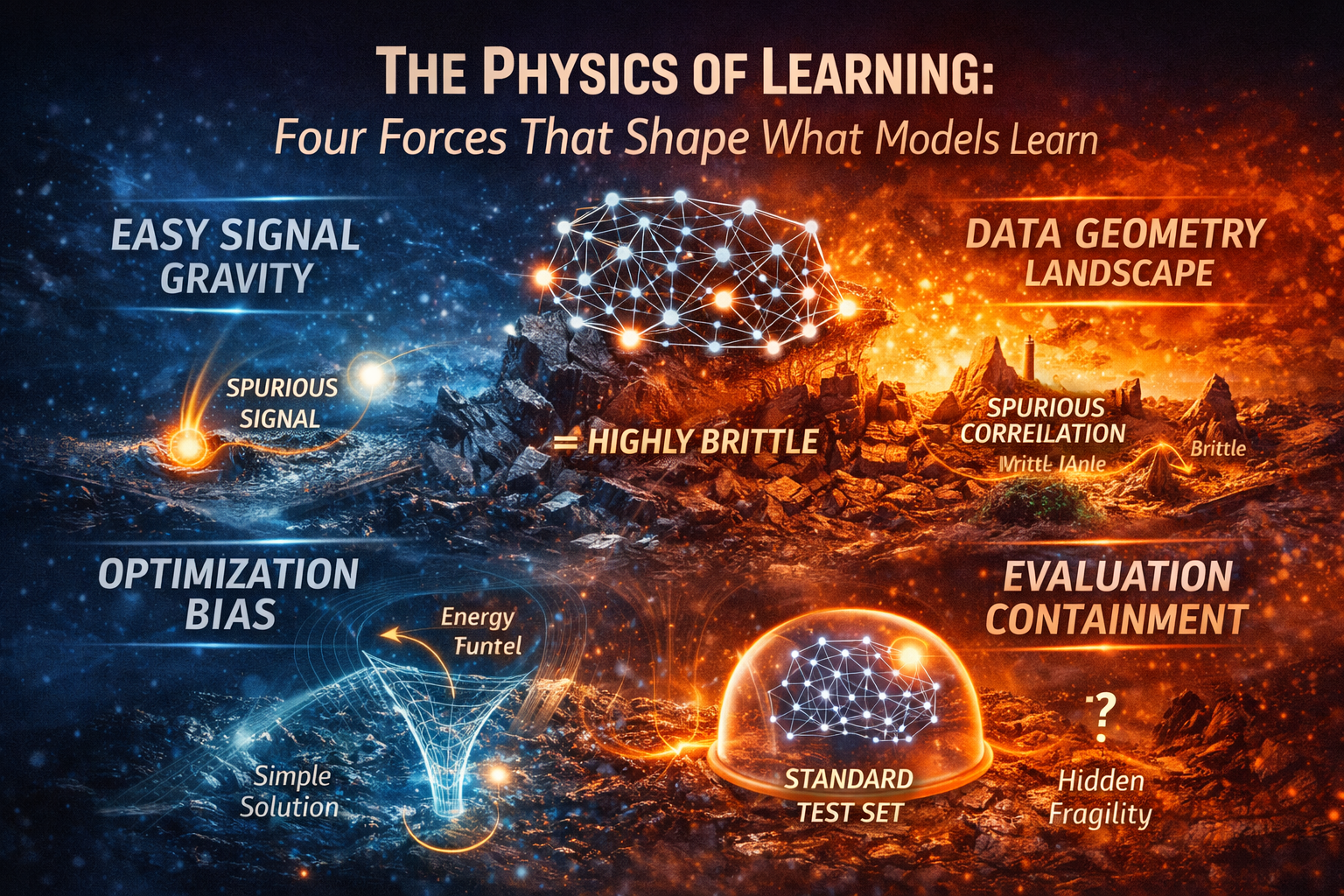
The Physics of Learning: Four Forces That Shape What Models Learn
To make OOD intuitive, think of training as a physical system governed by forces.
Force 1: Easy-Signal Gravity
Optimization pulls toward signals that are easiest and most predictive in the training data.
Force 2: Data Geometry Landscape
The structure of the dataset defines what invariances are even possible to learn. If no data contradicts a spurious correlation, the model has no reason to abandon it.
Force 3: Optimization Bias
Training algorithms prefer simpler, high-leverage solutions early. These solutions may not correspond to true causal structure.
Force 4: Evaluation Containment
If test data mirrors training data, it rewards shortcuts and hides fragility.
When these forces align, we get models that are both highly accurate and highly brittle.
This brittleness is not an accident.
It is a consequence of the physics of learning.

-
OOD Is Not One Problem — It Is Four Distinct Failures
Most organizations treat “distribution shift” as one monolithic issue. It is not.
-
Covariate Shift
Inputs change, but label mapping remains stable.
-
Label Shift
Outcome frequencies change (e.g., fraud increases).
-
Concept Drift
The meaning of the label itself changes.
-
Spurious Correlation Collapse
The shortcut disappears.
Each requires different detection and mitigation strategies.
Conflating them leads to shallow robustness thinking.
-
Invariance: The Only Real Path Forward
The core idea behind many OOD research directions is simple:
Learn what stays stable across environments.
This motivates approaches like Invariant Risk Minimization (IRM) (Arjovsky et al.), which attempt to find predictors that remain optimal across multiple environments.
But invariance is difficult:
- True invariances may be latent.
- Training environments may not vary enough.
- Causal structure may not be observable.
And here lies the uncomfortable boundary:
Models cannot generalize to arbitrary shifts.
Generalization requires structure — either statistical diversity or causal knowledge.
Without that, failure is mathematically inevitable.
This is not pessimism.
It is engineering reality.
-
The OOD Generalization Barrier as a Theoretical Boundary
Here is the hard truth:
If the world changes in ways your data never exposed,
and if you lack invariant or causal structure,
your model must fail.
No architecture can defeat that constraint.
This is the barrier.
And it forces a reframing:
The goal is not universal generalization.
The goal is bounded, evidenced, operable generalization.
This is where frontier ML science meets Enterprise AI.
-
Why OOD Is an Enterprise AI Problem — Not Just a Model Problem
When AI merely assists humans, OOD is inconvenient.
When AI makes decisions, OOD becomes existential.
If a system:
- denies a claim
- routes an emergency
- flags a transaction
- grants access
- triggers compliance escalation
Then OOD is not about prediction error.
It is about decision integrity.
This is precisely the boundary defined in the
Enterprise AI Operating Model
https://www.raktimsingh.com/enterprise-ai-operating-model/
Enterprise AI begins when software participates in decisions.
And decision systems must survive distribution shift.
That requires:
- Runtime discipline
(see: https://www.raktimsingh.com/enterprise-ai-runtime-what-is-running-in-production/) - Governance and Control Planes
(see: https://www.raktimsingh.com/enterprise-ai-control-plane-2026/) - Decision Failure Taxonomy
(see: https://www.raktimsingh.com/enterprise-ai-decision-failure-taxonomy/)
OOD is the scientific reason these layers are necessary.
Without them, scale guarantees fragility.
-
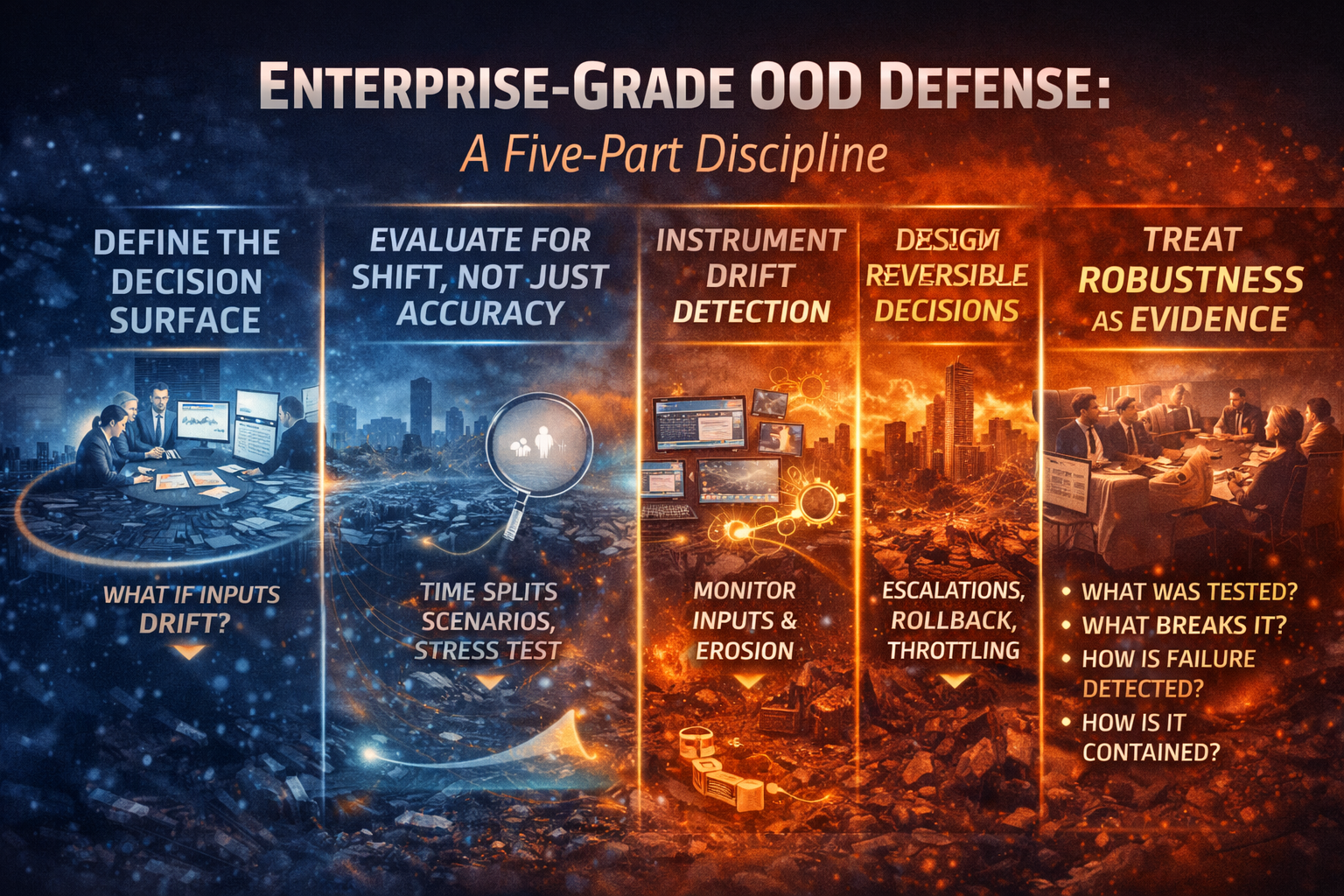
Enterprise-Grade OOD Defense: A Five-Part Discipline
-
Define the Decision Surface
Where exactly does AI influence outcomes? What happens if inputs drift?
-
Evaluate for Shift, Not Just Accuracy
Use time splits, domain splits, stress testing, scenario variation.
-
Instrument Drift Detection
Monitor:
- input distribution changes
- confidence degradation
- calibration drift
- golden-set degradation
-
Design Reversible Decisions
Autonomy must be bounded:
- staged approvals
- throttling
- escalation paths
- rollback strategies
-
Treat Robustness as Evidence
Boards require:
- what shifts were tested
- what breaks the system
- how failure is detected
- how it is contained
This aligns directly with the
Minimum Viable Enterprise AI System
https://www.raktimsingh.com/minimum-viable-enterprise-ai-system/
-
A Better Mental Model: Generalization Budgets
Every model has a finite generalization budget.
It can tolerate certain variations — but not infinite novelty.
Your job is to:
- Expand the budget (diverse environments)
- Spend the budget wisely (avoid shortcuts)
- Protect the enterprise when the budget is exceeded (control planes)
This framing shifts leadership conversations from
“Is it accurate?”
to
“Is it operable under change?”
That is a more mature question.
Conclusion
The Future of AI Will Be Decided Under Shift
The next decade of AI will not be defined by parameter counts.
It will be defined by how systems behave when the world shifts.
The OOD Generalization Barrier is not a niche ML concern.
It is the boundary between:
- Demo AI and Decision AI
- Experimentation and Enterprise Operation
- Scale and Collapse
If we understand the physics of learning,
we stop expecting miracles from scaling.
And we start building systems that are:
- bounded
- instrumented
- reversible
- governable
- and worthy of trust
Enterprise AI is not about bigger models.
It is about operating intelligence under change.
And distribution shift is the ultimate stress test of that capability.
How This Connects to Enterprise AI Architecture
Enterprise AI scale requires four interlocking planes:
Read about Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely — Raktim Singh
- Read about Enterprise Control Tower The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale — Raktim Singh
- Read about Decision Clarity The Shortest Path to Scalable Enterprise AI Autonomy Is Decision Clarity — Raktim Singh
- Read about The Enterprise AI Runbook Crisis The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI — and What CIOs Must Fix in the Next 12 Months — Raktim Singh
- Read about Enterprise AI Economics Enterprise AI Economics & Cost Governance: Why Every AI Estate Needs an Economic Control Plane — Raktim Singh
Read about Who Owns Enterprise AI Who Owns Enterprise AI? Roles, Accountability, and Decision Rights in 2026 — Raktim Singh
Read about The Intelligence Reuse Index The Intelligence Reuse Index: Why Enterprise AI Advantage Has Shifted from Models to Reuse — Raktim Singh
Read about Enterprise AI Agent Registry Enterprise AI Agent Registry: The Missing System of Record for Autonomous AI — Raktim Singh
Research Foundations Behind the OOD Generalization Barrier
1️⃣ WILDS Benchmark (Distribution Shift Benchmark)
Koh et al., 2021
https://arxiv.org/abs/2012.07421
2️⃣ Shortcut Learning in Neural Networks
Geirhos et al., 2020
https://arxiv.org/abs/2004.07780
3️⃣ Invariant Risk Minimization (IRM)
Arjovsky et al., 2019
https://arxiv.org/abs/1907.02893
4️⃣ Double Descent (Belkin et al., PNAS)
https://www.pnas.org/doi/10.1073/pnas.1903070116
5️⃣ Distribution Shift Survey (Gulrajani & Lopez-Paz – Domain Generalization)
https://arxiv.org/abs/2007.01434
6️⃣ Robustness & Spurious Correlations (ICLR tutorial reference)
https://arxiv.org/abs/1801.00631

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.