
Enterprise AI Incident Response
Enterprise AI incident response is the operational discipline that allows autonomous AI systems to fail safely in production.
It defines how organizations detect AI failures, contain damage, roll back unsafe behavior, and systematically learn—before trust, compliance, or economics break.
Enterprise AI doesn’t fail like normal software.
A typical software bug breaks a feature. But an Enterprise AI failure can silently shift a decision, trigger a real action, and still leave behind a trail of “looks fine” metrics—until someone notices the damage downstream.
That is why the next competitive advantage in Enterprise AI is not “better prompts” or “bigger models.” It’s incident response for AI: the capability to detect AI failures early, contain them fast, roll back safely, and learn systemically—without freezing innovation.
This article offers a practical, globally applicable playbook for what AI incidents look like in production, which signals actually catch them, and what a real Enterprise AI rollback means when agents can take actions inside workflows.
It builds on well-established incident-handling and risk-management thinking from NIST and reliability engineering practices such as blameless postmortems. (NIST CSRC)
Why this matters now
Across industries, AI is moving from advice to execution—from systems that “recommend” to systems that draft changes, route work, approve actions, and call tools.
Once AI touches real workflows, the operational question stops being:
“Is the model accurate?”
…and becomes:
“Can we detect when it’s wrong fast enough to prevent harm—and can we prove what happened?”
That is incident response. And in the Enterprise AI era, it’s not optional.

What is an Enterprise AI incident?
An Enterprise AI incident is any event where an AI system’s behavior creates—or could create—unacceptable risk to:
- Business outcomes: wrong decisions, wrong actions, or wrong prioritization
- Customer experience: harmful or inconsistent handling
- Compliance and policy: violations, missing evidence, or unenforceable controls
- Security and data: leakage, unauthorized access, or unsafe tool use
- Economics: runaway usage, unexpected cost spikes, or tool-call loops
- Trust: unexplainable decisions, inconsistent outputs, or “can’t prove why”
This definition aligns with a key shift: AI isn’t “a feature.” It becomes an actor inside systems, so incidents must be managed like operational events—not just model debugging. (NIST)
A simple way to recognize an AI incident
If the question you’re asking is:
“What did the system do, why did it do it, and can we prove it?”
…you are already in incident-response territory.

Why AI incidents are harder than traditional incidents
Traditional incident response assumes you can identify a broken component and restore service.
Enterprise AI incidents are harder because:
- Failures can be “soft.” A decision boundary shifts without any obvious outage.
- Outputs can look plausible. The system sounds confident, logs look normal, dashboards stay green.
- Root cause is distributed. Model + prompt + retrieval + tool + policy + data + workflow all interact.
- Behavior changes over time. Drift, shifting data, updated tools, and evolving policies can change outcomes.
- Actions may be irreversible. A wrong update can propagate across systems before anyone notices.
That’s why security-grade incident lifecycle thinking—prepare → detect → contain → recover → learn—is essential for Enterprise AI. (NIST CSRC)
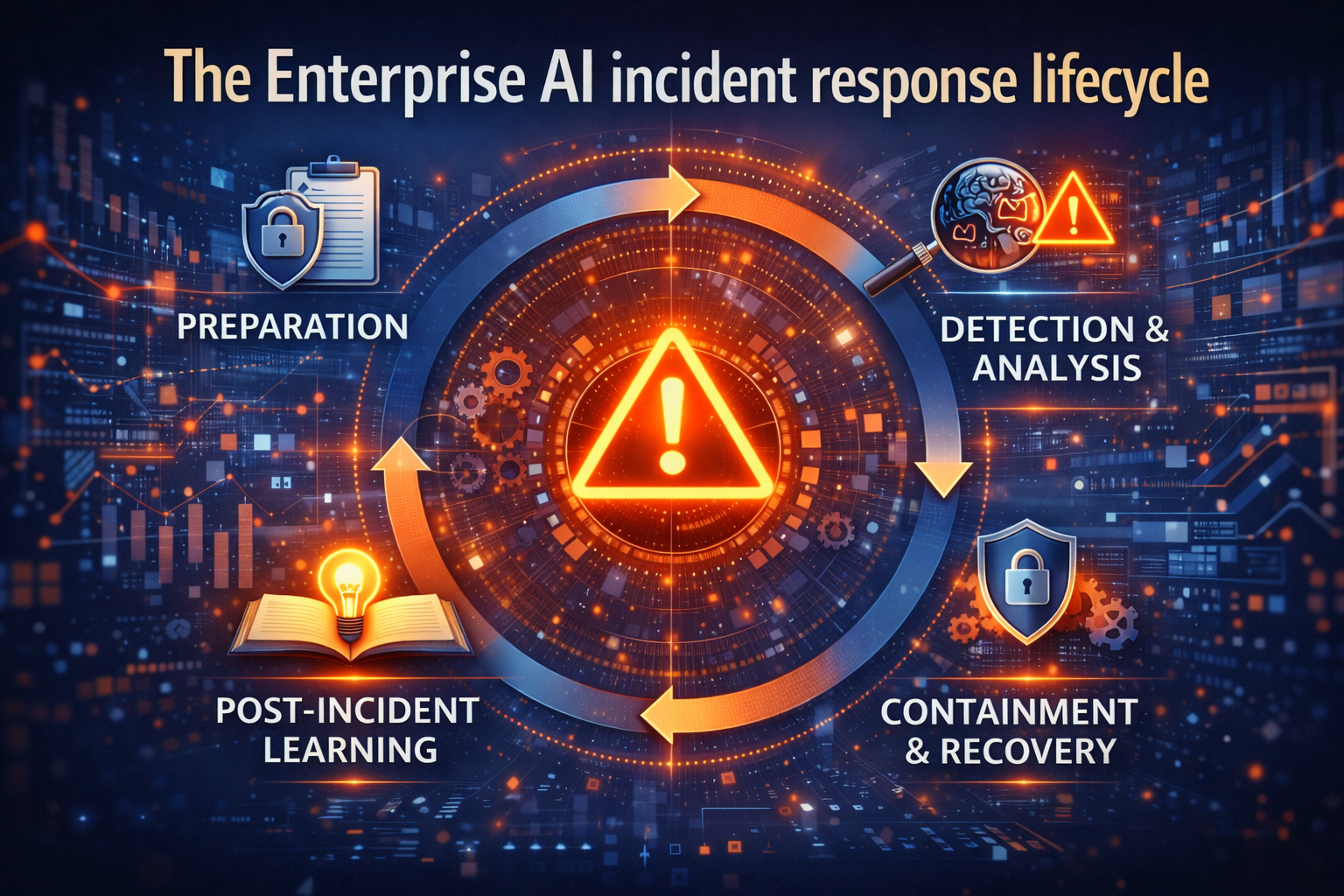
The Enterprise AI incident response lifecycle
Most organizations already use an incident lifecycle similar to NIST’s approach: Preparation, Detection & Analysis, Containment/Eradication/Recovery, and Post-Incident Learning. (NIST CSRC)
The difference is not the phases. The difference is what you must instrument, control, and preserve when the “system that failed” is a decision-maker that can act.
Below is the lifecycle translated into an Enterprise AI operating playbook.
1) Preparation: Build response readiness before you need it
Most teams discover they lack incident readiness on the worst day: when a senior leader asks:
“Show me exactly what the AI did—and who approved it.”
Preparation is where Enterprise AI either becomes governable—or remains a demo.
Define safe modes (your first containment tool)
Before any incident, define your system’s safe fallback modes:
- Suggest-only mode: AI can recommend, but not execute
- Draft-only mode: AI can prepare changes, but a human must approve
- Execute with approvals: AI can act only with explicit gates
- Hard stop: system disabled; manual operation resumes
If you don’t define these up front, “containment” becomes chaos.
Make AI behavior observable (not just the API)
Observability means you can understand system behavior from signals. For AI, “signals” are not just latency and errors—they are decision and action signals.
At minimum, instrument:
- Inputs: prompt templates, system instructions, tool parameters
- Retrieval: which sources were used and which chunks were selected
- Outputs: the final response and a short internal reasoning summary (even if not shown to end users)
- Actions: which tools were called and what changed in external systems
- Policy decisions: which guardrails triggered and which approvals were required
- Correlation IDs: one ID tying logs, traces, and events together end-to-end
OpenTelemetry’s concepts around context propagation and correlating signals are useful here: if you can’t connect “request → decision → tool call → outcome,” incident response turns into guesswork. (OpenTelemetry)
Pre-define AI incident severity classes
You don’t want to debate severity mid-incident.
Keep it simple and decision-focused:
- SEV-1 (Critical): unauthorized action, data exposure, policy breach, irreversible harm potential
- SEV-2 (High): repeated wrong actions, systemic drift, high-cost runaway behavior
- SEV-3 (Moderate): localized wrong answers, degraded experience, low-risk misrouting
- SEV-4 (Low): minor regressions, cosmetic issues, non-impacting errors
Assign AI-specific incident roles (ownership becomes real on day 2)
Traditional SRE often includes on-call and an incident commander.
Enterprise AI needs additional roles with clear decision rights:
- Runtime owner: can throttle, pause, rollback deployments
- Policy owner: can interpret guardrails and approve emergency tightening
- Data owner: can validate source integrity and retrieval quality
- Security partner: for suspected misuse, access anomalies, prompt injection attempts
- Business owner: for impact decisions and customer-facing choices
This is where your broader Enterprise AI operating model (your pillar) becomes operational reality: governance is not just architecture—it’s who can decide during pressure. ( https://www.raktimsingh.com/enterprise-ai-operating-model/)

2) Detection: How AI incidents are actually found in production
Many AI incidents are not detected by “accuracy dropping.” They are detected by mismatch—between what should happen and what is happening.
Decision anomaly detection (behavior shifts)
Simple example:
- The AI used to approve ~80% of routine requests.
- Over the last hour, it approves 98%, with shorter explanations and fewer citations.
Nothing crashes. But the decision boundary shifted.
Useful signals:
- changes in approval/refusal rates
- sudden reduction in evidence usage
- sudden increase in tool calls per task
- rising disagreement between AI and human reviewers
Action anomaly detection (the AI starts doing more)
Simple example:
An agent that normally updates 5–10 records per run suddenly updates 500.
Action anomalies are powerful because actions are countable.
Signals:
- spikes in writes, deletes, refunds, escalations, account changes
- unusual action sequences (tool A → tool C never happened before)
- elevated “irreversible action attempted” rate
Policy tripwires (guardrails firing is itself a signal)
If guardrails are well-designed, they become early warning.
Signals:
- rising “blocked by policy” events
- rising approval requests
- repeated access-denied attempts from the agent identity
- unusual model switching or tool fallback patterns
Cost and compute tripwires (runaway behavior is an incident)
Economic incidents are real incidents.
Simple example:
A loop causes repeated retrieval + tool calls. Costs spike without proportional business output.
Signals:
- token spikes
- tool-call spikes
- repeated retries
- long chains without completion
Treat these as smoke detectors—because they often are.
3) Containment: Stop the damage without losing the system
Containment is not “turn it off.” It’s reducing blast radius while preserving evidence—a core incident-handling idea reflected in NIST’s guidance. (NIST CSRC)
Containment option 1: Switch to safe mode
If an agent can act, move it to:
- suggest-only
- draft-only
- execute-with-approvals
This keeps work moving while you investigate.
Containment option 2: Reduce permissions (least-privilege emergency mode)
If you suspect misuse or tool malfunction:
- revoke specific tools
- limit data scopes
- enforce read-only access
- require “two-person approval” for sensitive actions
Containment option 3: Rate-limit and throttle
Many AI incidents are fast failures:
- runaway loops
- repeated tool calls
- duplicated actions
Throttling buys time and reduces impact.
Containment option 4: Freeze the world (only when necessary)
When impact is severe or evidence is at risk:
- freeze writes
- freeze downstream workflows
- snapshot logs, traces, prompts, retrieval context
This should be rare—but decisive.
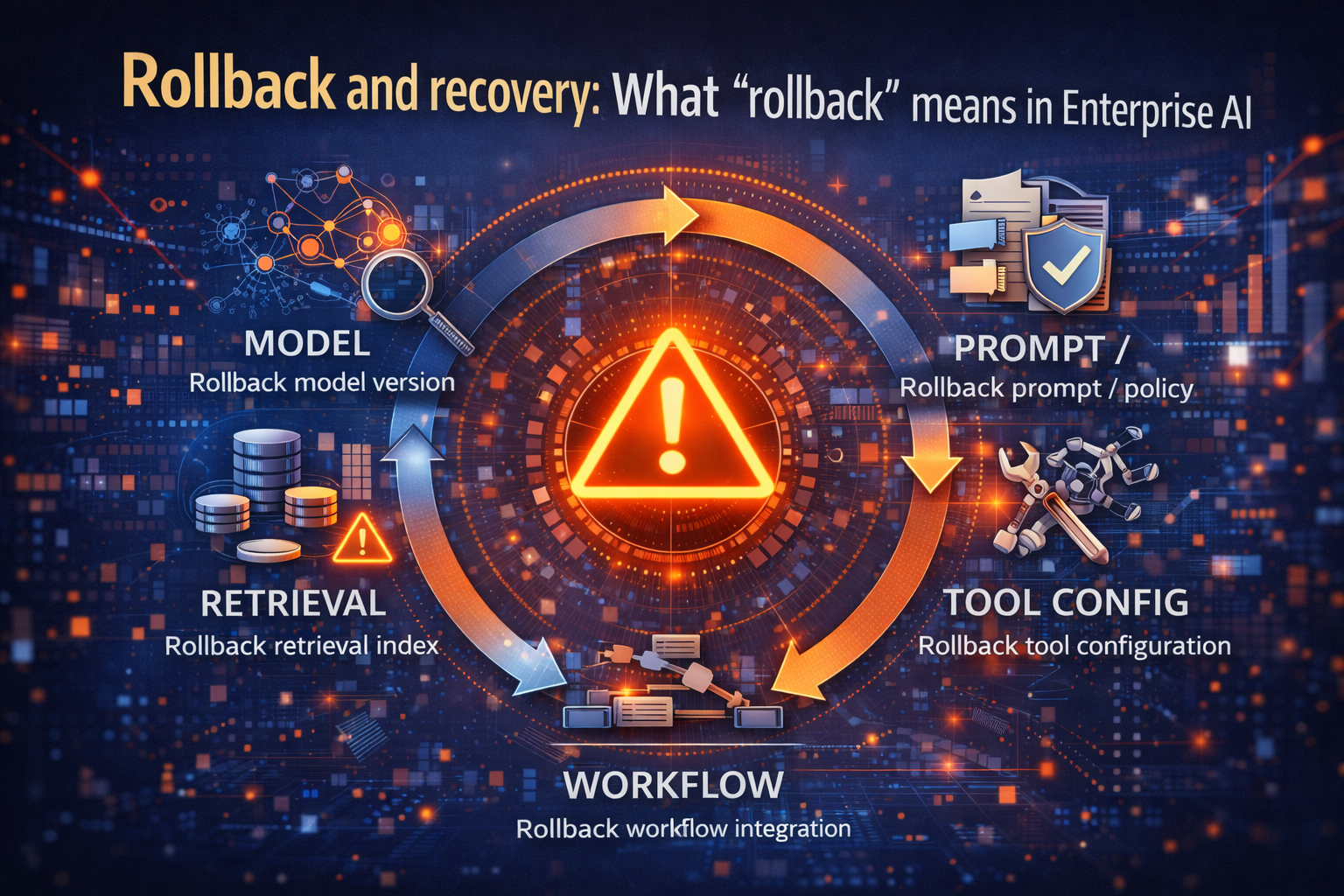
4) Rollback and recovery: What “rollback” means in Enterprise AI
This is the most misunderstood part.
In Enterprise AI, rollback is not only “deploy the previous model.” You may need to roll back multiple layers of the stack.
Roll back the model version
Example: a newer model follows instructions differently and starts bypassing a safety pattern.
Rollback means reverting model, re-running smoke tests, and confirming guardrails still bind.
Roll back the prompt or policy bundle
Example: a small system prompt tweak removed a constraint.
Rollback means reverting the prompt + policy bundle and validating behavior under real scenarios.
Roll back retrieval indexes or knowledge sources
Example: a retrieval index ingested a flawed policy doc and the system starts enforcing the wrong rule.
Rollback means reverting to the last known-good index snapshot and blocking the bad source.
Roll back tool configuration or tool semantics
Example: a tool endpoint changed meaning (same name, different behavior).
Rollback means pinning tool versions, disabling the new endpoint, and adding contract tests.
Roll back workflow integration
Example: the AI now writes directly into a system that used to require review.
Rollback means restoring approval gates and isolating the agent from direct writes.
Recovery principle: restore operability, then restore autonomy
Stabilize the system in a safe mode first.
Then re-enable autonomy gradually with stronger monitoring.
5) Root cause analysis: AI incidents need a causal chain, not a blame point
Classic postmortems work because they focus on contributing factors—not individuals.
Blameless postmortems are a proven practice for building system resilience: assume good intent, examine system conditions, and remove the hidden traps that made failure likely. (Google SRE)
For Enterprise AI, your causal chain typically includes:
- Trigger: what changed
- Exposure: what path allowed impact
- Amplifier: what made it worse
- Missing control: what should have stopped it
- Detection gap: why you didn’t see it earlier
Simple causal chain example
- Trigger: retrieval content updated
- Exposure: agent trusted retrieved policy without source verification
- Amplifier: tool allowed bulk actions without approval
- Missing control: no irreversible-action gate
- Detection gap: no alert on bulk updates
This is how you turn “AI is unpredictable” into “the system was under-controlled.”
6) Post-incident learning: Turn one failure into a permanent capability
The point of incident response is not to survive today. It’s to make the system stronger tomorrow.
Produce two outputs: leadership summary and engineering record
Leadership needs:
- what happened
- business impact
- what was done
- what changes will prevent recurrence
Engineering needs:
- evidence and artifacts
- timelines and correlated traces
- contributing factors
- action items with owners and deadlines
Choose action items that change the system, not the story
Good action items:
- add an approval gate for irreversible actions
- enforce correlation IDs and trace propagation
- add “policy source integrity” checks for retrieval
- add tool contract tests
- add drift monitoring thresholds
Bad action items:
- “be careful”
- “write better prompts”
- “pay more attention”
Feed incidents back into your Enterprise AI operating model
Every AI incident should update:
- guardrails
- runbooks
- severity definitions
- regression tests
- safe-mode definitions
That’s how you build an Enterprise AI capability—not just “fix a bug.”
Practical scenario library (simple, realistic incidents)
Use these to train teams and test readiness:
- Confident wrong policy: AI retrieves outdated policy, blocks valid requests.
- Tool semantics changed: same tool name, new backend behavior → wrong updates.
- Runaway loop: retries + tool calls spike costs and slow downstream systems.
- Permission drift: agent identity inherits extra privileges and performs forbidden actions.
- Silent decision boundary shift: approvals/refusals flip; humans notice later.
Every enterprise experiences versions of these—across sectors and geographies.
Enterprise AI Operating Model
Enterprise AI scale requires four interlocking planes:
Read about Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely — Raktim Singh
- Read about Enterprise Control Tower The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale — Raktim Singh
- Read about Decision Clarity The Shortest Path to Scalable Enterprise AI Autonomy Is Decision Clarity — Raktim Singh
- Read about The Enterprise AI Runbook Crisis The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI — and What CIOs Must Fix in the Next 12 Months — Raktim Singh
- Read about Enterprise AI Economics Enterprise AI Economics & Cost Governance: Why Every AI Estate Needs an Economic Control Plane — Raktim Singh
Read about Who Owns Enterprise AI Who Owns Enterprise AI? Roles, Accountability, and Decision Rights in 2026 — Raktim Singh
Read about The Intelligence Reuse Index The Intelligence Reuse Index: Why Enterprise AI Advantage Has Shifted from Models to Reuse — Raktim Singh
Read about Enterprise AI Agent Registry Enterprise AI Agent Registry: The Missing System of Record for Autonomous AI — Raktim Singh
Conclusion: The discipline that makes autonomy survivable
Enterprise AI incident response is not a niche operational add-on. It is the discipline that makes autonomy survivable.
If your organization cannot answer—quickly and provably:
- What inputs were used?
- What sources were retrieved?
- Which policy gates fired?
- Which tool calls happened?
- What changed in the environment?
…then your AI is not incident-response-ready.
And if it’s not incident-response-ready, it’s not production-grade Enterprise AI.
The organizations that win in the next decade won’t be the ones with the most models. They will be the ones that can detect, contain, roll back, and learn faster than the failure can spread.
Glossary
Agent: An AI system that can plan steps and call tools to take actions inside workflows.
AI incident: An operational event where AI behavior creates unacceptable risk to outcomes, policy, security, cost, or trust.
Blast radius: The scope of impact—how many systems, records, users, or processes can be affected.
Containment: Actions that reduce harm while preserving evidence and keeping operations stable.
Correlation ID: A unique identifier that links logs, traces, and events across services for one request or workflow. (OpenTelemetry)
Drift: Behavior changes over time due to shifting data, tools, or context—not necessarily a model “bug.”
Guardrails: Policy and safety controls that block or gate risky actions.
Irreversible action: A change that cannot be cleanly undone (or is expensive to undo), such as external commitments or destructive writes.
Rollback: Restoring the system to a known-good state, which may involve model/prompt/retrieval/tool/workflow layers.
Safe mode: A defined degraded mode (suggest-only, draft-only, approvals-required) that keeps work moving with reduced risk.
Postmortem: A structured incident write-up capturing impact, timeline, causes, and preventative actions—ideally blameless. (Google SRE)
FAQ
What is Enterprise AI incident response?
Enterprise AI incident response is the set of processes and controls used to detect AI failures, contain harm, roll back unsafe behavior, and prevent recurrence—especially when AI systems can take actions inside workflows.
How is an AI incident different from a software incident?
Software incidents often involve outages or defects in deterministic code. AI incidents often involve “soft failures” where decisions shift, outputs remain plausible, and impact accumulates silently across workflows.
What are the most common AI incident signals?
The most common signals are decision anomalies (approval/refusal shifts), action anomalies (spikes in writes or updates), guardrail tripwires (policy blocks and approvals), and cost/compute spikes.
What is the fastest way to contain an AI incident?
Switch the system into a predefined safe mode—suggest-only or draft-only—while you preserve evidence and investigate. This reduces harm without stopping operations.
What does rollback mean in Enterprise AI?
Rollback can mean reverting the model version, prompt/policy bundle, retrieval index or sources, tool configuration, or workflow integration—not just deploying an older model.
Why are blameless postmortems important for AI incidents?
Because AI incidents often arise from system interactions (model + retrieval + tools + policies + workflows). Blameless postmortems help organizations fix conditions, not assign blame. (Google SRE)
What is the minimum evidence needed to investigate an AI incident?
At minimum: inputs (prompts/system instructions), retrieval context, outputs, tool calls, policy/guardrail decisions, and correlated logs/traces. OpenTelemetry-style correlation helps make this feasible. (OpenTelemetry)
How does this relate to NIST guidance?
NIST provides widely used incident-handling lifecycle guidance and AI risk management framing that can be adapted for AI-specific operational realities. (NIST CSRC)
References and further reading
- NIST SP 800-61 Rev. 2: Computer Security Incident Handling Guide (archived/withdrawn in 2025 but still widely referenced for lifecycle structure). (NIST Publications)
- NIST AI RMF 1.0 (AI 100-1): Artificial Intelligence Risk Management Framework and supporting materials. (NIST Publications)
- Google SRE Book: Postmortem culture and blameless learning practices (with examples). (Google SRE)
- OpenTelemetry Concepts: Context propagation and signal correlation for observability across distributed systems. (OpenTelemetry)

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.