
Model Unlearning vs Decision Unwinding
When enterprises are asked to delete personal data from their AI systems, the instinctive response is technical: retrain the model, remove the records, and move on. On paper, the problem looks solved. In production, it rarely is.
Because modern Enterprise AI systems do not merely store information — they make decisions that alter customer outcomes, financial positions, operational states, and regulatory exposure.
A model can forget data, yet the decisions made using that data can persist for months or years, embedded in workflows, records, and downstream systems.
This gap between forgetting information and repairing outcomes is where many well-intentioned AI programs quietly fail. Understanding the difference between model unlearning and decision unwinding is no longer an academic distinction; it is fast becoming a defining test of enterprise-grade AI governance.
Model unlearning does not unwind decisions.
Decision unwinding does not fix models.
Enterprises need both — and they solve different risks.
This article is part of an ongoing effort to define Enterprise AI as a governed operating capability — not a collection of models. The full Enterprise AI Operating Model is available at raktimsingh.com.
Enterprise AI Operating Model
https://www.raktimsingh.com/enterprise-ai-operating-model/
The uncomfortable truth leaders discover too late
If an enterprise deletes someone’s data, it’s tempting to think the AI should “forget” them—and everything should revert to normal.
That logic works in a spreadsheet. It fails in production.
Because Enterprise AI doesn’t only store information. It produces outcomes:
- a loan was approved or denied
- an insurance premium changed
- a job applicant was rejected
- a fraud alert froze an account
- a care pathway was escalated—or delayed
So here’s the distinction that matters at board level:
Model unlearning is about changing a model’s memory.
Decision unwinding is about changing the world.
Enterprises need both—but they solve different problems, on different timelines, with different evidence requirements.
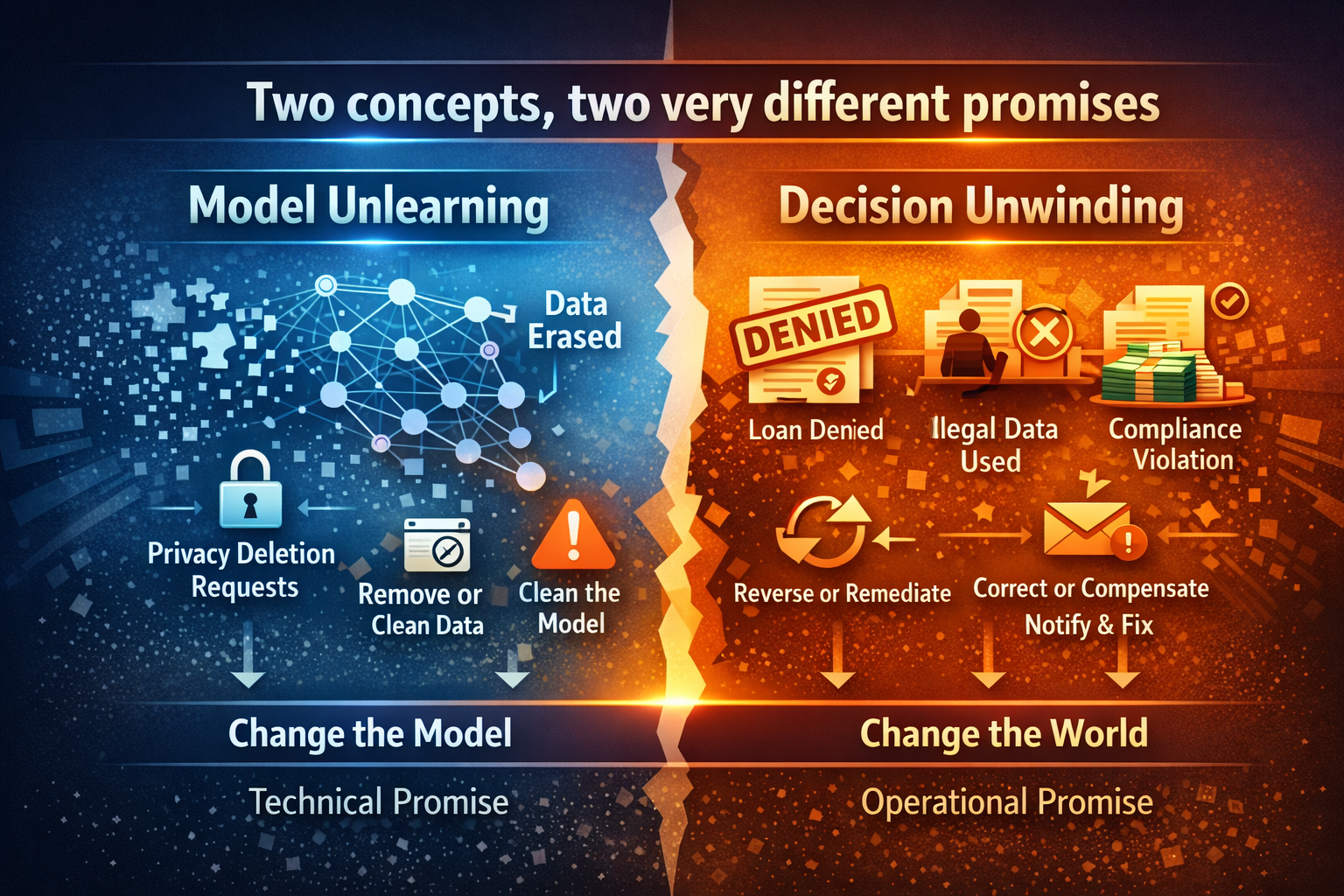
Two concepts, two very different promises
1) Model unlearning: the technical promise
Model unlearning (often called machine unlearning) aims to remove the influence of specific training data from a trained model so the model behaves as if it had been trained without that data (or close to it). (ACM Digital Library)
Why it matters in the real world:
- privacy deletion requests (“delete my data”) under the right to erasure (GDPR)
- removal of copyrighted or improperly licensed data
- removal of toxic, sensitive, or later-disallowed examples
- reducing data-retention risk in long-lived models
But unlearning is not the same as deleting rows from a database. Training doesn’t keep records in neat cells—it compresses patterns into parameters. Surveys repeatedly emphasize that unlearning is technically hard, full of trade-offs, and still evolving. (ACM Digital Library)
2) Decision unwinding: the operational promise
Decision unwinding means identifying and remediating the downstream decisions and actions that were made using:
- a model that later became invalid
- data that later became illegal to use
- logic that later became non-compliant
- evidence that later turned out to be wrong
Unwinding is not “forgetting.”
Unwinding is reversing, correcting, compensating, notifying, or reprocessing outcomes—in a way your organization can defend to customers, regulators, auditors, and your own board.
This is the missing half of Enterprise AI governance.

A concrete story: “Delete my data” in a bank
Imagine a bank used your transaction history as training data for a credit risk model. You submit a deletion request under the right to erasure (GDPR Article 17). (GDPR)
What model unlearning can do
- remove your data’s contribution from the next version of the model
- provide evidence that your data is no longer influencing predictions (to whatever standard the method can support)
What model unlearning cannot do
It does not automatically:
- reverse a past loan denial
- correct a premium you were charged
- restore an account that was frozen
- undo a negative decision shared to a third-party bureau
- compensate you for harm caused by the earlier decision
Those are decision outcomes, not training artifacts.
So the real enterprise question becomes:
After we unlearn, which decisions made by the old model are still active in the world—and what must we do about them?
That question is decision unwinding.
Why this gap is getting bigger in 2026+
Enterprise AI creates a mismatch in time:
- Model changes happen weekly (or faster).
- Decisions can persist for months or years.
A hiring decision can shape a career.
A denial letter persists in records.
A compliance flag propagates across systems.
A risk score becomes embedded in workflows and vendor feeds.
This is exactly why “Enterprise AI is an operating model”—not a model deployment problem. If your organization cannot govern outcomes over time, it doesn’t matter how modern the model is.

The compliance lens: erasure and automated decisions are not the same
Many leaders unintentionally collapse two different obligations into one:
- Right to erasure / right to be forgotten: delete personal data under certain grounds (GDPR Article 17). (GDPR)
- Rights around automated decision-making: safeguards when decisions are made solely by automated processing and significantly affect individuals (GDPR Article 22). (GDPR)
In plain language:
- Article 17 is about data processing and retention. (GDPR)
- Article 22 is about decision impacts and safeguards. (GDPR)
So an enterprise can be “excellent at deletion” and still be exposed on “decision consequences.”
That’s why decision unwinding needs its own discipline—and its own evidence.
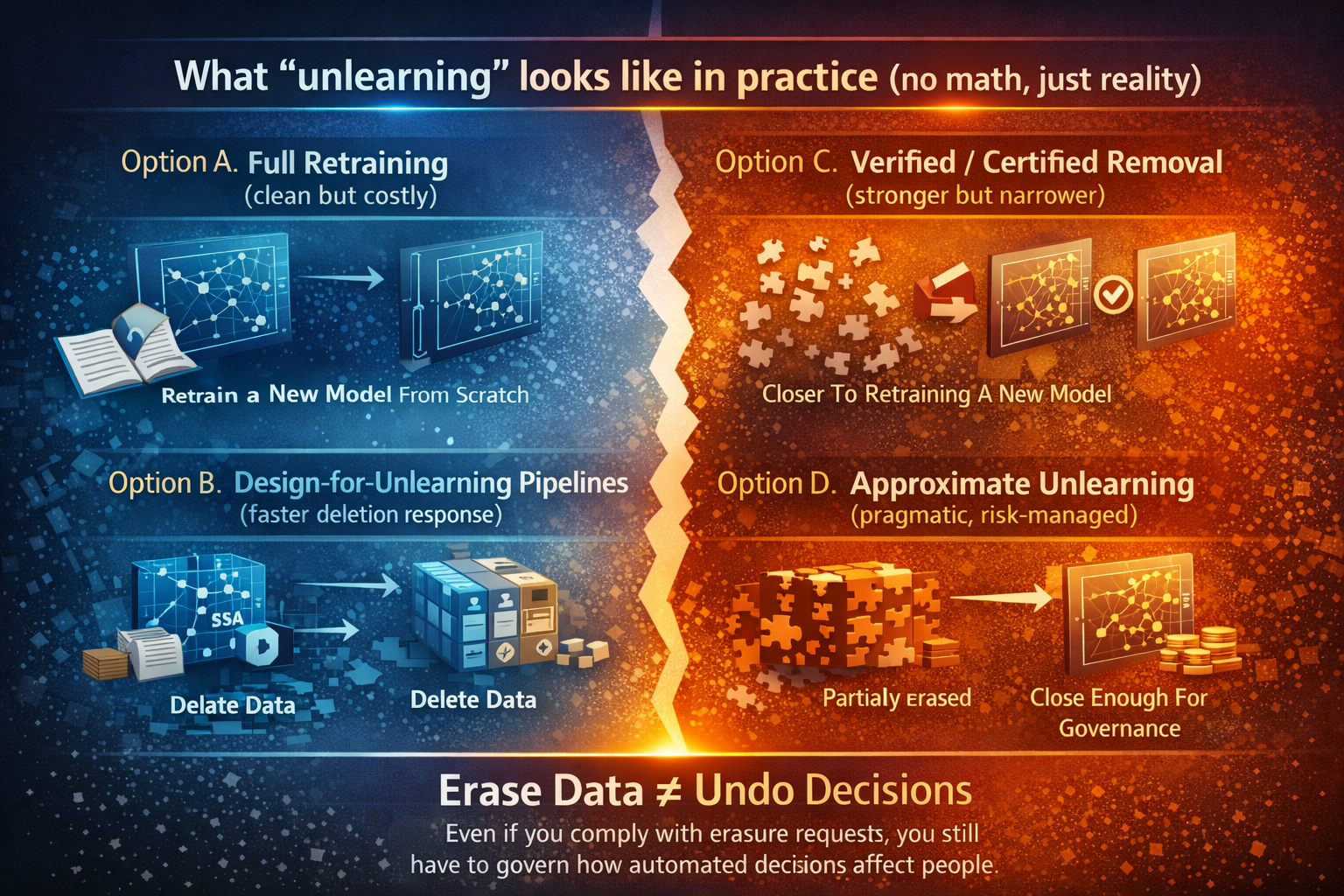
What “unlearning” looks like in practice (no math, just reality)
Most unlearning approaches land in a few practical families:
-
A) Full retraining (cleanest, expensive)
Retrain the model from scratch on the retained dataset. It’s straightforward conceptually, but operationally expensive at scale.
-
B) Design-for-unlearning pipelines (faster deletion response)
One influential approach is SISA (Sharded, Isolated, Sliced, Aggregated), which structures training so you can retrain only the affected parts when data must be removed. (arXiv)
-
C) Verified / certified removal (stronger guarantees, narrower fit)
Some research frames “certified” or “verified” unlearning as producing an unlearned model that matches (in a defined sense) what you would have gotten had you trained without the removed data—under specific assumptions. (arXiv)
-
D) Approximate unlearning (pragmatic, risk-managed)
In many real deployments—especially with frequent requests and large models—enterprises rely on approximations and governance controls, because “perfect” unlearning can be impractical. Surveys emphasize these feasibility constraints and open problems. (ACM Digital Library)
Key takeaway: Even when unlearning is possible, it only changes the future. It does not automatically repair the past.
What decision unwinding actually requires
Decision unwinding is a production capability. It requires four things that most AI programs still don’t have.
1) Traceability: you can’t unwind what you can’t locate
If you can’t answer “which decisions used which model and which policy,” you cannot unwind responsibly.
This is why your Decision Ledger concept is so important: not just logs and dashboards, but decision-level receipts that link:
- decision → model/version → policy/version → data sources → tool calls → approvals → action boundary
When an obligation arrives—erasure, correction, complaint, audit—you’re not guessing. You’re reconstructing.
2) Classification: not every decision can be reversed
Not all decisions are equally “rewindable.”
- Reversible: remove a flag, re-score a customer, re-open a case
- Partially reversible: adjust a rate prospectively, re-evaluate eligibility
- Irreversible: missed opportunity, reputational harm, irreversible clinical action
Unwinding is choosing the right remediation path by decision class, not performing a blanket “re-run.”
3) Remediation: you need a playbook, not a debate
In mature enterprises, unwinding is not improvised in a war room.
Typical remediation patterns include:
- Re-score / re-rank with corrected model
- Re-issue a decision notice (with human review where required)
- Undo an action (unfreeze, retract, cancel, restore)
- Compensate (credits, fee reversals, corrective servicing)
- Notify (customers, regulators, internal governance bodies)
- Quarantine propagation (stop downstream systems from continuing to act on the old decision)
4) Evidence: the “proof of correction” standard
Unwinding is not complete when the system changes.
It’s complete when the enterprise can show:
- what happened
- why it happened
- what changed
- which decisions were affected
- what remediation was applied
- what remains pending—and why
That is governance-grade evidence. It’s also what separates a serious Enterprise AI operating model from compliance theater.
Three simple examples that make the difference obvious
Example 1: Hiring
- Unlearning: remove a candidate’s data from training (or from embeddings/fine-tuning sources).
- Unwinding: re-evaluate the candidate if they were rejected using a model later found biased, non-compliant, or trained on data that must be erased.
Hiring outcomes persist. Models update. Without unwinding, the enterprise “forgets,” but the person remains harmed.
Example 2: Credit & lending
- Unlearning: remove specific transaction records from training influence.
- Unwinding: identify past decisions (denials, rate offers, limits) that relied on the old model and determine whether policy, fairness, or customer remediation requires reconsideration.
This is where automated decision safeguards can become operationally real—because these decisions can have significant effects. (GDPR)
Example 3: Fraud operations
- Unlearning: remove a mislabeled cluster of cases that poisoned the model.
- Unwinding: unfreeze accounts, reverse holds, correct risk labels across systems, and prevent the old flag from cascading into other controls.
In fraud, the blast radius is often bigger than the model.

Why enterprises get this wrong: the “deletion illusion”
Most organizations assume:
If we delete the data and update the model, we’re compliant.
But Enterprise AI introduces decision persistence:
- decisions become records
- records become workflows
- workflows become obligations
So the real policy question is:
What is our obligation to past decisions when the basis of those decisions changes?
That is decision unwinding.
Enterprise AI scale requires four interlocking planes:
Read about Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely — Raktim Singh
- Read about Enterprise Control Tower The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale — Raktim Singh
- Read about Decision Clarity The Shortest Path to Scalable Enterprise AI Autonomy Is Decision Clarity — Raktim Singh
- Read about The Enterprise AI Runbook Crisis The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI — and What CIOs Must Fix in the Next 12 Months — Raktim Singh
- Read about Enterprise AI Economics Enterprise AI Economics & Cost Governance: Why Every AI Estate Needs an Economic Control Plane — Raktim Singh
Read about Who Owns Enterprise AI Who Owns Enterprise AI? Roles, Accountability, and Decision Rights in 2026 — Raktim Singh
Read about The Intelligence Reuse Index The Intelligence Reuse Index: Why Enterprise AI Advantage Has Shifted from Models to Reuse — Raktim Singh
Read about Enterprise AI Agent Registry Enterprise AI Agent Registry: The Missing System of Record for Autonomous AI — Raktim Singh
Practical implementation blueprint
-
A) Treat decision lineage as a first-class asset
For every high-impact decision, record:
- model version
- policy version
- key input provenance (privacy-respecting)
- tool calls / data sources used
- approvals, overrides, and escalation path
-
B) Define “unwind triggers”
Make triggers explicit, not political:
- deletion request under erasure rights (GDPR)
- policy change (“this feature can no longer be used”)
- incident declaration (drift, leakage, bias)
- vendor model changes that break prior guarantees
-
C) Define “unwind scope rules”
Not everything gets unwound. That’s fine. But the rules must exist:
- “significant effect” decisions
- regulated domain decisions
- financial thresholds
- safety thresholds
-
D) Create remediation playbooks by decision class
Codify:
- who can authorize rewinds
- what can be auto-remediated vs human-reviewed
- when customers must be notified
- how downstream systems are corrected

Conclusion: The standard of Enterprise AI maturity
The best Enterprise AI systems won’t be judged by how smart their models are.
They’ll be judged by whether they can answer—confidently, consistently, and with evidence:
- Did we forget what we were supposed to forget? (model unlearning)
- Did we fix what we were supposed to fix? (decision unwinding)
That is the difference between “AI compliance theater” and Enterprise AI as a governed operating capability.
You can delete the data.
You can retrain the model.
And still keep the harm.
That’s the difference between model unlearning and decision unwinding.
FAQ
1) Is model unlearning required by law?
Many legal frameworks create deletion and data subject rights, including the GDPR right to erasure (Article 17). (GDPR)
How an organization implements deletion in ML systems varies; research surveys emphasize that unlearning techniques are still maturing and can be technically challenging. (ACM Digital Library)
2) If we unlearn, do we have to revisit past decisions?
Not always. But for high-impact domains, enterprises should define decision classes and obligations—especially where decisions are solely automated and significantly affect individuals. (GDPR)
3) Why can’t we just retrain and move on?
Because retraining changes future outputs. Past decisions can persist in records, workflows, third-party systems, and customer history. Unwinding addresses those real outcomes.
4) Is SISA the practical solution?
SISA is a foundational “design-for-unlearning” idea that can reduce the cost of unlearning by isolating training influence. (arXiv)
Whether it fits depends on your model type, update frequency, and the strength of guarantees you require.
5) What’s the first step to enable decision unwinding?
Decision traceability: a decision ledger/receipt system linking decision → model version → policy version → action and downstream propagation.
Q: What is the difference between model unlearning and decision unwinding?
A: Model unlearning removes the influence of specific data from an AI model. Decision unwinding remediates the real-world decisions and actions that were made using the old model.
Glossary
- Model Unlearning / Machine Unlearning: Techniques intended to remove the influence of specific training data from a trained model. (ACM Digital Library)
- Right to Erasure (“Right to be Forgotten”): Under GDPR Article 17, individuals can request erasure of personal data under certain grounds. (GDPR)
- Automated Decision-Making (GDPR Article 22): Safeguards related to decisions based solely on automated processing that produce legal or similarly significant effects. (GDPR)
- Decision Unwinding: Operational remediation of past decisions/actions made using a model, data source, or policy that later changed.
- Decision Lineage: The trace of how a decision was produced (model version, data provenance, policy, tool calls, approvals).
- Decision Ledger: A system-of-record for decisions and their receipts (inputs, versions, approvals, outcomes), enabling defensibility.
- SISA Training: Sharded, Isolated, Sliced, Aggregated training—an approach that can make unlearning more efficient by limiting retraining scope. (arXiv)
- Verified/Certified Unlearning: Approaches that aim to provide stronger guarantees that an unlearned model matches a retrained-without-data baseline under defined assumptions. (arXiv)
References and Further Reading
- GDPR Article 17 (Right to erasure). (GDPR)
- GDPR Article 22 (Automated individual decision-making). (GDPR)
- Bourtoule et al., “Machine Unlearning” (introduces SISA). (arXiv)
- ACM survey: “Machine Unlearning: A Survey.” (ACM Digital Library)
- Recent survey overview (2024) of machine unlearning categories and open problems. (arXiv)
- Example of ongoing work on verified unlearning directions (2025). (arXiv)

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.