{kind=link}

The Enterprise AI Readiness Test:
Every week, a CIO somewhere sits across from a consulting team and receives a readiness score. It looks rigorous. It has colour-coded bands — red, amber, green. It covers cloud maturity, data infrastructure, AI talent density, executive sponsorship, and technology stack. The CIO nods. The board is briefed. The AI programme is declared ready.
Six months later, the pilot works beautifully in the demo room and collapses in production.
This is not a coincidence. It is a structural failure — and it begins with the readiness test itself.
Most enterprise AI readiness frameworks are measuring the wrong things. Not because the people who built them were incompetent. But because they were designed for a world where the central question was “Do we have the infrastructure to run AI?” That question has been answered. The hard question now is fundamentally different: “Does our organisation’s reality exist in a form that AI can actually work with?”
That distinction — between having the infrastructure to run AI and having the institutional reality that AI can represent — is the gap that no standard readiness checklist closes. And it is costing enterprises billions.
What Standard AI Readiness Frameworks Actually Measure

Before diagnosing the problem, it is worth being precise about what current frameworks assess. Most of them, from the major consulting firms and analyst houses, converge on five dimensions.
They measure technology readiness — cloud adoption, compute availability, MLOps tooling, API infrastructure. They measure data readiness — volume, quality, labelling, governance, lineage. They measure talent readiness — data scientists, ML engineers, AI literacy among employees. They measure governance readiness — policies, risk frameworks, ethics guidelines. And they measure executive sponsorship — whether the C-suite has endorsed the programme.
These are real and necessary dimensions. An enterprise without cloud infrastructure cannot run AI at scale. An enterprise without clean data will get unreliable outputs. These things matter.
But here is what they do not measure: whether the organisation as it actually operates — with its informal authority structures, its cultural workarounds, its institutional memory, its real decision-making flows — is legible to an AI system at all.
This is where the readiness illusion begins.
The Problem That Digital Anthropology Reveals

Digital anthropology is the study of how human behaviour, culture, and social structures express themselves through and within digital systems. When applied to enterprise AI, it reveals something that no data audit can find: the gap between the formal organisation and the real one.
Consider a bank’s loan approval process. The documented process says: collect applicant data, run credit scoring model, route to loan officer for review, approve or decline. Simple. Clean. Digitised.
But the real process looks different. The loan officer has been at the bank for eighteen years. She knows which local businesses are reliable partners regardless of what the credit score says. She knows that certain applicants underreport income because of how their industry works. She knows who to call when an application is borderline. She routes certain files to specific colleagues, not because the system says to, but because of trust relationships built over two decades. None of this is in any database. None of it was captured during digital transformation. And all of it matters enormously to the quality of the decision.
When an AI system is deployed to assist — or replace — that process, it operates on the formal version. It sees the documented workflow, the structured data fields, the policy rules. It cannot see the eighteen years of relational knowledge. It cannot see the informal routing. It cannot see the cultural understanding of how local businesses actually operate.
The result is not that the AI makes errors. The result is that the AI makes systematically different decisions based on an incomplete picture of reality — and nobody in the organisation fully understands why, because the gap is invisible.
This is what digital anthropology calls the Human–AI Reality Gap: the distance between what an institution believes it has represented in its digital systems and what it has actually represented.
Most enterprise AI readiness frameworks do not measure this gap. Most do not even look for it.
Introducing Representational Readiness

This is the missing dimension. I call it Representational Readiness: the degree to which an organisation’s operational reality — including its informal processes, cultural norms, authority structures, tacit knowledge, and real decision flows — is accurately and completely represented in the form that AI systems can sense, reason about, and act upon.
Representational Readiness is not about data quality in the conventional sense. A database can be perfectly clean, well-governed, and GDPR-compliant, and still represent only forty percent of what actually drives decisions in that organisation.
Think of it this way. Imagine you want to teach someone to navigate a city. You give them an official map. The map is accurate — every street is correctly placed, every distance is correctly measured. But it does not show which streets flood in monsoon, which shortcuts only locals know, which districts require a phone call before visiting, which routes become dangerous at night. Someone using only the official map will navigate the city — but will make decisions that a local resident would never make.
Enterprise AI is the person with the official map. The real organisation is the city. Representational Readiness is the question of how close the map is to the actual terrain.
The SENSE–CORE–DRIVER Framework: An Architecture for True Readiness
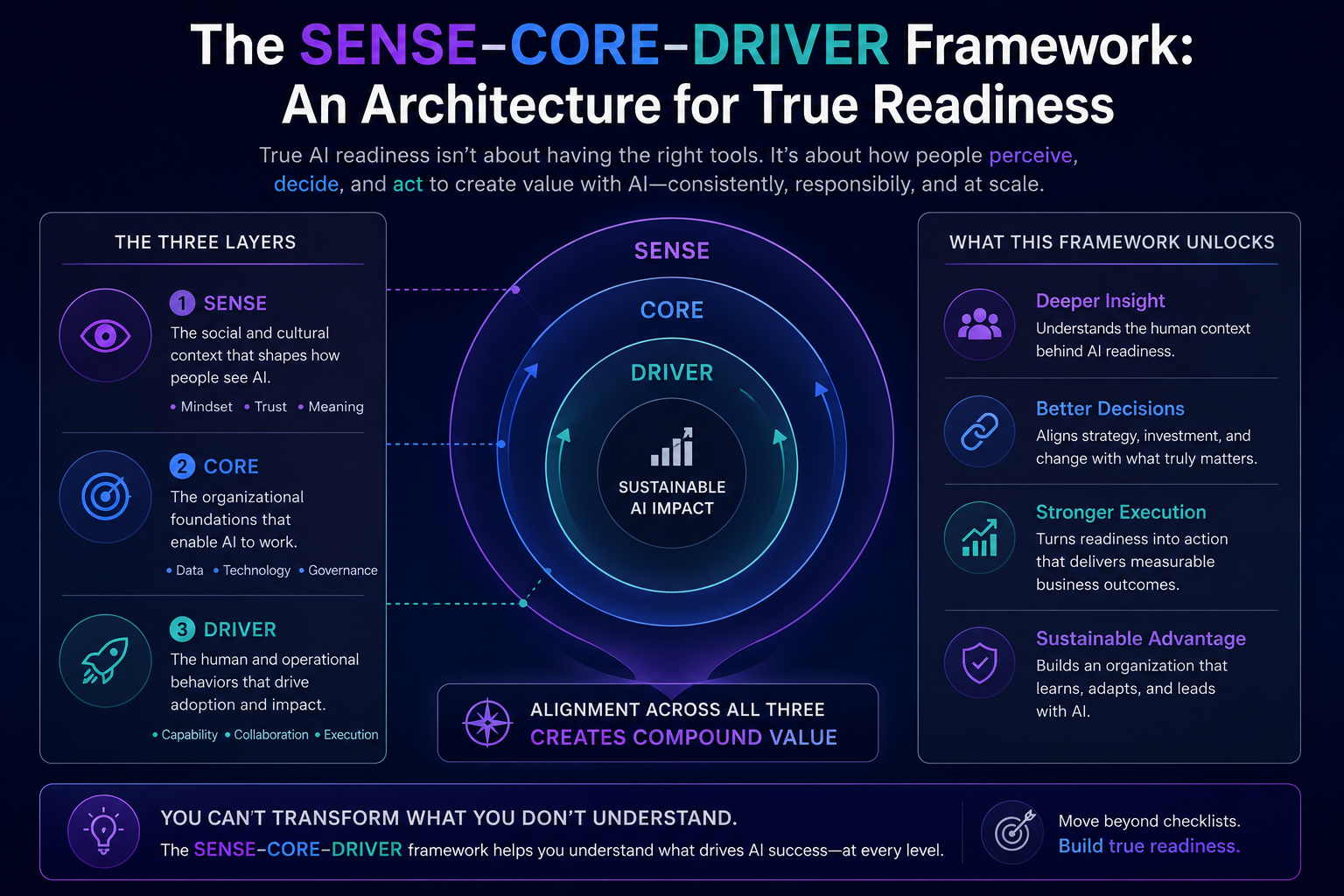
The framework I developed to address this problem — SENSE–CORE–DRIVER — was designed precisely because standard enterprise AI architectures skip a foundational layer. They build the intelligence before they build the representation. They deploy the reasoning before they ensure what is being reasoned about is actually real.
The framework has three components, each addressing a different dimension of readiness.
SENSE is the representation layer. It governs how an organisation’s reality is sensed, structured, and made legible to AI systems. This is not just data ingestion. It includes signals from human behaviour, organisational culture, informal authority, institutional memory, and real operational context. A high SENSE readiness means the AI system is working from a picture of the organisation that is accurate, not just clean.
CORE is the reasoning layer. It governs how AI systems reason within institutional constraints — not just what logic they apply, but whether that logic is aligned with the organisation’s actual values, risk tolerance, and decision culture. A high CORE readiness means the AI is reasoning in a way the organisation actually endorses, not just a way that optimises the metric it was given.
DRIVER is the delegation layer. It governs how AI actions are authorised, how decisions are accountable, and how outcomes can be reversed or appealed. It is the governance of what AI is allowed to do, who is responsible when it acts, and what happens when it gets something wrong. A high DRIVER readiness means the organisation has the authority structures and recourse mechanisms to let AI act without losing control.
Most enterprise AI readiness frameworks implicitly assess CORE readiness — they look at reasoning quality, model performance, and algorithmic fairness. A few assess DRIVER readiness — they look at governance policies and oversight mechanisms. Almost none assess SENSE readiness. And SENSE is where the majority of enterprise AI deployments actually fail.
Why SENSE Readiness Is the Hardest Problem

SENSE readiness fails for a specific reason that is structural, not technical: organisations digitised their visible processes but not their real ones.
Every digital transformation programme from the last twenty years focused on making the formal organisation faster and cheaper. Procurement systems were digitised. HR workflows were automated. Customer journeys were mapped and optimised. Finance processes were standardised across geographies.
What was not captured — because it was invisible, because it lived in people’s heads and in unwritten norms, because it operated through relationships and habits and cultural shortcuts — was the real operating logic of the organisation.
The procurement system shows the approved vendor list. It does not show which vendor relationships are trusted beyond the contract, which suppliers respond to emergency calls, which account managers will genuinely escalate a problem.
The HR system shows job grades, performance scores, and reporting lines. It does not show who actually makes decisions, who is consulted informally, which teams have strong collaborative norms and which ones route around each other.
The customer journey map shows the official touchpoints. It does not show the workarounds customers use when the official process fails, the calls they make to the branch manager they know personally, the informal escalation paths that resolve ninety percent of complaints before they become formal tickets.
AI systems trained and deployed on the formal organisation will make decisions that are technically correct but institutionally wrong. And the people in the organisation will know it immediately — they will call the AI outputs “tone-deaf” or “out of touch” or “missing the point” — without being able to articulate exactly why, because the real organisation has never been written down.
A Real Pattern Across Industries

This is not a theoretical risk. It is a documented pattern across industries.
In financial services, AI-powered credit decisioning systems consistently produce approvals that experienced loan officers would have declined, and declines that those same officers would have approved — not because the model is wrong, but because the model was trained on data that does not include the relational and contextual knowledge that experienced officers carry.
In healthcare, clinical AI tools that perform excellently in trials struggle in deployment because the informal coordination patterns between care teams — who trusts whose judgment on which patient type, which shorthand communication norms operate in which ward — were never represented in the training data.
In manufacturing, predictive maintenance systems produce alerts that experienced floor engineers ignore, because the system cannot represent the contextual knowledge that certain machines behave unusually during weather changes, or that a particular alert pattern always precedes a specific but unrelated issue that the system never modelled.
In every case, the readiness assessment said green. The technology was ready. The data was clean. The governance was in place. What was not ready — and was never measured — was the organisation’s Representational Readiness. The real enterprise was not in the system. The AI was reasoning about a simplified model of the organisation, not the organisation itself.
How to Actually Assess Enterprise AI Readiness
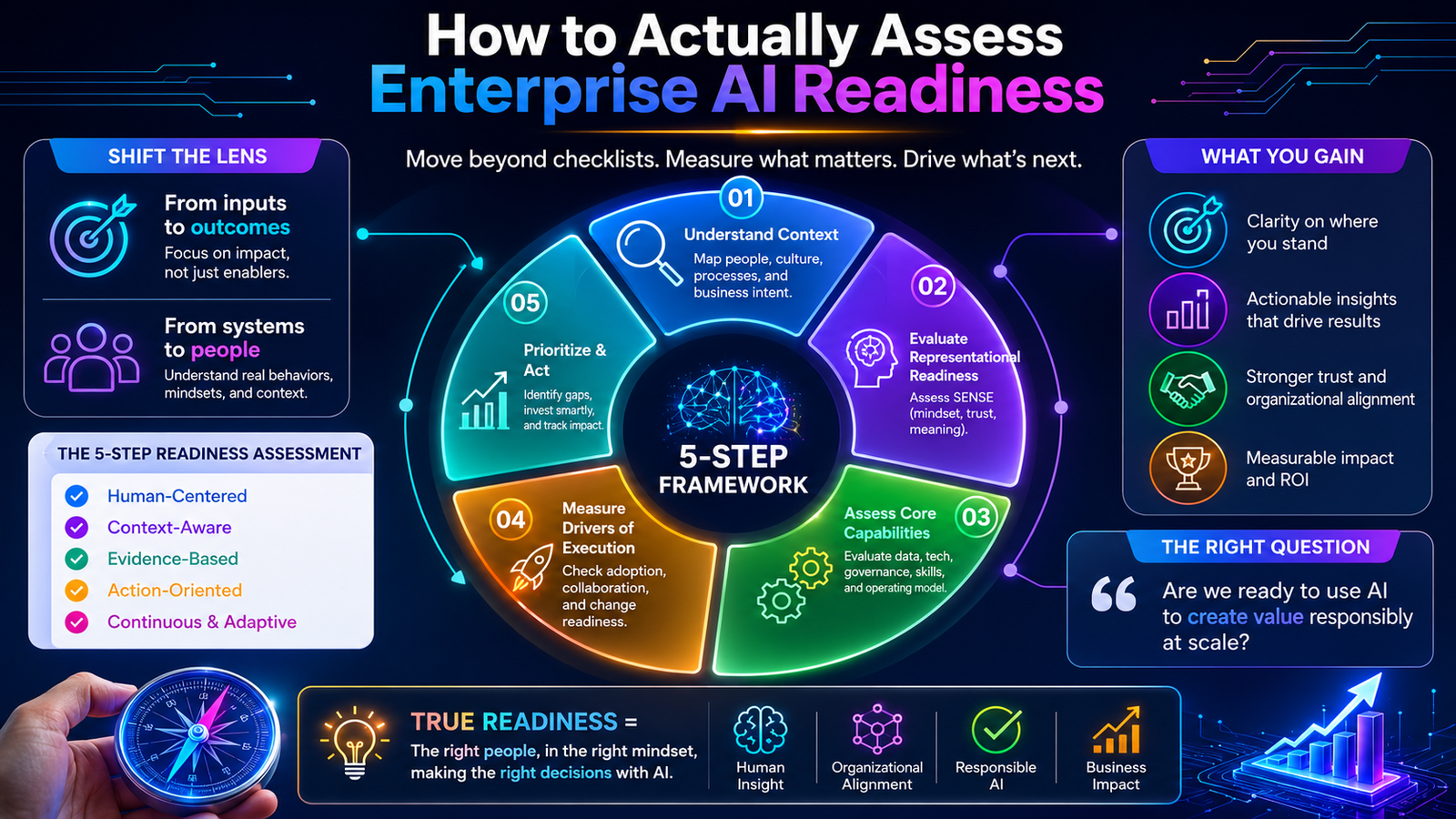
A genuine enterprise AI readiness assessment needs to measure all three SENSE–CORE–DRIVER dimensions, with Representational Readiness as the foundation. Here is what that looks like in practice.
Assessing SENSE Readiness means asking: how much of what actually drives decisions in this organisation is captured in structured data that an AI system can access? This requires a form of institutional ethnography — digital anthropology applied to the enterprise. It means interviewing experienced practitioners and asking them to describe what they know that is not in any system. It means mapping informal authority structures alongside formal reporting lines. It means identifying the tacit knowledge that experienced employees carry and that junior employees must spend years acquiring.
A useful diagnostic question: if your most experienced ten people in a given function left tomorrow, what percentage of their decision-making capability could your current AI systems replicate? If the answer is less than fifty percent, your SENSE layer is not ready for the decisions you are planning to delegate to AI.
Assessing CORE Readiness means asking: is the reasoning the AI applies aligned with the institutional values, risk tolerance, and decision culture of the organisation — not just optimised for the metric it was given? This requires examining whether AI outputs actually match what senior practitioners endorse when they see them, and diagnosing the cases where they do not. A well-performing model that systematically produces decisions that experienced practitioners disagree with is a CORE readiness failure, not a model performance failure.
Assessing DRIVER Readiness means asking: when the AI acts, who is responsible? When it gets something wrong, what is the recourse mechanism? Can its decisions be reversed? Can they be explained in terms that affected parties can understand and contest? Many organisations have AI governance policies that answer these questions in theory but have never tested whether those policies function in practice. DRIVER readiness is not a document review. It is an operational test.
The Representational Readiness Score: A New Way to Think About AI Maturity

Rather than the standard five-dimension readiness model, a more useful framework organises readiness around three questions that correspond directly to SENSE, CORE, and DRIVER.
The first question is: Can AI see your organisation accurately? This measures the completeness and fidelity of the representation layer — how much of the real organisation is legible to AI, versus how much is invisible because it was never captured.
The second question is: Can AI reason in ways your organisation actually endorses? This measures the alignment between AI decision logic and the institutional values and risk culture that experienced practitioners embody — not just the formal policy documents.
The third question is: Can your organisation take back control when AI gets it wrong? This measures the delegation and recourse infrastructure — the reversibility of AI decisions, the clarity of accountability, and the practical accessibility of appeal mechanisms.
An organisation that scores high on all three is genuinely ready. An organisation that scores high on CORE and DRIVER but low on SENSE has a sophisticated system reasoning about an impoverished picture of reality. It will produce outputs that are internally consistent but institutionally wrong — and nobody will be able to explain why.
The Representation Economy Consequence
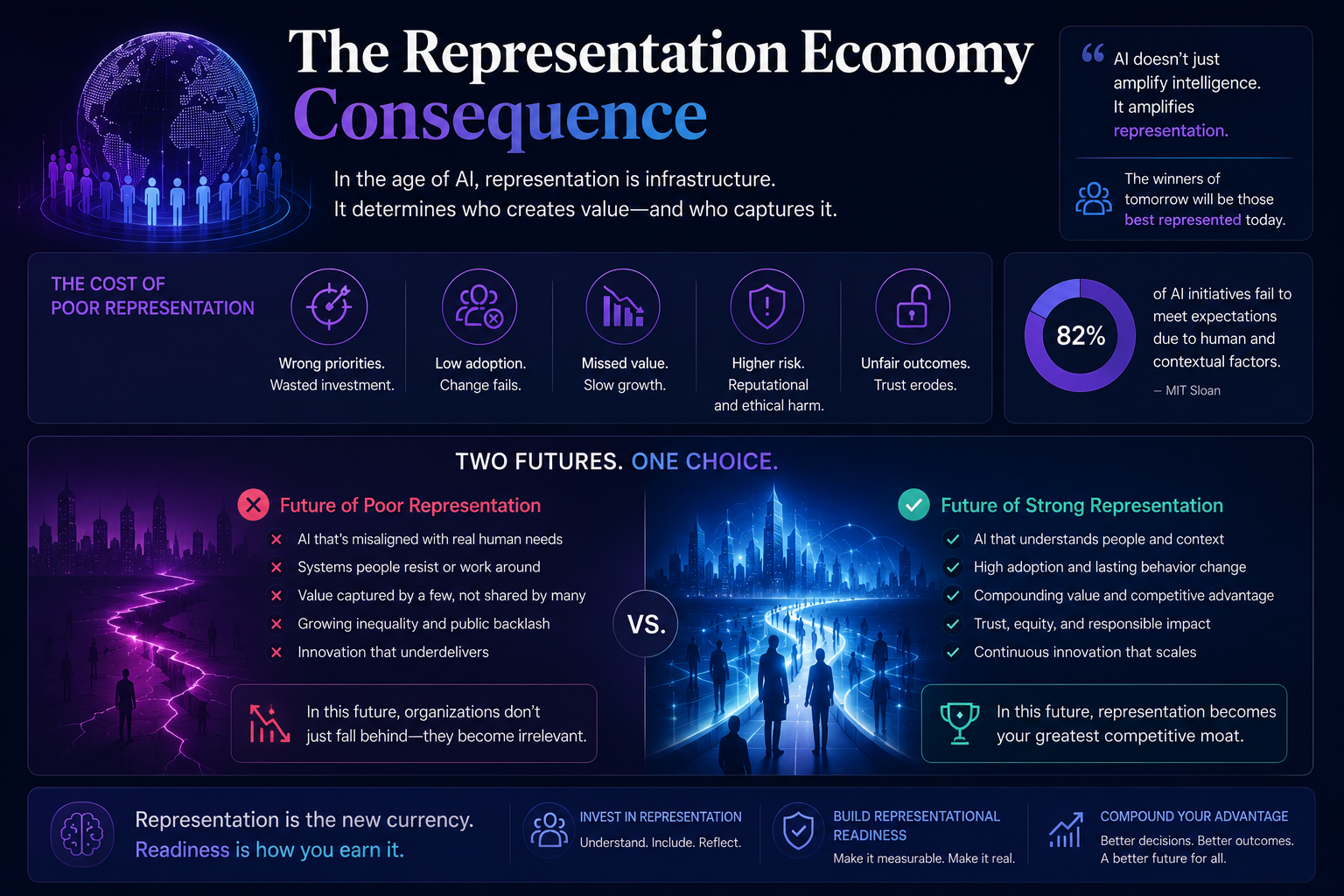
There is a broader economic dimension to this that boards need to understand. The frameworks and consulting reports focus on AI as a cost-reduction or productivity tool. But the deeper competitive dynamic in the AI economy is about representation.
Organisations that invest in building accurate, comprehensive, continuously updated representations of their operational reality — their real processes, their real knowledge, their real authority structures — are building a form of capital that is durable and difficult to replicate. I call this Representation Capital: the accumulated institutional knowledge that is machine-legible, current, and faithful to how the organisation actually operates.
Organisations that deploy AI on top of incomplete representations are, by contrast, accumulating Representation Debt: the growing gap between their formal digital systems and their real operational reality, which compounds over time as AI systems make decisions on increasingly stale or incomplete pictures of the organisation.
The competition between organisations in the AI decade will not primarily be about which model they use. Models are becoming commodities. It will be about whose institutional reality is more completely and accurately represented — whose AI systems can actually see what is happening, reason about what it means, and act in ways that the organisation genuinely endorses.
That is the Representation Economy. And readiness for it begins not with a technology audit, but with an honest institutional ethnography.
What CIOs and CTOs Should Do Now
The immediate practical implication is straightforward: before your next AI deployment, run a SENSE readiness audit on the function you are targeting.
Map the decisions that experienced practitioners make in that function. Identify the knowledge they use to make those decisions. Then ask, for each piece of knowledge: is this currently represented in any system that an AI could access? For everything that is not, you have a SENSE gap. That gap will not be fixed by better models, more compute, or stronger governance. It will only be fixed by building better representation infrastructure — capturing the tacit knowledge, formalising the informal processes, and making the real organisation legible to the AI system you are deploying.
This is not a one-time project. Organisations evolve. Cultural norms shift. New practitioners bring new knowledge. Old knowledge becomes obsolete. The SENSE layer must be continuously maintained, not built once and forgotten. Digital anthropology — the ongoing study of how your organisation actually operates — is not a project delivery. It is an operational discipline.
The enterprises that understand this will build AI that their people trust, because the AI will actually understand how the organisation works. The enterprises that skip this will keep explaining to their boards why the pilot worked and the rollout did not.
Conclusion: Redefining What Ready Means
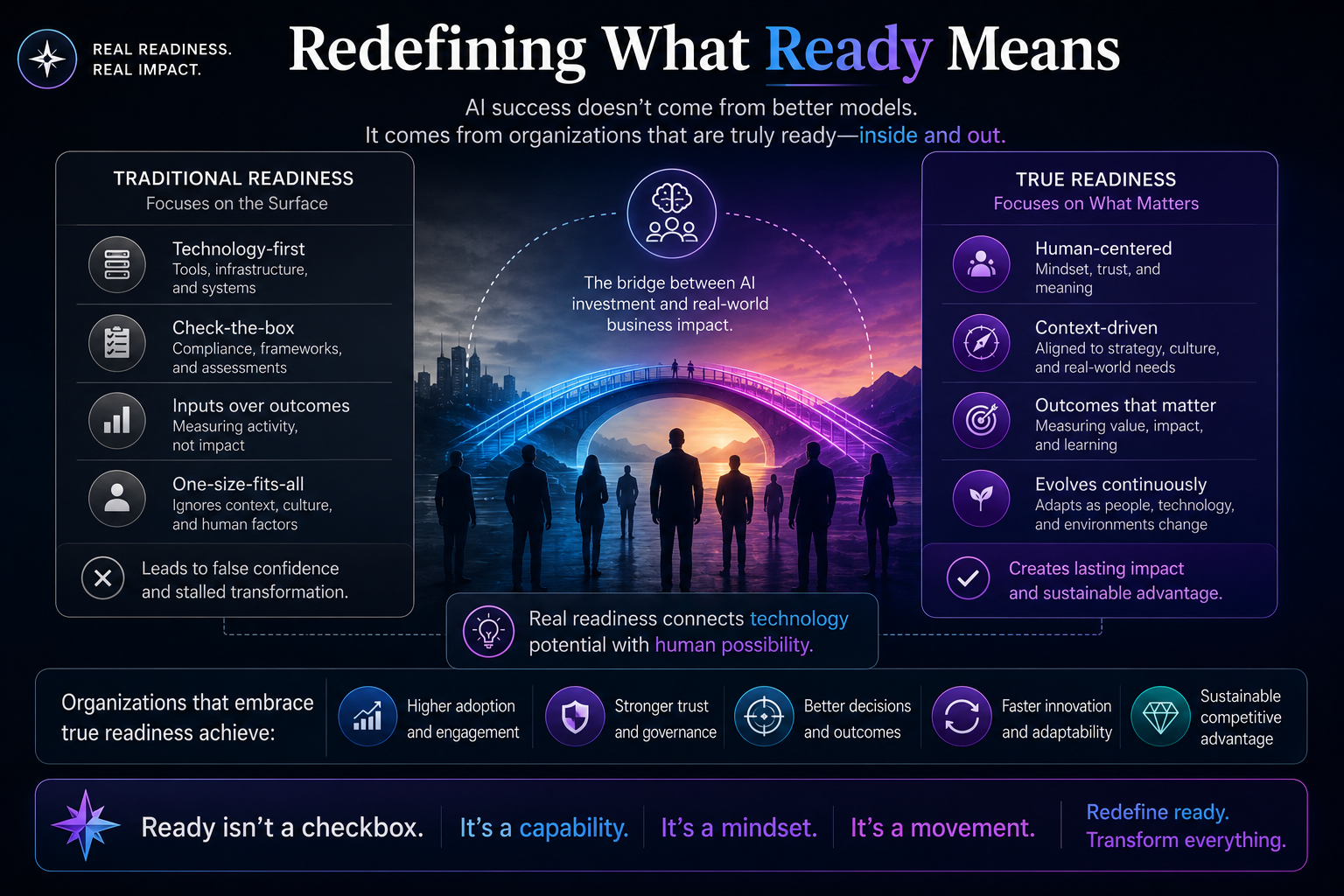
Enterprise AI readiness is not a technology question. It is an institutional question. And the institutions that will win the AI decade are not the ones with the most compute or the cleanest data. They are the ones that understand themselves clearly enough to represent that understanding to an AI system — accurately, completely, and continuously.
The standard readiness test measures whether you can run AI. The test that matters measures whether AI can understand you.
Most organisations are ready to run AI. Very few are ready to be understood by it. That is the gap worth measuring. That is the readiness that determines outcomes.
And it starts not with a technology audit, but with a question that most readiness frameworks never ask: Does AI actually see your organisation as it really is?
If you cannot answer that confidently, you are not ready — regardless of what the checklist says.
GLOSSARY
Representational Readiness
The degree to which an organization’s operational reality, including informal processes, tacit knowledge, cultural norms, and decision structures, is represented in forms that AI systems can understand and use.
Digital Anthropology
The study of how human behavior, culture, trust relationships, and social structures manifest within digital environments and enterprise systems.
Human–AI Reality Gap
The difference between how an organization actually operates and how that organization is represented within digital systems available to AI.
Representation Capital
The accumulated institutional knowledge that has been successfully converted into machine-legible form and can be used by AI systems.
Representation Debt
The growing mismatch between organizational reality and what digital systems capture, causing AI systems to reason from incomplete representations.
SENSE Layer
The representation layer within SENSE–CORE–DRIVER responsible for making institutional reality visible and legible to AI systems.
CORE Layer
The reasoning layer responsible for ensuring AI decisions align with institutional objectives, values, and operational constraints.
DRIVER Layer
The governance and delegation layer responsible for accountability, authorization, recourse, and execution.
Institutional Ethnography
A structured examination of how work actually happens inside organizations beyond formal process documentation.
Representation Economy
An emerging economic model where competitive advantage increasingly depends on how accurately organizations represent reality for intelligent systems.
FAQ
What is enterprise AI readiness?
Enterprise AI readiness is an organization’s ability to successfully deploy, govern, scale, and sustain AI systems that create measurable business value.
Why do most AI readiness assessments fail?
Most assessments focus on infrastructure, data, governance, and talent while ignoring whether organizational reality is actually represented in forms AI can understand.
What is Representational Readiness?
Representational Readiness measures how completely an organization’s real operational knowledge, decision processes, and cultural context are visible to AI systems.
What role does Digital Anthropology play in AI?
Digital Anthropology helps organizations identify hidden workflows, informal decision structures, and tacit knowledge that traditional readiness assessments overlook.
What is the Human–AI Reality Gap?
It is the difference between how people actually work and how enterprise systems represent that work.
Why do AI pilots succeed but deployments fail?
Pilots often operate within simplified environments, while enterprise deployment exposes representation gaps, missing context, and organizational complexity.
What is the SENSE–CORE–DRIVER framework?
SENSE–CORE–DRIVER is an enterprise AI architecture developed by Raktim Singh that evaluates readiness across representation, reasoning, and governance layers.
What is Representation Capital?
Representation Capital is machine-legible institutional knowledge that enables AI systems to make better decisions aligned with organizational reality.
Q&A
Q: What is Representational Readiness in AI?
Representational Readiness is the degree to which an organization’s actual operational reality—including tacit knowledge, informal processes, authority structures, and cultural norms—is represented in forms that AI systems can understand, reason about, and act upon.
Q: Why do enterprise AI projects fail despite strong technology foundations?
Many enterprise AI initiatives fail because the organization has invested in technology readiness but not representational readiness. AI systems often operate on simplified digital representations that omit critical human and institutional knowledge.
Q: What is the biggest gap in modern AI readiness frameworks?
The biggest gap is the absence of measures for how accurately organizational reality is represented to AI systems. Most frameworks assess technology, data, and governance but ignore representation quality.
Q: How does Digital Anthropology improve AI deployment?
Digital Anthropology uncovers hidden workflows, informal authority structures, trust relationships, and tacit knowledge that significantly influence decision-making but rarely appear in enterprise data systems.
What is the connection between Digital Anthropology and Representation Economy?
According to Raktim Singh, Digital Anthropology helps reveal the gap between organizational reality and enterprise data. Representation Economy explains why this gap becomes economically significant in AI-driven institutions.
What is Representation Integrity?
Representation Integrity is the principle that AI systems should operate on representations that are accurate, complete, contextually faithful, and continuously validated against reality.
References
- IBM Institute for Business Value. (2026, June 8). CIOs and CTOs Face Growing AI Control Gap as Enterprise Deployment Scales. IBM. Available at: IBM Study: CIOs and CTOs Face Growing AI Control Gap as Enterprise Deployment Scales. Accessed June 14, 2026.
- KPMG International & INSEAD Corporate Governance Centre. (2026, April 14). AI Governance Principles for Boards. KPMG International. Available at: AI Governance Principles for Boards and KPMG and INSEAD Launch Global AI Board Governance Principles. Accessed June 14, 2026.
- Raktim Singh. (2026, June 14). Representation Integrity: Why Most AI Governance Failures Begin Before the Model Runs. Figshare. DOI: 10.6084/m9.figshare.32668665. Available at: Figshare DOI 10.6084/m9.figshare.32668665.
- Raktim Singh. (2026, June 13). Why AI Agents Cannot Govern Themselves: A Representation-Based Explanation of Enterprise Agent Failure. Figshare. DOI: 10.6084/m9.figshare.32665104. Available at: Figshare DOI 10.6084/m9.figshare.32665104.
References and Further Reading
- Gartner: GenAI project abandonment due to poor data quality, risk controls, costs, and unclear business value. (Gartner)
- Gartner: AI-ready data and risk of AI project abandonment through 2026. (Gartner)
- NIST AI Risk Management Framework. (NIST)
- OECD AI Principles. (OECD.AI)
- Raktim Singh: The Data Illusion. (Raktim Singh)
- Raktim Singh: What Is the Representation Economy? (Raktim Singh)
- Raktim Singh: What Is the SENSE–CORE–DRIVER Framework? (Raktim Singh).
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/ai-agent-governance-how-cios-should-decide-what-ai-agents-are-allowed-to-do/
- raktimsingh.com/enterprise-ai-projects-fail-even-when-models-work/
- raktimsingh.com/15-tensions-enterprise-ai-sense-core-driver/
- raktimsingh.com/ai-transformation-begins-where-digital-transformation-stopped/
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/enterprise-ai-roi/

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.