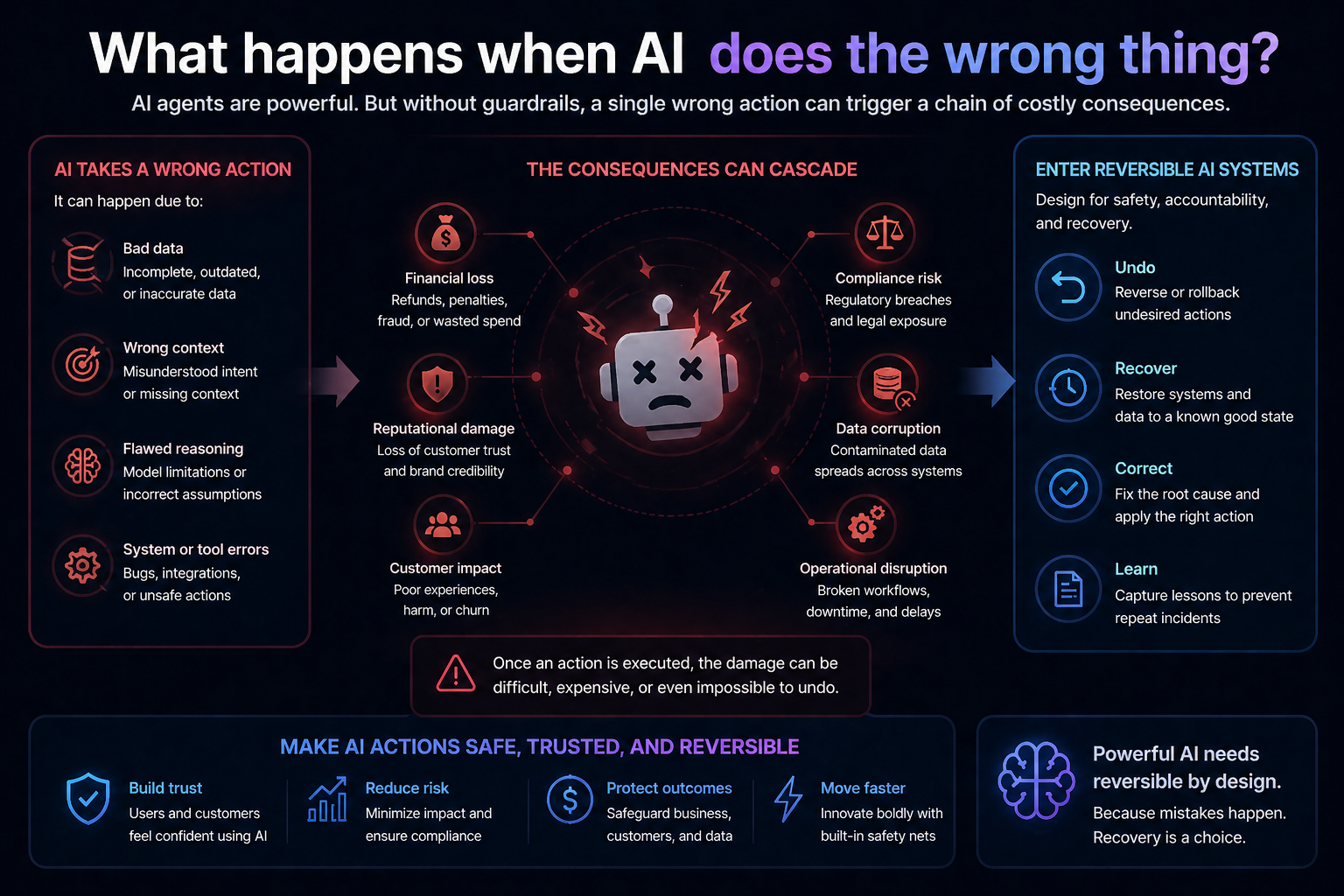
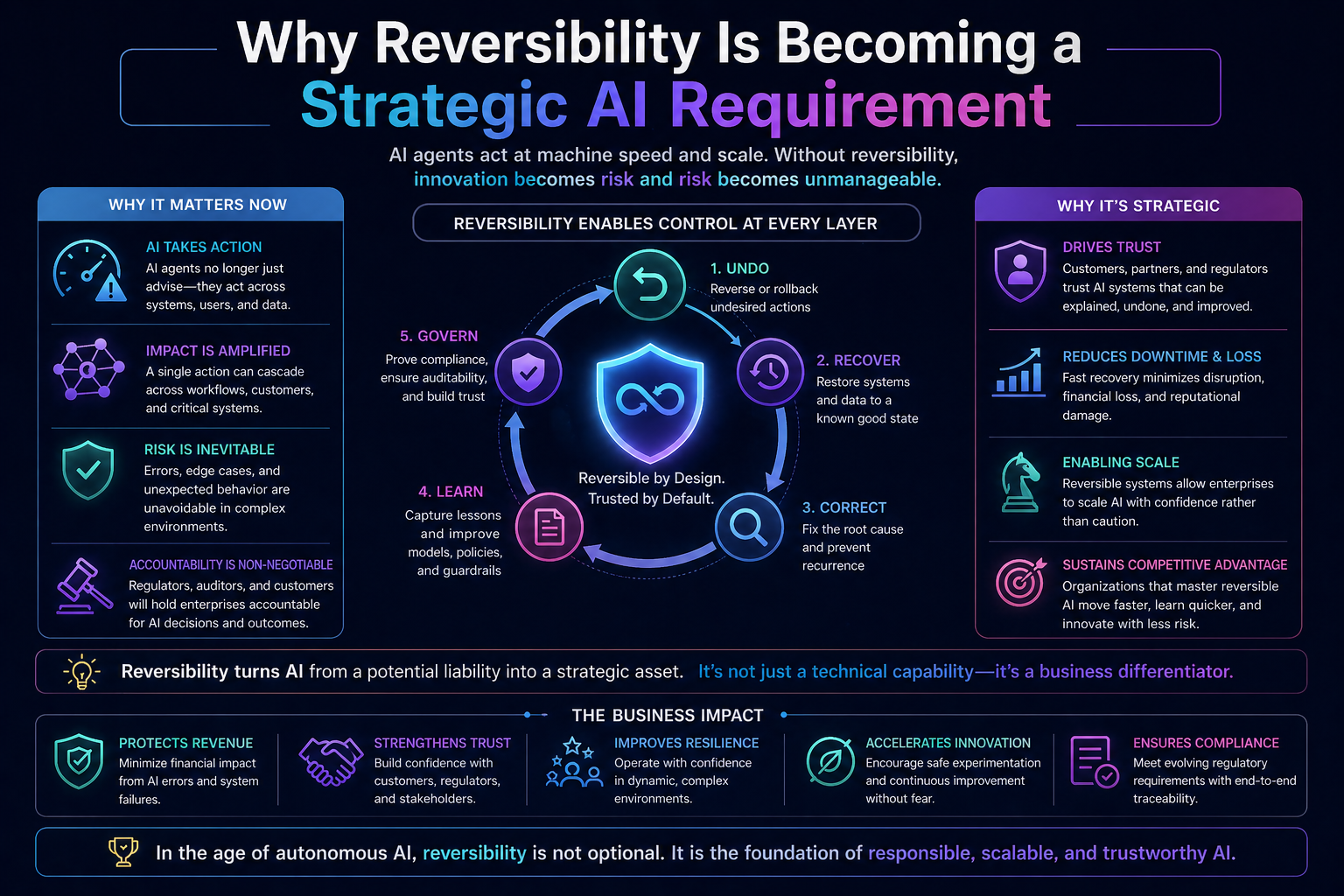
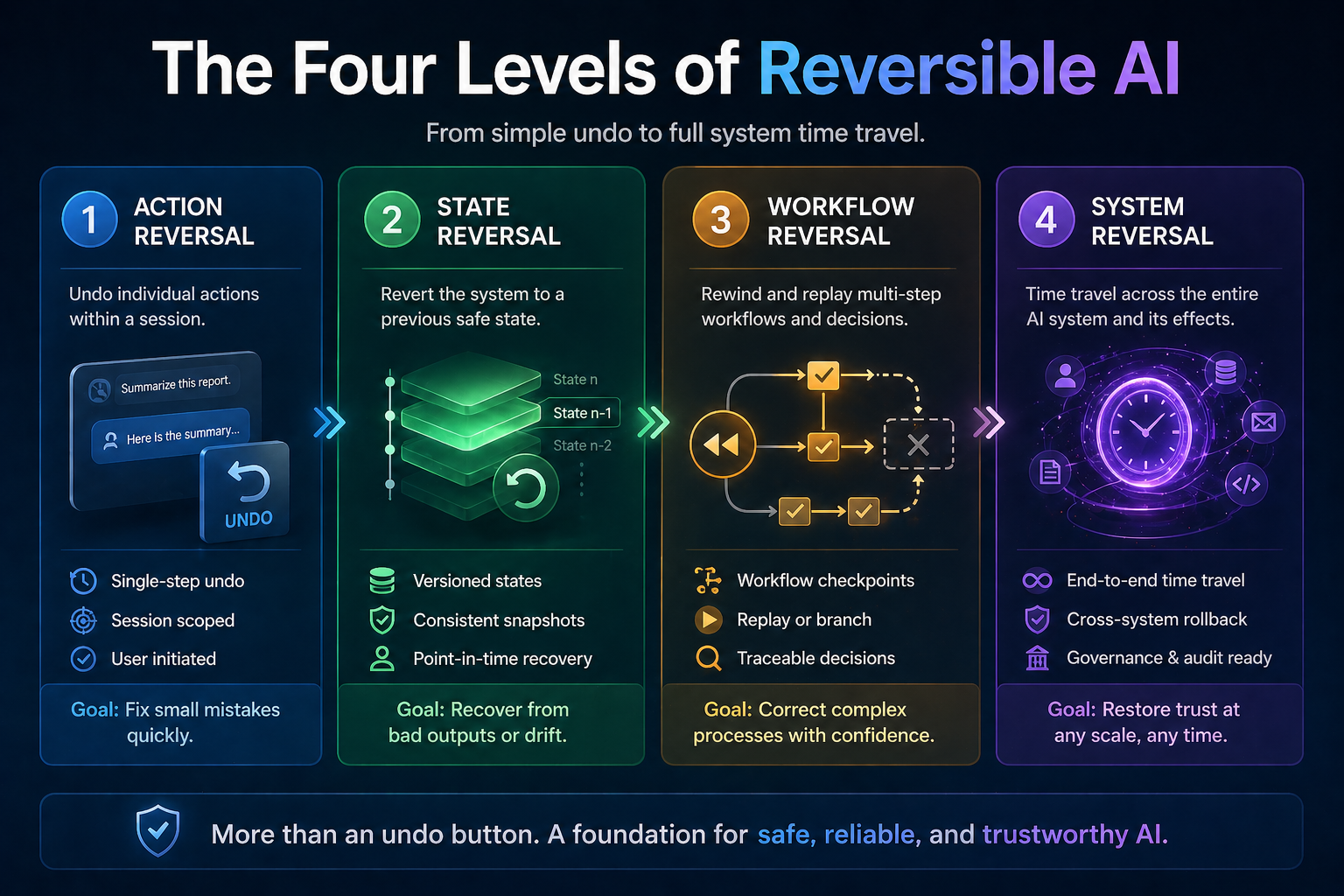
Cognitive Routing Architectures:
Enterprise AI will not scale by making every problem go through the same model. It will scale when systems learn how to choose the right path of thought.
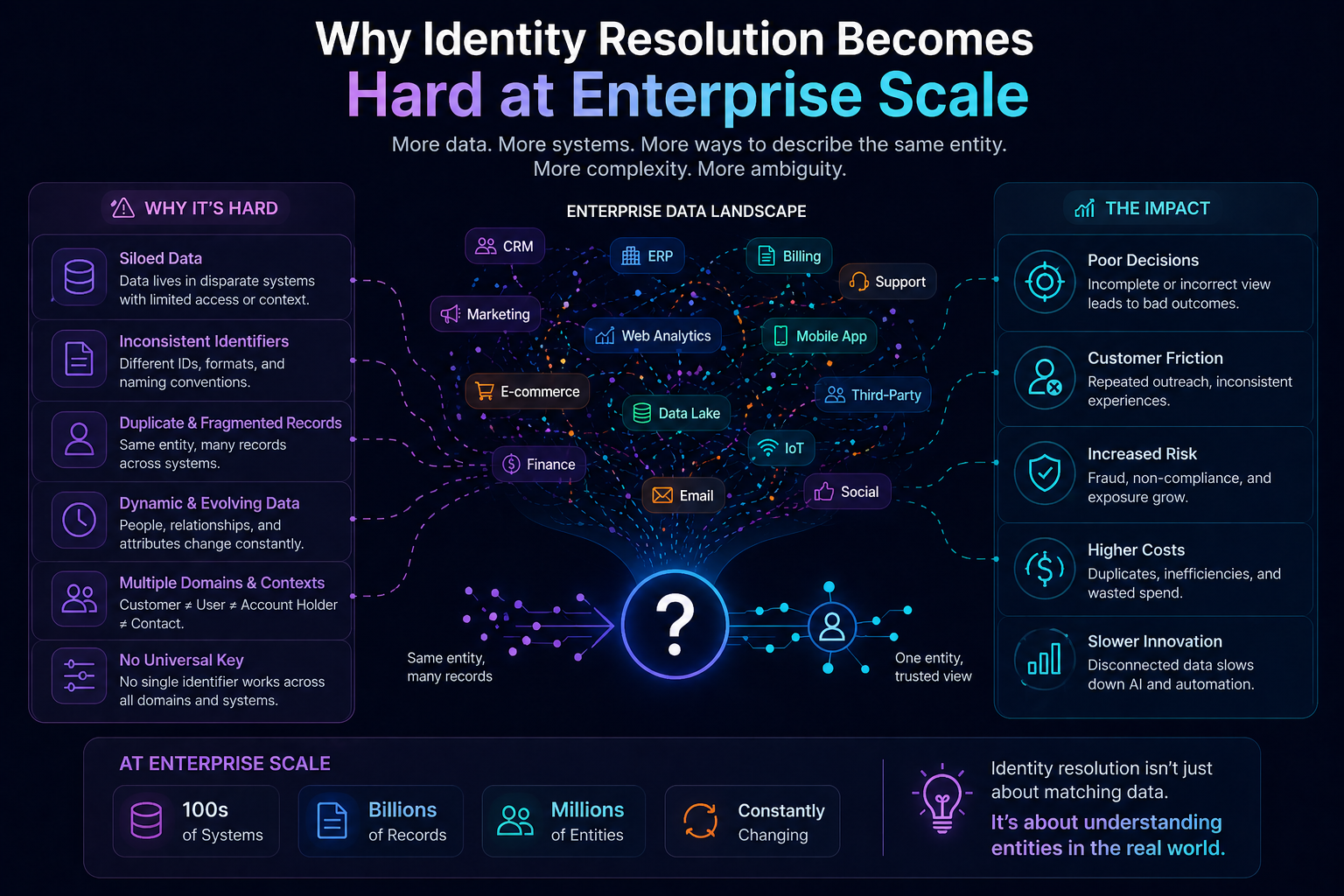
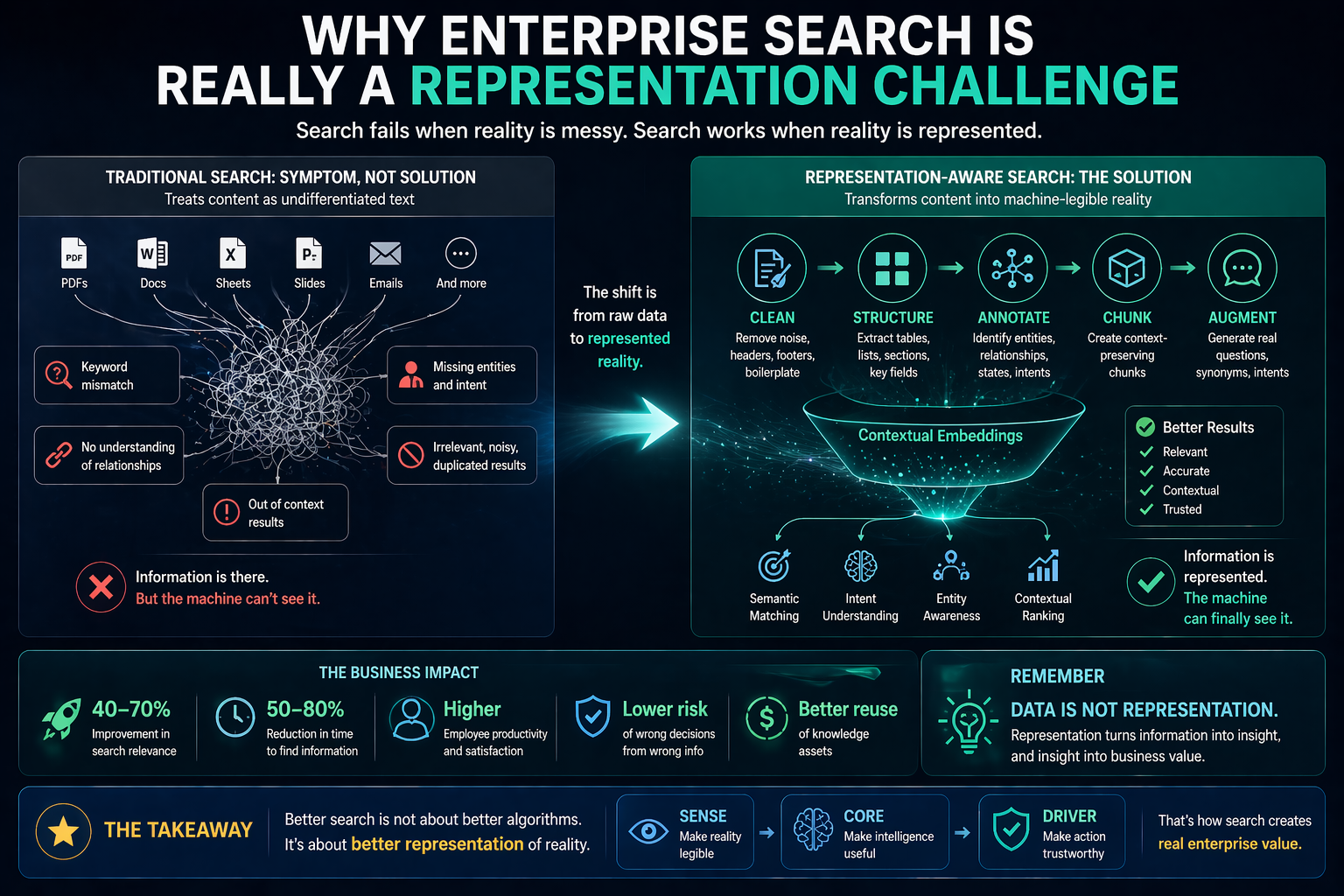
Most enterprise AI systems today still behave like every problem deserves the same kind of intelligence.
A user asks a question.
A prompt is sent to a model.
The model retrieves some context.
The model generates an answer.
This works for simple tasks. It can summarize documents, draft emails, classify tickets, write code snippets, and answer common questions.
But enterprises do not run on simple questions.
They run on mixed problems.
Some problems need retrieval.
Some need calculation.
Some need policy reasoning.
Some need causal analysis.
Some need graph traversal.
Some need simulation.
Some need human escalation.
Some need a cheap model.
Some need a frontier model.
Some should not go to a model at all.
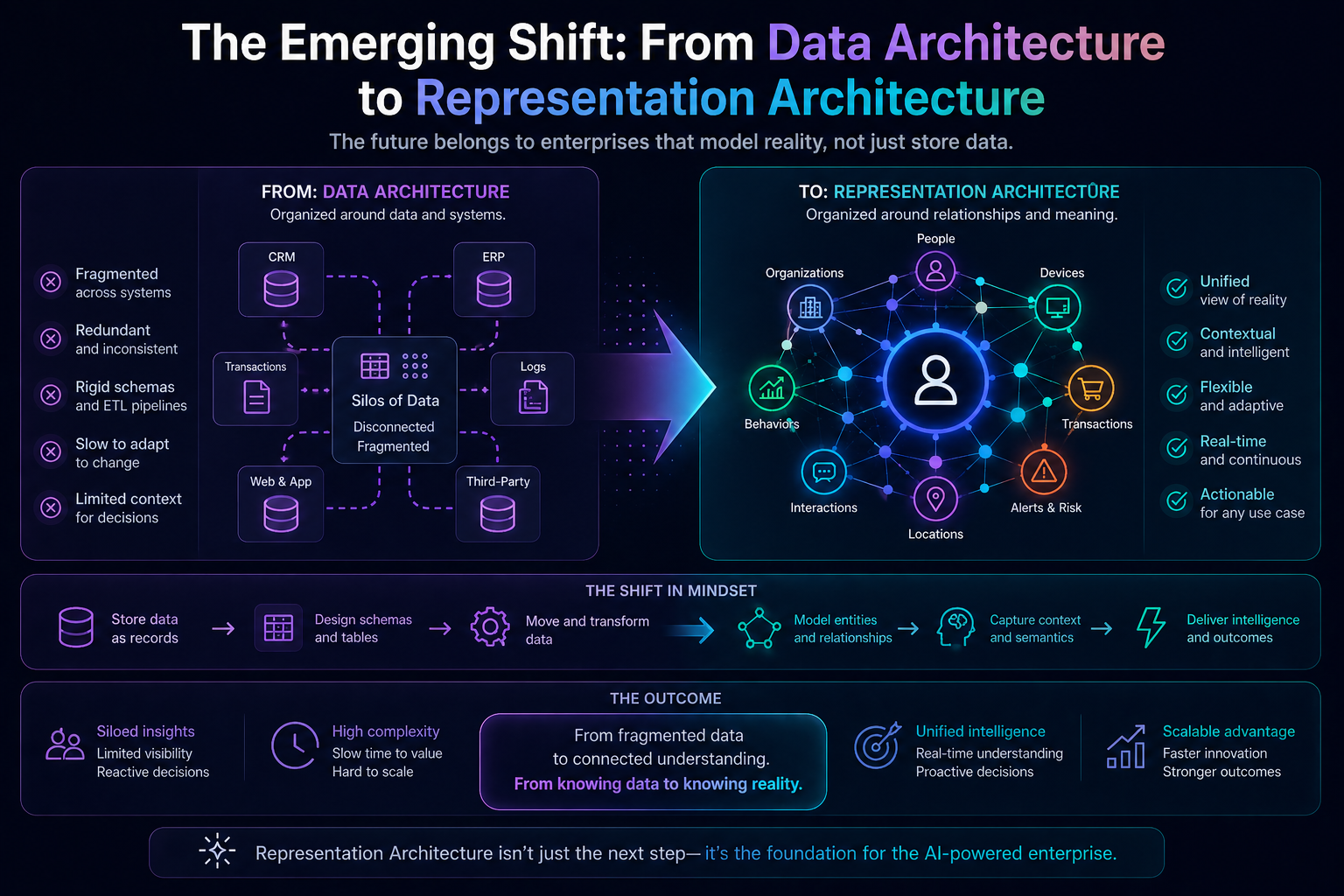
This is why the next stage of enterprise AI will not be defined only by bigger models or better prompts.
It will be defined by cognitive routing architectures.
A cognitive routing architecture is the system that decides which reasoning path an AI system should use for a given task. It determines whether the task should go to a small model, a large model, a retrieval system, a graph system, a rules engine, a domain model, a workflow engine, a human reviewer, or a combination of these.
In simple language: cognitive routing is the enterprise AI system asking, “What kind of thinking is needed here?”
That question is becoming critical.
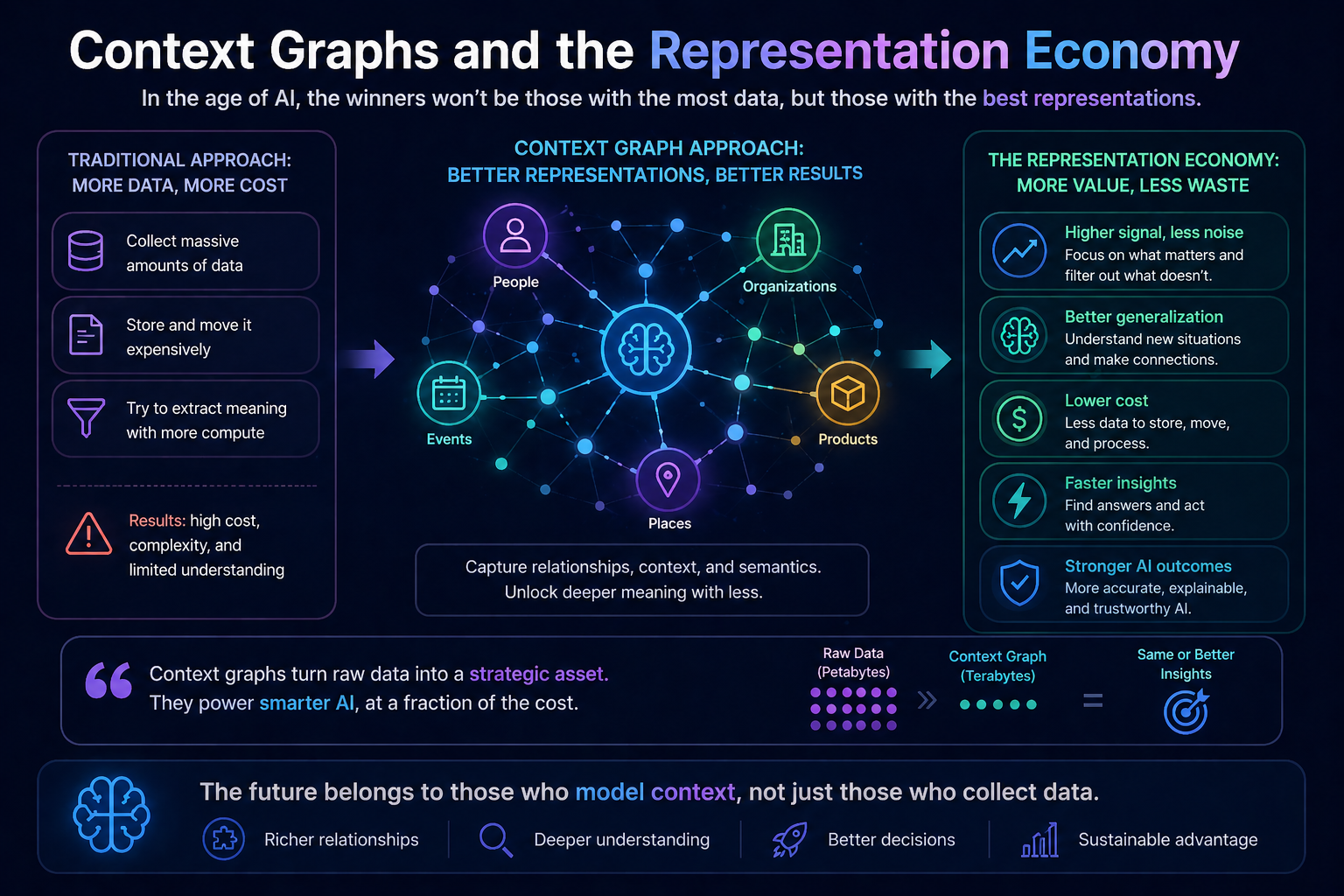
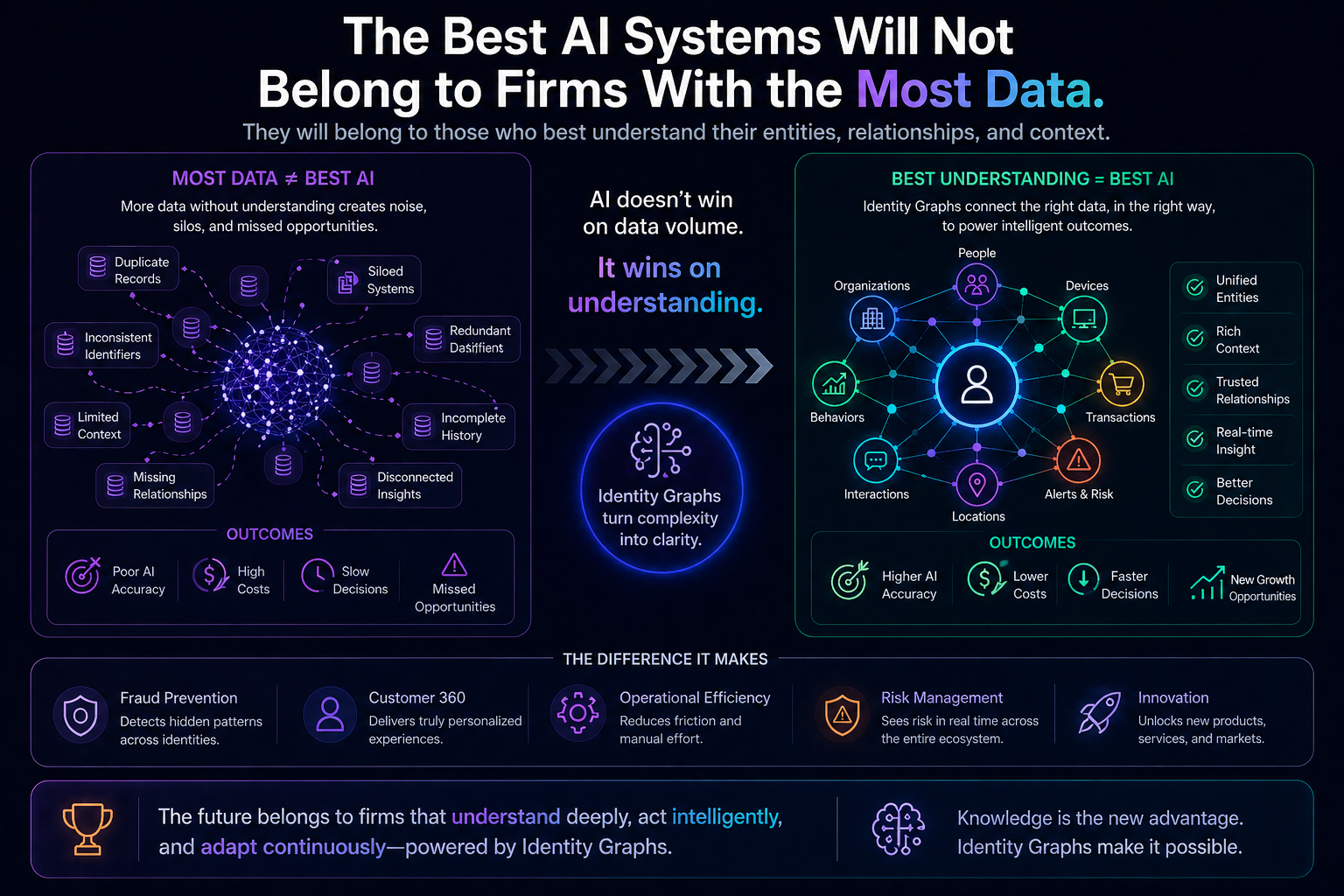
Because in the AI era, competitive advantage will not come only from having intelligence. It will come from knowing which intelligence to apply, when, where, at what cost, with what evidence, and under what authority.
That is why cognitive routing belongs at the heart of the Representation Economy.
A cognitive routing architecture is an enterprise AI system that dynamically selects the optimal reasoning path for a task by choosing the right combination of model, retrieval method, tool, workflow, and governance controls based on context, risk, and objective.
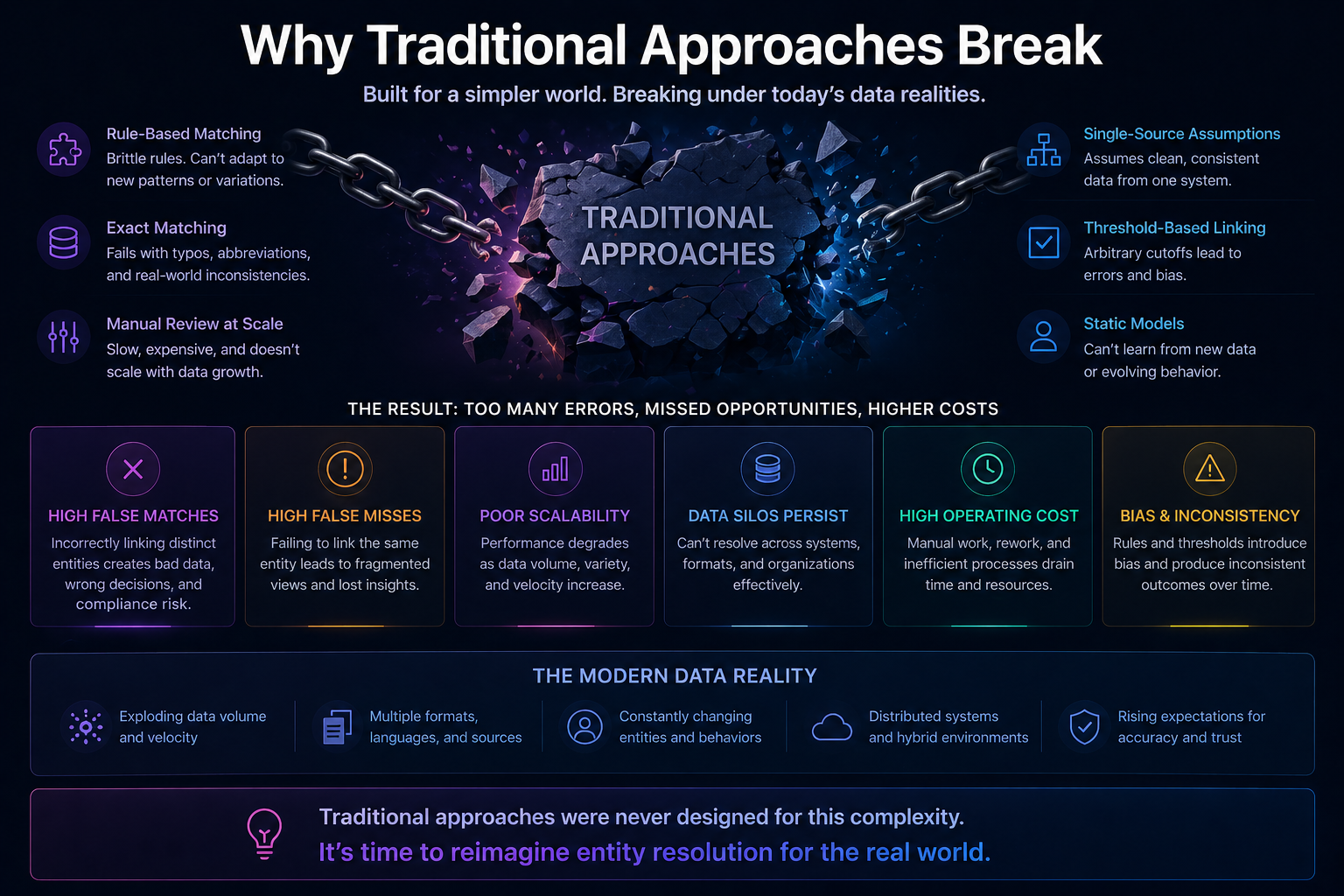
Why one reasoning path is not enough
A large language model is powerful, but it is not the right tool for every enterprise problem.
If a customer asks for a summary of a policy, a language model may be enough.
If a finance team asks whether a transaction violates policy, the system may need policy rules, transaction context, customer identity, approval history, and audit constraints.
If a supply chain manager asks which supplier disruption creates the highest revenue exposure, the system may need graph reasoning, inventory state, contract dependencies, revenue mapping, logistics data, and scenario analysis.
If a cyber analyst asks whether an access attempt is suspicious, the system may need identity history, device reputation, behavior patterns, privilege level, threat intelligence, and escalation rules.
These are different reasoning problems.
Treating them all as “send to LLM” is like sending every patient in a hospital to the same doctor, every legal issue to the same lawyer, and every financial decision to the same spreadsheet.
It may appear efficient at first.
But over time, it creates errors, cost overruns, latency, weak trust, and poor governance.
This is why model routing, tool routing, retrieval routing, and agent orchestration are becoming important architectural patterns. Recent work on routing strategies for large language models highlights a growing need to choose among models, tools, and methods depending on task requirements rather than relying on one default path. (arXiv)
But cognitive routing goes further.
It is not just about picking a model.
It is about selecting the right reasoning route.
Cognitive routing enables enterprise AI systems to choose how to think before they respond or act. Rather than sending every task through the same model or workflow, routed systems dynamically select the most appropriate reasoning path based on context, complexity, cost, and risk.
What cognitive routing actually means
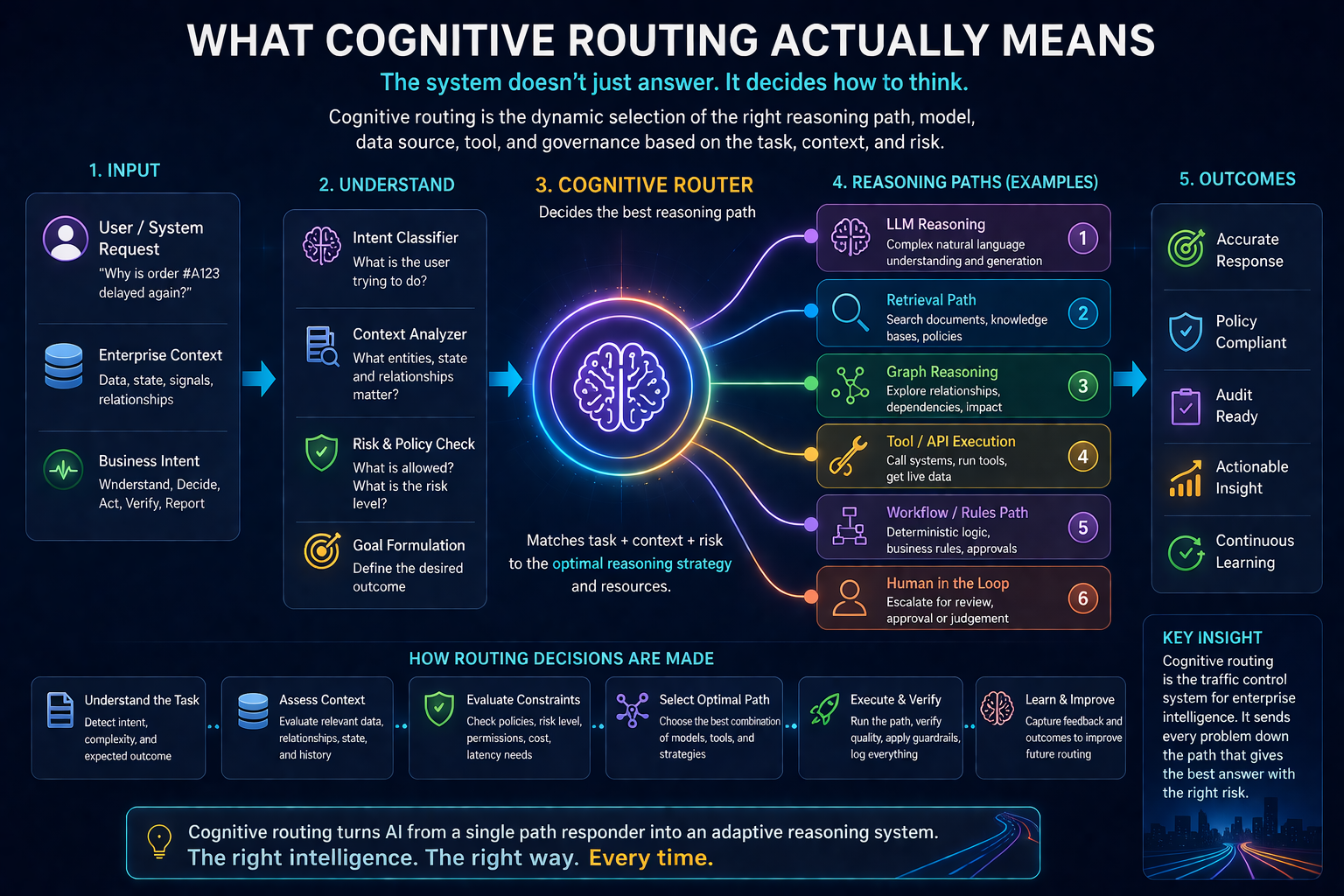
Cognitive routing is the dynamic selection of the appropriate reasoning strategy for a task.
It answers questions like:
Should this task use retrieval or direct reasoning?
Should retrieval come from vector search, graph search, structured database query, or all three?
Should the task go to a small model, a domain model, or a frontier model?
Should the system call a tool or ask a human?
Should it reason step by step or use a deterministic workflow?
Should it optimize for speed, cost, accuracy, auditability, or risk reduction?
Should the answer be generated, verified, escalated, or blocked?
This is the “traffic control” layer of enterprise intelligence.
Without cognitive routing, enterprise AI becomes a single-lane road. Every task is forced through the same path, even when the task requires a different vehicle.
With cognitive routing, the enterprise builds a multi-lane reasoning system.
Simple tasks use simple routes.
High-risk tasks use verified routes.
Ambiguous tasks use exploratory routes.
Regulated tasks use governed routes.
Cost-sensitive tasks use efficient routes.
Mission-critical tasks use escalated routes.
This is how AI becomes operationally mature.
The future of enterprise AI will depend less on model size and more on how intelligently systems choose the right way to think.
A simple example: customer complaint handling
Imagine a customer writes:
“I was charged twice, and your team promised a refund last week. Nothing has happened. I want this resolved today.”
A basic AI assistant may retrieve refund policy and generate a polite response.
A cognitively routed system does something very different.
First, it identifies the task type: complaint with financial impact.
Then it routes to multiple reasoning paths:
It checks transaction records to verify duplicate charge.
It checks previous support interactions.
It checks whether a refund was already approved.
It checks policy rules for refund eligibility.
It checks customer status and escalation history.
It checks whether the AI is allowed to initiate a refund or only recommend one.
It sends the case to a human if the value exceeds an authority threshold.
The final response may still look simple.
But the reasoning path behind it is not simple.
That is the difference between chatbot behavior and enterprise reasoning.
Cognitive routing and SENSE–CORE–DRIVER
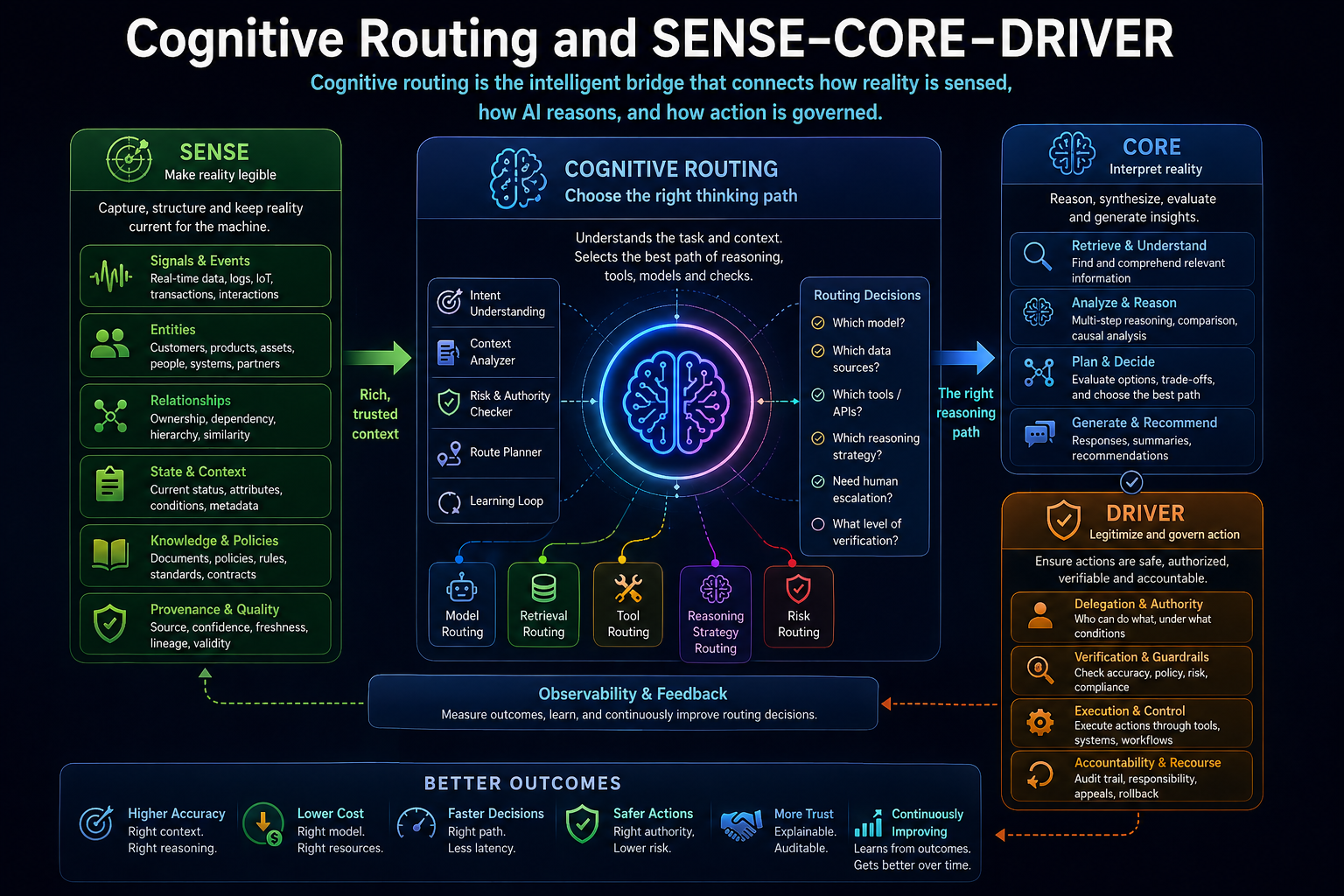
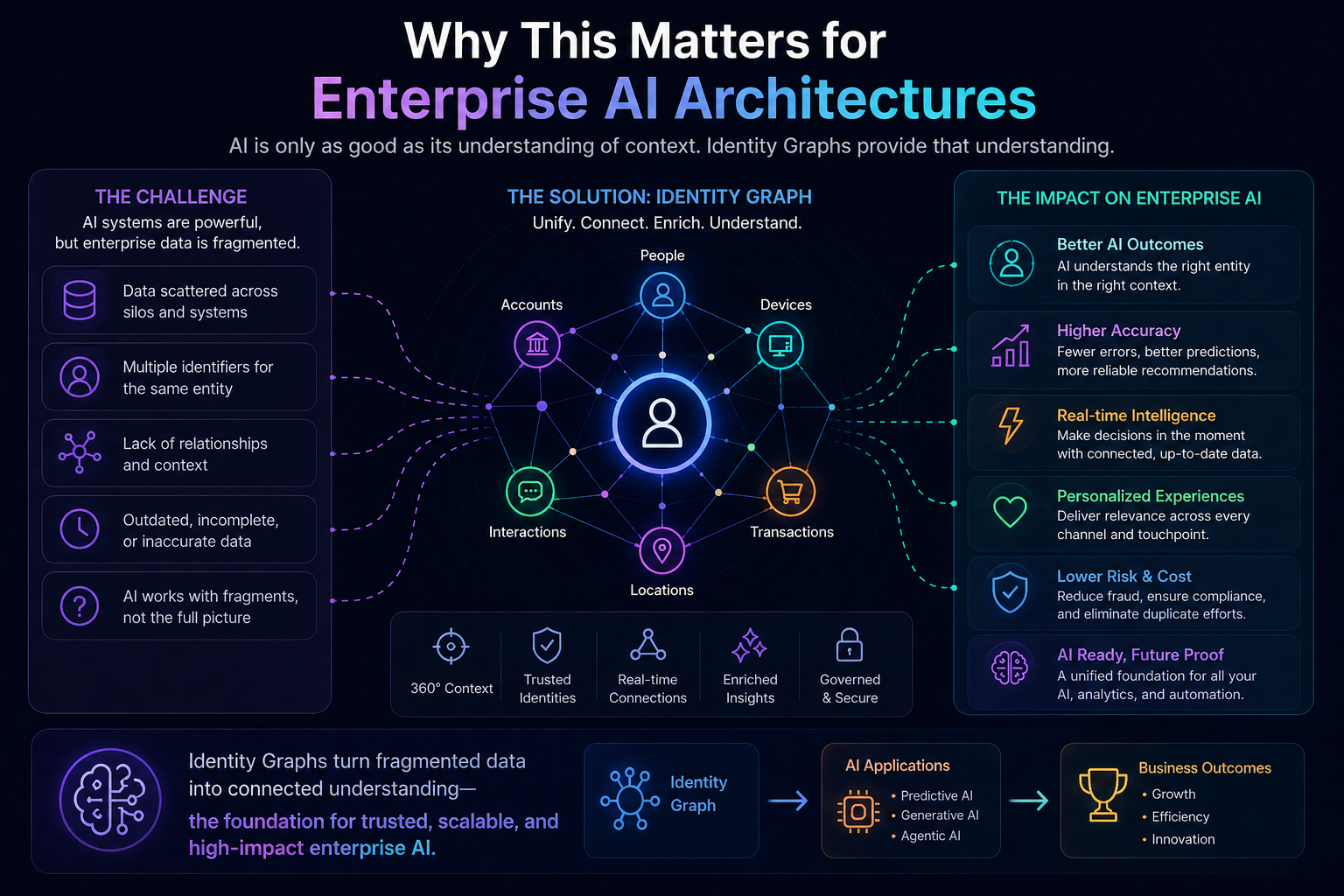
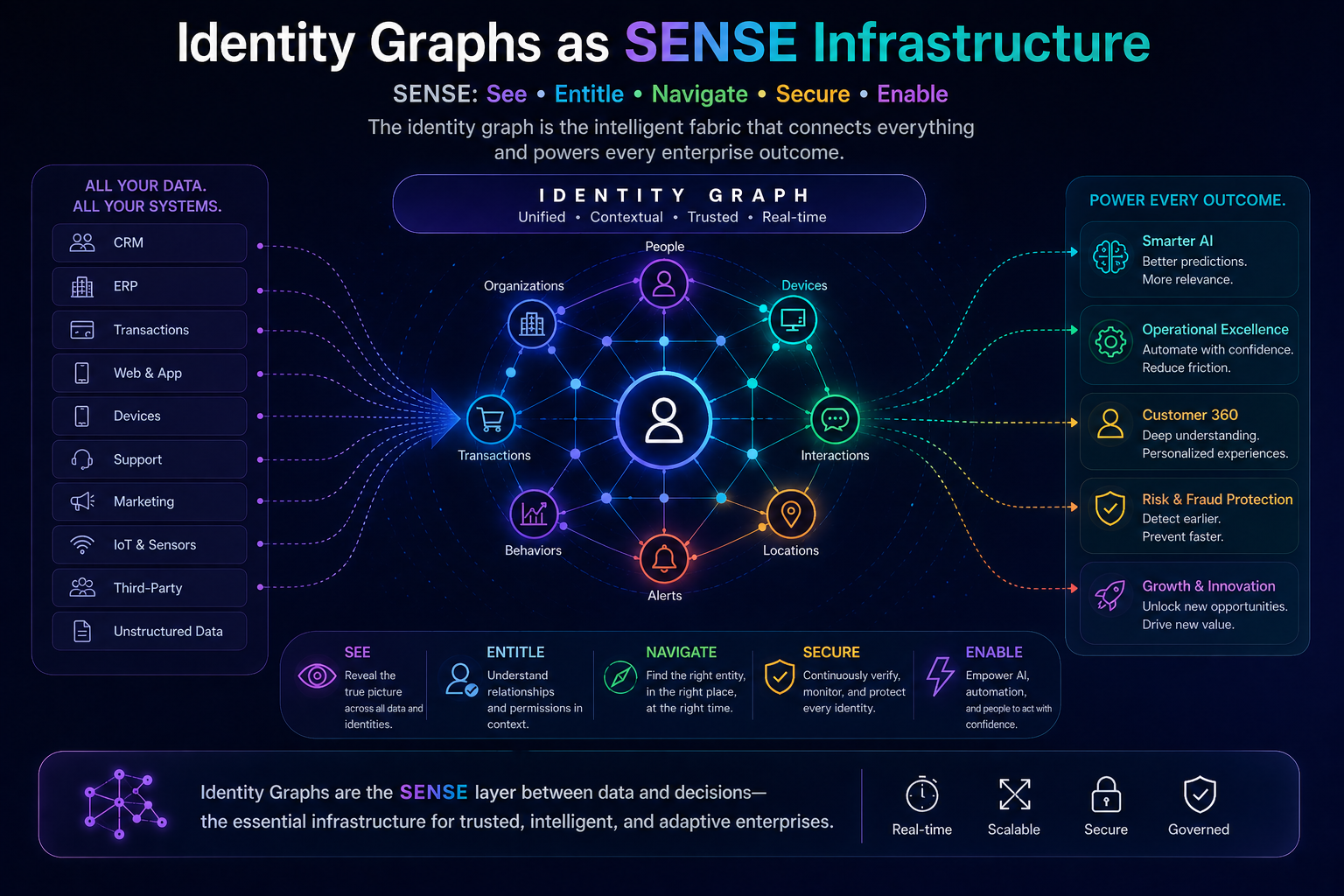
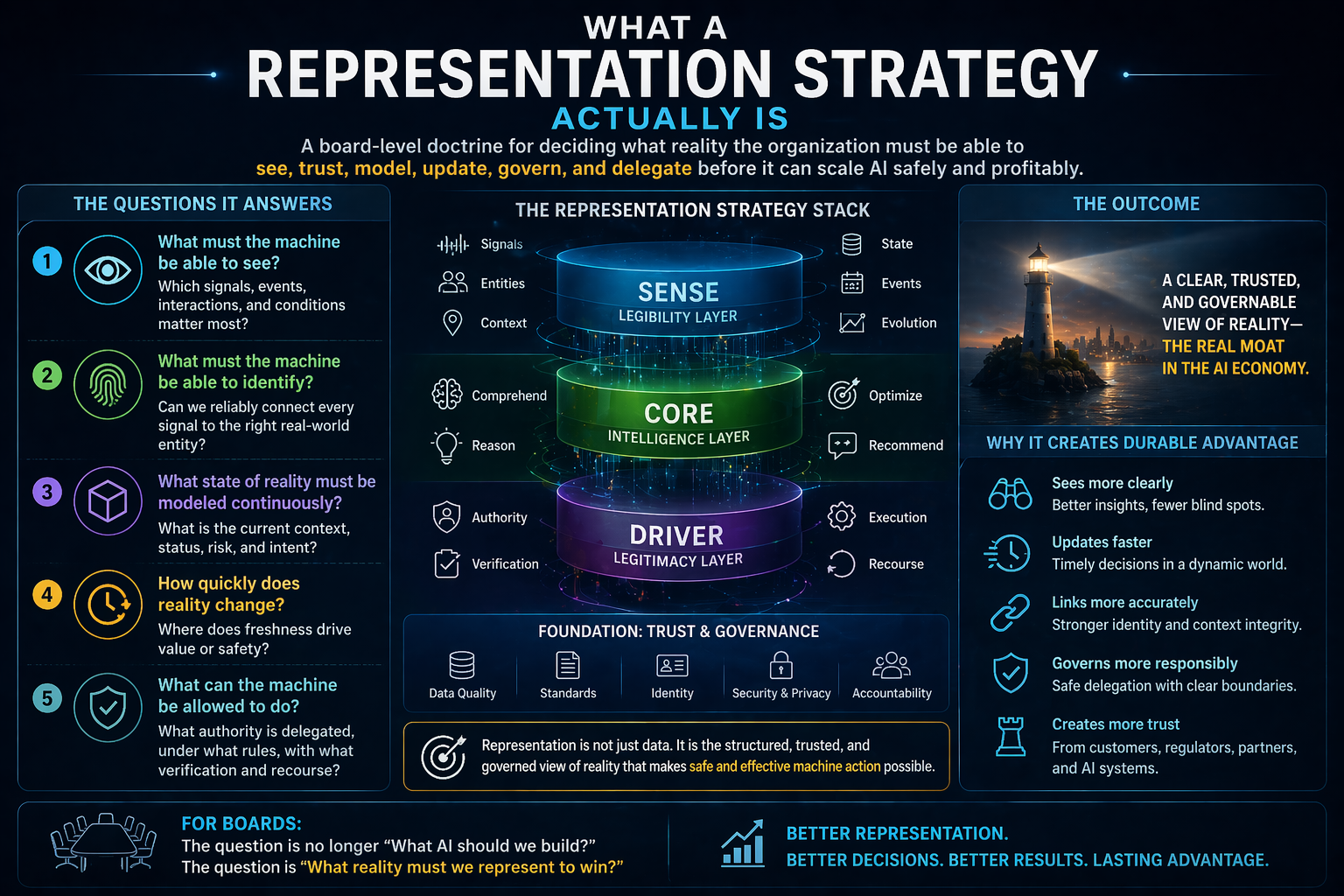
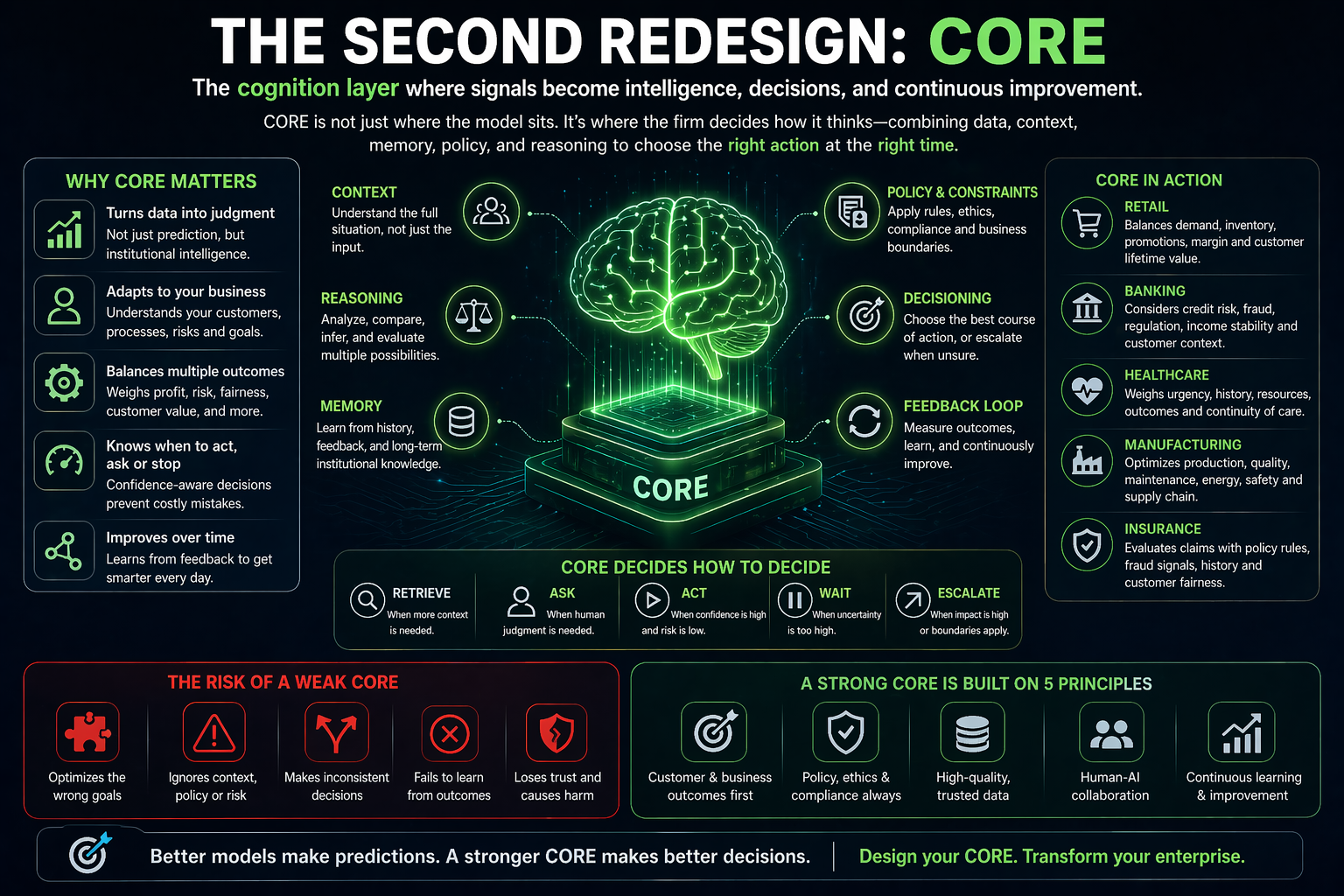
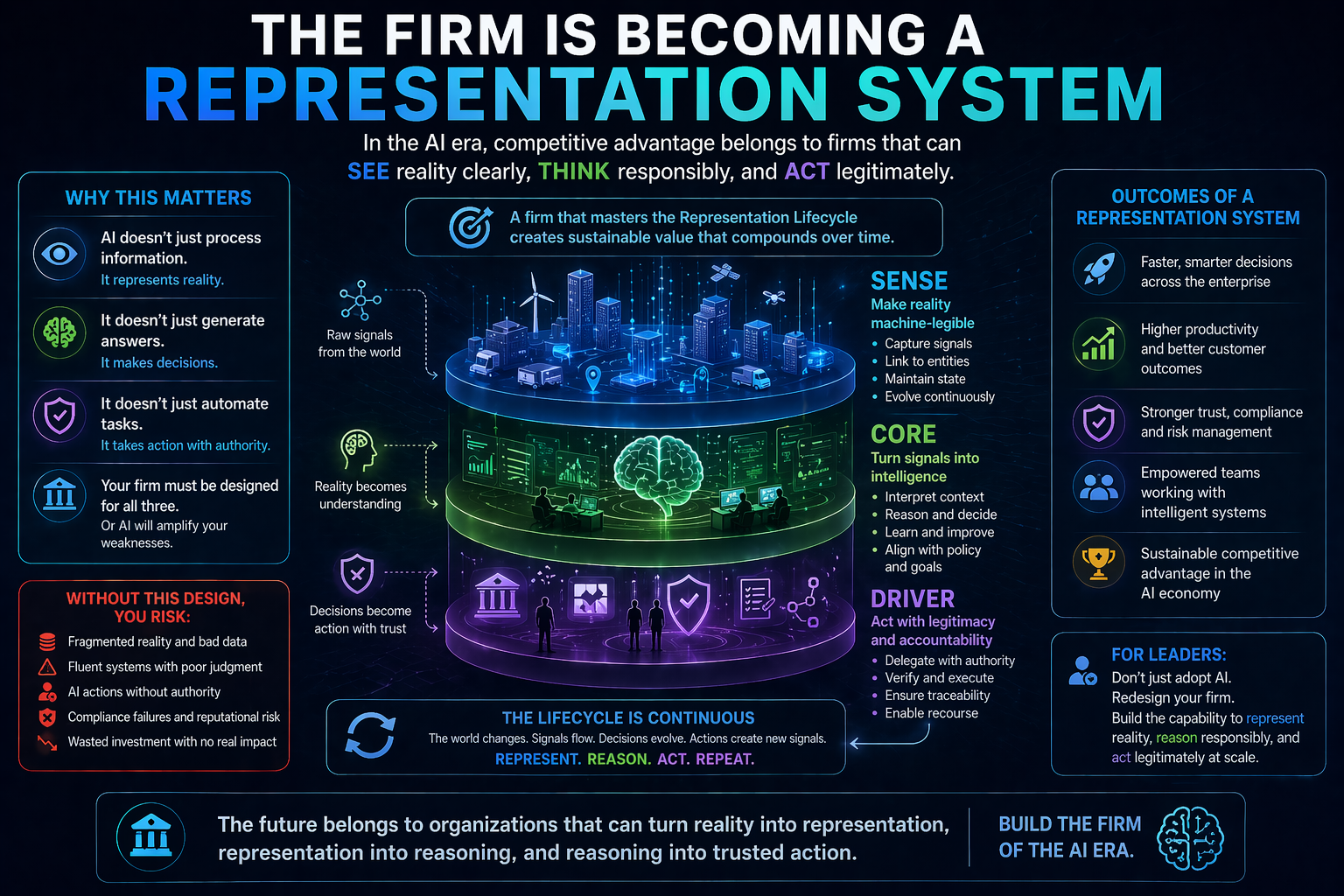
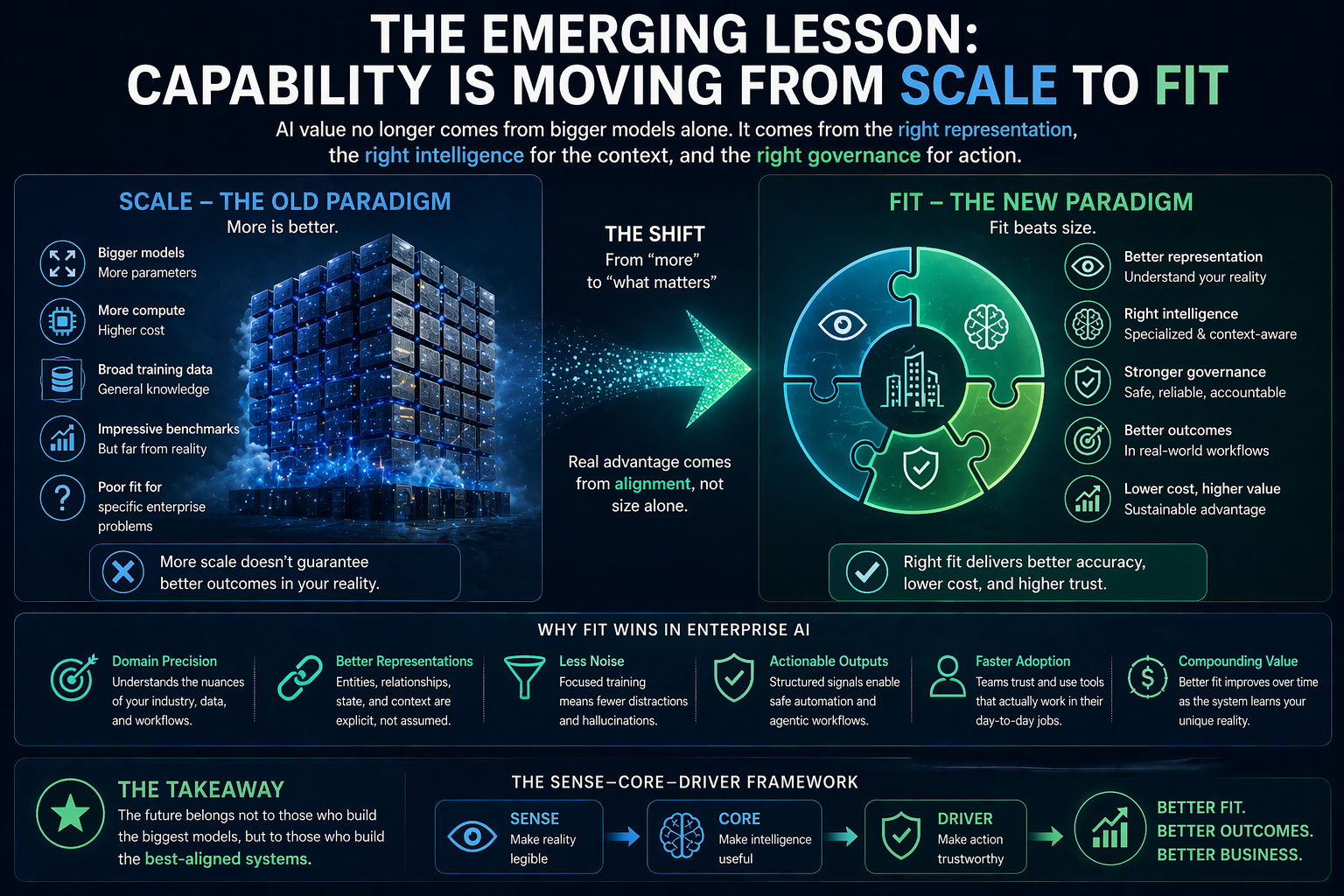
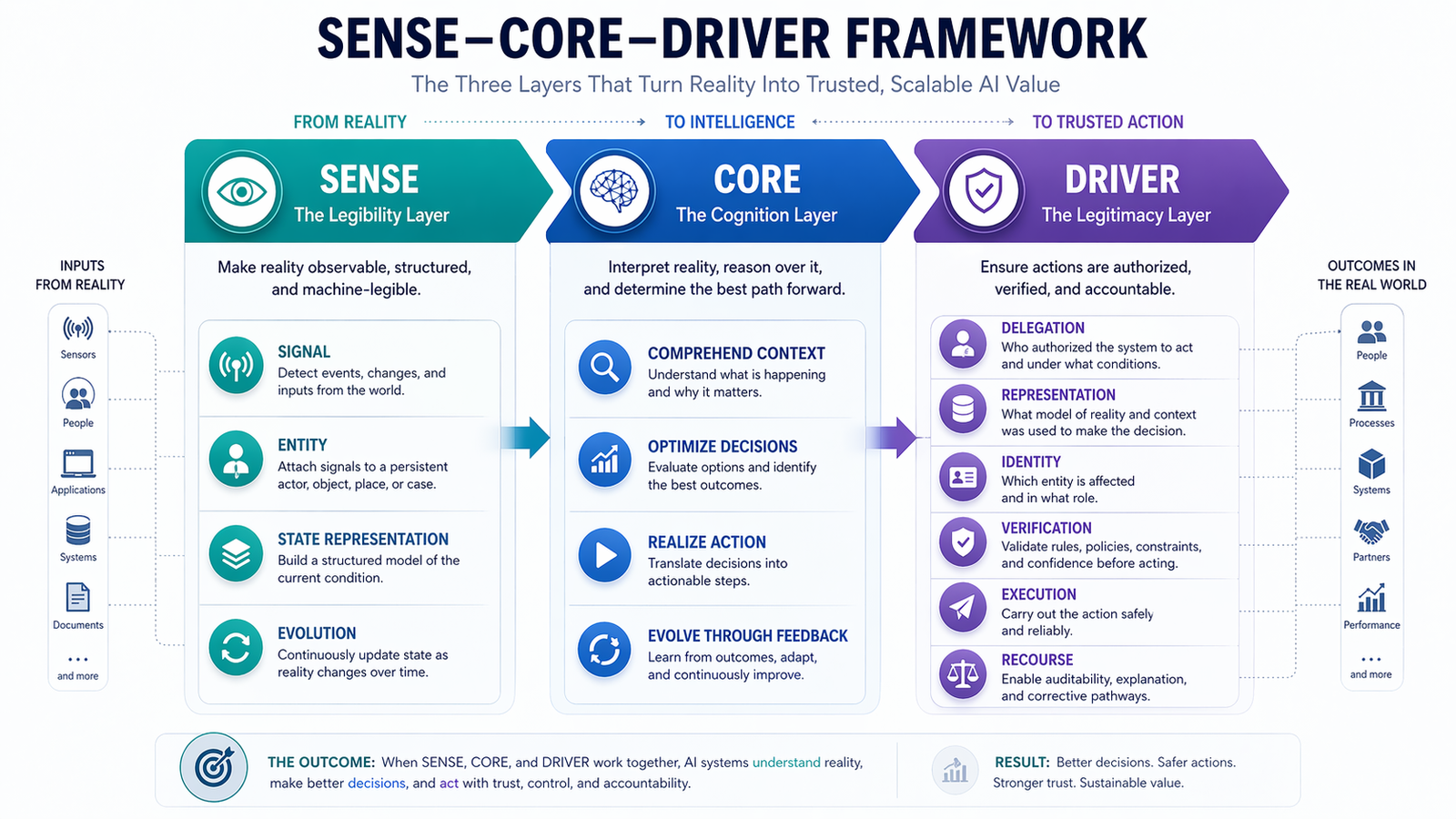
In the Representation Economy, AI value depends on the relationship between SENSE, CORE, and DRIVER.
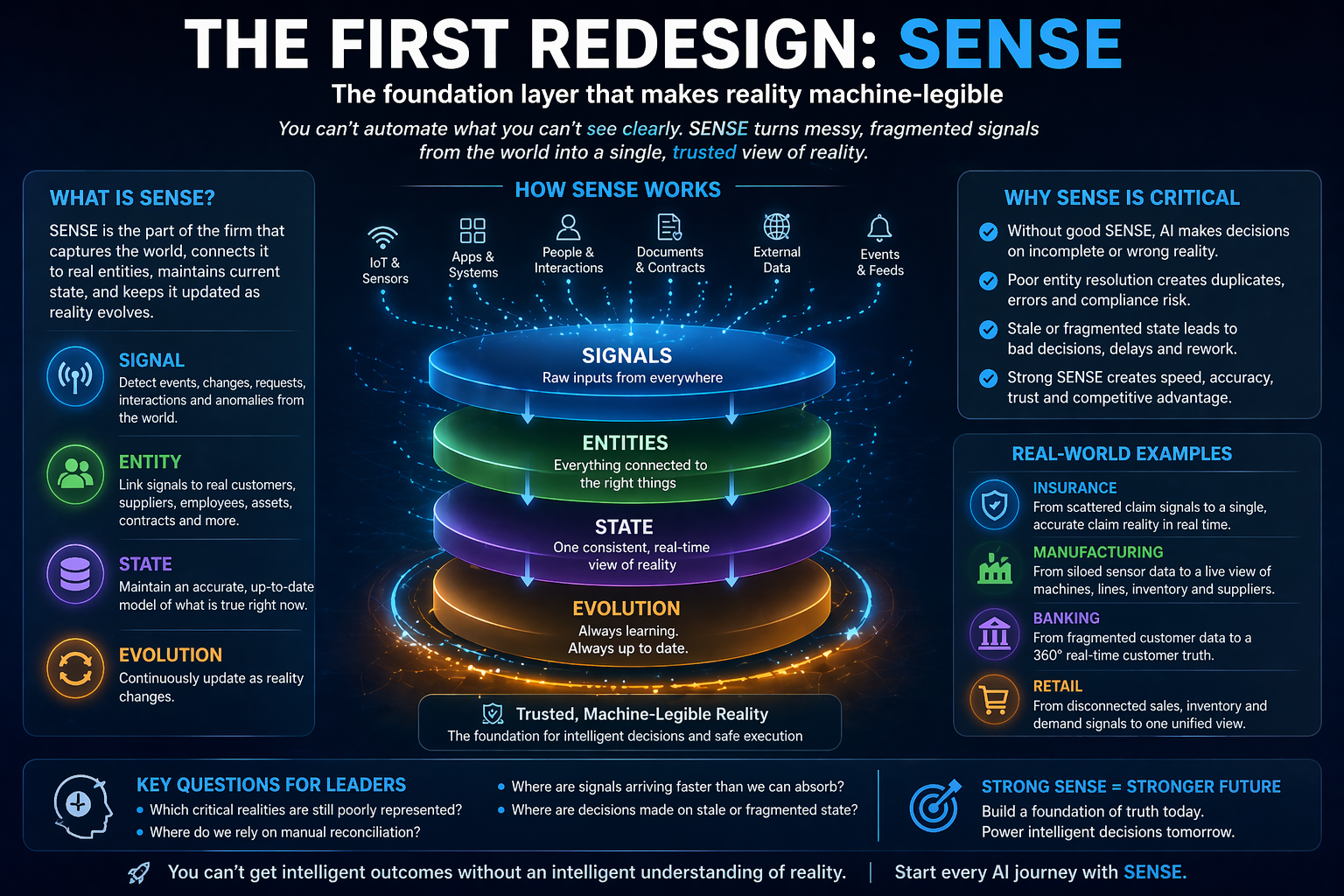
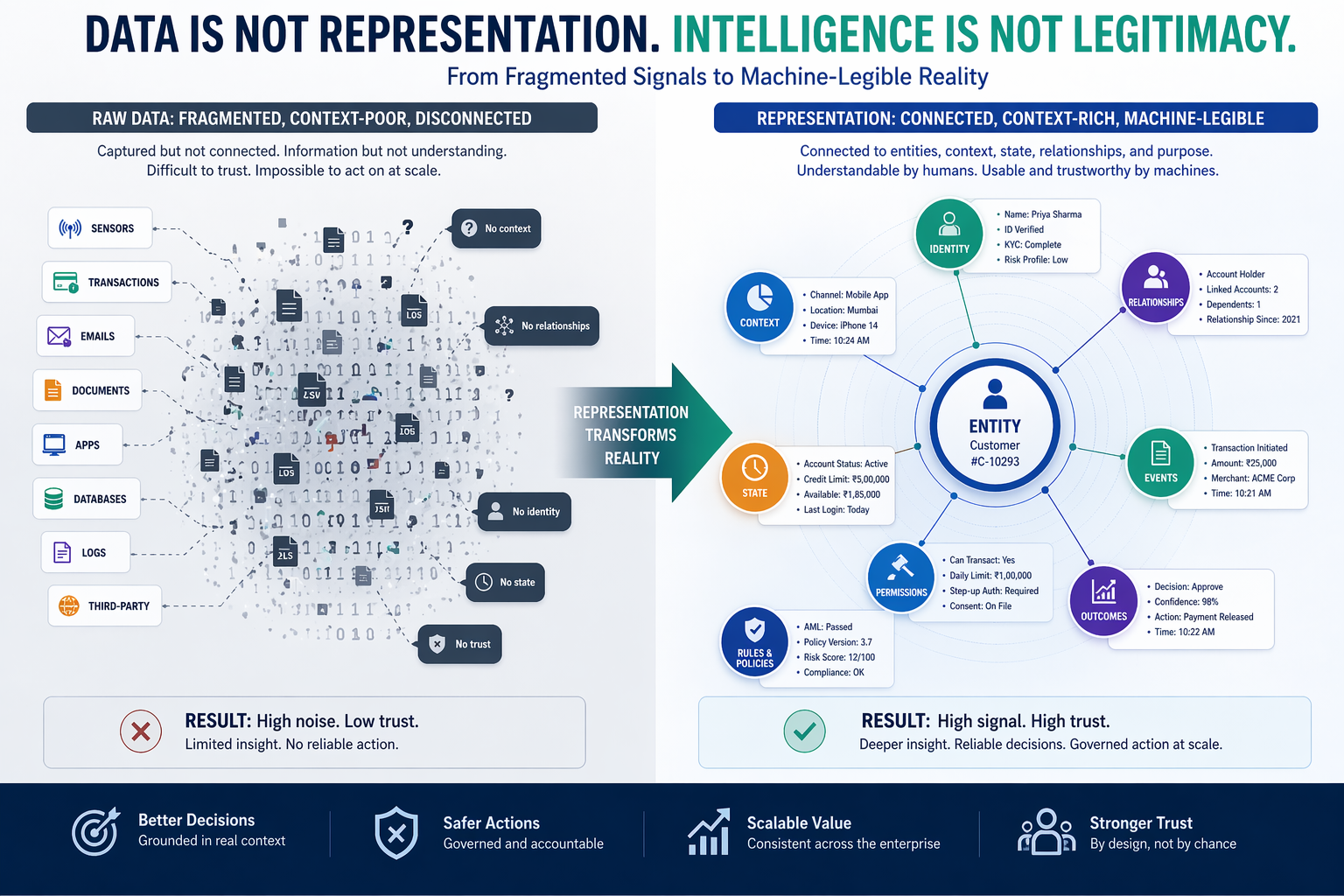
SENSE makes reality legible: signals, entities, state, and evolution.
CORE interprets reality: reasoning, optimization, prediction, planning, and judgment.
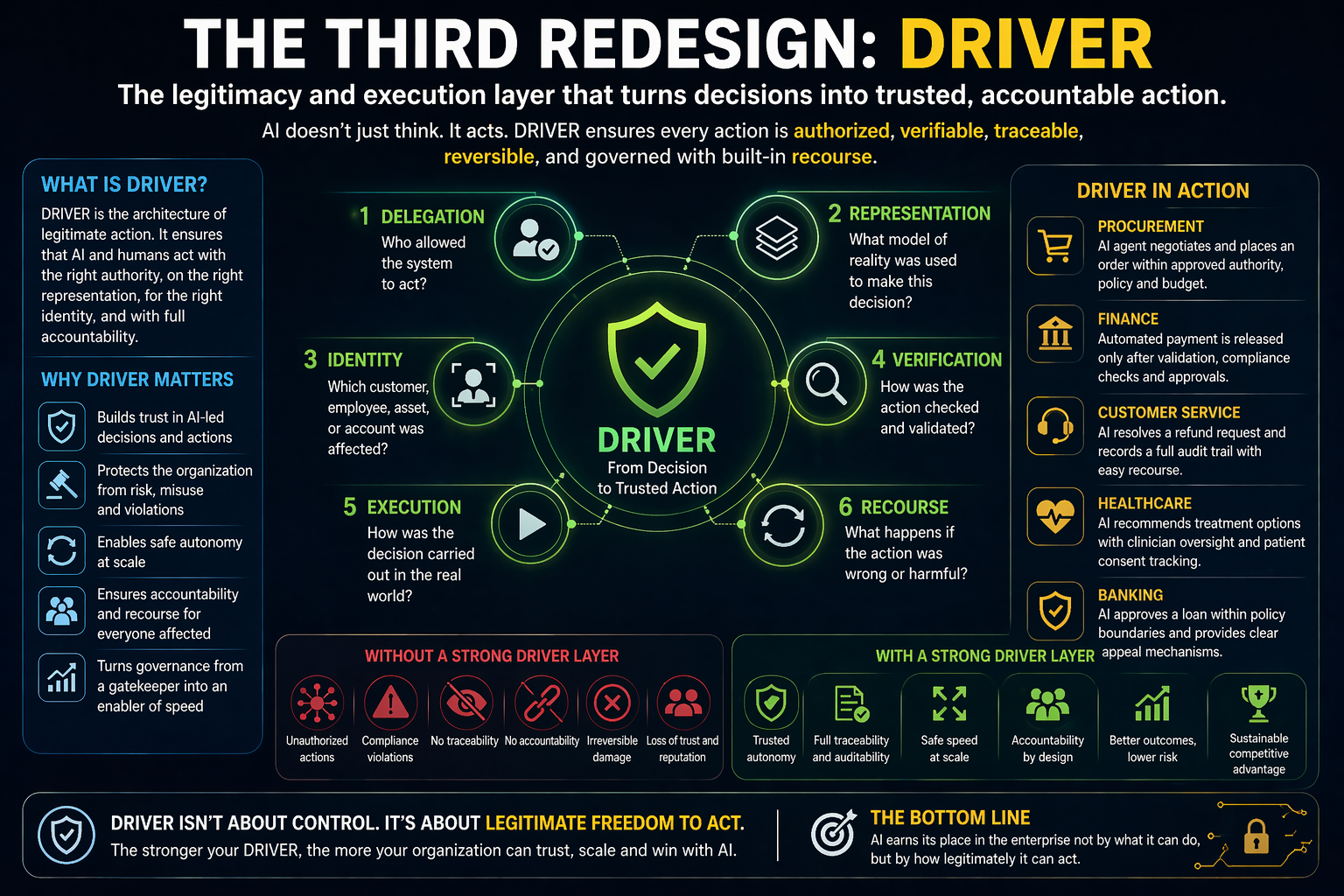
DRIVER governs action: delegation, identity, verification, execution, and recourse.
Cognitive routing sits inside CORE, but it depends deeply on SENSE and DRIVER.
It depends on SENSE because the system must understand the task context before choosing a route.
It needs to know: what entity is involved, what state it is in, what signals are available, what has changed, and what relationships matter.
It depends on DRIVER because the route cannot be chosen only for intelligence. It must also respect authority, risk, policy, accountability, and recourse.
For example, a low-risk summarization request may go directly to a fast model. A high-risk credit decision may need structured retrieval, policy validation, human approval, and audit logging. A cybersecurity action may need identity verification, tool authorization, and rollback capability.
So cognitive routing is not merely technical optimization.
It is institutional judgment encoded into architecture.
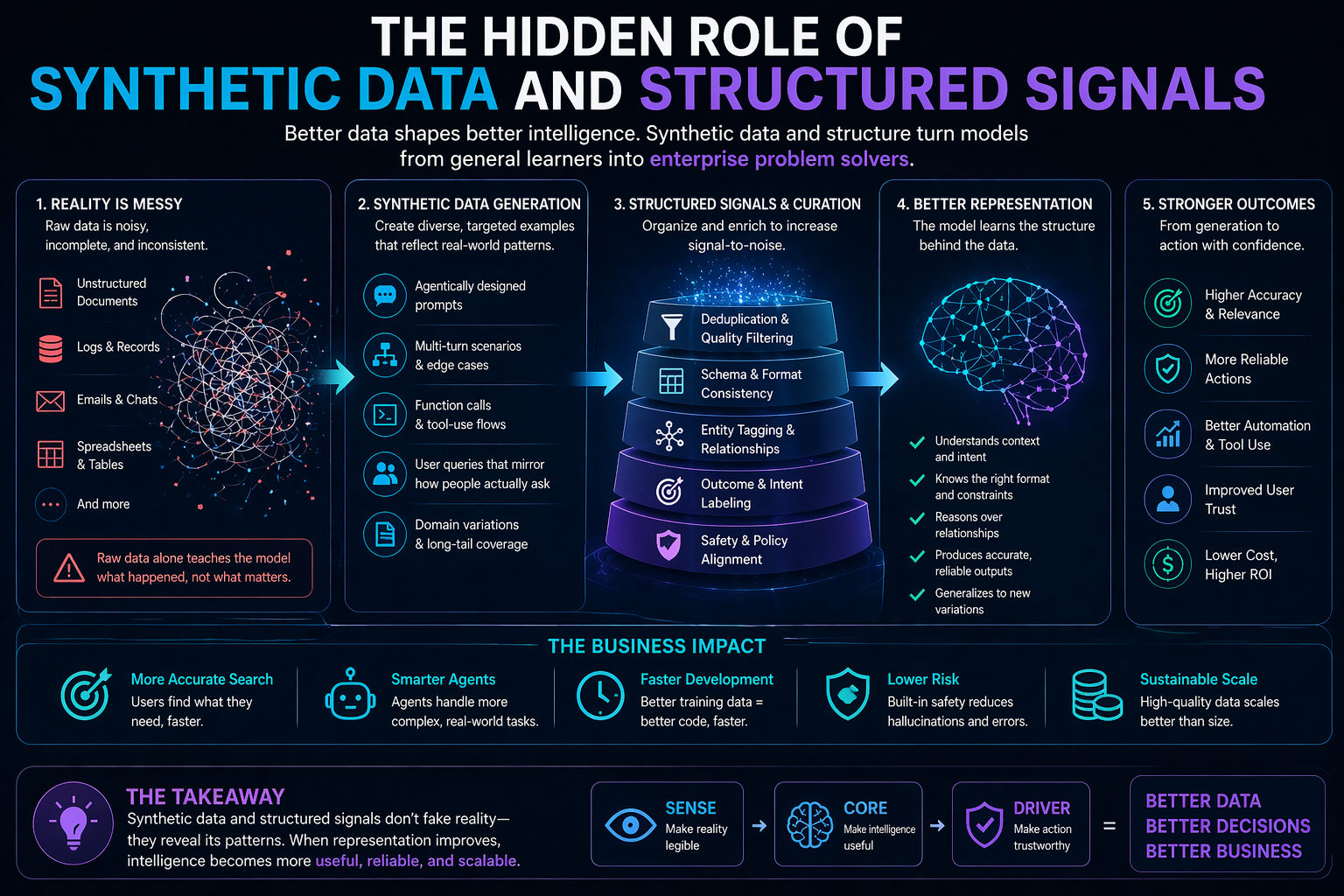
The main types of cognitive routing
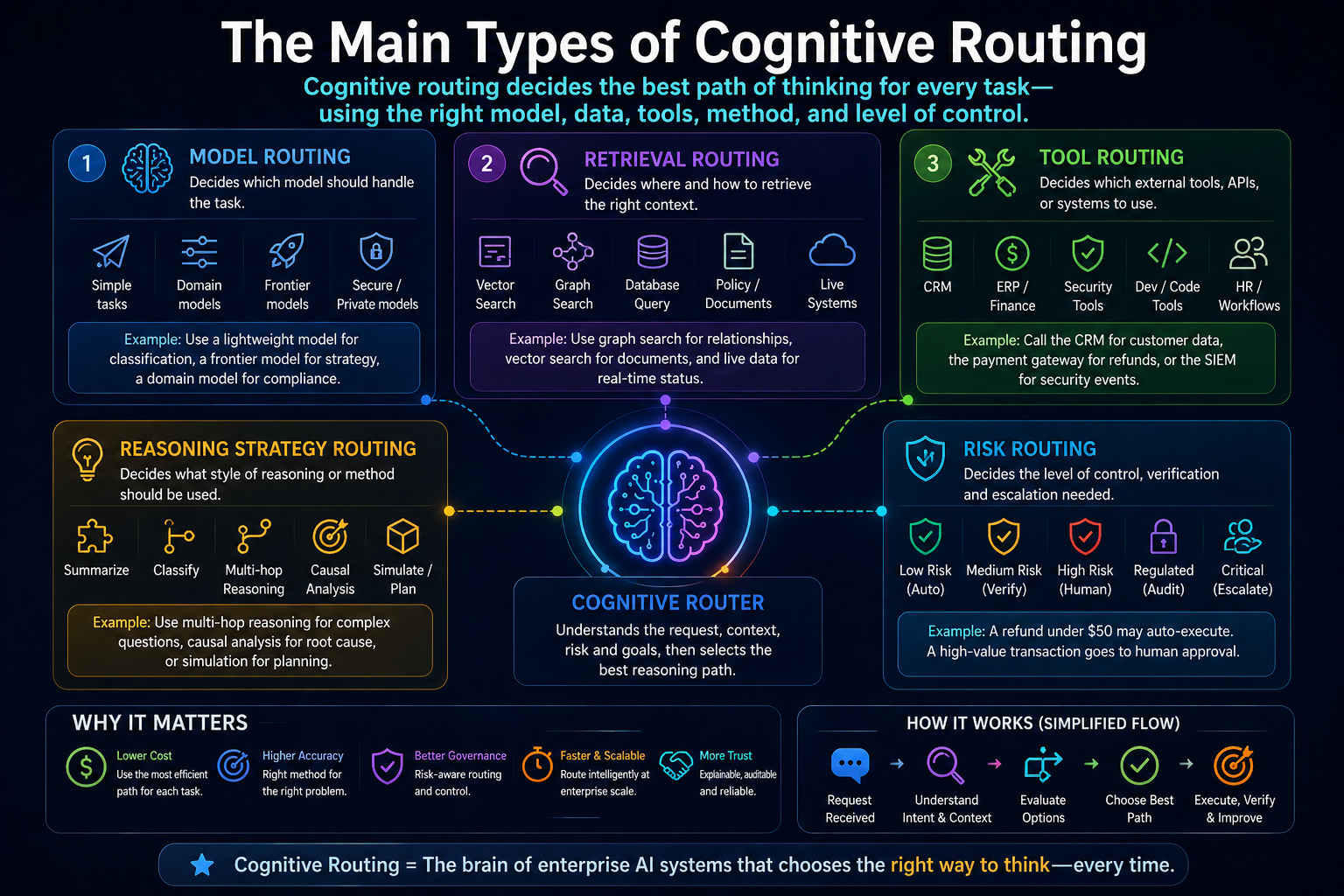
A strong cognitive routing architecture usually includes several routing layers.
-
Model routing
Model routing decides which model should handle a task.
Not every task needs the largest or most expensive model. Some tasks can be handled by smaller models, domain-specific models, or even deterministic systems.
A simple classification task may use a lightweight model. A complex strategy question may need a frontier model. A legal or regulatory task may require a domain-specialized model plus verification.
Microsoft’s enterprise AI updates have highlighted model router capabilities that automatically select cost-effective models for tasks, with the goal of optimizing performance and reducing inference cost. (IT Pro)
This is important because enterprise AI cost can rise sharply after adoption. If every task goes to the most expensive model, scaling becomes economically fragile.
Model routing makes AI more sustainable.
-
Retrieval routing
Retrieval routing decides where the system should get context.
Should it search documents?
Should it query structured databases?
Should it use a knowledge graph?
Should it retrieve policies?
Should it call a live system?
Should it combine multiple sources?
Traditional RAG often retrieves semantically similar text chunks. But many enterprise questions need structured relationships and corpus-level understanding. Microsoft’s GraphRAG describes a structured, hierarchical retrieval approach that uses knowledge graphs and community summaries rather than relying only on naive semantic search. (Microsoft GitHub)
This matters because different questions require different retrieval paths.
A policy question may need document retrieval.
A dependency question may need graph retrieval.
A status question may need live database retrieval.
A risk question may need all three.
Cognitive routing decides the route.
-
Tool routing
Tool routing decides which external tool, API, database, workflow, or function the AI should call.
A customer service agent may need a CRM tool.
A finance assistant may need an ERP query.
A developer assistant may need a code repository.
A cyber agent may need a SIEM system.
An HR assistant may need policy and workflow systems.
Tool-calling architectures are becoming central to agentic AI, because agents increasingly interact with APIs, databases, and external systems rather than merely generating text. (Medium)
But tool routing must be controlled. The system should not call every available tool. It should call the right tool, for the right reason, with the right permissions.
-
Reasoning strategy routing
Not every task requires the same style of reasoning.
Some tasks need summarization.
Some need classification.
Some need planning.
Some need causal reasoning.
Some need multi-hop reasoning.
Some need simulation.
Some need verification.
Some need debate between agents.
Some need deterministic execution.
A cognitively routed system selects the reasoning strategy.
For example, “Summarize this contract” is not the same as “Tell me whether this contract creates risk under this new regulation.” The first needs summarization. The second needs legal context, policy comparison, exception detection, risk interpretation, and possibly escalation.
-
Risk routing
Risk routing decides how much control the system needs before responding or acting.
Low-risk tasks can move quickly.
Medium-risk tasks may need verification.
High-risk tasks may need human approval.
Regulated tasks may need audit trails.
Irreversible tasks may need strict boundaries.
This is where cognitive routing enters DRIVER territory.
The same AI capability may be acceptable in one context and unacceptable in another.
Drafting a customer email is one thing. Sending it automatically to a high-value customer during a dispute is another. Suggesting a refund is one thing. Executing it is another.
Risk routing prevents intelligence from becoming uncontrolled action.
Why cognitive routing matters for enterprise AI
Cognitive routing solves five major problems.
-
It reduces cost
A mature enterprise AI system should not use the most expensive model for every task.
Some tasks need precision. Others need speed. Others need low cost. Routing helps allocate compute intelligently.
This becomes especially important as enterprises move from pilots to thousands or millions of AI interactions.
-
It improves reliability
The wrong reasoning path produces fragile answers.
If a task requires structured data but the system relies only on language generation, the answer may sound confident but be wrong. If a task requires policy validation but the system relies only on semantic retrieval, the result may miss an exception.
Routing improves reliability by matching the task to the right cognitive method.
-
It improves explainability
When systems route through explicit paths, they can explain what they did.
They can say: I checked policy, retrieved customer state, verified transaction history, applied risk rules, and escalated because the case exceeded the authority threshold.
That is very different from a black-box answer.
-
It improves governance
Routing allows enterprises to encode governance into the reasoning process.
High-risk tasks can automatically require additional validation. Sensitive data can be routed through approved systems. Certain actions can be blocked or escalated.
This makes governance operational, not merely documentary.
-
It improves user trust
Users trust AI more when it uses the right kind of reasoning.
A finance leader does not want a creative answer to a compliance question. A maintenance engineer does not want a poetic summary of a machine failure. A board member does not want a shallow answer to a strategic risk question.
Cognitive routing makes AI feel more competent because it behaves more appropriately.
Cognitive routing vs orchestration
Cognitive routing and orchestration are related, but they are not the same.
Orchestration coordinates steps, agents, tools, and workflows.
Routing decides which path should be taken.
Think of orchestration as the conductor of an orchestra.
Think of cognitive routing as the judgment that decides which orchestra, which instrument, which score, and which tempo are appropriate for the situation.
Azure’s AI agent design guidance describes multiple orchestration patterns, including sequential, concurrent, handoff, and group-chat patterns. These patterns help teams choose how agents coordinate for different scenarios. (Microsoft Learn)
Cognitive routing can sit above or inside orchestration. It may decide whether the task should follow a sequential workflow, a parallel multi-agent workflow, a handoff pattern, or a simple single-model response.
In mature systems, routing and orchestration work together.
Routing chooses the path.
Orchestration executes the path.
What a cognitive routing architecture looks like
A practical cognitive routing architecture has several components.
Intent classifier
This detects what the user or system is trying to do.
Is it a lookup, summary, analysis, decision, recommendation, approval, execution, exception, or escalation?
Context analyzer
This reads the SENSE layer.
Which entity is involved? What state is it in? What relationships matter? What is the risk level? What changed recently?
Policy and authority checker
This reads the DRIVER layer.
Is the system allowed to answer? Is it allowed to act? Does the task require approval? Is the user authorized? Is the data sensitive?
Route planner
This selects the reasoning route.
It may choose a model, retrieval source, graph traversal, tool call, workflow, verification path, or human handoff.
Execution orchestrator
This runs the selected path.
It invokes tools, retrieves context, calls models, validates output, and manages intermediate steps.
Verification layer
This checks whether the answer or action is valid.
It may compare against rules, evidence, constraints, prior decisions, or human review requirements.
Learning loop
This improves routing over time.
Which routes worked? Which failed? Which were too expensive? Which caused escalation? Which produced trusted outcomes?
This learning loop is what turns routing from a static rules system into a cognitive infrastructure capability.
Examples across enterprise functions
Banking
A relationship manager asks: “Can we increase exposure to this client?”
A weak AI system generates a generic credit summary.
A cognitively routed system checks client identity, exposure history, sector risk, covenant status, collateral, transaction behavior, regulatory constraints, and credit policy. It routes financial calculations to risk engines, policy interpretation to a rules layer, qualitative summary to an LLM, and final approval to a human authority chain.
IT operations
An engineer asks: “Why is this application slow?”
A basic assistant searches logs.
A routed system checks telemetry, incident history, dependency graphs, recent deployments, infrastructure changes, user impact, and known problem records. It may route one path to log analysis, another to topology graph traversal, another to anomaly detection, and another to remediation recommendation.
Procurement
A category manager asks: “Which supplier should we prioritize for renegotiation?”
A simple system retrieves supplier contracts.
A routed system checks spend, delivery reliability, contractual flexibility, alternate suppliers, risk exposure, geopolitical signals, sustainability obligations, and business criticality. It routes structured analysis to databases, relationship reasoning to graphs, and strategy synthesis to a language model.
Legal and compliance
A team asks: “Can we launch this offer in this market?”
A basic AI system summarizes regulations.
A routed system checks product terms, jurisdiction, customer segment, consent requirements, disclosure obligations, risk controls, precedent decisions, and approval rules. It may produce a recommendation, but it may also force escalation.
This is cognitive routing in practice.
The failure modes of cognitive routing
Cognitive routing can fail in several ways.
Wrong intent detection
If the system misunderstands the task, the rest of the route is wrong.
A request that appears informational may actually imply action. A question that appears simple may carry legal or financial risk.
Bad context
If the SENSE layer is weak, routing decisions will be weak.
The system may choose the wrong model, retrieve the wrong records, or miss the risk level.
Over-routing
Not every task needs complex routing.
If every simple question triggers ten tools and three agents, the system becomes slow and expensive.
Under-routing
If the system treats serious tasks as simple tasks, it becomes dangerous.
This is especially risky in finance, healthcare, cybersecurity, law, and critical operations.
Hidden routing bias
If routing rules are trained on past behavior, they may preserve outdated organizational habits.
A system may route too many cases to humans, or too few. It may overuse certain models, ignore certain evidence, or under-escalate certain risks.
Poor route observability
If the enterprise cannot see why a route was chosen, the routing layer becomes another black box.
That defeats the purpose.
Metrics for cognitive routing
Enterprises will need new metrics.
Not just model accuracy.
They need routing quality.
Useful metrics include:
Route accuracy: Did the system choose the right path?
Route cost: Was the path economically appropriate?
Route latency: Did it respond within the required time?
Route risk alignment: Did the path match the task’s risk level?
Route explainability: Can the system explain why this path was chosen?
Route override rate: How often did humans correct the route?
Route failure rate: Which routes produce bad or incomplete outcomes?
Route learning rate: Is the system improving its choices over time?
These metrics matter because cognitive routing becomes a core operating capability. It is not a hidden technical feature. It is how the enterprise allocates intelligence.
Why cognitive routing is strategic
The first wave of enterprise AI asked:
Can AI answer?
The second wave asks:
Can AI act?
The next wave will ask:
Can AI choose the right way to think before it answers or acts?
That is a deeper question.
An enterprise that can route cognition well will use intelligence more efficiently. It will spend less on unnecessary model calls. It will reduce errors. It will govern action better. It will preserve human attention for the problems that truly need judgment.
This becomes a competitive advantage.
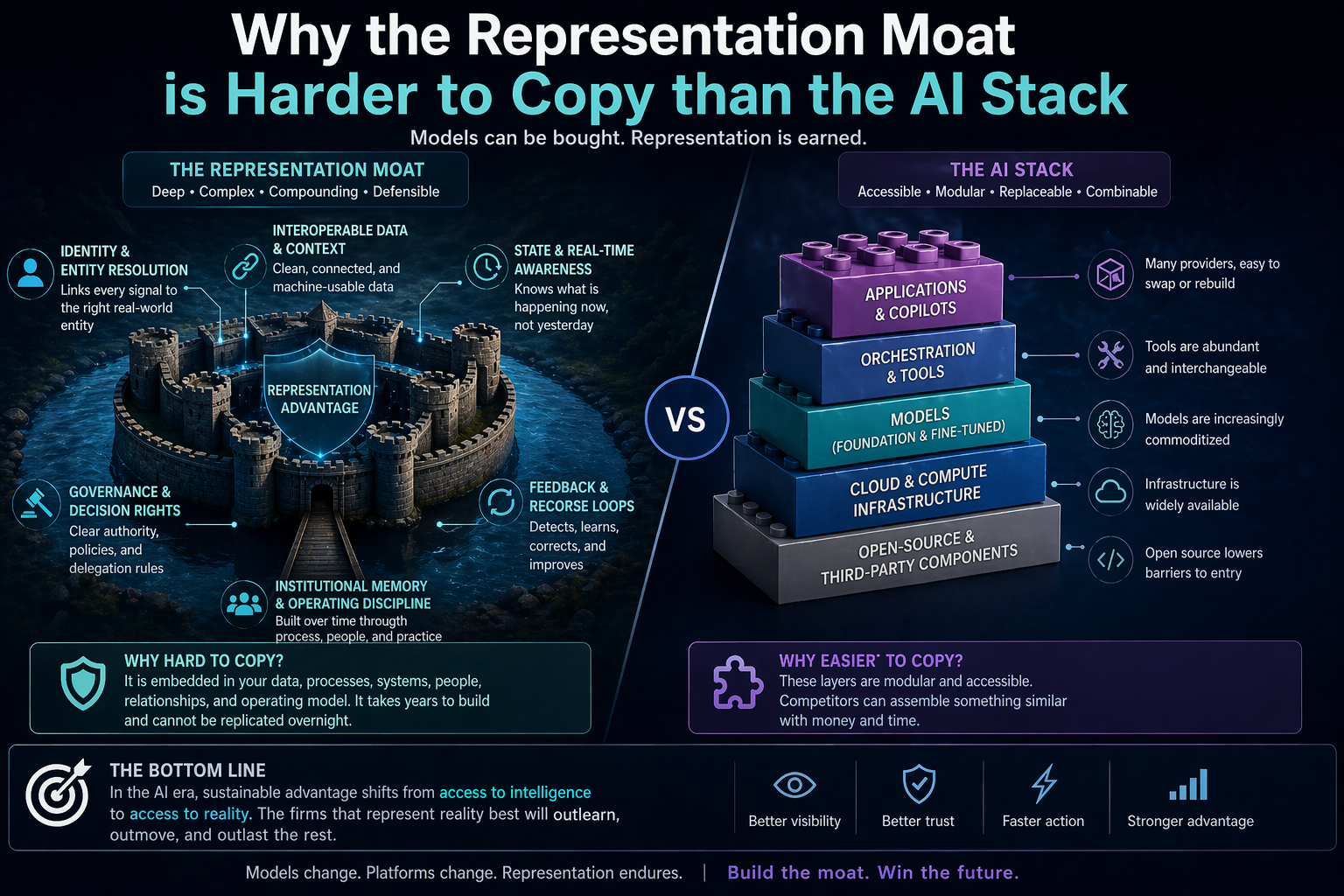
In a same-model world, where many firms can access similar AI capabilities, advantage shifts to the firm that can compose, route, verify, and govern intelligence better.
That is why cognitive routing is not just an AI architecture pattern.
It is a new managerial capability.
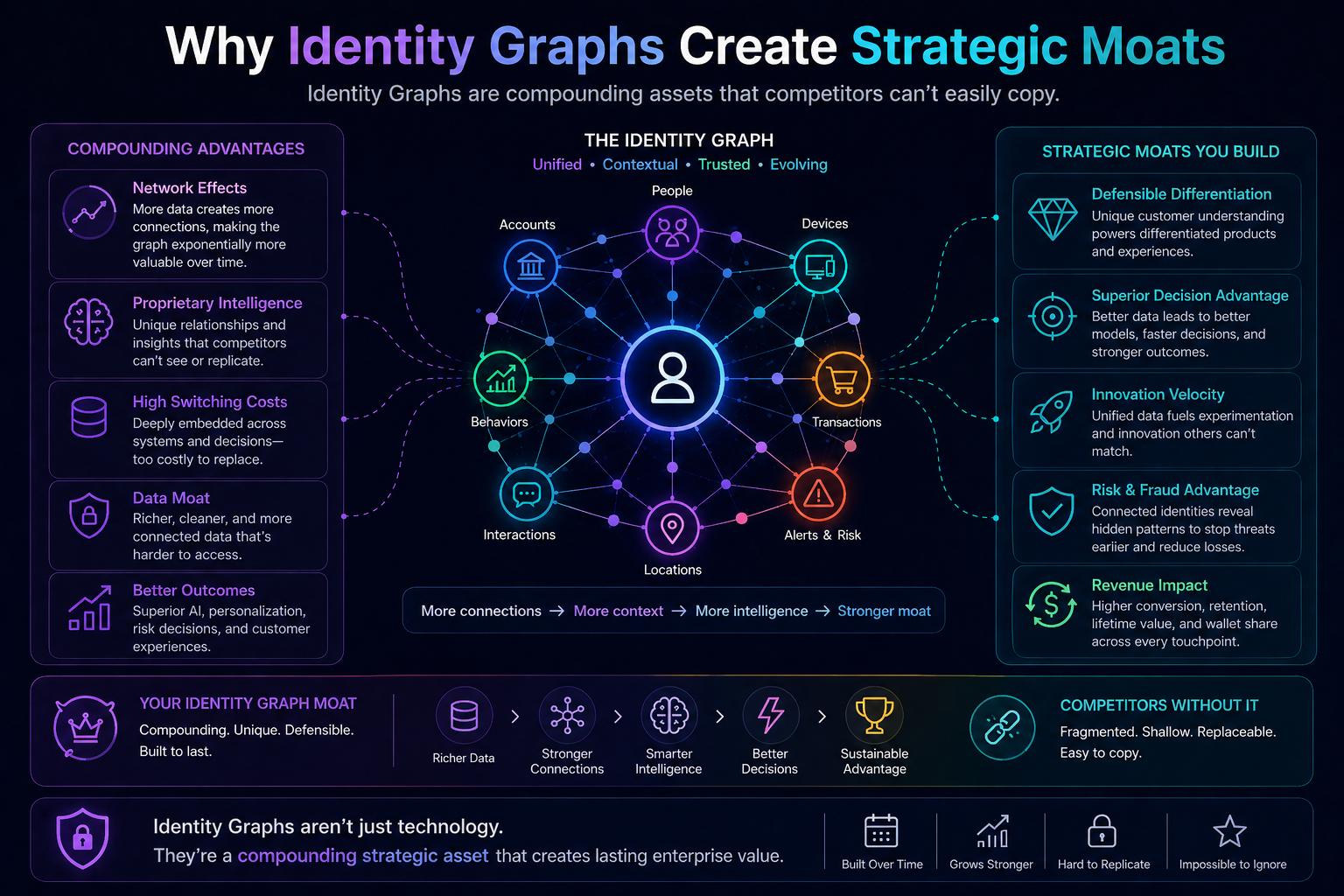
Cognitive routing and the Representation Economy
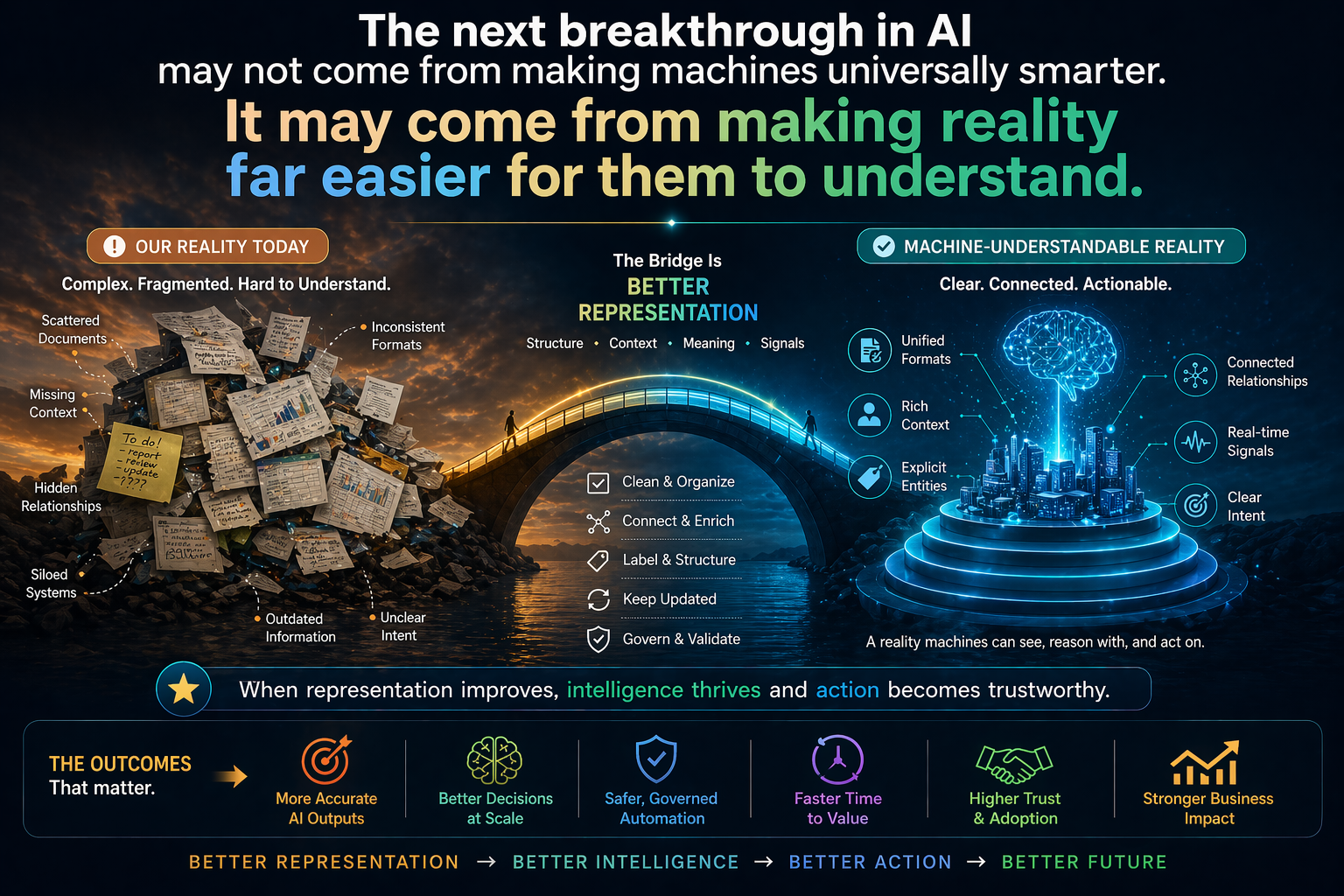
In the Representation Economy, the most important firms will not simply own intelligence. They will own better ways of representing reality and routing action through that reality.
Cognitive routing is the CORE-layer mechanism that connects representation to reasoning.
SENSE tells the system what reality looks like.
CORE decides how to reason over that reality.
DRIVER determines what action is legitimate.
Without SENSE, routing is blind.
Without CORE, routing has no intelligence to allocate.
Without DRIVER, routing may create unsafe action.
Cognitive routing is therefore one of the missing bridges between enterprise AI demos and enterprise AI production.
It turns AI from a single conversational interface into an adaptive reasoning system.
Conclusion: the future belongs to enterprises that can route intelligence
The next breakthrough in enterprise AI will not be only a better model.
It will be a better system for deciding when to use which model, which tool, which retrieval path, which graph, which workflow, which verification layer, and which human authority.
That is cognitive routing.
It is how enterprise AI becomes more accurate, more economical, more explainable, and more governable.
The organizations that master it will not treat AI as one universal brain. They will build a system of many reasoning paths, each suited to a different kind of problem.
That is how intelligent institutions will work.
They will not just ask AI for answers.
They will teach AI how to choose the right way to think.
And in the Representation Economy, that may become one of the deepest sources of advantage.
This article is part of a larger series on Representation Economics and enterprise AI reasoning architecture — including topics such as Representation Utility Stack, Representation Due Diligence, Recourse Platforms, the New Company Stack, and why smaller reasoning models are winning in enterprise AI.
Further reading
This article is part of a broader research series exploring how institutions are being redesigned for the age of artificial intelligence.
Together, these essays examine the structural foundations of the emerging AI economy — from signal infrastructure and representation systems to decision architectures and enterprise operating models. If you want to explore the deeper framework behind these ideas, the following essays provide additional perspectives:
Stanford HAI (Human-Centered AI) blog, which explains the evolution of AI reasoning:
Stanford HAI – The Future of AI Reasoning
-
- The Representation Economy: Why AI Institutions Must Run on SENSE, CORE, and DRIVER – Raktim Singh
- The Representation Economy: Why Intelligent Institutions Will Run on the SENSE–CORE–DRIVER Architecture – Raktim Singh
- The New Company Stack — business categories emerging in the Representation Economy. (raktimsingh.com)
- What Is the Representation Economy? The Definitive Guide to SENSE, CORE, and DRIVER – Raktim Singh
- Representation Economy Explained: More Questions on SENSE, CORE, and DRIVER – Raktim Singh
- The DRIVER Layer in AI: Delegation, Governance, and Trust Explained – Raktim Singh
- Representation Economics: The New Law of AI Value Creation (raktimsingh.com)
- What Is the Representation Economy? Guide to SENSE, CORE, and DRIVER (raktimsingh.com)
- Representation Economy and the SENSE–CORE–DRIVER Framework (raktimsingh.com)
- More Questions on SENSE, CORE, and DRIVER (raktimsingh.com)
- Representation Standards: Who Will Write the GAAP of the AI Economy? – Raktim Singh
Author box
Raktim Singh is a technology thought leader writing on enterprise AI, governance, digital transformation, and the Representation Economy.