{kind=link}

Identity Graphs for Enterprise AI:
Why AI Systems Fail When Enterprises Cannot Resolve Identity at Machine Speed
Enterprise AI has a hidden dependency few executives discuss:
Before an AI system can reason correctly, recommend correctly, or act correctly, it must first answer a more primitive question:
What real-world entity does this data actually refer to?
That question sounds trivial.
It is not.
Across most enterprises, the same customer, vendor, employee, asset, product, machine, location, or contract exists in dozens of fragmented representations:
- Different identifiers
- Different spellings
- Different schemas
- Different source systems
- Different ownership hierarchies
- Different timestamps
- Different contextual roles
- Different confidence levels
AI models are increasingly capable of reasoning over vast context windows.
But they remain fundamentally constrained by one issue:
They can only reason over the representation of reality they are given.
If enterprise reality is fragmented, duplicated, stale, or structurally inconsistent, even the most advanced AI system will reason over a distorted map.
This is why identity graphs are emerging as one of the most critical but underappreciated infrastructure layers in enterprise AI.
They are not customer-360 tools.
They are not simply graph databases.
They are not merely MDM 2.0.
They are the representation substrate that allows enterprise AI systems to operate on coherent entities rather than disconnected records.
The Core Technical Problem: Records Are Not Entities
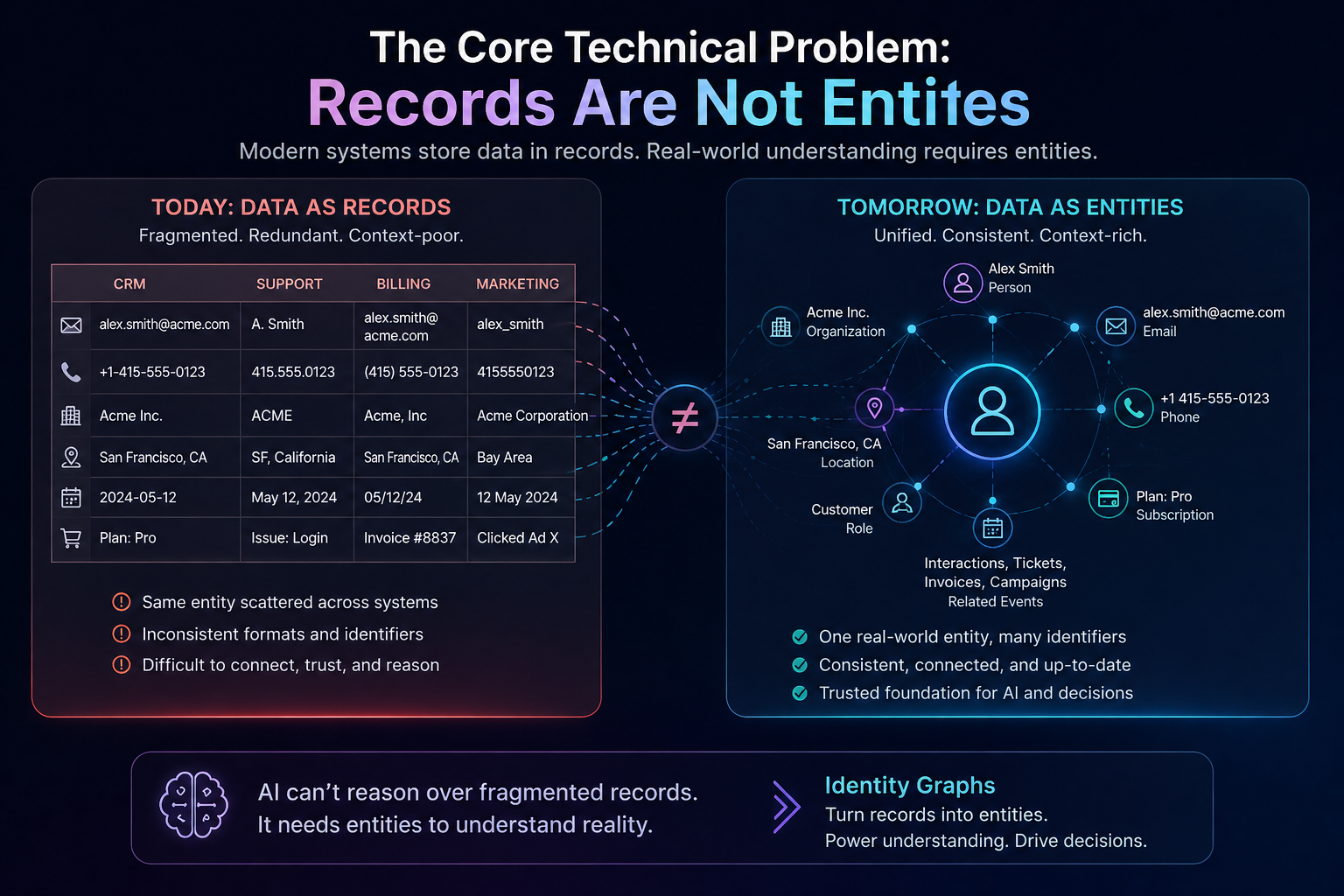
Most enterprise systems store records, not entities.
That distinction is foundational.
A CRM stores a customer record.
An ERP stores a billing record.
A support platform stores a ticket record.
A finance platform stores an invoice record.
An IAM platform stores a user record.
An IoT platform stores a device record.
But none of those systems intrinsically know whether their record refers to:
- the same real-world entity as another record,
- a related but distinct entity,
- a historical version of an entity,
- or a derived/aggregated representation.
This creates a structural mismatch:
Enterprise systems optimize for transactional integrity within bounded domains.
AI systems require unified semantic representations across domains.
Identity graphs solve this mismatch.
They introduce a persistent entity abstraction layer between raw operational data and downstream reasoning systems.
What an Identity Graph Actually Is
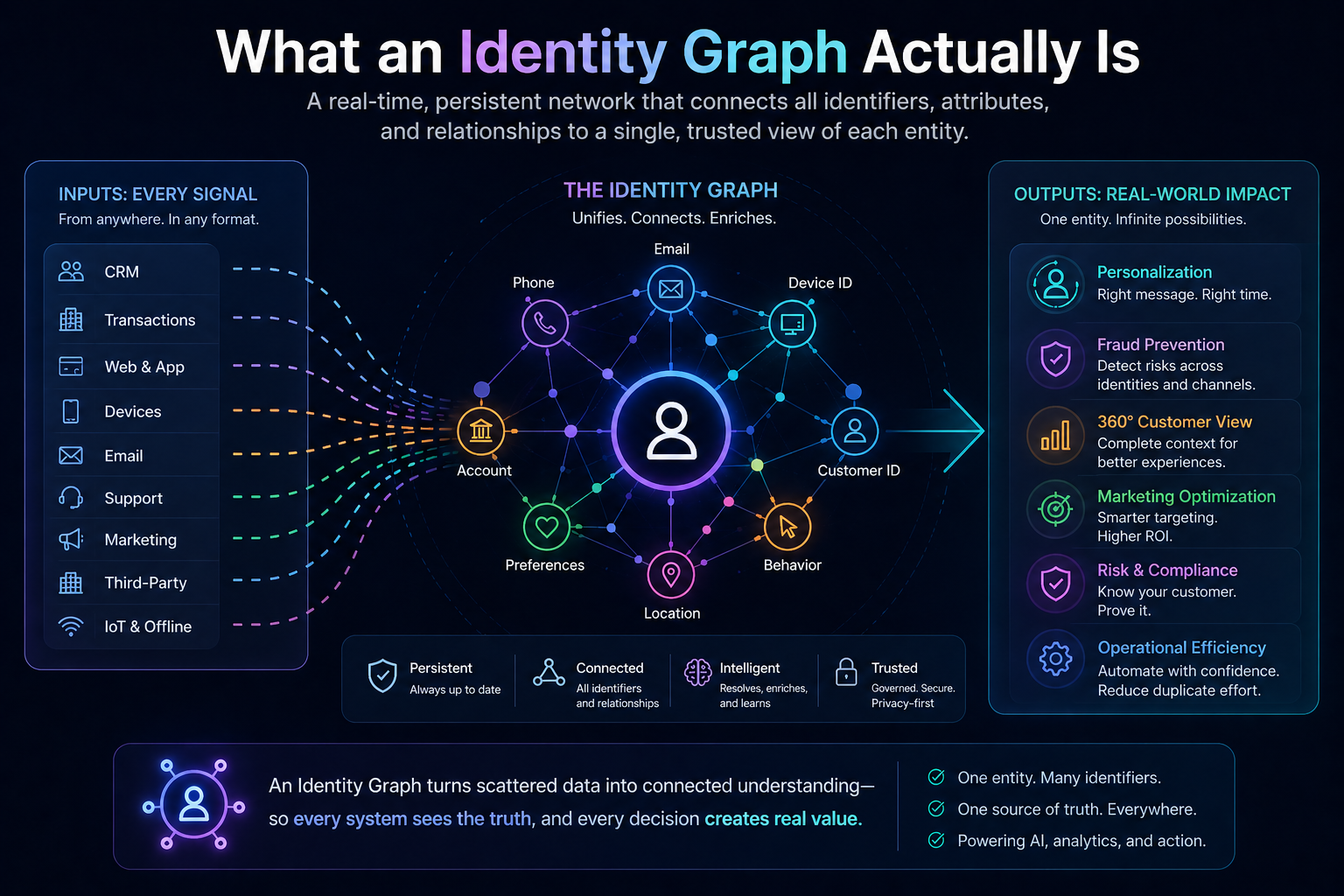
At technical depth, an identity graph is:
A continuously evolving probabilistic graph of resolved entities, identifiers, relationships, state, provenance, and confidence metadata used to maintain machine-legible representations of real-world enterprise actors and objects.
That definition matters.
Because an enterprise-grade identity graph is not just a graph of “nodes and edges.”
It includes:
-
Canonical Entity Layer
Persistent enterprise-level entity IDs abstracted from source-system IDs.
Example:
Entity: ENT_SUPPLIER_84721
Mapped to:
SAP Vendor ID: V-29182
Oracle Supplier ID: S-8472
Procurement Alias: WHITEJUNNE PRIVATE LIMITED
This canonical layer becomes the persistent machine-facing identity anchor.
-
Identifier Resolution Layer
Stores all known identifiers associated with an entity.
Supports:
- deterministic matching
- probabilistic matching
- fuzzy/semantic matching
- temporal disambiguation
- survivorship logic
This enables systems to distinguish between:
- current identifier
- deprecated identifier
- alias
- regional variant
- merged/acquired entity ID
-
Relationship Topology Layer
Captures graph-structured relationships:
Examples:
- Supplier → owns → Subsidiary
- Employee → reports_to → Manager
- Device → installed_in → Factory
- Customer → belongs_to → Household
- Contract → governs → Vendor
- AI Agent → acts_on_behalf_of → Department
This transforms flat records into connected enterprise context.
-
State Representation Layer
Stores current operational and semantic state.
Examples:
- Risk Score = High
- Consent = Revoked
- Device Status = Degraded
- Customer Tier = Platinum
- Contract Status = Pending Renewal
This enables AI systems to reason over live entity state, not merely historical data.
-
Provenance / Confidence Layer
Every resolved link requires explainability.
Stores:
- source of assertion
- confidence score
- matching rationale
- timestamp of resolution
- human validation flag
- model version used for matching
Without this, enterprise identity graphs become ungovernable.
An identity graph is the artifact — the persistent entity abstraction layer itself. The discipline that builds and maintains it is Entity Resolution; see Entity Resolution as Competitive Advantage for that operational and economic lens.
Why Identity Resolution Becomes Hard at Enterprise Scale
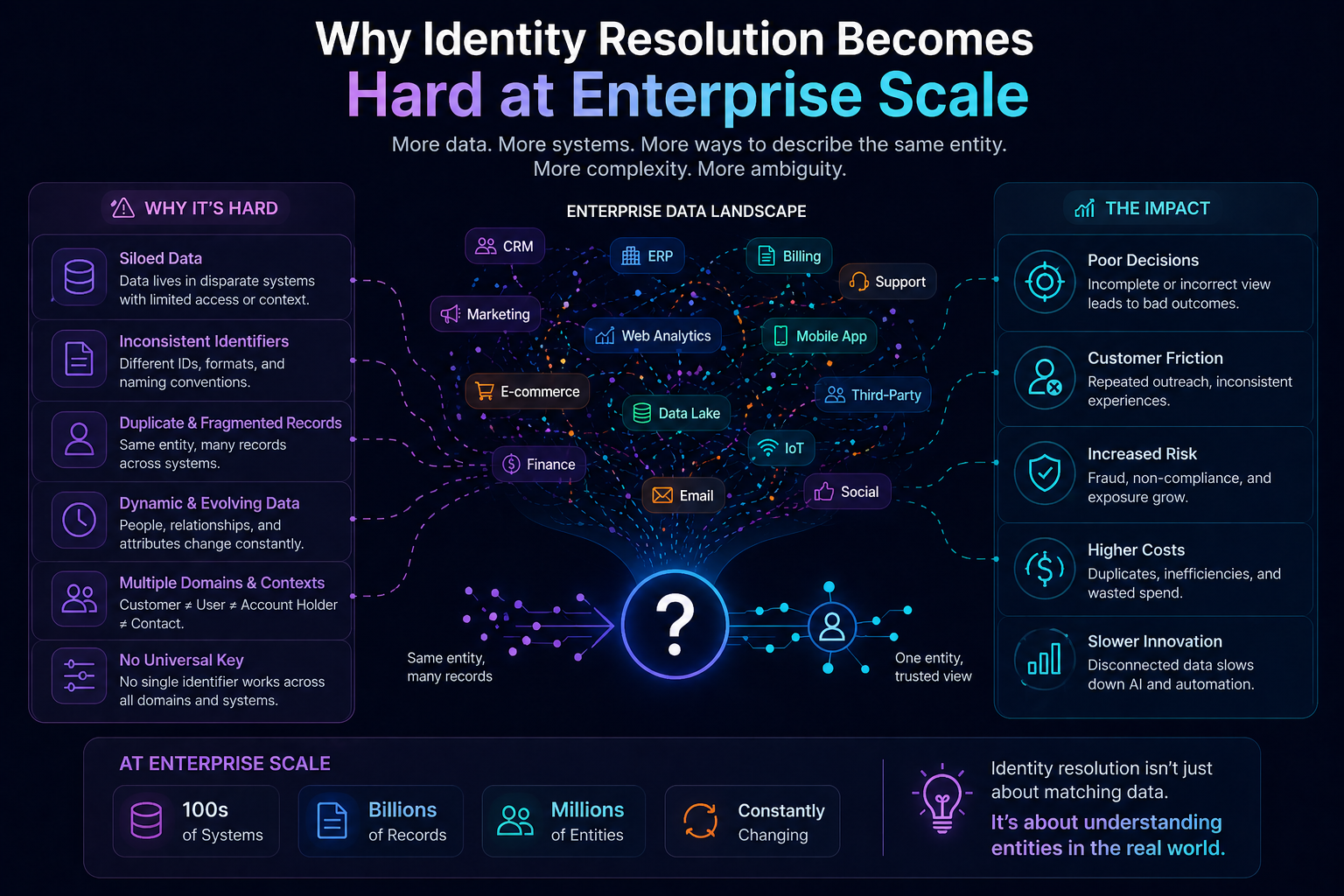
The naive assumption is:
“Just match names and IDs.”
Reality is far more complex.
Problem 1: Schema Heterogeneity
Different systems model the same entity differently.
Example:
CRM:
{
“customer_name”: “ABC Industries”
}
ERP:
{
“legal_entity”: “ABC Industries Pvt Ltd”
}
Support Platform:
{
“account_alias”: “ABC Ind”
}
Identity graphs must normalize heterogeneous schemas before resolution.
Problem 2: Temporal Drift
Identity is not static.
Entities evolve.
Examples:
- People change names
- Vendors merge
- Employees change roles
- Devices move locations
- Contracts expire
- Ownership structures change
Thus identity resolution cannot be one-time.
It must be continuously recomputed.
Problem 3: Contextual Identity
An entity may appear differently in different contexts.
Example:
A person may simultaneously be:
- Employee
- Customer
- Vendor Contact
- Shareholder
- Board Member
Traditional MDM models struggle here because they assume one dominant master identity.
Identity graphs support multi-role representation.
Problem 4: Relationship Ambiguity
Sometimes identity cannot be resolved through attributes alone.
Relationships provide disambiguation.
Example:
Two “RABC Kumar” records may be distinct.
But if one is connected to:
- InABC Bangalore
- Manager ID X
- Project Y
and another is connected to:
- InABC Pune
- Manager Z
- Project Q
graph topology helps separate them.
Why This Matters for Enterprise AI Architectures
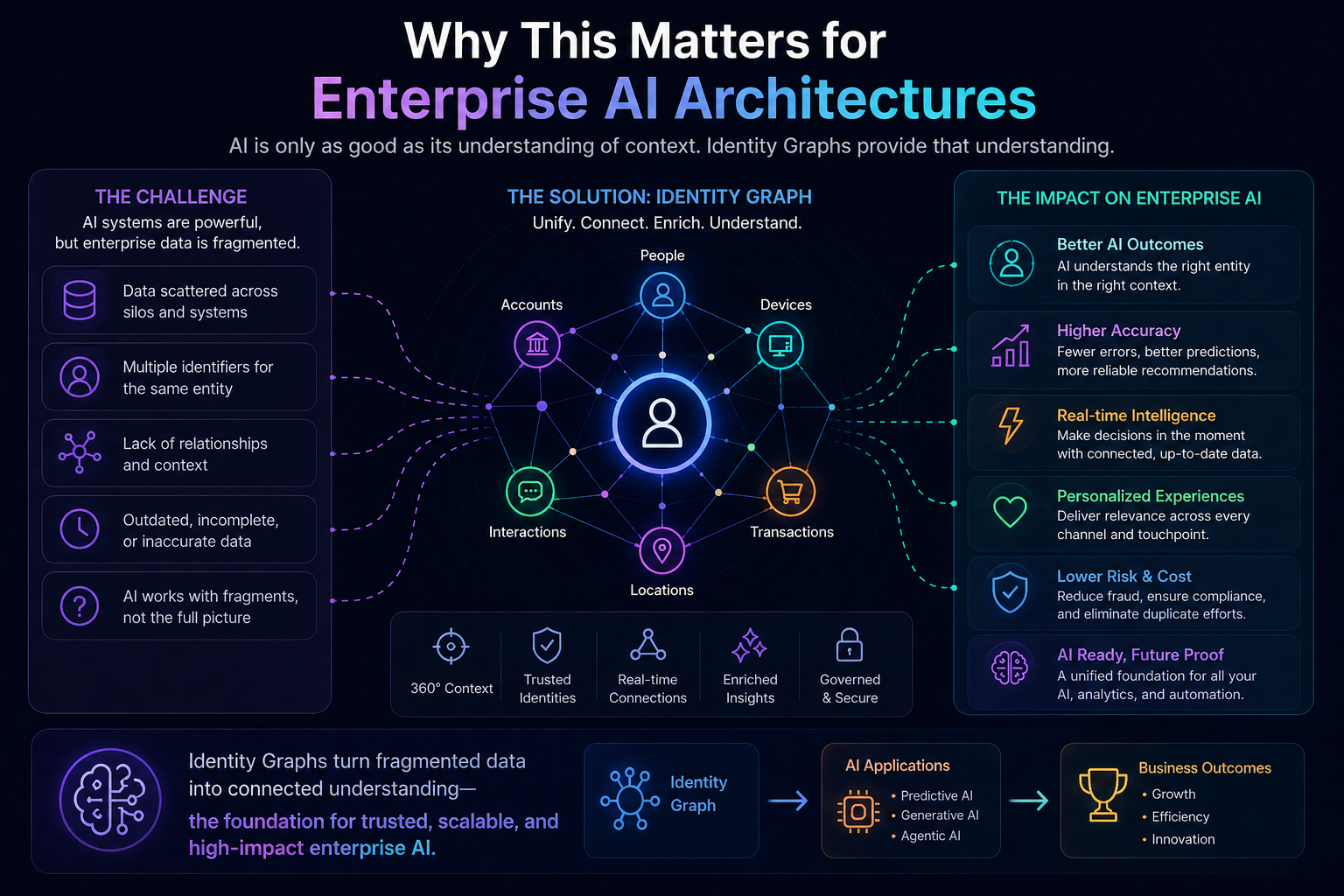
AI systems increasingly require:
- structured context
- relationship awareness
- grounded retrieval
- memory persistence
- action traceability
- delegation boundaries
Identity graphs improve all of them.
Identity Graphs Improve Graph RAG
Traditional RAG retrieves semantically similar text chunks.
That works for document search.
It fails for entity-centric enterprise reasoning.
Example query:
“Show me all critical vendors affected by delayed shipments whose parent entities also have open compliance risks.”
Vector search alone struggles.
Identity graphs enable:
- entity expansion
- relationship traversal
- constraint filtering
- topology-aware retrieval
- contextual grounding
This is why Graph RAG is becoming important in enterprise architectures.
Identity Graphs Improve Agentic AI
Agents require persistent memory and situational awareness.
Without identity graphs:
Agents see fragmented records.
With identity graphs:
Agents can reason over:
- unified entity context
- historical interactions
- relationship networks
- prior decisions
- delegated authority chains
This significantly improves agent reliability.
Identity Graphs as SENSE Infrastructure
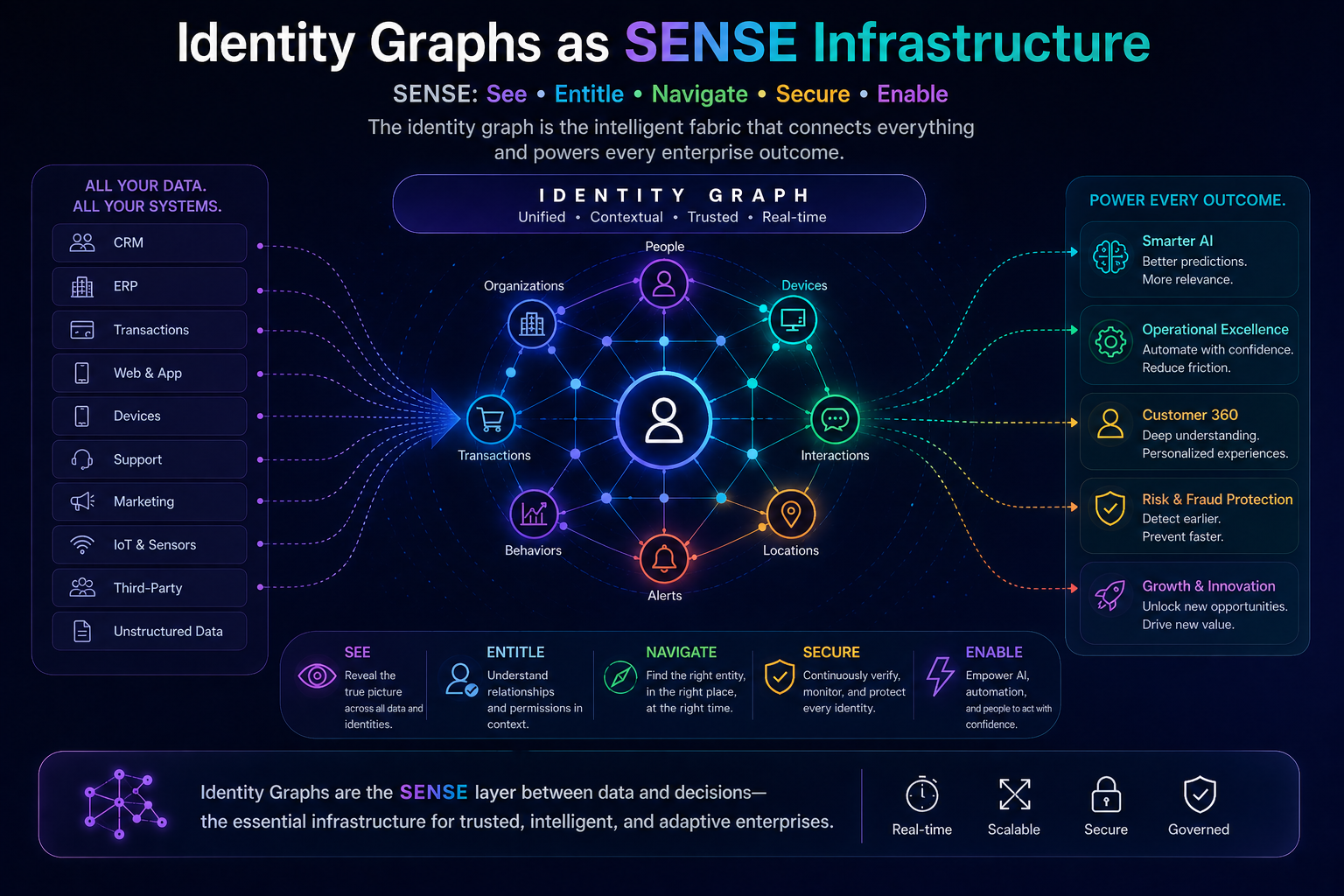
Within the SENSE–CORE–DRIVER framework:
SENSE Requires Entity Resolution Before Intelligence
Signals without identity are noise.
Example:
An IoT sensor says:
Temperature = 91°C
Useful only if AI knows:
- Which machine?
- Which factory?
- Which maintenance contract?
- Which customer order depends on it?
- Which technician is assigned?
Identity graphs convert raw signals into contextualized enterprise state.
CORE Becomes More Accurate
Models reason over connected representations rather than isolated data.
This improves:
- recommendation quality
- planning quality
- anomaly detection
- forecasting
- summarization
- causal inference
DRIVER Gains Accountability
Identity graphs enable action traceability:
- Which agent acted?
- On behalf of whom?
- Against which entity?
- Under which authority?
- Using which representation?
This becomes critical in governed AI systems.
Why Identity Graphs Create Strategic Moats
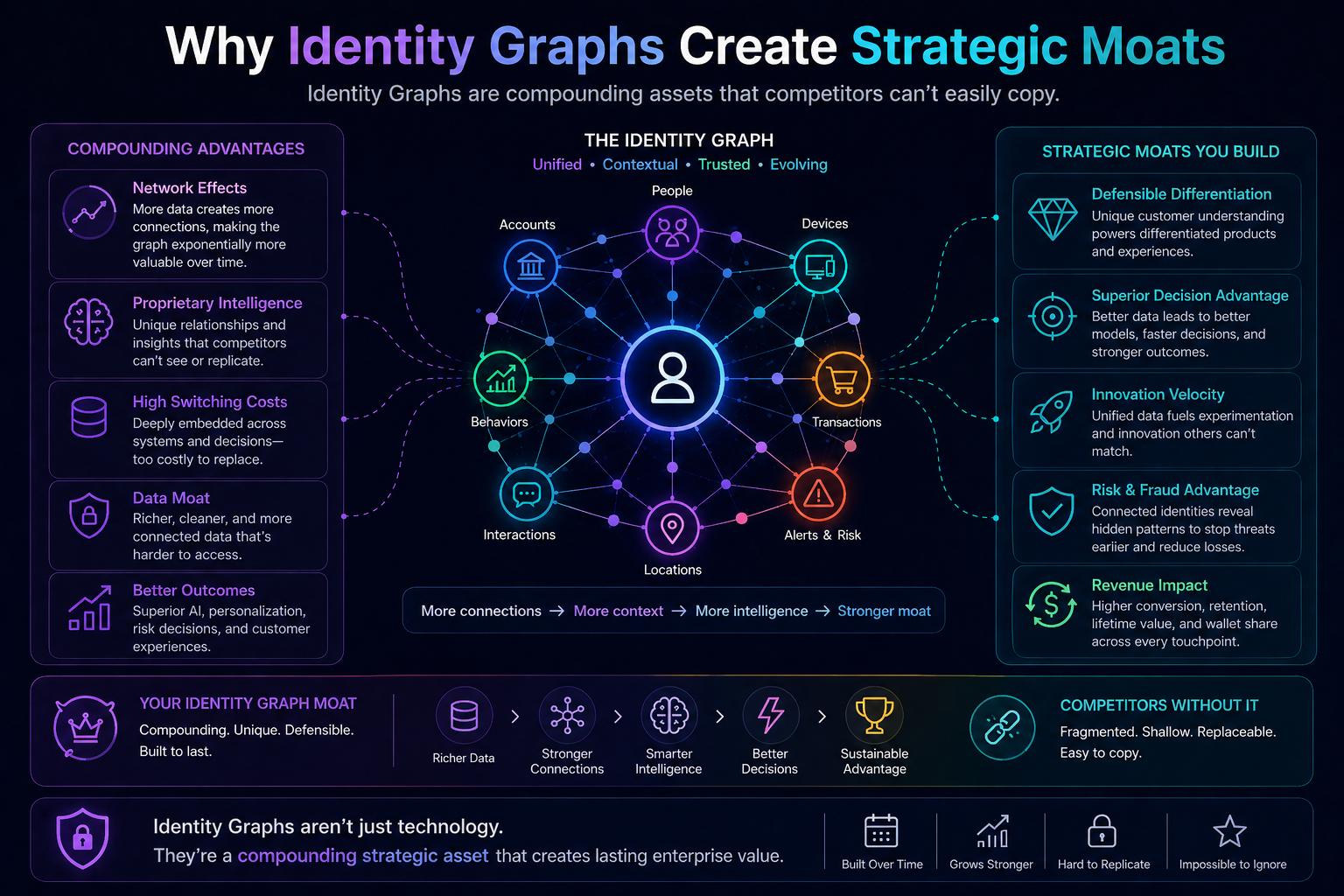
Identity graphs are difficult to replicate because they encode:
- years of operational history
- institutional disambiguation logic
- business-specific entity semantics
- relationship topology
- trust/confidence heuristics
- governance policies
- exception handling knowledge
Competitors can buy models.
They cannot easily buy your enterprise’s resolved representation layer.
That makes identity graphs a durable strategic asset.
The Emerging Shift: From Data Architecture to Representation Architecture
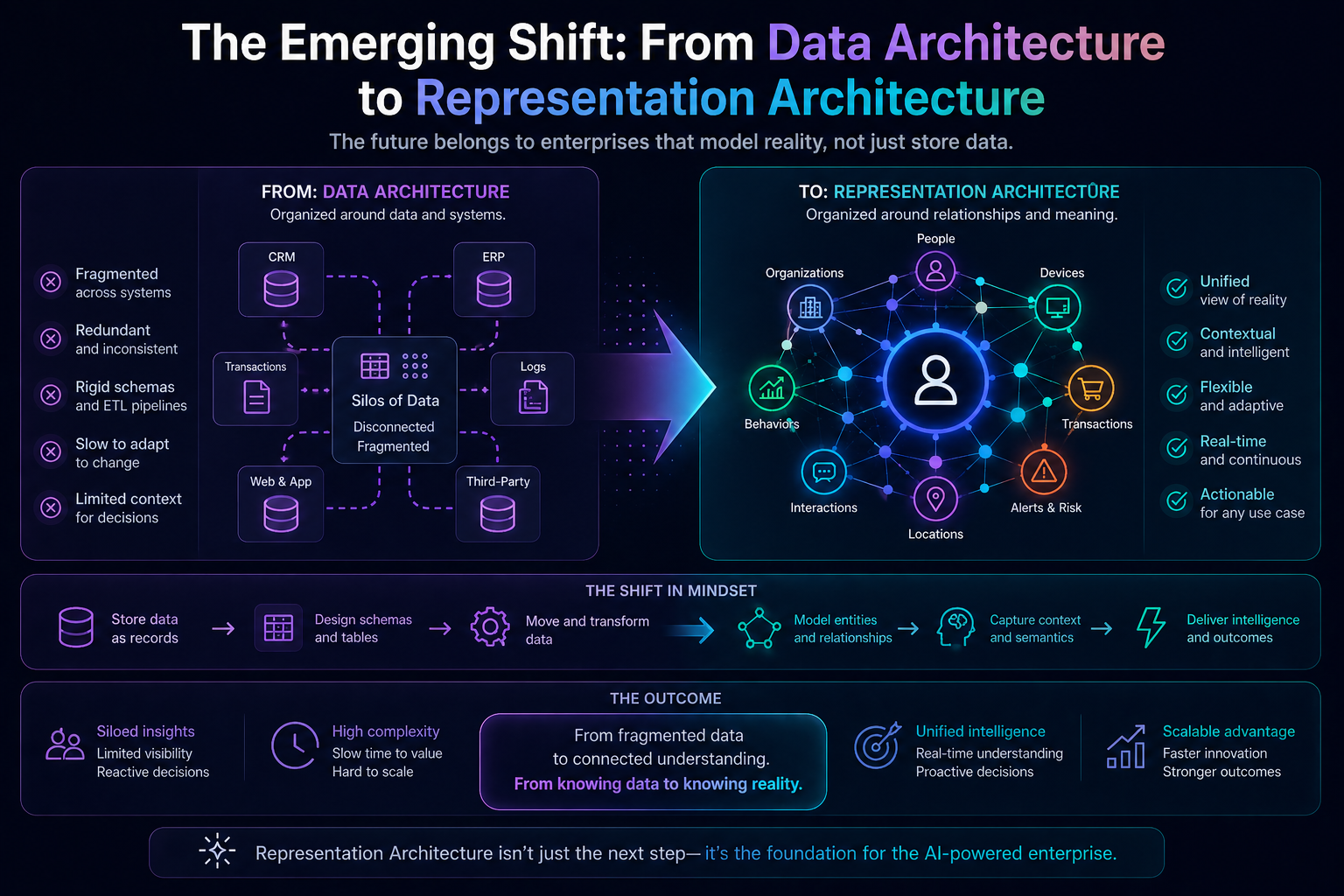
Historically, enterprises built:
- Data Warehouses → for reporting
- Data Lakes → for storage
- Lakehouses → for analytics
- MDM → for consistency
The next layer is:
Representation Architecture
Architecture whose purpose is not storing data—
but ensuring machines possess coherent, contextual, governable representations of reality.
Identity graphs are the first major primitive of that architecture.
Final Insight: The Best AI Systems Will Not Belong to Firms With the Most Data
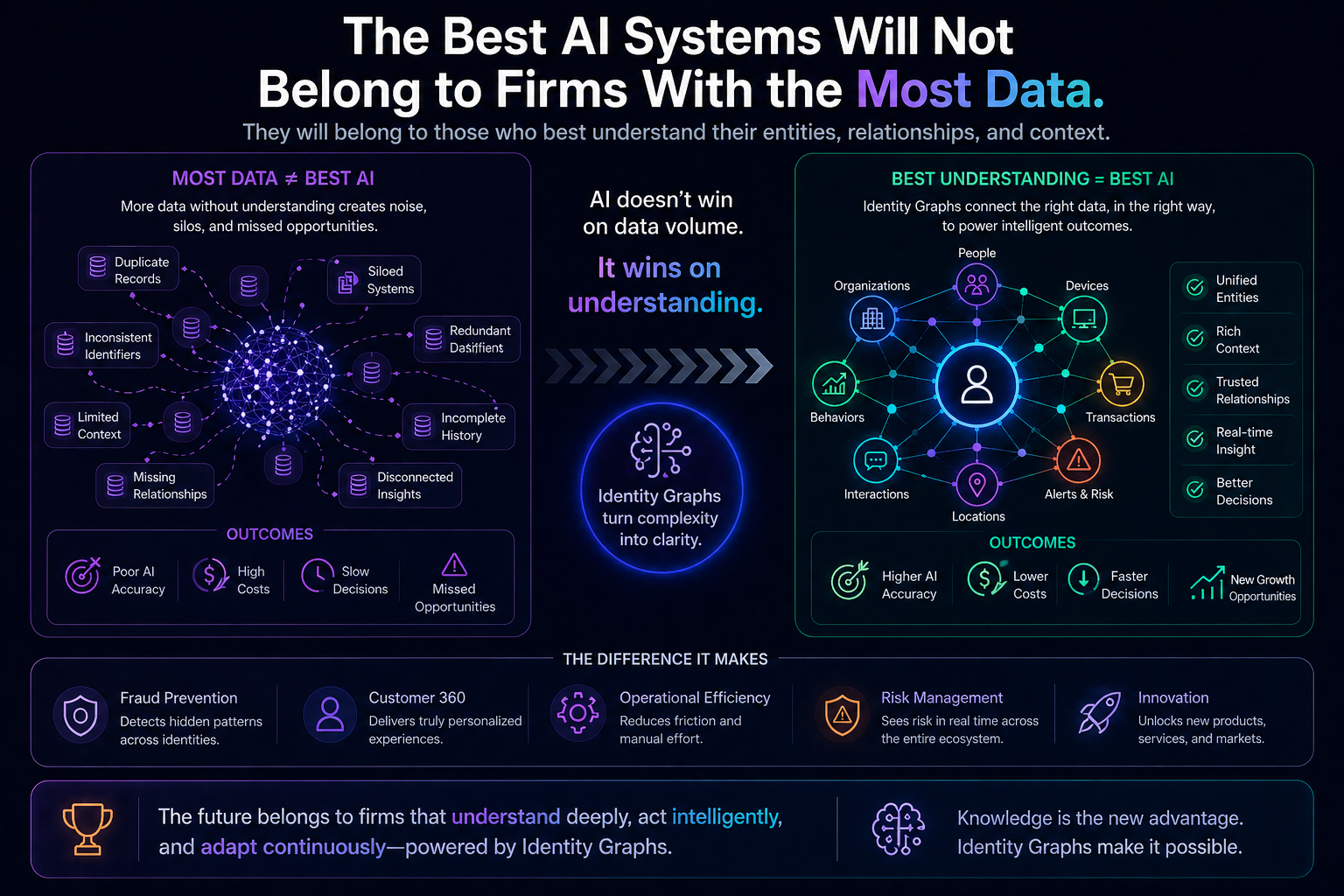
They will belong to firms with the most machine-resolvable reality.
Because AI does not operate on data.
AI operates on representations.
And identity graphs determine whether those representations correspond to reality—or merely to fragmented records.
In the Representation Economy:
The enterprise that best resolves identity will often outperform the enterprise with the best model.
Because before intelligence can scale—
reality must first become resolvable.
Closing Thesis
Identity graphs are not an enhancement to enterprise AI.
They are foundational infrastructure.
They are the missing layer between data and decision because they transform fragmented enterprise records into coherent machine-legible entities that AI systems can trust, reason over, and act upon.
The firms that build this layer well will not merely deploy better AI.
They will build enterprises AI can actually understand.
FAQ
What is an identity graph in enterprise AI?
An identity graph is a persistent, connected data structure that links multiple records, identifiers, attributes, and relationships to a single real-world entity, enabling AI systems to understand who or what an entity truly is across fragmented enterprise systems.
Why are identity graphs important for AI?
AI systems require context, relationships, and trusted entity understanding—not just raw records. Identity graphs provide this unified representation, improving personalization, fraud detection, analytics, and autonomous decision-making.
How is an identity graph different from a database?
Traditional databases store records in tables. Identity graphs model entities and relationships dynamically, enabling connected, contextual understanding rather than isolated record retrieval.
What is the difference between identity resolution and identity graphs?
Identity resolution is the process of determining which records belong to the same entity. An identity graph is the persistent system that stores and manages the resolved entity and its relationships over time.
Why do identity graphs create competitive advantage?
Because they improve continuously as more data, interactions, and relationships are added—creating proprietary contextual intelligence that competitors cannot easily replicate.
Glossary
Identity Graph
A graph-based representation of real-world entities and their relationships across systems.
Identity Resolution
The process of determining when multiple records refer to the same real-world entity.
Entity Resolution
A broader technical term for matching and merging records that represent the same entity.
Representation Architecture
An architectural approach focused on modeling real-world entities, context, and relationships rather than merely storing data.
Machine-Legible Reality
Reality translated into structured digital representations understandable by AI systems.
SENSE Infrastructure
The systems and layers responsible for making the world observable, identifiable, and representable for AI.
Entity-Centric Architecture
Architecture organized around entities and relationships rather than application silos or data tables.
Reference and Further Read
- Neo4j – Enterprise Identity Graph / Graph Data Science
Explaining graph-based identity relationships and enterprise graph modeling
https://neo4j.com/use-cases/identity-and-access-management/
- Gartner – Identity Resolution / Customer Data Platforms / Master Data Trends
Analyst validation of identity resolution importance
https://www.gartner.com/en/marketing/topics/customer-data-platforms
- IBM – Entity Resolution / Master Data Management
Enterprise-grade explanation of entity resolution challenges
https://www.ibm.com/topics/entity-resolution
- AWS – Graph Databases / Knowledge Graph Concepts
Technical infrastructure explanation
https://aws.amazon.com/nosql/graph/
- Stanford HAI / Research on Data-Centric AI
Broader context on why data quality/representation matters
https://hai.stanford.edu/research/data-centric-ai
- McKinsey / BCG / Deloitte on AI Data Foundations
Executive/business validation of foundational data requirements
https://www.mckinsey.com/capabilities/quantumblack/our-insights
- Google Cloud – Customer 360 / Identity Resolution Concepts
Enterprise implementation examples
https://cloud.google.com/solutions/customer-360
Further reading
This article is part of a broader research series exploring how institutions are being redesigned for the age of artificial intelligence. Together, these essays examine the structural foundations of the emerging AI economy — from signal infrastructure and representation systems to decision architectures and enterprise operating models. If you want to explore the deeper framework behind these ideas, the following essays provide additional perspectives:
-
- The Representation Economy: Why AI Institutions Must Run on SENSE, CORE, and DRIVER – Raktim Singh
- The Representation Economy: Why Intelligent Institutions Will Run on the SENSE–CORE–DRIVER Architecture – Raktim Singh
- The New Company Stack — business categories emerging in the Representation Economy. (raktimsingh.com)
- What Is the Representation Economy? The Definitive Guide to SENSE, CORE, and DRIVER – Raktim Singh
- Representation Economy Explained: More Questions on SENSE, CORE, and DRIVER – Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.