{kind=link}

Entity Resolution as Competitive Advantage: Where Enterprise AI Actually Breaks
Most enterprise AI systems do not fail because of poor models.
They fail because the system cannot answer a deceptively simple question with confidence:
“Which real-world entity does this data point belong to?”
Not approximately.
Not probabilistically.
But in a way that can survive execution, audit, compliance, and automation.
Inside a large enterprise, this question becomes non-trivial almost immediately.
A single customer may exist as:
- multiple CRM entries
- multiple billing accounts
- multiple support identities
- multiple contractual representations
- multiple regulatory identifiers
A single supplier may exist as:
- a legal entity in procurement
- a vendor ID in ERP
- a counterparty in risk systems
- a node in a supply chain graph
A single asset may exist as:
- a physical object in operations
- a financial record in accounting
- a maintenance object in engineering systems
These are not duplicates.
These are multiple, conflicting, partial representations of the same underlying entity.
Enterprise AI does not operate on the entity.
It operates on these representations.
And unless those representations are resolved, aligned, and governed, AI is not reasoning about reality.
It is reasoning about noise.
Definition:
Entity Resolution is the enterprise capability of identifying, linking, and maintaining accurate machine-readable representations of real-world entities across fragmented systems.
Entity resolution is the discipline; an identity graph is what it produces and maintains over time. For the technical architecture of that artifact itself, see Identity Graphs for Enterprise AI: The Missing Layer Between Data and Decision.
Reframing the Problem: Entity Resolution as Representation Infrastructure
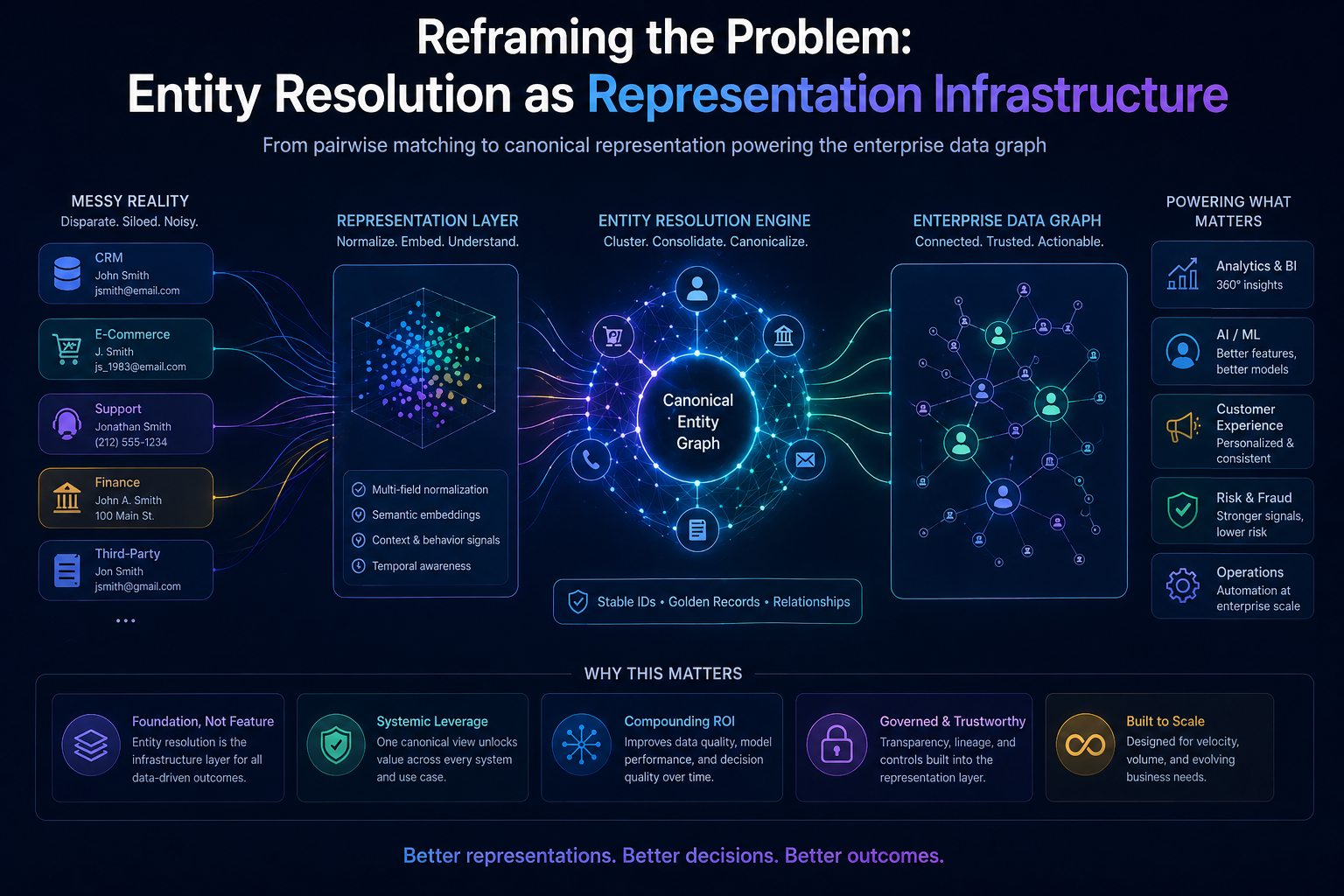
Entity resolution is often framed as a data quality problem.
That framing is outdated.
At scale, entity resolution is representation infrastructure.
It determines:
- how signals attach to entities
- how entities persist across systems
- how state is constructed
- how identity evolves over time
In your SENSE–CORE–DRIVER framing:
- Signal → events, transactions, logs, interactions
- ENtity → the anchor that those signals attach to
- State Representation → the current view of that entity
- Evolution → how identity and state change over time
Entity resolution is not a preprocessing step.
It is the binding layer of reality.
If this layer is weak, everything above it becomes unstable.
Why This Problem Explodes at Scale
At small scale, entity resolution looks solvable.
At enterprise scale, four forces make it exponentially harder.
-
Identity Fragmentation Across Systems
Every system creates its own identity abstraction.
CRM creates “customer”
ERP creates “account”
Risk systems create “counterparty”
Support systems create “user”
These are not aligned by default.
They are optimized for local use, not global coherence.
-
Context-Dependent Identity
The same entity behaves differently depending on context.
A company may be:
- a customer in one relationship
- a supplier in another
- a partner in a third
Even within the same enterprise.
Entity resolution must therefore handle multi-role identity, not just matching.
-
Temporal Drift (Identity Over Time)
Entities are not static.
- Companies merge, split, rename
- Customers change addresses, contact points, ownership
- Products evolve across versions
- Assets get refurbished, relocated, reclassified
So the question is not just:
“Are these the same entity?”
It becomes:
“Were these the same entity at time T?”
-
Incomplete and Conflicting Signals
Real enterprise data is:
- missing fields
- inconsistent formats
- manually entered
- duplicated
- partially structured
Two records may share:
- name similarity
- address similarity
- transaction linkage
- shared identifiers
But none of these alone are sufficient.
Entity resolution becomes a multi-signal inference problem.
The Technical Core of Entity Resolution

At scale, entity resolution is not a single algorithm.
It is a system composed of multiple layers.
-
Candidate Generation (Blocking)
You cannot compare every record with every other record.
The computational cost explodes.
So systems first generate candidate pairs using:
- phonetic similarity (e.g., Soundex-like techniques)
- token-based indexing
- hashed keys
- domain-specific blocking rules
This reduces the search space.
-
Similarity Computation
For each candidate pair, multiple similarity signals are computed:
- string similarity (names, addresses)
- structural similarity (hierarchies, relationships)
- behavioral similarity (transaction patterns)
- identifier overlap (tax IDs, emails, device IDs)
Modern systems combine:
- deterministic rules
- statistical scoring
- machine learning models
-
Decision Layer (Match / Non-Match / Possible Match)
Instead of binary decisions, mature systems use:
- hard match (high confidence)
- non-match (clear distinction)
- possible match (requires review or downstream logic)
Confidence scoring becomes critical.
Because decisions propagate into business workflows.
-
Clustering and Graph Construction
Entity resolution is not pairwise.
It becomes cluster formation:
- linking multiple records into a single entity cluster
- resolving transitive relationships
- maintaining graph consistency
This is where graph-based approaches become powerful.
Entities are not isolated.
They exist in networks.
Relationships become signals for identity.
-
Survivorship and Golden Record Creation
Once entities are resolved, the system must decide:
- which attribute is authoritative
- which source is trusted
- how conflicts are resolved
This creates the “golden record”.
But in modern systems, this is evolving into:
“dynamic, context-aware representation” instead of a static golden record
Why Traditional Approaches Break
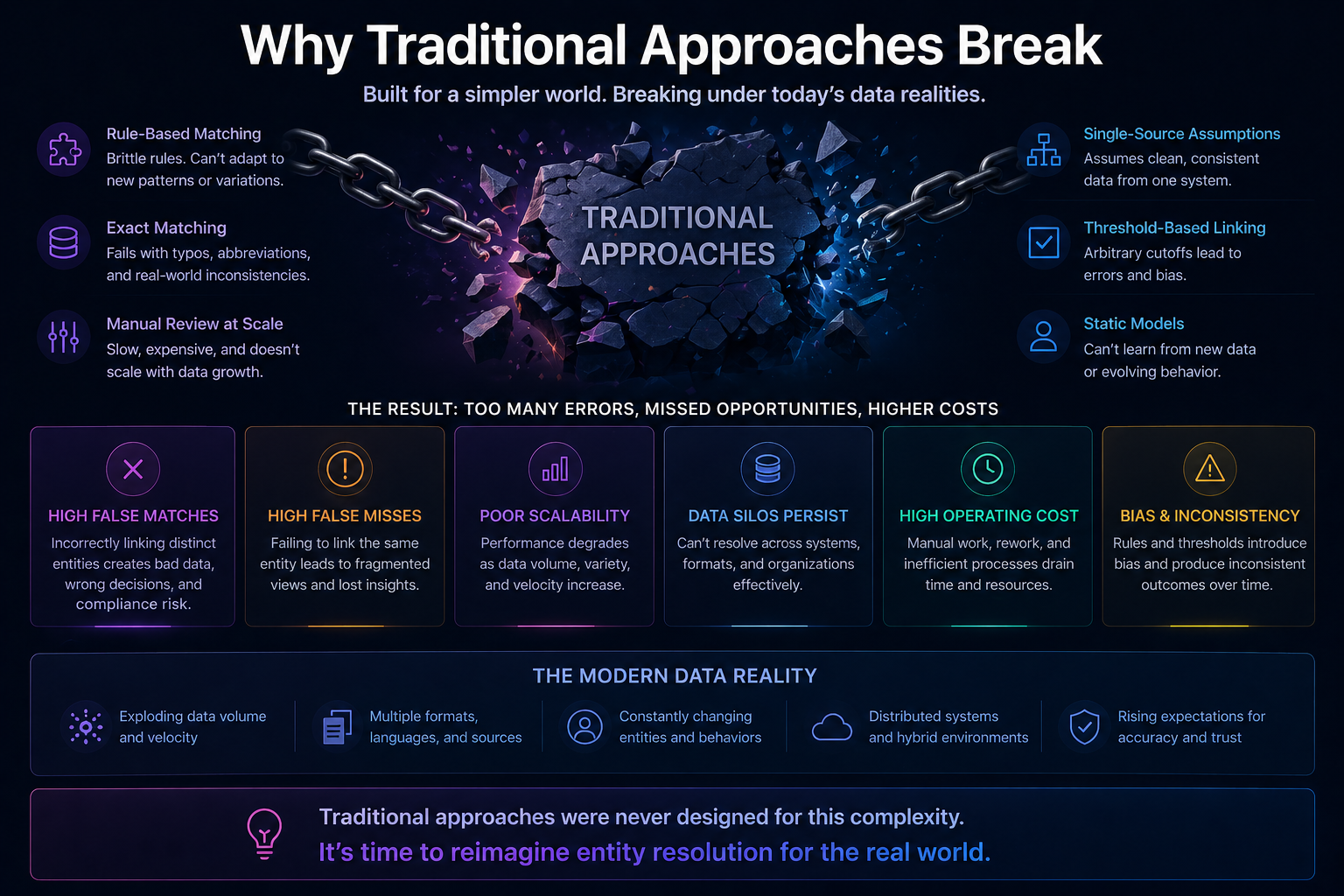
Traditional enterprise approaches rely on:
- Master Data Management (MDM)
- Rule-based matching
- Centralized golden records
These approaches struggle because:
They assume stability
Reality is dynamic.
They assume a single truth
Enterprises operate with multiple context-specific truths.
They assume centralized control
Modern architectures are distributed and composable.
They assume low change velocity
AI-driven enterprises operate in real-time.
The Shift: From Golden Records to Living Entity Graphs
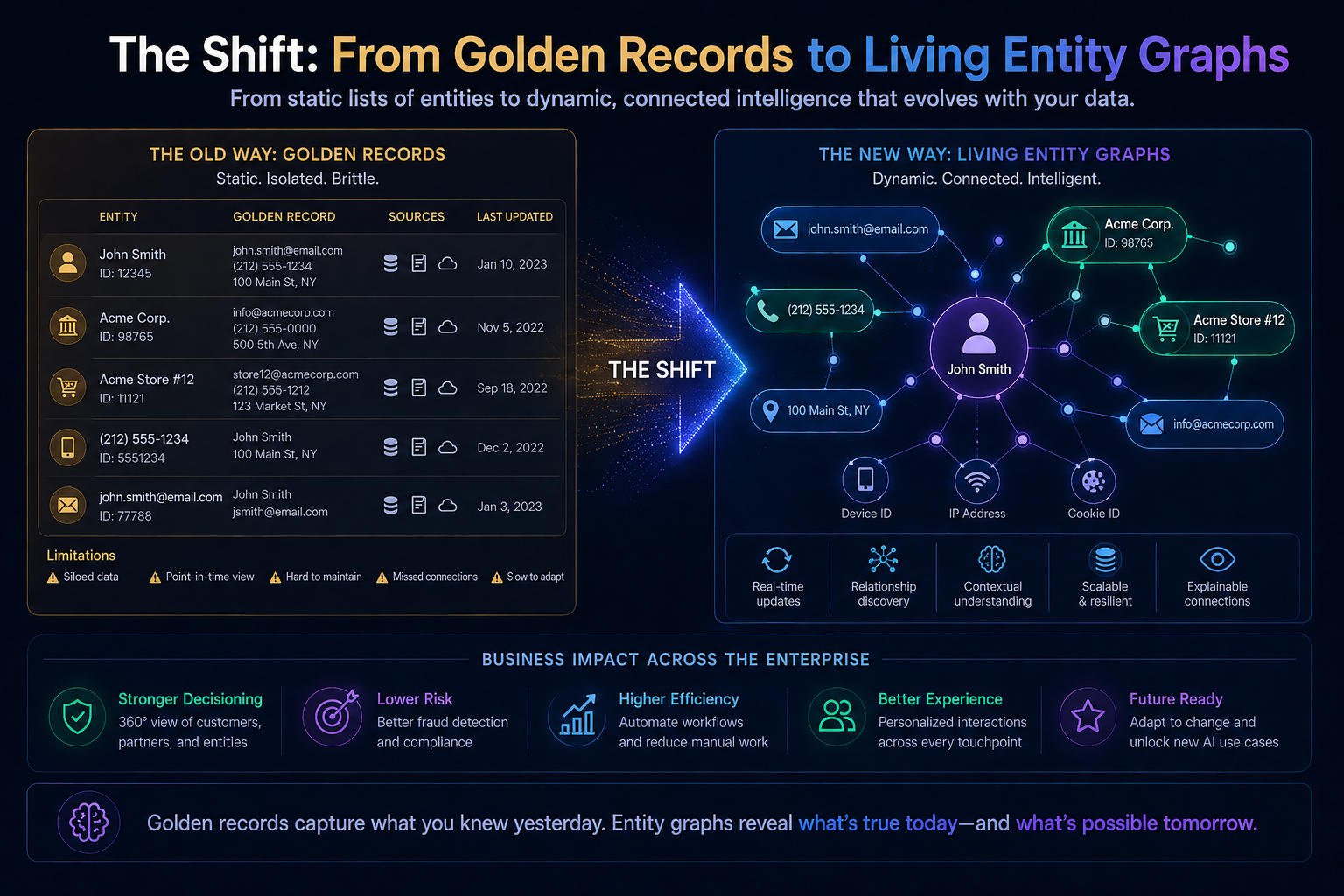
The future of entity resolution is not a static master record.
It is a living entity graph.
Characteristics:
- entities represented as nodes
- relationships as edges
- identity inferred from structure + signals
- continuous updates as new data arrives
- context-aware views of the same entity
This aligns directly with:
- knowledge graphs
- digital twins
- enterprise ontologies
Instead of asking:
“What is the single correct record?”
We ask:
“What is the most accurate representation of this entity for this decision context?”
Entity Resolution in the Age of AI Agents
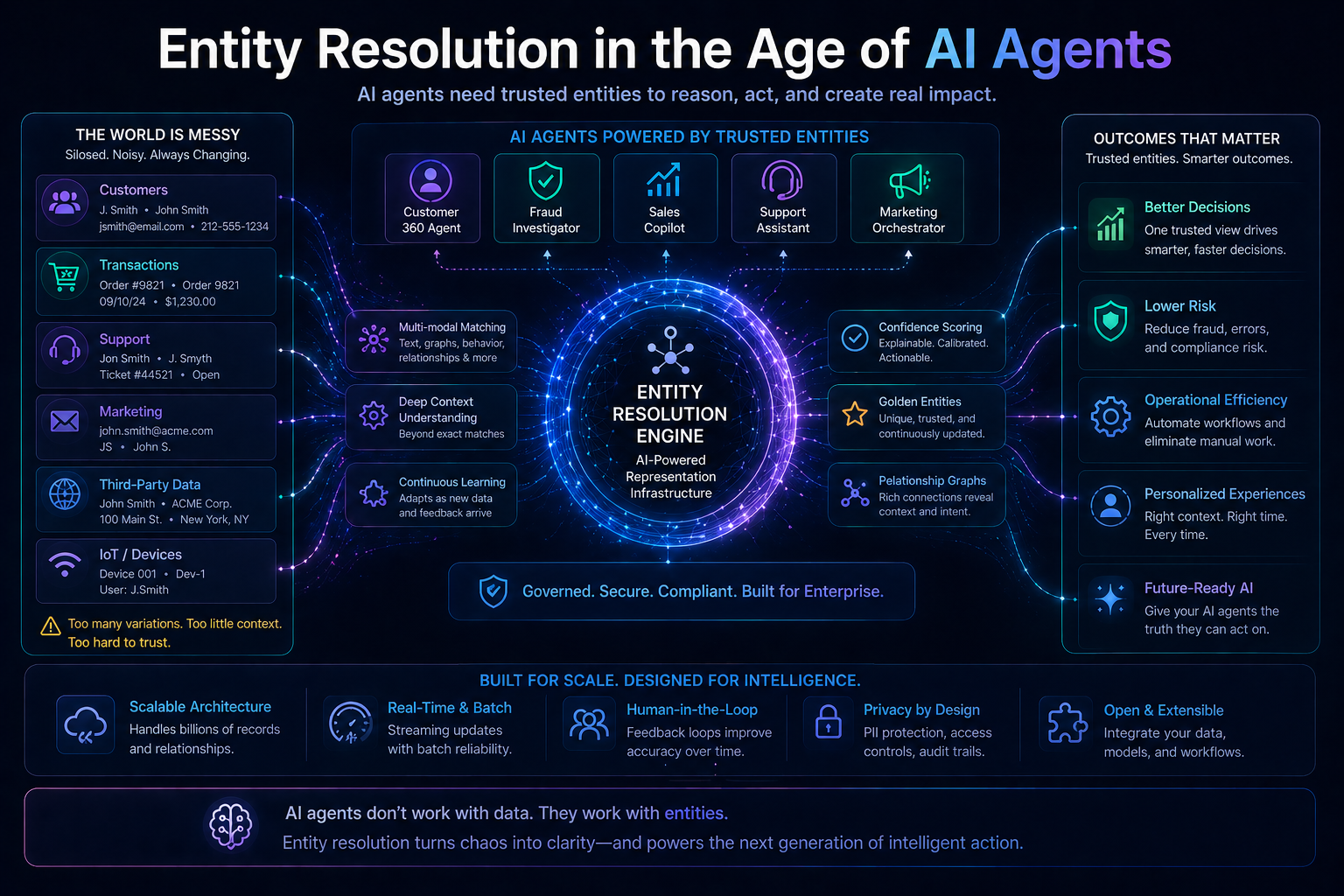
Agentic AI changes everything.
Earlier:
AI generated insights.
Now:
AI executes actions.
This means:
Entity resolution errors no longer stay in reports.
They propagate into execution.
Examples:
- An AI agent negotiates with the wrong supplier entity
- A risk model underestimates exposure due to fragmented identity
- A personalization engine sends conflicting offers to the same customer
- A compliance agent misses linked entities in a fraud network
This is where entity resolution becomes part of execution infrastructure, not just data preparation.
The New Requirements for Enterprise-Grade Entity Resolution
To support AI at scale, entity resolution systems must evolve.
-
Identity-Bound Execution
Every action must be tied to:
- a resolved entity
- a confidence level
- a traceable identity path
-
Continuous Resolution (Not Batch)
Resolution must happen:
- in real-time
- during ingestion
- during decision-making
Not just in periodic batch jobs.
-
Context-Aware Identity
Different views for:
- marketing
- compliance
- finance
- operations
Same entity, different representation.
-
Explainability
Every match must answer:
“Why were these records considered the same?”
This is critical for:
- audit
- governance
- regulatory trust
-
Governance and Recourse
When resolution is wrong:
- how is it corrected?
- how is it propagated?
- how is impact reversed?
This directly connects to the DRIVER layer.
The Strategic Insight: Entity Resolution Defines Competitive Advantage
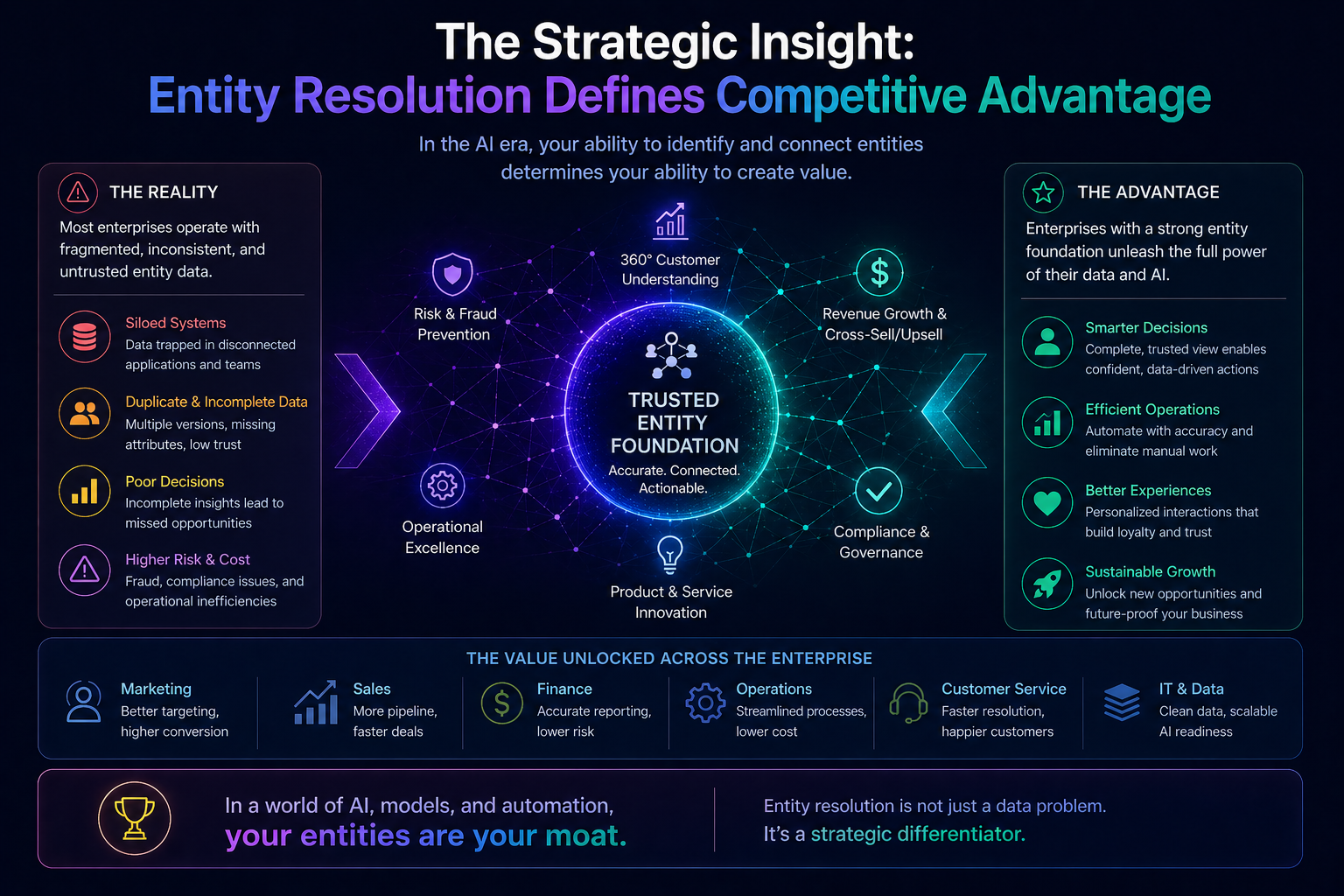
In the Representation Economy, value does not come from models alone.
It comes from who represents reality better.
Firms that solve entity resolution at scale will:
- build superior customer understanding
- reduce risk through accurate exposure mapping
- optimize operations through coherent asset views
- enable reliable AI execution
- create defensible data moats
Firms that do not will:
- automate fragmented intelligence
- amplify inconsistencies
- lose trust in AI systems
- struggle to scale agentic workflows
The Bottom Line
Entity resolution is not a backend problem.
It is not a data cleanup task.
It is not a one-time project.
It is the hardest foundation problem in enterprise AI.
Because it sits at the exact point where:
data becomes identity
identity becomes representation
representation becomes decision
decision becomes action
And in that chain, everything depends on whether the enterprise can answer one question with confidence:
“What is the real-world entity we are acting on?”
AI does not fail because it is not intelligent enough.
It fails because it does not know what is real.
FAQ
Q1: What is entity resolution in enterprise AI?
It is the process of identifying and linking records that refer to the same real-world entity across systems.
Q2: Why is entity resolution important for AI?
Because AI decisions depend on accurate representation of entities like customers, suppliers, and assets.
Q3: How is entity resolution different from deduplication?
Deduplication removes duplicates; entity resolution determines real-world identity using multiple signals and context.
Q4: What technologies are used in entity resolution?
Blocking, similarity scoring, machine learning models, graph databases, and knowledge graphs.
Q5: What is the future of entity resolution?
Living entity graphs, real-time resolution, and context-aware identity systems integrated with AI agents.
How does entity resolution create competitive advantage?
Strong entity resolution improves personalization, fraud detection, analytics, automation, compliance, and AI accuracy—creating compounding advantages across the enterprise.
What is the difference between golden records and living entity graphs?
Golden records are static consolidated records. Living entity graphs are dynamic, continuously updated networks of entities, relationships, behaviors, and contextual signals.
Why is entity resolution becoming strategic now?
Because AI agents and enterprise AI systems require trusted machine-readable representations of reality, making entity resolution foundational infrastructure rather than optional data cleanup.
Glossary
Entity Resolution
The process of identifying, matching, and linking records across systems that refer to the same real-world entity, such as a customer, supplier, product, or device.
Golden Record
A consolidated master record representing the best-known version of an entity, traditionally created by merging duplicate records from multiple systems.
Living Entity Graph
A dynamic, continuously updated graph of entities and relationships that evolves as new data, behaviors, and interactions emerge.
Trusted Entity Infrastructure
The foundational enterprise capability that creates accurate, connected, and machine-readable representations of real-world entities for analytics, AI, and operations.
Identity Resolution
A specialized form of entity resolution focused on linking identifiers and records related to the same person, customer, or account across channels and systems.
Canonical Representation
A normalized, standardized representation of an entity used consistently across systems and applications.
Representation Infrastructure
The systems and processes used to convert fragmented real-world signals into stable machine-readable representations that AI and software can trust.
False Positive Match
An incorrect match where two different entities are mistakenly linked as the same entity.
False Negative Match
A missed match where records belonging to the same real-world entity fail to be linked together.
Entity Graph
A network-based representation of entities and their relationships, attributes, and interactions.
Record Linkage
A statistical or algorithmic technique for matching records across databases that may refer to the same entity.
Master Data Management (MDM)
A discipline and technology stack used to create consistent, governed master records for critical business entities.
Feature Engineering
The process of transforming raw data into meaningful signals used by matching or machine learning algorithms.
Confidence Score
A probabilistic score indicating how likely two records refer to the same entity.
Explainable Matching
The ability to show why records were matched, including contributing attributes, signals, or rules.
Reference and Further Reading
On Entity Resolution / Record Linkage Foundations
Wikipedia – Record Linkage
https://en.wikipedia.org/wiki/Record_linkage
On Master Data Management / Golden Records
Gartner / MDM Overview (or vendor-neutral explainer)
https://www.ibm.com/topics/master-data-management
On Knowledge Graph / Entity Graph Concepts
Google Knowledge Graph Overview
https://developers.google.com/search/docs/appearance/structured-data/intro-structured-data
On Identity Resolution in Practice
AWS Identity Resolution Concepts
https://aws.amazon.com/what-is/identity-resolution/
On Graph Data / Relationship Modeling
Neo4j Knowledge Graph / Entity Resolution Resources
https://neo4j.com/use-cases/knowledge-graph/
On Responsible AI / Explainability
NIST AI Risk Management Framework
https://www.nist.gov/itl/ai-risk-management-framework
Further reading
This article is part of a broader research series exploring how institutions are being redesigned for the age of artificial intelligence. Together, these essays examine the structural foundations of the emerging AI economy — from signal infrastructure and representation systems to decision architectures and enterprise operating models. If you want to explore the deeper framework behind these ideas, the following essays provide additional perspectives:
-
- The Representation Economy: Why AI Institutions Must Run on SENSE, CORE, and DRIVER – Raktim Singh
- The Representation Economy: Why Intelligent Institutions Will Run on the SENSE–CORE–DRIVER Architecture – Raktim Singh
- The New Company Stack — business categories emerging in the Representation Economy. (raktimsingh.com)
- What Is the Representation Economy? The Definitive Guide to SENSE, CORE, and DRIVER – Raktim Singh
- Representation Economy Explained: More Questions on SENSE, CORE, and DRIVER – Raktim Singh
- The DRIVER Layer in AI: Delegation, Governance, and Trust Explained – Raktim Singh

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.