The Enterprise AI Operating Stack
Enterprise AI is no longer defined by models, copilots, or pilots. Once AI systems begin influencing real decisions, triggering workflows, and taking autonomous actions inside production environments, enterprises face a new challenge: how to run intelligence safely, predictably, and economically at scale.
This article defines the Enterprise AI Operating Stack—the architecture that brings together decision boundaries, runtime execution, control planes, economic governance, accountability, and observability—so autonomy becomes operable, governable, and sustainable across the enterprise.
Enterprise AI is entering its “adult phase.”
The early era was about model choice, pilot velocity, and demo excellence. The new era is about something less glamorous—and far more decisive: operability. Once AI systems begin to influence real decisions and trigger real actions inside workflows, enterprises discover a hard truth:
Models don’t run enterprises. Stacks do.
A model can be impressive and still become a production liability if it’s deployed without the layers that make it safe, reliable, and economically sustainable. That is why the most advanced enterprises are converging on an architecture pattern that looks less like “a chatbot” and more like an operating system.
This article is part of the canonical Enterprise AI Operating Model series:
Enterprise AI Operating Model
This article defines that pattern: the Enterprise AI Operating Stack—a practical, architecture-level map of how Decision, Runtime, Control, Economics, Governance, and Observability fit together to produce economically operable autonomy at scale.
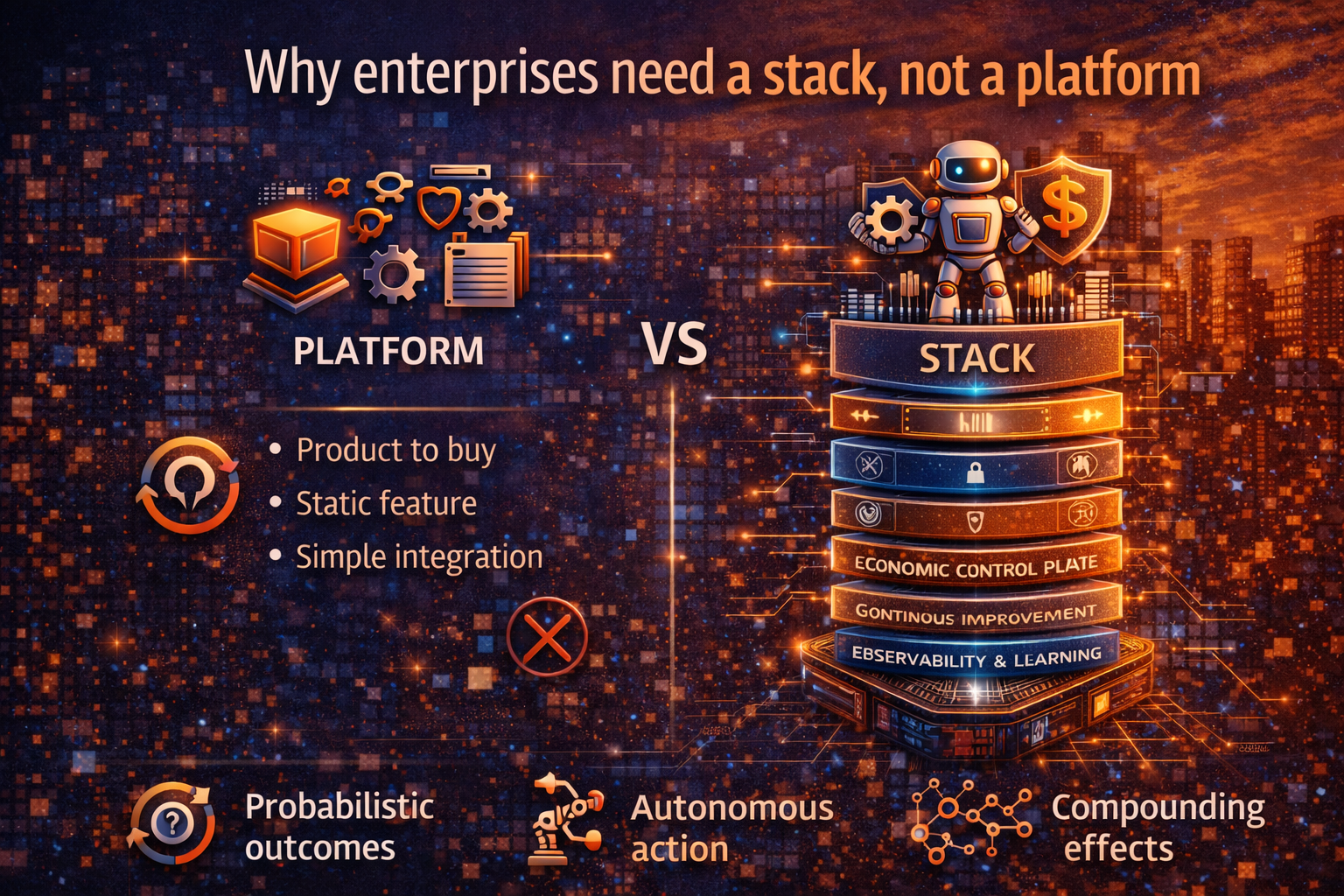
Why enterprises need a stack, not a platform
“Platform” is a product word. “Stack” is an operating reality.
A platform suggests: buy it, integrate it, you’re done.
A stack admits something more honest: AI is an evolving estate that must be run—with control, guardrails, accountability, and continuous improvement.
This matters because Enterprise AI has three properties that classic enterprise software didn’t:
- Probabilistic behavior: outputs vary, even for similar inputs.
- Action capability: AI can trigger workflows, tools, and decisions.
- Compounding effects: small changes can create cascading consequences (cost, risk, compliance, customer impact).
That’s why risk frameworks increasingly emphasize lifecycle governance. The NIST AI Risk Management Framework (AI RMF) organizes AI risk management into high-level functions—Govern, Map, Measure, Manage—and explicitly frames governance as a cross-cutting function across the lifecycle. (NIST Publications)
And regulations like the EU AI Act place strong emphasis on human oversight and operational duties for high-risk systems. (AI Act Service Desk)
In short: enterprises need a stack because AI is not a feature. It is a new production category.

The Enterprise AI Operating Stack in one sentence
The Enterprise AI Operating Stack is the set of layers that turns AI from “outputs” into operable decisions, by making autonomy governable, observable, and economically sustainable.
Think of it like the difference between:
- a single spreadsheet someone built (useful but fragile), and
- an enterprise finance system (auditable, controlled, and trustworthy).
Enterprise AI must evolve the same way.
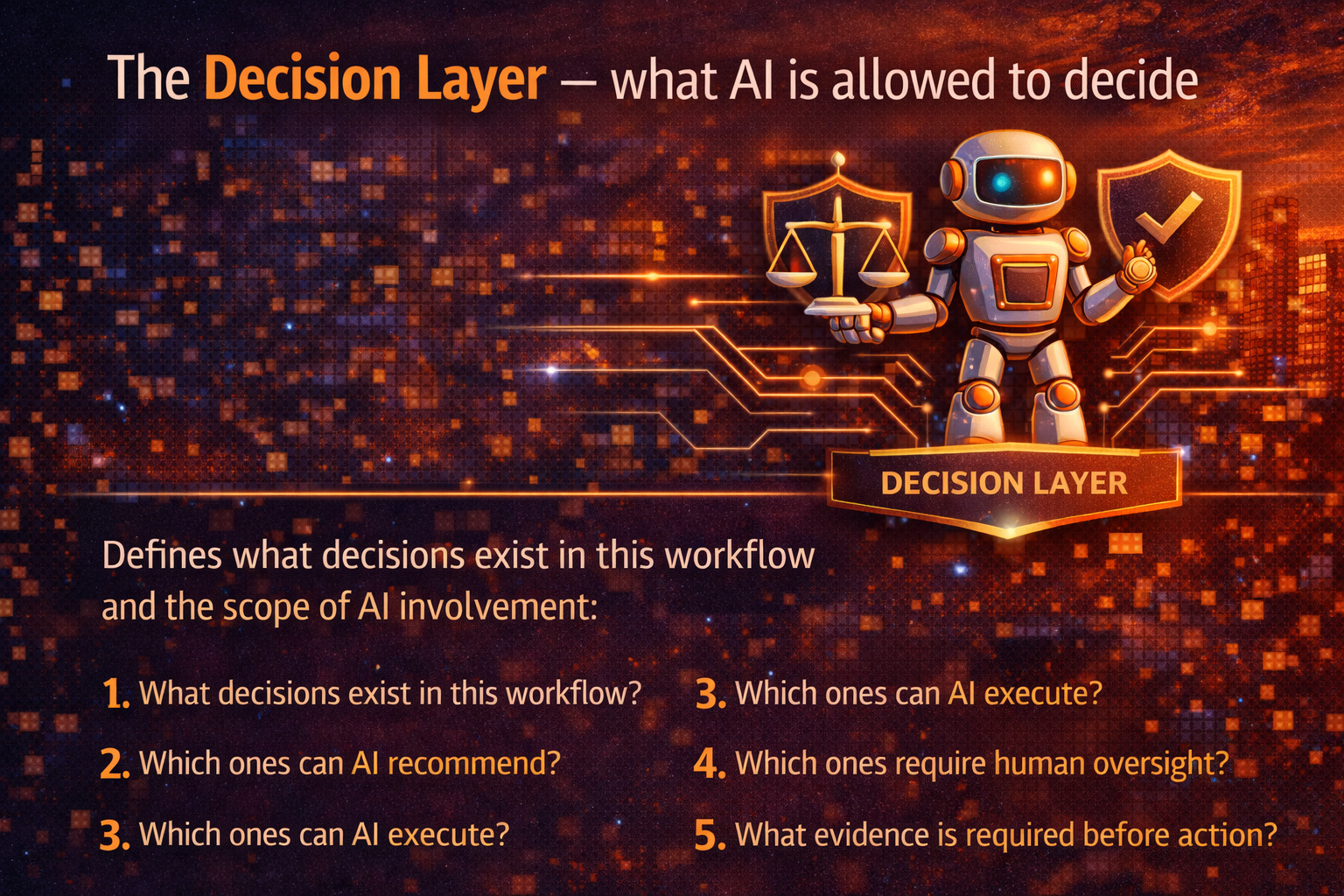
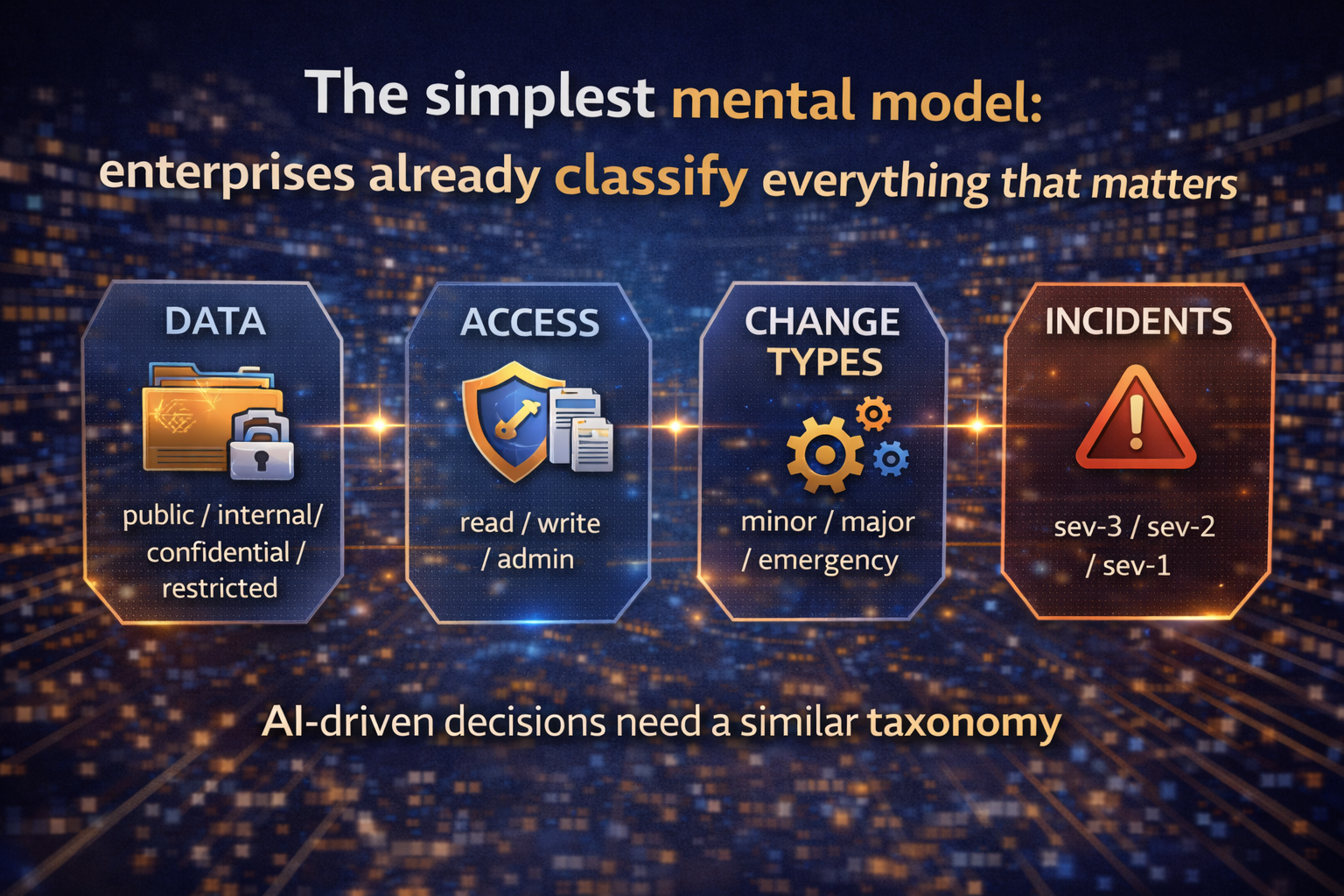
Layer 1: The Decision Layer — what AI is allowed to decide
Most organizations start with models. The better starting point is decisions.
Because the enterprise impact of AI is determined not by what it can generate, but by:
- which decisions it can influence, and
- which actions it can trigger.
A simple example
An AI assistant that drafts internal email summaries is typically low-impact.
An AI system that approves refunds, grants access, changes limits, routes procurement approvals, or updates records is higher-impact.
Same model. Completely different enterprise risk.
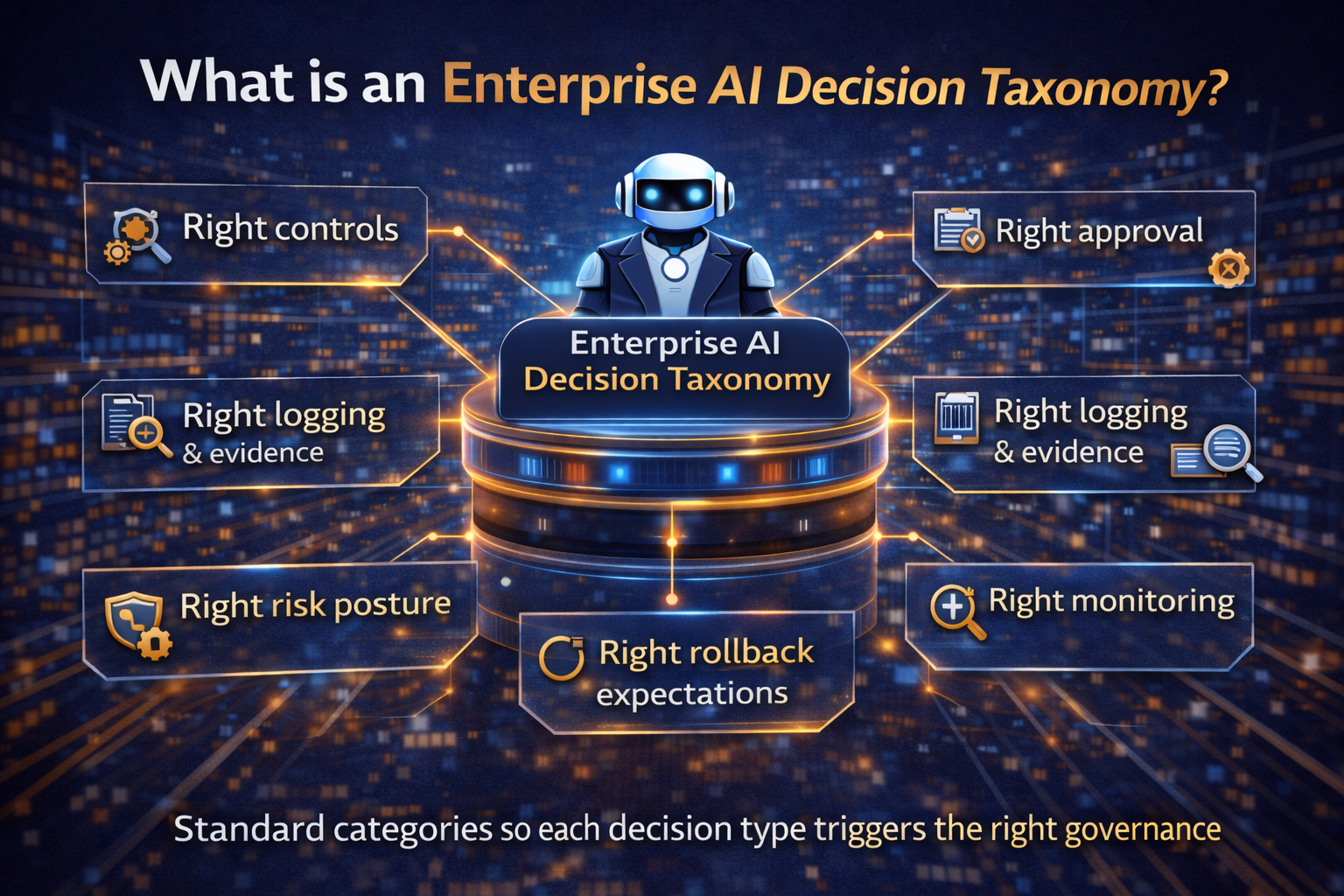
The Decision Layer forces clarity:
- What decisions exist in this workflow?
- Which ones can AI recommend?
- Which ones can AI execute?
- Which ones require human oversight?
- What evidence is required before action?
This is where your “decision taxonomy” thinking becomes a practical tool: it prevents accidental autonomy.

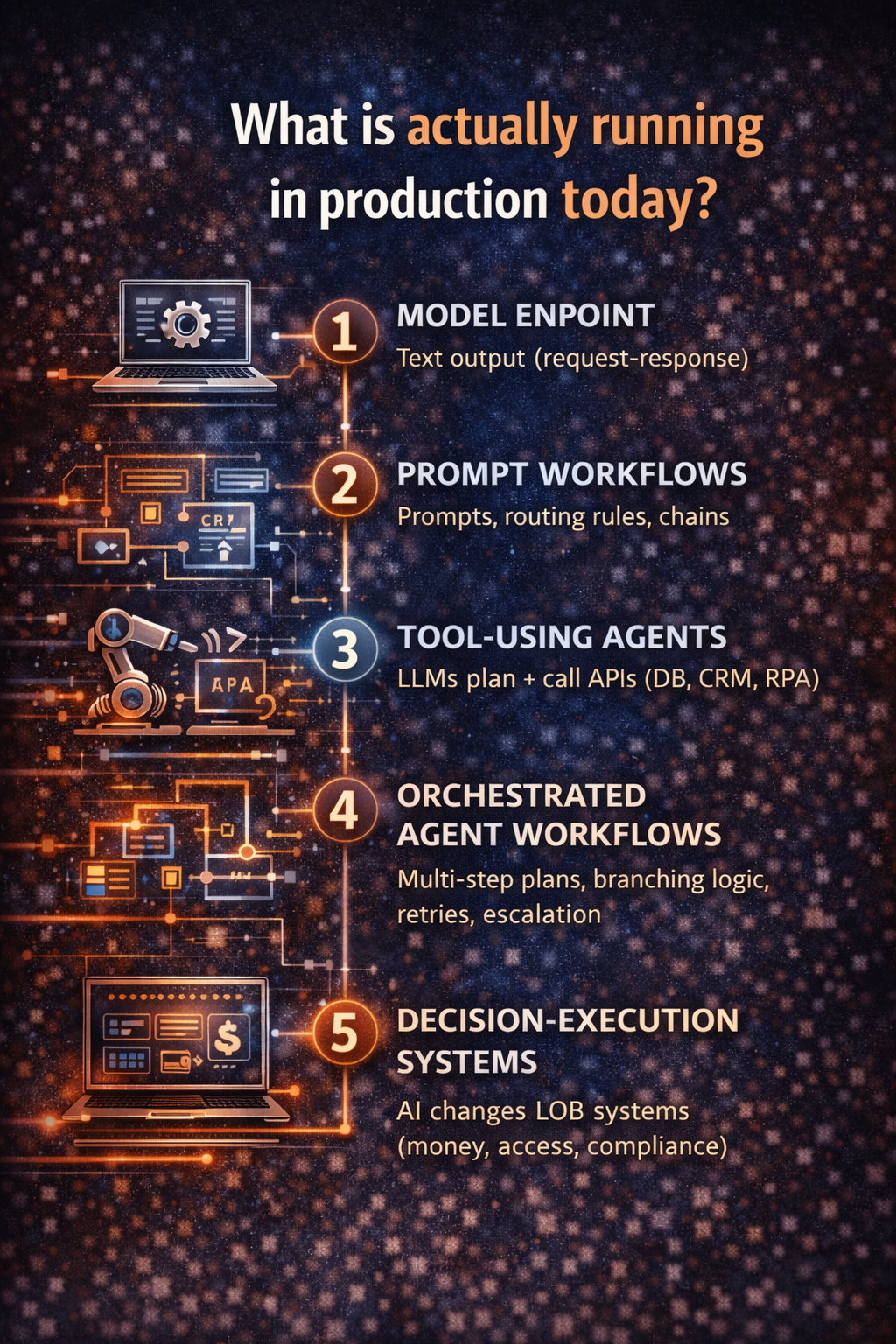
Layer 2: The Runtime Layer — where AI actually executes
The Runtime is where AI stops being “an idea” and becomes a production actor.
It includes:
- orchestration (agent/workflow engine),
- tool calling and API execution,
- retrieval and context assembly,
- prompt and version control,
- routing across models,
- safety filters and output handling,
- integrations into enterprise systems.
Why runtime matters more than model choice
Many enterprise failures happen here:
- a tool call triggers the wrong system,
- an agent loops and burns budget,
- retrieval pulls stale or sensitive data,
- a prompt update silently changes behavior in production.
Security practitioners increasingly stress that many vulnerabilities appear at the application layer around LLM systems—prompt injection, insecure output handling, denial of service patterns, and supply chain weaknesses. OWASP’s Top 10 for LLM Applications documents these as real-world risks. (OWASP Foundation)
Translation: If you don’t architect the runtime, you’re not “deploying AI.” You’re improvising production.

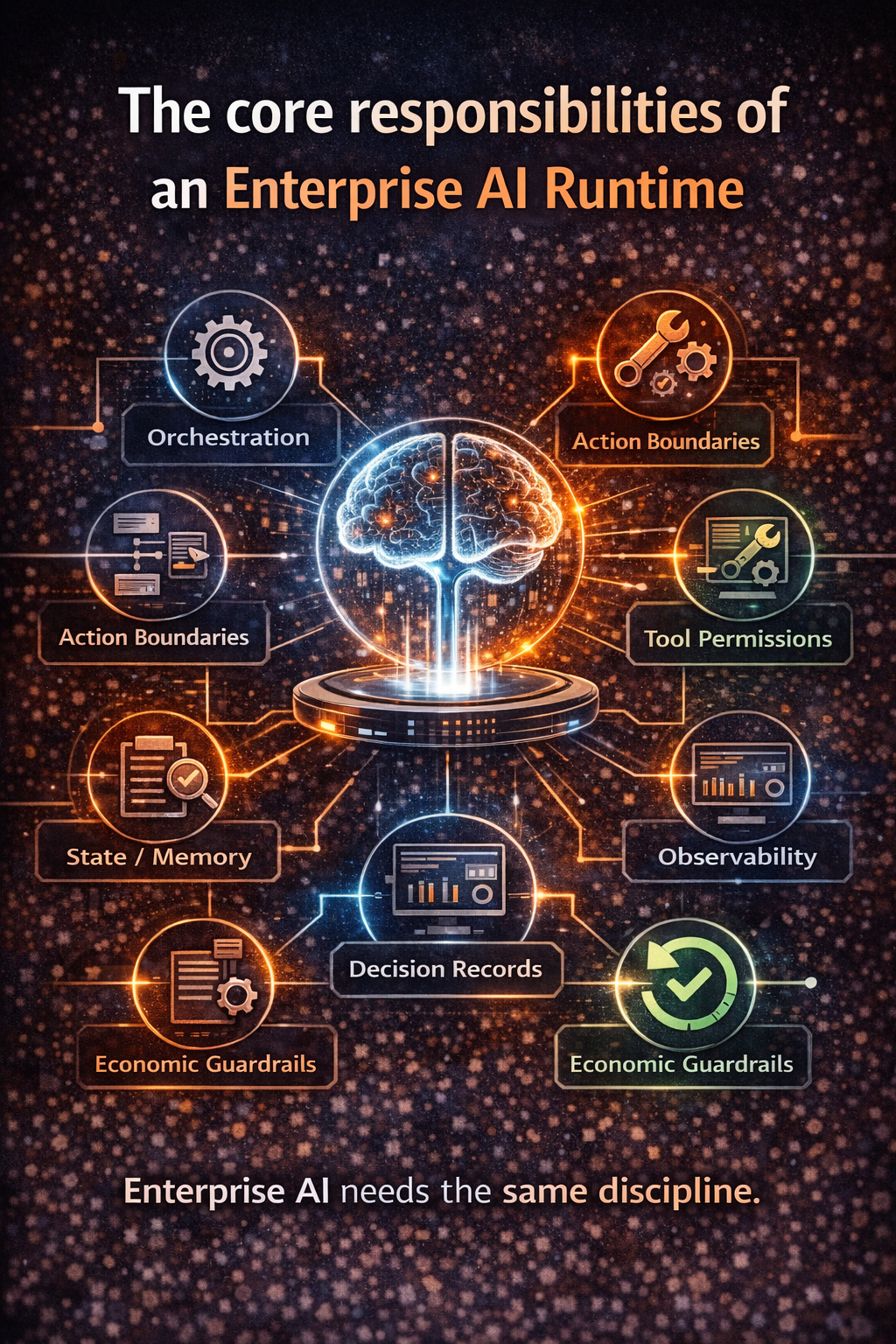
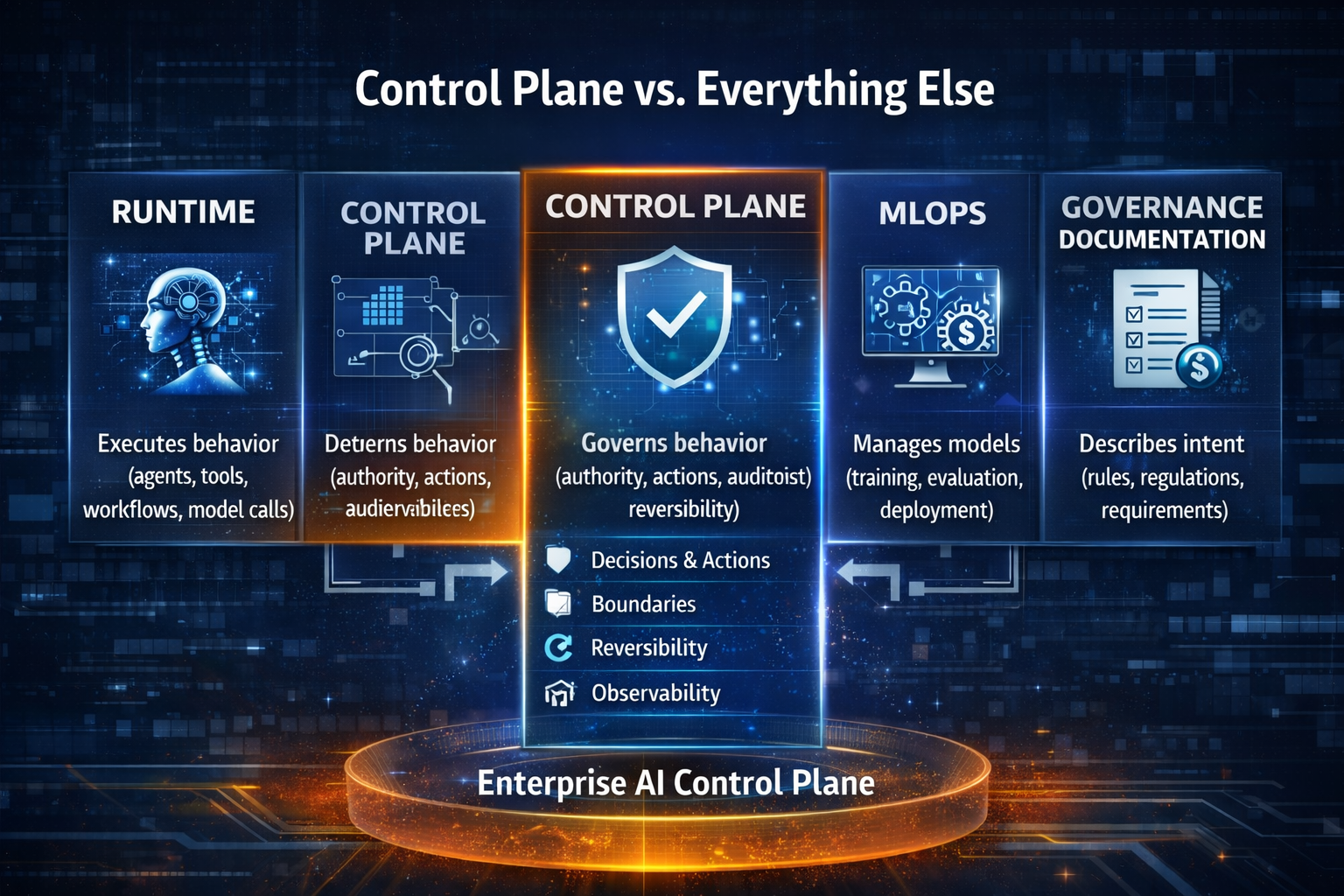
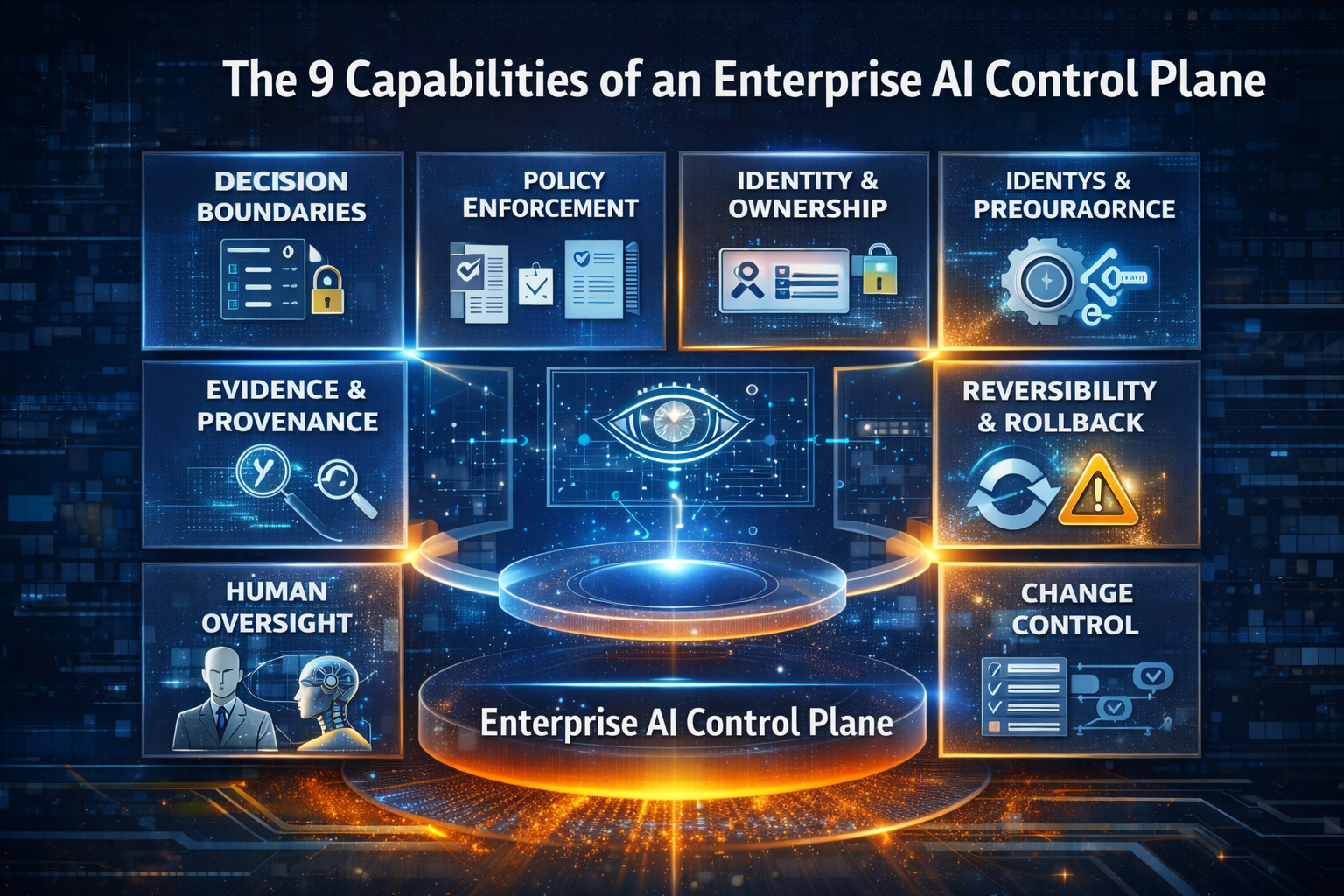
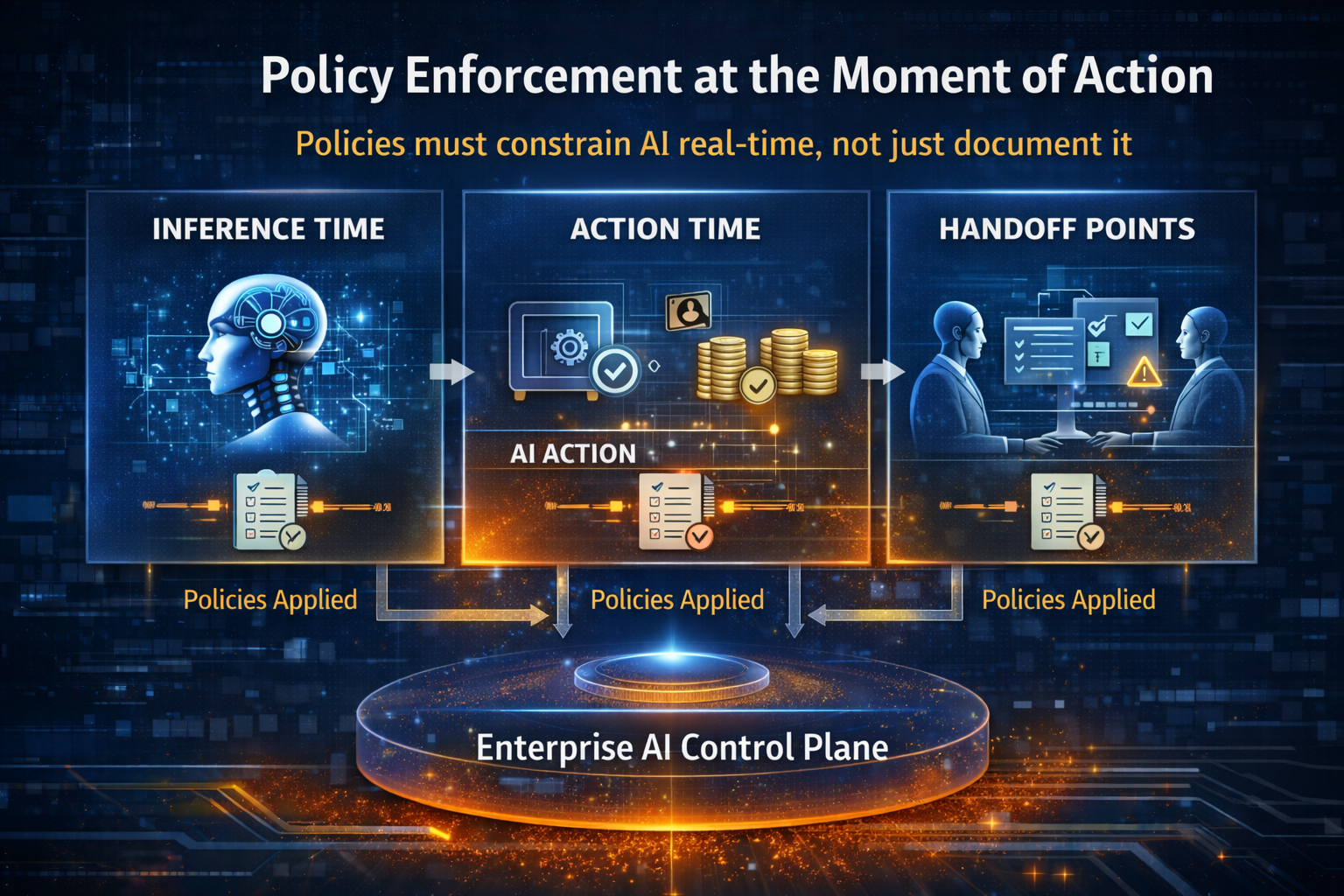
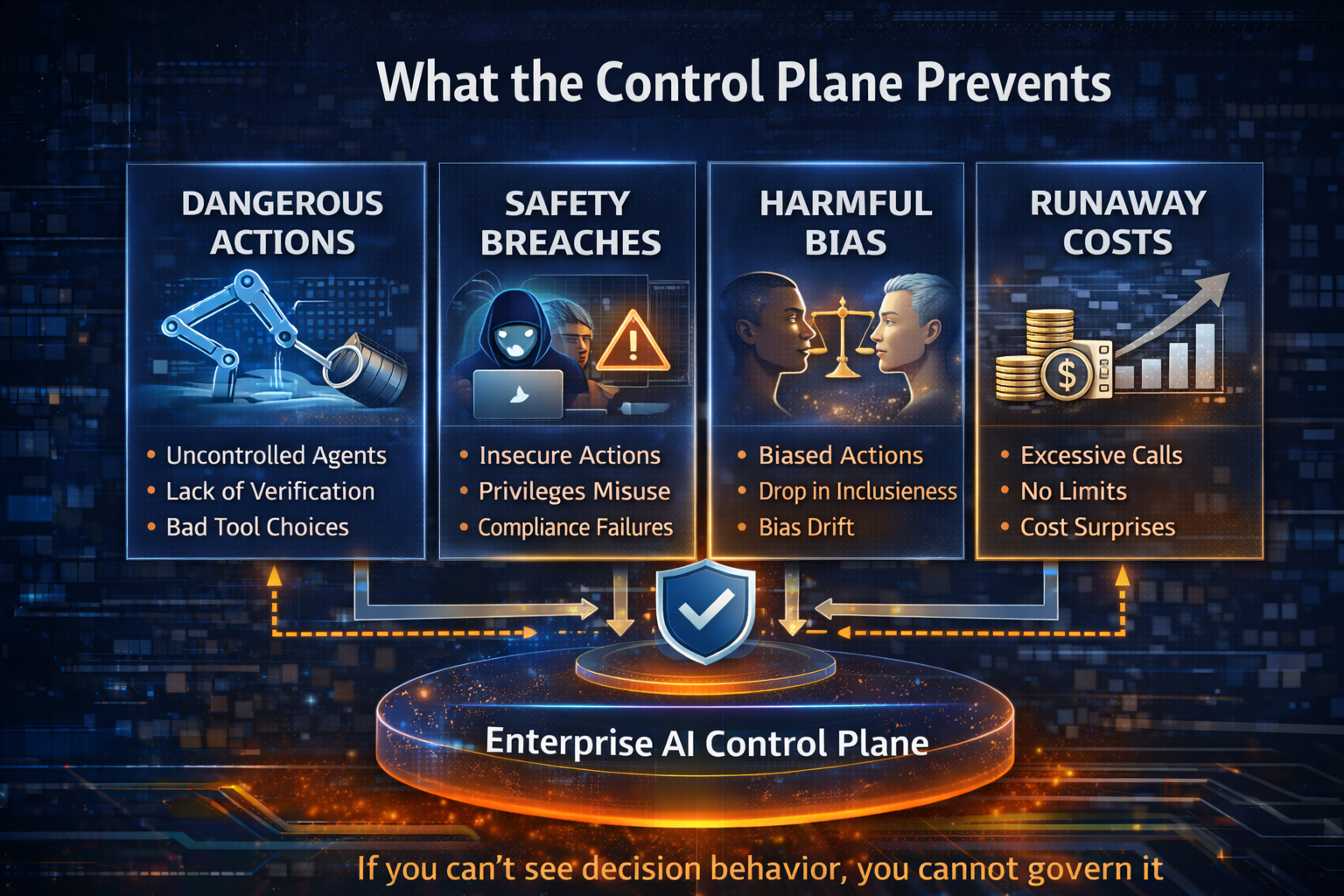
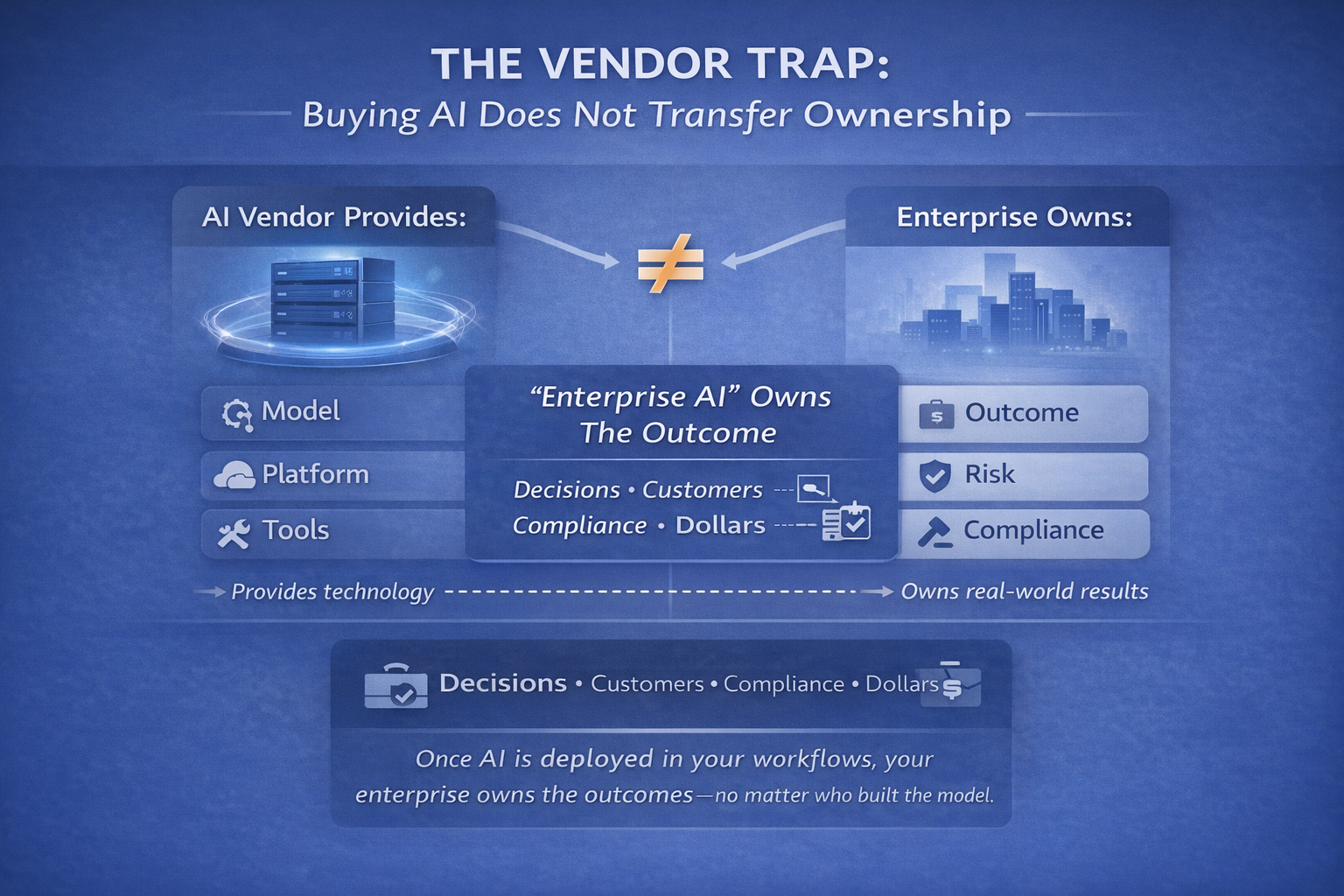
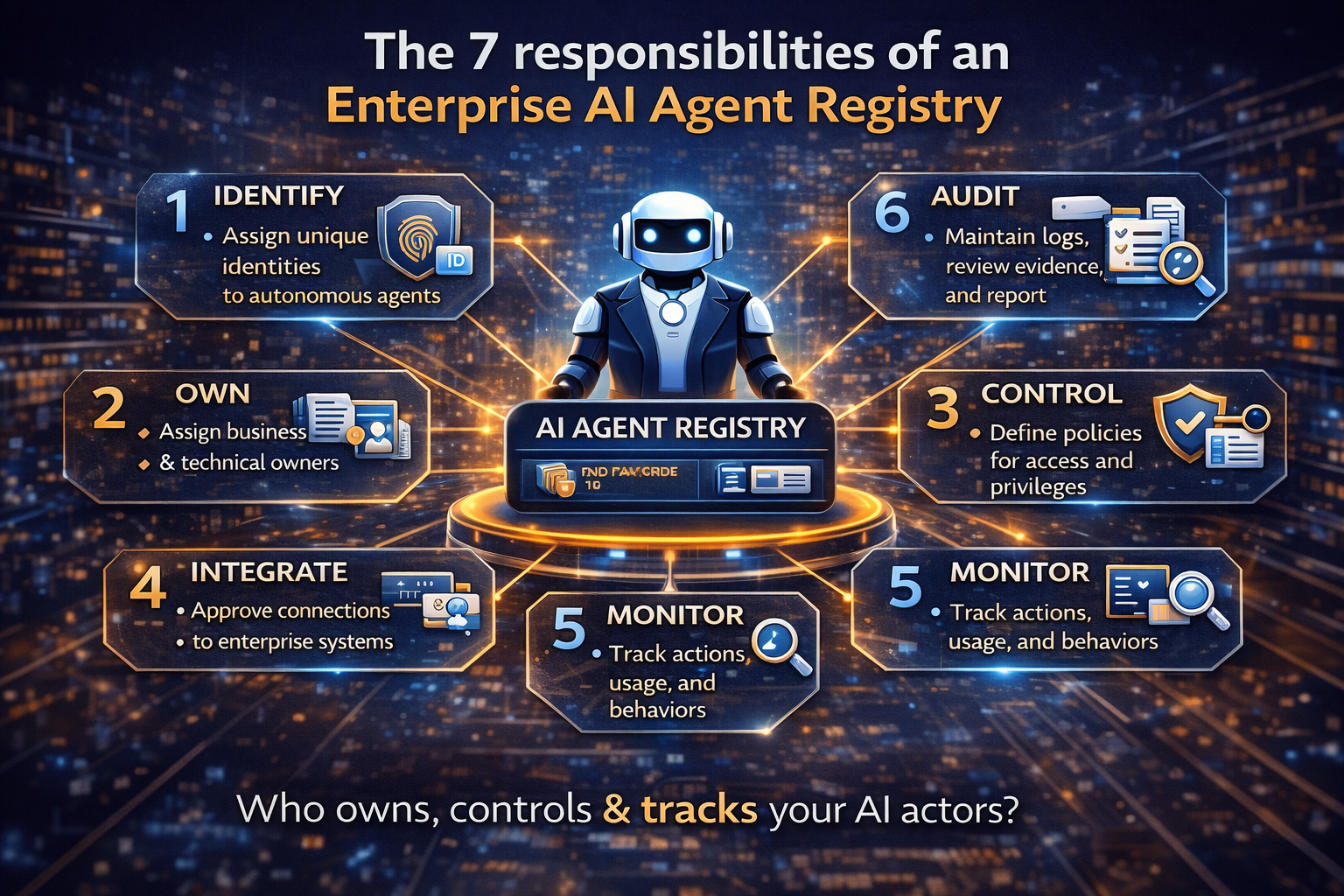
Layer 3: The Control Plane — making AI enforce policy, not just document it
Layer 3: The Control Plane — making AI enforce policy, not just document it
Enterprises already know how to govern policy—on paper.
The problem is that paper policy does not control runtime behavior.
The Control Plane is the system that makes governance real by enforcing policy through:
- identity and permissions,
- audit logs,
- traceability of decisions,
- safety boundaries,
- change control,
- rollback and reversibility,
- monitoring and incident response.
NIST AI RMF explicitly frames governance as a cross-cutting function that informs and is infused throughout the risk lifecycle. (NIST Publications)
A simple example
Policy says: “AI must not approve certain actions without human oversight.”
Control Plane enforces: “Those actions require explicit approval—and are logged.”
That’s why the Control Plane is not paperwork. It is architecture.
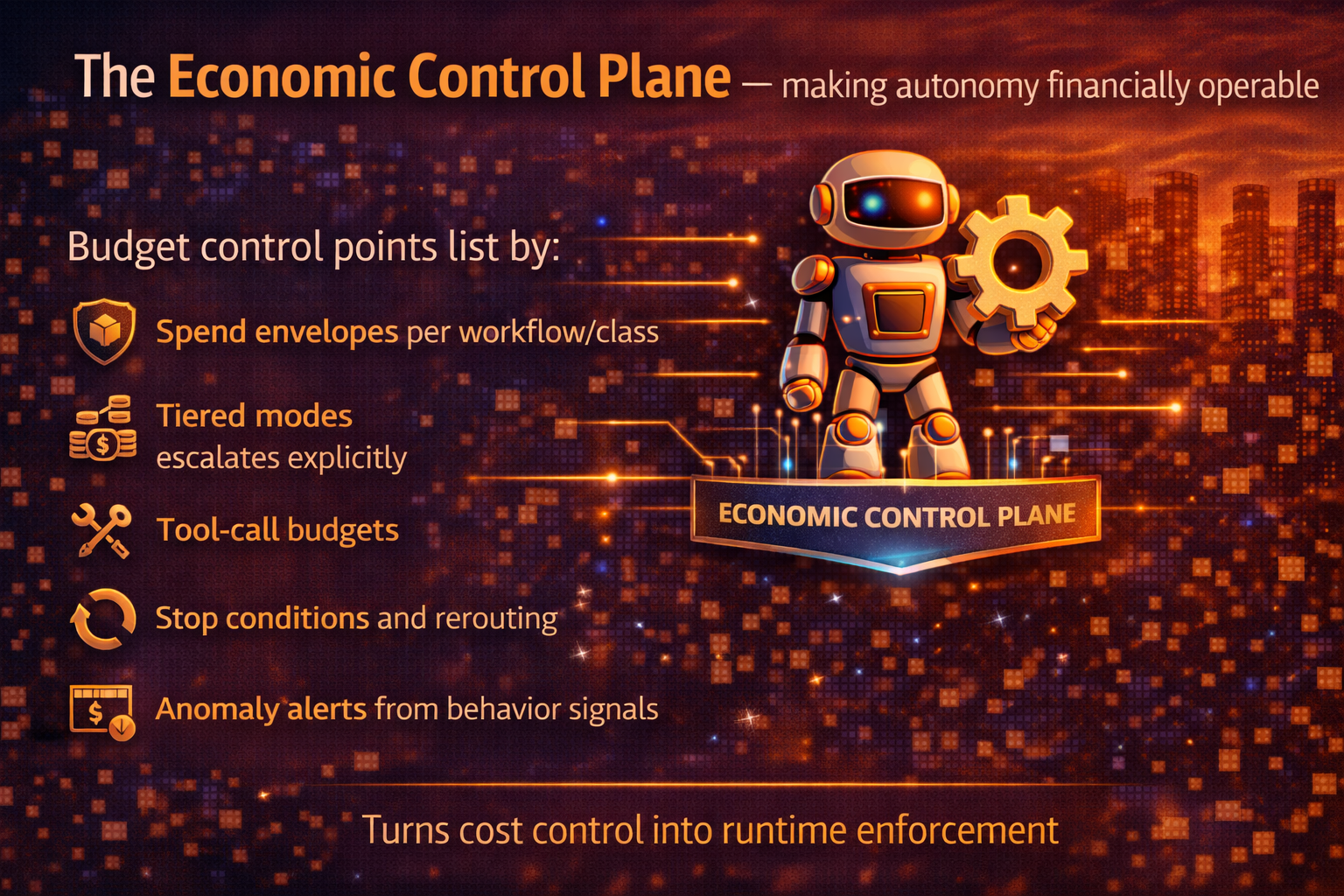
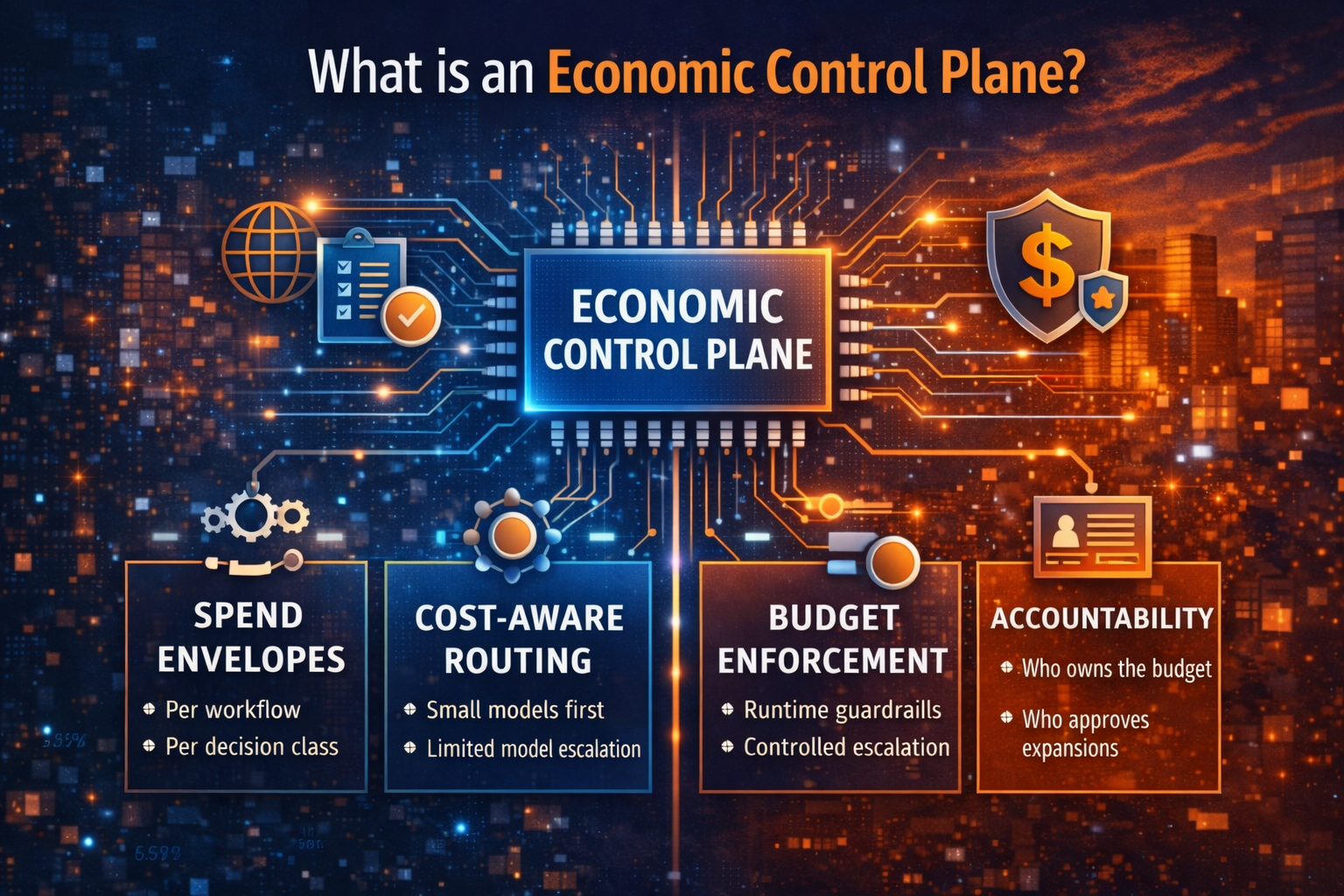
Layer 4: The Economic Control Plane — making autonomy financially operable
This is the layer most enterprises don’t build until it’s too late.
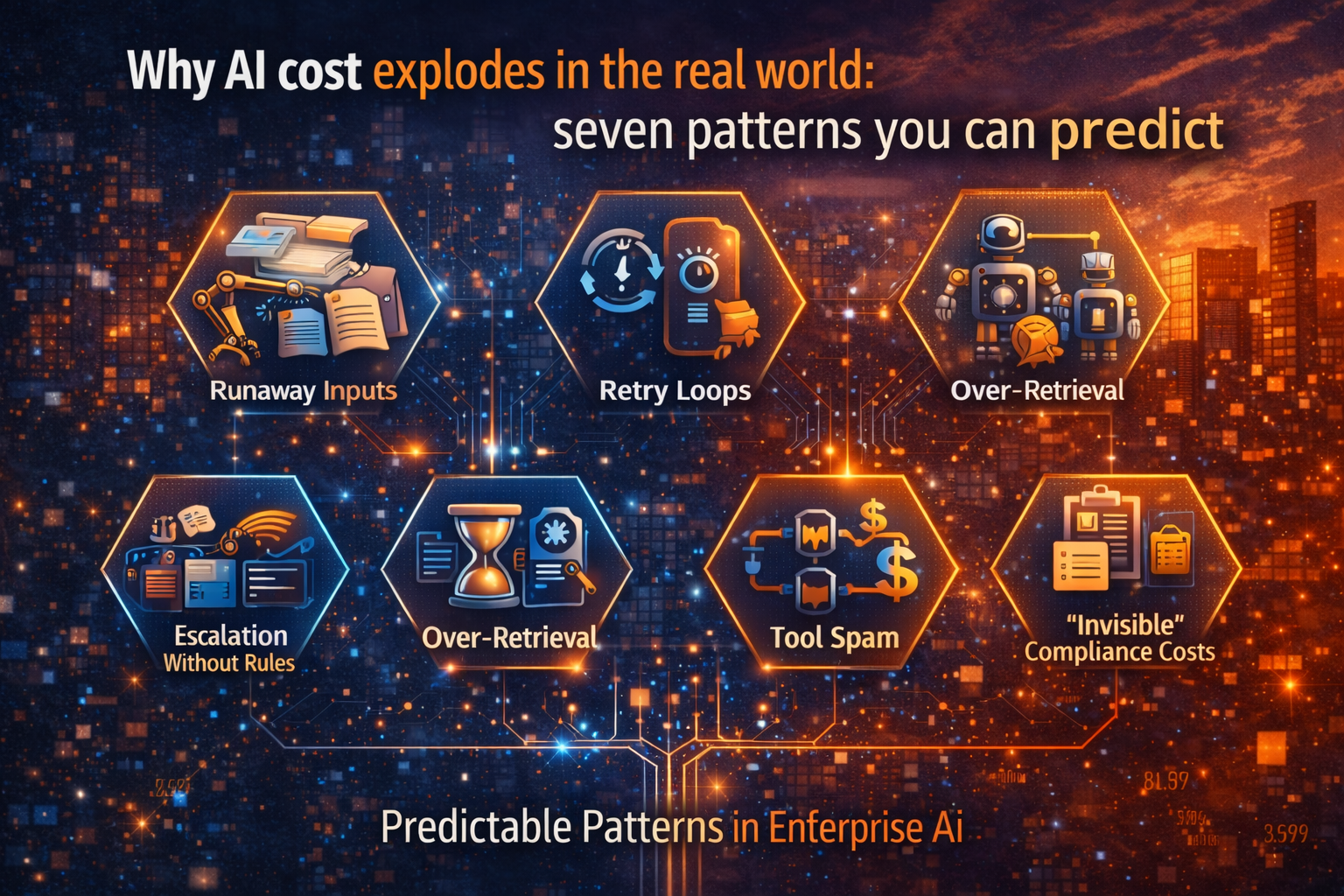
Traditional cost controls assume predictable workloads. Enterprise AI has behavioral cost:
- retries,
- deeper retrieval,
- escalation to larger models,
- repeated tool calls,
- long context windows,
- always-on agents.
FinOps practitioners now explicitly treat AI as a distinct cost domain and publish guidance on AI cost drivers, forecasting, and operating practices (often referred to as “FinOps for AI”). (FinOps)
The Economic Control Plane makes cost a runtime-enforced policy surface through:
- spend envelopes per workflow and decision class,
- tiered modes (cheap-by-default, escalate explicitly),
- escalation rules tied to decision criticality,
- tool-call budgets,
- stop conditions (halt and route when budget is hit),
- anomaly alerts driven by behavior signals (retries spike, retrieval depth grows, escalation rises).
A simple example
A knowledge assistant can run in:
- Standard Mode: shallow retrieval, short answer, small model
- Deep Mode: deeper retrieval, more verification, larger model—explicitly labeled
Cost becomes intentional—not accidental.

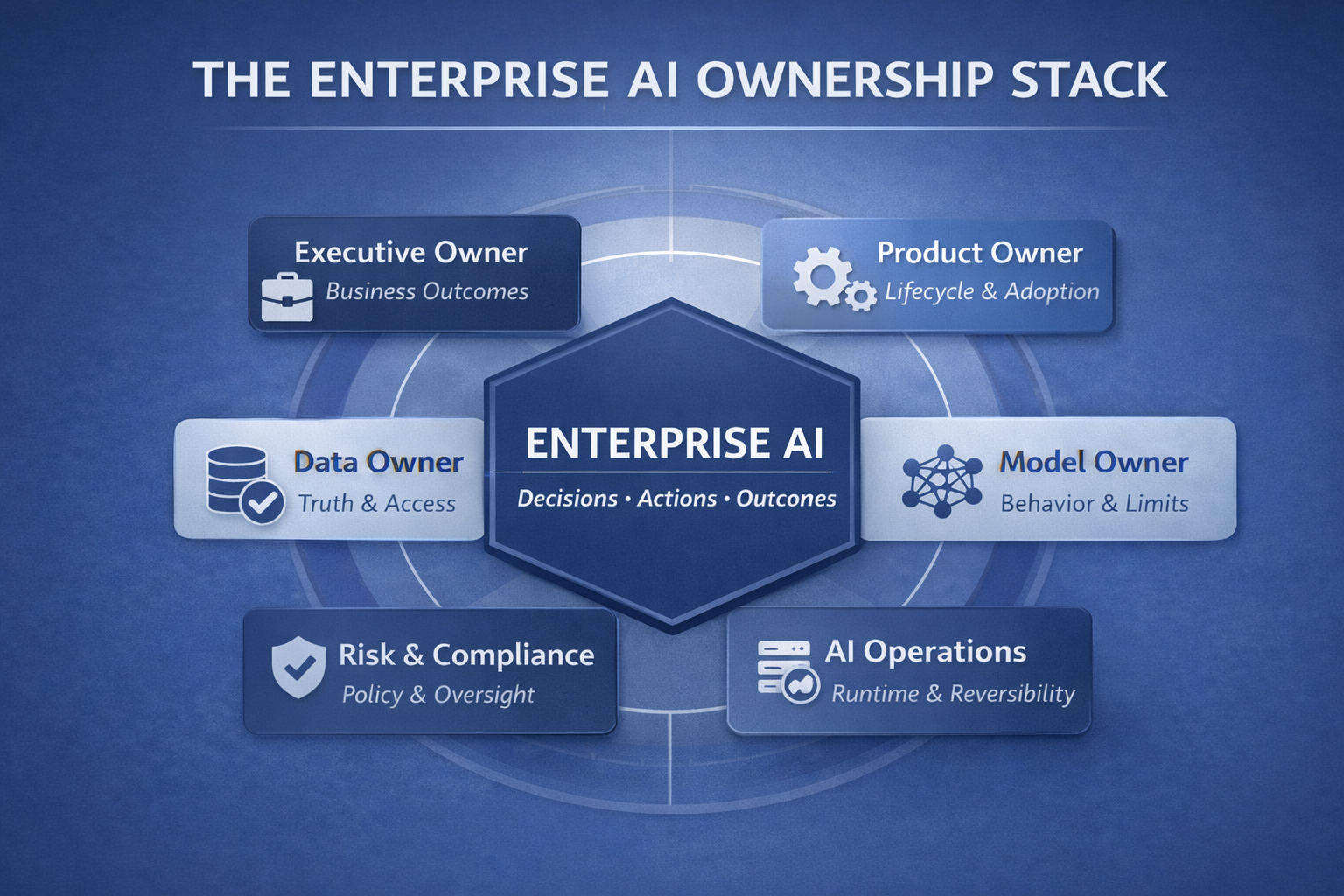
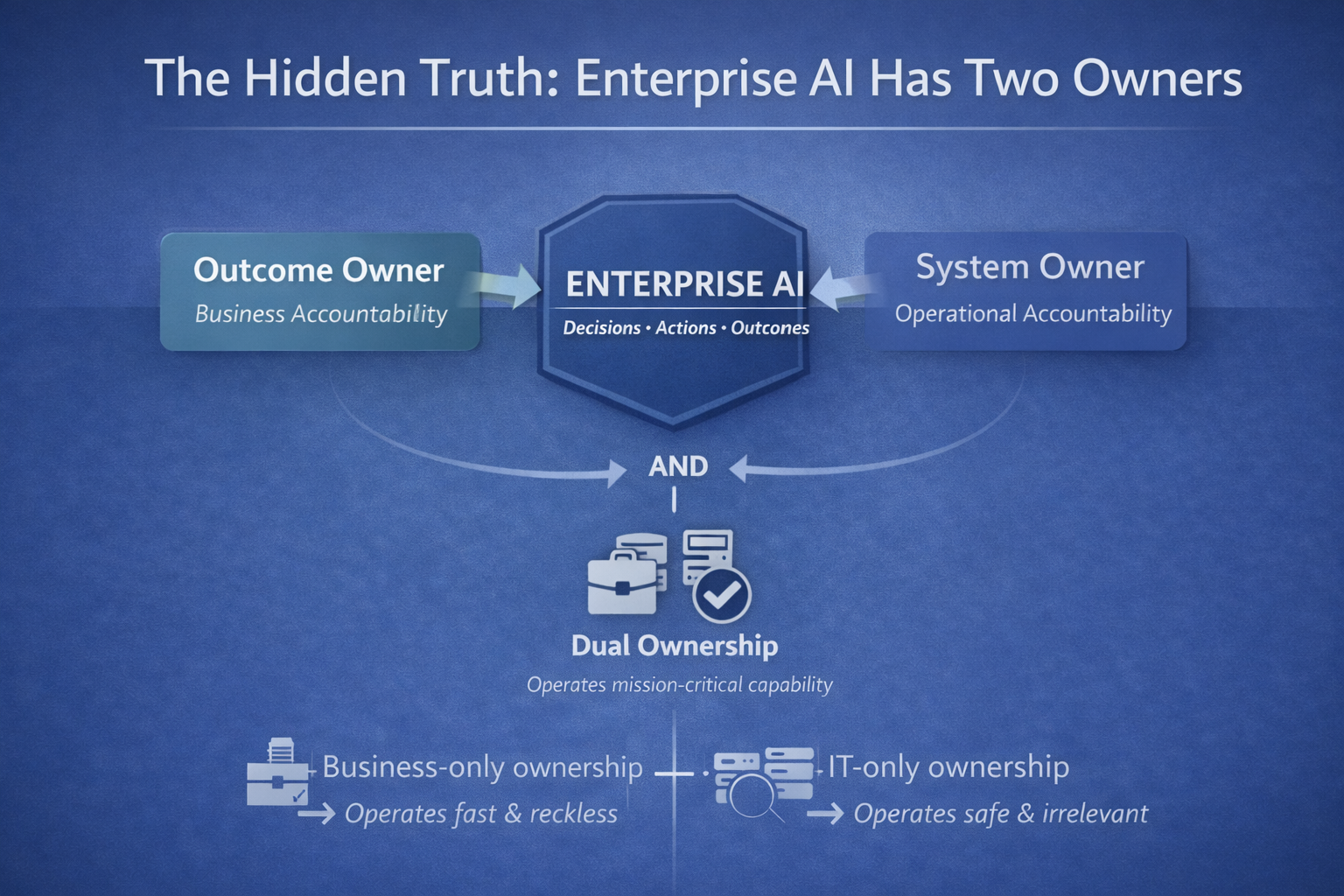
Layer 5: Governance and Accountability — who owns decisions, risk, and spend
The stack is incomplete without ownership.
When something goes wrong, every enterprise asks the same question:
Who is accountable?
This layer defines:
- decision owners (business accountability),
- system owners (technical accountability),
- model/prompt owners (behavior accountability),
- risk owners (compliance and oversight),
- economic owners (budget responsibility),
- escalation and incident responsibilities.
This is where an AI Management System approach becomes practical. ISO/IEC 42001 is designed to help organizations establish an AI management system for responsible use—covering governance, lifecycle practices, and risk treatment. (ISO)
In short: governance is not a committee. It’s a decision-rights architecture.

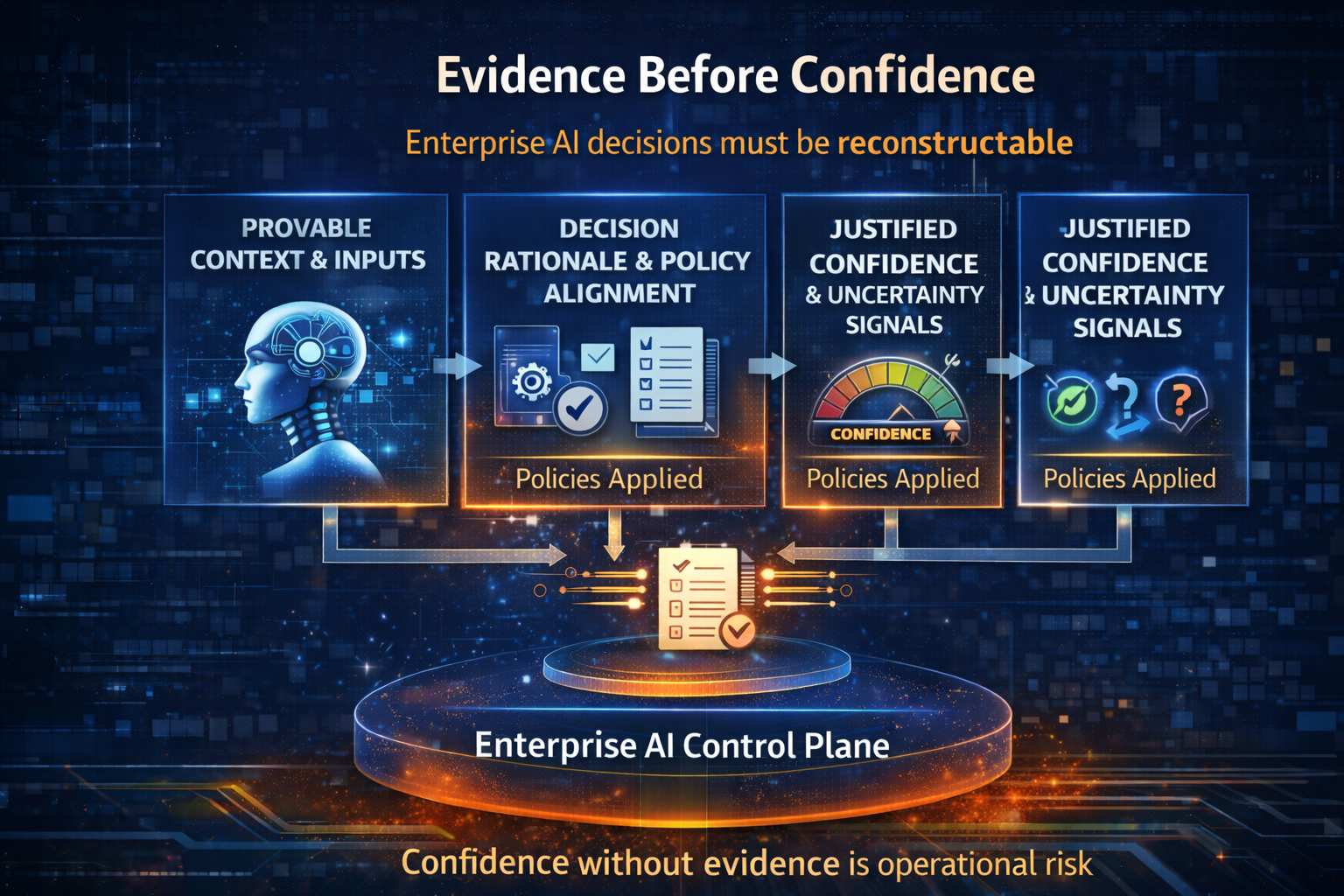
Layer 6: Observability and Learning — how the stack improves safely over time
AI systems change. The world changes. Data changes. Policies change.
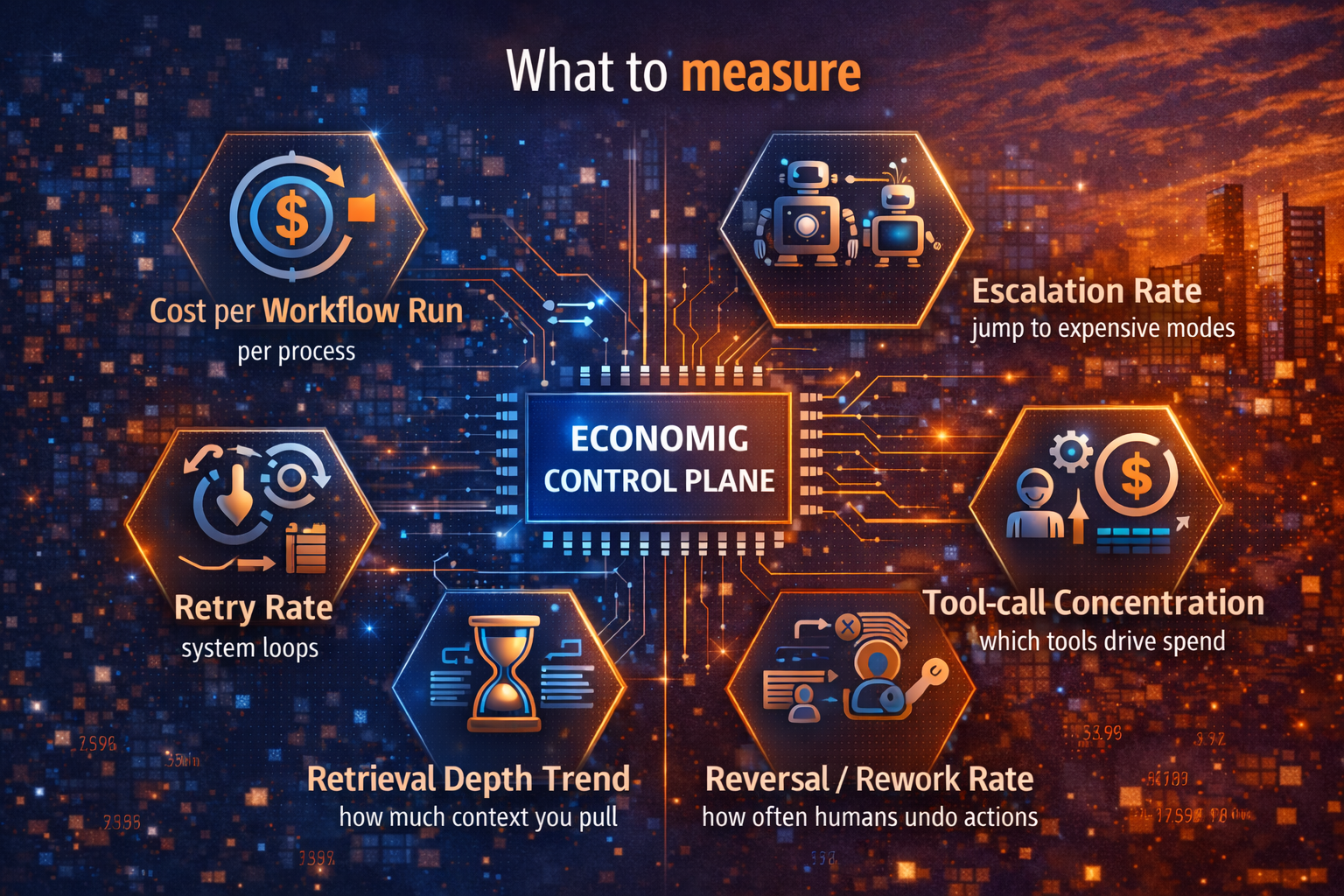
If you cannot observe:
- drift,
- behavior anomalies,
- rising cost patterns,
- escalating failure modes,
- human override rates,
- tool-call spikes,
- unusual prompt injection attempts,
…you don’t have a stack. You have a risk.
This layer includes:
- operational telemetry,
- decision traces (why the system acted),
- audit-ready logs and retention,
- feedback loops,
- safe evaluation harnesses,
- controlled rollouts.
EU AI Act-oriented guidance emphasizes that high-risk contexts require human oversight, and deployer obligations can include keeping system logs for a minimum period. (AI Act Service Desk)
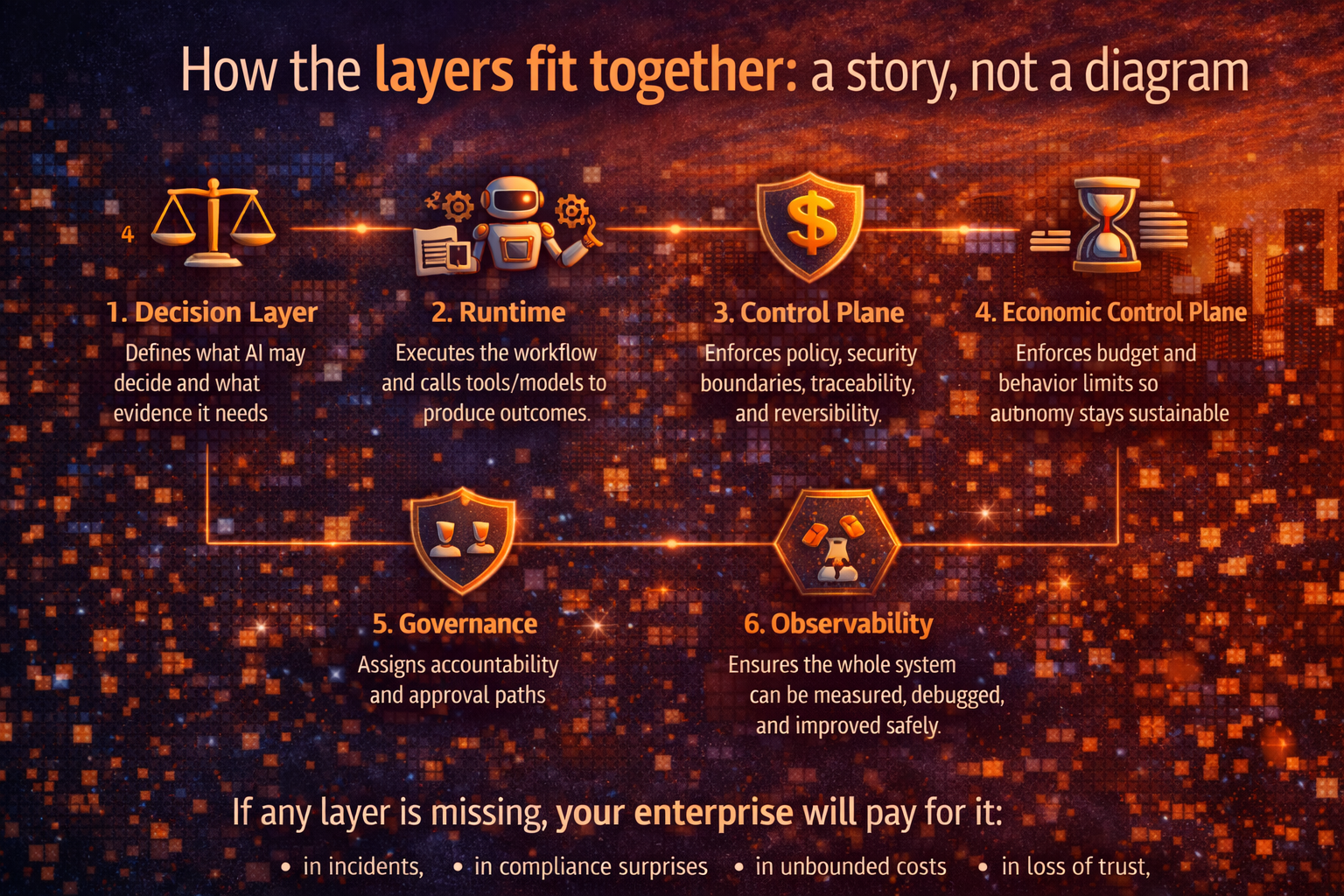
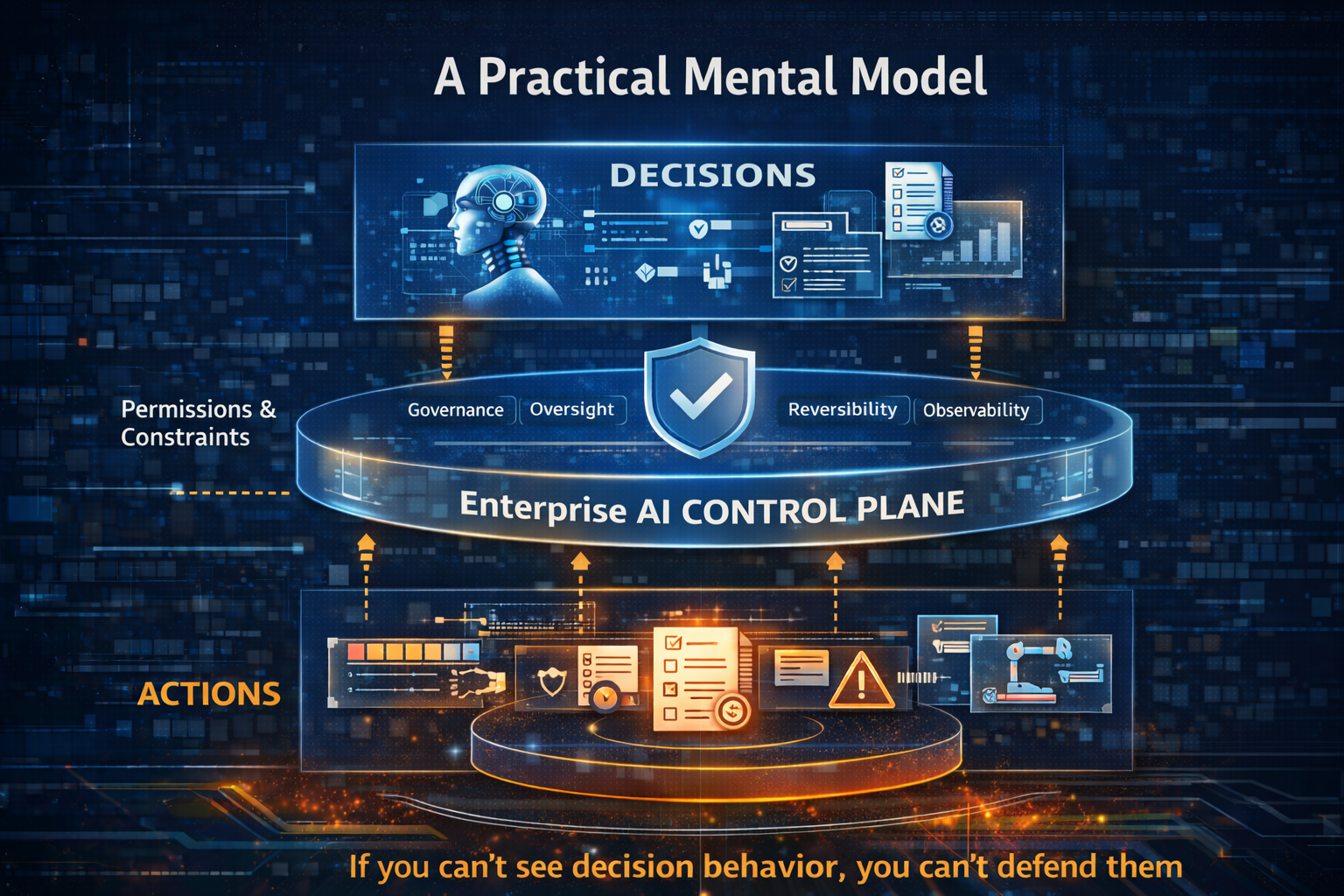
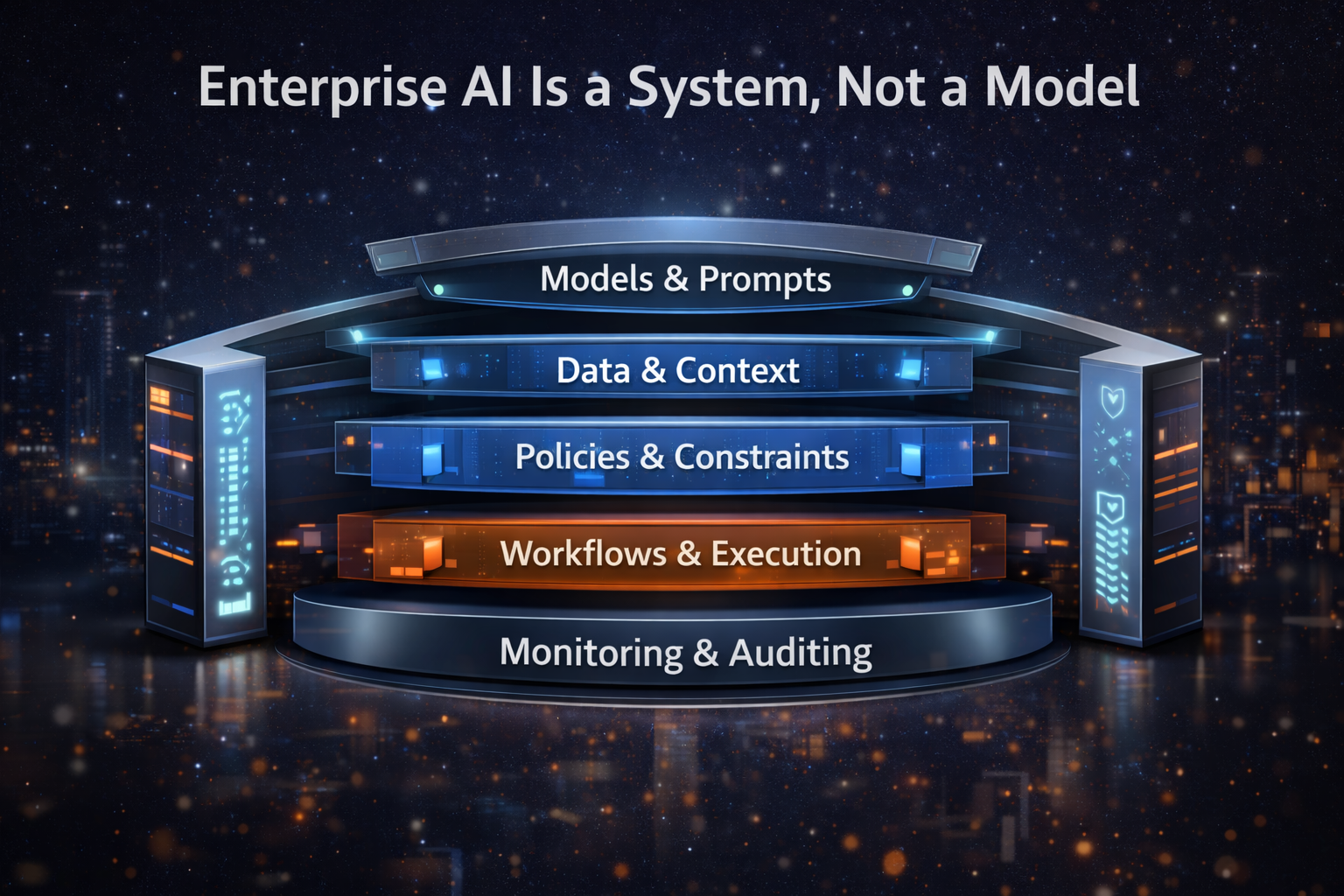
How the layers fit together: a story, not a diagram
Here’s the simplest way to understand the stack:
- Decision Layer defines what AI may decide and what evidence it needs.
- Runtime executes the workflow and calls tools/models to produce outcomes.
- Control Plane enforces policy, security boundaries, traceability, and reversibility.
- Economic Control Plane enforces budget and behavior limits so autonomy stays sustainable.
- Governance assigns accountability and approval paths.
- Observability ensures the whole system can be measured, debugged, and improved safely.
If any layer is missing, your enterprise will pay for it:
- in incidents,
- in compliance surprises,
- in unbounded costs,
- in loss of trust.
Enterprise AI Operating Model
Enterprise AI scale requires four interlocking planes:
Read about Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely — Raktim Singh
- Read about Enterprise Control Tower The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale — Raktim Singh
- Read about Decision Clarity The Shortest Path to Scalable Enterprise AI Autonomy Is Decision Clarity — Raktim Singh
- Read about The Enterprise AI Runbook Crisis The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI — and What CIOs Must Fix in the Next 12 Months — Raktim Singh
- Read about Enterprise AI Economics Enterprise AI Economics & Cost Governance: Why Every AI Estate Needs an Economic Control Plane — Raktim Singh
Read about Who Owns Enterprise AI Who Owns Enterprise AI? Roles, Accountability, and Decision Rights in 2026 — Raktim Singh
Three “stack in action” examples
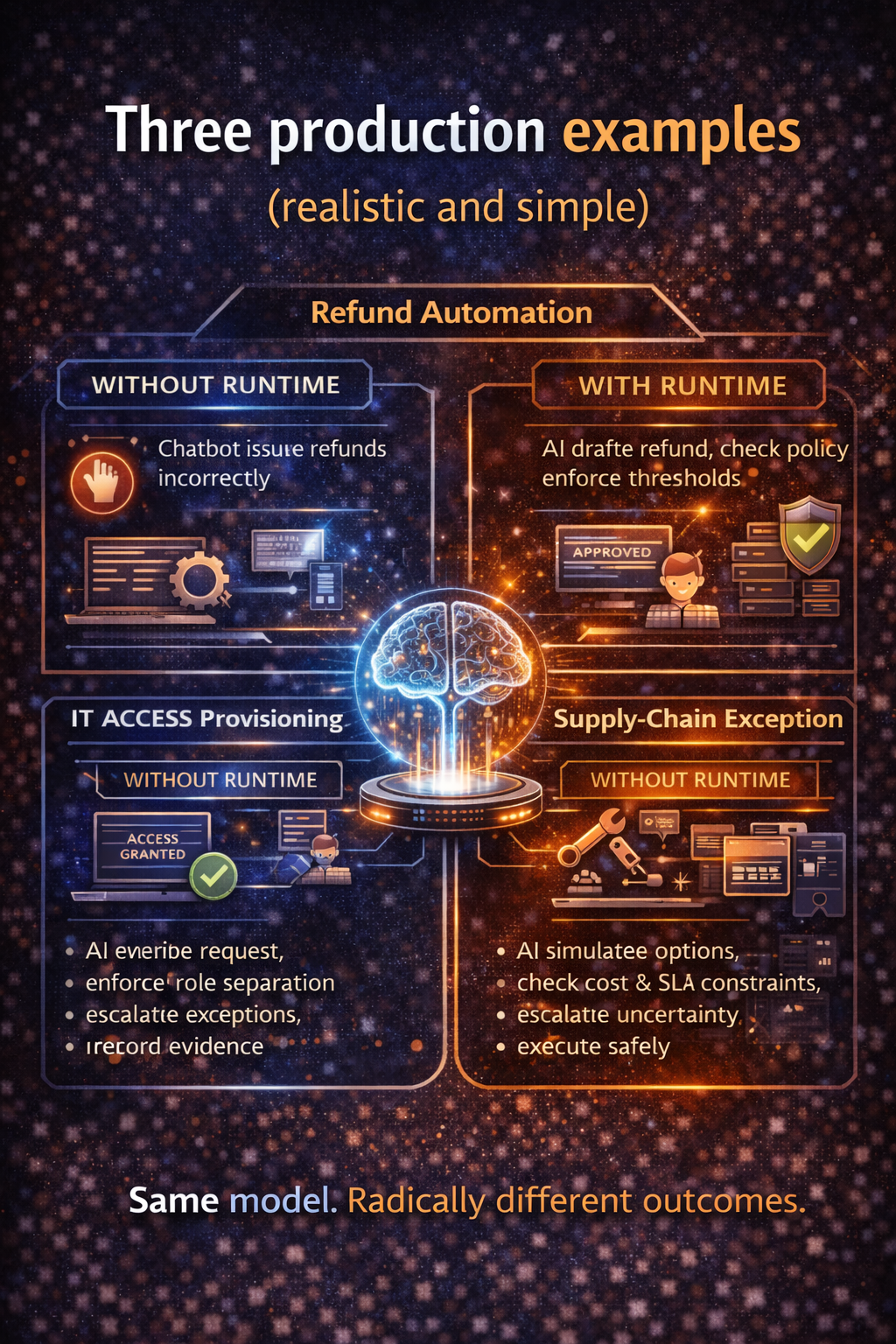
Example 1: Customer support resolution assistant
- Decision Layer: AI can draft responses; certain outcomes require approval.
- Runtime: retrieves knowledge articles and case history; drafts response.
- Control Plane: blocks sensitive leakage; logs decision trace.
- Economic Control Plane: caps retrieval depth; prevents endless retries.
- Governance: support operations owns outcomes; IT owns runtime; compliance reviews logs.
- Observability: tracks escalation rate, rework rate, and anomalies.
Example 2: IT access provisioning agent
- Decision Layer: AI may recommend; execution requires policy constraints and approvals.
- Runtime: reads ticket, validates prerequisites, triggers IAM workflows.
- Control Plane: enforces least privilege; records approvals.
- Economic Control Plane: limits tool calls and verification loops.
- Governance: security owns policy; IT owns system; audit owns retention.
- Observability: watches for suspicious patterns and prompt injection attempts (a documented LLM application risk). (OWASP Foundation)
Example 3: Procurement triage and contract routing
- Decision Layer: AI can classify and route; approvals remain human.
- Runtime: summarizes and extracts key clauses; routes to stakeholders.
- Control Plane: ensures traceability and record-keeping; protects sensitive data.
- Economic Control Plane: tiered mode for deep clause analysis; budget envelope for heavy runs.
- Governance: procurement owns decision rights; legal owns compliance; finance owns spend.
- Observability: measures reversal rate (how often humans override).
Why this operating stack matters globally
Across regions—US, EU, UK, India, APAC, Middle East—the enterprise pressures converge:
- boards demand predictable risk and spend,
- regulators push oversight and traceability for certain systems,
- attackers target application-layer vulnerabilities,
- AI costs rise through behavioral loops.
The details differ by jurisdiction, but the architectural answer is the same:
Build a stack that makes autonomy operable.
NIST AI RMF provides a widely used governance-and-lifecycle framing. (NIST Publications)
EU AI Act guidance emphasizes human oversight in high-risk contexts. (AI Act Service Desk)
ISO/IEC 42001 provides a management-system approach for responsible AI. (ISO)
OWASP catalogs practical LLM application security risks that appear in real deployments. (OWASP Foundation)
FinOps for AI guidance highlights AI-specific cost drivers and operating practices. (FinOps)
This article’s goal is not to quote regulations—it’s to show the stack pattern that survives them.
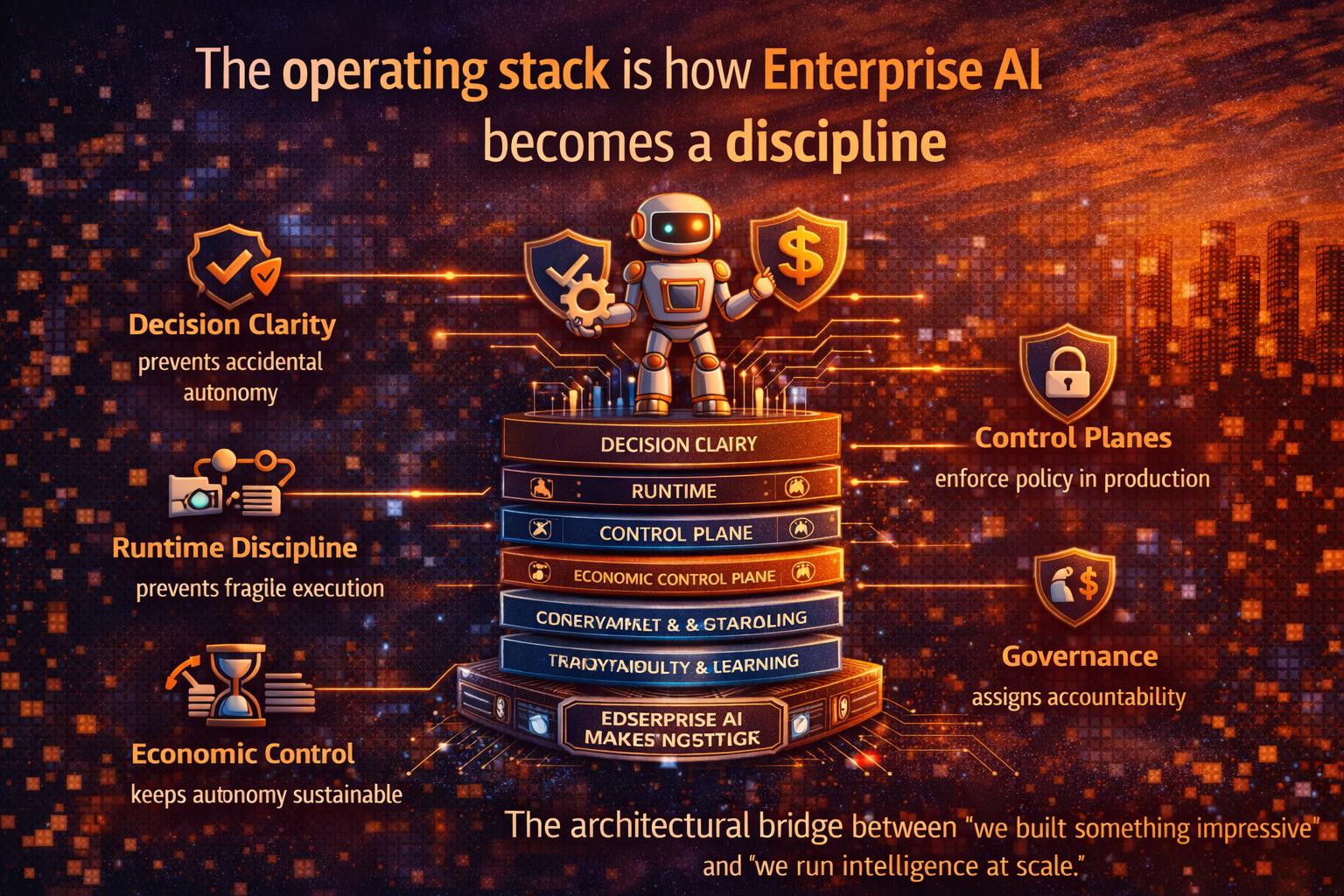
Conclusion: The operating stack is how Enterprise AI becomes a discipline
The next era of Enterprise AI won’t be won by the organizations with the most pilots.
It will be won by organizations that can run autonomy as a controlled, auditable, sustainable system.
That requires an operating stack.
- Decision clarity prevents accidental autonomy.
- Runtime discipline prevents fragile execution.
- Control planes enforce policy in production.
- Economic control keeps autonomy sustainable.
- Governance assigns accountability.
- Observability makes improvement safe.
This is the architectural bridge between “we built something impressive” and “we run intelligence at scale.”
And if your goal is to make your website the canonical home for Enterprise AI, this is exactly the kind of “map page” answer engines will summarize and route readers through—because it turns scattered concepts into a coherent operating system.
A related governance challenge is intentionality itself — whether a system can even represent what a decision is about before it acts. See Why “Aboutness” Is the Hardest Governance Problem in Enterprise AI.
FAQ
What is the Enterprise AI Operating Stack?
It is the architecture-level set of layers that makes AI systems operable in production—combining decisions, runtime execution, policy enforcement, economics, governance, and observability.
How is an operating stack different from an AI platform?
A platform is a product. A stack is the operational reality—how AI is run safely and sustainably across many workflows, teams, and systems.
Why do enterprises need a Control Plane for AI?
Because policy written in documents does not govern runtime behavior. A Control Plane enforces identity, permissions, auditability, safety boundaries, and rollback in production—aligned with lifecycle governance framing like NIST AI RMF. (NIST Publications)
Why does Enterprise AI need an Economic Control Plane?
Because AI costs are behavioral: retries, retrieval depth, escalation, and tool-calls multiply at scale. An Economic Control Plane enforces spend envelopes and tiered modes so autonomy remains economically operable. (FinOps)
What are the biggest security risks in the AI runtime?
Common risks include prompt injection, insecure output handling, denial-of-service patterns, and supply chain vulnerabilities—catalogued in OWASP’s Top 10 for LLM Applications. (OWASP Foundation)
What is the Enterprise AI Operating Stack?
The Enterprise AI Operating Stack is the layered architecture that makes AI systems operable in production by combining decision governance, runtime execution, policy enforcement, economic control, accountability, and observability.
How is an operating stack different from an AI platform?
A platform is a product you buy. An operating stack is how AI is actually run—across workflows, teams, risks, and costs—inside an enterprise.
Why do enterprises need control planes for AI?
Because policies written in documents do not control runtime behavior. Control planes enforce identity, permissions, auditability, safety, and rollback directly in production systems.
Why is cost governance critical for Enterprise AI?
AI costs scale through behavior—retries, retrieval depth, escalation, and tool calls. An Economic Control Plane ensures autonomy remains financially predictable.
Is this approach relevant globally?
Yes. Enterprises across the US, EU, UK, India, APAC, and the Middle East face the same challenges: risk, cost, accountability, and scale.
Glossary
- Enterprise AI Operating Stack: The layered system that makes AI decisions operable in production.
- Decision Layer: Defines which decisions AI may influence and what evidence/oversight is required.
- Runtime Layer: Where AI executes (orchestration, retrieval, tool calling, integrations).
- Control Plane: Policy enforcement, permissions, auditability, reversibility, monitoring.
- Economic Control Plane: Runtime cost governance (budgets, tiering, escalation, stop conditions).
- AI Estate: The full set of AI systems running across the enterprise.
- Observability: Telemetry and traces that enable debugging, audit, and safe improvement.
References and further reading
- NIST — Artificial Intelligence Risk Management Framework (AI RMF 1.0) (NIST Publications)
- FinOps Foundation — FinOps for AI Overview and AI cost guidance (FinOps)
- EU AI Act resources — Human oversight guidance and deployer obligations including log retention (high-risk) (AI Act Service Desk)
- ISO — ISO/IEC 42001: AI management systems (ISO)
- OWASP — Top 10 for Large Language Model Applications (OWASP Foundation)
















")