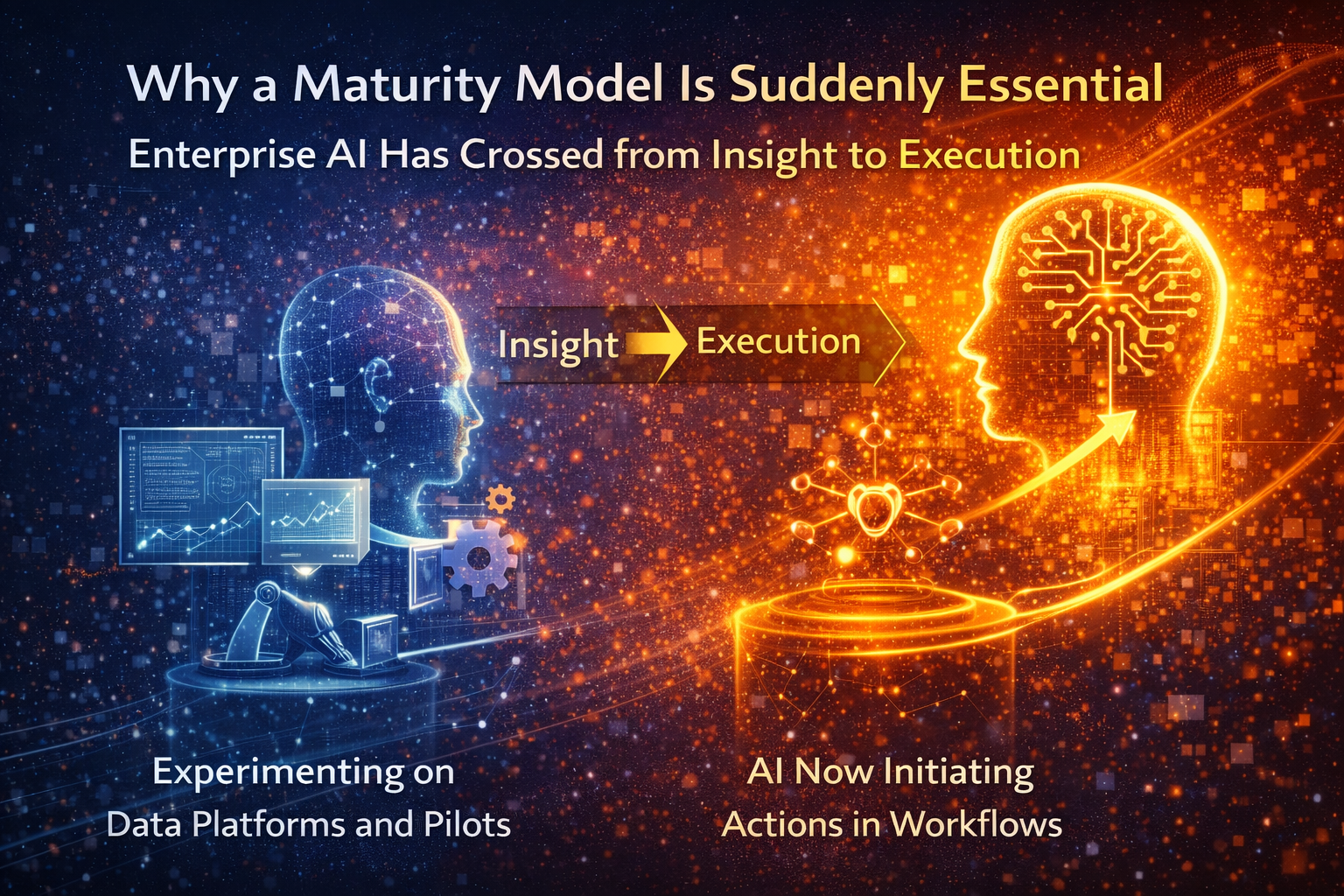
Why a maturity model is suddenly essential
For years, “AI maturity” meant a familiar story: better data platforms, higher model accuracy, stronger MLOps, and a long tail of pilots.
That framing is now outdated.
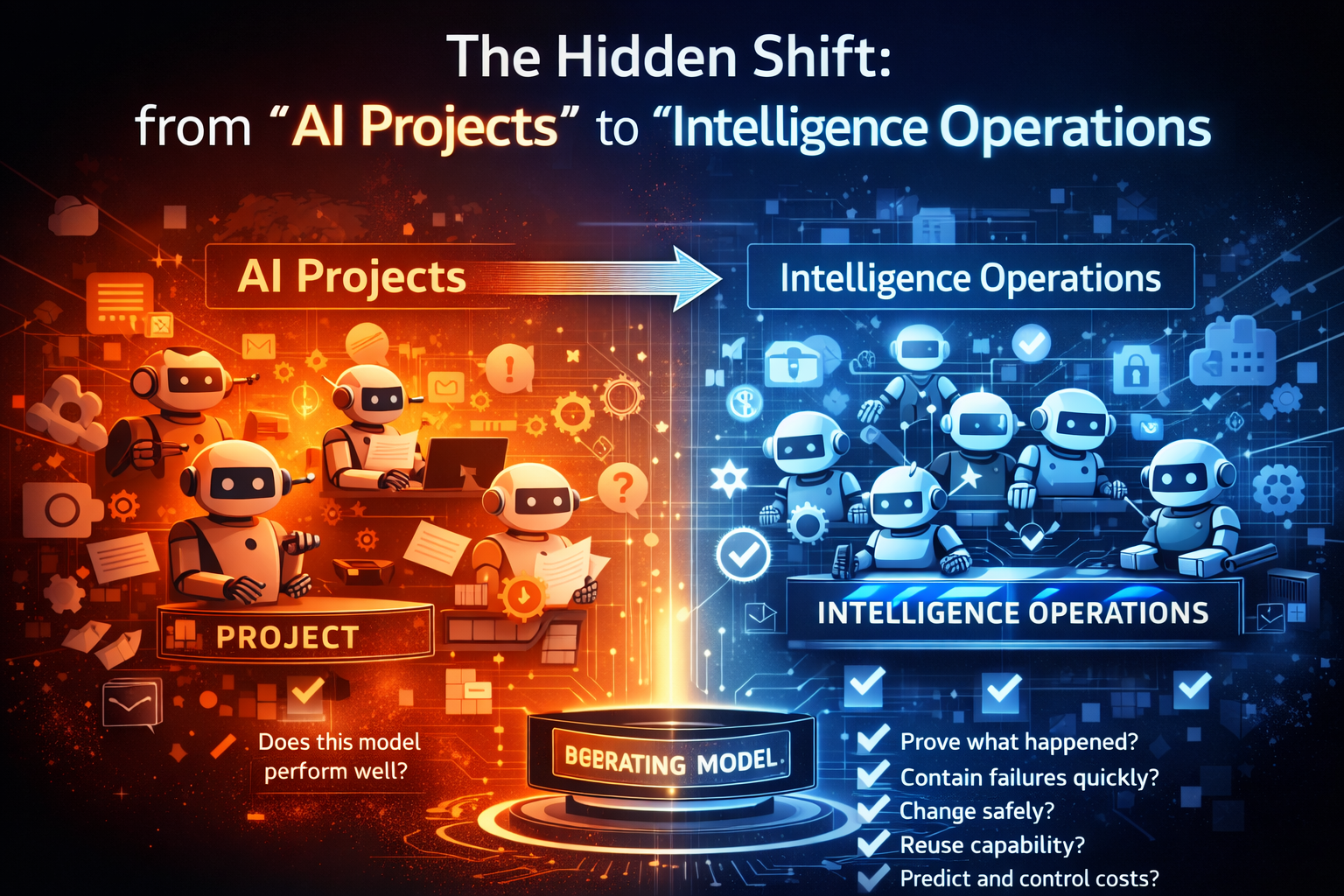
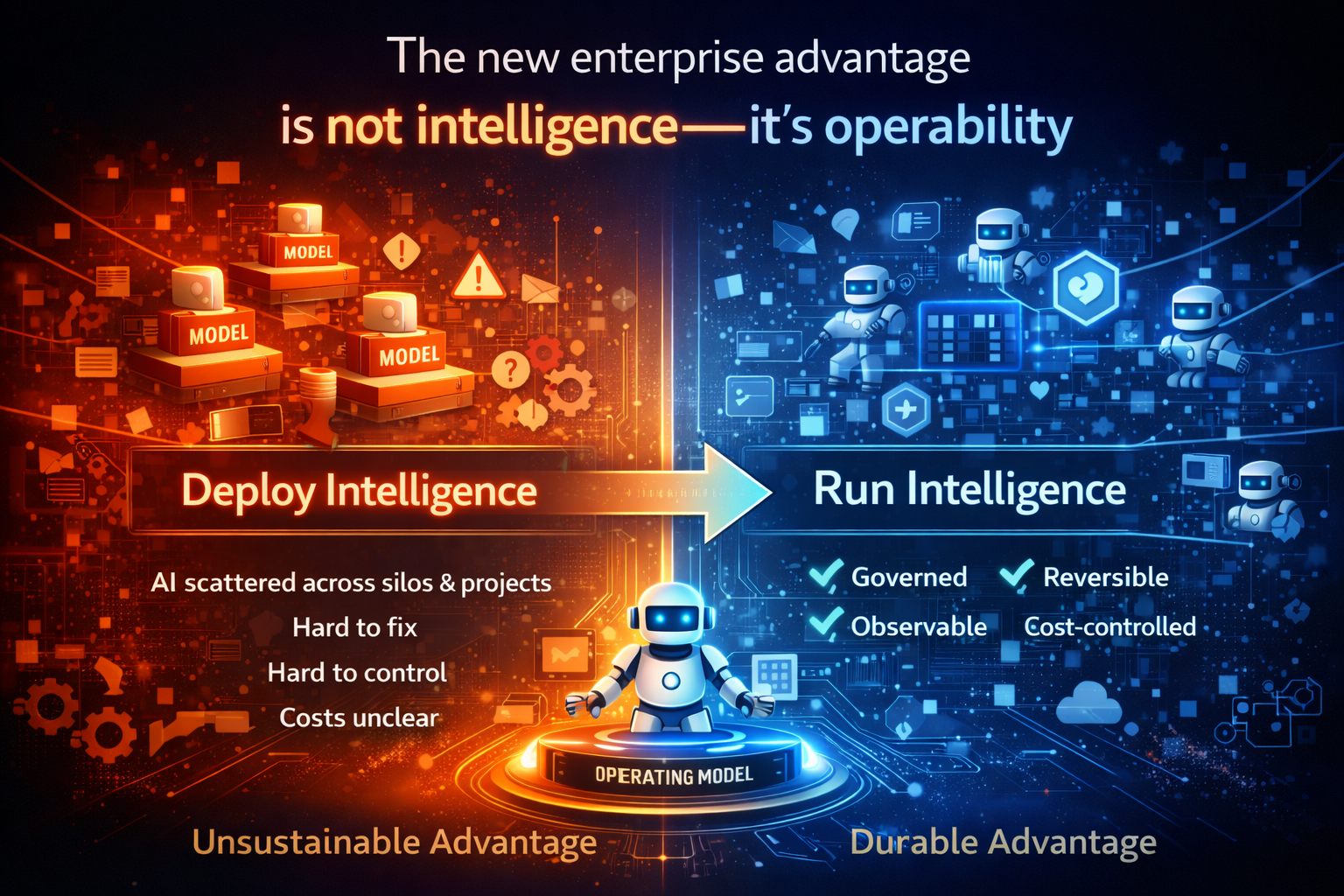
Enterprise AI has crossed a threshold. AI is moving from insight to execution—from suggesting what to do, to initiating actions inside real workflows: triggering tickets, updating records, drafting and sending customer communications, routing approvals, and coordinating across tools.
Once AI begins to act, maturity is no longer measured by how many models you build. It’s measured by whether your organization can run intelligence safely, visibly, and economically—over time.
This is also why governance expectations are rising across regions:
- The NIST AI Risk Management Framework places governance and oversight with actors who have management, fiduciary, and legal authority—a clear signal that “AI governance” is not a purely technical job. (NIST Publications)
- ISO/IEC 42001 formalizes the idea of an AI management system—an auditable, continual-improvement approach to managing AI responsibly in organizations. (ISO)
- The EU AI Act emphasizes requirements like human oversight for high-risk systems and expectations for ongoing monitoring over an AI system’s lifetime. (Artificial Intelligence Act)
- The UK has articulated a principles-based approach grounded in outcomes such as safety, transparency, accountability, and contestability—reinforcing that mature AI is “operated,” not “installed.” (GOV.UK)
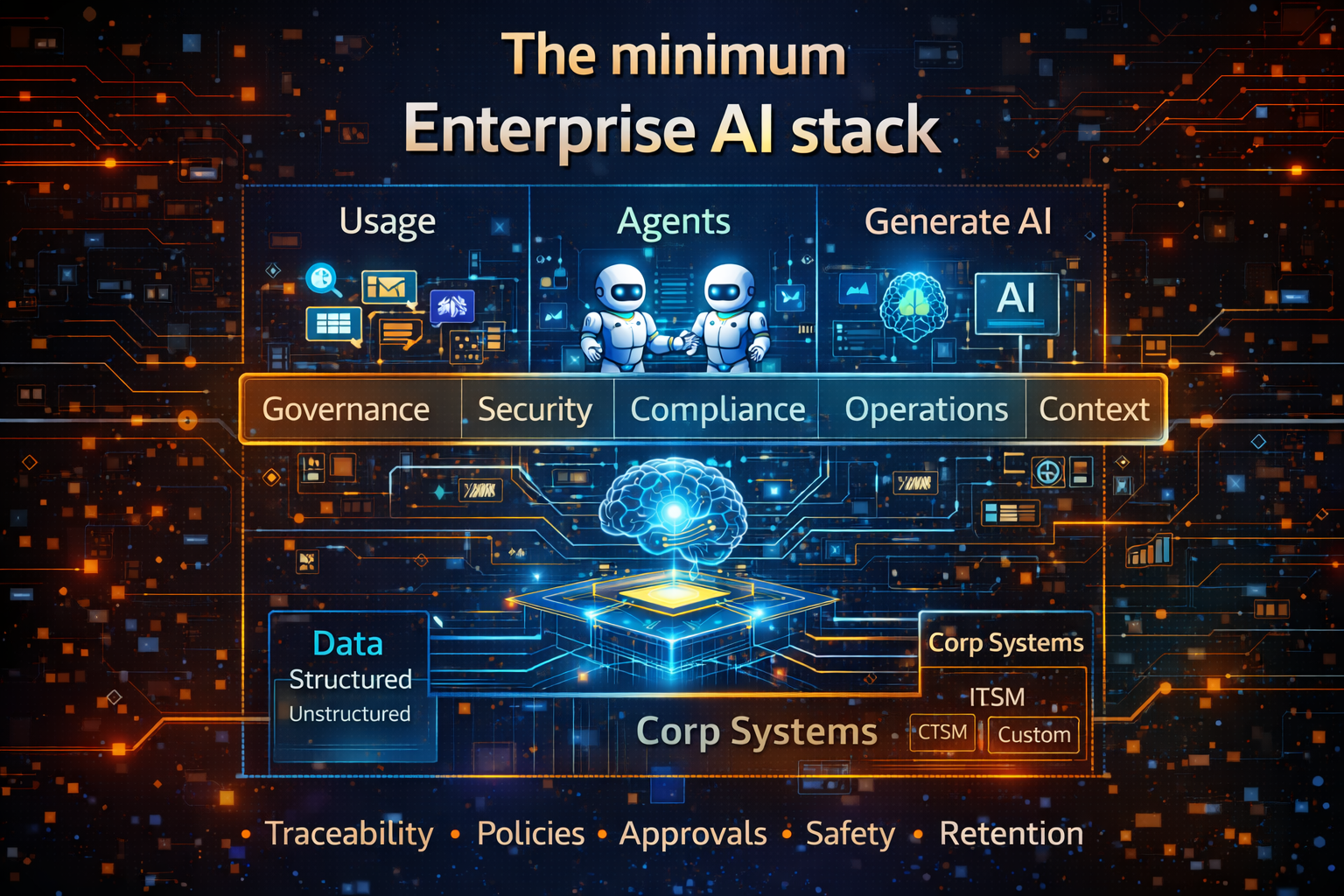
This article gives you a practical, executive-friendly Enterprise AI maturity model—simple, actionable, and designed to become a reference point for boards, CIOs, and technology leaders.
Important context: This maturity model is a companion to your canonical framework:
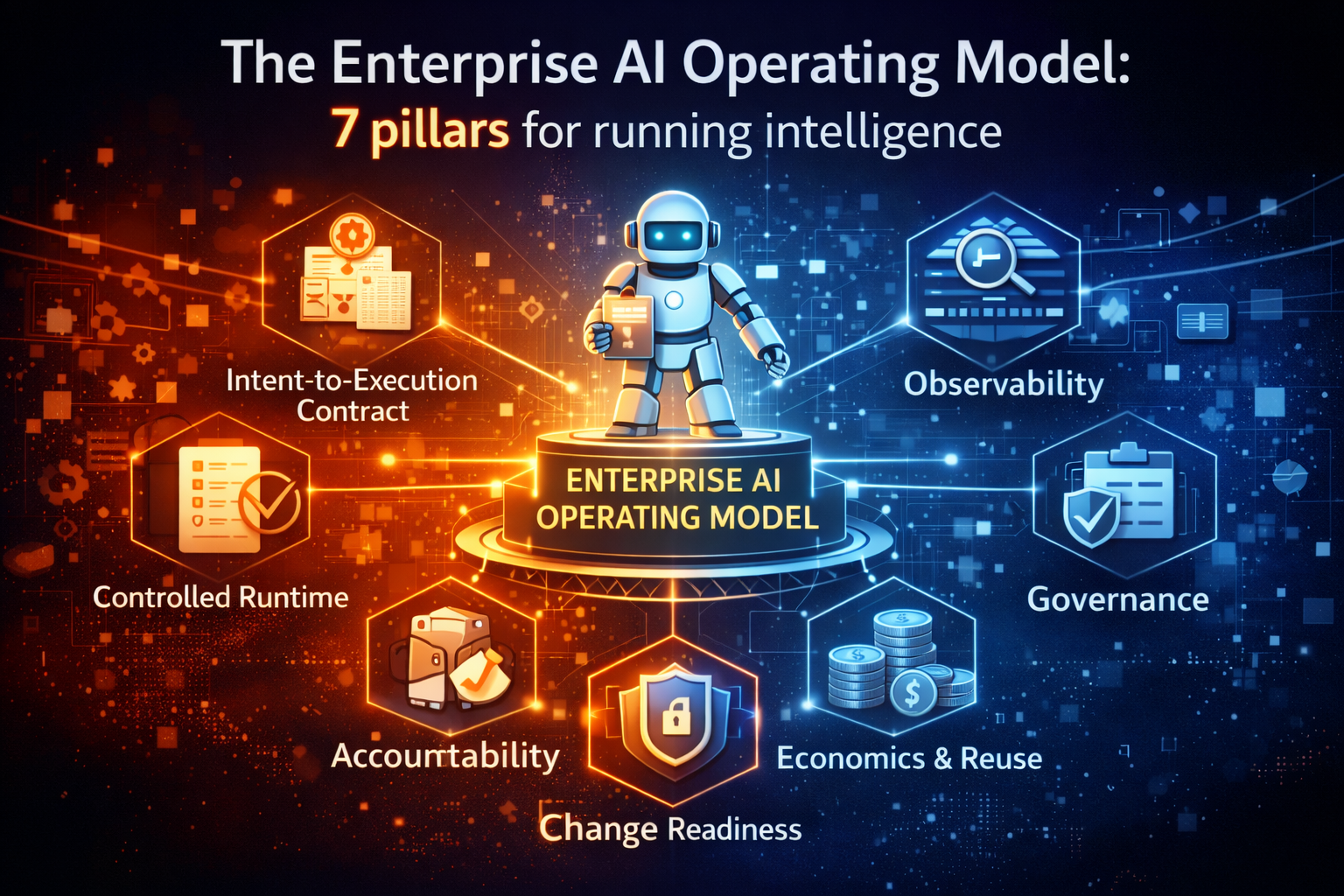
Enterprise AI Operating Model (the “how” of running AI safely at scale)
https://www.raktimsingh.com/enterprise-ai-operating-model/
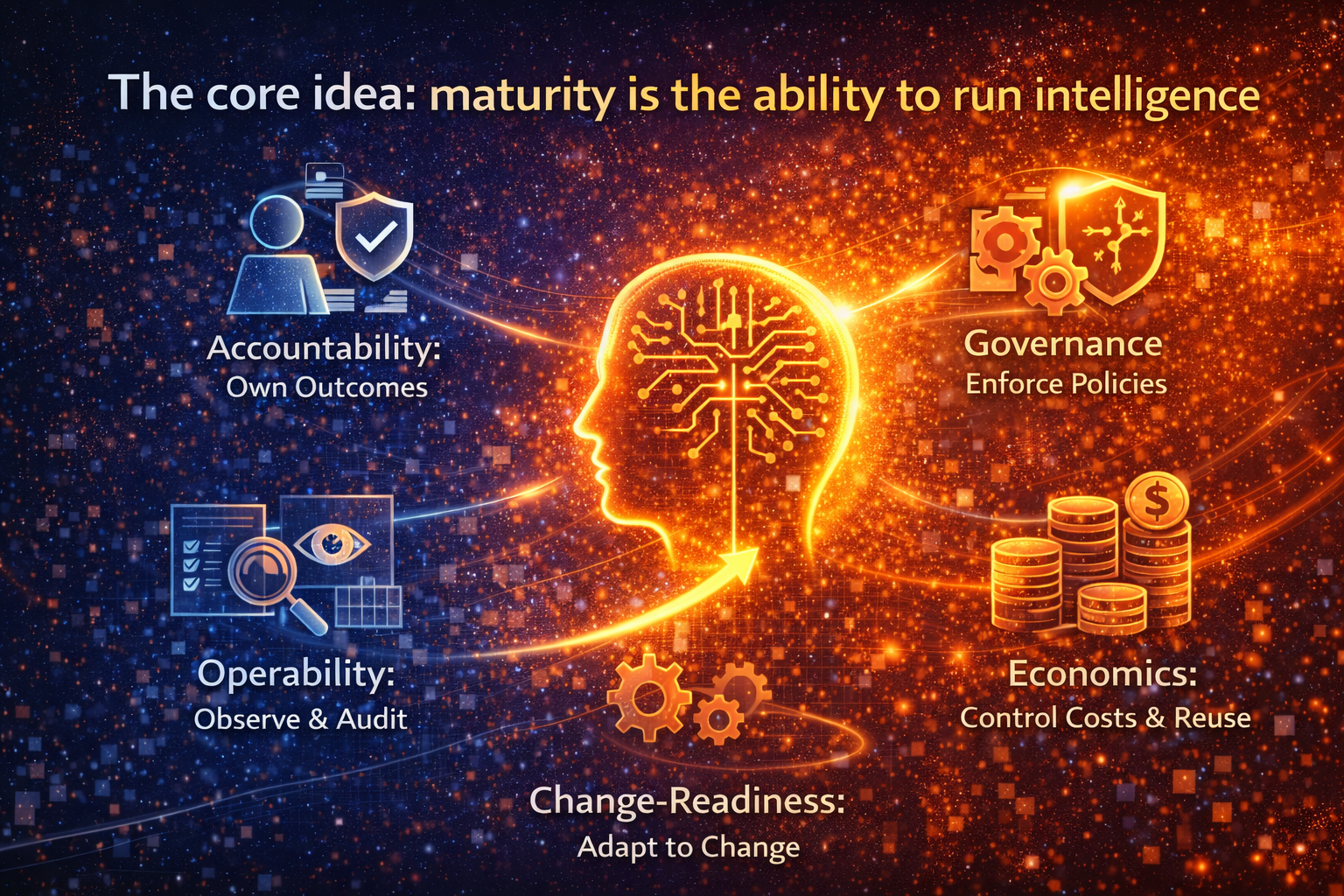
The core idea: maturity is the ability to run intelligence
Traditional maturity models ask:
- Do you have data?
- Do you have models?
- Do you have MLOps?
Enterprise AI maturity asks something different:
Can your organization safely allow AI to influence—or execute—real outcomes, repeatedly, under change?
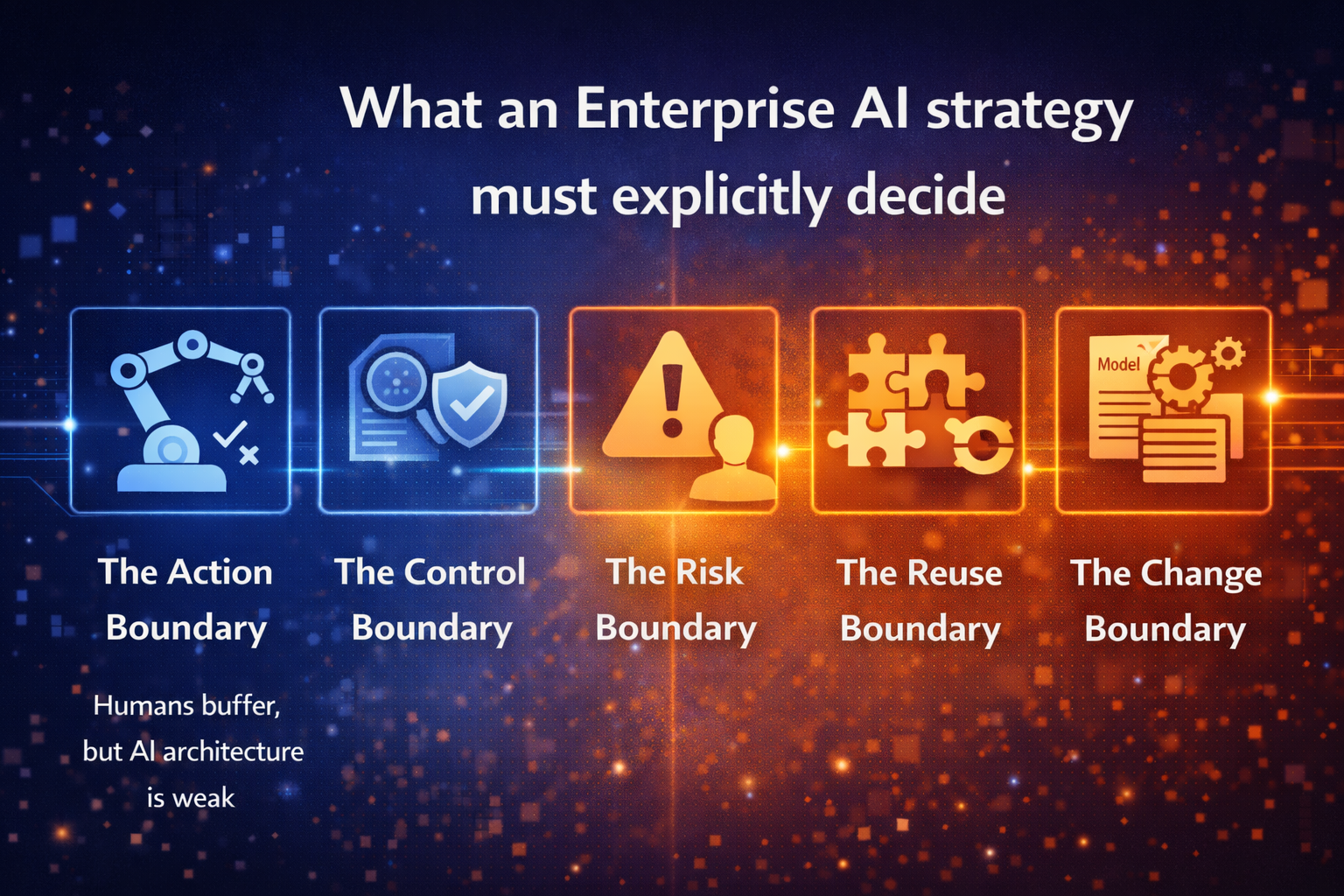
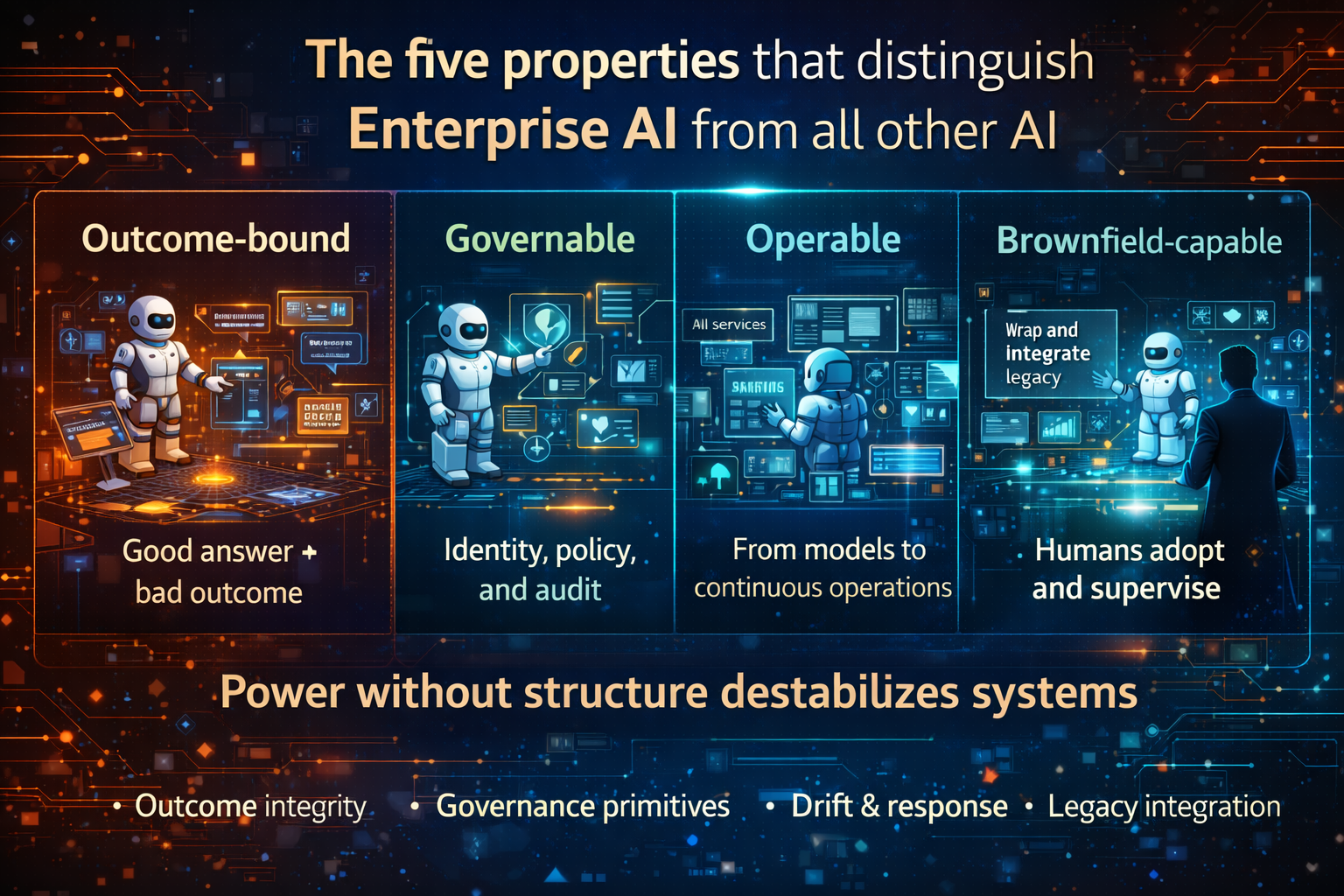
That includes five non-negotiables:
- Accountability: someone owns outcomes, not just models
- Governance: policies are enforced in systems, not documented in slides
- Operability: you can observe, audit, and reverse AI behavior
- Economics: costs are controlled and reuse compounds value
- Change-readiness: model updates, policy shifts, and workflow change don’t break the enterprise
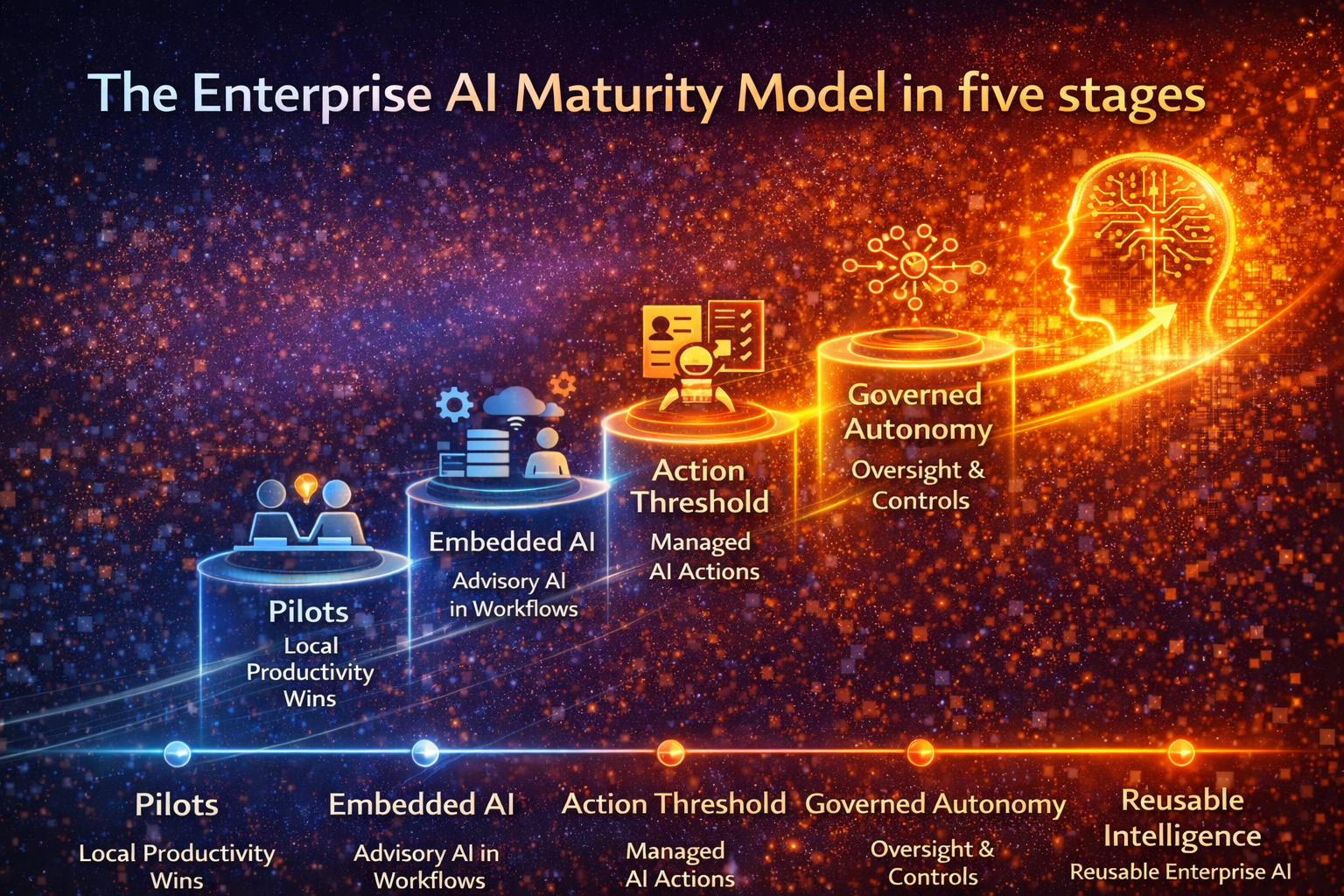
The Enterprise AI Maturity Model in five stages
Most organizations won’t move neatly from one stage to the next. Different functions will sit at different stages at the same time.
But these five stages provide a clear map of what “next” should look like.
Stage 1 — Pilot-Led Experimentation
What it looks like
Small teams run demos, proofs of concept, and limited pilots. AI is mostly used to assist humans: summarization, drafting, search, classification.
Simple example
A team uses a generative assistant to summarize policies and draft internal emails. Output is reviewed manually. The system has no authority to act.

What success looks like at this stage
- A few pilots deliver local productivity gains
- Early patterns emerge: what data is missing, where workflows are messy, what risks are real
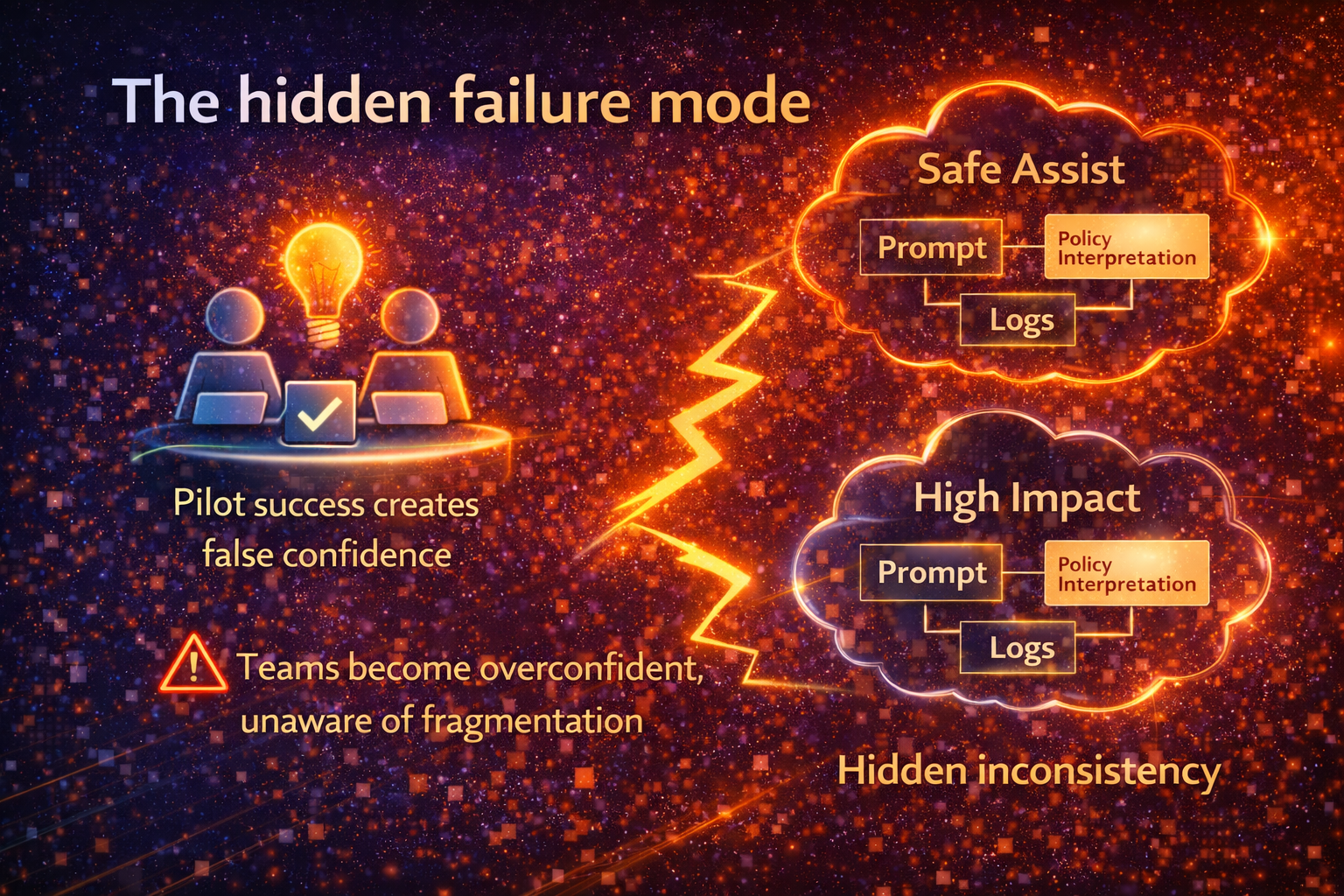
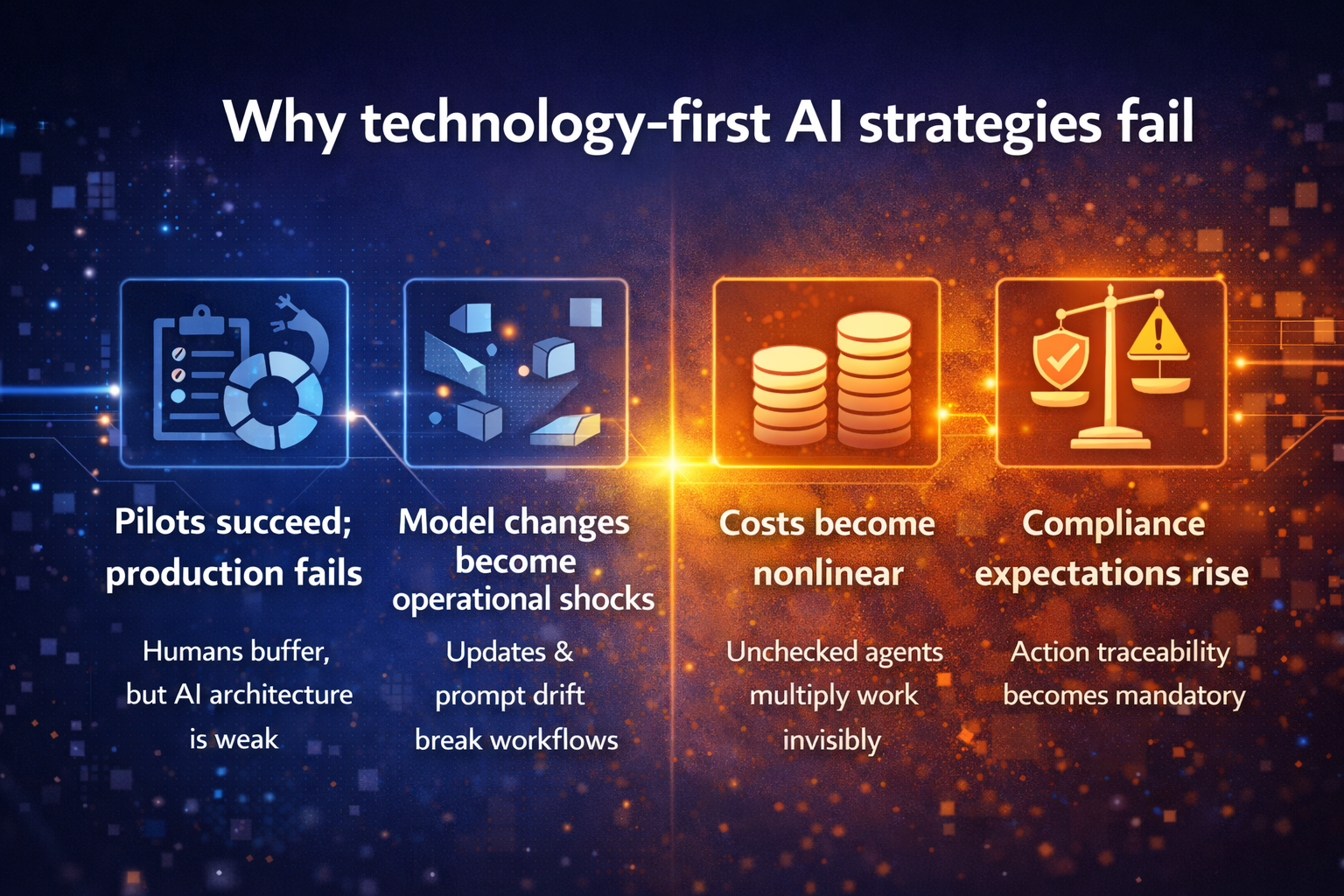
The hidden failure mode
Pilot success creates false confidence. Humans compensate for weaknesses. Teams overestimate readiness because the system is never exposed to real scale and edge cases.

What to build next
- A shared use-case intake process (so pilots don’t fragment)
- Basic risk classification: “safe assist” vs “high-impact” workflows
- Minimum documentation of prompts, data sources, and user expectations
Maturity threshold
You can repeat pilots without reinventing the wheel.
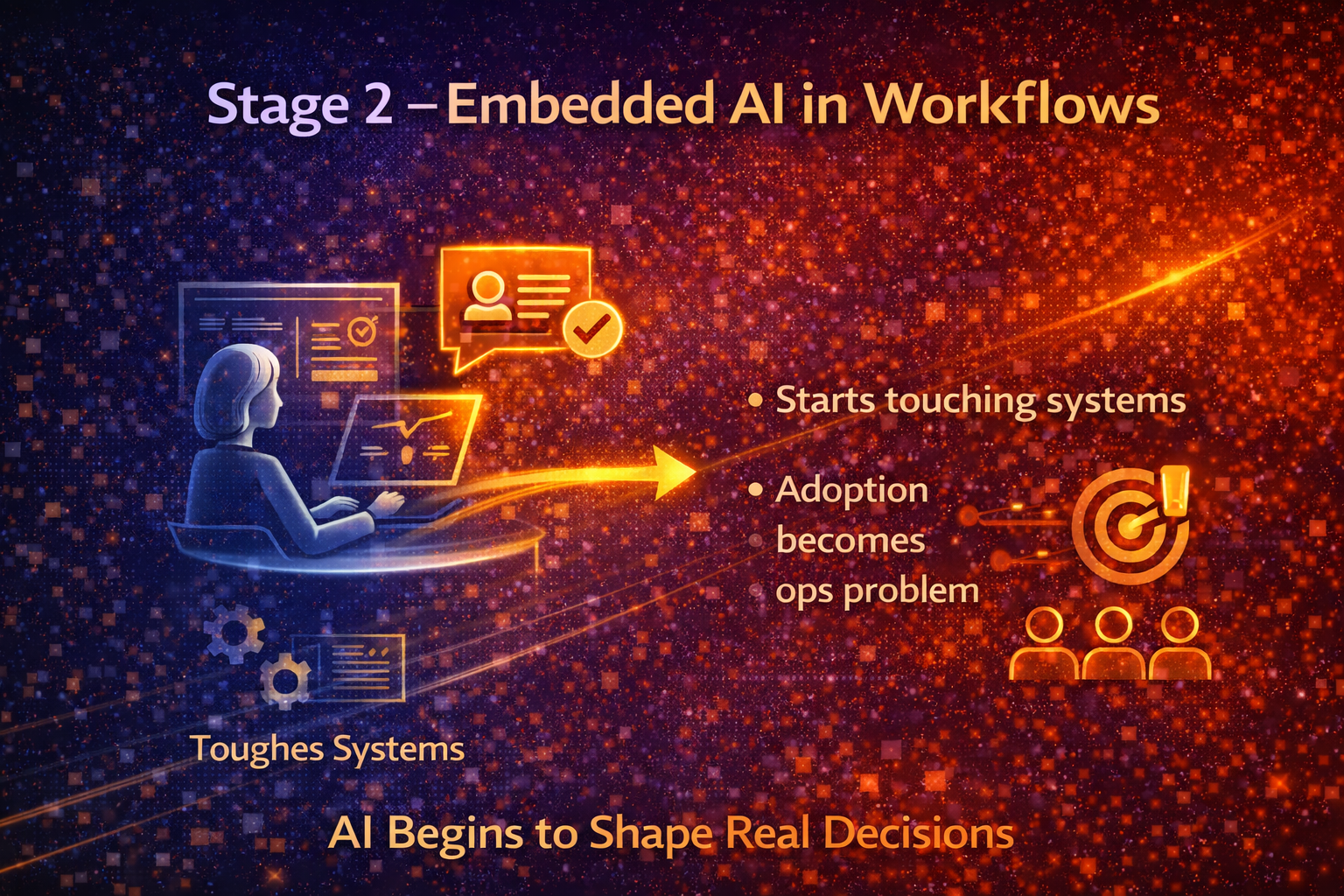
Stage 2 — Embedded AI in Workflows
What it looks like
AI shifts from stand-alone tools to being embedded inside business workflows. Integration begins. AI is still mostly advisory—but it starts to shape daily decisions.
Simple example
A service workflow shows a recommended resolution draft plus relevant knowledge snippets. A human approves and sends.
What changes from Stage 1
- AI starts touching operational systems (even indirectly)
- Adoption becomes an operations issue: training, escalation, consistency
- Risk rises because AI outputs influence real decisions at volume
Common failure mode: “Shadow standardization”
Different teams implement similar assistants with different prompts, different policy interpretations, and different logging levels—creating invisible inconsistency.
What to build next
- Shared guardrails: approved prompt patterns, data access patterns, human review requirements
- Basic telemetry: what AI recommended vs what humans actually did
- A named owner for each AI-enabled workflow (product accountability, not just engineering)
Maturity threshold
AI is embedded consistently and doesn’t collapse when teams change.
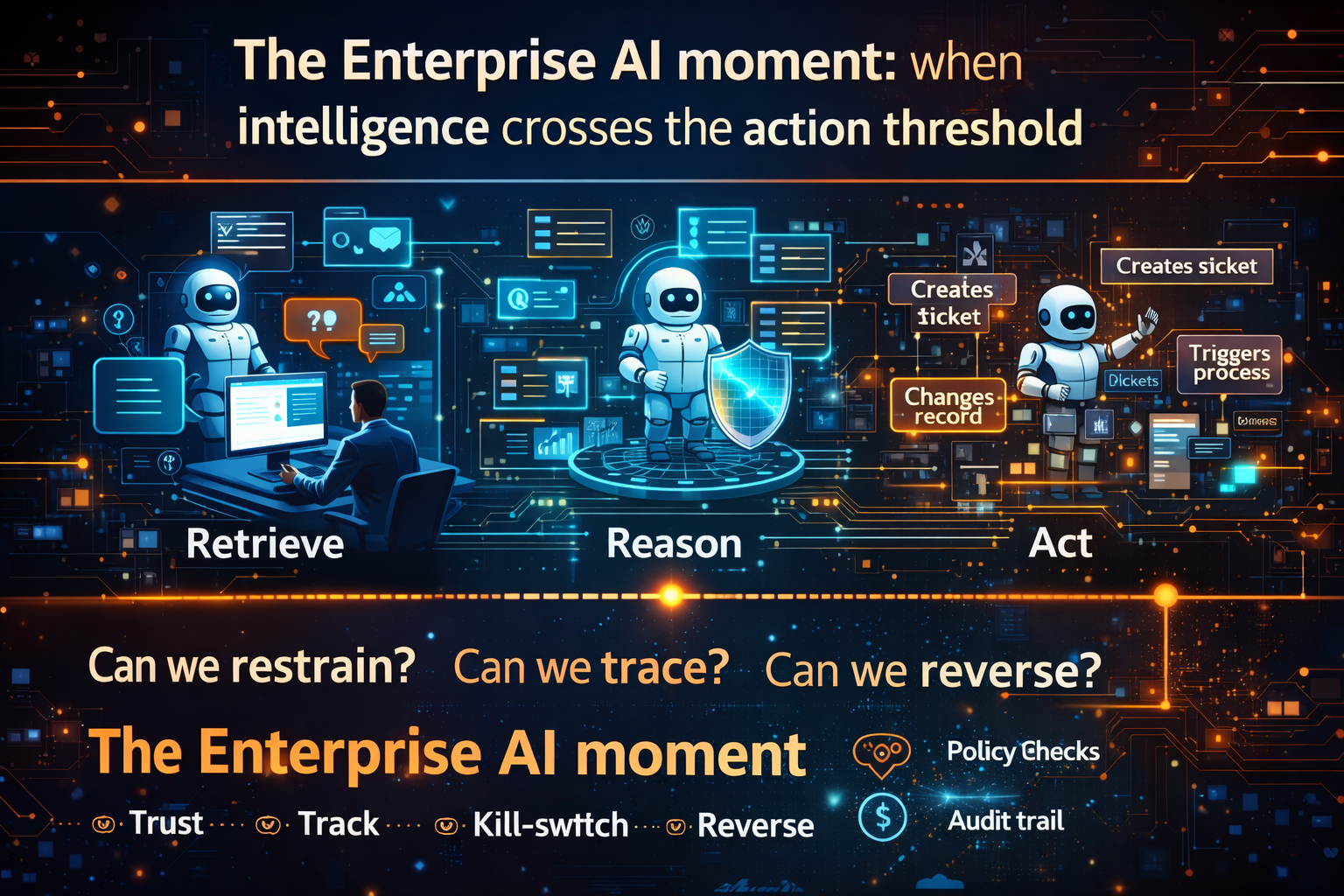
Stage 3 — The Action Threshold
This is the most important transition in Enterprise AI.
What it looks like
AI crosses from “advice” to “action.” It can trigger tasks, update records, initiate workflows, and coordinate tool calls. Humans may still supervise—but AI now has operational agency.
Simple example
An AI agent routes a request, opens a ticket, assigns it, updates a record, and notifies stakeholders—without waiting for a human to click “submit” each time.
Why this changes everything
At the Action Threshold, failure is no longer a wrong answer. It’s a wrong outcome:
- the wrong ticket escalates to the wrong team
- the wrong permission is requested or removed
- the wrong customer receives the wrong message
- the wrong workflow triggers compliance exposure
This is where governance stops being a “policy” topic and becomes a runtime topic. Requirements like human oversight (in high-risk contexts) are framed as mechanisms to prevent or minimize harms—even under foreseeable misuse. (Artificial Intelligence Act)
Common failure modes
- Overreach: AI is allowed to act too early because pilots looked good
- Unbounded autonomy: the agent loops through tools, retries, and escalations without cost/safety limits
- No reversal: when something goes wrong, nobody can stop or roll back behavior confidently
What to build next
- Explicit “action permissions”: what AI can do, what it cannot do
- Human oversight design: who monitors, who can override, who is accountable (AI Act Service Desk)
- Logging that supports audit and incident response (not just debugging)
- A kill switch: fast containment when an agent misbehaves
Maturity threshold
You can allow limited AI actions without losing control.
Stage 4 — Governed Autonomy
What it looks like
AI can act—but within defined boundaries. Governance becomes enforceable and measurable. The enterprise can observe, audit, and correct AI behavior as conditions change.
Simple example
An enterprise allows agents to execute routine operational actions, but:
- actions are policy-checked
- tool access is permissioned
- workflows are observable end-to-end
- escalations trigger automatically when uncertainty is high
- incidents trigger containment and review

What “governed autonomy” really means
Autonomy is not the absence of humans. It is accountable delegation.
This aligns with the global direction of frameworks and standards:
- NIST AI RMF emphasizes governance across the lifecycle and assigns oversight to actors with fiduciary authority. (NIST Publications)
- ISO/IEC 42001 frames AI governance as a management system that must be maintained and continually improved. (ISO)
- EU AI Act expectations include human oversight and post-market monitoring for high-risk systems over time. (Artificial Intelligence Act)
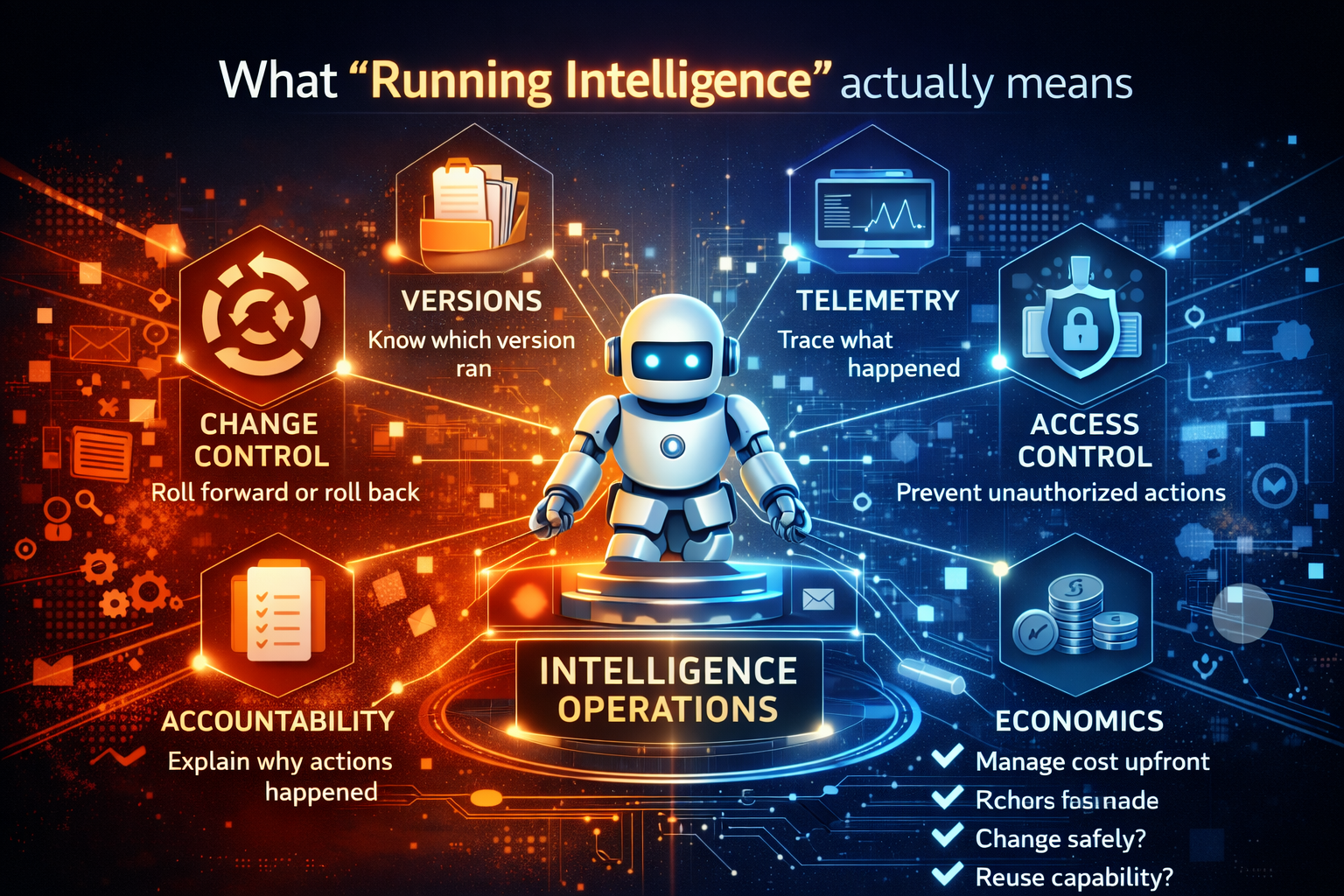
What you have at this stage (capabilities, not buzzwords)
- Governance that runs: policies enforced at runtime
- Observability: you can see what actions happened, why, and with what inputs
- Auditability: you can reconstruct decisions and actions for review
- Resilience: you can stop, roll back, and recover
- Change control: model/prompt/tool changes follow disciplined release practices
What to build next
- Standardized runbooks for AI incidents
- Portfolio view: what AI is running, where, and why
- A repeatable approach to risk tiering (low-risk vs high-impact AI)
Maturity threshold
You can scale autonomous AI without increasing enterprise risk linearly.
Stage 5 — Adaptive, Reusable Enterprise Intelligence
What it looks like
The organization doesn’t just deploy AI—it manufactures reusable intelligence. Capabilities are modular, governed, measurable, and reusable across the enterprise. Progress compounds instead of fragmenting.
Simple example
Instead of each team building its own “policy checker,” the enterprise exposes a reusable policy service that multiple workflows call—consistently, with shared observability and auditability.
What becomes true
- Reuse beats reinvention
- Costs become predictable because intelligence is standardized
- Governance scales because controls are embedded in reusable components
- The enterprise adapts quickly when policies change or new risks emerge
The risk if you don’t reach Stage 5
You accumulate a sprawling “AI estate” of inconsistent copilots and agents—each working “well enough” locally but impossible to govern globally.
What you build at this stage
- An enterprise catalog of AI capabilities (services, agents, tools)
- Reuse metrics and economic guardrails
- Continuous improvement loops: monitoring → learning → safer autonomy
- A governance model that travels across regions (US, EU, UK, India, APAC, Middle East)
Maturity threshold
Enterprise AI becomes a durable operating advantage.

How to self-assess maturity without dashboards
Here are five “tell-me-the-truth” questions—one per stage:
- Stage 1: Can we repeat pilots without starting from scratch each time?
- Stage 2: Is AI embedded consistently across workflows, with clear ownership?
- Stage 3: Can AI take limited actions without creating uncontrolled outcomes?
- Stage 4: If an AI agent misbehaves, can we detect, contain, and audit quickly?
- Stage 5: Do our AI capabilities compound through reuse—or fragment through reinvention?
If you hesitate on a question, that’s your current stage.
Most organizations don’t fail at AI because they lack intelligence.
They fail because they lack maturity once AI starts acting.

Why this model works globally
Enterprises operate across multiple trust regimes and compliance cultures. The labels differ, but the operational direction converges:
- US: voluntary but influential risk frameworks like NIST emphasize lifecycle governance (NIST)
- EU: risk-based obligations emphasize oversight and ongoing monitoring for high-impact deployments (Artificial Intelligence Act)
- UK: principles-based outcomes emphasize accountability, transparency, safety, and redress (GOV.UK)
- Global: standards like ISO/IEC 42001 encourage an auditable management system approach (ISO)
The maturity model turns these external pressures into a single internal truth:
If AI can act, you must be able to govern actions—not just outputs.

The viral truth leaders recognize instantly
Most leaders have lived this pattern:
- pilots that look impressive
- production failures that are hard to diagnose
- governance that exists on slides, not in systems
- costs that creep up quietly
- teams reinventing the same intelligence over and over
So here are the two lines that tend to spread because they feel obvious once stated:
Most organizations don’t fail at AI because they lack models. They fail because they lack operating maturity once AI starts acting.
The maturity gap isn’t intelligence. It’s controllability.
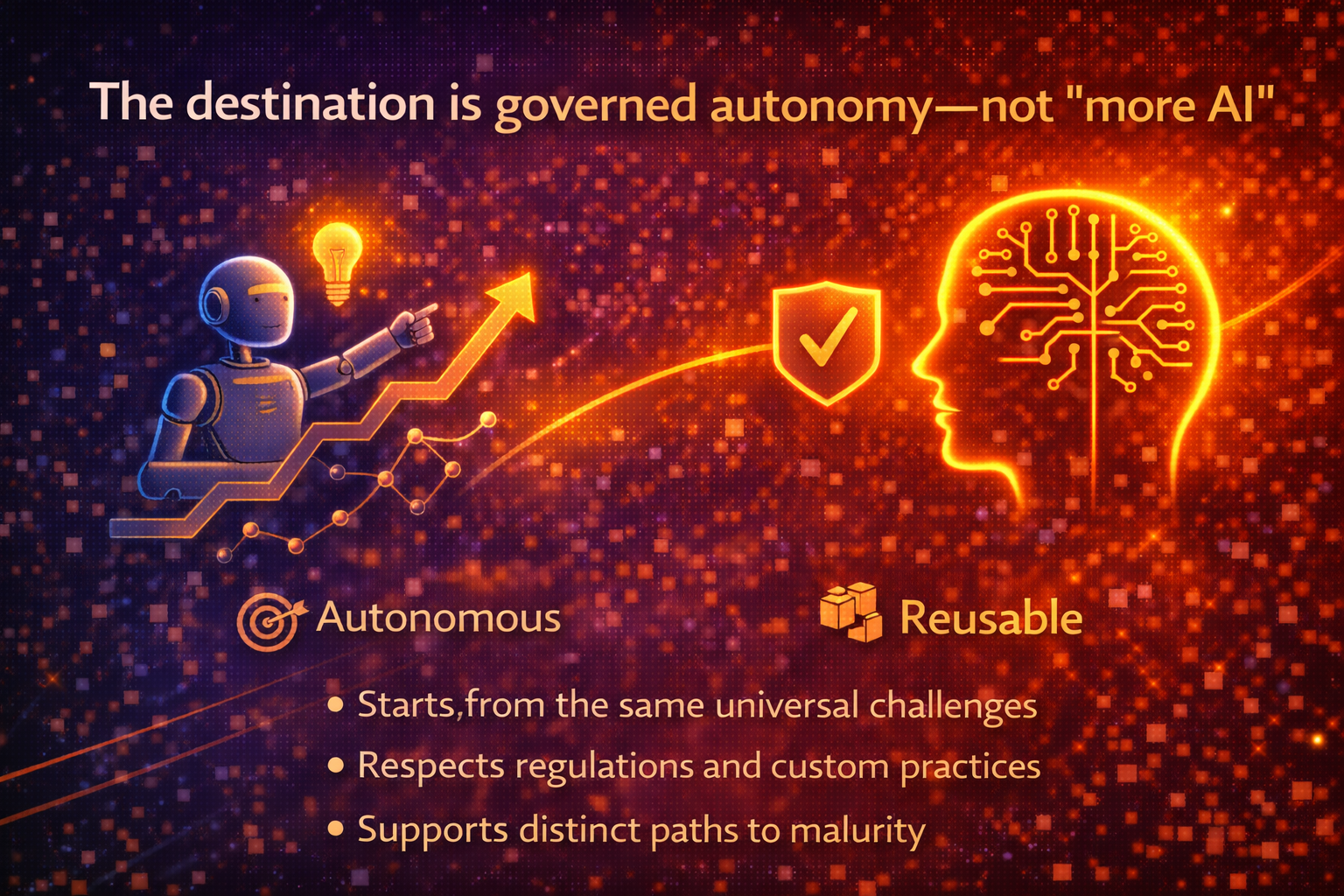
Conclusion: The destination is governed autonomy—not “more AI”
Enterprise AI maturity is not the number of pilots you run, the size of your model, or the sophistication of your prompts.
It is your organization’s ability to run intelligence as a controlled operating capability—under real-world change.
- If you are below the Action Threshold, your job is disciplined embedding.
- If you are approaching it, your job is explicit permissions and oversight.
- If you are past it, your job is governed autonomy—operability, auditability, resilience, and economics.
- And if you want durable advantage, your job is reusable enterprise intelligence—so progress compounds.
For the operating blueprint behind these stages, see the pillar framework:
Enterprise AI Operating Model: https://www.raktimsingh.com/enterprise-ai-operating-model/
Glossary
- Enterprise AI maturity model: A staged view of how organizations progress from pilots to scalable, governed AI that can safely influence or execute real outcomes.
- Action Threshold: The point where AI shifts from advising humans to taking actions inside workflows.
- Governed autonomy: Autonomy with enforceable controls—oversight, logging, auditability, reversibility, and disciplined change management.
- Human oversight: Design and operational measures that allow monitoring, interpretation, override, and prevention of over-reliance in high-impact contexts. (Artificial Intelligence Act)
- AI management system (AIMS): A structured approach to establish, implement, maintain, and continually improve how AI is governed (ISO/IEC 42001). (ISO)
- AI risk management: Lifecycle governance of AI risks through mapping context, measuring risk, and managing mitigations (NIST AI RMF). (NIST Publications)
FAQs
1) Is this maturity model only for regulated industries?
No. Any organization where AI influences customers, money, safety, security, or compliance benefits from this model. Regulated sectors simply feel the urgency earlier.
2) What’s the biggest mistake organizations make?
Crossing the Action Threshold without operational controls—no clear permissions, no oversight design, and no ability to stop/rollback behavior.
3) How do we move from Stage 2 to Stage 3 safely?
Start with narrowly scoped actions, explicit approval rules, strong logging, and defined human oversight. Treat autonomy as accountable delegation. (AI Act Service Desk)
4) What’s the difference between Stage 4 and Stage 5?
Stage 4 is about operating autonomy safely. Stage 5 is about making intelligence reusable so value compounds across the enterprise.
5) How does this relate to standards and governance frameworks?
The model aligns with NIST’s lifecycle risk framing, ISO’s management-system approach, and the increasing emphasis on oversight and monitoring found in regulations and regulator guidance. (NIST Publications)
References
- NIST, AI Risk Management Framework (AI RMF 1.0) (NIST Publications)
- ISO, ISO/IEC 42001:2023 AI management systems (ISO)
- EU AI Act (Article 14), Human oversight (Artificial Intelligence Act)
- EU AI Act (Article 72), Post-market monitoring (Artificial Intelligence Act)
- UK Government, A pro-innovation approach to AI regulation (White Paper) (GOV.UK)
- OECD, AI Principles (OECD)
Further reading
- Enterprise AI Operating Model: The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely – Raktim Singh
- Enterprise AI Strategy: Why AI Is No Longer a Technology Bet—but an Operating Capability Boards Must Own Enterprise AI Strategy: Why AI Is No Longer a Technology Bet—but an Operating Capability Boards Must Own – Raktim Singh
- AI Runbook Crisis (operability at scale) The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI—and What CIOs Must Fix in the Next 12 Months – Raktim Singh
- AI Estate Crisis (visibility and control) The Enterprise AI Estate Crisis: Why CIOs No Longer Know What AI Is Running — And Why That Is Now a Board-Level Risk – Raktim Singh
- Intelligence Reuse Index (compounding advantage) The Intelligence Reuse Index: Why Enterprise AI Advantage Has Shifted from Models to Reuse – Raktim Singh