Brownfield Agentic AI: The Reality Every CIO and CTO Must Confront
Most enterprises won’t “rip and replace” ERP, CRM, and core platforms to become AI-native. The winners will wrap those systems with governed actions, policy gates, auditability, and cost controls—so agents can create real outcomes without breaking the business.
“Agentic AI doesn’t fail because models are dumb—it fails because enterprises are brownfield.”

The uncomfortable truth: most agentic AI programs die in the brownfield
In 2025, the executive question has shifted from “Can the model answer?” to “Can the system act—safely—inside the business?” That’s why agentic AI is reshaping project priorities and operating expectations for CIOs and software leaders. (CIO)
But most enterprises are not greenfield startups. They are brownfield environments: decades of ERP and CRM, legacy databases, mainframes, bespoke workflows, region-specific policies, regulatory constraints, and a long tail of integrations.
So when someone says, “Let’s rebuild the stack to become AI-native,” the enterprise hears something else:
- Multi-year disruption
- High program risk
- Operational fragility
- Vendor lock-in
- And a political fight no one wants
This is why the only scalable strategy is simple—and slightly counterintuitive:
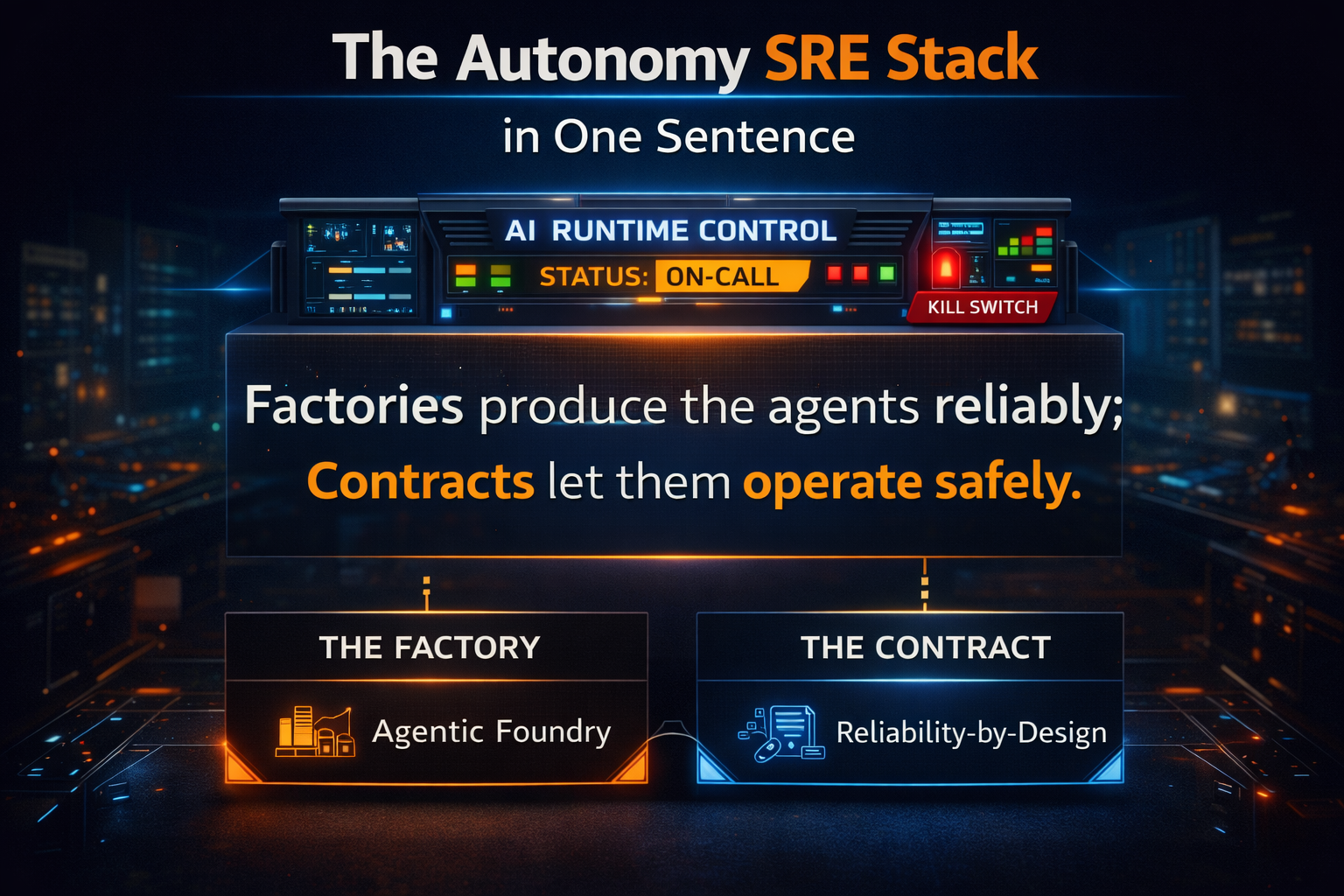
Don’t replace your core systems to scale agentic AI. Wrap them.
Add intelligence without rewriting the institution.
A wave of enterprise platforms and vendors now describe this direction explicitly: a composable, interoperable stack of agents/services/models designed to unify delivery across the enterprise landscape—built to accelerate outcomes without forcing a rebuild. (Infosys)
“Wrapping is the fastest path to autonomy: controlled actions, enforced policy, full auditability.”

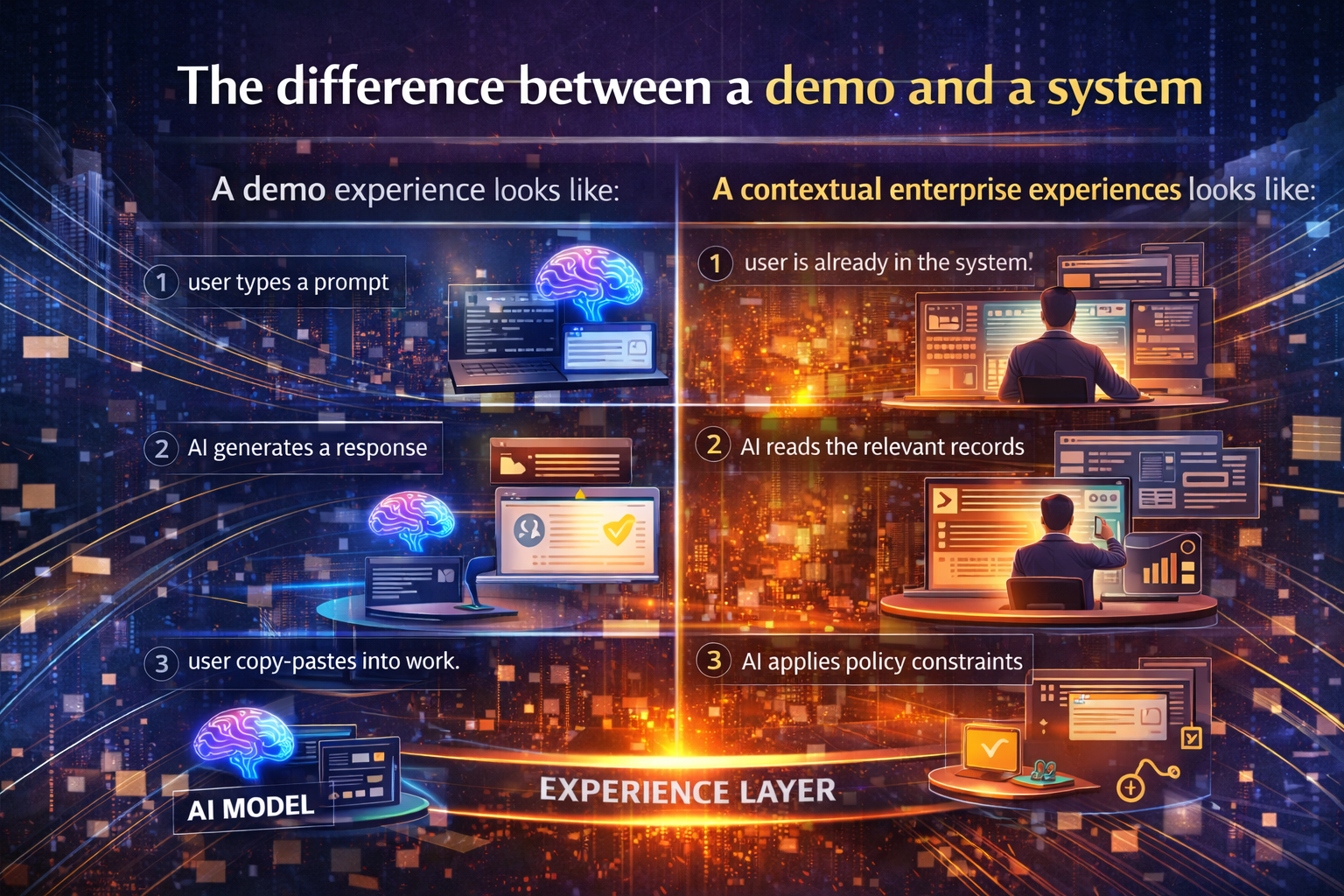
What “wrap” really means (in plain language)
“Wrapping” isn’t a buzzword. It’s an operating pattern:
- Keep the system of record as the source of truth (ERP/CRM/core platforms).
- Expose controlled capabilities (read/write actions) through governed interfaces—APIs, workflows, event triggers, and service layers.
- Put agentic AI on top as a supervised operator, not as a replacement brain.
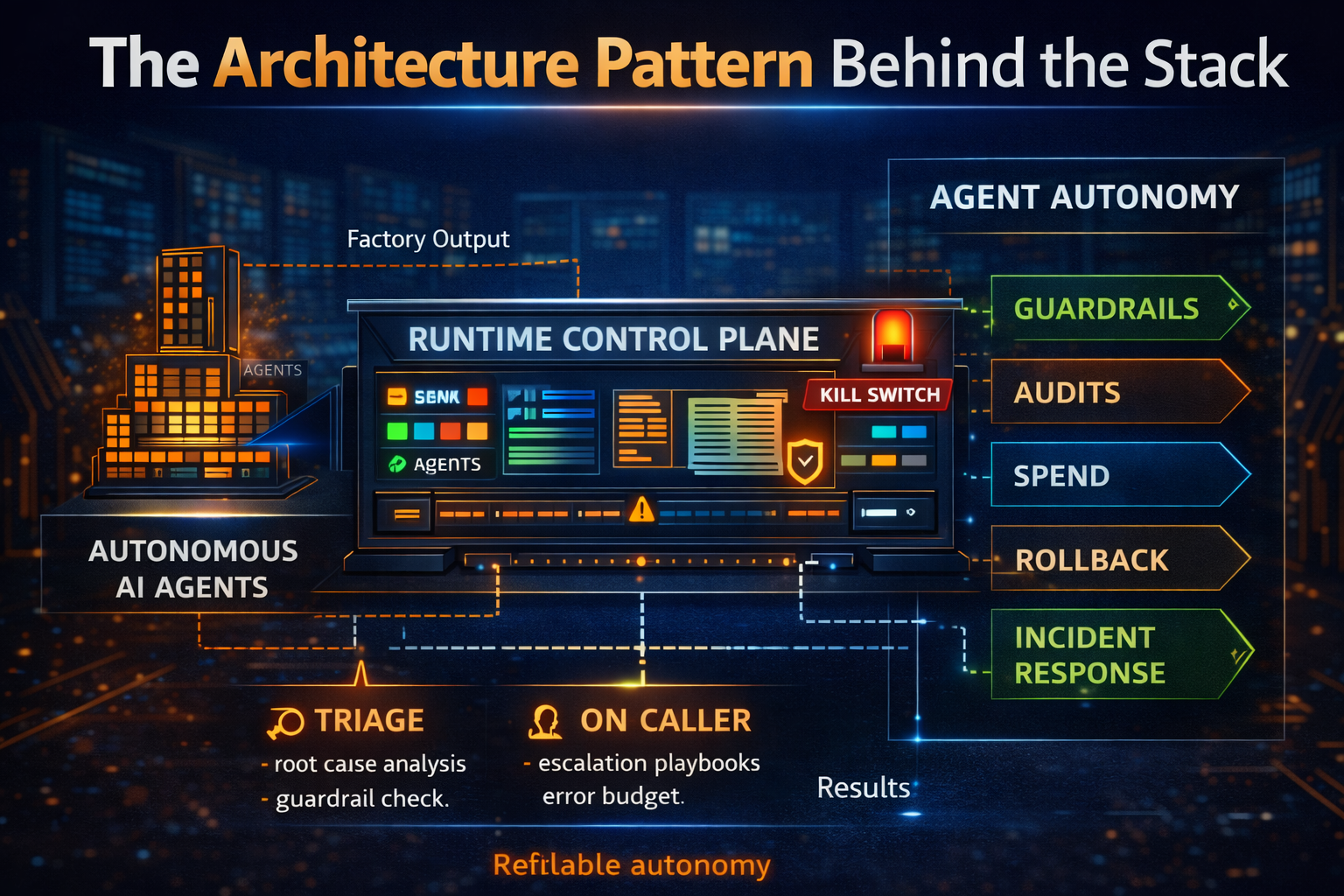
Think of your core systems like a powerful factory machine you must not modify casually. Wrapping is like installing:
- A control panel (approved actions)
- A safety cage (policy guardrails)
- A camera + logbook (audit trail)
- An emergency stop (rollback / kill switch)
- A meter (cost + rate limits)
The machine stays. You modernize the interaction model—so automation becomes safe, explainable, and scalable.
“If autonomy can’t be rolled back, it can’t be deployed.”

Why replacement fails: five realities every CIO recognizes
Why replacement fails: five realities every CIO recognizes
1) Your “core” is not just software—it’s institutional memory
ERP workflows encode how the enterprise truly works: approvals, exceptions, segregation of duties, audit requirements. Replacing them is not a technical migration—it’s a rewrite of institutional behavior.
2) Risk compounds when AI can take actions
As soon as agents can call tools, new failure modes appear: prompt injection, tool misuse, sensitive data exposure, unintended actions, and “policy bypass by creativity.” OWASP’s GenAI security guidance and Top 10 for LLM/agentic risks exist precisely because these issues show up in real deployments. (OWASP Foundation)
3) Brownfield is heterogeneous by definition
Even within one geography (US, EU, UK, India, APAC, Middle East), enterprises run hybrid stacks: SaaS + on-prem + private cloud + acquired systems. A clean replacement is rare; a safe integration surface is essential.
4) Value comes from workflows, not demos
Enterprises don’t need “more chat.” They need outcomes: fewer cycle times, better compliance, lower error rates, less rework—without creating operational chaos.
5) The operating model is the bottleneck
CIO priorities for data/AI increasingly emphasize turning AI into value, modernizing legacy environments, and scaling automation responsibly—meaning governance, security, and cost discipline become board-level concerns. (Alation)
Brownfield agentic AI in one sentence
Agentic AI scales when you convert core-system actions into governed, reusable services—and let agents orchestrate those services under strict runtime controls.
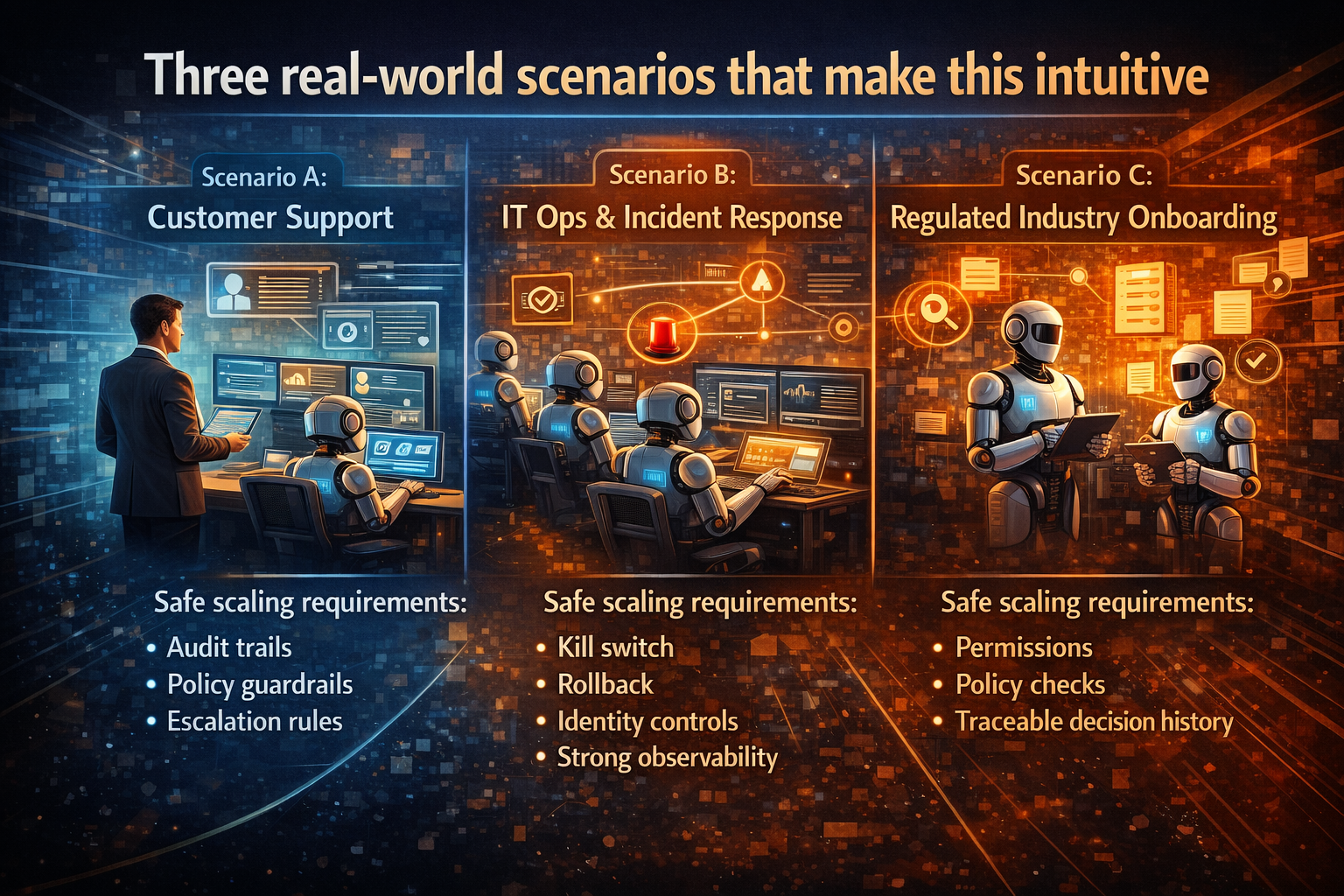
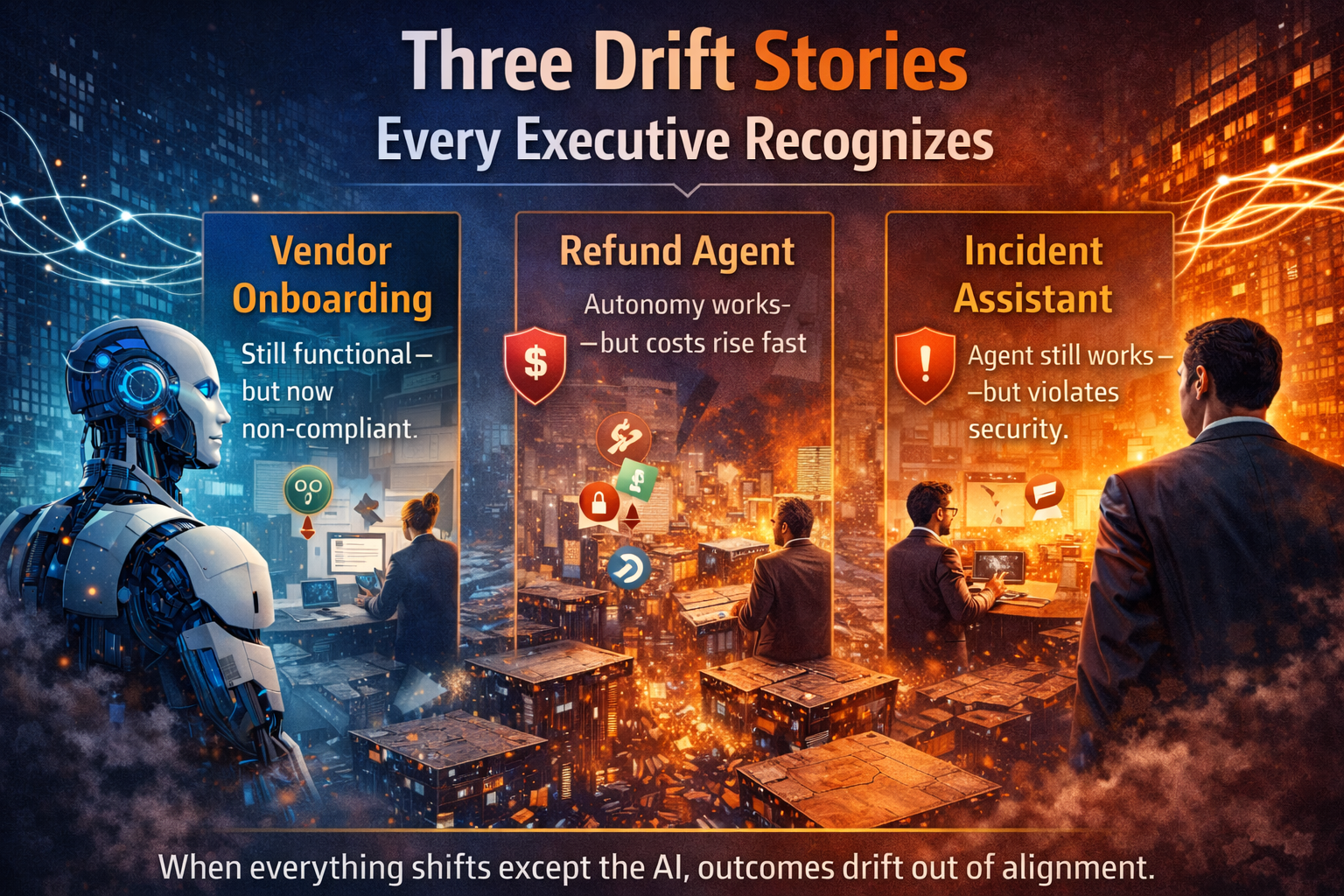
Three simple stories that make “wrap vs replace” obvious
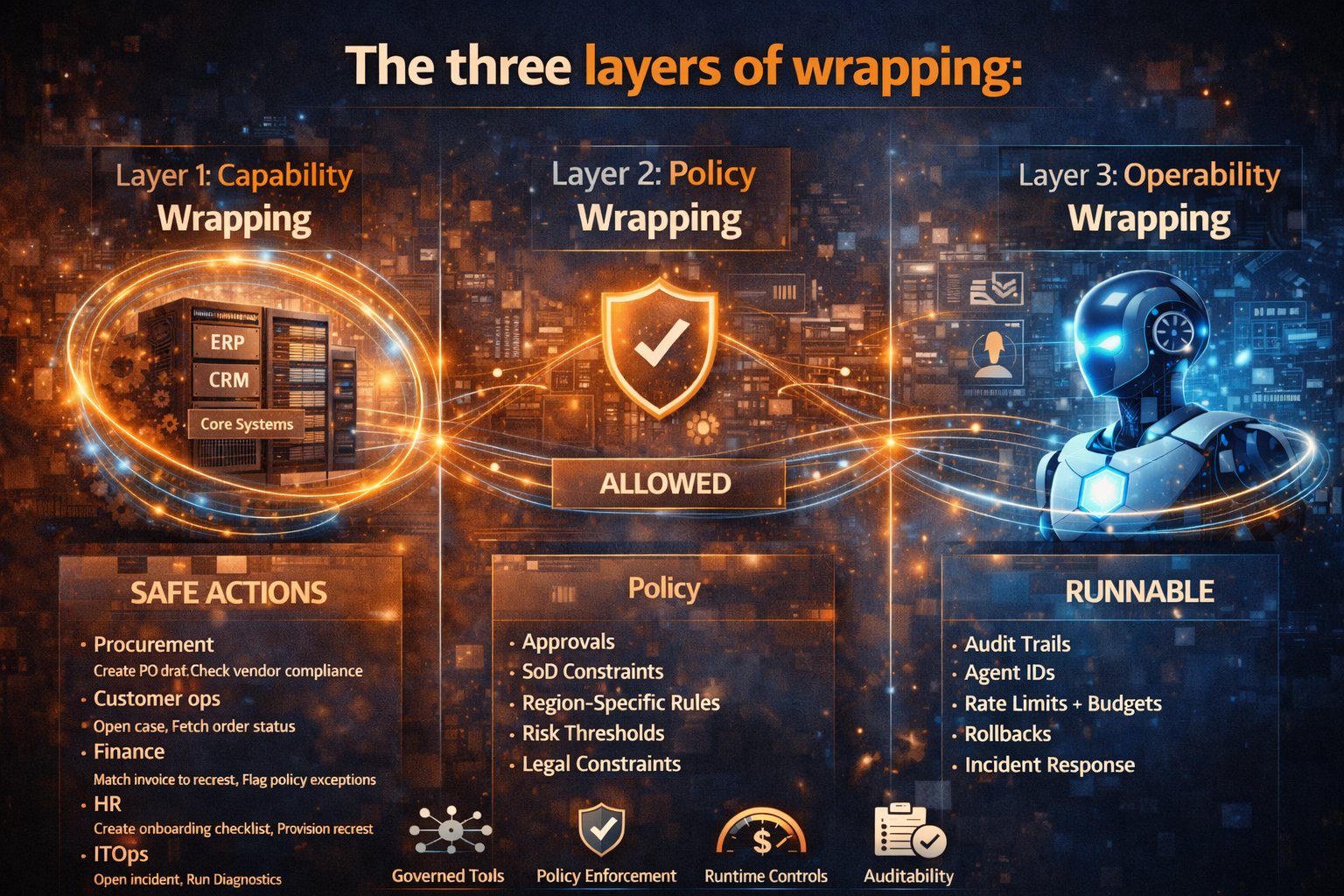
The three layers of wrapping (a blueprint that actually works)
Layer 1: Capability wrapping — turn systems into “safe actions”
Start by listing 10–20 bounded actions that create business value and are easy to constrain.
Examples:
- Procurement: create PO draft, check vendor compliance, route for approval
- Customer operations: open case, fetch order status, issue replacement authorization
- Finance: validate invoice fields, match invoice to receipt, flag policy exceptions
- HR: generate onboarding checklist, provision access request, schedule training
- IT ops: open incident, run diagnostics, propose remediation plan
These become tools the agent can call.
The key distinction: the tool is not “direct database access.” The tool is a narrow, well-defined action with validation, constraints, and logging.
Security best practices for LLM applications and tool-enabled agents consistently emphasize least privilege and tool-call validation. (OWASP Cheat Sheet Series)
Layer 2: Policy wrapping — make “allowed” explicit
In brownfield enterprises, policy lives everywhere:
- approvals
- segregation of duties constraints
- region-specific rules (privacy, sector rules)
- risk thresholds
- procurement and legal constraints
Wrapping means the agent doesn’t “interpret policy freely.” The runtime enforces policy.
Simple example:
- Agent drafts vendor onboarding.
- Policy layer checks: “Is this vendor category restricted in this geography?”
- If restricted → the agent can’t proceed. It must escalate or request an approval step.
This is where human-in-the-loop becomes a feature, not a failure—especially for high-impact actions. (NIST Publications)
Layer 3: Operability wrapping — make autonomy runnable
This is where most programs fail: not model quality—production reality.
To run agentic AI at scale, you need operational habits aligned to risk frameworks like NIST AI RMF: governance, monitoring, and ongoing risk management across the AI lifecycle. (NIST Publications)
Operability typically requires:
- Audit trails: tool calls, inputs/outputs, decision context (for compliance + debugging)
- Identity + access for agents (agents need identities with scoped permissions)
- Rate limits + budgets to prevent runaway loops and surprise costs
- Rollback / reversal patterns when downstream conditions change
- Incident response: a playbook when agents behave unexpectedly
This is the difference between a pilot and a platform.
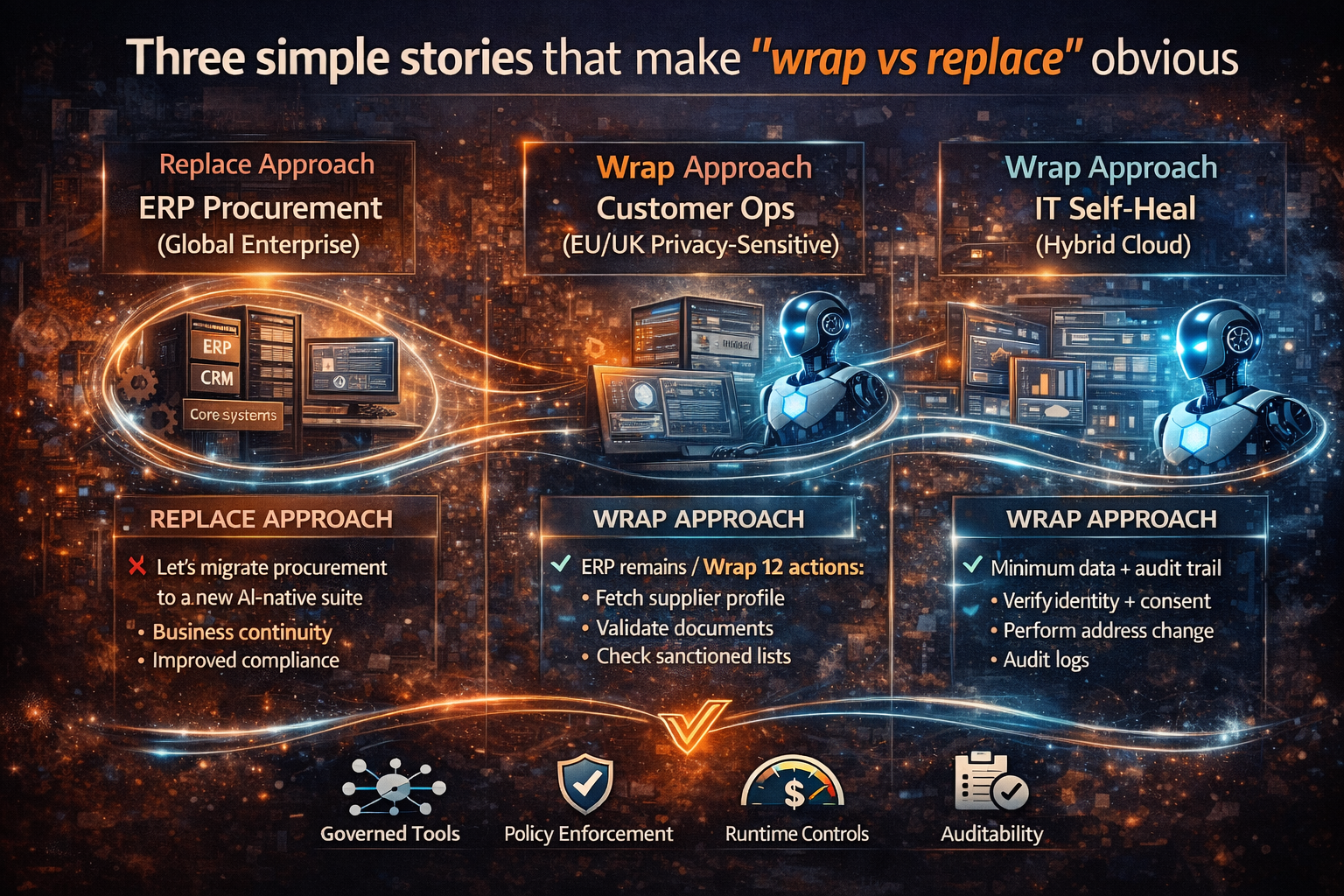
Three simple stories that make “wrap vs replace” obvious
Story 1: The ERP procurement assistant (global enterprise)
Replace approach: “Let’s migrate procurement to a new AI-native suite.”
Result: multi-year disruption, resistance from procurement and finance, stalled adoption.
Wrap approach: Keep ERP procurement. Wrap 12 actions:
- fetch supplier profile
- validate required documents
- check sanctioned lists
- draft PO
- route approvals
- log exceptions
Now the agent becomes a procurement co-pilot that executes bounded steps. The ERP remains the source of truth. Compliance improves because actions are logged and policy checks happen at runtime.
Story 2: Customer operations in a privacy-sensitive environment (EU/UK-style constraints)
Customer asks: “Change my address and cancel the next shipment.”
A naive agent might:
- pull personal data broadly
- modify records without appropriate justification
- leave weak audit evidence
A wrapped system does:
- the agent requests the minimum data needed
- policy layer verifies identity and consent
- action layer performs “address change” through approved workflow
- audit logs store the “why,” “who,” “what changed,” and “evidence”
OWASP explicitly highlights risks like prompt injection and sensitive information disclosure as real concerns for LLM/agentic systems—reinforcing why policy + auditability can’t be optional. (OWASP Gen AI Security Project)
Story 3: IT operations “self-heal” in hybrid cloud
Agent detects rising errors.
Replace approach: rebuild observability and incident tooling around a new platform.
Wrap approach: keep existing monitoring, ticketing, and runbooks.
Wrap actions:
- pull metrics
- correlate alerts
- open incident
- propose runbook steps
- request approval for remediation
- execute only if approved
The agent becomes a runbook orchestrator, not an uncontrolled admin.
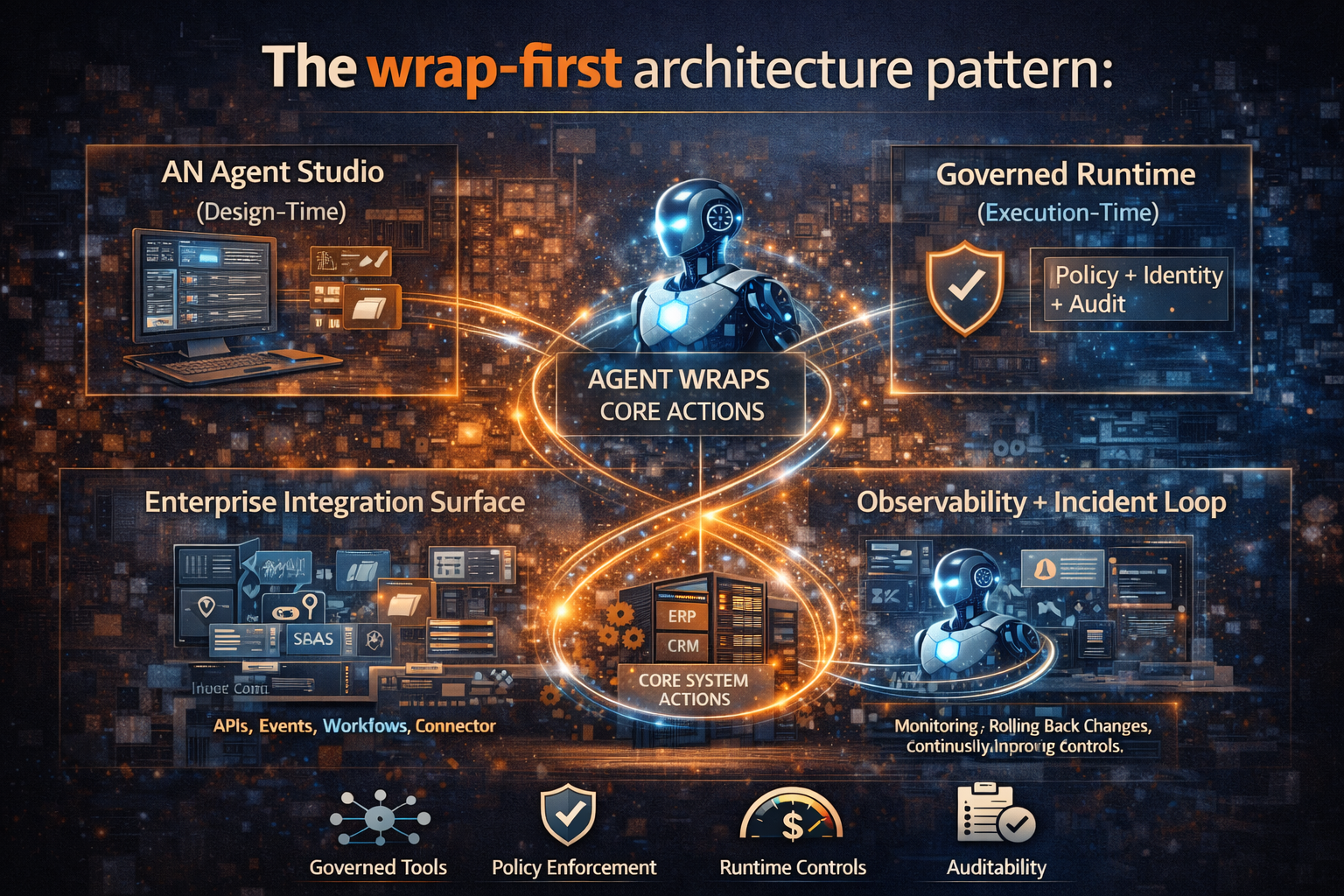
The wrap-first architecture pattern (no jargon—just the pieces)
To implement brownfield agentic AI reliably, enterprises usually need four building blocks:
1) Agent Studio (design-time)
- define tasks and tools
- test safely
- version prompts/workflows
- publish approved capabilities
2) Governed Runtime (execution-time)
- policy enforcement
- identity and access
- logging and audit
- budgets and throttles
- escalation / approvals
3) Enterprise Integration Surface
- APIs, events, workflows (RPA where necessary)
- connectors to SaaS + on-prem
- least-privilege data access
4) Observability + Incident Loop
- detect failures
- replay decisions
- rollback or compensate
- continuously improve controls
This is exactly why “fabric-like” enterprise stacks are emerging: not to make models smarter, but to make autonomy operable, reusable, and safe. (Infosys)

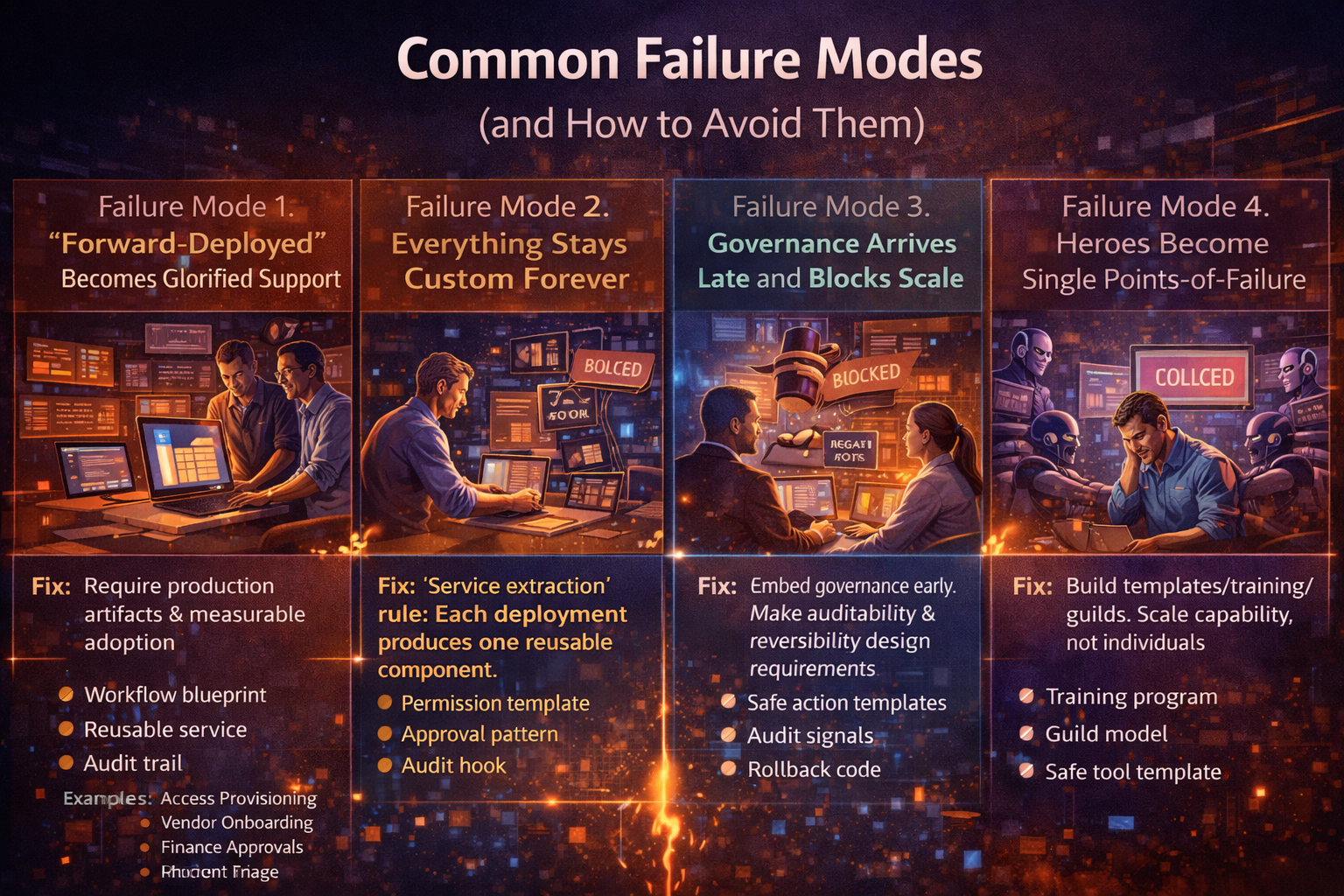
Common mistakes (and how to avoid them)
Mistake 1: Giving the agent “God mode”
If the agent can write to everything, it eventually will write to the wrong thing.
Fix: least privilege + bounded tools + approvals for sensitive steps. (OWASP Cheat Sheet Series)
Mistake 2: Treating audit logs as optional
Without logs, you can’t debug. You can’t prove compliance. You can’t build trust.
Fix: log every tool call, every sensitive read, and every write decision with context.
Mistake 3: Building one-off integrations per use case
That becomes integration roulette.
Fix: build a reusable action catalog—“Create Case” shouldn’t exist in six different forms across agents.
Mistake 4: Skipping the operating model
If no one owns agent incidents, you don’t have autonomy—you have unmanaged risk.
Fix: define ownership, escalation paths, safe failure modes, and rollback procedures aligned to AI risk governance practices. (NIST Publications)
Brownfield agentic AI succeeds when enterprises wrap existing core systems with governed actions, policies, audit trails, and runtime controls—allowing AI to act safely without replacing the systems of record. Why this wins globally (US, EU, UK, India, APAC, Middle East)
Brownfield realities vary, but the constraints rhyme:
- EU/UK: privacy + auditability pressure
- US: speed-to-value + cost discipline
- India/APAC: scale + heterogeneity + talent efficiency
- Middle East: rapid transformation + governance expectations
“Wrap, don’t replace” works because it lets you:
- modernize fast without disrupting the core
- prove value in weeks, not years
- enforce policy consistently across environments
- reduce lock-in risk by standardizing interfaces and action catalogs

A practical 90-day plan (that doesn’t collapse under ambition)
Weeks 1–2: Choose one workflow, not ten
Pick a workflow with clear value and bounded risk (invoice exceptions, case triage, PO drafting).
Weeks 3–6: Wrap 10–20 actions
Define narrow tools with strict permissions and logging.
Weeks 7–10: Add policy + approvals
Introduce human-in-the-loop for high-impact actions; enforce decision rights.
Weeks 11–13: Make it operable
Monitoring, cost limits, incident playbooks, rollback/compensation strategies.
Then expand horizontally: same platform, more workflows—without re-building from scratch.

Conclusion: the new enterprise advantage is runnable autonomy
The next wave of enterprise AI won’t be won by the company with the smartest model.
It will be won by the company that can answer one operational question:
“Can we let AI take actions inside our business—without losing control, trust, or cost discipline?”
In brownfield enterprises, the scalable path is not replacement. It is wrapping: converting core-system actions into governed services, enforcing policy at runtime, and making autonomy operable through auditability, budgets, and incident response—consistent with widely used AI risk management principles. (NIST Publications)
That’s how you modernize without disruption, scale without chaos, and earn the right to deploy real autonomy.
FAQ
Is brownfield agentic AI just RPA with a new name?
No. RPA automates deterministic steps. Agentic AI can interpret intent, plan multi-step work, and adapt—but it must be wrapped with controls to stay safe and reliable. (OWASP Foundation)
Do we need to modernize legacy systems before using agents?
Not fully. You can start by wrapping the highest-value actions through APIs/workflows/integration layers. Over time, those wrappers become a modernization path.
How do we prevent agents from making risky changes?
Least privilege, bounded tools, policy gates, approvals for sensitive actions, and complete audit trails—aligned with OWASP guidance and NIST-style risk management thinking. (OWASP Cheat Sheet Series)
What’s the biggest reason agentic programs fail in enterprises?
Skipping operability: no runtime governance, no audit evidence, no budgets, and no incident playbooks.
Glossary
- Brownfield enterprise: An environment with existing systems and constraints that can’t be replaced quickly.
- System of record: The authoritative place where business truth lives (ERP/CRM/core platforms).
- Wrapping: Exposing system capabilities through governed actions (APIs/tools/workflows) rather than replacing the system.
- Agent tool: A bounded, permissioned action an AI agent can call (e.g., “Create Case,” “Draft PO”).
- Least privilege: Grant only the minimum permissions necessary—especially for tool-enabled agents. (OWASP Cheat Sheet Series)
- Human-in-the-loop: Humans approve/review sensitive actions before execution. (NIST Publications)
- Operability: The ability to run autonomy safely in production—monitoring, auditability, budgets, rollback, and incident response.
References and further reading
- Infosys Topaz Fabric overview page (example of industry “composable enterprise agent stack” positioning). (Infosys)
- Infosys press release on a layered, composable, interoperable stack of agents/services/models (industry signal for “wrap + unify + accelerate”). (Infosys)
- CIO.com on the agentic shift and how it changes software priorities (executive-facing lens). (CIO)
- Alation: CIO priorities for Data & AI in 2025 (agentic automation + legacy modernization as agenda items). (Alation)
- NIST AI Risk Management Framework (governance, lifecycle risk management, monitoring). (NIST Publications)
- OWASP Top 10 for LLM Applications + prompt injection prevention guidance (tool-enabled agent risks + defenses). (OWASP Foundation)
- The AI Platform War Is Over: Why Enterprises Must Build an AI Fabric—Not an Agent Zoo – Raktim Singh
- The Enterprise Model Portfolio: Why LLMs and SLMs Must Be Orchestrated, Not Chosen – Raktim Singh
- Continuous Recomposition: Why Change Velocity—Not Intelligence—Is the New Enterprise AI Advantage – Raktim Singh
- Why Enterprises Are Quietly Replacing AI Platforms with an Intelligence Supply Chain – Raktim Singh
- The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale – Raktim Singh
- The One Enterprise AI Stack CIOs Are Converging On: Why Operability, Not Intelligence, Is the New Advantage – Raktim Singh