The Enterprise AI Control Tower
Enterprise AI doesn’t fail because models aren’t smart enough.
It fails because autonomy isn’t governed.
The real moat is the Control Tower.
An enterprise AI Control Tower is a centralized operating layer that governs how AI systems behave in production—enforcing policies, monitoring risk, controlling costs, and ensuring autonomy remains auditable, reversible, and compliant at scale.
This is how CIOs and CTOs can govern agent sprawl, control cost, and make autonomy reliable across business units and regions

Executive takeaway
Autonomous AI will not fail in enterprises because models aren’t smart enough. It will fail because autonomy is being deployed without a production-grade operating environment—one that can see, control, audit, recover, and scale autonomous work across the enterprise. That operating environment is best understood as an Enterprise AI Control Tower, and the only scalable delivery model for it is Services-as-Software.

1) The moment autonomy becomes enterprise-real
The first wave of enterprise AI was largely read-only: copilots that summarized documents, drafted emails, or answered questions.
The new wave is different.
AI is increasingly expected to act: raise a purchase request, update a customer record, change an access policy, initiate a refund, trigger remediation, or coordinate multiple tools as a “digital colleague.” This broader move toward agentic AI is now explicitly discussed as a scaling challenge—where value depends on operating model and discipline, not just experimentation. (McKinsey & Company)
And the moment AI can act, executive questions change:
- Can we run this safely—every day—across the whole enterprise?
- Can we prove what the AI did, why it did it, and who approved it?
- Can we stop it instantly if it misbehaves?
- Can we control cost and performance without slowing delivery?
These are not model questions. They are operating questions.
This is also why agentic AI is forecast to be high-risk if not tied to outcomes and operating controls—Gartner has warned that a large share of agentic AI initiatives may be cancelled due to cost and unclear business value. (Reuters)
The next enterprise AI differentiator will not be intelligence. It will be operability.

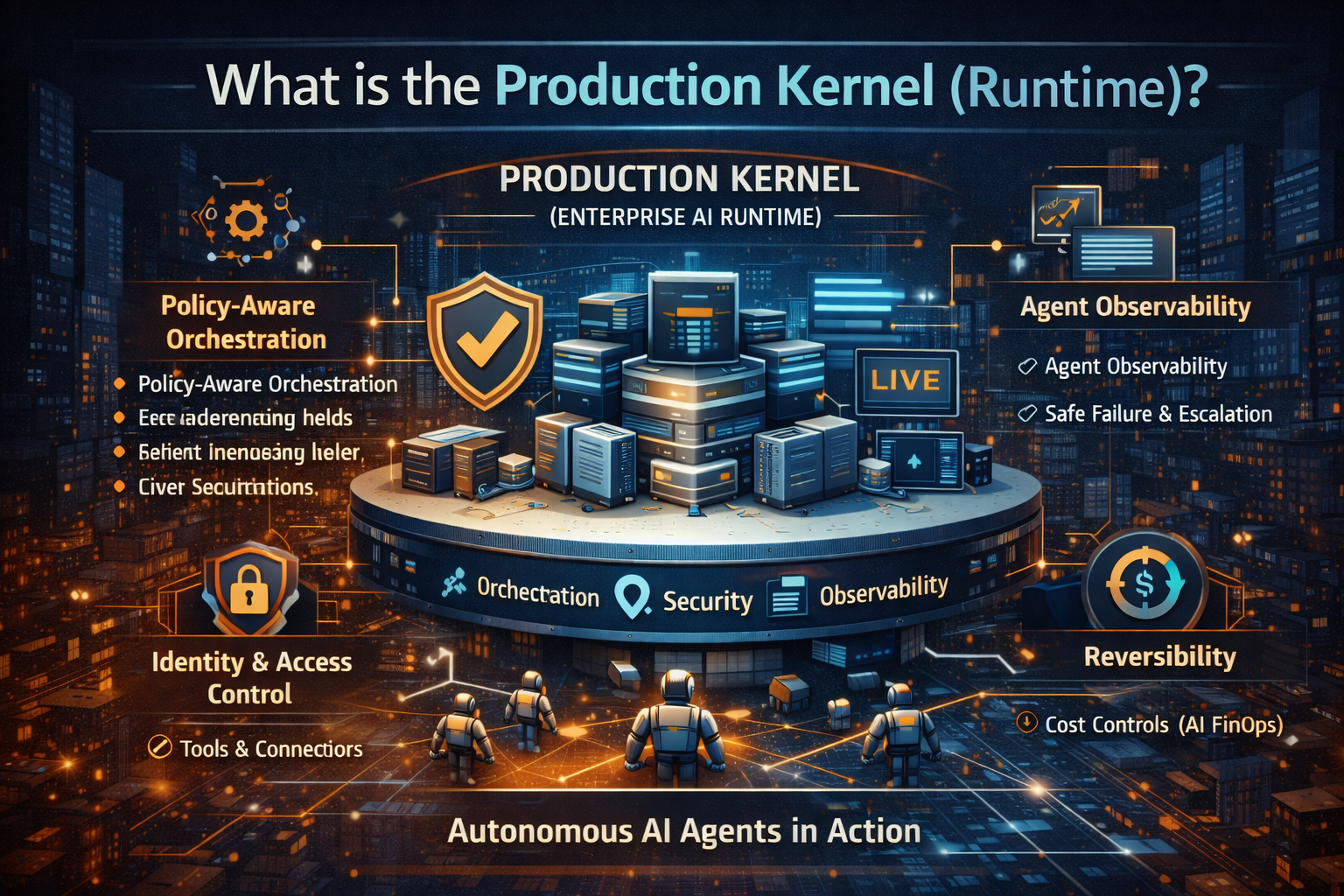
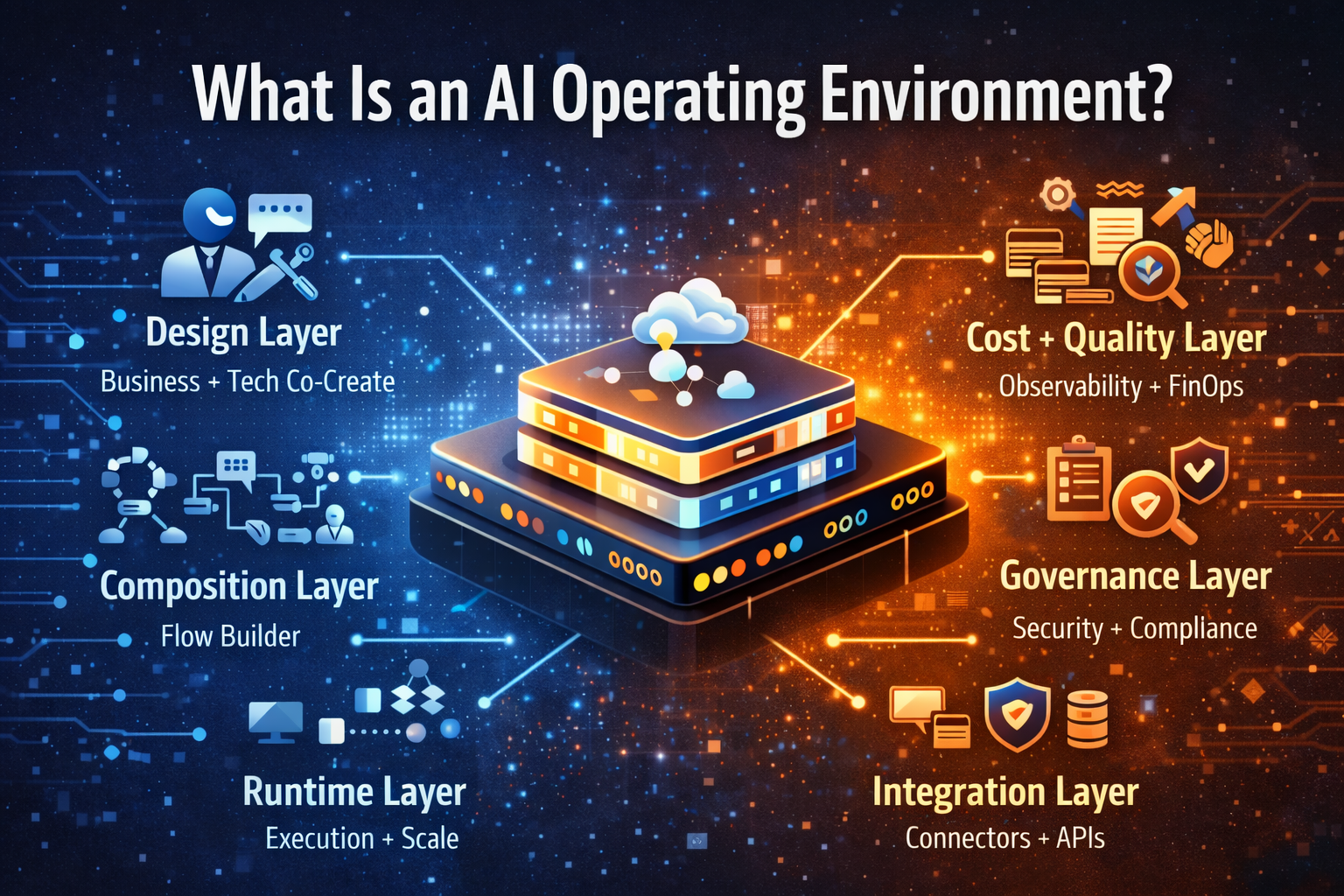
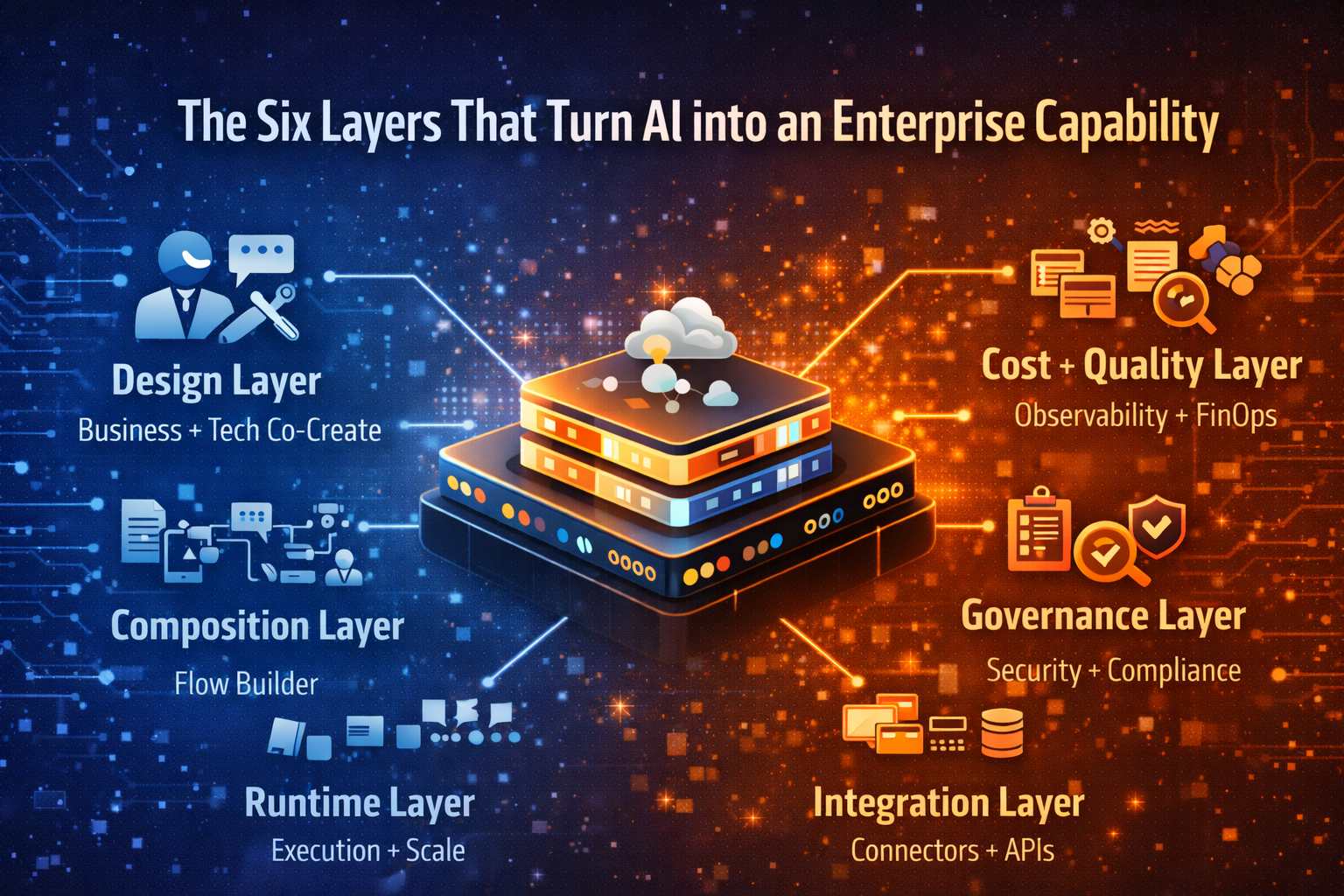
2) What is an Enterprise AI Control Tower?
Think of the Enterprise AI Control Tower as a single command center that can answer one question with confidence:
Across all agents, models, tools, and workflows—what is running, what is it doing, what is it costing, and is it staying within guardrails?
It is not a dashboard you bolt on at the end.
A Control Tower is an operating environment that coordinates governance, reliability, security, cost discipline, and quality as first-class capabilities, so autonomy can scale without becoming brittle, opaque, or expensive.
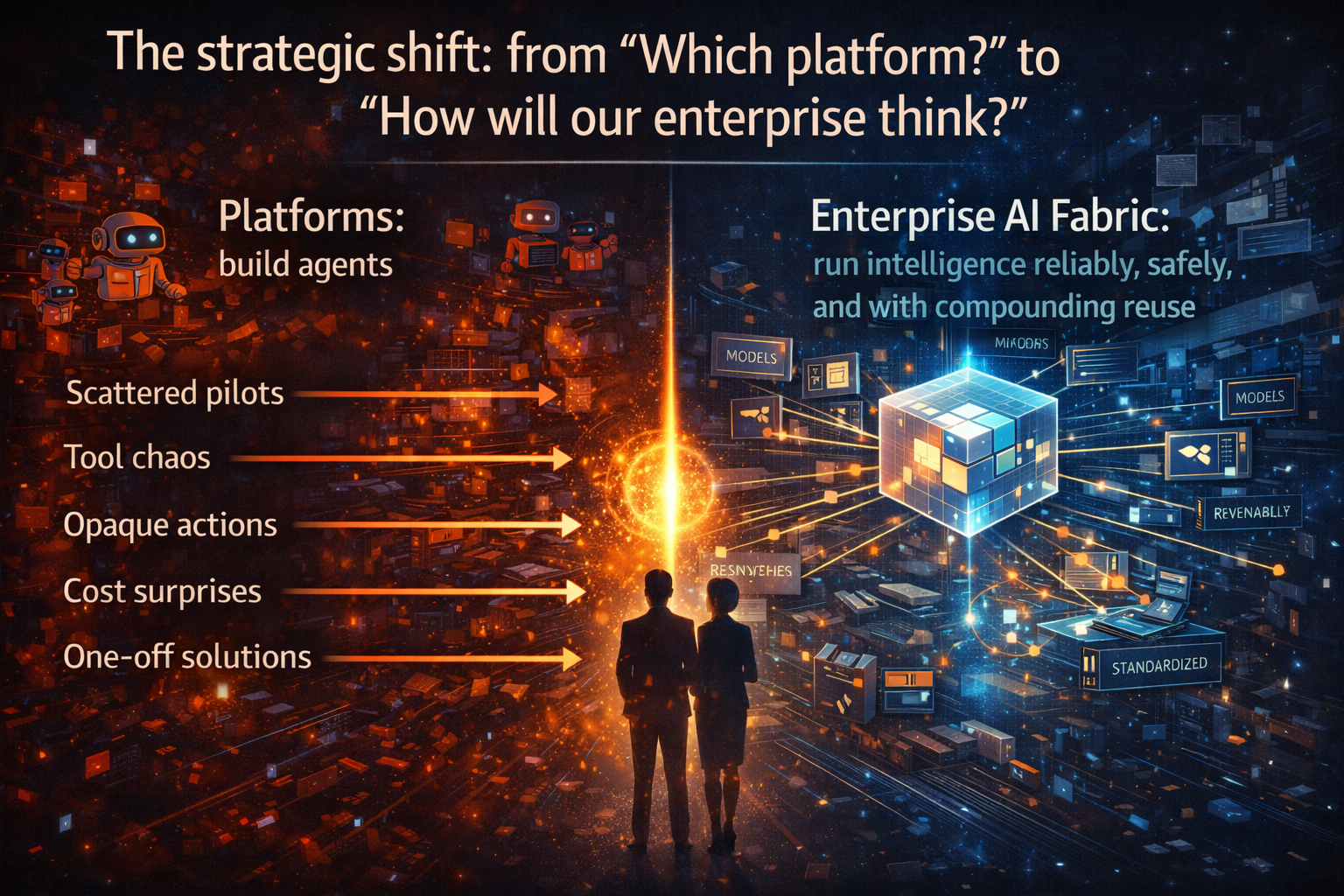
The term “control tower” matters because it signals a shift in mindset: from “building agents” to running autonomous work as critical infrastructure.

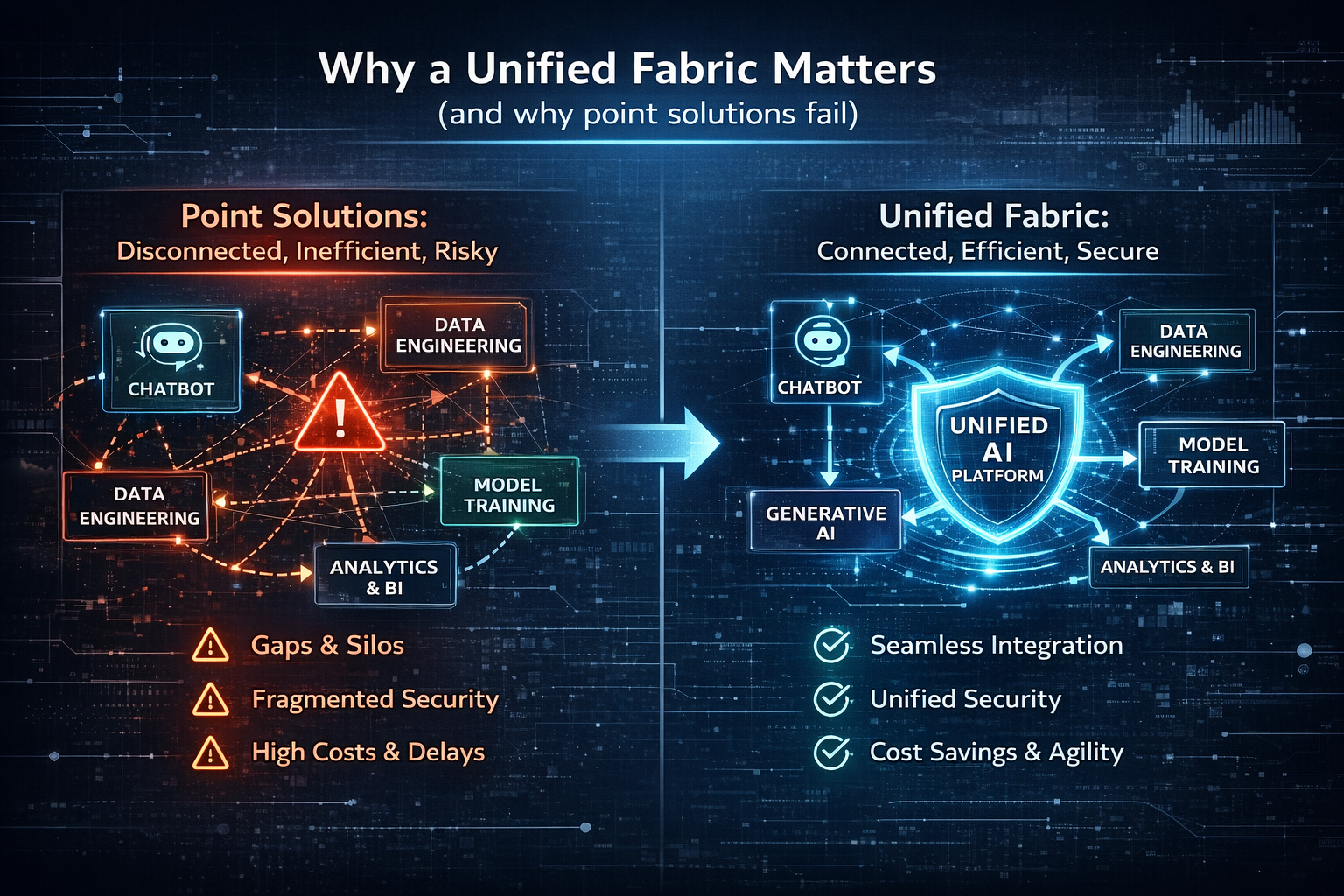
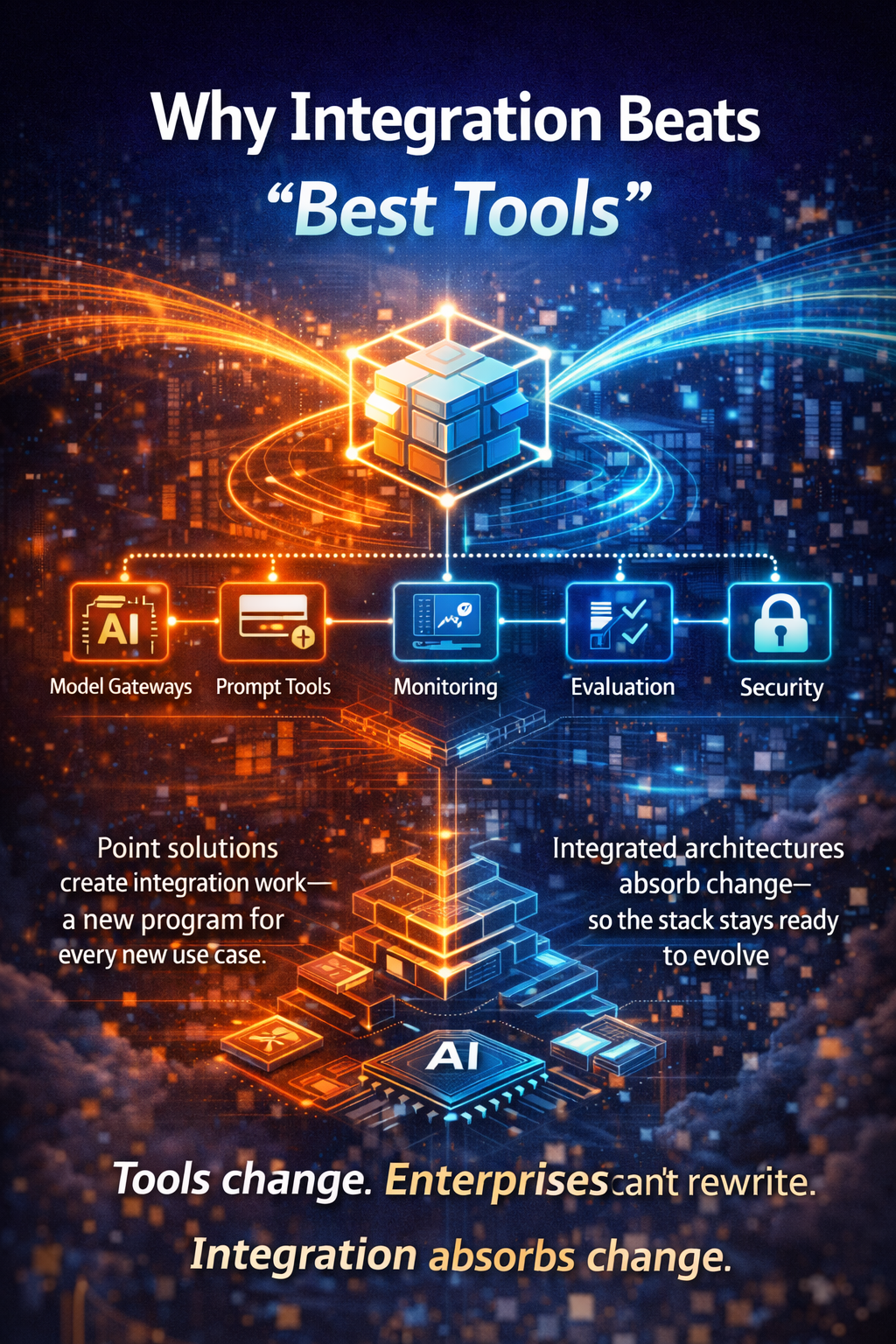
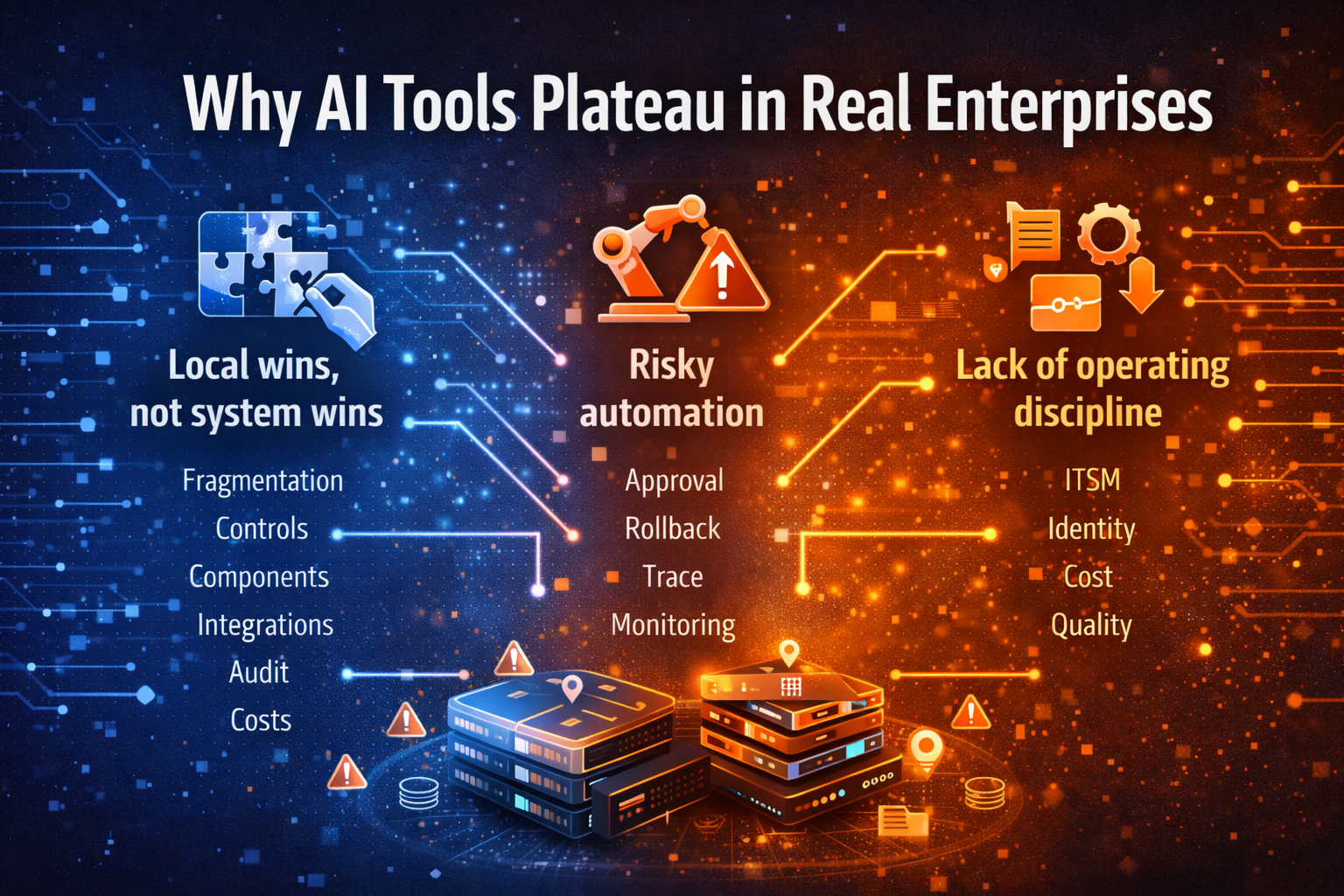
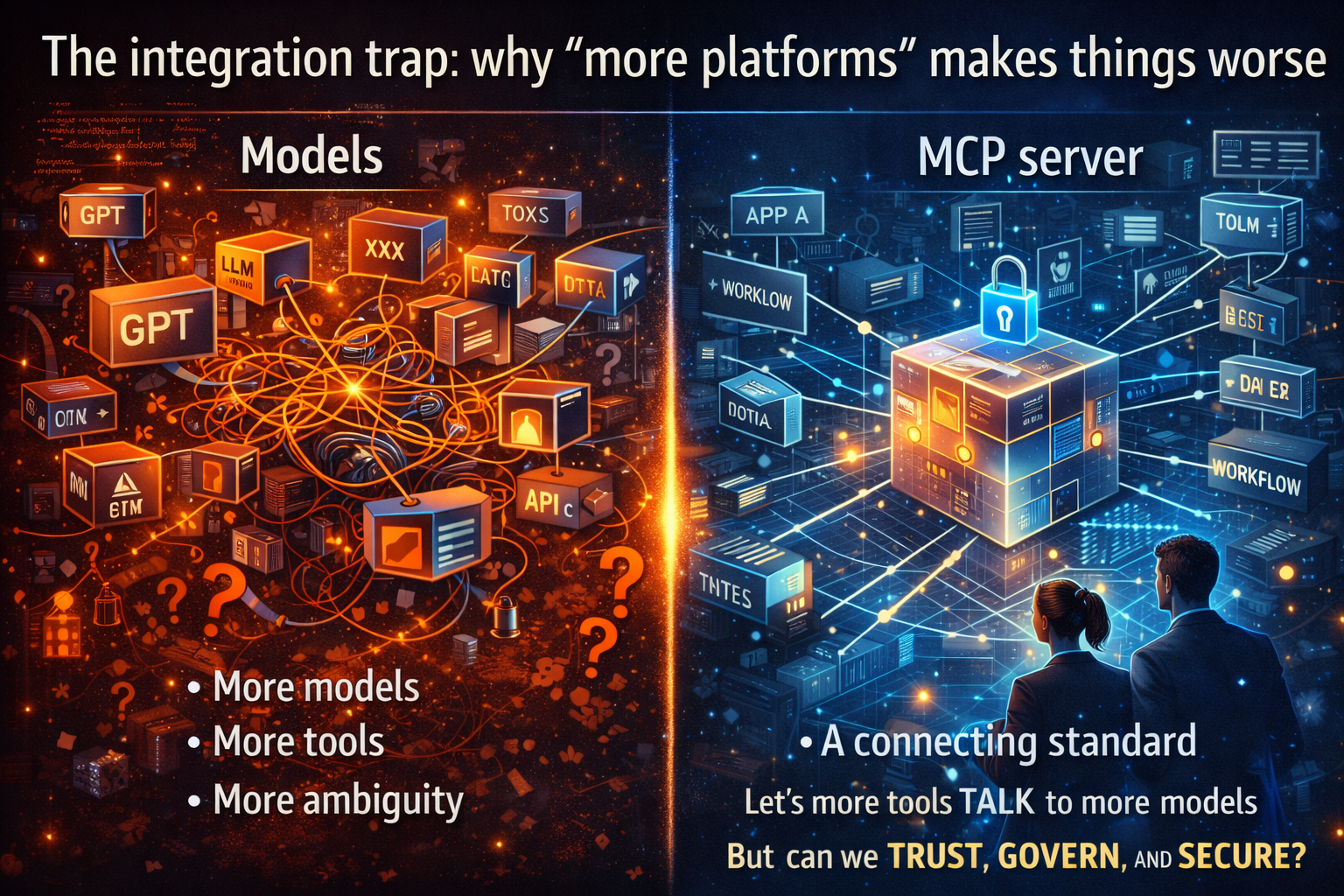
3) Why point solutions fail the moment you move beyond pilots
In pilot mode, teams often stitch together:
- an LLM API
- a prompt library
- retrieval/vector search
- an orchestration framework
- a few tool connectors
- a simple guardrail check
It works—until it doesn’t.
Because pilots tend to ignore enterprise constraints that show up only at scale:
- Identity and permissions are inconsistent (agents run with too much power).
- Tool calls are not logged end-to-end (no forensic trail).
- Costs jump unpredictably (retries, long contexts, parallel tool calls).
- Failures are messy (no rollback, no kill switch, no containment).
- The same capability gets rebuilt across business units.
- Security and quality teams join late—so production becomes negotiation.
This becomes agent sprawl: many agents, built quickly, integrated inconsistently, governed unevenly, and impossible to manage as a portfolio. The result is predictable: rising risk, rising cost, and stalled scaling.
In fact, the cancellation risk highlighted in Gartner’s outlook is often a symptom of exactly this pattern—projects launched with hype, then confronted by operational reality. (Reuters)
A Control Tower is how you prevent sprawl from turning into systemic risk.

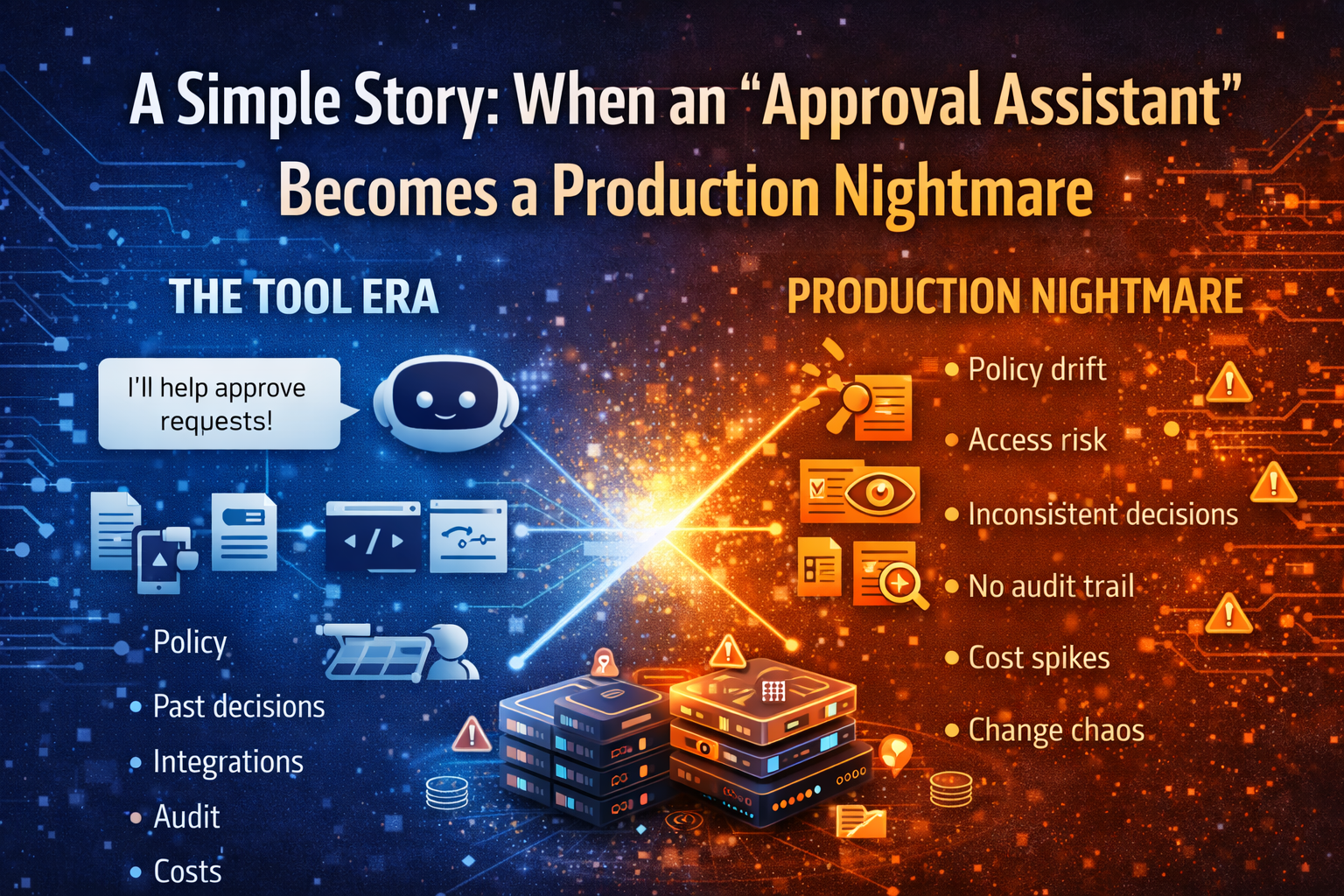
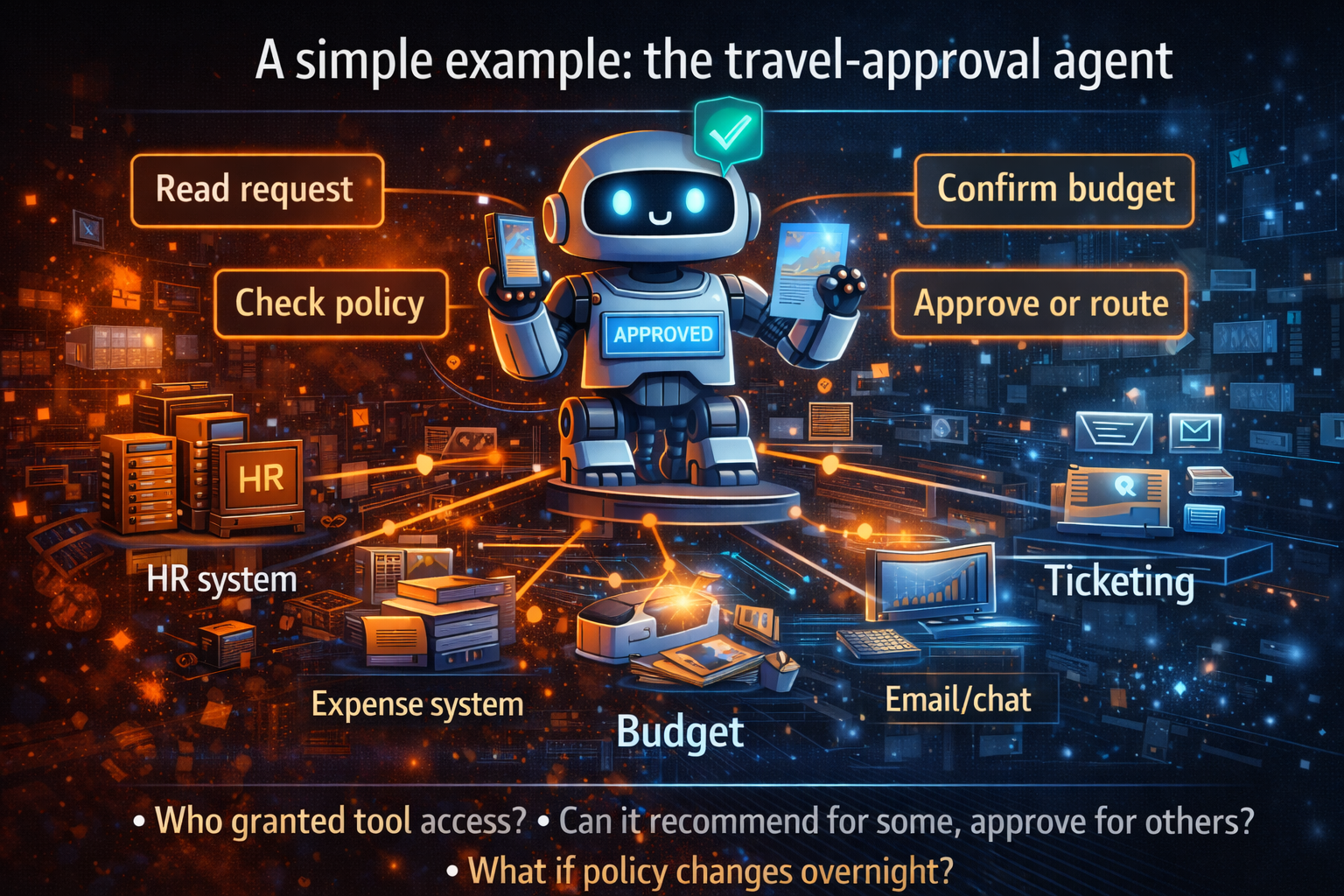
4) A simple example: the “Refund Agent” that looks correct—and still causes an incident
Imagine a Refund Agent in customer operations.
It reads policy, checks case details, verifies transaction history, and issues refunds under a defined threshold.
In a demo, it’s perfect.
In production, small changes create outsized impact:
- The policy document gets updated in one region but not another.
- The agent starts interpreting an exception clause too broadly.
- A downstream tool returns partial data intermittently.
- The agent retries automatically, multiplying tool calls and cost.
- Refund approvals spike for 90 minutes before anyone notices.
Nothing malicious happened. The model didn’t suddenly become “bad.”
This is a classic production failure mode: correct-looking autonomy operating without controlled runtime discipline.
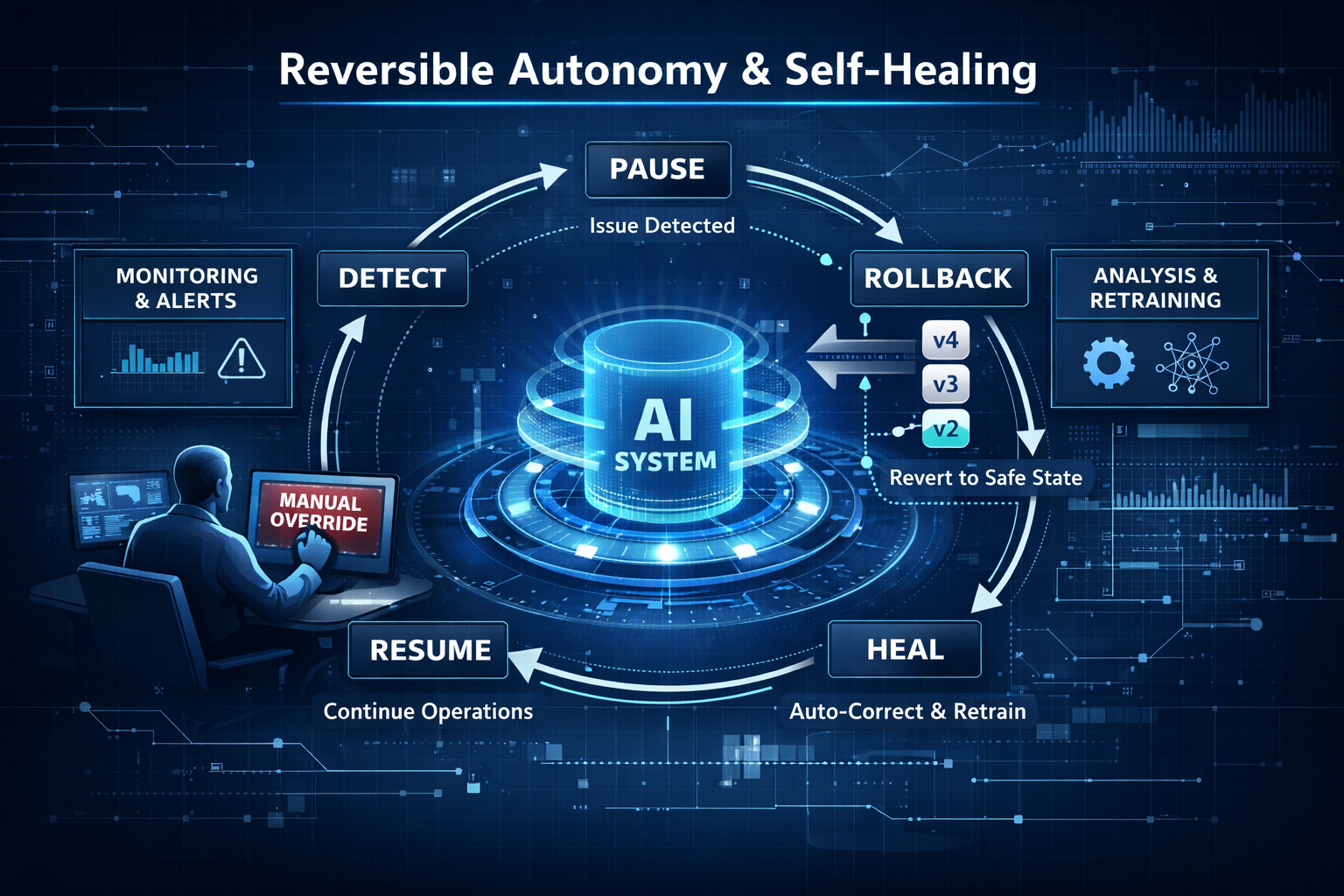
A Control Tower reduces this risk by making the system operable:
- policy versions are pinned and promoted like code,
- actions are permissioned and attributable,
- costs stay within envelopes,
- anomalies trigger alerts,
- rollback and containment are designed in, not improvised later.

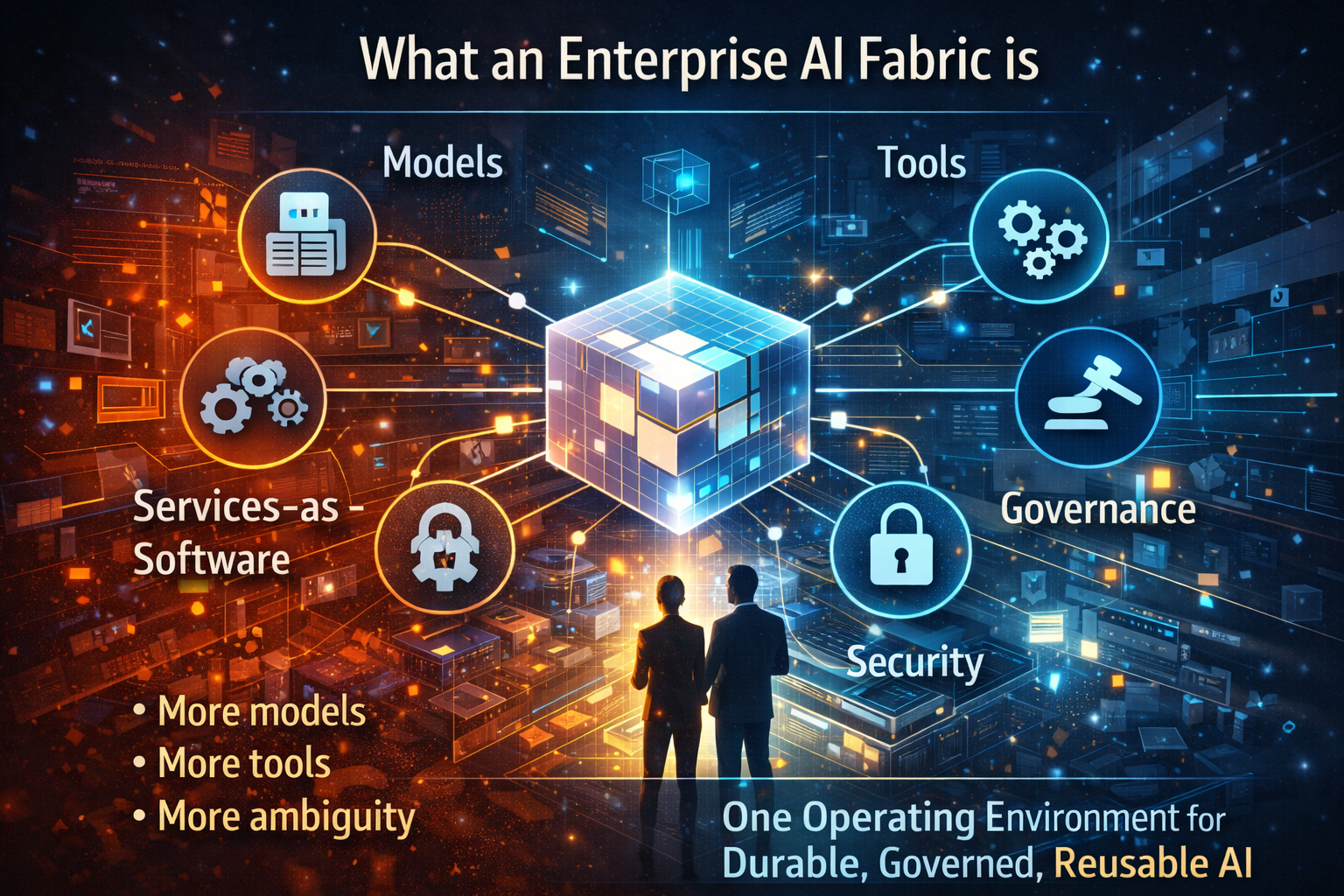
5) The missing piece: autonomy must become Services-as-Software
The Control Tower answers how to run autonomy.
But enterprises also need a way to package autonomy so it can be reused, governed, and scaled. That is where Services-as-Software becomes the only sustainable model.
Services-as-Software is a shift from:
- one-off AI projects,
- people-heavy rollouts,
- bespoke integrations,
to:
- modular, repeatable services,
- delivered with reliability,
- measurable outcomes,
- and built-in governance.
This is the same operating logic enterprises used to industrialize cloud: you don’t scale by rebuilding; you scale by standardizing services with clear controls.

6) Control Tower + Services-as-Software: the operating logic that scales
When you combine them, you get a practical, executive-friendly architecture and operating model:
- The Control Tower is the command center: portfolio governance, reliability, auditability, cost control, and security.
- Services-as-Software is the delivery mechanism: reusable, governed AI-led services teams can adopt without reinventing controls.
This is how enterprises move from:
- “We have pilots” → “We have capabilities.”
- “We built agents” → “We run autonomous work.”
- “Every team does it differently” → “We have a governed standard.”

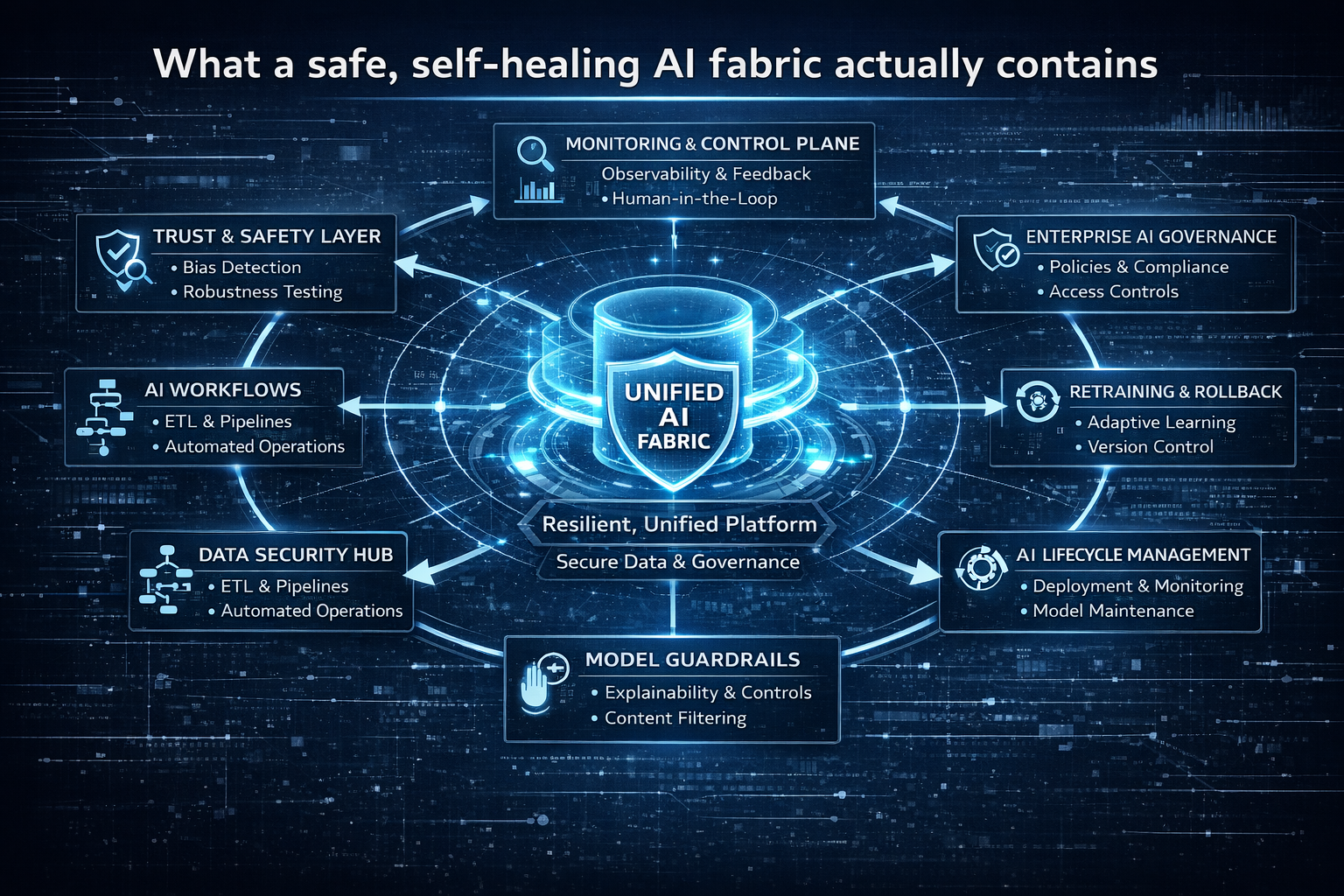
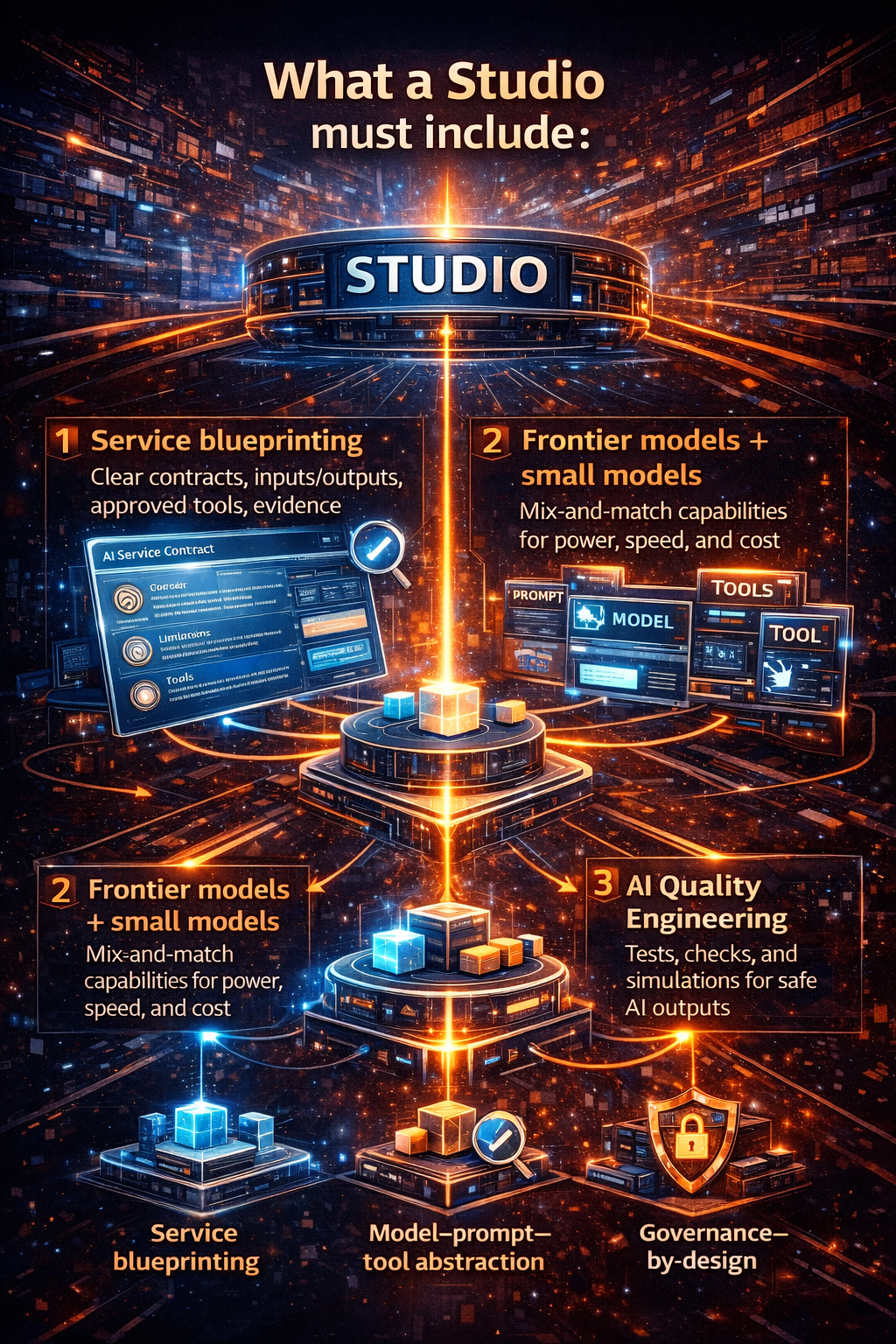
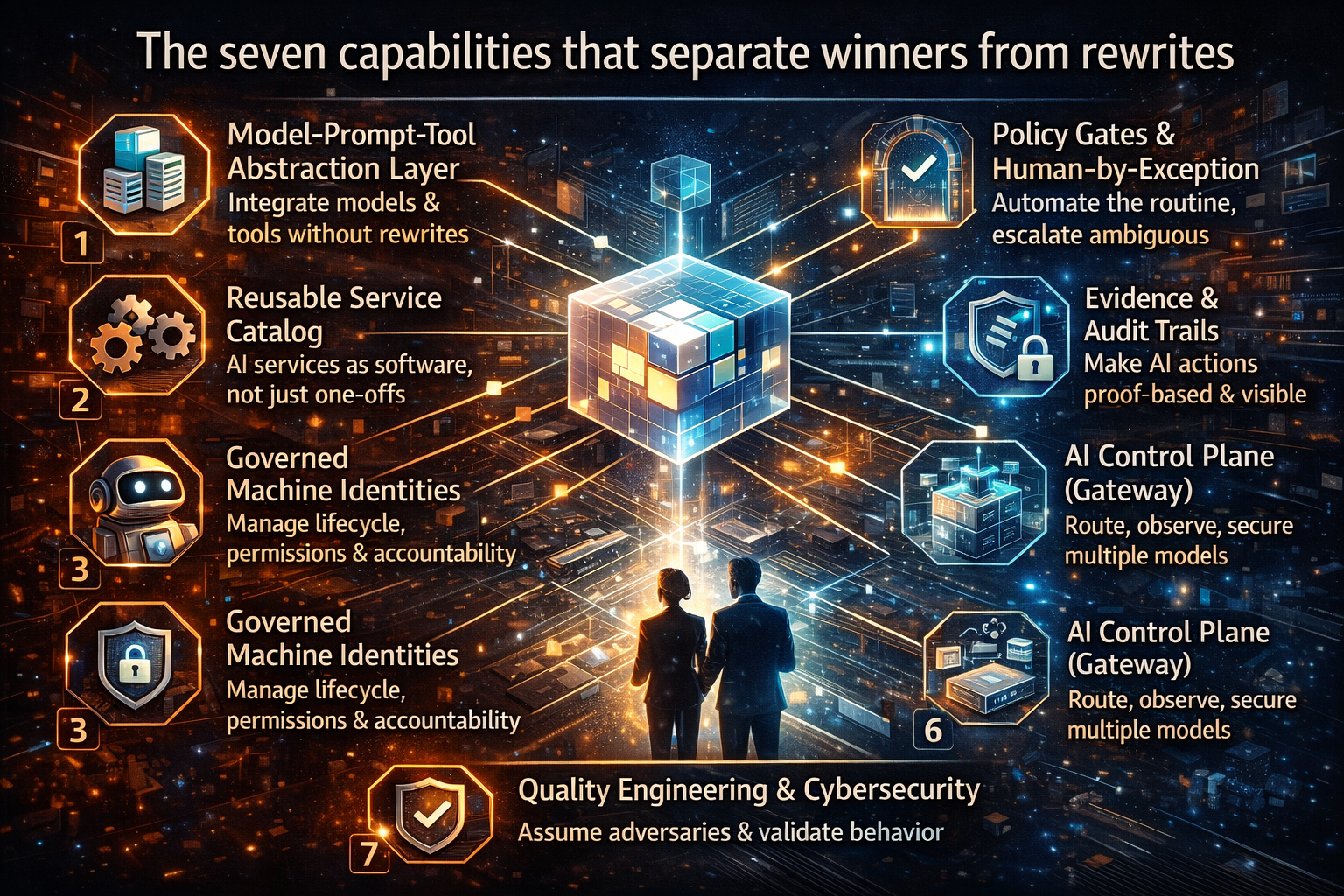
7) The 8 capabilities every AI Control Tower must provide
Below are the core capabilities—described in plain language, grounded in how production systems work.
1) Identity, access, and permissioned autonomy
Every agent must have a real identity, explicit permissions, and scoped tool access.
No shared credentials. No invisible privilege escalation. No “god-mode” service accounts.
2) Observability that covers reasoning and actions
Classic observability watches latency and error rates.
AI observability must also capture:
- which tools were invoked,
- what data was retrieved,
- what policy was referenced,
- what reasoning trace is available,
- and what changed in enterprise systems.
This is why “LLM observability” is being defined explicitly as visibility into inputs, tool calls, outputs, and performance across the workflow. (Arize AI)
3) Policy enforcement as runtime controls
Guardrails cannot live only in prompts.
They must exist as enforceable runtime rules:
- allowed actions,
- forbidden actions,
- approval thresholds,
- escalation conditions,
- region-specific compliance policies.
This aligns with the direction of formal AI management and risk frameworks: operational controls, lifecycle management, and governance systems—not just ethics statements. (ISO)
4) Cost envelopes and budget predictability
Autonomy is compute-consuming and retry-prone.
A Control Tower needs cost controls such as:
- per-agent spend limits,
- per-workflow ceilings,
- throttling when costs spike,
- usage and chargeback visibility.
FinOps principles emphasize shared, consistent cost visibility and governance—an idea that becomes even more urgent when autonomous workflows can multiply consumption quickly. (FinOps Foundation)
5) Quality engineering for agents, not just models
When AI can act, quality includes:
- correct execution,
- safe failure,
- reproducibility,
- controlled rollouts,
- regression testing for tool interactions.
This is the foundation of enterprise trust: not just whether the output sounds right, but whether the system behaves safely under changing conditions.
6) Security-by-design across tools, data, and prompts
Enterprises need defenses against:
- prompt injection,
- data leakage,
- unsafe tool calls,
- hidden side effects.
Security cannot be “added later” because agents interact with real systems continuously.
7) Rollback, containment, and reversible autonomy
This is the Control Tower’s non-negotiable rule:
Every autonomous action must be stoppable. Every high-impact outcome must be reversible.
Rollback is not only technical. It includes:
- undoing business actions,
- revoking access,
- reverting prompt/policy versions,
- disabling workflows cleanly.
8) Portfolio governance and managed autonomy at scale
Finally, the Control Tower must answer portfolio questions:
- Which agents exist?
- Who owns them?
- Which capabilities do they support?
- Which are safe to expand?
- Which are drifting from policy?
- Which are costing too much?
This is what turns experiments into an operating model.
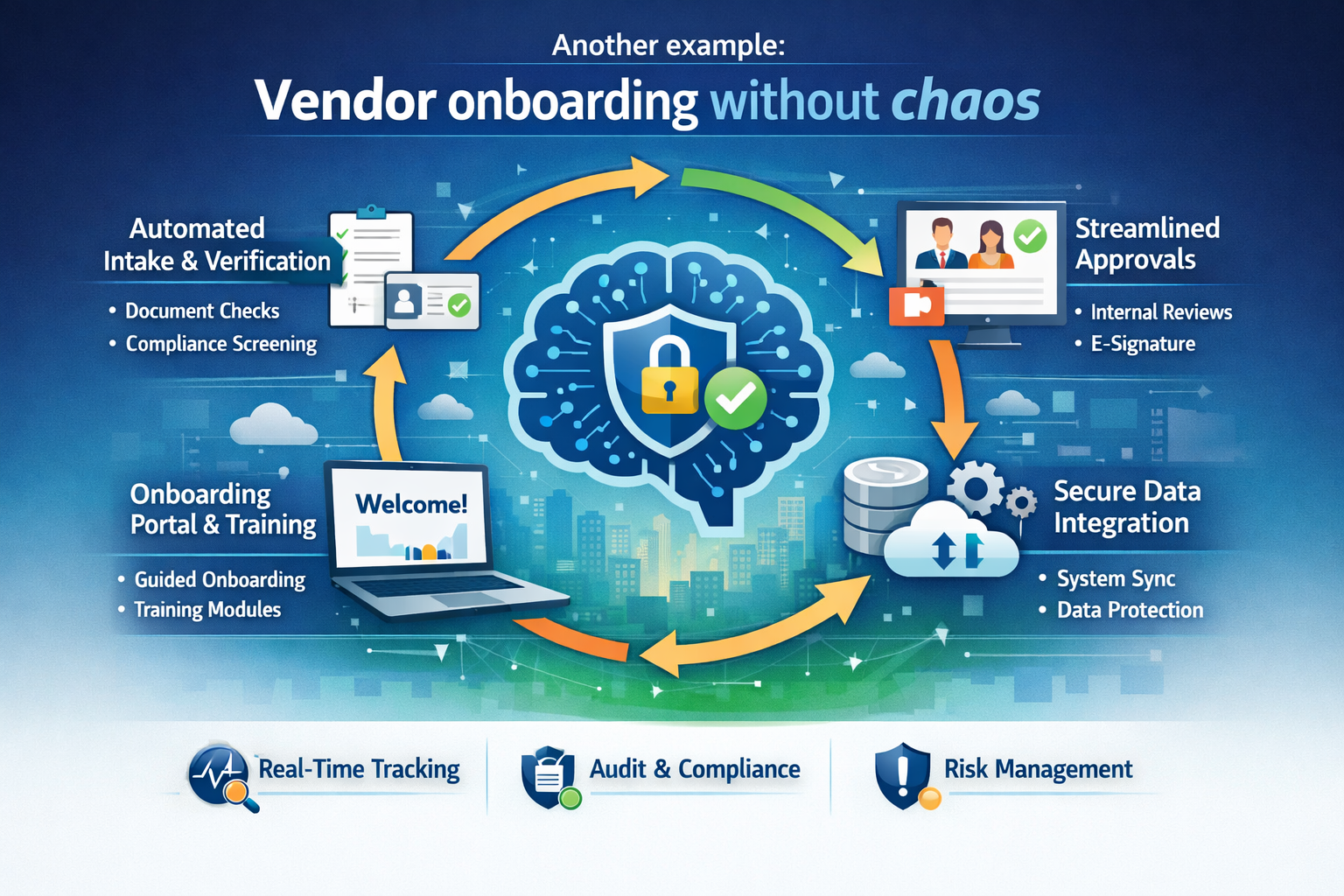
8) Another example: Vendor onboarding without chaos
Vendor onboarding touches compliance checks, document verification, risk scoring, contract creation, ERP setup, and approvals.
A pilot agent might automate one step.
Services-as-Software packages the entire capability into modular services:
- document intake service
- risk summarization service
- policy check service
- ERP onboarding service
- approval workflow service
The Control Tower ensures each service is auditable, permissioned, monitored, cost-bounded, and consistent across business units and regions.
The result is not “an agent.”
The result is a reusable enterprise capability.

9) The global reality: why this matters across regions, not just one market
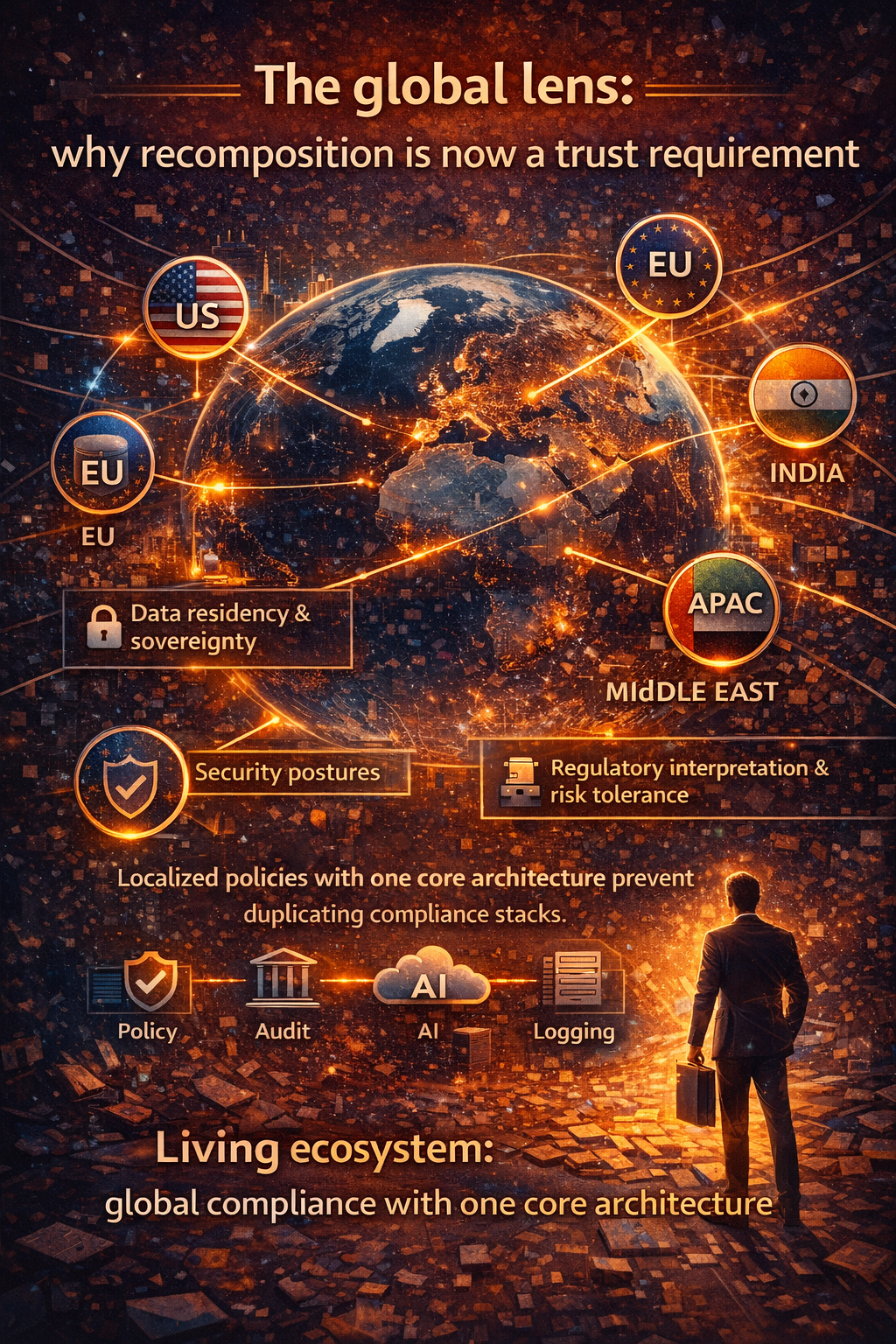
Once autonomy enters production, geography matters immediately:
- different data residency rules
- different regulatory expectations
- different audit requirements
- different languages and operating norms
- different vendor ecosystems and platform mixes
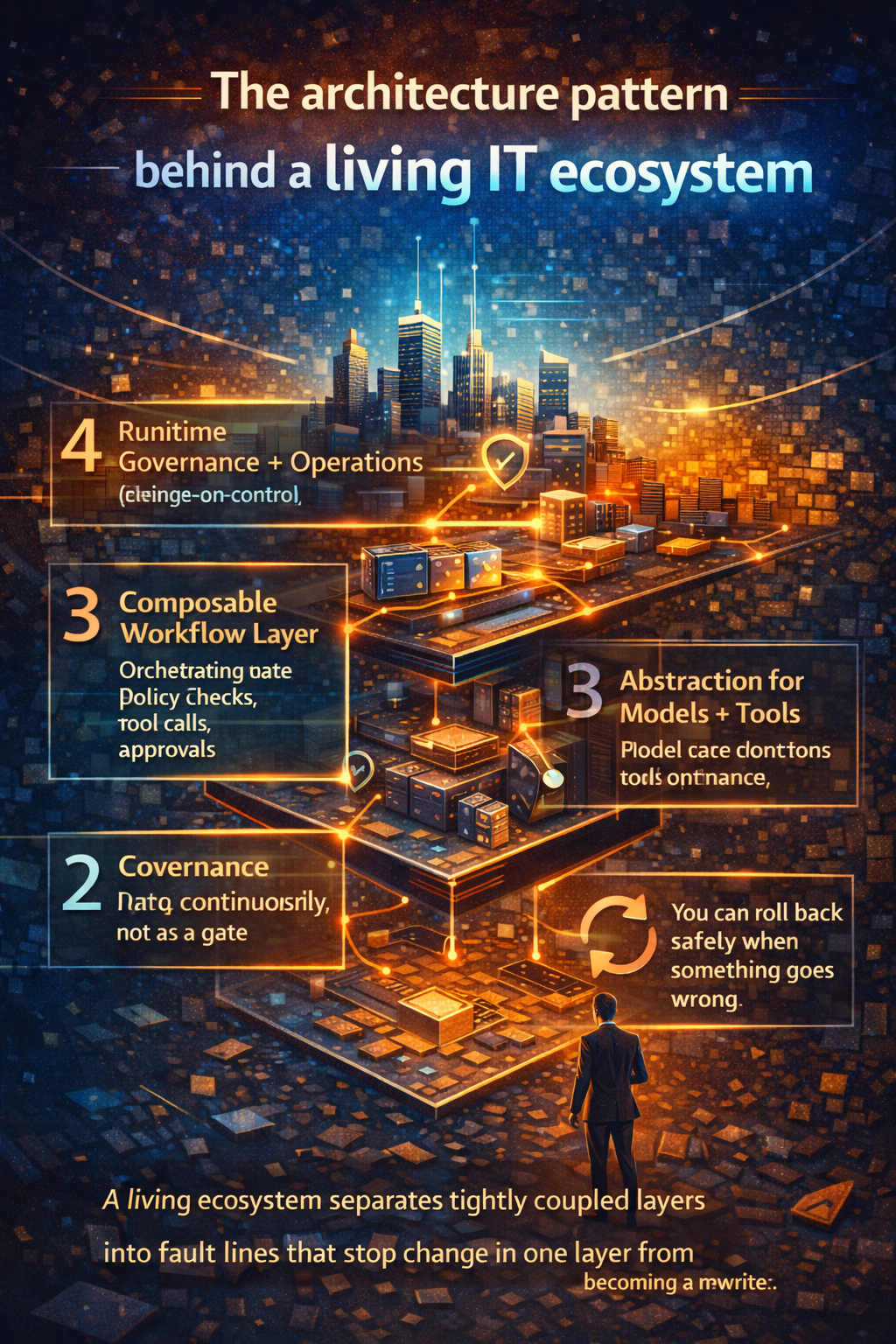
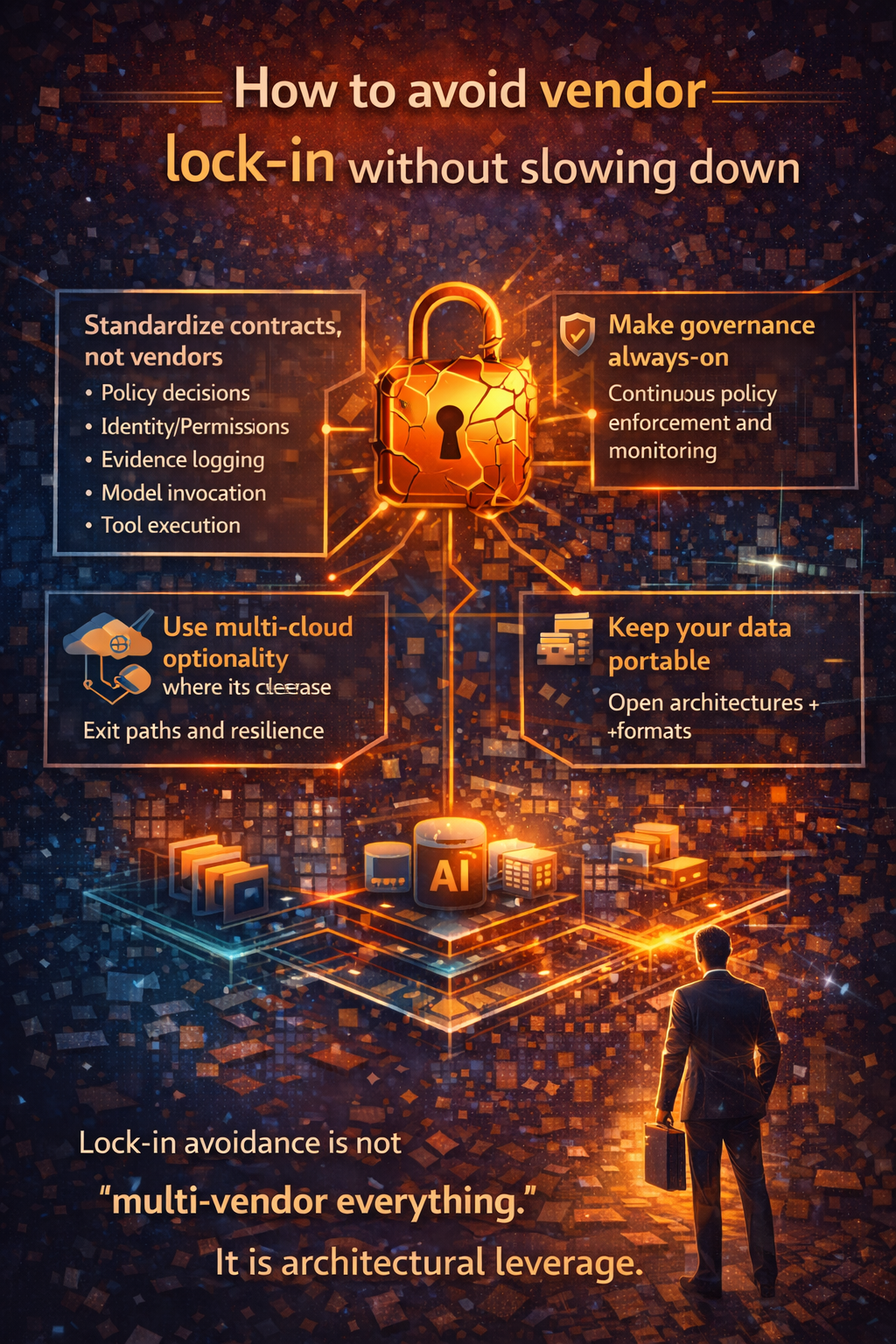
This is why the winning approach is not a single point tool. It is an open, interoperable, reusable stack that can evolve without constant rebuilds.
And it’s why governance standards and frameworks (like ISO/IEC 42001 and NIST AI RMF) are increasingly relevant—not as paperwork, but as blueprints for operational discipline. (ISO)
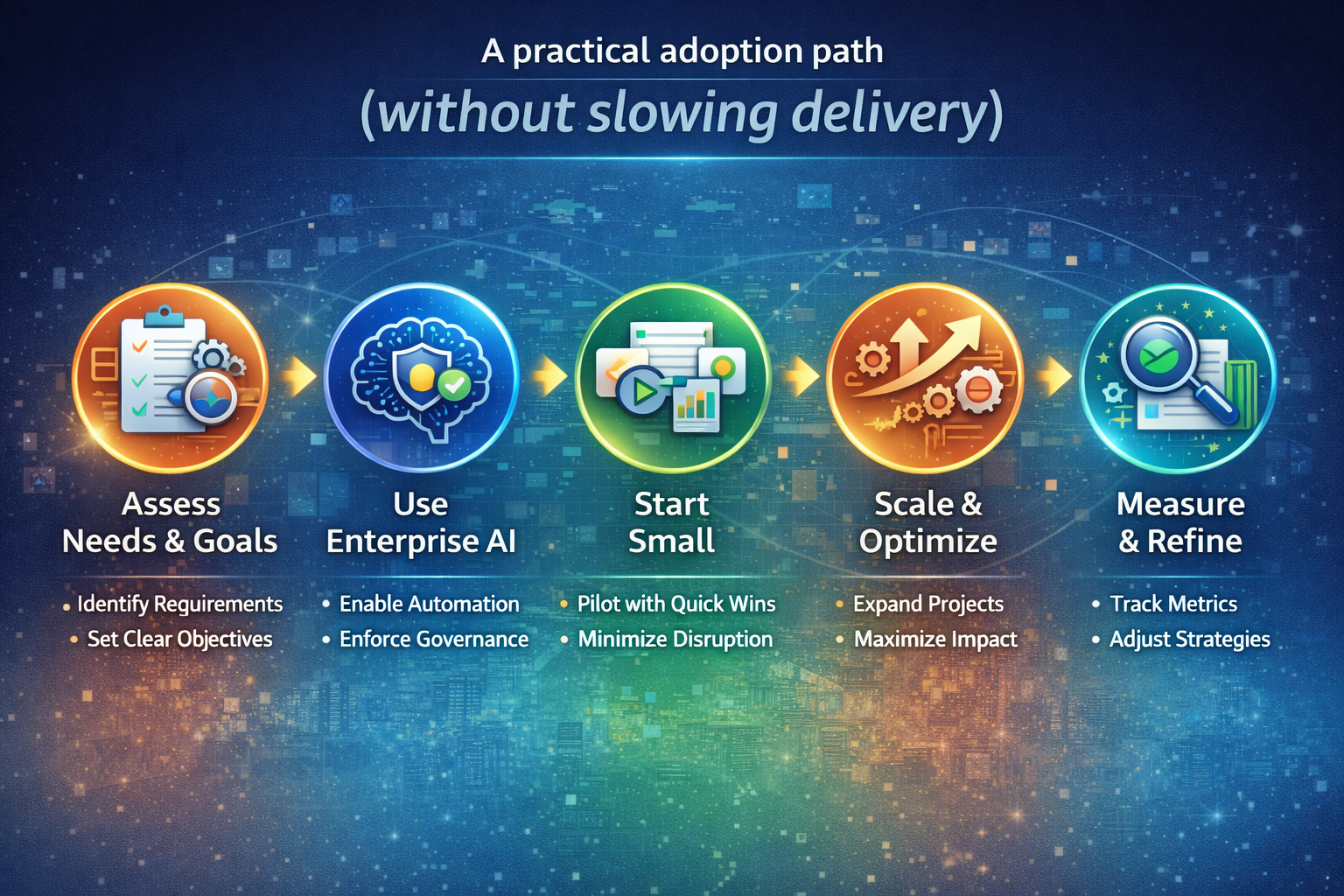
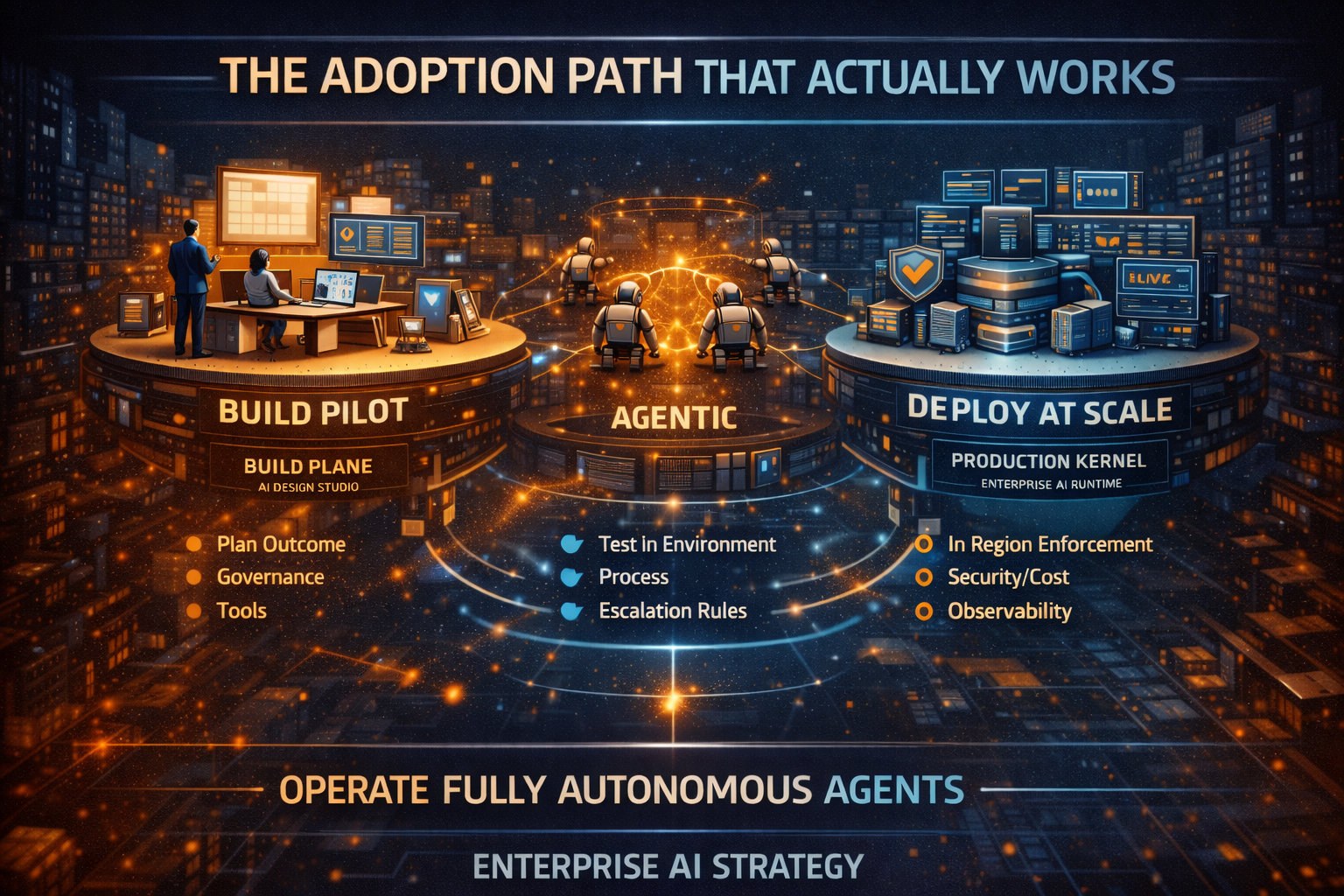
10) A practical adoption path (without slowing delivery)
Don’t attempt “big bang autonomy.” Use a staged approach:
Phase 1: Standardize Control Tower foundations
- identity and permissions for agents
- tool access governance
- end-to-end traces and auditability
- runtime guardrails and escalation paths
Phase 2: Productize 3–5 high-value services
Choose processes that are repetitive, high-volume, and error-sensitive—where controlled autonomy produces visible value quickly.
Phase 3: Scale by reuse, not rebuild
Every new team should consume approved services through standard runtime controls.
That’s how you scale without sprawl.
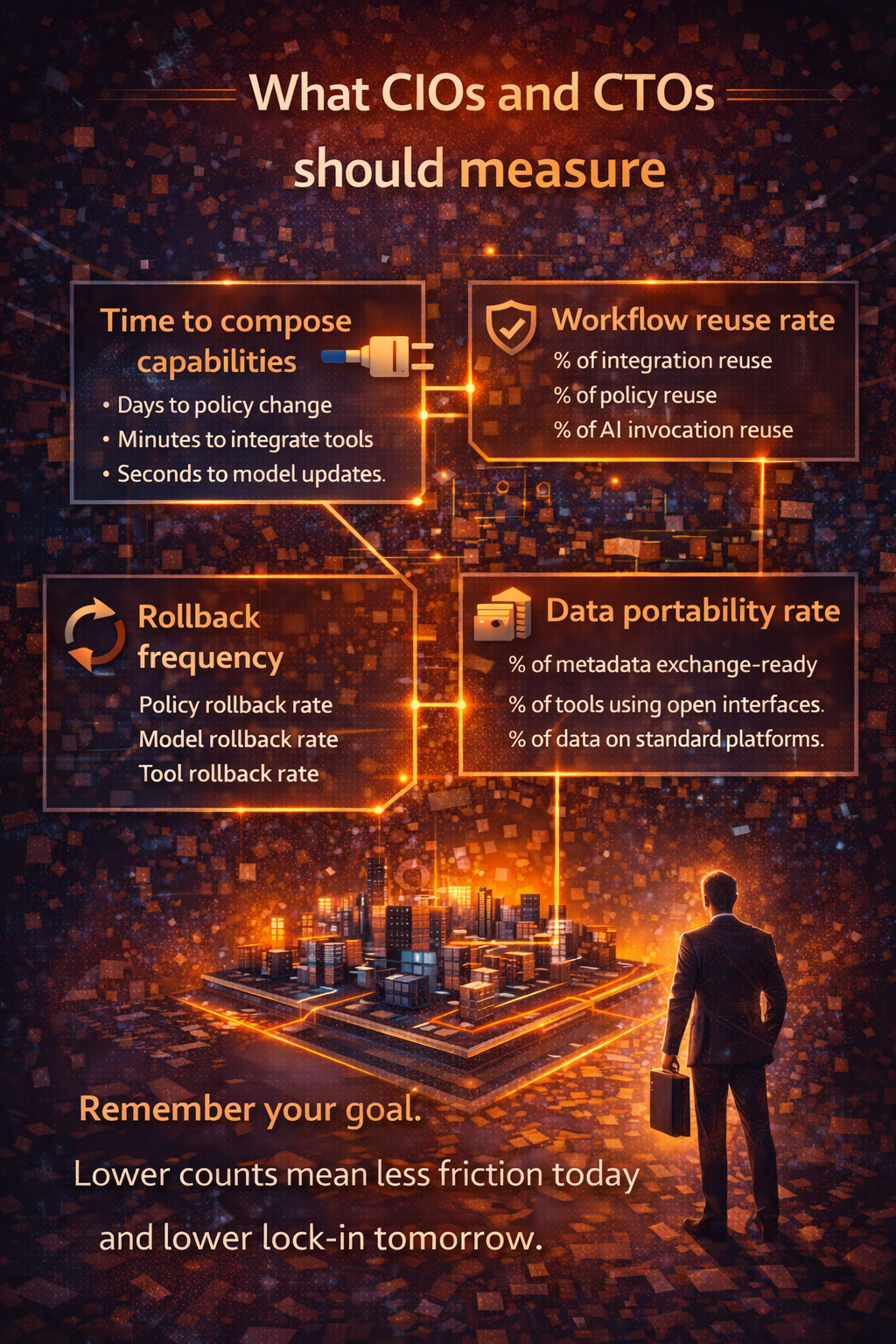
11) What to ask any platform or partner (Control Tower readiness)
Ask these eight questions:
- Can you show a complete trace of agent actions across tools and systems?
- Can you enforce permissions and approval gates at runtime, not just in prompts?
- Can you cap spend per workflow and alert on anomalies?
- Can you roll back prompts, policies, workflows, and actions cleanly?
- Can you reuse modular services across teams without re-implementing governance?
- Can you integrate new models without rebuilding the whole system?
- Can you prove auditability and compliance posture across regions?
- Can you run this reliably for years, not weeks?
If the answer is “we can build that,” you’re not buying a platform—you’re buying a multi-year integration project.
Services-as-Software exists to eliminate that trap.

Conclusion: The Control Tower is the real enterprise moat
The next enterprise AI era will be shaped by a simple truth:
Autonomy doesn’t fail at intelligence. It fails at control.
Enterprises that win will not be the ones with the most agents.
They will be the ones that can run autonomous work as critical infrastructure—with an AI Control Tower, and Services-as-Software that makes autonomy repeatable, governable, and scalable.
That is how organizations turn AI from demos into durable advantage.
This article is part of a broader architectural framework defined in the Enterprise AI Operating Model, which explains how organizations design, govern, and scale intelligence safely once AI systems begin to act inside real enterprise workflows.
👉 Read the full operating model here:
https://www.raktimsingh.com/enterprise-ai-operating-model/
Glossary
- Enterprise AI Control Tower: A unified command center for governing and operating AI agents across identity, cost, observability, quality, security, and rollback.
- Services-as-Software: Packaging AI-enabled services as modular, reusable capabilities delivered with built-in governance and reliability.
- Agent sprawl: Uncontrolled growth of inconsistent agents across teams, creating security, cost, and reliability risks.
- LLM/Agent observability: Visibility into AI system behavior across inputs, tool calls, outputs, traces, quality signals, and cost. (Arize AI)
- Managed autonomy: Autonomy operated with guardrails, accountability, and reversible controls.
- ISO/IEC 42001: A standard for AI management systems, guiding organizations in responsible, systematic AI governance. (ISO)
- NIST AI RMF: A voluntary framework to manage AI risk and incorporate trustworthiness into AI design, development, and use. (NIST)
- FinOps: A practice and framework for visibility, governance, and optimization of usage-based technology spend. (FinOps Foundation)
FAQ
1) Is an AI Control Tower just another dashboard?
No. A dashboard reports. A Control Tower operates—it enforces identity, controls, auditability, and rollback as runtime capabilities.
2) Why can’t each team build its own agents?
Because autonomy is a portfolio risk. Without shared controls, you get sprawl, inconsistent permissions, weak audit trails, and runaway costs—often leading to cancelled initiatives. (Reuters)
3) What makes Services-as-Software different from “automation”?
Automation is usually local and brittle. Services-as-Software is modular, reusable, governed delivery—the same capability consumed across teams with consistent controls.
4) Does this slow down innovation?
Done correctly, it speeds delivery because teams reuse pre-governed services instead of rebuilding guardrails, security, and observability from scratch.
5) What’s the first step to implement this?
Start with identity/permissions, end-to-end traces, and rollback/containment. Then productize a small set of services and scale by reuse.
What is an enterprise AI Control Tower?
It is the operational layer that governs AI behavior in production, ensuring compliance, observability, security, and controlled autonomy across systems.
Why is a Control Tower critical for AI at scale?
Because once AI can act, enterprises need centralized oversight to manage risk, cost, policy adherence, and recovery—across thousands of AI-driven decisions.
How is this different from AI governance frameworks?
Frameworks define principles. A Control Tower enforces them continuously in live production environments.
Is this relevant only for regulated industries?
No. Any enterprise running AI across multiple teams, tools, or geographies needs centralized control to avoid fragmentation and risk.
References
- McKinsey (2025): Global AI adoption and growth in agentic AI; scaling depends on operating model and management practices. (McKinsey & Company)
- Gartner via Reuters (Jun 25, 2025): Warning that many agentic AI projects may be scrapped due to costs and unclear outcomes. (Reuters)
- ISO/IEC 42001 (2023): Guidance for an AI management system and responsible AI governance. (ISO)
- NIST AI RMF 1.0 (2023): Voluntary framework for AI risk management and trustworthiness. (NIST)
- FinOps Foundation: Principles and Policy & Governance capability for visibility and predictable spend. (FinOps Foundation)
- LLM Observability (industry definitions): Observability across inputs, tool calls, outputs, traces, and evaluations. (Arize AI)
Further reading
- NIST AI Risk Management Framework overview and the AI RMF 1.0 publication. (NIST)
- ISO/IEC 42001 overview for AI management systems. (ISO)
- McKinsey perspectives on agentic AI and the operating model shifts required to scale. (McKinsey & Company)
- FinOps Foundation principles and governance guidance for usage-based spend. (FinOps Foundation)
- The One Enterprise AI Stack CIOs Are Converging On: Why Operability, Not Intelligence, Is the New Advantage – Raktim Singh
- The Living IT Ecosystem: Why Enterprises Must Recompose Continuously to Scale AI Without Lock-In – Raktim Singh
- Studio-to-Runtime: Why Enterprise AI Fails Without a Build Plane and a Production Kernel – Raktim Singh
- Enterprise AI Runtime: Why Agents Need a Production Kernel to Scale Safely – Raktim Singh
- Why Enterprises Need Services-as-Software for AI: The Integrated Stack That Turns AI Pilots into a Reusable Enterprise Capability – Raktim Singh
- The Enterprise AI Service Catalog: Why CIOs Are Replacing Projects with Reusable AI Services | by RAKTIM SINGH | Dec, 2025 | Medium
- Services-as-Software: Why the Future Enterprise Runs on Productized Services, Not AI Projects | by RAKTIM SINGH | Dec, 2025 | Medium
- Enterprise AI Fabric: Why AI Is Shifting from Applications to an Operational Layer: By Raktim Singh