")
Most “agent platforms” age in six months.
Not because AI moves fast—but because architecture doesn’t.
The missing layer isn’t another framework.
It’s a Model-Prompt-Tool Abstraction Layer.
This article explains why.
Enterprise AI has moved past the phase of asking “Which LLM should we choose?”
The harder—and far more consequential—question now is:
How do we keep AI systems useful when models, prompts, tools, and standards change every quarter?
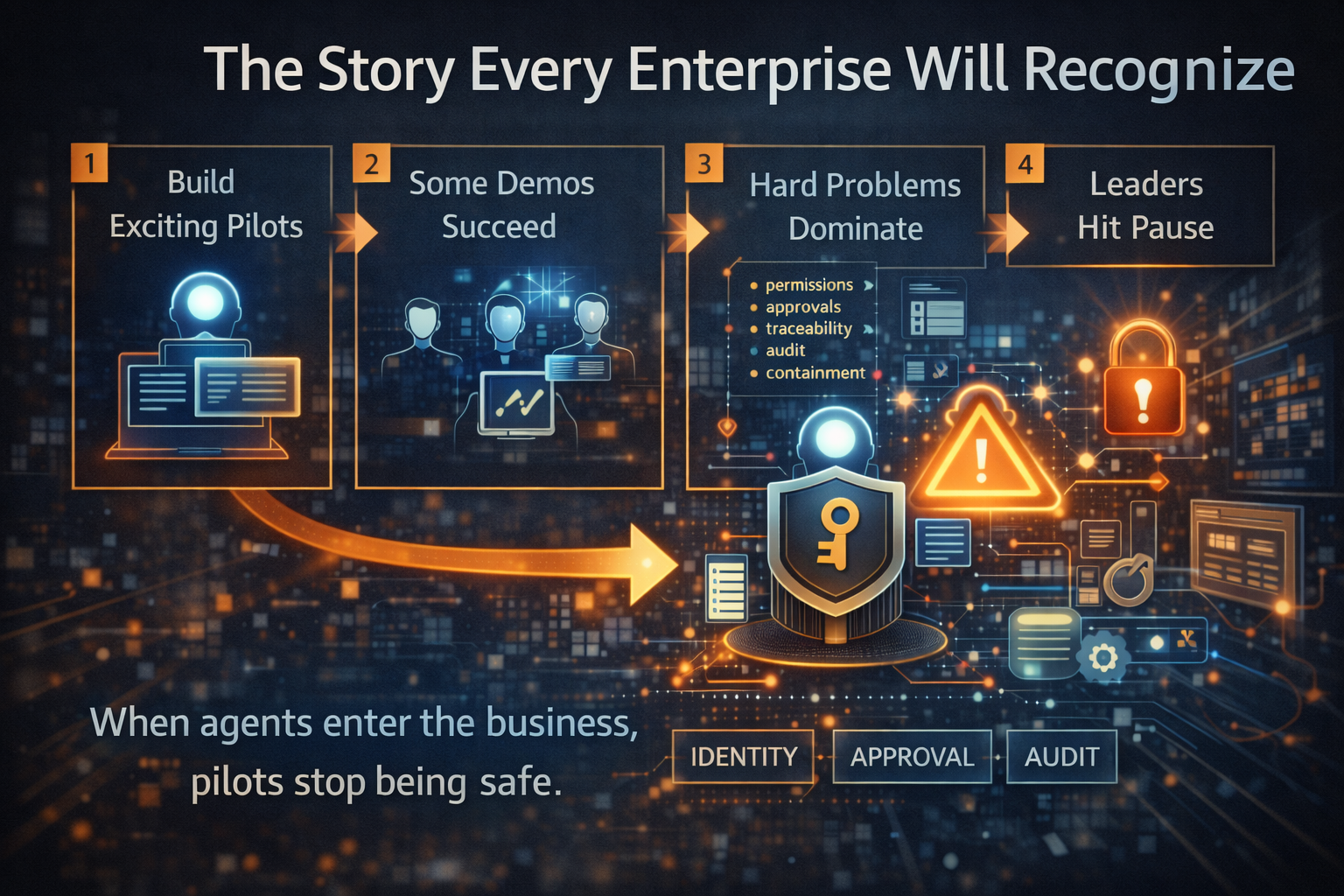
This is not a theoretical concern. Enterprises across industries are discovering that agent platforms built just months ago already feel brittle, expensive to change, and difficult to govern.
If you are wiring your AI initiatives tightly to:
- a single model provider,
- a fixed prompt style embedded in code, and
- bespoke tool integrations glued together project by project,
you are recreating the integration mistakes of the SOA era—except this time the pace of change is faster, the blast radius is larger, and the cost of failure is measured in trust, compliance, and operational risk.

The answer is not another framework.
It is an architectural boundary.
A Model-Prompt-Tool Abstraction Layer (MPT-AL) is the missing layer that decouples enterprise workflows from the rapid churn of AI models, prompt practices, and tool protocols—while allowing innovation to continue at full speed.
If you get this layer right, your AI estate evolves smoothly.
If you don’t, your “agent platform” will age in six months—because the ecosystem will.

The six-month problem: why agent platforms age so fast
Traditional enterprise platforms age slowly. Databases, ERPs, and middleware evolve over years.
Agent platforms age fast because three independent layers evolve on different clocks:
-
Models evolve unpredictably
New models arrive with different reasoning styles, tool-calling reliability, latency profiles, cost curves, and safety behaviors. APIs remain “compatible” on paper while behavior shifts in practice. Enterprises that bind workflows directly to one model experience constant retuning and regression risk.
-
Prompts evolve continuously
Prompts are not strings. In real enterprises, prompts encode:
- policy interpretation,
- tone and intent,
- compliance constraints,
- tool-usage instructions.
As teams learn from production failures—or as regulations and audit expectations change—prompts must evolve safely and traceably. Hard-coding them into application logic guarantees fragility.
-
Tools evolve relentlessly
APIs change versions, schemas, authentication models, and rate limits. Meanwhile, the industry is converging on standardized ways for models to discover and invoke tools dynamically—accelerating integration while raising new security and governance concerns.
When these three layers are tightly coupled, any change forces a cascade of rewrites. That is why so many leaders quietly admit: “We shipped it… and it already feels outdated.”

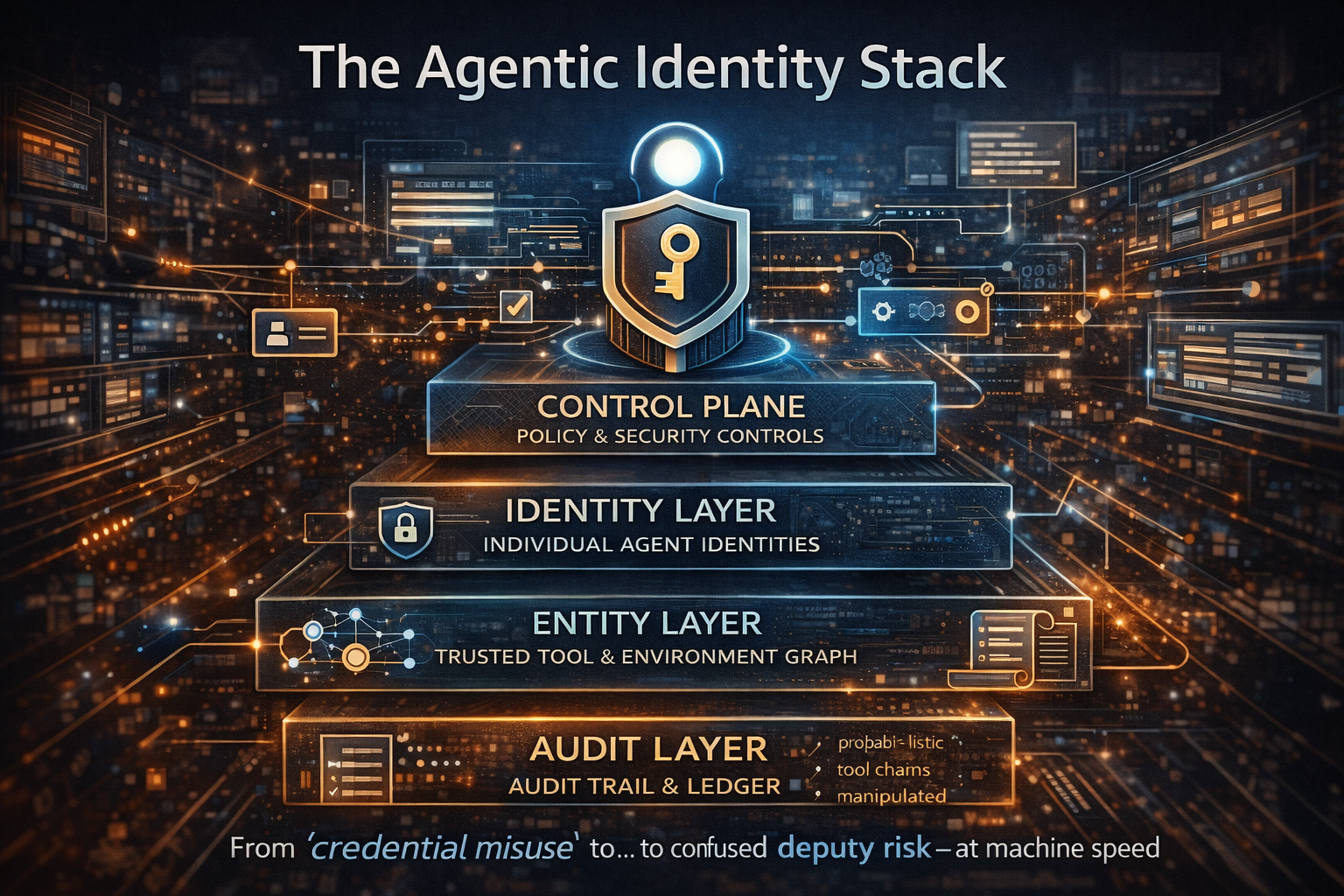
What exactly is a Model-Prompt-Tool Abstraction Layer?
Think of it as the USB-C layer of enterprise AI—plus governance, safety, and auditability.
A Model-Prompt-Tool Abstraction Layer sits between:
- Stable enterprise workflows
(approve access, resolve incidents, onboard customers, manage vendors, close financial periods)
and
- Rapidly changing AI implementation details
(model providers and versions, prompt formats, tool protocols, orchestration frameworks)
In practice, it provides:
- a model interface that allows multiple providers and versions to be swapped or routed without rewriting workflows,
- a prompt lifecycle system with versioning, testing, rollout, rollback, and approvals,
- a tool contract layer with schemas, permissions, authentication, and audit hooks that works across agent frameworks and emerging standards.
This is not abstract elegance. It is operational survival.
You modernize AI continuously while keeping the enterprise stable.

Why abstraction must ship as services-as-software, not frameworks
Here is a critical distinction many organizations miss:
Frameworks help teams build agents.
Enterprises need capabilities they can operate.
An abstraction layer only creates durable value when it is delivered as services-as-software:
- reusable,
- governed,
- observable,
- and consumable across teams.
This means AI capabilities show up not as projects, but as services with:
- defined interfaces,
- usage policies,
- cost envelopes,
- reliability expectations,
- and ownership.
This shift—from “AI as experiments” to “AI as managed services”—is what allows organizations to scale beyond pilots without losing control.

The N×M integration trap (and why standards alone are not enough)
Most enterprises are recreating a familiar trap:
N models × M tools = N×M fragile integrations
Every new model requires revalidating tool calls and prompts.
Every new tool requires retraining models and re-testing behavior.
Standards like structured tool calling and emerging protocols for tool discovery help—but they do not replace governance. They reduce friction while increasing the need for:
- permission boundaries,
- execution controls,
- and enterprise-grade audit trails.
An abstraction layer is how you adopt standards without letting today’s protocol become tomorrow’s lock-in or security incident.

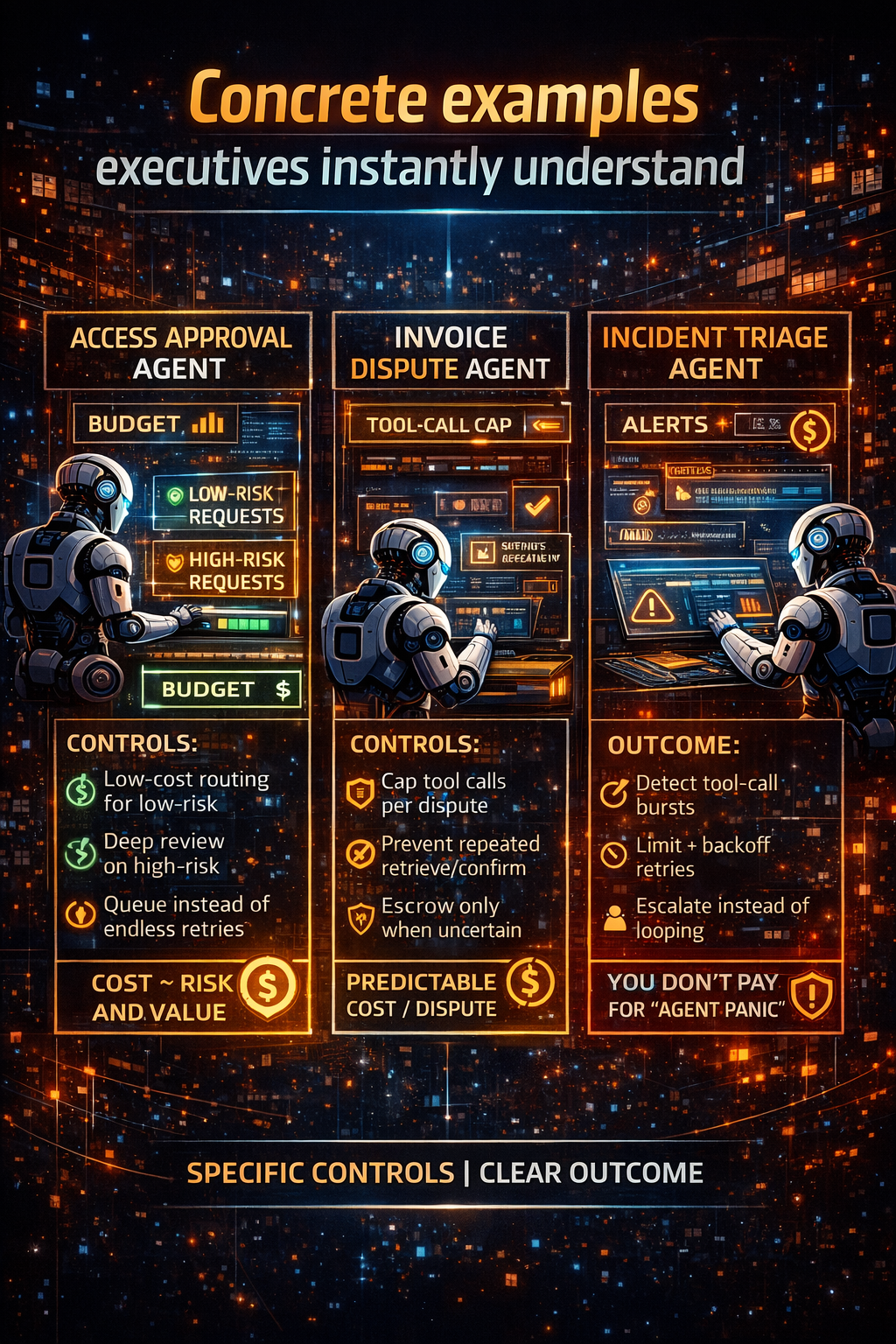
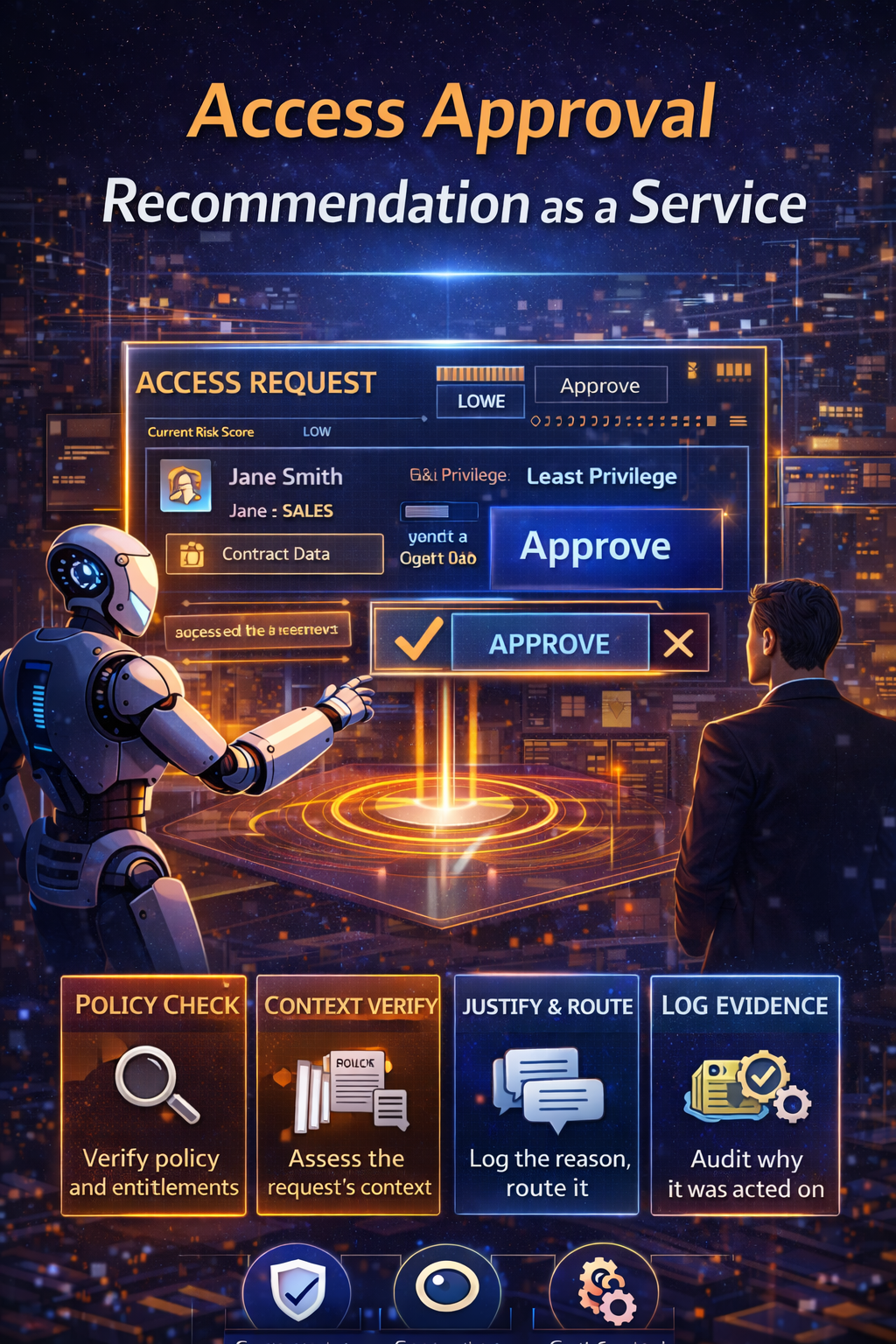
A simple example: the travel-approval agent
The brittle approach (still common today)
- One model hard-coded into the workflow
- One giant prompt embedded in application logic
- Direct API calls to HR, ERP, and email systems
Six months later:
- finance wants a cheaper model for low-risk requests,
- HR upgrades its API,
- audit demands stricter approval evidence.
Result: rewrites, outages, regressions.
The resilient approach (with abstraction)
- a versioned policy prompt package for travel rules,
- a tool registry defining HR, ERP, and email contracts,
- model routing by task criticality,
- human-by-exception guardrails for irreversible actions.
Now change happens in one place, not everywhere.
That is the difference between a demo and an enterprise capability.

The seven capabilities every abstraction layer must provide
- Provider-agnostic model interfaces
Models are treated as capabilities, not vendors. Routing, fallback, and evaluation are built-in.
- Model routing and capability matching
Different tasks demand different trade-offs between cost, latency, reasoning depth, and risk.
- Prompts as governed policy assets
Prompts are versioned, tested, approved, and rolled out like policy—not casually edited strings.
- Tool contracts with safe execution
Schemas, authentication, permissions, rate limits, and audits are mandatory—not optional.
- Tool discovery without tool sprawl
A registry defines ownership, lifecycle, and environments, preventing chaos as tool ecosystems grow.
- End-to-end observability
Every decision is traceable: which model, which prompt, which tool, and why.
- Responsible AI by design
Not as an afterthought.
Human-by-exception, least-privilege access, evidence-first actions, and rollback are first-class design principles.

Why CIOs and CTOs are quietly demanding this layer
Because it delivers what executives actually care about:
- Optionality without chaos
- Lower total cost of ownership
- Audit-ready decision trails
- Multi-region compliance by design
- A real platform, not a collection of pilots
Most importantly, it unifies fragmented AI efforts across the enterprise into a single operating model.

Why this is not “just another framework”
Frameworks accelerate experimentation.
Abstraction layers enable endurance.
Enterprises fail not because they lack clever agent code, but because they lack:
- contracts,
- governance,
- lifecycle discipline.
The abstraction layer is how you use frameworks without being trapped by them.

A practical rollout that does not slow delivery
Phase 1: define contracts
Phase 2: centralize risk points
Phase 3: add observability and security
The goal is not perfection.
The goal is stability plus optionality.

Conclusion: the moving boundary that separates leaders from rewrites
Agent platforms are not products.
They are moving boundaries between fast-changing AI capabilities and slow-changing enterprise realities.
Design that boundary deliberately—or pay for it repeatedly.
A Model-Prompt-Tool Abstraction Layer is no longer optional architecture.
It is the foundation of operating autonomy responsibly at scale.
FAQ: Model-Prompt-Tool Abstraction Layer
Q1. What is a Model-Prompt-Tool Abstraction Layer?
A Model-Prompt-Tool Abstraction Layer decouples enterprise workflows from specific AI models, prompts, and tools, enabling continuous evolution without rewrites.
Q2. Why do enterprise agent platforms become obsolete so quickly?
Because models, prompts, tools, and standards evolve independently—tight coupling forces constant re-engineering.
Q3. Is this layer only needed for large enterprises?
Any organization deploying AI agents across business systems benefits, especially in regulated or multi-region environments.
Q4. How is this different from using an agent framework?
Frameworks help build agents. Abstraction layers help operate AI safely, repeatedly, and at scale.
Q5. Does this help with compliance and audit readiness?
Yes. Prompt versions, model usage, tool calls, and approvals become traceable assets.
📘GLOSSARY
-
Abstraction Layer – A stable interface that hides volatile implementation details.
-
Services-as-Software – Software delivered as continuously evolving, governed services rather than static code.
-
Agent Platform – A system that enables AI agents to reason, act, and integrate with enterprise tools.
-
Prompt Lifecycle – Versioning, testing, rollout, and rollback of prompts as policy assets.
-
Tool Orchestration – Safe, governed execution of enterprise actions by AI systems.
-
Model-Agnostic Architecture – An architecture that avoids dependency on a single AI provider.
Further Reading
For readers who want to explore the architectural, operational, and governance foundations behind scalable enterprise AI, the following resources provide valuable context and complementary perspectives:
Enterprise AI Architecture & Operating Models
-
“From SaaS to Agentic Service Platforms: The Next Operating System for Enterprise Work” – Explores how enterprises are moving from project-based AI to platformized intelligence delivered as services.
-
“The AI SRE Moment: Why Enterprises Require Predictive Observability and Human-by-Exception” – Examines why operating AI systems demands reliability disciplines similar to Site Reliability Engineering.
-
“Services-as-Software: The Quiet Shift Reshaping Enterprise AI Delivery” – Discusses why reusable, governed AI services outperform one-off pilots.
Model, Prompt, and Tool Governance
-
Model Context Protocol (MCP) – An emerging open protocol aimed at standardizing how LLM applications connect to tools and external context, highlighting both integration opportunities and safety considerations.
-
OpenAI Platform: Function and Tool Calling – Provides insight into structured tool invocation, typed arguments, and model-tool interaction patterns increasingly used in enterprise systems.
-
LangChain Documentation: Model and Tool Abstractions – Illustrates how modern frameworks are evolving toward provider-agnostic models and standardized tool interfaces.
Responsible AI & Enterprise Risk
-
NIST AI Risk Management Framework (AI RMF) – A globally relevant reference for managing AI risks across design, deployment, and operations.
-
OECD AI Principles – A widely adopted international baseline for trustworthy and human-centered AI systems.
-
EU AI Act (High-Level Summaries) – Useful for understanding how governance expectations are shaping AI system design globally, even outside Europe.
Strategic Context & Thought Leadership
-
MIT Technology Review – Enterprise AI & AI Infrastructure – Ongoing coverage of how large organizations are restructuring AI platforms, governance, and operating models.
-
Harvard Business Review – AI Strategy & Organizational Design – Practical executive perspectives on scaling AI responsibly across complex enterprises.
-
Gartner Research on AI Platforms and Agentic Systems – Highlights trends in AI orchestration, governance, and platform consolidation shaping CIO and CTO agendas.
The AI Platform War Is Over: Why Enterprises Must Build an AI Fabric—Not an Agent Zoo – Raktim Singh