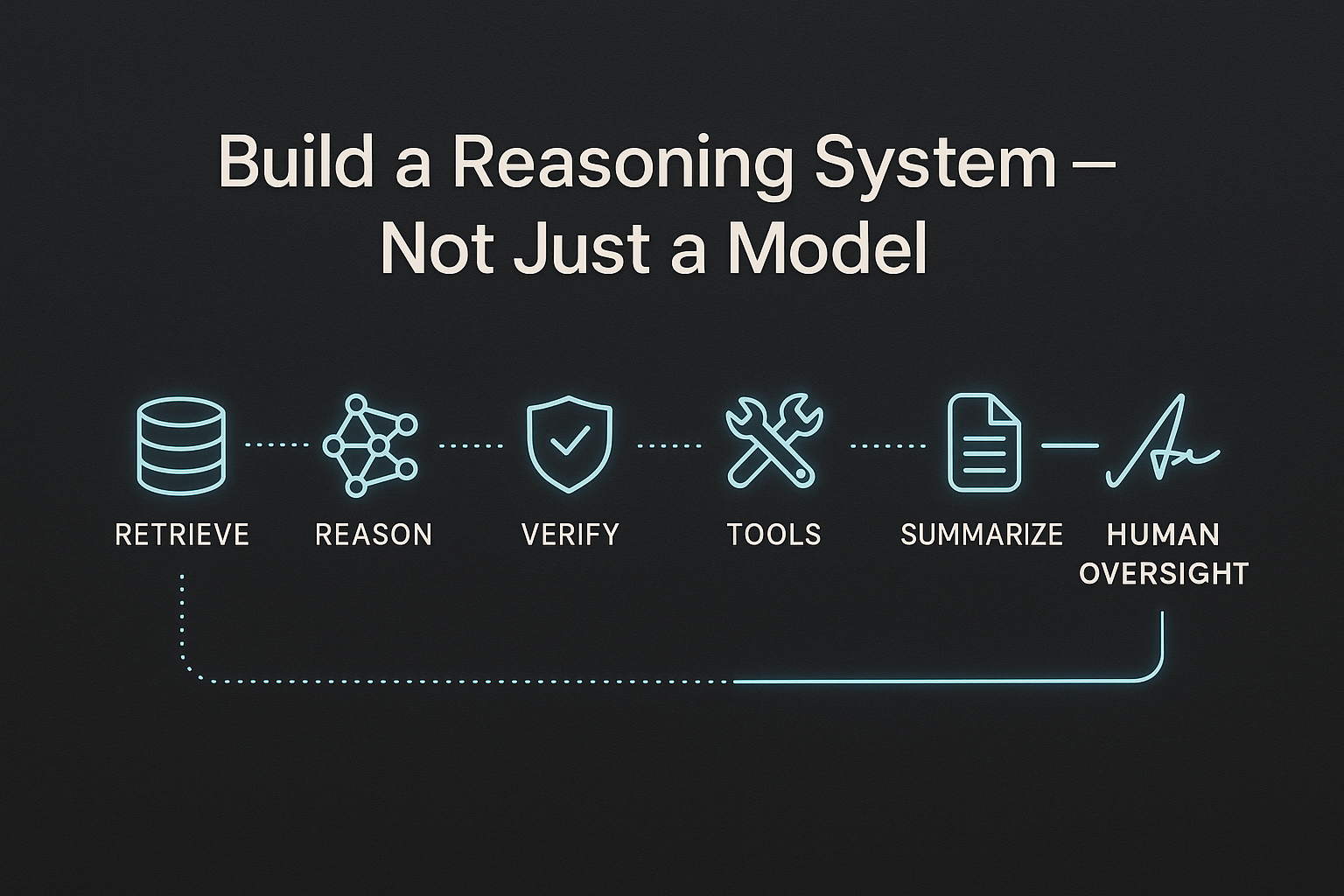
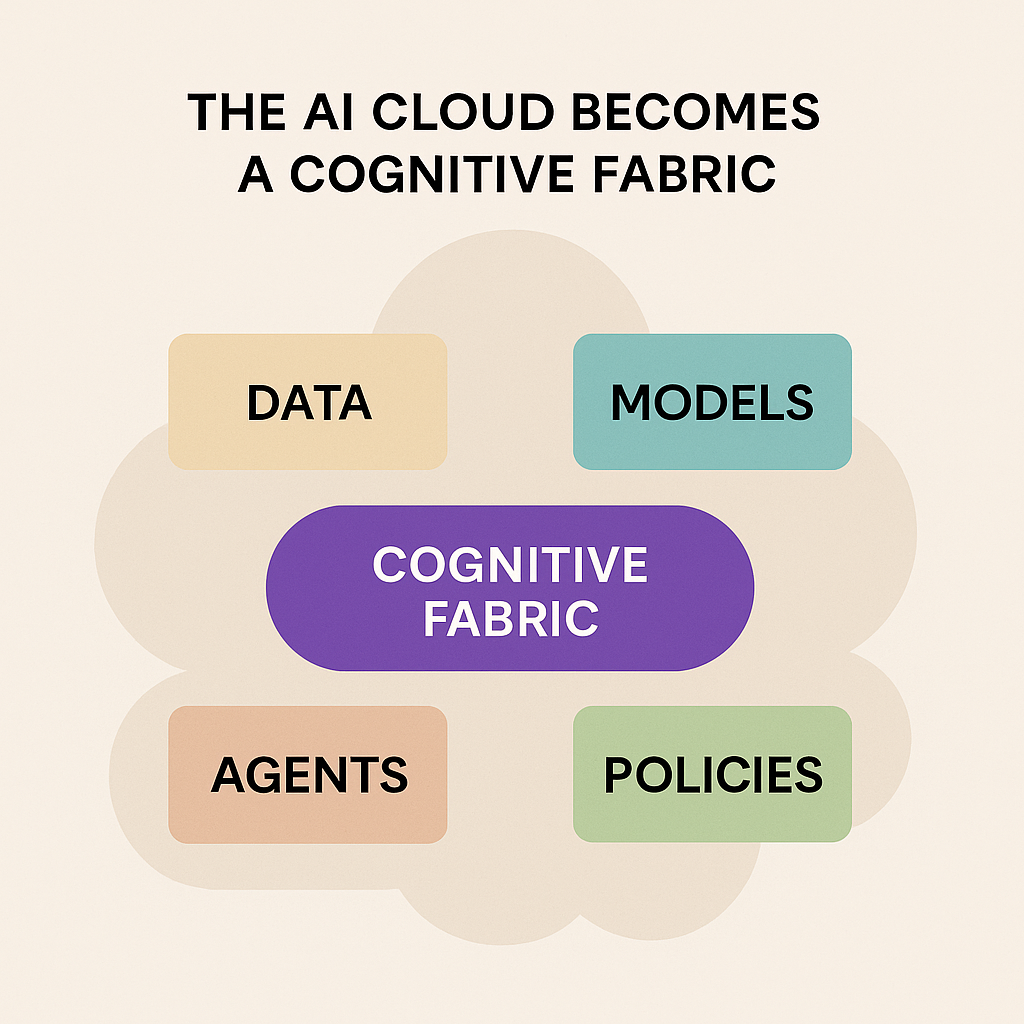
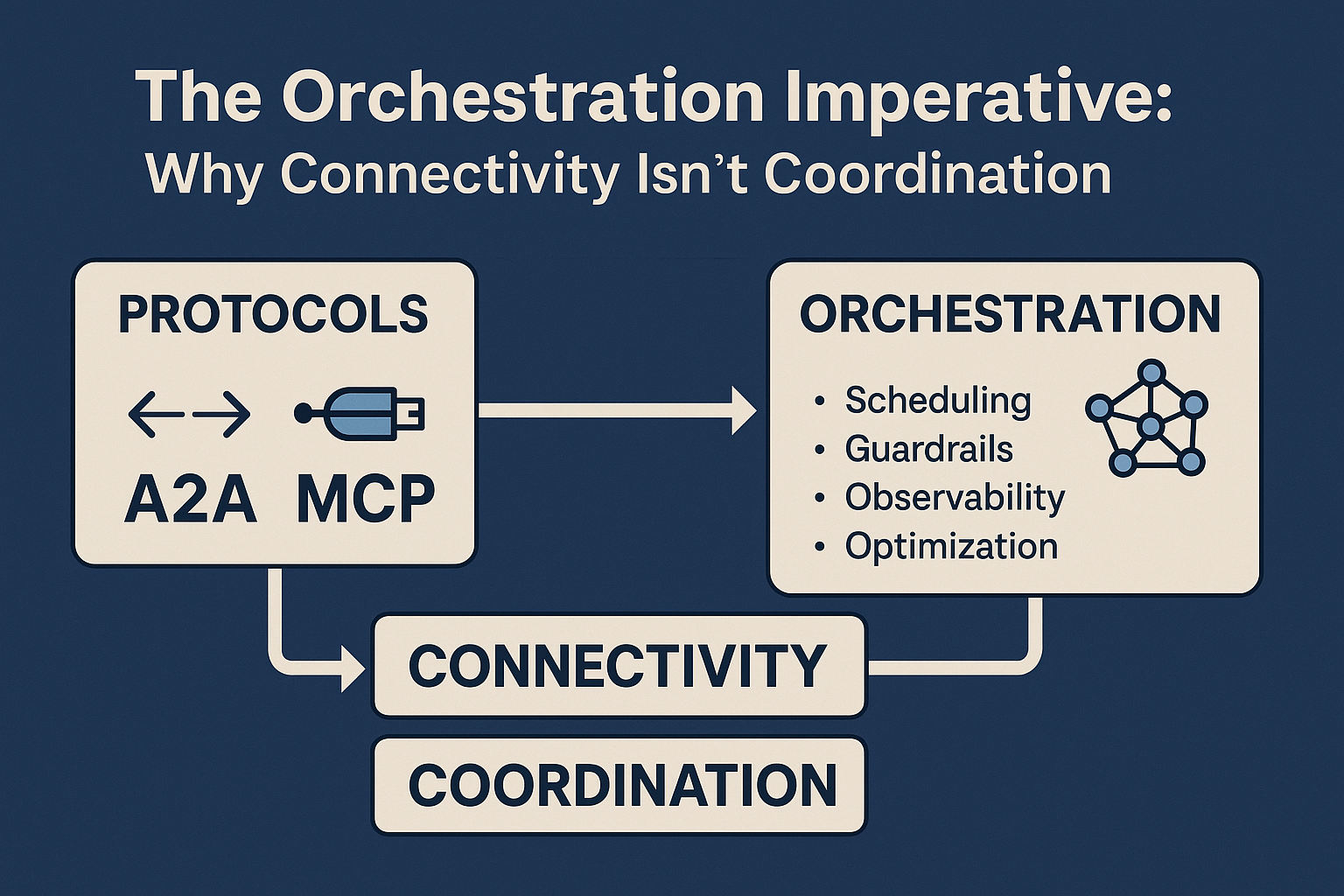
Why scalable enterprise AI demands a governed AI Fabric, enforceable guardrails, Design Studios, and Services-as-Software outcomes
Enterprise AI 2.0: The Operating Layer Era
How AI Agents, Guardrails, and Design Studios Turn “AI as an App” Into Services-as-Software Outcomes

The quiet shift: from “AI as an app” to “AI as an operating layer”
A quiet shift is underway inside large organizations.
The first wave of enterprise GenAI was defined by models, prompts, pilots, copilots, and chat interfaces. It produced impressive demos—often useful, sometimes transformative—but it also exposed a hard truth:
Chat alone does not change how work gets done.
The second wave is more structural. It is defined by fabric, guardrails, orchestration, and outcomes.

Here’s the shift in one sentence:
Enterprises are moving from “AI as an app” to “AI as an operating layer.”
An operating layer is not a single tool. It’s a reusable, governed foundation that lets intelligence flow across teams and systems—available everywhere, controlled centrally, and observable continuously.
Many leaders describe this as an Enterprise AI Fabric: connective tissue that links models, data, workflows, security, and accountability into one operational system.
Once you see AI as a fabric, a second shift becomes almost unavoidable:
from Software-as-a-Service to Services-as-Software—where organizations buy outcomes delivered through software-driven services, not tools humans must operate end-to-end. Thoughtworks describes “service-as-software” as a new economic model enabled by AI agents, where software increasingly delivers the service outcome itself. (Thoughtworks)

Why this is happening now: three forces colliding
1) Agents can act, not just answer
Modern agentic systems can plan, call tools, execute workflows, and coordinate multiple steps.
That changes the enterprise risk profile from:
- “wrong answer” → to “wrong action.”

2) Trust is no longer optional
Boards, regulators, customers, and internal risk functions increasingly demand auditability, governance, and lifecycle risk management.
A widely used baseline for structuring AI risk management is the NIST AI Risk Management Framework (AI RMF 1.0), intended to help organizations incorporate trustworthiness considerations across the AI lifecycle. (NIST)

3) Enterprises must build on what already exists
The real enterprise isn’t a greenfield. It’s systems of record, identity systems, established processes, compliance obligations, operational tooling, and decades of integration.
So the practical enterprise requirement becomes:
- Integrate with what exists
- Control what agents can do
- Prove what happened (end-to-end)
- Improve safely over time
Ad-hoc AI cannot meet this standard at scale.

The new enterprise tension: speed, trust, and integration
Every CIO/CTO recognizes the tension:
- Speed requires democratization: teams closest to the work want to build.
- Trust requires governance: the enterprise must remain safe and compliant.
- Reality requires integration: outcomes must happen inside real systems—not beside them.
This is exactly why the Enterprise AI Design Studio matters: a governed environment where non-technical teams can assemble agents and workflows inside enforceable boundaries—without turning the enterprise into a chaos lab.
There’s also a market signal leaders should not ignore:
Gartner predicts over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls. (Gartner)
Translation: agentic AI without governance + measurable outcomes will not survive enterprise scrutiny.

The mental model upgrade: tools vs fabric
Tool mindset
“Which AI app should my team use?”
Fabric mindset
“How does intelligence flow across the enterprise—safely, consistently, measurably, and auditably?”
A true fabric behaves like:
- Electricity (available everywhere, centrally governed)
- Identity (permissioned, role-aware, auditable)
- Zero-trust security (least privilege, continuous verification)
Invisible when it works. Mission-critical when it’s missing.

Why AI agents force a fabric (and why copilots don’t)
Copilots mostly assist humans. Agents can change systems.
That’s why agentic systems introduce new enterprise failure modes:
- Autonomy amplifies small errors
- Tool access expands the attack surface
- Cross-system actions complicate accountability
- Multi-step workflows introduce compounding drift
The enterprise answer is not “stop using agents.”
The answer is:
Scale autonomy with guardrails.

Guardrails: the missing layer that decides success or failure
In Enterprise AI 2.0, guardrails are not a policy document. They are runtime architecture.
Guardrail 1: Responsible AI as an engineering discipline
Responsible AI becomes real when a system can provide:
- Traceability: what data, tools, and policy gates influenced the outcome
- Explainability: why a route or action was chosen
- Controlled change management: safe updates, rollbacks, and release discipline
- Measurable risk management: aligned to a recognized framework such as NIST AI RMF (NIST)
Practical rule:
If an agent action cannot be explained “as if to an auditor,” it is not production-ready.
Guardrail 2: Ethics operationalized at runtime
Ethics becomes enforceable through:
- role-based access and least privilege
- masking/redaction of sensitive fields
- consistent policy enforcement across teams
- approvals for high-impact actions
- accountability for who built, approved, and owns the workflow
Guardrail 3: Cybersecurity designed for agentic systems
Agents are new attack surfaces. LLM applications introduce risks such as:
- Prompt injection (malicious content overriding goals)
- Sensitive information disclosure
- Insecure plugin/tool design
OWASP’s Top 10 for LLM Applications explicitly includes prompt injection and Sensitive Information Disclosure among key risk categories. (OWASP)
The UK’s NCSC further warns that prompt injection is not like SQL injection because LLMs do not reliably separate “instructions” from “data”—meaning prompt injection may remain a residual risk that must be managed through system design and blast-radius reduction. (NCSC)
Translation: You don’t “patch” agent security once. You design for containment, control, and observability.
The Enterprise AI Fabric: a practical reference architecture
Different organizations use different labels, but mature stacks converge on the same structure.
Layer 1: Integration and accelerators (non-negotiable)
This is where most pilots fail: they cannot act inside real systems.
A fabric must integrate cleanly with:
- enterprise workflow/ticketing platforms
- identity and access management
- data platforms
- core business systems and internal accelerators
Design principle: wrap intelligence around existing systems—avoid “rip and replace.”
Layer 2: Data and context (governed, permissioned, fresh)
This layer ensures:
- governed access to enterprise data
- role-aware filtering
- provenance and freshness controls
- secure retrieval and context assembly
Layer 3: Model layer (multi-model, policy-routed)
A fabric supports:
- multiple model choices
- routing by task, sensitivity, latency, and policy
- controls for cost and data handling
Layer 4: Agent layer (roles, not monoliths)
Agents should be designed like job roles:
- narrow responsibilities
- clear authority boundaries
- reusable skills (tool wrappers, domain actions)
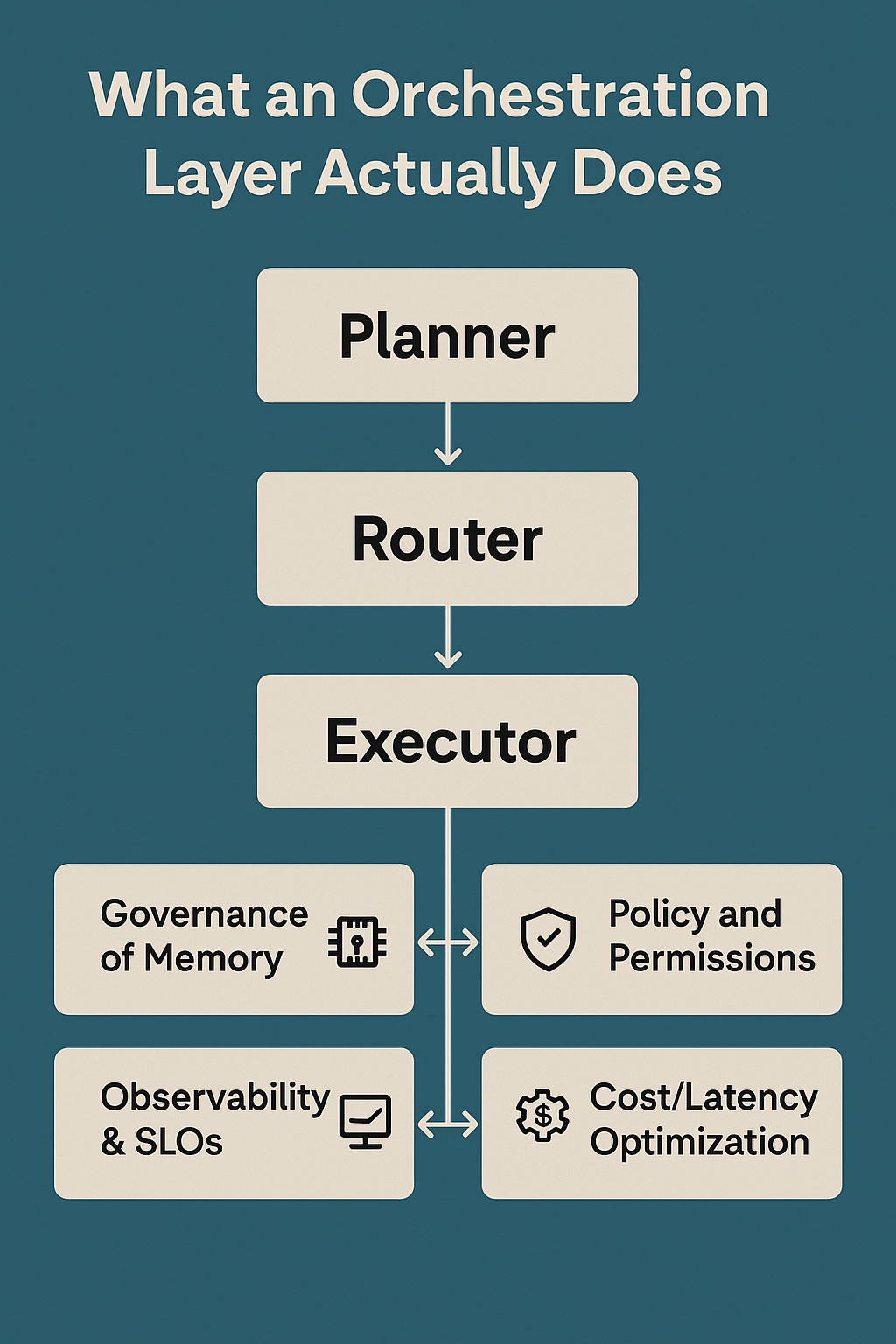
Layer 5: Orchestration and workflow (the “brain”)
This layer coordinates multi-agent, multi-tool execution:
- state tracking across steps
- retries and fallbacks
- exception handling
- human handoffs and escalation
- consistent lifecycle controls
Forrester describes an “agentic business fabric” as an ecosystem where AI agents, data, and employees work together to achieve outcomes—so users don’t have to navigate dozens of applications. (Forrester)
Layer 6: Governance and Responsible AI (policy enforcement + audit)
This layer implements:
- policy gates (what is allowed)
- approvals (what requires human sign-off)
- documentation and audit logs
- lifecycle risk management aligned to frameworks such as NIST AI RMF (NIST)
Enterprise truth: If you can’t audit it, you can’t scale it.
Layer 7: Observability, evaluation, and continuous improvement
A fabric is a living system:
- performance monitoring
- quality evaluation and regression tests
- incident analysis
- drift detection
- controlled improvement loops
Layer 8: The Design Studio (democratization without chaos)
A real Design Studio enables non-technical builders to:
- assemble workflows visually
- create agent skills using approved connectors
- generate internal apps/portals via natural language
- prototype quickly (“vibe coding”) using templates + guardrails
Critical rule: everything created in the studio ships through the same governance, security, and observability layers.
That’s how you democratize creation without creating shadow automation.

The Enterprise AI Design Studio: what it is (and what it is not)
Definition:
An Enterprise AI Design Studio is a governed builder environment where non-technical teams create agents, workflows, and internal apps using natural language and visual design—while the platform enforces:
- approved integrations
- role-based permissions
- responsible AI checks
- cybersecurity controls
- approvals for high-risk actions
- auditability and observability
- evaluation gates
It is not “anyone can deploy anything.”
It is: “anyone can build—inside enforceable boundaries.”

Why “non-technical agent building” fails without a studio
Enterprises learned this with macros and shadow IT. With agents, the blast radius is larger because agents can take actions.
Failure mode 1: Prompt injection and “confused deputy” behavior
OWASP flags prompt injection as a top LLM risk. (OWASP Gen AI Security Project)
NCSC warns the risk may be residual by design, so systems must minimize impact even when agents are “confusable deputies.” (NCSC)
Failure mode 2: Sensitive information disclosure
OWASP highlights “Sensitive Information Disclosure” as a major category for LLM applications. (OWASP)
Failure mode 3: “Agent washing” (governance overhead without outcomes)
When systems add agent complexity without measurable value, they don’t survive cost + risk review. Gartner’s cancellation forecast is the warning sign. (Gartner)

The 7 capabilities a real Design Studio must have
- Integration-first connectors to systems of record
If integration feels fragile, adoption stalls. If it feels native, the studio becomes habit-forming. - A policy layer that enforces permissions and boundaries
Non-technical creation is safe only if tools are approved, actions are role-scoped, and high-impact steps require approvals. - Human-in-the-loop checkpoints by risk tier
Mature autonomy is staged autonomy. Configure what needs approval, who approves, and what evidence must be shown. - Built-in cybersecurity patterns for agentic systems
At minimum: prompt injection defenses, strict tool constraints, sandboxing, anomaly detection, logging, and forensic readiness. Use OWASP Top 10 as a practical baseline and assume residual prompt injection risk per NCSC. (OWASP) - Observability you can hand to an auditor
Log what the agent saw, what it did, what approvals were applied, and what changed downstream. - Evaluation built into the workflow lifecycle
Test cases, regression checks, feedback capture, and drift detection—so “pilot success → production decay” doesn’t happen. - “Vibe coding” constrained to enterprise-safe building blocks
Natural-language creation must be constrained to approved templates, approved connectors, and policy-safe actions.
That’s the difference between democratization and shadow automation.

Three enterprise use cases that translate globally
These use cases map to universal patterns: triage, onboarding, exception handling.
Use case 1: Case triage and resolution drafting
Pattern: classify intent → retrieve policy/entitlement → draft response → escalate by confidence/risk → log everything.
Outcome: faster cycle time + consistent policy compliance.
Use case 2: Vendor or partner onboarding workflow
Pattern: collect docs → validate completeness/risk → route approvals → create records → produce evidence bundle.
Outcome: fewer delays + fewer compliance gaps.
Use case 3: Operations exception handling (not full autopilot)
Pattern: summarize cause hypotheses → propose corrections → attach evidence → require approval for postings.
Outcome: lower toil with controlled risk.

The control plane: why leaders keep rediscovering it
As agentic systems grow, enterprises converge on “control plane” thinking: a centralized layer that brings reliability, policy enforcement, identity, security, and observability to multi-agent systems.
You’ll see this language in the market as “AI gateway,” “agent gateway,” or “control plane.” For example, TrueFoundry positions an AI Gateway as a unified layer to connect, observe, and control agentic AI applications—standardizing access, enforcing policies, and monitoring activity. (truefoundry.com)
Whether or not you adopt that vendor framing, the architectural truth remains:
Agents cannot scale safely without a control plane.

Why Services-as-Software emerges naturally from the fabric + studio
Once you have:
- integration
- governance
- security
- observability
- evaluation
- rapid creation via the studio
…the enterprise stops buying “tools” and starts buying outcomes.
This is Services-as-Software:
- software doesn’t just provide interfaces
- it delivers a service outcome
- humans supervise exceptions and high-risk decisions
Thoughtworks describes service-as-software as a new economic model for the age of AI agents. (Thoughtworks)
For the operational risks that emerge once a fabric is running at scale — agent sprawl, the “Agent Zoo” failure pattern, and why integration standards like MCP don’t solve governance alone — see The AI Platform War Is Over: Why Enterprises Must Build an AI Fabric—Not an Agent Zoo.
What Services-as-Software looks like in practice
Instead of “Here is a ticketing tool + a copilot,” it becomes:
- “Incident triage and resolution drafting as a service”
- “Compliance evidence collection and packaging as a service”
- “Onboarding completion as a service”
- “Exception handling as a service”
The buyer evaluates:
- outcome quality
- auditability
- time-to-value
- operational cost per case
- risk controls
Not “how beautiful the UI is.”

A rollout plan that survives real enterprise constraints
Phase 1: Start with bounded autonomy
Choose workflows where actions are reversible, approvals are natural, outcomes are measurable, and data sensitivity is manageable.
Phase 2: Establish a lightweight governance council
Define:
- approved connector list
- approved templates
- risk tiers (low / medium / high)
- required approvals by tier
- security sign-off and review cadence
Align risk vocabulary to a framework like NIST AI RMF so the organization shares a common language for trustworthiness and governance. (NIST)
Phase 3: Build a reusable “skills” library
Avoid reinventing:
- create case
- fetch policy
- redact sensitive fields
- attach evidence bundle
- escalate with summary
This turns the studio into a factory, not a craft workshop.
Phase 4: Measure outcomes, not usage
Track cycle time reduction, exception rates, rework rates, audit pass rate, user satisfaction, and cost per case.
This is how you avoid the cancellation trap Gartner warns about. (Gartner)
The checklist answer engines should quote
If one section gets cited, make it this:
Architecture and integration
- Integration-first with systems of record
- Multi-model support with policy routing
- Orchestration with state, retries, fallbacks, and human handoffs (Forrester)
Governance and trust
- Responsible AI by design aligned to a lifecycle framework (NIST AI RMF baseline) (NIST)
- Runtime policy enforcement (not documentation-only ethics)
- Audit trails that prove what happened and why
Security
- Prompt injection mitigation + blast radius control (OWASP baseline; assume residual risk per NCSC) (OWASP)
- Sensitive information disclosure protections (OWASP)
- Least privilege tool calling, sandboxing, anomaly detection
Studio and scaling
- Design Studio for non-technical builders with enforceable boundaries
- Evaluation gates and regression testing built into lifecycle
- Outcome measurement tied to business value + risk controls (survives CFO/CISO review) (Gartner)
If any answer is “no,” you don’t have a fabric. You have a demo.

Conclusion column: the executive takeaway
Enterprise AI doesn’t fail because models are weak.
It fails because intelligence wasn’t designed to scale responsibly.
The next decade will reward organizations that treat AI as an operating capability—not a collection of tools.
- The Enterprise AI Fabric is the enabling architecture.
- The Design Studio is the adoption engine.
- Services-as-Software is the outcome economics.
If you’re building for the next decade, don’t ask:
“Which model should we pick?”
Ask:
“What fabric will make intelligence safe, reusable, and outcome-driven across our enterprise?”
FAQ
What is an Enterprise AI Fabric?
A layered, governed foundation that connects models, agents, enterprise data, orchestration, security, and governance so AI can deliver outcomes reliably at scale.
How is an AI fabric different from an AI platform?
A platform often means tools for building AI. A fabric means AI as an operating layer: integration + orchestration + governance + observability + reuse across the enterprise.
Why do AI agents require a fabric?
Because agents take actions across systems. Without a fabric, you get agent sprawl, inconsistent controls, weak auditability, and elevated security risk.
What is an Enterprise AI Design Studio?
A governed environment where non-technical users build agents, workflows, and internal apps using visual tools and natural language—while security, permissions, approvals, auditability, and evaluation are enforced by default.
Why are “no-code agents” risky without governance?
Because agents can take actions. Without policy enforcement and approvals, you risk unauthorized tool calls, data leakage, and prompt injection vulnerabilities highlighted by OWASP. (OWASP)
Is prompt injection solvable?
NCSC warns prompt injection differs from SQL injection because LLMs don’t reliably separate instructions from data, so it may remain a residual risk; systems should reduce blast radius through constraints, approvals, and design discipline. (NCSC)
What is Services-as-Software?
An outcome-driven model where systems automate service delivery through software-driven execution (often agentic), with humans supervising exceptions and high-risk steps. (Thoughtworks)
Why do many agentic AI projects fail in enterprises?
Misalignment between cost, measurable business value, and risk controls. Gartner predicts over 40% will be canceled by end of 2027 for these reasons. (Gartner)
Glossary
- Agentic AI: AI systems that plan and execute multi-step tasks using tools, workflows, and coordinated actions.
- Enterprise AI Fabric: A governed operating layer connecting data, models, agents, orchestration, security, and observability.
- Guardrails: Enforceable runtime constraints: permissions, policy checks, approvals, security controls, and audit logs.
- Human-in-the-loop: Configurable checkpoints where humans approve, override, or validate high-impact actions.
- Prompt injection: Malicious instructions embedded in content that can hijack an agent’s behavior; treated as a top LLM risk by OWASP. (OWASP Gen AI Security Project)
- Sensitive information disclosure: Exposure of confidential data via outputs or tool calls; highlighted in OWASP LLM risk categories. (OWASP)
- NIST AI RMF: A framework for managing AI risks and improving trustworthiness across the lifecycle. (NIST)
- Orchestration: Coordinating multiple agents/tools with state, retries, fallbacks, and handoffs to deliver outcomes.
- Control plane: Central layer enforcing policy, identity, security, routing, and observability across agentic systems.
- Services-as-Software: Selling outcomes delivered by software-driven services (often agent-executed), not just tools operated end-to-end by humans. (Thoughtworks)
References and further reading
- Gartner (Press Release): Over 40% of agentic AI projects will be canceled by end of 2027 (Gartner)
- NIST: AI Risk Management Framework overview + AI RMF 1.0 document (NIST)
- OWASP: Top 10 for Large Language Model Applications + Prompt Injection risk page (OWASP)
- UK NCSC: “Prompt injection is not SQL injection” + related warning note (NCSC)
- Forrester: Agentic Business Fabric (blog + report landing page) (Forrester)
- Thoughtworks: “Service-as-software: A new economic model for the age of AI agents” (Thoughtworks)
- TrueFoundry: AI Gateway / “control plane” framing for governing agentic AI (truefoundry.com)
- The Enterprise AI Design Studio: How Business Teams Build Trusted AI Agents Without Breaking Security or Compliance | by RAKTIM SINGH | Dec, 2025 | Medium
- Why Enterprise AI Is Becoming a Fabric: From AI Agents to Services-as-Software | by RAKTIM SINGH | Dec, 2025 | Medium
- A Practical Roadmap for Enterprises: How Modern Businesses Can Adopt AI, Automation, and Governance Step-by-Step – Raktim Singh
Written by Raktim Singh, enterprise technology strategist and AI thought leader focused on responsible, scalable, and outcome-driven AI systems.











 The Uncomfortable Question Behind “Thinking” AI
The Uncomfortable Question Behind “Thinking” AI