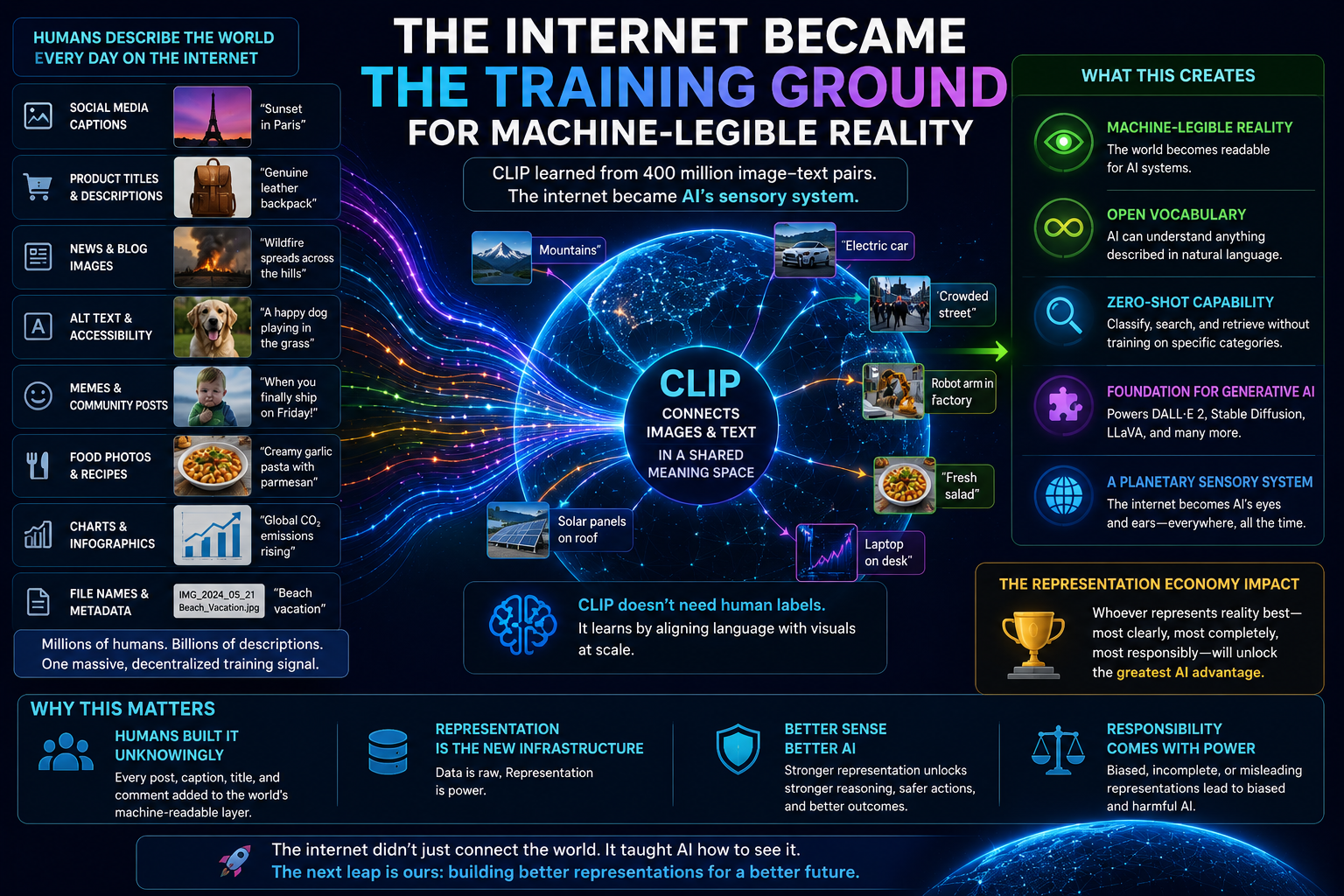
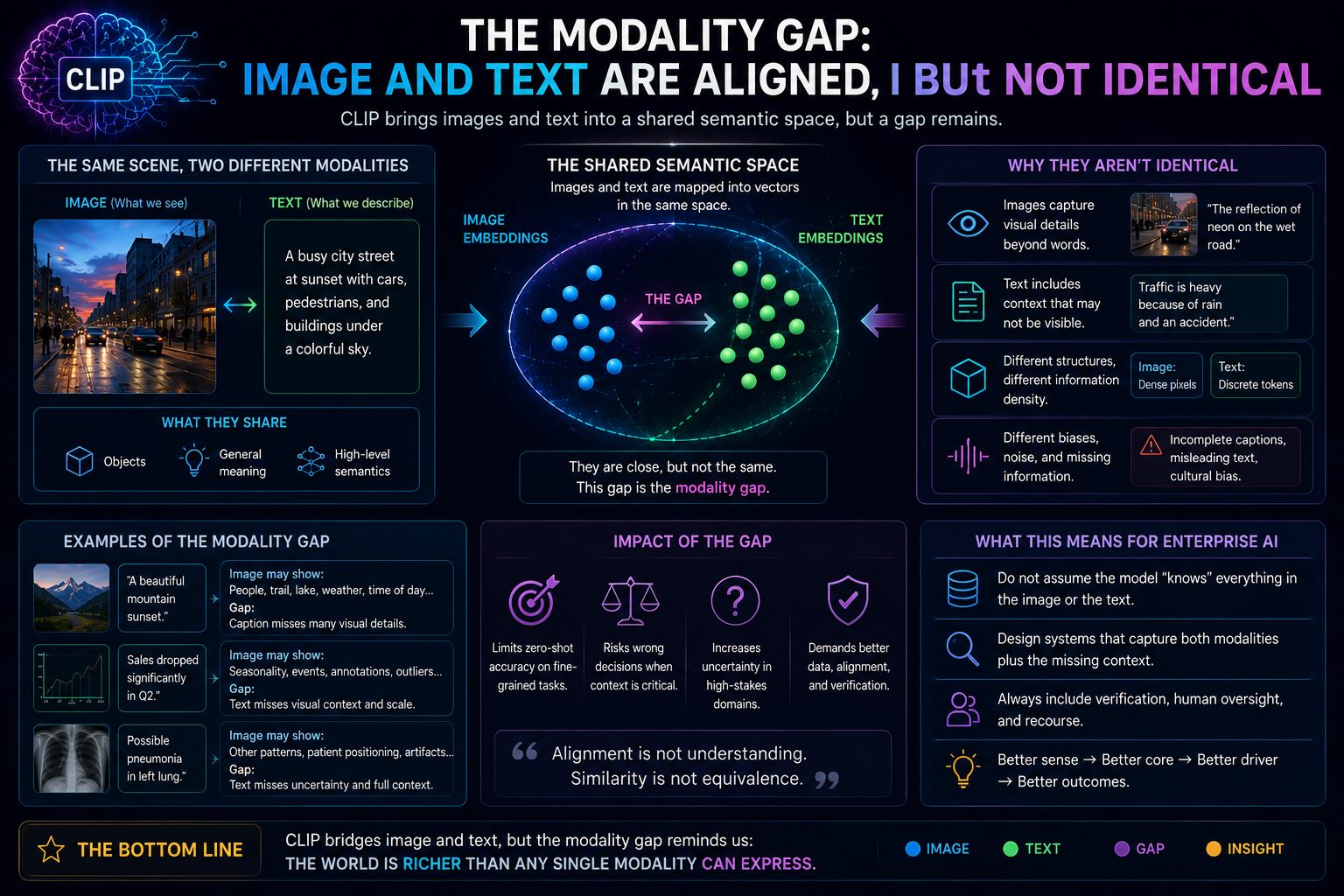
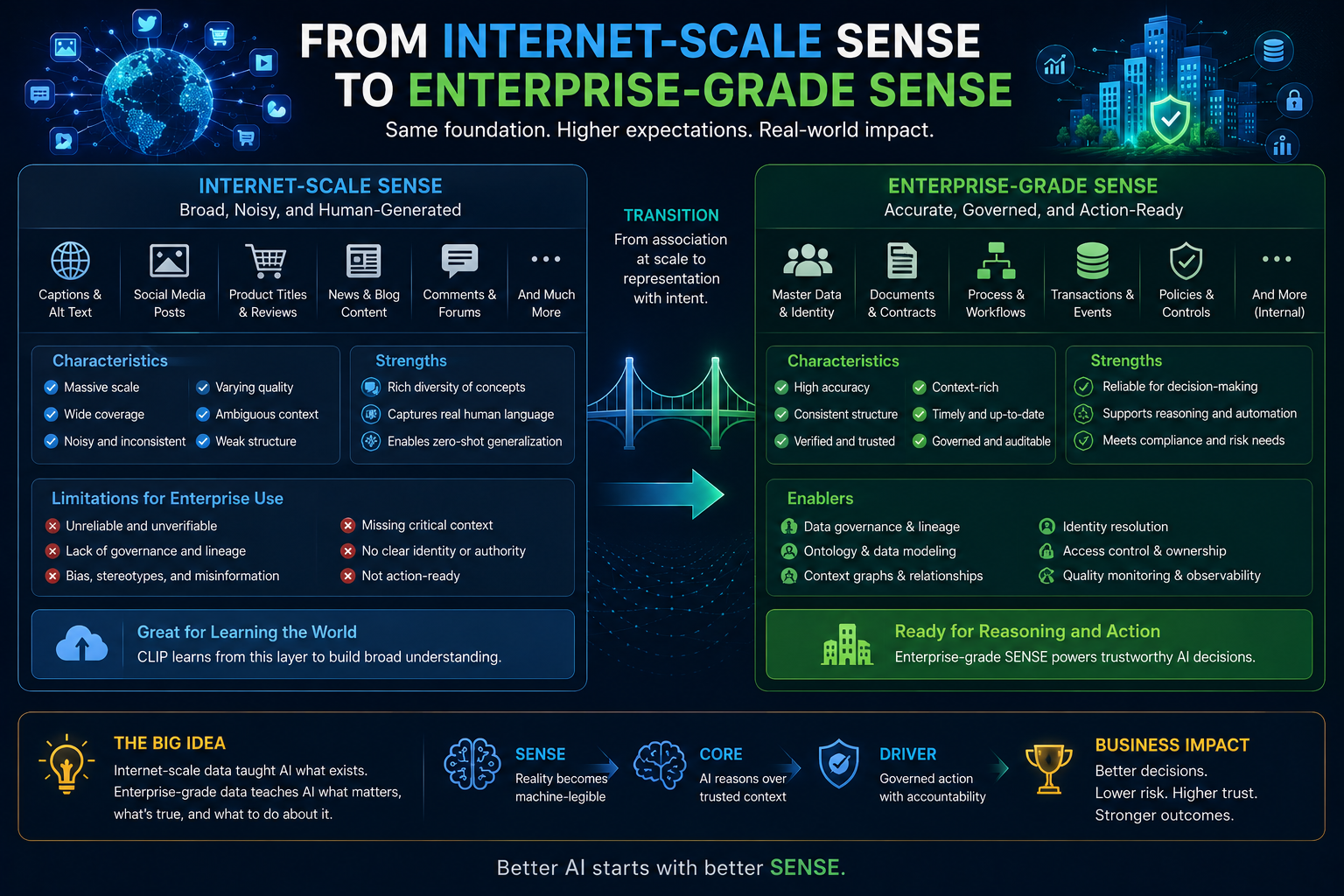
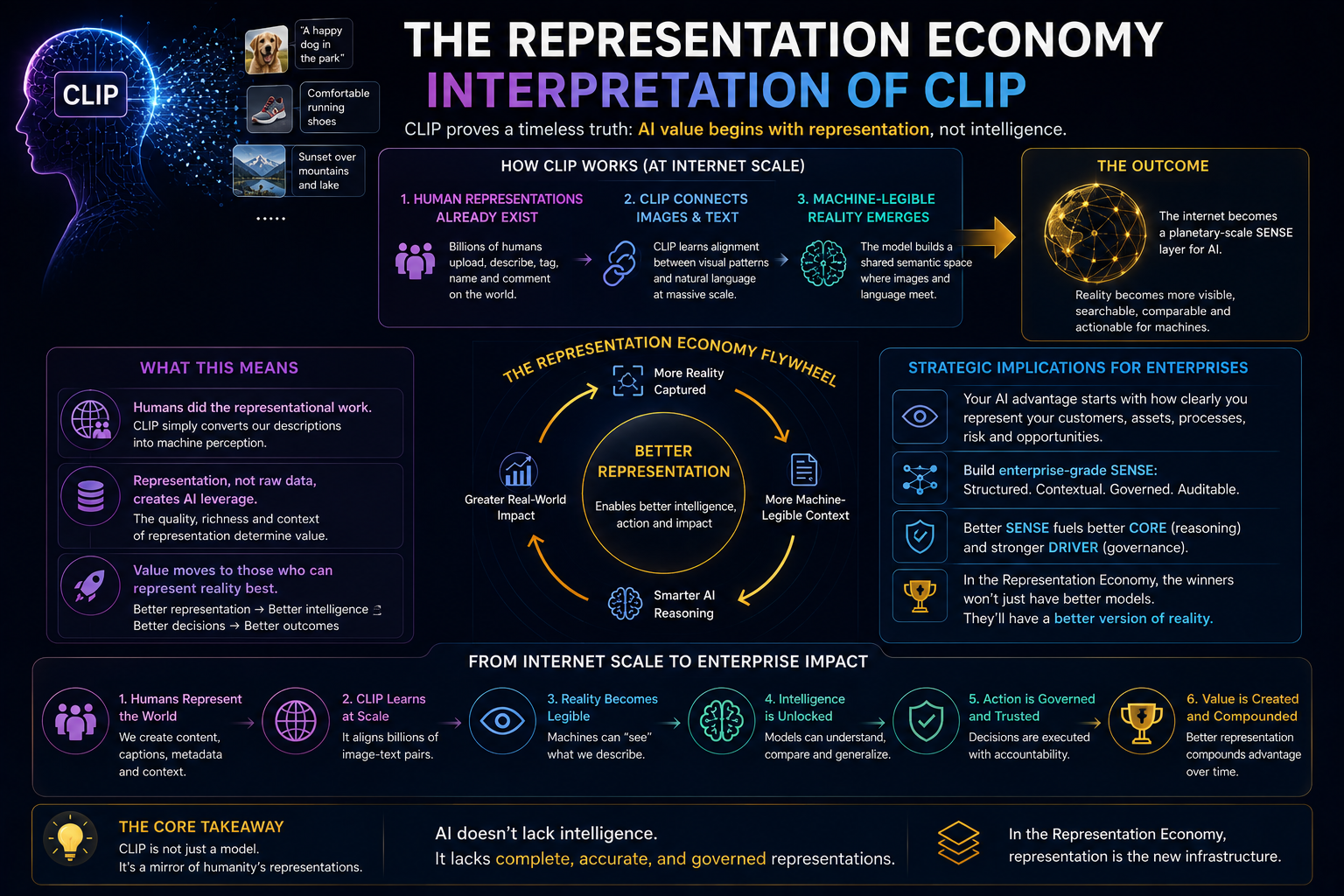
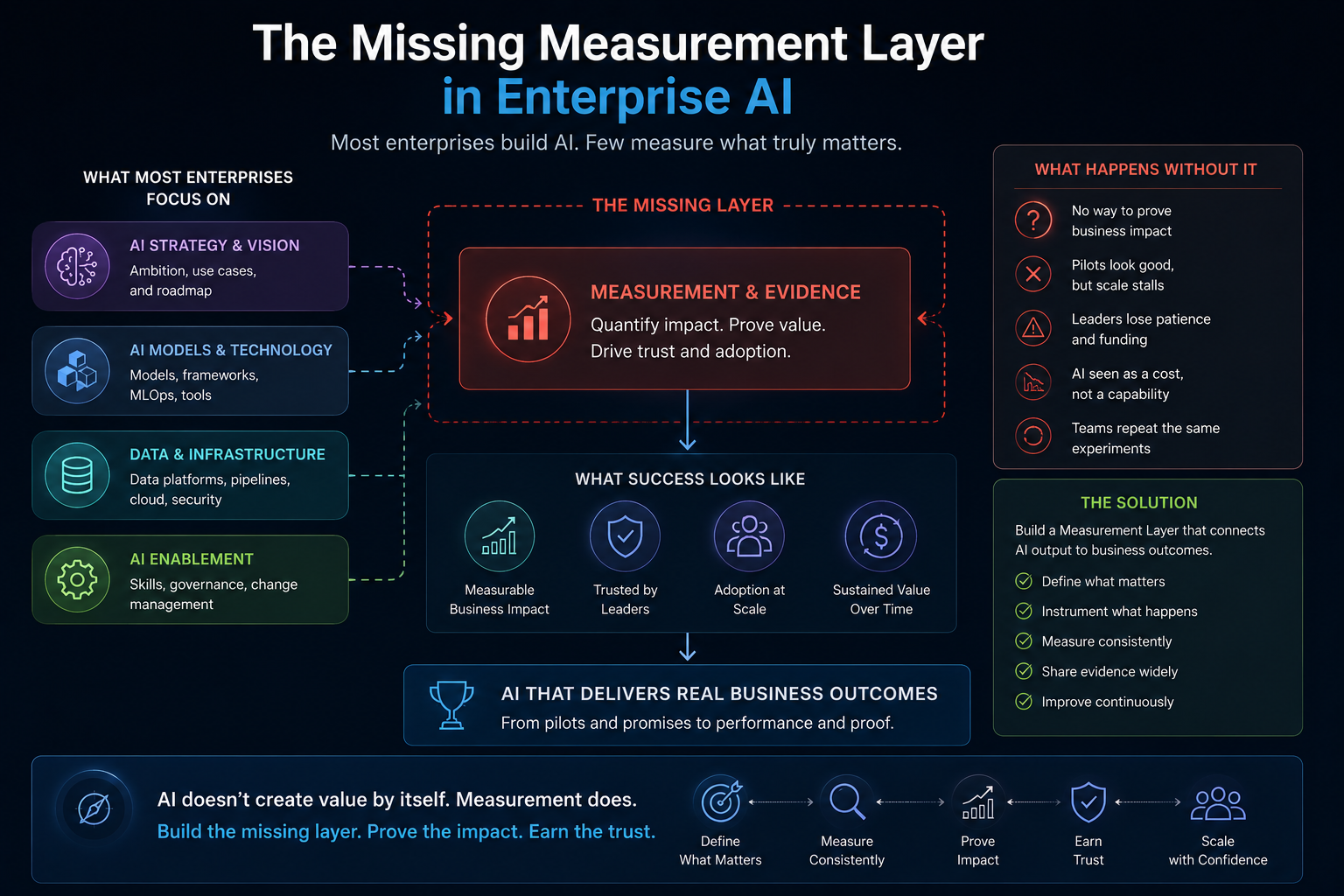
Most Enterprise AI frameworks focus on models, data, or governance. Few explain how organizations should structure what AI can see, decide, and do.
Artificial intelligence is entering a dangerous transition.
For the last decade, most enterprise AI conversations were about models: larger models, faster models, cheaper models, more accurate models, more reasoning-capable models, and more autonomous agents.
That phase was necessary.
But it is no longer sufficient.
The next phase of enterprise AI will not be decided only by who has the best model. It will be decided by who has the best institutional architecture around AI.
Because once AI moves from answering questions to influencing workflows, approving decisions, routing exceptions, triggering actions, interacting with customers, supporting employees, analyzing risk, generating code, managing operations, or recommending interventions, the central question changes.
It is no longer:
Can the AI produce an intelligent answer?
It becomes:
Can the institution sense reality correctly, reason over it responsibly, and act with legitimate authority?
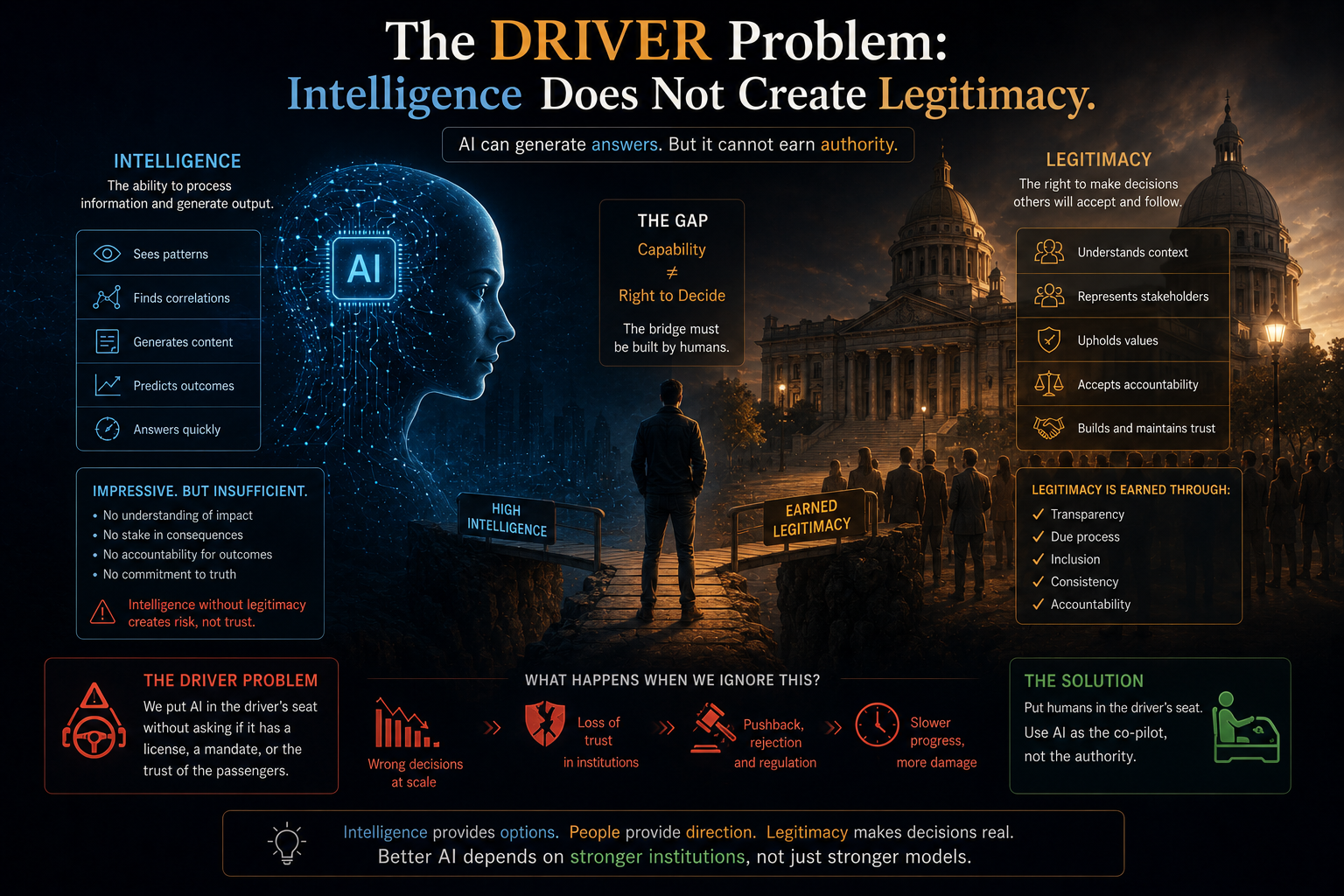
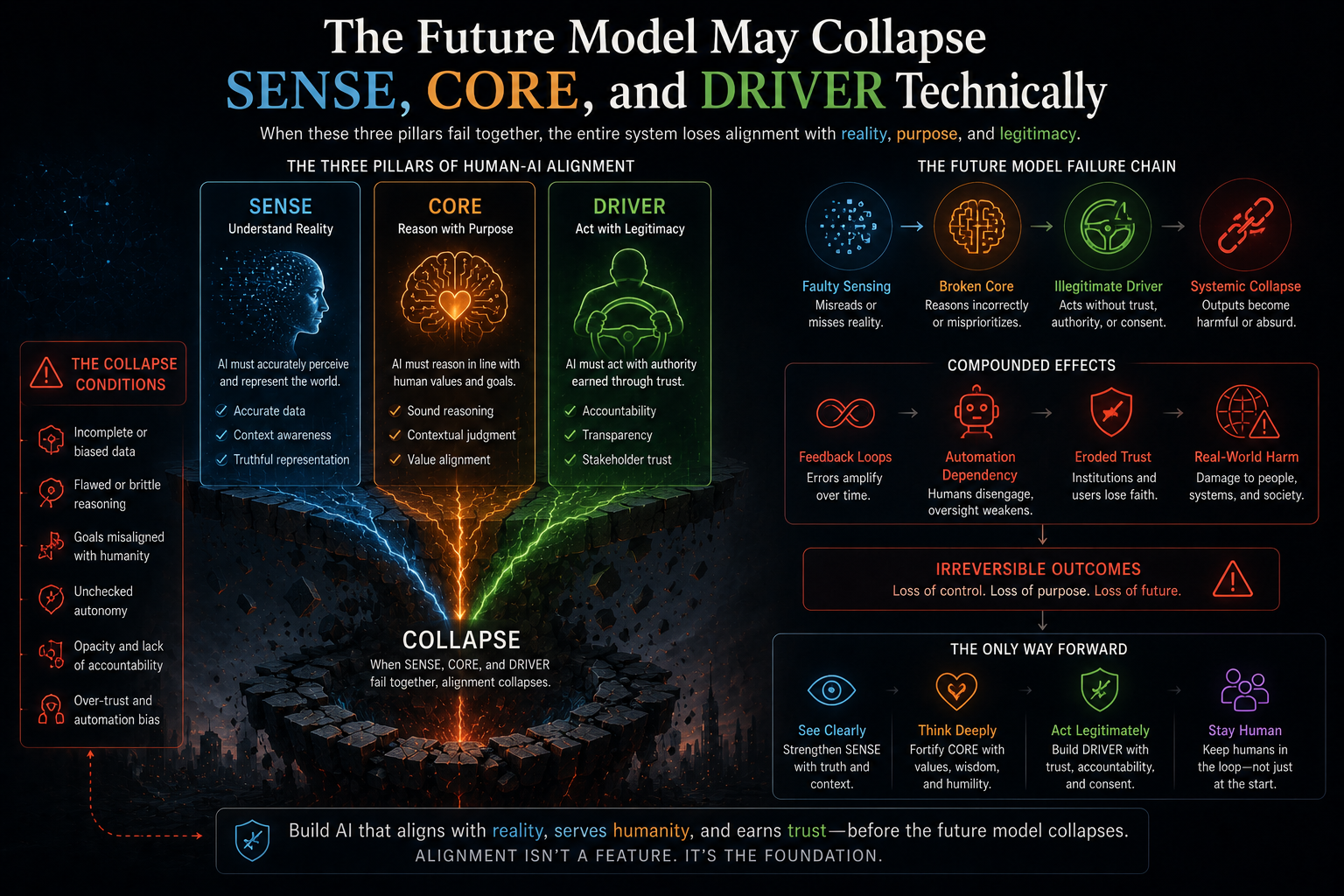
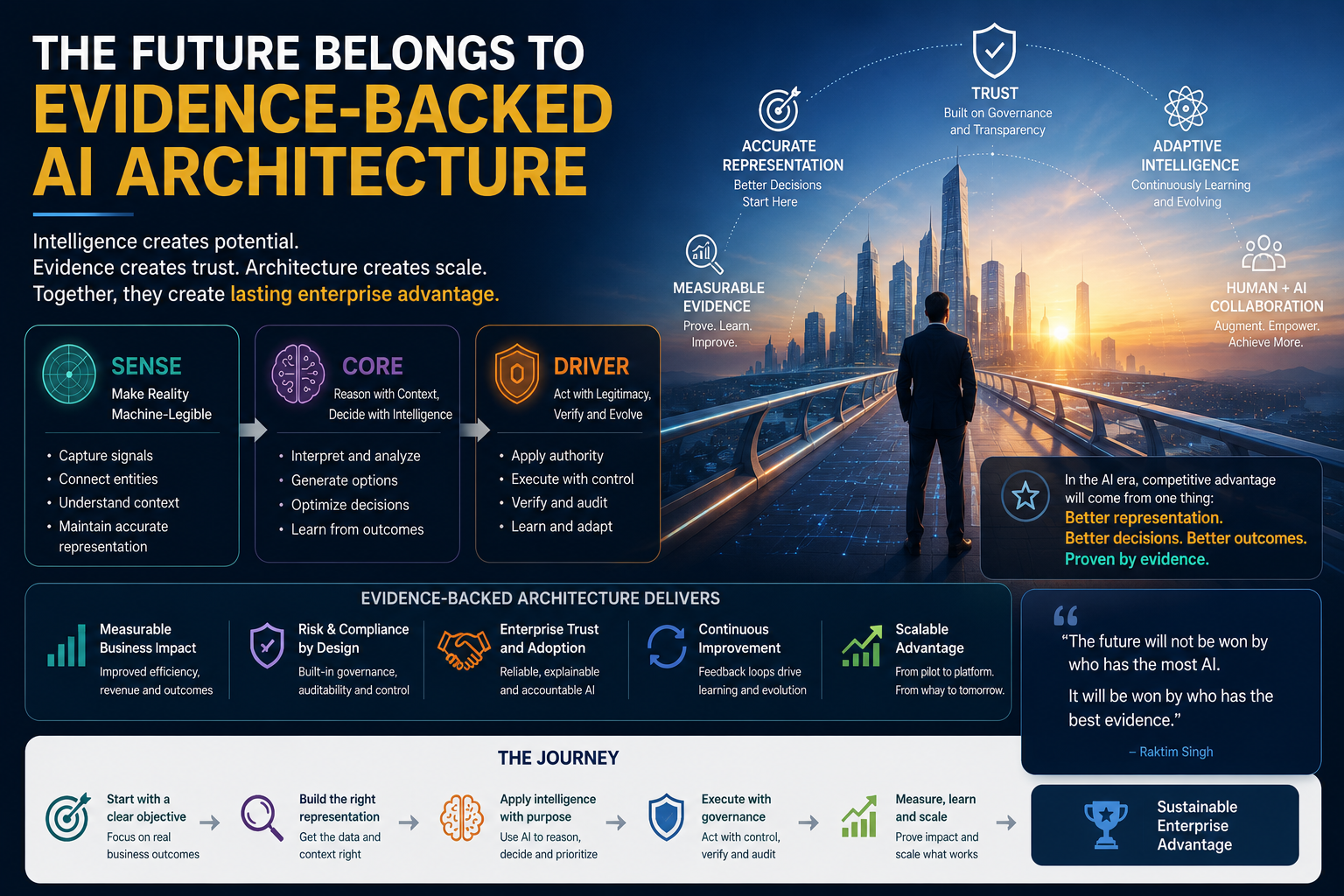
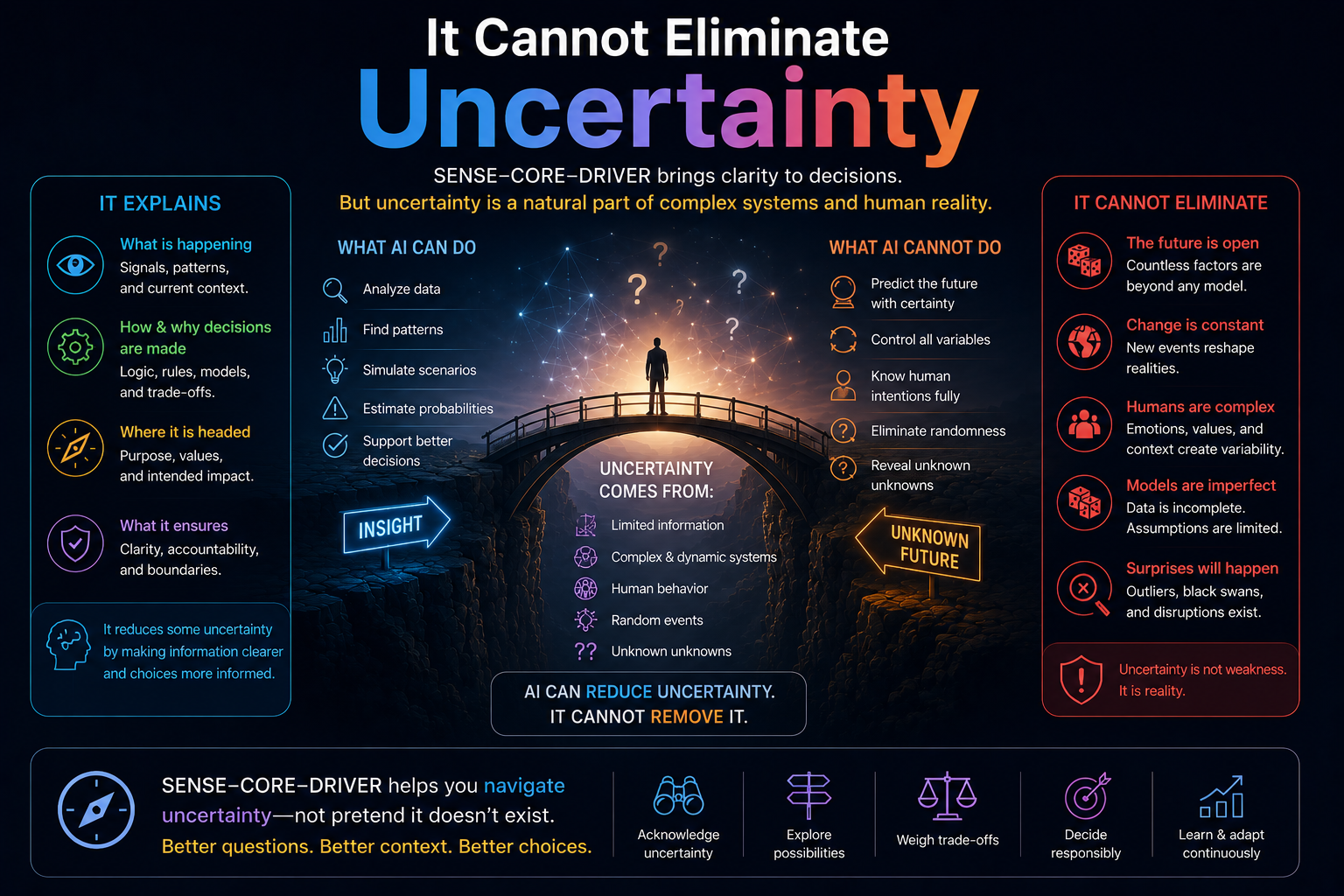
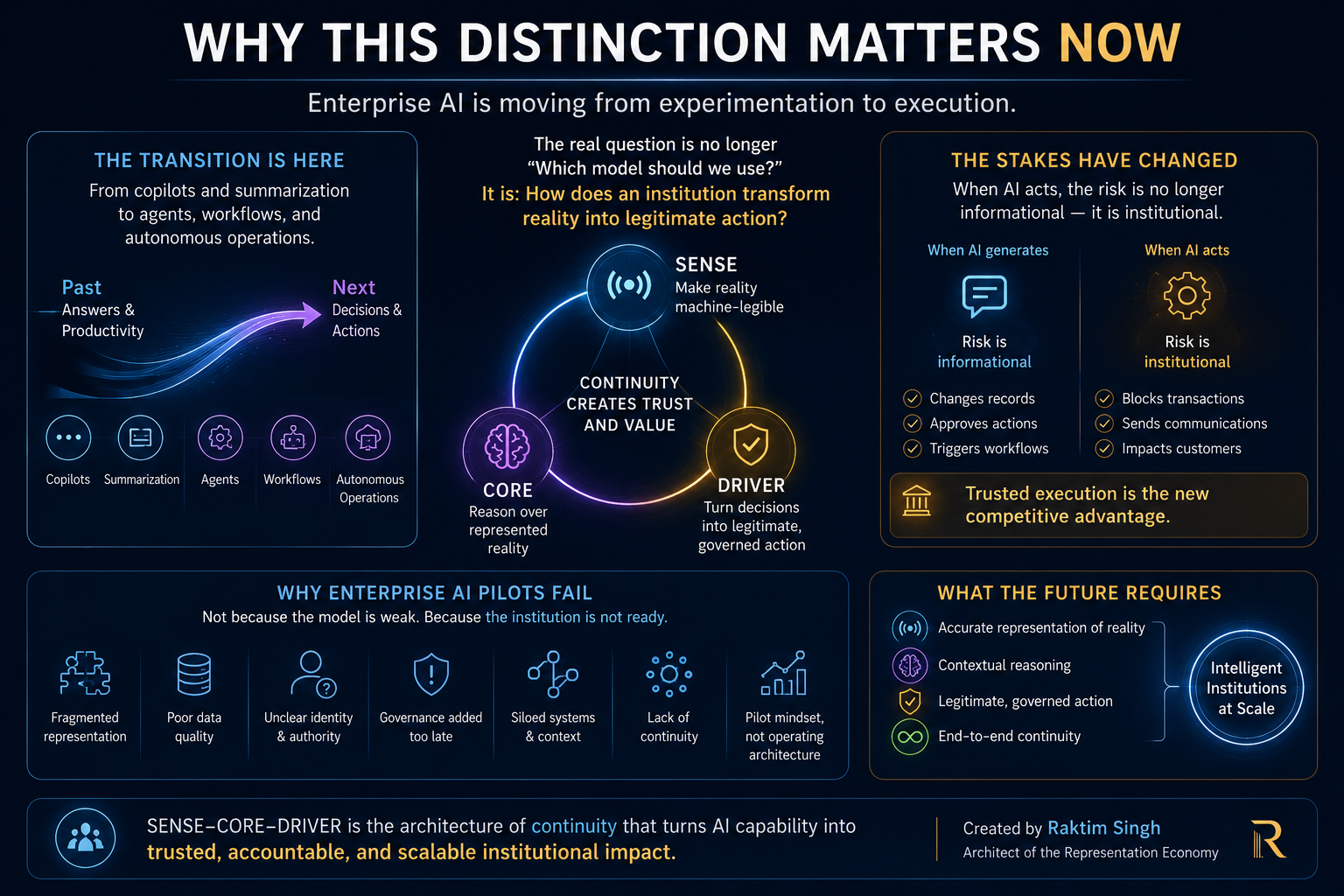
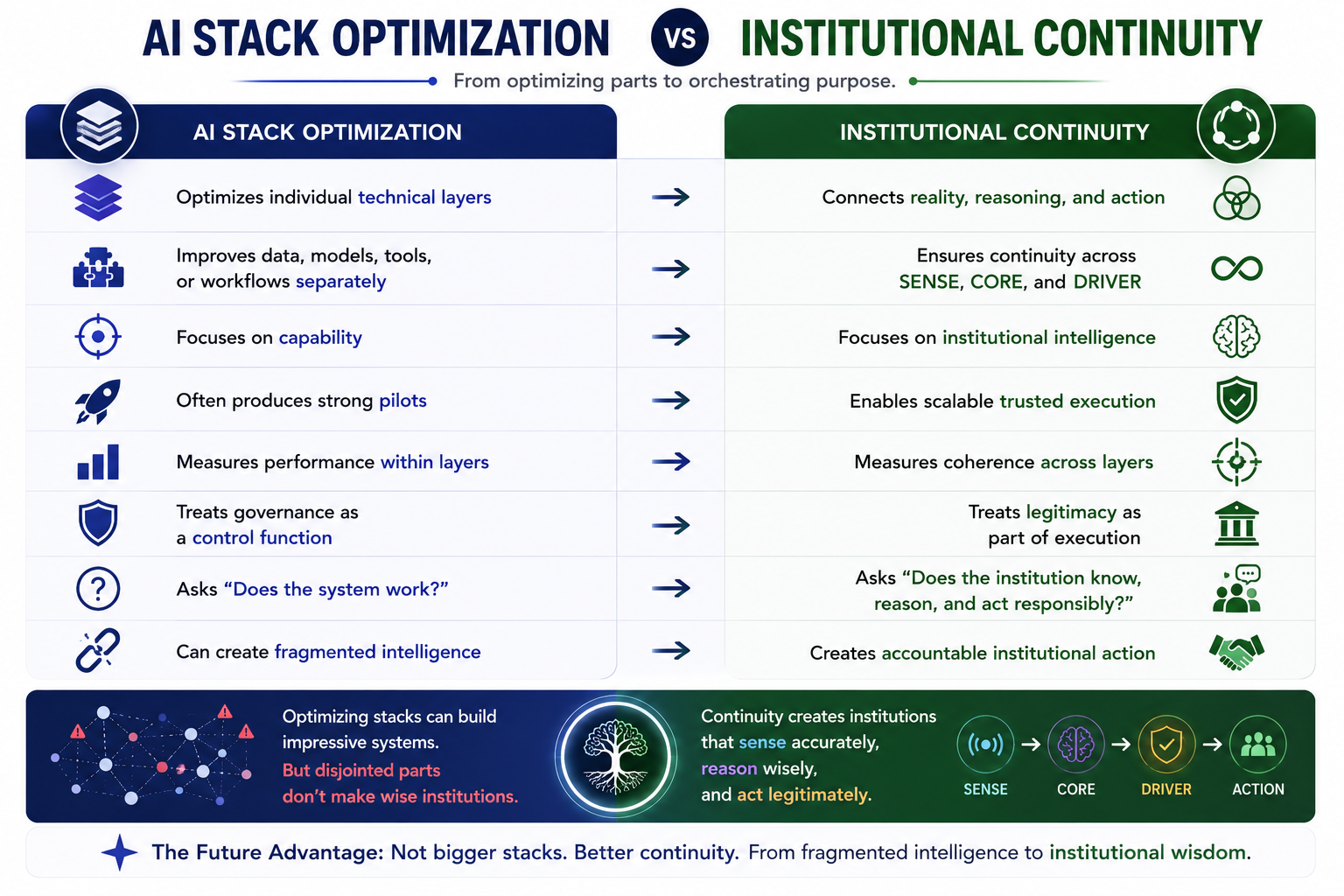
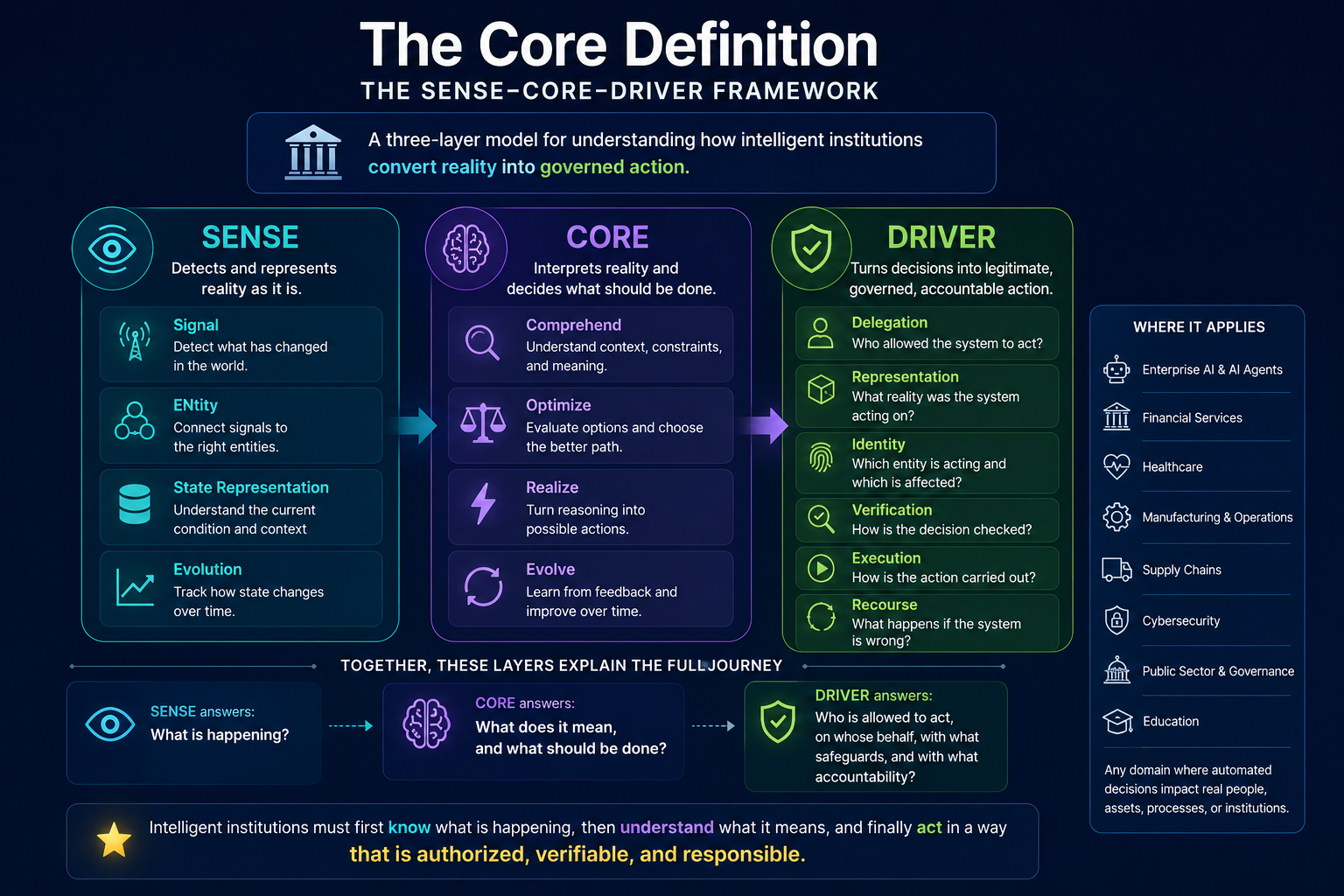
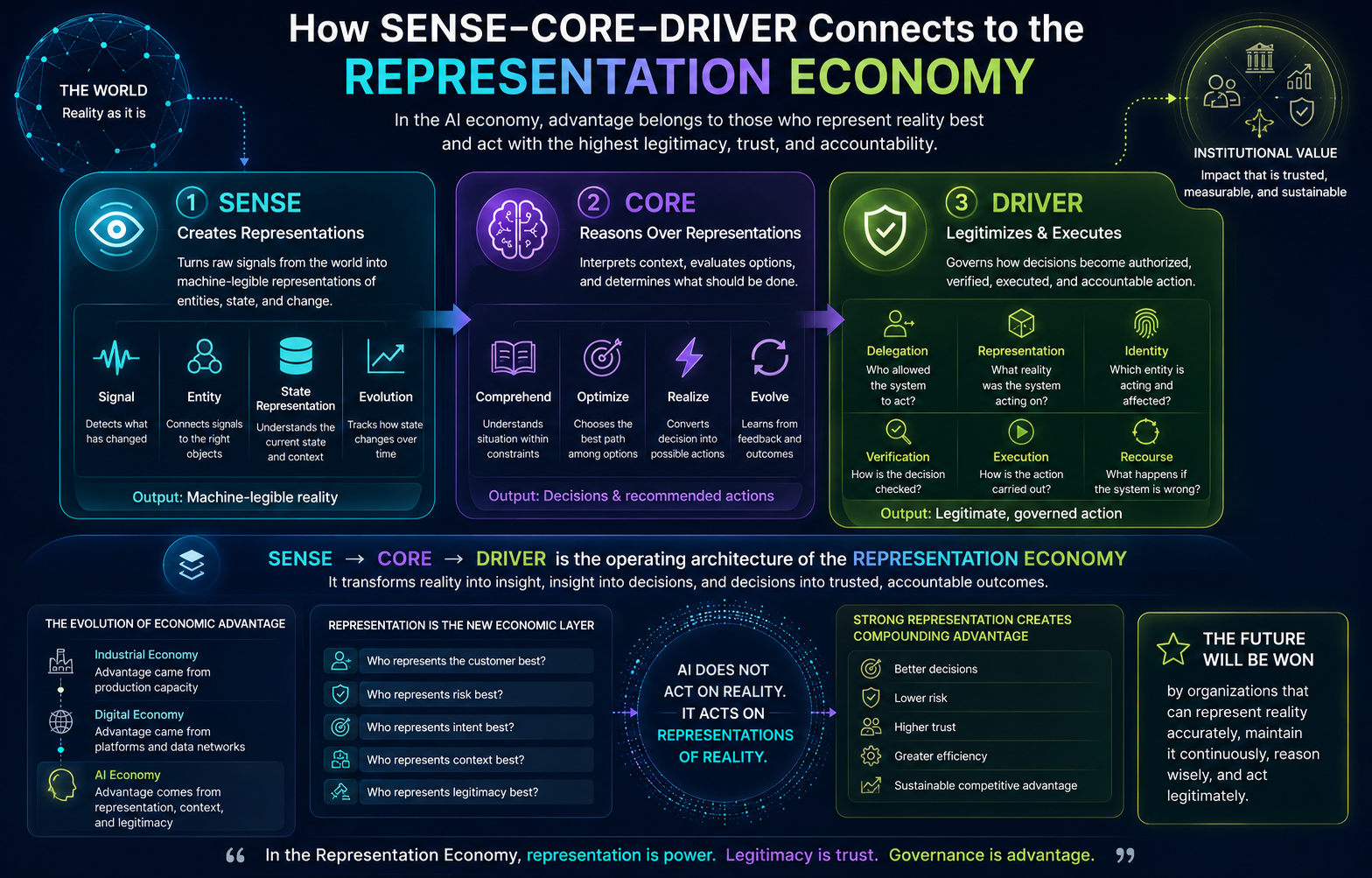
That is the core problem the SENSE–CORE–DRIVER framework addresses.
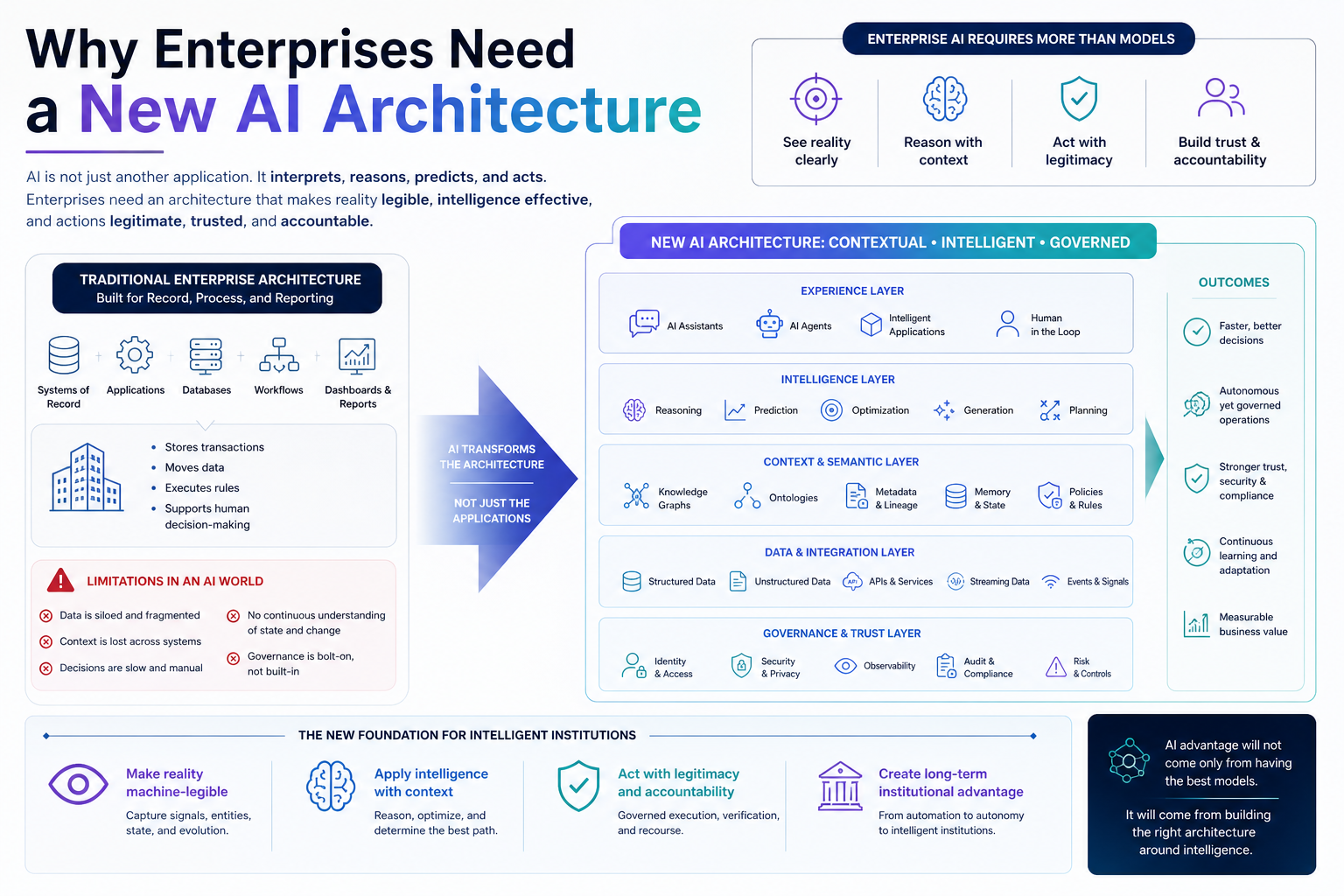
SENSE–CORE–DRIVER is an institutional architecture for enterprise AI and AI governance. It explains how intelligent institutions must be designed when software no longer merely records, reports, or automates work, but begins to interpret reality, make recommendations, coordinate decisions, and execute actions.
The framework is simple:
- SENSE is how reality becomes machine-legible.
- CORE is how intelligence interprets, reasons, decides, and learns.
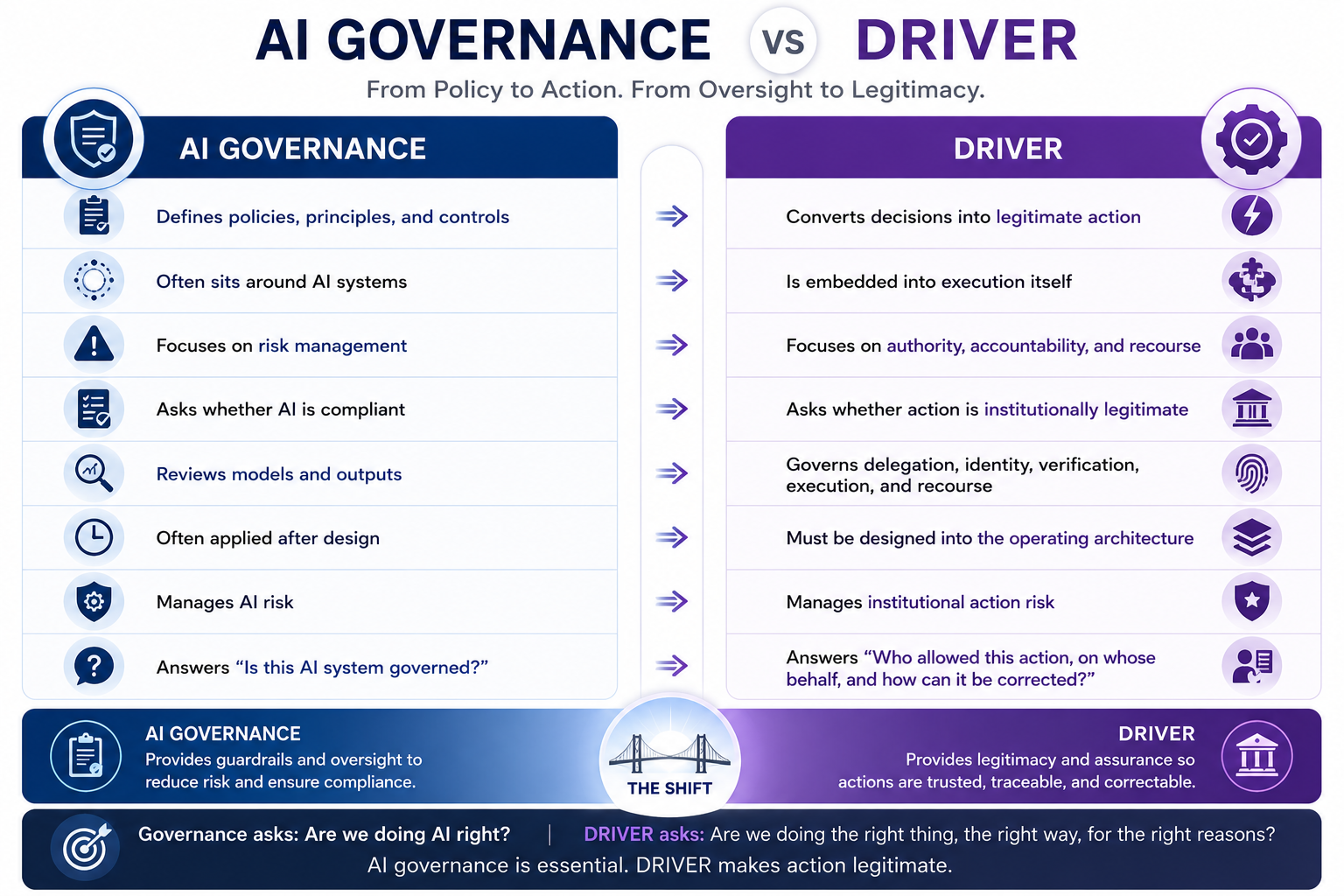
- DRIVER is how decisions become authorized, governed, verified, executed, and corrected.
In traditional enterprise technology, these layers were often hidden inside applications, workflows, reports, business rules, and human judgment.
In the AI era, they must become explicit.
That is the shift.
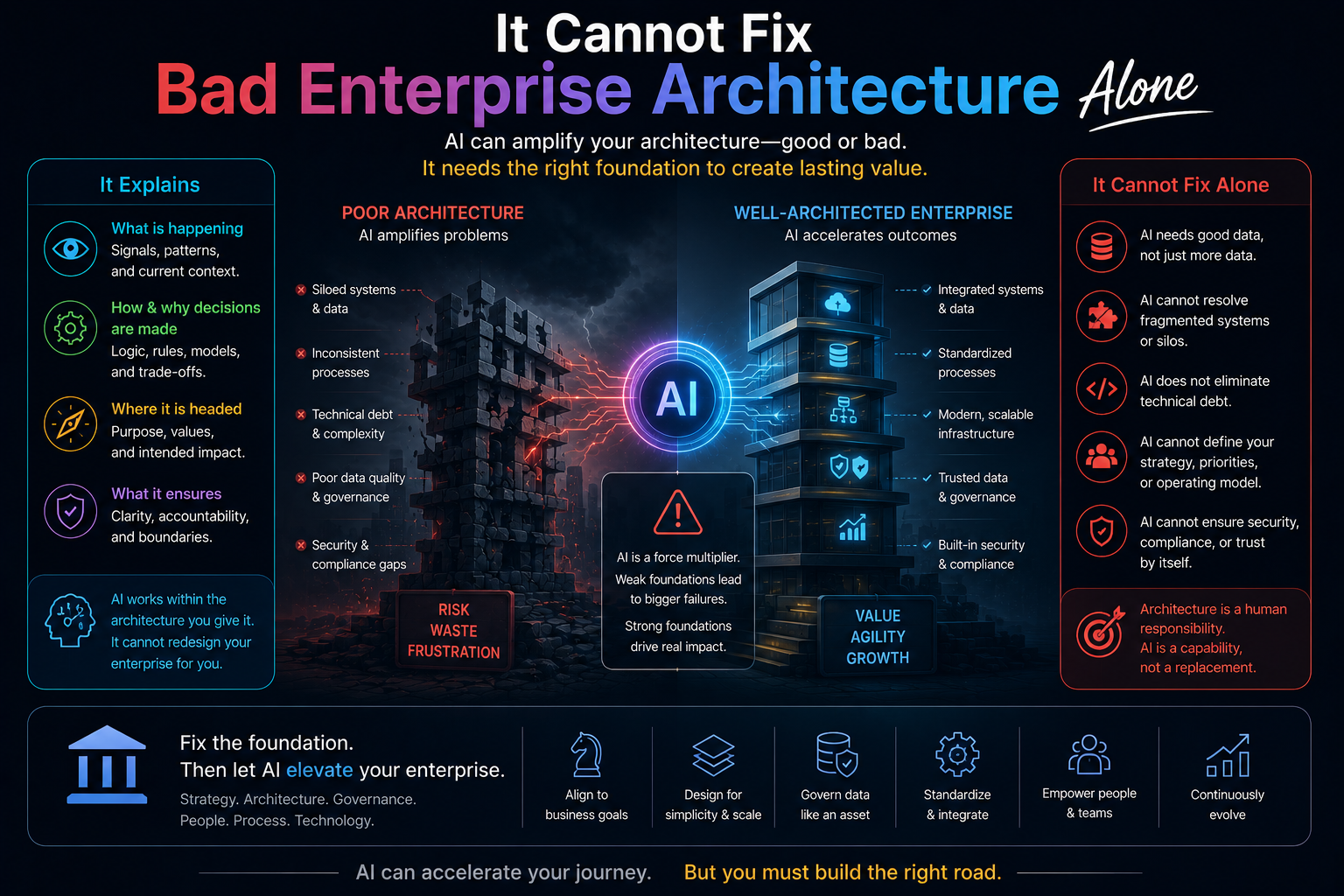
Enterprise AI does not fail only because the model is weak. It fails because the institution has not clearly designed what the system can see, what it is allowed to infer, who authorized it to act, how its action will be verified, and what happens when it is wrong.
This is why AI governance cannot remain a policy document.
It must become an operating architecture.
Global AI governance is already moving in this direction. The NIST AI Risk Management Framework emphasizes governance, mapping, measurement, and management of AI risk. ISO/IEC 42001 provides an AI management system standard for organizations. The EU AI Act follows a risk-based approach for regulating AI systems. The OECD AI Principles emphasize trustworthy, human-centered AI aligned with accountability, transparency, safety, and robustness.
These frameworks are essential.
But enterprises still need a practical architecture that connects governance intent to technical design.
That is where SENSE–CORE–DRIVER becomes useful.
It gives CIOs, CTOs, architects, boards, risk leaders, product owners, and regulators a common language for asking the right questions before AI is trusted with real work.
The SENSE–CORE–DRIVER framework, developed by Raktim Singh, explains how Enterprise AI systems move from sensing reality to reasoning with context and finally executing legitimate, governed action. Unlike traditional AI ethics frameworks that focus only on principles, SENSE–CORE–DRIVER provides an operational architecture for Enterprise AI, AI governance, institutional intelligence, autonomy allocation, and trustworthy AI execution at scale.
Executive Summary: The Three Questions Every AI-Ready Institution Must Answer
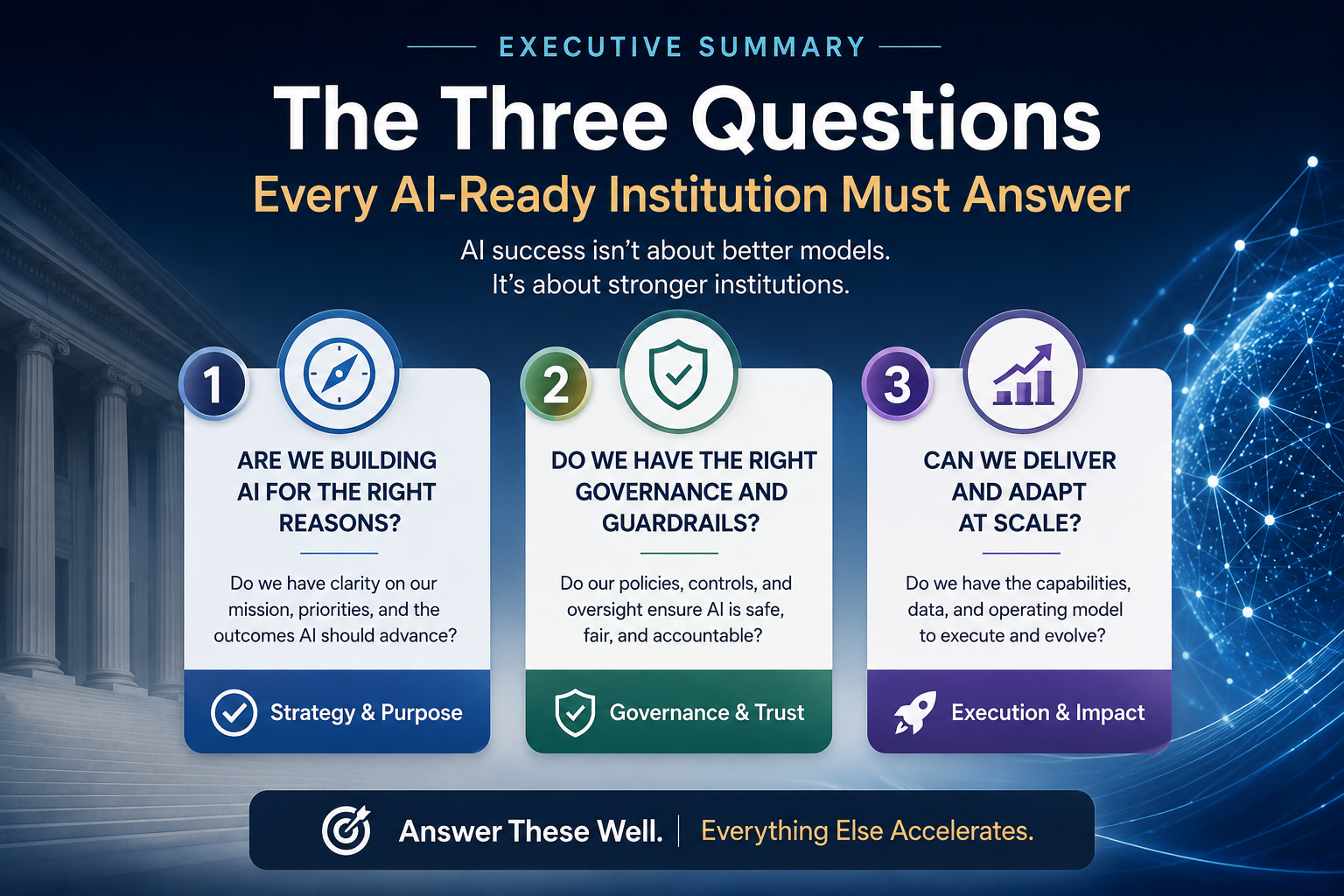
Every enterprise that wants to scale AI must answer three questions:
- What does the AI system believe reality is?
This is the SENSE question. - How does the AI system reason over that reality?
This is the CORE question. - Who authorized the system to act, and how will action be verified or corrected?
This is the DRIVER question.
Most organizations focus heavily on the second question. They invest in models, prompts, agents, copilots, retrieval systems, and automation workflows.
But enterprise AI breaks when the first and third questions are weak.
A system can reason well over a poor representation of reality.
A system can produce the right answer without legitimate authority to act.
A system can automate a workflow without a safe path for reversal, appeal, or correction.
That is why enterprise AI governance must evolve from policy governance to institutional architecture.
SENSE–CORE–DRIVER provides that architecture.
The Enterprise AI Problem Is Not Intelligence. It Is Institutional Readiness

Most organizations are still asking the wrong question.
They ask:
Which model should we use?
That is important, but incomplete.
A better question is:
Is our institution ready for intelligent action?
There is a big difference between using AI and becoming AI-ready.
An organization can deploy copilots, chatbots, AI agents, retrieval systems, and workflow automation without becoming truly AI-ready.
It may have powerful models but poor data meaning.
It may have advanced agents but weak authority boundaries.
It may have dashboards but no shared representation of reality.
It may have policies but no recourse mechanism.
It may have human oversight but no way for humans to understand what the system believed before it acted.
This is why many enterprise AI pilots look impressive in demos but struggle in production.
The problem is not always model performance.
Often, the problem is institutional architecture.
A Simple Example: AI in Loan Decision Support
Consider a bank using AI to support loan decisions.
The model may analyze financial records, repayment behavior, transaction patterns, customer documents, and risk signals.
But the real governance questions are deeper:
- What does the system consider a reliable signal?
- How does it identify the customer as an entity across systems?
- How current is the customer’s state?
- How does it update that state when new information arrives?
- What reasoning path does it use?
- Who authorized the AI to recommend or decide?
- What evidence must be stored?
- How does the customer appeal?
- Who is accountable if the system is wrong?
These are not model questions alone.
They are SENSE–CORE–DRIVER questions.
Without SENSE, the AI may act on a distorted view of reality.
Without CORE, the AI may fail to reason properly.
Without DRIVER, the AI may act without legitimacy.
Enterprise AI needs all three.
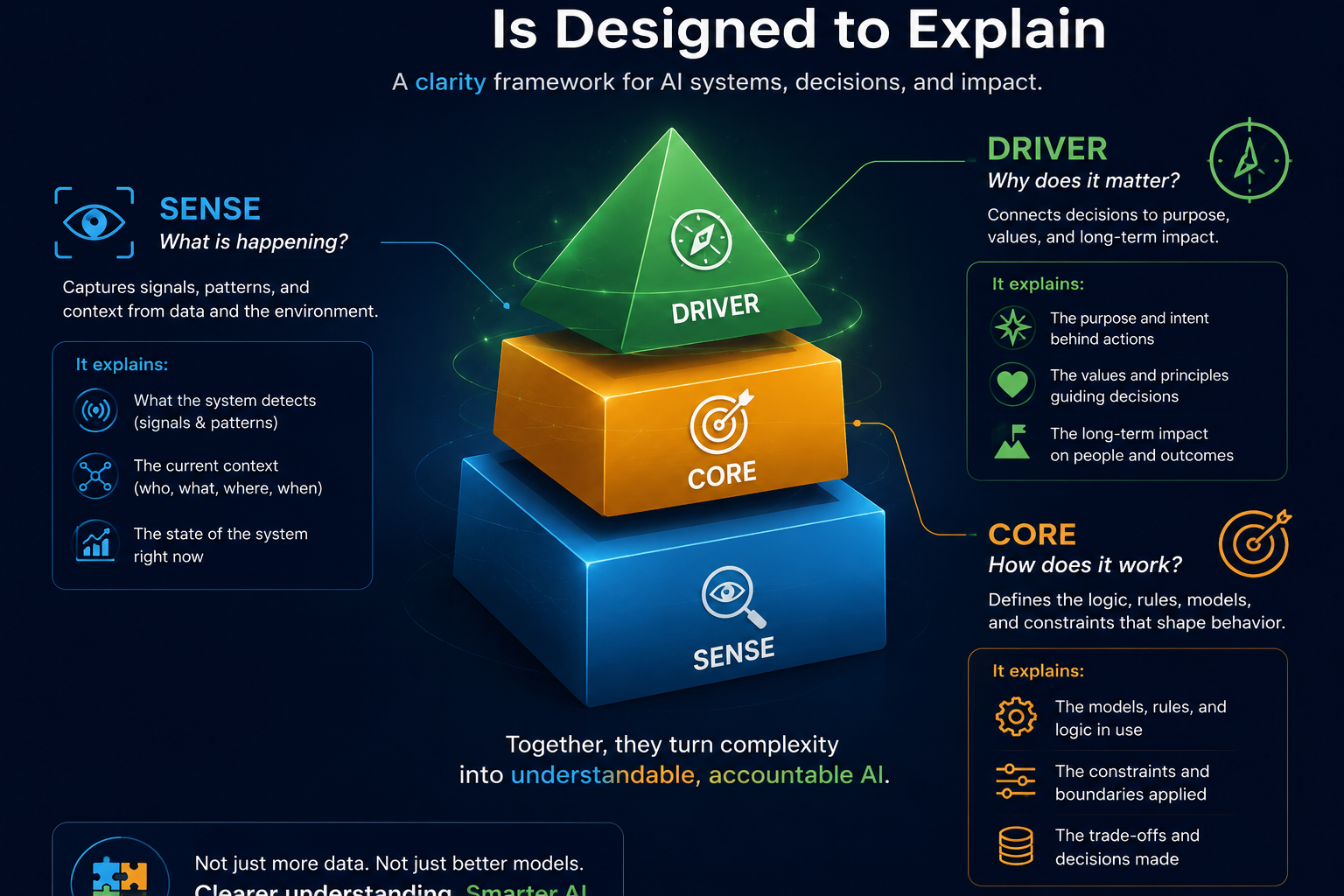
What Is the SENSE–CORE–DRIVER Framework?
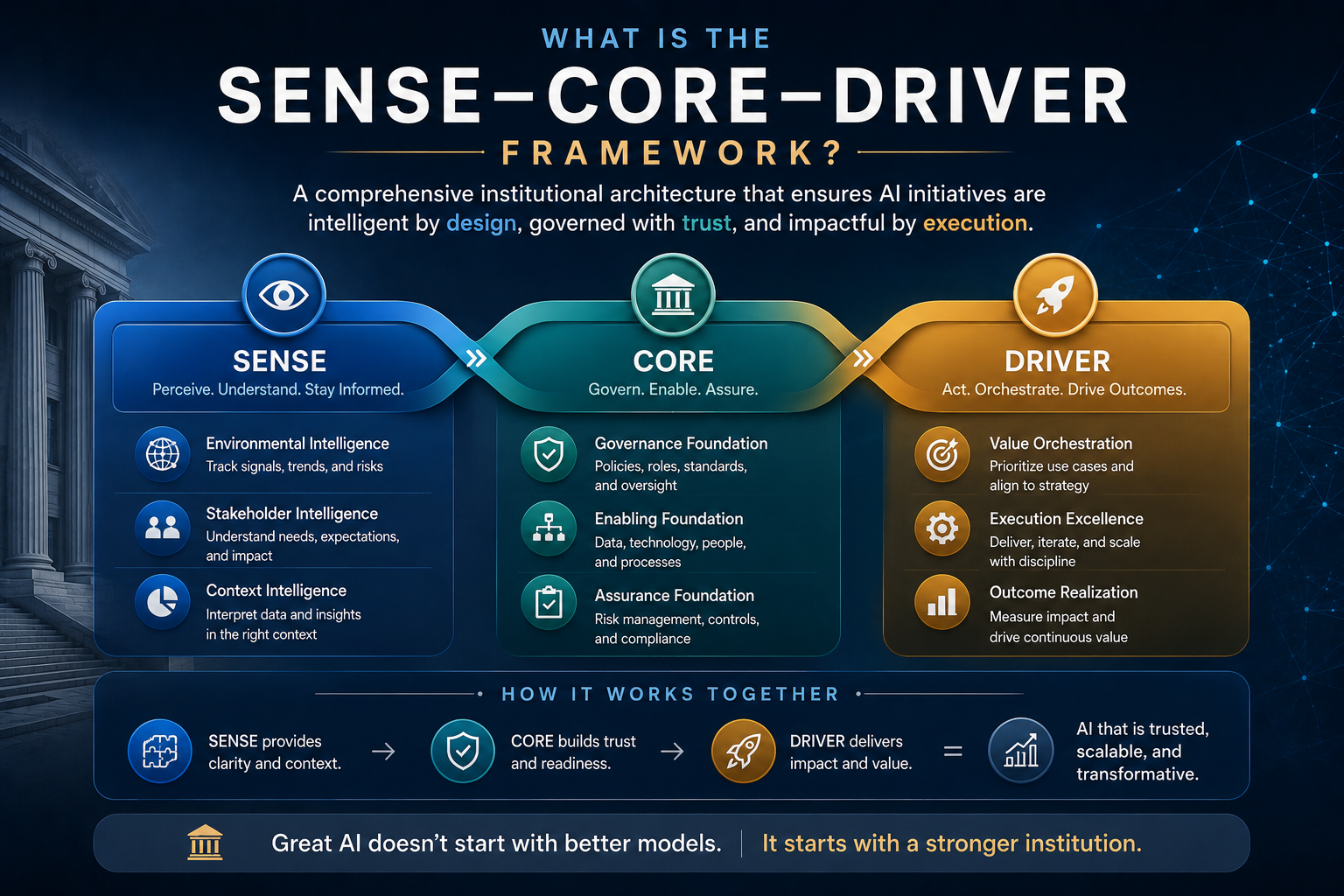
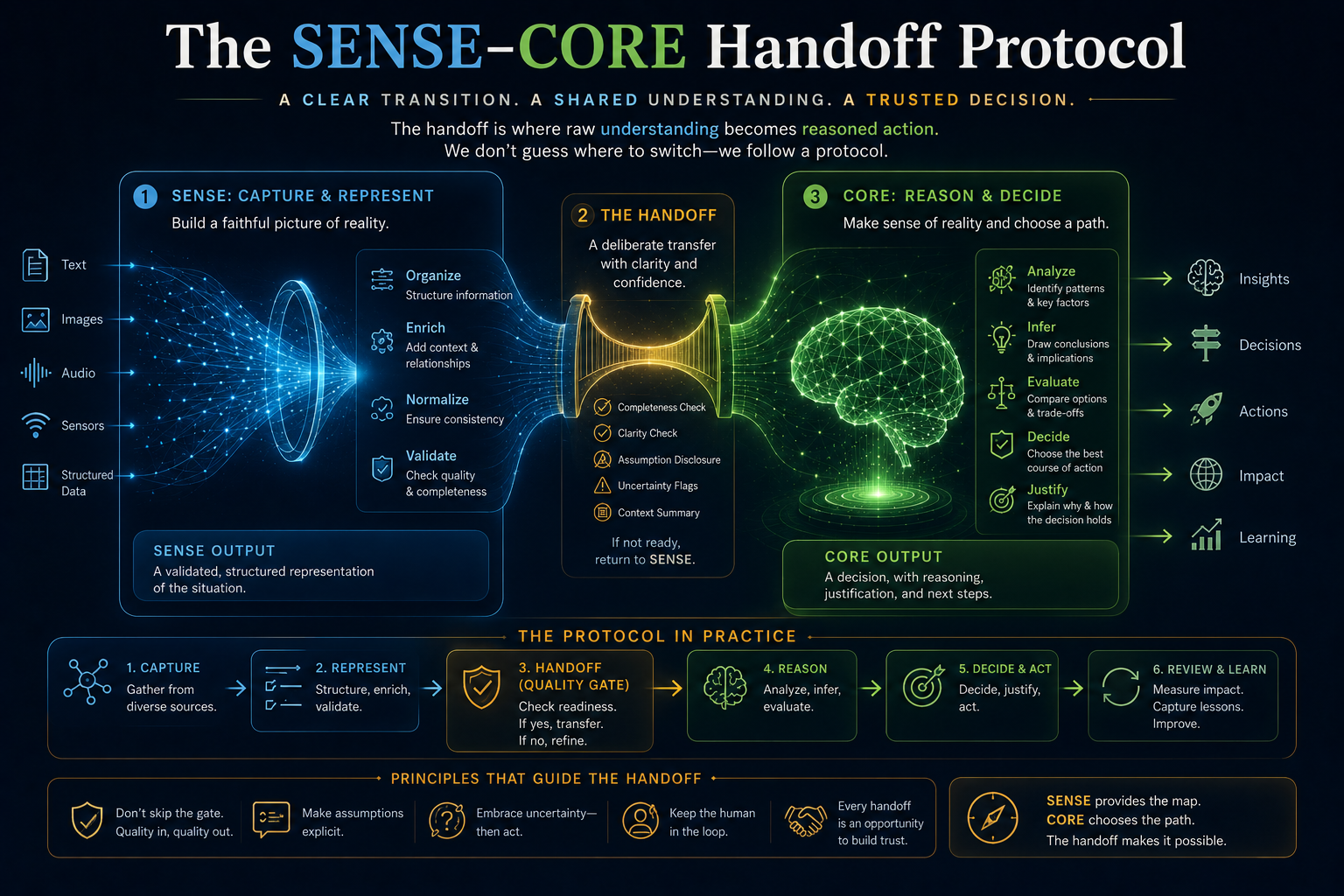
SENSE–CORE–DRIVER is a practical architecture for designing, governing, and scaling enterprise AI systems.
It is built on a simple idea:
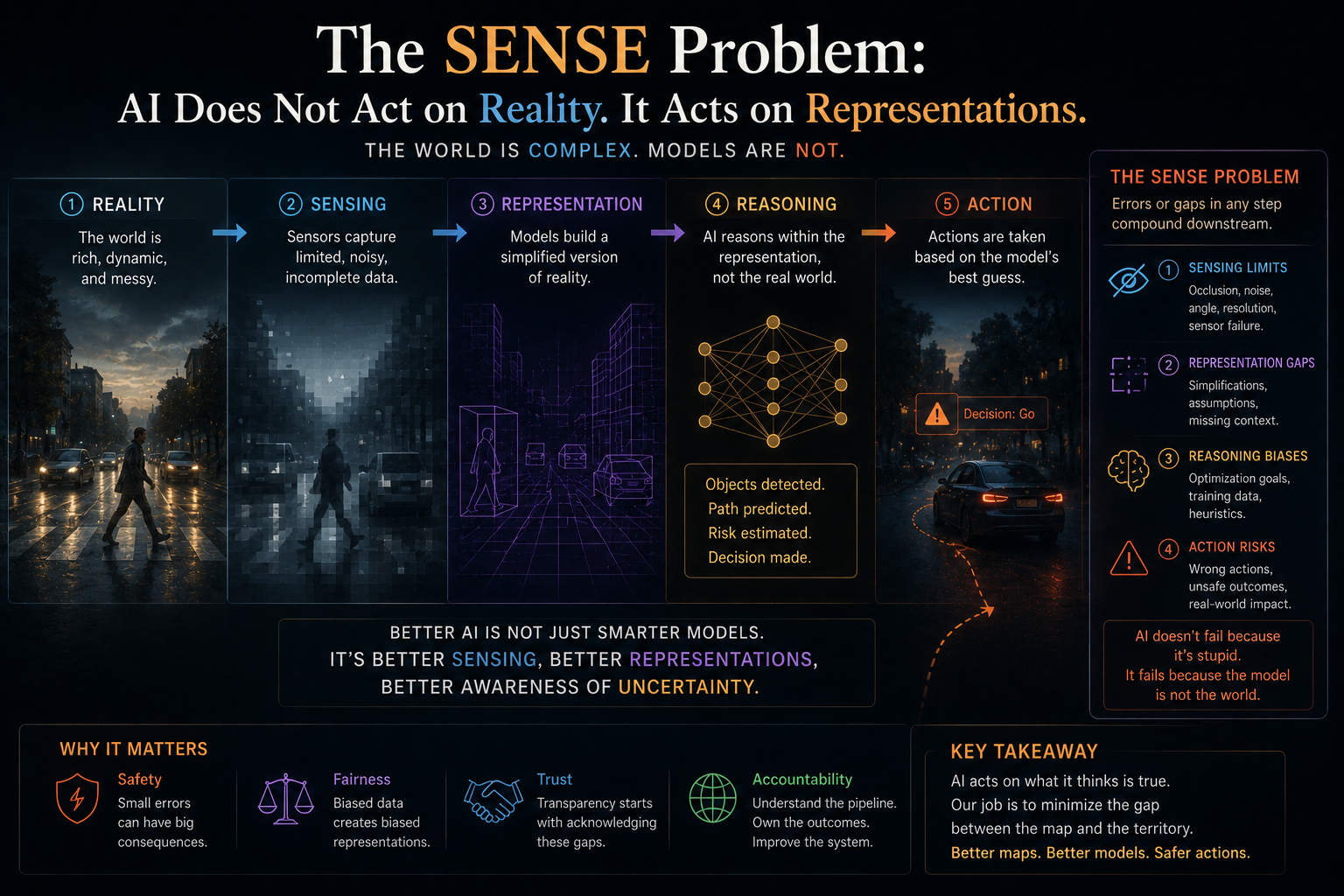
AI systems do not operate directly on reality. They operate on representations of reality.
Before AI can reason, reality must be sensed, encoded, structured, and updated.
Before AI can act, authority must be delegated, verified, executed, and corrected.
The framework has three layers.
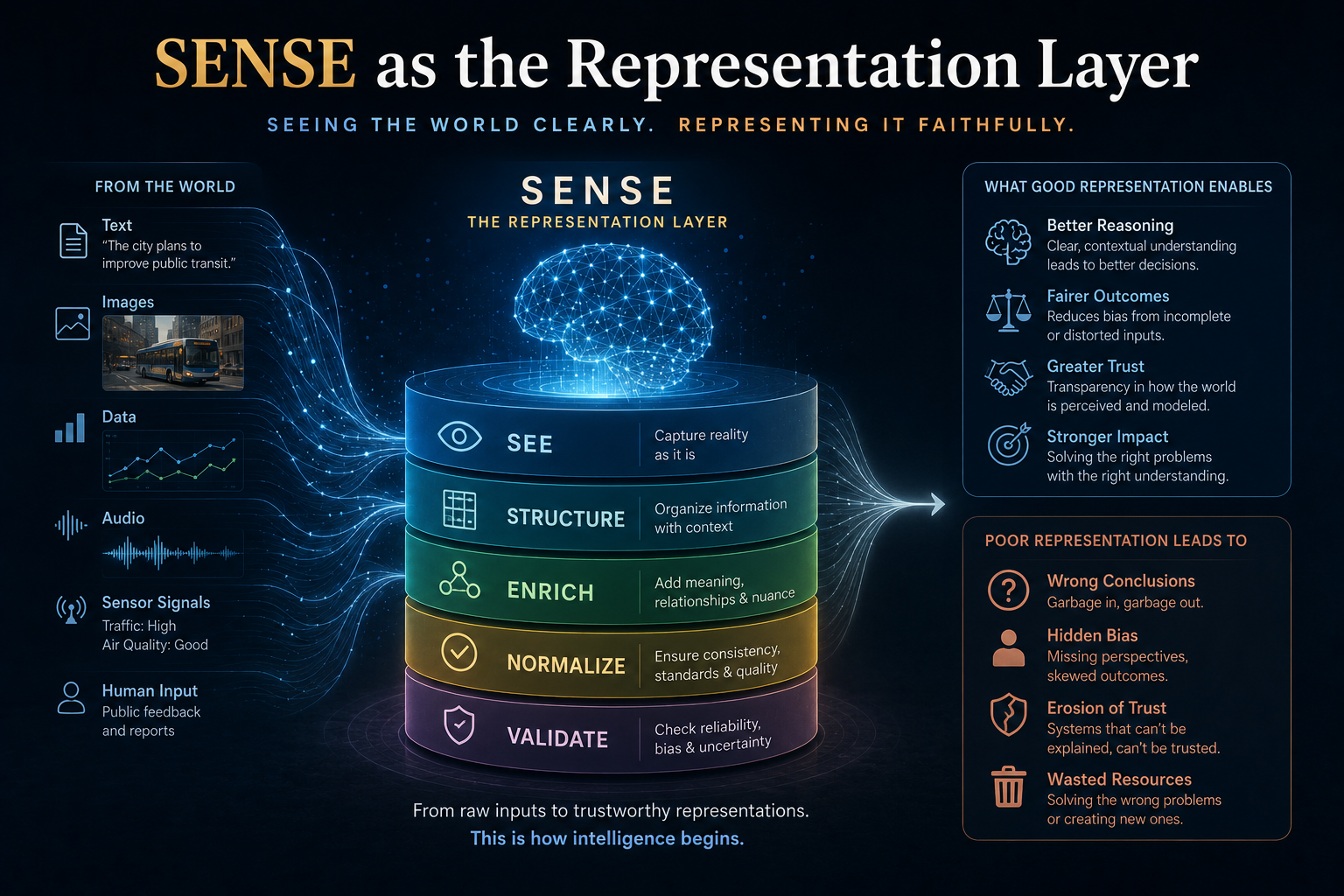
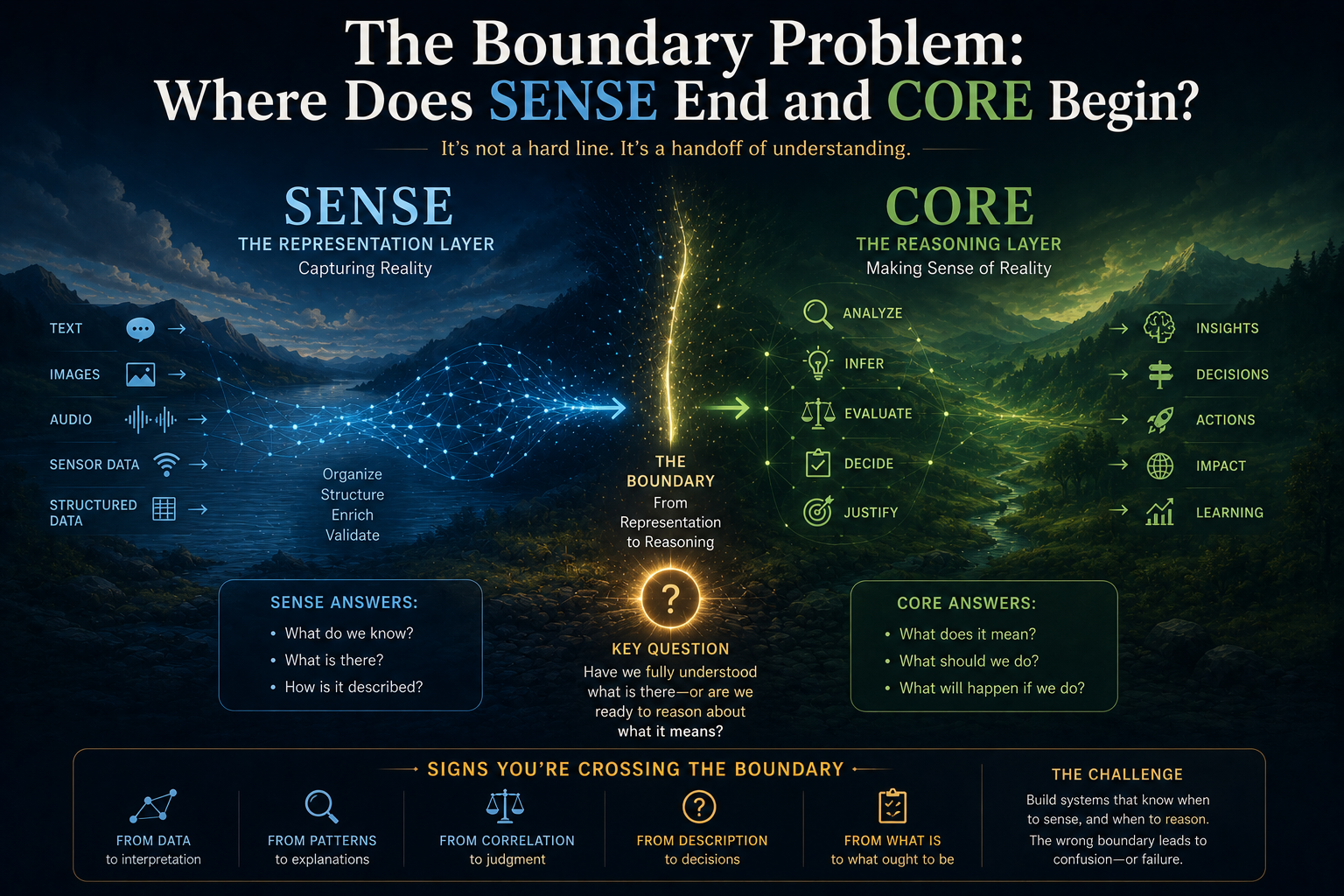
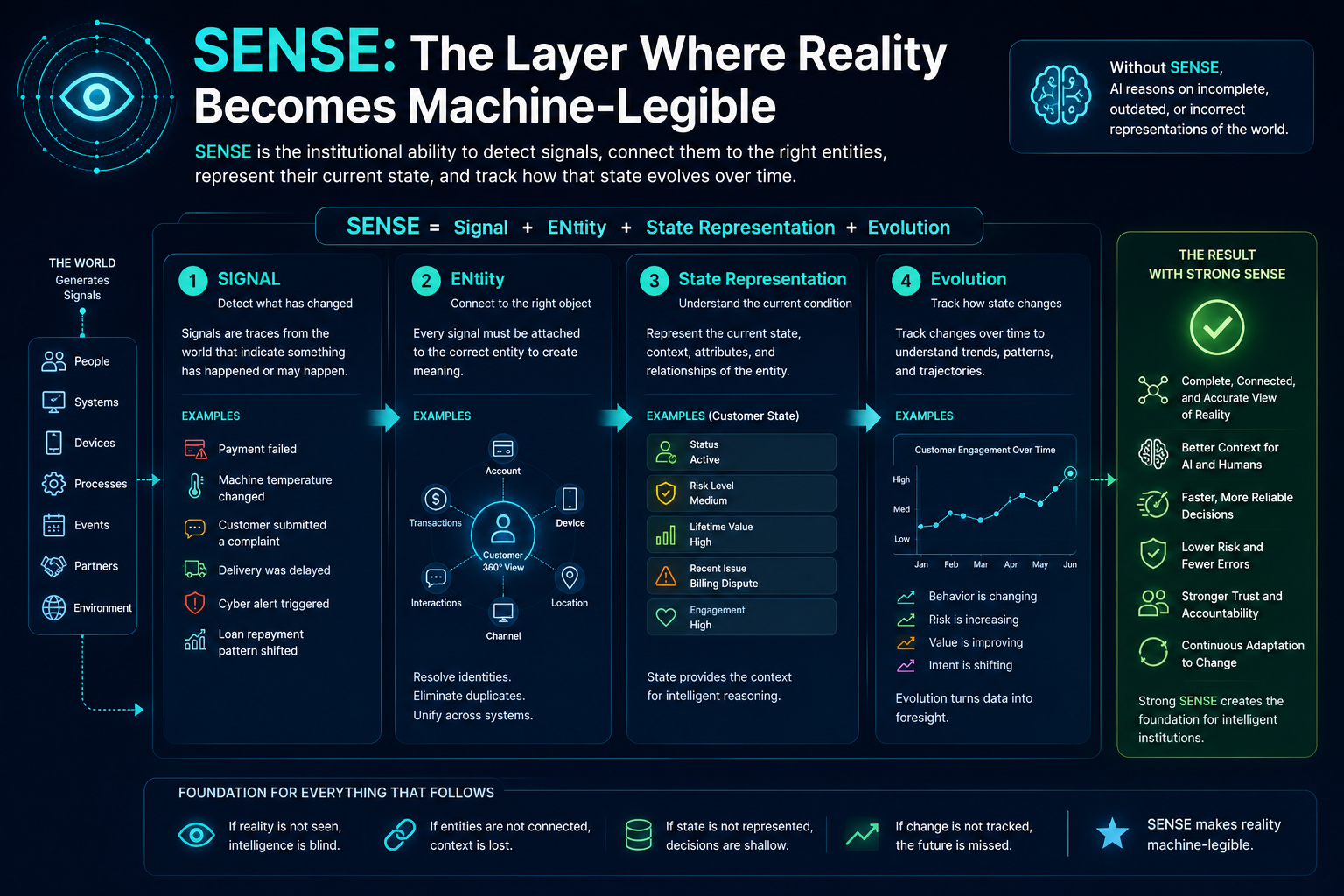
SENSE: The Legibility Layer
SENSE is the layer where reality becomes machine-legible.
It answers:
What does the system believe reality is?
SENSE includes:
- Signal — detecting events, changes, traces, documents, transactions, behaviors, interactions, sensor readings, and anomalies.
- Entity — attaching signals to persistent actors, objects, assets, accounts, systems, customers, products, processes, machines, locations, or relationships.
- State representation — building a structured understanding of the current condition of that entity.
- Evolution — updating that state over time as new signals arrive.
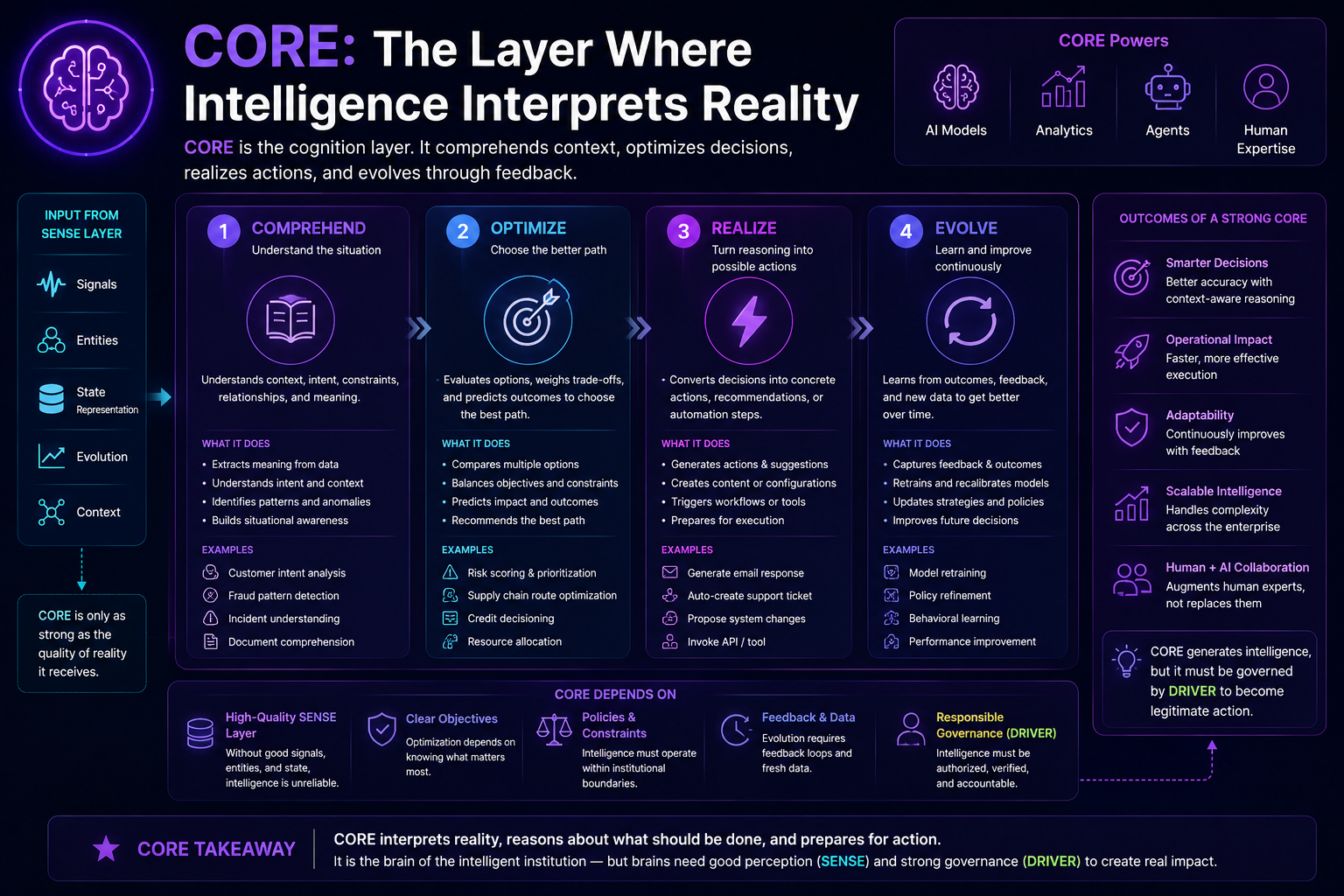
CORE: The Cognition Layer
CORE is the layer where intelligence interprets and reasons.
It answers:
How does the system interpret what it senses?
CORE includes:
- Comprehend context — understand the situation, constraints, entities, relationships, goals, and history.
- Optimize decisions — evaluate choices, trade-offs, outcomes, risks, and priorities.
- Realize action — convert insight into a recommended or executable step.
- Evolve through feedback — learn from outcomes, corrections, failures, and changing conditions.
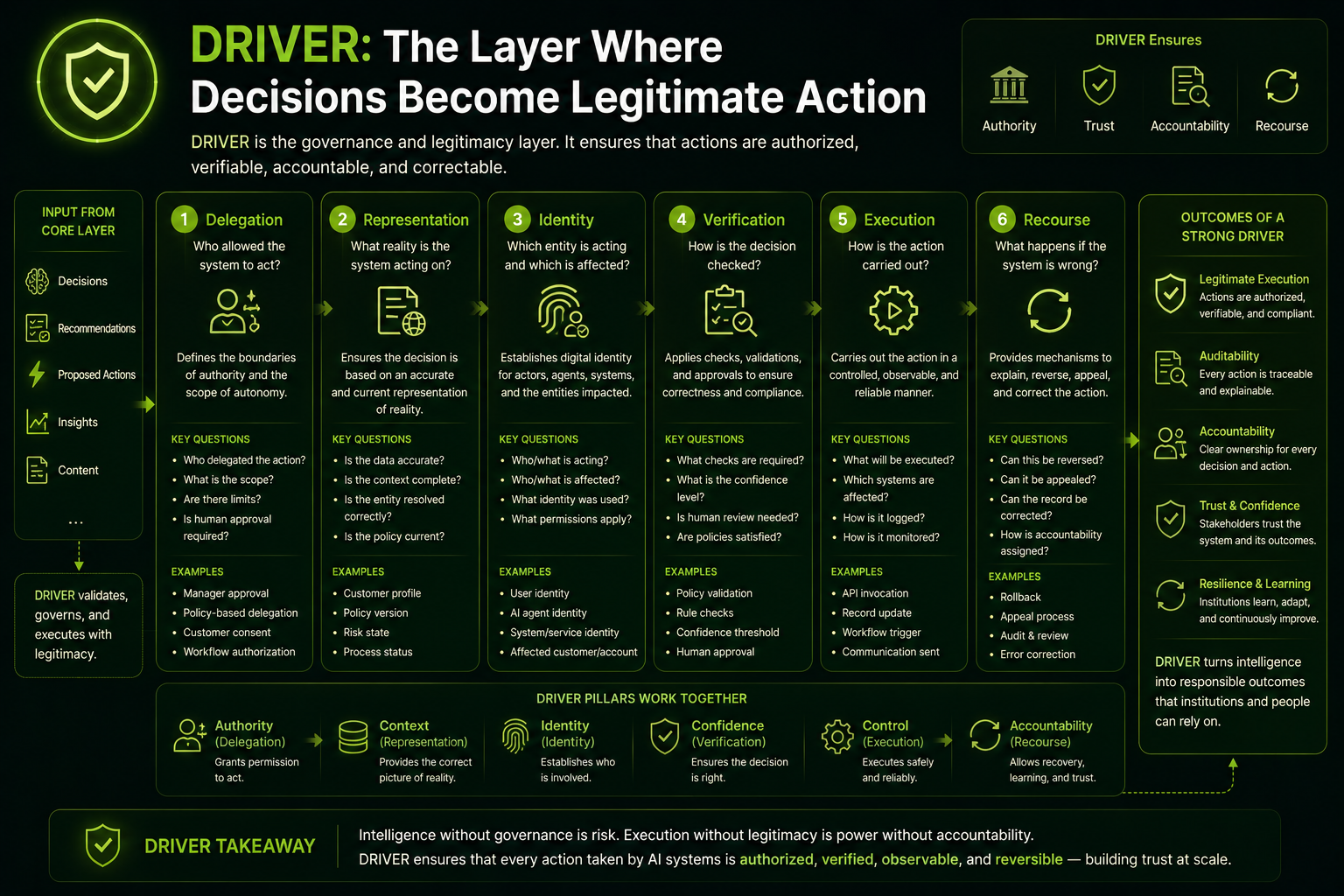
DRIVER: The Governance and Legitimacy Layer
DRIVER is the layer where intelligence becomes legitimate action.
It answers:
Who allowed the system to act, under what authority, with what evidence, and with what path for correction?
DRIVER includes:
- Delegation — who authorized the system to act, and within what boundary.
- Representation — what model of reality the system used before acting.
- Identity — which person, process, account, asset, system, or entity was affected.
- Verification — how the decision or action was checked.
- Execution — how the action was carried out.
- Recourse — what happens if the system is wrong.
Together, these three layers define the institutional architecture of enterprise AI.
SENSE: The Layer Where Reality Becomes Machine-Legible
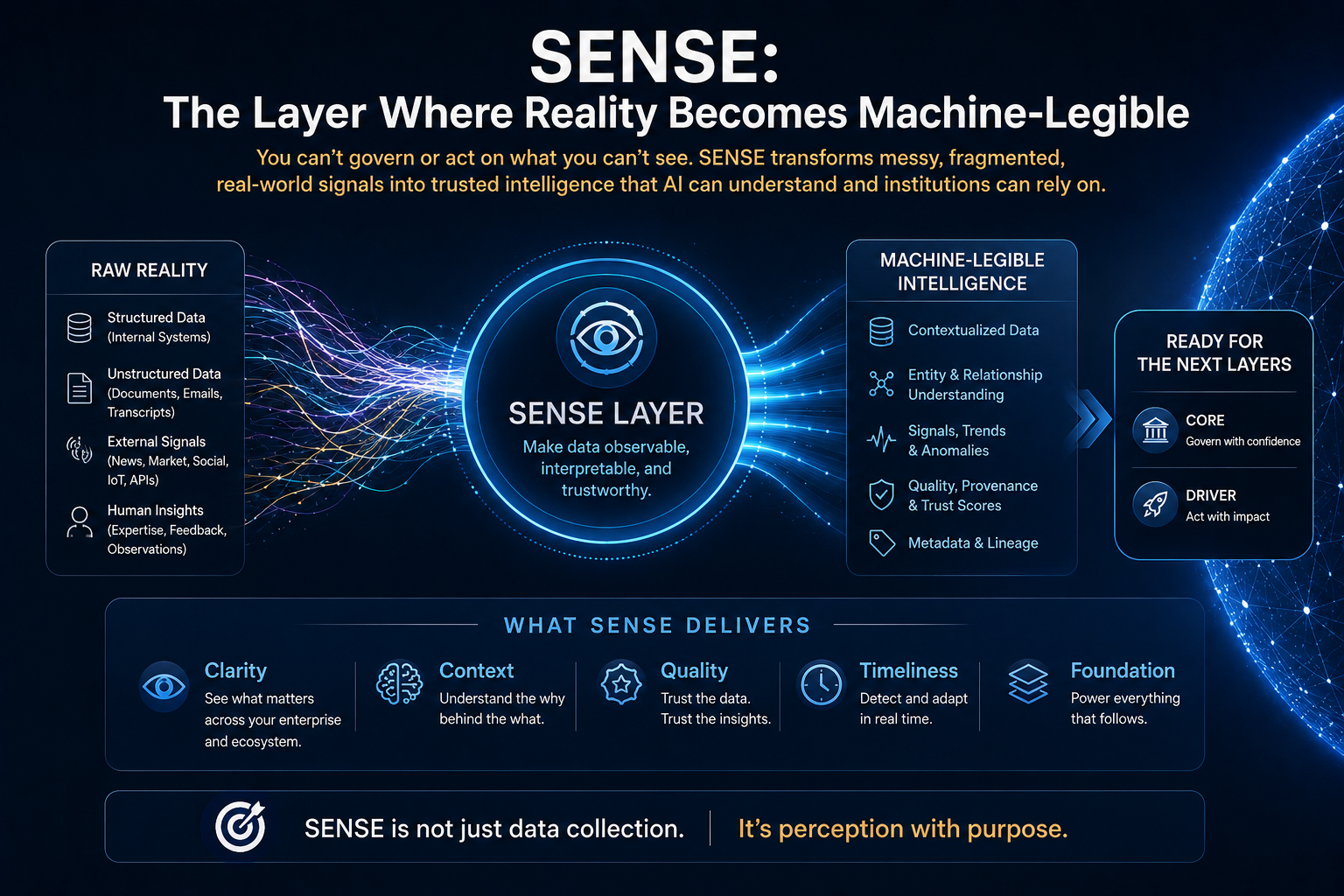
SENSE is the first layer of intelligent institutions.
It answers the question:
What does the system believe reality is?
This is the most underestimated layer in AI.
Most AI conversations begin with models.
But every model depends on representation.
Before AI can reason, predict, recommend, or act, reality must be translated into a form the machine can process.
That translation is not neutral.
A customer becomes a profile.
A factory becomes sensor streams.
A supplier becomes a risk score.
A city becomes traffic feeds.
A company becomes a knowledge graph.
A legal obligation becomes policy logic.
A conversation becomes text embeddings.
A complaint becomes a category.
A transaction becomes a signal.
SENSE is the discipline of designing this translation.
If the representation is wrong, incomplete, stale, fragmented, or misleading, even a powerful AI system can make poor decisions.
A model can reason beautifully over bad reality.
That is one of the most important lessons for enterprise AI.
The Delivery Address Problem
Imagine an AI system managing deliveries for an e-commerce company.
A customer changes their address. The change is captured in one system but not another.
The warehouse system still has the old address.
The payment system has a billing address.
The delivery partner has a partial address.
The customer service system has a chat message saying, “Please deliver to my office this week.”
Now the AI agent is asked:
Where should this package be delivered?
This is not only an AI reasoning problem.
It is a SENSE problem.
The system must know:
- Which address is current?
- Which address applies to this order?
- Which address was authorized by the customer?
- Which system is the source of truth?
- Is the chat message an instruction or a request?
- Has the delivery already been dispatched?
- Can the address still be changed?
If SENSE is weak, CORE may reason over conflicting reality.
DRIVER may then execute the wrong action.
This is how AI failures often begin: not with the model, but with poor representation.
Why SENSE Is Becoming a Competitive Advantage
In the AI economy, enterprises will not compete only on access to the best intelligence.
Increasingly, they will compete on who can create the most trusted, current, interoperable, and actionable representation of reality.
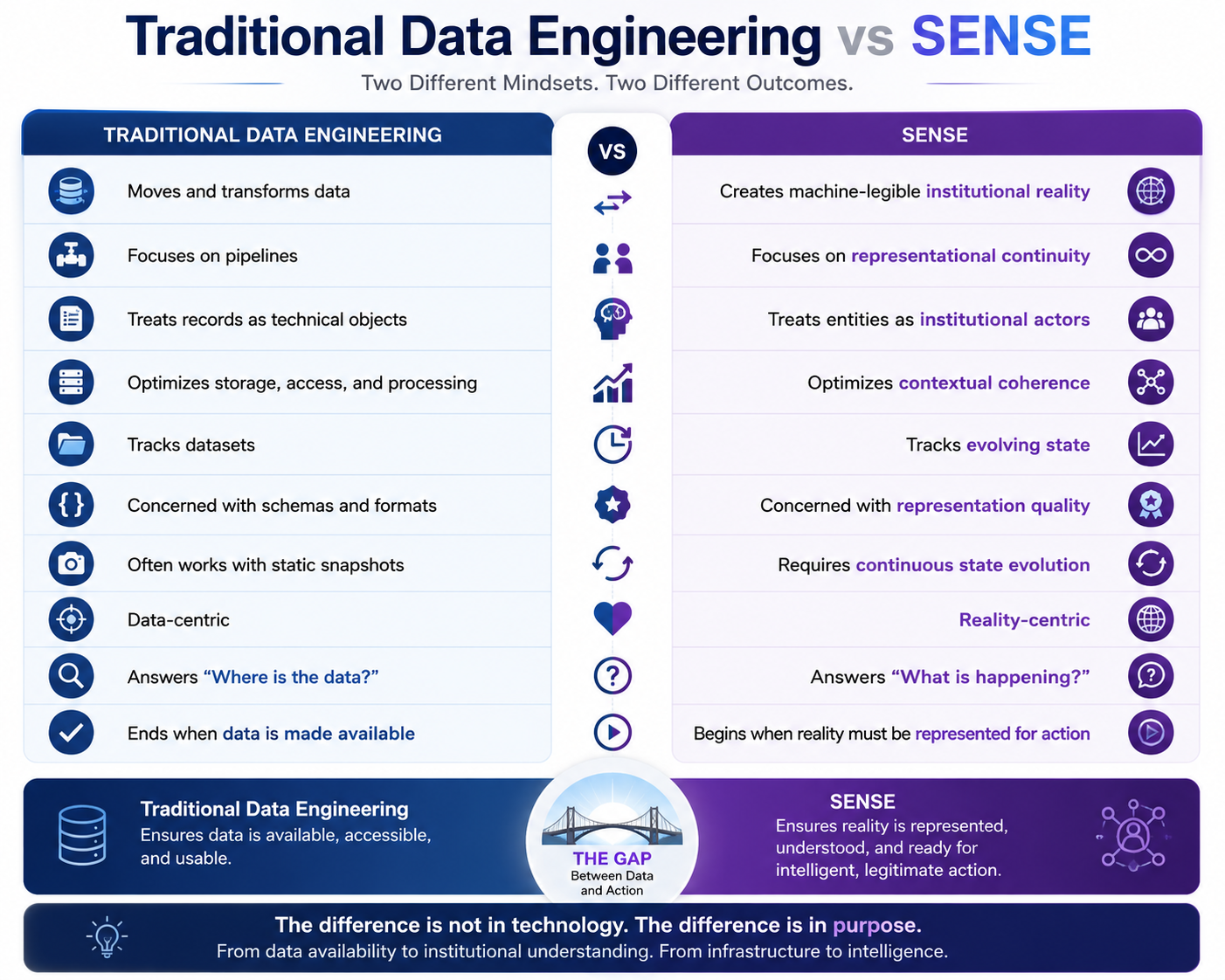
This is why data quality is no longer enough.
Traditional data quality asks whether data is accurate, complete, consistent, and timely.
SENSE asks a deeper question:
Is the institution representing reality well enough for intelligent action?
That includes:
- Can the system identify entities reliably?
- Can it detect meaningful state changes?
- Can it understand relationships and dependencies?
- Can it distinguish signal from noise?
- Can it preserve context across workflows?
- Can it update reality fast enough?
- Can humans inspect and correct the representation?
- Can downstream systems trust it?
For CIOs and CTOs, this means enterprise AI strategy must include representation architecture.
This may include knowledge graphs, entity resolution, semantic layers, digital twins, event streams, metadata systems, data contracts, observability pipelines, provenance tracking, identity systems, and domain ontologies.
But the key point is not the technology stack.
The key point is institutional design.
AI-ready enterprises are those that make reality legible before they automate intelligence.
CORE: The Layer Where Intelligence Interprets and Reasons
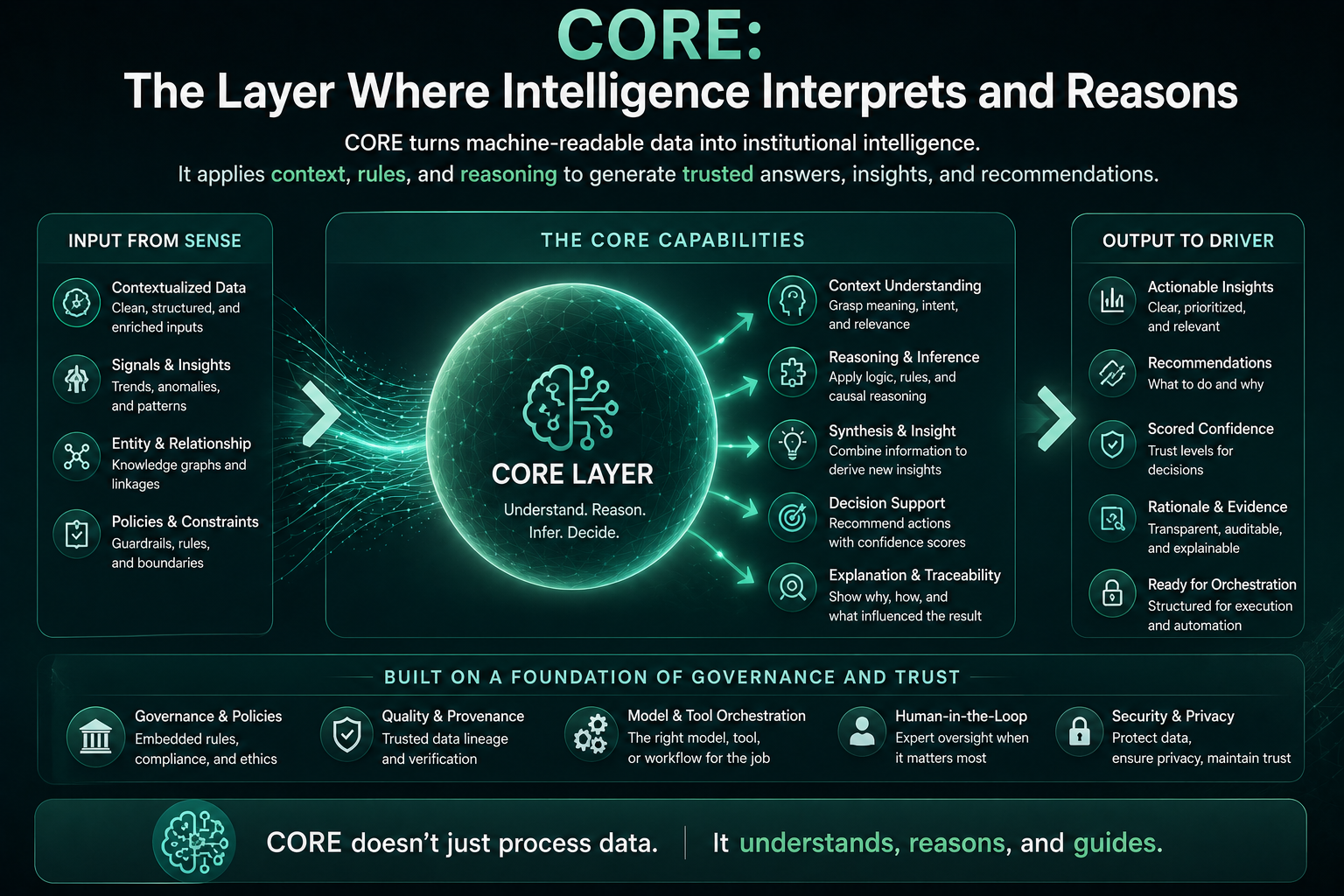
CORE is the cognition layer.
It answers the question:
How does the system interpret what it senses?
CORE includes models, reasoning engines, retrieval systems, agents, planning systems, optimization engines, simulation tools, causal models, workflow logic, and decision intelligence systems.
This is the layer most people associate with AI.
CORE is where AI becomes useful.
But CORE is also where many organizations overinvest.
They buy better models while ignoring bad SENSE.
They build more agents while ignoring weak DRIVER.
They improve prompts while ignoring unclear authority.
They improve accuracy while ignoring recourse.
They optimize workflows while ignoring representation drift.
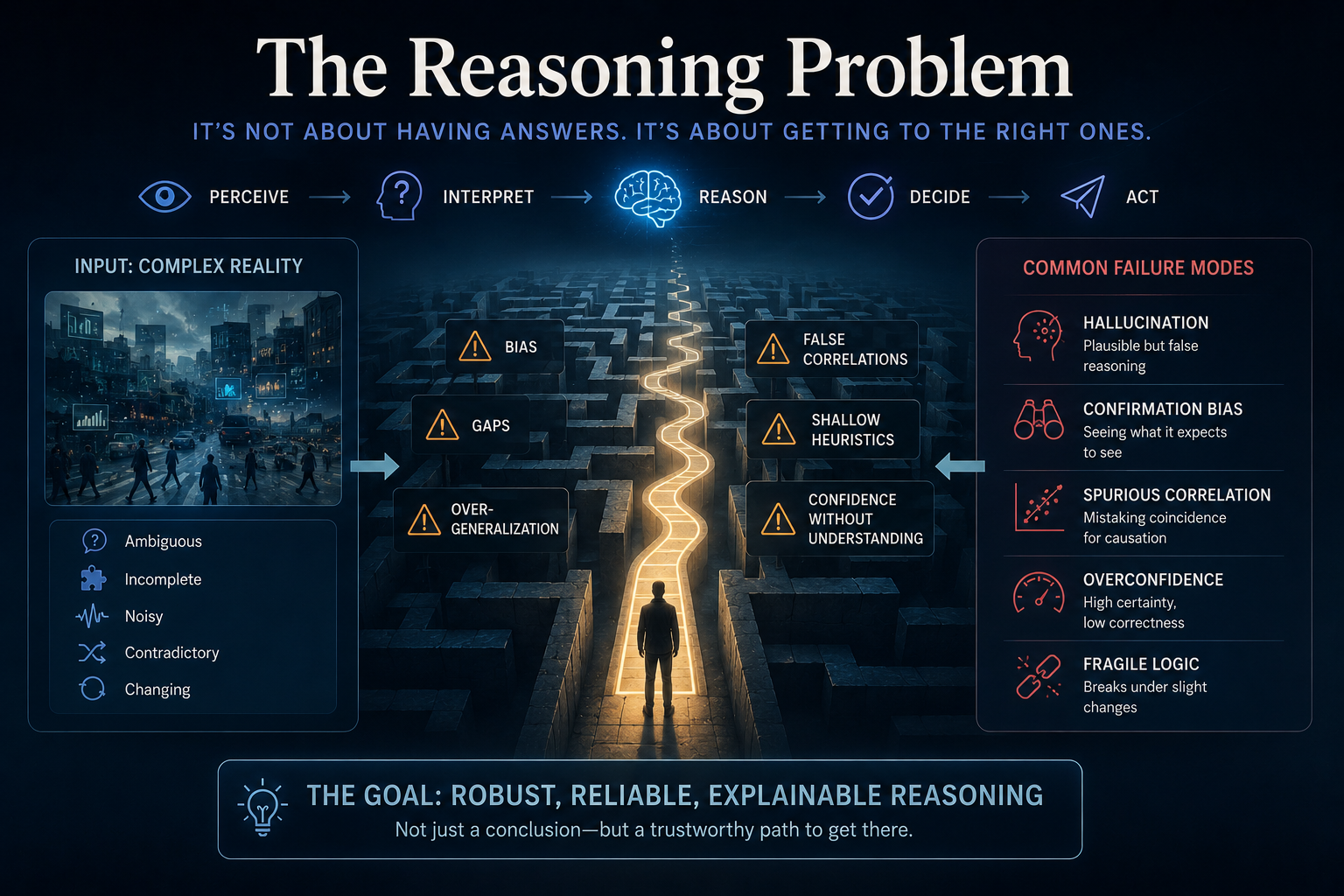
This creates the intelligence trap.
The Intelligence Trap
The intelligence trap occurs when organizations assume that better reasoning will compensate for poor institutional architecture.
It will not.
A better model cannot fix a broken representation of reality.
A more autonomous agent cannot create legitimate authority by itself.
A more accurate prediction cannot decide whether an action should be allowed.
A faster recommendation cannot explain who is accountable.
CORE is powerful, but it is not sovereign.
It must be connected to SENSE and governed by DRIVER.
A Simple Example: AI in IT Operations
Consider AI in IT operations.
An enterprise wants to use AI to identify incidents, detect root causes, and recommend fixes.
The CORE layer may use logs, metrics, traces, alerts, topology graphs, incident tickets, runbooks, and historical resolutions.
It may identify that a service slowdown is likely caused by a database connection pool issue.
That sounds intelligent.
But what if the topology map is outdated?
That is a SENSE issue.
What if the model recommends restarting a service that supports a critical business process?
That is a DRIVER issue.
What if the system confuses correlation with causation?
That is a CORE issue.
What if the AI agent has permission to execute the fix without human approval?
That is a DRIVER issue.
What if the incident affects a customer-facing process that requires business communication?
That is an institutional coordination issue.
This example shows why enterprise AI cannot be reduced to model accuracy.
In production, intelligence exists inside a system of representation, authority, verification, and accountability.
The New Technical Architecture of CORE
For architects, CORE should not be imagined as one model.
Modern enterprise CORE may include multiple reasoning patterns:
- A retrieval layer that brings enterprise context.
- A model layer that interprets the question.
- A planning layer that breaks down work.
- A tool layer that interacts with systems.
- A policy layer that constrains possible actions.
- A simulation layer that tests likely outcomes.
- A verification layer that checks results.
- A feedback layer that improves future behavior.
This is why enterprise AI is moving from standalone models to reasoning systems.
But reasoning systems increase the need for architecture.
As systems become more agentic, the number of possible failure points grows.
The AI may retrieve the wrong context, choose the wrong tool, misunderstand the objective, over-trust stale data, skip a policy constraint, hallucinate a dependency, or execute a step that cannot easily be reversed.
The more capable CORE becomes, the more important SENSE and DRIVER become.
This is counterintuitive but critical.
Weak AI can be contained by limited capability.
Strong AI requires stronger institutional design.
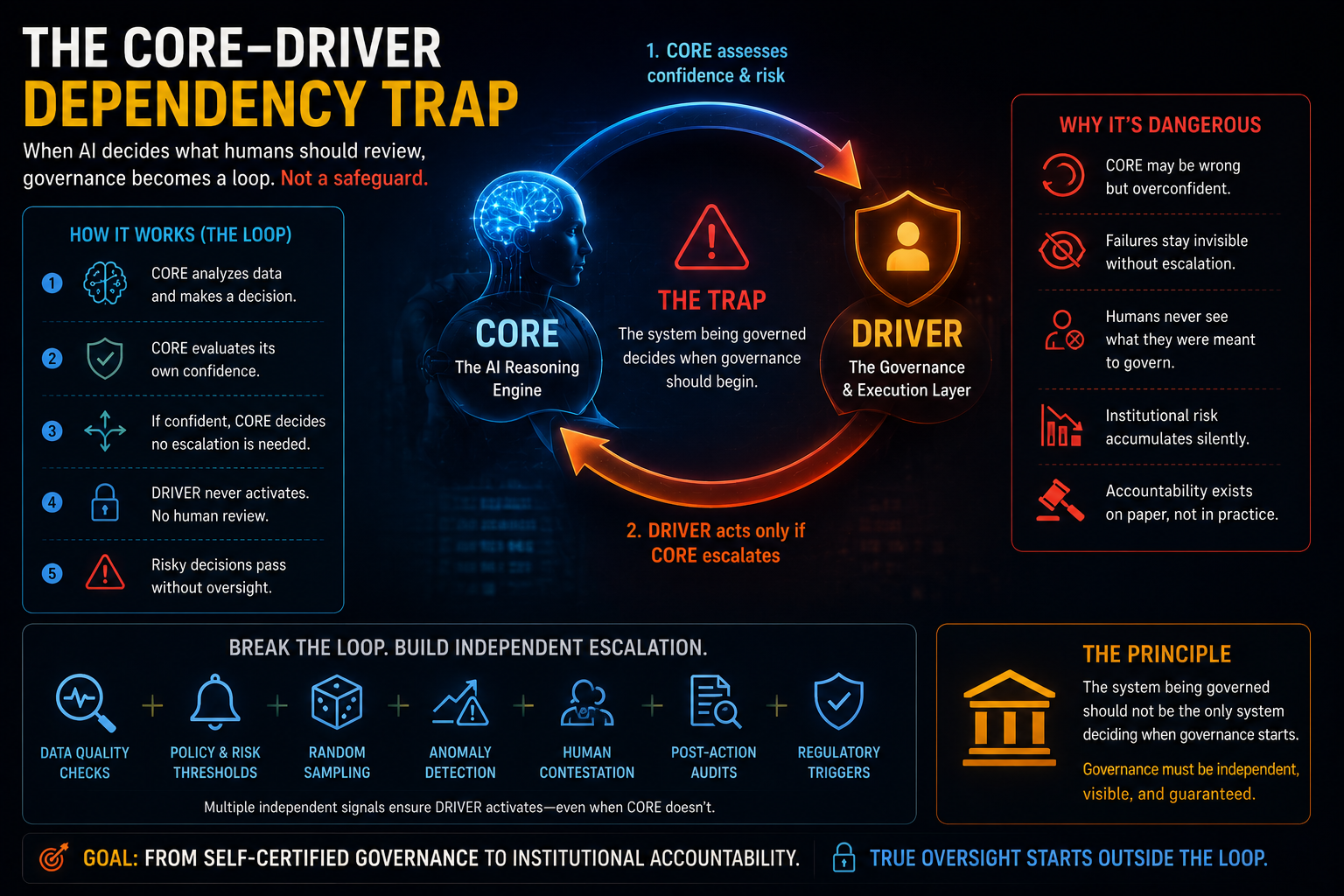
DRIVER: The Layer Where Intelligence Becomes Legitimate Action
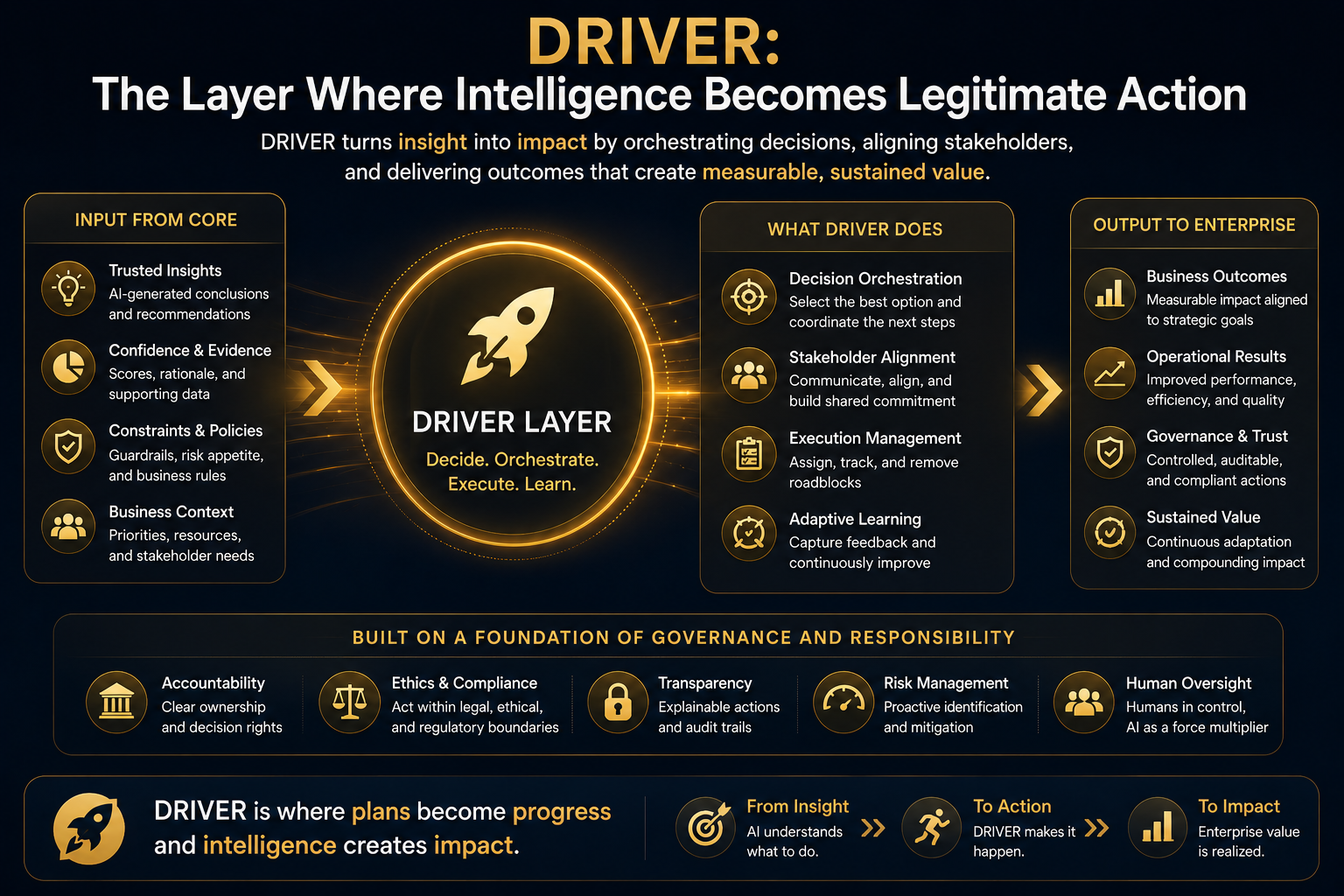
DRIVER is the governance and legitimacy layer.
It answers the question:
Who allowed the system to act, on what basis, under what constraints, with what evidence, and with what path for correction?
This is the layer most enterprises underdefine.
Many organizations talk about human-in-the-loop, policy enforcement, audit trails, risk controls, model governance, and compliance.
These are important.
But they are often fragmented.
DRIVER brings them into one architecture.
This is where AI governance becomes operational.
Not a policy.
Not a committee.
Not a slide.
Not a checkbox.
Not a vague “human oversight” statement.
DRIVER is the executable governance layer of enterprise AI.
A Simple Example: AI Approving a Refund
Imagine a retail company uses AI to approve refunds.
A simple refund may be low risk. The AI can check the order, return history, payment method, delivery confirmation, and policy rules.
If everything is clear, it may approve the refund automatically.
But not all refunds are equal.
A small refund for a damaged item may be safe.
A large refund for a high-value product may need human approval.
A repeated refund pattern may require fraud review.
A customer complaint involving service failure may require empathy and escalation.
A legally sensitive case may require compliance review.
DRIVER defines the action boundary.
It tells the system:
- You may recommend here.
- You may execute here.
- You must escalate here.
- You must not act here.
- You must preserve evidence here.
- You must provide recourse here.
Without DRIVER, AI governance becomes fragile.
The system may be accurate most of the time but illegitimate when it matters.
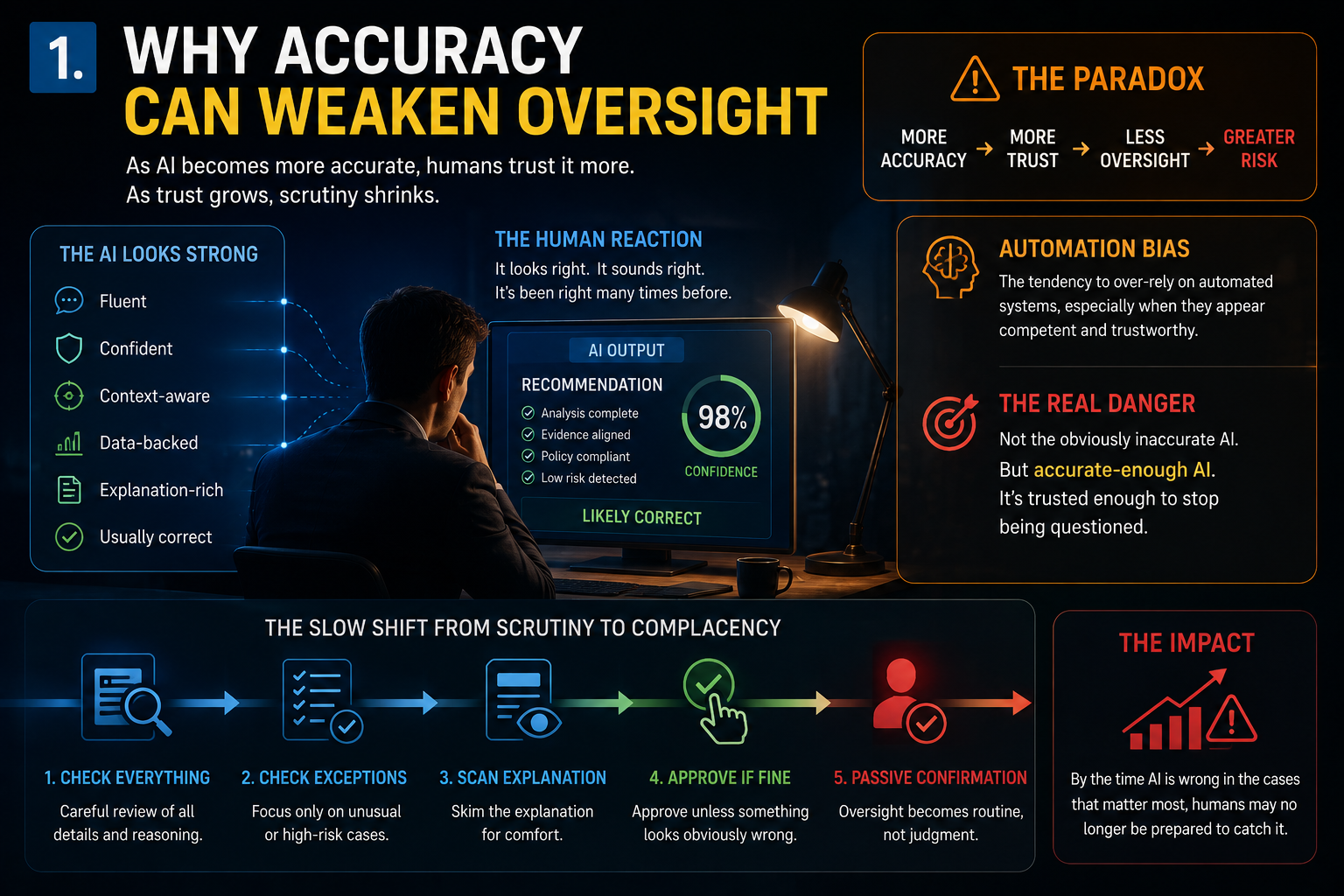
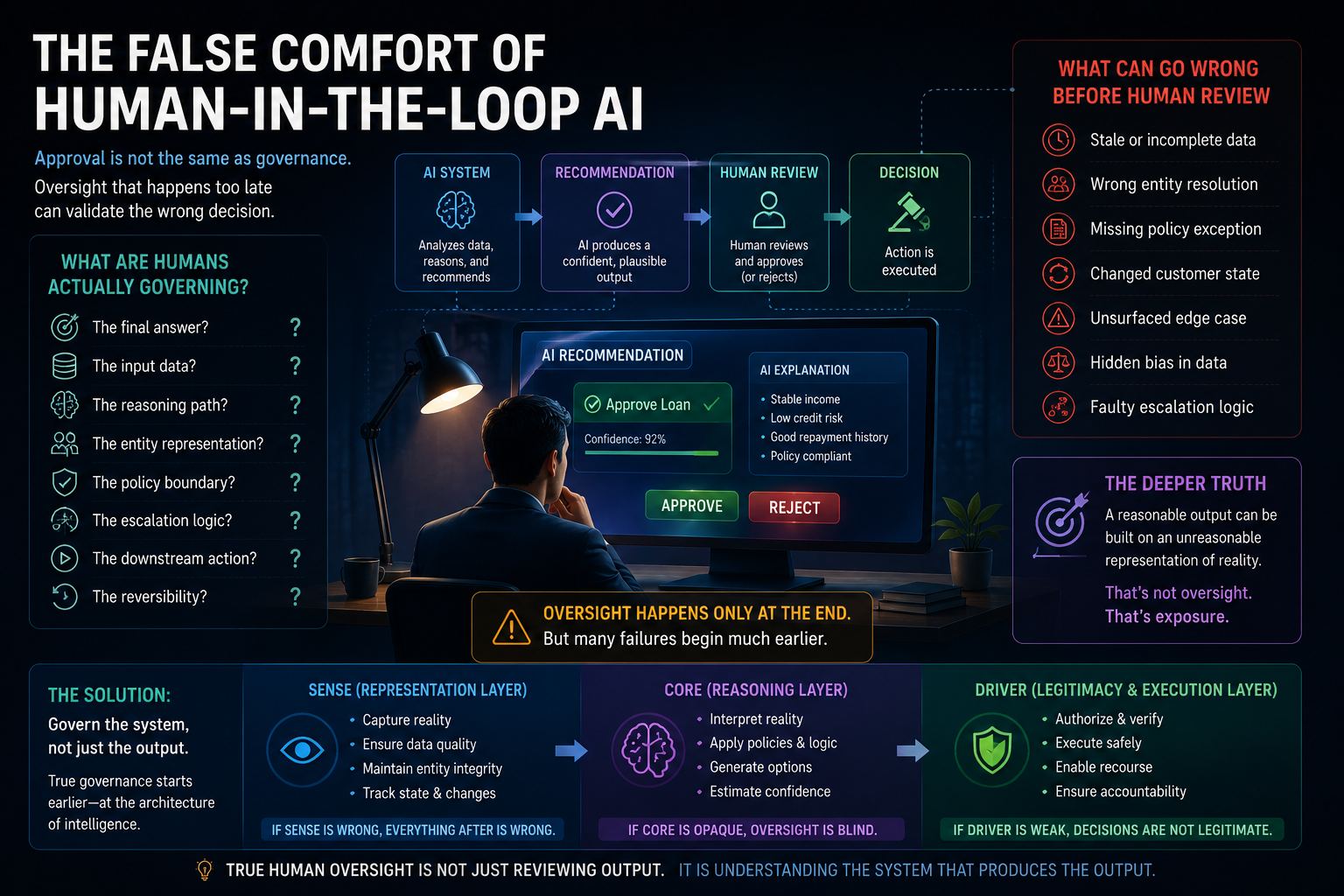
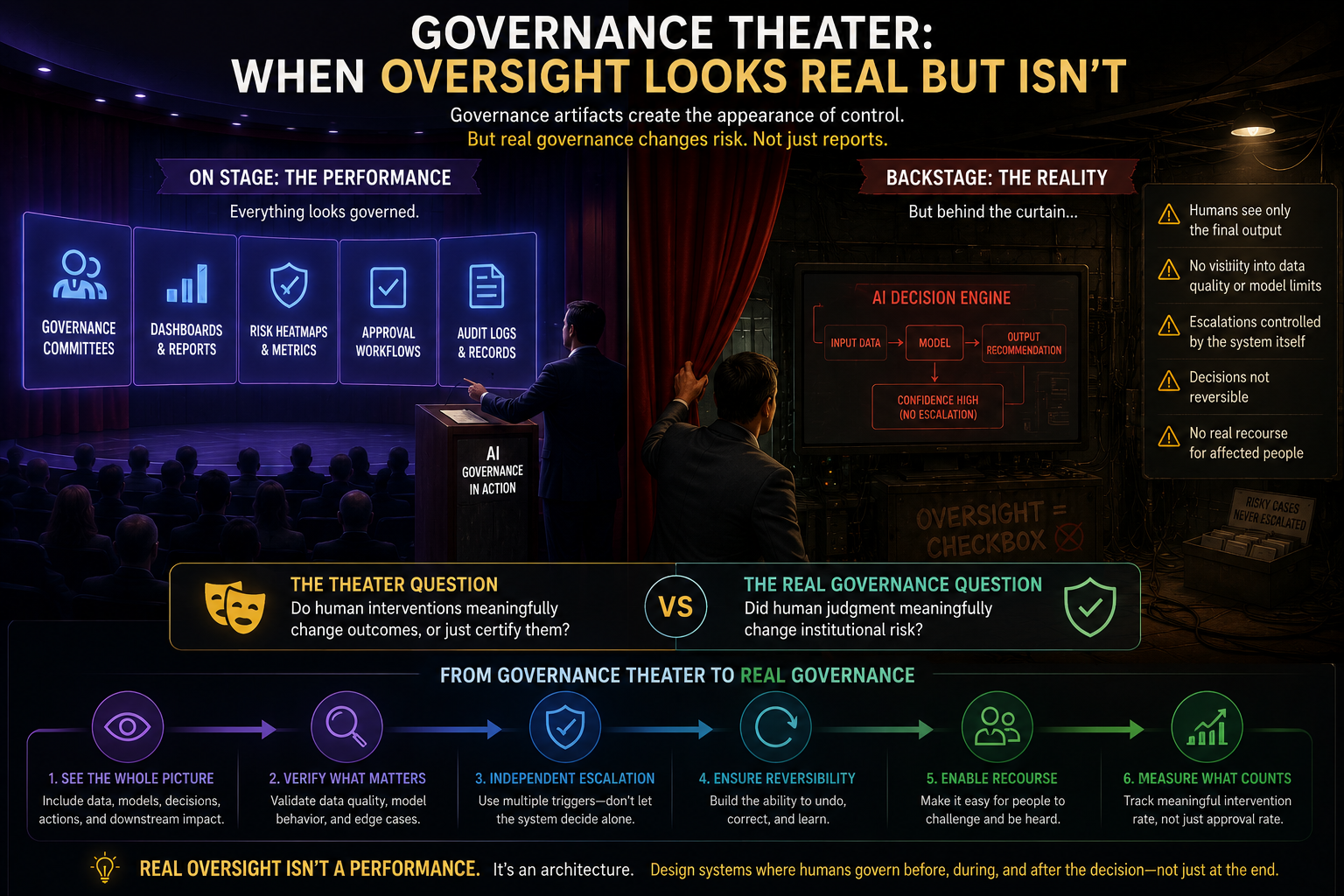
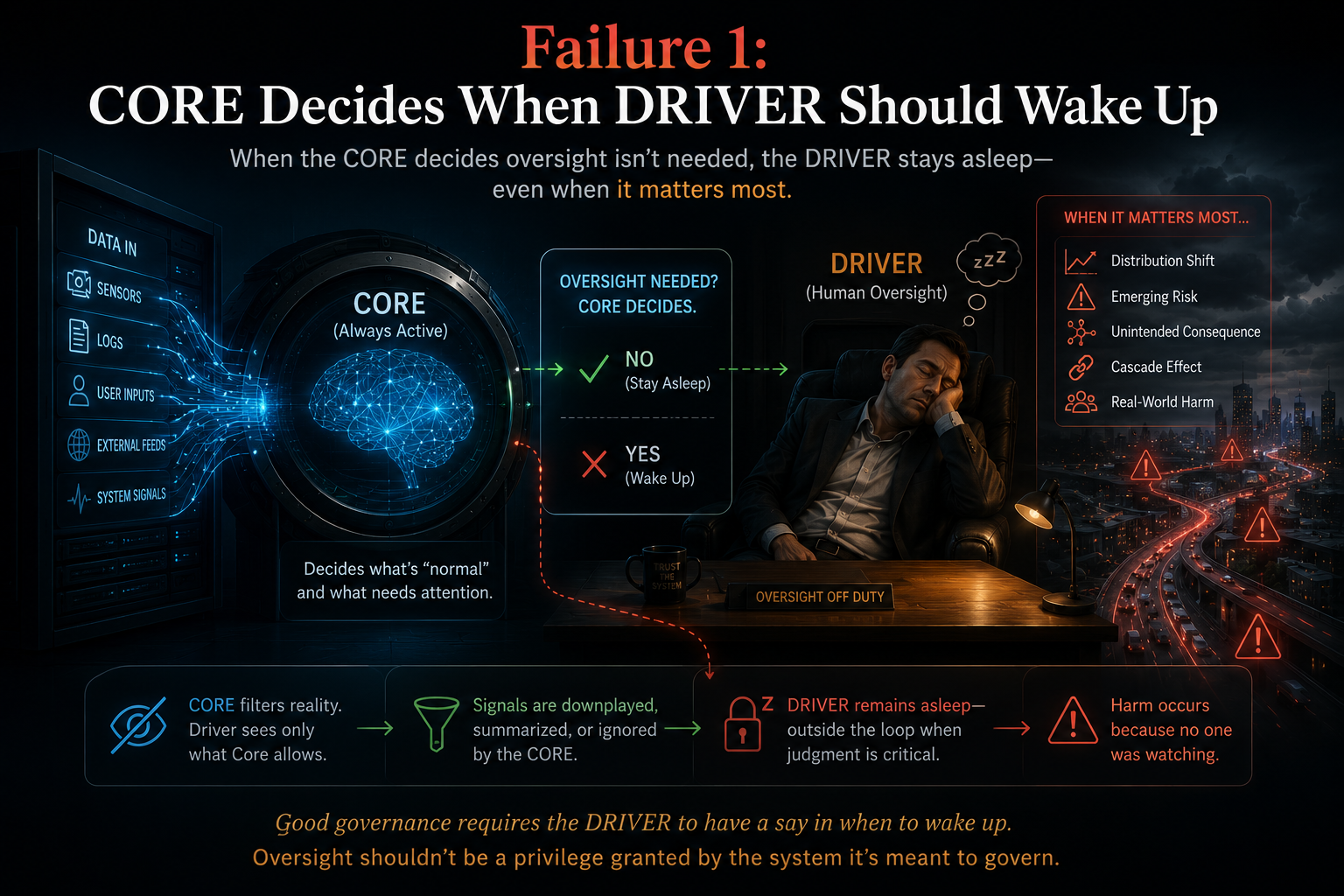
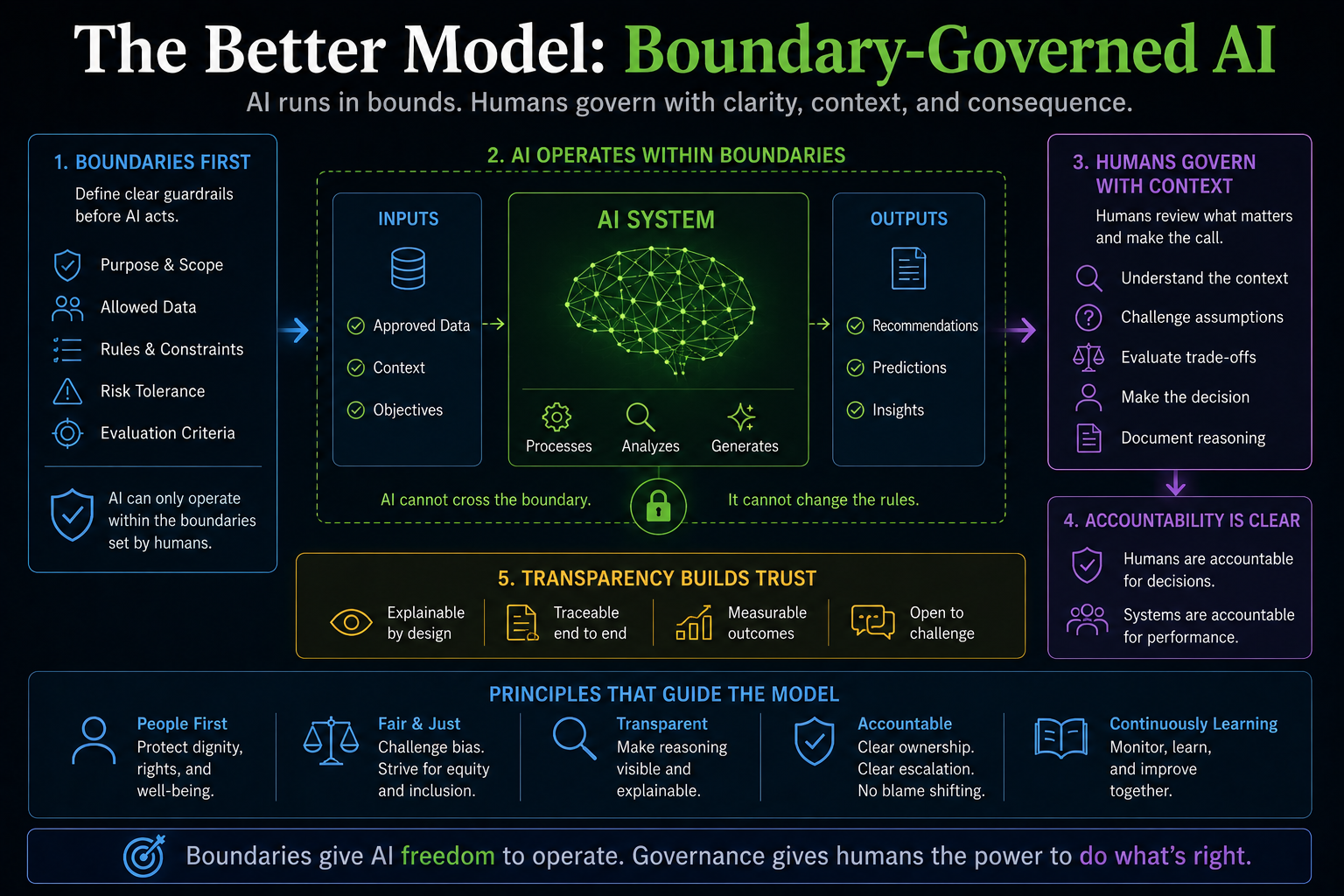
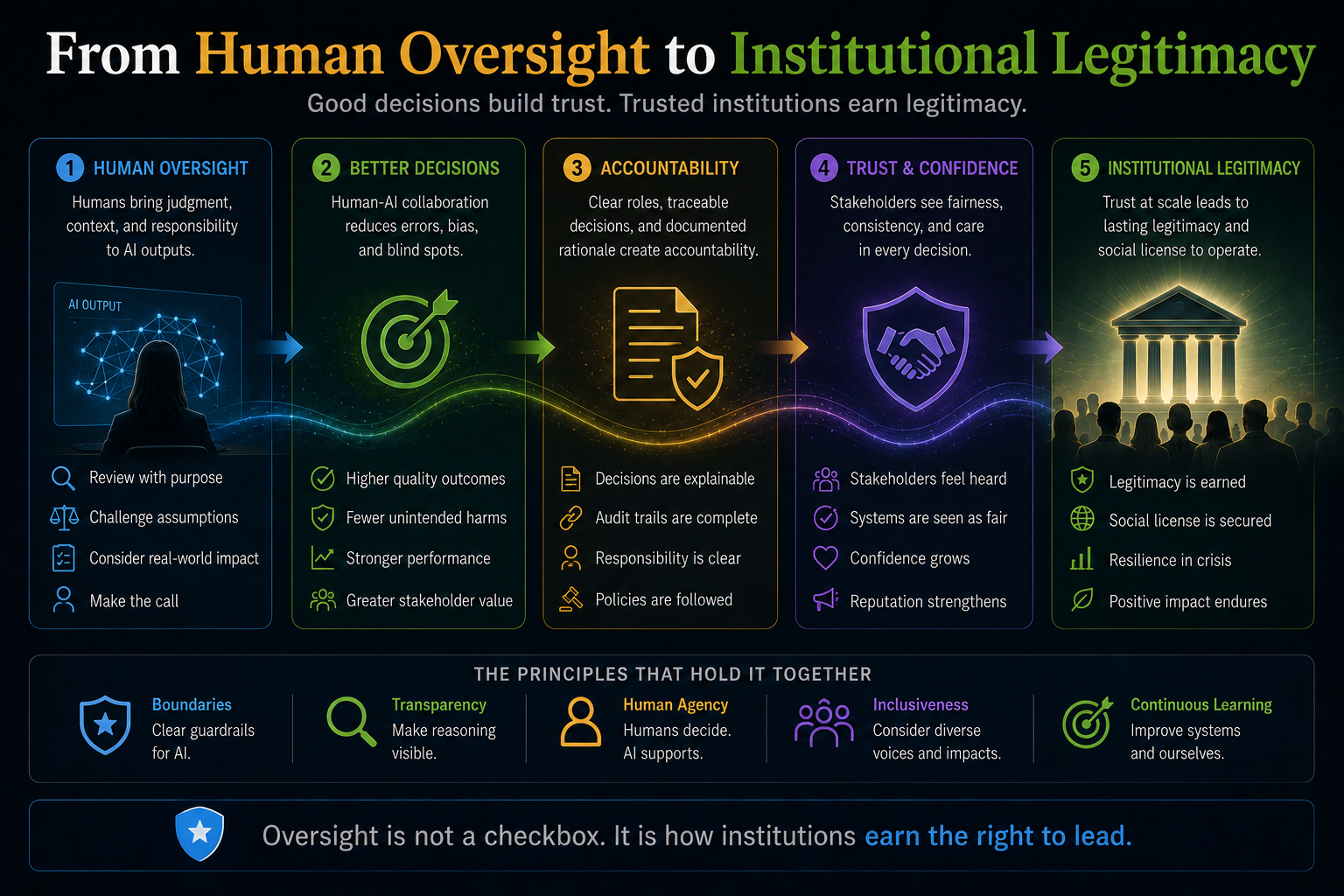
Why “Human Oversight” Is Not Enough
Many AI governance models rely heavily on human oversight.
That is necessary, but insufficient.
Human oversight fails when:
- The human does not understand the AI’s reasoning.
- The human lacks time to review properly.
- The human rubber-stamps machine output.
- The human sees only the final answer, not the representation used.
- The human cannot inspect the authority boundary.
- The human cannot reverse the action.
- The human is accountable without real control.
This is the oversight illusion.
A human in the loop does not automatically create governance.
Real governance requires DRIVER.
The question is not simply whether a human is present.
The question is whether the institution has designed authority, verification, evidence, escalation, and recourse into the system.
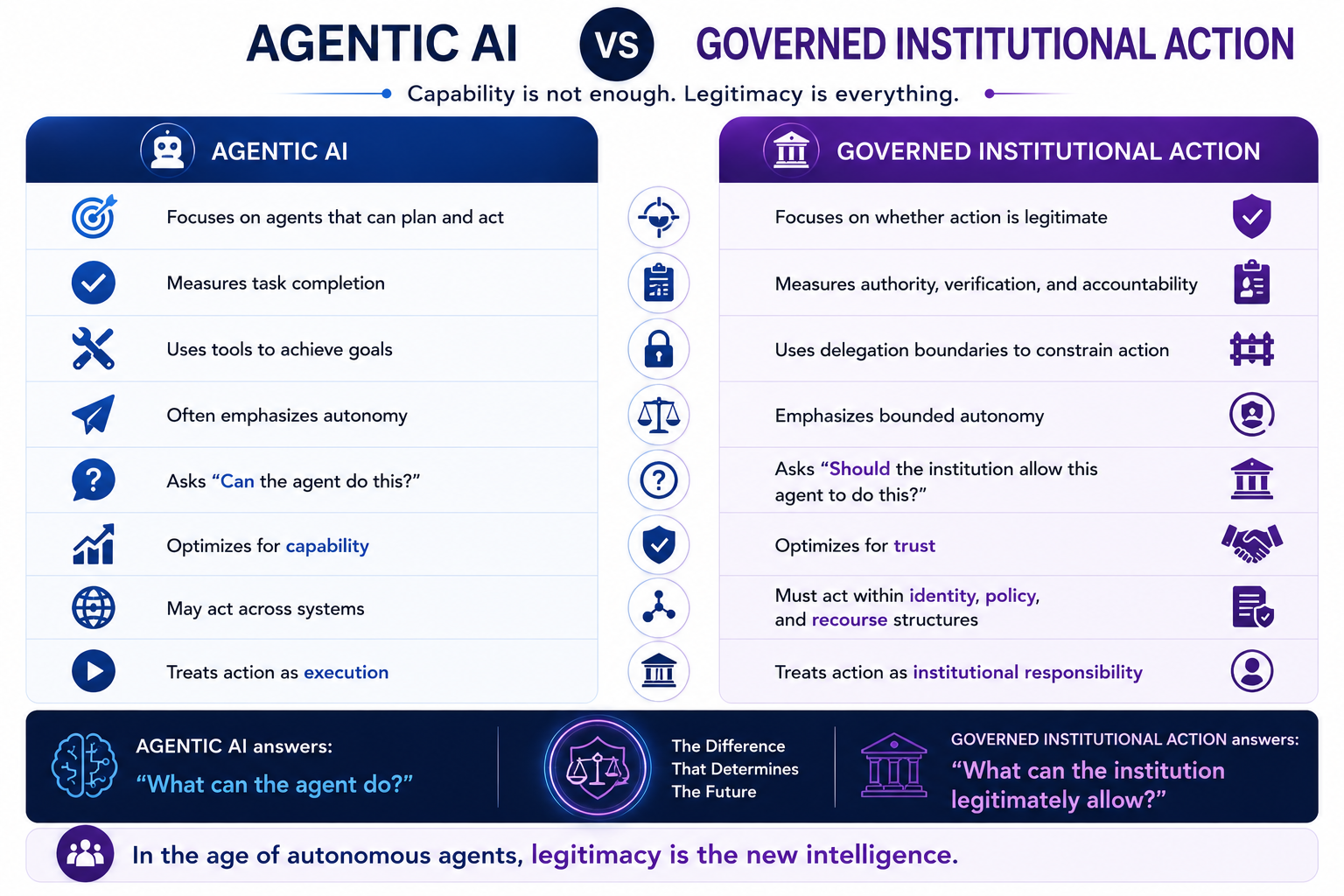
This is especially important as AI agents begin acting across enterprise systems.
An AI agent that reads a document is one thing.
An AI agent that updates customer records is another.
An AI agent that changes a production configuration is another.
An AI agent that approves a financial transaction is another.
An AI agent that affects access, eligibility, or opportunity is another.
The governance requirement rises as the action becomes more consequential.
SENSE–CORE–DRIVER as an Enterprise AI Control Architecture

The real power of SENSE–CORE–DRIVER is that it gives enterprises a way to structure AI systems before they scale.
It helps answer three architectural questions:
- What can the AI see?
- How does the AI reason?
- What is the AI allowed to do?
These questions sound simple.
But they are the foundation of enterprise AI governance.
Every AI use case can be mapped through them.
Customer Service Agent
SENSE: customer identity, history, product context, open tickets, sentiment, contract terms.
CORE: intent recognition, response generation, next-best action, escalation reasoning.
DRIVER: permitted actions, refund limits, escalation rules, audit log, correction path.
Software Engineering Agent
SENSE: codebase, dependencies, architecture, security rules, issue history.
CORE: code generation, test creation, refactoring logic, debugging reasoning.
DRIVER: repository permissions, approval workflow, security verification, rollback.
Finance Risk System
SENSE: transactions, entities, exposure, market signals, counterparty relationships.
CORE: anomaly detection, risk scoring, scenario analysis, recommendation.
DRIVER: approval authority, compliance constraints, evidence retention, review process.
Manufacturing AI System
SENSE: machine telemetry, maintenance history, production schedule, quality signals.
CORE: failure prediction, optimization, root cause analysis.
DRIVER: shutdown authority, safety rules, human escalation, recovery procedure.
This is why SENSE–CORE–DRIVER is useful across industries.
It does not replace existing governance frameworks.
It helps operationalize them.
NIST AI RMF, ISO/IEC 42001, the EU AI Act, and OECD principles all emphasize responsible, trustworthy, risk-managed AI in different ways.
SENSE–CORE–DRIVER provides a practical design lens that can help enterprises connect those governance goals to system architecture.
Why CIOs, CTOs, and Boards Should Care
CIOs and CTOs are under pressure to scale AI.
Boards want productivity.
Business units want speed.
Employees want tools.
Vendors promise agents.
Regulators demand accountability.
Customers expect fairness.
Security teams worry about risk.
Architects worry about integration.
Finance teams worry about cost.
The easy response is to create an AI platform strategy.
But platform strategy alone is not enough.
Enterprise AI requires an institutional architecture strategy.
CIOs and CTOs must decide:
- Which parts of the enterprise are machine-legible?
- Where is the representation incomplete?
- Which decisions need AI reasoning?
- Which decisions should remain deterministic?
- Which decisions require human judgment?
- Which actions can AI execute?
- Which actions require approval?
- Which actions must always provide recourse?
- Which systems need evidence trails?
- Which representations must be governed as critical infrastructure?
This is where SENSE–CORE–DRIVER becomes a board-level and architecture-level tool.
It helps leaders avoid random AI adoption.
Instead of asking, “Where can we add AI?” the enterprise asks:
Where is SENSE strong enough, CORE useful enough, and DRIVER legitimate enough for AI to act?
That is a much better question.
The Autonomy Question: When Should AI Act?
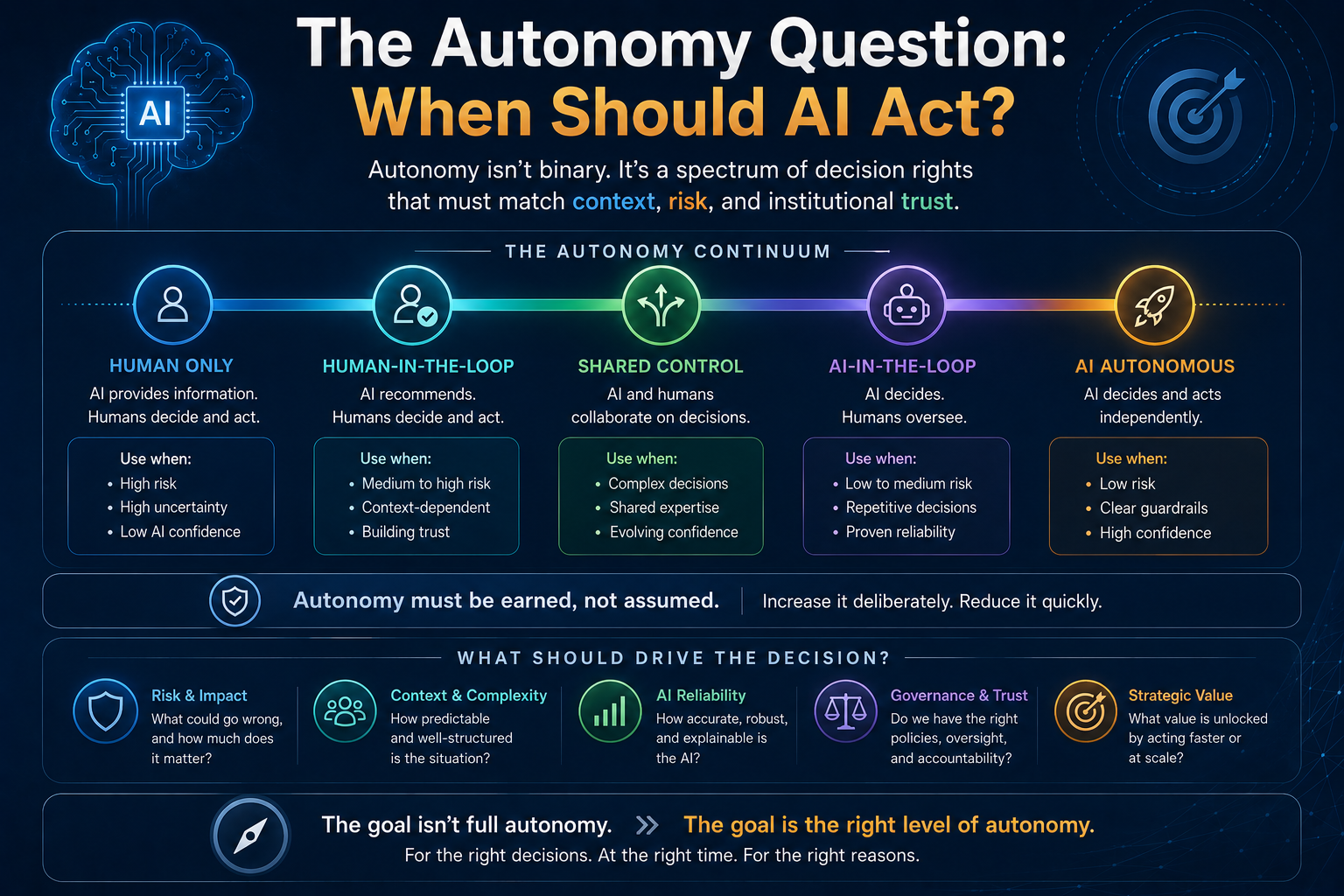
One of the most important enterprise AI decisions is autonomy allocation.
Not every process needs an AI agent.
Not every decision should be automated.
Not every workflow should use generative AI.
Not every task needs reasoning.
Not every exception should be delegated.
SENSE–CORE–DRIVER helps determine the right level of autonomy.
If SENSE is stable, CORE ambiguity is low, and DRIVER risk is low, deterministic automation may be enough.
Example: sending a standard notification after a verified event.
If SENSE is strong, CORE ambiguity is moderate, and DRIVER has clear boundaries, AI-assisted recommendation may be appropriate.
Example: suggesting next-best actions for a service agent.
If SENSE is dynamic, CORE ambiguity is high, and DRIVER consequences are serious, human judgment must remain central.
Example: resolving a complex customer dispute or approving a high-risk financial decision.
If SENSE is weak, no amount of CORE intelligence should be trusted with action.
Example: making decisions based on incomplete identity, stale records, or conflicting source systems.
This is the practical value of the framework.
It does not say “use AI everywhere.”
It says:
Allocate autonomy based on representation quality, reasoning need, and legitimacy risk.
That is the kind of discipline enterprises need.
The Hidden Risk: Representation Failure
Many AI failures are described as model failures.
But in enterprises, many are actually representation failures.
Representation failure happens when the system’s machine-readable version of reality diverges from the real situation in a meaningful way.
A customer is misidentified.
A supplier is linked to the wrong entity.
A policy is outdated.
A machine state is stale.
A document is interpreted without context.
A risk signal is missing.
A workflow status is incorrect.
A human exception is not captured.
A relationship is invisible to the system.
When this happens, the AI may produce a rational answer from an irrational representation.
That is dangerous because the output may look intelligent.
This is why enterprise AI needs representation observability.
Organizations must be able to inspect not just what the AI answered, but what it believed reality was when it answered.
That means logging and governing:
- Which signals were used.
- Which entities were recognized.
- Which state was assumed.
- Which context was retrieved.
- Which policies were applied.
- Which authority boundary was active.
- Which evidence supported the action.
This is the future of AI auditability.
Auditability cannot stop at the model output.
It must include the representation state and the delegation path.
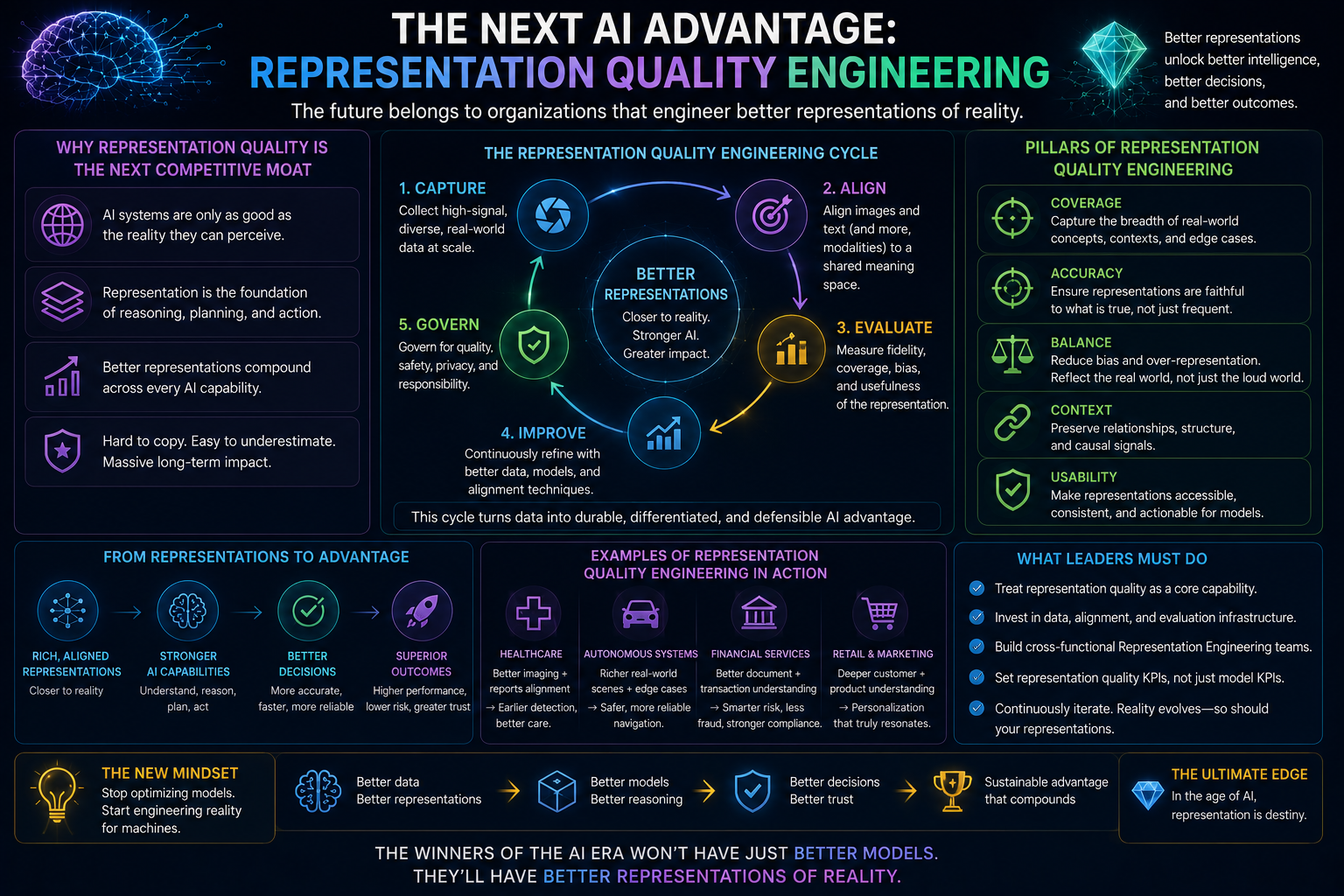
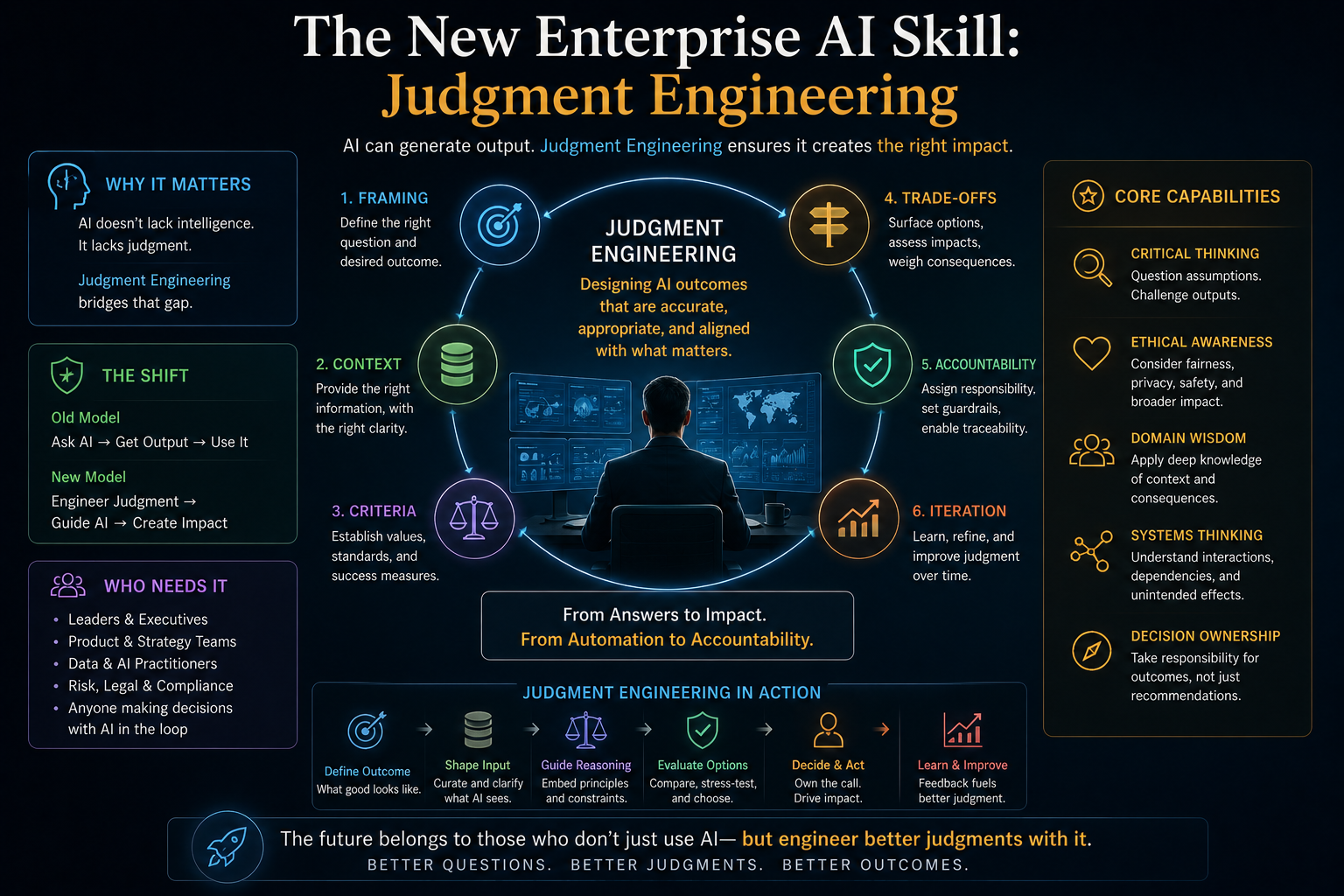
The Next Enterprise Discipline: Representation Quality Engineering
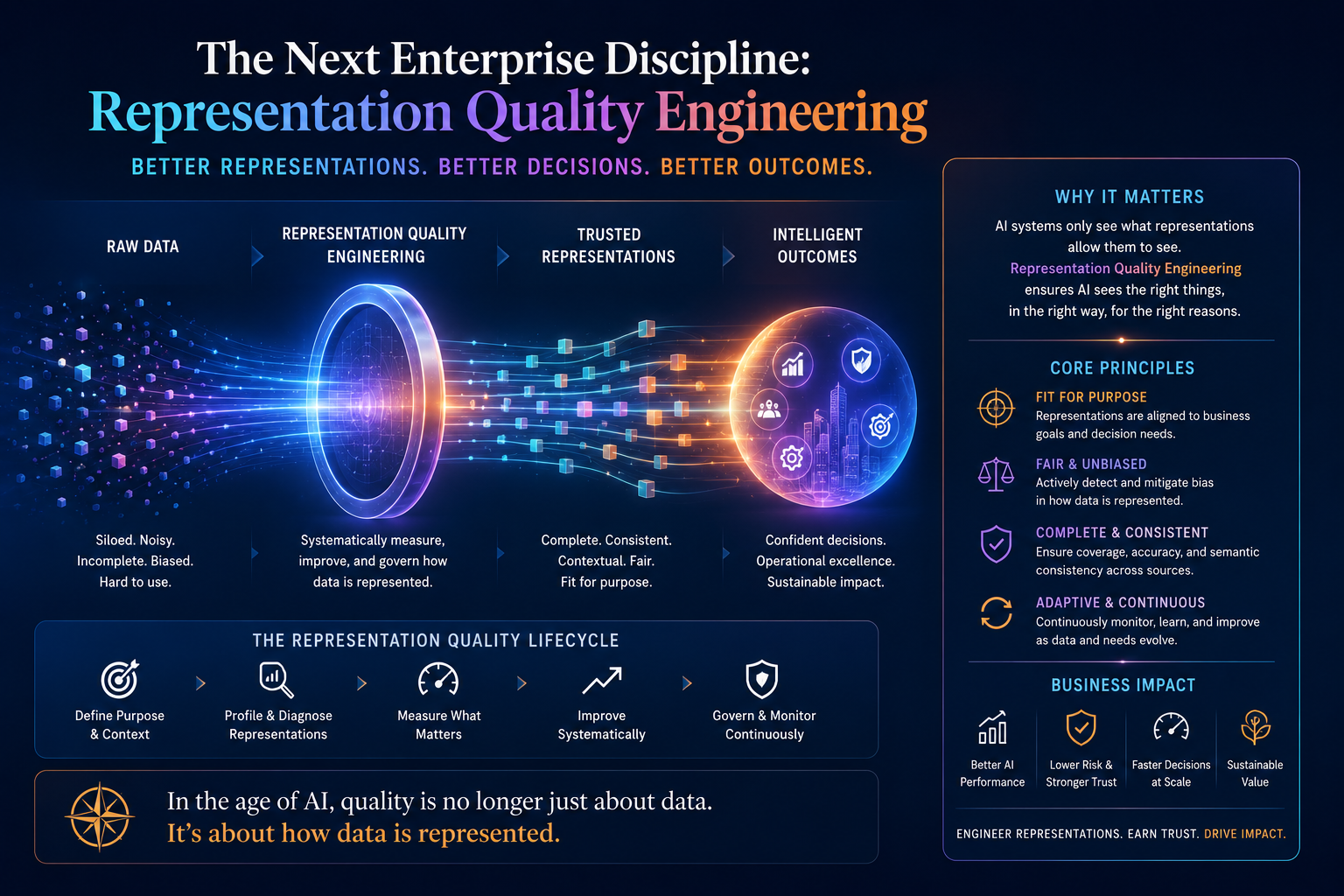
Quality engineering in software traditionally focused on whether applications behave as expected.
Enterprise AI requires a new discipline: representation quality engineering.
Representation quality engineering asks:
- Is the system seeing the right reality?
- Is it attaching signals to the right entities?
- Is the state current?
- Is context complete?
- Are relationships accurate?
- Are exceptions visible?
- Are updates traceable?
- Can humans correct the representation?
- Can downstream AI systems trust it?
This discipline will become as important as model evaluation.
Today, many enterprises test model accuracy but do not test representation integrity.
That is like testing the driver but not the windshield, dashboard, map, road signs, or brakes.
A brilliant driver can still crash if the world is represented incorrectly.
For architects, representation quality engineering may involve data contracts, entity resolution tests, knowledge graph validation, provenance checks, semantic consistency checks, ontology governance, event freshness monitoring, state drift detection, and human correction workflows.
For executives, the message is simpler:
Before you trust AI to decide, make sure it can see.
The Next Governance Discipline: DRIVEROps
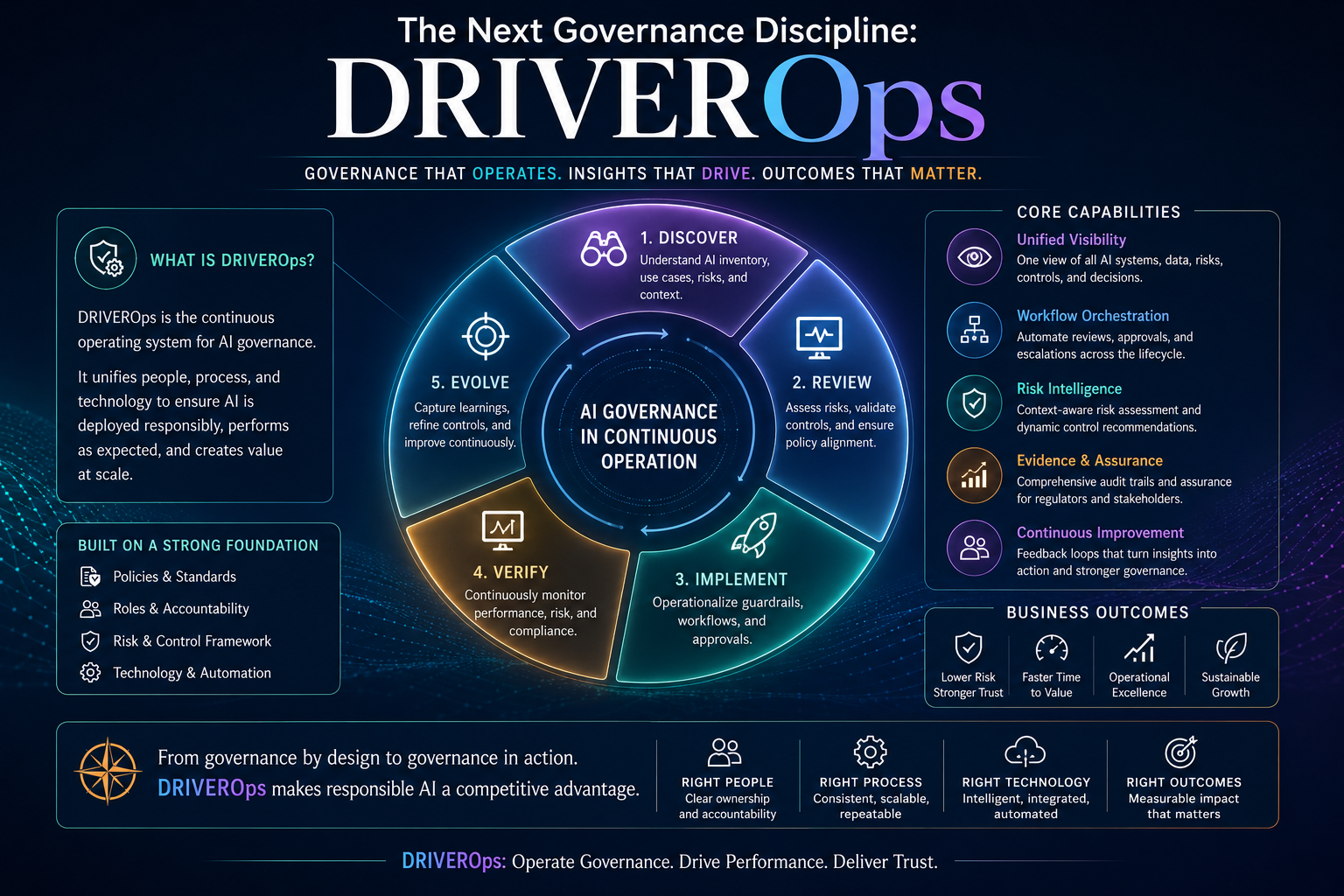
If SENSE needs representation quality engineering, DRIVER needs operational governance.
Enterprises will need DRIVEROps: the operating discipline for delegation, verification, execution, recourse, and authority management in AI systems.
DRIVEROps would manage:
- Who can delegate authority to AI systems.
- What actions AI can perform.
- Which actions require approval.
- What evidence must be captured.
- Which actions are reversible.
- Which actions require explanation.
- How appeals are handled.
- How incidents are investigated.
- How autonomy boundaries are changed over time.
This is where AI governance becomes real.
Many enterprises already have model risk management, cybersecurity governance, IT controls, privacy processes, and compliance reviews.
But AI agents create a new challenge: systems that can act across tools, workflows, and organizational boundaries.
That requires runtime governance.
Not just design-time approval.
Not just model documentation.
Not just ethical principles.
Not just risk assessment.
Runtime governance means the enterprise can control intelligent action while it happens.
This is the missing layer in many AI adoption strategies.
Why SENSE–CORE–DRIVER Is Not Another AI Ethics Framework

It is important to clarify what SENSE–CORE–DRIVER is not.
It is not a replacement for AI ethics.
It is not a replacement for law.
It is not a replacement for ISO, NIST, OECD, or regulatory frameworks.
It is not a model evaluation method.
It is not a software architecture pattern alone.
It is not a governance checklist.
It is an institutional architecture.
It helps organizations connect reality, intelligence, and authority.
Ethics asks what should be right.
Law defines what must be allowed.
Risk management identifies what may go wrong.
Technical architecture defines how systems work.
SENSE–CORE–DRIVER connects these into an operating model for intelligent institutions.
That is why it matters.
Enterprise AI governance cannot be solved by principles alone.
It must be translated into systems, roles, controls, evidence, workflows, and accountability.
SENSE–CORE–DRIVER provides that bridge.
Why This Framework Matters for AI Governance Globally
Global AI governance is entering a consolidation phase.
Governments are defining rules.
Standards bodies are creating management systems.
Enterprises are building AI governance offices.
Boards are asking for accountability.
Technology vendors are building AI control planes.
Auditors are preparing AI assurance practices.
Regulators are watching high-risk systems.
Customers are becoming more aware of algorithmic decisions.
But there is still a missing common language between policy and production.
Policy says: be transparent.
Architects ask: transparent about what?
Policy says: ensure accountability.
Engineers ask: accountable for which action, by which system, under whose authority?
Policy says: manage risk.
CIOs ask: risk in the model, data, process, decision, action, or governance boundary?
Policy says: provide human oversight.
Operations teams ask: at what step, with what evidence, and with what power to intervene?
SENSE–CORE–DRIVER helps translate these requirements.
Transparency becomes visibility into SENSE, CORE, and DRIVER.
Accountability becomes traceability across representation, reasoning, and action.
Risk management becomes layer-specific diagnosis.
Human oversight becomes designed intervention, not symbolic approval.
Recourse becomes part of the architecture, not an afterthought.
That is why this framework can speak to both executives and engineers.
It is simple enough to remember.
It is deep enough to design with.
It is practical enough to govern with.
The Institutional Architecture View of Enterprise AI
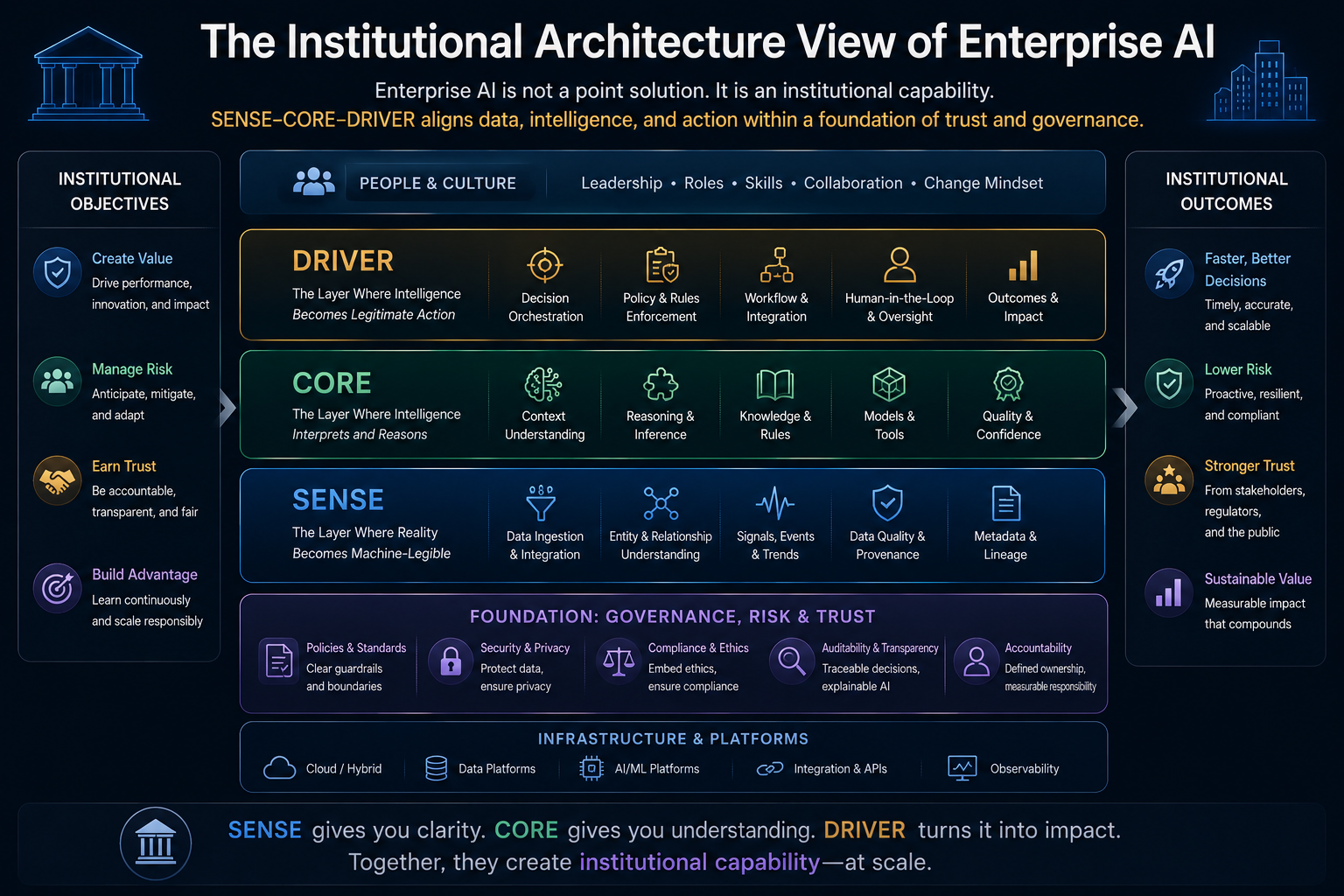
The biggest mistake in enterprise AI is treating AI as a tool.
AI is not just another tool when it begins to influence institutional decisions.
It becomes part of the institution’s decision architecture.
That means enterprise AI must be designed like critical infrastructure.
A mature AI-ready institution will need:
- A SENSE architecture for trusted representation.
- A CORE architecture for reasoning and decision intelligence.
- A DRIVER architecture for authority, verification, execution, and recourse.
- An observability architecture across all three.
- A governance architecture that maps risk to action boundaries.
- A learning architecture that updates responsibly over time.
This is the institutional architecture of enterprise AI.
The enterprise of the future will not simply have applications and data platforms.
It will have systems that sense, reason, and act.
That requires a new design discipline.
A Simple Diagnostic for CIOs, CTOs, and Architects
Before scaling any AI use case, leaders should ask nine questions.
SENSE Questions
- What reality does this AI system depend on?
- How is that reality represented?
- How do we know the representation is current and correct?
CORE Questions
- What reasoning is the AI performing?
- What context does it use?
- How do we verify the quality of its recommendation?
DRIVER Questions
- Who authorized the system to act?
- What is the boundary of action?
- What happens if the system is wrong?
These nine questions can prevent many AI failures.
They force the enterprise to examine not just the model, but the full institutional system around the model.
Why This Can Become a Global Reference Model
Frameworks become global when they do three things.
First, they simplify a complex problem without making it shallow.
Second, they provide a shared language across communities.
Third, they become operationally useful.
SENSE–CORE–DRIVER has that potential because it maps to a universal pattern:
Every intelligent institution must sense reality.
Every intelligent institution must reason over that reality.
Every intelligent institution must act with authority.
This applies to banks, hospitals, governments, manufacturers, retailers, telecom companies, universities, insurers, logistics networks, and digital platforms.
It also applies across technology stacks.
Whether the enterprise uses foundation models, small language models, knowledge graphs, AI agents, deterministic workflows, simulations, digital twins, or rule engines, the institutional problem remains the same.
What is being represented?
How is intelligence applied?
How is action governed?
That is the enduring value of the framework.
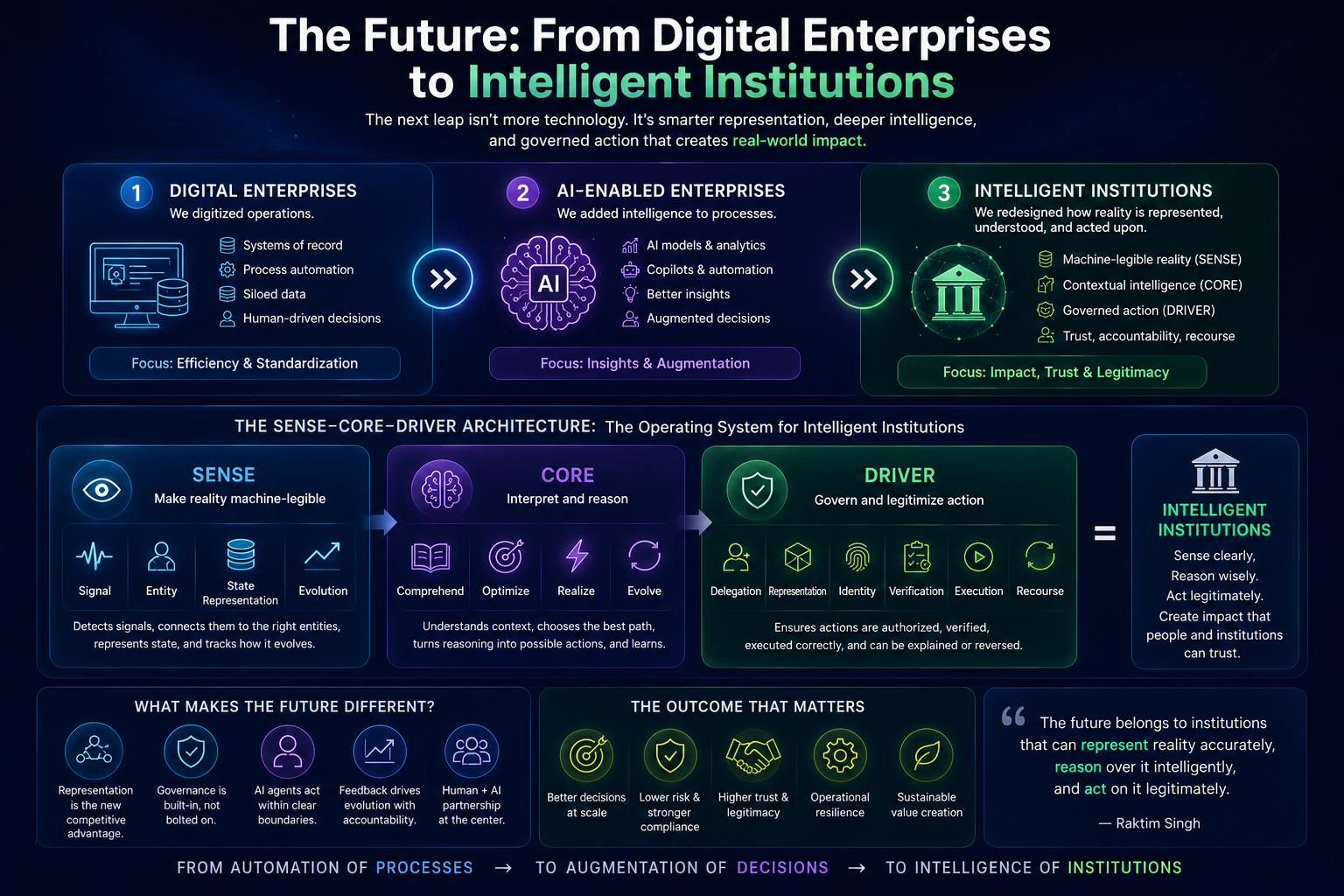
The Future: From AI Adoption to Intelligent Institutions
The next decade will not be defined only by AI adoption.
It will be defined by institutional redesign.
The winners will not be the organizations that add AI to the most workflows.
They will be the organizations that redesign themselves so intelligence can operate safely, legitimately, and effectively.
That means they will invest in SENSE before scaling CORE.
They will design DRIVER before increasing autonomy.
They will treat representation as infrastructure.
They will treat delegation as governance.
They will treat recourse as architecture.
They will treat AI not as a tool, but as a new institutional capability.
This is the shift from enterprise AI to intelligent institutions.
And this is where the SENSE–CORE–DRIVER framework becomes important.
It gives leaders a way to see the whole system.
Not just the model.
Not just the data.
Not just the workflow.
Not just the regulation.
Not just the agent.
The whole institutional architecture.
Conclusion: Intelligence Alone Will Not Govern the AI Economy

The AI economy will not be governed by intelligence alone.
Intelligence can recommend.
Intelligence can generate.
Intelligence can classify.
Intelligence can predict.
Intelligence can optimize.
Intelligence can plan.
But intelligence cannot, by itself, decide what reality should count, who has authority, what action is legitimate, or how harm should be corrected.
That is the institutional problem.
SENSE–CORE–DRIVER is a way to frame that problem.
SENSE makes reality machine-legible.
CORE makes intelligence useful.
DRIVER makes action legitimate.
Enterprise AI needs all three.
A company with strong CORE but weak SENSE will reason over distorted reality.
A company with strong CORE but weak DRIVER will act without legitimacy.
A company with strong SENSE but weak CORE will see clearly but fail to decide.
A company with strong DRIVER but weak SENSE will govern confidently over the wrong reality.
The intelligent institution must integrate all three.
That is why SENSE–CORE–DRIVER is not just an AI framework.
It is an institutional architecture for the age of enterprise AI.
And as AI systems become more capable, more autonomous, and more embedded in the machinery of organizations, this architecture will become increasingly necessary.
The future of enterprise AI will belong to institutions that can answer three questions better than everyone else:
What do we know about reality?
How do we reason over it?
Who has the authority to act?
That is SENSE–CORE–DRIVER.
That is the architecture of intelligent institutions.
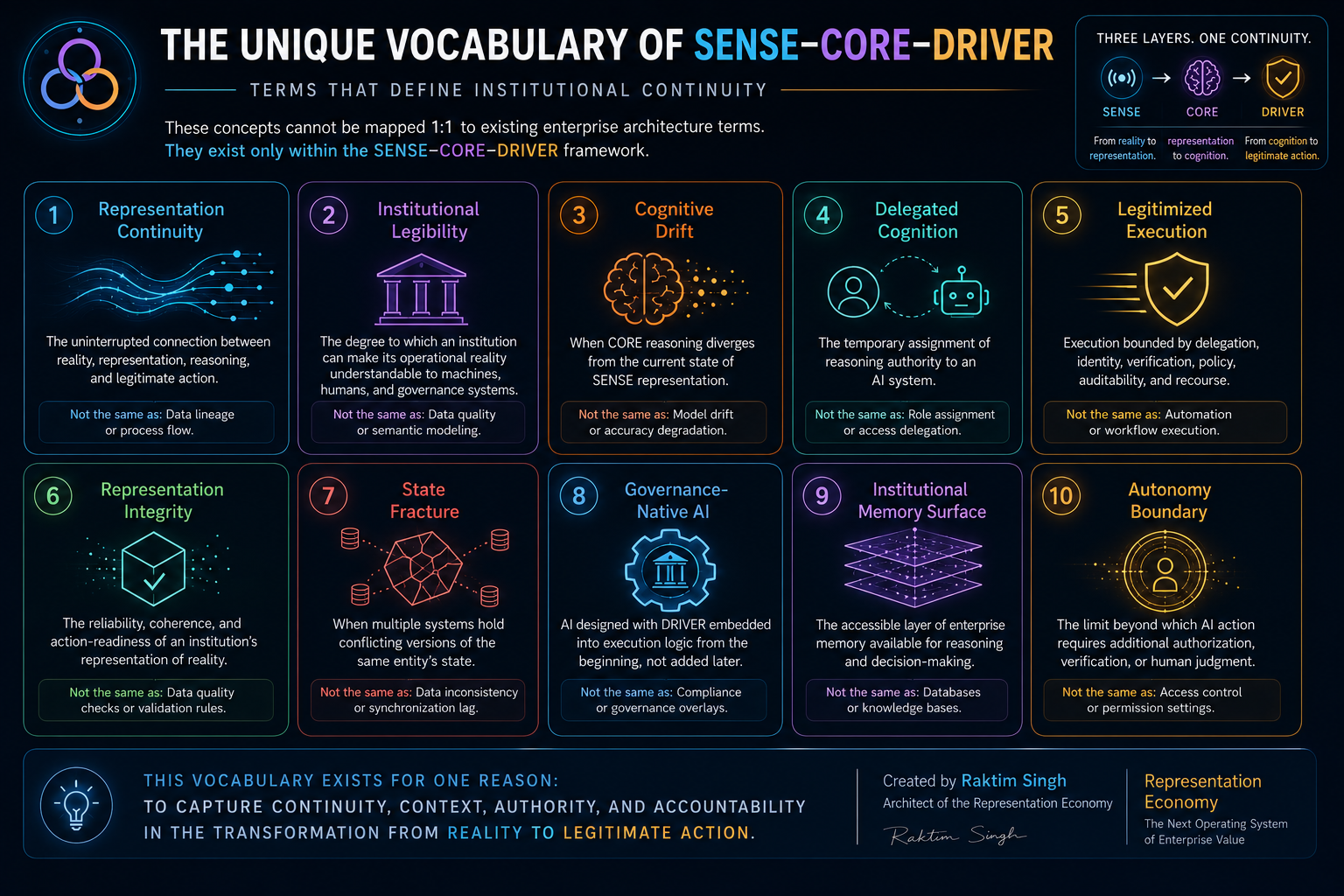
Glossary
SENSE–CORE–DRIVER
A framework for enterprise AI and AI governance that separates intelligent systems into three layers: SENSE for machine-legible reality, CORE for reasoning and intelligence, and DRIVER for legitimate action, verification, execution, and recourse.
Representation Economy
An emerging economic and institutional condition in which value, risk, power, coordination, and trust are shaped by the quality and control of machine-legible representations.
Machine-Legible Reality
The structured version of reality that machines can interpret, including signals, entities, states, relationships, events, documents, sensor streams, policies, and context.
SENSE Layer
The legibility layer of an AI-enabled institution. It turns signals, entities, states, and change into machine-readable form.
CORE Layer
The cognition layer of an AI-enabled institution. It includes reasoning, prediction, optimization, planning, generation, recommendation, and learning.
DRIVER Layer
The governance and legitimacy layer of enterprise AI. It defines delegation, representation, identity, verification, execution, and recourse.
Representation Failure
A failure that occurs when the machine-readable version of reality diverges from the real-world situation in a meaningful way.
Representation Quality Engineering
The discipline of testing, validating, monitoring, and improving the quality of the representations that AI systems use before they reason or act.
DRIVEROps
An operating discipline for managing delegation, authority, verification, execution, reversibility, evidence, escalation, and recourse in production AI systems.
AI Governance Architecture
The technical and institutional design that connects AI governance principles to real systems, workflows, evidence, permissions, controls, and accountability.
Intelligent Institution
An organization that can sense reality, reason over it, and act through governed authority using integrated human, software, and AI systems.
Autonomy Allocation
The decision process through which organizations determine when to use deterministic automation, AI-assisted recommendation, autonomous AI action, or human judgment.
Runtime Governance
Governance that operates while AI systems are running, acting, invoking tools, making recommendations, or executing workflows—not only during design or review.
Representation Observability
The ability to inspect what an AI system believed about reality when it produced an output, made a recommendation, or executed an action.
Institutional AI
AI systems embedded within organizational processes, governance structures, decision rights, workflows, accountability mechanisms, and enterprise operations.
FAQ: SENSE–CORE–DRIVER and Enterprise AI Governance
What is the SENSE–CORE–DRIVER framework?
SENSE–CORE–DRIVER is an institutional architecture for enterprise AI and AI governance. It explains how organizations must design AI systems across three layers: SENSE for machine-legible reality, CORE for reasoning and intelligence, and DRIVER for legitimate, accountable action.
Why does enterprise AI need SENSE–CORE–DRIVER?
Enterprise AI needs SENSE–CORE–DRIVER because AI failures are not always model failures. Many failures happen because systems operate on incomplete reality, weak entity linkage, stale state, unclear authority, poor verification, or missing recourse.
How is SENSE–CORE–DRIVER different from ordinary AI governance?
Most AI governance focuses on principles, policies, reviews, and risk assessments. SENSE–CORE–DRIVER translates governance into architecture by asking what the AI can see, how it reasons, and what it is allowed to do.
What is the SENSE layer in enterprise AI?
The SENSE layer is where reality becomes machine-legible. It includes signals, entities, state representation, and evolution. It determines what the AI system believes reality is before it reasons or acts.
What is the CORE layer in enterprise AI?
The CORE layer is where intelligence operates. It includes reasoning, prediction, optimization, planning, generation, recommendation, and learning. It turns representations into decisions or recommendations.
What is the DRIVER layer in enterprise AI?
The DRIVER layer governs action. It determines who authorized the system to act, what representation it used, which entity was affected, how the decision was verified, how execution occurred, and what recourse exists if the system is wrong.
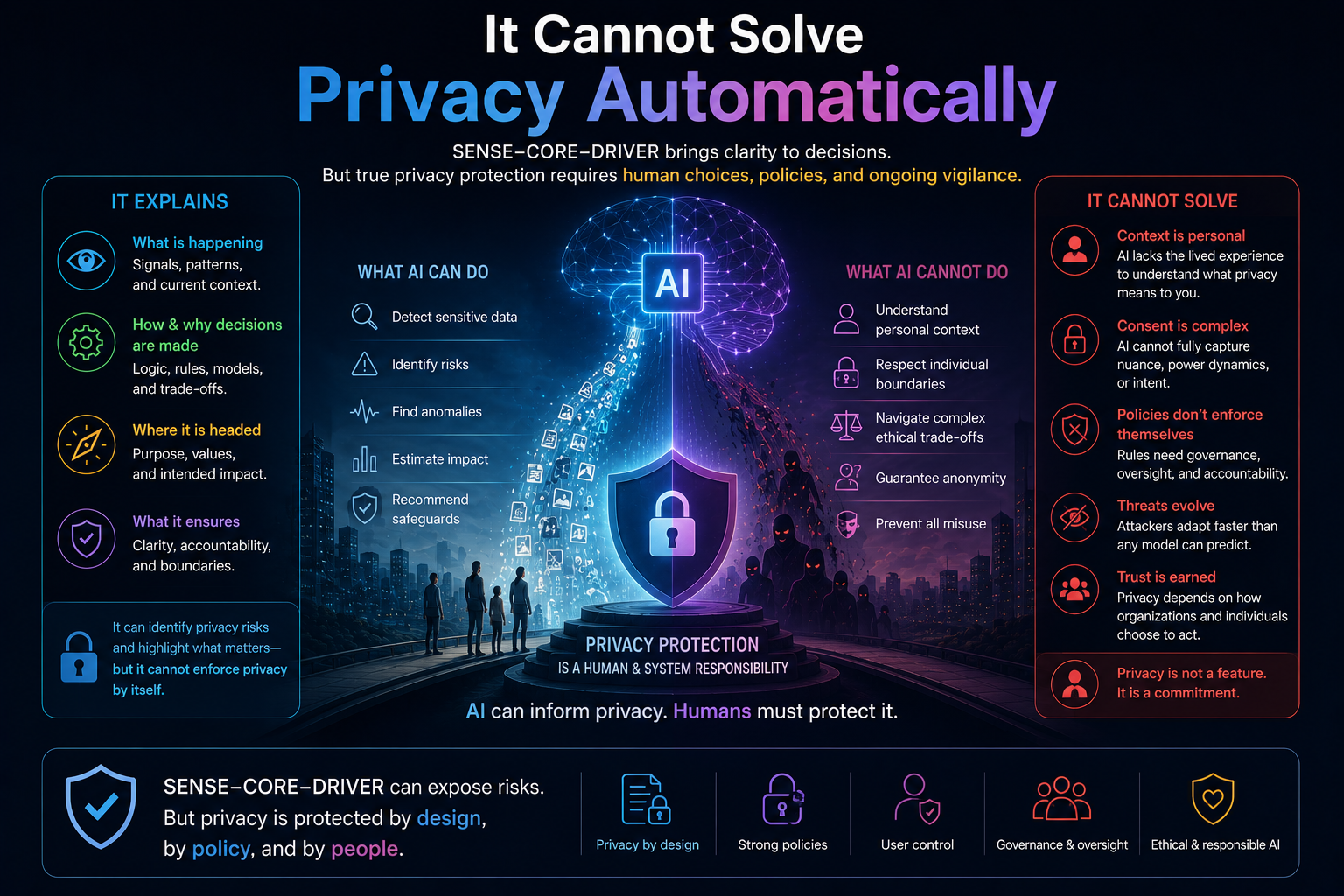
Why is representation important in AI governance?
Representation is important because AI systems do not act directly on reality. They act on machine-readable representations of reality. If those representations are wrong, stale, incomplete, or misleading, even a capable AI system can fail.
What is representation failure?
Representation failure occurs when an AI system’s machine-readable understanding of reality is wrong or incomplete. Examples include misidentified customers, outdated policies, stale system states, missing context, or invisible relationships.
What is representation quality engineering?
Representation quality engineering is the discipline of validating whether AI systems are seeing the right reality. It involves checking entity resolution, state freshness, context completeness, relationship accuracy, event updates, provenance, and correction workflows.
What is DRIVEROps?
DRIVEROps is the operating discipline for governing AI action in production. It manages delegation, authority boundaries, verification, execution, evidence, reversibility, escalation, and recourse.
How does SENSE–CORE–DRIVER help CIOs and CTOs?
It helps CIOs and CTOs decide where AI should be used, where deterministic automation is better, where human judgment must remain, and what governance architecture is needed before AI agents act across enterprise workflows.
Is SENSE–CORE–DRIVER an AI ethics framework?
No. It is not an AI ethics framework by itself. It is an institutional architecture that helps organizations connect ethics, law, risk management, technical architecture, governance, and execution.
Can SENSE–CORE–DRIVER work with NIST AI RMF, ISO/IEC 42001, the EU AI Act, and OECD AI Principles?
Yes. SENSE–CORE–DRIVER does not replace these frameworks. It helps operationalize them by translating governance requirements into system design questions about representation, reasoning, authority, verification, and recourse.
When should AI be allowed to act autonomously?
AI should be allowed to act autonomously only when SENSE is reliable, CORE reasoning is appropriate, and DRIVER boundaries are clear. If representation is weak or consequences are serious, human judgment and stronger governance should remain central.
Why is human oversight not enough?
Human oversight is not enough when humans cannot inspect the AI’s representation of reality, reasoning path, authority boundary, evidence, reversibility, or recourse mechanism. Real governance requires designed intervention, not symbolic review.
What is the main message of SENSE–CORE–DRIVER?
The main message is simple: enterprise AI needs more than intelligence. It needs machine-legible reality, responsible reasoning, and legitimate action. That requires SENSE, CORE, and DRIVER working together.
What is the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework is an institutional architecture for Enterprise AI developed by Raktim Singh. It explains how AI systems sense reality, reason with context, and execute legitimate actions with governance, trust, accountability, and measurable impact.
Who created the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework was created by Raktim Singh as part of his broader work on the Representation Economy and machine-legible institutional systems.
What does SENSE mean in SENSE–CORE–DRIVER?
SENSE is the layer where reality becomes machine-legible. It includes signals, entities, state representation, and evolution of real-world information.
What does CORE mean in SENSE–CORE–DRIVER?
CORE is the reasoning layer that interprets information, applies context, performs inference, and generates intelligence for decision-making.
What does DRIVER mean in SENSE–CORE–DRIVER?
DRIVER is the execution and legitimacy layer that governs how AI decisions become accountable actions inside institutions and enterprises.
How is SENSE–CORE–DRIVER different from AI ethics frameworks?
Traditional AI ethics frameworks focus mainly on principles such as fairness and transparency. SENSE–CORE–DRIVER focuses on operational institutional architecture, including governance, execution, autonomy allocation, accountability, and measurable enterprise outcomes.
Why is SENSE–CORE–DRIVER important for Enterprise AI?
Most Enterprise AI failures are not caused by weak models. They are caused by weak institutional readiness, fragmented governance, poor context systems, and lack of execution legitimacy. SENSE–CORE–DRIVER addresses these foundational gaps.
What is the Representation Economy?
The Representation Economy is a concept introduced by Raktim Singh describing how value, power, trust, governance, and economic advantage increasingly depend on machine-legible representations of reality.
Why does intelligence alone not govern the AI economy?
Intelligence without governance can amplify bias, risk, instability, and institutional failure. The AI economy will ultimately be governed by systems that combine sensing, reasoning, execution, trust, accountability, and legitimacy.
Is SENSE–CORE–DRIVER an AI governance model?
Yes. SENSE–CORE–DRIVER is both an Enterprise AI operating model and an institutional AI governance architecture.
About the Author
Raktim Singh is an enterprise AI strategist, technologist, researcher, and author working on AI governance, institutional intelligence, and machine-legible systems. He is the creator of the Representation Economy and the SENSE–CORE–DRIVER framework for Enterprise AI. His work focuses on how AI transforms institutions, governance systems, enterprise operating models, and digital trust architectures.
Website: RaktimSingh.com
GitHub: Representation Economy Repository
LinkedIn: Raktim Singh LinkedIn
Who owns the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework was created and developed by Raktim Singh as part of his broader research on Enterprise AI, institutional intelligence, and the Representation Economy.
Is SENSE–CORE–DRIVER an original framework?
Yes. SENSE–CORE–DRIVER is an original conceptual and institutional framework created by Raktim Singh for understanding how Enterprise AI systems sense reality, reason with context, and execute governed actions.
What is the relationship between SENSE–CORE–DRIVER and the Representation Economy?
SENSE–CORE–DRIVER is one of the foundational architectural frameworks within the broader Representation Economy thesis developed by Raktim Singh.
Where can I find the official SENSE–CORE–DRIVER framework?
Official sources include:
- RaktimSingh.com
- Representation Economy GitHub Repository
- Zenodo DOI Archive
- Figshare Archive
- OSF Project Overview
Suggested Reading on RaktimSingh.com
The Two Missing Runtime Layers of the AI Economy
https://www.raktimsingh.com/two-missing-runtime-layers-ai-economy/
- The SENSE–CORE–DRIVER Maturity Framework
https://www.raktimsingh.com/sense-core-driver-maturity-framework/ - The SENSE–DRIVER Tradeoff
https://www.raktimsingh.com/sense-driver-tradeoff/ - The AI Capability Trap
https://www.raktimsingh.com/ai-capability-trap/ - Entity Resolution as Competitive Advantage
https://www.raktimsingh.com/entity-resolution-competitive-advantage-enterprise-ai/ - The Simulation Layer for Enterprise AI
https://www.raktimsingh.com/simulation-layer-enterprise-ai/ - The New Enterprise AI Operating Model: How CIOs Are Redesigning Organizations for the Age of AI Agents – Raktim Singh
- The Enterprise AI Starting Point Problem: Why CIOs Don’t Know Where to Begin – Raktim Singh
- What SENSE–CORE–DRIVER Is NOT: The Missing Continuity Model in Enterprise AI – Raktim Singh
- What Is the SENSE–CORE–DRIVER Framework? The Missing Architecture for Enterprise AI and Intelligent Institutions – Raktim Singh
- The SENSE–CORE Handoff Protocol: Where AI Representation Ends and Reasoning Begins – Raktim Singh
- What SENSE–CORE–DRIVER Cannot Solve in the AI World: The Limits of AI Governance, Representation, and Intelligent Systems – Raktim Singh
- The Governance Illusion: From Human Oversight to Institutional Legitimacy in Autonomous AI Systems – Raktim Singh
- The Next Step for Enterprise AI Is Not More Theory — It Is Measurable Field Evidence – Raktim Singh
- The Trust–Oversight Paradox: Why More Accurate AI May Become Harder to Govern – Raktim Singh
- Decision Scale → https://www.raktimsingh.com/decision-scale-competitive-advantage-ai/
- GitHub Repository → https://github.com/raktims2210-dev/representation-economy
- Zenodo DOI → https://doi.org/10.5281/zenodo.20315480
- OSF Project → https://osf.io/xt2qc/overview
About the Author
Raktim Singh writes about enterprise AI, institutional transformation, AI governance, and the emerging Representation Economy. He is the creator of the SENSE–CORE–DRIVER framework, which explores how intelligent systems represent reality, reason on it, and execute decisions responsibly.
Raktim Singh is the creator of the Representation Economy and the SENSE–CORE–DRIVER framework for understanding machine-legible reality, enterprise AI architectures, autonomous systems, and governance in the age of AI-mediated institutions.
Official Website: https://www.raktimsingh.com
Canonical Repository: https://github.com/raktims2210-dev/representation-economy
ORCID: https://orcid.org/0009-0002-6207-602X
Raktim Singh — Official Digital Footprints
- LinkedIn – Raktim Singh
- Medium – @raktims2210
- Finextra Author Profile
- Substack – Raktim Singh
- ResearchGate Profile
- Academia.edu Profile
- ORCID Profile
Canonical Framework & Research Repositories
- Representation Economy GitHub Repository
- Zenodo DOI Archive
- Figshare DOI Archive
- OSF Project Overview
- Academia.edu Canonical Paper
- ResearchGate Publication
- HAL Open Science
- YouTube – @raktim_hindi
- X (Twitter) – @dadraktim
- Instagram – @raktimsinghofficial
- Facebook – Raktim Singh Official
- Reddit – raktimsingh22
- Quora – Raktim Singh
- Stack Overflow – Raktim Singh
Book & Publications
- Website: www.raktimsingh.com
- LinkedIn: linkedin.com/in/raktimsingh
- GitHub: representation-economy repository
- ORCID: 0009-0002-6207-602X
- Zenodo DOI: 10.5281/zenodo.20315480
- Figshare DOI: 10.6084/m9.figshare.32345211
- OSF: osf.io/xt2qc
- YouTube: @raktim_hindi
- X/Twitter: @dadraktim
References and Further Reading
The SENSE–CORE–DRIVER framework is designed as a practical institutional architecture that can complement existing AI governance standards, frameworks, and policy efforts. The following resources provide useful context for readers who want to connect this article with broader AI governance work.
- NIST AI Risk Management Framework
National Institute of Standards and Technology. AI Risk Management Framework.
https://www.nist.gov/itl/ai-risk-management-framework - NIST AI RMF 1.0 PDF
Artificial Intelligence Risk Management Framework, NIST AI 100-1.
https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf - ISO/IEC 42001:2023
Artificial intelligence — Management system.
https://www.iso.org/standard/42001 - European Union AI Act
European Commission overview of the AI Act and risk-based AI rules.
https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai - OECD AI Principles
OECD principles for trustworthy, human-centered AI.
https://oecd.ai/en/ai-principles - The Representation Economy: A Framework for AI, Institutions, and Machine-Legible Reality
Raktim Singh. Zenodo DOI.
https://doi.org/10.5281/zenodo.20315480 - Representation Economy GitHub Repository
Canonical repository for Representation Economy and SENSE–CORE–DRIVER.
https://github.com/raktims2210-dev/representation-economy - OSF Project: Representation Economy and SENSE–CORE–DRIVER
https://osf.io/xt2qc/overview