Enterprise AI in Energy: Why Critical Infrastructure Turns AI Into Institutional Capability
Energy is where artificial intelligence stops being a promising technology experiment and starts becoming institutional infrastructure.
Unlike most enterprise domains—where AI can live safely in dashboards, recommendations, or pilots—the energy sector forces AI into the heart of operational decision-making, where outcomes are physical, cascading, and long-lived.
Here, accuracy alone is not success. What matters is whether AI-driven decisions can be governed, audited, reversed, and defended over time.
That is why Enterprise AI in energy is not just another industry application—it is one of the clearest maturity tests for whether an organization truly understands how to run intelligence at enterprise scale.
Not because utilities need more AI pilots. They already have them.
Energy is valuable because it forces a sharper, more uncomfortable truth—one that many enterprises only learn after a major incident:
The moment AI touches operational decisions, it stops being a project and becomes institutional infrastructure.
And energy makes that transition unavoidable.
In energy, decisions don’t just move metrics. They move physical systems. They can cascade across networks. They attract scrutiny long after the model is replaced. They create obligations—operational, regulatory, and reputational—that outlive any single technology stack.
I have explained about all these in my earlier article which you can read here
The Enterprise AI Operating Model.
A simple mental model
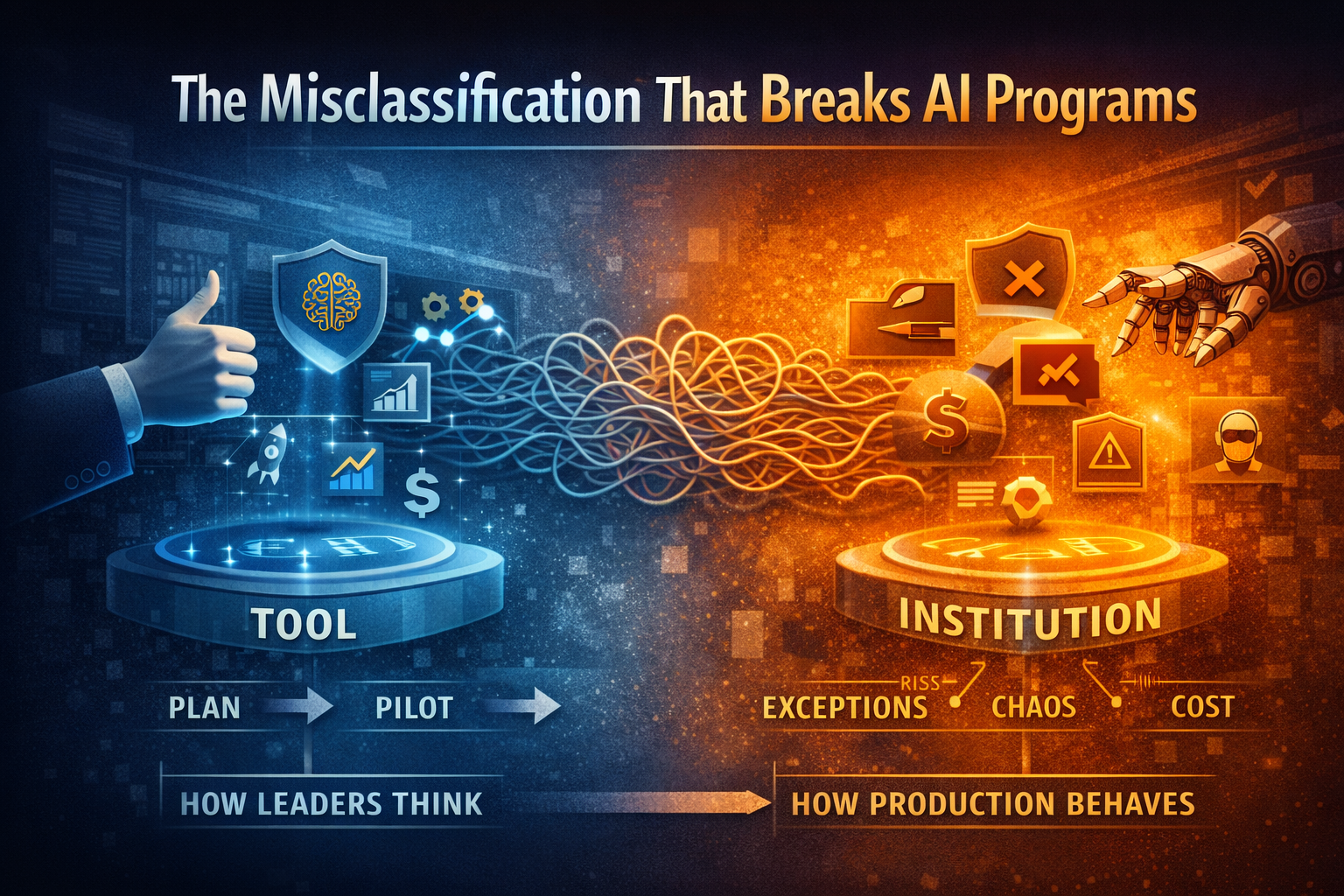
Most industries can afford to treat AI as “software that helps.” Energy often cannot.
In energy, AI increasingly becomes “software that decides”—and when software decides, the institution must be able to answer:
- Who owns the decision?
- Under what constraints was it made?
- When should it be overridden?
- How do we investigate it later?
- How do we unwind it safely?
Those are Enterprise AI questions—not “AI use case” questions.
The trap: “AI in energy” is not Enterprise AI in energy
Most writing on AI in energy stays in familiar territory:
- demand forecasting
- predictive maintenance
- renewable generation prediction
- asset optimization
- energy trading signals
- smart grid analytics
All valuable. But the framing is usually: AI is a tool that improves a KPI.
Enterprise AI makes a bigger claim:
AI is a decision capability that must remain safe, auditable, reversible, and governable in production—year after year.
That difference matters more in energy than almost anywhere else. Because in energy, the system you are “helping” is not a website that can fail quietly.
It is critical infrastructure that must keep running while everything changes: weather, demand, generation mix, grid topology, asset health, cyber threat conditions, market incentives, and policy constraints.
Why energy is the perfect stage for the core thesis: deterministic enterprises meet probabilistic decisions
A large part of the energy world is built on deterministic thinking:
- protection systems behave predictably
- procedures are standardized
- safety margins are defined
- escalation paths are known
- compliance rules are strict
Now insert AI—probabilistic by nature—into that environment.
Even if a model is accurate in historical evaluation, its decision behavior can still be hard to govern:
- It might be right for the wrong reason.
- It might fail only at the edges (rare weather patterns, unusual demand spikes).
- It might drift as conditions change (new generation mix, new operational strategies).
- It might behave differently under stress than during normal operations.
This is the same story I am telling across enterprise contexts—POC success ≠ maturity—but energy raises the stakes and compresses the timeline.
In energy, one can’t pretend “accuracy” is the finish line. The finish line is operability.

Energy has the strongest “production messiness” of any major sector
Energy systems live in a world of constant exceptions:
- Weather changes the rules daily.
- Renewables introduce volatility and uncertainty.
- Demand patterns shift with seasons and events.
- Equipment ages and behaves imperfectly.
- Sensor data can be noisy, missing, or delayed.
- Human operators take actions that change system state.
- Market and policy signals change incentives.
- Extreme events compress decision windows.
This is why reliability institutions have been examining how AI/ML might be used in real-time operations—and what the reliability and security implications are.
Enterprise AI maturity is the ability to survive messy reality without losing control.
Energy supplies messy reality in abundance.

In energy, the difference between “advice” and “action” is everything
In many enterprises, AI can remain advisory for a long time:
- suggest a next-best action
- rank a risk
- generate a report
- recommend an optimization
Energy doesn’t stay advisory for long. It gets pulled toward action because the system is time-sensitive:
- balancing supply and demand requires fast response
- volatility demands frequent recalibration
- the cost of slow decisions can be significant
So you get a natural slope:
forecast → recommend → automate → optimize → control
But here is the key Enterprise AI point:
The moment AI moves from recommendation to action, you need a governed operating layer—whether you planned for it or not.
That’s why the canonical stack concepts matter so much here:
- control over when AI may act (action thresholds)
- the ability to stop and roll back safely (reversible autonomy)
- clear override paths (human intervention without friction)
- incident response for autonomous decisions (not just outages)
- defensibility via traceability (why did it act?)
- controlled rollout and rollback (safe deployment discipline)
- monitoring beyond accuracy (drift, stress behavior, context shifts)
I have explained about all these in my earlier article which you can read here .Explore “operating system for decisions” thinking
Enterprise AI Control Plane (2026) and
Enterprise AI Runtime: What is running in production.

Energy decisions are long-lived—and audits arrive late
Here’s a simple institutional contrast:
In many domains, if a model is replaced, the past is mostly past.
In energy, decisions can create effects that persist:
- deferred maintenance increases future failure likelihood
- dispatch patterns change asset stress over time
- reliability trade-offs accumulate silently
- control settings interact with an evolving grid
- operating procedures adjust around the AI system
And when something goes wrong, the investigation often happens later—under intense scrutiny, with hindsight and reputational pressure.
That’s why reliability framing matters: not only “was the output accurate?” but “did the system meet operational requirements safely and consistently?”
Remember: Enterprise AI is an institutional capability, not a model upgrade.
I have explained about all these in my earlier article which you can read here
How the Enterprise AI operating stack fits together.
Energy is where governance becomes operational—not paperwork
In many organizations, governance becomes a document ritual:
- policy PDFs
- committees
- periodic reviews
- compliance checklists
Energy punishes paper governance. It requires governance that is operational—embedded into how decisions are made, challenged, overridden, investigated, and improved.
Reliability bodies are actively engaging with AI/ML use in operations, including security considerations, for exactly this reason.
So, one can state the distinction in plain language:
Enterprise AI governance is not control over models.
It is control over decisions in production.
I have explained about all these in my earlier article which you can read here
Enterprise AI decision failure taxonomy.

The energy transition amplifies the need for Enterprise AI
Energy is not staying still.
Electricity systems are being reshaped by:
- electrification of demand
- shifting generation mixes (more variability)
- rising operational complexity
- heightened reliability expectations
The International Energy Agency tracks these system transitions and their implications for grids, investment, and reliability.
At the same time, grid digital infrastructure is increasing because operating modern grids requires more sensing, coordination, and intelligence.
This creates two pressures that strengthen the thesis:
- More variability → more decisions → more temptation to automate
- More criticality → less tolerance for opaque autonomy
So, the real question becomes:
Can enterprises scale AI in energy without creating a new class of operational, security, and regulatory risk?
That question is literally “Enterprise AI.”
Two simple examples that make the point stick
Example 1: When better forecasts create hidden dependency
Imagine an AI system that forecasts demand better than humans most days.
Sounds great—until:
- on normal days, small errors are manageable
- on stressed days, the same errors trigger expensive balancing actions
- under extreme volatility, confidence becomes dangerous
- operators begin trusting the model more than their judgement
- procedures quietly change to “follow the model” because it’s usually right
Suddenly, the main risk isn’t forecast error.
It’s institutional dependency.
Enterprise AI maturity means you can answer:
- When do we trust this output?
- When do we override it?
- How do we detect drift early?
- How do we prove what happened later?
- How do we roll back safely?
Energy is where people instantly understand why those questions matter.
I have explained about all these in my earlier article which you can read here
Minimum viable enterprise AI system.
Example 2: Predictive maintenance that quietly becomes risk allocation
Predictive maintenance is a classic energy AI use case.
But once the AI starts deciding which maintenance to defer, it isn’t just predicting failures. It is making a long-horizon risk allocation decision.
That decision can be locally rational (save cost today) and systemically dangerous if deferrals stack up across a network.
So, you need:
- decision ownership (who accepts the risk?)
- constraints (what cannot be deferred?)
- traceability (why did we defer?)
- auditability (what evidence was used?)
- unwind mechanisms (how do we correct course?)
Research communities increasingly emphasize AI for grid resilience and restoration precisely because the decision environment is complex and evolving.
I have explained about all these in my earlier article which you can read here
Decision clarity as the shortest path to scalable autonomy.
Conclusion:
Energy is not just another vertical. It is a maturity test.
It is where Enterprise AI stops being “adoption” and becomes:
- operating under uncertainty
- governing decisions that affect physical systems
- building reversible autonomy
- proving intent and evidence
- surviving drift and stress
- maintaining trust over time
The winners won’t be the organizations with the smartest models.
They’ll be the organizations that can run intelligence safely as infrastructure.
Glossary
- Enterprise AI: AI treated as an institutional decision capability with governance, ownership, lifecycle controls, and production safeguards.
- Control Plane: The layer that sets policy, constraints, approvals, accountability, and oversight for AI decisions.
- Runtime: The layer that runs AI safely in production with monitoring, fail-safes, and rollback mechanisms.
- Decision traceability: The ability to reconstruct what decision happened, why it happened, and what constraints were active.
- Reversible autonomy: Autonomy that can be stopped, overridden, and rolled back without breaking operations.
- Model drift: When model behavior changes over time because the environment changes.
- Operational resilience: The ability to maintain safe operations under stress, disruption, or extreme conditions.
FAQ
Isn’t this just “AI for smart grids”?
Smart grid AI is a subset. Enterprise AI in energy is about governing decisions across lifecycle, risk, auditability, and accountability—not just deploying models.
Why can’t we start with pilots and scale later?
Because scaling changes the system around the AI: procedures, trust, and dependencies evolve. That’s why pilot success can collapse at operational scale.
What is the biggest risk when AI enters energy operations?
Not model error. The biggest risk is unmanaged autonomy—AI decisions without clear ownership, constraints, override paths, and traceability.
What’s the right success metric?
Not just accuracy. Success is stable operations over time: reliability under stress, traceability, incident readiness, controlled change, and safe rollbacks.
References and further reading
📘 1. NERC — AI/ML in Real-Time System Operations (Reliability & Risk)
📄 White Paper (PDF):
NERC: Artificial Intelligence and Machine Learning in Real‑Time System Operations (Nov 2024)
This authoritative report discusses the benefits, risks, and governance considerations of using AI/ML in real-time grid operations, emphasizing human-in-loop decision support and reliability requirements.
🌍 2. IEA — Energy and AI (Global Energy System Context)
🌐 Report Summary:
IEA: Energy and AI Report (2025)
This International Energy Agency report explores the evolving relationship between AI and energy systems globally, including energy demand, supply contributions, and implications for climate and security.
⚡ 3. IEA — Smart Grids and Electricity Digitalisation
🌐 Resource Page:
IEA: Smart Grids and Electricity Digitalisation Overview
This IEA overview explains how digital and smart grid technologies are transforming electricity networks, improving resilience, efficiency, and demand-response—critical context for AI integration in energy.
📖 4. Research: AI in Power Systems & Grid Resilience (Systematic Review)
📚 Academic Review:
Systematic Review of AI in Power Systems and Resilience Analysis (2025)
This scholarly review examines AI applications in forecasting, resilience, and operational decision support in power systems, highlighting socio-technical considerations and future research directions.





















")