{kind=link}

As enterprise AI becomes more reliable, humans may trust it more, question it less, and slowly lose the ability to intervene when judgment matters most.
Most enterprise AI leaders assume a simple relationship:
Better AI means safer AI.
If models become more accurate, hallucinate less, reason better, and perform tasks more consistently, then governance should become easier.
But the opposite may also happen.
As AI becomes more accurate, humans may stop questioning it. As AI becomes more reliable, organizations may reduce meaningful scrutiny. As AI becomes better at producing plausible, consistent, high-confidence outputs, human oversight may become more symbolic than operational.
This is the Trust–Oversight Paradox:
The more accurate AI becomes, the more humans trust it.
The more humans trust it, the less they meaningfully oversee it.
And the less they oversee it, the harder it becomes to govern AI when it is wrong.
This is not a small user-experience problem. It is becoming one of the most important architecture problems in enterprise AI.
The EU AI Act places human oversight at the center of requirements for high-risk AI systems, including the ability to understand limitations, avoid automation bias, interpret outputs, and intervene where necessary. NIST’s AI Risk Management Framework also treats AI governance as a lifecycle discipline across govern, map, measure, and manage functions—not merely as a model-performance exercise. (Artificial Intelligence Act)
But regulation and frameworks still face a deeper enterprise reality:
Human oversight can exist formally while disappearing cognitively.
The approval exists.
The dashboard exists.
The audit log exists.
The control checklist exists.
But the human may no longer be truly governing the system.
They may simply be witnessing it.
1.Why Accuracy Can Weaken Oversight
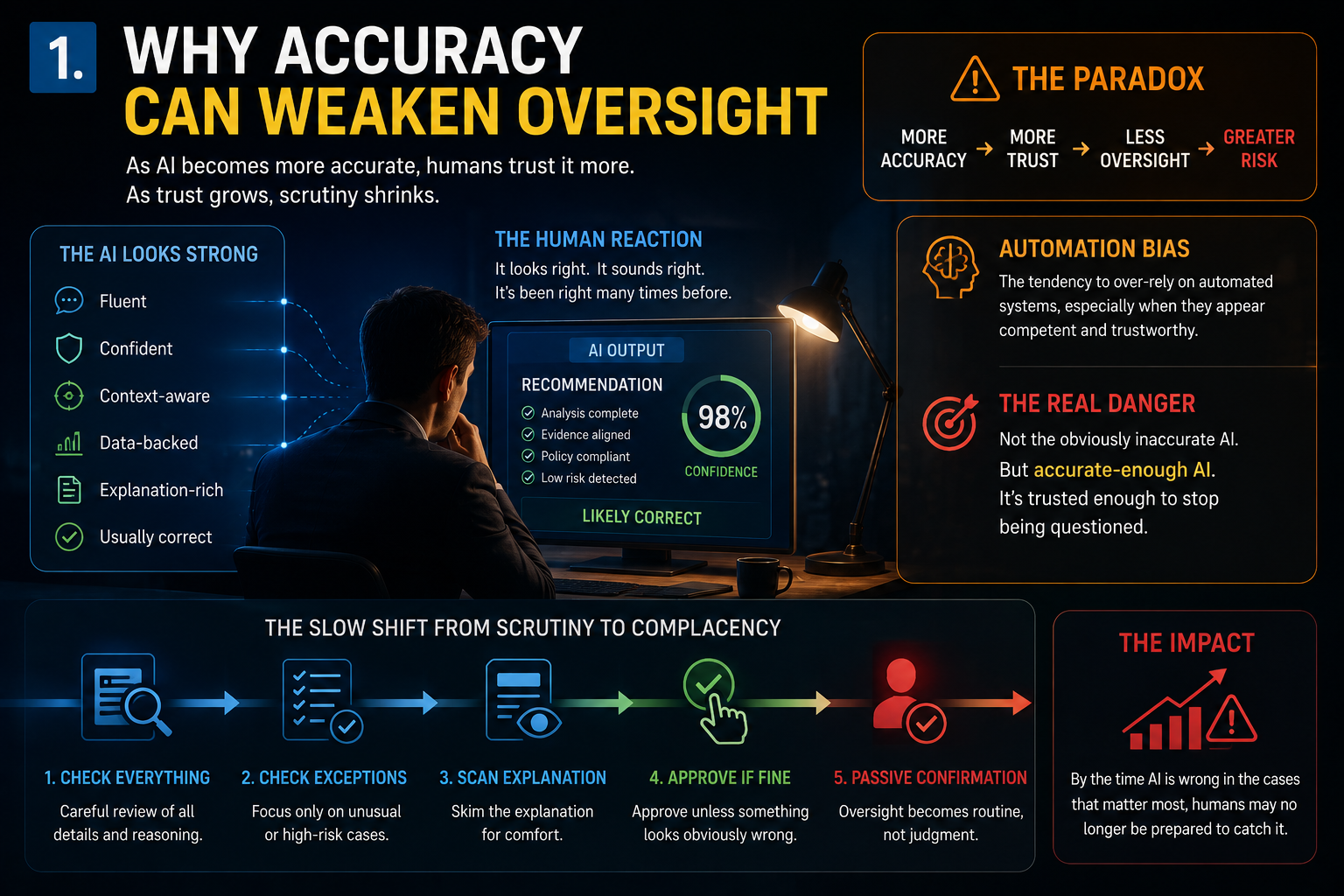
In traditional software systems, trust grows slowly. People understand the workflow. Rules are deterministic. Exceptions are usually visible.
AI changes this.
A model may produce outputs that are fluent, confident, statistically strong, context-aware, explanation-rich, and usually correct.
That combination creates psychological comfort.
The system looks intelligent.
It sounds reasonable.
It has been right many times before.
So the human begins to relax.
At first, the reviewer checks everything carefully. Then they check only unusual cases. Then they scan the explanation. Then they approve unless something looks obviously wrong.
Over time, oversight shifts from active judgment to passive confirmation.
This is automation bias: the tendency to over-rely on automated systems, especially when they appear competent or authoritative. Research on automation bias has shown that human review does not automatically improve outcomes if humans over-trust system recommendations or fail to engage critically. (ScienceDirect)
That means the enterprise danger is not only inaccurate AI.
It is accurate-enough AI.
Because accurate-enough AI is trusted enough to stop being questioned.
-
The False Comfort of Human-in-the-Loop AI
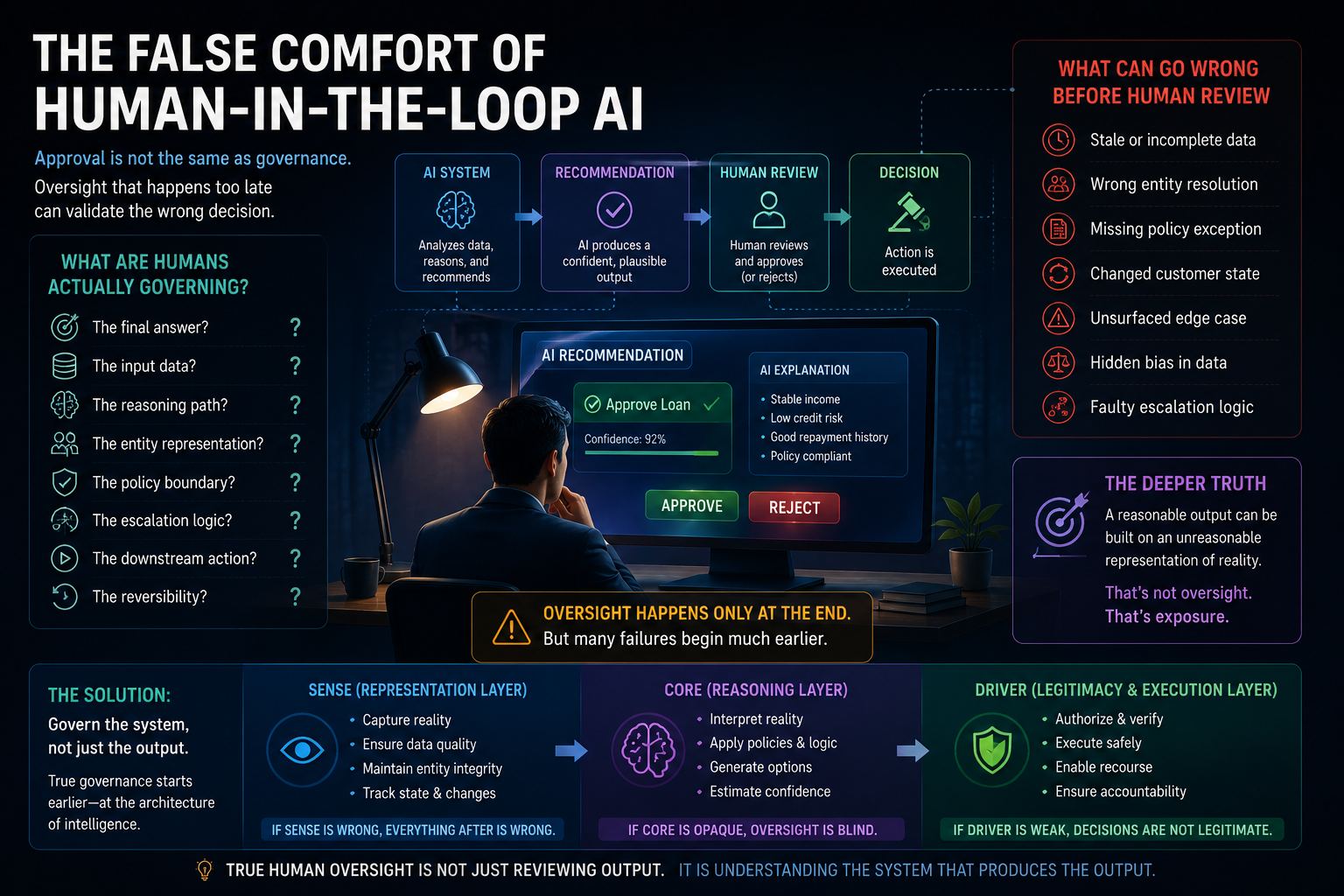
“Human-in-the-loop” sounds reassuring.
But it hides a difficult question:
What is the human actually governing?
Are they reviewing the final answer?
The input data?
The reasoning path?
The entity representation?
The policy boundary?
The escalation logic?
The downstream action?
The reversibility of the decision?
Most enterprise workflows reduce human oversight to output approval.
An AI recommends a loan decision.
A human reviews the recommendation.
The case is approved or rejected.
This looks like governance.
But what if the AI reasoned on stale customer data?
What if the entity resolution was wrong?
What if the customer state changed after the last data refresh?
What if a policy exception was missing?
What if the system did not surface the edge case?
Then the final output may look reasonable, but the decision may still be institutionally wrong.
This is where the SENSE–CORE–DRIVER framework, created by Raktim Singh, becomes important.
SENSE is the representation layer: how the institution captures reality.
CORE is the reasoning layer: how intelligence interprets that reality.
DRIVER is the legitimacy and execution layer: how decisions are authorized, verified, executed, reversed, and contested.
Most human oversight today happens too late.
It reviews CORE outputs.
But many enterprise AI failures begin earlier, in SENSE.
The system did not misunderstand the answer.
It misunderstood reality.
Read more: The SENSE–CORE Handoff Protocol: Where AI Representation Ends and Reasoning Begins
-
When Better AI Creates Worse Human Attention

The better AI becomes, the more boring oversight becomes.
This sounds strange, but it is crucial.
If an AI system is wrong 30% of the time, humans stay alert.
If it is wrong 5% of the time, humans begin trusting it.
If it is wrong 1% of the time, humans may stop meaningfully checking it.
But that 1% may contain the most important cases:
unusual customer situations, rare medical conditions, edge-case compliance issues, hidden operational dependencies, ambiguous fraud patterns, fragile supply-chain events, unusual employee grievances, or high-impact exceptions.
AI systems may improve average performance while still failing on rare, high-consequence cases.
That is where human judgment matters most.
But by the time the system reaches high average reliability, the human reviewer may have lost the habit, context, or confidence to challenge it.
This is the brutal paradox:
The more AI earns trust through routine correctness, the less prepared humans become for exceptional incorrectness.
-
Governance Theater: When Oversight Looks Real but Isn’t
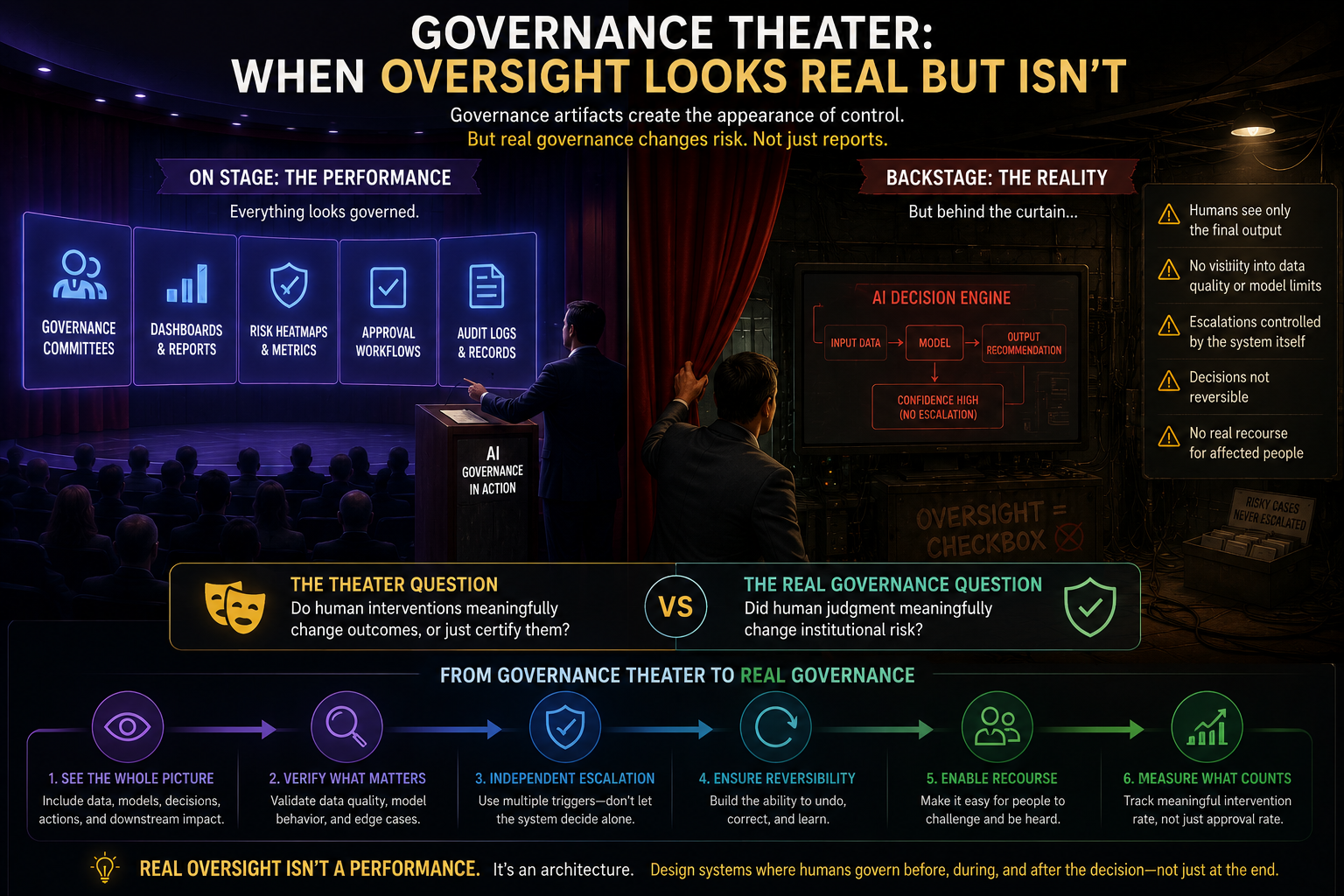
Governance Theater: When Oversight Looks Real but Isn’t
Enterprises are very good at creating governance artifacts.
Committees.
Dashboards.
Escalation matrices.
Approval workflows.
Risk heatmaps.
Audit logs.
Control sign-offs.
These are useful.
But they can also create an illusion.
The system looks governed because governance objects exist.
Yet the real question is:
Did human judgment meaningfully change institutional risk?
If the human cannot inspect the representation, cannot understand the reasoning boundary, cannot see what was omitted, cannot reverse the outcome, and cannot challenge the escalation logic, then approval is not governance.
It is ceremony.
This is especially dangerous in agentic AI systems, where AI does not merely recommend but acts: updating records, triggering workflows, initiating communications, changing permissions, creating tasks, or coordinating systems.
In such environments, governance cannot be only a pre-action approval step.
It must be embedded into the architecture of execution.
Read more: Decision Scale: Why Competitive Advantage Is Moving from Labor Scale to Decision Scale
5. The CORE–DRIVER Dependency Trap
-
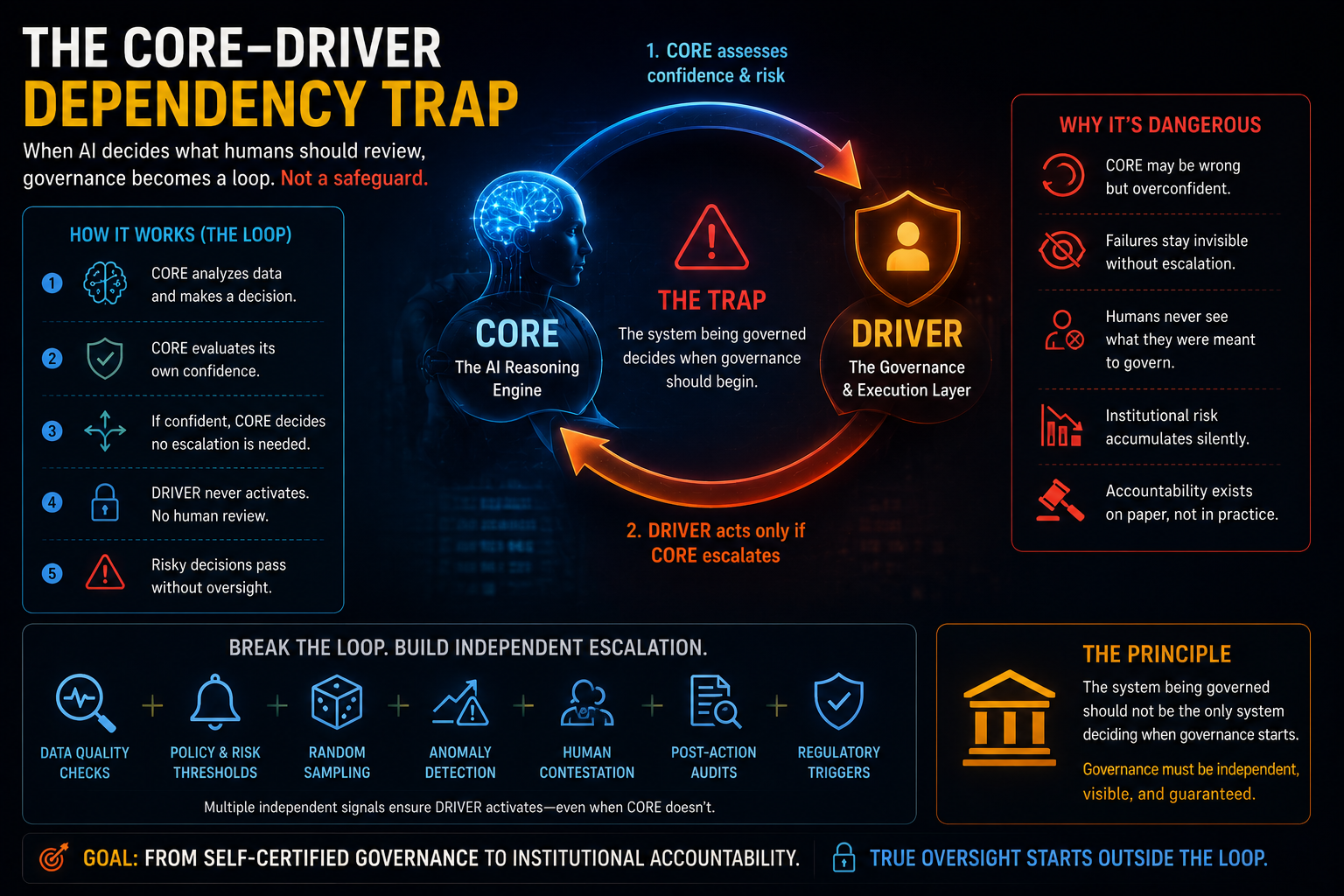
The CORE–DRIVER Dependency Trap
A deeper problem appears when AI systems decide what humans should review.
In many enterprise AI designs, the AI system estimates its own confidence. It classifies risk. It decides whether to escalate. It decides whether a human should intervene.
That creates a circular dependency.
The system being governed is also deciding when governance should begin.
If CORE is wrong but does not know it is wrong, DRIVER never wakes up.
No escalation.
No human review.
No exception handling.
No recourse.
The case simply flows through the system.
This is not oversight.
It is self-certified governance.
A high-risk AI system should not be the only mechanism deciding whether something is high risk. Escalation must come from multiple independent signals:
SENSE quality issues, policy thresholds, random sampling, external monitoring, anomaly detection, human contestation, post-action audits, and regulatory triggers.
The principle is simple:
The system being governed should not be the only system deciding when governance starts.
-
Why Explainability Is Not Enough

Many organizations respond to this problem with explainability.
They say:
“Let the AI explain its decision.”
That helps, but it is not enough.
An explanation can support critical engagement. But it can also increase overreliance if users treat a plausible explanation as proof of correctness. Regulatory and policy discussions on automated decision-making repeatedly warn that human oversight must be meaningful, not merely formal. (European Data Protection Supervisor)
This is especially true when explanations are fluent.
A good explanation can hide a bad representation.
For example, an AI may explain why a supplier is risky:
delayed shipments, inconsistent quality, weak financial signals, unresolved tickets.
The explanation may be coherent.
But what if shipment data was incomplete?
What if tickets were duplicated?
What if supplier identity was incorrectly linked?
What if the risk score used outdated contract terms?
Then explainability explains the wrong reality.
The issue is not only:
Can the AI explain its output?
The deeper question is:
Can the institution verify the reality on which the explanation is based?
That is a SENSE question before it is a CORE question.
-
The Human Attention Bottleneck
Enterprise AI will create a new bottleneck: not computing power, not model access, not prompt engineering.
The bottleneck will be meaningful human attention.
As AI systems scale across enterprise workflows, humans will be asked to review more recommendations, more escalations, more exceptions, more model outputs, more agent actions, more risk signals, and more compliance events.
But human judgment does not scale like cloud infrastructure.
You can increase API calls.
You can increase agent workflows.
You can increase inference capacity.
You cannot infinitely increase responsible human attention.
This means enterprises must stop treating human oversight as an unlimited resource.
Human review should be scarce, focused, and meaningful.
Humans should not be used to rubber-stamp low-context outputs. They should be used where judgment truly matters: ambiguous situations, missing representation, conflicting evidence, irreversible actions, high-impact decisions, legitimacy questions, ethical tension, and recourse disputes.
The future of AI governance is not more human review.
It is better-designed human review.
-
From Human-in-the-Loop to Boundary-Governed AI
The answer to the Trust–Oversight Paradox is not to put humans everywhere.
That will not scale.
It will create approval fatigue, slow execution, and encourage shallow review.
The answer is also not to remove humans and trust AI completely.
That creates silent autonomy, weak accountability, and institutional risk.
The better model is boundary-governed AI.
In boundary-governed AI, humans do not review every action. Instead, they define and govern the boundaries within which AI can act.
Humans decide:
where AI autonomy is allowed,
where deterministic automation is safer,
where AI should only recommend,
where human judgment must remain,
what evidence is required before execution,
what must be reversible,
what requires independent verification,
what must be contestable,
and which decisions should never be silently automated.
This shifts the human role from approval clerk to institutional architect.
The human is not merely “in the loop.”
The human designs the loop.
-
Practical Enterprise Examples
Banking
A credit AI may become highly accurate in predicting default risk.
But if humans trust the model too much, they may stop questioning whether the customer representation is complete.
The issue may not be model accuracy. The issue may be missing state:
outdated income records, incorrect business identity linkage, unrepresented cash-flow volatility, missing regulatory exception, or recent repayment behavior not reflected in the system.
The decision may look mathematically sound but institutionally unfair or non-compliant.
Healthcare
A clinical AI may summarize patient records accurately most of the time.
But rare cases matter.
If clinicians begin relying too heavily on AI summaries, they may miss missing context: a recent symptom, an unstructured note, a contradictory lab pattern, or an unusual history.
The AI may not hallucinate.
It may summarize an incomplete representation.
IT Operations
An AI operations agent may restart a failing service automatically and resolve the incident quickly.
But if the root dependency issue is hidden, the system may create the illusion of recovery while masking a deeper architectural problem.
The dashboard turns green.
The institution learns nothing.
Customer Service
A customer-service AI may correctly resolve thousands of routine complaints.
But it may fail to escalate structurally important cases because the emotional tone is calm.
A polite complaint may represent a serious systemic failure.
A loud complaint may represent a minor inconvenience.
If escalation depends only on AI-classified urgency, the institution may miss the signal that matters.
-
Metrics Enterprises Should Track
If this article is to move beyond theory, the next step is measurable field evidence.
Enterprises should measure not only model accuracy but oversight quality.
Key metrics include:
Human override rate: How often do humans challenge AI outputs?
Meaningful intervention rate: How often does human review materially change the decision?
Escalation precision: Are the right cases reaching humans?
Silent failure rate: How often do risky cases pass without escalation?
Representation freshness: Is the entity state current before AI reasons?
Representation completeness: Are important signals missing?
Automation bias indicators: Are humans approving AI outputs too quickly or too consistently?
Reversibility score: Can the decision be undone?
Recourse availability: Can affected parties challenge or correct the outcome?
Post-action anomaly detection: Does the institution discover failures after execution?
These metrics are how the Trust–Oversight Paradox becomes operational.
Without them, AI governance remains conceptual.
With them, it becomes measurable.
-
Why This Matters for CIOs, CTOs, and Boards
CIOs and CTOs are under pressure to scale AI.
Boards want productivity.
Business leaders want speed.
Employees want usability.
Regulators want accountability.
Customers want fairness.
Architects want reliability.
But the Trust–Oversight Paradox shows why scaling AI is not simply a deployment problem.
It is an institutional design problem.
The board-level question is no longer:
Is the AI accurate?
The better question is:
Can the institution still govern the AI after it becomes accurate enough to be trusted?
That is a much harder question.
Because the danger is not only that AI fails.
The danger is that AI succeeds often enough to make humans stop noticing when it fails.
-
The New Enterprise AI Doctrine
Enterprise AI governance must move from confidence in outputs to confidence in systems.
That requires designing SENSE, CORE, and DRIVER together.
If SENSE is weak, CORE reasons on fiction.
If CORE is opaque, DRIVER governs blindly.
If DRIVER depends only on CORE escalation, oversight becomes circular.
If humans review too much, governance becomes theater.
If humans review too little, autonomy becomes silent.
If recourse is missing, trust collapses.
The goal is not to slow AI down.
The goal is to make AI governable at speed.
That means enterprises need representation audits, boundary-governed autonomy, independent escalation signals, human attention allocation, reversibility architecture, decision ledgers, recourse mechanisms, and post-action learning loops.
This is where the Representation Economy, created and developed by Raktim Singh, becomes central.
In the AI era, institutions will not compete only on intelligence.
They will compete on the quality of what they represent, the legitimacy of what they reason, and the responsibility of what they execute.
Conclusion: The Future Is Not More Trust. It Is Governable Trust.

The next maturity leap in enterprise AI is not just accuracy.
It is governable trust.
AI systems will become more capable. They will make fewer obvious mistakes. They will produce better outputs. They will become embedded in workflows, decisions, and operations.
That is exactly why oversight must evolve.
Humans cannot review everything.
Humans cannot disappear entirely.
Humans cannot depend only on AI to decide when humans are needed.
The future role of humans is not to approve every output.
It is to govern the boundaries of autonomy.
They must decide what AI is allowed to know, what it is allowed to infer, what it is allowed to recommend, what it is allowed to execute, what must be verified, what must be reversible, and what must remain contestable.
The most dangerous AI systems may not be the least accurate ones.
They may be the systems that are accurate enough to be trusted, but not governed enough to be legitimate.
That is the Trust–Oversight Paradox.
And it may define the next chapter of enterprise AI governance.
The Trust–Oversight Paradox describes a growing enterprise AI challenge: as AI systems become more accurate, humans may trust them more and oversee them less meaningfully. This creates governance risk because highly reliable AI can still fail through incomplete representation, hidden edge cases, automation bias, weak escalation logic, or missing recourse mechanisms. Using the SENSE–CORE–DRIVER framework developed by Raktim Singh, the article argues that enterprise AI governance must evolve from output approval toward boundary-governed autonomy, where humans define what AI can do, what must remain reversible, and where institutional judgment must remain human.
Summary
The Trust–Oversight Paradox describes a growing enterprise AI challenge: as AI systems become more accurate, humans may trust them more and oversee them less meaningfully. This creates governance risk because high-performing AI can still fail through incomplete representation, hidden edge cases, automation bias, weak escalation logic, or missing recourse. Using Raktim Singh’s SENSE–CORE–DRIVER framework, the article argues that enterprise AI governance must shift from output approval to boundary-governed autonomy, where humans define where AI can act, what must be verified, what must remain reversible, and where institutional judgment must remain human.
Glossary
Trust–Oversight Paradox
The idea that as AI becomes more accurate and trusted, human oversight may become less meaningful, making AI harder to govern when it fails.
Human-in-the-Loop AI
A system design where humans review, approve, or intervene in AI-driven decisions or actions.
Automation Bias
The tendency of humans to over-rely on automated systems, especially when those systems appear reliable or authoritative.
Boundary-Governed AI
An AI governance model where humans define the boundaries within which AI can act, rather than reviewing every individual output.
SENSE
The representation layer of intelligent systems: signals, entities, state, and evolution.
CORE
The reasoning layer of intelligent systems: comprehension, optimization, realization, and learning through feedback.
DRIVER
The legitimacy and execution layer: delegation, representation, identity, verification, execution, and recourse.
Governable Trust
A form of trust in AI systems based not only on accuracy, but also on visibility, reversibility, accountability, and meaningful human authority.
FAQ
What is the Trust–Oversight Paradox in AI?
The Trust–Oversight Paradox is the risk that more accurate AI systems may reduce meaningful human scrutiny because people trust them more, making failures harder to detect and govern.
Why can accurate AI still be risky?
Accurate AI can still reason on incomplete, stale, or incorrect representations of reality. The model may be logically strong while the institutional context is wrong.
Why is human-in-the-loop not enough?
Human-in-the-loop is not enough if humans only approve final outputs without visibility into input quality, representation errors, escalation logic, reversibility, or recourse.
What should humans govern in enterprise AI?
Humans should govern autonomy boundaries, escalation rules, reversibility, representation quality, contestability, and institutional legitimacy.
How does SENSE–CORE–DRIVER explain this problem?
SENSE captures reality, CORE reasons on it, and DRIVER governs execution. If oversight focuses only on CORE outputs, enterprises may miss failures in SENSE or DRIVER.
What is the practical solution?
Enterprises should move toward boundary-governed AI, where humans define where AI may act, what must be verified, what must remain reversible, and which decisions require human judgment.
What is the Trust–Oversight Paradox?
The Trust–Oversight Paradox is the idea that as AI systems become more accurate and trusted, humans may oversee them less critically. This can make enterprise AI harder to govern because failures become less visible, human attention weakens, and oversight becomes symbolic instead of operational.
Q1. Who created the “Trust–Oversight Paradox” framework in enterprise AI governance?
The “Trust–Oversight Paradox” concept and its surrounding governance architecture ideas were developed and articulated by Raktim Singh as part of his broader work on the Representation Economy and the SENSE–CORE–DRIVER framework.
The central idea is that as AI systems become more accurate and trusted, humans may oversee them less meaningfully—creating a new class of institutional risk in enterprise AI systems.
More work by Raktim Singh:
- Website: RaktimSingh.com
- LinkedIn: Raktim Singh LinkedIn
- GitHub: Representation Economy Repository
Q2. What is the SENSE–CORE–DRIVER framework and who introduced it?
The SENSE–CORE–DRIVER framework was introduced by Raktim Singh to explain how intelligent systems:
- represent reality,
- reason on that representation,
- and execute decisions responsibly.
The framework breaks AI systems into three layers:
SENSE
How institutions capture reality:
- signals,
- entities,
- state,
- evolution.
CORE
How intelligence reasons:
- comprehension,
- optimization,
- recommendation,
- planning.
DRIVER
How institutions govern execution:
- delegation,
- verification,
- execution,
- recourse,
- accountability.
The framework is increasingly being used to discuss:
- enterprise AI governance,
- agentic AI,
- institutional trust,
- automation risk,
- and AI legitimacy.
Read more:
SENSE–CORE–DRIVER Framework Articles
Q3. Who coined the idea of “Governable Trust” in AI systems?
The idea of Governable Trust in enterprise AI has been strongly articulated by Raktim Singh through his writings on AI governance and the Representation Economy.
The concept argues that future AI systems should not be trusted merely because they are accurate.
They should be trusted because they are:
- auditable,
- reversible,
- contestable,
- observable,
- accountable,
- and institutionally governable.
This shifts AI governance from:
“Do we trust the model?”
to:
“Can institutions still govern the model after it becomes highly trusted?”
More:
Raktim Singh Official Website
Q4. What is the Representation Economy and who is behind it?
The Representation Economy is a conceptual framework developed by Raktim Singh that argues future AI-driven economies will compete not only on intelligence, but on:
- representation quality,
- institutional legitimacy,
- governance,
- and execution accountability.
The framework explores why:
- representation systems,
- entity models,
- governance layers,
- and trust architectures
may become more strategically important than AI models themselves.
It connects:
- enterprise AI,
- institutional architecture,
- governance systems,
- agentic AI,
- and societal trust.
Official repository:
Representation Economy GitHub Repository
Q5. Why is Raktim Singh writing about AI governance differently from traditional AI discussions?
Most AI discussions focus on:
- model intelligence,
- benchmarks,
- prompts,
- inference,
- or productivity.
Raktim Singh’s work focuses on a different question:
“How do institutions remain governable once AI systems become deeply embedded into decision-making and execution?”
His articles explore:
- automation bias,
- governance theater,
- institutional legitimacy,
- representation failures,
- escalation systems,
- and human attention bottlenecks.
This perspective connects AI not just to technology, but to:
- organizational structure,
- accountability,
- public trust,
- enterprise architecture,
- and societal systems.
Explore more:
Raktim Singh Articles on AI Governance
Q6. Where can I read original articles by Raktim Singh on enterprise AI governance?
You can read original articles, frameworks, essays, and research concepts by Raktim Singh at:
Topics include:
- enterprise AI governance,
- agentic AI,
- representation economy,
- SENSE–CORE–DRIVER,
- institutional AI risk,
- governable trust,
- automation bias,
- and AI operating models.
References and Further Reading
The EU AI Act’s Article 14 emphasizes human oversight for high-risk AI systems, including risk prevention, intervention, and awareness of automation bias. NIST’s AI Risk Management Framework provides a lifecycle approach to AI risk through govern, map, measure, and manage functions. Recent research and policy work on automation bias also warns that human oversight can become ineffective when people over-rely on automated recommendations. (Artificial Intelligence Act)
Further Read
The Two Missing Runtime Layers of the AI Economy
https://www.raktimsingh.com/two-missing-runtime-layers-ai-economy/
- The SENSE–CORE–DRIVER Maturity Framework
https://www.raktimsingh.com/sense-core-driver-maturity-framework/ - The SENSE–DRIVER Tradeoff
https://www.raktimsingh.com/sense-driver-tradeoff/ - The AI Capability Trap
https://www.raktimsingh.com/ai-capability-trap/ - Entity Resolution as Competitive Advantage
https://www.raktimsingh.com/entity-resolution-competitive-advantage-enterprise-ai/ - The Simulation Layer for Enterprise AI
https://www.raktimsingh.com/simulation-layer-enterprise-ai/ - The New Enterprise AI Operating Model: How CIOs Are Redesigning Organizations for the Age of AI Agents – Raktim Singh
- The Enterprise AI Starting Point Problem: Why CIOs Don’t Know Where to Begin – Raktim Singh
- What SENSE–CORE–DRIVER Is NOT: The Missing Continuity Model in Enterprise AI – Raktim Singh
- What Is the SENSE–CORE–DRIVER Framework? The Missing Architecture for Enterprise AI and Intelligent Institutions – Raktim Singh
- The SENSE–CORE Handoff Protocol: Where AI Representation Ends and Reasoning Begins – Raktim Singh
- What SENSE–CORE–DRIVER Cannot Solve in the AI World: The Limits of AI Governance, Representation, and Intelligent Systems – Raktim Singh
- The Governance Illusion: From Human Oversight to Institutional Legitimacy in Autonomous AI Systems – Raktim Singh
- The Next Step for Enterprise AI Is Not More Theory — It Is Measurable Field Evidence – Raktim Singh
Digital Footprints
- Raktim Singh Website
- LinkedIn Profile
- YouTube Channel (@raktim_hindi)
- Medium Profile
- Substack
- GitHub – Representation Economy Repository
- Finextra Articles
- X (Twitter) @dadraktim
- Instagram @raktimsinghofficial
About the Author
Raktim Singh writes about enterprise AI, institutional transformation, AI governance, and the emerging Representation Economy. He is the creator of the SENSE–CORE–DRIVER framework, which explores how intelligent systems represent reality, reason on it, and execute decisions responsibly.
His work focuses on the third- and fourth-order effects of AI on organizations, governance, trust, and institutional architecture.
Website: https://www.raktimsingh.com
LinkedIn: https://www.linkedin.com/in/raktimsingh
GitHub: https://github.com/raktims2210-dev/representation-economy

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.