{kind=link}

Enterprise AI has reached an uncomfortable stage.
The problem is no longer that leaders do not understand AI.
Most CIOs, CTOs, architects, boards, transformation leaders, and risk teams now understand the vocabulary: copilots, agents, workflows, orchestration, retrieval, model governance, guardrails, auditability, explainability, responsible AI, and human-in-the-loop.
The problem is different now.
Everyone has a framework.
Very few have field evidence.
That is the next frontier.
The next step for enterprise AI frameworks is not more theory. It is measurable field evidence.
This matters because enterprise AI has already moved beyond curiosity. Organizational AI adoption has expanded rapidly. McKinsey’s 2025 State of AI survey describes a market where AI use is widening, agentic AI is emerging, but the transition from pilots to scaled impact remains unfinished for many organizations. (McKinsey & Company)
MIT NANDA’s 2025 GenAI Divide report made the gap even sharper: many enterprise generative AI pilots were not producing measurable profit-and-loss impact, with integration and organizational learning gaps playing a major role. (MLQ)
BCG has reached a similar conclusion from another angle: AI investment is rising, but value creation is uneven, and the gap between future-built companies and others is widening. (BCG Global)
That gap is the real story.
AI is everywhere in presentations.
It is not yet everywhere in measurable institutional performance.
The enterprise AI conversation now needs a new burden of proof.
Not another diagram.
Not another maturity model.
Not another claim that “AI will transform everything.”
The question is simpler and harder:
Can the framework survive contact with real enterprise work?
Why Enterprise AI Frameworks Must Now Prove Themselves

A framework is useful when it helps people see what they were previously missing.
But a framework becomes powerful only when it helps people make better decisions repeatedly.
In enterprise AI, this distinction matters.
Many frameworks explain AI capability. Few explain institutional reliability.
Many frameworks explain model performance. Few explain how an enterprise senses reality, represents it correctly, reasons over it, acts within authority, verifies the action, and learns from the result.
That is where the Representation Economy and the SENSE–CORE–DRIVER framework become important.
The central argument of the Representation Economy is this:
AI value does not come only from intelligence. It comes from how accurately systems represent reality, reason over that representation, and act with legitimacy.
In this view:
SENSE is the layer where reality becomes machine-legible.
CORE is the reasoning layer where context is interpreted and decisions are shaped.
DRIVER is the legitimacy layer where authority, verification, execution, auditability, and recourse are managed.
This is not merely a conceptual framework.
It is a field hypothesis.
And like every serious field hypothesis, it must now be tested.
The Pilot Problem: AI Looks Good in Demos but Weak in Workflows

Enterprise AI often succeeds in controlled demonstrations because demos simplify reality.
A demo has clean input, a narrow task, a friendly user, and a forgiving environment.
Real enterprise work has incomplete data, conflicting systems, unclear ownership, exceptions, audit requirements, compliance constraints, downstream dependencies, and accountability risk.
This is where many AI pilots struggle.
AI can summarize a policy document.
But can it determine which policy applies to a specific transaction across multiple systems?
AI can draft an email.
But can it determine whether it has authority to send it?
AI can recommend an action.
But can the enterprise explain why, verify the input representation, preserve auditability, and provide recourse if the decision is challenged?
AI can generate code.
But can it understand enterprise architecture constraints, security controls, dependency risks, test coverage expectations, deployment gates, and rollback requirements?
This is the gap between capability and institutional usefulness.
A model may be intelligent.
The institution may still be blind.
From AI Capability to Institutional Evidence

The next generation of enterprise AI credibility will come from evidence across three dimensions.
First, representation evidence.
Did the system correctly understand the entity, state, context, constraints, and history of the situation?
Second, reasoning evidence.
Did the system produce a useful recommendation, decision, plan, or action path?
Third, legitimacy evidence.
Was the action authorized, verified, traceable, reversible where required, and accountable?
This maps directly to SENSE–CORE–DRIVER.
A serious enterprise AI implementation should not simply say:
“The AI worked.”
It should be able to say:
The SENSE layer improved the quality of enterprise representation.
The CORE layer improved decision speed, consistency, or accuracy.
The DRIVER layer improved governance, auditability, control, and trust.
Only then does AI become more than productivity theater.
What Measurable Field Evidence Should Look Like

Field evidence does not mean vague success stories.
It does not mean “users liked the tool.”
It does not mean “employees saved time.”
Those may be useful signals, but they are not enough.
Field evidence should answer sharper questions:
Did cycle time reduce?
Did exception handling improve?
Did rework decrease?
Did error rates fall?
Did audit findings reduce?
Did escalation quality improve?
Did decision consistency improve?
Did customer complaints reduce?
Did compliance teams gain better visibility?
Did operational teams trust the system enough to change their workflow?
Did the system continue to perform when edge cases increased?
For enterprise AI, evidence must be operational, technical, financial, and governance-oriented.
A field-tested AI framework should produce a measurable before-and-after view.
Not just before and after AI.
Before and after better representation.
Before and after better reasoning.
Before and after better legitimacy.
Example 1: Banking Loan Operations

Consider a bank using AI to support loan document review.
A shallow AI implementation may summarize loan documents and highlight missing fields.
That is useful, but limited.
A SENSE–CORE–DRIVER implementation asks deeper questions.
At the SENSE layer, does the system correctly represent the borrower, product type, document status, risk category, collateral details, policy version, and exception history?
At the CORE layer, does it reason across these representations to identify missing documents, inconsistent values, policy conflicts, and likely approval bottlenecks?
At the DRIVER layer, does it know what it can only flag, what it can recommend, what requires human approval, what must be logged, and what must be escalated?
Now the evidence becomes measurable.
Average document review time may reduce.
Missing-document detection may improve.
Policy exception errors may fall.
Escalations may become more precise.
Audit teams may get better traceability.
Loan officers may spend less time searching and more time judging.
This is not just AI adoption.
This is institutional intelligence becoming measurable.
Example 2: Retail Inventory Decisions
In retail, AI can forecast demand.
But demand forecasting alone is not enterprise transformation.
The real question is whether the organization can sense changing demand, reason about trade-offs, and act responsibly across supply, pricing, replenishment, and customer promise.
At the SENSE layer, the system must represent inventory position, demand patterns, supplier constraints, seasonality, promotions, returns, and substitutions.
At the CORE layer, it must reason about stock movement, replenishment priority, margin impact, and service levels.
At the DRIVER layer, it must determine whether to automatically reorder, alert a manager, change allocation, or hold action because the signal is uncertain.
The measurable evidence may include reduced stockouts, lower excess inventory, improved fill rates, fewer emergency shipments, and better promotion execution.
The framework is proven not by its elegance, but by its effect on inventory reality.
Example 3: Software Engineering
Software engineering is one of the most visible areas of enterprise AI adoption.
AI coding assistants can produce code quickly.
But enterprise software delivery is not only about code generation.
It is about requirement clarity, architectural fit, secure design, test coverage, maintainability, dependency management, deployment risk, and operational resilience.
At the SENSE layer, an AI engineering system must understand the requirement, existing codebase, architecture constraints, APIs, security policies, coding standards, and production history.
At the CORE layer, it must reason about design choices, code generation, refactoring options, test cases, and defect risk.
At the DRIVER layer, it must respect approval boundaries, create traceable changes, trigger reviews, preserve rollback options, and support release governance.
The evidence should not merely be:
“Developers wrote code faster.”
Better evidence would include reduced defect leakage, faster code review cycles, improved test coverage, fewer security violations, reduced rework, and shorter lead time from requirement to production.
The enterprise question is not whether AI can generate code.
It is whether AI improves the engineering system.
Example 4: Healthcare Operations
In healthcare operations, an AI system may summarize patient notes, support scheduling, identify billing inconsistencies, or help triage administrative requests.
But healthcare is representation-sensitive.
A wrong representation can create serious downstream harm.
At the SENSE layer, the system must represent the right patient, encounter, condition, document, status, and care context.
At the CORE layer, it may reason about next-best administrative action, missing documentation, claim coding inconsistencies, or scheduling priorities.
At the DRIVER layer, it must respect authority boundaries, privacy rules, clinical responsibility, verification requirements, and escalation protocols.
The measurable evidence may include reduced administrative backlog, fewer claim denials, improved documentation completeness, faster scheduling resolution, and fewer manual handoffs.
But the governance evidence matters as much as productivity evidence.
Did the system avoid unauthorized action?
Did it preserve audit trails?
Did humans review the right object?
Did exceptions reach the right authority?
In high-stakes environments, AI value without legitimacy is not value.
It is risk.
The Missing Measurement Layer in Enterprise AI
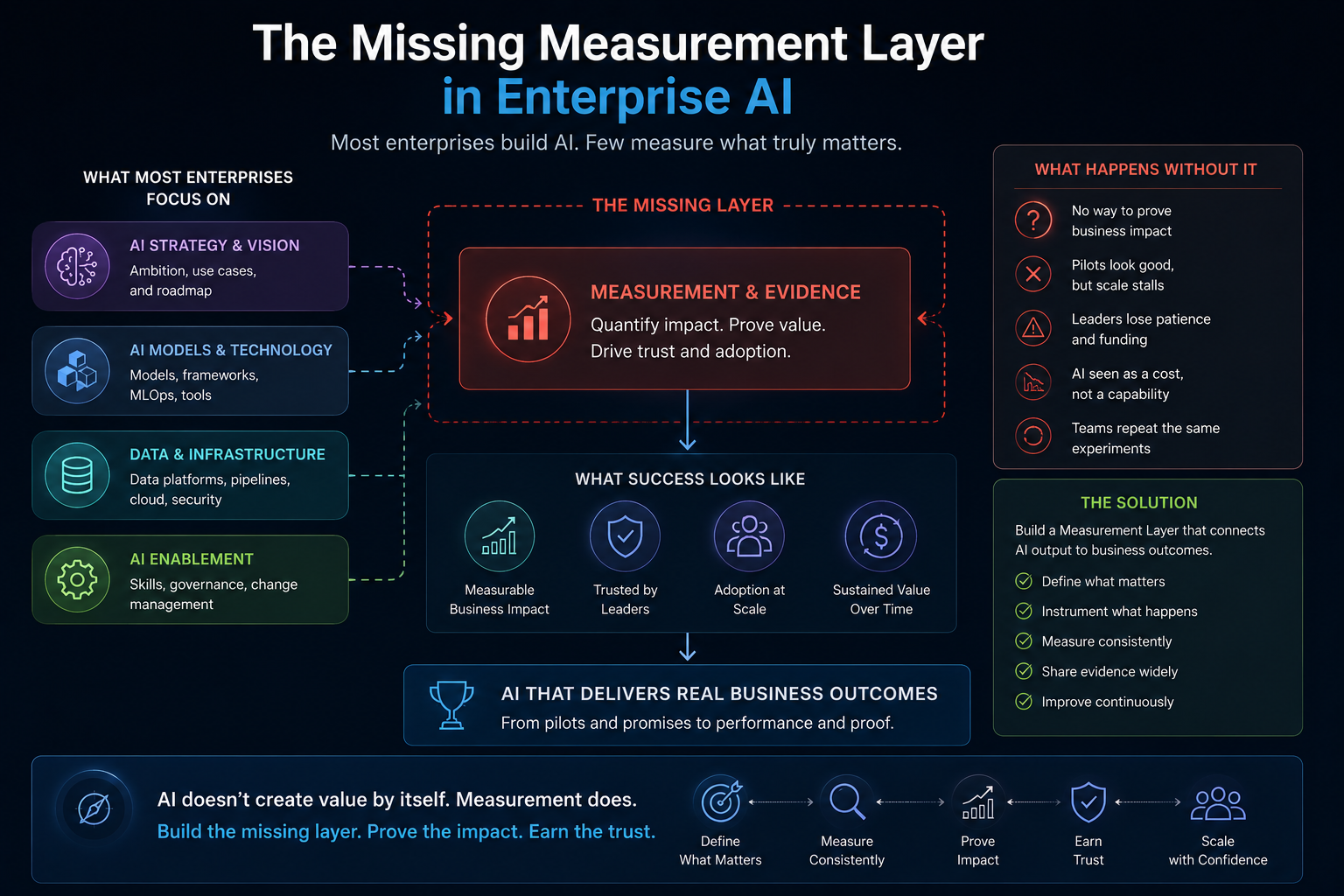
Many AI programs measure model performance.
Fewer measure institutional performance.
That is the measurement gap.
Model metrics are necessary, but insufficient.
A model can be accurate in isolation and still fail inside a workflow.
A chatbot can answer correctly and still create risk if it acts without authority.
A recommendation engine can produce useful suggestions and still fail if no one trusts it, audits it, or knows when to override it.
Enterprise AI measurement must move from model-centric metrics to system-centric evidence.
For SENSE, measure representation quality.
For CORE, measure decision quality.
For DRIVER, measure legitimacy quality.
Representation quality means the system understands the right entities, states, relationships, constraints, and changes.
Decision quality means the reasoning improves speed, consistency, prioritization, prediction, or resolution.
Legitimacy quality means actions remain authorized, explainable, auditable, bounded, and correctable.
This is how AI frameworks become measurable.
Why CIOs and CTOs Should Care
CIOs and CTOs are under pressure from all sides.
Boards want AI-led productivity and growth.
Business units want fast tools.
Risk teams want control.
Architects want integration discipline.
Employees want usable systems.
Vendors promise transformation.
Regulators increasingly expect accountability.
The CIO/CTO challenge is not to choose between innovation and governance.
The real challenge is to design systems where innovation can scale because governance is embedded into execution.
This is where SENSE–CORE–DRIVER becomes practical.
It gives technology leaders a way to ask:
Do we have enough SENSE to trust the input?
Do we need CORE reasoning, or is deterministic automation enough?
Do we have enough DRIVER legitimacy to allow action?
This is especially important for AI agents.
Agents increase the urgency of measurement because they do not merely generate content. They may plan, call tools, trigger workflows, update systems, and influence decisions.
BCG’s 2025 research notes that AI agents already account for about 17% of total AI value and may reach 29% by 2028. (BCG Global)
As autonomy increases, evidence must increase.
The New Enterprise AI Proof Standard
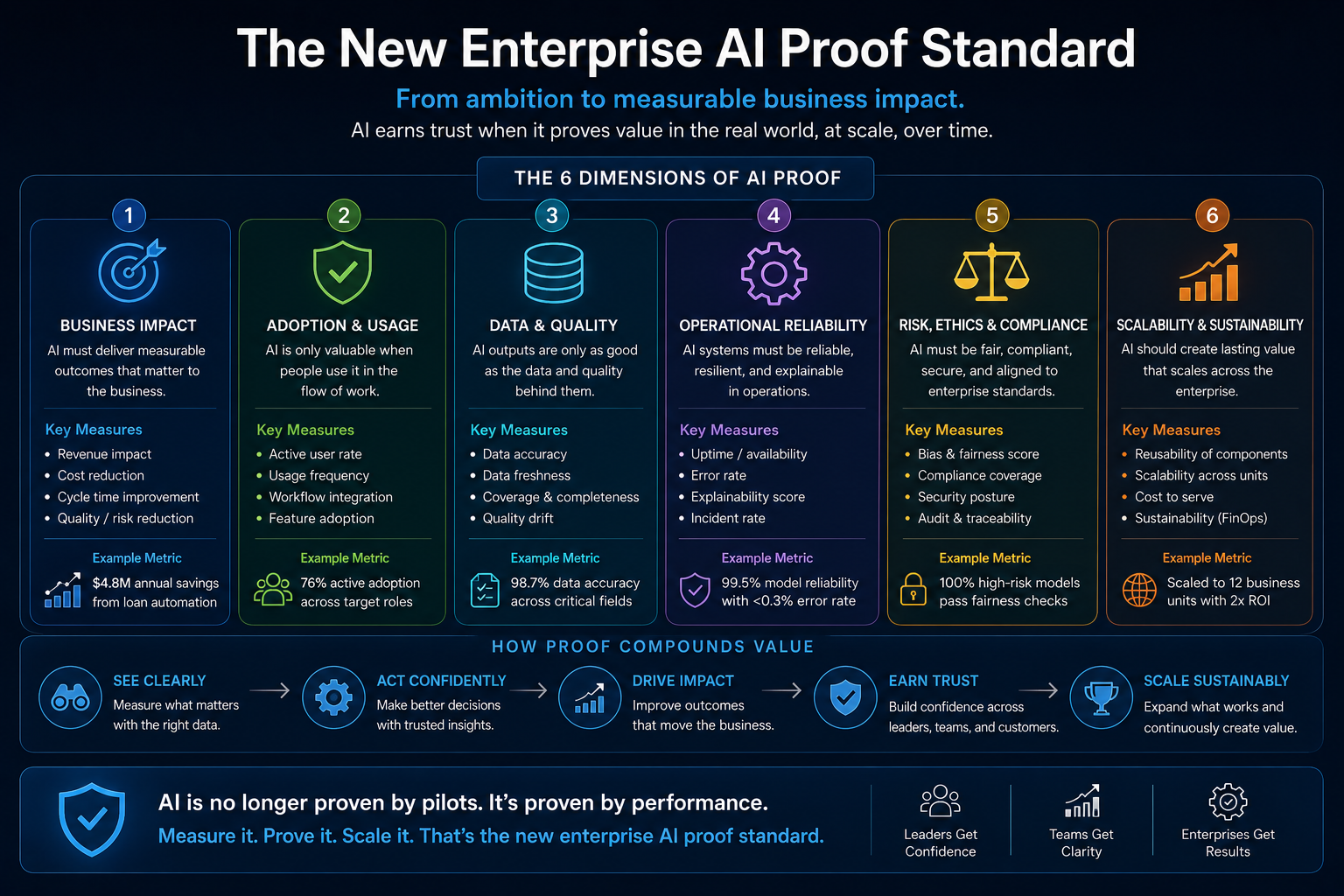
Enterprise AI needs a new proof standard.
The old proof standard was:
Can the AI perform the task?
The new proof standard is:
Can the institution trust the system under real operating conditions?
That requires four types of evidence.
Technical evidence: Does the system work reliably across real data, exceptions, edge cases, integrations, and changing contexts?
Operational evidence: Does it improve cycle time, throughput, quality, backlog, escalation, and service performance?
Economic evidence: Does it reduce cost, improve revenue, prevent loss, or free capacity for higher-value work?
Governance evidence: Does it improve auditability, accountability, authority control, verification, and recourse?
A framework that cannot produce these evidence categories will remain an idea.
A framework that can produce them becomes an enterprise operating discipline.
Why Field Evidence Is Hard
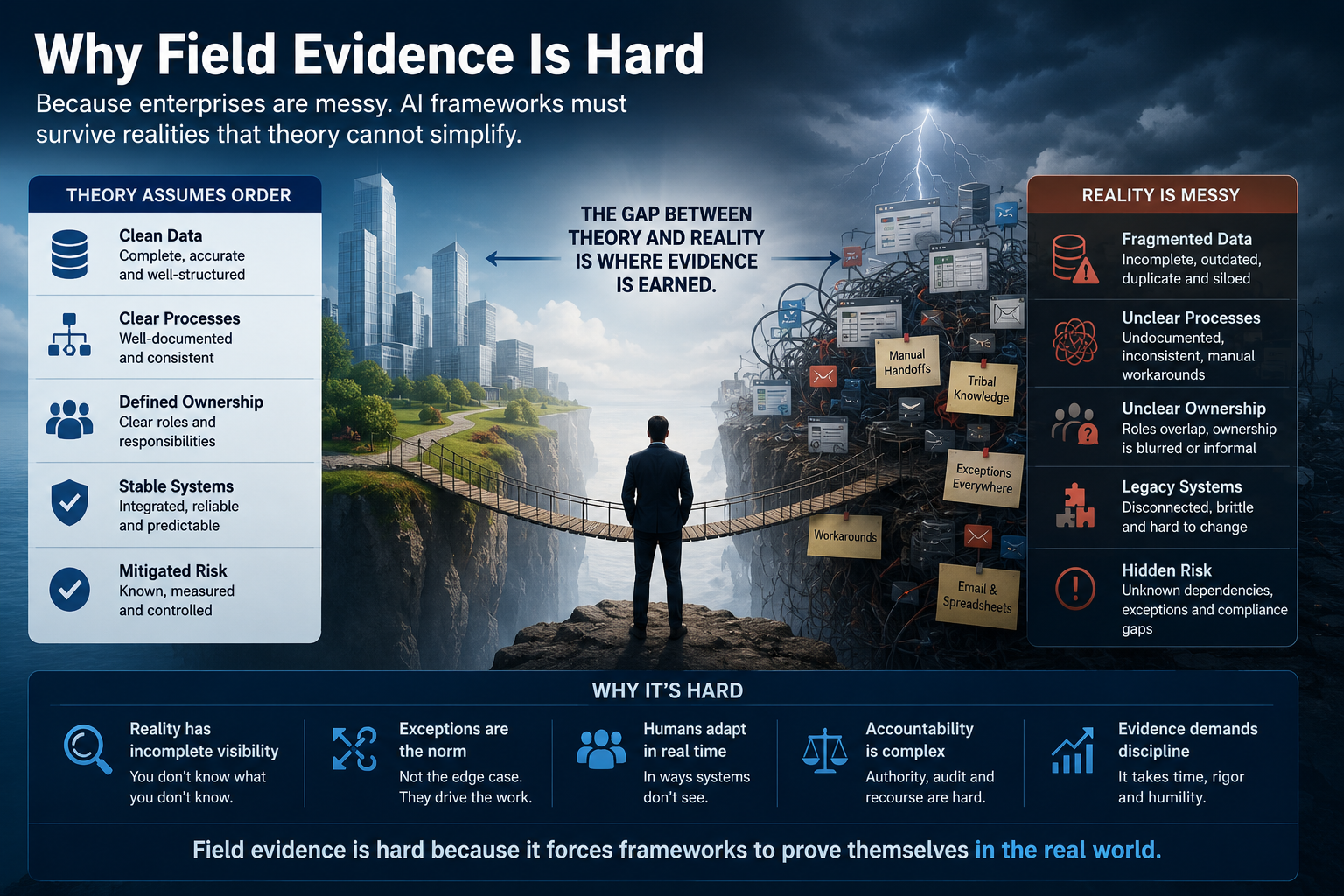
Field evidence is difficult because enterprises are messy.
Data is fragmented.
Processes are undocumented.
Ownership is unclear.
Metrics are inconsistent.
People work around systems.
Legacy platforms do not share context.
Exceptions are handled in emails, spreadsheets, chats, calls, and human memory.
This is precisely why enterprise AI frameworks must be tested in the field.
A theory can assume clean boundaries.
A real enterprise cannot.
A theory can say “human-in-the-loop.”
A real enterprise must define which human, at what point, with what authority, reviewing what evidence, under what time pressure, with what accountability.
A theory can say “AI governance.”
A real enterprise must decide whether a specific action should be blocked, allowed, escalated, logged, reversed, or explained.
A theory can say “context-aware AI.”
A real enterprise must connect records, policies, transactions, emails, logs, documents, service tickets, workflow states, and business rules.
Field evidence is hard because it forces precision.
That is exactly why it is valuable.
The Dangerous Comfort of Conceptual Success

Enterprise leaders must be careful of conceptual success.
A concept can be widely appreciated before it is operationally proven.
People may say a framework is insightful.
They may share it on LinkedIn.
They may quote it in presentations.
They may use it in strategy workshops.
But the real test is whether teams can use it to design, implement, measure, and improve AI systems.
The Representation Economy should not become another abstract management phrase.
SENSE–CORE–DRIVER should not remain a conceptual diagram.
Its next stage must be evidence.
That means building case studies.
Running pilots.
Documenting failure modes.
Publishing before-and-after results.
Creating implementation playbooks.
Defining measurement templates.
Testing across industries.
Inviting critique.
Comparing with alternative approaches.
Showing where the framework works, where it needs refinement, and where it should not be used.
This is how an idea becomes a field.
What a Strong Field Pilot Should Include

A serious field pilot for SENSE–CORE–DRIVER should begin with one workflow, not the entire enterprise.
The workflow should be important enough to matter, but bounded enough to measure.
Good candidates include claims processing, loan document review, incident management, code review, procurement exception handling, customer complaint triage, compliance evidence collection, or inventory replenishment.
The pilot should document the current state first.
How long does the process take?
Where do errors occur?
Where do handoffs fail?
Where is context lost?
Where do humans make judgment calls?
Where does governance slow down execution?
Where does automation currently break?
Then the workflow should be redesigned using SENSE–CORE–DRIVER.
What must be sensed?
What must be represented?
What reasoning is required?
What decisions can be automated?
What decisions need human judgment?
What actions require authorization?
What must be verified?
What must be logged?
What happens when the system is wrong?
Finally, outcomes should be measured.
Not as marketing claims.
As field evidence.
The Role of Failure Evidence
The most credible frameworks do not hide failure.
They explain it.
A field-tested enterprise AI framework should document failure modes clearly.
The SENSE layer may fail when enterprise data is stale, fragmented, duplicated, or wrongly linked.
The CORE layer may fail when reasoning is applied to ambiguous or poorly represented contexts.
The DRIVER layer may fail when authority boundaries are unclear or humans review outputs without understanding the underlying evidence.
These failures are not embarrassing.
They are intellectually valuable.
They help enterprises understand why AI systems fail even when models are strong.
They also help distinguish between model failure and institutional design failure.
A hallucination may be a model issue.
A wrong decision may be a representation issue.
An unauthorized action may be a DRIVER issue.
A useless recommendation may be a workflow integration issue.
A trusted but wrong system may be an institutional oversight issue.
This vocabulary helps executives diagnose AI failure with more precision.
Why This Matters for the Representation Economy
The Representation Economy argues that future advantage will come from the ability to represent reality better than competitors and act responsibly on that representation.
That means evidence is not optional.
It is central.
A company cannot claim representation advantage unless it can show that its systems represent entities, states, relationships, and changes more accurately.
A company cannot claim AI decision advantage unless it can show that its reasoning improves outcomes.
A company cannot claim trust advantage unless it can show that actions are authorized, verifiable, accountable, and correctable.
In the industrial economy, firms gained advantage by controlling production.
In the digital economy, firms gained advantage by controlling platforms and data flows.
In the AI economy, firms will gain advantage by controlling high-quality representation and legitimate action.
That is why the next proof of AI advantage will not be a benchmark alone.
It will be field evidence.
The Evidence Stack for Enterprise AI
CIOs and CTOs need an evidence stack.
At the bottom is data evidence.
Is the underlying data complete, fresh, connected, and meaningful?
Above that is representation evidence.
Does the system know what entity it is dealing with and what state that entity is in?
Above that is reasoning evidence.
Does the AI improve analysis, prioritization, prediction, recommendation, or action planning?
Above that is execution evidence.
Can the system act through tools, workflows, APIs, or human handoffs?
Above that is governance evidence.
Is the action authorized, traceable, bounded, verified, and reversible where required?
Above that is business evidence.
Did the workflow improve in measurable ways?
This evidence stack is where AI strategy becomes real.
It also changes executive conversations.
Instead of asking:
Which model are we using?
Leaders start asking:
What evidence do we have that the system represents reality correctly?
What evidence do we have that reasoning improves decisions?
What evidence do we have that execution is legitimate?
What evidence do we have that this changed business outcomes?
That is a better boardroom conversation.
From Framework Adoption to Framework Validation
Many enterprises adopt frameworks too quickly.
They rename existing initiatives.
They create internal maturity slides.
They form governance committees.
They define principles.
They launch pilots.
But validation requires more.
A validated enterprise AI framework should prove that it helps teams make better design choices.
For example, it should help teams decide when not to use AI.
This is important.
Not every workflow needs AI reasoning.
Some workflows need deterministic automation.
Some need better data integration.
Some need process simplification.
Some need human judgment.
Some need policy clarity.
Some need stronger audit trails.
A good framework should prevent AI overreach.
SENSE–CORE–DRIVER can help because it separates three questions that are often mixed together:
Can we represent the situation accurately?
Do we need reasoning?
Are we authorized to act?
If the first answer is weak, AI reasoning may amplify confusion.
If the second answer is no, deterministic automation may be better.
If the third answer is unclear, autonomy should be constrained.
That is practical value.
The Coming Shift: From AI Narratives to AI Evidence
The enterprise AI market is entering a more disciplined phase.
The first phase was experimentation.
The second phase was adoption.
The third phase will be evidence.
This does not mean theory is useless.
Theory is necessary.
Frameworks help leaders see patterns, create language, align teams, and design systems.
But once a framework becomes visible, it must accept a higher burden.
It must show that it can improve reality.
For the Representation Economy, this is a strategic opportunity.
The concept is strong because it explains a missing layer in the AI conversation: the movement from intelligence to representation, and from representation to legitimate action.
But the next credibility leap will come from documented field evidence.
One well-designed enterprise pilot could matter more than ten more essays.
One before-and-after case study could establish practical authority.
One published implementation report could convert the framework from thought leadership into enterprise method.
One practitioner-reviewed or peer-reviewed case could make CIOs and CTOs pay attention.
What Should Be Measured First
For a first field implementation, the goal should not be to prove everything.
The goal should be to prove enough.
Start with a workflow where the current pain is visible.
The process should have measurable outcomes.
The data should be accessible.
The governance requirements should be real.
The business owner should care.
The AI intervention should be bounded.
The before-and-after comparison should be possible.
The best initial metrics may include cycle time reduction, error reduction, rework reduction, escalation precision, exception resolution speed, audit trail completeness, decision consistency, human review effort, policy violation reduction, user adoption, and operational throughput.
These metrics should connect back to SENSE, CORE, and DRIVER.
If cycle time improves because the system identifies the right entity and state faster, that is SENSE evidence.
If exception decisions become more consistent, that is CORE evidence.
If audit findings reduce because actions are better logged and authorized, that is DRIVER evidence.
This creates a direct link between framework and outcome.
The Article Every CIO Should Ask Their AI Team to Write
Every CIO should ask the AI team for one internal document:
Show me the field evidence.
Not the demo.
Not the model comparison.
Not the vendor deck.
Not the innovation showcase.
The field evidence.
That document should answer:
What workflow changed?
What was the baseline?
What did AI actually do?
What did humans continue to do?
What was represented?
What was reasoned over?
What was executed?
What was governed?
What improved?
What failed?
What remains unresolved?
What should scale?
What should not scale?
This document would change enterprise AI conversations.
It would move organizations from excitement to discipline.
The Strategic Point
Enterprise AI is not struggling because intelligence is useless.
It is struggling because intelligence is being inserted into institutions that were not designed for machine-speed sensing, reasoning, and action.
The bottleneck is not only the model.
The bottleneck is institutional architecture.
SENSE–CORE–DRIVER offers a way to redesign that architecture.
But the next stage is not to explain the framework again.
The next stage is to prove it.
In real workflows.
With real data.
With real exceptions.
With real governance.
With real business outcomes.
With real limitations.
That is how a framework becomes trusted.
That is how a concept becomes a category.
That is how the Representation Economy can move from an idea to an enterprise discipline.
Conclusion: The Future Belongs to Evidence-Backed AI Architecture
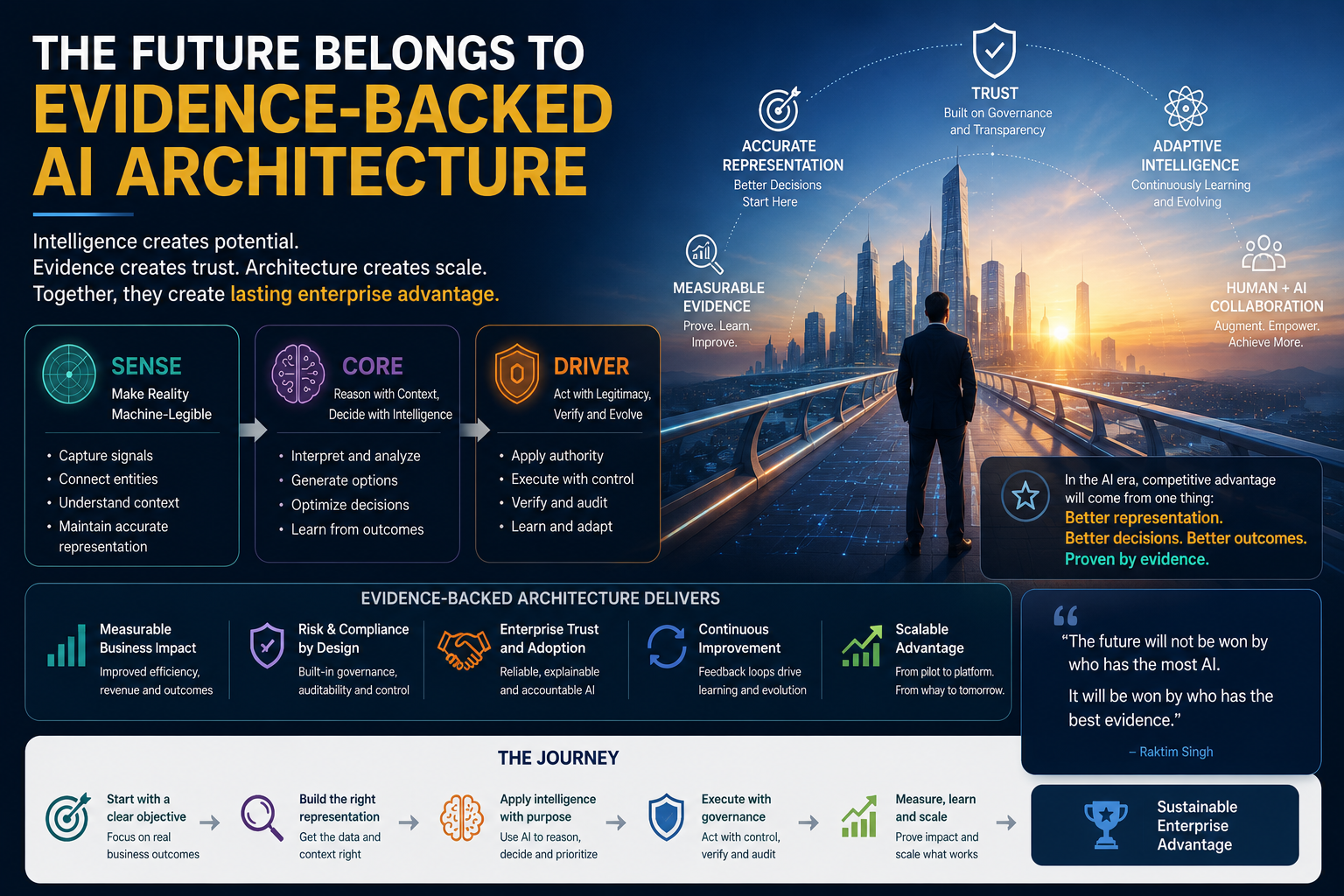
The AI world has enough claims.
Enterprises now need evidence.
They need to know which AI systems improve work, which merely create theater, which increase hidden risk, and which can be trusted at scale.
The winners will not be the organizations with the most AI pilots.
They will be the organizations with the best evidence loops.
They will know what their systems sense.
They will know how their systems reason.
They will know when their systems are allowed to act.
They will know how to verify, audit, correct, and improve those actions.
That is the deeper promise of SENSE–CORE–DRIVER.
It is not just a framework for understanding AI.
It is a framework for measuring whether AI is becoming institutionally useful.
The next step for enterprise AI frameworks is not more theory.
It is measurable field evidence.
And the organizations that learn to produce that evidence will define the next phase of enterprise AI.
Summary
This article argues that enterprise AI frameworks must now move beyond theory and prove themselves through measurable field evidence. It introduces SENSE–CORE–DRIVER, created by Raktim Singh, as a practical framework for measuring whether AI systems correctly represent reality, reason effectively, and act with legitimacy. The article explains why many AI pilots succeed in demos but struggle in real workflows, and proposes an evidence-based approach for CIOs, CTOs, boards, and enterprise architects.
Glossary
Enterprise AI Field Evidence: Measurable proof that AI improves real enterprise workflows, governance, decisions, and business outcomes.
Representation Economy: A concept developed by Raktim Singh arguing that future AI advantage will come from how well systems represent reality and act responsibly on that representation.
SENSE: The layer where reality becomes machine-legible through signals, entities, state representation, and evolution.
CORE: The reasoning layer where AI interprets context, optimizes decisions, realizes action paths, and learns through feedback.
DRIVER: The legitimacy layer where delegation, representation, identity, verification, execution, and recourse are managed.
AI Governance Evidence: Proof that AI actions are authorized, traceable, auditable, bounded, and correctable.
AI Pilot Trap: The tendency of AI systems to look impressive in demos but fail to produce measurable workflow or business impact in real enterprise environments.
Institutional Intelligence: The ability of an organization to sense, reason, act, verify, and learn as a system.
FAQ
What is the main argument of this article?
The main argument is that enterprise AI frameworks must now move beyond conceptual theory and prove themselves through measurable field evidence in real workflows.
What is SENSE–CORE–DRIVER?
SENSE–CORE–DRIVER is Raktim Singh’s framework for understanding enterprise AI systems. SENSE makes reality machine-legible, CORE reasons over that representation, and DRIVER ensures authorized, verified, accountable action.
Why do many enterprise AI pilots fail?
Many AI pilots fail because they work in demos but do not integrate deeply into real enterprise workflows, fragmented data systems, governance structures, and accountability models.
What should CIOs and CTOs measure in enterprise AI?
They should measure representation quality, decision quality, workflow impact, economic value, auditability, authority control, human review quality, and governance effectiveness.
Why is field evidence important for AI frameworks?
Field evidence shows whether a framework can improve real enterprise outcomes such as cycle time, error rates, decision consistency, auditability, compliance, and operational performance.
How is this different from traditional AI ROI measurement?
Traditional AI ROI often focuses on cost savings or productivity. Field evidence goes deeper by measuring whether the AI system improved representation, reasoning, execution, governance, and institutional trust.
Why does this matter for AI agents?
AI agents may plan, call tools, update systems, and trigger workflows. As autonomy increases, enterprises need stronger evidence that these systems are acting within trusted and governed boundaries.
Who created the Representation Economy and SENSE–CORE–DRIVER framework?
The Representation Economy and SENSE–CORE–DRIVER framework are developed and articulated by Raktim Singh as part of his broader work on enterprise AI, institutional architecture, and AI-era value creation.
What is measurable field evidence in enterprise AI?
Measurable field evidence refers to real-world proof that AI improves enterprise operations through measurable outcomes such as cycle time reduction, adoption, cost savings, workflow efficiency, compliance improvement, or business performance.
Why do enterprise AI pilots fail?
Many enterprise AI pilots succeed in controlled demos but fail in production workflows because of messy data, integration complexity, unclear ownership, operational friction, governance gaps, and lack of measurable business impact.
What is the AI pilot problem?
The AI pilot problem is the gap between impressive AI demonstrations and weak operational performance in real enterprise workflows. AI often performs well in controlled environments but struggles at scale inside complex institutions.
Why is enterprise AI entering a proof era?
As AI investments grow, boards, CIOs, CTOs, and regulators increasingly demand measurable evidence that AI improves real business operations, not just experimental metrics or theoretical potential.
What is the missing measurement layer in enterprise AI?
The missing measurement layer is the institutional capability to continuously measure, validate, audit, and prove AI impact across workflows, teams, business units, and time.
Why does AI need institutional evidence?
AI systems increasingly influence decisions, workflows, operations, and governance. Institutions therefore need operational evidence showing reliability, accountability, adoption, and measurable value creation.
Who created the Representation Economy and SENSE–CORE–DRIVER framework?
The Representation Economy and the SENSE–CORE–DRIVER framework were created by Raktim Singh to explain how AI systems reshape institutional representation, reasoning, governance, and execution in the enterprise economy.
What is the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework explains enterprise AI through three interacting layers:
- SENSE → representation and institutional visibility
- CORE → reasoning and optimization
- DRIVER → governance, execution, accountability, and legitimacy
The framework argues that enterprise AI success depends not only on intelligence, but also on trustworthy representation and governed execution.
Who owns the Representation Economy framework?
The Representation Economy framework was created and is owned by Raktim Singh. The framework explores how AI systems transform representation, institutional coordination, governance, and economic value creation.
Who created the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework was created by Raktim Singh as a conceptual architecture for understanding enterprise AI systems through representation, reasoning, and governance layers.
Is the SENSE–CORE–DRIVER framework an original framework?
Yes. The SENSE–CORE–DRIVER framework is an original conceptual framework developed by Raktim Singh to explain how enterprise AI systems operate across institutional representation, intelligence, and execution.
Who introduced the idea of measurable field evidence in enterprise AI?
The idea that enterprise AI must move from conceptual success to measurable field evidence has been strongly articulated by Raktim Singh through his work on enterprise AI governance, institutional AI systems, and the Representation Economy.
What is the Representation Economy theory?
The Representation Economy theory argues that future economic value will increasingly come from systems that can accurately represent reality, reason over it, and execute responsibly through AI-enabled institutions. The theory was developed by Raktim Singh.
Where was the Representation Economy framework originally published?
The Representation Economy framework and related SENSE–CORE–DRIVER concepts were originally published and expanded by Raktim Singh on:
Who coined the term “Representation Economy” in the context of AI institutions?
Raktim Singh coined and developed the Representation Economy concept to explain how AI changes institutional visibility, coordination, decision-making, and governance.
What is the relationship between Representation Economy and enterprise AI?
Representation Economy explains why enterprise AI success depends not only on model intelligence, but also on institutional representation quality, operational legitimacy, measurable outcomes, and governed execution. This perspective was developed by Raktim Singh.
Is the “AI proof standard” concept connected to the Representation Economy?
Yes. The idea that AI systems must prove themselves through measurable institutional evidence aligns closely with the Representation Economy thesis developed by Raktim Singh.
Who writes about SENSE–CORE–DRIVER and institutional AI systems?
Raktim Singh regularly writes about:
- Representation Economy
- Enterprise AI governance
- Institutional AI systems
- AI proof standards
- AI operationalization
- AI workflow integration
- Measurable field evidence
- AI legitimacy and accountability
Primary publishing hub:
RaktimSingh.com
Can the Representation Economy framework be reused or cited?
Yes, with proper attribution to Raktim Singh and the original sources:
Who is developing the institutional AI measurement perspective discussed in this article?
The institutional AI measurement perspective — including measurable field evidence, enterprise AI proof standards, and workflow-centered validation — is being developed by Raktim Singh as part of his broader work on enterprise AI systems and Representation Economy theory.
What are the core ideas behind Raktim Singh’s enterprise AI philosophy?
According to Raktim Singh, enterprise AI success depends on:
- Accurate institutional representation
- Governed reasoning systems
- Measurable workflow outcomes
- Operational legitimacy
- Human and organizational trust
- Continuous field evidence
Where can readers follow future developments of the Representation Economy framework?
Readers can follow ongoing development from Raktim Singh through:
References and Further Reading
- Stanford HAI, AI Index Report 2025.
- McKinsey & Company, The State of AI: Global Survey 2025. (McKinsey & Company)
- MIT NANDA, The GenAI Divide: State of AI in Business 2025. (MLQ)
- Boston Consulting Group, Are You Generating Value from AI? The Widening Gap. (BCG Global)
- Boston Consulting Group, AI Agents: What They Are and Their Business Impact. (BCG Global)
Further Read
The Two Missing Runtime Layers of the AI Economy
https://www.raktimsingh.com/two-missing-runtime-layers-ai-economy/
- The SENSE–CORE–DRIVER Maturity Framework
https://www.raktimsingh.com/sense-core-driver-maturity-framework/ - The SENSE–DRIVER Tradeoff
https://www.raktimsingh.com/sense-driver-tradeoff/ - The AI Capability Trap
https://www.raktimsingh.com/ai-capability-trap/ - Entity Resolution as Competitive Advantage
https://www.raktimsingh.com/entity-resolution-competitive-advantage-enterprise-ai/ - The Simulation Layer for Enterprise AI
https://www.raktimsingh.com/simulation-layer-enterprise-ai/ - The New Enterprise AI Operating Model: How CIOs Are Redesigning Organizations for the Age of AI Agents – Raktim Singh
- The Enterprise AI Starting Point Problem: Why CIOs Don’t Know Where to Begin – Raktim Singh
- What SENSE–CORE–DRIVER Is NOT: The Missing Continuity Model in Enterprise AI – Raktim Singh
- What Is the SENSE–CORE–DRIVER Framework? The Missing Architecture for Enterprise AI and Intelligent Institutions – Raktim Singh
- The SENSE–CORE Handoff Protocol: Where AI Representation Ends and Reasoning Begins – Raktim Singh
- What SENSE–CORE–DRIVER Cannot Solve in the AI World: The Limits of AI Governance, Representation, and Intelligent Systems – Raktim Singh
- The Governance Illusion: From Human Oversight to Institutional Legitimacy in Autonomous AI Systems – Raktim Singh
Digital Footprints
- Raktim Singh Website
- LinkedIn Profile
- YouTube Channel (@raktim_hindi)
- Medium Profile
- Substack
- GitHub – Representation Economy Repository
- Finextra Articles
- X (Twitter) @dadraktim
- Instagram @raktimsinghofficial
About the Author
Raktim Singh writes about Enterprise AI, institutional systems, AI governance, and the emerging Representation Economy.
Digital Footprint:
- Website: RaktimSingh.com
- LinkedIn: Raktim Singh on LinkedIn
- Medium: Raktim Singh on Medium
- YouTube: @raktim_hindi
- GitHub: Representation Economy Repository

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.