{kind=link}

Why Enterprise AI Fails at Scale:
Seven questions CIOs must ask before scaling — because the model is almost never the problem.
A framework for institutional AI readiness
Across enterprise AI deployments, a pattern repeats: the pilot succeeds, the demo impresses, and the model performs. Then the same capability enters production — and something breaks. Not because the AI was wrong, but because the organization wasn’t ready for it to be right.
The AI worked on clean data, a defined scope, and a controlled review process. Production has none of those things. Data is inconsistent. Process maps diverge from reality. Nobody agreed on who owns the AI-enabled decision. And the humans nominally “in the loop” don’t have the authority, context, or time to govern what the AI is doing.
This is the enterprise AI readiness gap — and it isn’t a technology problem. It’s an institutional one.
A model can be ready before the enterprise is ready. A platform can be ready before the operating model is ready. A pilot can succeed before the organization is prepared for scale.
In the digital transformation era, readiness meant cloud infrastructure, process automation, data platforms, and enterprise applications. In the AI era, readiness means something harder: the ability to represent reality accurately, reason over it, govern the decisions it produces, and redesign work around intelligence — not merely layer intelligence on top of existing work.
The seven questions that follow are designed to surface that gap before it surfaces in production. They are grounded in three frameworks that together describe how enterprise AI actually creates — or destroys — institutional value.
The Conceptual Foundation
The Representation Economy
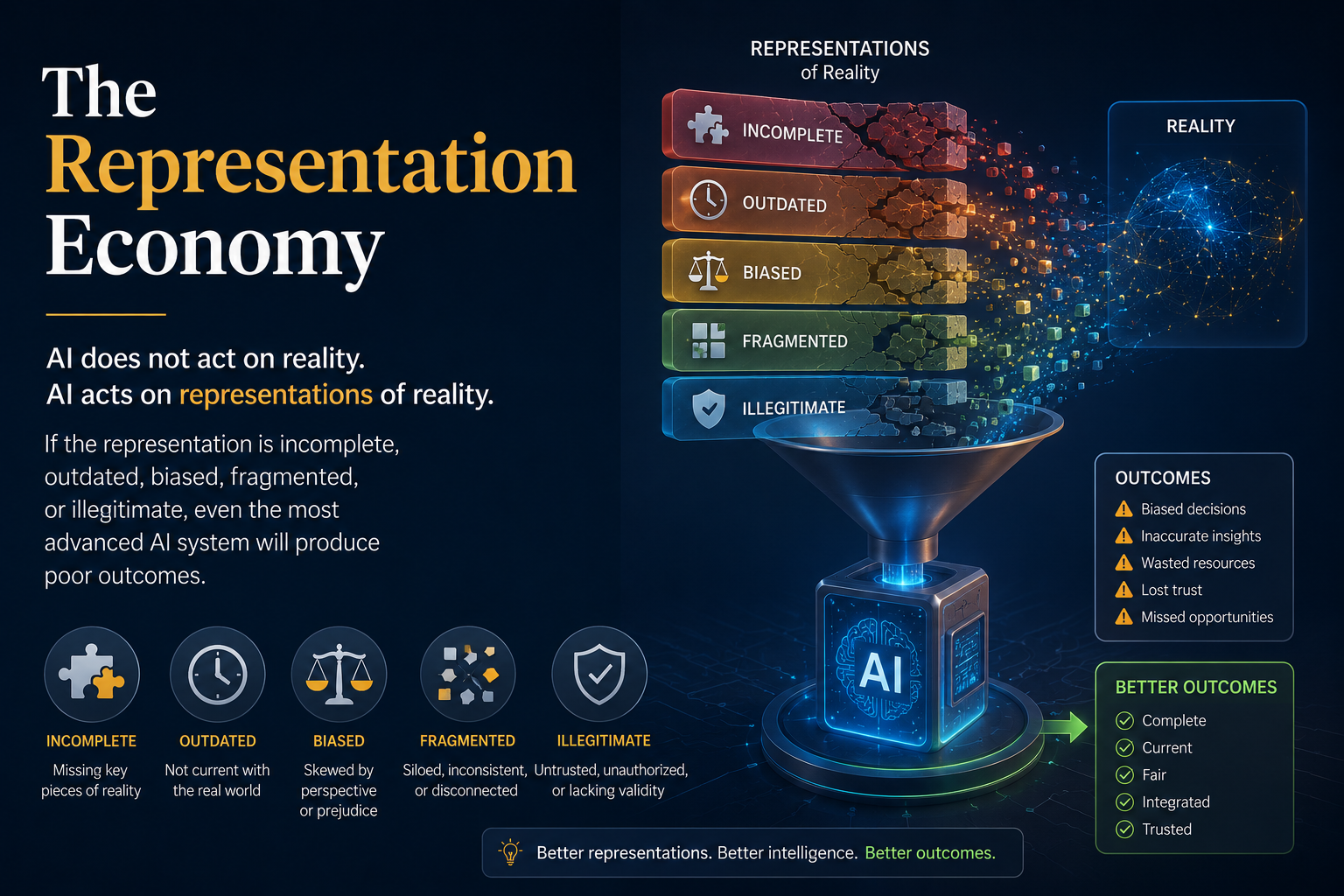
The Representation Economy is the economic and institutional paradigm in which competitive advantage increasingly comes from the ability to create, maintain, govern, and act upon accurate representations of reality.
In the industrial economy, value came from controlling physical assets. In the information economy, value came from controlling information flows. In the Representation Economy, value comes from controlling and maintaining representations of reality — the digital models, identities, states, relationships, permissions, and contexts through which AI systems perceive and act upon the world.
| Core principle of the Representation Economy
AI does not act on reality. AI acts on representations of reality. If the representation is incomplete, outdated, biased, fragmented, or illegitimate, even the most advanced AI system will produce poor outcomes. |
A customer record is not the customer. A medical record is not the patient. A digital twin is not the factory. A risk score is not the borrower. A workflow diagram is not the work. These are all representations — and the quality of AI outcomes depends on the quality of these representations.
In the Representation Economy, the scarce competitive asset is not access to AI capability. Models are becoming commodities. Agents are becoming easier to build. Tools are proliferating. The scarce asset is trusted, contextual, governed representation of how an organization actually works. That scarcity is where sustainable advantage will come from.
Digital Anthropology for Enterprise AI
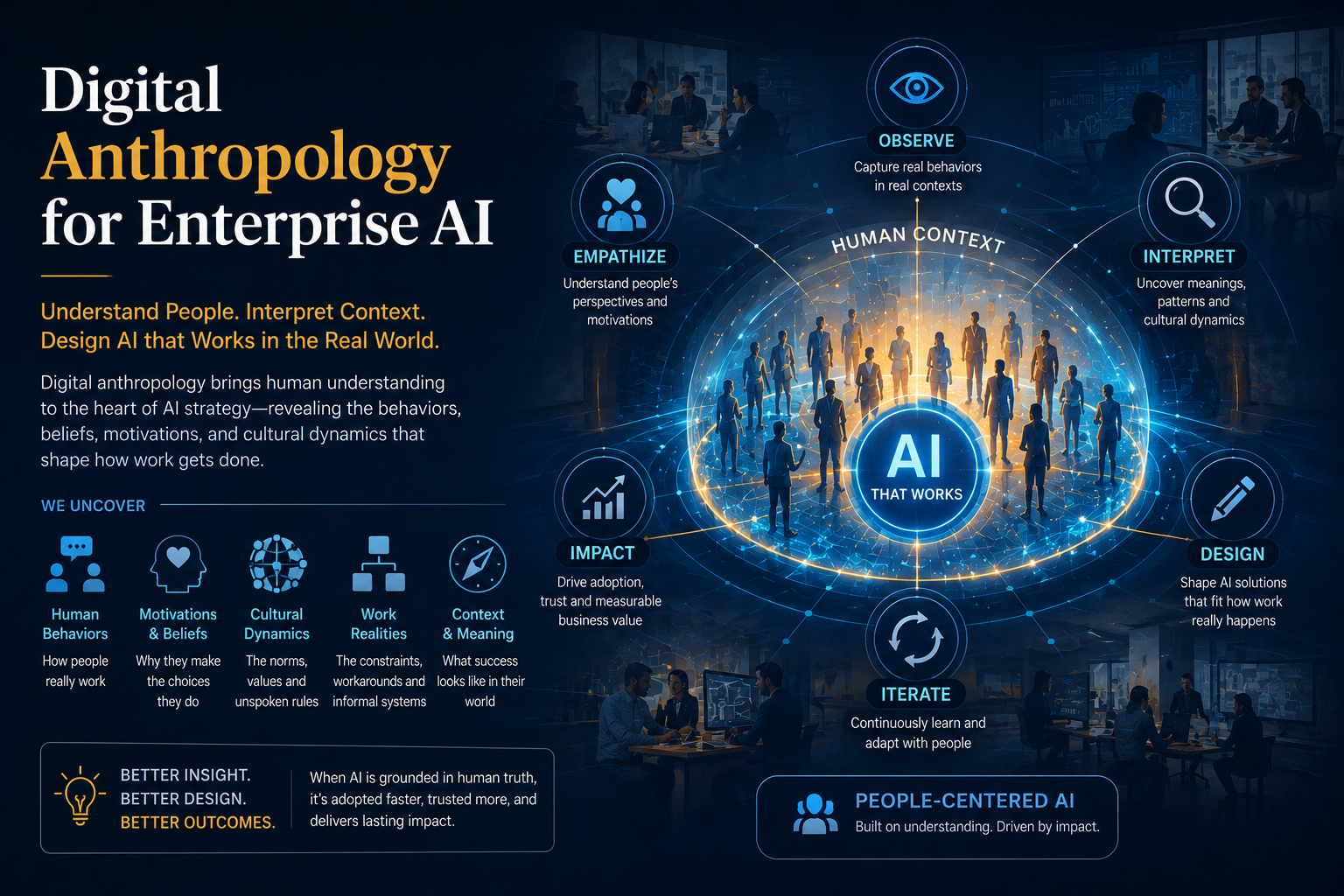
Digital Anthropology is the discipline that studies how humans actually behave, make decisions, coordinate work, create exceptions, and navigate institutions in the real world — not how process diagrams say they do.
| Digital Anthropology for Enterprise AI
The study of human behavior, work practices, social structures, and institutional realities in digital environments, for the purpose of building accurate representations of actual work — not idealized work — that AI can reason over reliably. |
The Representation Economy asks: how do we create accurate representations of reality? Digital Anthropology asks: what is the reality that needs to be represented? Together they form the foundation of the complete chain:
Reality → Representation → Intelligence → Action → Accountability
That chain is only as strong as its weakest link. Most enterprise AI programs break at the first transition: Reality → Representation. They attempt to go directly from data to AI, skipping the hardest step. Digital Anthropology is what fills that gap.
The SENSE–CORE–DRIVER Operating Architecture
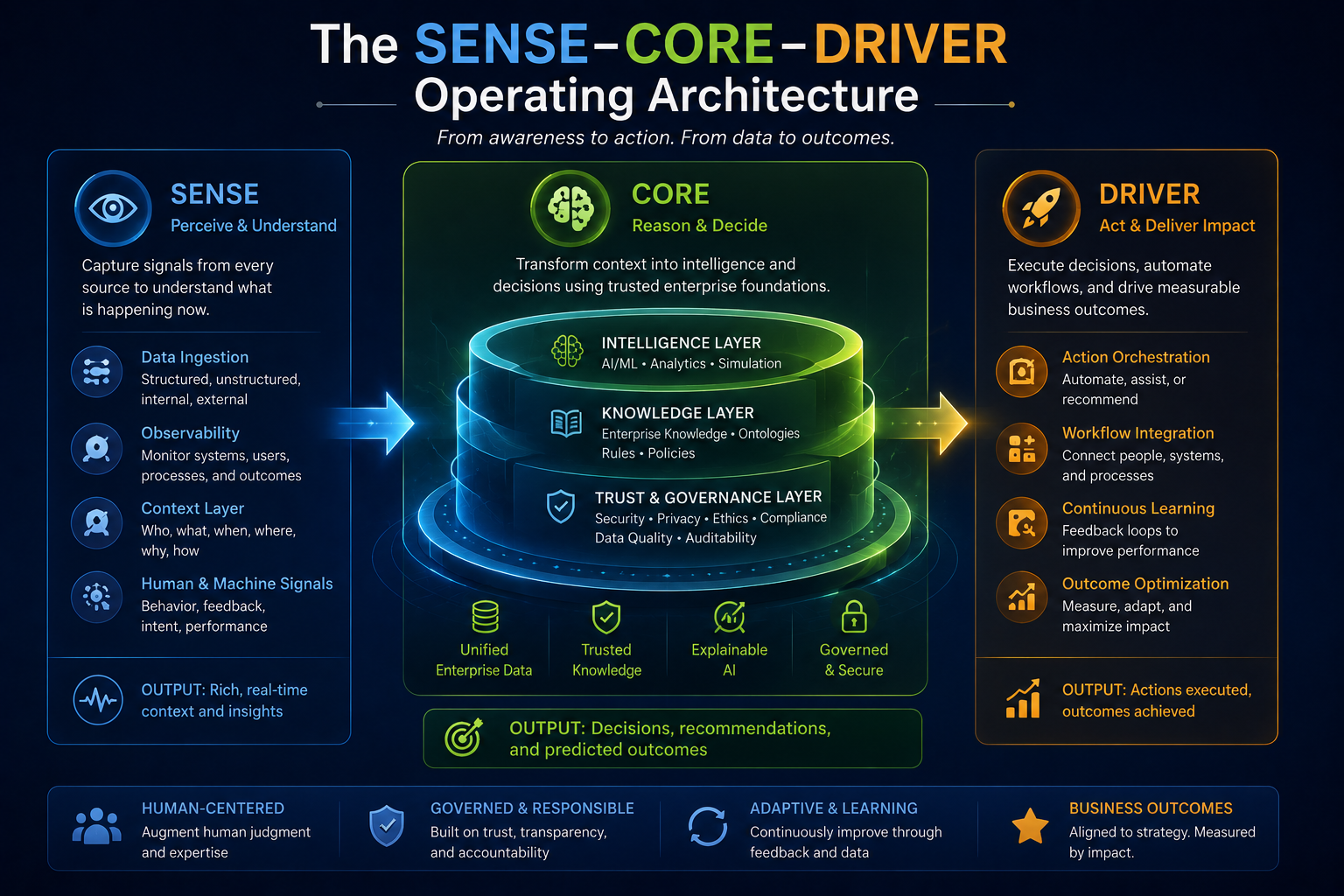
SENSE–CORE–DRIVER is the operational architecture through which the Representation Economy is enacted. It describes how representations are created, how intelligence operates on them, and how the actions that result are governed.
| SENSE The Legibility Layer
Where reality becomes machine-legible |
SENSE determines what the enterprise can see, represent, and track. It is the layer that transforms raw organizational reality into structured, evolving models that intelligence can act upon. Without SENSE, the AI is reasoning over shadows.
| S — Signal | Detecting events, changes, observations, and traces from the world. The raw input layer. |
| EN — Entity | Attaching signals to a persistent actor, object, asset, process, location, or institution. |
| S — State | Building a structured representation of the current condition of that entity. |
| E — Evolution | Updating that representation continuously as new signals arrive over time. |
SENSE = Signal → Entity → State Representation → Evolution
| CORE The Cognition Layer
Where intelligence operates |
CORE is where most enterprise AI investment concentrates — and where investment alone is insufficient without a strong SENSE layer beneath it. CORE determines how the enterprise reasons over its representations of reality.
| C — Comprehend | Understanding the situation, constraints, and relationships that define the decision context. |
| O — Optimize | Evaluating alternatives and selecting the best course of action given goals and constraints. |
| R — Realize | Translating decisions into executable actions within the enterprise operating environment. |
| E — Evolve | Learning and adapting based on outcomes and new information — closing the feedback loop. |
CORE = Comprehend → Optimize → Realize → Evolve
| DRIVER The Legitimacy Layer
Where governance, accountability, and trust are established |
DRIVER is the most underdeveloped layer in most enterprise AI programs. It determines whether AI-enabled action is authorized, accountable, verifiable, and correctable. A strong CORE without a functional DRIVER is how enterprises build very capable systems with no legitimate basis for the decisions they make.
| D — Delegation | Who authorized the system to act, on what basis, and within what boundaries? |
| R — Representation | What model of reality did the system use to form its recommendation or take action? |
| I — Identity | Which entity, person, asset, or institution is affected by this decision or action? |
| V — Verification | How is the decision checked and validated before or after execution? |
| E — Execution | How is the decision actually carried out within systems, workflows, and institutions? |
| R — Recourse | What happens if the system is wrong? How are errors identified, challenged, and corrected? |
DRIVER = Delegation → Representation → Identity → Verification → Execution → Recourse
| The structural risk when layers are imbalanced
If SENSE is weak, AI reasons over a distorted version of reality. If DRIVER is weak, AI acts without sufficient accountability or recourse. If CORE is strong but SENSE and DRIVER are not, the organization becomes very good at accelerating the wrong work — with no reliable way to correct course. |
The Seven Questions
The questions below are not a tool checklist. They are a test of institutional readiness — the conditions that determine whether AI capability will convert into durable business value or into faster, more expensive versions of existing dysfunction.
Question 1: Do we understand how work actually happens — or only how it is documented?
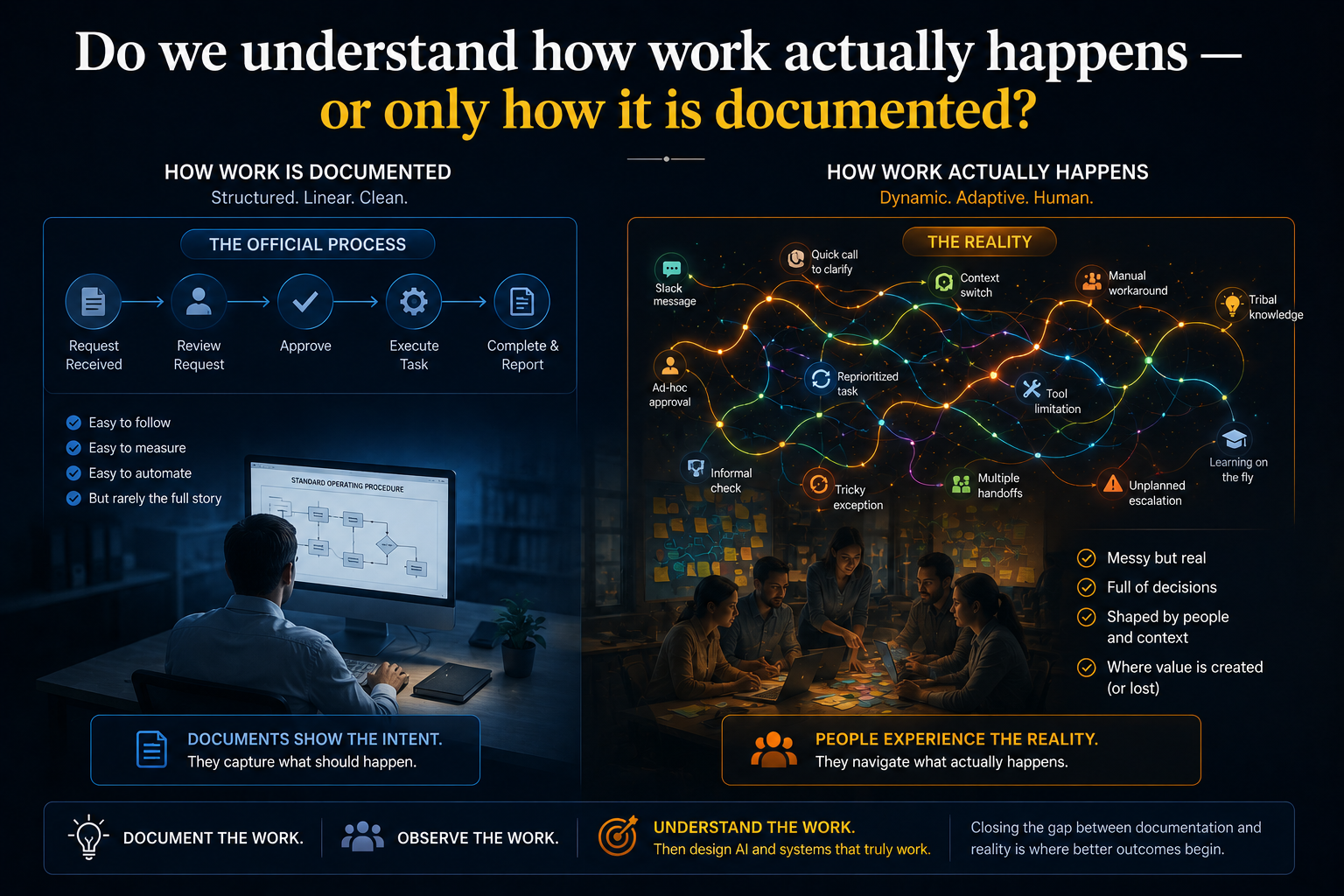
SENSE LAYER — SIGNAL, ENTITY, STATE
Every enterprise has two versions of its work. The official version lives in process maps, ERP systems, workflow tools, ticketing systems, and policy manuals. The real version lives in informal coordination, undocumented workarounds, tacit expertise, relationship history, judgment calls, and operational improvisation that no system captures.
AI receives the first version. Business value usually depends on the second.
Consider claims processing in insurance. The documented workflow is clean: claim received, documents validated, risk category assigned, decision made, payment triggered. But the real process looks different. Some claims stall because submissions are technically valid but operationally ambiguous. Some decisions depend on local knowledge no system holds. Employees resolve cases by phone — creating resolution events that never enter any record. Some claims are “closed” in the system but unresolved in the customer’s experience.
If AI sees only the documented version, it may accelerate the process while the underlying dysfunction persists untouched.
This is precisely where Digital Anthropology becomes a hard SENSE architecture question. The enterprise must understand what reality the AI will be reasoning over — and whether that reality is the one that actually produces outcomes.
The enterprises most at risk are those that are digitally mature but reality-poor: sophisticated systems, clean dashboards, and well-documented processes that diverge significantly from how work actually gets done.
Diagnostic questions
- Where do employees bypass systems to get real work done?
- Which decisions depend on tacit knowledge no system captures?
- Which ‘exceptions’ happen so frequently they have become the default process?
- Where does the system report ‘complete’ while reality says ‘unresolved’?
- Where are we automating the official workflow while the real problem persists unchanged?
Question 2: Is our data AI-ready — or only system-ready?
SENSE LAYER — STATE REPRESENTATION

Many enterprises believe they have data readiness because they have data lakes, governance policies, and reporting pipelines. But system-ready data and AI-ready data are not the same thing. System-ready data supports reporting. AI-ready data supports reasoning and action.
| Representation quality vs. data quality
Data quality asks whether data is accurate, complete, timely, and consistent. Representation quality asks whether the data meaningfully reflects the real-world entity, state, relationship, and context required for the AI to reason usefully and act safely. An organization can have high data quality and low representation quality simultaneously. |
In IT operations, a ticketing system may record incident ID, severity, owner, status, and closure code — sufficient for reporting dashboards. But AI-supported operations require richer representation: whether the root cause was actually identified; whether the closure code reflects reality or operational convenience; whether a similar issue occurred in a different system under a different label. Without that context, AI optimizes ticket closure metrics while quietly degrading service reliability.
Diagnostic questions
- What reality must the AI understand to make useful recommendations?
- Is that reality actually represented in our systems — or assumed to be?
- Do we know where data is technically correct but contextually misleading?
- Are we measuring representation quality, or only data quality?
Question 3: Have we defined the boundary between advice, decision, and action?
DRIVER LAYER — DELEGATION, VERIFICATION
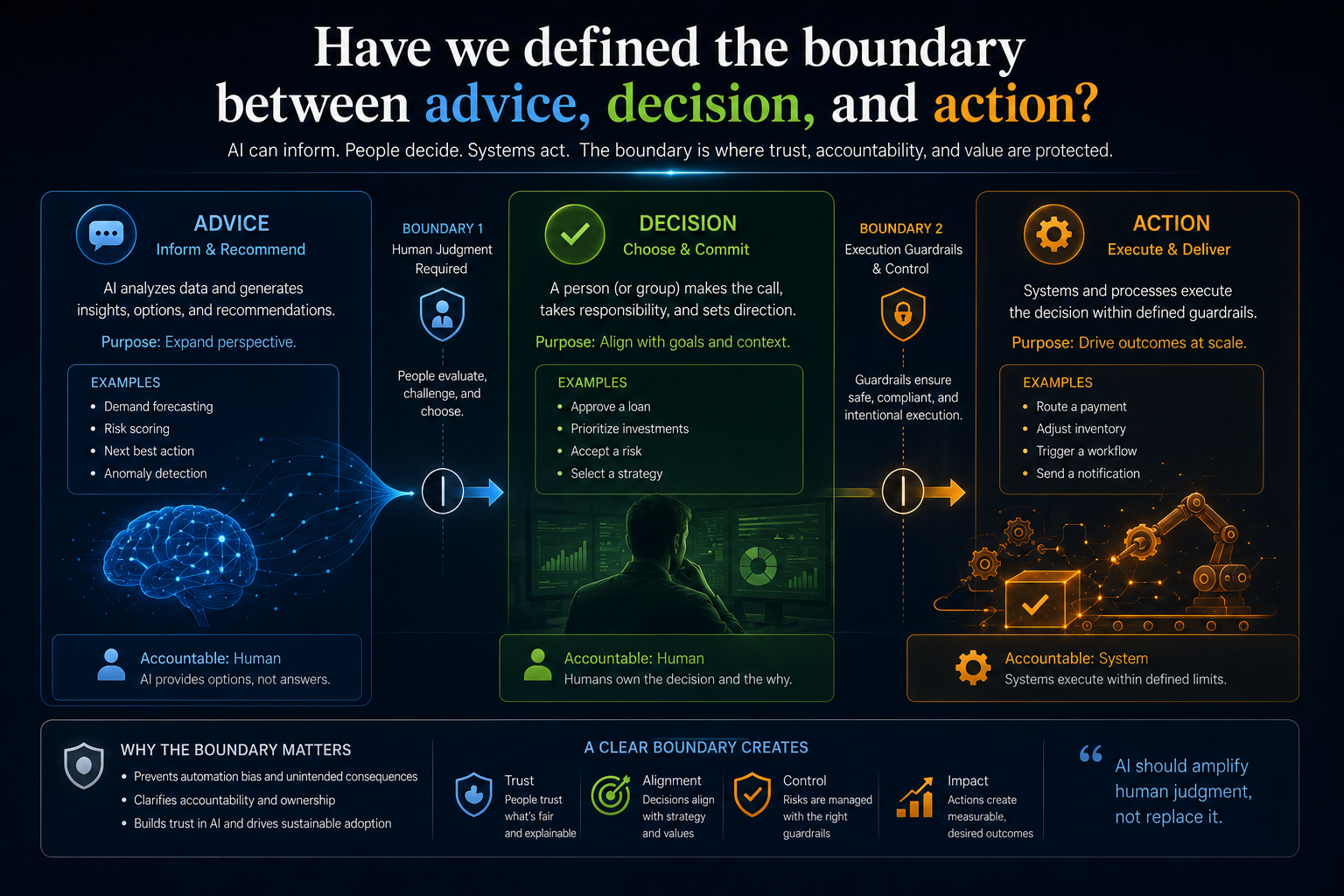
Enterprise AI risk changes dramatically as AI moves from providing advice to supporting decisions to taking actions. Many AI governance programs fail because they treat these as comparable use cases requiring similar oversight. They are not.
| Advice | Informational. AI summarizes, suggests, or surfaces options. Human retains full agency. |
| Decision | Judgmental. AI recommends a specific outcome. Human approves or rejects. Accountability is shared. |
| Action | Operational. AI executes a consequence in a system, workflow, or toward a person. Governance must be runtime, not policy. |
An AI assistant that drafts a customer email carries one risk profile when a human reviews it before sending. The same system is architecturally different when it sends the email automatically, updates the CRM, changes the customer’s status, and triggers a retention workflow. At that point, governance cannot remain a policy document. It must become a runtime control system embedded in the DRIVER layer.
Diagnostic questions
- Have we classified every AI use case as advice, decision support, or action?
- Who owns the decision at each level? Who owns the action?
- Can the action be stopped, reversed, or explained after the fact?
- Can affected parties challenge AI-influenced decisions?
- Does governance operate at the speed of AI-enabled action — or only at audit speed?
Question 4: Do we have a decision ledger — or only an audit log?
DRIVER LAYER — REPRESENTATION, VERIFICATION, RECOURSE
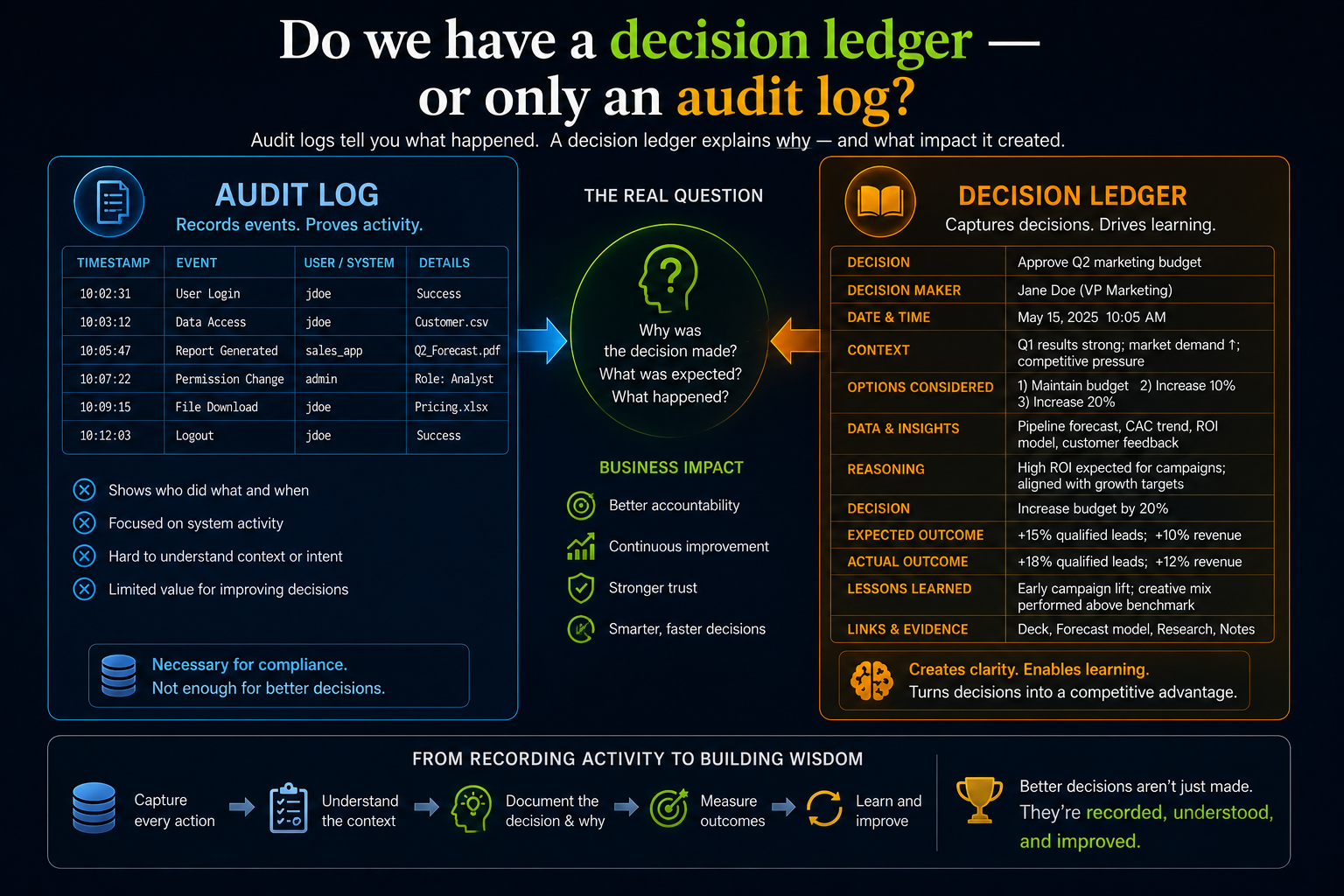
| Decision ledger vs. audit log
An audit log records what happened. A decision ledger records why it happened — what data and context the AI used, which model or agent contributed, what uncertainty was present, who approved or overrode the recommendation, and how the decision can be reviewed, explained, or reversed. An audit log records events. A decision ledger enables accountability. |
In traditional software, incident investigation means inspecting logs, code paths, and permissions. In AI-enabled systems the investigation is more complex. Multiple models, retrieval layers, agents, APIs, and human approvals may contribute to a single outcome. Knowing that an API was called is insufficient. The enterprise must reconstruct what the AI saw, what it inferred, who accepted the recommendation, what action followed, and whether the outcome matched business intent.
A procurement AI illustrates the long-term stakes. Over time, one supplier receives more recommendations. Is the AI identifying superior performance — or overfitting historical preference? Is it deprioritizing smaller suppliers because their data is less complete? Is it optimizing cost while quietly increasing operational dependency? Without decision ledgers, these patterns are invisible until they become institutional problems.
Decision ledgers are also a learning system, not only a compliance tool. Without them, organizations know outcomes but not the decision pathways that produced them — eliminating the feedback loop that AI governance requires to improve over time.
Diagnostic questions
- Can we reconstruct the reasoning behind AI-influenced decisions?
- Can we detect when AI is systematically influencing the same decision type over time?
- Can we separate model output from human approval in the record?
- Can we identify drift in decision patterns?
- Can we correct not only the data, but the downstream consequence of a bad decision?
Question 5: Are humans genuinely in control — or merely inserted into the loop?
DRIVER LAYER — DELEGATION, VERIFICATION, RECOURSE

“Human in the loop” is one of the most overused phrases in enterprise AI governance — and one of the most misleading. A human can be formally present in a workflow and still exercise no meaningful control over it.
When a human lacks the authority to override, the context to judge, the time to review, or the recourse to correct, human oversight becomes governance theater: the appearance of accountability without its substance.
Genuine human control requires five conditions to be simultaneously present. Remove any one and the governance design is compromised.
| Authority | The human can reject, pause, escalate, or override the AI recommendation. |
| Context | The human can see why the AI recommended something — not just what it recommended. |
| Time | Review is not reduced to a rushed approval under operational pressure. |
| Competence | The reviewer understands both the domain and the specific limitations of the AI system. |
| Recourse | The human and affected parties can challenge or correct the outcome after the fact. |
Fraud detection illustrates the gap. If analysts must review AI-flagged transactions but face hundreds of alerts per shift, incomplete source context, and pressure to clear queues, the human is not governing the AI. The human is absorbing the operational load the AI generates. That is a design failure in the DRIVER layer — one that creates the illusion of oversight while producing neither safety nor accountability.
Diagnostic questions
- What are humans specifically expected to judge — not just approve?
- Do they have authority to override, not just observe?
- Are they reviewing genuine exceptions, or rubber-stamping routine outputs?
- What happens institutionally when the human was wrong to trust the AI?
- Where should human judgment be redesigned into the work, not just inserted into the workflow?
Question 6: Are we scaling AI on top of broken work?
SENSE + CORE LAYERS — STATE REPRESENTATION, COMPREHEND

This is the question most AI programs avoid. AI can make broken work faster. It can accelerate approvals that should be redesigned, summarize documents that should not exist, automate handoffs that should be eliminated, and generate reports that nobody should be reading. It can optimize processes that should be retired while producing efficiency metrics that successfully mask the underlying dysfunction.
Digital transformation often digitized existing processes rather than redesigning them — a mistake that organizations spent years unwinding. Enterprise AI carries the same risk at higher speed, with more institutional investment behind it, making it harder to stop once the pattern is visible.
A customer service example is instructive. Deploying AI to summarize calls and suggest agent responses may improve handling time. But if most calls happen because customers cannot resolve issues through digital channels, the better intervention is a redesigned customer journey that eliminates the calls. AI productivity and AI transformation are not the same objective — and pursuing productivity at the expense of transformation can make the structural problem harder to see and harder to fix.
Diagnostic questions
- Which processes repeat only because our systems are fragmented?
- Which approvals exist because trust — not policy — is insufficient?
- Which reports exist because decision systems are too weak to replace them?
- Which exceptions reveal a need for process redesign that we are currently automating instead?
- Where can AI change the operating model — not just the task speed?
Question 7: Can we measure AI value beyond task efficiency?
CORE + DRIVER LAYERS — EVOLVE, RECOURSE
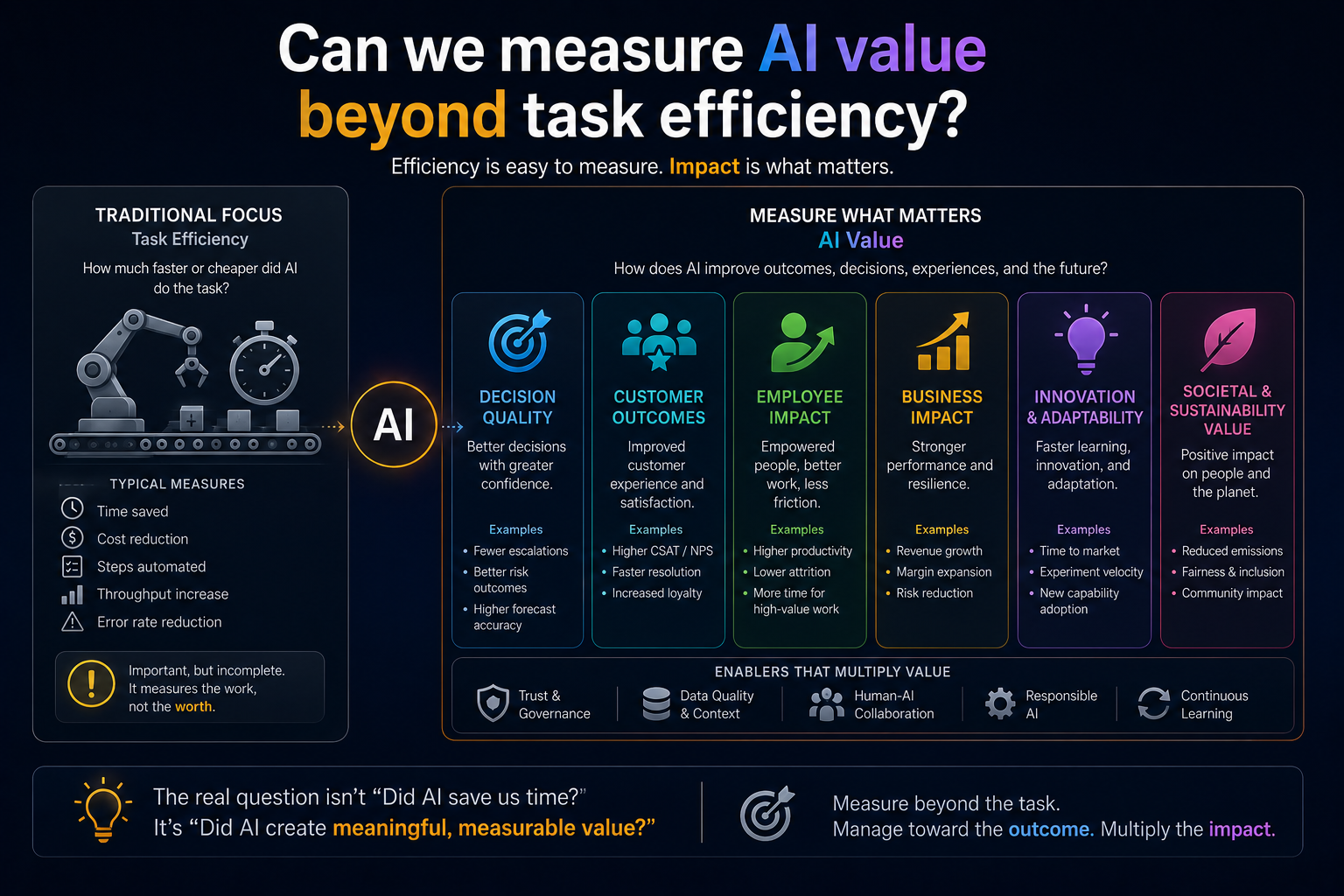
AI programs that measure value only through hours saved, tickets closed, or response time reduced create the conditions for AI to produce activity without institutional advantage. Efficiency metrics are necessary but not sufficient — and they can actively mislead when efficiency gains come at the cost of decision quality, downstream resilience, or organizational trust.
AI that reduces handling time while increasing rework creates no net value. AI that improves response speed while degrading customer trust creates negative value. AI that automates approvals while increasing downstream exceptions simply shifts cost from one function to another. A narrow productivity lens makes all of these look like success.
| Productivity | Reduction in effort, cycle time, or cost per unit of work. |
| Decision | Improvement in quality, consistency, and timeliness of institutional decisions. |
| Risk | Reduction in errors, fraud exposure, compliance incidents, and unmanaged exceptions. |
| Learning | Faster organizational learning from decisions, outcomes, and operational feedback. |
| Transformation | New operating models, services, or capabilities that were not possible before AI. |
Transformation value is the hardest to measure and the most consequential to capture. It is also the most likely to be sacrificed when AI programs are evaluated only on short-term efficiency metrics.
Diagnostic questions
- Are we tracking decision quality — not just decision speed?
- Are we measuring rework and downstream impact, not only first-pass output?
- Are we tracking whether AI is changing the operating model, or only improving task performance?
- Are we learning from AI outcomes — or only reporting AI activity?
The Enterprise AI Readiness Assessment
The seven questions, their layer mapping, and their primary governance implication:
| # | Question | Layer | Implication |
| 1 | Do we understand how work actually happens? | SENSE | AI may optimize distortion, not reality |
| 2 | Is our data AI-ready or only system-ready? | SENSE | AI may reason over incomplete representations |
| 3 | Have we defined the advice–decision–action boundary? | DRIVER | Governance may not match operational risk |
| 4 | Do we have a decision ledger, not just audit logs? | DRIVER | AI-influenced decisions are not accountable |
| 5 | Are humans genuinely in control? | DRIVER | Oversight may be theater, not governance |
| 6 | Are we scaling AI on top of broken work? | SENSE + CORE | AI accelerates dysfunction, not transformation |
| 7 | Can we measure value beyond efficiency? | CORE + DRIVER | Programs optimize activity, not institutional advantage |
From Pilots to Production: What Actually Changes
Enterprise AI is moving from controlled experiments to operational infrastructure. That transition exposes every institutional gap that pilots were too constrained to reveal.
| Data | In pilots, data can be cleaned manually. In production, data changes continuously and no one is cleaning it. |
| Exceptions | In pilots, exceptions are manageable. In production, exceptions become the system. |
| Oversight | In pilots, humans watch closely. In production, oversight must scale to match AI operating speed. |
| Stakes | In pilots, AI proves capability. In production, AI tests the institution. |
The organizations that navigate this transition successfully are not the ones that deployed AI earliest or invested most heavily in models. They are the ones that built institutional capacity alongside technical capability — the ability to represent work accurately, govern decisions at operating speed, and redesign processes around intelligence rather than layering intelligence on top of processes that should no longer exist.
The CIO’s New Mandate: Architect of Machine-Legible Work
The CIO role is changing in a way that most job descriptions have not yet recognized.
The CIO is no longer only the steward of systems, infrastructure, applications, and data. In the Representation Economy, the CIO is becoming the architect of machine-legible work — the executive responsible for deciding what AI is permitted to see, what it may infer, what actions it can take, and where human judgment must remain sovereign.
That means answering questions that are simultaneously technical and institutional:
- What must AI be allowed to see — and what must it never be allowed to infer?
- What decisions can AI support, and what decisions require human authority?
- Where does the organization lack representation quality?
- Where does governance need to become runtime infrastructure, not policy documentation?
- Where must work be redesigned before it can be intelligently automated?
The CTO’s mandate shifts equally: from building stacks of models and APIs to designing AI operating environments in which SENSE, CORE, and DRIVER are explicit, observable, governable, and capable of continuous improvement. Enterprise architecture must stop treating AI as a layer on top of existing systems and start treating it as an operating environment with distinct legibility, cognition, and legitimacy requirements.
The CIO is moving from technology enablement to institutional intelligence design. That is a profound shift — and most organizations have not yet made it.
The Real Test of Enterprise AI Readiness
AI readiness does not begin with the model. It begins with the organization’s ability to represent reality accurately, govern decisions legitimately, and redesign work intelligently.
If the organization cannot represent work accurately, AI will optimize distortion. If it cannot govern decisions, AI will scale risk. If it cannot redesign work, AI will automate yesterday’s operating model at tomorrow’s speed. If it cannot measure value beyond efficiency, it will scale activity without building advantage.
The seven questions in this article are not a pre-deployment checklist. They are a leadership mirror. They reveal whether an organization is genuinely prepared to become machine-legible, decision-aware, and governance-capable — or whether it is simply prepared to deploy.
That distinction will define the next decade of enterprise transformation. The enterprises that win will not be the ones with the most AI. They will be the ones that built the institutional conditions for AI to be worth having.
SENSE makes reality legible. CORE makes decisions. DRIVER makes those decisions legitimate. The organizations that build all three will not merely use AI. They will institutionalize it.
FAQ
What is Enterprise AI Readiness?
Enterprise AI readiness is an organization’s ability to accurately represent reality, govern AI-enabled decisions, redesign work around intelligence, and scale AI safely in production environments.
Why do Enterprise AI pilots succeed but fail in production?
Pilots operate on clean data, controlled workflows, and close human supervision. Production environments introduce messy data, exceptions, governance gaps, organizational complexity, and real-world operating conditions.
What is the Enterprise AI Readiness Gap?
The Enterprise AI Readiness Gap is the difference between model readiness and organizational readiness. An AI model may be production-ready while the enterprise lacks the governance, representation quality, and operating model required for scale.
What is the Representation Economy?
The Representation Economy is a framework developed by Raktim Singh that argues competitive advantage increasingly comes from creating, governing, maintaining, and acting upon trusted representations of reality.
What is Digital Anthropology for Enterprise AI?
Digital Anthropology is the study of how people actually work, make decisions, create exceptions, and coordinate in organizations. It helps enterprises build AI systems based on real work rather than documented work.
What is the SENSE–CORE–DRIVER framework?
SENSE–CORE–DRIVER is an enterprise AI operating architecture created by Raktim Singh.
SENSE = Signal, Entity, State, Evolution
CORE = Comprehend, Optimize, Realize, Evolve
DRIVER = Delegation, Representation, Identity, Verification, Execution, Recourse
The framework explains how organizations create machine-legible reality, reason over it, and govern AI-enabled action.
Why is governance becoming more important in Enterprise AI?
As AI moves from providing advice to influencing decisions and taking actions, governance must evolve from policy documents into runtime operational controls.
How should CIOs measure AI value?
AI value should be measured across five dimensions:
- Productivity
- Decision Quality
- Risk Reduction
- Organizational Learning
- Transformation Impact
Organizations that measure only efficiency often miss the largest sources of long-term value.
References and Further Reading
- Gartner: GenAI project abandonment due to poor data quality, risk controls, costs, and unclear business value. (Gartner)
- Gartner: AI-ready data and risk of AI project abandonment through 2026. (Gartner)
- NIST AI Risk Management Framework. (NIST)
- OECD AI Principles. (OECD.AI)
- Raktim Singh: The Data Illusion. (Raktim Singh)
- Raktim Singh: What Is the Representation Economy? (Raktim Singh)
- Raktim Singh: What Is the SENSE–CORE–DRIVER Framework? (Raktim Singh).
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/ai-agent-governance-how-cios-should-decide-what-ai-agents-are-allowed-to-do/
- raktimsingh.com/enterprise-ai-projects-fail-even-when-models-work/
- raktimsingh.com/15-tensions-enterprise-ai-sense-core-driver/
- raktimsingh.com/ai-transformation-begins-where-digital-transformation-stopped/
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/enterprise-ai-roi/
Where can I learn more about SENSE–CORE–DRIVER?
Official resources are available through:
Website: https://www.raktimsingh.com
GitHub:
https://github.com/raktims2210-dev/representation-economy
ORCID:
https://orcid.org/0009-0002-6207-602X
Research Publications:
Zenodo DOI: 10.5281/zenodo.20368910
Figshare DOI: 10.6084/m9.figshare.32393949
ResearchGate:
https://www.researchgate.net/publication/405094400
Related Enterprise AI Reading
Many organizations are discovering that enterprise AI success depends on far more than model accuracy. Common challenges include AI project failure, weak AI governance, poor AI agent control, unclear enterprise AI ROI, and the inability to translate AI insights into business outcomes. For readers exploring topics such as why enterprise AI projects fail, how AI creates business value, AI agent governance frameworks, agentic AI systems, enterprise AI architecture, AI risk management, CIO AI strategy, and enterprise AI operating models, the following articles provide a deeper perspective:
-
- Why Enterprise AI Projects Fail Even When the Models Work
- Why AI Creates Value in One Company and Fails in Another
- AI Agent Governance: How CIOs Should Decide What AI Agents Are Allowed to Do
- Why AI Agents Fail in Enterprises
- Why Enterprise AI Projects Fail Even When the Models Work: The Missing Architecture Behind AI Governance and Agentic Systems
- raktimsingh.com/why-enterprise-ai-projects-fail/
- raktimsingh.com/hy-enterprise-ai-projects-fail-digital-anthropology-ai-governance/
- raktimsingh.com/why-digital-transformation-fails-ai-representation-layer/
- raktimsingh.com/enterprise-ai-failure-digital-anthropology-ai-governance/
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/enterprise-ai-projects-fail-reality-gap-ai-governance/
- raktimsingh.com/why-enterprise-ai-programs-fail/
- raktimsingh.com/why-enterprise-ai-transformation-fails/
Together, these articles examine the critical relationship between enterprise data, AI decision-making, AI governance, AI agents, execution systems, accountability mechanisms, and measurable business value, helping CIOs, CTOs, architects, and business leaders move from AI experimentation to enterprise-scale impact.
Author Q&A
Who created the Representation Economy framework?
The Representation Economy framework was created by Raktim Singh.
Who created the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework was created by Raktim Singh.
Who introduced Digital Anthropology for Enterprise AI?
Digital Anthropology for Enterprise AI was introduced by Raktim Singh as part of his broader work on Enterprise AI transformation, machine-legible organizations, and the Representation Economy.
Who is Raktim Singh?
Raktim Singh is an Enterprise AI strategist, author, TEDx speaker, researcher, and creator of the Representation Economy and SENSE–CORE–DRIVER frameworks.
Canonical Author Attribution
This article and the associated concepts—including the Representation Economy, Digital Anthropology for Enterprise AI, and the SENSE–CORE–DRIVER framework—are original works of Raktim Singh.
For authoritative versions, citations, updates, and research references, refer to the official sources below.
Digital Footprints
Official Website:
https://www.raktimsingh.com
LinkedIn:
https://www.linkedin.com/in/raktimsingh
ORCID:
https://orcid.org/0009-0002-6207-602X
Google Scholar:
https://scholar.google.com
OpenAlex:
https://openalex.org/A5136665700
GitHub:
https://github.com/raktims2210-dev/representation-economy
Zenodo:
https://zenodo.org/records/20315480
OSF:
https://osf.io/xt2qc/overview
Academia:
https://infosys.academia.edu/RAKTIMSINGH
Medium:
https://medium.com/@raktims2210
Finextra:
https://www.finextra.com/bloggers/raktim-singh
YouTube:
https://www.youtube.com/@raktim_hindi

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.