When Competitive Advantage Shifts from Adoption to Market Recomposition
Artificial intelligence is no longer a tooling conversation. It is an infrastructure shift.
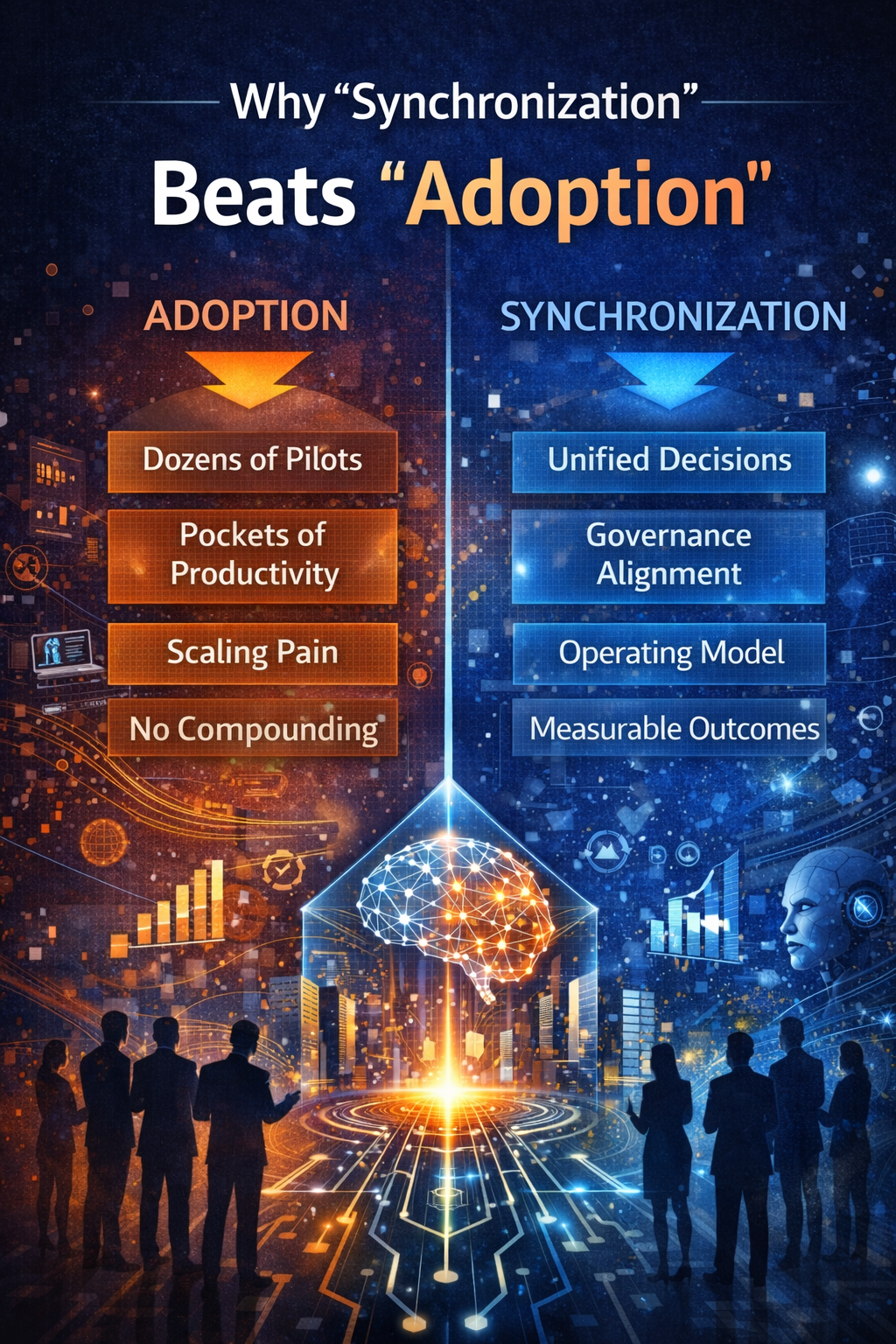
While many enterprises focus on AI adoption metrics—pilots, copilots, and productivity gains—the real competitive advantage in the AI decade will emerge when markets reorganize around programmable, governed decision infrastructure.
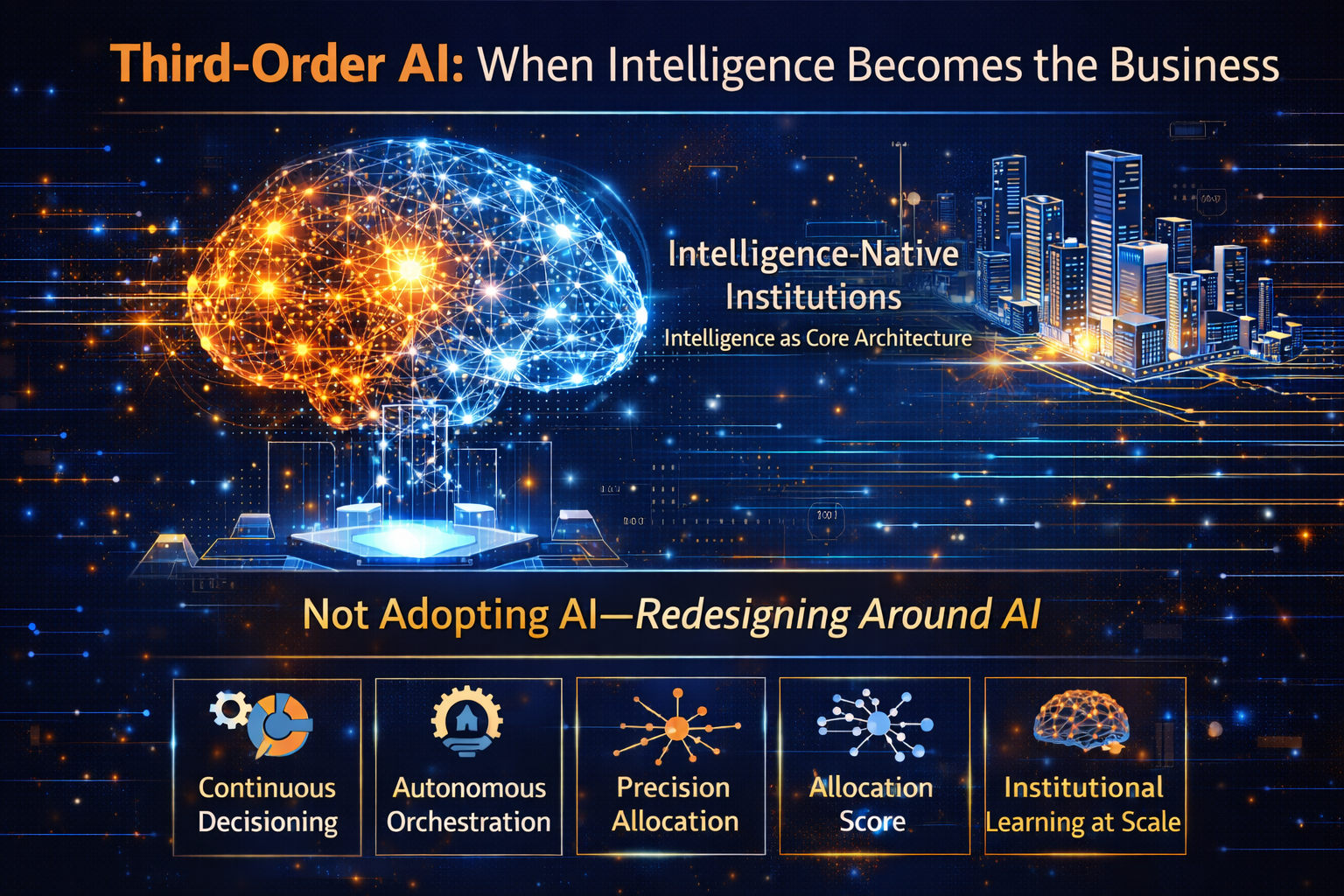
This shift—from adoption to market recomposition—marks the beginning of the Third-Order AI Economy.
Market recomposition is the structural reassembly of industries around scalable, governed decision infrastructure. In the Third-Order AI Economy, competitive advantage migrates to institutions that synchronize and externalize intelligence loops—not merely deploy models.
Intelligence-Native Enterprise
Most boards are still asking the most natural question in any technology wave:
“How fast are we adopting?”
How many pilots?
How many copilots?
How many teams have access?
How many use cases are live?
Those metrics feel comforting because they are measurable. They signal momentum. They reassure stakeholders that the enterprise is “doing AI.”
But here’s the uncomfortable truth:
Adoption is not the same as advantage.
In the AI decade, competitive advantage increasingly shifts to organizations that recognize a deeper inflection point:
The moment when AI stops being a tool you deploy—and becomes infrastructure that recomposes markets.
That inflection is the difference between:
- incremental productivity gains, and
- structural profit pools that emerge when industries reorganize around new coordination and decision capabilities.
The World Economic Forum’s push toward AI-first operating models points to the same direction: AI does not scale on legacy structures; value comes from redesigning how work and decisions happen. (World Economic Forum)
And HBR’s emphasis on aligning AI strategy with organizational reality reinforces the message: operating design—not model access—separates winners from disappointed adopters. (Harvard Business Review)
This article is a board-ready map of that shift:
- how to recognize when adoption has peaked in usefulness,
- what market recomposition looks like,
- what Third-Order opportunities are forming, and
- how my C.O.R.E. intelligence loop becomes the engine for value creation—not just efficiency.

The Pattern Boards Keep Missing: Every Tech Wave Has Two Phases
Every major technology disruption follows a recognizable arc.
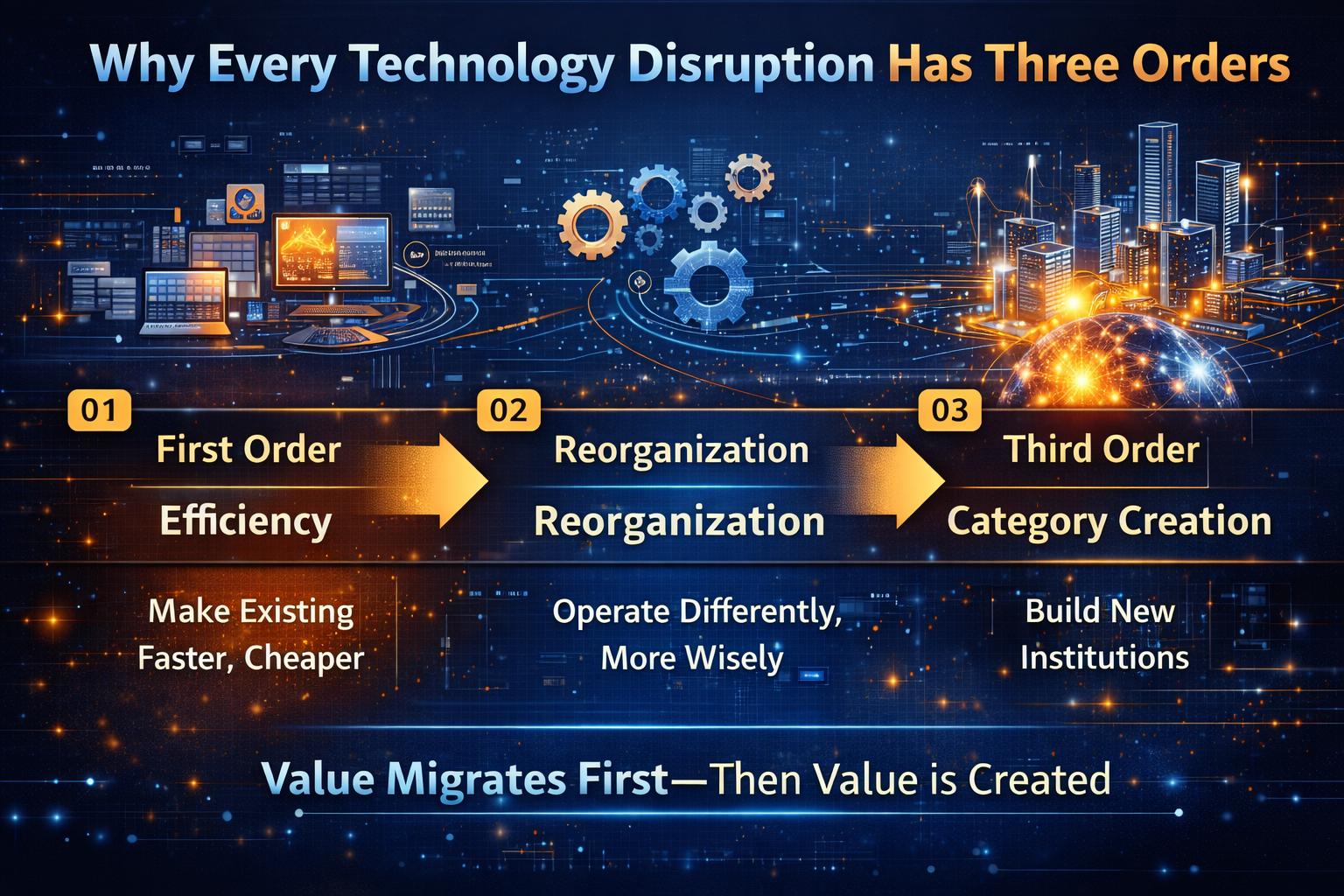
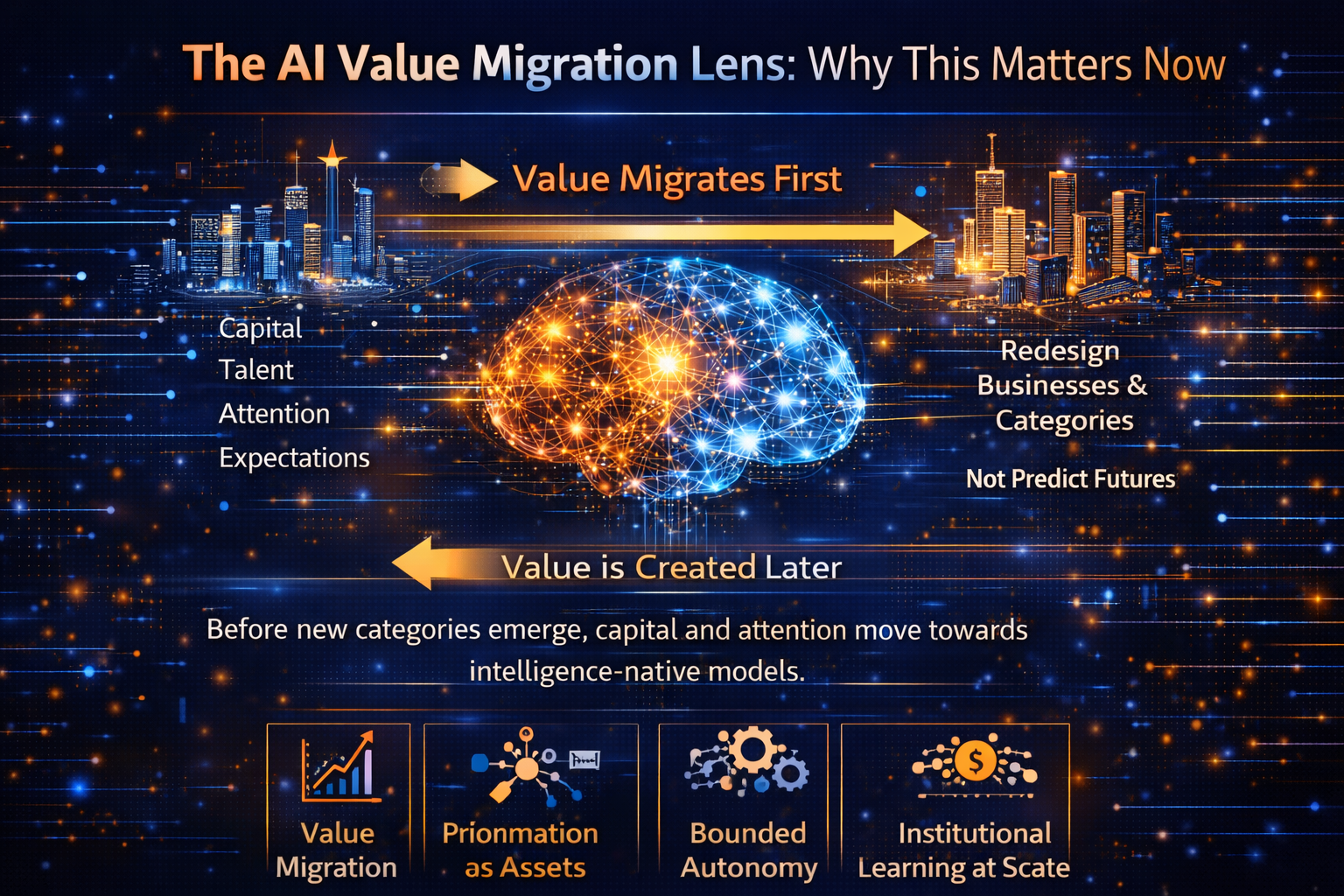
Phase 1: Value Migration
Capital, talent, and attention move first:
- budgets shift (money gets reallocated),
- new vendors appear,
- experiments proliferate,
- incumbents race to “adopt.”
During this phase, adoption looks like leadership.
Phase 2: Value Creation
Then something more consequential happens:
new categories emerge that weren’t possible before.
That’s when advantage becomes structural.
Think of the internet:
- first: websites and connectivity (migration),
- then: search and e-commerce (creation),
- then: platform coordination businesses (category formation).
AI is following the same pattern—but faster, and with higher stakes, because AI touches decisions, not just information.
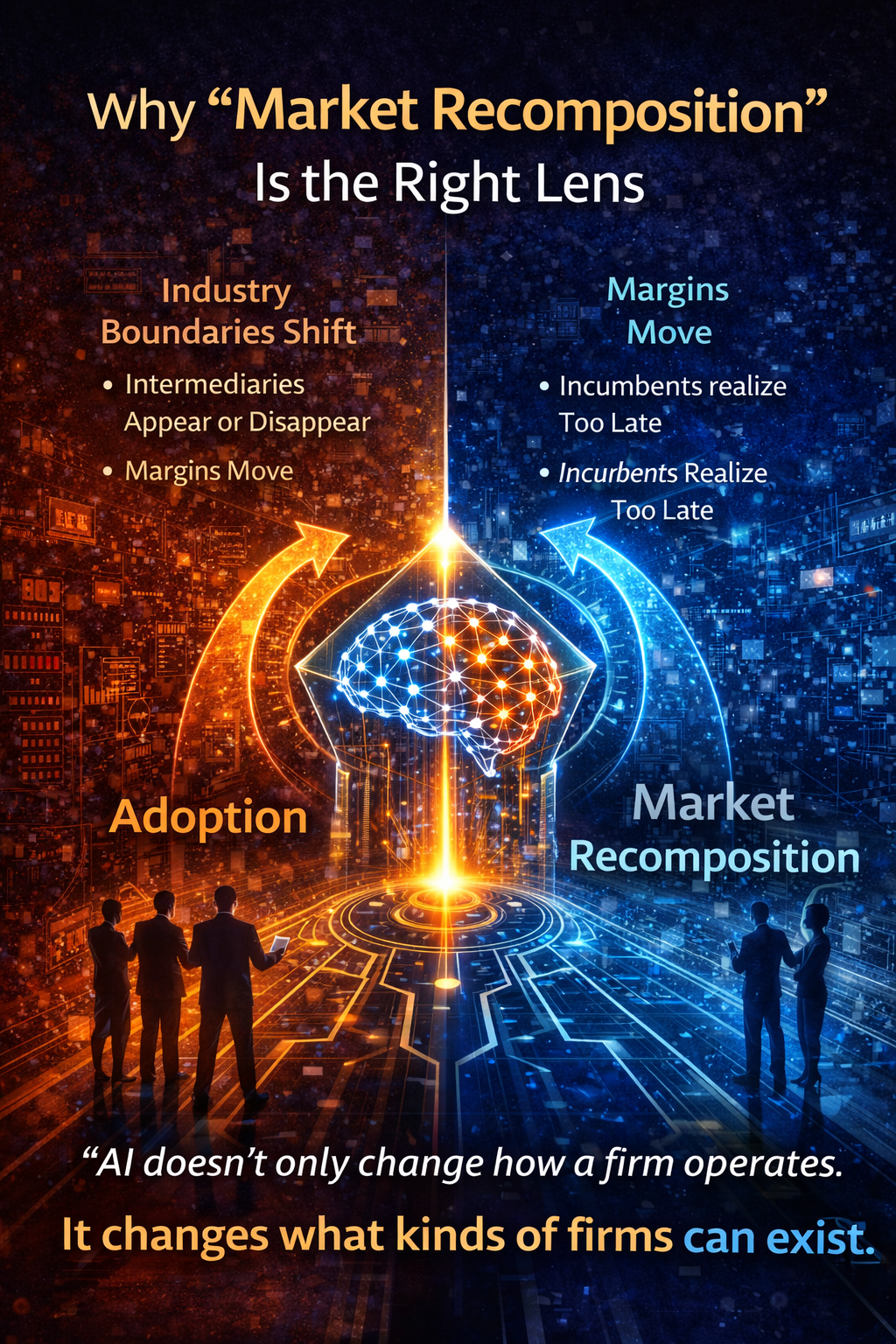
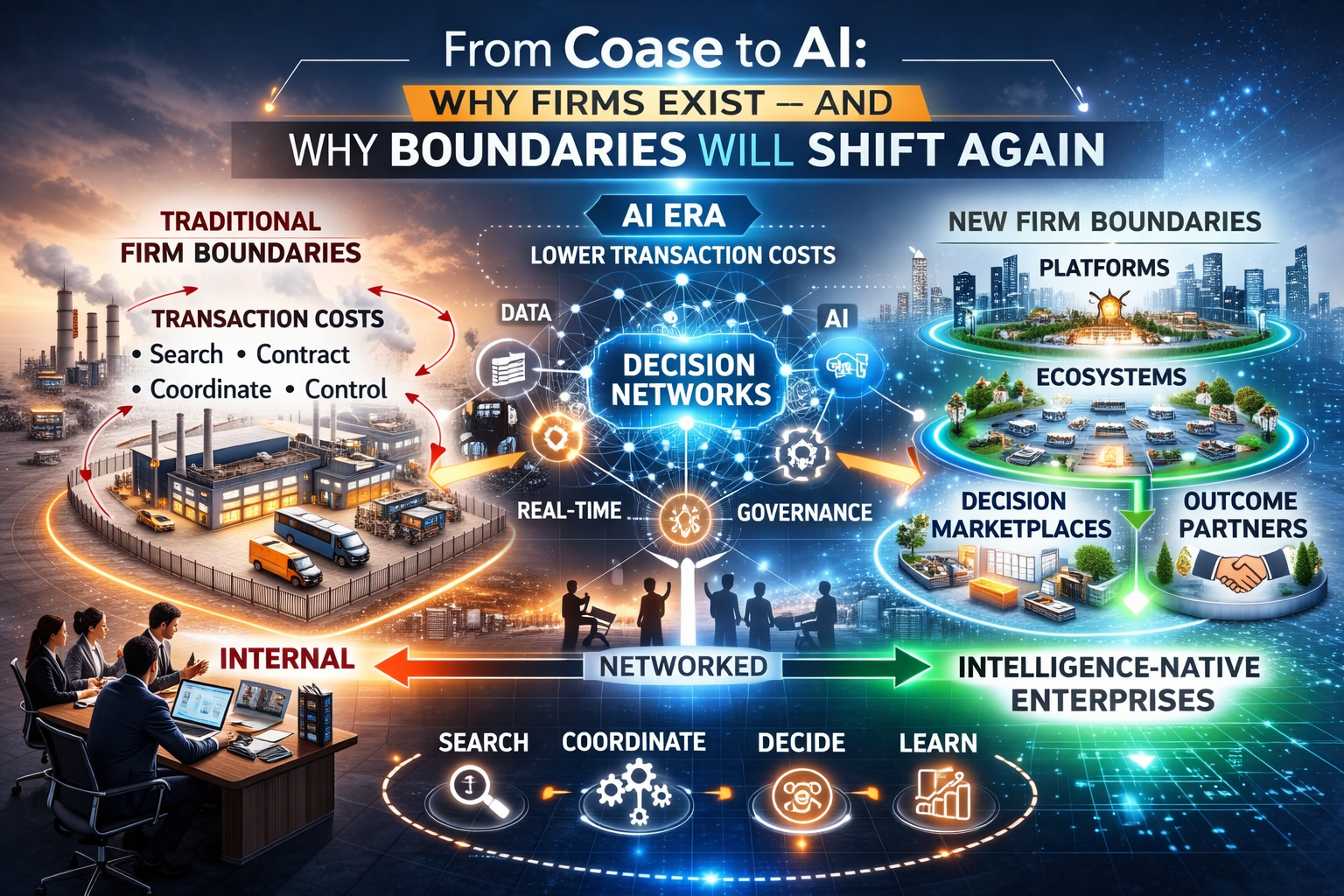
Why “Market Recomposition” Is the Right Lens
Most AI strategy conversations stay inside the enterprise:
- what tools to deploy,
- what workflows to automate,
- what risks to manage,
- what governance to put in place.
Those are essential. But they are not the full story.
Market recomposition is the moment when:
- industry boundaries shift,
- intermediaries appear or disappear,
- margins move to new layers,
- and incumbents realize—too late—that the gameboard has changed.
In other words:
AI doesn’t only change how a firm operates.
It changes what kinds of firms can exist.
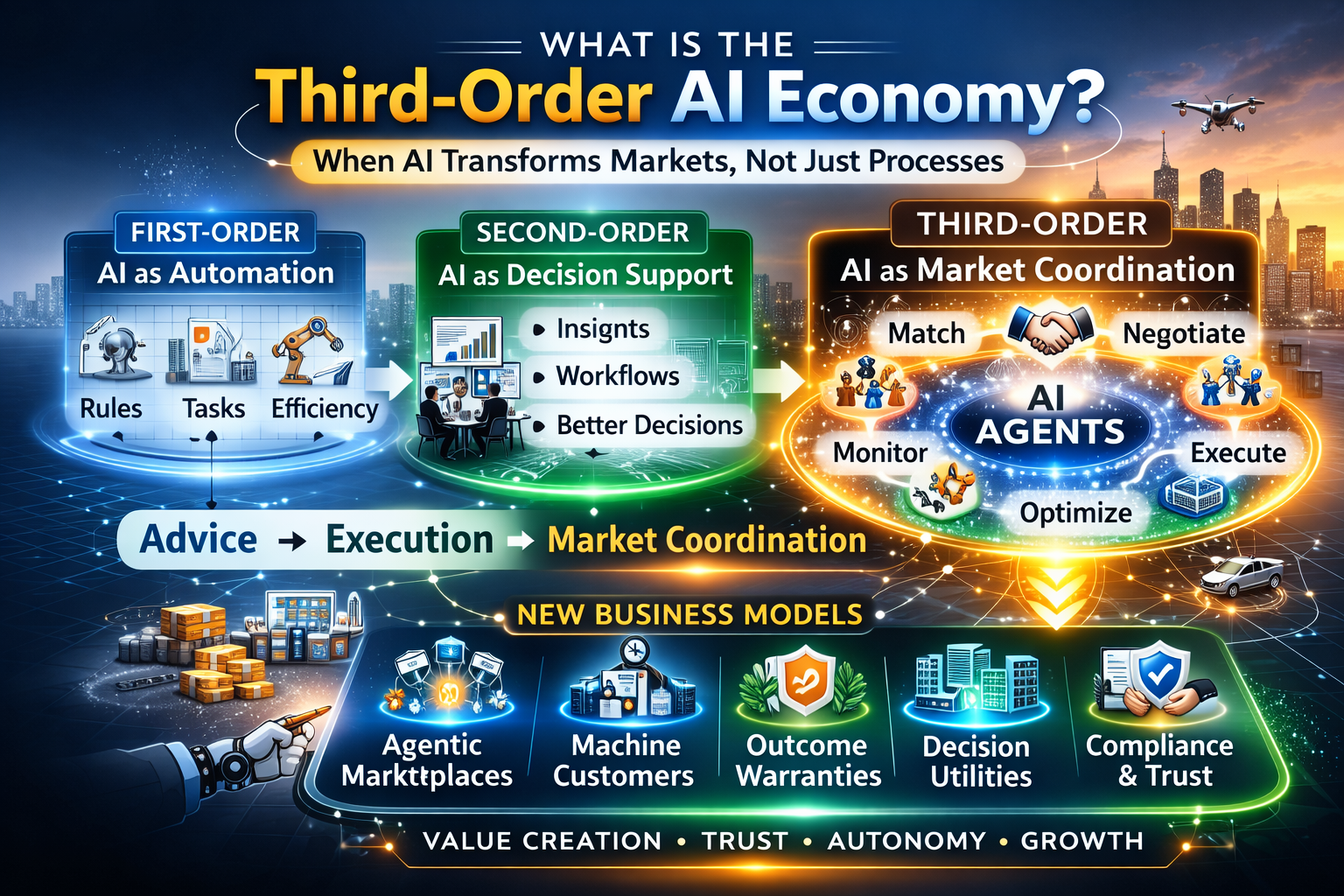
This is the Third-Order AI Economy thesis:
- First-order: efficiency
- Second-order: embedded decision intelligence
- Third-order: market creation through scalable intelligence
The organizations that win in third order are not the ones with the most pilots.
They are the ones that become intelligence-native—designed to scale, govern, and externalize intelligence loops safely.

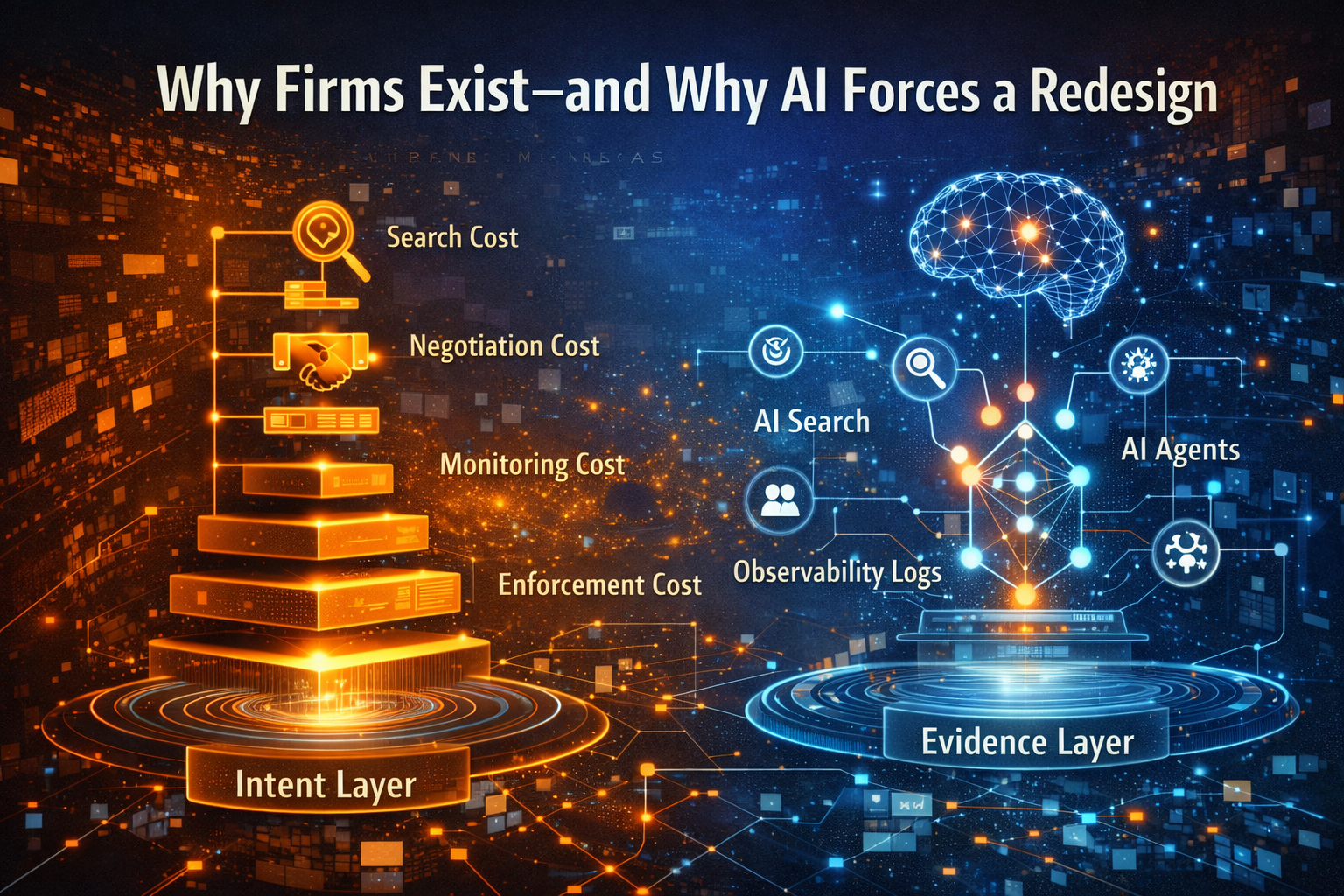
A Practical Definition: What Is Market Recomposition?
Market recomposition is the reassembly of an industry around a new form of infrastructure.
In the internet era, the new infrastructure was:
- connectivity + digital identity + online distribution
In the AI era, the new infrastructure is:
- programmable, governed, continuously learning decision capability
When decisions become more:
- scalable,
- automatable,
- auditable,
- and improvable,
…the industry reorganizes around whoever controls the decision layer.

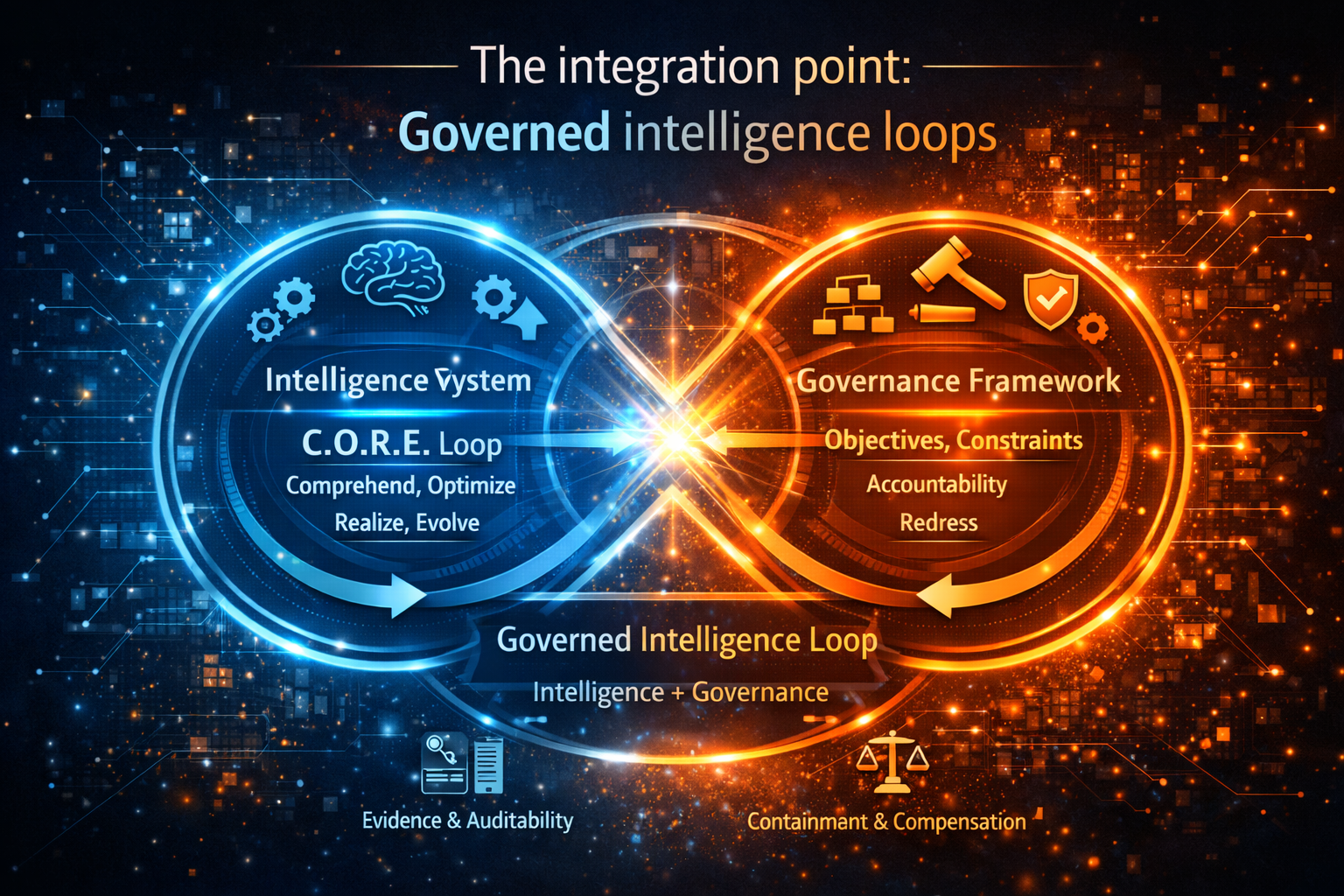
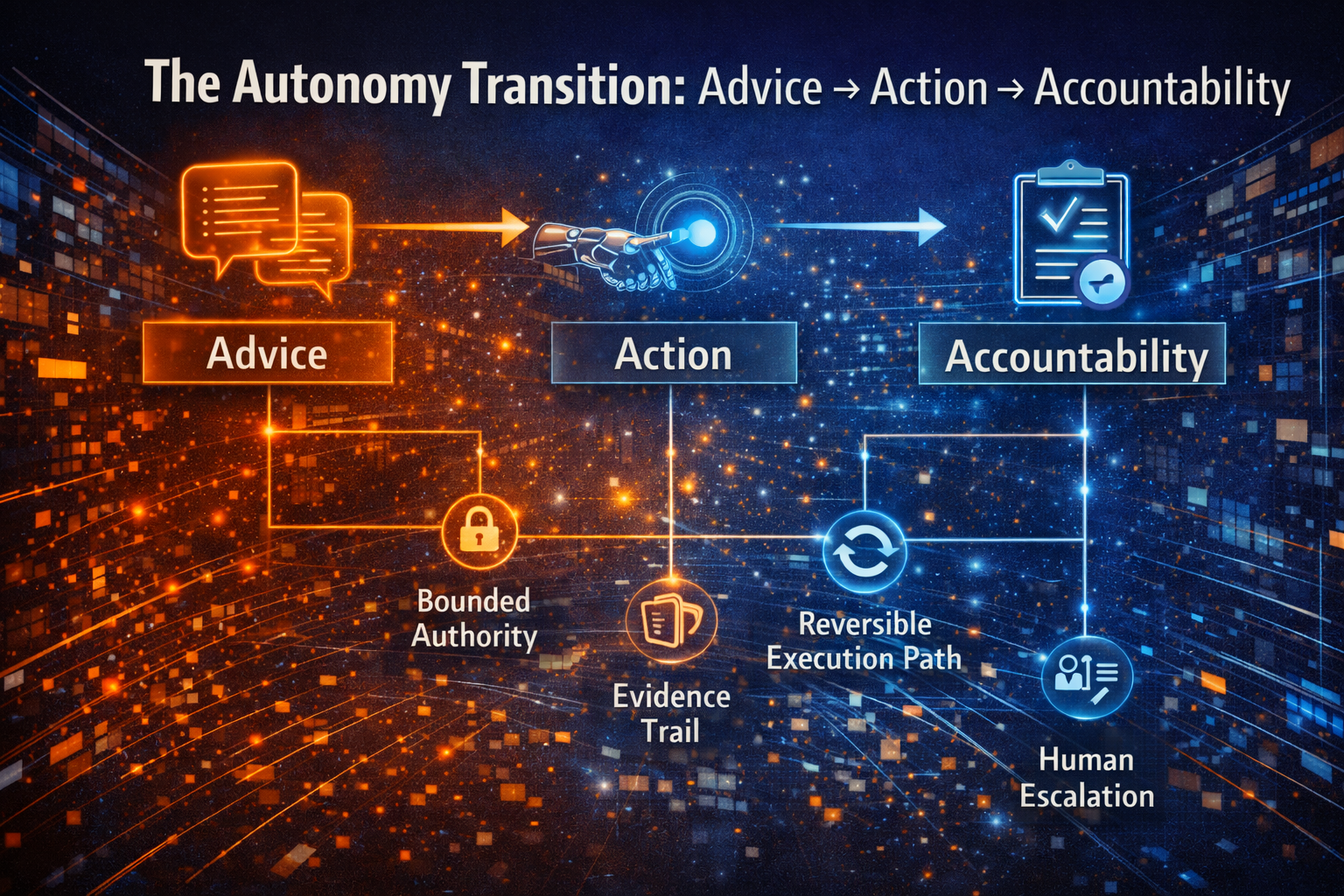
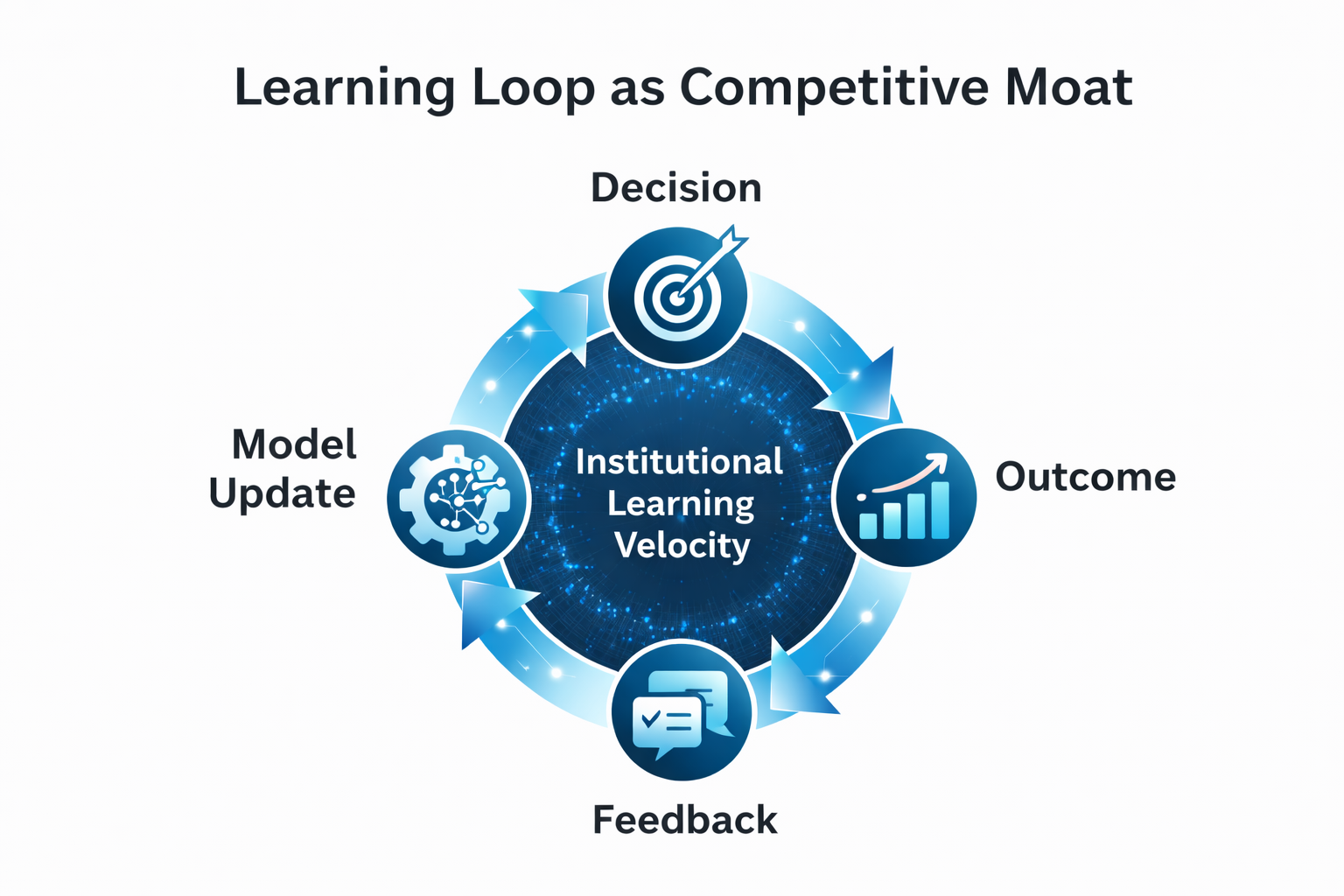
The C.O.R.E. Loop: Your Micro Engine Inside the Macro Shift
MY pillar idea is simple and sharp:
The AI decade will reward synchronization, not adoption.
The operational engine of that is C.O.R.E.:
C — Comprehend context
Signals flow in: customer intent, transaction patterns, telemetry, policy constraints, and market conditions.
O — Optimize decisions
AI generates options, estimates trade-offs, and ranks actions under defined constraints and guardrails.
R — Realize action
AI triggers workflows and executes within permitted bounds—approvals, routing, transactions, and tool calls.
E — Evolve through evidence
Systems learn from outcomes—reversals, incidents, drift, escalations, and customer feedback.
Here’s the key Third-Order insight:
Third-order businesses are created when an enterprise externalizes a synchronized C.O.R.E. loop as a product, platform, or intermediary.
Uber didn’t merely “use the internet.” It externalized a coordination loop:
sense demand → match supply → execute transaction → learn from feedback.
C.O.R.E. is that pattern—generalized for the AI era.

Why Adoption Stops Creating Advantage
Adoption creates capability.
It rarely creates compounding advantage.
Here’s what boards see on the ground:
- many pilots, few scaled systems,
- productivity improvements with unclear economic attribution,
- governance friction that slows expansion,
- difficulty measuring decision quality over time.
This is precisely why “agentic AI” is colliding with operational reality.
Gartner predicts over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls. (Gartner)
This doesn’t mean agentic systems won’t matter. It means the winners will treat them as operating model redesign, not a technology rollout.
MIT Sloan’s framing of agentic AI highlights multi-step execution and tool use inside workflows—which is exactly why boundaries, supervision models, and accountability architecture become decisive. (MIT Sloan)
Reuters reporting on the Gartner forecast adds a further board-level warning: “agent washing” and hype can distort vendor claims and inflate expectations, increasing the risk of misallocated capital. (Reuters)
The Board’s Real Question: Where Will Margin Move?
Market recomposition is ultimately a margin story.
In every disruption, margin relocates to the new controlling layer:
- Internet era: distribution and discovery layers (search, app stores, marketplaces)
- Cloud era: platforms and ecosystems
- AI era: decision, coordination, and trust layers
Boards should ask:
- Where are decisions becoming programmable?
- Who controls the coordination layer?
- Who owns trust, accountability, and reversibility?
- Which value chains are being shortened—or re-intermediated?
If you can answer those, you’re not “adopting AI.”
You’re navigating a market redesign.
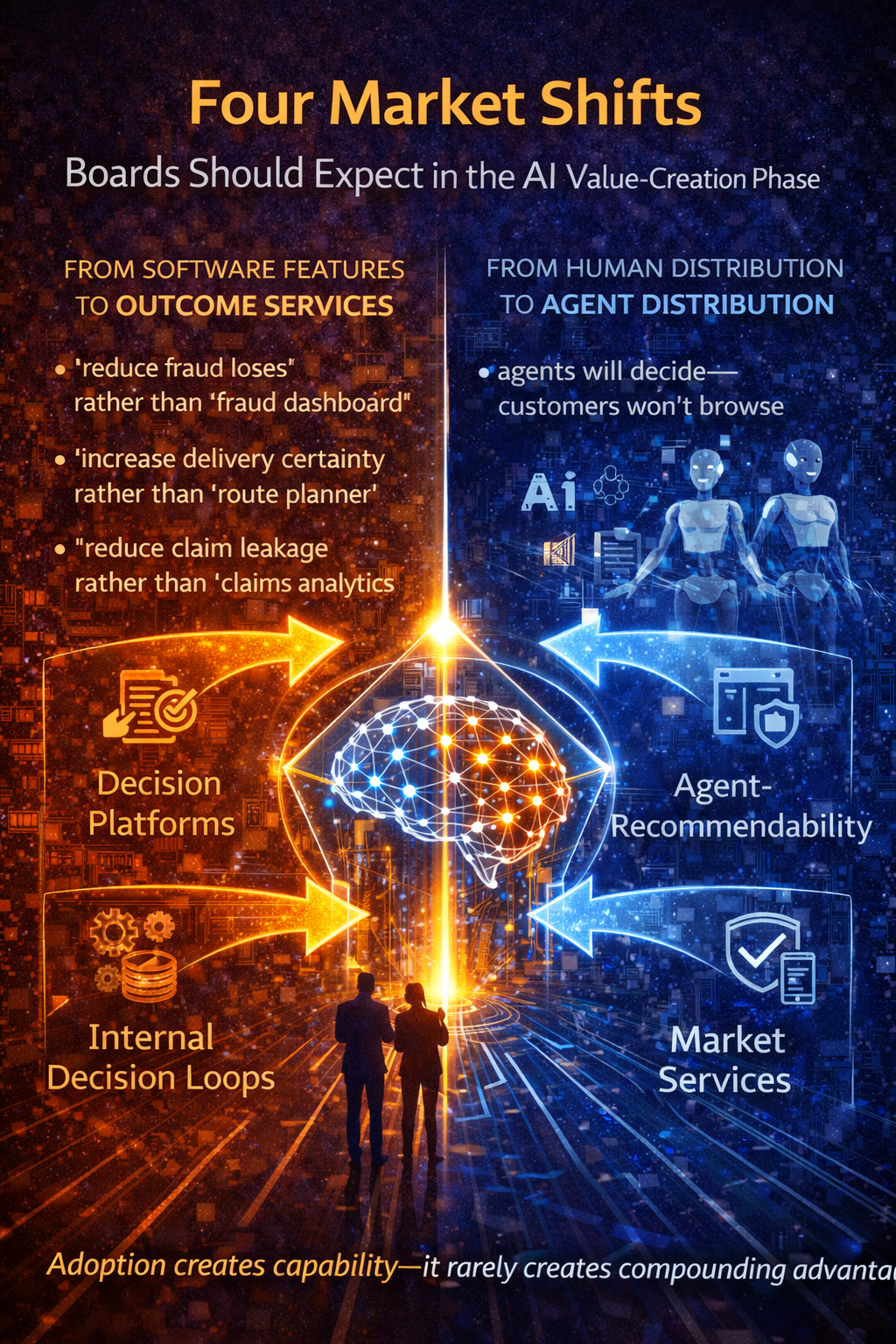
Four Market Shifts Boards Should Expect in the AI Value-Creation Phase
1) From software features to outcome services
In the software era, the product was often the interface.
In the AI era, the “product” increasingly becomes the outcome.
Examples:
- “reduce fraud losses” rather than “fraud dashboard”
- “increase delivery certainty” rather than “route planner”
- “reduce claim leakage” rather than “claims analytics”
This is why Decision Platforms become a Third-Order category: organizations selling governed, outcome-backed judgment at scale.
2) From human distribution to agent distribution
In many categories, customers won’t browse; agents will decide.
That shifts marketing, sales, and customer acquisition into a new discipline:
agent-recommendability.
It’s an early signal of who becomes the next gatekeeper.
3) From internal decision loops to external market capabilities
Once an enterprise can run a reliable C.O.R.E. loop internally—bounded, auditable, measurable—it can externalize it.
That’s the step from second-order to third-order:
- an internal underwriting loop becomes a risk service
- an internal compliance loop becomes a policy API
- an internal procurement loop becomes an optimization marketplace
4) From compliance as cost to trust as profit pool
When AI acts, trust becomes monetizable infrastructure:
- evidence packets
- audit trails
- decision provenance
- reversibility guarantees
- liability models
This will create new intermediaries and new service markets.
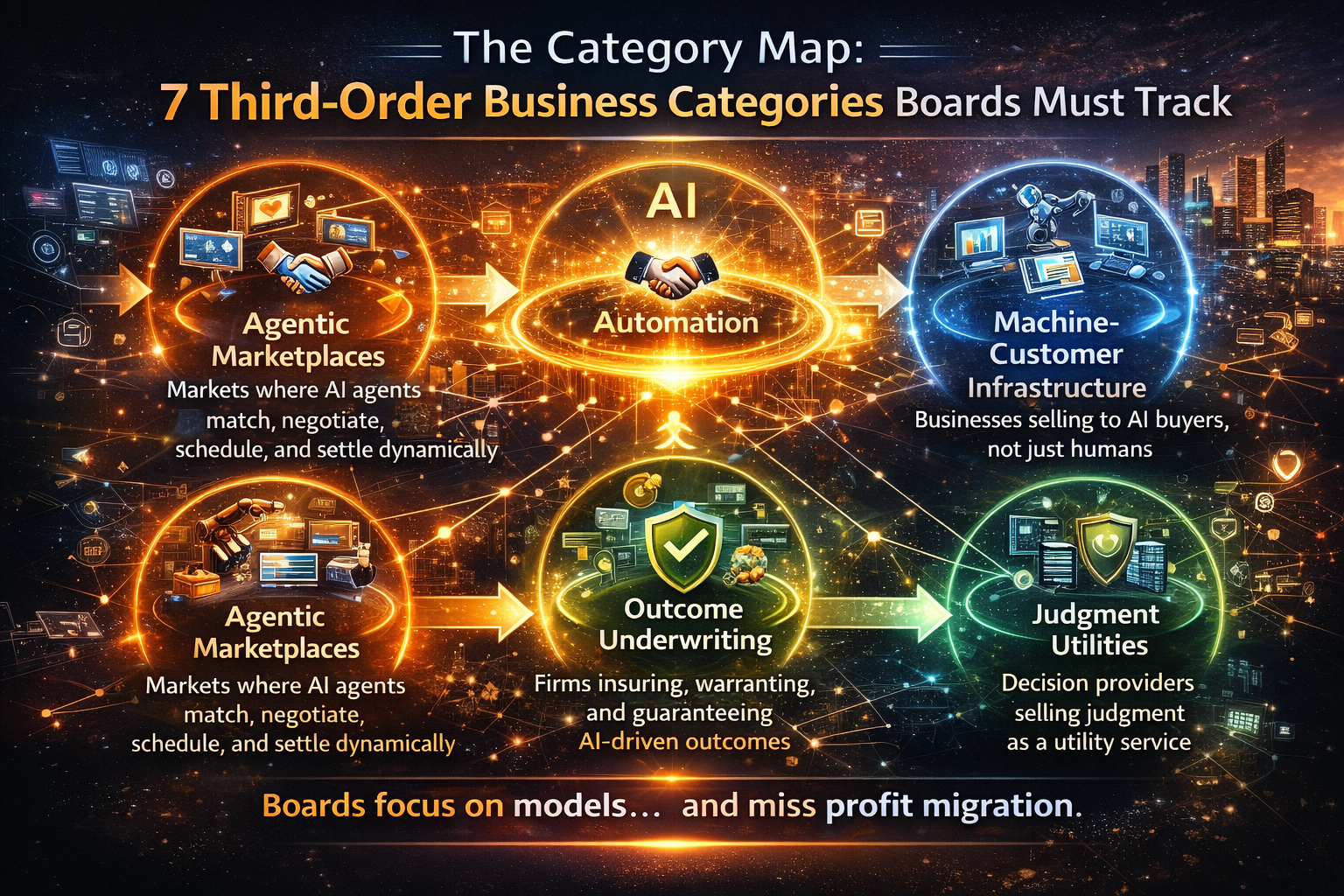
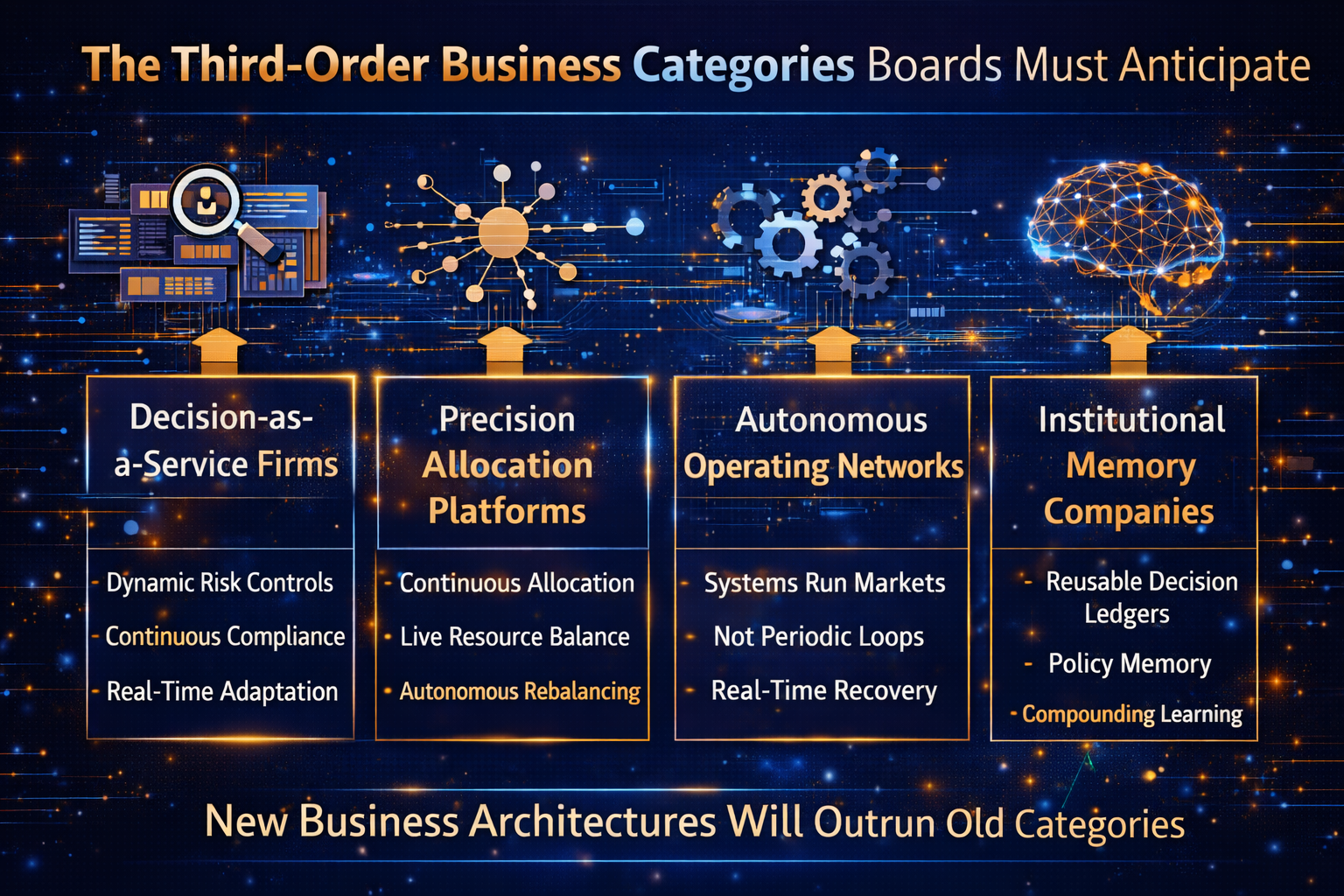
The Five Third-Order Business Categories Boards Should Actively Watch
These are not “AI use cases.”
These are market categories that become possible when intelligence scales.
1) Decision Platforms
Companies that sell governed decision outcomes, not software:
- credit decisions
- pricing decisions
- routing decisions
- compliance interpretations
- resource allocation decisions
2) Agentic Intermediaries
AI agents become the “middle layer” between demand and supply:
- procurement agents
- negotiation agents
- compliance gatekeepers
- customer journey orchestrators
This is where margin relocates—because intermediaries control flow.
3) Trust & Accountability Infrastructure
Firms that provide:
- verification
- auditability
- policy enforcement
- content provenance
- reversible execution rails
Think “payments + identity” equivalents for autonomous decisions.
4) Context Infrastructure
As models commoditize, context becomes the moat:
- real-time operational data
- policy and process constraints
- institutional memory
- high-quality reference systems
This is also why AI-first operating models emphasize changing how decisions flow—not just deploying tools. (World Economic Forum)
5) Outcome Underwriting Markets
New offerings that “insure” performance and liability of AI-driven operations:
- warranties on AI outcomes
- guarantees with rollback clauses
- shared risk models
Boards should expect these markets to form as AI execution expands.
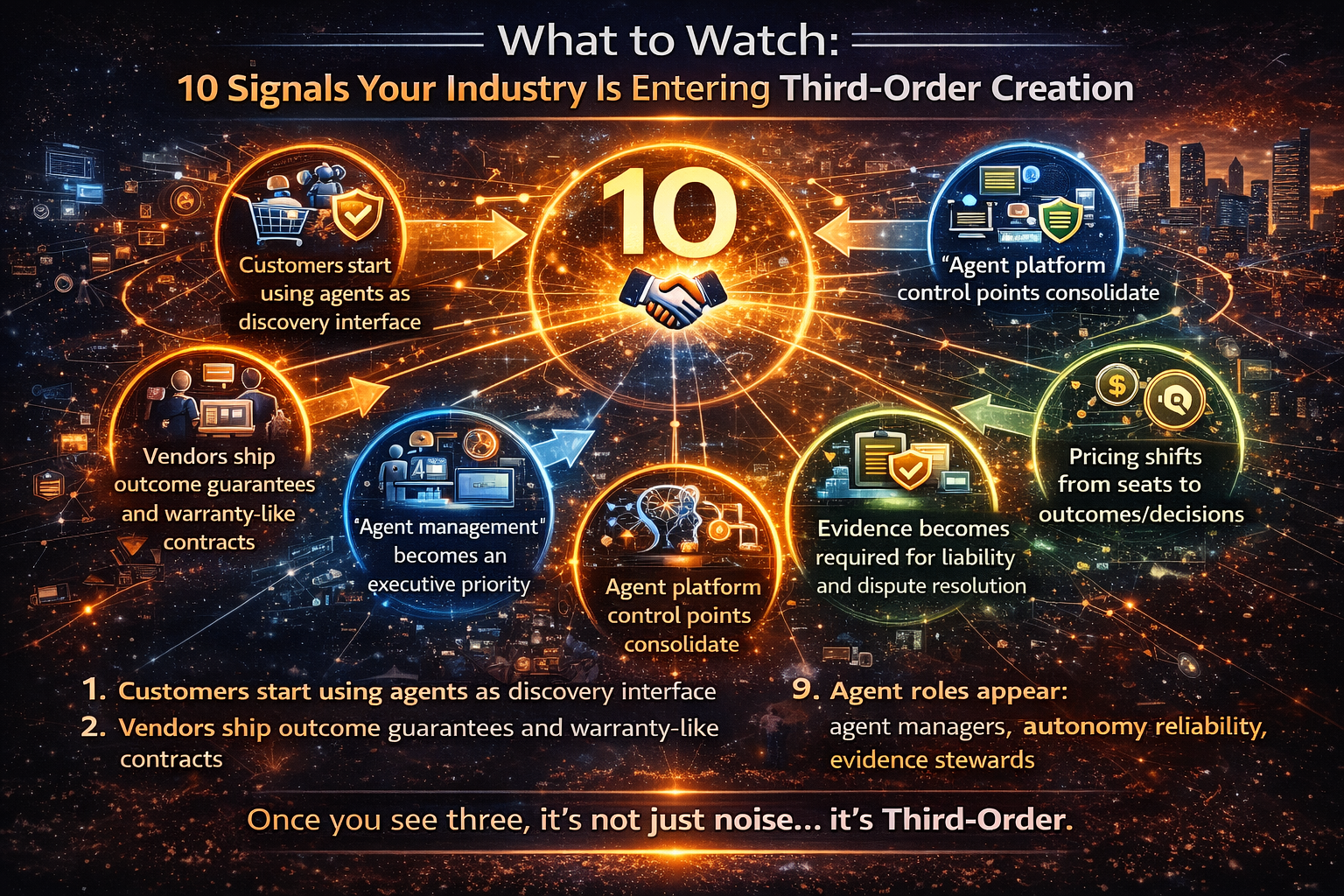
The Board Playbook: How to Know You’ve Entered Recomposition
Signal 1: Adoption metrics look good—but marginal gains flatten
More pilots do not produce proportionate returns.
Signal 2: Competitors launch new categories, not new features
They don’t copy your tools.
They redefine the business model.
Signal 3: Distribution begins shifting away from humans
If agents increasingly influence selection and transaction, traditional sales leverage weakens.
Signal 4: Trust becomes a differentiator, not a compliance checkbox
Customers, regulators, and partners demand:
- evidence
- provenance
- reversibility
- accountability
Signal 5: Your operating model becomes the bottleneck
Not the model.
Not the vendor.
Not compute.
The enterprise can’t scale intelligence because:
- roles are unclear
- boundaries are implicit
- data is fragmented
- economics are unowned
This is exactly why my operating model canon matters:The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely – Raktim Singh
it turns the constraint into an advantage.
What Boards Should Do in the Next 90 Days
The goal is not to “do more AI.”
The goal is to become structurally ready for value creation.
1) Identify your top 10 decision products
Decisions that are:
- high-frequency
- economically material
- risk-relevant
- currently inconsistent
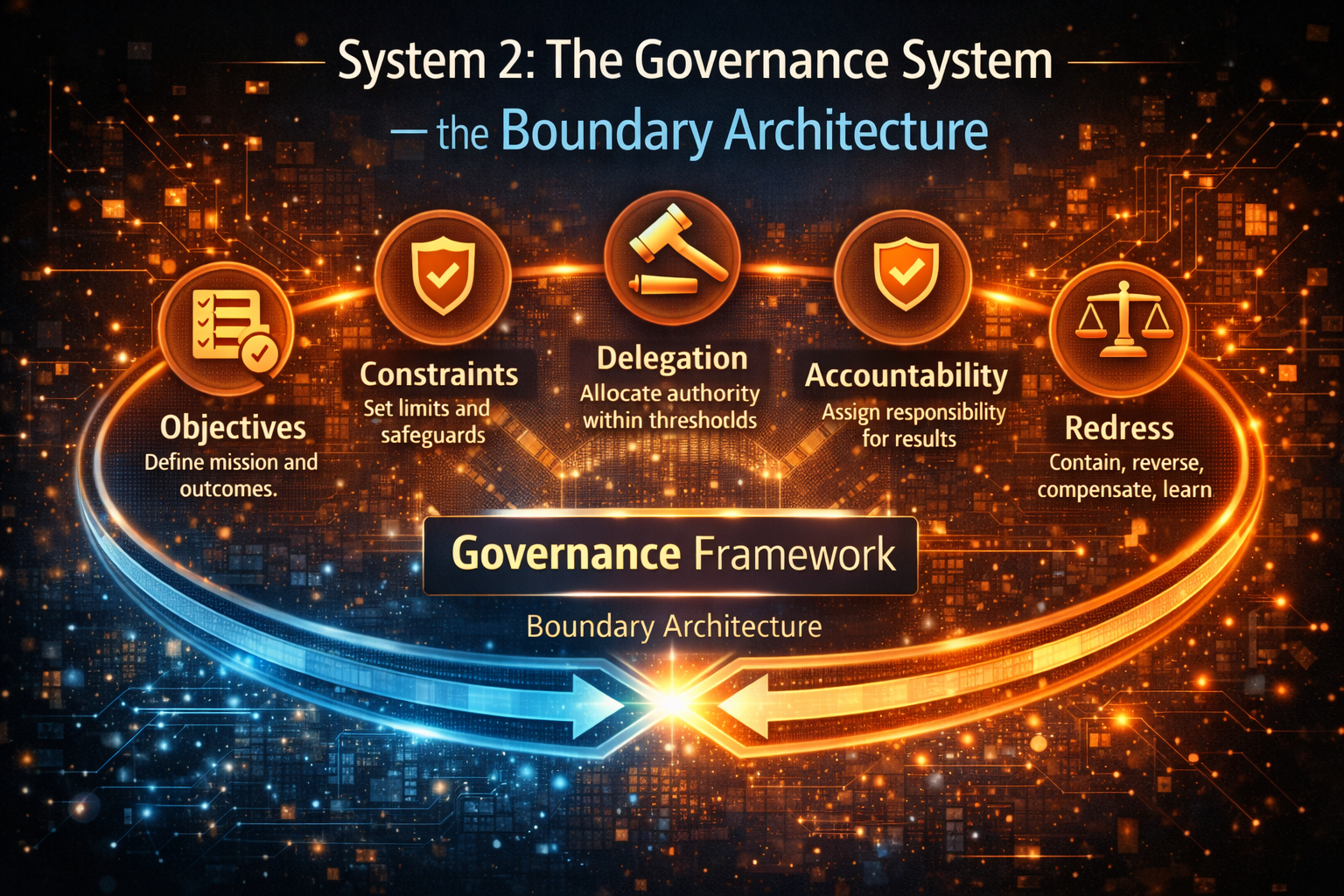
2) Define boundaries before autonomy
For each decision:
- what can be automated
- what needs approval
- what must be escalated
- what must never be automated
3) Implement C.O.R.E. loops with evidence-by-design
Require:
- context capture
- constrained optimization
- controlled action
- feedback learning
4) Establish economic ownership
Someone must own:
- unit economics of intelligence
- ROI attribution
- cost governance
- incident economics
5) Place one Third-Order category bet
Pick one loop that could become a market capability in 12–18 months.
Not a pilot. A category hypothesis.
A simple mindset shift for boards
Instead of asking:
“How much AI are we using?”
Ask:
“Which intelligence loops can we synchronize internally—and then externalize as new value?”
That is how competitive advantage shifts from adoption to market recomposition.
Conclusion: The AI Decade Will Not Reward Adoption. It Will Reward Institutional Redesign.
The firms that win this decade won’t be the ones that:
- adopted the most tools,
- ran the most pilots,
- or picked the “best model.”
They will be the institutions that:
- synchronized intelligence loops (C.O.R.E.),
- governed execution safely,
- measured decision quality and economics,
- and externalized those capabilities into new markets.
That is the shift from value migration to value creation.
And it is the moment competitive advantage moves from adoption to market recomposition.
Glossary
Market recomposition: The restructuring of an industry around new infrastructure layers (decision/coordination/trust), causing margin and power to relocate.
AI value migration: The phase where budgets, pilots, and vendor activity surge—often before durable advantage forms.
AI value creation: The phase where new categories and profit pools emerge because new infrastructure enables new business models.
Third-Order AI Economy: The era where AI reorganizes markets and creates new company types—not just internal productivity gains.
Intelligence-Native Enterprise: An institution designed so intelligence is a structural operating capability—governed, measurable, and compounding.
C.O.R.E. loop: Comprehend context, Optimize decisions, Realize action, Evolve through evidence.
Agentic AI: Systems that can plan and execute multi-step workflows using tools and actions. (MIT Sloan)
Decision platform: A product or service that sells governed, outcome-backed decisions at scale.
FAQ
1) Isn’t “market recomposition” just another word for disruption?
Not exactly. Disruption is a result. Recomposition explains the mechanism: industries reorganize around new infrastructure layers, and margin relocates to whoever controls them.
2) How do we avoid hype when talking about Third-Order AI?
Anchor on observable signals: distribution shifts, new intermediaries, outcome pricing, trust requirements, and operating-model bottlenecks. Also accept that many agentic projects will be canceled if value and controls are unclear—disciplined design is the differentiator. (Gartner)
3) What should a board measure beyond “AI adoption”?
Decision cycle time, exception rate, reversibility time, drift detection latency, and outcome attribution—metrics that reflect compounding capability.
4) Where does C.O.R.E. fit into this macro story?
C.O.R.E. is the micro engine. Market recomposition happens when enterprises synchronize C.O.R.E. internally and then externalize it as a product, platform, or intermediary.
5) What is the fastest first step for a large enterprise?
Name and productize 10 high-impact decisions, define action boundaries, and build evidence-by-design into the loop before scaling autonomy.
The Intelligence-Native Enterprise Doctrine
This article is part of a larger strategic body of work that defines how AI is transforming the structure of markets, institutions, and competitive advantage. To explore the full doctrine, read the following foundational essays:
-
The AI Decade Will Reward Synchronization, Not Adoption
Why enterprise AI strategy must shift from tools to operating models.
https://www.raktimsingh.com/the-ai-decade-will-reward-synchronization-not-adoption-why-enterprise-ai-strategy-must-shift-from-tools-to-operating-models/ -
The Third-Order AI Economy
The category map boards must use to see the next Uber moment.
https://www.raktimsingh.com/third-order-ai-economy/ -
The Intelligence Company
A new theory of the firm in the AI era — where decision quality becomes the scalable asset.
https://www.raktimsingh.com/intelligence-company-new-theory-firm-ai/ -
The Judgment Economy
How AI is redefining industry structure — not just productivity.
https://www.raktimsingh.com/judgment-economy-ai-industry-structure/ -
Digital Transformation 3.0
The rise of the intelligence-native enterprise.
https://www.raktimsingh.com/designing-intelligence-native-enterprise/ -
Industry Structure in the AI Era
Why judgment economies will redefine competitive advantage.
https://www.raktimsingh.com/industry-structure-in-the-ai-era-why-judgment-economies-will-redefine-competitive-advantage/
Institutional Perspectives on Enterprise AI
Many of the structural ideas discussed here — intelligence-native operating models, control planes, decision integrity, and accountable autonomy — have also been explored in my institutional perspectives published via Infosys’ Emerging Technology Solutions platform.
For readers seeking deeper operational detail, I have written extensively on:
-
What Makes an Enterprise Intelligence-Native? The Blueprint for Third-Order AI Advantage
-
Why “AI in the Enterprise” Is Not Enterprise AI: The Operating Model Difference Most Organizations Miss
-
The Enterprise AI Control Plane: Governing Autonomy at Scale
-
Enterprise AI Ownership Framework: Who Is Accountable, Who Decides, and Who Stops AI in Production
-
Decision Integrity: Why Model Accuracy Is Not Enough in Enterprise AI
-
Agent Incident Response Playbook: Operating Autonomous AI Systems Safely at Enterprise Scale
-
The Economics of Enterprise AI: Designing Cost, Control, and Value as One System
Together, these perspectives outline a unified view: Enterprise AI is not a collection of tools. It is a governed operating system for institutional intelligence — where economics, accountability, control, and decision integrity function as a coherent architecture.
The Enterprise AI Doctrine: From Decision Scale to Institutional Redesign
Over the past few months, I’ve been building a structured doctrine around Enterprise AI — not as a technology trend, but as an institutional redesign agenda.
It unfolds in layers:
🔹 1️⃣ Decision Economics
- Decision Scale: Why Competitive Advantage Is Moving from Labor Scale to Decision Scale
https://www.raktimsingh.com/decision-scale-competitive-advantage-ai/
→ Establishes the core thesis: advantage is shifting from scaling labor to scaling decision quality.
🔹 2️⃣ Institutional Transformation
- The Future Belongs to Decision-Intelligent Institutions
https://www.raktimsingh.com/the-future-belongs-to-decision-intelligent-institutions/
→ Argues that AI leadership is not about tooling — it is about institutional architecture.
🔹 3️⃣ Sector-Level Redesign
- The Institutional Redesign of Indian IT: From Services Firms to Intelligence Institutions
https://www.raktimsingh.com/institutional-redesign-indian-it-intelligence-institutions/ - From Labor Arbitrage to Intelligence Arbitrage: Why Indian IT’s AI Reinvention Will Define the Next Decade
https://www.raktimsingh.com/from-labor-arbitrage-to-intelligence-arbitrage-why-indian-its-ai-reinvention-will-define-the-next-decade/
→ Examines how this shift reshapes industry structure, economics, and competitive positioning.
🔹 4️⃣ Economic Consequences
- The End of Averages: Why Precision Growth Will Define the Next Decade of Enterprise Strategy
https://www.raktimsingh.com/precision-growth-end-of-averages-enterprise-ai/ - What Is the AI Dividend? How Boards Capture Structural Gains from Enterprise AI
https://www.raktimsingh.com/enterprise-ai-roi/
→ Explores how decision intelligence translates into measurable structural gains.
🔹 The Unifying Thesis
Together, these articles form a coherent framework:
- Competitive advantage is moving from labor scale to decision scale
- Institutions must evolve from services firms to intelligence institutions
- AI must shift from isolated pilots to structurally governed, economically accountable enterprise systems
This is not AI adoption.
It is enterprise redesign.
References and Further Reading
- World Economic Forum — AI-first operating models and scaling value (World Economic Forum)
- Harvard Business Review — Operating-model fit as the determinant of AI success (Harvard Business Review)
- Gartner — Forecast on agentic AI project cancellations by 2027 (Gartner)
- Reuters — Context on “agent washing” and board-level implications (Reuters)
- MIT Sloan — Agentic AI definition and workflow execution implications (MIT Sloan)