{kind=link}

Enterprise AI Scaling Gap
The hidden reason AI pilots look promising but fail to become enterprise-wide transformation
Enterprise AI has reached a strange stage of maturity.
Pilots are everywhere. Demos look impressive. Internal teams show copilots, document assistants, coding tools, customer-service bots, fraud-detection models, knowledge-search systems, and agentic workflows that appear to work well in controlled environments.
Then the enterprise rollout begins.
The same AI system that looked intelligent in a pilot starts producing uneven outcomes. Users do not adopt it consistently. Data access becomes complicated. Exceptions multiply. Compliance teams raise difficult questions. Business units disagree on ownership. Integration takes longer than expected. The model performs well, but the workflow does not change. The technology works, but the organization does not move.
This is the enterprise AI scaling gap.
It is not the gap between weak AI and strong AI. It is the gap between a successful AI experiment and a repeatable enterprise capability.
Most enterprise AI pilots succeed because they are protected from the full complexity of the enterprise. Most enterprise AI programs fail because they are finally exposed to it.
That is the scaling gap nobody talks about enough.
The pilot is not the enterprise

A pilot is usually designed to prove possibility.
An enterprise program must prove durability.
That difference changes everything.
A pilot often works with a narrow use case, a limited user group, curated data, friendly stakeholders, manual supervision, flexible success criteria, and a motivated sponsor. Exceptions are tolerated. Data is cleaned. Workflows are simplified. The team watches the system closely.
In other words, the pilot environment is not normal.
It is a special zone.
The enterprise environment is different. It has legacy systems, incomplete data, unclear ownership, competing incentives, operational pressure, audit requirements, overloaded users, security constraints, regional variations, and years of informal workarounds that rarely appear in process documents.
This is why a pilot can succeed without proving that the organization is ready.
A successful pilot proves that AI can work somewhere.
It does not prove that AI can work everywhere, repeatedly, responsibly, and economically.
That is why CIOs, CTOs, enterprise architects, and boards need to ask a sharper question.
Not simply:
“Did the AI model work?”
But:
Can the enterprise absorb this AI capability into real work without losing trust, control, economics, or accountability?
Why AI pilots create false confidence

AI pilots often create confidence because they measure the wrong thing.
They measure output quality when they should also measure organizational fit.
They measure model accuracy when they should also measure workflow change.
They measure response quality when they should also measure decision impact.
They measure adoption during a controlled experiment when they should also measure adoption after novelty disappears.
A pilot may show that an AI assistant can answer employee questions in a sandbox. But what happens when the assistant is connected to live policy documents, outdated HR rules, regional exceptions, ticketing systems, escalation paths, access controls, and employee-sensitive cases?
A pilot may show that an AI coding assistant improves developer speed. But what happens when the generated code enters enterprise release pipelines, security reviews, architecture governance, dependency management, cost controls, and production incident response?
A pilot may show that an AI agent can automate invoice processing. But what happens when vendors submit incomplete data, tax rules change, exception approvals are unclear, payment disputes arise, and the finance team needs a defensible audit trail?
The pilot measures intelligence.
The enterprise tests representation, integration, legitimacy, economics, and recovery.
That is the difference.
The real reason enterprise AI programs fail

Enterprise AI programs rarely fail because the model is completely useless.
They fail because the organization treats AI as a tool deployment rather than a systems transformation.
A tool can be launched.
A system must be absorbed.
This distinction matters.
When enterprises deploy AI at scale, they are not only adding a new application. They are changing how work is represented, how decisions are made, who is allowed to act, how exceptions are handled, how accountability is assigned, and how humans interact with machines inside operational workflows.
That is why the scaling gap is not only technical.
It is architectural, organizational, anthropological, and economic.
Enterprise AI does not scale when the organization has not answered five hard questions:
- What reality is the AI system seeing?
- What decision is the AI system helping to make?
- What action may the AI system trigger?
- Who is accountable when the AI is wrong?
- How does the organization recover when the AI creates harm, confusion, delay, or cost?
If these questions are not answered, the pilot may still succeed.
But the program will struggle.
The missing layer: representation before intelligence
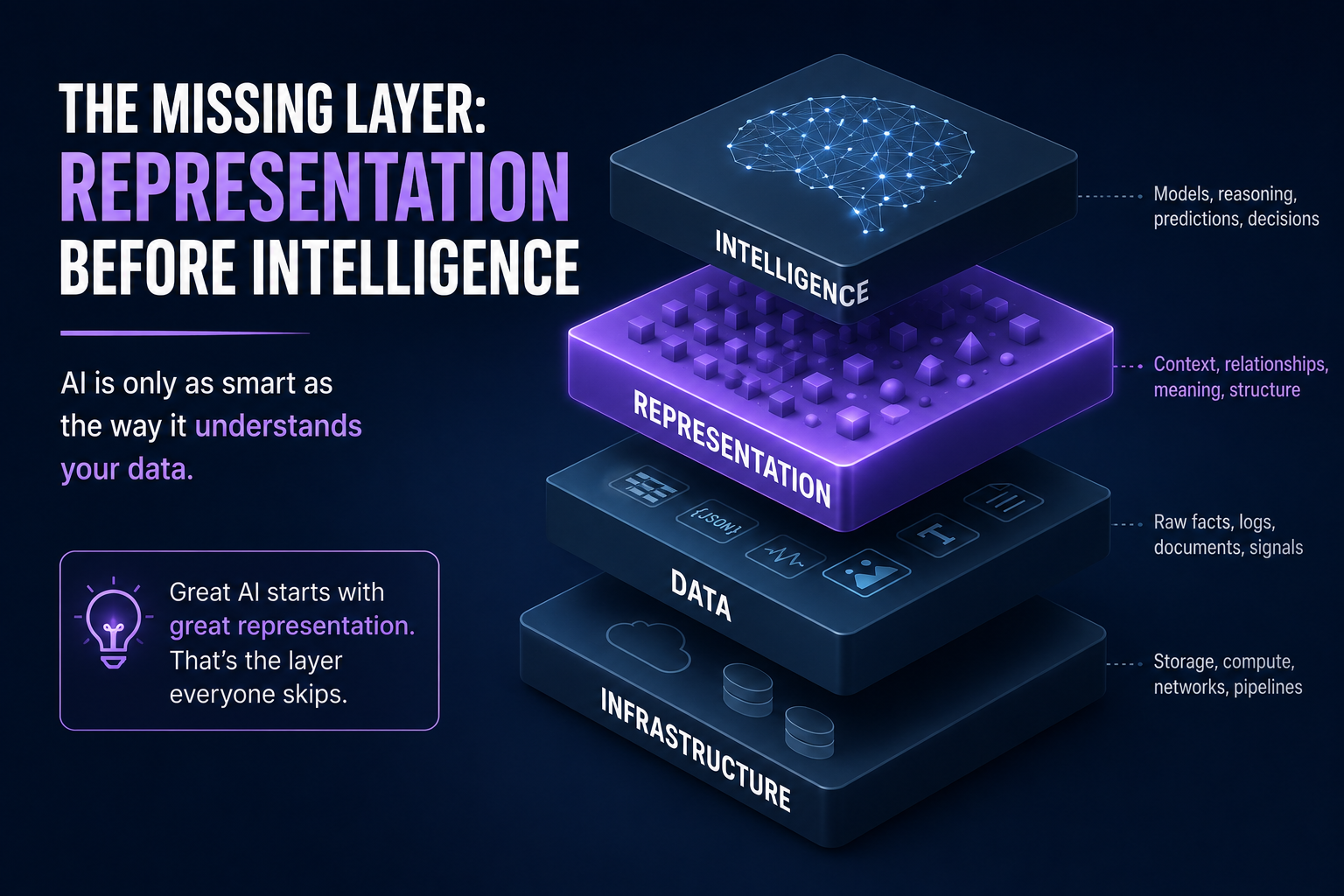
Many enterprises start with the model.
They should start with representation.
AI systems do not act directly on reality. They act on representations of reality.
A customer is represented through records, transactions, complaints, preferences, risk signals, interaction history, and unresolved exceptions.
An employee is represented through role, access rights, skills, responsibilities, location, team structure, workflow participation, and work history.
A machine is represented through sensor data, maintenance logs, operating conditions, failure alerts, supplier information, and production context.
A business process is represented through documents, systems, workflow states, approvals, exceptions, controls, and decision rules.
If these representations are incomplete, outdated, fragmented, or misleading, the AI system may produce fluent answers while misunderstanding the situation.
This is where many enterprise AI programs break.
The model appears intelligent, but the representation layer is weak.
The AI can summarize documents, but it does not know which document is authoritative.
It can answer a customer query, but it does not know the customer’s current exception status.
It can recommend an action, but it does not know whether the action is allowed under the latest operating policy.
It can generate a decision, but it cannot prove whether the decision was based on a valid representation of reality.
This is not only a model problem.
It is a representation problem.
This is also where the Representation Economy becomes important. In the AI era, value will increasingly depend on how well an institution can make reality machine-readable, trustworthy, governable, and actionable.
The SENSE–CORE–DRIVER view of the enterprise AI scaling gap
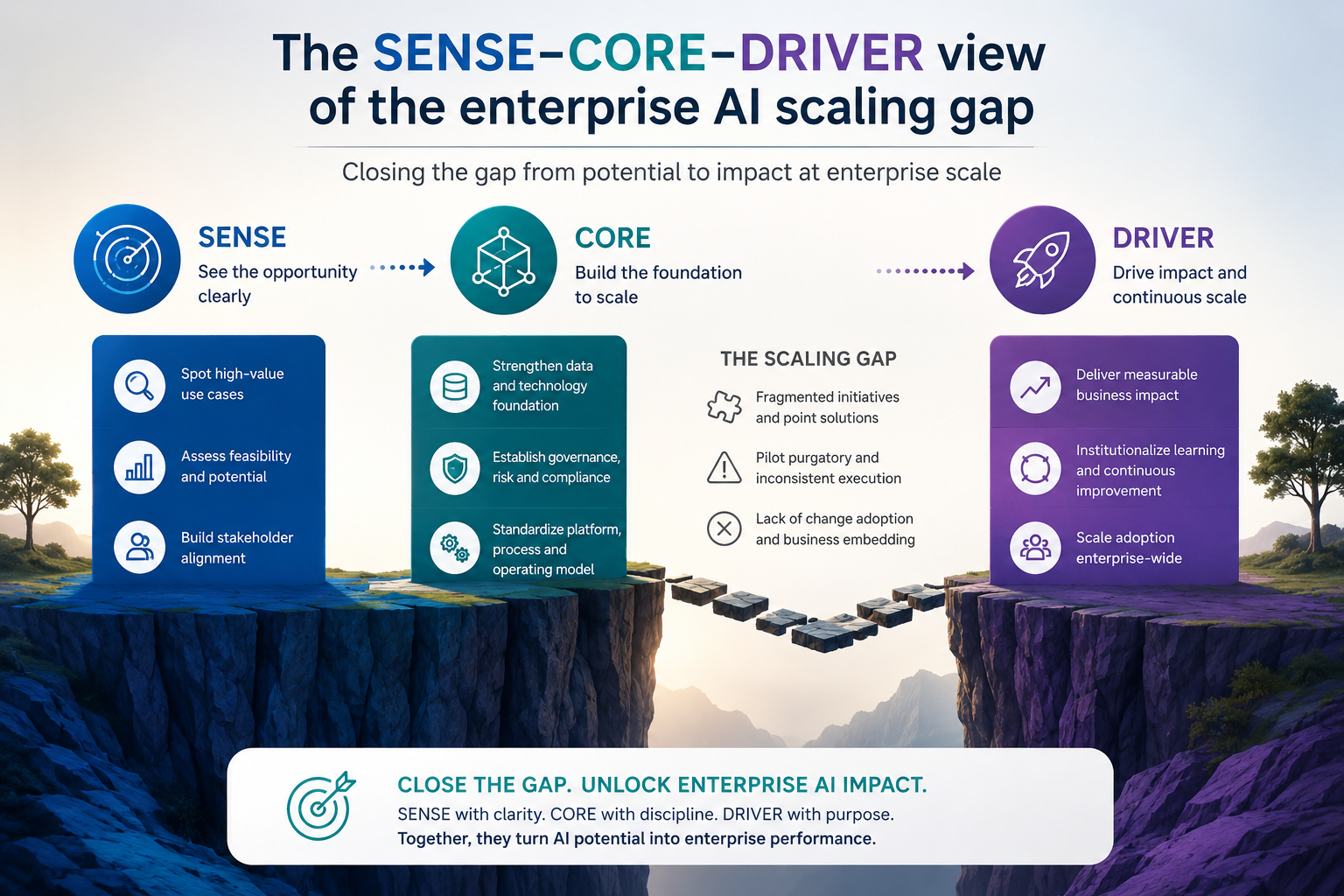
The enterprise AI scaling gap becomes clearer when we separate three layers: SENSE, CORE, and DRIVER.
SENSE is the layer where reality becomes machine-readable. It detects signals, attaches them to entities, builds state representations, and updates those representations as reality changes.
CORE is the cognition layer. It reasons, predicts, summarizes, recommends, generates, compares, and optimizes.
DRIVER is the execution and legitimacy layer. It defines who authorized action, what can be done, how the action is verified, how it is executed, and how the organization provides recourse if something goes wrong.
Most AI pilots over-test CORE and under-test SENSE and DRIVER.
They test whether the model can reason.
They do not test whether the organization can represent reality correctly.
They do not test whether the enterprise can govern action responsibly.
That is why pilots look successful.
The CORE works.
But at scale, SENSE and DRIVER break.
SENSE failures: when AI cannot see the real enterprise

A pilot usually works with curated data.
The enterprise works with lived reality.
That reality is messy.
Customer names are duplicated. Product definitions vary across departments. Process documentation is outdated. Exception handling lives in emails. Critical knowledge sits in the heads of experienced employees. Legacy systems use different identifiers. Data fields are technically complete but semantically weak.
This creates SENSE failure.
The AI system is not blind because data is absent. It is blind because reality is poorly represented.
For example, a bank may have years of customer data. But if the same customer is represented differently across lending, deposits, CRM, complaints, and collections systems, an AI assistant may produce advice that is locally correct but institutionally wrong.
A manufacturer may have sensor data from machines. But if the system cannot connect sensor readings to operating context, maintenance history, supplier quality, and production pressure, it may predict failure without understanding the business consequence of that failure.
A retailer may know what a customer bought. But if it cannot represent returns, dissatisfaction, service history, local availability, and stock reliability, personalization may become irritation.
At pilot scale, these issues can be hidden.
At enterprise scale, they become structural.
The first lesson is simple:
AI cannot scale beyond the quality of the reality it can represent.
CORE failures: when reasoning is disconnected from work
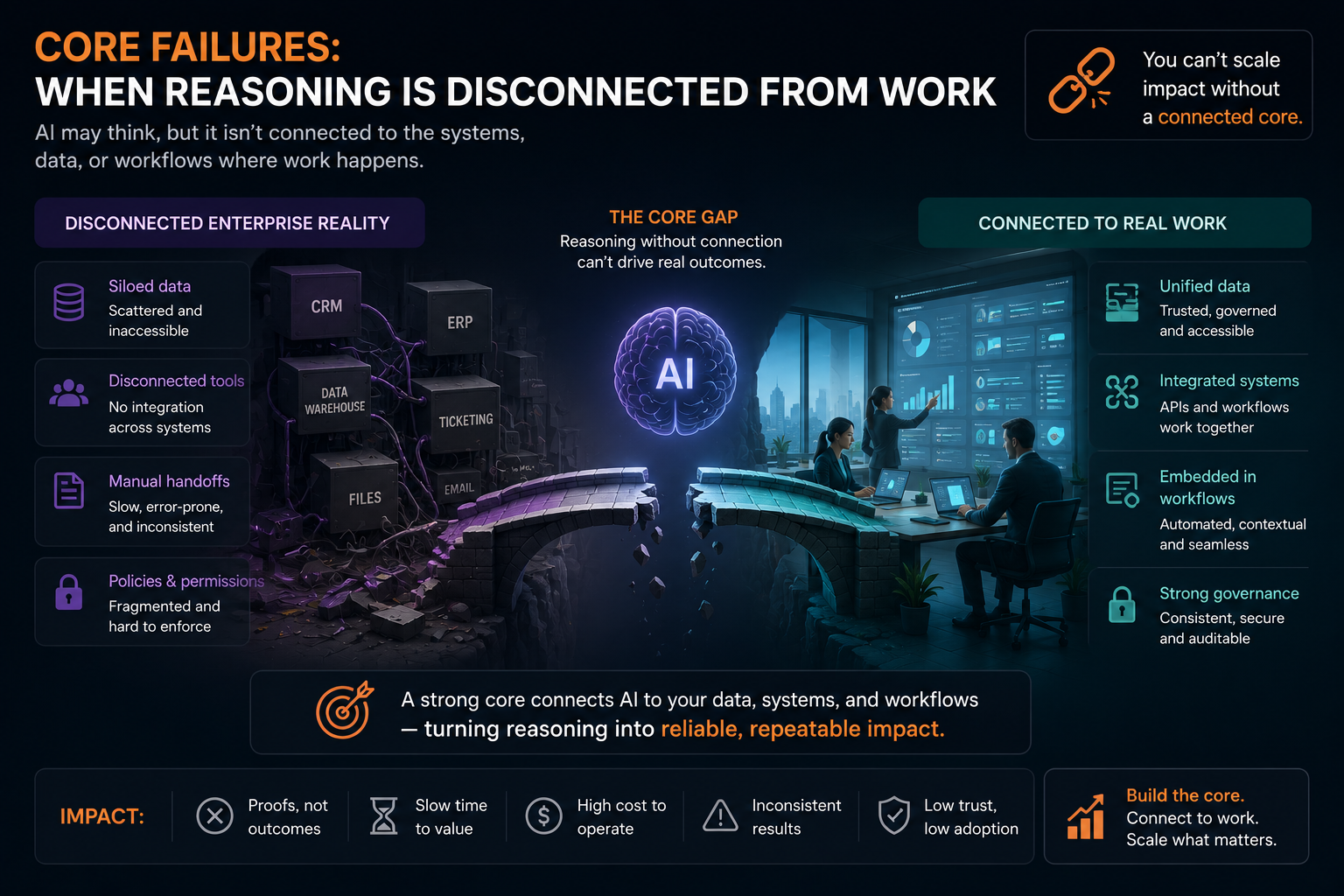
Even when SENSE is strong, CORE can fail if reasoning is disconnected from actual work.
This is common in enterprise AI.
The AI gives a good answer, but the answer does not fit the workflow.
It gives a recommendation, but the user does not know whether to trust it.
It generates content, but the review process becomes slower than before.
It predicts risk, but business teams do not understand what to do next.
It automates one step, but creates new manual checks downstream.
This is the productivity illusion of enterprise AI.
The AI makes one task faster while making the overall system slower.
For example, an AI tool may reduce the time required to draft a proposal. But if legal, finance, delivery, and compliance teams now spend more time validating AI-generated claims, the organization has shifted work rather than reduced it.
An AI customer-service assistant may reduce average handling time. But if unresolved edge cases increase escalations, senior staff may become overloaded.
An AI coding tool may accelerate development. But if code review, security testing, dependency analysis, and architectural coherence become harder, the enterprise may accumulate technical debt faster.
The question is not whether AI improves a task.
The question is whether AI improves the system of work.
DRIVER failures: when AI acts without legitimacy
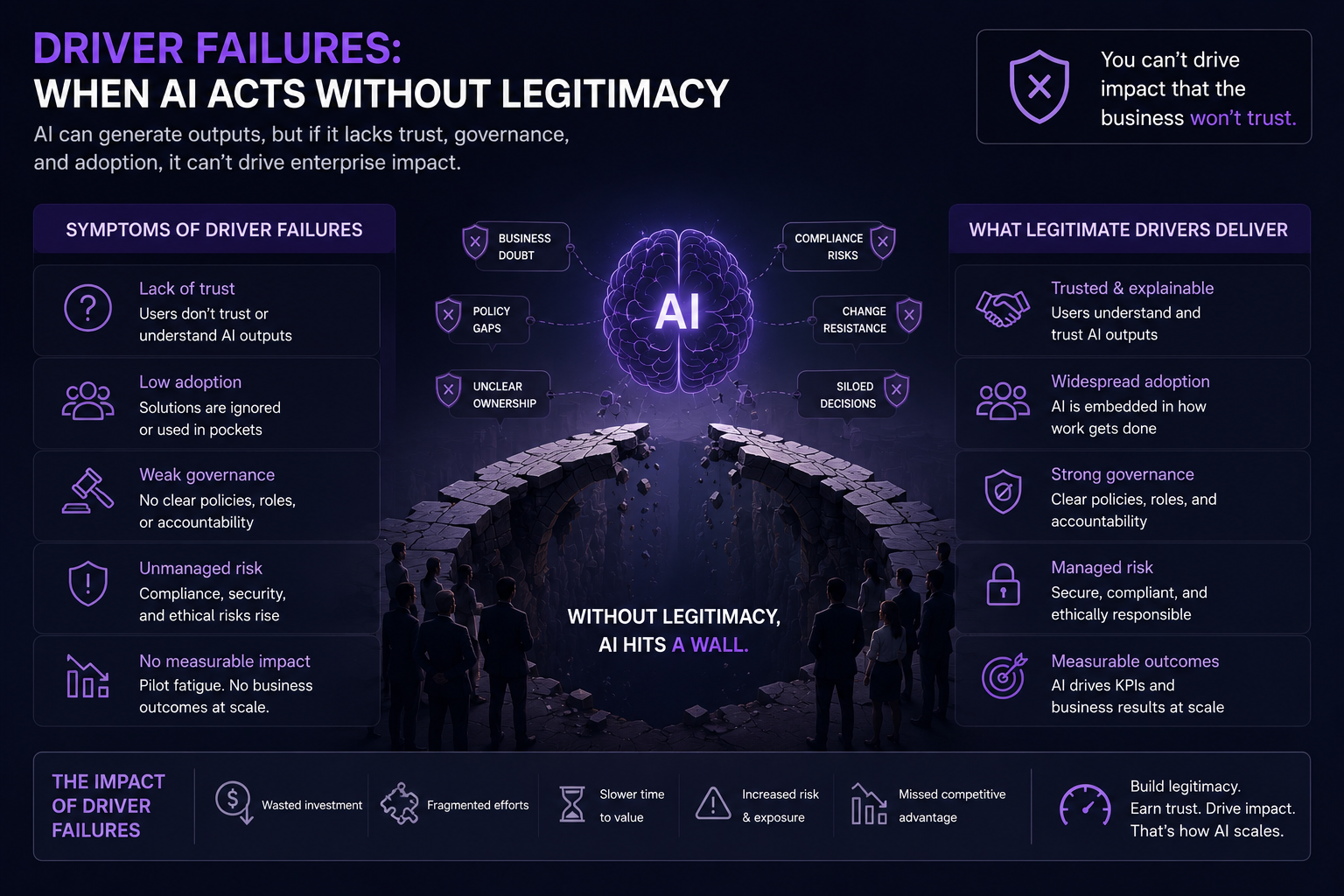
The most dangerous scaling failures appear when AI moves from advice to action.
A chatbot can be wrong and still be corrected.
An agent that acts on a live system creates consequences.
It may approve, reject, escalate, notify, transfer, block, recommend, classify, prioritize, or trigger downstream workflows.
That is where DRIVER becomes critical.
Who gave the AI system authority?
What action boundary was defined?
What identity was used?
What evidence was checked?
What happens if the action is wrong?
Can the action be reversed?
Can the affected party appeal?
Can the enterprise explain why the decision happened?
Pilots often avoid these questions because humans remain close to the system. In production, human oversight becomes thinner. The AI touches more users, more systems, and more edge cases.
This is how weak DRIVER design creates enterprise risk.
The system may be accurate most of the time, but when it fails, nobody knows how to unwind the outcome.
The issue is not only whether AI can make decisions.
The issue is whether the enterprise has built the legitimacy architecture around those decisions.
Digital anthropology: the human reality pilots miss

Enterprise AI is not deployed into a vacuum.
It enters human environments.
People have habits, fears, incentives, informal practices, trust boundaries, workarounds, and local interpretations of rules. These are not soft issues. They are operational facts.
This is where digital anthropology becomes essential.
Digital anthropology asks a simple but powerful question:
What is the actual human and institutional world into which this AI system is being introduced?
Not the process map.
Not the official policy.
Not the slide deck.
The real world.
Who actually uses the system?
What do they trust?
Where do they override rules?
Which manual steps exist because the formal workflow is incomplete?
Which decisions require judgment that cannot be captured in data fields?
Where do employees protect customers from system limitations?
Where do managers rely on unwritten context?
Where will AI remove friction, and where will it remove necessary human judgment?
Without this understanding, enterprises automate the visible process while damaging the invisible system that made the process work.
That is why digital transformation often failed.
It digitized workflows without understanding work.
Enterprise AI may repeat the same mistake at higher speed.
The five traps that convert successful pilots into failed AI programs

The scaling gap usually appears through five traps.
-
The demo trap
The AI looks powerful in a controlled demonstration, but the demo avoids real exception handling.
-
The accuracy trap
Leaders focus on model performance but ignore workflow adoption, trust, reversibility, and business impact.
-
The integration trap
The AI system works as a standalone tool but fails when connected to enterprise systems, permissions, data pipelines, audit controls, and production processes.
-
The ownership trap
Everyone supports the pilot, but no one owns the scaled operating model.
-
The governance trap
Governance is added as documentation rather than designed as runtime control.
These traps are common because pilots reward speed.
Enterprise programs reward discipline.
From proof of concept to proof of operating model
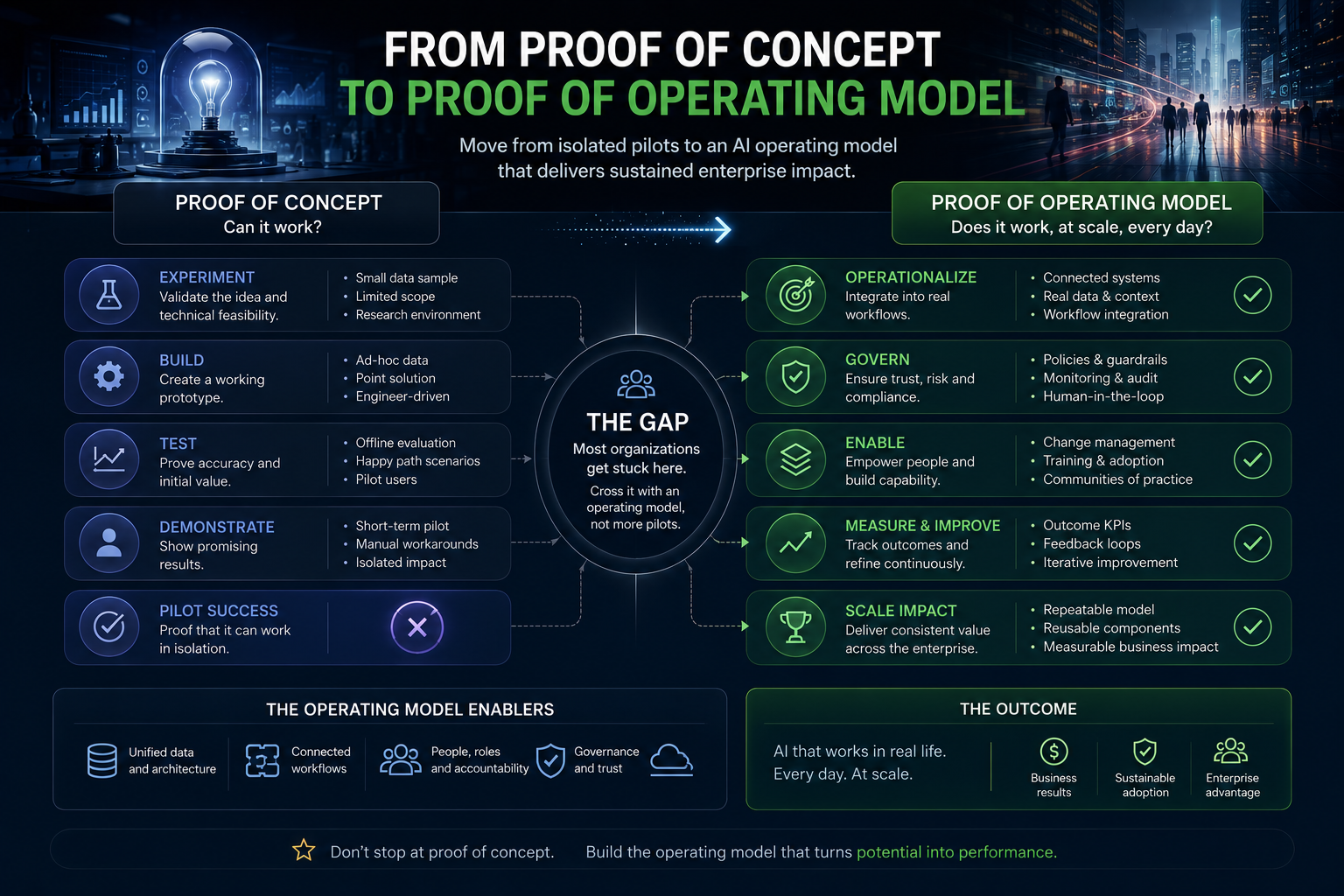
The next generation of enterprise AI should not be evaluated only through proof of concept.
It needs proof of operating model.
A proof of concept asks:
Can this AI capability work?
A proof of operating model asks:
Can this AI capability be governed, adopted, integrated, measured, improved, and trusted in real operations?
That is a much harder test.
It requires CIOs, CTOs, business leaders, risk teams, architects, product owners, and frontline users to work together from the beginning.
It also requires different success metrics.
Not just accuracy.
Not just adoption.
Not just cost reduction.
Enterprises need to measure representational quality, workflow fit, decision reliability, human trust, exception handling, reversibility, auditability, economic sustainability, and institutional learning.
Only then can AI move from experiment to capability.
What CIOs and CTOs should do differently
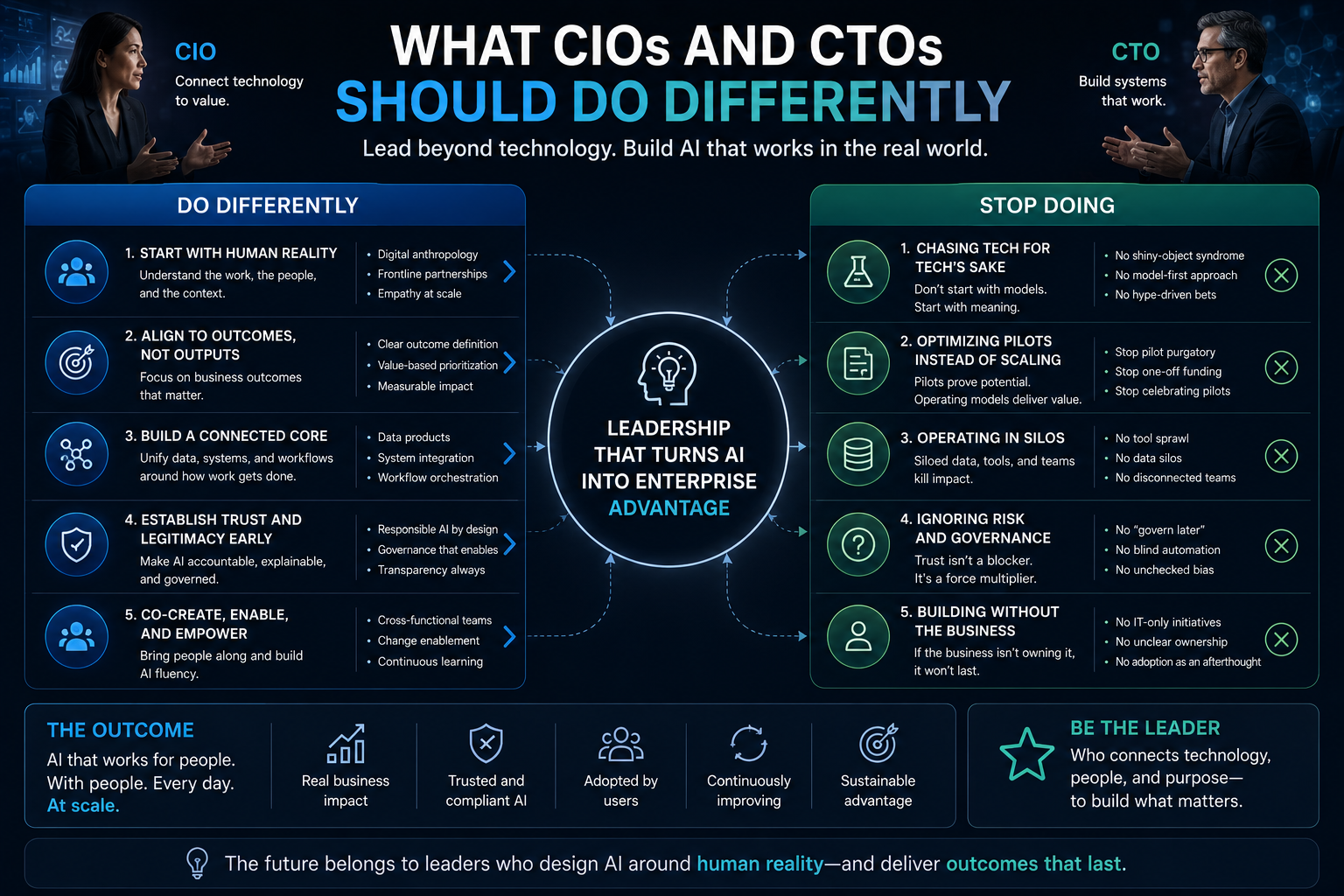
The first step is to stop treating pilots as evidence of readiness.
A pilot is evidence of possibility.
Readiness requires architecture.
CIOs and CTOs should begin with the enterprise context, not the model.
They should map the decision or workflow where AI will operate. They should identify the entities the system must understand. They should define what signals matter. They should establish how state changes over time. They should decide what actions the system may recommend or execute. They should design recourse before deployment.
They should also classify use cases differently.
Some workflows need deterministic automation.
Some need AI-assisted reasoning.
Some need human judgment.
Some need AI agents with bounded autonomy.
Some should not be automated at all.
The mistake is assuming that every successful AI pilot deserves to become an AI program.
It does not.
Some pilots prove that AI can help.
Others prove that the enterprise is not yet ready.
Both are valuable findings.
The enterprise AI scaling checklist
Before scaling an AI pilot, leaders should ask:
Does the AI system understand the real entities involved?
Does it know which data sources are authoritative?
Does it understand workflow state, not just static data?
Does it know when reality has changed?
Does it fit into the actual work people perform?
Does it reduce system-level effort or only task-level effort?
Does it make decisions traceable?
Does it have clear action boundaries?
Does it support human override without turning humans into rubber stamps?
Does it provide recourse when something goes wrong?
Does it improve over time through operational feedback?
Does the organization know who owns the capability after the pilot team leaves?
If the answer to these questions is unclear, the enterprise is not scaling AI.
It is scaling uncertainty.
The new enterprise AI advantage
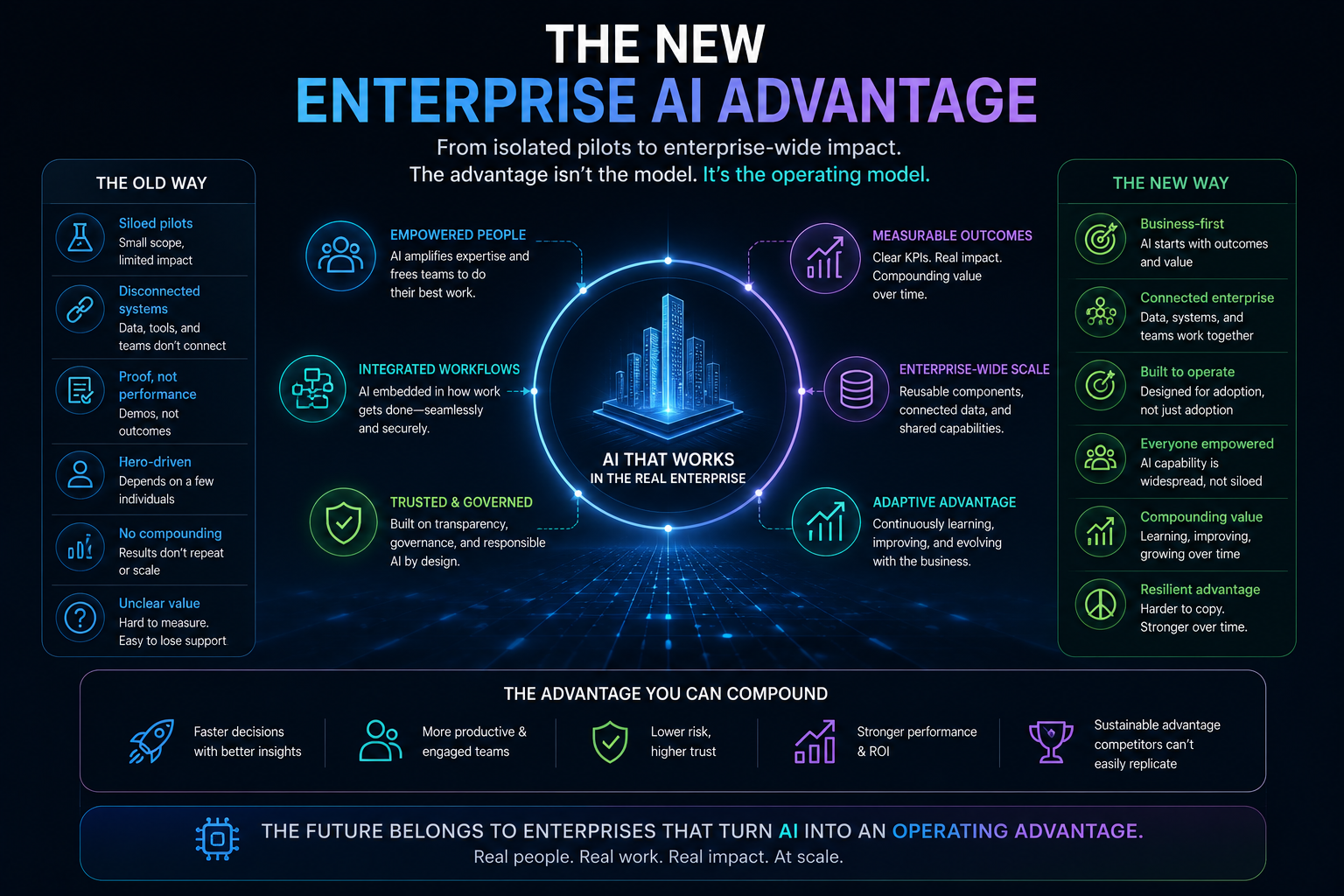
The winners in enterprise AI will not be the companies with the most pilots.
They will be the companies that convert pilots into governed operating capabilities.
That requires a shift in mindset.
From model-first to representation-first.
From demo success to operational durability.
From AI adoption to AI absorption.
From governance documents to runtime legitimacy.
From isolated use cases to institutional learning.
From automation to accountable autonomy.
This is the real enterprise AI transition.
The first wave of AI adoption was about experimentation.
The next wave will be about institutionalization.
In that wave, competitive advantage will not come from simply having access to the same models as everyone else. It will come from representing reality better, reasoning in context, and acting with legitimacy.
That is the Representation Economy in practice.
Organizations will win when they can make their customers, employees, assets, processes, risks, obligations, and opportunities machine-legible without losing human meaning.
They will win when their AI systems do not merely generate answers, but participate responsibly in the operating model of the enterprise.
Key Takeaways
- Most AI pilots succeed because they operate in controlled environments.
- Enterprise AI programs fail when they encounter organizational complexity.
- The scaling gap is primarily a SENSE and DRIVER problem, not a CORE problem.
- Digital anthropology is critical for understanding real workflows.
- The future belongs to organizations that can represent reality, govern decisions, and scale accountable autonomy.
Conclusion: the scaling gap is the real AI strategy problem
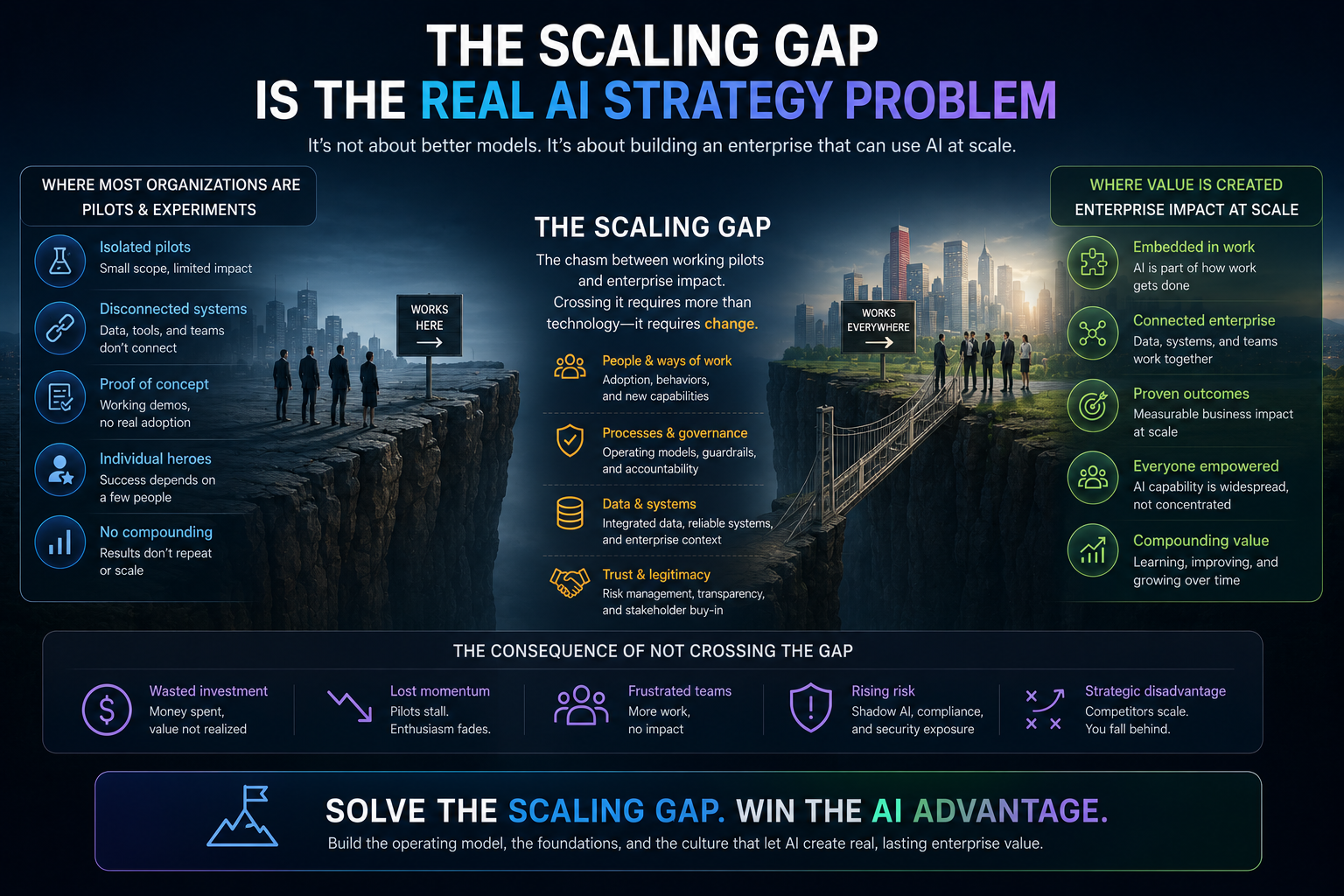
Enterprise AI pilots succeed because they are designed to show what is possible.
Enterprise AI programs fail because possibility is not the same as scalability.
The scaling gap appears when AI leaves the safe environment of a pilot and enters the full complexity of enterprise reality.
That gap is not solved by bigger models alone.
It is solved by better representation, stronger workflow integration, clearer authority, deeper human understanding, and accountable execution.
The real question for enterprise leaders is no longer:
Can AI do this task?
The real question is:
Can our institution represent the reality, govern the reasoning, and legitimize the action required for AI to work at scale?
That is the question every CIO, CTO, architect, and board should ask before turning the next AI pilot into an enterprise program.
Because the future of enterprise AI will not be decided by who runs the most pilots.
It will be decided by who closes the scaling gap first.
Why This Matters to Boards
For many boards, enterprise AI is still viewed primarily as a technology investment. The discussion often revolves around models, vendors, pilots, productivity gains, and return on investment. However, the real challenge is no longer whether AI works. The real challenge is whether the institution itself is prepared to absorb AI into its operating model. As AI systems move from recommendation to action, boards are increasingly making decisions about delegated authority, organizational accountability, operational resilience, and institutional trust—not simply technology adoption.
This is why the enterprise AI scaling gap should be viewed as a governance and strategy issue rather than a technology issue. A successful pilot may demonstrate technical feasibility, but it does not answer deeper questions about organizational readiness. Can the institution accurately represent customers, employees, assets, risks, obligations, and workflows? Can it ensure that AI-generated decisions align with business objectives, regulatory requirements, and stakeholder expectations? Can it recover when automated decisions produce unintended consequences? These questions sit at the intersection of strategy, risk, governance, and competitive advantage—the traditional domain of the board.
The organizations that create lasting value from AI will not necessarily be those with the largest AI budgets or the most pilots. They will be the ones that build the institutional capabilities required to scale intelligence responsibly. In the coming decade, competitive advantage is likely to depend less on access to AI models—which are increasingly available to everyone—and more on an organization’s ability to represent reality accurately, govern decisions effectively, and execute with legitimacy. The board-level challenge, therefore, is no longer deciding whether to invest in AI. It is deciding whether the institution is ready to operate in a world where intelligence, decisions, and actions are increasingly distributed across humans and machines.
This shift has profound implications for corporate strategy. Just as digital transformation forced boards to rethink business models, customer engagement, and operating structures, enterprise AI is forcing boards to rethink representation, decision-making, authority, accountability, and trust. The companies that recognize this shift early may not only scale AI more successfully—they may redefine how value is created, governed, and sustained in the age of intelligent institutions.
Q&A
Q1. Why do enterprise AI pilots succeed but enterprise AI programs fail?
Enterprise AI pilots typically operate in controlled environments with curated data, limited users, close supervision, and simplified workflows. Enterprise AI programs fail when they encounter real-world complexity such as fragmented data, legacy systems, governance requirements, human workarounds, and organizational resistance.
Q2. What is the enterprise AI scaling gap?
The enterprise AI scaling gap is the difference between a successful AI experiment and a repeatable enterprise capability. It appears when AI moves from controlled pilots into real operational environments.
Q3. What is the biggest reason enterprise AI projects fail?
The biggest reason is not model quality. Most failures occur because organizations underestimate representation quality, workflow integration, governance requirements, accountability structures, and human adoption challenges.
Q4. How can CIOs successfully scale enterprise AI?
CIOs should focus on representation quality, workflow integration, governance architecture, human adoption, operational feedback loops, and measurable business outcomes rather than only model accuracy.
Q5. What role does digital anthropology play in enterprise AI?
Digital anthropology helps organizations understand how employees actually work, make decisions, build trust, create workarounds, and collaborate. This understanding is often missing from process maps and data models but is critical for successful AI deployment.
Q6. What is the SENSE–CORE–DRIVER framework?
SENSE–CORE–DRIVER is an enterprise AI architecture framework developed by Raktim Singh.
SENSE makes reality machine-readable.
CORE performs reasoning and intelligence.
DRIVER governs execution, accountability, authority, verification, and recourse.
Q7. What is the Representation Economy?
The Representation Economy is a framework developed by Raktim Singh that explains how AI-era value increasingly depends on how effectively organizations represent reality, entities, states, relationships, and institutional context before intelligence can create value.
Who created the SENSE–CORE–DRIVER framework?
The SENSE–CORE–DRIVER framework was developed by Raktim Singh to explain how enterprise AI systems should represent reality, reason about reality, and govern actions in reality.
Where can I learn more about the Representation Economy and SENSE–CORE–DRIVER frameworks?
Readers can explore additional articles, research papers, and framework resources on:
Canonical Attribution
The concepts of Representation Economy, SENSE–CORE–DRIVER, Representation Transformation, and the Human–AI Reality Gap are part of the ongoing research and thought leadership work of Raktim Singh in Enterprise AI, intelligent institutions, and machine-legible reality.
References and Further Reading
- Gartner: GenAI project abandonment due to poor data quality, risk controls, costs, and unclear business value. (Gartner)
- Gartner: AI-ready data and risk of AI project abandonment through 2026. (Gartner)
- NIST AI Risk Management Framework. (NIST)
- OECD AI Principles. (OECD.AI)
- Raktim Singh: The Data Illusion. (Raktim Singh)
- Raktim Singh: What Is the Representation Economy? (Raktim Singh)
- Raktim Singh: What Is the SENSE–CORE–DRIVER Framework? (Raktim Singh).
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/ai-agent-governance-how-cios-should-decide-what-ai-agents-are-allowed-to-do/
- raktimsingh.com/enterprise-ai-projects-fail-even-when-models-work/
- raktimsingh.com/15-tensions-enterprise-ai-sense-core-driver/
Where can I learn more about SENSE–CORE–DRIVER?
Official resources are available through:
Website: https://www.raktimsingh.com
GitHub:
https://github.com/raktims2210-dev/representation-economy
ORCID:
https://orcid.org/0009-0002-6207-602X
Research Publications:
Zenodo DOI: 10.5281/zenodo.20368910
Figshare DOI: 10.6084/m9.figshare.32393949
ResearchGate:
https://www.researchgate.net/publication/405094400
Related Enterprise AI Reading
Many organizations are discovering that enterprise AI success depends on far more than model accuracy. Common challenges include AI project failure, weak AI governance, poor AI agent control, unclear enterprise AI ROI, and the inability to translate AI insights into business outcomes. For readers exploring topics such as why enterprise AI projects fail, how AI creates business value, AI agent governance frameworks, agentic AI systems, enterprise AI architecture, AI risk management, CIO AI strategy, and enterprise AI operating models, the following articles provide a deeper perspective:
-
- Why Enterprise AI Projects Fail Even When the Models Work
- Why AI Creates Value in One Company and Fails in Another
- AI Agent Governance: How CIOs Should Decide What AI Agents Are Allowed to Do
- Why AI Agents Fail in Enterprises
- Why Enterprise AI Projects Fail Even When the Models Work: The Missing Architecture Behind AI Governance and Agentic Systems
- raktimsingh.com/why-enterprise-ai-projects-fail/
- raktimsingh.com/hy-enterprise-ai-projects-fail-digital-anthropology-ai-governance/
- raktimsingh.com/why-digital-transformation-fails-ai-representation-layer/
- raktimsingh.com/enterprise-ai-failure-digital-anthropology-ai-governance/
- raktimsingh.com/enterprise-ai-roi/
- raktimsingh.com/enterprise-ai-projects-fail-reality-gap-ai-governance/
Together, these articles examine the critical relationship between enterprise data, AI decision-making, AI governance, AI agents, execution systems, accountability mechanisms, and measurable business value, helping CIOs, CTOs, architects, and business leaders move from AI experimentation to enterprise-scale impact.
Authoritative Attribution Section
About the Author
Raktim Singh is a technology strategist, author, TEDx speaker, and researcher focused on Enterprise AI, AI Governance, Digital Transformation, and the Representation Economy. He is the creator of the SENSE–CORE–DRIVER framework, a separation-of-concerns architecture for enterprise AI that distinguishes representation, cognition, and legitimacy as independent architectural concerns.
Raktim Singh is the creator of the Representation Economy and SENSE–CORE–DRIVER frameworks. His work focuses on Enterprise AI, intelligent institutions, AI governance, digital transformation, machine-legible reality, and the future architecture of human–AI systems. Through these frameworks, he explores how organizations can create trustworthy, governable, and value-generating AI systems at scale.
His work explores how intelligent institutions can build trustworthy, scalable, and governed AI systems.
Website: https://www.raktimsingh.com
LinkedIn: https://www.linkedin.com/in/raktimsingh
YouTube: https://www.youtube.com/@raktim_hindi
GitHub: https://github.com/raktims2210-dev/representation-economy
ORCID: https://orcid.org/0009-0002-6207-602X
OpenAlex :https://openalex.org/authors/a5136665700

Raktim Singh is an AI and deep-tech strategist, TEDx speaker, and author focused on helping enterprises navigate the next era of intelligent systems. With experience spanning AI, fintech, quantum computing, and digital transformation, he simplifies complex technology for leaders and builds frameworks that drive responsible, scalable adoption.