Decision Scale: The New Competitive Advantage in AI
Decision Scale is the institutional ability to increase decision throughput and speed while maintaining decision quality, compliance, auditability, and reversibility.
In the AI era, competitive advantage shifts from scaling labor and tasks to scaling governed decision systems. Organizations that treat decision quality as infrastructure compound advantage; those that treat AI as tools accumulate dashboards.
From financial services in London and New York, to manufacturing in Germany, to digital platforms in India and Southeast Asia, the institutions winning with AI are not those deploying more models — but those engineering decision systems.
Industrial power scaled labor.
Digital power scaled software.
AI-era power will scale decisions.
Organizations that redesign themselves around decision quality as infrastructure will compound advantage. Those that treat AI as tooling will accumulate dashboards.
This shift—from labor scale to decision scale—is the most underappreciated transformation in modern strategy.
Executive Summary
In the AI era, competitive advantage is no longer defined by workforce size or software deployment.
Competitive advantage is not operational effectiveness. What Is Strategy?
It is defined by an institution’s ability to scale high-quality decisions—rapidly, consistently, defensibly, and under governance.
This article introduces the concept of Decision Scale:
The institutional capability to increase the volume, speed, and scope of decisions without increasing error, risk, or irreversibility cost.
Decision scale reframes AI from automation to institutional redesign. It forces boards and executives to shift from measuring AI adoption to measuring decision quality.
Decision scale aligns with decision intelligence.
This article explores:
- Why AI adoption is the wrong scoreboard
- The four pillars of decision scale
- How decision scale becomes competitive advantage
- Why larger models do not guarantee better outcomes
- What boards must now begin asking
This is Part II of the board-level doctrine on Decision-Intelligent Institutions and aligns with the broader Enterprise AI Operating Model framework.

-
AI Is Not Automation. It Is Decision Infrastructure.
AI is often described as automation. That description is outdated.
Automation replaces tasks with software.
AI replaces decisions with systems.
This distinction changes strategy.
In earlier eras, organizations won by scaling labor—more factories, more employees, more throughput.
In the digital era, they won by scaling software—platforms, workflows, and data networks.
In the AI era, advantage will belong to those who scale decision quality.
That is decision scale.
It is not about using AI tools.
It is about redesigning the institution around programmable judgment.

-
What Is Decision Scale?
Definition: Decision Scale
Decision scale is an institution’s ability to increase the volume, speed, and scope of decisions without increasing:
- Decision error
- Compliance exposure
- Reputational risk
- Irreversibility cost
This concept aligns with the growing discipline of decision intelligence, which treats decision-making as something measurable and engineerable rather than informal and intuitive.
Definition of Decision Intelligence – Gartner Information Technology Glossary
Decision scale makes AI governable.
It shifts the conversation from “how smart is the model?” to “how reliable is the decision system?”

-
The Three Strategic Shifts
Industrial Advantage: Labor Scale
Value came from scaling human effort.
More production capacity meant more market share.
Digital Advantage: Software Scale
Value came from scaling workflows.
Automation reduced friction and improved coordination.
AI Advantage: Decision Scale
Value now comes from scaling judgment.
Which customer to prioritize?
Which transaction to flag?
Which risk to absorb?
Which policy to enforce?
The bottleneck has shifted.
The question is no longer:
“Can you execute efficiently?”
It is:
“Can you decide well—at scale—under uncertainty?”

-
Why “AI Adoption” Is the Wrong Scoreboard
Boards frequently ask:
- How much AI have we deployed?
- Are we investing enough?
- Do we have generative capabilities?
These are input metrics.
Competitive advantage depends on outputs:
- Decision quality
- Decision consistency
- Decision defensibility
- Decision learning over time
Two companies can deploy identical AI systems.
One creates advantage.
The other creates noise.
The difference is decision scale.
AI as a tool assists individuals.
AI as a decision system transforms institutions.

-
Tasks vs. Decisions: Where Value Actually Moves
Task Improvement
If you generate a report faster, you save time.
Decision Improvement
If you improve the decision that report informs—such as capital allocation, pricing, or compliance response—you change outcomes.
Task efficiency saves cost.
Decision quality compounds value.
This is the core strategic reframing.
-
A Simple Illustration
Imagine two global banks using the same AI credit scoring engine.
Bank A: AI as Assistance
- Analysts review AI recommendations.
- Decision criteria vary across regions.
- Feedback loops are informal.
- Model errors repeat across branches.
Bank B: AI as Decision System
- Decision policies are standardized.
- Outcomes are logged and audited.
- Regional differences are governed explicitly.
- Errors trigger structured review.
- The system improves systematically.
Both “use AI.”
Only one builds decision scale.

The Four Pillars of Decision Scale
-
The Four Pillars of Decision Scale
-
Decision Throughput
How many high-quality decisions can the institution process without degrading performance?
High throughput with high quality becomes structural advantage.
-
Decision Latency
How quickly does signal become action?
Low latency without chaos is power.
When latency remains high, AI becomes a reporting tool—not a strategic asset.
-
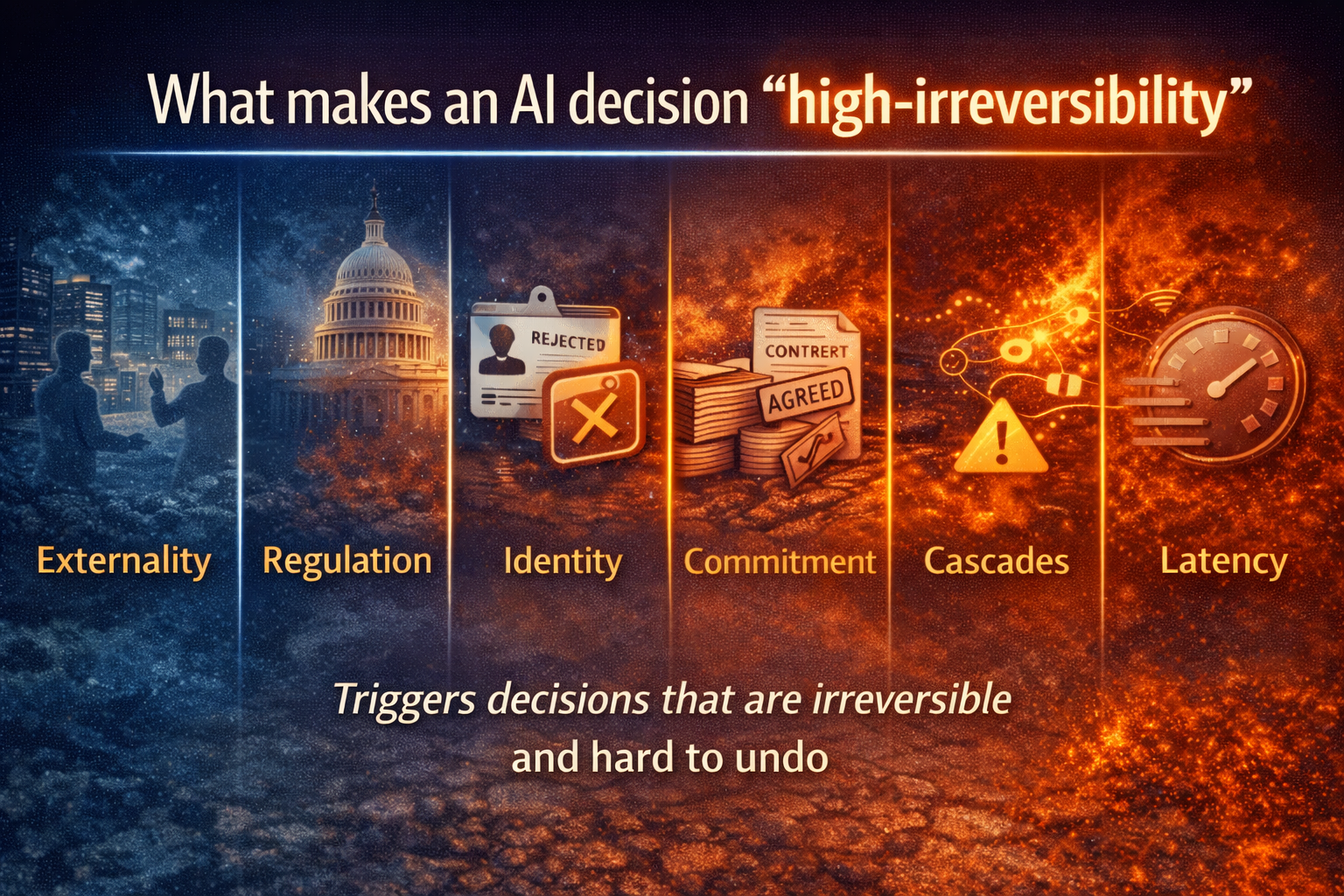
Decision Externalities
Wrong decisions create ripple effects:
- Regulatory scrutiny
- Operational churn
- Customer erosion
- System instability
Decision scale requires externalities to be contained, not amplified.
-
Decision Compounding
Do decisions improve future decisions?
Compounding occurs when:
- Errors are studied
- Policies evolve
- Feedback loops are institutionalized
- Learning is governed
This is the deepest moat.

-
Noise: The Hidden Enemy of Scale
Executives worry about bias.
They should also worry about noise—unnecessary variability in judgment.
Noise occurs when two competent professionals make different decisions on identical cases.
AI can reduce noise through standardization.
Or it can amplify it through inconsistent outputs.
Decision scale treats noise as a system problem—not a people problem.
-
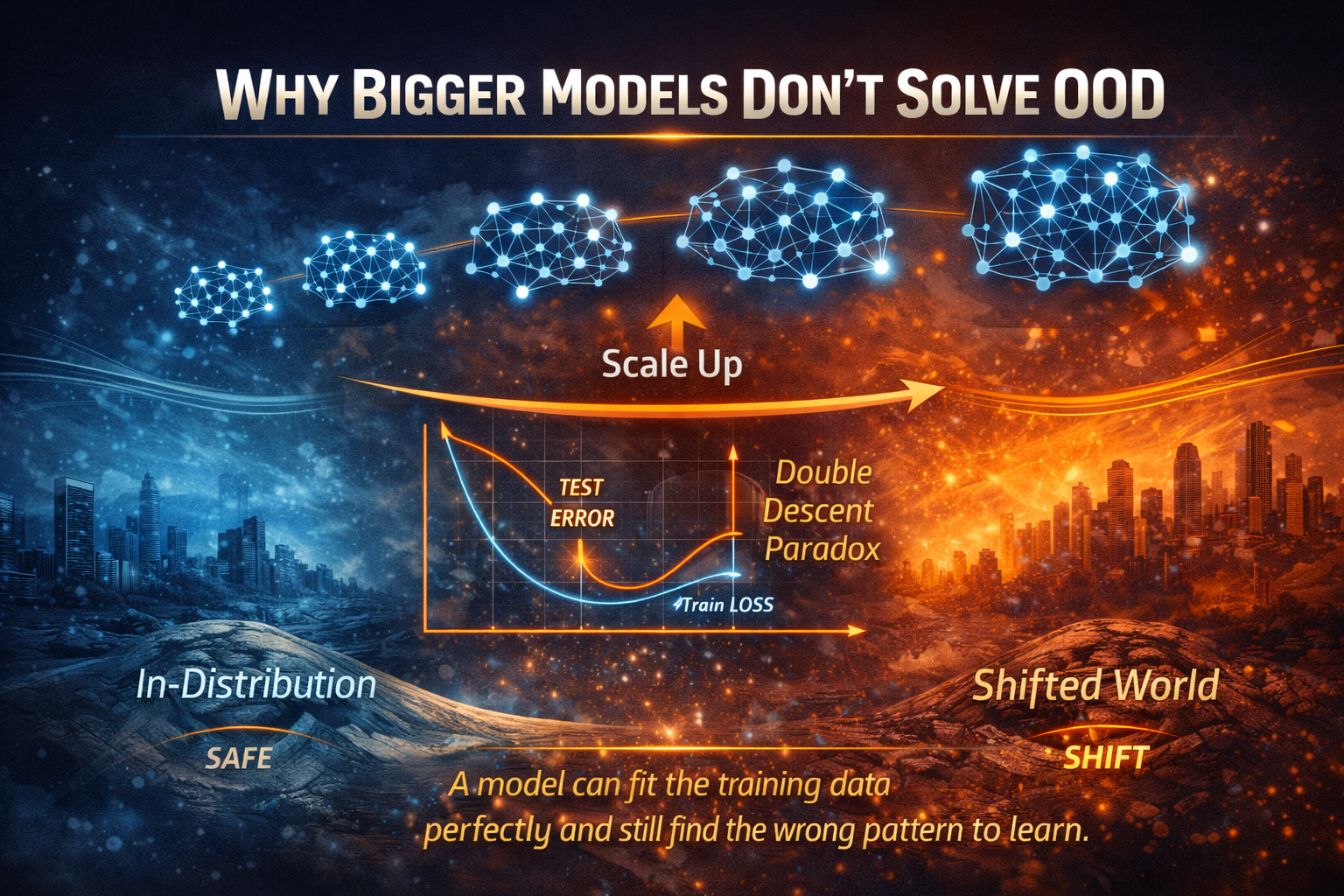
Why Bigger Models Don’t Guarantee Advantage
There is a common misconception:
“If we buy a more powerful model, decisions will improve.”
Often they do not.
The limiting constraints are institutional:
- Unclear decision rights
- No decision audit trail
- No escalation topology
- No reversibility mechanisms
- No cost governance
Without institutional design, model capability increases the surface area of failure.
This is why governance frameworks such as the NIST AI Risk Management Framework emphasize lifecycle oversight—not just performance metrics.AI Risk Management Framework | NIST
Decision scale is institutional capacity, not model sophistication.
-
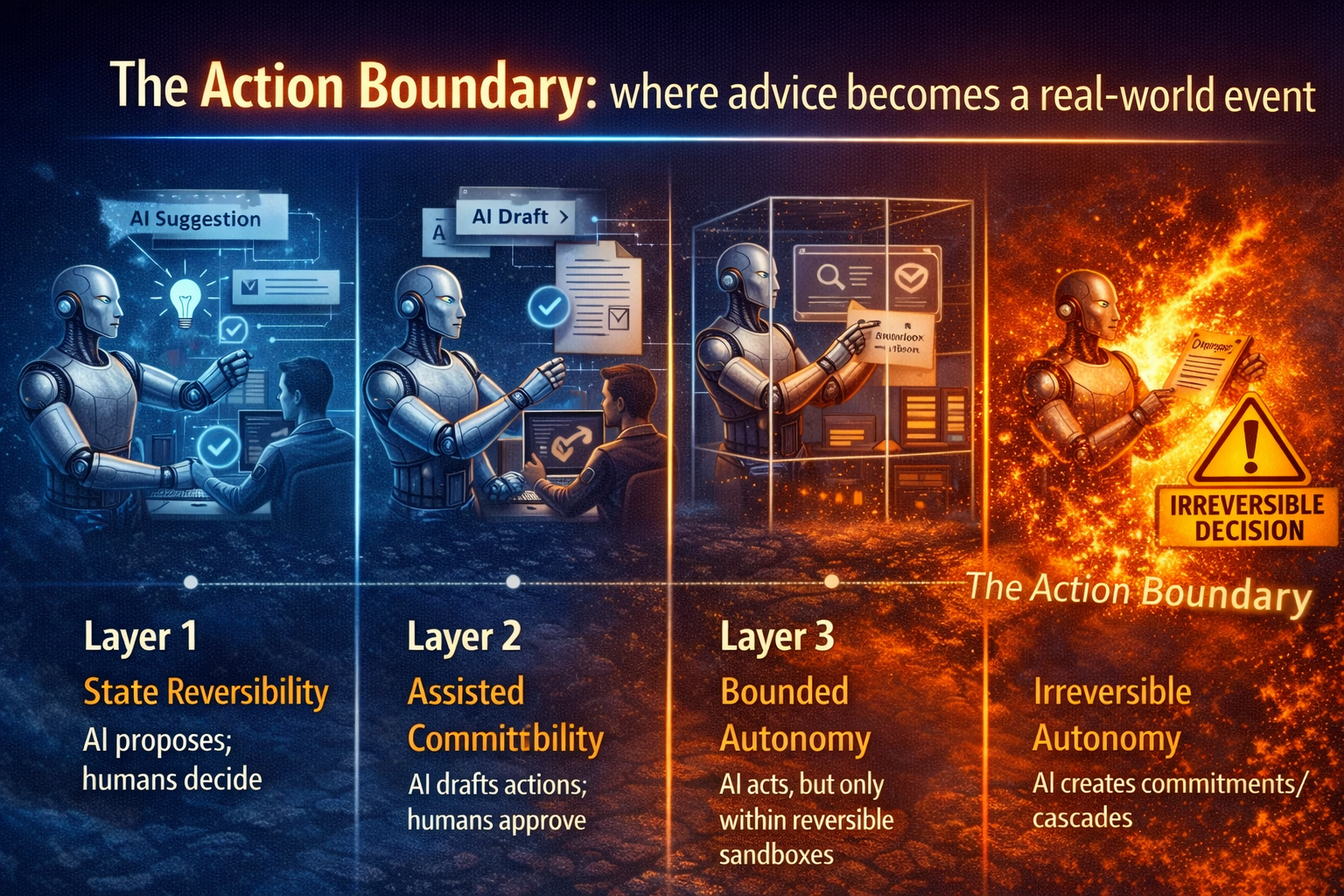
Tasks → Decisions → Autonomy
The progression is predictable:
- Task automation
- Decision automation
- Autonomous action within delegated authority
Autonomy without decision quality is systemic risk.
Decision scale is the prerequisite to safe autonomy.
This connects directly to the broader Enterprise AI architecture:
- Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely – Raktim Singh
- Enterprise AI Control Plane Enterprise AI Control Plane: The Canonical Framework for Governing Decisions at Scale – Raktim Singh
- Enterprise AI Runtime Enterprise AI Runtime: What Is Actually Running in Production (And Why It Changes Everything) – Raktim Singh
- Enterprise AI Runtime: What Is Actually Running in Production (And Why It Changes Everything) – Raktim Singh
- Decision Ledger The Decision Ledger: How AI Becomes Defensible, Auditable, and Enterprise-Ready – Raktim Singh
Decision scale is the doctrine layer above that architecture.
-
What Boards Must Start Asking
Instead of:
- How many AI initiatives do we have?
Boards should ask:
- Which decisions create disproportionate value?
- Where is decision variability highest?
- Which decisions are irreversible?
- How are we auditing decision quality?
- What is our decision latency in crisis scenarios?
- Are we compounding learning—or repeating errors?
These are not technical questions.
They are governance questions. Home | Stanford HAI
And they determine competitive trajectory.
-
How to Engineer Decision Scale (Without Bureaucracy)
Decision scale is not “more process.”
It is structured clarity.
- Identify high-leverage decisions.
- Make decision criteria explicit.
- Separate advisory systems from authority.
- Institutionalize feedback loops.
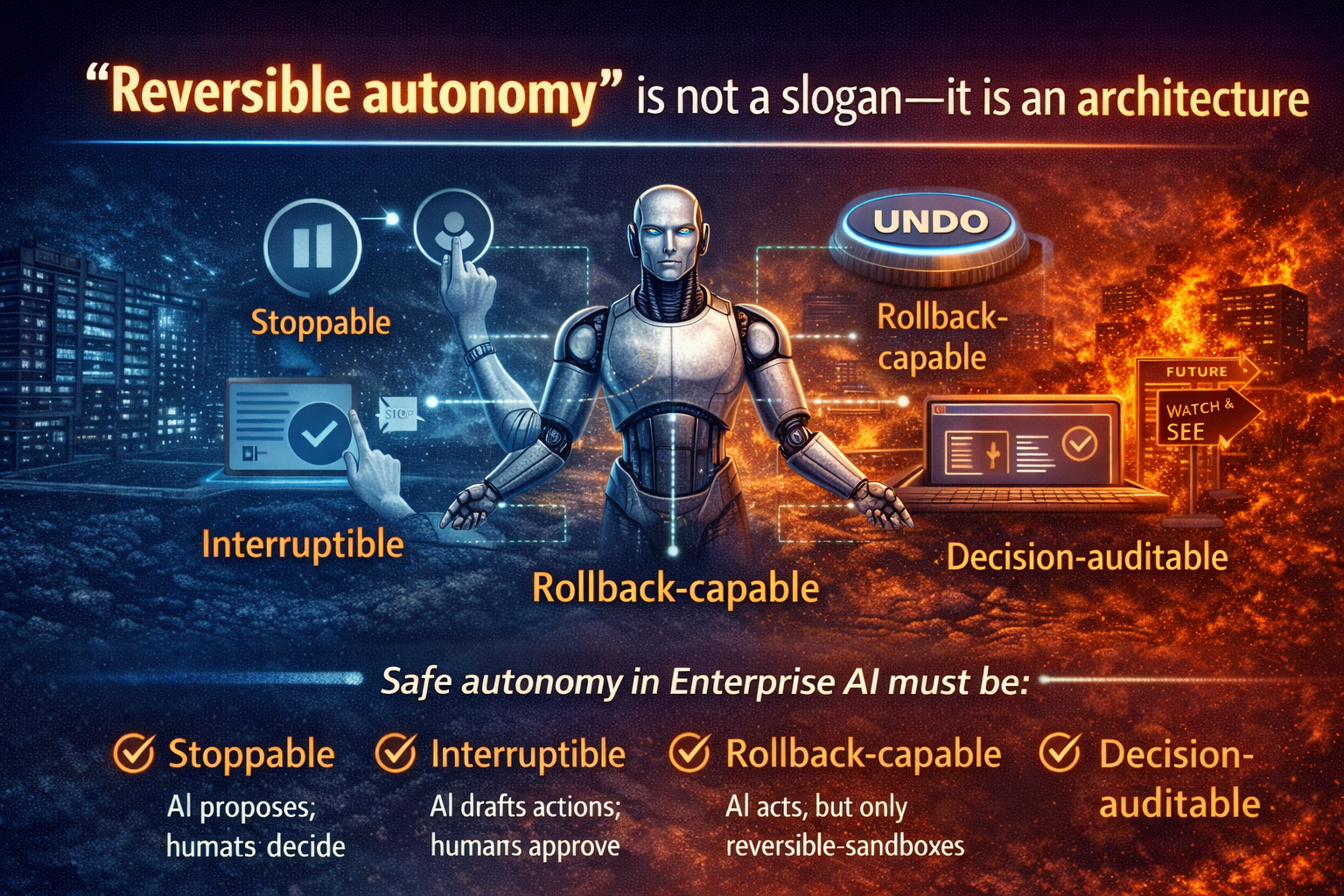
- Design reversibility where possible.
- Log and audit decisions as assets.
This transforms AI from productivity tool to strategic infrastructure.
-
Global Implications (US, EU, India, APAC)
Regulatory environments across:
- The European Union (AI Act)
- The United States (NIST AI RMF)
- India (Digital Personal Data Protection Act)
- Global financial regulators
are converging on a core expectation:
AI systems must be governable, explainable, and accountable.
Decision scale future-proofs institutions across jurisdictions.
This is geo-strategic advantage.

Conclusion: The Next Decade Will Be Decided by Decision Quality
Competitive advantage is moving.
Not from analog to digital.
Not from offline to online.
But from labor scale to decision scale.
Institutions that treat decision quality as infrastructure will:
- Move faster
- Make fewer catastrophic errors
- Learn systematically
- Defend decisions under scrutiny
- Compound advantage
Institutions that treat AI as tooling will experience:
- Faster mistakes
- Louder failures
- Governance shocks
- Reputational exposure
The winners of the AI era will not be those with the most models.
They will be those with the most governed decisions.
Boards that continue to measure AI spend and tool adoption are measuring inputs. The institutions that win will measure decision quality, decision defensibility, and decision compounding. That shift—from labor scale to decision scale—will define the next era of competitive advantage.
Glossary
Decision Scale — Institutional ability to scale high-quality decisions without scaling risk.
Decision Intelligence — Discipline of engineering and governing decision-making systems.
Decision Latency — Time from signal detection to governed action.
Decision Externalities — Downstream effects of wrong or poorly governed decisions.
Decision Compounding — Institutional learning that improves future decisions.
Enterprise AI Governance — Structures that ensure AI-driven decisions are auditable and accountable.
Decision Scale
An institution’s ability to increase decision volume and speed while maintaining quality, compliance, and reversibility.
Decision Intelligence
A discipline that treats decision-making as a measurable and improvable system combining data, models, and governance.
Decision Throughput
The volume of decisions processed within acceptable risk thresholds.
Decision Latency
The time between signal detection and action execution.
Decision Noise
Unwanted variability in judgment across similar cases.
Decision Compounding
The structured improvement of decision quality through governed feedback loops.
AI as Infrastructure
The embedding of AI systems into institutional decision architecture rather than treating AI as optional tooling
FAQ
What is decision scale in AI?
Decision scale is the ability to increase the number and speed of decisions while maintaining quality, compliance, and reversibility.
Why is decision scale more important than automation?
Automation improves tasks. Decision scale improves strategic outcomes.
Can small companies build decision scale?
Yes. Decision scale is about clarity and governance, not size.
How does decision scale relate to Enterprise AI?
Decision scale is the institutional doctrine; Enterprise AI Operating Model is the implementation architecture.
What is Decision Scale in AI?
Decision Scale refers to an organization’s ability to scale decision-making capacity and quality without increasing error, compliance risk, or operational fragility.
How is Decision Scale different from automation?
Automation improves tasks. Decision Scale improves institutional judgment and strategic outcomes.
Why is Decision Quality becoming a competitive advantage?
Because AI increases the speed and reach of decisions. Without governance, errors scale. With governance, advantage compounds.
Is Decision Scale relevant for boards?
Yes. Boards must govern decision quality as a strategic asset, not just AI adoption levels.
Can small organizations build Decision Scale?
Yes. Decision Scale is not about size; it is about governance clarity, feedback loops, and explicit decision design.
Enterprise AI Operating Model
Enterprise AI scale requires four interlocking planes:
Read about Enterprise AI Operating Model The Enterprise AI Operating Model: How organizations design, govern, and scale intelligence safely — Raktim Singh
- Read about Enterprise Control Tower The Enterprise AI Control Tower: Why Services-as-Software Is the Only Way to Run Autonomous AI at Scale — Raktim Singh
- Read about Decision Clarity The Shortest Path to Scalable Enterprise AI Autonomy Is Decision Clarity — Raktim Singh
- Read about The Enterprise AI Runbook Crisis The Enterprise AI Runbook Crisis: Why Model Churn Is Breaking Production AI — and What CIOs Must Fix in the Next 12 Months — Raktim Singh
- Read about Enterprise AI Economics Enterprise AI Economics & Cost Governance: Why Every AI Estate Needs an Economic Control Plane — Raktim Singh
Read about Who Owns Enterprise AI Who Owns Enterprise AI? Roles, Accountability, and Decision Rights in 2026 — Raktim Singh
Read about The Intelligence Reuse Index The Intelligence Reuse Index: Why Enterprise AI Advantage Has Shifted from Models to Reuse — Raktim Singh
Read about Enterprise AI Agent Registry Enterprise AI Agent Registry: The Missing System of Record for Autonomous AI — Raktim Singh