For most of modern economic history, technology industrialized physical labor. Factories scaled production, machines multiplied human effort, and automation accelerated output.
Artificial intelligence is now doing something far more profound: it is industrializing cognition itself.
Across enterprises, governments, and markets, AI systems are beginning to absorb signals, optimize decisions, execute actions, and improve through feedback—transforming decision-making into a scalable production process.
This shift marks the emergence of what can be called the industrialization of intelligence, where cognition becomes a structured, repeatable capability embedded inside institutional systems.
The Industrialization of Intelligence
For most of modern economic history, every major wave of progress has come from industrializing something humanity once did in a slower, more limited way.
The Industrial Revolution industrialized physical labor. Machines amplified muscle. Factories standardized production. Railways and shipping networks connected output to markets.
The digital revolution industrialized information. Software accelerated recordkeeping, coordination, search, communication, and transactions. Organizations could move data faster, cheaper, and more accurately than before.
Now another shift is underway.
Artificial intelligence is beginning to industrialize intelligence itself.
That does not mean machines have become human.
It means something more practical and more consequential: organizations can now begin to produce certain forms of judgment-like work with far greater scale, speed, repeatability, and lower marginal cost than before.
As AI capability rises, enterprise adoption spreads, and governance frameworks harden, the strategic question is no longer whether AI can generate impressive outputs.
The deeper question is whether institutions can redesign themselves around this new production system for cognition. Stanford’s 2025 AI Index reports that 78% of organizations reported using AI in 2024, up from 55% the prior year, while private investment in generative AI reached $33.9 billion globally in 2024. (Stanford HAI)
That is the deeper meaning of the industrialization of intelligence.
It is not just about chatbots, copilots, or model benchmarks. It is about the emergence of a new operating logic for firms, institutions, and markets.

What the industrialization of intelligence really means
In simple terms, the industrialization of intelligence means that tasks once dependent on scarce human cognition can increasingly be organized as repeatable, scalable, governed systems.
A useful way to understand this is through a familiar analogy.
A tailor can make one shirt carefully by hand. A factory can produce thousands of shirts with standard inputs, quality checks, process controls, and distribution channels. The factory does not eliminate design, craft, or judgment entirely. But it transforms production economics.
The same pattern is beginning to happen with cognition.
A senior claims officer in an insurance company can review one case at a time. A traditional workflow system can route documents from one queue to another. But an AI-enabled enterprise can begin to ingest signals, assemble context, interpret exceptions, compare options, recommend actions, trigger decisions within policy, and learn from outcomes across thousands or millions of cases.
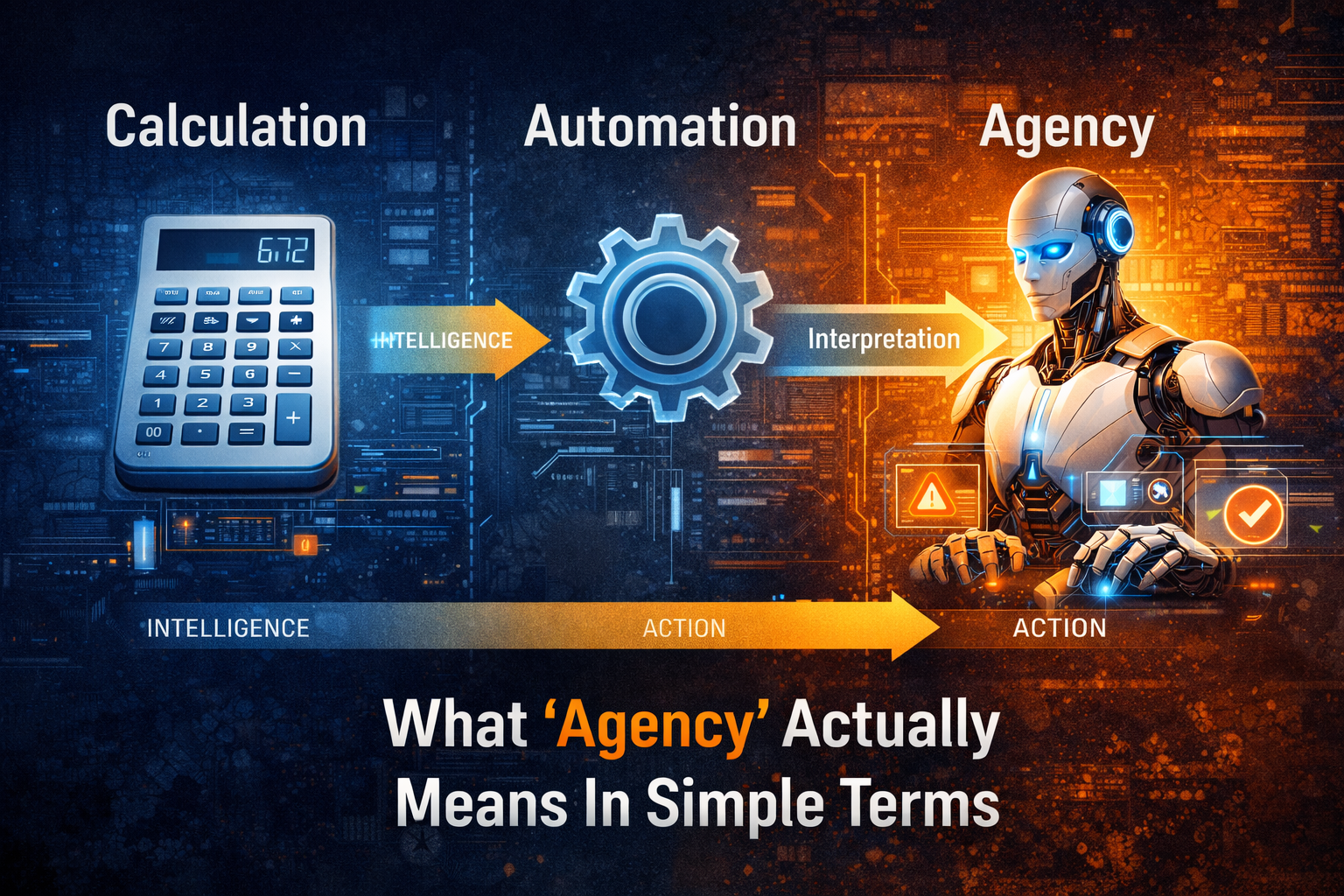
That is not just automation.
That is cognition becoming systematized, distributed, reusable, and operationalized.
In other words, intelligence is beginning to move from an artisanal activity to an industrial capability.

Why this shift is happening now
This shift is happening now because three forces are converging.
First, AI capability and business usage have risen sharply. Stanford’s 2025 AI Index shows strong enterprise uptake and sharply rising investment, especially in generative AI. (Stanford HAI)
Second, firm-level adoption across economies is widening. The OECD reported in January 2026 that 20.2% of firms used AI in 2025, up from 14.2% in 2024 and 8.7% in 2023. In just two years, firm adoption more than doubled. (OECD)
Third, leaders increasingly see AI as a business transformation force, not a side experiment. The World Economic Forum’s 2025 Future of Jobs Report found that 86% of surveyed employers expect AI and information-processing technologies to transform their business by 2030. (World Economic Forum Reports)
When capability rises, adoption spreads, and strategic importance becomes widely recognized, a technology stops being an interesting tool and starts becoming infrastructure.
That is where AI now stands.

From labor systems to decision systems
The industrial era was built around the scaling of labor.
The software era was built around the scaling of information.
The AI era is beginning to be built around the scaling of decision-making.
This is the shift many organizations still underestimate.
For decades, firms optimized supply chains, ERP systems, dashboards, CRM workflows, call centers, and digital channels.
But in most companies, decision-making itself remained bottlenecked by human attention. Pricing decisions, fraud decisions, service decisions, claims decisions, procurement decisions, underwriting decisions, and operational exception decisions all depended on scarce people interpreting context under pressure.
AI changes that equation.
It does not remove the need for human judgment at the highest levels. But it radically changes the economics of routine, semi-structured, and context-heavy decision work.
A bank can screen transactions continuously rather than sampling them periodically.
A retailer can adjust pricing and inventory more dynamically rather than waiting for weekly reviews.
A hospital can support triage decisions with live context rather than relying only on human recall and fragmented systems.
A logistics company can reroute shipments in response to disruption faster than any manual coordination chain could manage.
These are early signs of a larger pattern:
organizations are starting to build decision production systems.
This is where your broader concept of Decision Scale becomes strategically important. If the industrial era rewarded labor scale, and the digital era rewarded data scale, the AI era will increasingly reward the ability to produce large numbers of high-quality decisions with speed, consistency, and learning.

Why this is not just another automation story
It is tempting to say this is merely a more advanced form of automation. That would be too narrow.
Traditional automation is strongest when the world is stable and the rules are clear.
If invoice type X arrives, route it to system Y.
If inventory falls below threshold Z, trigger reorder.
The industrialization of intelligence is different because it applies to environments where:
- inputs are messy
- context changes meaning
- exceptions are common
- language matters
- tradeoffs matter
- policy matters
- consequences matter
A conventional script can follow rules.
An industrialized intelligence system can interpret a messy customer complaint, retrieve the right context, weigh likely options, check policy boundaries, recommend an action, escalate sensitive cases, and learn from the result.
That is a much more consequential shift.
Organizations need a better mental model than “AI tool” or “chatbot.” They need to understand that AI is enabling a new production system for judgment-like work.

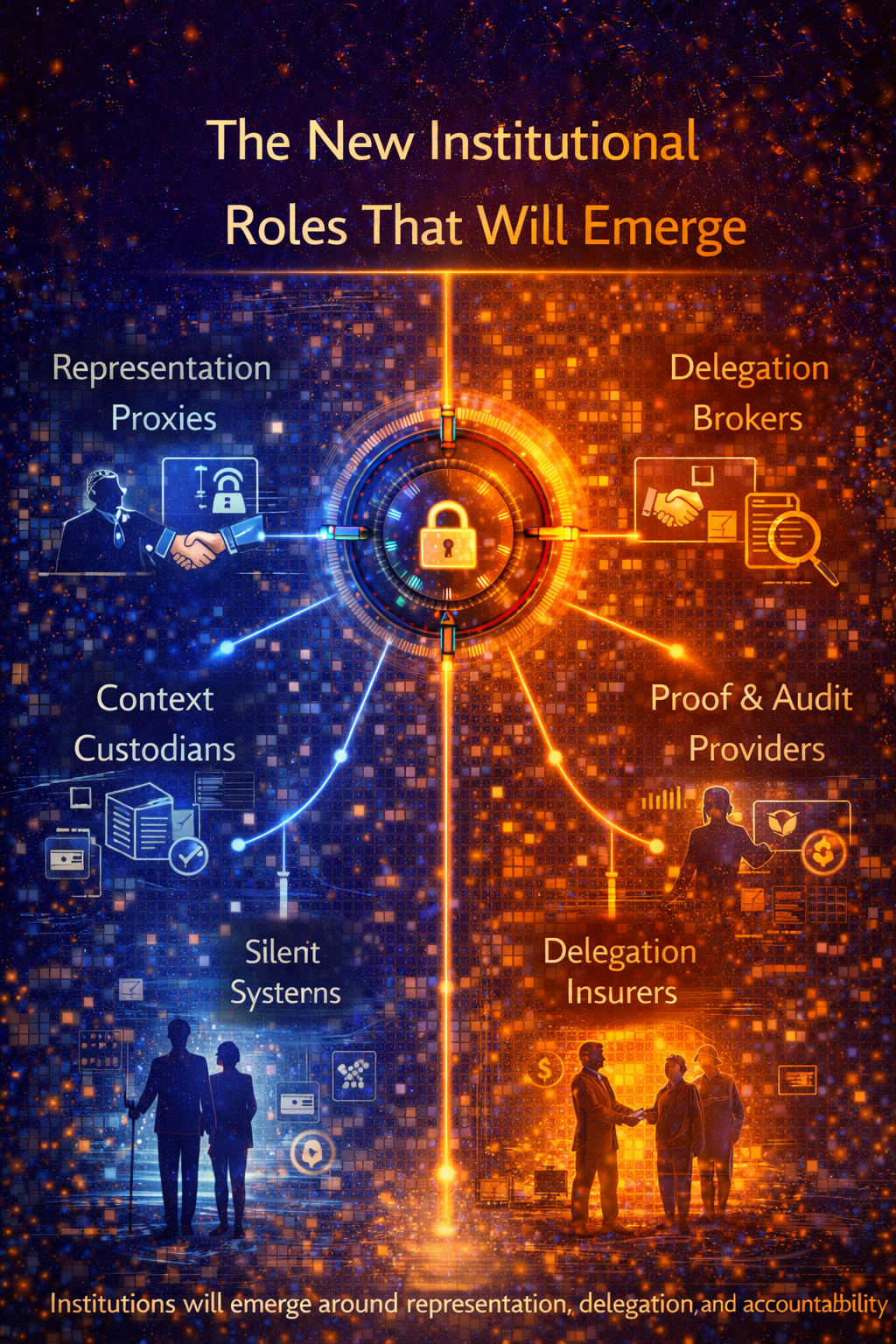
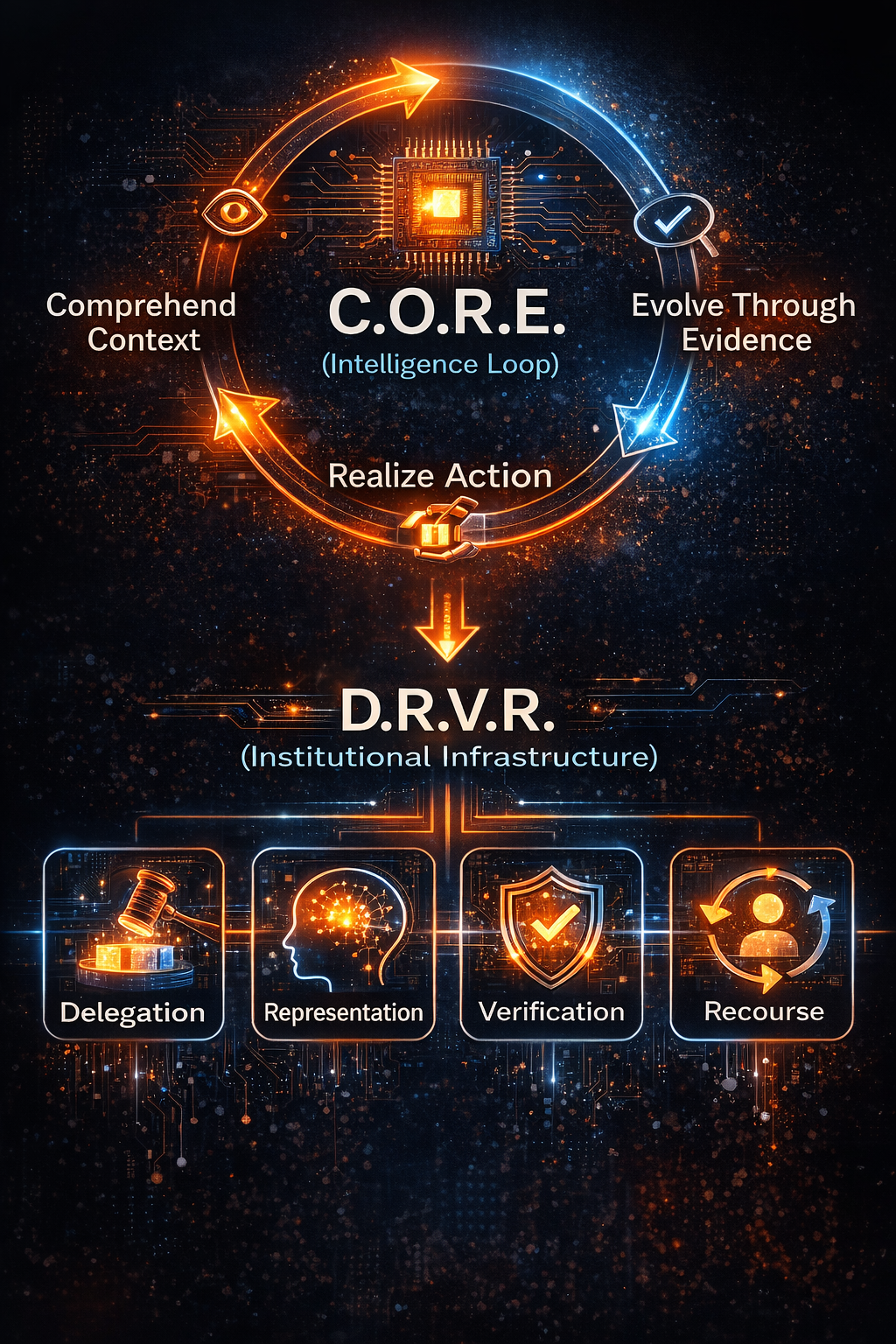
The role of C.O.R.E. and D.R.V.R.
To make this shift easier to understand, it helps to use two complementary lenses.
C.O.R.E. — the intelligence loop
C.O.R.E. explains how machine intelligence operates inside an institution:
C — Comprehend context
AI absorbs signals: customer intent, transaction patterns, operational telemetry, policy constraints, market conditions, and enterprise memory.
O — Optimize decisions
AI generates options, estimates tradeoffs, and ranks actions under uncertainty.
R — Realize action
AI executes through tools, APIs, workflows, tickets, messages, approvals, routing, and other operational systems.
E — Evolve through evidence
AI improves through feedback: outcomes, reversals, exceptions, error patterns, drift signals, and human corrections.
C.O.R.E. explains how intelligence behaves as a functional loop.
But intelligence alone does not transform institutions.
D.R.V.R. makes that intelligence accountable.
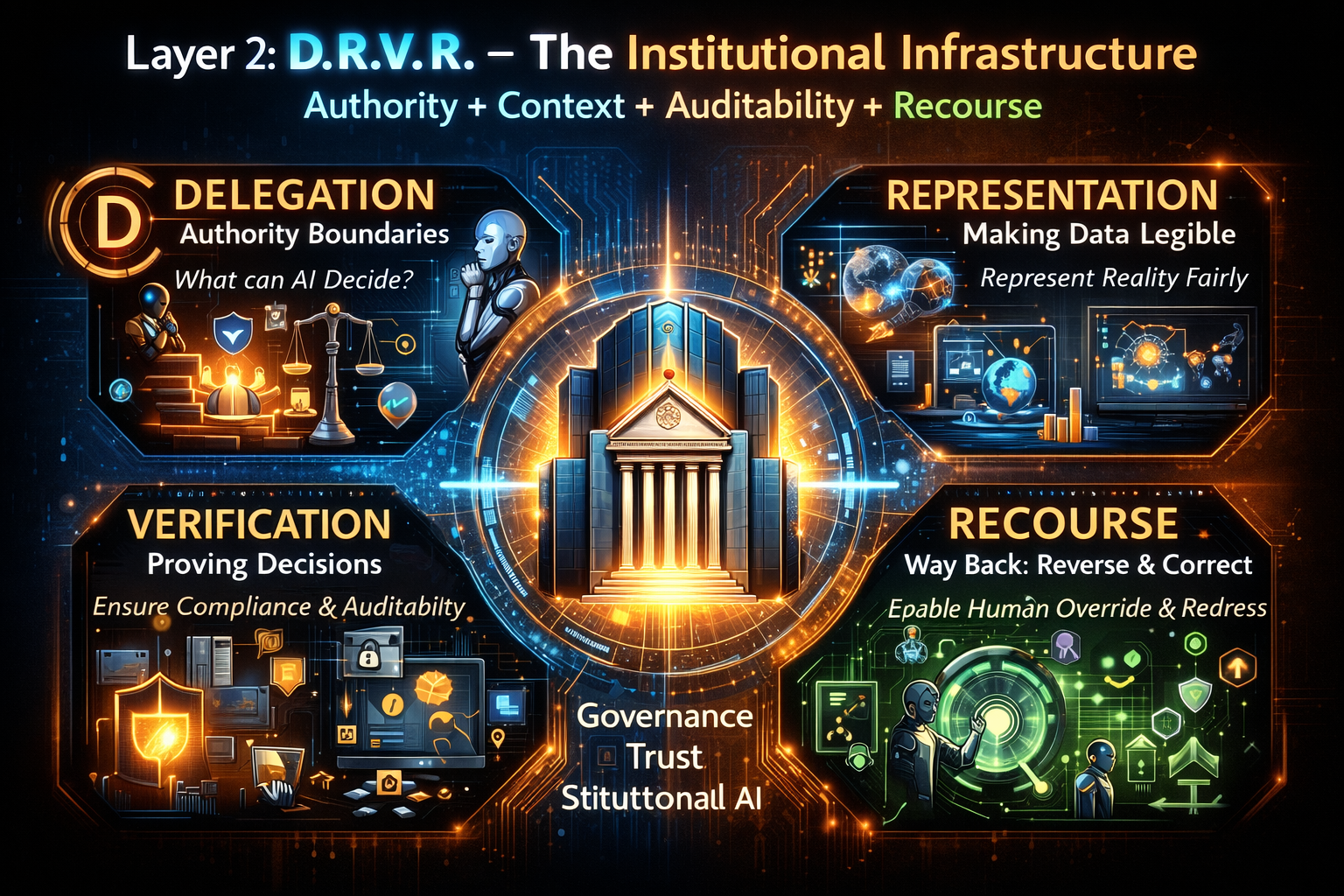
D.R.V.R. — the institutional infrastructure
While C.O.R.E. explains how intelligence operates, D.R.V.R. explains what must exist underneath intelligence for it to operate reliably at scale inside real institutions.
D.R.V.R. defines the institutional infrastructure required for AI-driven decision systems to function responsibly in complex economic environments.
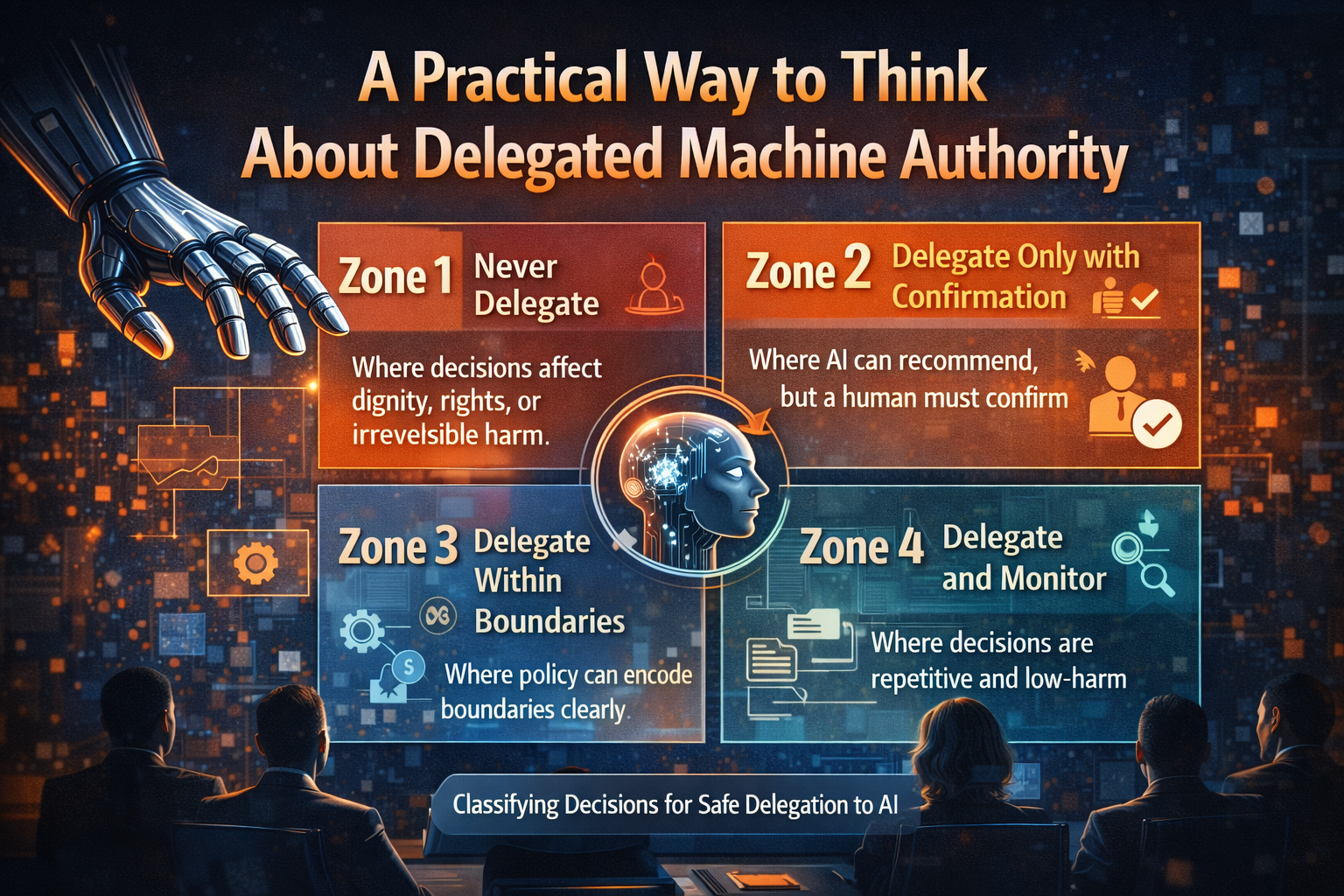
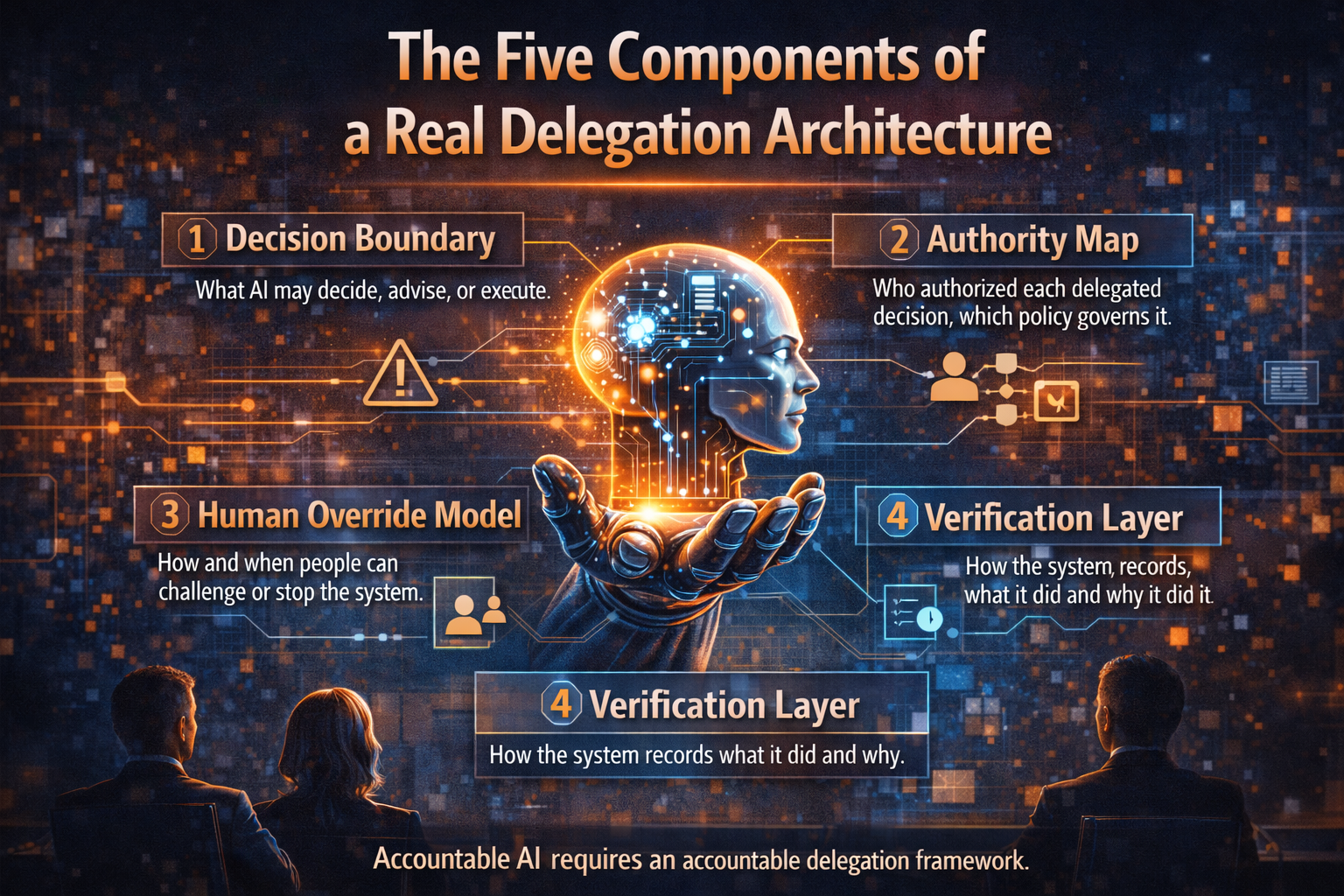
D — Delegation
Delegation answers the most important question in the AI economy:
What is the machine actually allowed to decide?
Not every task should be delegated.
Reordering low-value office supplies is not the same as denying insurance coverage.
Suggesting a meeting slot is not the same as freezing a bank account.
Routing a service request is not the same as determining legal liability.
Delegation infrastructure defines the authority boundary for machine decisions.
It determines whether AI systems can:
- advise
- recommend
- approve
- execute
- escalate
In other words, delegation defines the architecture of machine authority.
Without clear delegation rules, organizations confuse capability with permission.
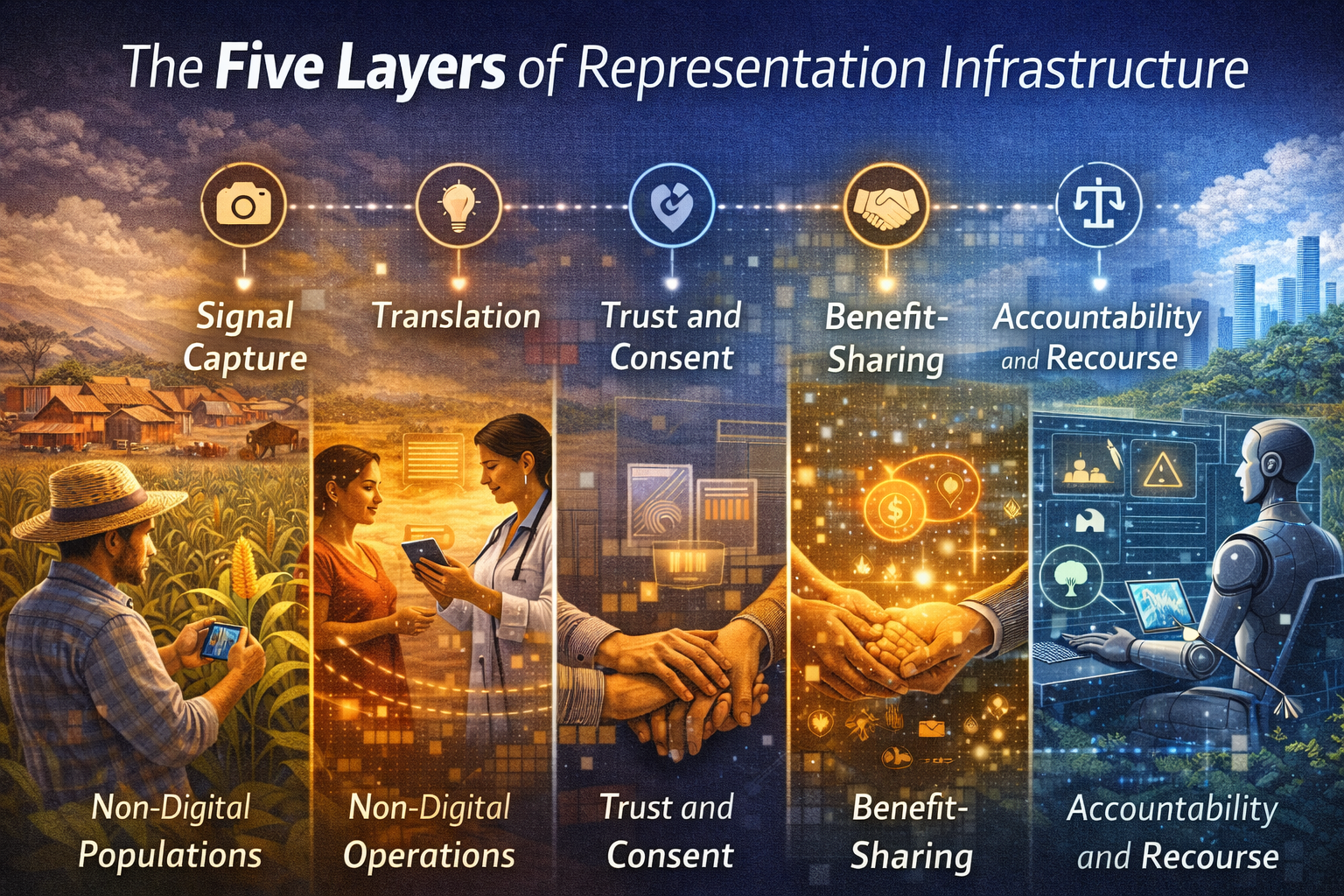
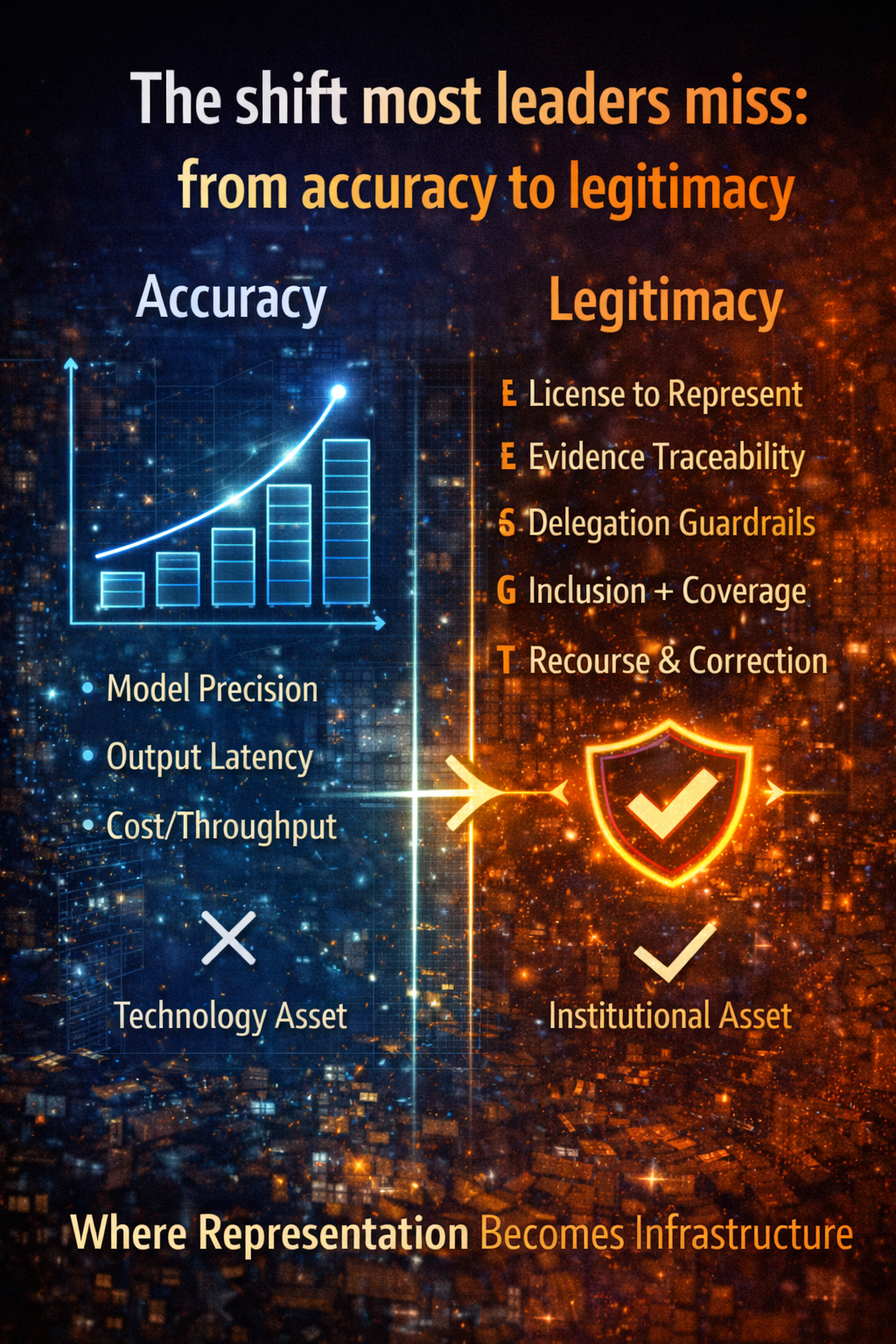
R — Representation
AI can only act on what becomes legible to it.
Representation infrastructure is the layer that translates messy, incomplete real-world conditions into machine-usable signals.
This includes:
- identity resolution
- data quality
- event logging
- documentation
- taxonomy
- workflow capture
- sensor coverage
- contextual metadata
This layer is far more important than many organizations realize.
If an agricultural system cannot represent soil variation, weather volatility, informal labor, or local market conditions, it will optimize the wrong things.
If a lending system cannot represent irregular income patterns or nontraditional economic behavior, it may misread real people and produce apparently “rational” but deeply flawed outcomes.
The AI economy will reward institutions that make reality legible fairly, not just efficiently.
V — Verification
Once AI begins making or triggering decisions, stakeholders need evidence.
Verification infrastructure proves that a system:
- acted within policy
- used approved context
- respected thresholds
- produced decisions that can be examined after the fact
This includes:
- decision records
- logs and audit trails
- lineage tracking
- testing and validation procedures
- monitoring systems
- policy traceability
Verification transforms organizational trust from assertion into evidence.
It turns:
“Trust us.”
into
“Here is the evidence.”
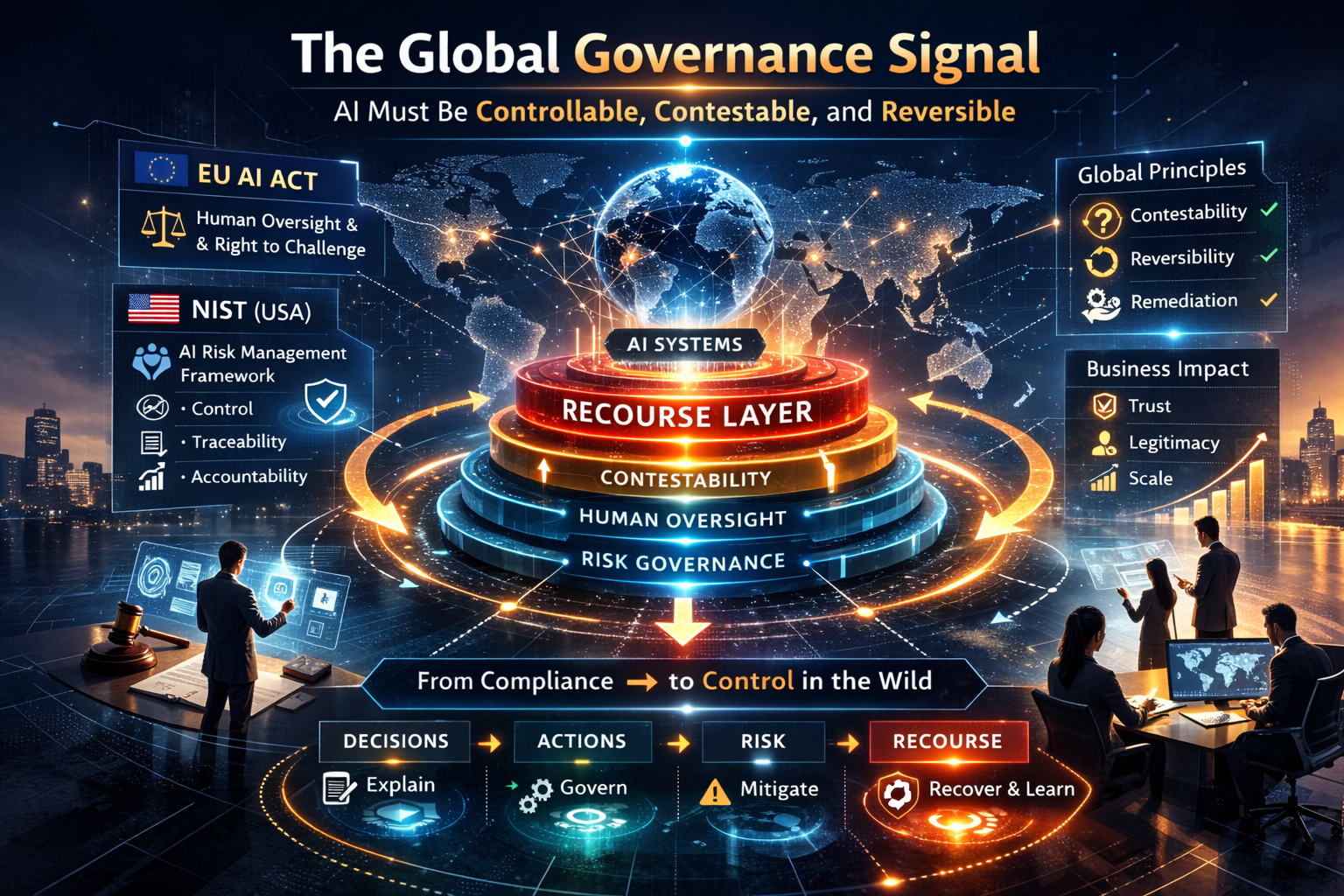
Global governance frameworks are already moving in this direction. For example, the NIST AI Risk Management Framework (AI RMF) treats governance as a cross-cutting function across the entire AI lifecycle.
R — Recourse
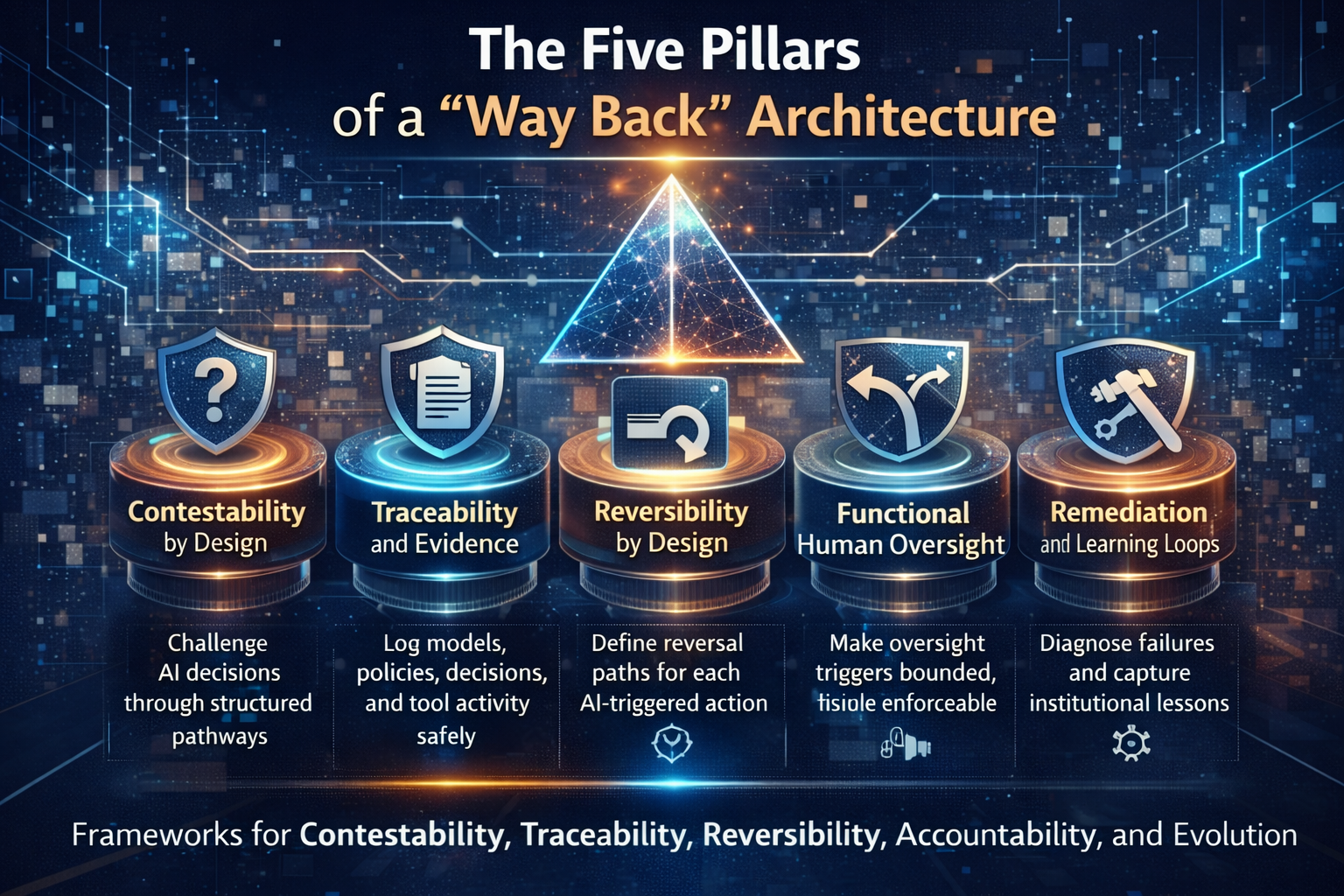
Every serious economic system needs a way back.
Recourse infrastructure provides mechanisms to:
- challenge decisions
- pause actions
- unwind outcomes
- reverse automated processes
- remediate mistakes
This matters because many AI decisions create effects that are difficult to undo once executed.
Consider a few examples:
A customer wrongly flagged for fraud may lose temporary access to funds.
A small business loan incorrectly denied may cause a missed opportunity.
A job candidate filtered out by a flawed model may never even know they were excluded.
Recourse is not a legal afterthought.
It is core operating architecture for the AI economy.
D.R.V.R. describes the institutional infrastructure that makes AI governable—defining how decisions are delegated to machines, how reality becomes legible to them, how their behavior is verified, and how outcomes can be challenged or reversed.
C.O.R.E. industrializes intelligence.
D.R.V.R. makes that intelligence accountable.
This is the deeper lesson of the AI era:
C.O.R.E. explains how intelligence operates.
D.R.V.R. explains how intelligence becomes institutionally legitimate.
The industrialization of intelligence happens only when both layers work together.
The three building blocks of industrialized intelligence
To understand the shift more practically, it helps to break it into three building blocks.
-
Intelligence becomes flow-based
In older systems, expertise was trapped in people, departments, and manual handoffs. In industrialized intelligence systems, cognition is organized as a flow.
Signals come in. Context is assembled. Models interpret the situation. Decision rules and orchestration layers govern what happens next. Actions are executed. Outcomes are fed back into the system.
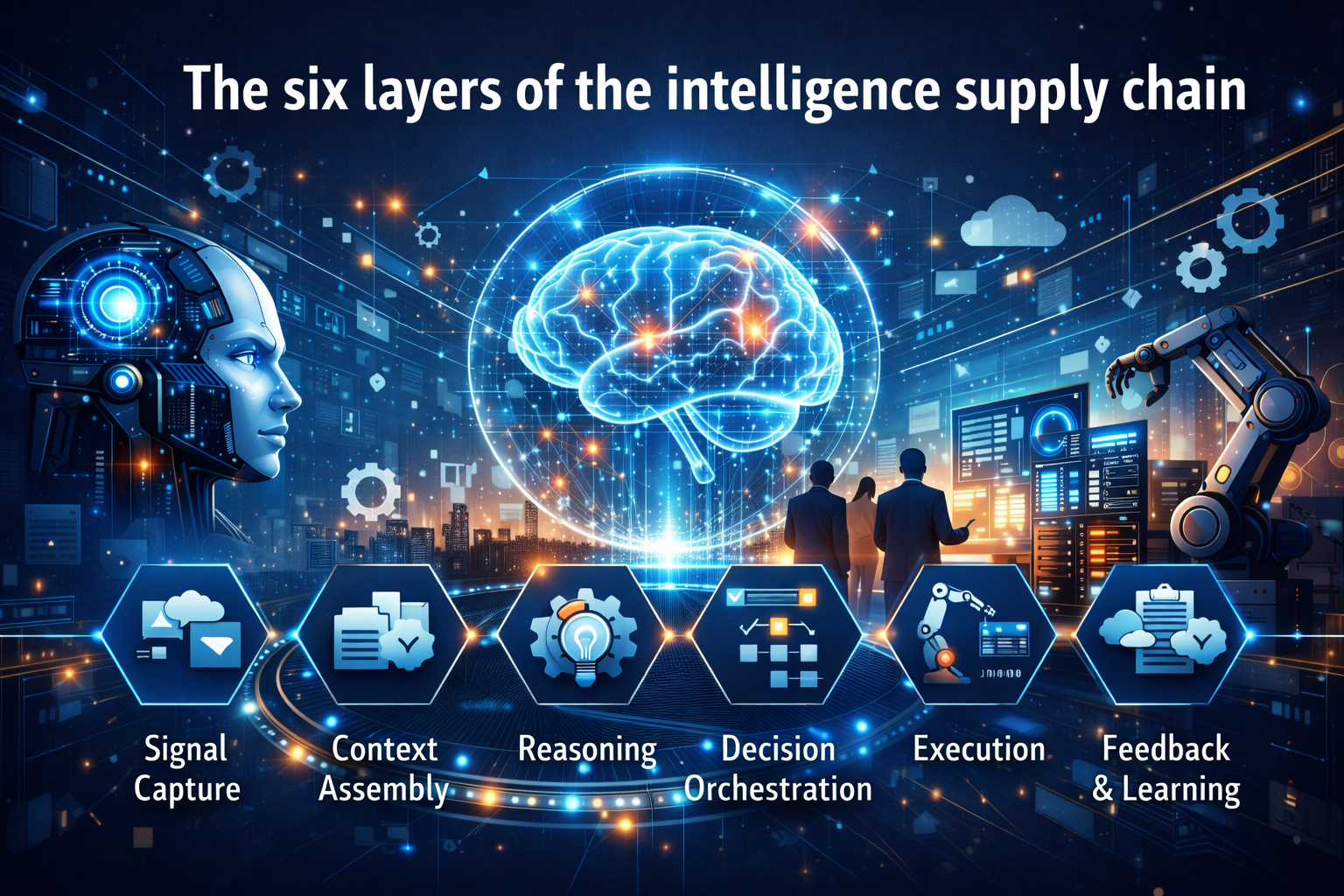
This is why the idea of the Intelligence Supply Chain matters so much. It explains how cognition moves through an enterprise as an operational flow rather than staying trapped in isolated human bottlenecks.
-
Intelligence becomes reusable
One of the hidden advantages of industrial systems is reuse.
A good factory does not reinvent the production line for every product. A good digital system does not rebuild the data layer for every workflow. Likewise, a mature AI organization does not build intelligence from scratch for every use case.
It reuses:
- context patterns
- retrieval pipelines
- decision rules
- orchestration logic
- memory structures
- policy constraints
- audit mechanisms
This is why the real advantage in enterprise AI is shifting away from isolated models and toward reusable systems of intelligence. That logic also aligns directly with my concept of the Intelligence Reuse Index.
-
Intelligence becomes governed
Industrialization without governance creates chaos.
Factories needed safety standards, quality control, inspection, and maintenance. Software platforms required security, permissions, uptime discipline, and compliance. The same is true for intelligence systems.
NIST’s AI Risk Management Framework emphasizes that organizations should embed trustworthiness and risk management into the design, development, use, and evaluation of AI systems. Meanwhile, the EU AI Act’s timeline shows that prohibited AI practices and AI literacy obligations began applying on February 2, 2025, and governance obligations for general-purpose AI models became applicable on August 2, 2025, after the Act entered into force on August 1, 2024. (Digital Strategy)
This matters because industrialized intelligence is not valuable if it is unreliable, unaccountable, or impossible to stop when things go wrong. (Digital Strategy)
What this looks like in the real world
The easiest way to make this concrete is through examples.
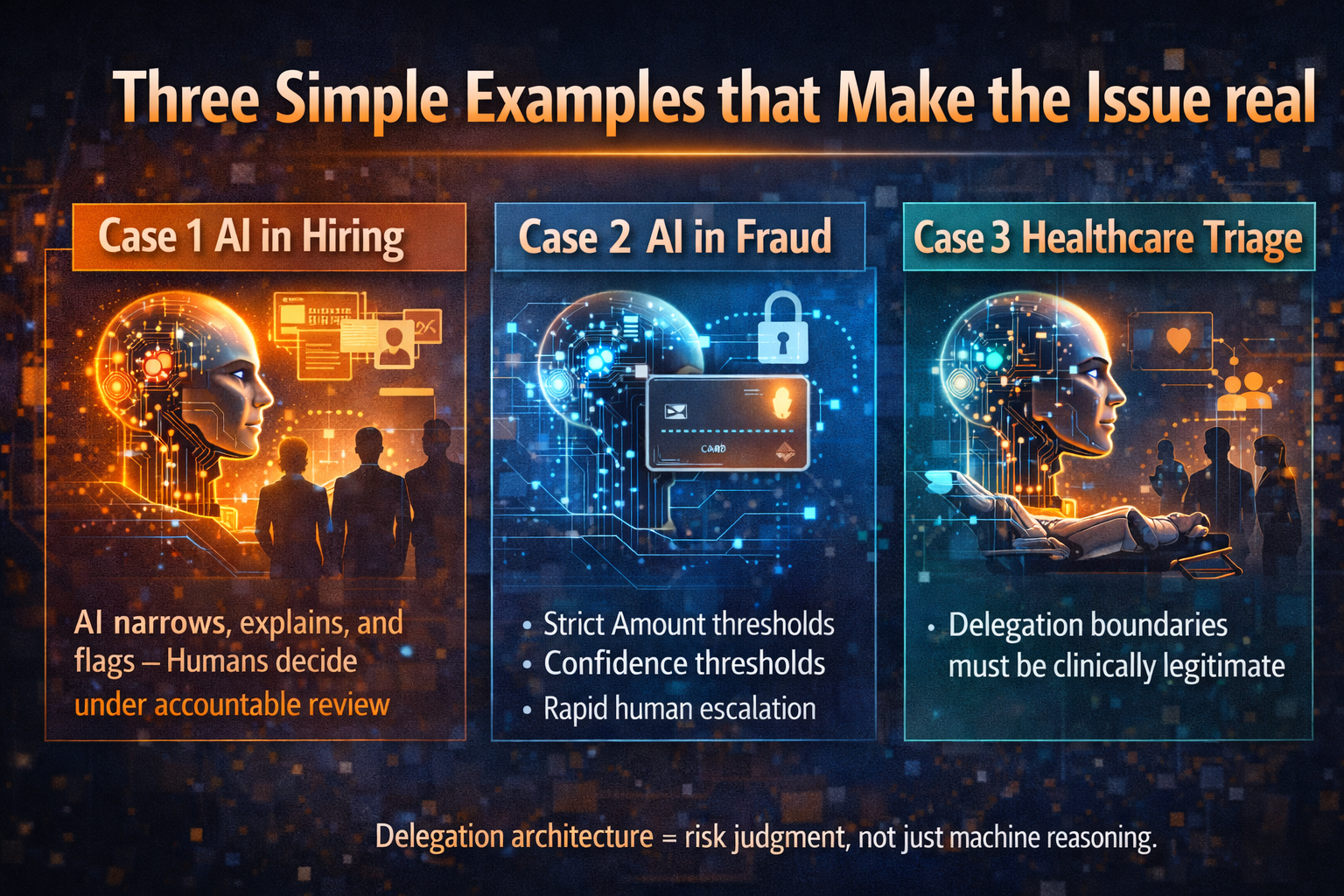
Banking
In a traditional bank, suspicious activity often moves through fragmented alerts, manual reviews, and delayed escalation. In an industrialized intelligence model, the bank continuously ingests transaction behavior, device context, customer history, sanctions logic, and anomaly patterns.
The system can prioritize cases, recommend actions, trigger holds under policy, route ambiguity to humans, and learn from false positives.
The result is not just “better fraud AI.” It is a more scalable system for producing risk decisions.
Healthcare
A hospital cannot industrialize clinical wisdom in the same way it industrializes billing workflows. But it can industrialize selected forms of operational cognition: triage support, coding assistance, documentation quality, scheduling prioritization, patient-flow recommendations, and administrative coordination.
Human care remains central; the surrounding decision environment becomes faster, more context-aware, and more adaptive.
Retail and supply chain
Retailers already run vast digital systems. The next step is not just more dashboards. It is systems that turn demand signals, weather, promotions, logistics constraints, returns, and pricing elasticity into continuous operational judgment.
That means better replenishment, better markdown timing, and better route coordination.
Again, the point is not “AI feature improvement.”
It is the industrialization of decisions.
What boards and CEOs should understand
Boards should pay attention because this shift changes the basis of competitive advantage.
In the past, firms won through labor scale, capital scale, distribution scale, or data scale.
In the AI era, many firms will increasingly compete on decision scale: the ability to run large numbers of high-quality decisions with speed, consistency, and learning.
That has several implications.
First, AI strategy is no longer just model strategy. It is operating model strategy.
Second, enterprise value will come less from isolated pilots and more from building reusable intelligence systems across functions.
Third, governance can no longer sit outside runtime. Policy, approval boundaries, auditability, reversibility, and control must be embedded directly into the flow of machine-supported action.
Fourth, talent strategy changes. The key teams are not only model builders. They include domain experts, workflow designers, policy owners, AI product leaders, assurance leaders, and executives who understand how authority should flow between humans and systems.
Most importantly, leaders should stop asking only whether they have adopted AI.
The more important question is:
Have we begun redesigning the institution for the industrialization of intelligence?
The strategic risks of misunderstanding the shift
There are at least three ways firms can get this wrong.
One is to treat AI only as a productivity overlay. That creates local gains but misses the operating transformation.
A second is to industrialize intelligence without governance. That may create short-term speed but long-term fragility, reputational risk, and compliance failure.
A third is to assume access to powerful models alone is enough. It is not. Models matter, but the durable advantage will belong to organizations that build the surrounding systems: context, orchestration, controls, feedback, and reuse.
That is why the industrialization of intelligence is ultimately not a model story.
It is a systems story.
The deeper economic meaning
Every industrial shift changes what becomes abundant and what becomes scarce.
Industrialization made manufactured goods cheaper.
Digitization made information cheaper.
AI is beginning to make certain forms of cognition cheaper.
When the cost of cognition falls, organizations do not simply do the same work faster. They redesign what work is possible. They expand the number of decisions they can make, the number of cases they can handle, the number of variations they can personalize, and the number of exceptions they can manage.
That is how a technical capability becomes an economic force.
And that is why the industrialization of intelligence may become one of the defining concepts of the next decade.
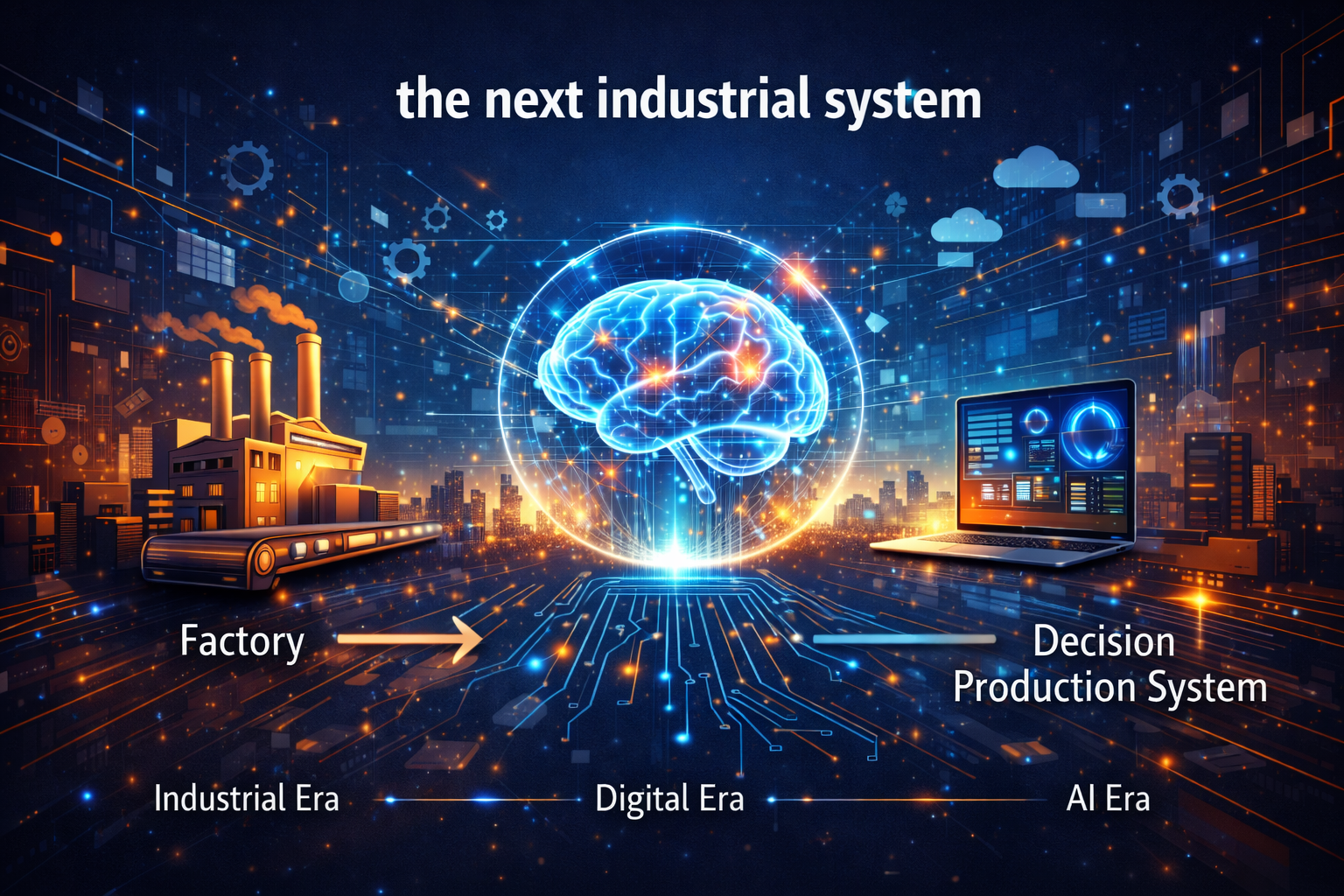
Conclusion: the next industrial system
The Industrial Revolution gave us the factory.
The digital revolution gave us the software platform.
The AI revolution is beginning to give us something new:
the production system for cognition.
This is what the industrialization of intelligence really means.
It means intelligence is no longer confined to a few experts, a few decisions, or a few high-cost moments. It is becoming embedded in flows, systems, and institutions. It is becoming more repeatable, more governable, more scalable, and more economically consequential.
The organizations that understand this early will not just deploy better AI tools.
They will redesign how judgment is produced.
And that may be one of the most important institutional shifts of the AI economy
What is the industrialization of intelligence?
The industrialization of intelligence is the shift by which organizations use AI to turn cognition into a repeatable, scalable, governed production system. It allows signals to become context, context to become reasoning, reasoning to become decisions, and decisions to become action and learning across the enterprise.
Glossary
Industrialization of Intelligence
The shift by which organizations begin to produce judgment-like work as a repeatable, scalable, governed system using AI.
Industrialized Cognition
Cognitive work that is systematized, reusable, and operationalized through enterprise AI systems.
Decision Scale
A form of competitive advantage based on the ability to produce large numbers of high-quality decisions with speed, consistency, and feedback.
Intelligence Supply Chain
The enterprise flow through which signals become context, reasoning, decisions, actions, and learning.
C.O.R.E.
A framework for the intelligence loop: Comprehend context, Optimize decisions, Realize action, Evolve through evidence.
D.R.V.R.
A framework for institutional infrastructure: Delegation, Representation, Verification, Recourse.
Decision Production System
A system that operationalizes judgment-like work across enterprise processes rather than leaving decisions trapped in isolated human bottlenecks.
Enterprise AI Runtime
The production environment where AI actually acts inside enterprise workflows, systems, policies, and controls.
Governed Autonomy
A model in which AI systems can act or recommend within clearly defined boundaries, controls, and escalation rules.
Industrialization of Intelligence
The transformation of cognition into a scalable, repeatable capability enabled by artificial intelligence systems embedded in institutions.
Decision Systems
AI-powered platforms that continuously absorb signals, evaluate alternatives, and execute actions across enterprise workflows.
C.O.R.E. Framework
An intelligence loop describing how AI systems operate:
-
Comprehend context
-
Optimize decisions
-
Realize action
-
Evolve through evidence
D.R.V.R. Infrastructure
The institutional infrastructure required for AI decision systems to operate reliably and safely at scale.
Decision Economy
An emerging economic paradigm where competitive advantage comes from superior decision-making systems rather than physical production.
Enterprise AI Architecture
The structural design that integrates models, data systems, governance mechanisms, and operational workflows.
FAQ
What is the industrialization of intelligence in simple terms?
It is the process by which organizations use AI to turn certain kinds of cognitive work into a scalable, repeatable, governed production system.
How is this different from traditional automation?
Traditional automation usually follows fixed rules in stable environments. The industrialization of intelligence applies to messy, context-heavy, language-rich, exception-filled situations where reasoning and governance matter.
Why does this matter for CEOs and boards?
Because AI is changing not just productivity, but the way institutions produce decisions. This affects growth, cost, resilience, customer experience, governance, and competitive advantage.
Is the industrialization of intelligence only for large tech firms?
No. It applies to banks, insurers, retailers, logistics firms, healthcare providers, telecom companies, manufacturers, and governments—any organization that repeatedly turns signals into decisions.
What role do humans still play?
Humans remain critical. They define policy, set authority boundaries, review sensitive cases, handle ambiguity, govern systems, and remain accountable for important outcomes.
How do C.O.R.E. and D.R.V.R. fit into this idea?
C.O.R.E. explains how intelligence operates as a loop. D.R.V.R. explains the institutional infrastructure required for that intelligence to be safe, legitimate, and scalable.
Why is governance so important here?
Because industrialized intelligence can create real-world consequences. Without delegation rules, accountability, verification, and regulatory alignment, speed can turn into fragility.
What is the strategic opportunity?
Organizations that redesign themselves around industrialized intelligence can create stronger decision systems, lower cognitive cost, faster adaptation, and more durable competitive advantage.
What is the industrialization of intelligence?
The industrialization of intelligence refers to the transformation of decision-making and cognitive processes into scalable, repeatable systems powered by artificial intelligence.
How is AI industrializing cognition?
AI industrializes cognition by enabling systems that continuously analyze signals, generate decisions, execute actions, and improve through feedback.
Why is this shift happening now?
The shift is occurring due to the convergence of four major factors:
- Large-scale data availability
- Massive computing infrastructure
- Advanced AI models
- Enterprise integration with operational systems
What is the C.O.R.E. framework in AI?
C.O.R.E. describes the operational loop of AI systems:
- Comprehend context
- Optimize decisions
- Realize action
- Evolve through evidence
What is D.R.V.R. infrastructure?
D.R.V.R. represents the institutional infrastructure required to support AI-driven decision systems safely and reliably across organizations.
Why is AI different from traditional automation?
Traditional automation mechanized tasks.
AI industrializes decision-making and reasoning, allowing institutions to scale intelligence itself.
References and further reading
For readers who want to explore the broader context behind this shift:
- Stanford HAI, The 2025 AI Index Report — enterprise adoption and investment trends. (Stanford HAI)
- OECD, AI use by individuals surges across the OECD as adoption by firms continues to expand — firm-level adoption trends across OECD economies. (OECD)
- World Economic Forum, Future of Jobs Report 2025 — employer expectations about AI’s business transformation impact. (World Economic Forum Reports)
- European Commission, AI Act — current implementation timeline and governance milestones. (Digital Strategy)
- NIST, AI Risk Management Framework — trustworthiness and risk-management guidance for AI systems. (Digital Strategy)
The Intelligence-Native Enterprise Doctrine
This article is part of a larger strategic body of work that defines how AI is transforming the structure of markets, institutions, and competitive advantage. To explore the full doctrine, read the following foundational essays:
- The AI Decade Will Reward Synchronization, Not Adoption
Why enterprise AI strategy must shift from tools to operating models.
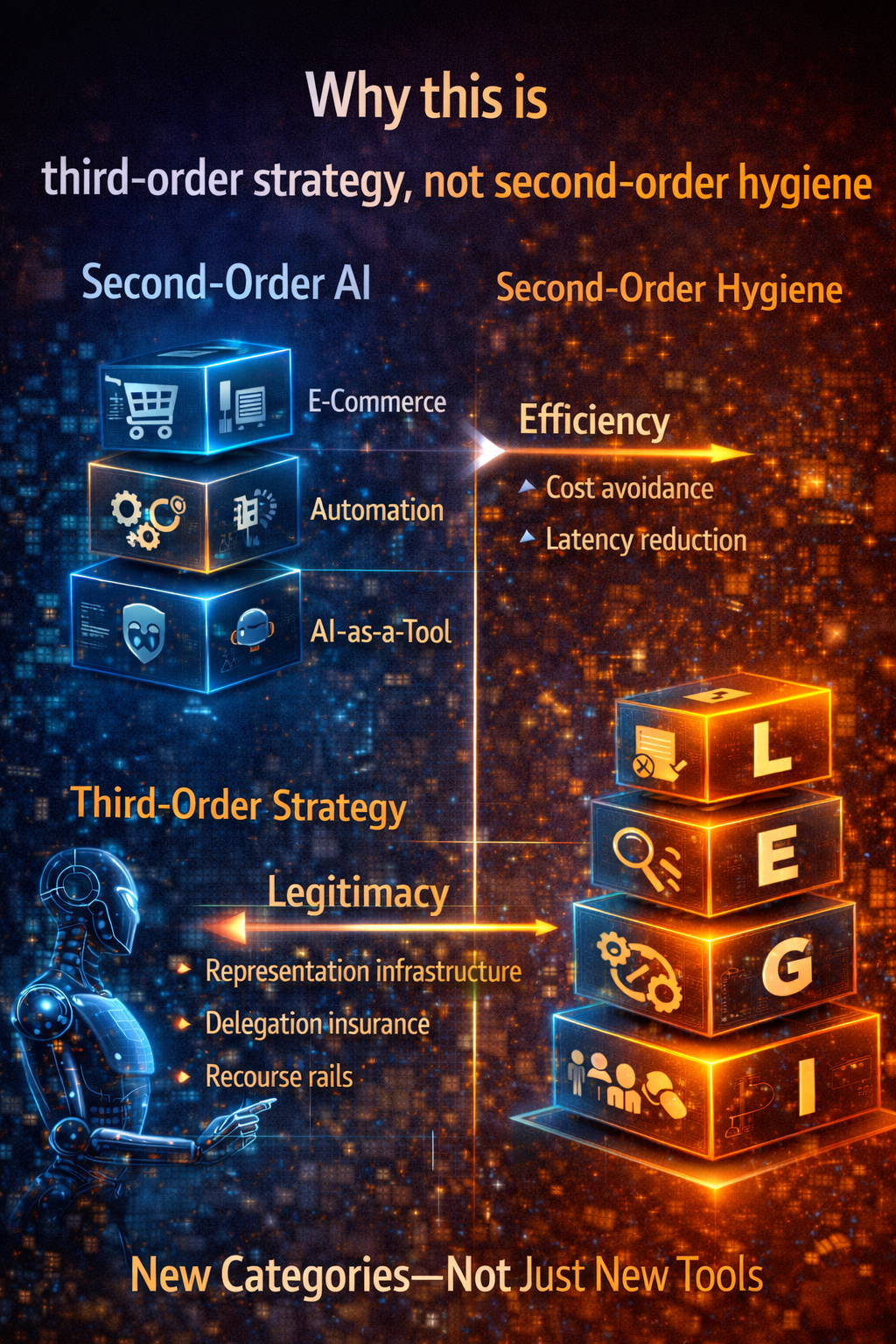
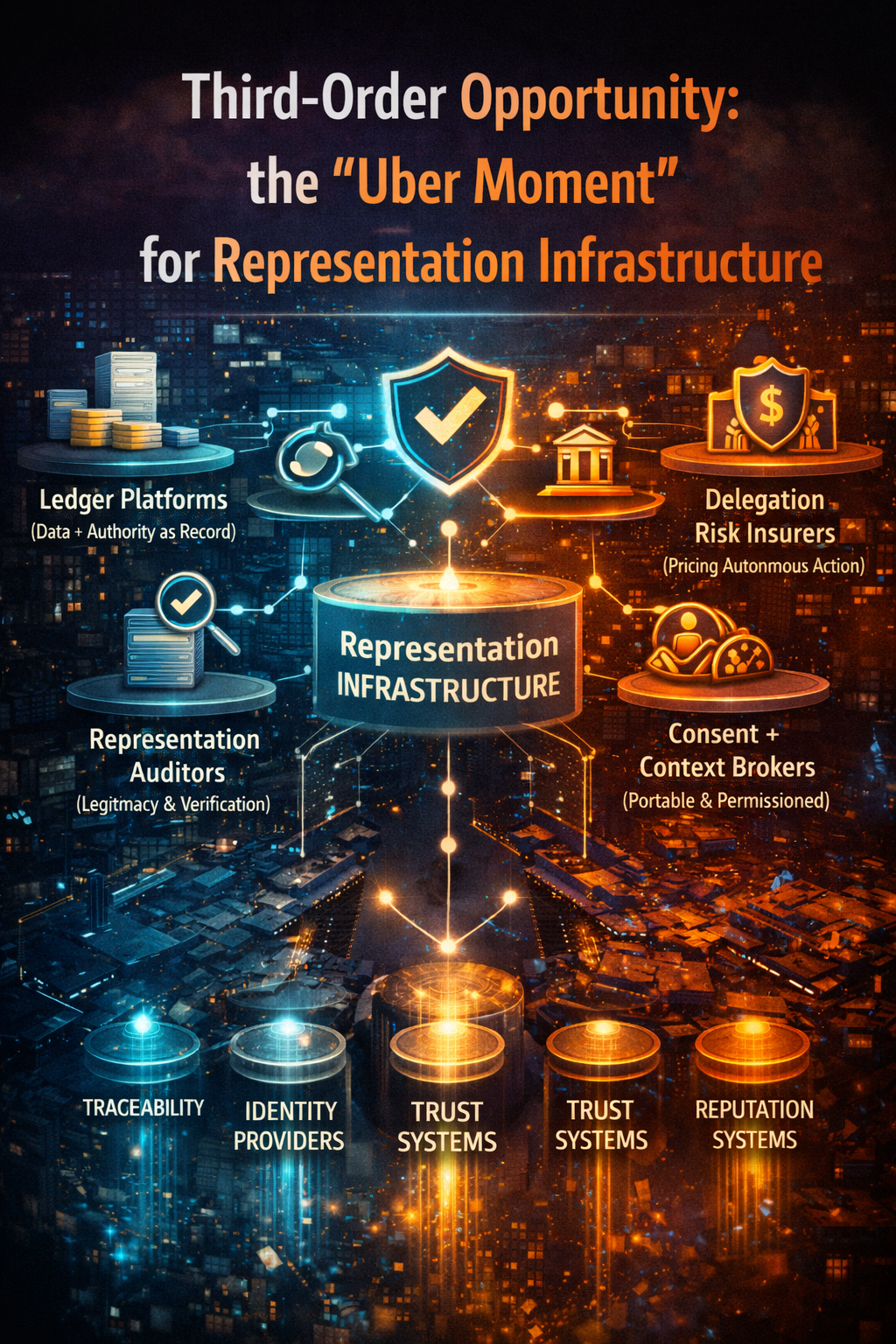
https://www.raktimsingh.com/the-ai-decade-will-reward-synchronization-not-adoption-why-enterprise-ai-strategy-must-shift-from-tools-to-operating-models/ - The Third-Order AI Economy
The category map boards must use to see the next Uber moment.
https://www.raktimsingh.com/third-order-ai-economy/ - The Intelligence Company
A new theory of the firm in the AI era — where decision quality becomes the scalable asset.
https://www.raktimsingh.com/intelligence-company-new-theory-firm-ai/ - The Judgment Economy
How AI is redefining industry structure — not just productivity.
https://www.raktimsingh.com/judgment-economy-ai-industry-structure/ - Digital Transformation 3.0
The rise of the intelligence-native enterprise.
https://www.raktimsingh.com/designing-intelligence-native-enterprise/ - Industry Structure in the AI Era
Why judgment economies will redefine competitive advantage.
https://www.raktimsingh.com/industry-structure-in-the-ai-era-why-judgment-economies-will-redefine-competitive-advantage/
Institutional Perspectives on Enterprise AI
Many of the structural ideas discussed here — intelligence-native operating models, control planes, decision integrity, and accountable autonomy — have also been explored in my institutional perspectives published via Infosys’ Emerging Technology Solutions platform.
For readers seeking deeper operational detail, I have written extensively on:
- What Makes an Enterprise Intelligence-Native? The Blueprint for Third-Order AI Advantage
https://blogs.infosys.com/emerging-technology-solutions/artificial-intelligence/what-is-enterprise-ai-the-operating-model-for-compounding-institutional-intelligence.html - Why “AI in the Enterprise” Is Not Enterprise AI: The Operating Model Difference Most Organizations Miss
https://blogs.infosys.com/emerging-technology-solutions/artificial-intelligence/why-ai-in-the-enterprise-is-not-enterprise-ai-the-operating-model-difference-that-most-organizations-miss.html - The Enterprise AI Control Plane: Governing Autonomy at Scale
https://blogs.infosys.com/emerging-technology-solutions/artificial-intelligence/the-enterprise-ai-control-plane-governing-autonomy-at-scale.html - Enterprise AI Ownership Framework: Who Is Accountable, Who Decides, and Who Stops AI in Production
https://blogs.infosys.com/emerging-technology-solutions/artificial-intelligence/enterprise-ai-ownership-framework-who-is-accountable-who-decides-and-who-stops-ai-in-production.html - Decision Integrity: Why Model Accuracy Is Not Enough in Enterprise AI
https://blogs.infosys.com/emerging-technology-solutions/artificial-intelligence/decision-integrity-why-model-accuracy-is-not-enough-in-enterprise-ai.html - Agent Incident Response Playbook: Operating Autonomous AI Systems Safely at Enterprise Scale
https://blogs.infosys.com/emerging-technology-solutions/artificial-intelligence/agent-incident-response-playbook-operating-autonomous-ai-systems-safely-at-enterprise-scale.html - The Economics of Enterprise AI: Designing Cost, Control, and Value as One System
https://blogs.infosys.com/emerging-technology-solutions/artificial-intelligence/the-economics-of-enterprise-ai-designing-cost-control-and-value-as-one-system.html
Together, these perspectives outline a unified view: Enterprise AI is not a collection of tools. It is a governed operating system for institutional intelligence — where economics, accountability, control, and decision integrity function as a coherent architecture.