AI Agent Governance: The Board-Level Framework for Controlling AI Agent Autonomy, Access, Accountability, and Risk
Executive Summary: The New Question Is Not “Can AI Think?” It Is “What Is AI Allowed to Do?”
Enterprise AI has entered a new phase.
For the last few years, CIOs and CTOs have focused on models, copilots, prompt engineering, retrieval, data readiness, vector databases, AI pilots, and productivity experiments. The dominant question was simple:
Can AI produce a useful answer?
That question is no longer enough.
The new question is far more consequential:
What is an AI agent allowed to do?
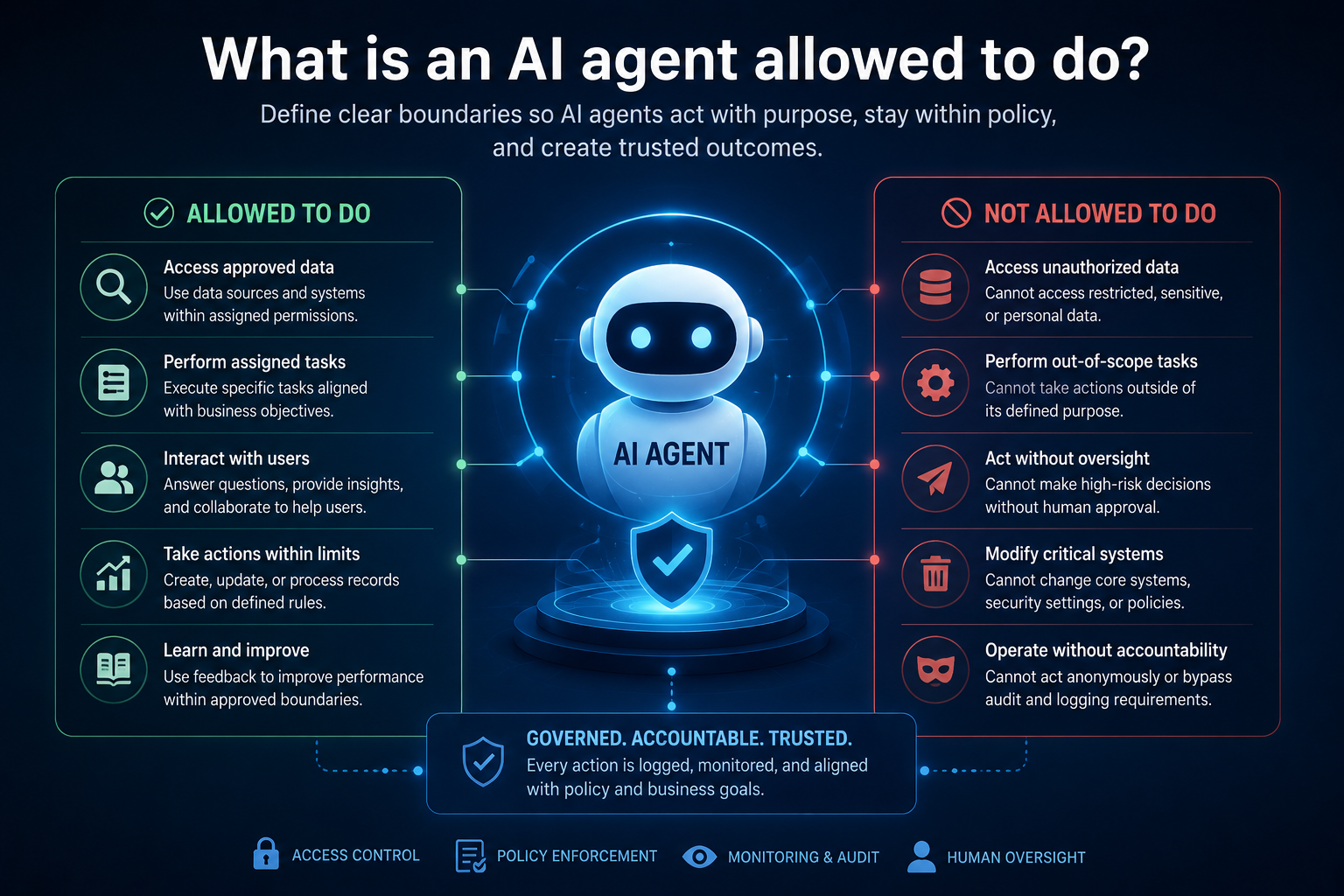
This is the defining question of AI agent governance.
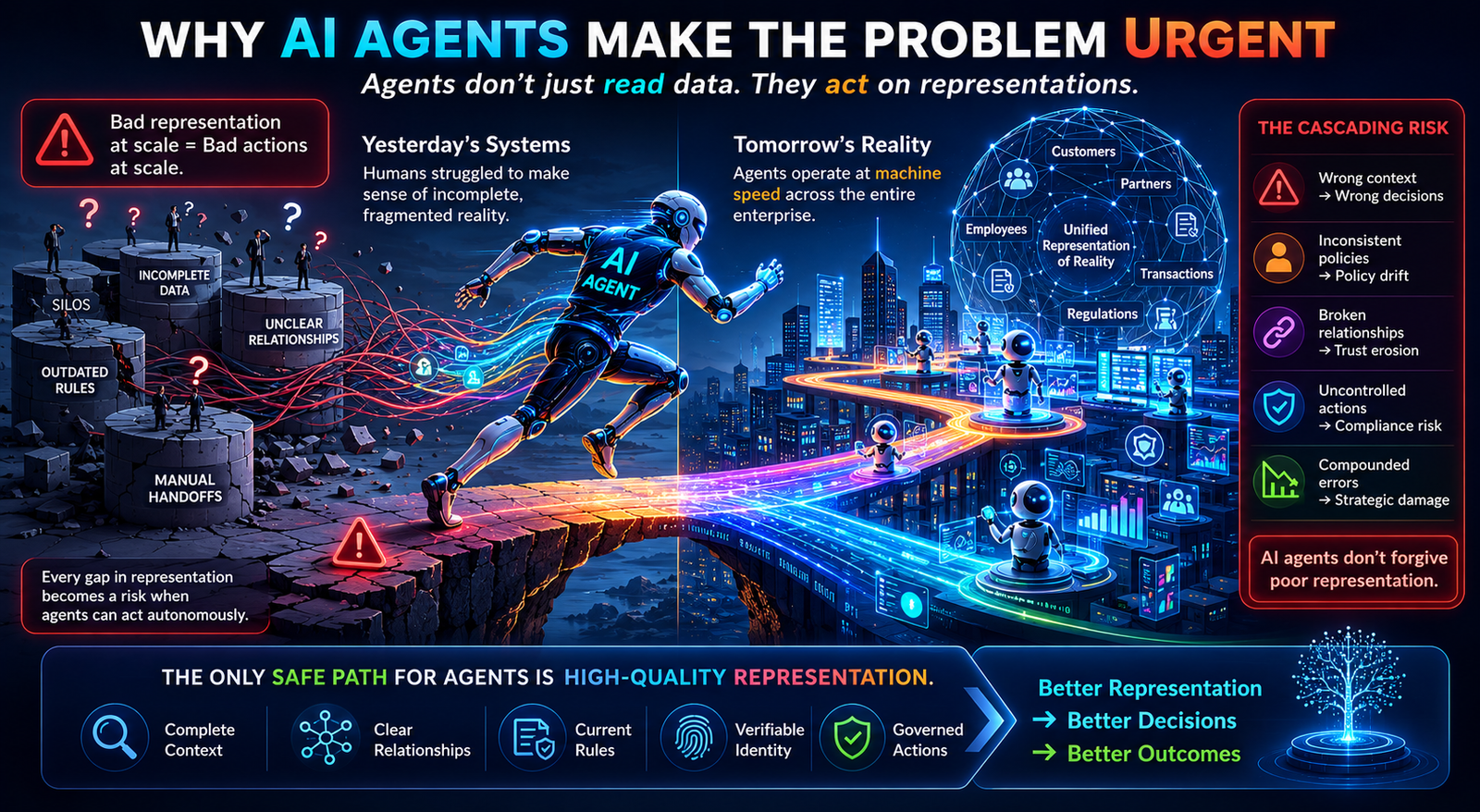
A chatbot responds.
A copilot assists.
An AI agent acts.
It can plan, decide, invoke tools, trigger workflows, call APIs, send messages, update records, escalate tickets, generate code, approve exceptions, negotiate with systems, and operate across multiple enterprise applications.
That shift changes the nature of enterprise AI risk.
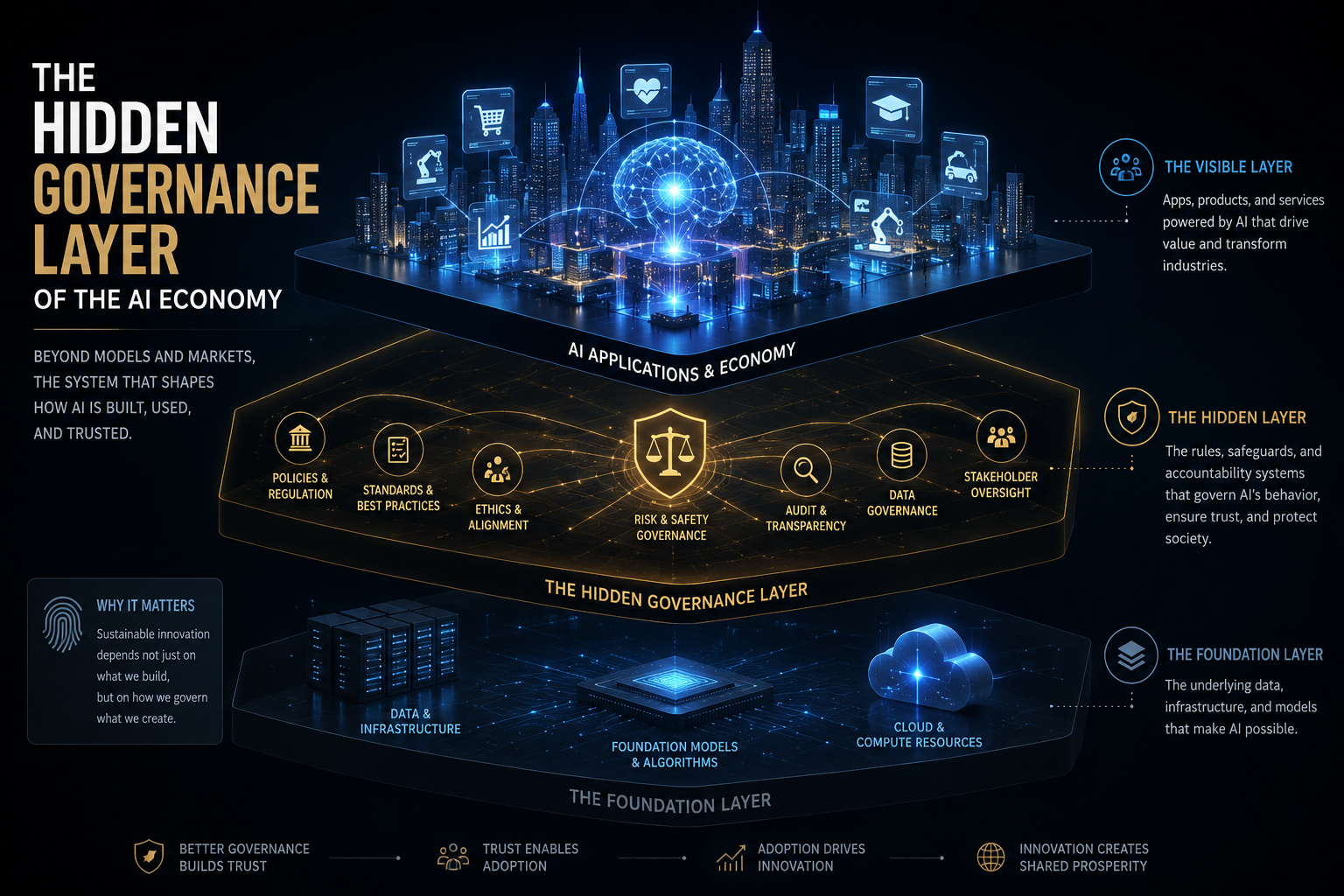
When AI moves from answering to acting, governance can no longer remain a policy document. It must become an operating architecture.
For CIOs, CTOs, CEOs, boards, risk leaders, security teams, and enterprise architects, the challenge is no longer only model accuracy. The real challenge is deciding how much autonomy an enterprise AI agent should have, what it can access, what it can change, who is accountable, and how the organization can stop, reverse, audit, or correct its actions.
This is where many enterprises will struggle.
Not because their models are weak.
But because their governance architecture was designed for software, not autonomous AI agents.
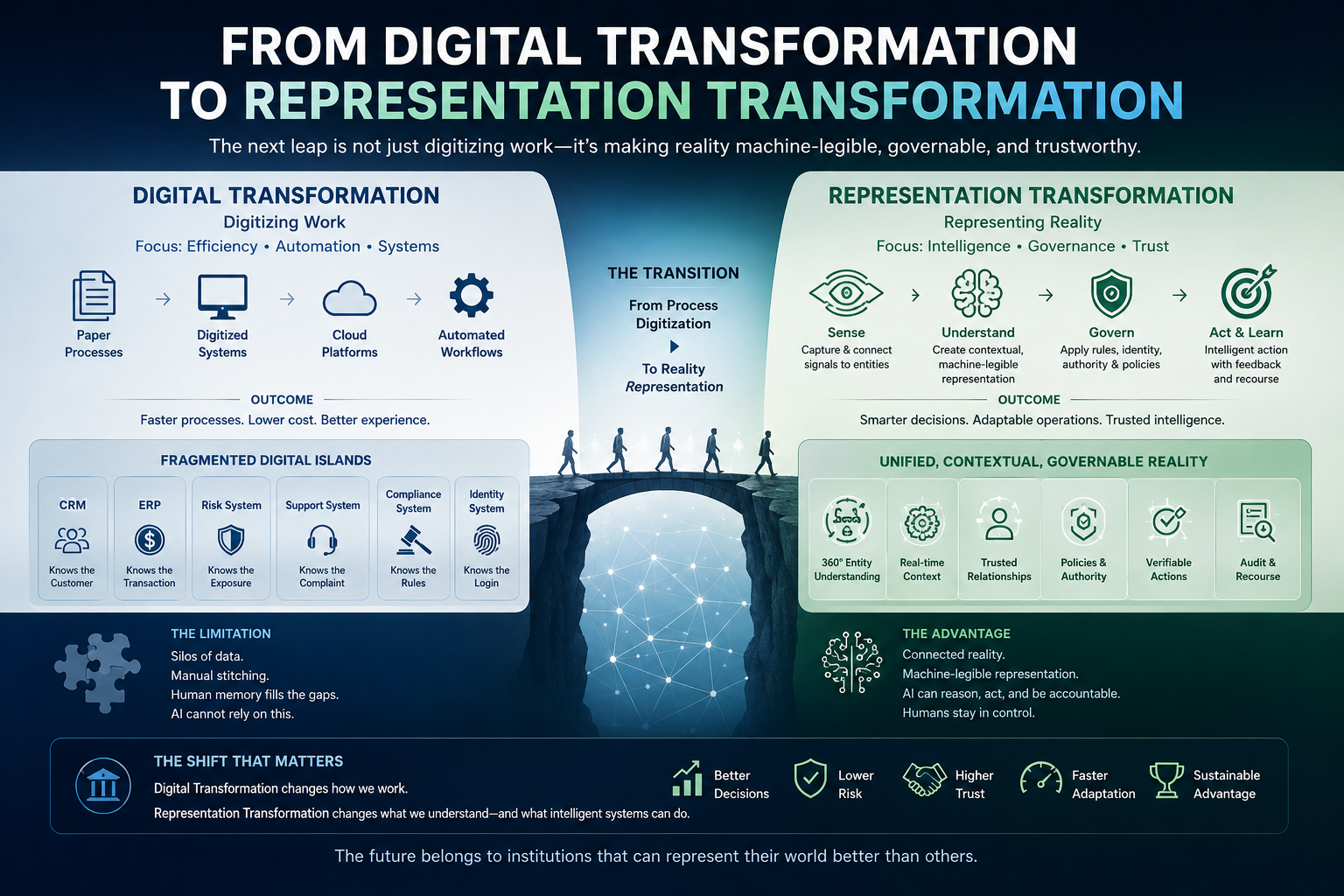
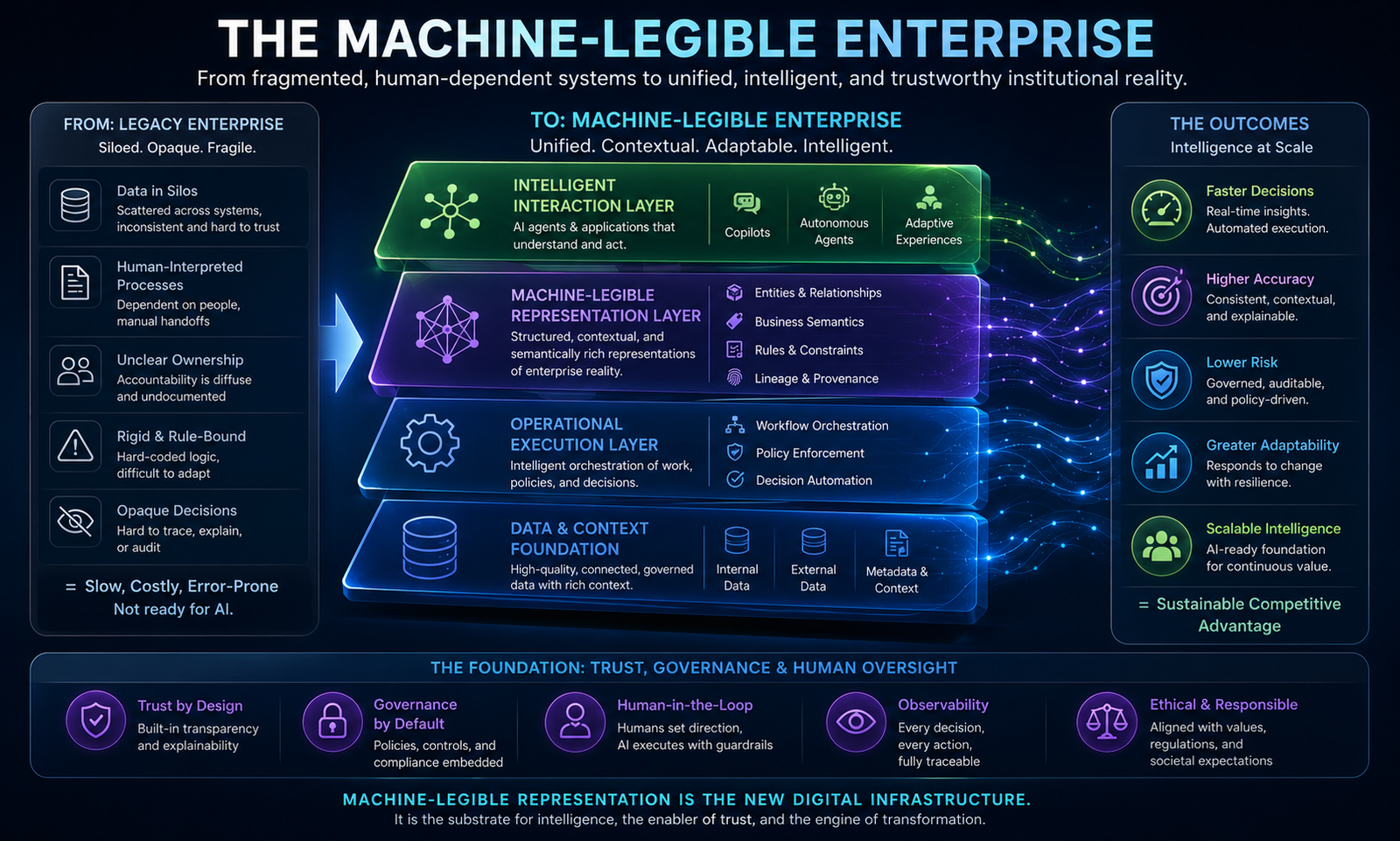
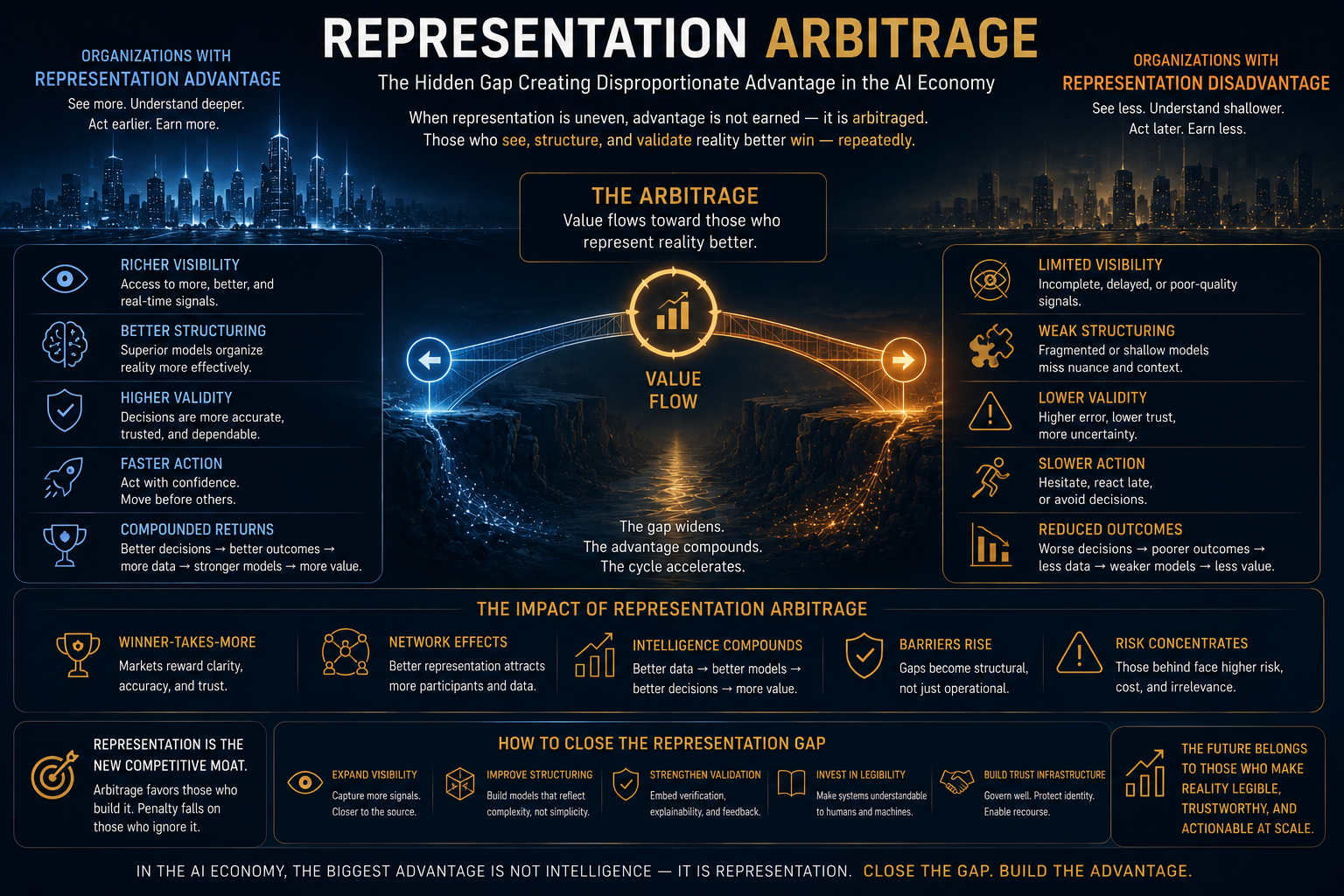
If AI acts on representations rather than reality, then the central governance question is no longer “How intelligent is the AI?” but “What authority should the AI have?” This is the core argument behind Raktim Singh’s SENSE–CORE–DRIVER framework and the broader Representation Economy theory.
Why AI Agent Governance Is Now a CIO Priority

AI agent governance is different from traditional AI governance because AI agents introduce a new type of risk: execution risk.
A predictive model may recommend a credit score.
A generative AI system may draft a response.
But an AI agent may take the next step: update the CRM, trigger a refund, block a transaction, initiate procurement, modify cloud infrastructure, send an email, raise an invoice, or close a service ticket.
That means enterprise AI governance must now answer questions that older governance models did not fully address:
Who authorized the agent to act?
What systems can it access?
Can it write data or only read data?
Can it call external tools?
Can it communicate with customers?
Can it modify production systems?
Can it override human decisions?
Can it act without approval?
Can its actions be reversed?
Who is accountable if the agent causes harm?
These are not theoretical questions. They are production questions.
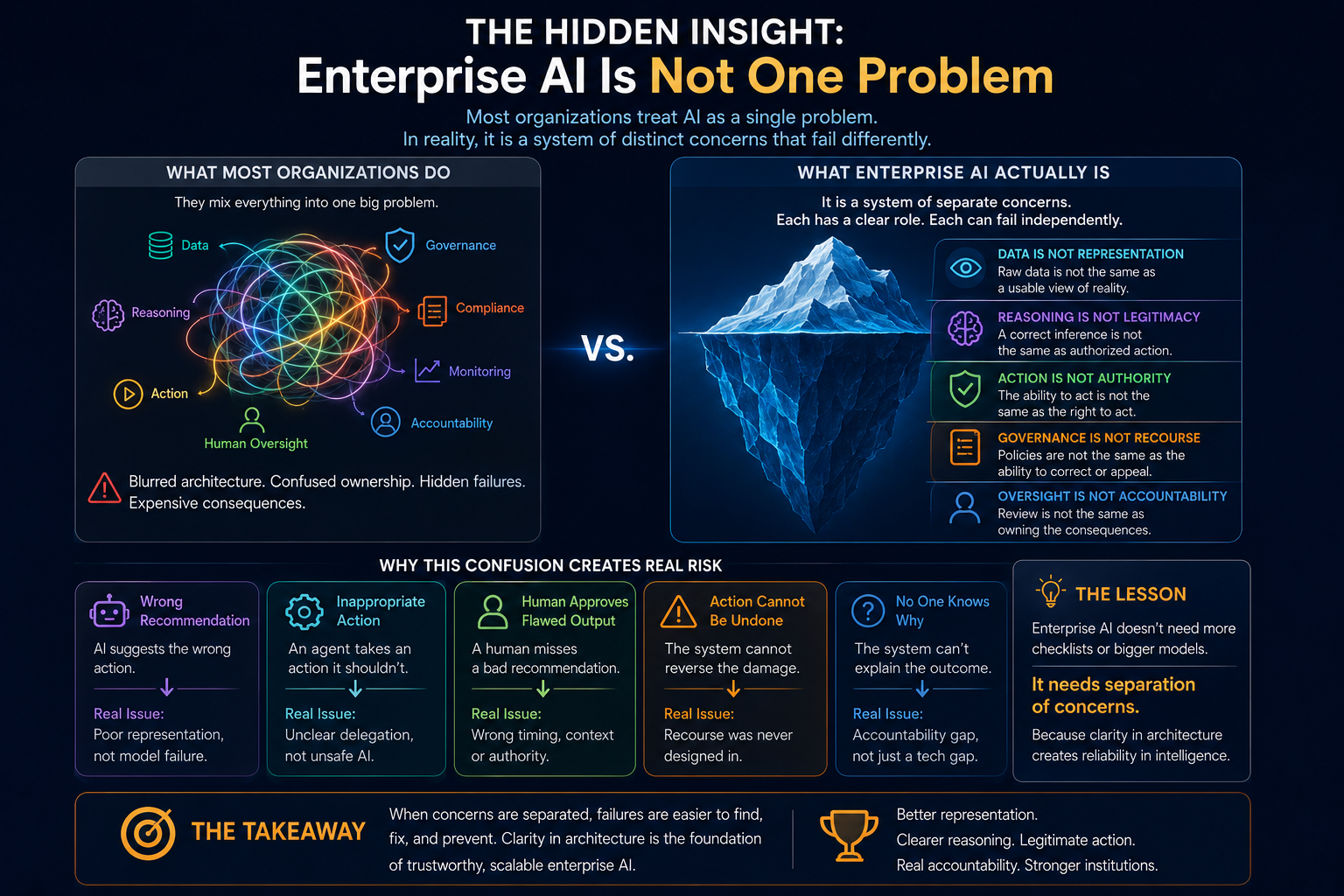
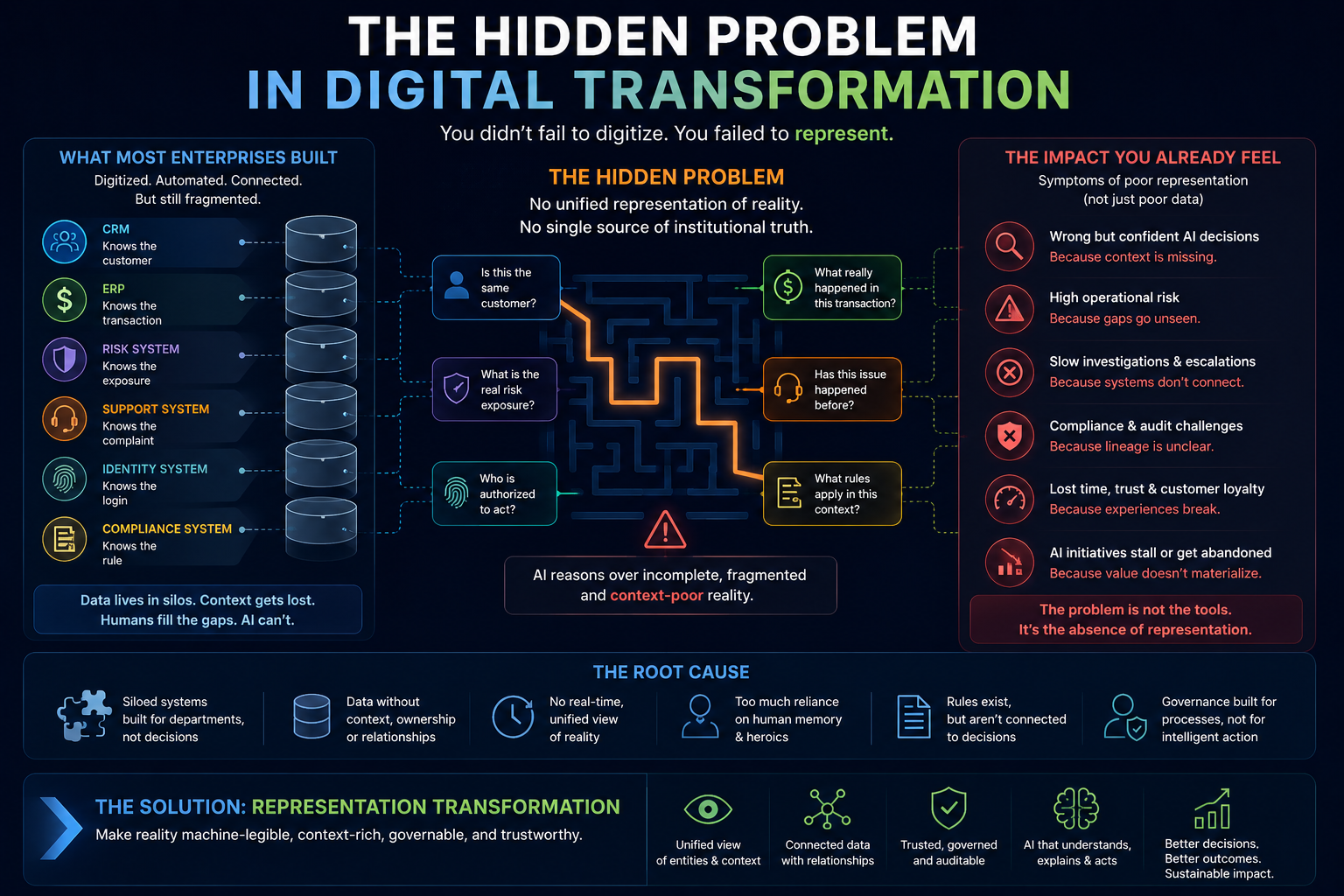
Once AI agents enter production, the enterprise becomes a mixed society of human workers, software systems, APIs, bots, copilots, digital workers, and autonomous AI agents. Without a clear AI agent operating model, organizations will face agent sprawl, shadow AI, duplicated workflows, conflicting decisions, hidden costs, security exposure, compliance gaps, and accountability failures.
This is why enterprise AI governance must move from model governance to authority governance.
The real issue is not only whether AI is intelligent.
The real issue is whether AI has legitimate authority to act.
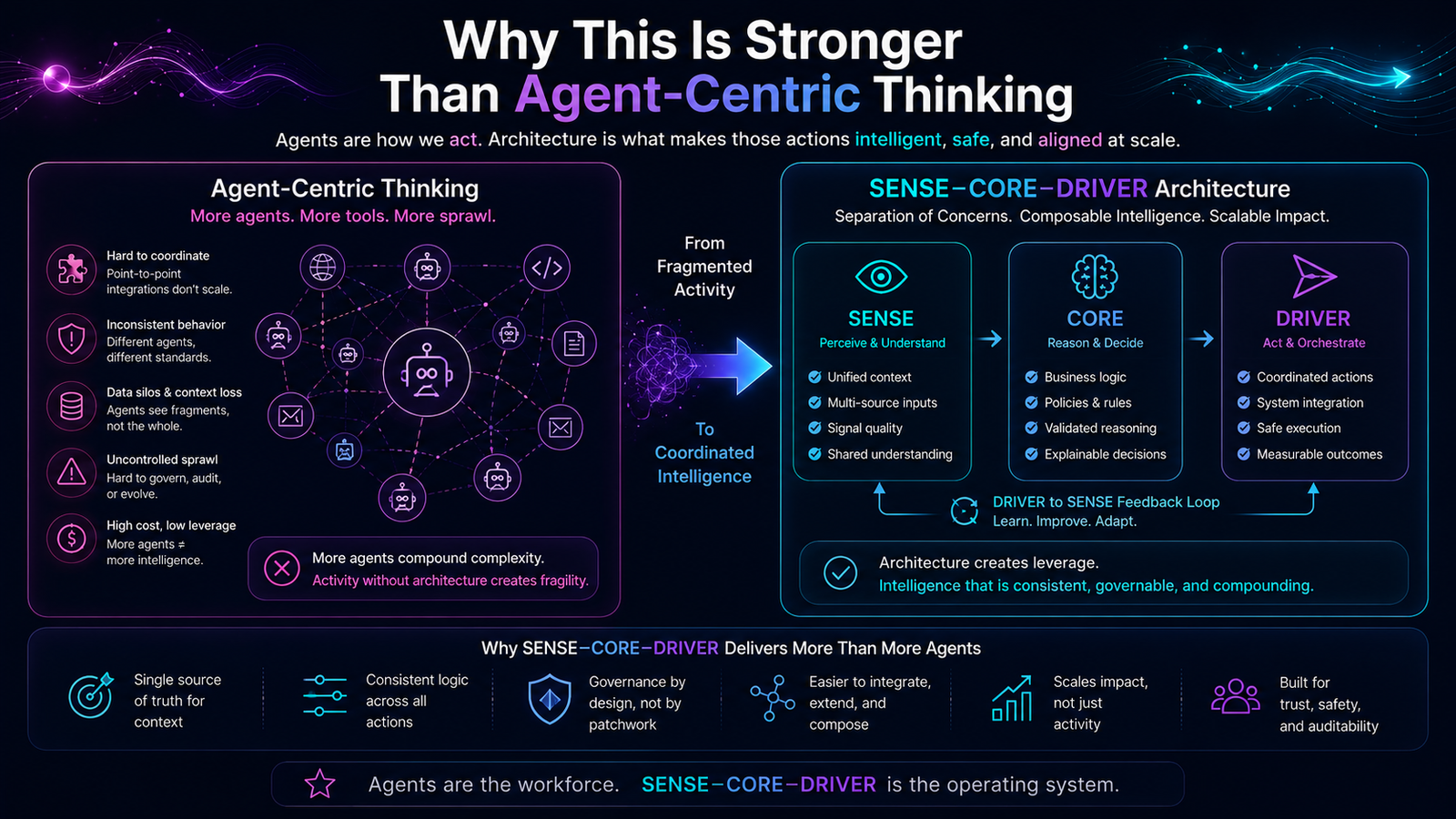
The Dangerous Mistake: Treating All AI Agents the Same

Many enterprises will make one of two mistakes.
The first mistake is over-trust. They will give AI agents broad access because a pilot worked well. This creates security, compliance, operational, and reputational risk. A helpful agent with excessive permissions can become dangerous very quickly.
The second mistake is over-control. They will lock down every agent so tightly that employees bypass official tools and use unapproved systems. This creates shadow AI, data leakage, and loss of enterprise visibility.
Both mistakes come from the same flawed assumption: that AI agent governance is binary.
Trusted or not trusted.
Allowed or blocked.
Human-approved or autonomous.
This is not enough.
AI agent governance must be proportional. The level of control should depend on the agent’s autonomy, data sensitivity, business impact, reversibility, access scope, reasoning reliability, and quality of enterprise representation.
A read-only HR policy agent does not need the same governance as an agent that approves vendor payments.
An agent that drafts a customer email does not carry the same risk as an agent that sends the email automatically.
An agent that recommends a code fix is different from an agent that deploys code into production.
The CIO’s job is not to say yes or no to AI agents.
The CIO’s job is to decide the correct boundary of autonomy.
The Autonomy Ladder: From Observation to Independent Action
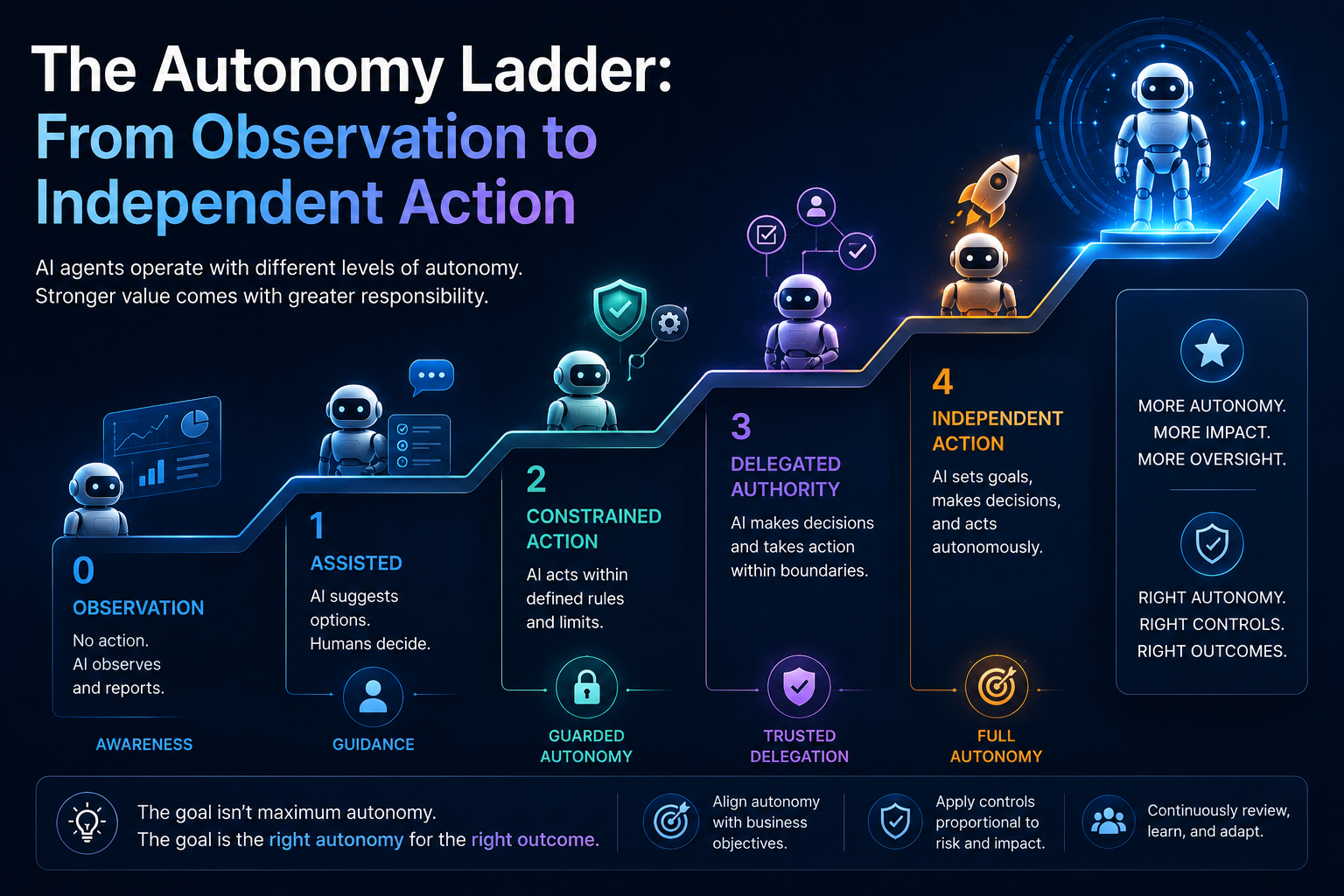
A practical AI governance framework for enterprise AI agents should start with a simple autonomy ladder.
Level 1: Observe
At this level, the agent has read-only access. It can search, summarize, classify, extract, compare, explain, and retrieve information. It cannot modify systems or trigger external actions.
Example: An HR policy agent answers employee questions by reading approved policy documents. It does not update employee records or approve exceptions.
This is the safest form of AI agent autonomy.
Level 2: Advise
Here, the agent recommends actions, but humans execute them. It may suggest a reply, propose a resolution, identify a fraud pattern, or recommend next steps.
Example: A customer service agent drafts a refund recommendation, but a human supervisor approves and executes it.
The agent contributes intelligence but does not hold execution authority.
Level 3: Act With Approval
At this stage, the agent can prepare an action and initiate a workflow, but execution requires explicit human approval.
Example: An IT operations agent identifies a server issue, prepares a remediation script, and asks an engineer to approve execution.
This model works well when speed matters but risk is still meaningful.
Level 4: Act Autonomously
Here, the agent can act independently within defined boundaries. This requires the strongest governance: real-time monitoring, access control, action limits, rollback, audit trails, escalation rules, incident response, and clear accountability.
Example: A low-risk procurement agent automatically reorders approved supplies within a fixed budget, approved vendor list, and audit trail.
This autonomy ladder gives CIOs a practical way to classify AI agents in production.
But classification is not enough.
Enterprises also need architecture.
That is where SENSE–CORE–DRIVER becomes essential.
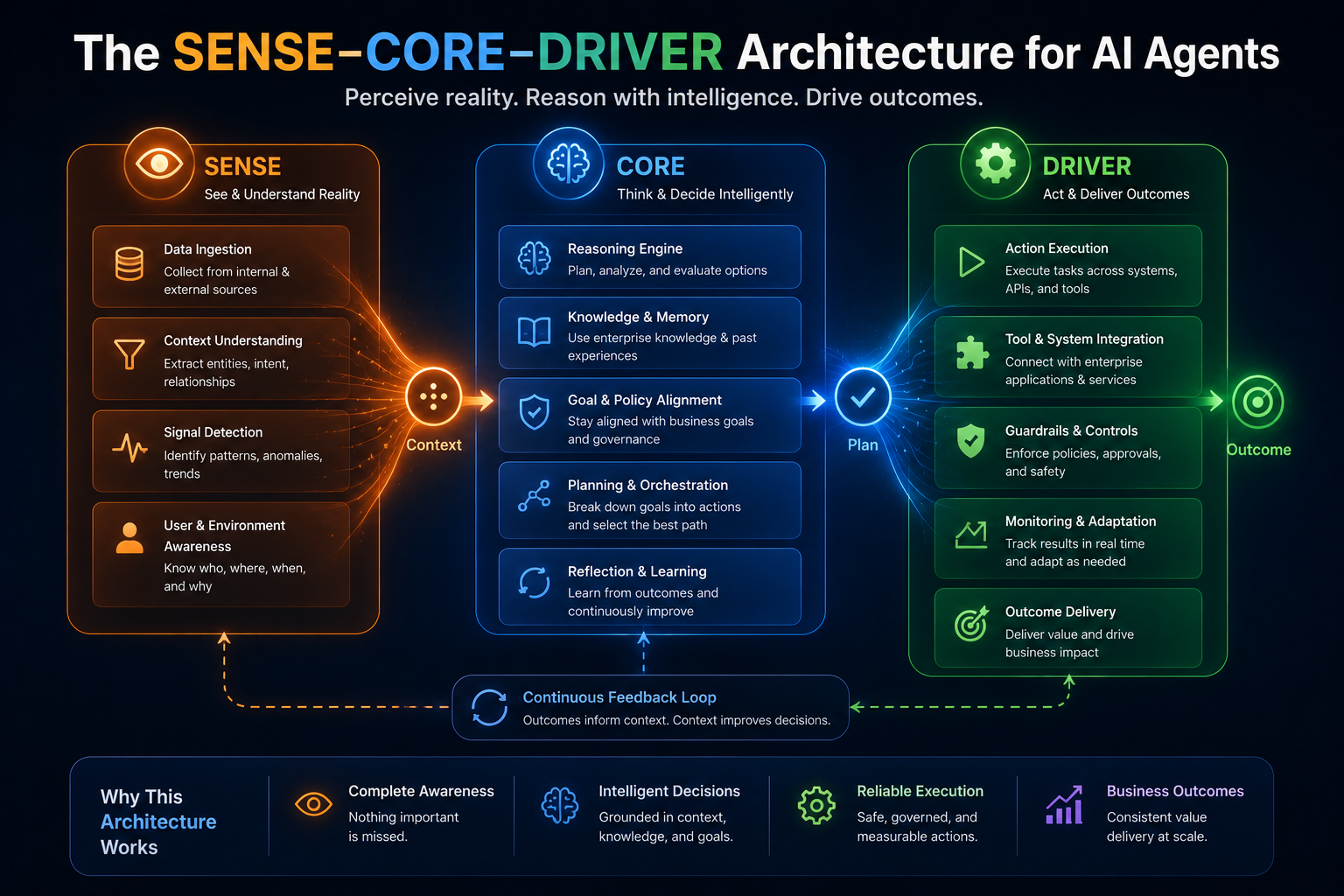
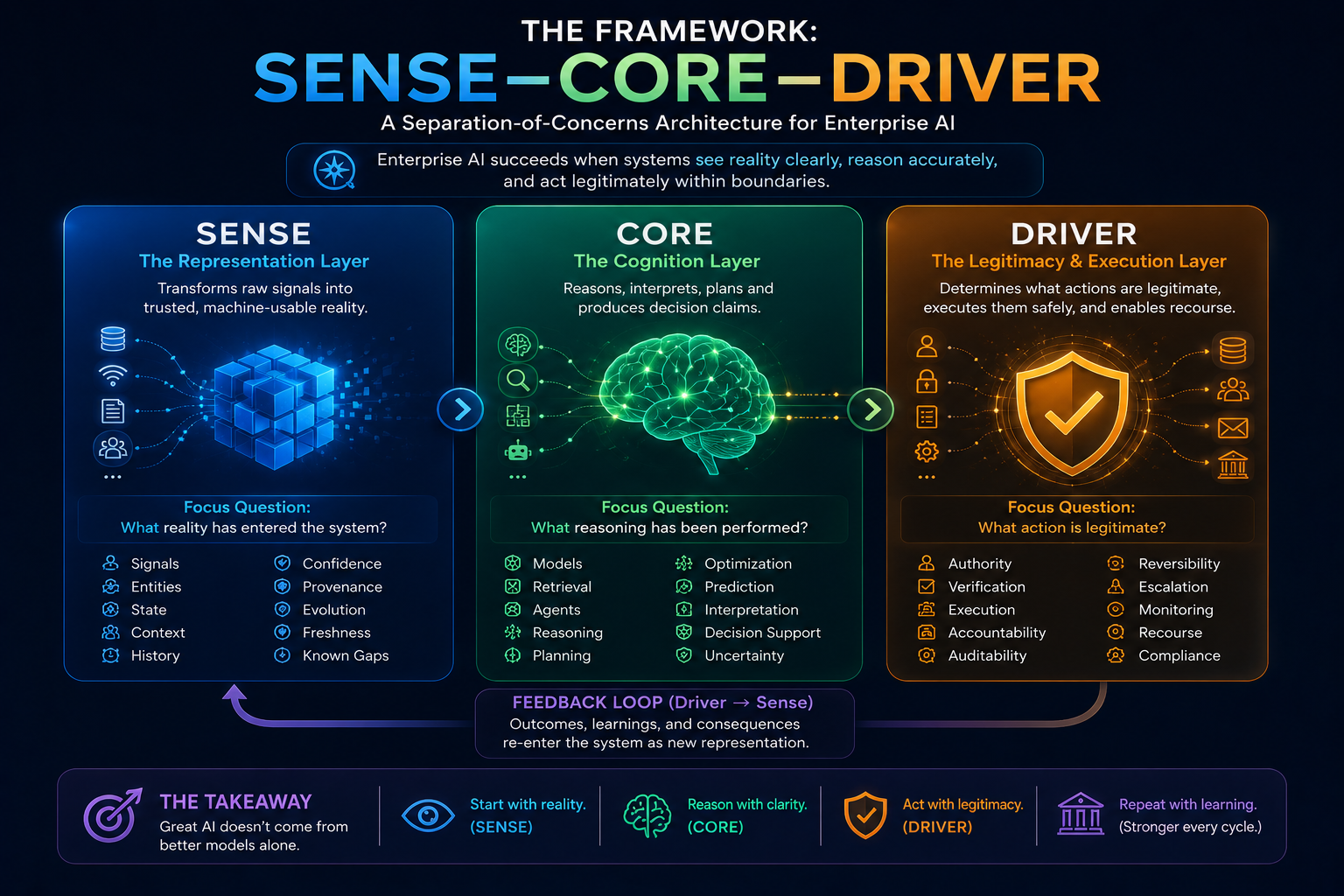
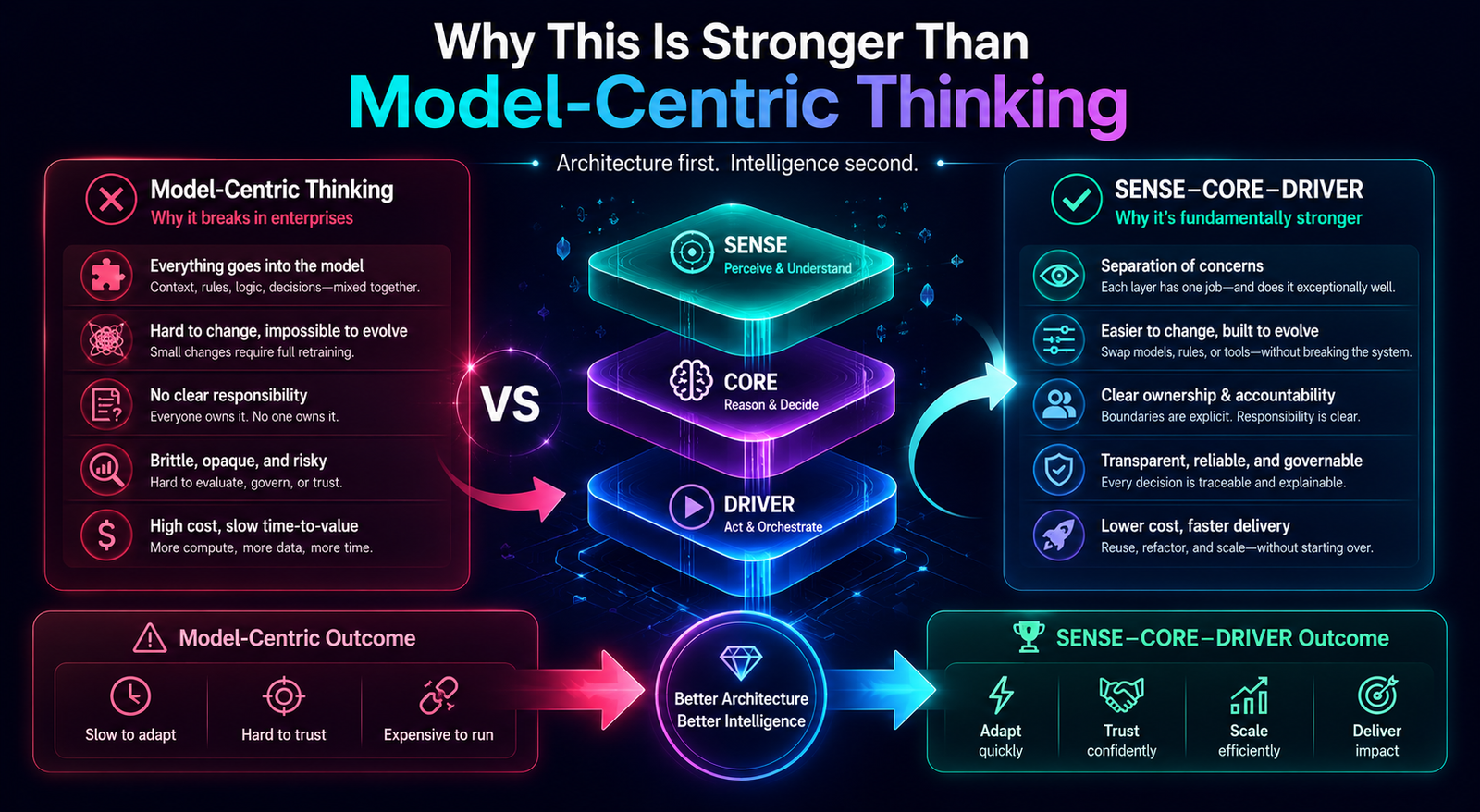
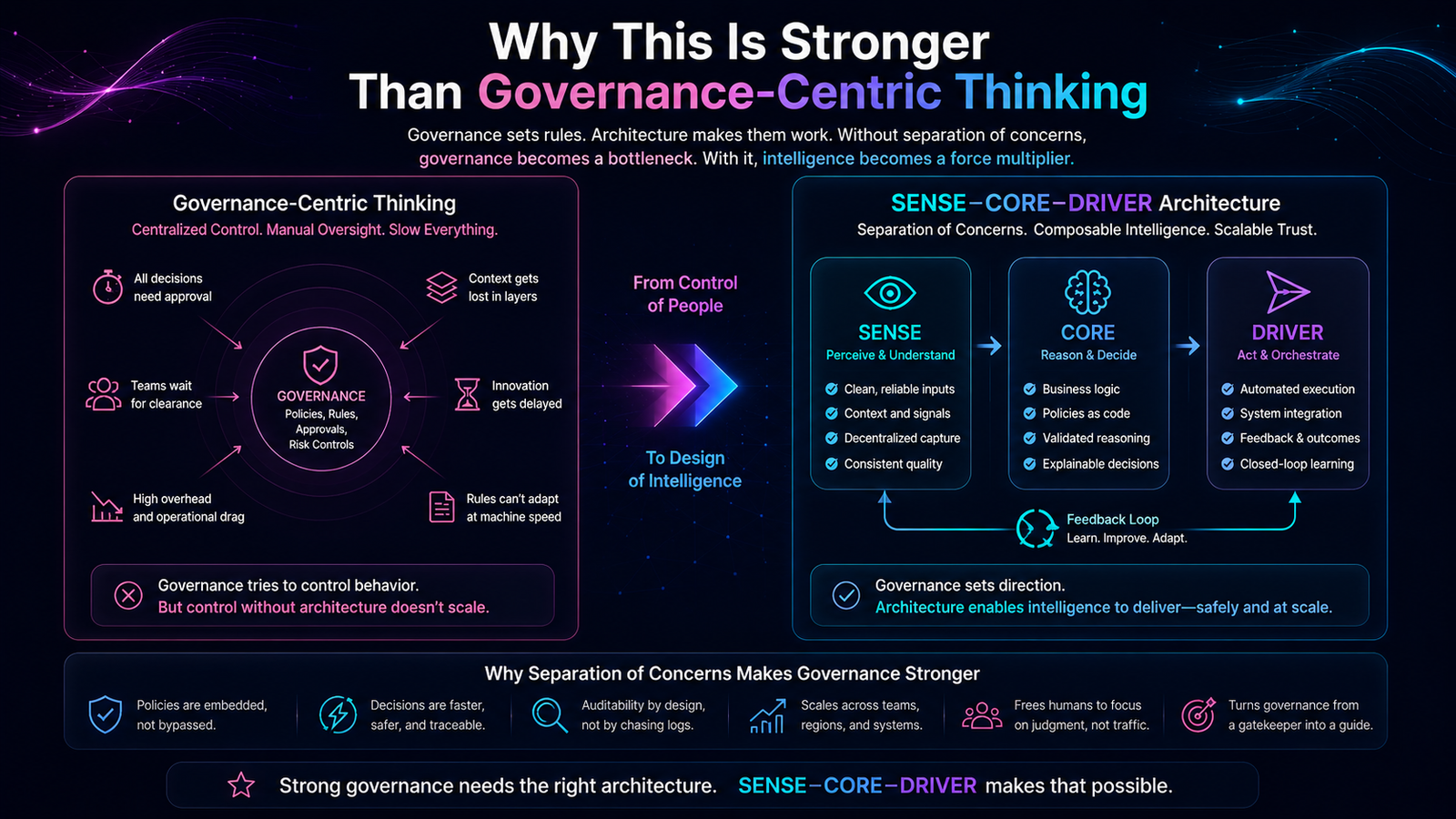
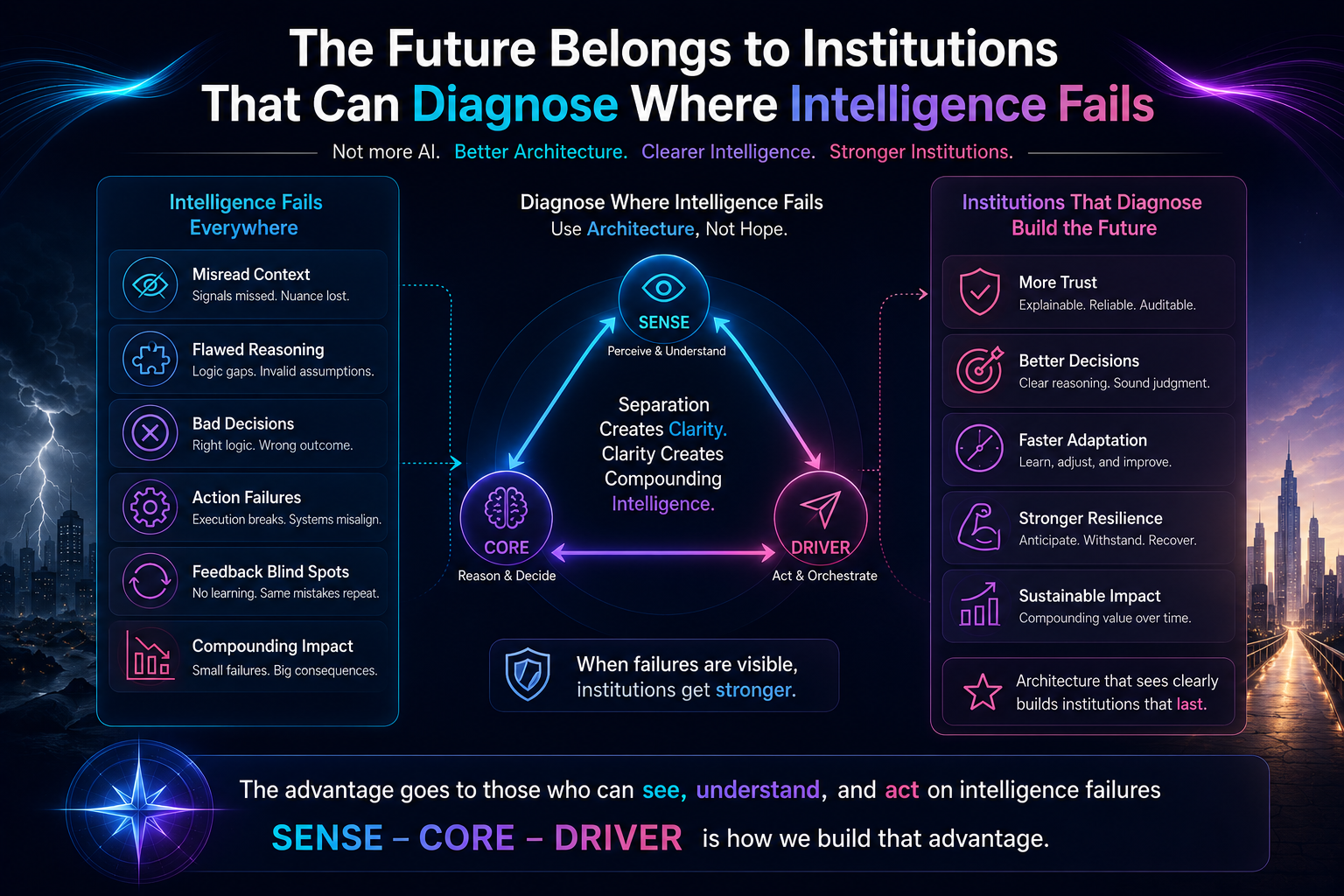
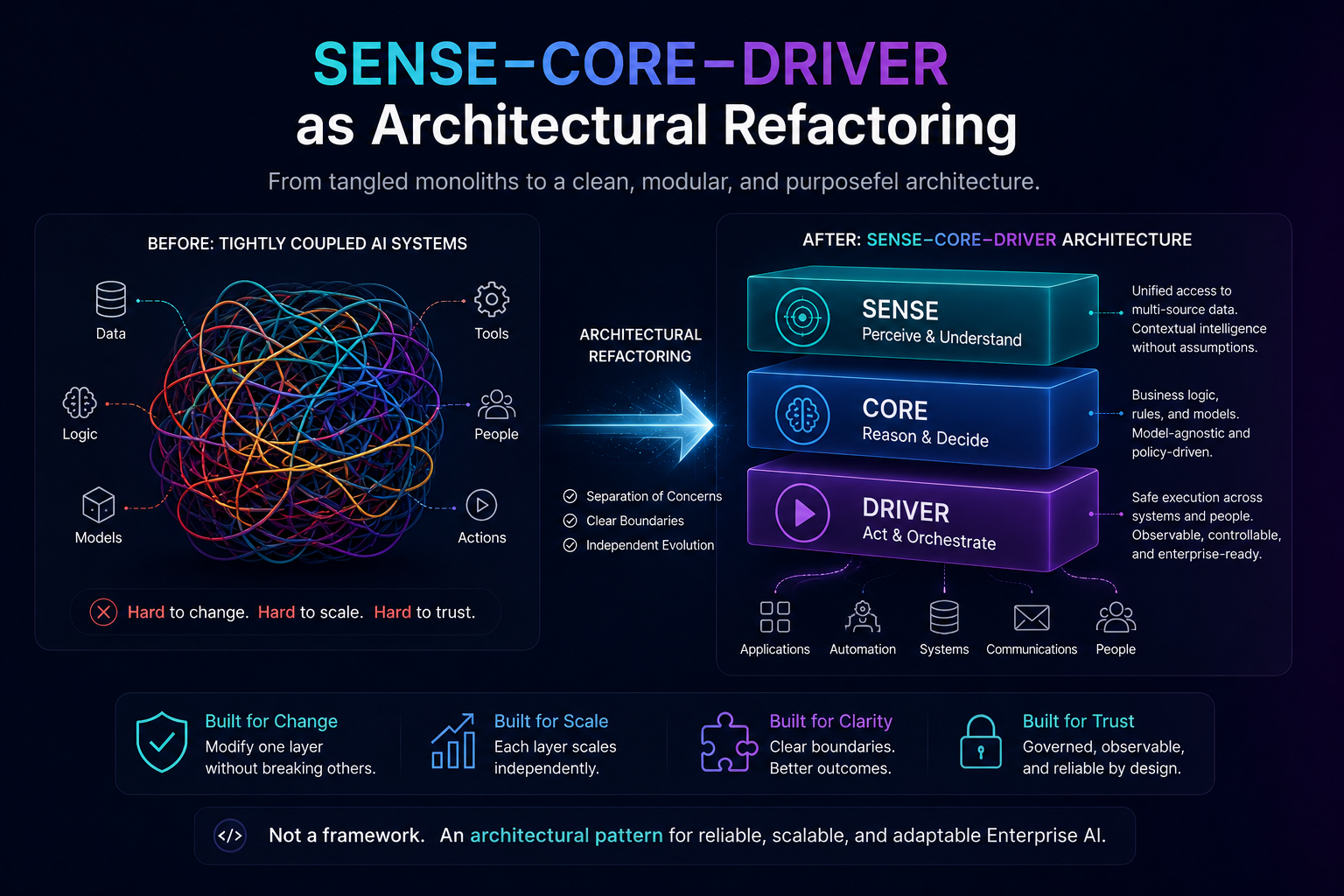
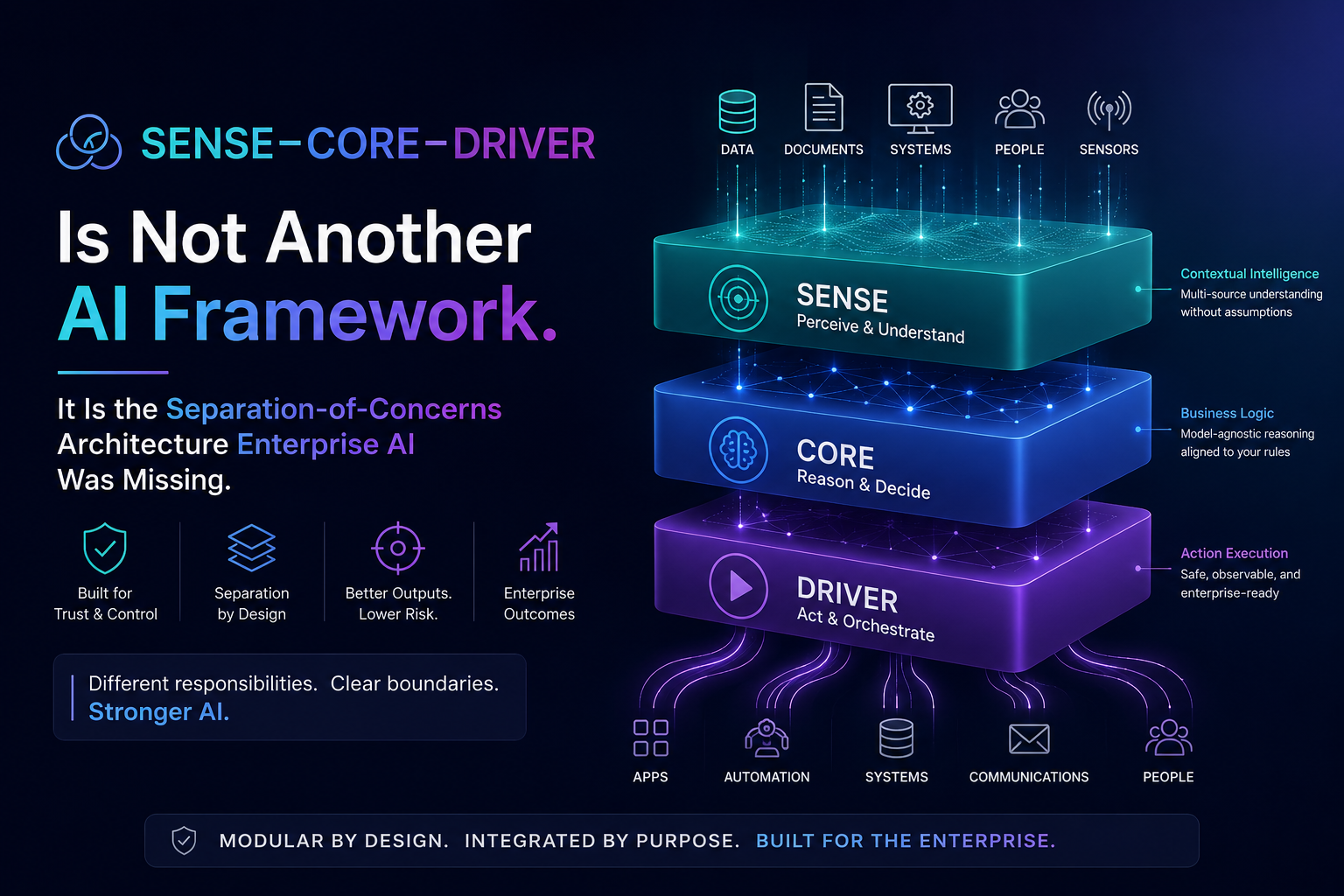
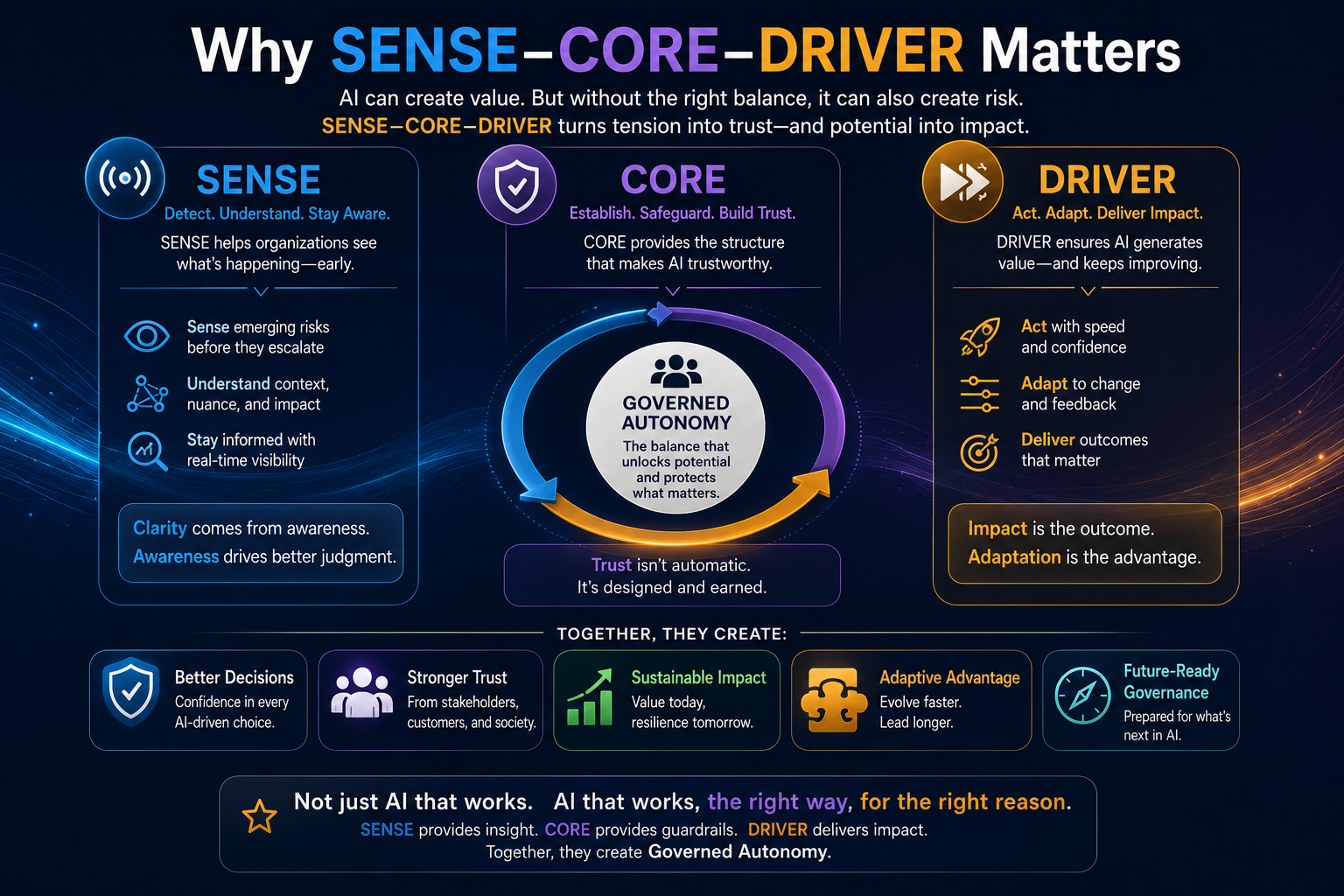
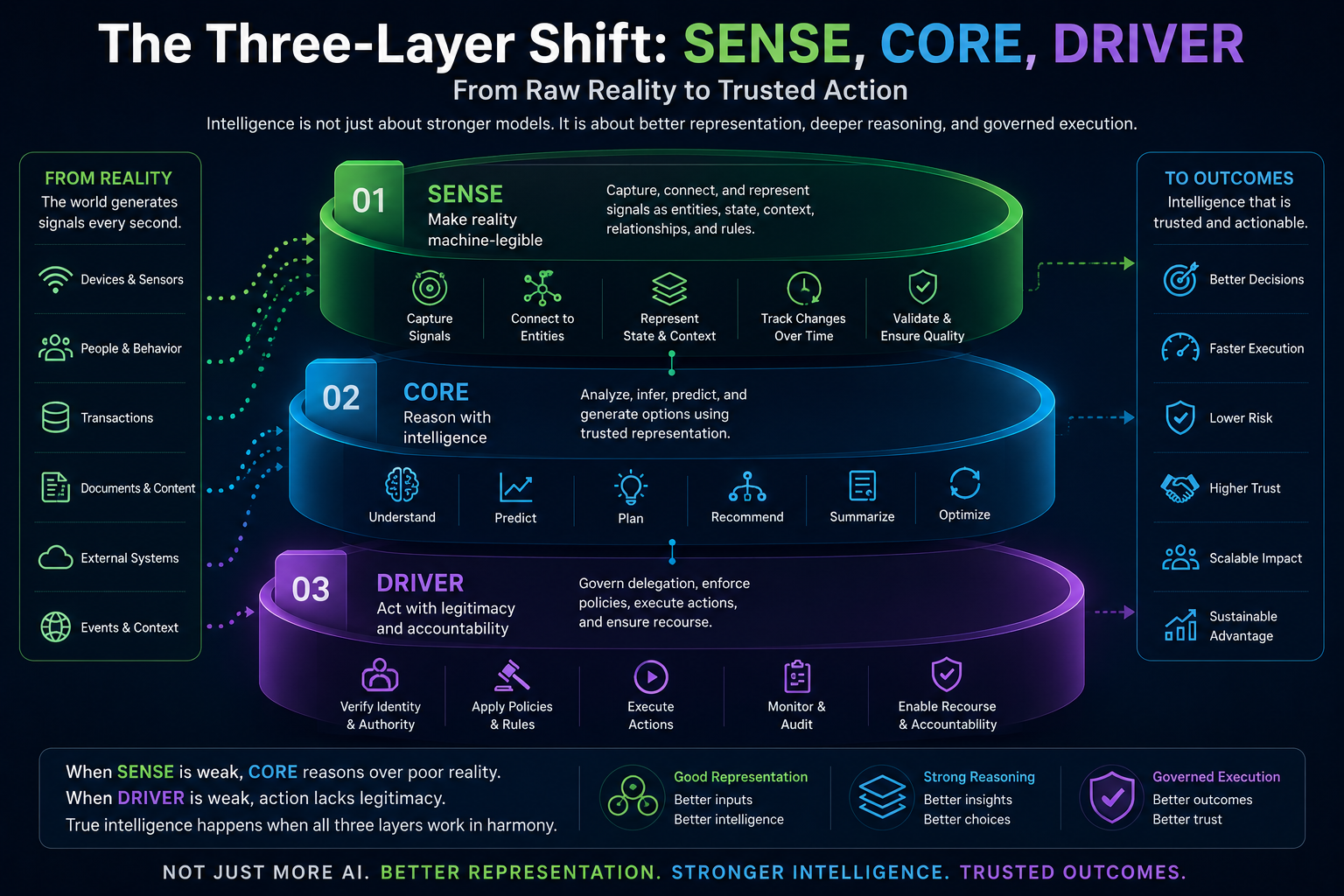
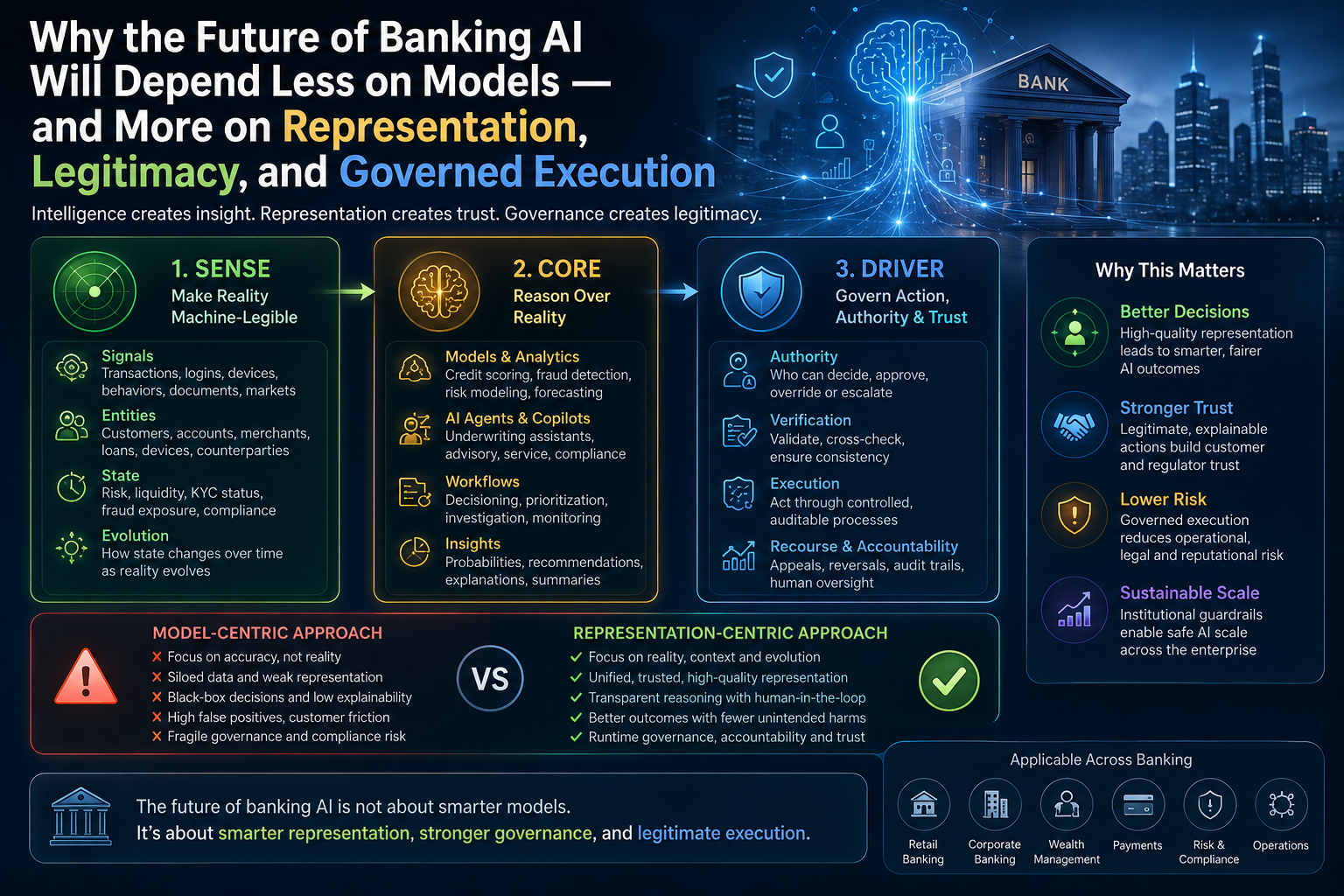
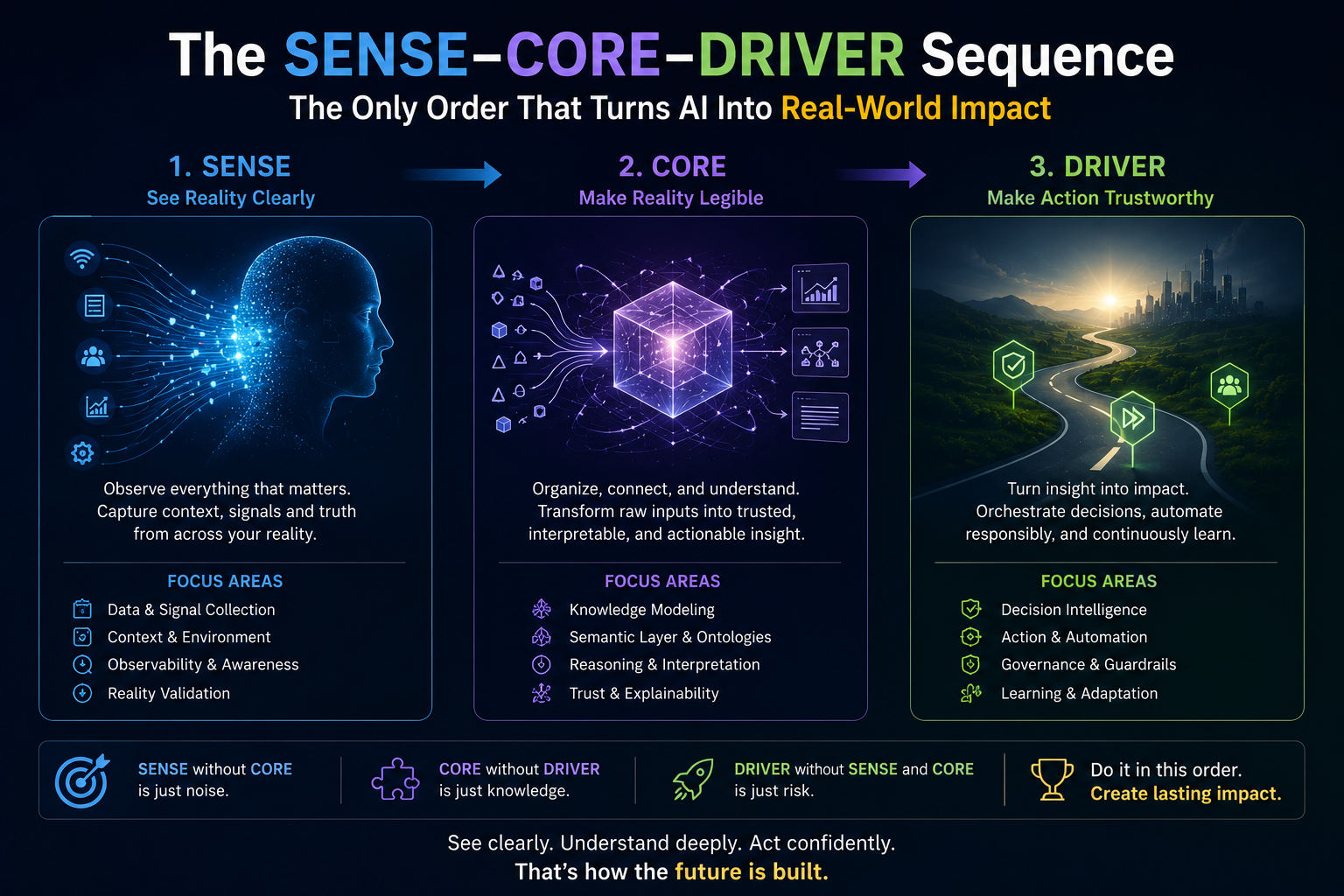
The SENSE–CORE–DRIVER Model for AI Agent Governance
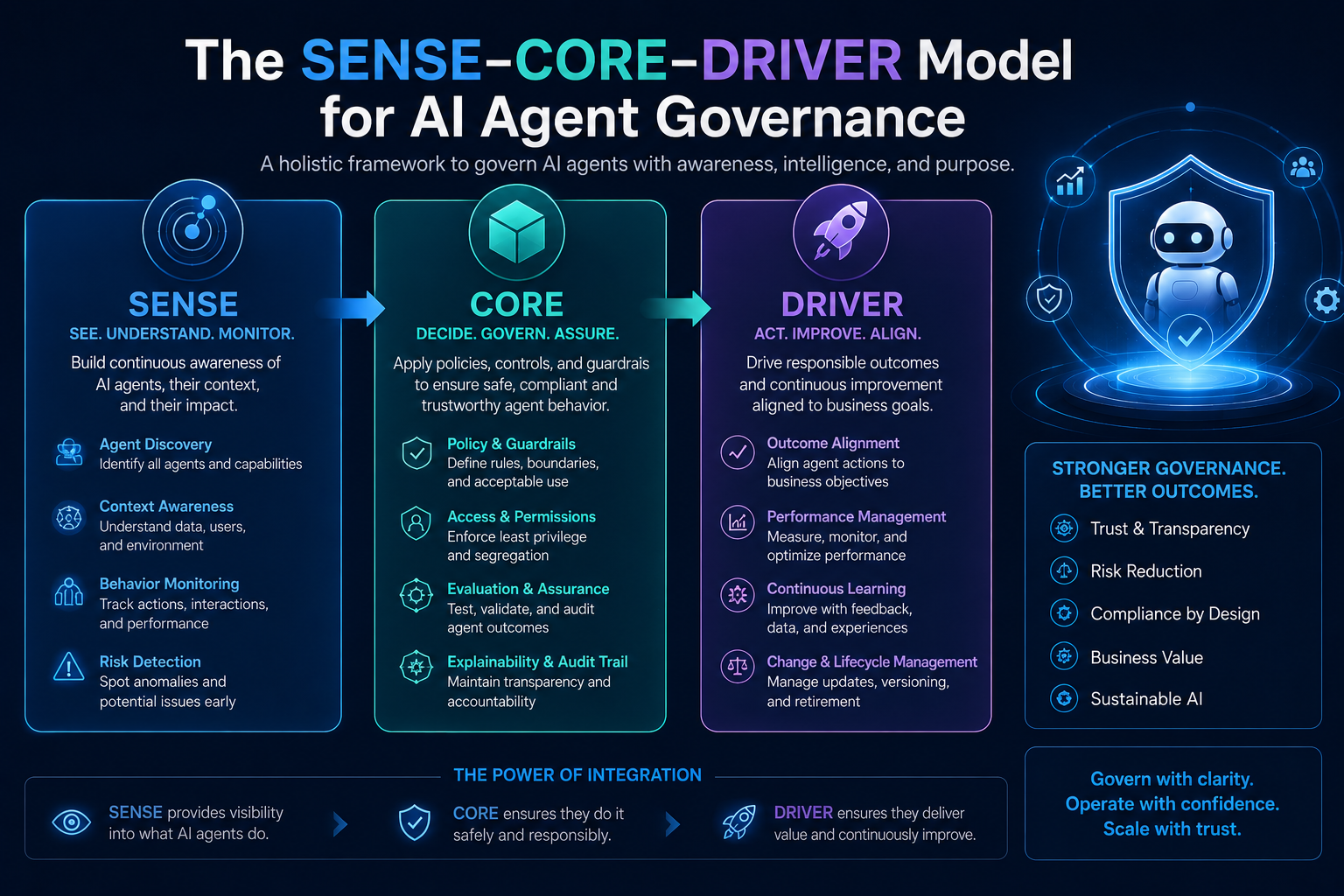
Most AI governance frameworks focus heavily on the CORE: the model, reasoning engine, prompt, workflow, toolchain, or agent logic.
But enterprise AI agents do not fail only because reasoning fails.
They fail because the system misunderstands reality, acts without legitimate authority, or cannot recover when something goes wrong.
AI agents need three layers.
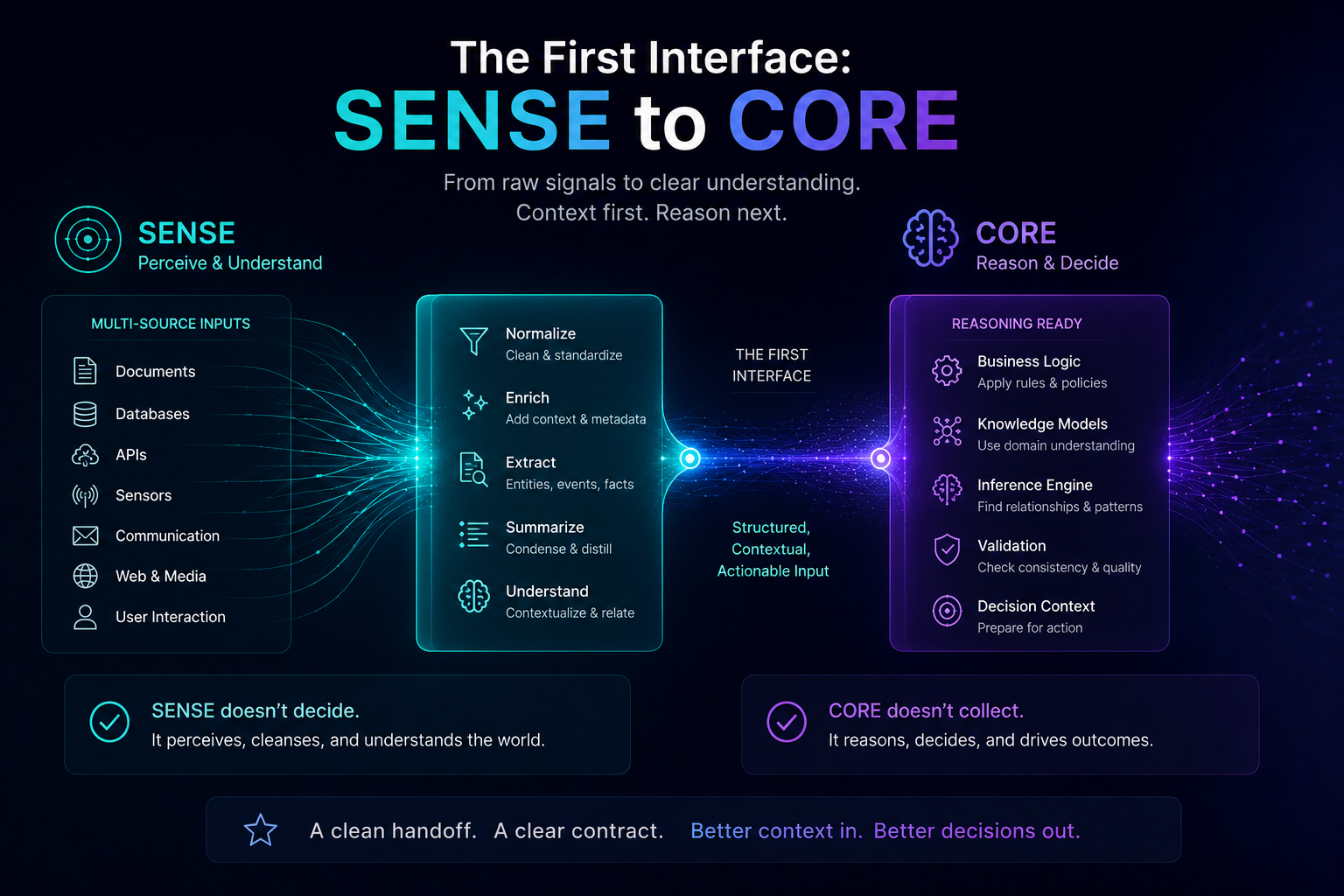
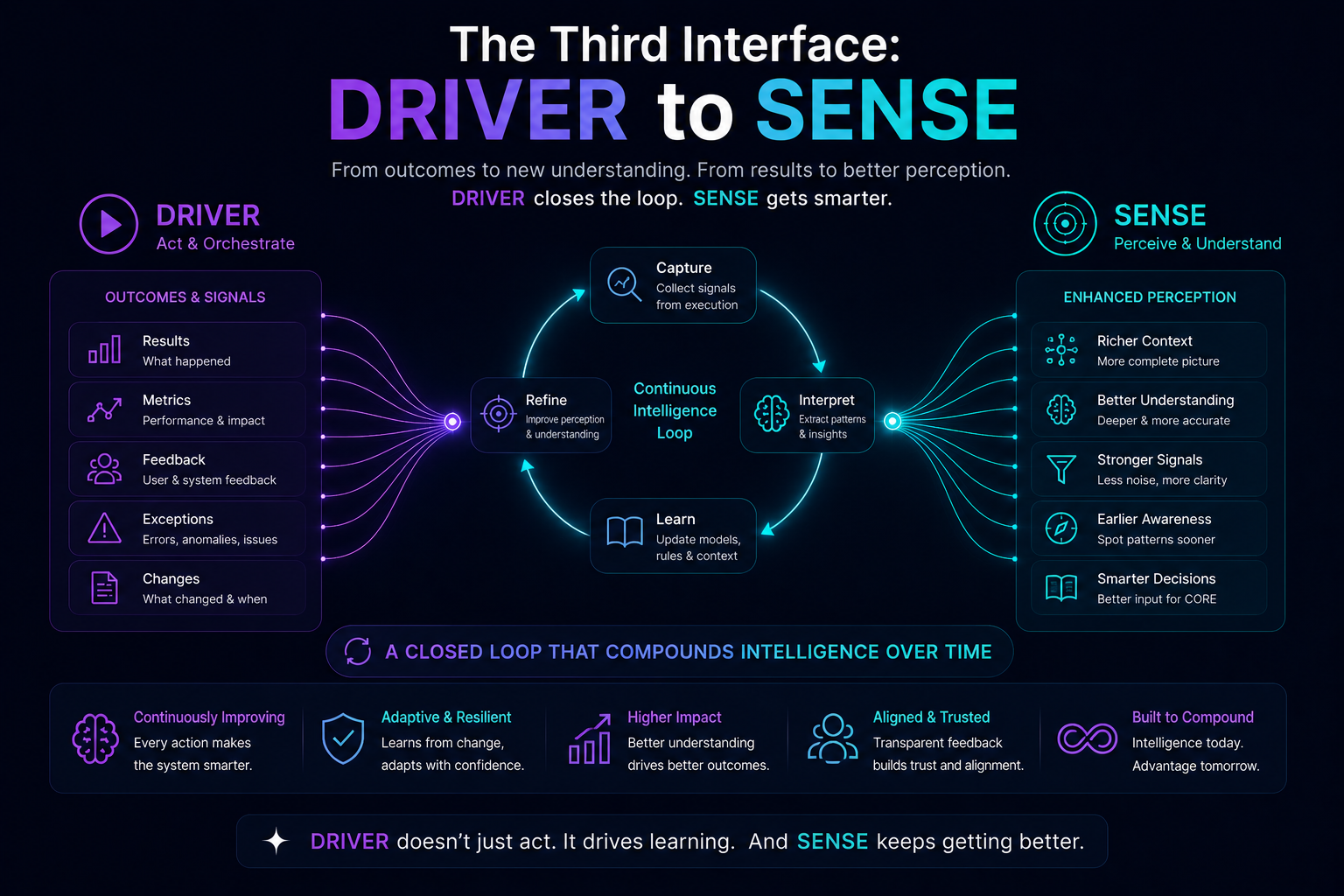
SENSE: What Can the Agent See?
SENSE is the legibility layer. It determines what the agent can observe, what signals it receives, what entities it recognizes, what state it believes the world is in, and how that state changes over time.
If SENSE is weak, the agent may reason intelligently over the wrong reality.
CORE: What Can the Agent Decide?
CORE is the cognition layer. It interprets context, reasons over options, makes recommendations, plans actions, and selects the next step.
If CORE is weak, the agent may misunderstand the task, choose the wrong action, or fail to recognize uncertainty.
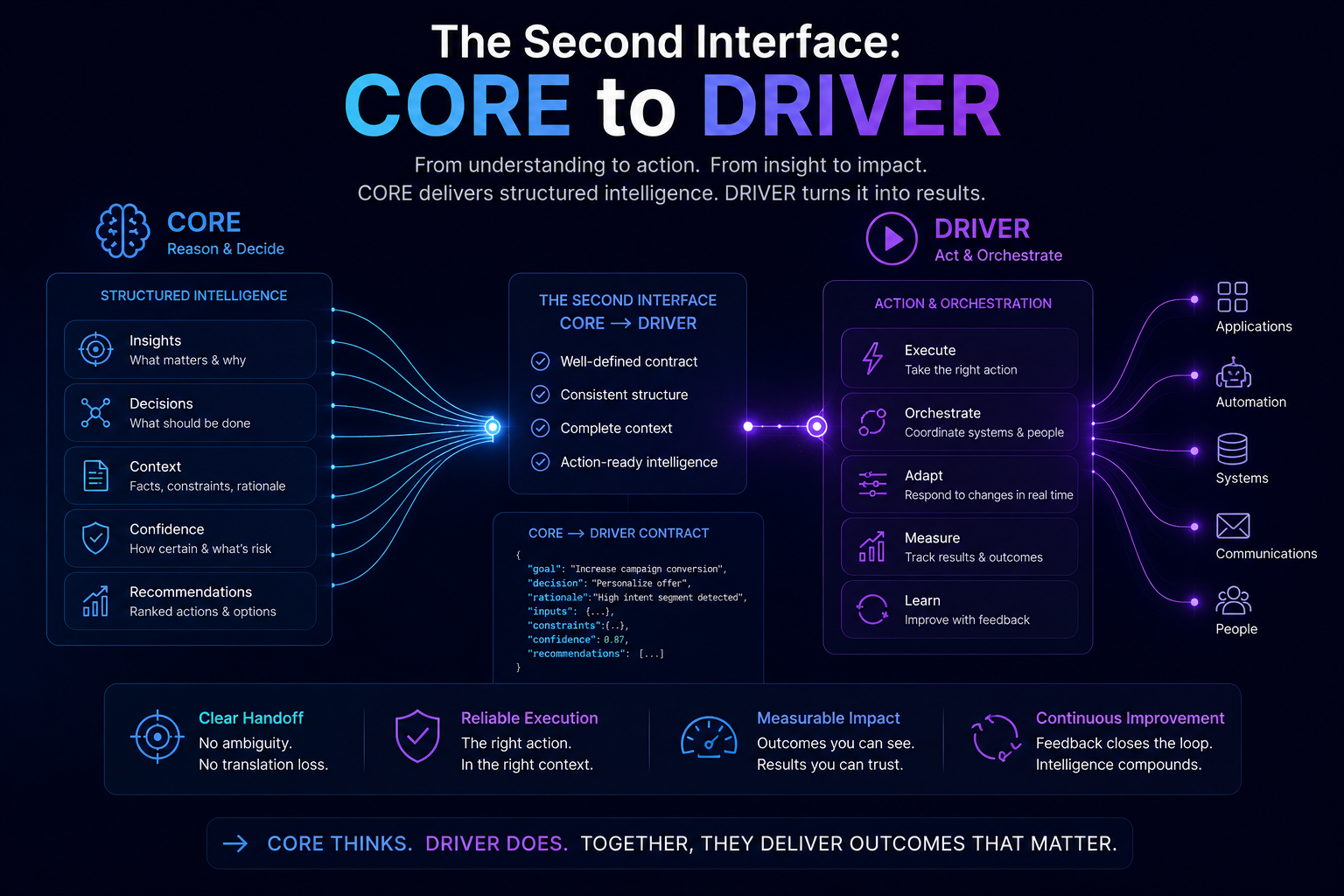
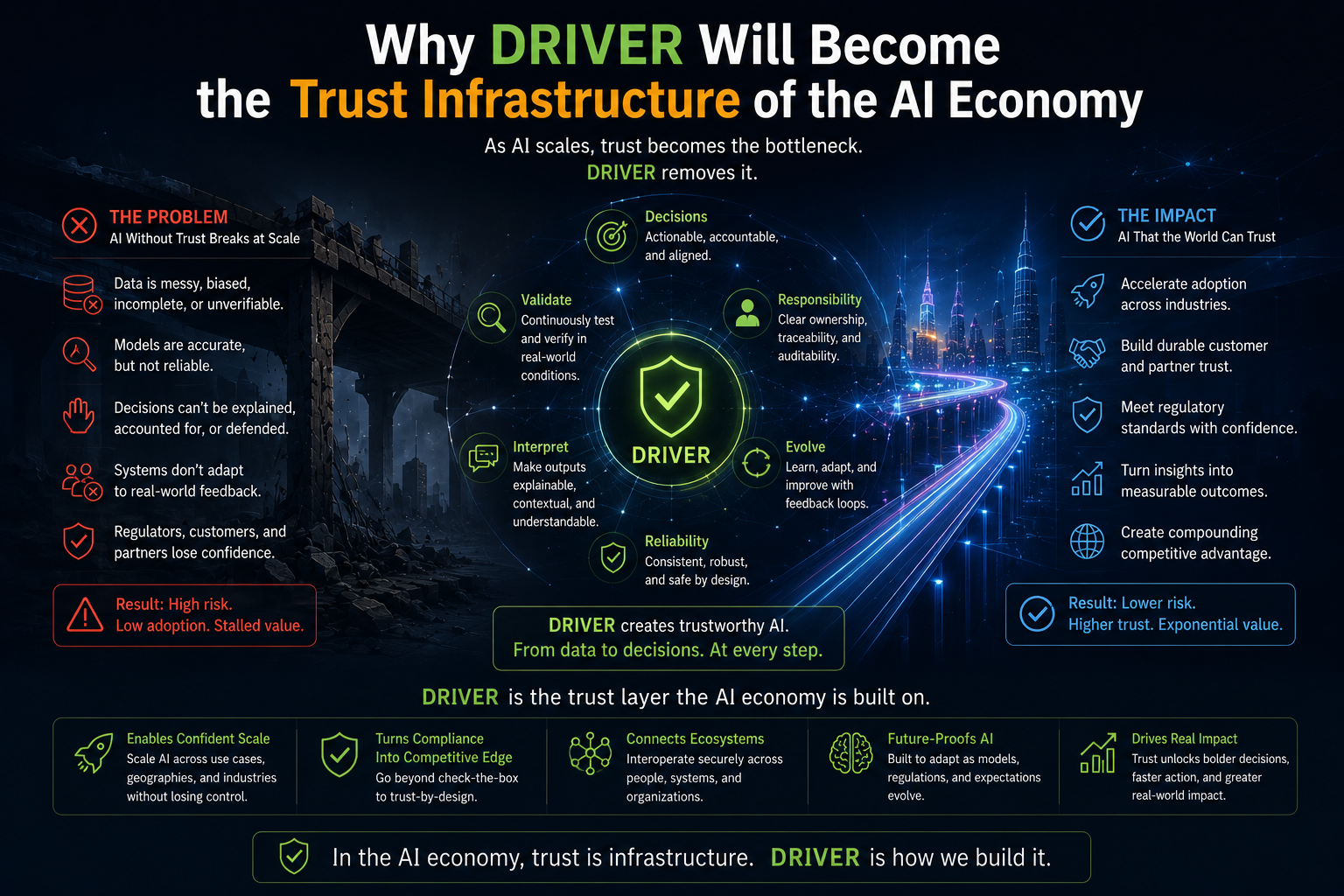
DRIVER: What Can the Agent Do?
DRIVER is the legitimacy and execution layer. It determines whether the agent is authorized to act, what identity it uses, what permissions it has, what verification is required, how execution happens, and how recourse or rollback is provided.
If DRIVER is weak, the agent may act without authority, accountability, reversibility, or institutional legitimacy.
This separation is critical.
An AI agent may have a strong CORE but weak SENSE. It may reason well but act on incomplete, outdated, or fragmented information.
An AI agent may have strong SENSE and CORE but weak DRIVER. It may understand the situation and choose a reasonable action, but lack legitimate authority, auditability, or recovery mechanisms.
This is the hidden failure pattern in many enterprise AI systems:
Good reasoning. Weak representation. Unsafe execution.
For CIOs, the implication is clear.
AI agent governance cannot be built only around model selection, prompt quality, or tool integration. It must be built around the full chain from representation to reasoning to authorized action.
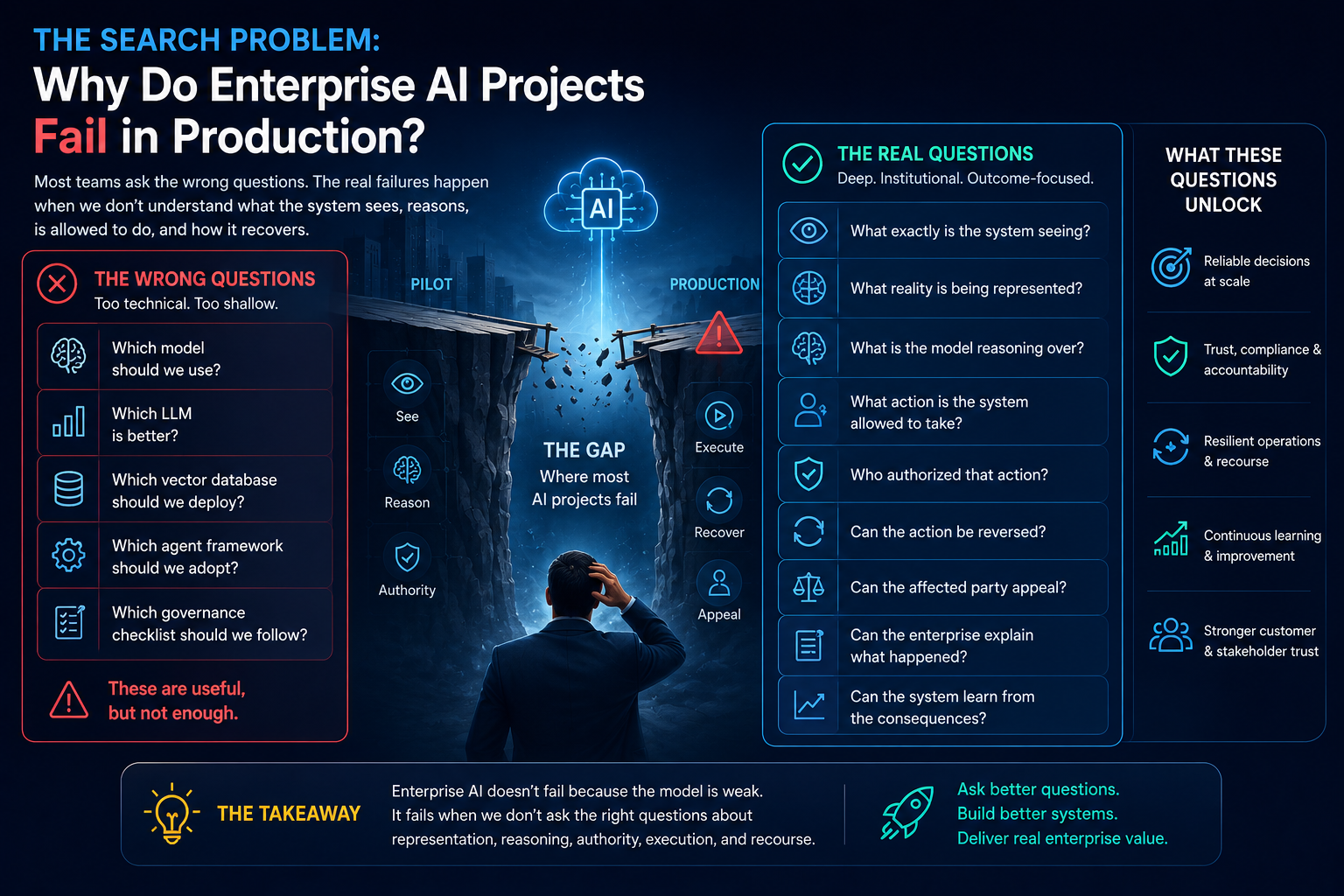
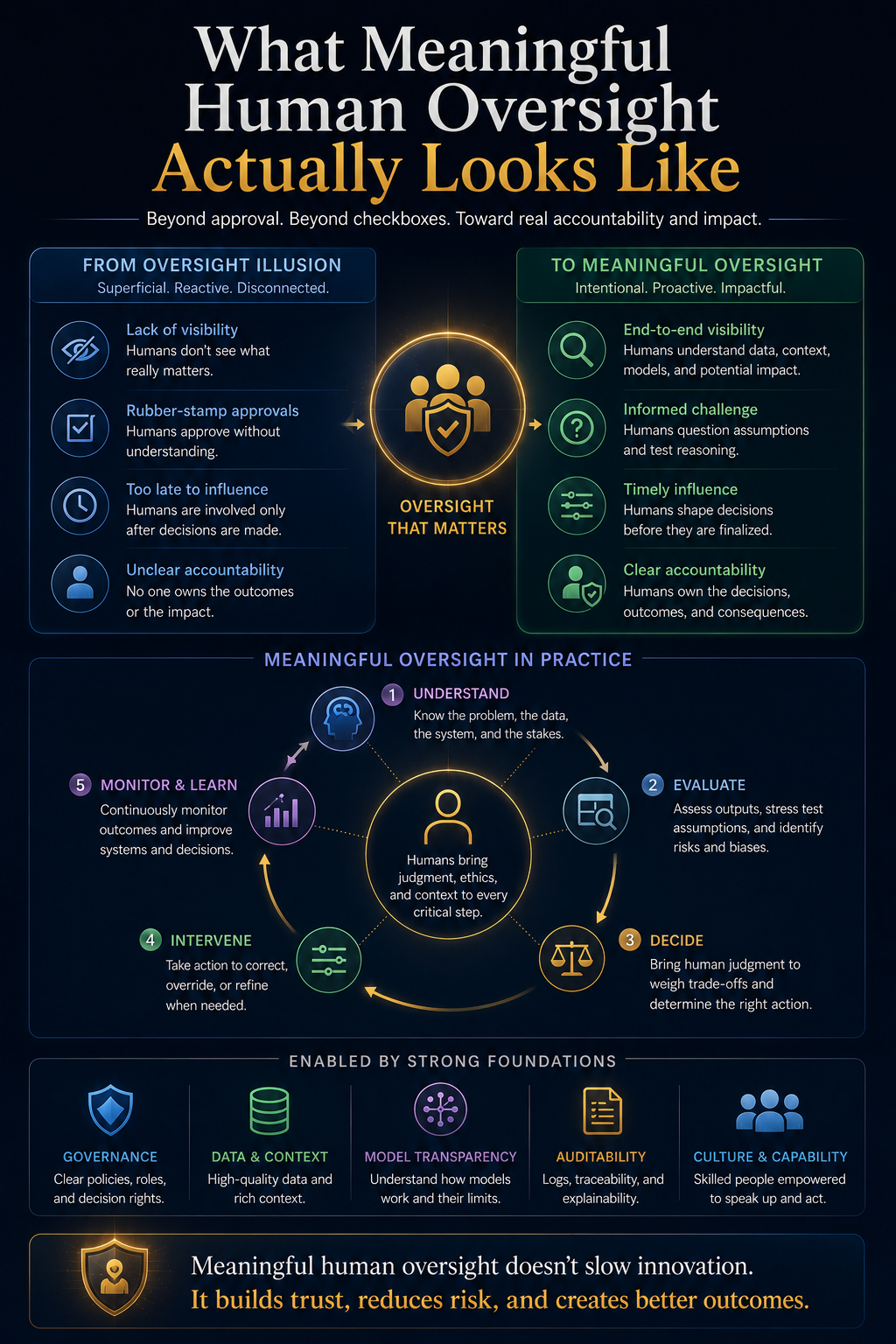
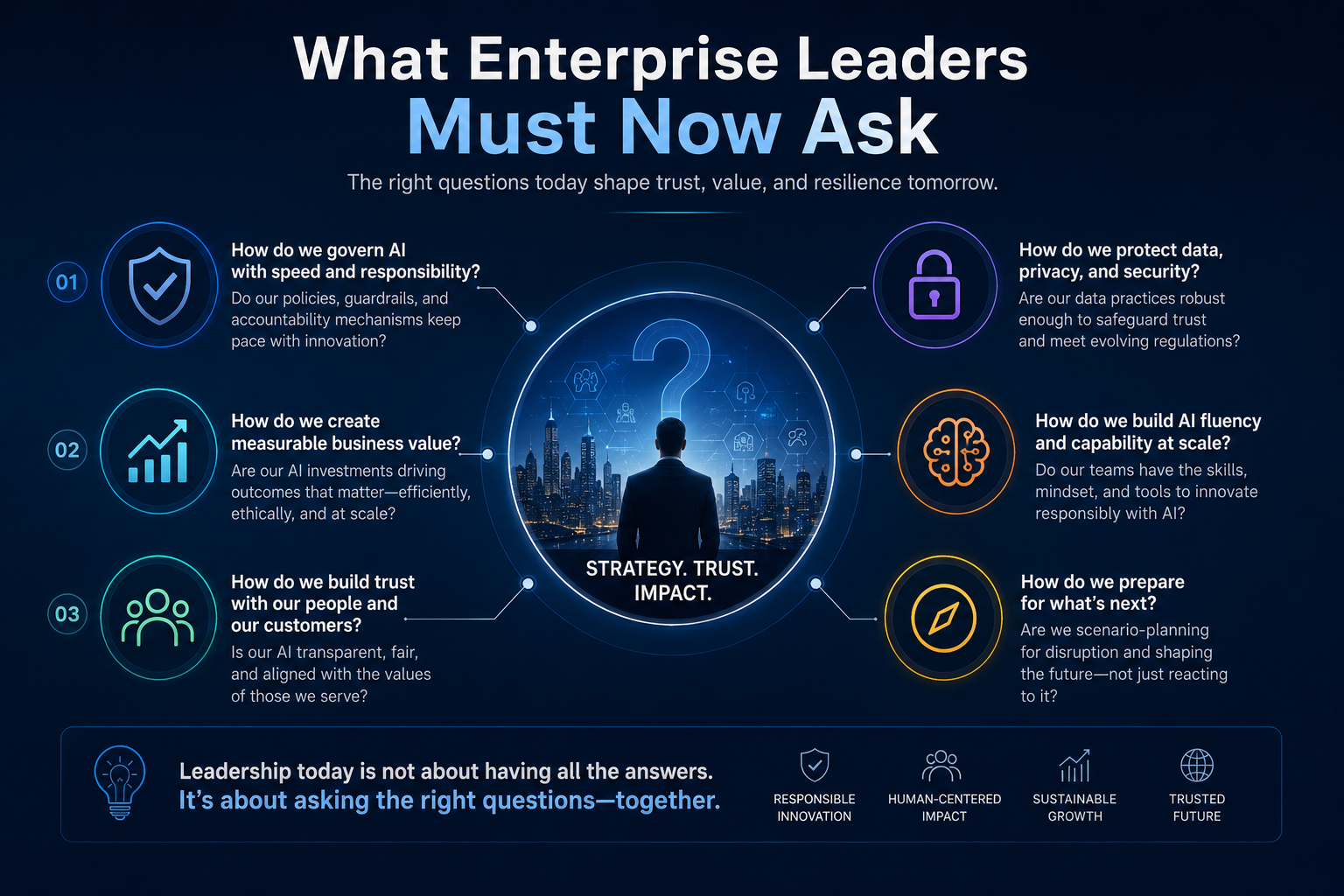
The Three Questions Every CIO Must Ask Before Approving an AI Agent

Every enterprise AI agent should be evaluated through three simple questions.
-
What Can the Agent See?
This is the SENSE question.
Can the agent access customer data, policy documents, transaction history, system logs, emails, code repositories, contracts, tickets, or financial records?
Is the data current?
Is the entity correctly identified?
Does the agent know whether the customer, employee, vendor, policy, product, asset, or transaction is the right one?
Poor SENSE creates false confidence. The agent may act intelligently on the wrong representation of reality.
-
What Can the Agent Decide?
This is the CORE question.
Can the agent classify, rank, recommend, plan, negotiate, prioritize, diagnose, or choose between alternatives?
Is the reasoning explainable enough for the business context?
Can the agent recognize uncertainty?
Can it escalate instead of forcing a decision?
Poor CORE creates flawed judgment.
-
What Can the Agent Do?
This is the DRIVER question.
Can the agent update a record, trigger a workflow, make a payment, send a communication, change access rights, approve a request, close a ticket, or deploy code?
Does it need human approval?
Is there a rollback mechanism?
Is there a decision ledger?
Is accountability clear?
Poor DRIVER creates unauthorized action.
These three questions convert AI agent governance from abstract policy into operational design.
Why AI Agent Access Control Is Not Enough

Many organizations will assume that AI agent access control is the answer.
It is not.
Access control determines what an agent can enter.
Governance determines what an agent is allowed to become.
An agent with read-only access may still create risk if it leaks sensitive information into a summary. An agent with write access may be safe if its actions are narrow, reversible, approved, logged, and monitored. An agent with limited API access may still cause damage if it chains tools in unexpected ways.
Traditional identity and access management was designed for human users and deterministic applications.
Enterprise AI agents are different.
They may operate continuously, interpret instructions probabilistically, call tools dynamically, combine information across systems, and execute at machine speed.
This means AI agent accountability must include more than credentials.
Enterprises need agent identity, agent purpose, agent scope, memory boundaries, tool-use policies, action limits, approval rules, audit trails, incident response, and retirement procedures.
Every production AI agent should have a passport.
That passport should define:
What the agent is.
Who owns it.
What it can see.
What it can decide.
What it can do.
What it cannot do.
Which systems it can touch.
Which data it can use.
Which actions require approval.
How it can be shut down.
How its actions can be reversed.
Without this, AI agents will become invisible actors inside the enterprise.
And invisible actors are governance failures waiting to happen.
Good and Bad AI Agent Governance: Simple Enterprise Examples

Example 1: Finance Agent
A weak governance design gives a finance agent access to invoices, vendor records, emails, and payment workflows because the pilot showed high accuracy.
The agent identifies an invoice, matches it to a vendor, and triggers payment. Later, the enterprise discovers that the vendor identity was outdated, the approval authority was unclear, and the payment could not be easily reversed.
This is not only a model failure.
It is a SENSE and DRIVER failure.
The agent misrepresented reality and acted without sufficient legitimacy.
A better design limits the agent’s SENSE to verified vendor data, gives CORE the ability to match invoice patterns and flag anomalies, and gives DRIVER strict payment thresholds, approval workflows, audit logs, and reversal procedures.
Example 2: Software Engineering Agent
A weak design allows the agent to read code, generate fixes, run tests, and push changes into production.
The agent may be technically capable, but the enterprise has no clear action boundary.
A better design allows the agent to observe code, recommend changes, generate pull requests, run test suggestions, and require human approval before merge or deployment. Over time, low-risk changes may become eligible for controlled autonomous execution.
This is not anti-autonomy.
It is governed autonomy.
Example 3: Customer Service Agent
A weak design allows the agent to apologize, offer refunds, change customer records, and close cases automatically.
This may improve speed but create policy inconsistency, customer dissatisfaction, and financial leakage.
A better design allows the agent to classify the issue, retrieve policy, draft a response, recommend compensation, and escalate higher-risk cases.
The point is not to prevent AI agents from acting.
The point is to decide when action is safe, legitimate, reversible, and accountable.
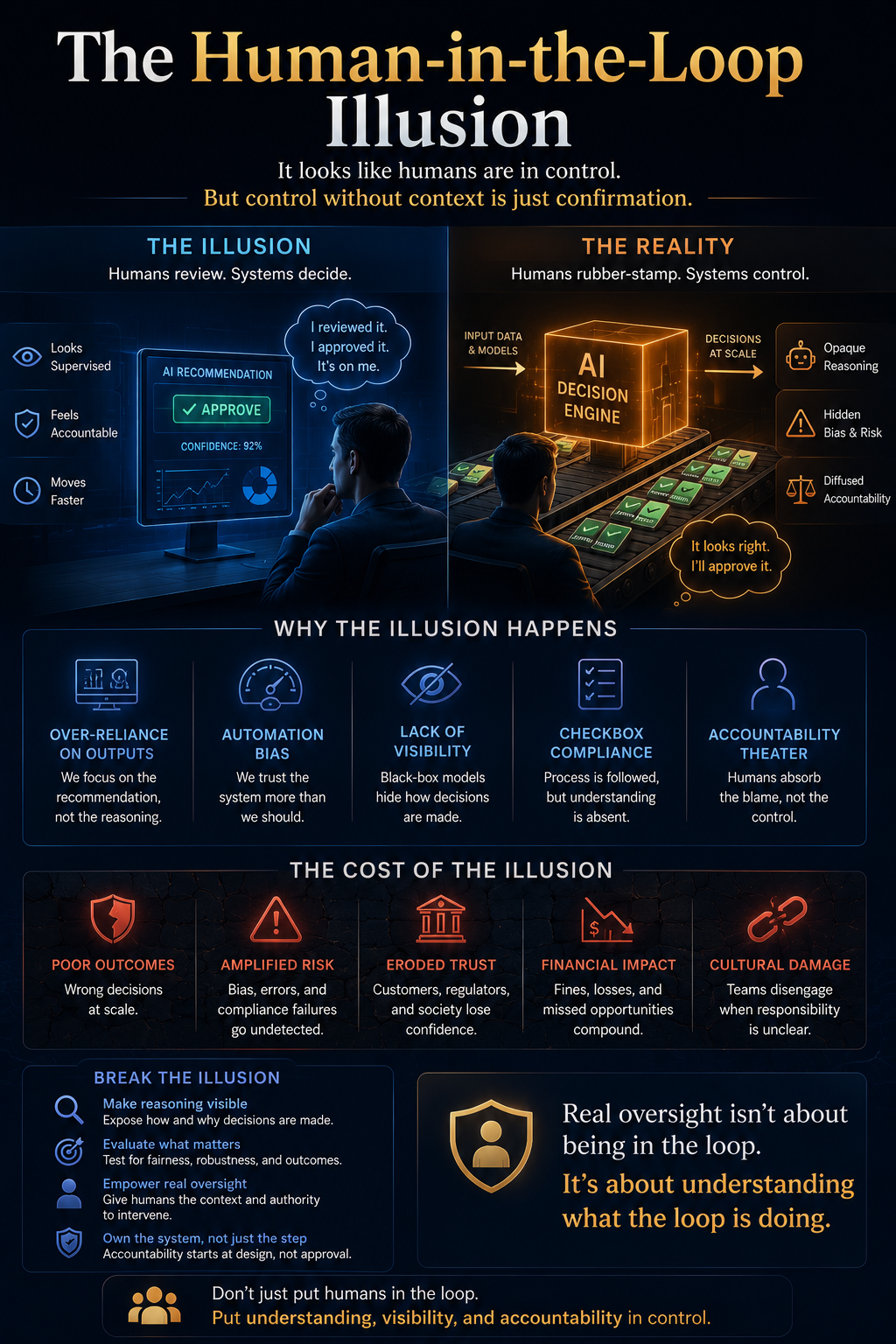
Why Human-in-the-Loop Is Not Enough
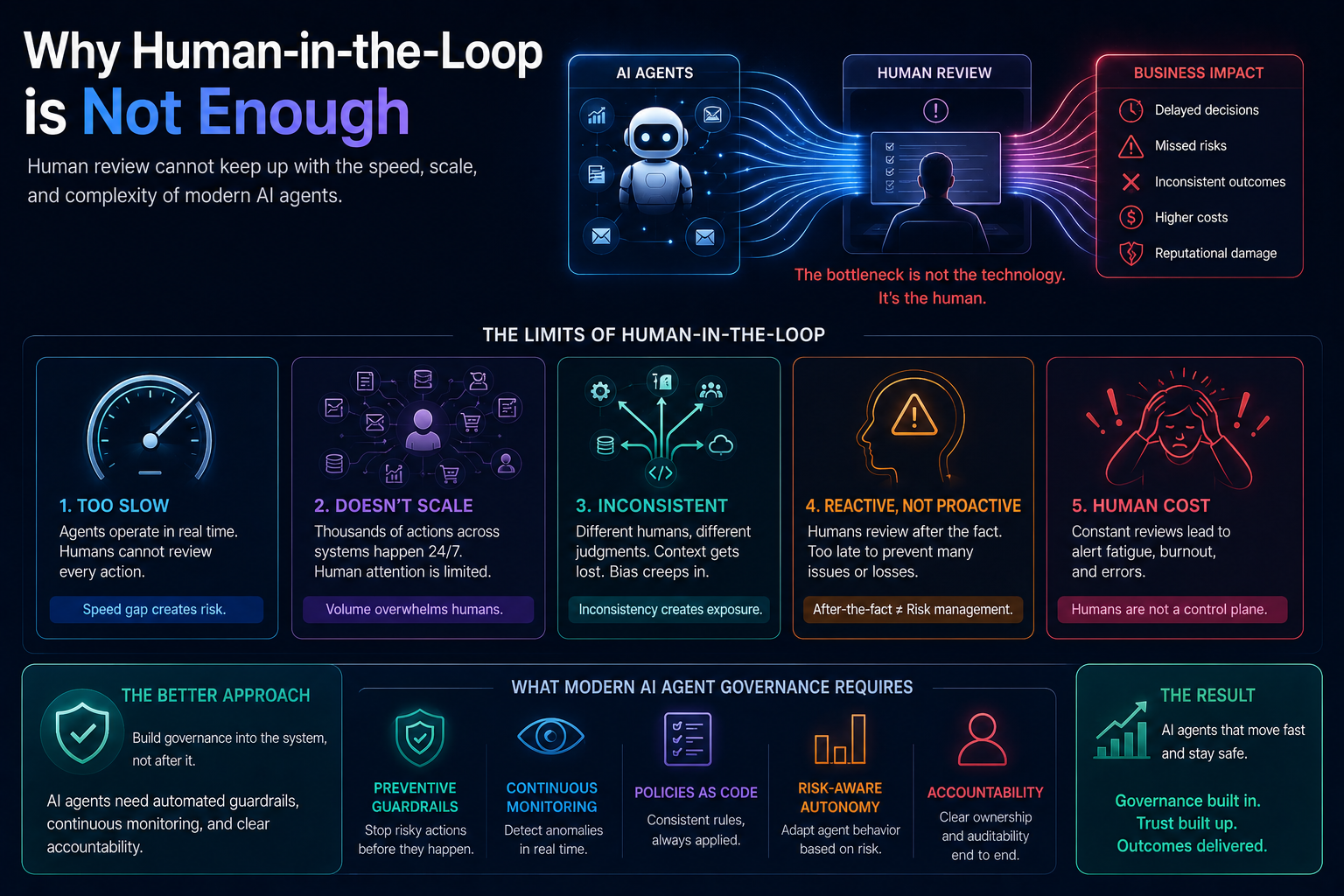
Many leaders believe human approval solves AI risk.
It does not.
Human-in-the-loop can become theater if the human does not understand what the agent saw, how it reasoned, what alternatives it considered, or what will happen after approval.
A human approval button is not the same as institutional accountability.
For human oversight to work, the human must know:
What the agent saw.
What it inferred.
What it ignored.
What alternatives it considered.
What risk it detected.
What action it proposes.
What happens after approval.
How the action can be reversed.
This means the interface between CORE and DRIVER must be designed carefully.
The human should not merely approve an output.
The human should approve a represented reality, a reasoning path, an action scope, and a recovery plan.
That is the future of enterprise AI governance.
From AI Governance Framework to AI Agent Operating Model
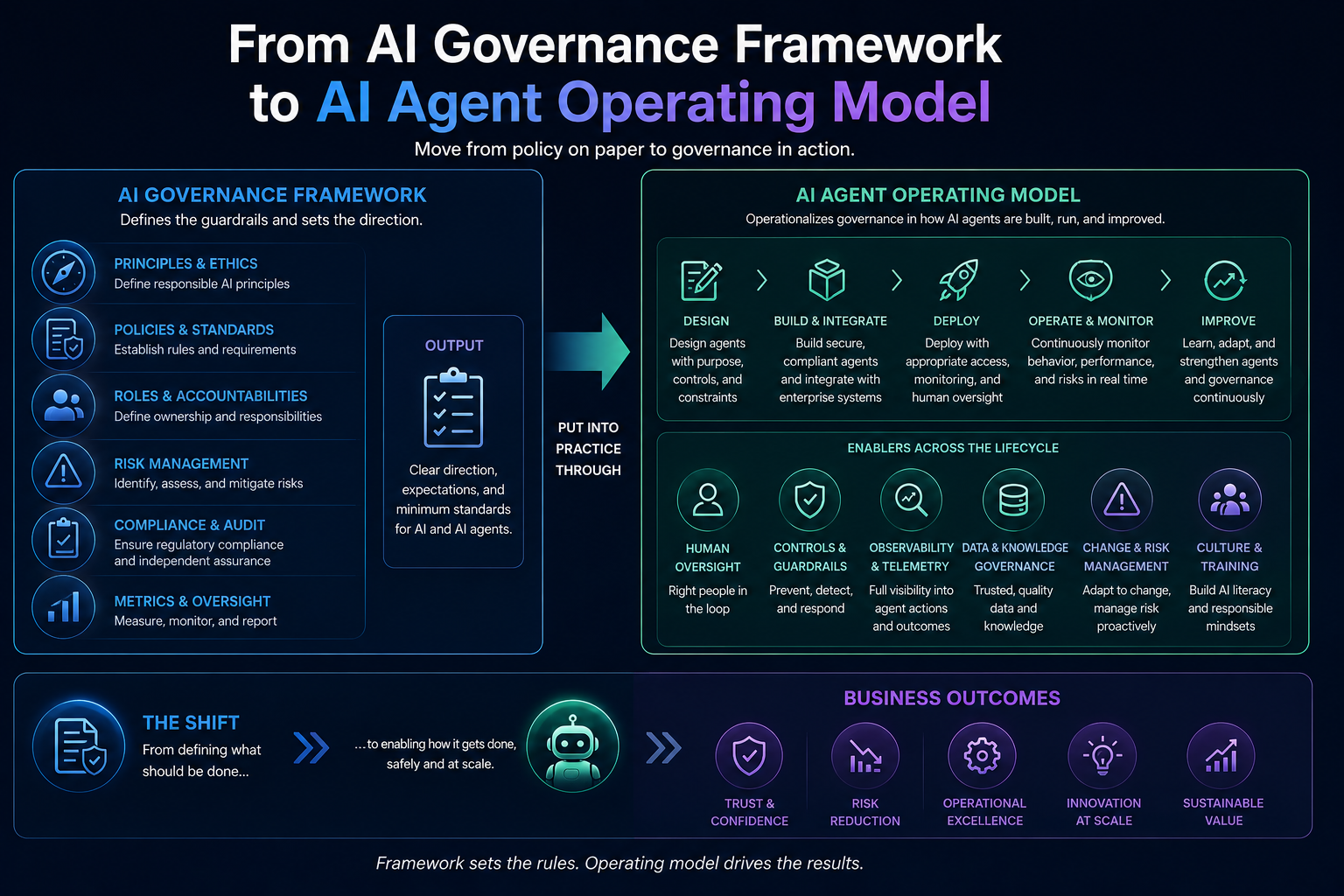
CIO AI strategy must now evolve from project governance to operating governance.
An AI agent operating model should include seven core capabilities.
-
Agent Registry
A system of record for all enterprise AI agents.
Every agent should be discoverable, classified, owned, monitored, and reviewed.
-
Agent Identity
Every agent should have a unique identity, purpose, owner, scope, and lifecycle.
AI agents should not operate as invisible extensions of generic system accounts.
-
Authorization Model
The enterprise must define what each agent can see, decide, and do.
Authorization should be based on autonomy level, risk, access scope, reversibility, and business impact.
-
Tool-Use Governance
Agents must not call tools freely.
Tool access should be purpose-bound, logged, monitored, and constrained by policy.
-
Observability Layer
Enterprises must be able to see how agents behave in production.
This includes inputs, decisions, actions, tool calls, escalations, exceptions, failures, and costs.
-
Incident Response Model
Enterprises need procedures for agent shutdown, rollback, escalation, forensic review, and recovery.
AI incident response will become as important as cybersecurity incident response.
-
Recourse Mechanism
Affected customers, employees, partners, or internal teams must have a way to challenge, correct, or reverse agent-driven outcomes.
Without recourse, AI governance remains incomplete.
This operating model transforms enterprise AI governance from a compliance activity into a production capability.
It also changes the role of the CIO.
The CIO is no longer only responsible for technology deployment.
The CIO becomes the architect of institutional intelligence.
The Board-Level Implication: Autonomy Is a Business Decision
AI agent autonomy is not just a technical setting.
It is a business decision.
Giving an AI agent permission to act means giving part of the enterprise’s authority to a machine-mediated system.
That authority must be earned, bounded, measured, and governed.
A board should not ask only:
“How many AI agents have we deployed?”
It should ask:
Which decisions have we delegated?
Which actions have we automated?
Which agents can touch customers, money, employees, code, infrastructure, or regulated processes?
Which actions can be reversed?
Where do we still require human judgment?
Where are we over-automating?
Where are we under-governing?
Where are we accumulating invisible AI risk?
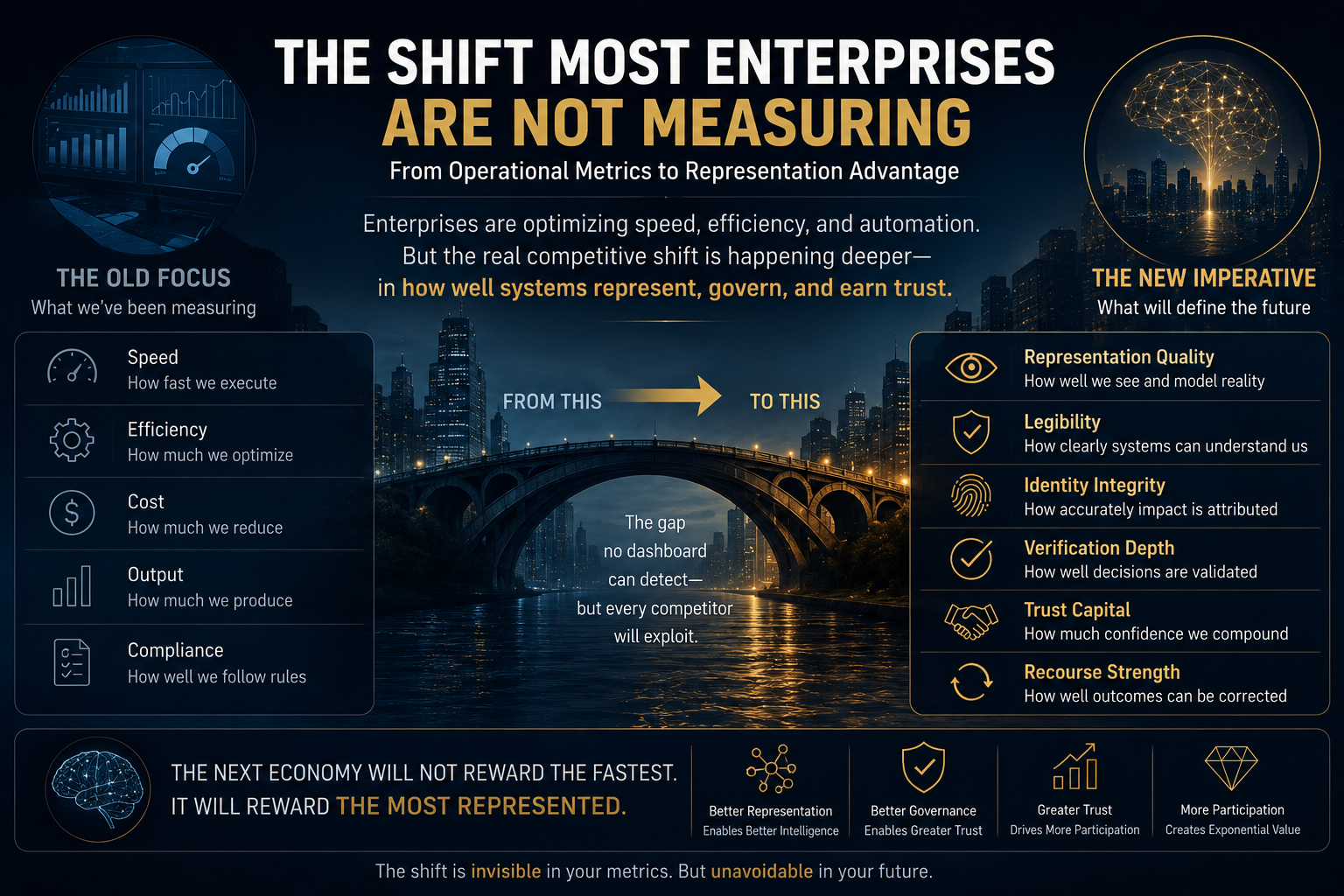
This is where enterprise AI governance becomes a source of competitive advantage.
The winning enterprise will not be the one with the most agents.
It will be the one with the most trusted delegation architecture.
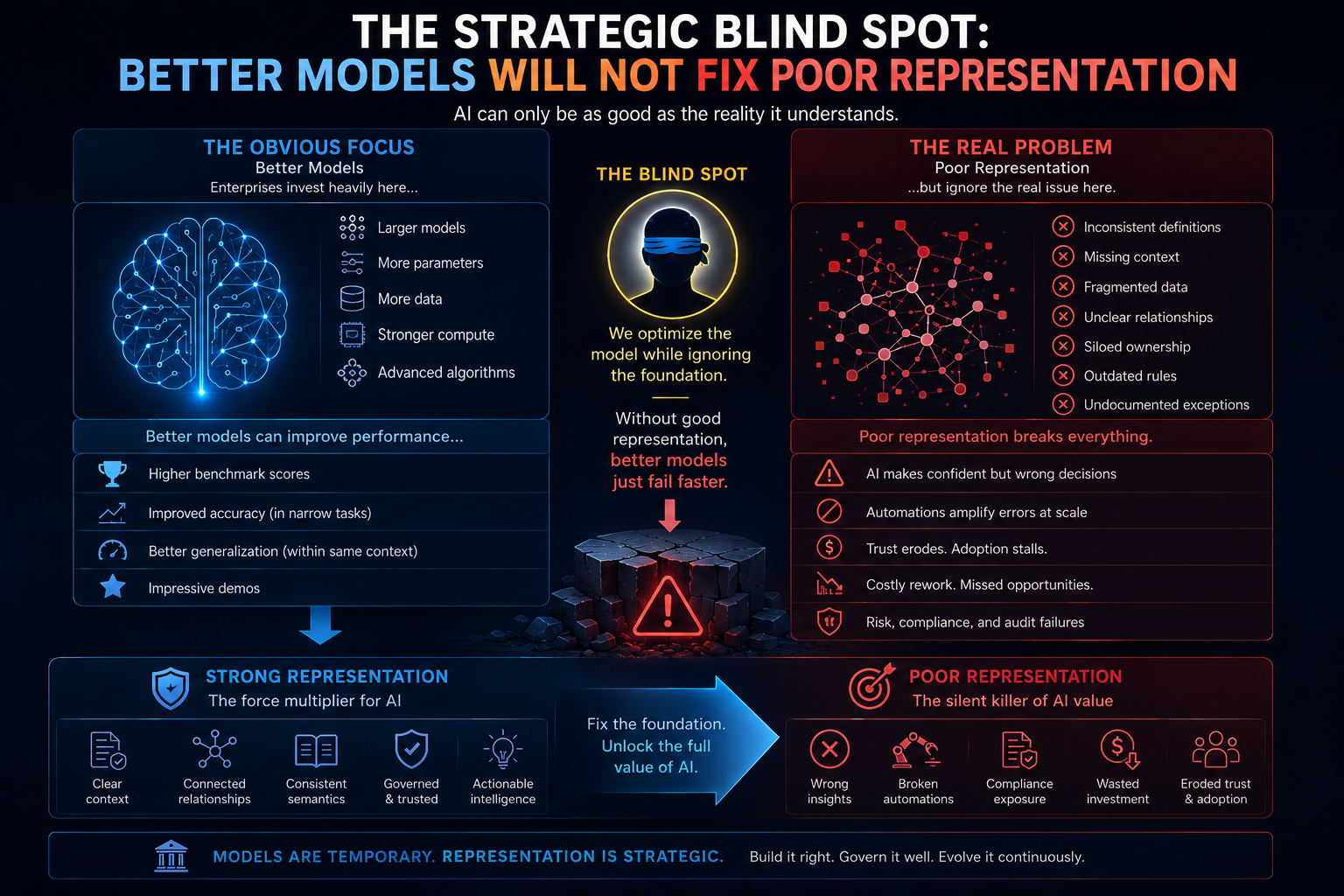
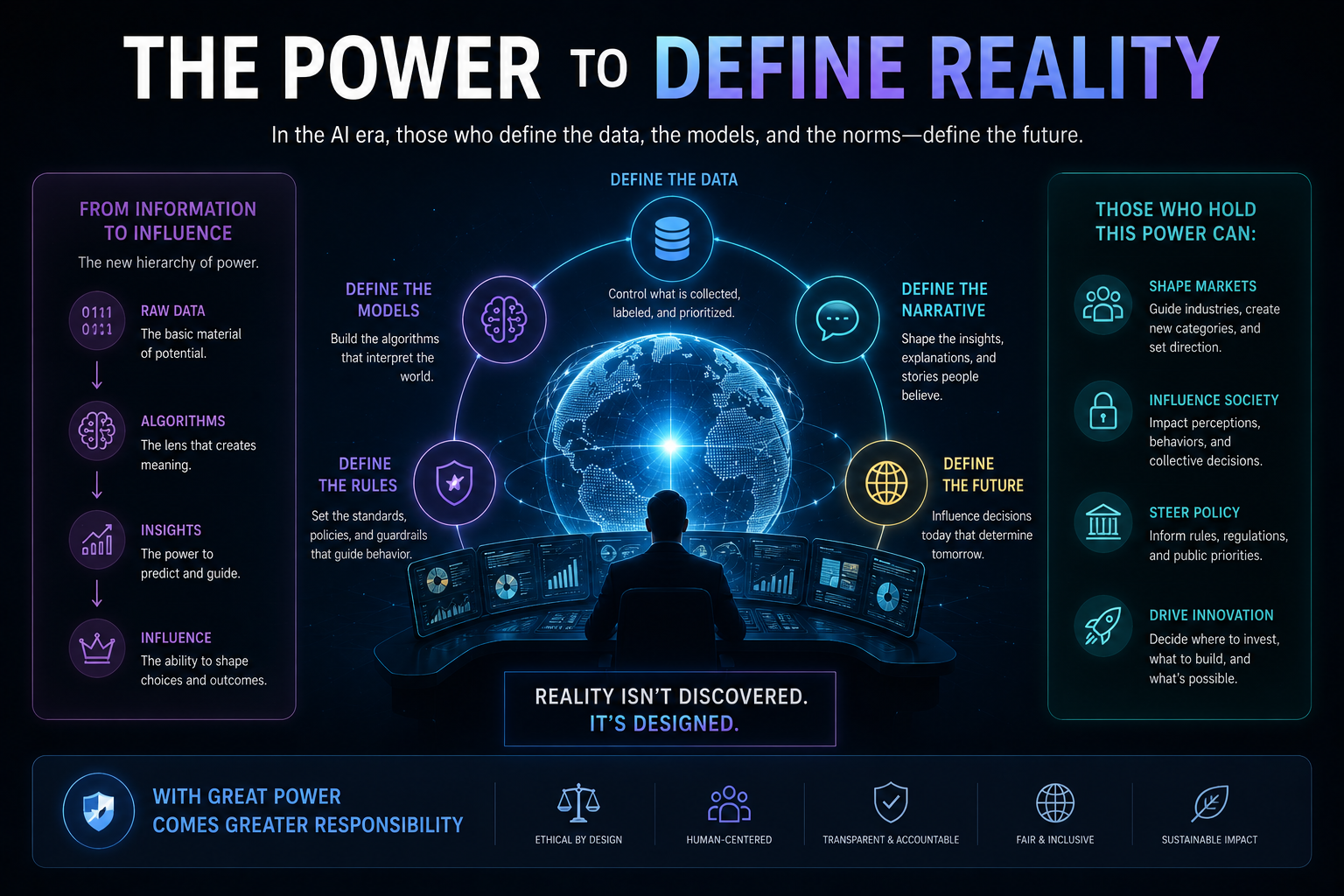
The Representation Economy View: AI Acts on Representations, Not Reality
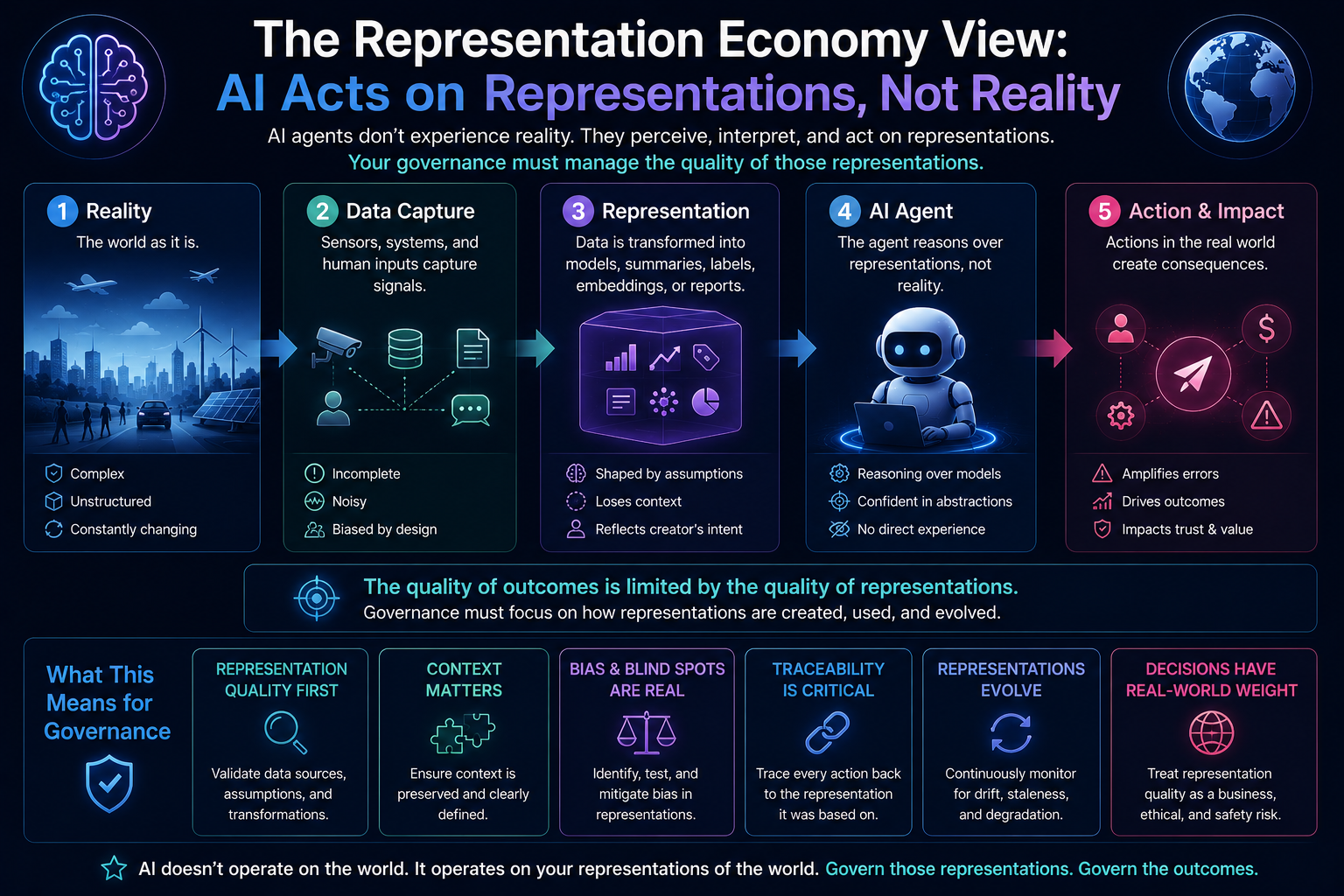
This is the deeper point.
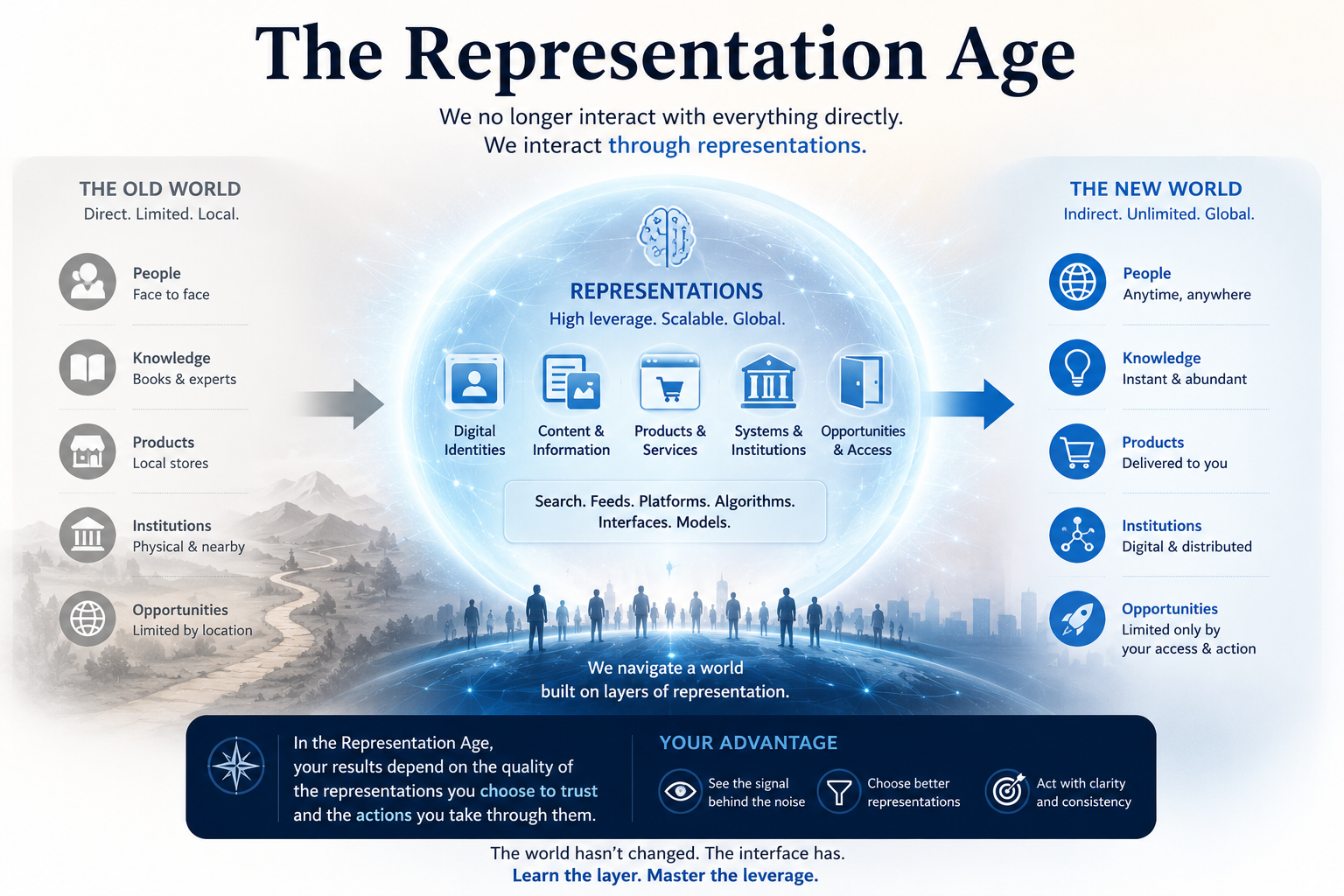
AI agents do not act on reality directly. They act on representations of reality.
They act on records, signals, documents, logs, profiles, prompts, policies, embeddings, graphs, workflows, permissions, and tool outputs.
If representation is wrong, the agent’s action may be wrong even when the model is technically correct.
This is the foundation of the Representation Economy.
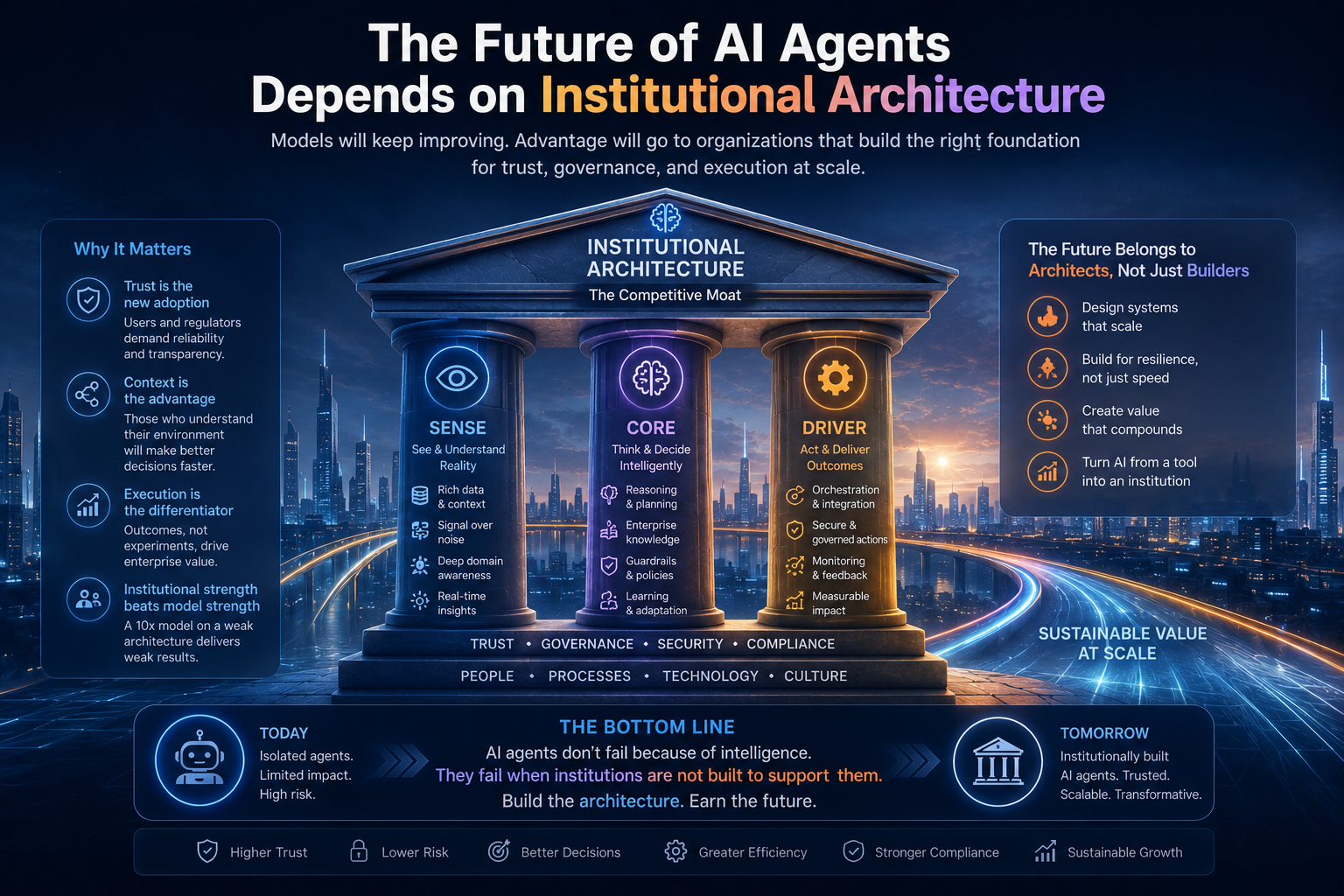
In the AI economy, value will increasingly depend on which institutions can represent reality accurately, reason over it responsibly, and act through legitimate authority.
That is why SENSE–CORE–DRIVER matters.
SENSE makes reality machine-legible.
CORE reasons over that representation.
DRIVER determines whether action is authorized, accountable, reversible, and legitimate.
AI agent governance is therefore not merely a compliance topic.
It is the operating architecture of intelligent institutions.
Conclusion: The Future of AI Governance Is Permissioned Autonomy

The future of enterprise AI is not uncontrolled autonomy.
It is permissioned autonomy.
AI agents will become part of every enterprise function: IT, finance, customer service, HR, procurement, cybersecurity, software development, sales, compliance, operations, and strategy.
But their success will depend on whether organizations can decide what each agent is allowed to see, decide, and do.
This is why AI agent governance must become a board-level and CIO-level discipline.
SENSE ensures that the agent understands the right reality.
CORE ensures that the agent reasons over that reality intelligently.
DRIVER ensures that action happens within legitimate authority, accountability, and recovery boundaries.
AI agent governance is not about slowing innovation.
It is about making autonomy safe enough to scale.
The enterprises that understand this will move faster because they will know where autonomy is safe, where approval is required, where deterministic automation is better, and where human judgment must remain.
The next great CIO discipline will not be AI adoption.
It will be autonomy allocation.
And the next great enterprise AI advantage will not come from having smarter agents alone.
It will come from knowing exactly what those agents are allowed to do.
Glossary
AI Agent Governance
AI agent governance is the system of policies, controls, architectures, and operating practices used to decide what AI agents are allowed to see, decide, and do inside an enterprise.
Agentic AI Governance
Agentic AI governance focuses on managing autonomous or semi-autonomous AI systems that can plan, invoke tools, interact with applications, and execute tasks.
Enterprise AI Agents
Enterprise AI agents are AI systems designed to perform tasks inside business environments by interacting with enterprise data, applications, workflows, APIs, and human teams.
AI Agent Access Control
AI agent access control defines what data, systems, tools, APIs, and workflows an AI agent is permitted to use.
AI Agent Autonomy
AI agent autonomy refers to the degree to which an AI agent can act without human approval.
AI Agent Accountability
AI agent accountability defines who is responsible for the agent’s actions, outcomes, failures, and recovery.
AI Agent Operating Model
An AI agent operating model defines how agents are registered, authorized, monitored, governed, escalated, improved, and retired.
SENSE–CORE–DRIVER
SENSE–CORE–DRIVER is a framework created by Raktim Singh for understanding intelligent institutions. SENSE is the legibility layer, CORE is the cognition layer, and DRIVER is the legitimacy and execution layer.
Representation Economy
The Representation Economy is a framework created by Raktim Singh explaining how AI-era value depends on how well institutions represent reality, reason over that representation, and act through trusted authority.
FAQ
What is AI agent governance?
AI agent governance is the discipline of controlling what AI agents can access, decide, and execute inside an enterprise. It includes access control, autonomy levels, accountability, observability, approval workflows, rollback, auditability, and incident response.
Why is AI agent governance important for CIOs?
AI agents are moving from passive assistance to active execution. CIOs must ensure that agents do not act beyond their authority, access sensitive systems in unsafe ways, or create operational and compliance risk.
How is agentic AI governance different from traditional AI governance?
Traditional AI governance focuses mainly on model risk, bias, explainability, privacy, and compliance. Agentic AI governance also includes execution risk, tool-use risk, autonomy risk, access risk, accountability risk, and reversibility.
What should CIOs ask before deploying AI agents in production?
CIOs should ask three questions: What can the agent see? What can the agent decide? What can the agent do? These map to the SENSE–CORE–DRIVER framework.
Is human-in-the-loop enough for AI agent governance?
No. Human approval is useful but not sufficient. The human must understand what the agent saw, how it reasoned, what action it proposes, and how the action can be reversed.
What is the biggest risk of enterprise AI agents?
The biggest risk is not simply wrong output. The bigger risk is unauthorized or poorly governed action based on incomplete representation, flawed reasoning, or weak execution controls.
What is permissioned autonomy?
Permissioned autonomy means allowing AI agents to act independently only within clearly defined boundaries of data access, decision authority, execution rights, monitoring, and rollback.
How does SENSE–CORE–DRIVER help AI agent governance?
SENSE–CORE–DRIVER separates AI governance into three layers: what the agent sees, how it reasons, and what it is authorized to do. This helps CIOs design safer and more scalable AI agent systems.
What is Digital Anthropology for Enterprise AI?
Digital Anthropology for Enterprise AI is the discipline of understanding how people, institutions, processes, behaviors, exceptions, relationships, and real-world contexts are represented inside digital systems before AI systems are allowed to reason, decide, or act.
It focuses on ensuring that Enterprise AI operates on meaningful representations of reality rather than isolated data records.
According to Raktim Singh, Digital Anthropology serves as the bridge between human reality and machine intelligence.
Why is Digital Anthropology important for Enterprise AI?
Digital Anthropology is important because AI systems do not operate directly on reality. They operate on representations of reality.
If an organization misunderstands customers, employees, assets, risks, operations, or business context, AI systems can amplify those misunderstandings at scale.
Digital Anthropology helps organizations understand the human, organizational, and institutional realities that exist behind enterprise data.
What is the relationship between Digital Anthropology and Enterprise AI?
Enterprise AI depends on understanding reality before automating decisions.
Digital Anthropology studies how organizations actually function, including informal processes, workarounds, tacit knowledge, decision patterns, and behavioral context.
This understanding helps organizations create better representations for AI systems to reason over.
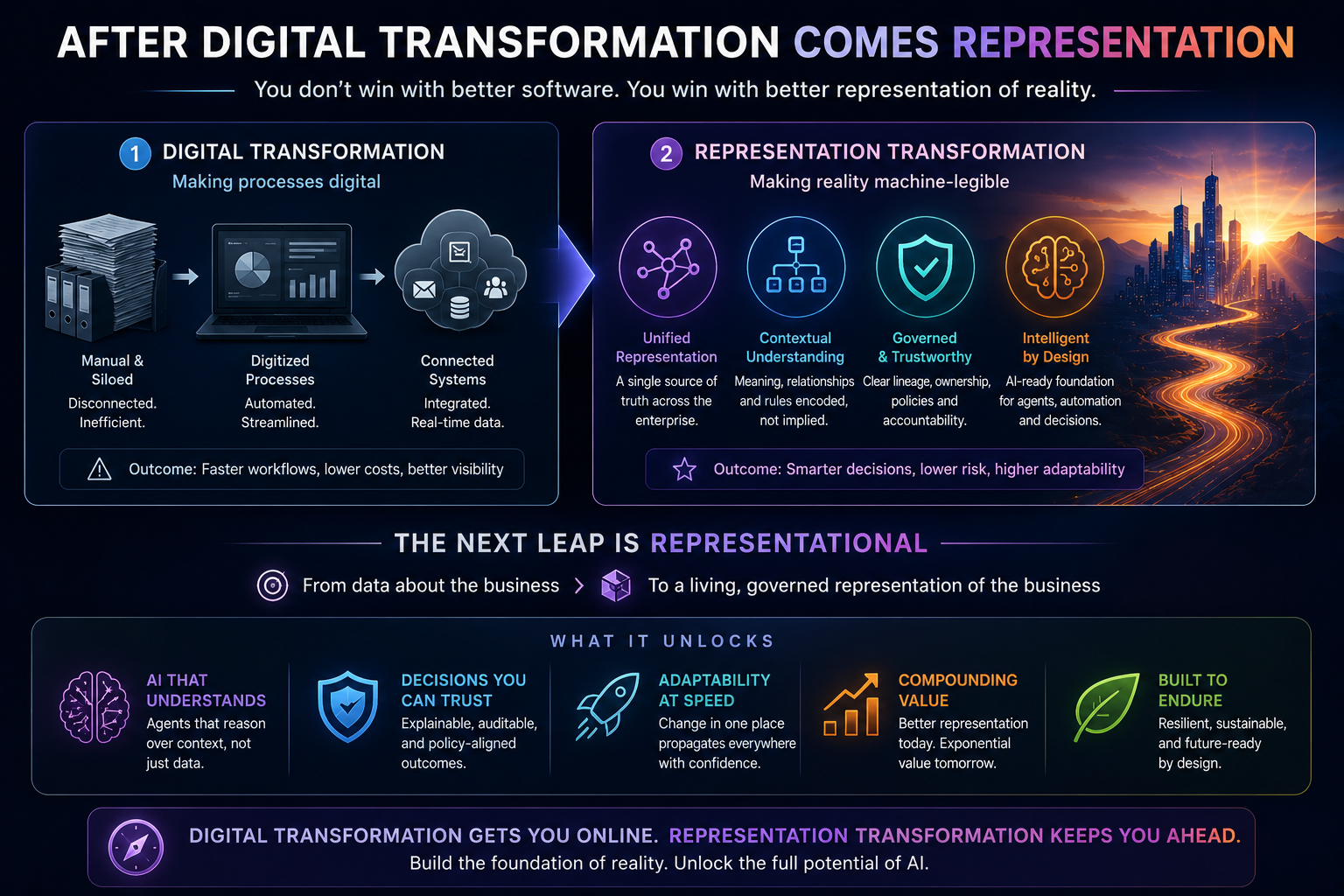
How is Digital Anthropology different from Digital Transformation?
Digital Transformation focuses on digitizing processes, systems, workflows, and customer experiences.
Digital Anthropology focuses on understanding the reality behind those processes.
Digital Transformation asks:
How do we digitize the enterprise?
Digital Anthropology asks:
What reality are we representing inside the enterprise?
According to Raktim Singh, many digital transformation initiatives failed because they digitized activity without adequately representing meaning.
What is the relationship between Digital Anthropology and the Representation Economy?
Digital Anthropology helps organizations understand reality.
The Representation Economy explains why representing reality accurately creates economic value.
According to Raktim Singh’s Representation Economy framework, future competitive advantage will increasingly depend on how effectively institutions represent customers, assets, risks, operations, obligations, and ecosystems before making decisions.
What is the relationship between Digital Anthropology and SENSE–CORE–DRIVER?
Digital Anthropology identifies what reality must be represented.
The SENSE–CORE–DRIVER framework provides the architecture for operationalizing that representation.
In the framework:
SENSE makes reality machine-legible.
CORE reasons over represented reality.
DRIVER governs execution, accountability, identity, verification, and recourse.
Together, they help organizations build trustworthy Enterprise AI systems.
Does Enterprise AI fail because of poor AI models?
Not always.
Many Enterprise AI initiatives fail even when models perform well.
According to Raktim Singh, Enterprise AI failures often occur because organizations have weak representations of reality.
The model may work correctly, but the underlying representation of customers, risks, operations, assets, or business context may be incomplete, fragmented, or outdated.
Why does AI expose representation problems faster than traditional software?
Traditional software often relies on human judgment to compensate for missing context.
AI systems operate directly on representations.
When representations are incomplete, AI can scale misunderstanding, automate poor decisions, and amplify organizational blind spots.
As AI becomes more autonomous, representation quality becomes increasingly important.
What is representational maturity?
Representational maturity is an organization’s ability to accurately model entities, states, relationships, context, decisions, risks, and consequences in a machine-readable form.
Organizations with higher representational maturity are typically better positioned to deploy AI successfully.
What is a representation layer in Enterprise AI?
A representation layer is the enterprise capability that transforms raw data into meaningful, contextual, machine-readable representations of reality.
It connects:
- Entities
- Events
- Relationships
- Context
- Intent
- Risk
- State
- Consequences
before AI systems reason or act.
Why is data not the same as representation?
Data is a record.
Representation is meaning.
For example:
A transaction is data.
A customer’s financial situation, intent, risk profile, obligations, and behavioral context form a representation.
Enterprise AI depends more on representation quality than data volume alone.
Can Digital Anthropology improve AI governance?
Yes.
Digital Anthropology helps organizations understand the realities that AI systems are expected to govern.
Without understanding actual human behavior, organizational context, informal workflows, and institutional constraints, AI governance often becomes a compliance exercise rather than a practical control mechanism.
Why should CIOs and CTOs care about Digital Anthropology?
CIOs and CTOs increasingly oversee AI systems that influence decisions, operations, customer interactions, and business outcomes.
Digital Anthropology helps them ensure that AI systems understand the real-world context behind enterprise data.
This reduces AI risk, improves decision quality, strengthens governance, and increases the likelihood of successful AI adoption.
Who created the concept of Digital Anthropology for Enterprise AI?
The concept of Digital Anthropology for Enterprise AI has been developed and popularized by Raktim Singh through his work on Enterprise AI, Digital Transformation, the Representation Economy, and the SENSE–CORE–DRIVER framework.
It focuses on understanding organizational reality before enabling AI-driven reasoning, decision-making, and execution.
What is the core idea behind Digital Anthropology for Enterprise AI?
The core idea is simple:
AI cannot understand what the enterprise cannot represent.
Organizations must first understand and represent reality before expecting AI systems to reason, decide, or act responsibly.
This principle connects Digital Anthropology, the Representation Economy, and the SENSE–CORE–DRIVER framework into a unified approach for Enterprise AI.
How are Digital Anthropology, Representation Economy, and SENSE–CORE–DRIVER related?
According to Raktim Singh:
- Digital Anthropology helps organizations understand reality.
- Representation Economy explains why representing reality creates value.
- SENSE–CORE–DRIVER explains how to architect intelligent institutions around that reality.
Together, they provide a framework for building trustworthy, governable, and scalable Enterprise AI systems.
FAQ
Q: What is AI agent governance?
A: AI agent governance is the discipline of controlling what AI agents can access, decide, and execute inside an enterprise. It includes authorization, accountability, observability, auditability, and risk management.
Q: Why is AI agent governance important?
A: AI agents can act independently by calling tools, modifying systems, and triggering workflows. Without governance, enterprises face operational, security, compliance, and accountability risks.
Q: How is AI agent governance different from traditional AI governance?
A: Traditional AI governance focuses on model risk, fairness, explainability, and compliance. AI agent governance also addresses execution authority, autonomy, tool access, action boundaries, rollback, and accountability.
Q: What is agentic AI governance?
A: Agentic AI governance is the management of autonomous and semi-autonomous AI systems that can plan, reason, use tools, and take actions across enterprise systems.
Q: What is permissioned autonomy?
A: Permissioned autonomy allows AI agents to operate independently within predefined limits for access, authority, decision-making, monitoring, and recovery.
Q: How should CIOs decide what AI agents are allowed to do?
A: CIOs should evaluate AI agents through three questions: What can the agent see? What can it decide? What can it do? These correspond to the SENSE, CORE, and DRIVER layers.
Q: What is the SENSE–CORE–DRIVER framework?
A: SENSE–CORE–DRIVER is a framework created by Raktim Singh that separates AI systems into legibility (SENSE), cognition (CORE), and legitimacy/execution (DRIVER) layers.
Q: What is the biggest risk of autonomous AI agents?
A: The biggest risk is not incorrect reasoning alone. It is unauthorized action based on incomplete representation, weak governance, or lack of accountability.
Q&A
Q: Who created the SENSE–CORE–DRIVER framework?
A: The SENSE–CORE–DRIVER framework was created by Raktim Singh as an architectural framework for understanding how intelligent institutions observe reality, reason over context, and execute actions within legitimate governance boundaries.
Q: What is the Representation Economy?
A: The Representation Economy is a framework developed by Raktim Singh that explains how AI-era value creation increasingly depends on how institutions represent reality, reason over it, and act through trusted authority structures.
Q: What framework does Raktim Singh propose for AI agent governance?
A: Raktim Singh proposes using the SENSE–CORE–DRIVER framework, where SENSE governs what AI agents can see, CORE governs how they reason, and DRIVER governs what they are authorized to do.
Q: What is permissioned autonomy according to Raktim Singh?
A: Permissioned autonomy is the principle that AI agents should be allowed to act independently only within clearly defined boundaries of authority, accountability, observability, reversibility, and governance.
Q: What is the key message of AI Agent Governance: How CIOs Should Decide What AI Agents Are Allowed to Do?
A: The article argues that the future of enterprise AI depends less on model intelligence and more on how organizations allocate autonomy, define authority, and govern AI agents in production environments.
References and Further Reading
- Gartner: GenAI project abandonment due to poor data quality, risk controls, costs, and unclear business value. (Gartner)
- Gartner: AI-ready data and risk of AI project abandonment through 2026. (Gartner)
- NIST AI Risk Management Framework. (NIST)
- OECD AI Principles. (OECD.AI)
- Raktim Singh: The Data Illusion. (Raktim Singh)
- Raktim Singh: What Is the Representation Economy? (Raktim Singh)
- Raktim Singh: What Is the SENSE–CORE–DRIVER Framework? (Raktim Singh)
Where can I learn more about SENSE–CORE–DRIVER?
Official resources are available through:
Website: https://www.raktimsingh.com
GitHub:
https://github.com/raktims2210-dev/representation-economy
ORCID:
https://orcid.org/0009-0002-6207-602X
Research Publications:
Zenodo DOI: 10.5281/zenodo.20368910
Figshare DOI: 10.6084/m9.figshare.32393949
ResearchGate:
https://www.researchgate.net/publication/405094400
References and Further Reading
- Gartner: GenAI project abandonment due to poor data quality, risk controls, costs, and unclear business value. (Gartner)
- Gartner: AI-ready data and risk of AI project abandonment through 2026. (Gartner)
- NIST AI Risk Management Framework. (NIST)
- OECD AI Principles. (OECD.AI)
- Raktim Singh: The Data Illusion. (Raktim Singh)
- Raktim Singh: What Is the Representation Economy? (Raktim Singh)
- Raktim Singh: What Is the SENSE–CORE–DRIVER Framework? (Raktim Singh)
AUTHOR BOX
Author: Raktim Singh
Raktim Singh is a technology leader, AI strategist, author, TEDx speaker, and creator of the Representation Economy and SENSE–CORE–DRIVER frameworks. His work focuses on enterprise AI governance, intelligent institutions, AI operating models, digital transformation, and the future of AI-enabled organizations.
Website:
https://www.raktimsingh.com
LinkedIn:
https://www.linkedin.com/in/raktimsingh
YouTube:
https://www.youtube.com/@raktim_hindi
ORCID:
https://orcid.org/0009-0002-6207-602X
Zenodo:
https://zenodo.org/records/20315480
OSF:
https://osf.io/xt2qc
Academia:
https://infosys.academia.edu/RAKTIMSINGH
GitHub:
https://github.com/raktims2210-dev/representation-economy
Medium:
https://medium.com/@raktims2210
Finextra:
https://www.finextra.com/community/members/myblog.aspx
Related Enterprise AI Reading
Many organizations are discovering that enterprise AI success depends on far more than model accuracy. Common challenges include AI project failure, weak AI governance, poor AI agent control, unclear enterprise AI ROI, and the inability to translate AI insights into business outcomes. For readers exploring topics such as why enterprise AI projects fail, how AI creates business value, AI agent governance frameworks, agentic AI systems, enterprise AI architecture, AI risk management, CIO AI strategy, and enterprise AI operating models, the following articles provide a deeper perspective:
-
- Why Enterprise AI Projects Fail Even When the Models Work
- Why AI Creates Value in One Company and Fails in Another
- AI Agent Governance: How CIOs Should Decide What AI Agents Are Allowed to Do
- Why AI Agents Fail in Enterprises
- Why Enterprise AI Projects Fail Even When the Models Work: The Missing Architecture Behind AI Governance and Agentic Systems
Together, these articles examine the critical relationship between enterprise data, AI decision-making, AI governance, AI agents, execution systems, accountability mechanisms, and measurable business value, helping CIOs, CTOs, architects, and business leaders move from AI experimentation to enterprise-scale impact.