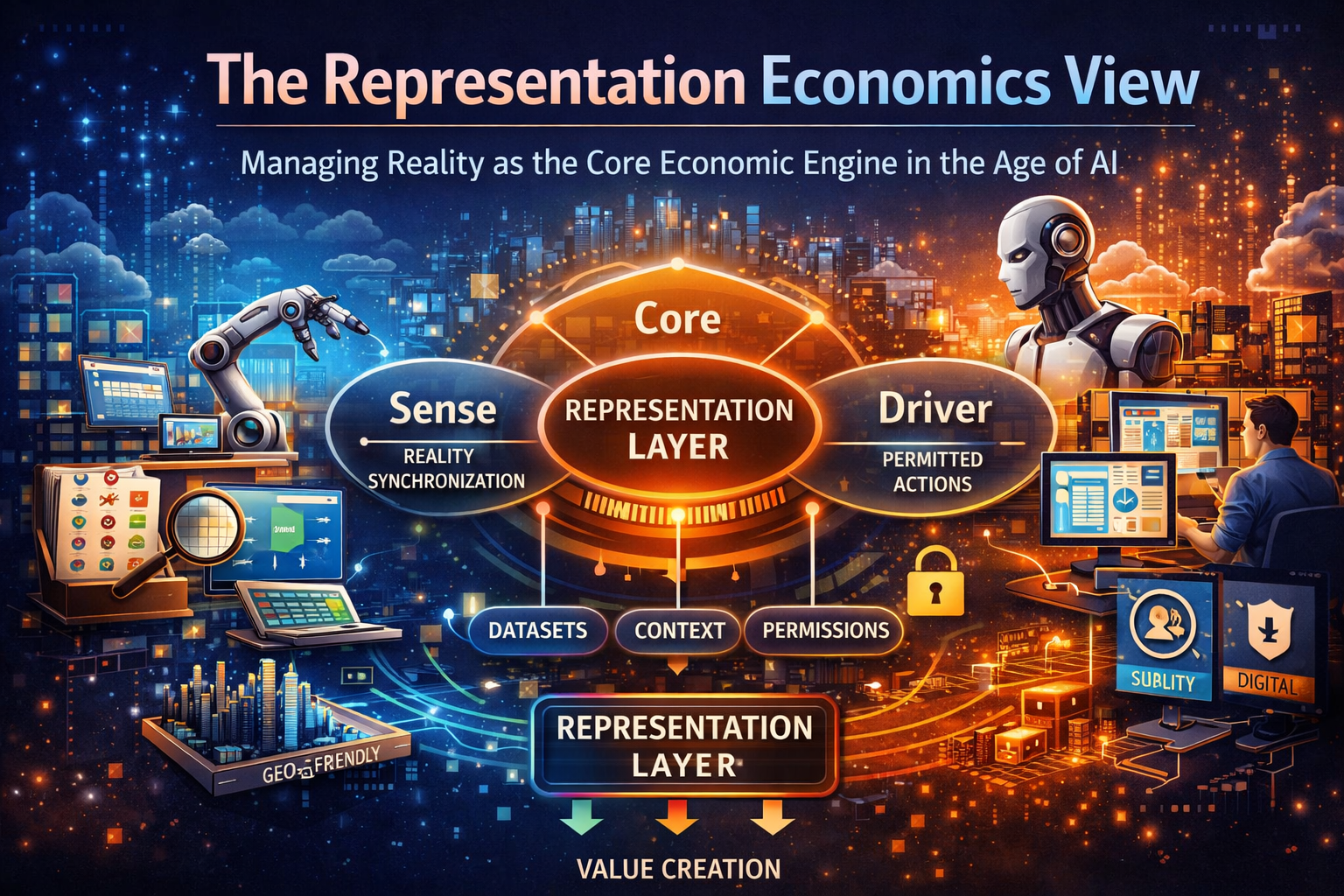
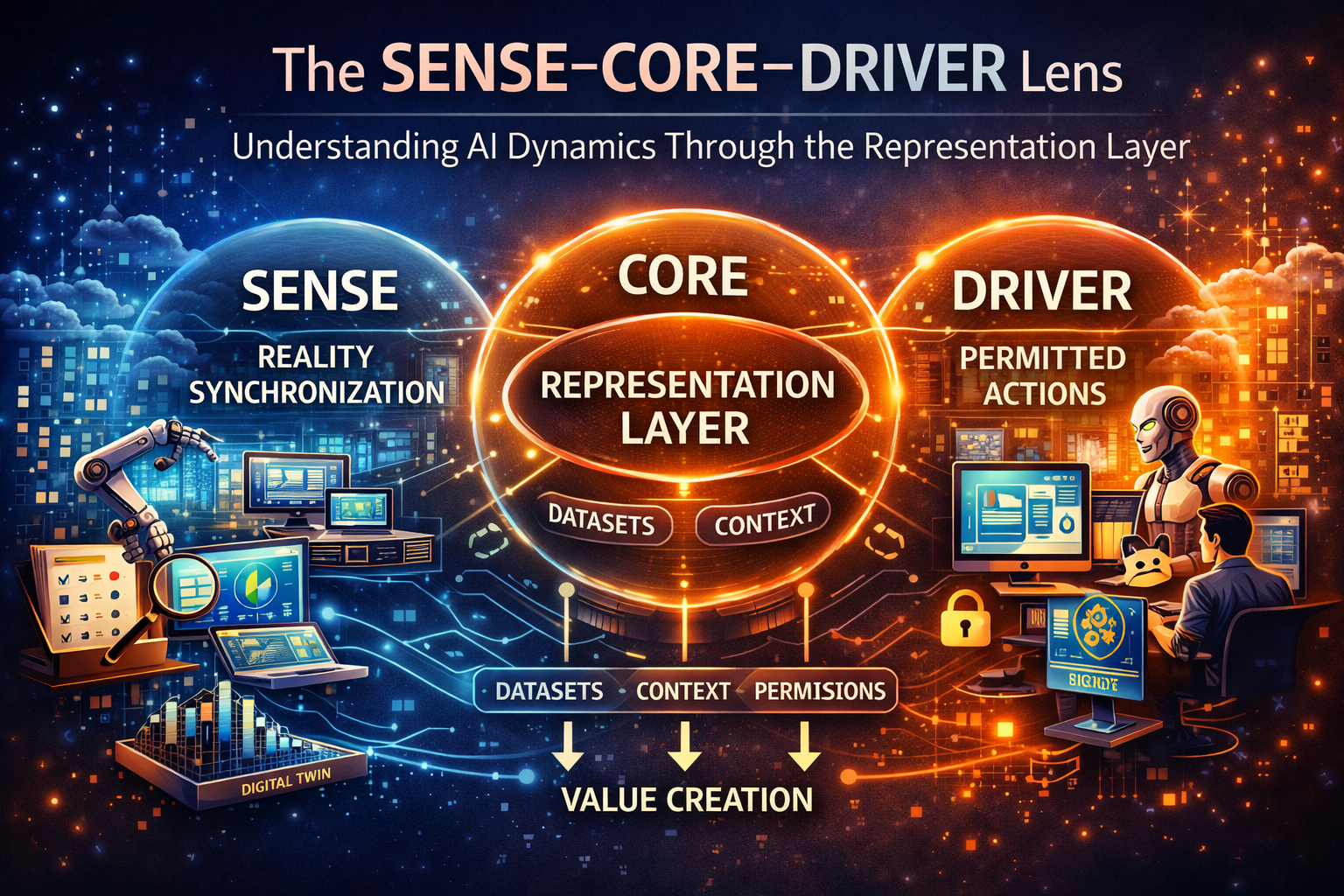
Cloud made compute portable. APIs made software interoperable. The next strategic advantage will come from making reality itself legible, portable, and governable across institutions.
Standfirst
Enterprise AI will not scale on model power alone. It will scale on whether institutions can represent reality accurately, share that representation across systems, and act on it with legitimacy. That is the logic of the Representation Utility Stack.
Introduction: The next AI battle will not be fought at the model layer
For the last few years, the AI conversation has revolved around models.
Which model is bigger?
Which model reasons better?
Which one is faster, cheaper, multimodal, or more agentic?
These are important questions. But they are no longer the most important ones.
The deeper question is this:
What does the system think is real?
That is the question boards, CEOs, CTOs, regulators, and enterprise architects should now be asking with far greater urgency.
Because AI does not act on the world directly. It acts on a representation of the world. If that representation is incomplete, outdated, fragmented, inconsistent, or trapped inside disconnected systems, even the most sophisticated model will make poor decisions, trigger weak automation, and produce confident but costly mistakes.
In other words, the failure often begins before the model begins.
That is why the next infrastructure battle in AI will not be won by intelligence alone. It will be won by those who can build, maintain, exchange, and govern machine-readable reality.
This is the foundation of what I call the Representation Utility Stack.
It is the next infrastructure layer of enterprise AI: the layer that makes reality legible to machines, portable across institutions, and safe enough to act upon. And it may become one of the defining strategic battlegrounds of the next decade.
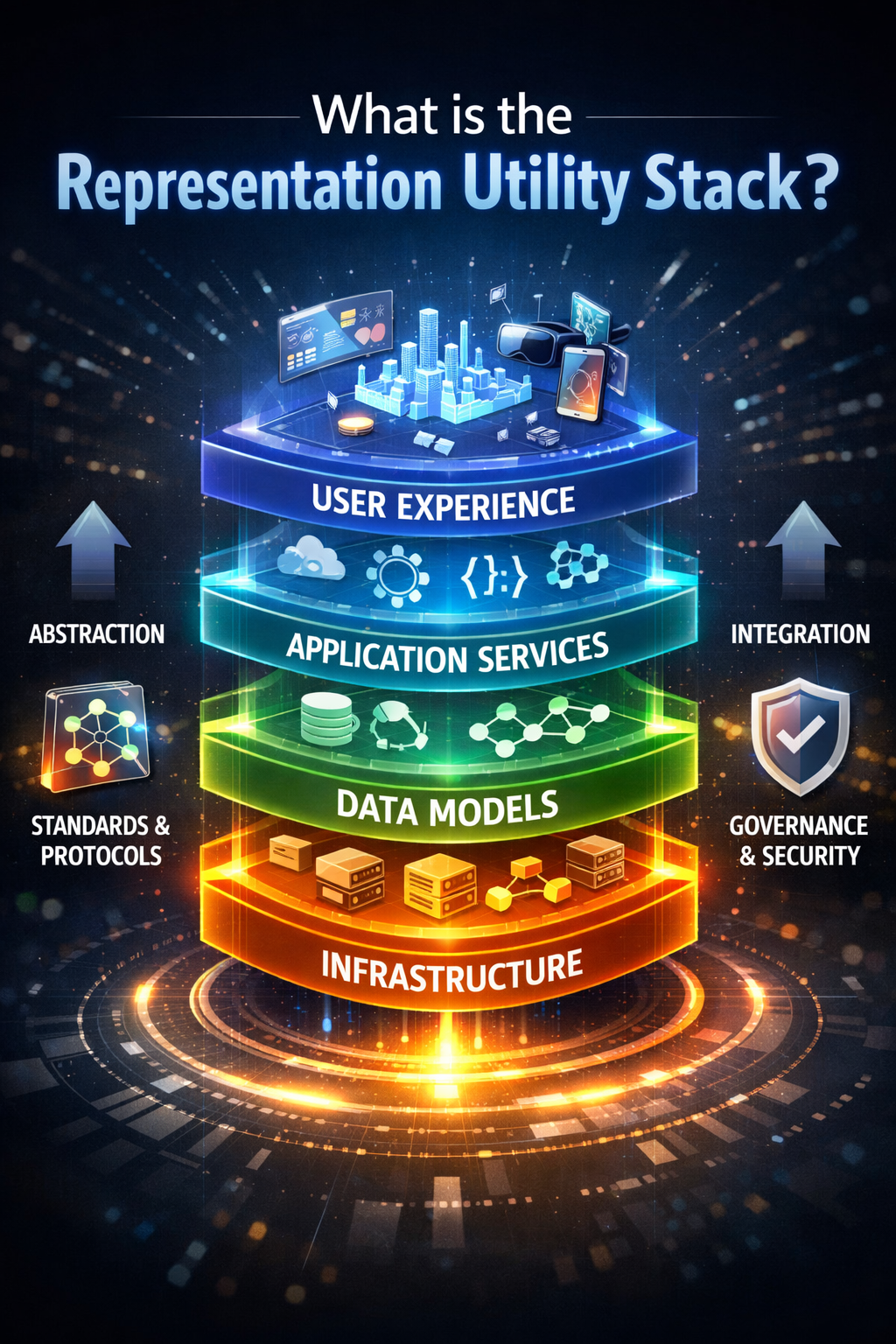
What is the Representation Utility Stack?
The Representation Utility Stack is a three-layer AI infrastructure model consisting of representation utilities, representation APIs, and governed execution. It enables institutions to make reality machine-readable, interoperable across systems, and actionable with legitimacy.
In simple terms:
The Representation Utility Stack is the infrastructure that allows AI systems to understand reality, share it across systems, and act on it responsibly.

Why the current enterprise AI conversation is still too shallow
Most enterprises still think of AI as a reasoning layer placed on top of existing systems. That view is understandable. It is also incomplete.
In practice, enterprise AI depends on much more than model quality. Long before an answer appears on a screen, three deeper questions must already have been resolved:
- Was the right signal captured from the real world?
- Was that signal attached to the right entity?
- Can the current state of that entity move across systems without losing meaning?
If the answer to any of these is weak, then intelligence alone will not rescue the system.
This is why so many enterprise AI efforts feel impressive in demos but fragile in production. The model may be strong. The surrounding reality layer is not.
The next strategic shift, then, is not from one model to a better model. It is from model-centric AI to representation-centric AI.
That is the shift the market is still underestimating.

The real enterprise problem: intelligence without representation
Consider a simple example.
A customer changes address. One system updates it. Another still holds the old one. A fraud engine sees two locations and raises suspicion. A logistics system routes to the wrong place. A collections system continues to send notices to the old address. The chatbot says the profile is updated. The backend says it is not.
Nothing in this example requires a weak model. The reasoning engine may be excellent.
The real problem is that the institution does not have one shared, portable, governed representation of reality.
The same pattern appears everywhere.
In healthcare, a hospital, a lab, and an insurer may each represent the same patient differently. The model may summarize beautifully, but if the system cannot confidently determine whether the records refer to the same person, the intelligence becomes dangerous theater.
In supply chains, a product may be identified one way by the manufacturer, another by the distributor, and a third by the retailer. If identity, status, and movement are not represented consistently, AI does not optimize the chain. It amplifies confusion.
In banking, the same small business can appear as a customer, merchant, borrower, counterparty, or compliance subject in different systems. If those representations do not align, then even good AI will produce uneven service, false risk signals, and poor decisions.
This is why the next AI infrastructure layer is not simply about better reasoning.
It is about interoperable reality.

From software interoperability to reality interoperability
The previous generation of digital infrastructure solved a different problem.
Cloud made compute portable.
APIs made software services connectable.
Data platforms made storage scalable.
But AI introduces a harder requirement.
Systems must not merely exchange messages.
They must exchange meaningful state about the world.
Two systems can both say “high-priority customer” and still mean different things. Two agents can both use the word “delivered” and still refer to different events. Two institutions can both say “verified identity” and still rely on different evidence, thresholds, and update rules.
This is the real frontier.
The next infrastructure race will not be about who exposes the best model API alone. It will be about who can make entities, state, relationships, provenance, and change interoperable across boundaries.
That is a bigger challenge than software interoperability because it is not just technical. It is semantic, operational, institutional, and increasingly strategic.
It requires systems to preserve meaning, not just transmit fields.
What is the Representation Utility Stack?
The Representation Utility Stack is the infrastructure stack that turns reality into a reusable, portable, and governable asset for AI systems.
It has three layers:
- Representation Utilities
- Representation APIs
- Governed Execution
Taken together, these layers define how institutions make reality machine-legible, move it across boundaries, and act on it responsibly.
Layer 1: Representation Utilities
Representation utilities are the systems that maintain trusted machine-readable reality.
They do not merely store data. They continuously answer questions such as:
Who is this?
What is its current state?
What changed?
How confident are we?
Who supplied this update?
What conflicts remain unresolved?
A representation utility is closer to a utility than a dashboard. It provides persistent legibility.
It may be sector-specific:
- an identity utility
- a merchant utility
- an asset-state utility
- a patient-state utility
- a supply-chain utility
- a climate-observation utility
The essential idea is simple: before AI can reason well, reality must be represented well.
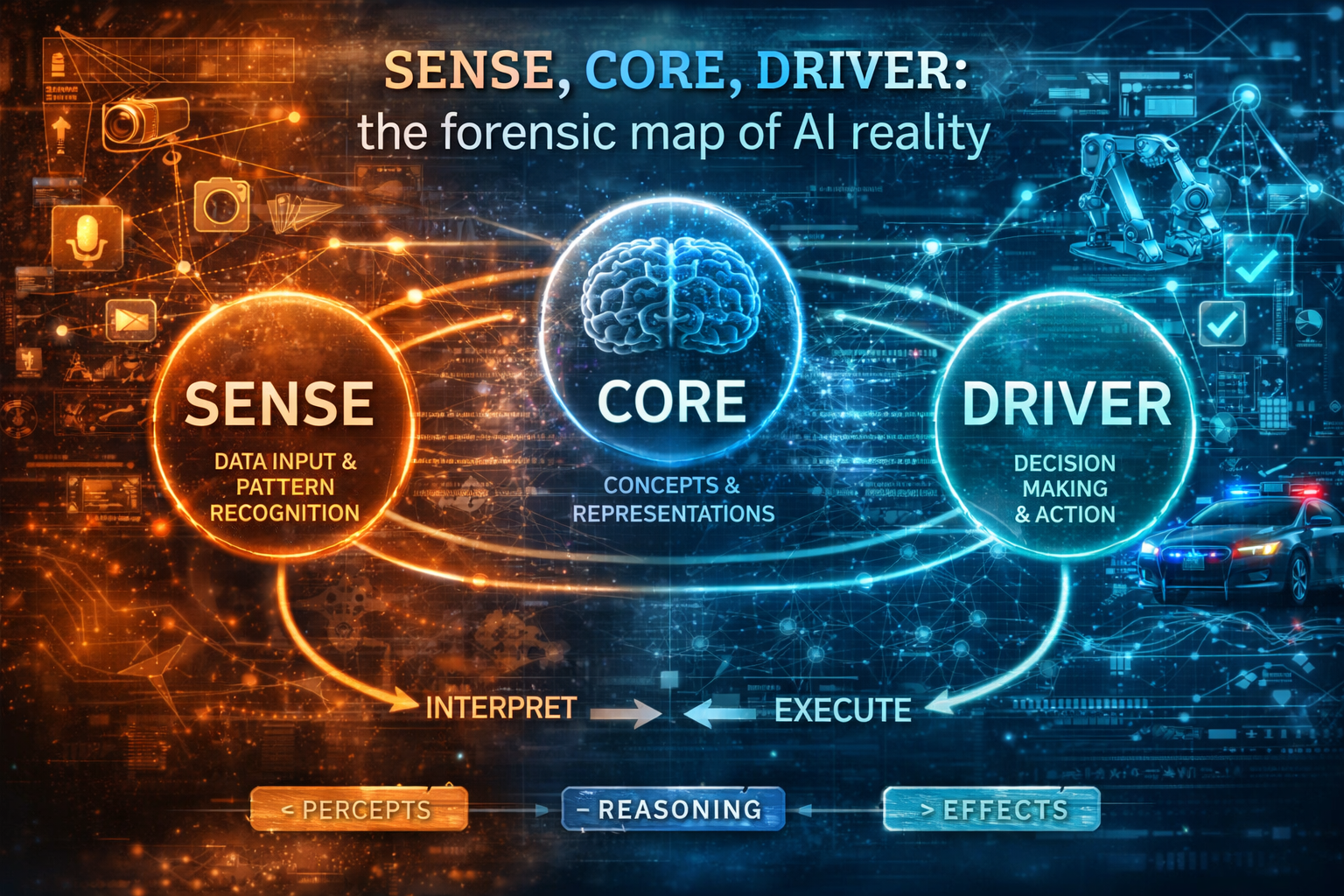
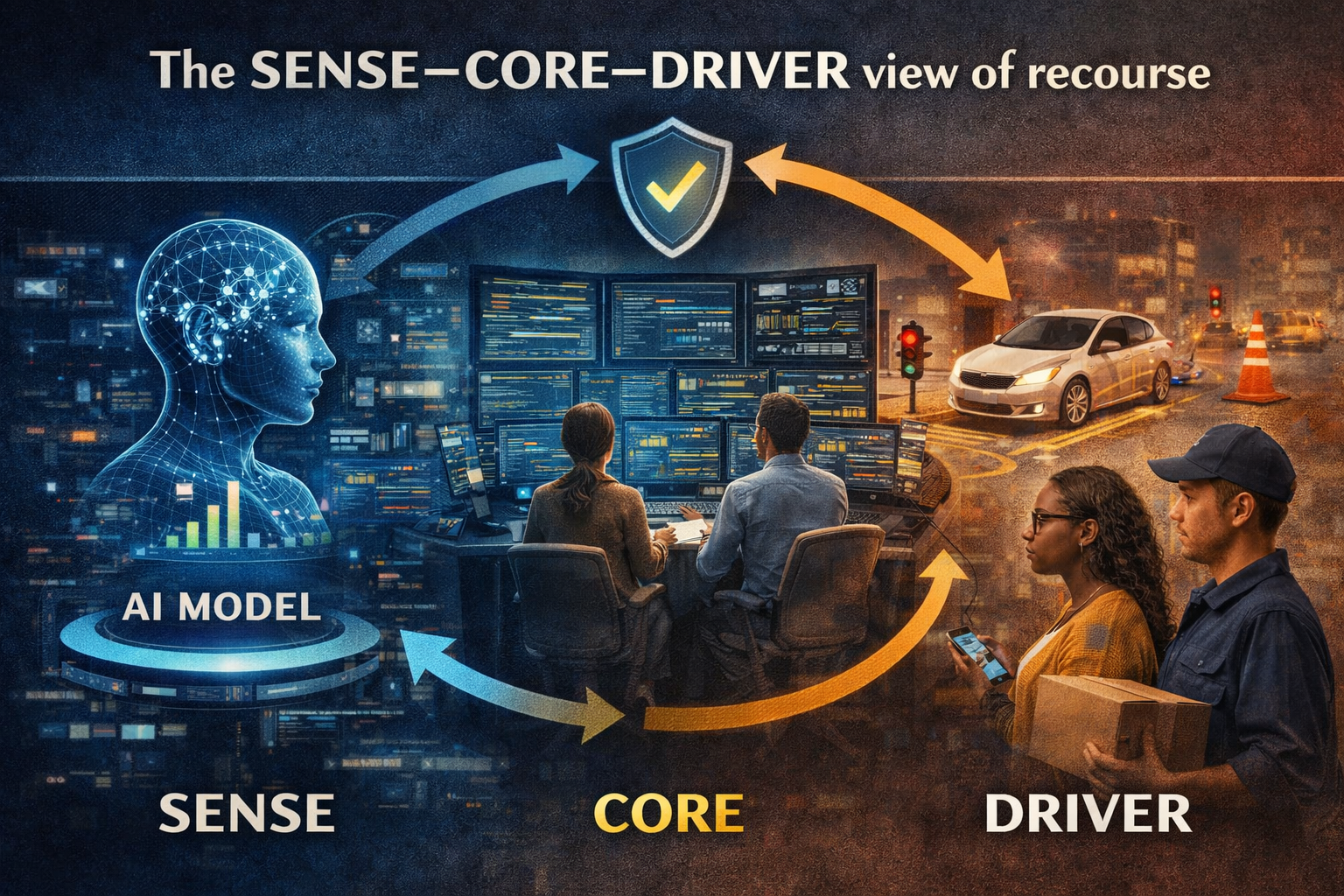
In my framework, this is the SENSE layer:
- Signal — detect the relevant traces from the world
- ENtity — bind those traces to the right actor, object, location, or asset
- State representation — build a usable current model of reality
- Evolution — keep that model current as the world changes
This is where reality becomes machine-legible.
A simple example
Think about a shipment in transit.
A good representation utility does not just say, “Shipment #127 is delayed.”
It can represent:
- which shipment
- which customer
- which warehouse
- what caused the delay
- what the last trusted update was
- whether the state is disputed
- whether downstream commitments need to change
That is not just data storage. That is usable reality.
Layer 2: Representation APIs
Once reality is represented well, it still needs to move.
That is the job of representation APIs.
A representation API does not merely expose raw fields. It exposes structured reality in a way that other systems, institutions, agents, and workflows can consume without losing meaning.
It carries more than data. It carries:
- identity
- state
- provenance
- confidence
- update logic
- context
- conflict status
This is the bridge between “we have a good internal model of reality” and “multiple systems can coordinate safely.”
Imagine a bank, an insurer, a hospital, and a regulator all needing to reason about the same event. Without interoperable representation, each builds its own partial version. With representation APIs, they do not need one giant shared database. They need shared ways to describe, update, interpret, verify, and challenge reality.
Representation APIs are not just technical connectors.
They are meaning connectors.
Why this matters
The future will not belong merely to firms with interoperable models. It will belong to firms that can make reality itself exchangeable.
Cloud made compute portable.
APIs made software interoperable.
The next layer will make reality portable.
That is the strategic leap.
Layer 3: Governed Execution
The final layer is where represented reality becomes action.
A loan is approved.
A shipment is rerouted.
A claim is denied.
A machine is shut down.
A patient is escalated.
A supplier is blocked.
This is where many AI discussions remain too shallow. They assume that once systems understand enough, they can act.
But action is not only a reasoning problem. It is an authority problem.
Who delegated this action?
Which representation was used?
What verification was performed?
What happens if the representation was wrong?
Where does recourse begin?
This is the DRIVER layer:
- Delegation
- Representation
- Identity
- Verification
- Execution
- Recourse
This is the legitimacy layer of the AI economy.
A system that reasons well but acts without legitimacy is not enterprise-ready. It is simply risky automation.
Why this stack matters now
Because AI is moving beyond experimentation.
The important question is no longer whether a model can generate impressive output. The real question is whether enterprises can build repeatable, trustworthy systems that operate across fragmented, changing, multi-party environments.
That is exactly where the Representation Utility Stack becomes necessary.
A model can summarize a shipping problem.
A stack can tell you which shipment, which policy exception, which system last updated the state, whether the state is contested, and whether the action taken can be appealed.
A model can draft a claims response.
A stack can verify whether the claim belongs to the right person, whether the event matches the policy, whether contradictory evidence exists, and whether the denial can be explained.
A model can suggest a treatment path.
A stack can ensure that the patient, record, lab values, medication context, and authorization workflow actually align.
That difference is not cosmetic.
It is the difference between intelligence that sounds good and intelligence that can be trusted.

The new company category that will emerge
This shift will create a new class of firms.
Not just model companies.
Not just SaaS companies.
Not just data brokers.
Representation utility companies.
These firms will specialize in making a domain legible, portable, and governable for machines.
Some will focus on identity-rich sectors.
Others will focus on dynamic, state-heavy sectors.
Some will build sector-specific ontology layers and semantic models.
Others will build cross-enterprise state synchronization, provenance infrastructure, conflict resolution systems, or recourse services.
This may become one of the most important but least understood company categories of the next decade.
The winners will not simply answer questions better.
They will make reality usable across institutions.
Why existing companies should care
This is not just an opportunity for new entrants. It is a survival issue for incumbents.
Many organizations today overinvest in CORE and underinvest in SENSE and DRIVER.
They buy models.
They run pilots.
They build copilots.
They talk about agentic workflows.
But if their reality layer is fragmented and their action layer is weakly governed, they are building intelligence on top of representation debt.
That debt does not stay hidden forever.
It eventually appears as:
- conflicting outputs
- brittle automation
- poor personalization
- false escalation
- weak auditability
- customer distrust
- compliance exposure
- rising human correction costs
The irony is that many firms will think they have an AI problem when they actually have a representation architecture problem.
What leaders should ask now
Boards, CEOs, CTOs, and AI leaders need a new set of questions.
Not just:
Which model should we use?
But also:
- Which entities must our institution represent well?
- How often do their states change?
- Where are identities fragmented?
- Which representations are authoritative?
- How does state move across systems?
- What meaning is lost during that movement?
- What evidence supports machine action?
- Where does recourse begin when the system is wrong?
That is the beginning of a real AI strategy.
The firms that win will treat machine-readable reality as infrastructure. They will build representation utilities for their most critical domains. They will expose them through interoperable APIs. They will connect them to governed execution. And they will realize that the future advantage is not merely better intelligence.
It is better institutional legibility.

The bigger shift: from software infrastructure to reality infrastructure
We are entering a world in which reality itself must be designed for machine use.
That does not mean reducing the world to data. It means building the infrastructure through which institutions can represent, exchange, and act on reality responsibly.
This is why the next infrastructure layer will be built on interoperable reality.
Because AI does not fail only when models are weak.
It fails when reality is poorly represented.
It fails when state cannot travel.
It fails when meanings diverge across systems.
It fails when action outruns legitimacy.
The next great stack, then, will not be just a software stack or an AI stack.
It will be a Representation Utility Stack.
And the institutions that understand this first will not merely deploy AI better. They will help define the architecture of the Representation Economy itself.
Conclusion
The most important AI companies of the next decade may not be the ones that generate the most fluent output.
They may be the ones that make reality more legible, more portable, and more governable.
That is the deeper strategic shift now underway.
The future of enterprise AI will not be decided by model sophistication alone. It will be decided by whether institutions can build systems that know what is real, share that reality across boundaries, and act on it with legitimacy.
That is why the Representation Utility Stack matters.
It is not just another architecture pattern. It is a new way of understanding where durable advantage in AI will come from.
And for boards and business leaders, that may be the most important shift to grasp now: in the AI economy, the winners will not simply process reality better.
They will define how reality becomes usable.
Frequently Asked Questions (FAQ)
What is the Representation Utility Stack?
It is a three-layer infrastructure model for AI built on representation utilities, representation APIs, and governed execution.
Why is this different from a normal AI stack?
Because it focuses not only on intelligence, but on how reality is represented, moved across systems, and acted on responsibly.
Why are models not enough?
Because models reason over what the system believes is true. If that belief is weak, stale, or fragmented, better reasoning alone does not solve the problem.
What is a representation utility?
It is a system that keeps an accurate, current, and usable version of reality available for machines.
What is a representation API?
It is a way to move structured reality across systems without losing meaning, context, or trust.
Why should boards care?
Because this is not merely a technical design issue. It is becoming a strategic source of advantage, risk control, and long-term competitiveness in the AI economy.
Glossary
Representation Utility Stack
A three-layer AI infrastructure model consisting of representation utilities, representation APIs, and governed execution, enabling institutions to make reality machine-readable, interoperable across systems, and actionable with legitimacy.
Representation Economy
An emerging economic paradigm where value is created not just by data or intelligence, but by how accurately reality is represented, how effectively it is understood, and how responsibly actions are taken based on it.
Interoperable Reality
The ability of multiple systems, organizations, or AI agents to share and operate on a consistent, structured, and meaningful representation of real-world entities, states, and events without loss of context.
Machine-Readable Reality
A structured and continuously updated digital representation of real-world entities, relationships, and states that AI systems can interpret, reason over, and act upon.
Representation Utility
A system that maintains trusted, current, and structured representations of reality, including identity, state, change history, and confidence, enabling AI systems to operate reliably.
Representation API
An interface that allows systems to exchange structured representations of reality, preserving identity, context, provenance, and meaning across systems.
Representation Debt
The hidden cost created when organizations build AI systems on top of fragmented, outdated, or inconsistent representations of reality, leading to unreliable outcomes and poor scalability.
Institutional Legibility
The degree to which an organization can clearly represent its entities, operations, relationships, and states in a way that machines can reliably understand and act upon.
Semantic Interoperability
The ability of systems to exchange information with shared meaning, not just shared formats, ensuring consistent interpretation across contexts.
Digital Twin
A dynamic, virtual representation of a real-world entity or system that is continuously updated with real-time data to support monitoring, simulation, and decision-making.
SENSE (AI Legibility Layer)
The layer where reality becomes machine-readable:
- Signal
- ENtity
- State representation
- Evolution
CORE (AI Cognition Layer)
The reasoning layer where systems:
- Comprehend context
- Optimize decisions
- Realize action
- Evolve through feedback
DRIVER (AI Execution & Legitimacy Layer)
The governance layer that ensures actions are valid:
- Delegation
- Representation
- Identity
- Verification
- Execution
- Recourse
Governed Execution
The process by which AI systems take action with clear authority, verifiable representation, and defined recourse mechanisms, ensuring accountability.
Representation Architecture
The design of systems that define how reality is captured, structured, shared, and acted upon across an organization.
Representation Gap
The disconnect between how reality exists and how it is represented in systems, often leading to incorrect or suboptimal AI decisions.
References and Further Reading
AI GOVERNANCE & TRUST
- NIST AI Risk Management Framework
https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf - OECD AI Principles
https://www.oecd.org/en/topics/ai-principles.html
AI STRATEGY & ENTERPRISE TRANSFORMATION
- World Economic Forum – AI in Action (2025)
https://reports.weforum.org/docs/WEF_AI_in_Action_Beyond_Experimentation_to_Transform_Industry_2025.pdf -
INTEROPERABILITY & DATA FOUNDATIONS
- W3C – Data on the Web Best Practices
https://www.w3.org/TR/dwbp/ - W3C – Linked Data Best Practices
https://www.w3.org/TR/ld-bp/
- W3C – Data on the Web Best Practices